⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-02 更新
KunServe: Elastic and Efficient Large Language Model Serving with Parameter-centric Memory Management
Authors:Rongxin Cheng, Yifan Peng, Yuxin Lai, Xingda Wei, Rong Chen, Haibo Chen
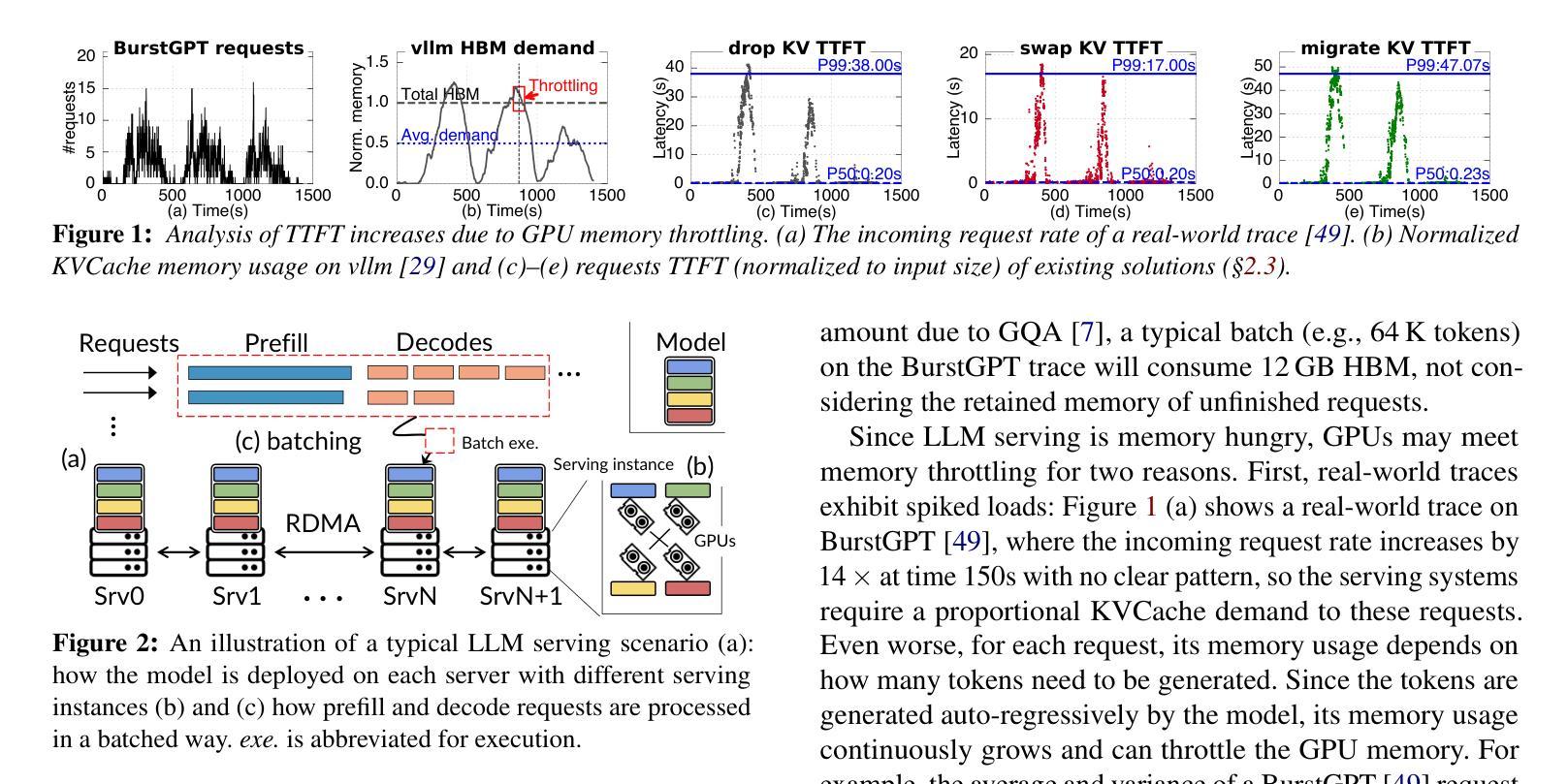
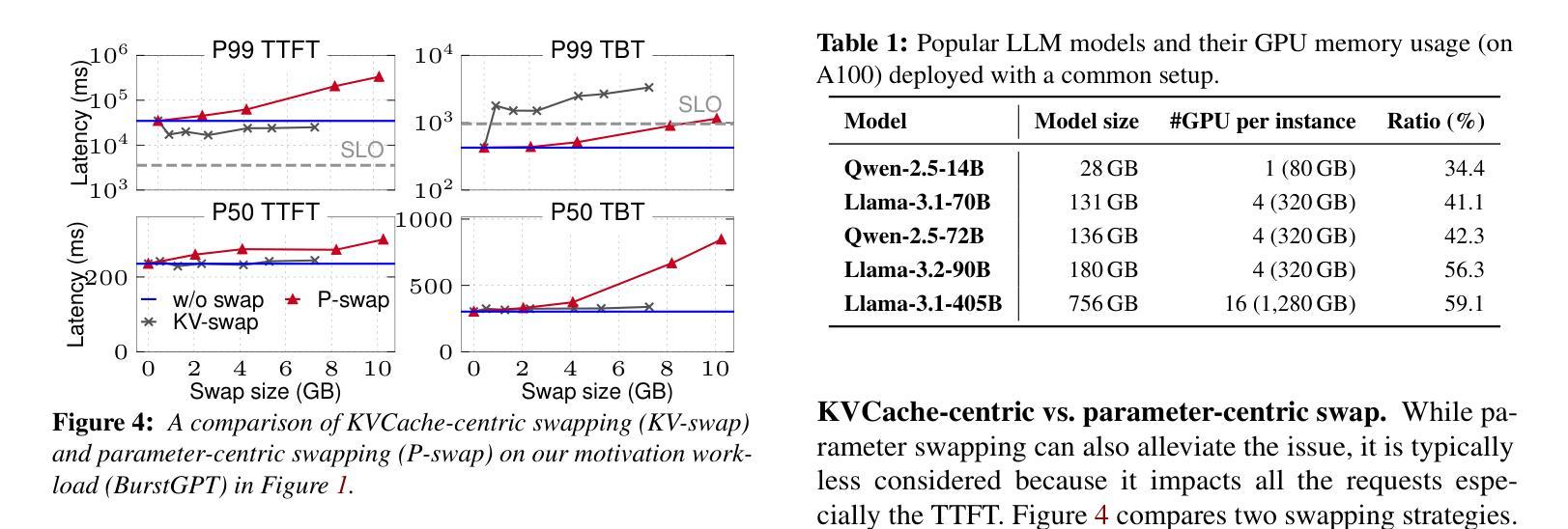
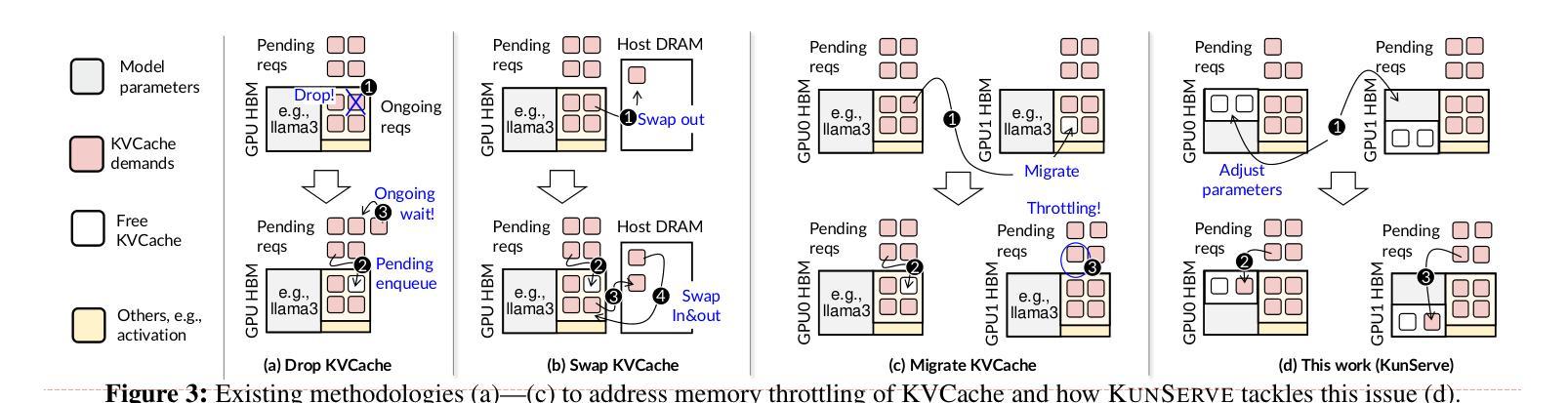
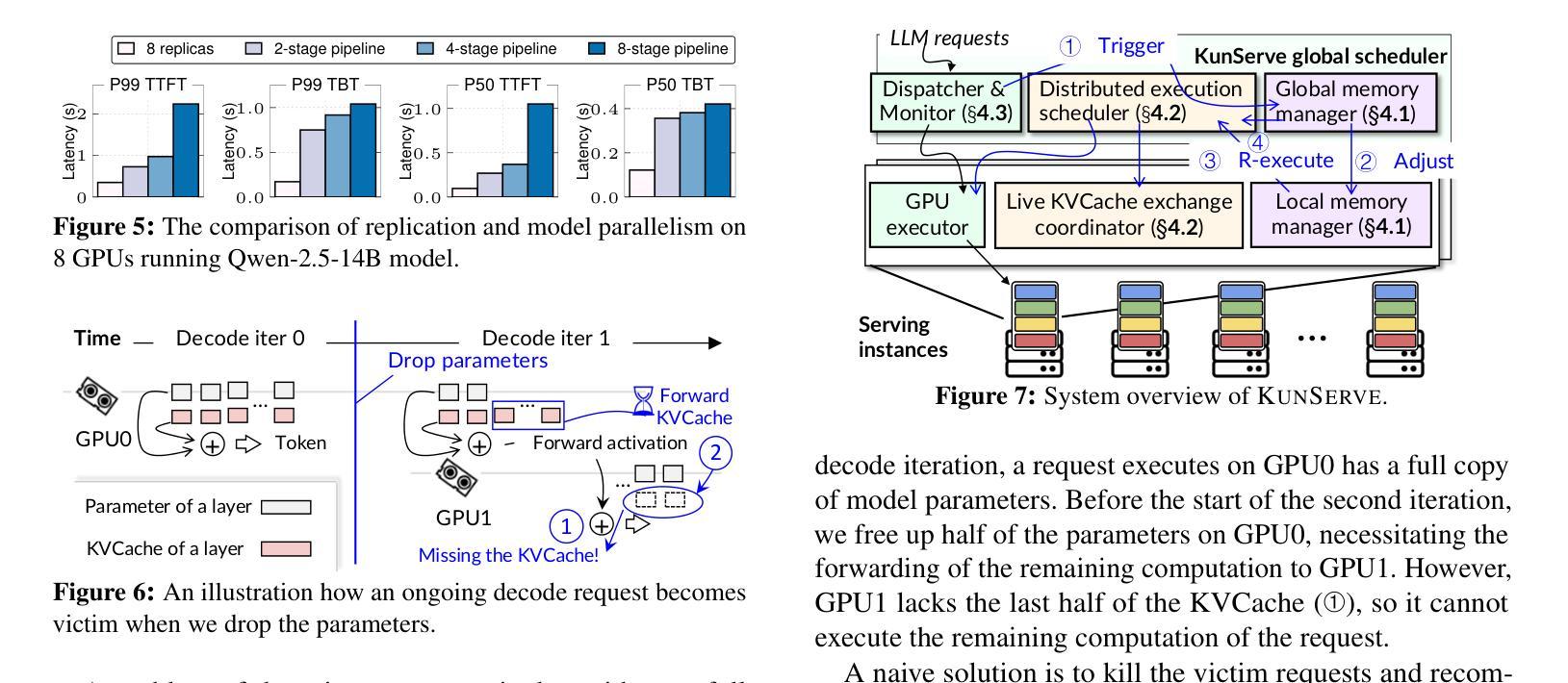
The stateful nature of large language model (LLM) servingcan easily throttle precious GPU memory under load burstor long-generation requests like chain-of-thought reasoning,causing latency spikes due to queuing incoming requests. However, state-of-the-art KVCache centric approaches handleload spikes by dropping, migrating, or swapping KVCache,which faces an essential tradeoff between the performance ofongoing vs. incoming requests and thus still severely violatesSLO.This paper makes a key observation such that model param-eters are independent of the requests and are replicated acrossGPUs, and thus proposes a parameter-centric approach byselectively dropping replicated parameters to leave preciousmemory for requests. However, LLM requires KVCache tobe saved in bound with model parameters and thus droppingparameters can cause either huge computation waste or longnetwork delay, affecting all ongoing requests. Based on the ob-servation that attention operators can be decoupled from otheroperators, this paper further proposes a novel remote attentionmechanism through pipeline parallelism so as to serve up-coming requests with the additional memory borrowed fromparameters on remote GPUs. This paper further addresses sev-eral other challenges including lively exchanging KVCachewith incomplete parameters, generating an appropriate planthat balances memory requirements with cooperative exe-cution overhead, and seamlessly restoring parameters whenthe throttling has gone. Evaluations show thatKUNSERVEreduces the tail TTFT of requests under throttling by up to 27.3x compared to the state-of-the-art.
大型语言模型(LLM)的有状态性质在服务过程中,在面临负载突发或像链式思维推理这样的长期生成请求时,很容易占用宝贵的GPU内存,导致由于排队等待传入请求而出现延迟峰值。然而,最新的以KVCache为中心的方法通过丢弃、迁移或交换KVCache来处理负载峰值,这在进行中请求与传入请求之间性能权衡方面面临重要取舍,因此仍然严重违反SLO(服务级别目标)。
论文及项目相关链接
摘要
大型语言模型(LLM)服务在有负载突发或长时推理请求(如链式思维)时,其有状态特性容易导致GPU内存限制,进而引发延迟峰值。现有的KVCache中心处理方法通过丢弃、迁移或交换KVCache来处理负载峰值,但在处理持续请求与即将到来的请求之间仍存在性能权衡,从而严重违反SLO(服务水平协议)。本文观察到模型参数独立于请求且已复制到GPU上,提出了一种基于参数的解决方案,通过选择性丢弃复制参数来腾出内存用于请求。然而,LLM要求将KVCache与模型参数绑定保存,因此丢弃参数可能会导致大量计算浪费或网络延迟延长,影响所有正在进行中的请求。本文观察到注意力运算符可以与其它运算符解耦,因此提出了一种通过管道并行性远程注意力机制的新方法,为即将到来的请求借用远程GPU上的内存。此外,本文还解决了其它挑战,包括与不完整参数进行活跃的KVCache交换、生成平衡内存需求和合作执行开销的适当计划、在节流发生时无缝恢复参数等。评估显示,KUNSERVE相较于现有技术减少了请求在节流时的尾部TTFT(时间到达故障阈值)高达27.3倍。
关键见解
- 大型语言模型(LLM)服务的状态特性在负载突发或长推理请求时可能导致GPU内存限制和延迟峰值。
- 现有KVCache处理方法面临性能权衡问题,需要在处理持续请求和即将到来的请求之间进行权衡。
- 本论文提出了一种基于参数的解决方案,通过选择性丢弃复制参数来处理内存问题,但同时也面临计算浪费和网络延迟的挑战。
- 观察到注意力运算符与其它运算符可以解耦,因此提出了一种通过管道并行性的远程注意力机制。
- 本论文解决了包括活跃的KVCache交换、生成平衡内存需求和合作执行开销的适当计划等挑战。
- KUNSERVE在减少请求延迟方面取得了显著成效,相较于现有技术减少了尾部TTFT高达27.3倍。
点此查看论文截图