⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-02 更新
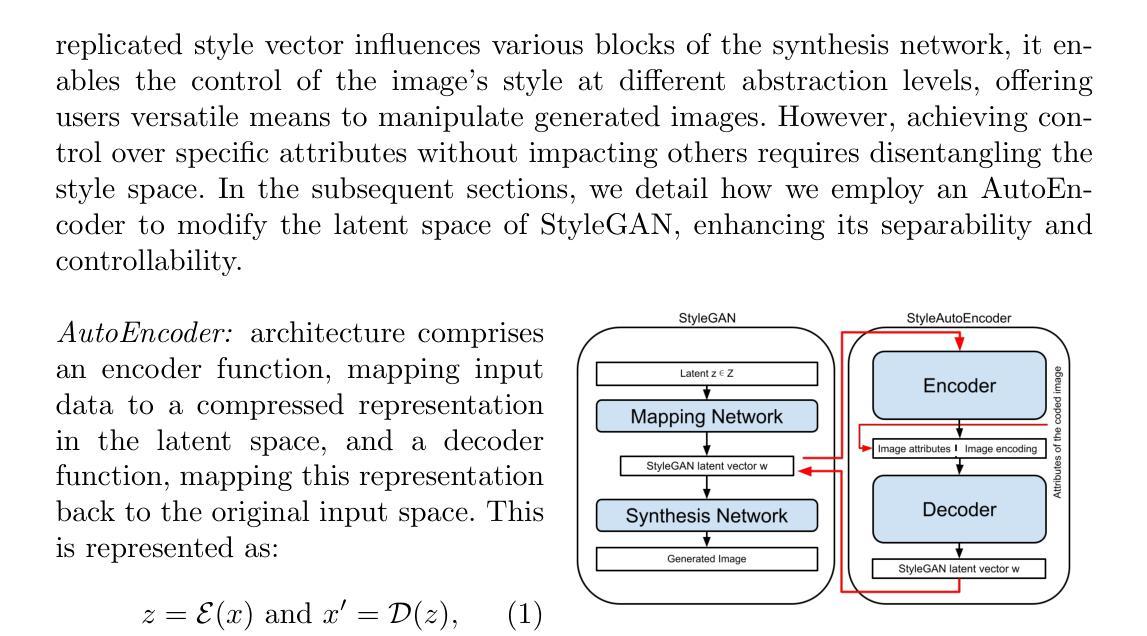
StyleAutoEncoder for manipulating image attributes using pre-trained StyleGAN
Authors:Andrzej Bedychaj, Jacek Tabor, Marek Śmieja
Deep conditional generative models are excellent tools for creating high-quality images and editing their attributes. However, training modern generative models from scratch is very expensive and requires large computational resources. In this paper, we introduce StyleAutoEncoder (StyleAE), a lightweight AutoEncoder module, which works as a plugin for pre-trained generative models and allows for manipulating the requested attributes of images. The proposed method offers a cost-effective solution for training deep generative models with limited computational resources, making it a promising technique for a wide range of applications. We evaluate StyleAutoEncoder by combining it with StyleGAN, which is currently one of the top generative models. Our experiments demonstrate that StyleAutoEncoder is at least as effective in manipulating image attributes as the state-of-the-art algorithms based on invertible normalizing flows. However, it is simpler, faster, and gives more freedom in designing neural
深度条件生成模型是创建高质量图像和编辑其属性的出色工具。然而,从头开始训练现代生成模型是非常昂贵的,并且需要巨大的计算资源。在本文中,我们介绍了StyleAutoEncoder(StyleAE),这是一个轻量级的AutoEncoder模块,可作为预训练生成模型的插件,允许操作图像的请求属性。所提出的方法为在有限的计算资源下训练深度生成模型提供了经济高效的解决方案,使其成为广泛应用的有前途的技术。我们通过将其与目前顶级的生成模型StyleGAN相结合来评估StyleAutoEncoder。我们的实验表明,StyleAutoEncoder在操纵图像属性方面至少与基于可逆归一化流的最新算法一样有效。但是它更简单、更快,并且在设计神经网络时提供了更大的自由度。
论文及项目相关链接
Summary
深度条件生成模型是创建高质量图像和编辑其属性的优秀工具。然而,从头开始训练现代生成模型非常昂贵,需要巨大的计算资源。本文介绍了StyleAutoEncoder(StyleAE),这是一款轻量级的AutoEncoder模块,可作为预训练生成模型的插件,允许操作图像的指定属性。所提出的方法为在有限的计算资源下训练深度生成模型提供了成本效益高的解决方案,成为广泛应用的有前途的技术。我们将StyleAutoEncoder与目前顶级的生成模型之一StyleGAN相结合进行评估。实验表明,StyleAutoEncoder在操纵图像属性方面至少与基于可逆归一化流的最新算法一样有效,但更简单、更快,并且在设计神经网络时提供了更大的自由度。
Key Takeaways
- StyleAutoEncoder是一种轻量级的AutoEncoder模块,可作为预训练生成模型的插件,用于操作图像的指定属性。
- 所提出的方法为在有限的计算资源下训练深度生成模型提供了成本效益高的解决方案。
- StyleAutoEncoder与StyleGAN相结合,展示了对图像属性的有效操作。
- StyleAutoEncoder的效果至少与基于可逆归一化流的最新算法一样好。
- StyleAutoEncoder具有简单、快速的特点,并且在设计神经网络时提供了更大的自由度。
- 该方法适用于广泛的应用领域。
点此查看论文截图



Comprehensive Review of EEG-to-Output Research: Decoding Neural Signals into Images, Videos, and Audio
Authors:Yashvir Sabharwal, Balaji Rama
Electroencephalography (EEG) is an invaluable tool in neuroscience, offering insights into brain activity with high temporal resolution. Recent advancements in machine learning and generative modeling have catalyzed the application of EEG in reconstructing perceptual experiences, including images, videos, and audio. This paper systematically reviews EEG-to-output research, focusing on state-of-the-art generative methods, evaluation metrics, and data challenges. Using PRISMA guidelines, we analyze 1800 studies and identify key trends, challenges, and opportunities in the field. The findings emphasize the potential of advanced models such as Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and Transformers, while highlighting the pressing need for standardized datasets and cross-subject generalization. A roadmap for future research is proposed that aims to improve decoding accuracy and broadening real-world applications.
脑电图(EEG)是神经科学中一种宝贵的工具,能以高时间分辨率提供对大脑活动的洞察。最近机器学习领域的进展以及生成模型的发展,促进了EEG在重建感知体验中的应用,包括图像、视频和音频。本文系统地回顾了EEG到输出的研究,重点关注最先进的生成方法、评估指标和数据挑战。我们按照PRISMA指南分析了1800项研究,并确定了该领域的关键趋势、挑战和机遇。研究结果强调了先进模型(如生成对抗网络(GANs)、变分自编码器(VAEs)和变压器)的潜力,同时强调了标准化数据集和跨主题泛化的迫切需求。为未来研究提出了路线图,旨在提高解码精度并扩大在现实世界中的应用。
论文及项目相关链接
PDF 15 pages. Submitted as a conference paper to IntelliSys 2025
Summary
本文系统综述了EEG在重建感知体验方面的应用,重点介绍了最新的生成方法、评估指标和数据挑战。通过对1800项研究的分析,强调了先进模型如生成对抗网络(GANs)、变分自编码器(VAEs)和Transformers的潜力,同时指出标准化数据集和跨主体推广的迫切需求。提出了未来研究的路线图,旨在提高解码精度并拓宽其在现实世界中的应用。
Key Takeaways
- EEG是神经科学中的宝贵工具,具有高的时间分辨率,能洞察大脑活动。
- 机器学习和生成模型的发展推动了EEG在重建感知体验方面的应用,如图像、视频和音频。
- 综述重点关注了最新的生成方法、评估指标和数据挑战。
- 生成对抗网络(GANs)、变分自编码器(VAEs)和Transformers等先进模型在EEG分析中具有巨大潜力。
- 标准化数据集和跨主体推广是当前的迫切需求。
- 研究提出了提高解码精度和拓宽现实应用中的路线图。
点此查看论文截图

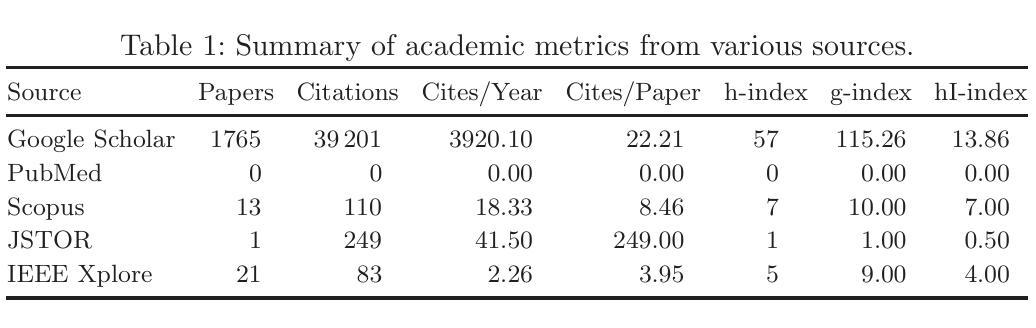
NijiGAN: Transform What You See into Anime with Contrastive Semi-Supervised Learning and Neural Ordinary Differential Equations
Authors:Kevin Putra Santoso, Anny Yuniarti, Dwiyasa Nakula, Dimas Prihady Setyawan, Adam Haidar Azizi, Jeany Aurellia P. Dewati, Farah Dhia Fadhila, Maria T. Elvara Bumbungan
Generative AI has transformed the animation industry. Several models have been developed for image-to-image translation, particularly focusing on converting real-world images into anime through unpaired translation. Scenimefy, a notable approach utilizing contrastive learning, achieves high fidelity anime scene translation by addressing limited paired data through semi-supervised training. However, it faces limitations due to its reliance on paired data from a fine-tuned StyleGAN in the anime domain, often producing low-quality datasets. Additionally, Scenimefy’s high parameter architecture presents opportunities for computational optimization. This research introduces NijiGAN, a novel model incorporating Neural Ordinary Differential Equations (NeuralODEs), which offer unique advantages in continuous transformation modeling compared to traditional residual networks. NijiGAN successfully transforms real-world scenes into high fidelity anime visuals using half of Scenimefy’s parameters. It employs pseudo-paired data generated through Scenimefy for supervised training, eliminating dependence on low-quality paired data and improving the training process. Our comprehensive evaluation includes ablation studies, qualitative, and quantitative analysis comparing NijiGAN to similar models. The testing results demonstrate that NijiGAN produces higher-quality images compared to AnimeGAN, as evidenced by a Mean Opinion Score (MOS) of 2.192, it surpasses AnimeGAN’s MOS of 2.160. Furthermore, our model achieved a Frechet Inception Distance (FID) score of 58.71, outperforming Scenimefy’s FID score of 60.32. These results demonstrate that NijiGAN achieves competitive performance against existing state-of-the-arts, especially Scenimefy as the baseline model.
生成式人工智能已经改变了动画产业。已经开发了几个图像到图像的翻译模型,特别专注于通过非配对翻译将现实世界图像转换为动漫。Scenimefy是一种利用对比学习的方法,通过半监督训练解决配对数据有限的问题,实现了高保真动漫场景翻译。然而,它依赖于精细调整的动漫领域StyleGAN的配对数据,因此面临局限性,经常产生低质量的数据集。此外,Scenimefy的高参数架构为计算优化提供了机会。本研究引入了NijiGAN,这是一个结合神经常微分方程(NeuralODEs)的新模型,与传统的残差网络相比,它在连续变换建模方面具有独特优势。NijiGAN成功地将现实世界场景转化为高保真动漫视觉,使用的是Scenimefy一半的参数。它采用通过Scenimefy生成伪配对数据进行监督训练,消除了对低质量配对数据的依赖,改进了训练过程。我们的综合评估包括消融研究、定性和定量分析,比较了NijiGAN与类似模型的表现。测试结果表明,NijiGAN生成的图像质量高于AnimeGAN,平均意见得分(MOS)为2.192,超过了AnimeGAN的MOS得分2.160。此外,我们的模型达到了Frechet Inception Distance(FID)得分58.71,超过了Scenimefy的FID得分60.32。这些结果表明,NijiGAN在现有先进技术中表现出竞争力,尤其是以Scenimefy为基准模型。
论文及项目相关链接
摘要
生成式AI已对动画产业产生深刻变革。新的模型被开发用于图像到图像的转换,特别是将现实世界图像转化为动漫的未配对翻译领域。尽管Scenimefy利用对比学习实现高保真动漫场景翻译,并解决了配对数据的限制问题,但其依赖于精细调整的动漫领域的StyleGAN配对数据,常产生低质量数据集。此外,Scenimefy参数架构复杂,存在计算优化的机会。本研究引入NijiGAN,结合神经网络常微分方程组(NeuralODEs)的新模型,在连续变换建模方面具有独特优势,相较于传统的残差网络。NijiGAN成功将现实场景转化为高保真动漫视觉图像,使用Scenimefy的一半参数。它利用伪配对数据用于监督训练,消除了对低质量配对数据的依赖,改进了训练过程。综合评价包括消融研究、定性和定量分析,比较NijiGAN与类似模型。测试结果表明,NijiGAN产生的图像质量高于AnimeGAN,平均意见得分(MOS)为2.192,超过AnimeGAN的MOS 2.160。此外,我们的模型的Frechet Inception Distance(FID)得分为58.71,优于Scenimefy的FID得分60.32。结果表明,NijiGAN在现有先进技术中表现具有竞争力,尤其是以Scenimefy为基线模型。
关键见解
- 生成式AI已深刻改变动画产业,尤其是图像到图像的转换领域。
- Scenimefy利用对比学习实现高保真动漫场景翻译,但仍面临依赖精细调整的配对数据的问题。
- NijiGAN模型引入神经网络常微分方程组(NeuralODEs),实现现实场景到高保真动漫的视觉转化。
- NijiGAN使用伪配对数据进行监督训练,提高训练过程的效率和质量。
- NijiGAN相较于Scenimefy和AnimeGAN,在图像质量上表现更优秀,平均意见得分(MOS)和Frechet Inception Distance(FID)等指标均有所改进。
- NijiGAN的参数数量仅为Scenimefy的一半,暗示其计算效率更高。
- 综合评价显示NijiGAN在现有模型中表现具有竞争力。
点此查看论文截图


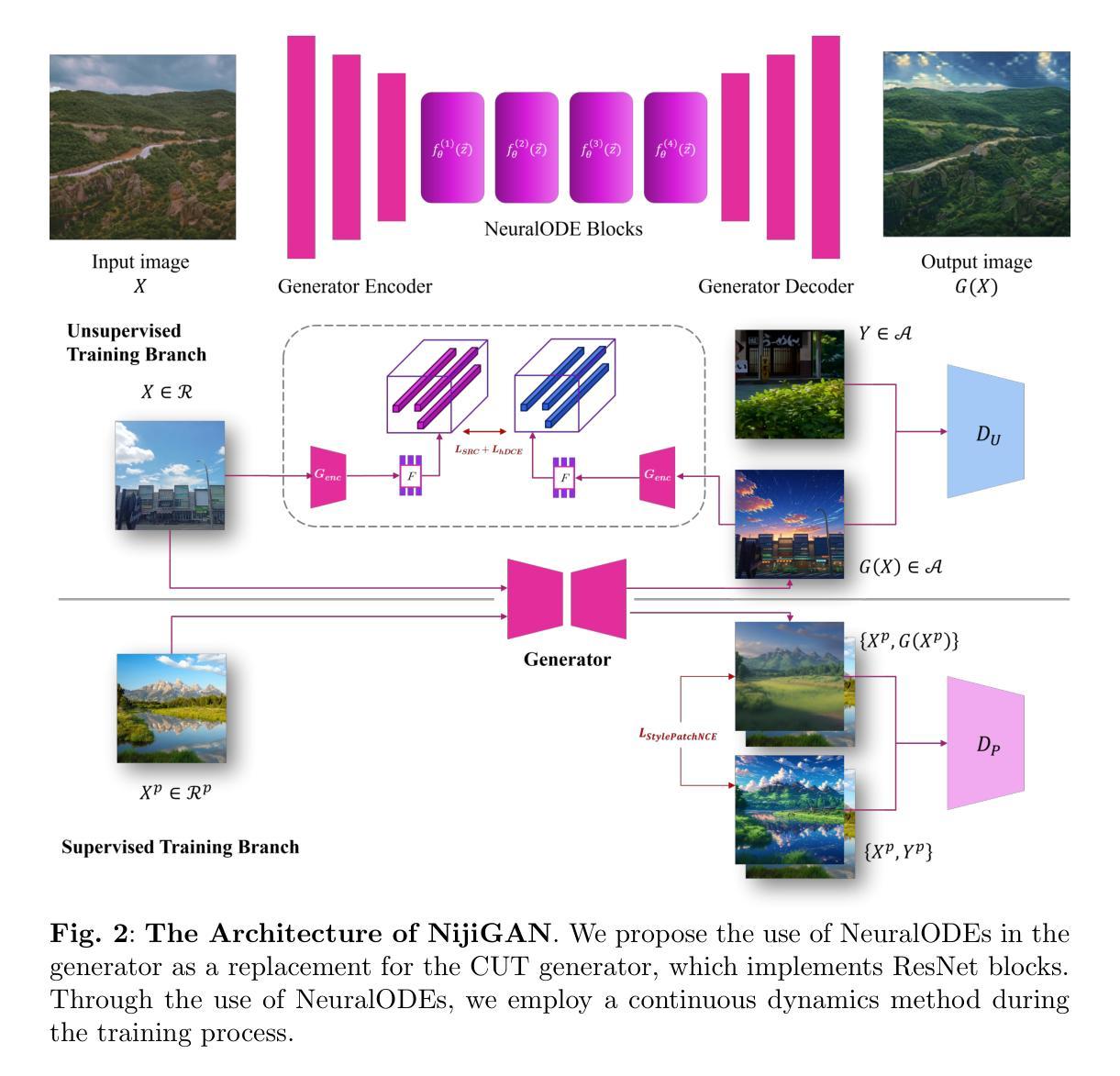
An End-to-End Depth-Based Pipeline for Selfie Image Rectification
Authors:Ahmed Alhawwary, Phong Nguyen-Ha, Janne Mustaniemi, Janne Heikkilä
Portraits or selfie images taken from a close distance typically suffer from perspective distortion. In this paper, we propose an end-to-end deep learning-based rectification pipeline to mitigate the effects of perspective distortion. We learn to predict the facial depth by training a deep CNN. The estimated depth is utilized to adjust the camera-to-subject distance by moving the camera farther, increasing the camera focal length, and reprojecting the 3D image features to the new perspective. The reprojected features are then fed to an inpainting module to fill in the missing pixels. We leverage a differentiable renderer to enable end-to-end training of our depth estimation and feature extraction nets to improve the rectified outputs. To boost the results of the inpainting module, we incorporate an auxiliary module to predict the horizontal movement of the camera which decreases the area that requires hallucination of challenging face parts such as ears. Unlike previous works, we process the full-frame input image at once without cropping the subject’s face and processing it separately from the rest of the body, eliminating the need for complex post-processing steps to attach the face back to the subject’s body. To train our network, we utilize the popular game engine Unreal Engine to generate a large synthetic face dataset containing various subjects, head poses, expressions, eyewear, clothes, and lighting. Quantitative and qualitative results show that our rectification pipeline outperforms previous methods, and produces comparable results with a time-consuming 3D GAN-based method while being more than 260 times faster.
从近距离拍摄的肖像或自拍图像通常会受到透视失真的影响。在本文中,我们提出了一种端到端的基于深度学习的校正管道,以减轻透视失真的影响。我们通过学习预测面部深度来训练深度卷积神经网络。估计的深度用于调整相机到主体的距离,通过将相机移得更远、增加相机的焦距,并将3D图像特征投影到新的透视点上。然后将重新投影的特征输入到填充模块中以填充缺失的像素。我们利用可微渲染器,实现对深度估计和特征提取网络的端到端训练,以提高校正后的输出效果。为了提升填充模块的效果,我们引入了辅助模块来预测相机的水平运动,这减少了需要虚构具有挑战性的面部部位(例如耳朵)的区域。与以前的工作不同,我们一次性处理全帧输入图像,而无需裁剪主体的面部并单独处理其与身体的其他部分,从而无需复杂的后期处理步骤将面部重新附加到主体的身体上。为了训练我们的网络,我们利用流行的游戏引擎Unreal Engine生成了一个大型合成面部数据集,其中包含各种主体、头部姿势、表情、眼镜、衣物和照明。定量和定性结果表明,我们的校正管道优于以前的方法,并且与耗时的基于3D GAN的方法产生相当的结果,同时速度提高了超过260倍。
论文及项目相关链接
Summary
本文提出了一种基于深度学习的端到端校正管道,用于减轻近距离拍摄肖像或自拍时常见的透视失真问题。通过训练深度卷积神经网络预测面部深度,并据此调整相机到主体的距离、增加相机焦距,以及将3D图像特征重新投影到新的透视角度。此方法利用可微渲染器进行端到端训练,提高了校正效果。为增强修复模块的效果,引入了一个辅助模块来预测相机的水平移动,减少了需要虚构具有挑战性的面部部位(如耳朵)的区域。与以往的工作不同,我们一次性处理全帧输入图像,无需将主体面部裁剪出来单独处理,从而避免了复杂的后期处理步骤。实验结果表明,我们的校正管道在性能和速度上均优于之前的方法,并且与耗时较长的基于3D GAN的方法产生的效果相当,但运行时间是其的约1/260。
Key Takeaways
- 论文针对近距离拍摄的肖像或自拍中的透视失真问题,提出了一个基于深度学习的端到端校正管道。
- 通过训练深度CNN预测面部深度,并利用此深度信息调整相机参数和重新投影图像来校正透视失真。
- 利用可微渲染器实现端到端训练,提升校正效果。
- 通过引入辅助模块预测相机水平移动,减少需要虚构的面部区域。
- 论文采用全帧处理方法,避免了复杂的后期处理步骤。
- 使用Unreal Engine生成大型合成面部数据集,用于网络训练。
点此查看论文截图

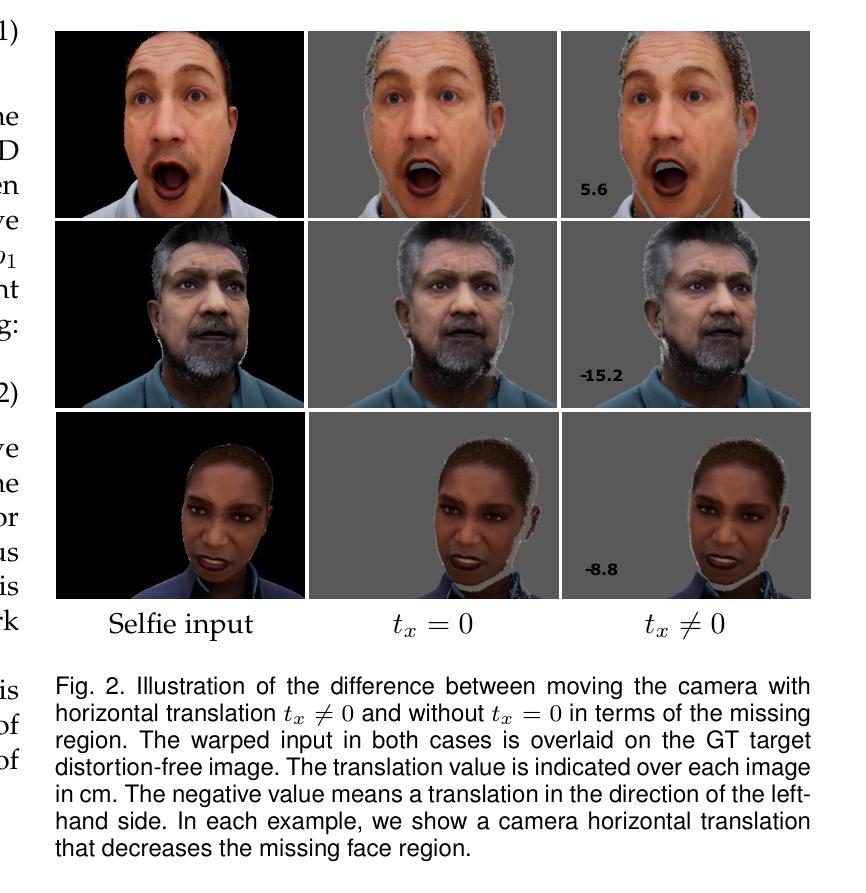

MGAN-CRCM: A Novel Multiple Generative Adversarial Network and Coarse-Refinement Based Cognizant Method for Image Inpainting
Authors:Nafiz Al Asad, Md. Appel Mahmud Pranto, Shbiruzzaman Shiam, Musaddeq Mahmud Akand, Mohammad Abu Yousuf, Khondokar Fida Hasan, Mohammad Ali Moni
Image inpainting is a widely used technique in computer vision for reconstructing missing or damaged pixels in images. Recent advancements with Generative Adversarial Networks (GANs) have demonstrated superior performance over traditional methods due to their deep learning capabilities and adaptability across diverse image domains. Residual Networks (ResNet) have also gained prominence for their ability to enhance feature representation and compatibility with other architectures. This paper introduces a novel architecture combining GAN and ResNet models to improve image inpainting outcomes. Our framework integrates three components: Transpose Convolution-based GAN for guided and blind inpainting, Fast ResNet-Convolutional Neural Network (FR-CNN) for object removal, and Co-Modulation GAN (Co-Mod GAN) for refinement. The model’s performance was evaluated on benchmark datasets, achieving accuracies of 96.59% on Image-Net, 96.70% on Places2, and 96.16% on CelebA. Comparative analyses demonstrate that the proposed architecture outperforms existing methods, highlighting its effectiveness in both qualitative and quantitative evaluations.
图像补全(Image inpainting)是计算机视觉中一种广泛使用的技术,用于重建图像中缺失或损坏的像素。由于生成对抗网络(GANs)的深度学习能力以及在多个图像领域中的适应性,其与传统方法的对比显示出卓越的性能。残差网络(ResNet)也因其增强特征表示和与其他架构的兼容性而受到广泛关注。本文提出了一种结合GAN和ResNet模型的新型架构,以提高图像补全的结果。我们的框架集成了三个组成部分:基于转置卷积的GAN用于有指导和无指导的补全、用于目标移除的快速ResNet卷积神经网络(FR-CNN)以及用于细化的协同调制GAN(Co-Mod GAN)。该模型在基准数据集上进行了评估,在Image-Net上准确率为96.59%,在Places2上准确率为96.70%,在CelebA上准确率为96.16%。对比分析表明,所提出的架构优于现有方法,在定性和定量评估中都凸显了其有效性。
论文及项目相关链接
PDF 34 pages
Summary
基于生成对抗网络(GAN)和残差网络(ResNet)的图像修复技术近年来取得了显著进展。本文提出了一种结合GAN和ResNet模型的新型架构,包括基于转置卷积的GAN用于引导和盲修复、用于对象移除的快速ResNet卷积神经网络(FR-CNN)以及用于精细化的协同调制GAN(Co-Mod GAN)。该模型在基准数据集上的性能评估表明,它在ImageNet上的准确率为96.59%,在Places2上的准确率为96.70%,在CelebA上的准确率为96.16%,并且在定性和定量评估中都优于现有方法。
Key Takeaways
- GAN和ResNet模型结合用于图像修复,达到优异性能。
- 提出新型架构包含三种组件:基于转置卷积的GAN、FR-CNN和Co-Mod GAN。
- 转置卷积GAN用于引导和盲修复。
- FR-CNN用于对象移除。
- Co-Mod GAN用于图像修复结果的精细化。
- 模型在多个基准数据集上表现出色,达到高准确率。
点此查看论文截图

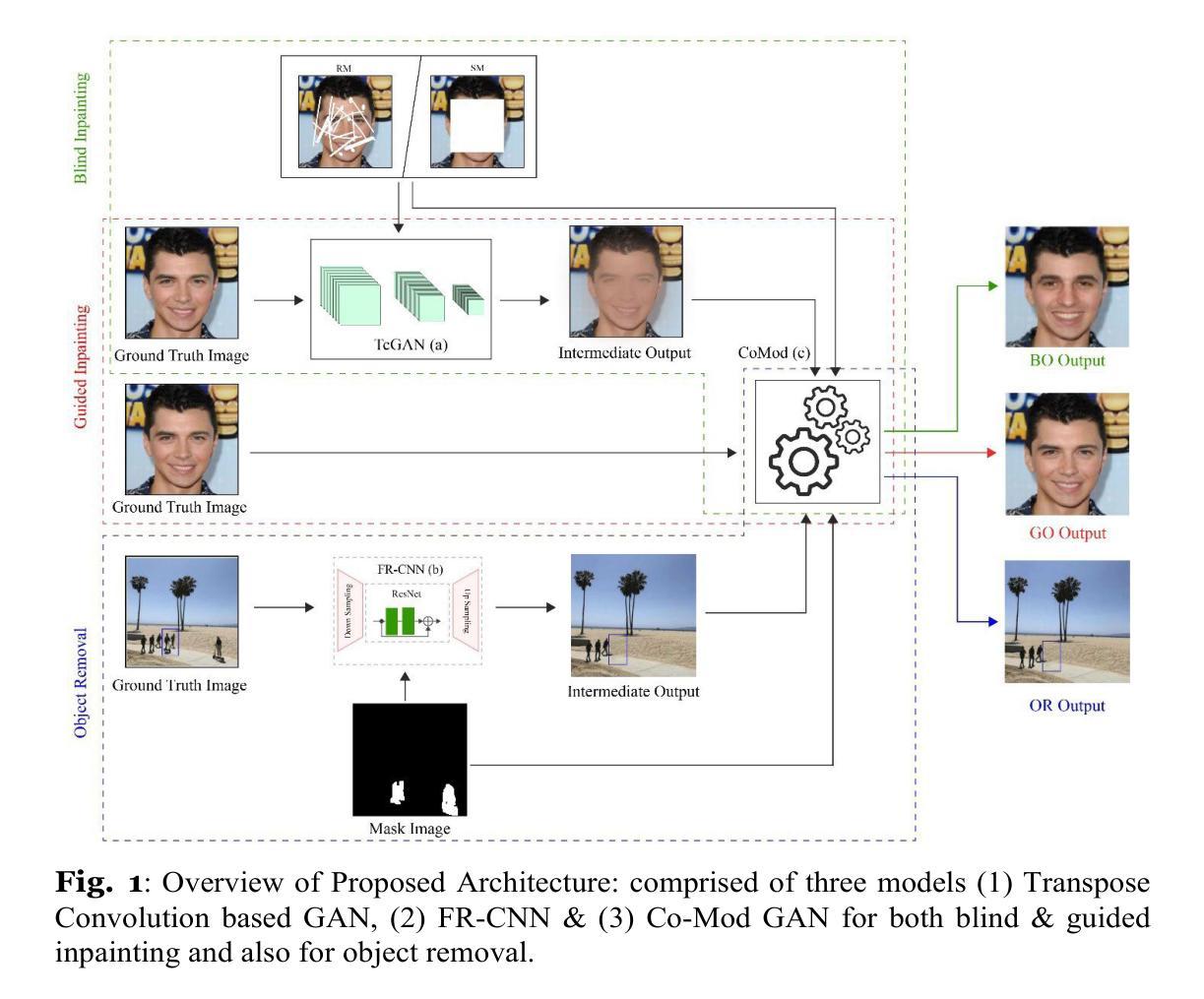
Video Is Worth a Thousand Images: Exploring the Latest Trends in Long Video Generation
Authors:Faraz Waseem, Muhammad Shahzad
An image may convey a thousand words, but a video composed of hundreds or thousands of image frames tells a more intricate story. Despite significant progress in multimodal large language models (MLLMs), generating extended videos remains a formidable challenge. As of this writing, OpenAI’s Sora, the current state-of-the-art system, is still limited to producing videos that are up to one minute in length. This limitation stems from the complexity of long video generation, which requires more than generative AI techniques for approximating density functions essential aspects such as planning, story development, and maintaining spatial and temporal consistency present additional hurdles. Integrating generative AI with a divide-and-conquer approach could improve scalability for longer videos while offering greater control. In this survey, we examine the current landscape of long video generation, covering foundational techniques like GANs and diffusion models, video generation strategies, large-scale training datasets, quality metrics for evaluating long videos, and future research areas to address the limitations of the existing video generation capabilities. We believe it would serve as a comprehensive foundation, offering extensive information to guide future advancements and research in the field of long video generation.
图像可能传达千言万语,但由数百或数千个图像帧组成的视频则讲述了一个更复杂的故事。尽管多模态大型语言模型(MLLMs)取得了重大进展,但生成长视频仍然是一项艰巨的挑战。截至本文写作时,当前最先进的系统OpenAI的Sora仍然仅限于生成最长为一分钟的视频。这一限制源于长视频生成的复杂性,不仅需要生成式AI技术来近似密度函数,而且规划、故事发展和保持空间和时间一致性等关键方面还存在额外的障碍。将生成式AI与分而治之的方法相结合,可以提高长视频的扩展性,同时提供更强大的控制能力。在本文中,我们考察了长视频生成的当前状况,涵盖了诸如GANs和扩散模型等基础技术、视频生成策略、大规模训练数据集、长视频质量评估指标,以及针对现有视频生成能力的局限性的未来研究领域。我们相信这将成为一项全面的基础,提供广泛的信息,以指导长视频生成领域的未来发展与研究。
论文及项目相关链接
PDF 35 pages, 18 figures, Manuscript submitted to ACM
Summary
视频生成技术面临生成长视频的难题,尽管多模态大型语言模型有所进步,但目前最先进系统OpenAI的Sora仍然只能生成一分钟长度的视频。长视频生成需要超越生成式人工智能技术的复杂技术,如规划、故事发展和保持时空一致性等,因此需要采用分而治之的集成策略来提高生成长视频的扩展性。当前文章对当前长视频生成领域进行了全面调查,包括基础技术、视频生成策略、大规模训练数据集等,对未来研究提出了一些解决现有视频生成能力局限性的方法。这篇文章将成为该领域一个全面的研究基础。
Key Takeaways
- 视频生成技术面临生成长视频的难题,目前最先进系统仍有限制。
- 长视频生成需要超越生成式人工智能技术的复杂技术,包括规划、故事发展等。
- 分而治之的集成策略可以提高生成长视频的扩展性。
- 当前文章对当前长视频生成领域进行了全面调查。
- 文章涵盖了基础技术、视频生成策略、大规模训练数据集等方面的内容。
- 对未来研究提出了一些解决现有视频生成能力局限性的方法。
点此查看论文截图


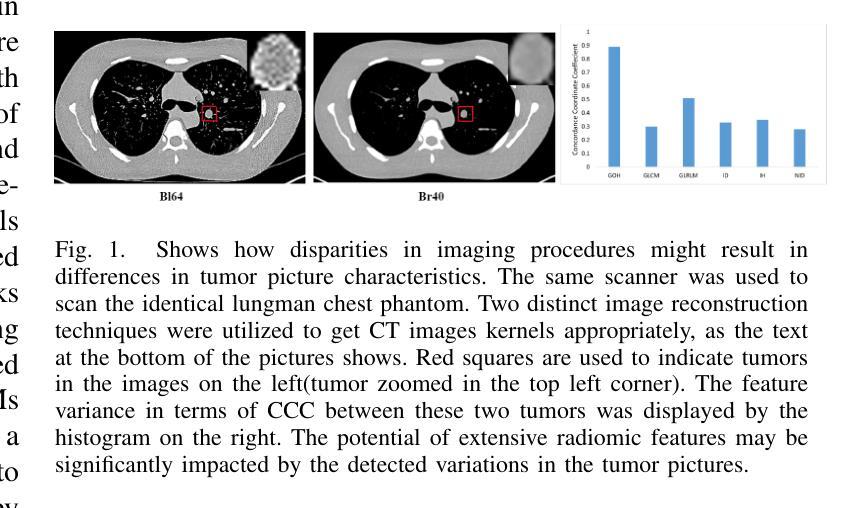
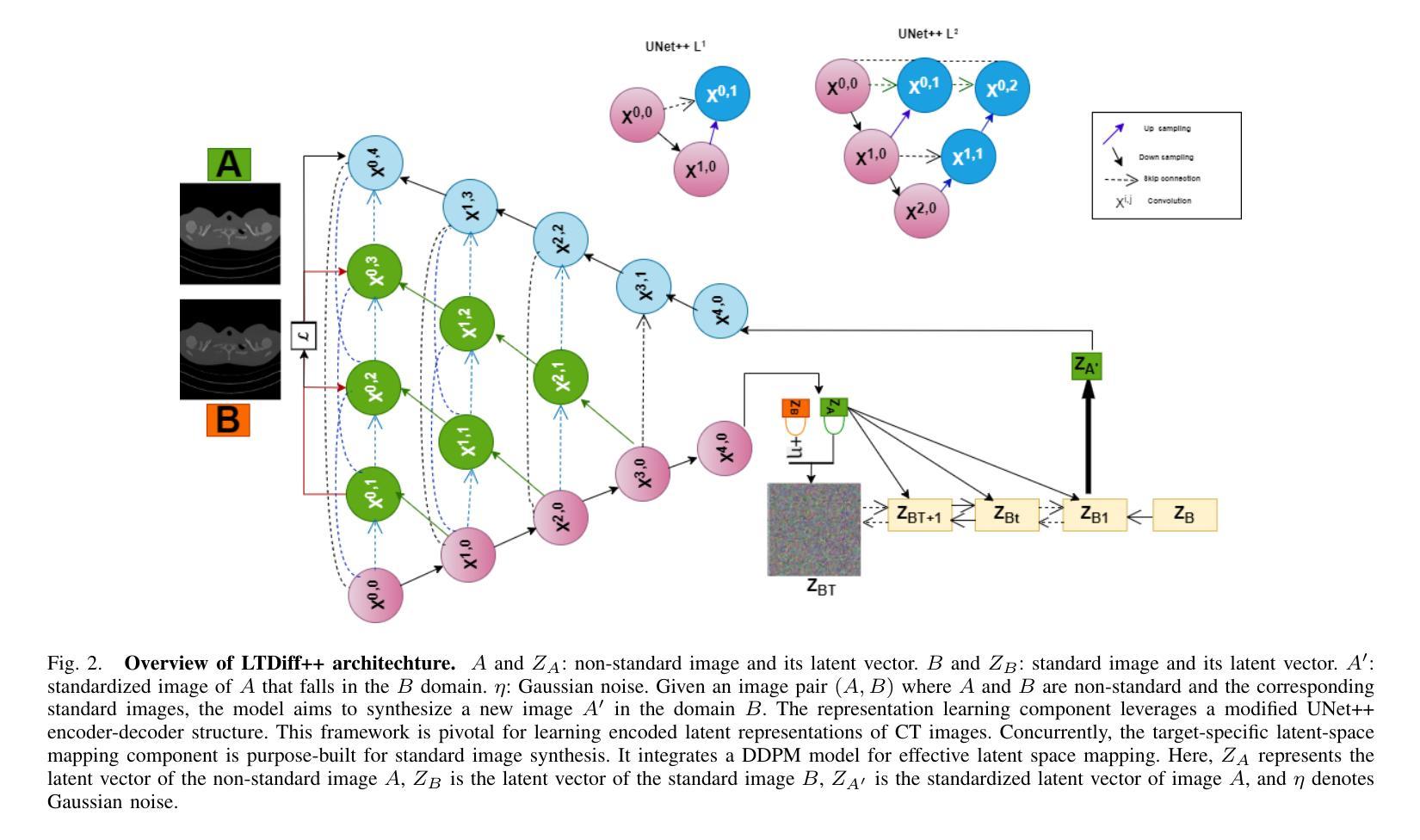
Multiscale Latent Diffusion Model for Enhanced Feature Extraction from Medical Images
Authors:Rabeya Tus Sadia, Jie Zhang, Jin Chen
Various imaging modalities are used in patient diagnosis, each offering unique advantages and valuable insights into anatomy and pathology. Computed Tomography (CT) is crucial in diagnostics, providing high-resolution images for precise internal organ visualization. CT’s ability to detect subtle tissue variations is vital for diagnosing diseases like lung cancer, enabling early detection and accurate tumor assessment. However, variations in CT scanner models and acquisition protocols introduce significant variability in the extracted radiomic features, even when imaging the same patient. This variability poses considerable challenges for downstream research and clinical analysis, which depend on consistent and reliable feature extraction. Current methods for medical image feature extraction, often based on supervised learning approaches, including GAN-based models, face limitations in generalizing across different imaging environments. In response to these challenges, we propose LTDiff++, a multiscale latent diffusion model designed to enhance feature extraction in medical imaging. The model addresses variability by standardizing non-uniform distributions in the latent space, improving feature consistency. LTDiff++ utilizes a UNet++ encoder-decoder architecture coupled with a conditional Denoising Diffusion Probabilistic Model (DDPM) at the latent bottleneck to achieve robust feature extraction and standardization. Extensive empirical evaluations on both patient and phantom CT datasets demonstrate significant improvements in image standardization, with higher Concordance Correlation Coefficients (CCC) across multiple radiomic feature categories. Through these advancements, LTDiff++ represents a promising solution for overcoming the inherent variability in medical imaging data, offering improved reliability and accuracy in feature extraction processes.
在患者诊断中,多种成像模式被广泛应用,每种模式都有其独特的优势和关于解剖学和病理学的宝贵见解。计算机断层扫描(CT)在诊断中至关重要,它提供高分辨率图像,用于精确的内部器官可视化。CT检测细微组织变化的能力对于诊断肺癌等疾病至关重要,能够实现早期检测和准确的肿瘤评估。然而,CT扫描仪型号和采集协议的变化会在提取放射学特征时引入重大差异,即使在成像同一患者时也是如此。这种差异给下游研究和临床分析带来了巨大挑战,后者依赖于一致和可靠的特征提取。当前基于医疗图像特征提取的方法,通常基于有监督学习方法,包括基于GAN的模型,在跨不同成像环境推广方面存在局限性。针对这些挑战,我们提出了LTDiff++,这是一个多尺度潜在扩散模型,旨在提高医疗成像中的特征提取能力。该模型通过标准化潜在空间中的非均匀分布来解决变异性问题,提高特征的一致性。LTDiff++采用UNet++编码器-解码器架构,结合潜在瓶颈处的条件去噪扩散概率模型(DDPM),实现稳健的特征提取和标准化。在患者和幻影CT数据集上的大量实证评估表明,图像标准化方面有了显着改进,多个放射学特征类别的符合度相关系数(CCC)更高。通过这些进展,LTDiff++成为克服医疗成像数据固有可变性的有前途的解决方案,为特征提取过程提供了改进的可靠性和准确性。
论文及项目相关链接
PDF version_3
Summary:
CT在诊断中极为重要,能提供高解析度图像以精确呈现内部器官。然而,不同CT扫描仪型号和采集协议导致的放射组学特征提取的变异性,为下游研究和临床分析带来挑战。我们提出LTDiff++模型,采用多尺度潜在扩散机制标准化潜在空间中的非均匀分布,改善特征一致性,提高医学成像中的特征提取效果。
Key Takeaways:
- CT在诊断中提供高解析度图像,有助于精确呈现内部器官和检测微妙组织变化。
- 不同CT扫描仪和采集协议导致放射组学特征提取的显著变异性。
- 现有基于监督学习的医学图像特征提取方法(包括基于GAN的模型)在跨不同成像环境中泛化时面临局限性。
- LTDiff++模型通过标准化潜在空间中的非均匀分布来应对这些挑战。
- LTDiff++利用UNet++编码器-解码器架构和潜在瓶颈处的条件去噪扩散概率模型实现稳健的特征提取和标准化。
- 在患者和幻影CT数据集上的广泛实验评估显示,LTDiff++在图像标准化方面实现了显著改进,多个放射组学特征类别的吻合度相关系数(CCC)更高。
点此查看论文截图

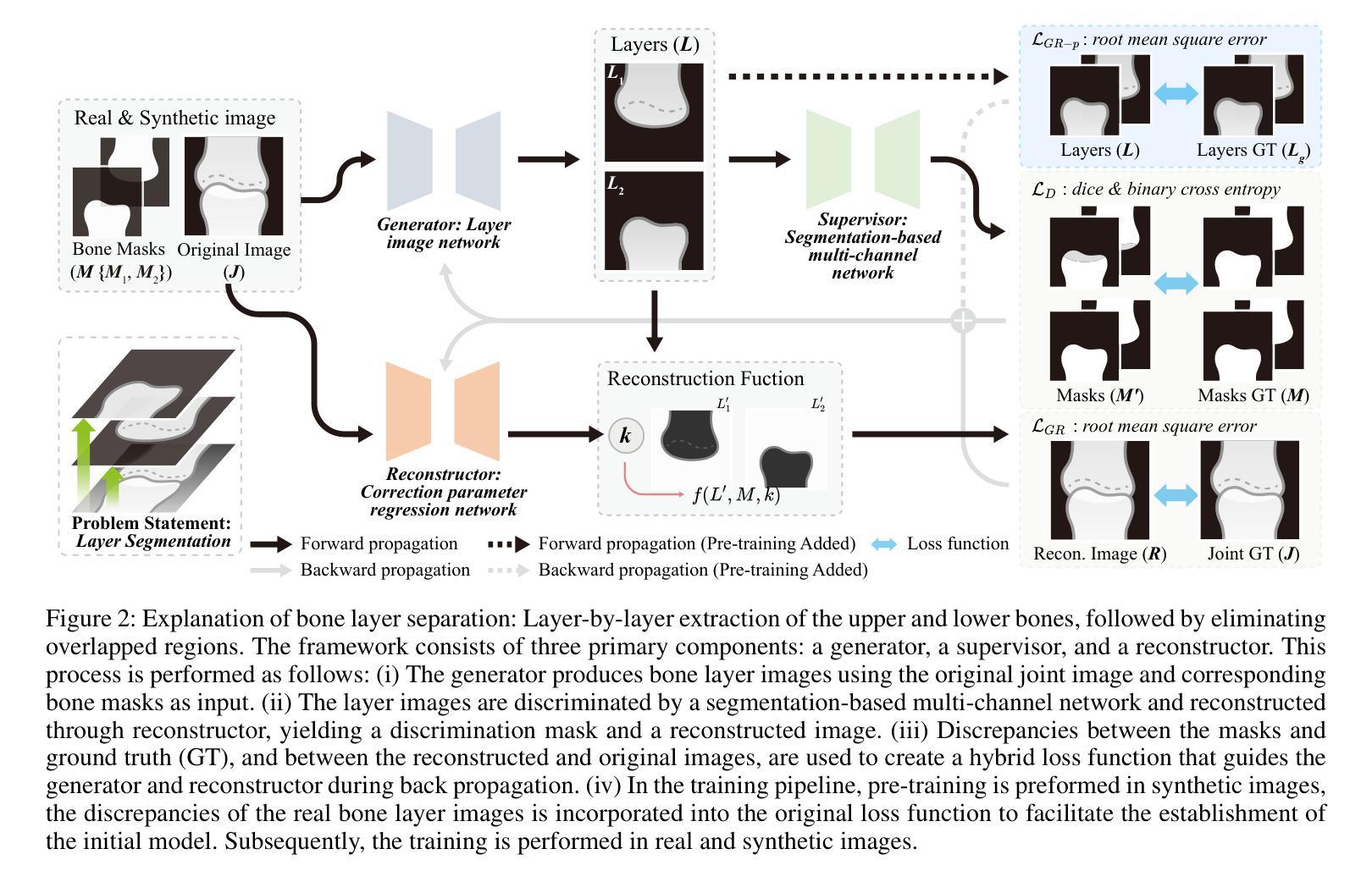
BLS-GAN: A Deep Layer Separation Framework for Eliminating Bone Overlap in Conventional Radiographs
Authors:Haolin Wang, Yafei Ou, Prasoon Ambalathankandy, Gen Ota, Pengyu Dai, Masayuki Ikebe, Kenji Suzuki, Tamotsu Kamishima
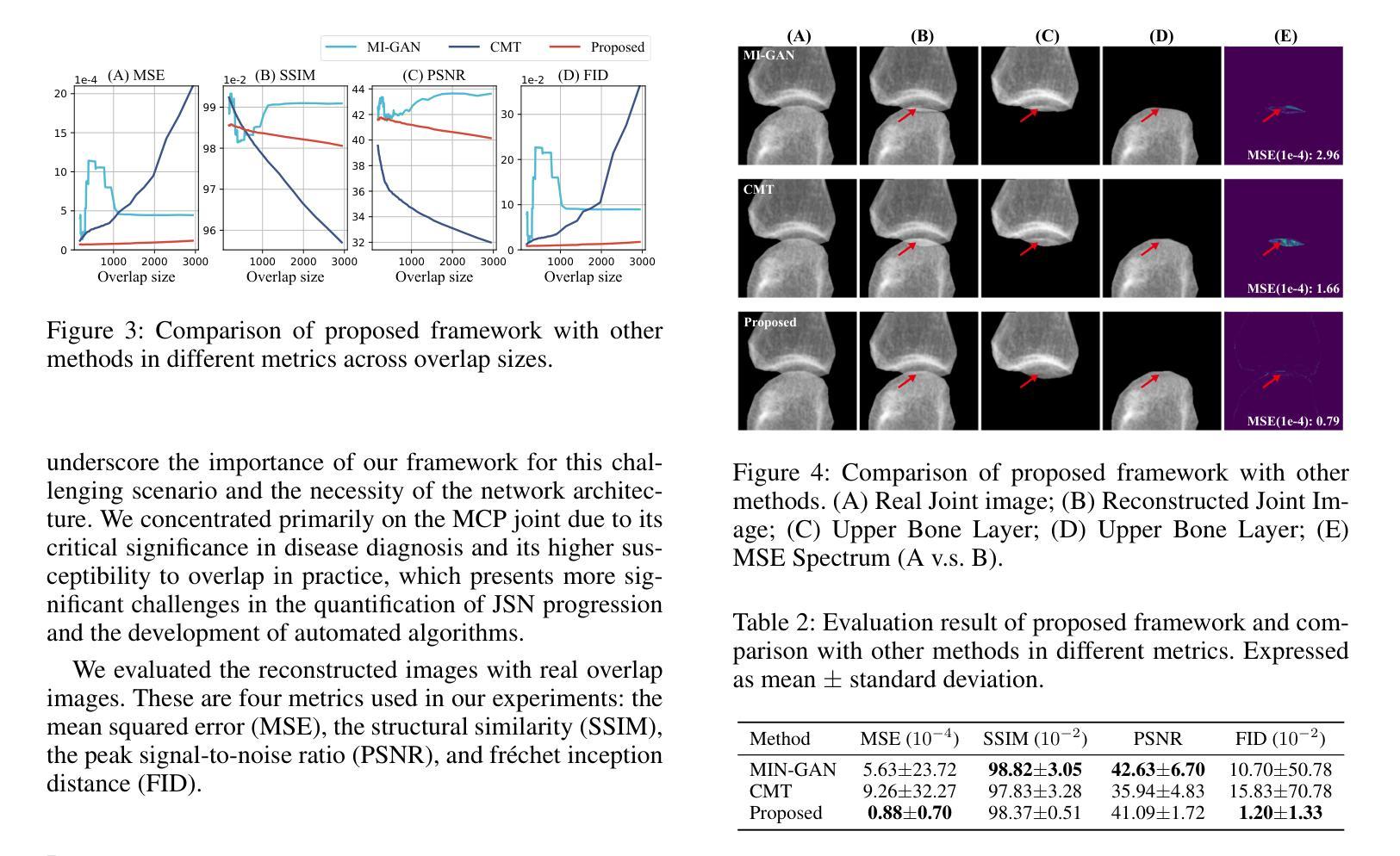
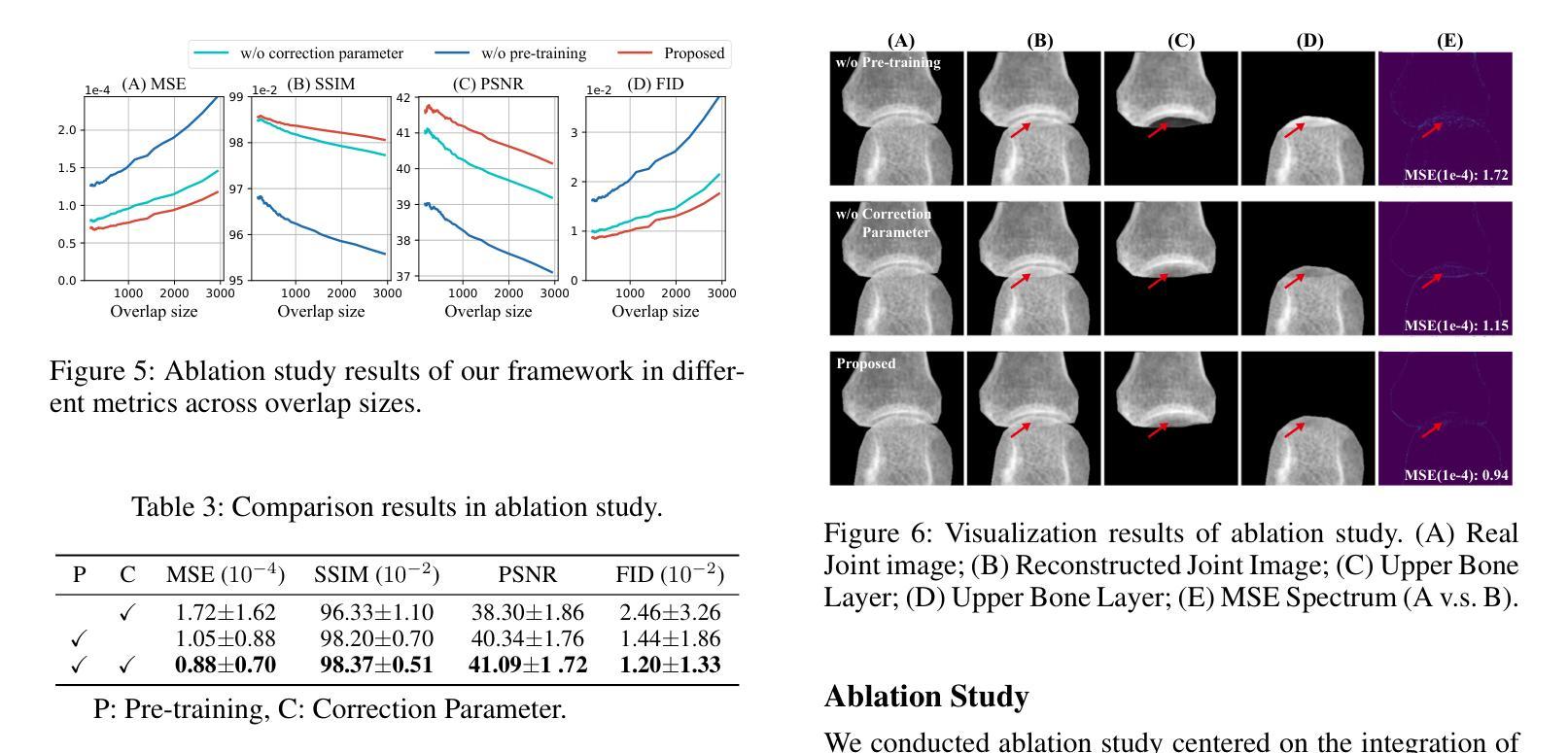
Conventional radiography is the widely used imaging technology in diagnosing, monitoring, and prognosticating musculoskeletal (MSK) diseases because of its easy availability, versatility, and cost-effectiveness. In conventional radiographs, bone overlaps are prevalent, and can impede the accurate assessment of bone characteristics by radiologists or algorithms, posing significant challenges to conventional and computer-aided diagnoses. This work initiated the study of a challenging scenario - bone layer separation in conventional radiographs, in which separate overlapped bone regions enable the independent assessment of the bone characteristics of each bone layer and lay the groundwork for MSK disease diagnosis and its automation. This work proposed a Bone Layer Separation GAN (BLS-GAN) framework that can produce high-quality bone layer images with reasonable bone characteristics and texture. This framework introduced a reconstructor based on conventional radiography imaging principles, which achieved efficient reconstruction and mitigates the recurrent calculations and training instability issues caused by soft tissue in the overlapped regions. Additionally, pre-training with synthetic images was implemented to enhance the stability of both the training process and the results. The generated images passed the visual Turing test, and improved performance in downstream tasks. This work affirms the feasibility of extracting bone layer images from conventional radiographs, which holds promise for leveraging bone layer separation technology to facilitate more comprehensive analytical research in MSK diagnosis, monitoring, and prognosis. Code and dataset: https://github.com/pokeblow/BLS-GAN.git.
传统放射摄影是广泛应用于诊断、监测和预测肌肉骨骼(MSK)疾病的成像技术,因其易于获取、多功能和成本效益高。在传统放射摄影中,骨骼重叠现象普遍,可能会阻碍放射科医生或算法对骨骼特征的准确评估,给传统和计算机辅助诊断带来重大挑战。这项工作开始研究一个具有挑战性的场景——传统放射摄影中的骨骼层次分离技术。在研究中,通过将重叠的骨骼区域进行分离评估,独立分析各个骨骼层次的骨骼特征,为MSK疾病的诊断和自动化诊断奠定基础。这项工作提出了一个骨层分离生成对抗网络(BLS-GAN)框架,可以生成具有合理骨骼特征和纹理的高质量骨层图像。该框架引入了一个基于传统放射成像原理的重构器,实现了有效的重建,并减轻了重叠区域软组织引起的重复计算和训练不稳定问题。此外,通过合成图像进行预训练,增强了训练过程和结果的稳定性。生成的图像通过了视觉图灵测试,并在下游任务中提高了性能。这项工作证实了从常规放射摄影中提取骨层图像的可行性,这为利用骨层分离技术促进MSK诊断、监测和预后预测的更全面分析研究提供了希望。代码和数据集链接:https://github.com/pokeblow/BLS-GAN.git。
论文及项目相关链接
PDF Accepted by AAAI 2025
Summary:
传统放射线照相术广泛应用于诊断、监测和预测肌肉骨骼疾病,但由于骨重叠问题给放射科医生或算法准确评估骨特征带来挑战。本研究提出一种名为BLS-GAN的骨层分离生成对抗网络框架,可生成高质量骨层图像,采用基于传统放射学成像原理的重构器,实现有效重建并减少重叠区域软组织引起的反复计算和训练不稳定问题。预训练合成图像增强了训练和结果的稳定性。生成图像通过视觉图灵测试,并在下游任务中表现出卓越性能。这项工作证实了从常规放射线照片中提取骨层图像的可能性,为利用骨层分离技术促进肌肉骨骼疾病的诊断、监测和预测的综合分析提供了希望。
Key Takeaways:
- 传统放射线照相术在诊断、监测和预测肌肉骨骼疾病方面仍被广泛使用,但由于骨重叠问题带来了评估挑战。
- 本研究提出了一种新的BLS-GAN框架,用于生成高质量的骨层图像。
- BLS-GAN采用了基于传统放射学成像原理的重构器,提高了重建效率并减少了重叠区域软组织引起的计算问题。
- 通过预训练合成图像增强了训练和结果的稳定性。
- 生成的图像通过了视觉图灵测试,并在下游任务中表现出卓越性能。
- 骨层分离技术的实现为更全面的肌肉骨骼疾病诊断、监测和预测提供了可能。
点此查看论文截图

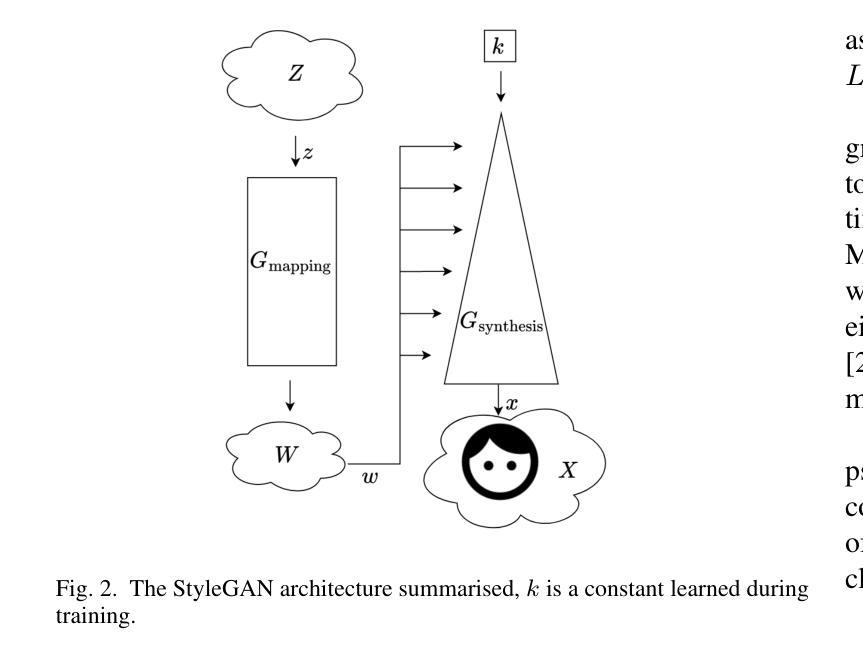
LatentForensics: Towards frugal deepfake detection in the StyleGAN latent space
Authors:Matthieu Delmas, Renaud Seguier
The classification of forged videos has been a challenge for the past few years. Deepfake classifiers can now reliably predict whether or not video frames have been tampered with. However, their performance is tied to both the dataset used for training and the analyst’s computational power. We propose a deepfake detection method that operates in the latent space of a state-of-the-art generative adversarial network (GAN) trained on high-quality face images. The proposed method leverages the structure of the latent space of StyleGAN to learn a lightweight binary classification model. Experimental results on standard datasets reveal that the proposed approach outperforms other state-of-the-art deepfake classification methods, especially in contexts where the data available to train the models is rare, such as when a new manipulation method is introduced. To the best of our knowledge, this is the first study showing the interest of the latent space of StyleGAN for deepfake classification. Combined with other recent studies on the interpretation and manipulation of this latent space, we believe that the proposed approach can further help in developing frugal deepfake classification methods based on interpretable high-level properties of face images.
视频伪造分类在过去几年中一直是一个挑战。深度伪造分类器现在可以可靠地预测视频帧是否被篡改。但是,它们的性能既取决于用于训练的数据集,也取决于分析人员的计算能力。我们提出了一种基于训练有素的最新生成对抗网络(GAN)的潜在空间的深度伪造检测方法,该网络使用高质量的人脸图像进行训练。该方法利用StyleGAN的潜在空间结构来学习轻量级的二分类模型。在标准数据集上的实验结果表明,该方法优于其他最新的深度伪造分类方法,特别是在可用数据稀少的情况下训练模型时表现得尤为出色,例如引入新的操作方法时。据我们所知,这是首次研究StyleGAN的潜在空间在深度伪造分类方面的兴趣。结合最近关于解释和操纵这一潜在空间的研究,我们相信所提出的方法可以帮助开发基于人脸图像可解释的高级特性的节俭型深度伪造分类方法。
论文及项目相关链接
PDF 7 pages, 3 figures, 5 tables
Summary
基于生成对抗网络(GAN)的潜在空间,提出一种深度伪造检测新方法。该方法利用StyleGAN的潜在空间结构,学习轻量级二分类模型。实验结果表明,该方法在标准数据集上优于其他先进深度伪造分类方法,特别是在新操纵方法引入等罕见数据情况下。这是首次研究StyleGAN潜在空间在深度伪造分类中的应用。
Key Takeaways
- 深度伪造视频分类是近年来的挑战。
- 现有深度伪造分类器可预测视频帧是否被篡改,但其性能受训练数据集和计算资源的影响。
- 提出一种基于StyleGAN潜在空间的深度伪造检测方法。
- 该方法学习轻量级二分类模型,利用StyleGAN的潜在空间结构。
- 实验结果表明,该方法在标准数据集上表现优异,特别是在数据稀缺的情况下。
- 这是首次研究StyleGAN潜在空间在深度伪造分类中的应用。
点此查看论文截图