⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-02 更新
Enhancing Multimodal Emotion Recognition through Multi-Granularity Cross-Modal Alignment
Authors:Xuechen Wang, Shiwan Zhao, Haoqin Sun, Hui Wang, Jiaming Zhou, Yong Qin
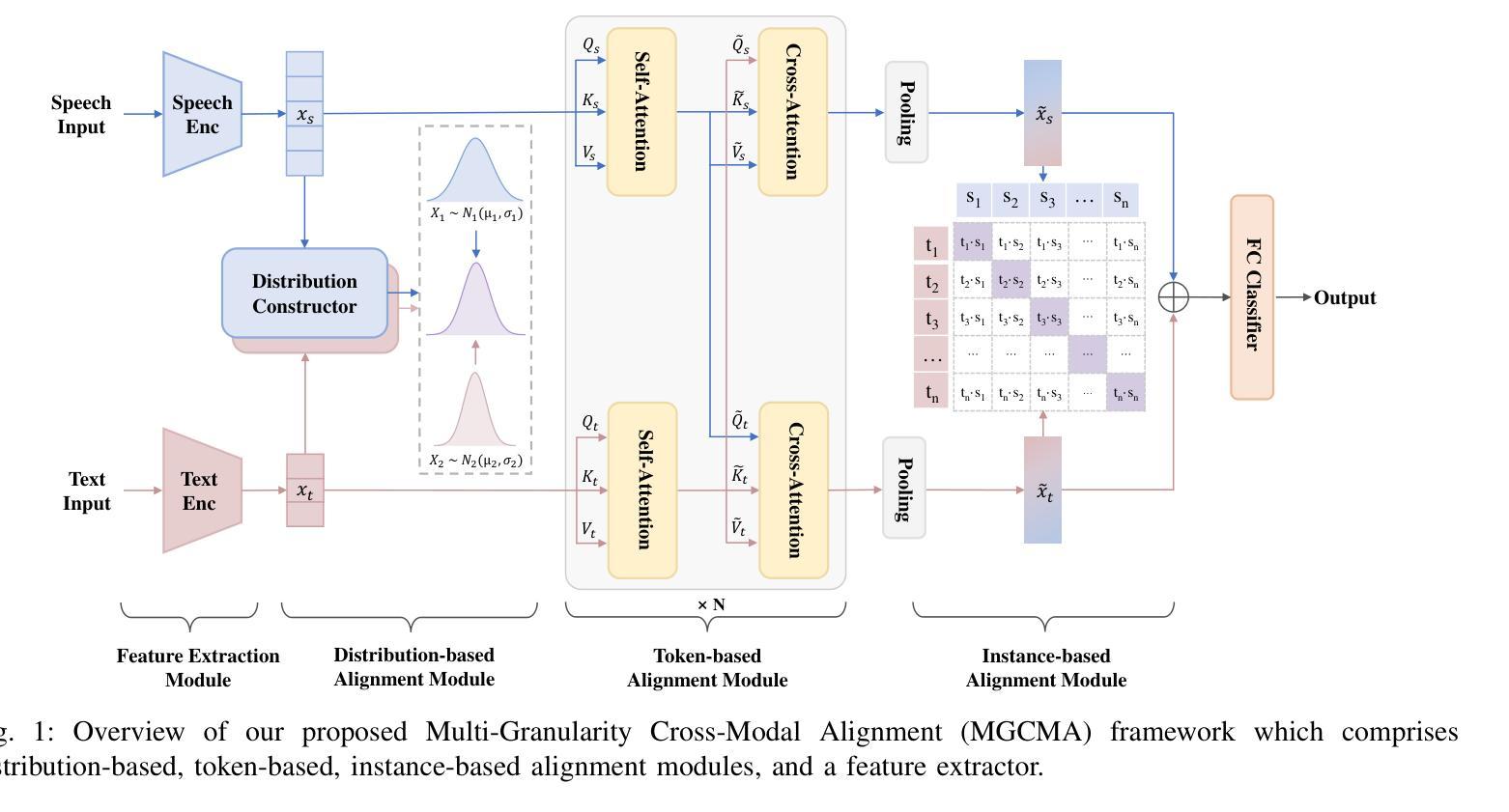
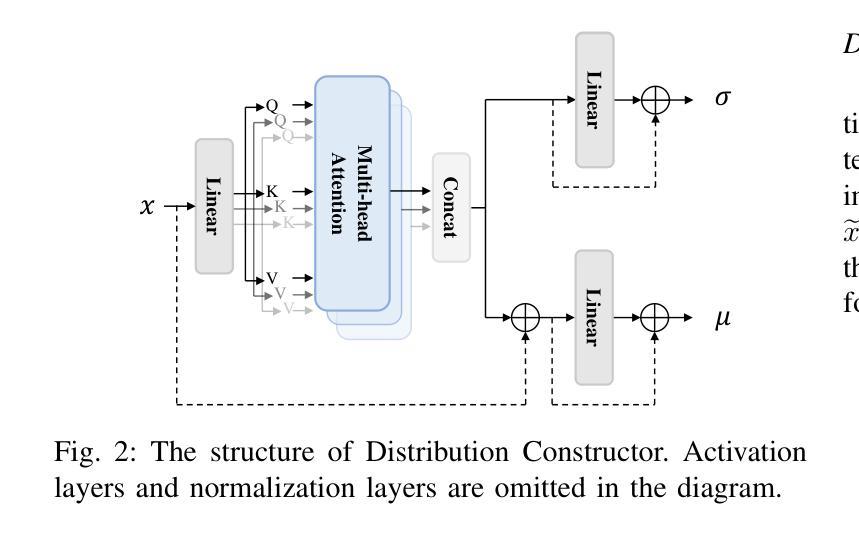
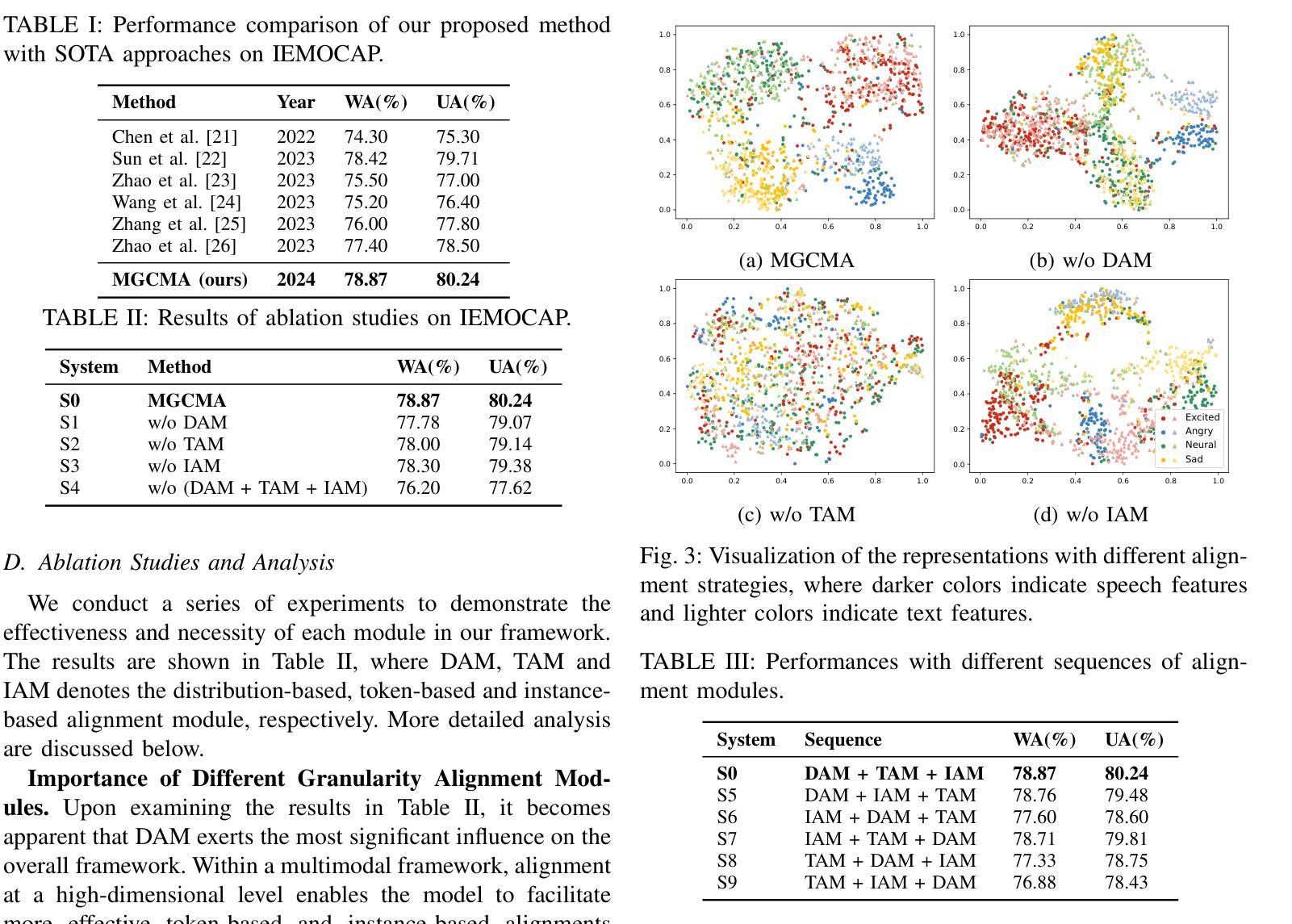
Multimodal emotion recognition (MER), leveraging speech and text, has emerged as a pivotal domain within human-computer interaction, demanding sophisticated methods for effective multimodal integration. The challenge of aligning features across these modalities is significant, with most existing approaches adopting a singular alignment strategy. Such a narrow focus not only limits model performance but also fails to address the complexity and ambiguity inherent in emotional expressions. In response, this paper introduces a Multi-Granularity Cross-Modal Alignment (MGCMA) framework, distinguished by its comprehensive approach encompassing distribution-based, instance-based, and token-based alignment modules. This framework enables a multi-level perception of emotional information across modalities. Our experiments on IEMOCAP demonstrate that our proposed method outperforms current state-of-the-art techniques.
多模态情感识别(MER),利用语音和文本,已成为人机交互中的关键领域,需要有效的方法进行多模态集成的高级方法。不同模态的特征对齐挑战巨大,现有的大多数方法都采用了单一的对齐策略。这种狭窄的焦点不仅限制了模型性能,而且未能解决情感表达中固有的复杂性和模糊性。针对这一问题,本文提出了基于多粒度跨模态对齐(MGCMA)的框架,其显著特点在于包括基于分布、基于实例和基于标记的对齐模块的综合方法。该框架实现了跨模态的情感信息多级感知。我们在IEMOCAP上的实验表明,我们提出的方法优于当前的最先进技术。
论文及项目相关链接
PDF ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
Summary
本文介绍了多模态情感识别(MER)领域的重要性和挑战,该领域利用语音和文本信息,是人与计算机交互中的一个关键领域。为了有效解决多模态融合的问题,本文提出了一种名为多粒度跨模态对齐(MGCMA)的框架,该框架包括分布对齐、实例对齐和令牌对齐三个模块,能够在多个层次上感知跨模态的情感信息。在IEMOCAP数据集上的实验表明,该方法优于当前最先进的技术。
Key Takeaways
- 多模态情感识别(MER)已成为人与计算机交互中的关键领域,需要先进的多模态融合方法。
- 现有方法大多采用单一的模态对齐策略,存在局限性,难以处理情感表达的复杂性和模糊性。
- 本文提出了多粒度跨模态对齐(MGCMA)框架,包含分布对齐、实例对齐和令牌对齐三个模块,以全面应对情感信息的多层次感知需求。
- MGCMA框架通过综合不同粒度的信息,提高了模型性能和对情感表达的适应性。
- 在IEMOCAP数据集上的实验表明,MGCMA框架的方法优于当前最先进的技术。
- 此方法有望为未来的情感识别和人机交互提供新的思路和方法。
点此查看论文截图

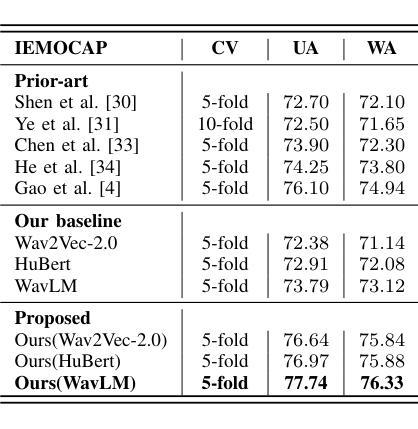
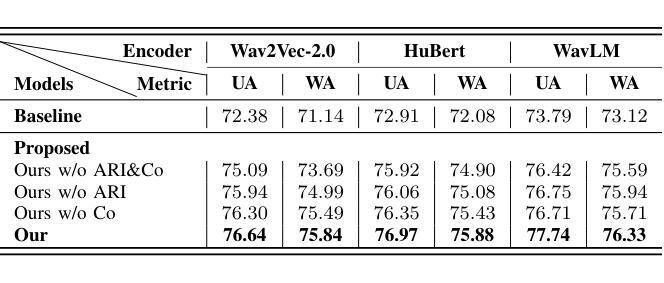
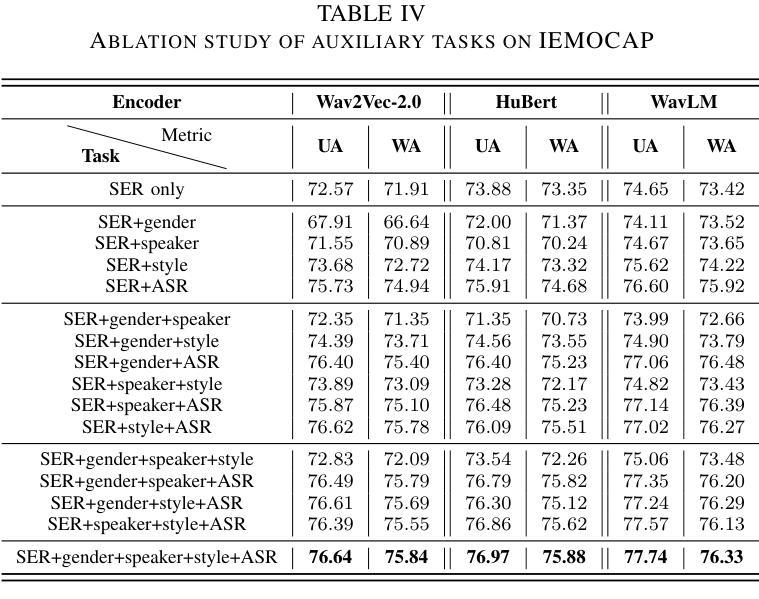
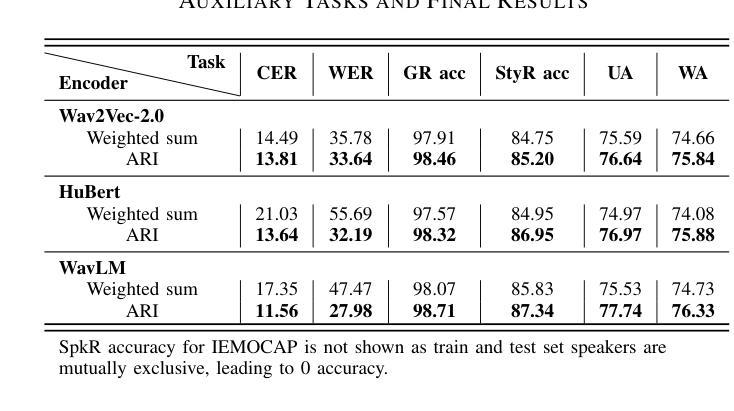
Metadata-Enhanced Speech Emotion Recognition: Augmented Residual Integration and Co-Attention in Two-Stage Fine-Tuning
Authors:Zixiang Wan, Ziyue Qiu, Yiyang Liu, Wei-Qiang Zhang
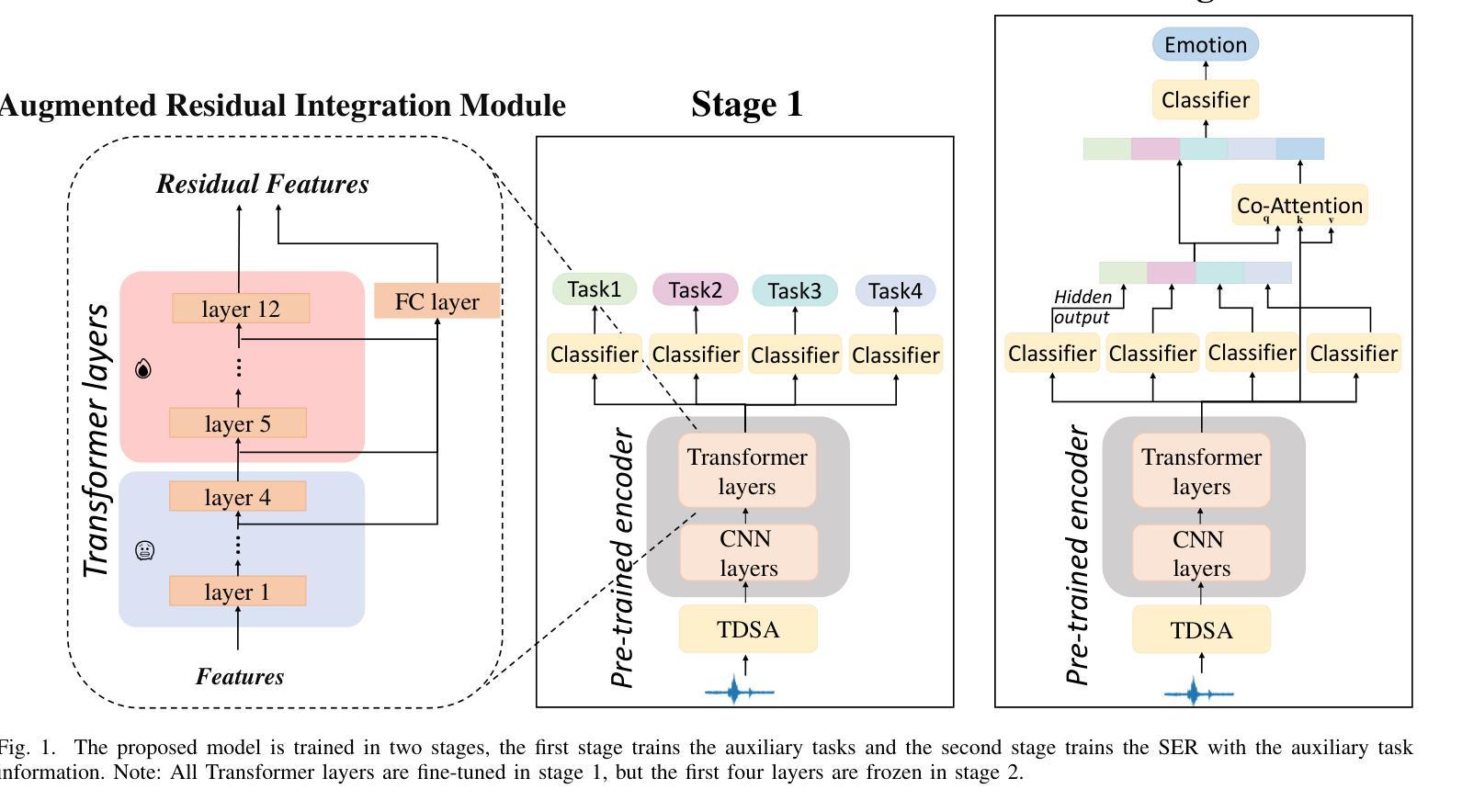
Speech Emotion Recognition (SER) involves analyzing vocal expressions to determine the emotional state of speakers, where the comprehensive and thorough utilization of audio information is paramount. Therefore, we propose a novel approach on self-supervised learning (SSL) models that employs all available auxiliary information – specifically metadata – to enhance performance. Through a two-stage fine-tuning method in multi-task learning, we introduce the Augmented Residual Integration (ARI) module, which enhances transformer layers in encoder of SSL models. The module efficiently preserves acoustic features across all different levels, thereby significantly improving the performance of metadata-related auxiliary tasks that require various levels of features. Moreover, the Co-attention module is incorporated due to its complementary nature with ARI, enabling the model to effectively utilize multidimensional information and contextual relationships from metadata-related auxiliary tasks. Under pre-trained base models and speaker-independent setup, our approach consistently surpasses state-of-the-art (SOTA) models on multiple SSL encoders for the IEMOCAP dataset.
语音情感识别(SER)涉及分析语音表达以确定说话人的情绪状态,其中全面彻底地利用音频信息至关重要。因此,我们提出了一种基于自监督学习(SSL)模型的新方法,该方法利用所有可用的辅助信息——特别是元数据——来提高性能。通过多任务学习中的两阶段微调方法,我们引入了增强残差集成(ARI)模块,该模块增强了SSL模型的编码器中的变压器层。该模块有效地保留了所有不同级别的声学特征,从而显著提高了与元数据相关的辅助任务的性能,这些任务需要不同级别的特征。此外,由于ARI的互补性质,还结合了协同注意模块,使模型能够有效利用来自元数据相关辅助任务的多维信息和上下文关系。在预训练基础模型和独立于说话人的设置下,我们的方法在多个SSL编码器上的表现始终超过了IEMOCAP数据集的最新模型。
论文及项目相关链接
PDF accepted by ICASSP2025. \c{opyright}2025 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component
Summary
本文提出了一种基于自监督学习(SSL)模型的语音情感识别(SER)新方法。该方法利用所有可用的辅助信息——特别是元数据——来提高性能。通过多任务学习中的两阶段微调方法,引入了增强残差集成(ARI)模块,该模块增强了SSL模型的编码器中的变压器层。此外,还引入了协同注意模块,与ARI模块互补,使模型能够有效地利用来自元数据相关辅助任务的多维信息和上下文关系。在预训练基础模型和独立于说话人的设置下,该方法在IEMOCAP数据集上的表现持续超越了最新的SSL编码器。
Key Takeaways
- 语音情感识别(SER)通过分析语音表达来确定说话人的情绪状态,其中音频信息的全面和彻底利用至关重要。
- 提出了一种基于自监督学习(SSL)模型的新方法,利用包括元数据在内的所有可用辅助信息来提高性能。
- 引入了增强残差集成(ARI)模块,该模块增强了SSL模型的编码器中的变压器层,能够保留不同层次的声学特征。
- 通过两阶段微调方法和多任务学习,ARI模块显著提高元数据相关辅助任务的性能。
- 引入了协同注意模块,与ARI模块互补,能更有效地利用元数据相关辅助任务的多维信息和上下文关系。
- 在独立于说话人的设置和预训练基础模型下,该方法在IEMOCAP数据集上的表现超越了最新的SSL编码器。
点此查看论文截图

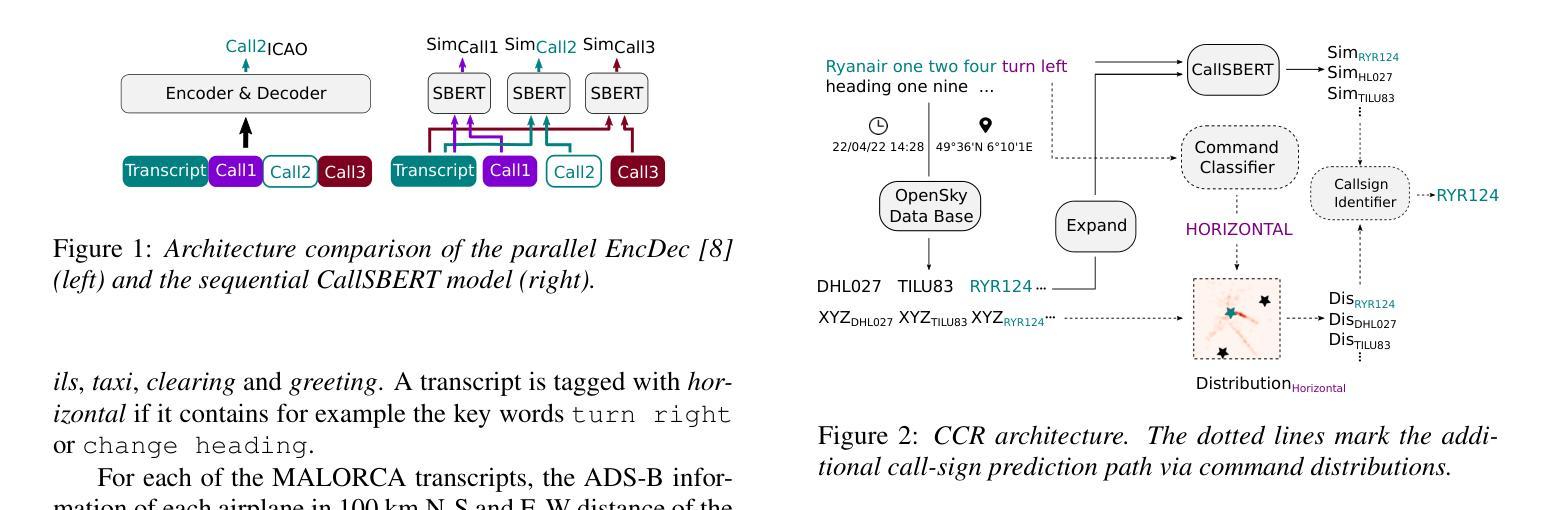
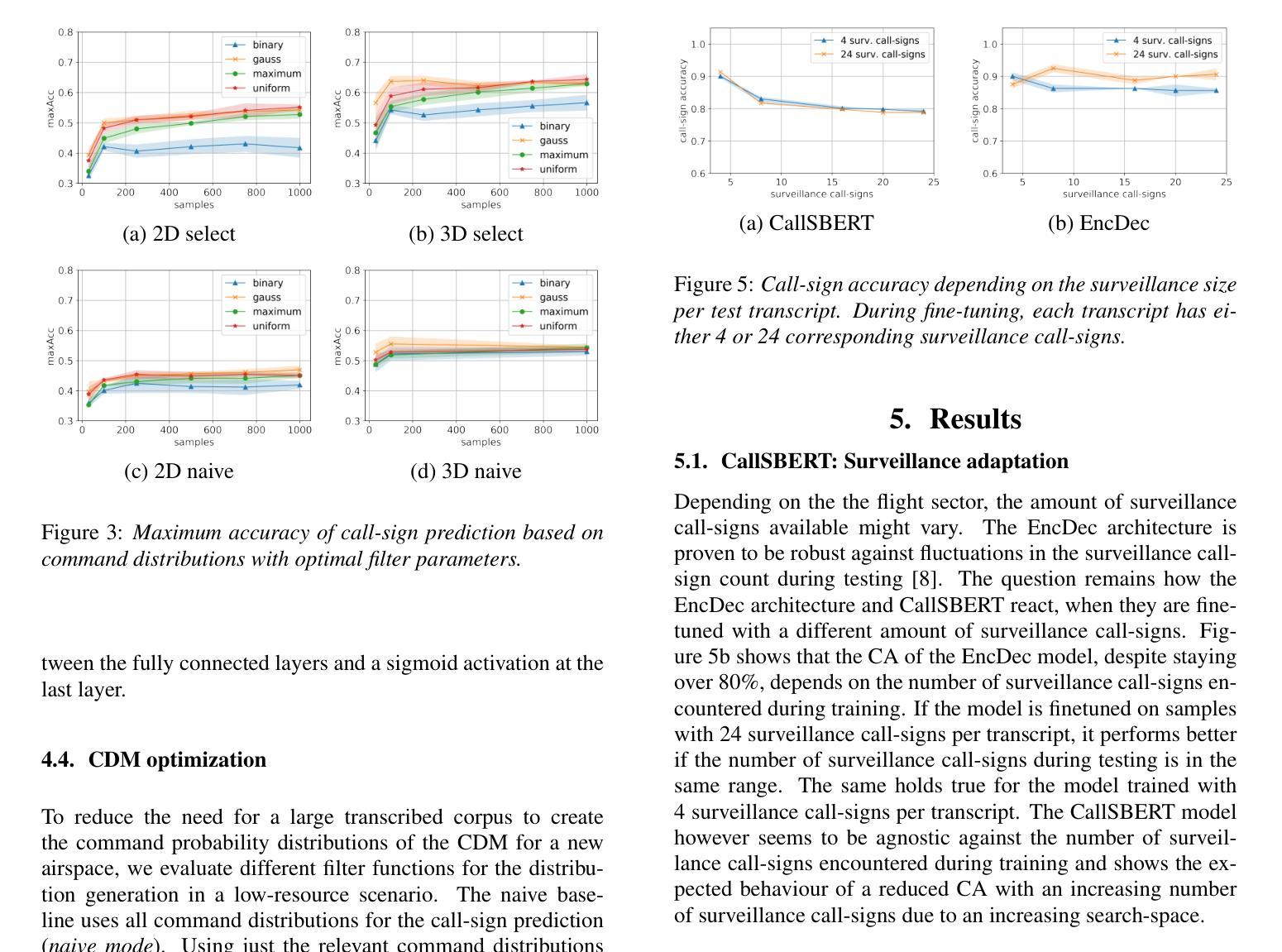
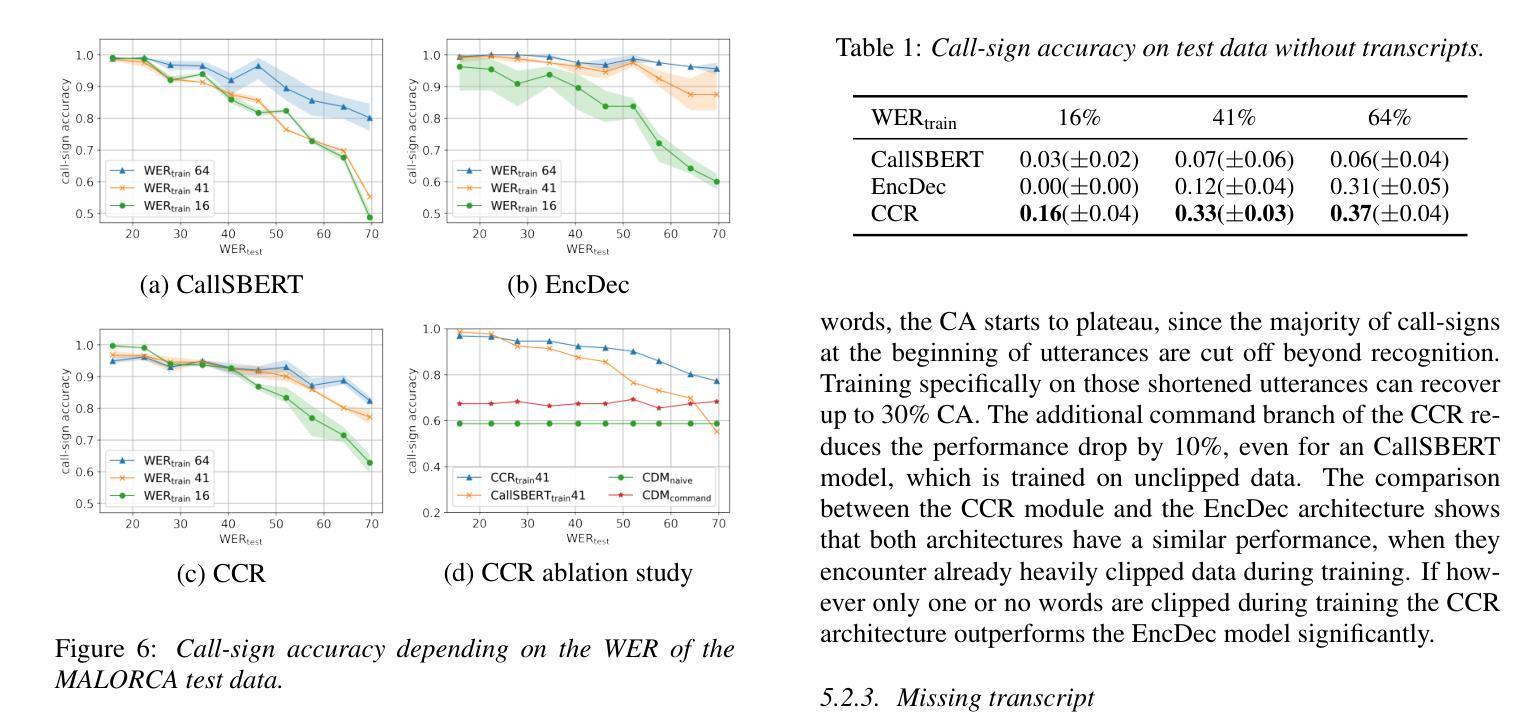
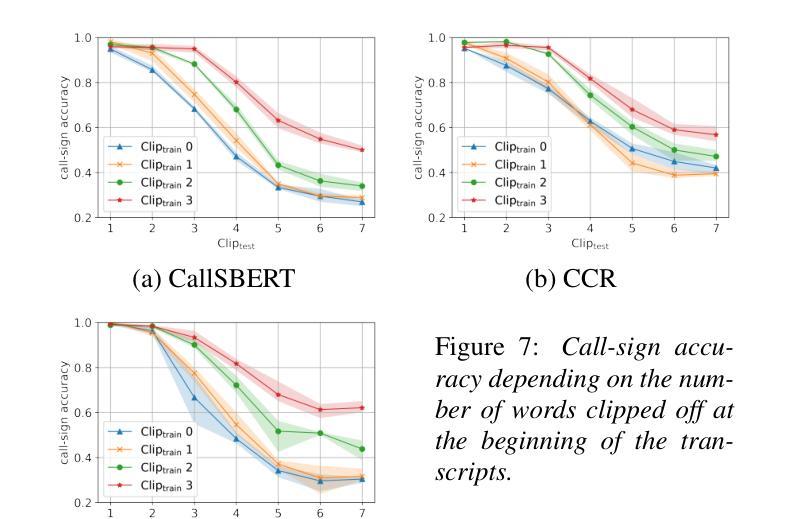
Utilizing Multimodal Data for Edge Case Robust Call-sign Recognition and Understanding
Authors:Alexander Blatt, Dietrich Klakow
Operational machine-learning based assistant systems must be robust in a wide range of scenarios. This hold especially true for the air-traffic control (ATC) domain. The robustness of an architecture is particularly evident in edge cases, such as high word error rate (WER) transcripts resulting from noisy ATC recordings or partial transcripts due to clipped recordings. To increase the edge-case robustness of call-sign recognition and understanding (CRU), a core tasks in ATC speech processing, we propose the multimodal call-sign-command recovery model (CCR). The CCR architecture leads to an increase in the edge case performance of up to 15%. We demonstrate this on our second proposed architecture, CallSBERT. A CRU model that has less parameters, can be fine-tuned noticeably faster and is more robust during fine-tuning than the state of the art for CRU. Furthermore, we demonstrate that optimizing for edge cases leads to a significantly higher accuracy across a wide operational range.
基于操作机器学习的辅助系统必须在各种场景中表现出强大的稳健性。这在航空交通管制(ATC)领域尤为准确。一个架构的稳健性在极端情况下尤为明显,例如由于嘈杂的ATC录音导致的高单词错误率(WER)转录或由于剪辑录音导致的部分转录。为了提高航空交通管制语音识别和理解的边缘情况稳健性(CRU是航空交通管制语音识别的核心任务之一),我们提出了多模式呼叫标志命令恢复模型(CCR)。CCR架构提高了边缘情况性能,最高可达15%。我们在第二个提出的架构CallSBERT上展示了这一点。CRU模型参数更少,微调速度明显更快,并且在微调过程中比现有的CRU技术更加稳健。此外,我们证明了针对极端情况进行优化可以在广泛的运行范围内显著提高准确性。
论文及项目相关链接
Summary
在航空交通管制(ATC)领域中,基于机器学习的助理系统需要在各种场景下具备稳健性。为提高呼叫符号识别与理解(CRU)的边缘情况稳健性,提出多模态呼叫符号命令恢复模型(CCR)。CCR架构提高了边缘案例的性能,达到15%。同时,我们展示了具有更少参数、更快微调速度和更精细的稳健性的CallSBERT模型。优化边缘情况显著提高宽操作范围内的准确性。
Key Takeaways
- 机器学习助理系统在航空交通管制领域需具备稳健性以应对各种场景。
- 呼叫符号识别与理解(CRU)的边缘情况稳健性对ATC语音识别至关重要。
- 提出的多模态呼叫符号命令恢复模型(CCR)提高了边缘案例的性能。
- CCR架构在提升边缘案例性能方面效果显著,性能提升达15%。
- CallSBERT模型具有更少参数、更快的微调速度和更高的稳健性。
- 优化边缘情况显著提高在各种操作场景下的准确性。
点此查看论文截图

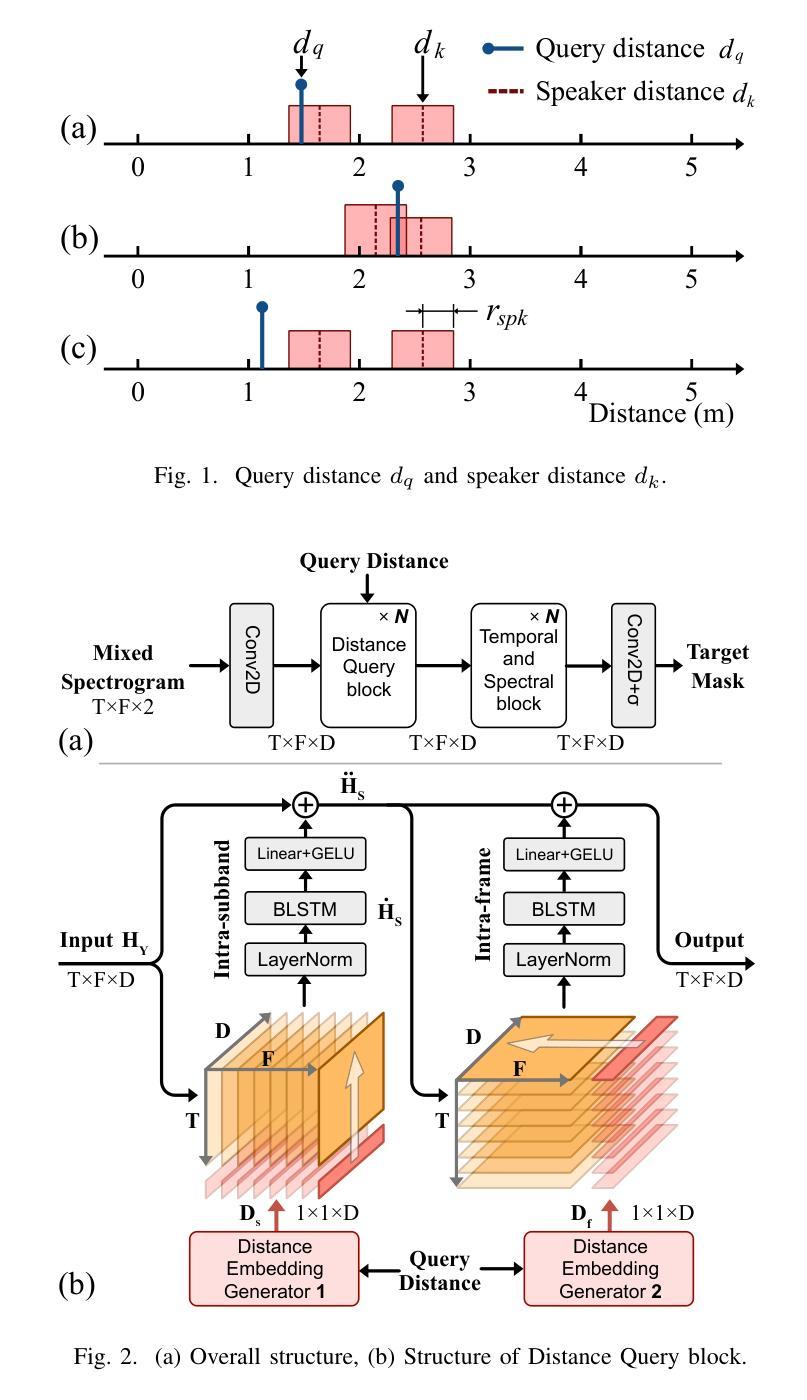
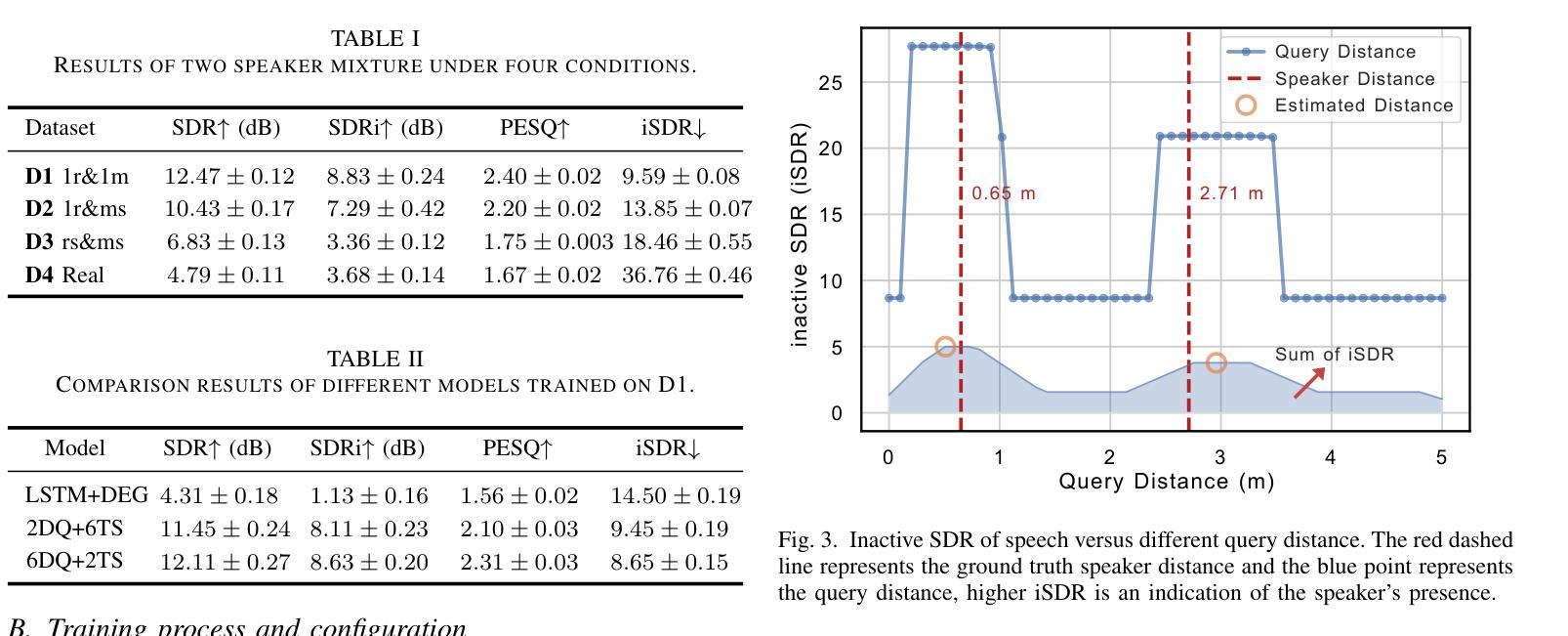
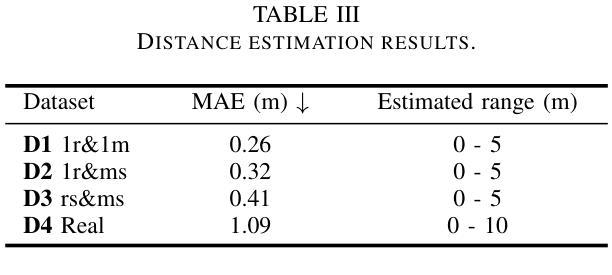
Distance Based Single-Channel Target Speech Extraction
Authors:Runwu Shi, Benjamin Yen, Kazuhiro Nakadai
This paper aims to achieve single-channel target speech extraction (TSE) in enclosures by solely utilizing distance information. This is the first work that utilizes only distance cues without using speaker physiological information for single-channel TSE. Inspired by recent single-channel Distance-based separation and extraction methods, we introduce a novel model that efficiently fuses distance information with time-frequency (TF) bins for TSE. Experimental results in both single-room and multi-room scenarios demonstrate the feasibility and effectiveness of our approach. This method can also be employed to estimate the distances of different speakers in mixed speech. Online demos are available at https://runwushi.github.io/distance-demo-page.
本文旨在通过仅利用距离信息实现封闭环境中的单通道目标语音提取(TSE)。这是第一项仅使用距离线索而无需说话人生理信息进行单通道TSE的工作。受最近的基于单通道距离的分离和提取方法的启发,我们引入了一种新型模型,该模型可以有效地将距离信息与时间频率(TF)结合进行TSE。在单室和多室场景下的实验结果证明了我们的方法的可行性和有效性。此方法还可以用于估计混合语音中不同说话人的距离。在线演示请访问:https://runwoshi.github.io/distance-demo-page。
论文及项目相关链接
PDF 5 pages, 3 figures, accepted by ICASSP 2025
总结
本论文旨在实现单通道目标语音提取(TSE),仅利用距离信息在封闭环境中进行。这是首次尝试在不使用说话人生理信息的情况下,利用距离线索进行单通道TSE。受近期单通道基于距离的分离和提取方法的启发,我们引入了一种新型模型,该模型能够高效地将距离信息与时间频率(TF)仓进行融合以实现TSE。在单室和多室场景下的实验结果证明了我们的方法的可行性和有效性。此方法也可用于估算混合语音中不同说话人的距离。在线演示请访问:https://runwoshi.github.io/distance-demo-page。
关键见解
- 本论文实现了仅利用距离信息进行单通道目标语音提取的方法,突破了传统方法的限制。
- 首次在不使用说话人生理信息的情况下,使用距离线索进行单通道TSE。
- 提出了一种融合距离信息与时间频率仓的新型模型,以提高TSE效率。
- 在单室和多室场景下进行的实验证明了该方法的可行性和有效性。
- 该方法可应用于估算混合语音中不同说话人的距离。
- 论文提供在线演示,便于进一步了解和验证所提出的方法。
点此查看论文截图

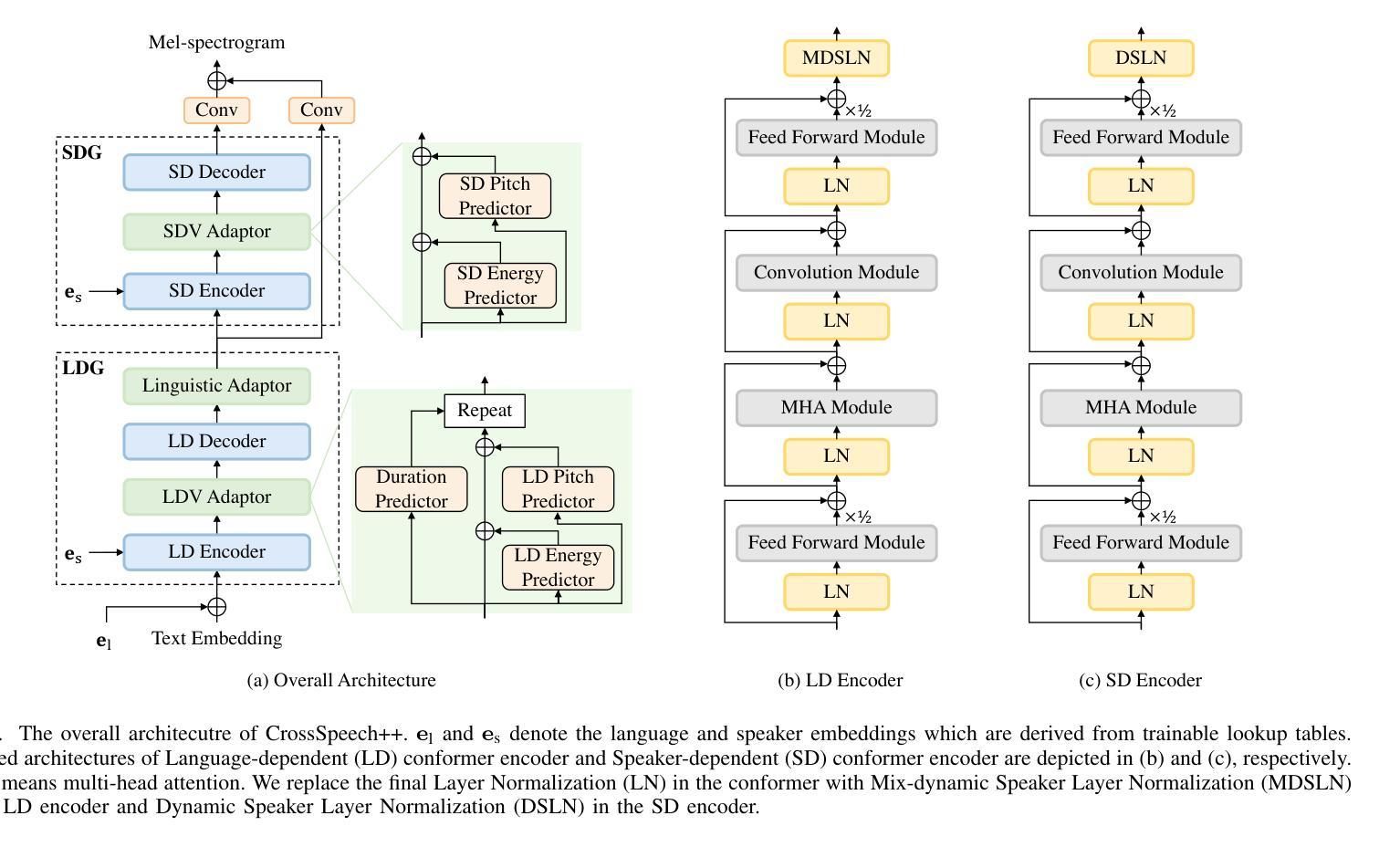
CrossSpeech++: Cross-lingual Speech Synthesis with Decoupled Language and Speaker Generation
Authors:Ji-Hoon Kim, Hong-Sun Yang, Yoon-Cheol Ju, Il-Hwan Kim, Byeong-Yeol Kim, Joon Son Chung
The goal of this work is to generate natural speech in multiple languages while maintaining the same speaker identity, a task known as cross-lingual speech synthesis. A key challenge of cross-lingual speech synthesis is the language-speaker entanglement problem, which causes the quality of cross-lingual systems to lag behind that of intra-lingual systems. In this paper, we propose CrossSpeech++, which effectively disentangles language and speaker information and significantly improves the quality of cross-lingual speech synthesis. To this end, we break the complex speech generation pipeline into two simple components: language-dependent and speaker-dependent generators. The language-dependent generator produces linguistic variations that are not biased by specific speaker attributes. The speaker-dependent generator models acoustic variations that characterize speaker identity. By handling each type of information in separate modules, our method can effectively disentangle language and speaker representation. We conduct extensive experiments using various metrics, and demonstrate that CrossSpeech++ achieves significant improvements in cross-lingual speech synthesis, outperforming existing methods by a large margin.
本文的目标是在多种语言生成自然语音的同时保持相同的说话人身份,这一任务被称为跨语言语音合成。跨语言语音合成的一个关键挑战是语言与说话人的纠缠问题,这导致跨语言系统的质量落后于单语言系统。在本文中,我们提出了CrossSpeech++,它有效地解开了语言和说话人的信息,并大大提高了跨语言语音合成的质量。为此,我们将复杂的语音生成管道分解为两个简单的组件:语言相关生成器和说话人相关生成器。语言相关生成器产生不受特定说话人属性影响的语言变化。说话人相关生成器对表征说话人身份的声学变化进行建模。通过在不同的模块中处理每种类型的信息,我们的方法可以有效地解开语言和说话人的表示。我们使用各种度量指标进行了广泛的实验,证明CrossSpeech++在跨语言语音合成方面取得了显著的改进,大大优于现有方法。
论文及项目相关链接
Summary
该论文旨在解决跨语言语音合成中的语言与说话者纠缠问题,提出一种名为CrossSpeech++的新方法,该方法可有效分离语言和说话者信息,显著提高跨语言语音合成的质量。通过把复杂的语音生成管道分解成两个简单组件:语言相关生成器和说话者相关生成器,分别处理语言和说话者信息,从而实现语言与说话者的有效分离。实验证明,CrossSpeech++在跨语言语音合成方面取得了显著改进,大幅超越了现有方法。
Key Takeaways
- 该论文旨在实现跨语言语音合成中的语言与说话者信息的有效分离。
- 提出了一种名为CrossSpeech++的新方法,将复杂的语音生成过程分解为两个简单组件来处理语言和说话者信息。
- 语言相关生成器可以产生不受特定说话人属性影响的语言变化。
- 说话者相关生成器可以模拟说话人的声学特征变化。
- 通过分离语言和说话者信息,CrossSpeech++提高了跨语言语音合成的质量。
- 实验证明,CrossSpeech++在跨语言语音合成方面取得了显著成效,大幅超越了现有方法。
点此查看论文截图


UniAvatar: Taming Lifelike Audio-Driven Talking Head Generation with Comprehensive Motion and Lighting Control
Authors:Wenzhang Sun, Xiang Li, Donglin Di, Zhuding Liang, Qiyuan Zhang, Hao Li, Wei Chen, Jianxun Cui
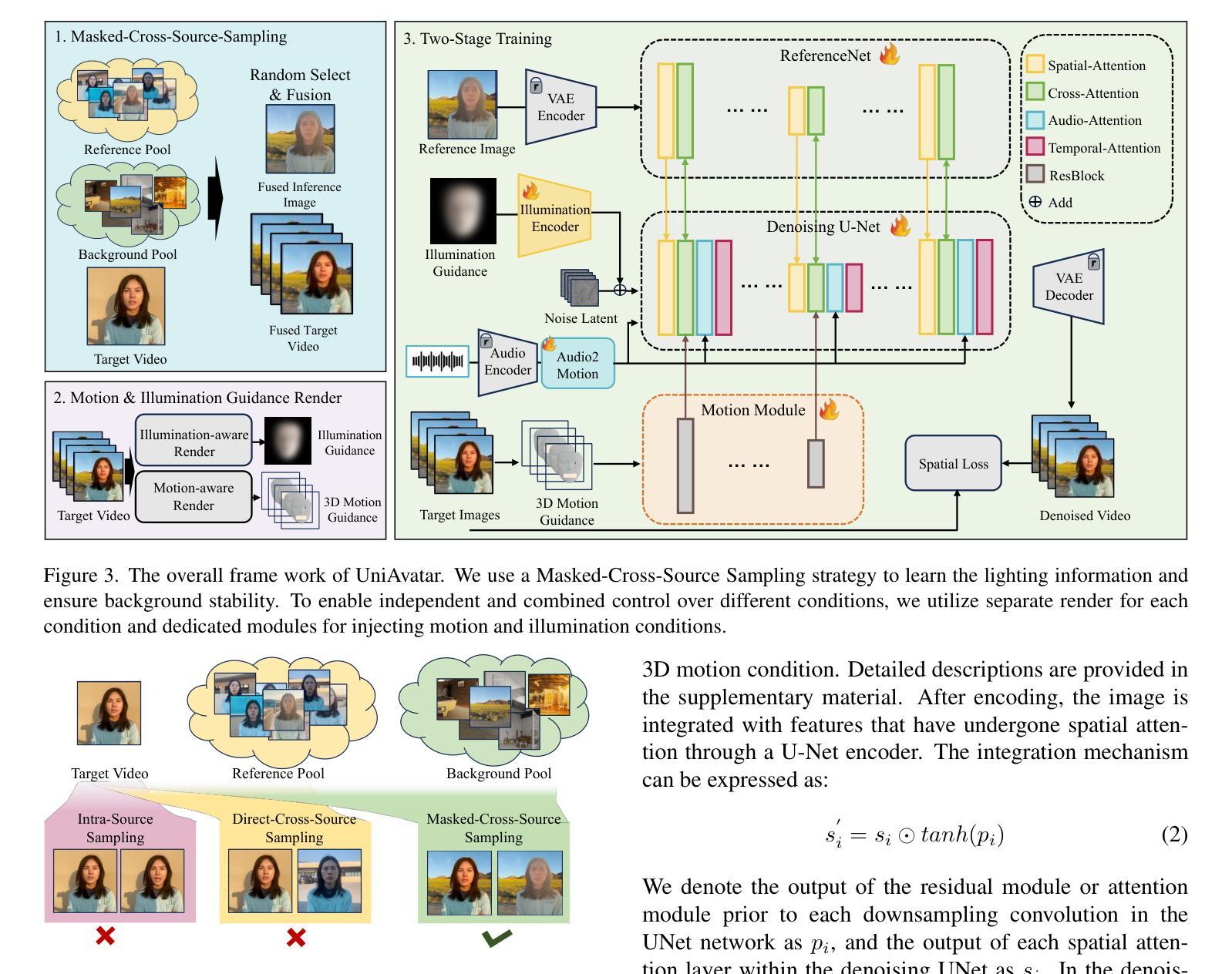
Recently, animating portrait images using audio input is a popular task. Creating lifelike talking head videos requires flexible and natural movements, including facial and head dynamics, camera motion, realistic light and shadow effects. Existing methods struggle to offer comprehensive, multifaceted control over these aspects. In this work, we introduce UniAvatar, a designed method that provides extensive control over a wide range of motion and illumination conditions. Specifically, we use the FLAME model to render all motion information onto a single image, maintaining the integrity of 3D motion details while enabling fine-grained, pixel-level control. Beyond motion, this approach also allows for comprehensive global illumination control. We design independent modules to manage both 3D motion and illumination, permitting separate and combined control. Extensive experiments demonstrate that our method outperforms others in both broad-range motion control and lighting control. Additionally, to enhance the diversity of motion and environmental contexts in current datasets, we collect and plan to publicly release two datasets, DH-FaceDrasMvVid-100 and DH-FaceReliVid-200, which capture significant head movements during speech and various lighting scenarios.
最近,使用音频输入来生成动画肖像图像是一项热门任务。创建逼真的谈话头部视频需要灵活和自然的动作,包括面部和头部动态、相机运动、逼真的光影效果。现有方法很难在这些方面提供全面、多元的控制。在这项工作中,我们引入了UniAvatar方法,该方法提供了对各种运动和照明条件的广泛控制。具体来说,我们使用FLAME模型将所有运动信息渲染到单个图像上,保持3D运动细节的完整性,同时实现精细的像素级控制。除了运动之外,这种方法还允许进行全面的全局照明控制。我们设计独立的模块来管理3D运动和照明,以实现单独和组合控制。大量实验表明,我们的方法在广泛的运动控制和照明控制方面都优于其他方法。此外,为了提高当前数据集中运动和环境上下文的多样性,我们收集并计划公开发布两个数据集DH-FaceDrasMvVid-100和DH-FaceReliVid-200,它们捕捉了演讲过程中的重要头部运动以及各种照明场景。
论文及项目相关链接
Summary:
近期,使用音频输入制作动态肖像图像是一项热门任务。创建逼真的谈话头视频需要灵活自然的动作,包括面部和头部动态、相机运动、真实的光影效果。现有方法难以全面控制这些方面。在这项工作中,我们推出了UniAvatar方法,提供广泛的动作和照明条件下的全面控制。具体来说,我们使用FLAME模型将所有动作信息渲染到一张图像上,保持3D动作细节的完整性,同时实现精细的像素级控制。除了动作控制外,该方法还允许全面的全局照明控制。我们设计独立的模块来管理3D动作和照明,允许单独和组合控制。大量实验证明,我们的方法在广泛的动作控制和照明控制方面都优于其他方法。此外,为了增强当前数据集的动作和环境上下文多样性,我们收集和计划公开两个数据集DH-FaceDrasMvVid-100和DH-FaceReliVid-200,它们捕捉了演讲过程中的重大头部动作和各种照明场景。
Key Takeaways:
- 使用音频输入创建动态肖像图像是热门任务,需实现灵活自然的动作和光影效果。
- 现有方法在动作和照明控制方面存在挑战。
- UniAvatar方法提供广泛的动作和照明条件下的全面控制。
- 使用FLAME模型实现3D动作细节的完整性和精细的像素级控制。
- 该方法允许独立的动作和照明控制模块。
- 实验证明UniAvatar方法在动作和照明控制方面优于其他方法。
点此查看论文截图





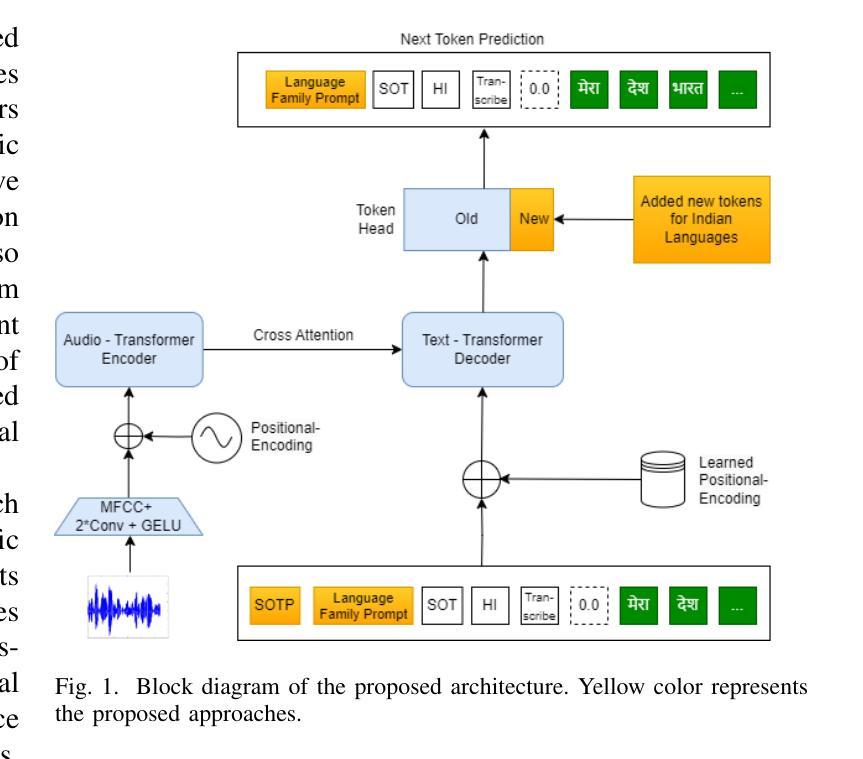
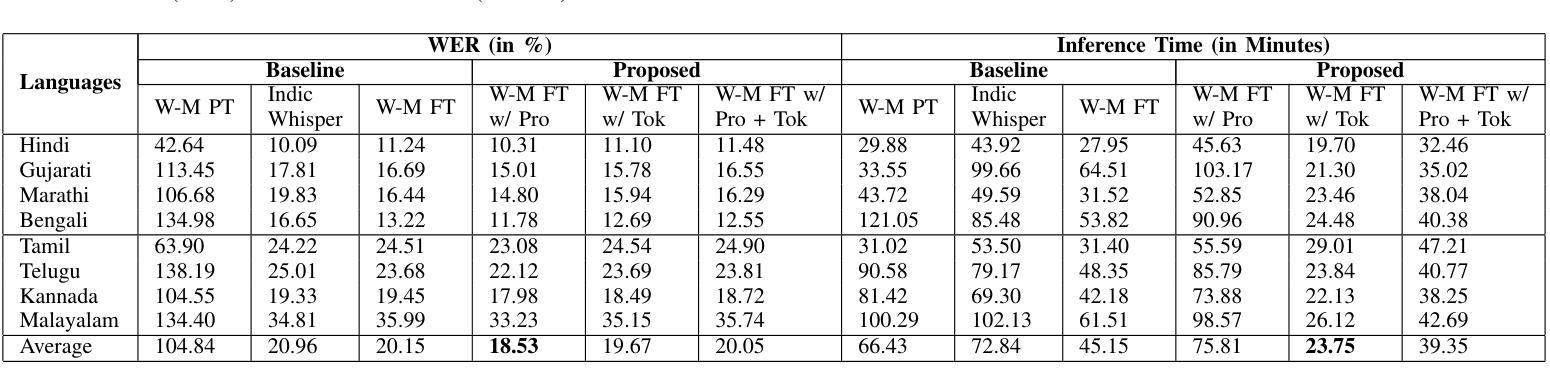
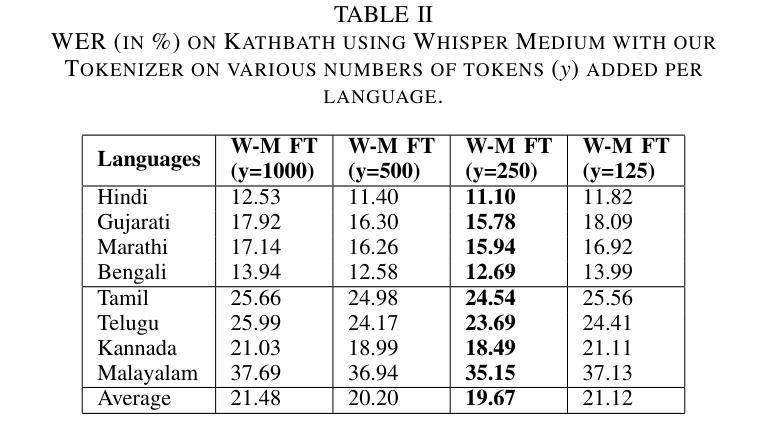
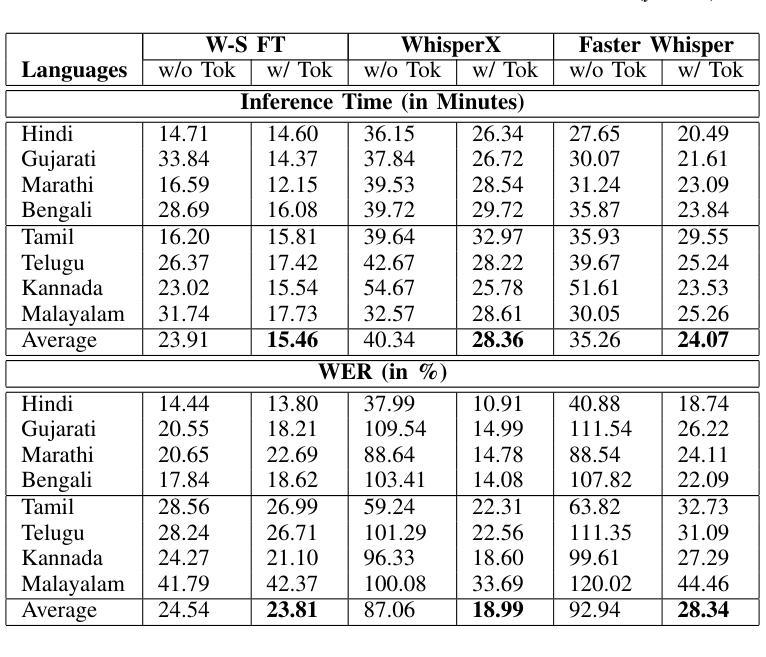
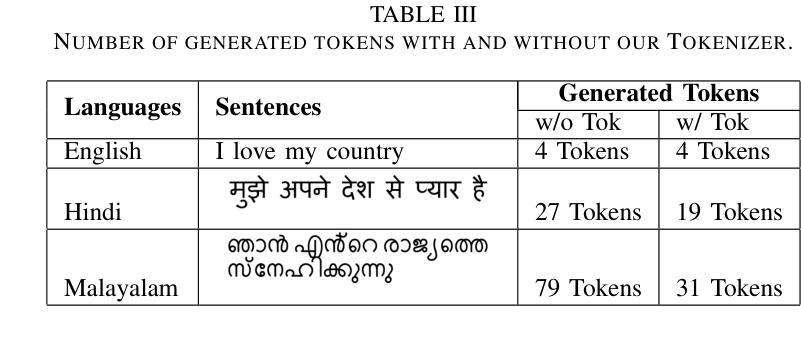
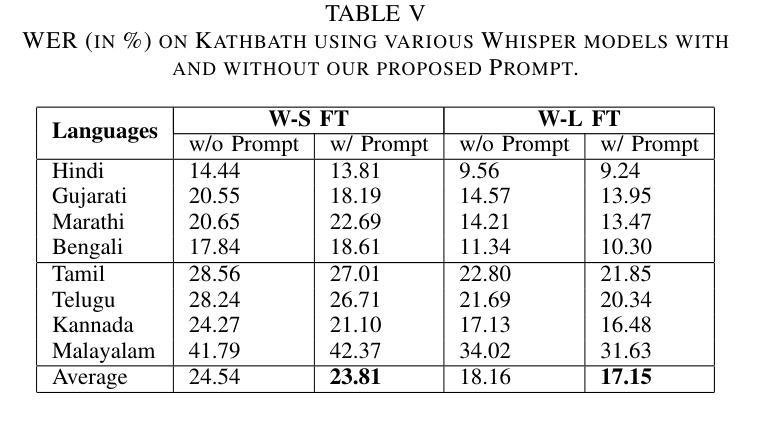
Enhancing Whisper’s Accuracy and Speed for Indian Languages through Prompt-Tuning and Tokenization
Authors:Kumud Tripathi, Raj Gothi, Pankaj Wasnik
Automatic speech recognition has recently seen a significant advancement with large foundational models such as Whisper. However, these models often struggle to perform well in low-resource languages, such as Indian languages. This paper explores two novel approaches to enhance Whisper’s multilingual speech recognition performance in Indian languages. First, we propose prompt-tuning with language family information, which enhances Whisper’s accuracy in linguistically similar languages. Second, we introduce a novel tokenizer that reduces the number of generated tokens, thereby accelerating Whisper’s inference speed. Our extensive experiments demonstrate that the tokenizer significantly reduces inference time, while prompt-tuning enhances accuracy across various Whisper model sizes, including Small, Medium, and Large. Together, these techniques achieve a balance between optimal WER and inference speed.
自动语音识别技术近期凭借大型基础模型(如whisper)取得了显著进展。然而,这些模型往往在低资源语言(如印度语言)中的表现不尽如人意。本文探索了两种新方法,旨在提高whisper在多语言语音识别中的印度语言性能。首先,我们提出使用带有语言家族信息的提示调整(prompt-tuning)方法,以提高在相似语言中的准确性。其次,我们引入了一种新型的分词器,可以减少生成的令牌数量,从而加快whisper的推理速度。我们的广泛实验表明,分词器可以大大减少推理时间,而提示调整则提高了各种whisper模型大小的准确性,包括小型、中型和大型。这些技术共同实现了最优的词错误率(WER)和推理速度的平衡。
论文及项目相关链接
PDF Accepted at ICASSP 2025, 5 pages, 1 figures, 5 tables
Summary
本文探讨了增强Whisper在多语种语音识别性能方面的两大策略。首先提出利用语言家族信息进行提示调整,提高在相似语言上的准确性。其次,引入了一种新颖的令牌化器,减少了生成的令牌数量,从而加快了Whisper的推理速度。实验表明,令牌化器显著减少了推理时间,提示调整则提高了不同规模的Whisper模型的准确性。结合使用这两种技术,实现了最佳字词错误率和推理速度的平衡。
Key Takeaways
- 介绍了增强Whisper在多语种语音识别方面的两大策略。
- 利用语言家族信息进行提示调整以提高类似语言识别的准确性。
- 提出了一种新颖的令牌化器来加快Whisper的推理速度并减少生成的令牌数量。
- 实验结果显示,令牌化器显著减少了推理时间。
- 提示调整提高了不同规模的Whisper模型的性能。
- 结合使用这两种技术实现了字词错误率和推理速度的平衡。
点此查看论文截图

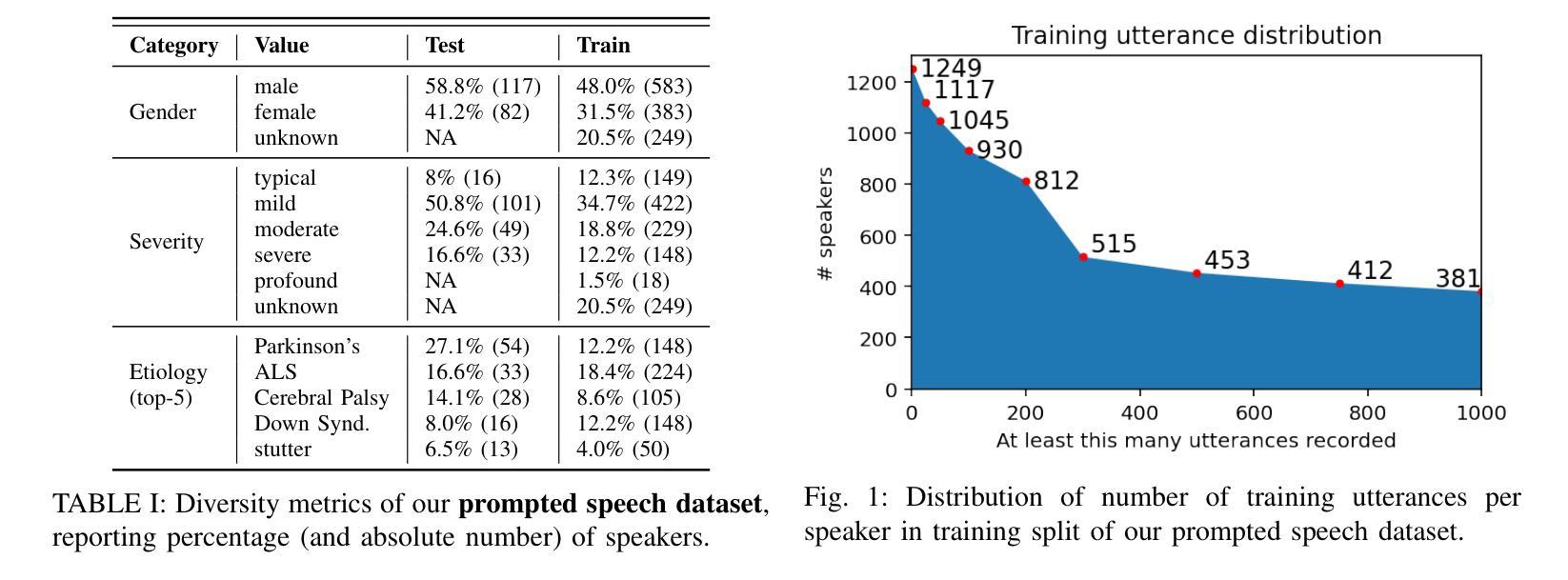
Towards a Single ASR Model That Generalizes to Disordered Speech
Authors:Jimmy Tobin, Katrin Tomanek, Subhashini Venugopalan
This study investigates the impact of integrating a dataset of disordered speech recordings ($\sim$1,000 hours) into the fine-tuning of a near state-of-the-art ASR baseline system. Contrary to what one might expect, despite the data being less than 1% of the training data of the ASR system, we find a considerable improvement in disordered speech recognition accuracy. Specifically, we observe a 33% improvement on prompted speech, and a 26% improvement on a newly gathered spontaneous, conversational dataset of disordered speech. Importantly, there is no significant performance decline on standard speech recognition benchmarks. Further, we observe that the proposed tuning strategy helps close the gap between the baseline system and personalized models by 64% highlighting the significant progress as well as the room for improvement. Given the substantial benefits of our findings, this experiment suggests that from a fairness perspective, incorporating a small fraction of high quality disordered speech data in a training recipe is an easy step that could be done to make speech technology more accessible for users with speech disabilities.
本研究探讨了将包含约1000小时无序语音记录的语音数据集整合到接近最新水平的ASR基线系统的微调中所产生的影响。与人们可能会预期的不同,尽管这些数据不到ASR系统训练数据的1%,但我们发现无序语音识别的准确度有了显著的提高。具体来说,我们在提示性语音上观察到提升了33%,并在新收集的无序语音的自发言论数据集中提升了26%。重要的是,在标准语音识别基准测试中,性能并没有出现显著下降。此外,我们还发现,所提出的调整策略有助于将基线系统与个性化模型之间的差距缩小64%,这既突出了显著的进步,也表明了仍有改进的空间。鉴于我们的发现所带来的巨大益处,本实验表明,从公平性的角度来看,在训练配方中加入一小部分高质量的无序语音数据是一个简单的步骤,可以使语音技术更易于供有言语障碍的用户使用。
论文及项目相关链接
PDF Accepted at ICASSP 2025
Summary
本研究探讨了将包含约1000小时的无序语音数据集融入先进的语音识别系统微调环节的影响。尽管这些数据不到训练数据的百分之一,但发现无序语音识别准确率显著提高,其中提示性语音提高了33%,新收集的随意对话数据集提高了26%,且在标准语音识别基准测试中性能没有明显下降。此外,该策略有助于缩小基准系统与个性化模型之间的差距,提高了显著进步的空间。因此,从公平性的角度考虑,在训练中加入一小部分高质量的无序语音数据,有助于让语音技术对有语音障碍的用户更加友好。
Key Takeaways
- 引入包含约1000小时无序语音的数据集进行ASR系统微调。
- 即使数据只占一小部分,无序语音识别的准确率也有显著提高。
- 提示性语音和随意对话数据集的识别准确率分别提高了33%和26%。
- 在标准语音识别基准测试中未见性能下降。
- 该策略有助于缩小基准系统与个性化模型之间的差距。
- 加入高质量的无序语音数据有助于提高语音技术的公平性和可及性。
点此查看论文截图


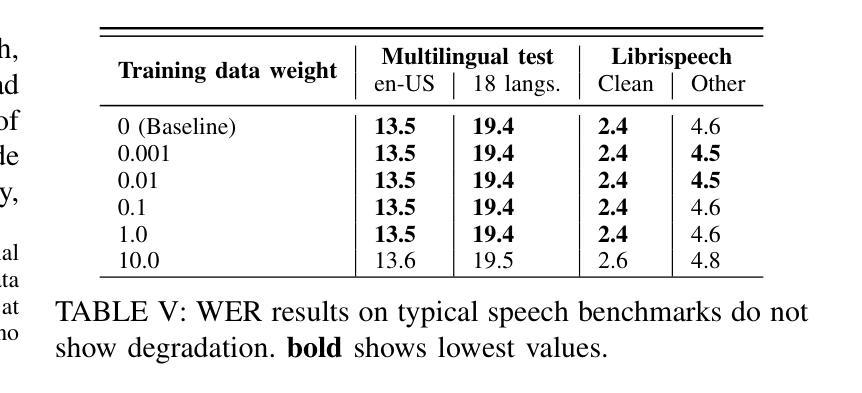
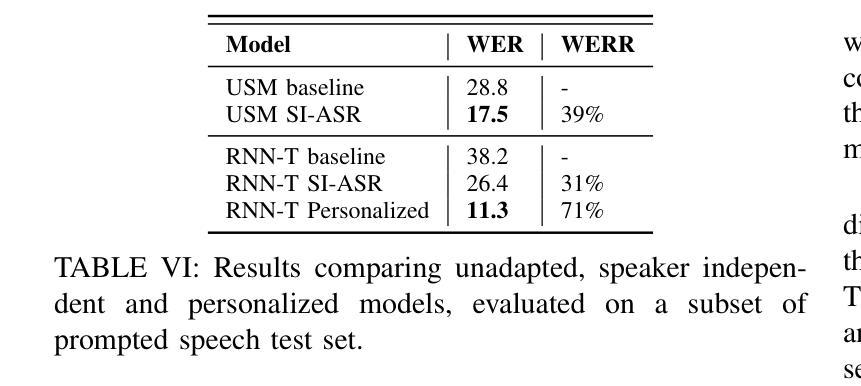
Causal Speech Enhancement with Predicting Semantics based on Quantized Self-supervised Learning Features
Authors:Emiru Tsunoo, Yuki Saito, Wataru Nakata, Hiroshi Saruwatari
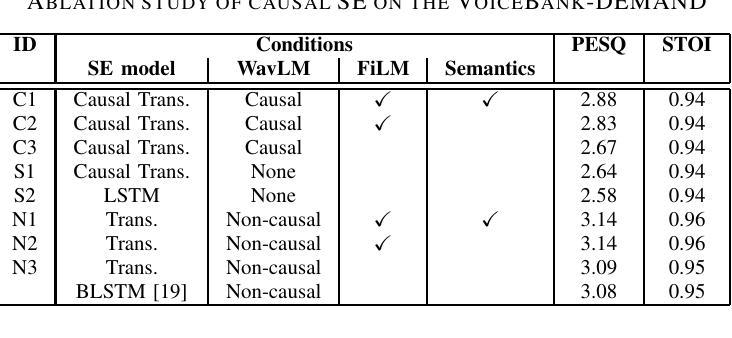
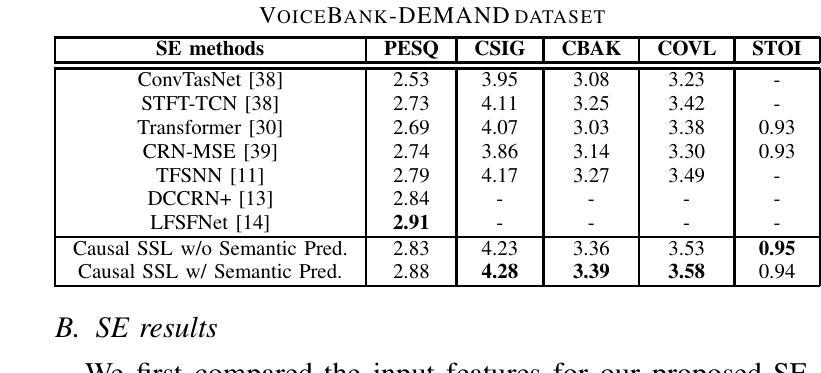
Real-time speech enhancement (SE) is essential to online speech communication. Causal SE models use only the previous context while predicting future information, such as phoneme continuation, may help performing causal SE. The phonetic information is often represented by quantizing latent features of self-supervised learning (SSL) models. This work is the first to incorporate SSL features with causality into an SE model. The causal SSL features are encoded and combined with spectrogram features using feature-wise linear modulation to estimate a mask for enhancing the noisy input speech. Simultaneously, we quantize the causal SSL features using vector quantization to represent phonetic characteristics as semantic tokens. The model not only encodes SSL features but also predicts the future semantic tokens in multi-task learning (MTL). The experimental results using VoiceBank + DEMAND dataset show that our proposed method achieves 2.88 in PESQ, especially with semantic prediction MTL, in which we confirm that the semantic prediction played an important role in causal SE.
实时语音增强(SE)对于在线语音通信至关重要。因果SE模型在预测未来信息时只使用先前的上下文,例如语音延续,这可能有助于进行因果SE。语音信息通常通过量化自监督学习(SSL)模型的潜在特征来表示。这项工作首次将SSL特征与因果性融入SE模型。因果SSL特征通过特征级线性调制与频谱特征编码相结合,以估计用于增强带噪输入语音的掩模。同时,我们使用向量量化来量化因果SSL特征,将其表示为表示语音特征的语义令牌。该模型不仅编码SSL特征,而且还在多任务学习(MTL)中预测未来的语义令牌。使用VoiceBank + DEMAND数据集进行的实验结果表明,我们提出的方法在PESQ上达到了2.88,特别是在语义预测MTL中,我们证实语义预测在因果SE中发挥了重要作用。
论文及项目相关链接
PDF Accepted for ICASSP 2025, 5 pages
Summary
实时语音增强(SE)对在线语音通信至关重要。因果SE模型仅使用过去的信息进行预测,而利用语音延续等未来信息可能有助于进行因果SE。本研究首次将自监督学习(SSL)模型的因果特性与语音增强模型结合。利用特征级线性调制将因果SSL特征与频谱图特征编码并合并,以估计用于增强噪声输入语音的掩膜。同时,使用向量量化对因果SSL特征进行量化,以语义令牌的形式表示语音特征。模型不仅编码SSL特征,还在多任务学习中预测未来的语义令牌。使用VoiceBank + DEMAND数据集的实验结果表明,我们提出的方法在PESQ上达到2.88,特别是通过语义预测的多任务学习,我们证实了语义预测在因果SE中的重要性。
Key Takeaways
- 实时语音增强(SE)在在线语音通信中至关重要。
- 因果SE模型通过使用未来的语音信息(如语音延续)来提高性能。
- 本研究结合了自监督学习(SSL)模型的因果特性与语音增强模型。
- 通过特征级线性调制,将因果SSL特征与频谱图特征结合,以估计语音掩膜。
- 向量量化用于量化因果SSL特征,表示为语义令牌。
- 模型在编码SSL特征的同时,还在多任务学习中预测未来的语义令牌。
点此查看论文截图

“I’ve Heard of You!”: Generate Spoken Named Entity Recognition Data for Unseen Entities
Authors:Jiawei Yu, Xiang Geng, Yuang Li, Mengxin Ren, Wei Tang, Jiahuan Li, Zhibin Lan, Min Zhang, Hao Yang, Shujian Huang, Jinsong Su
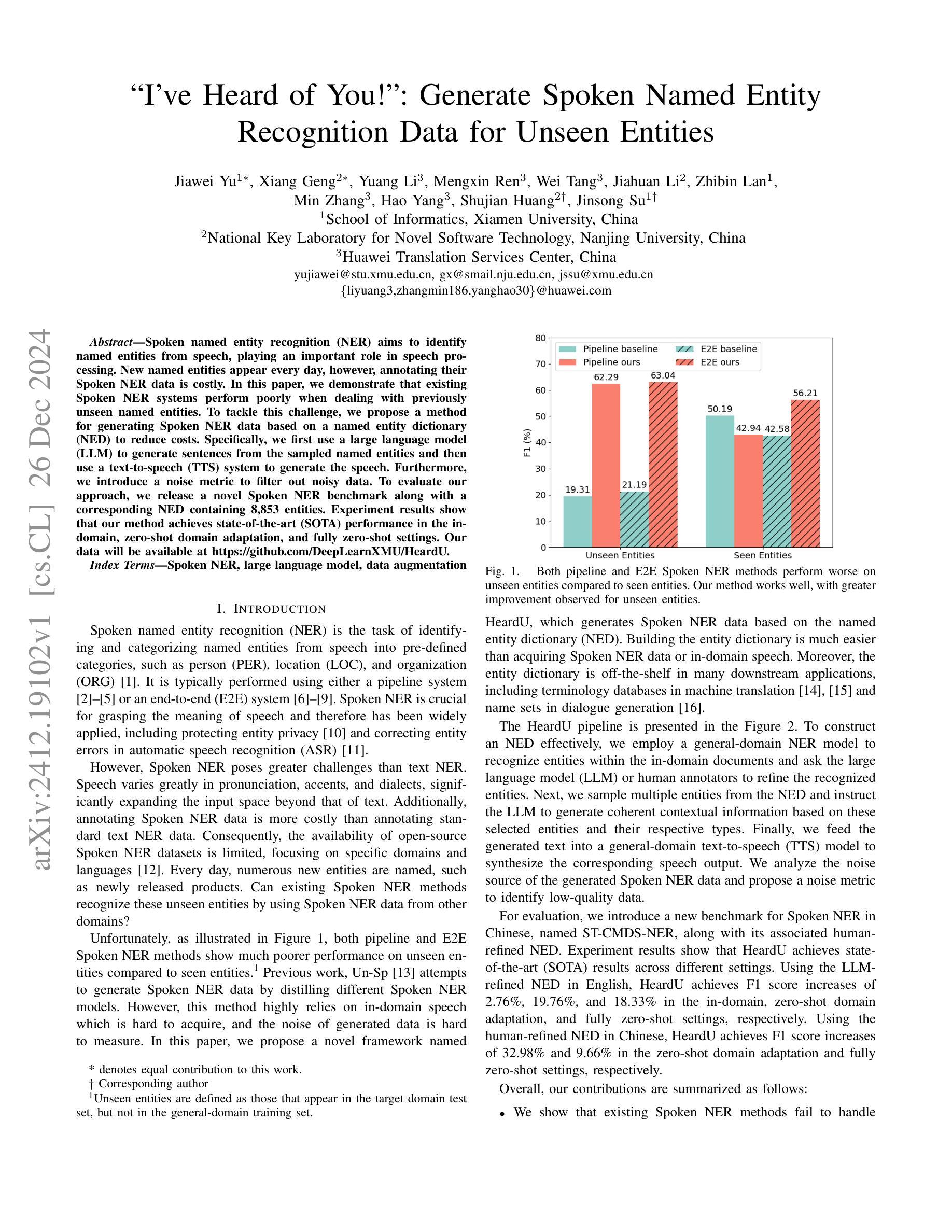
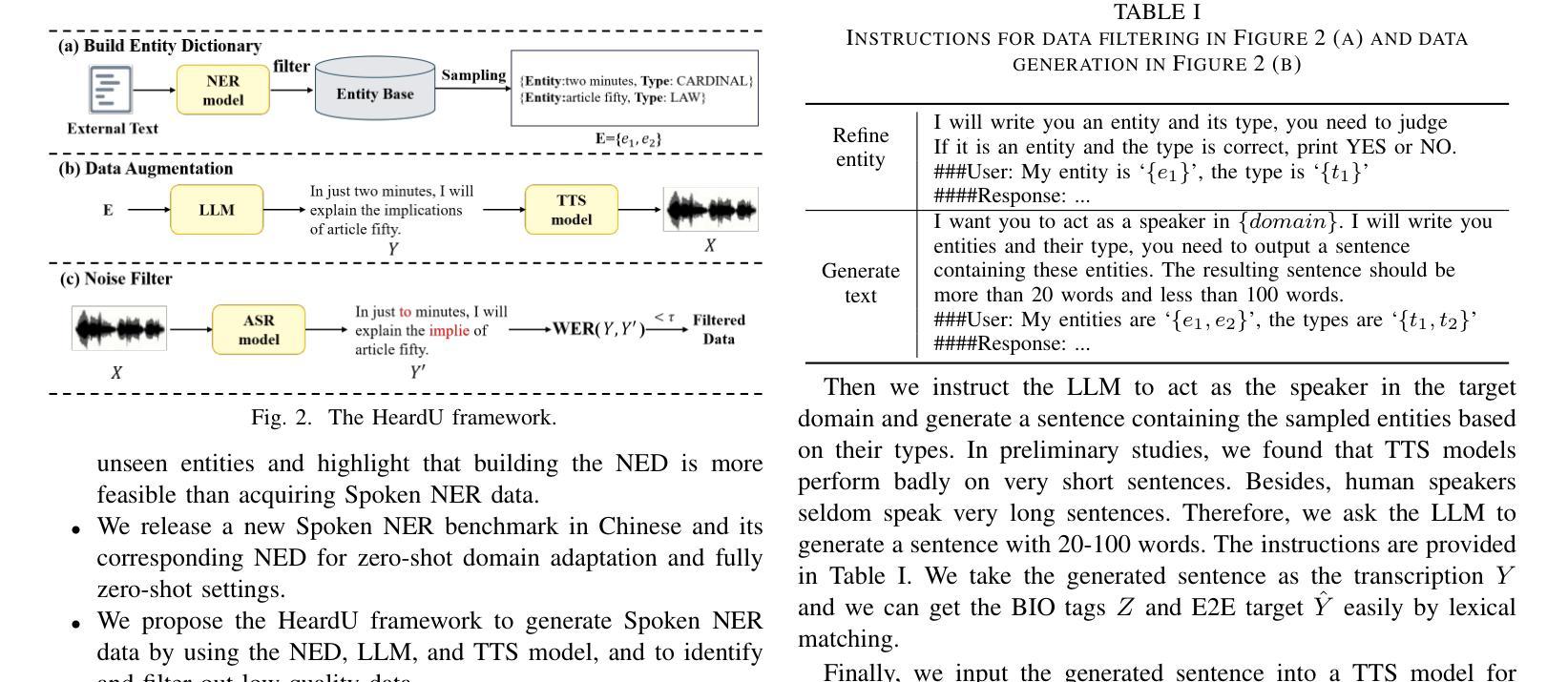
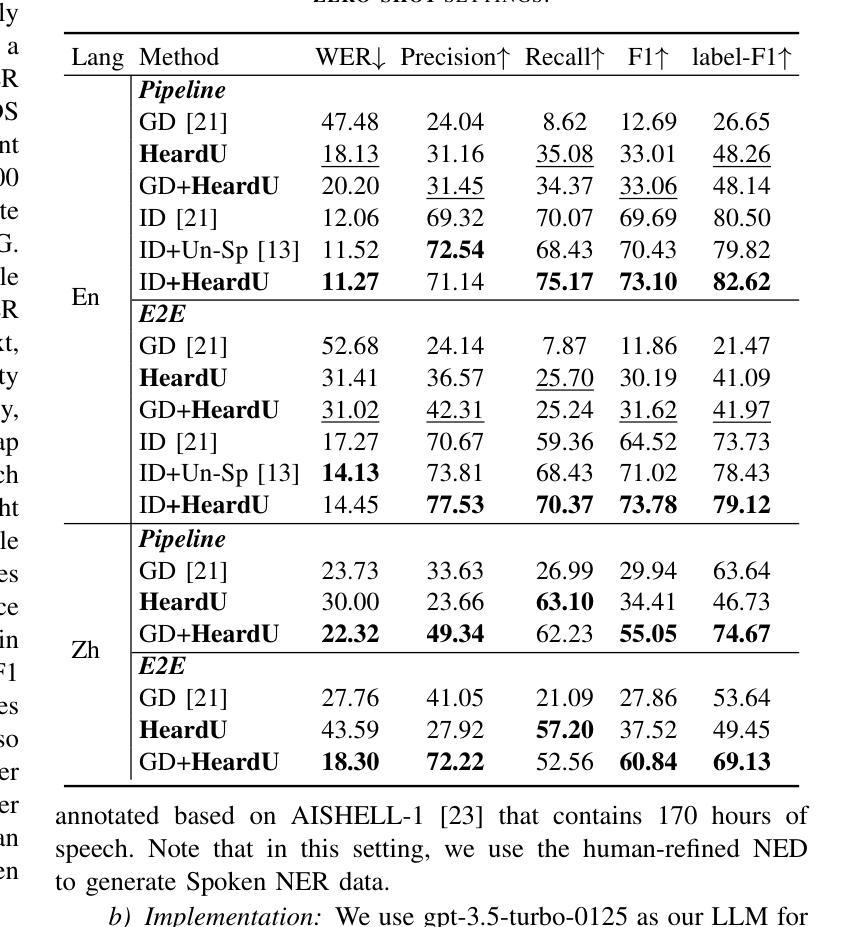
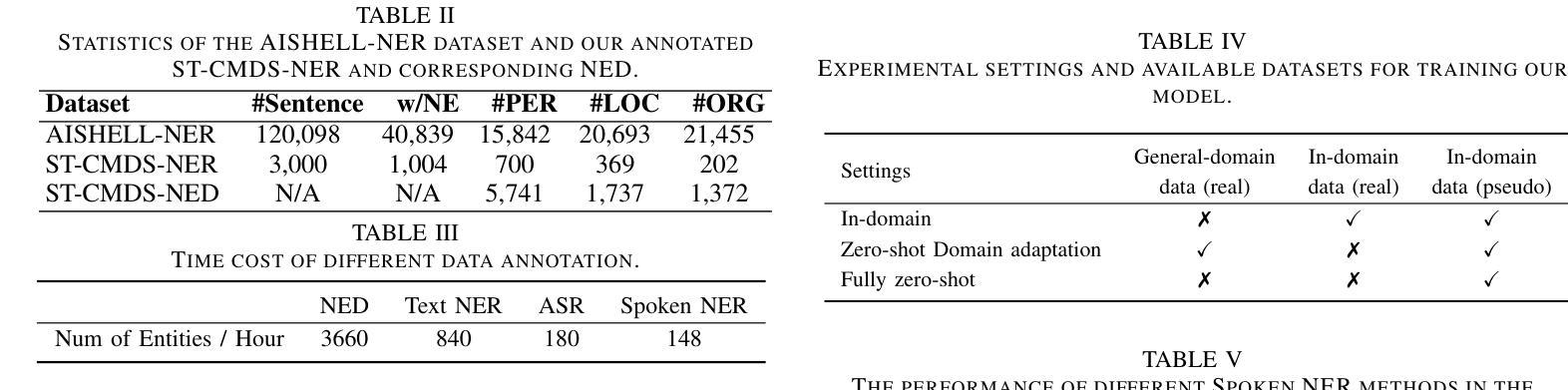
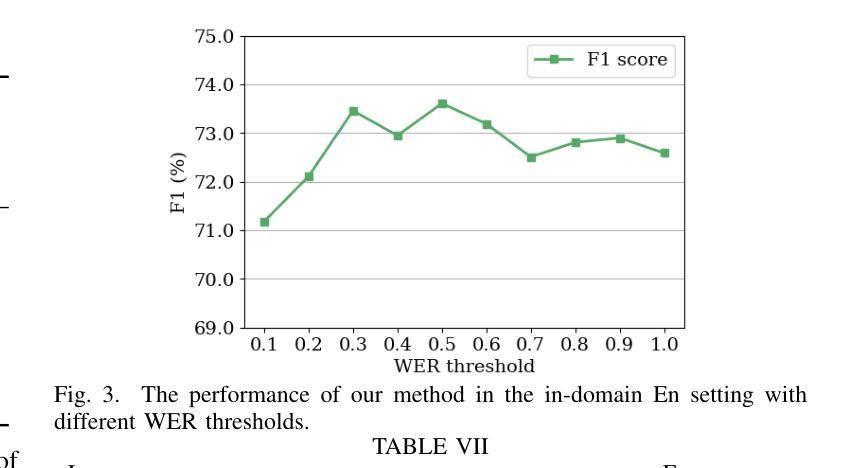
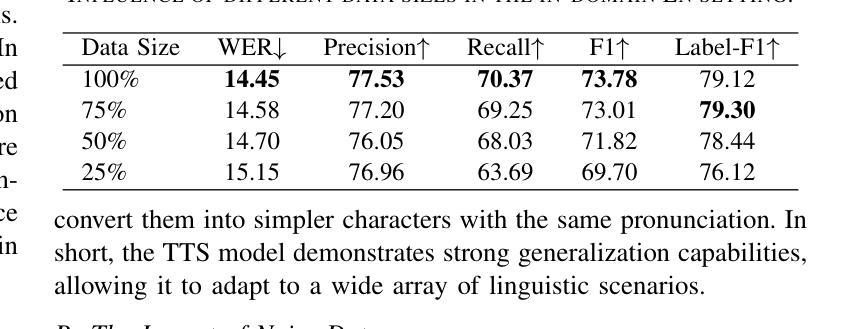
Spoken named entity recognition (NER) aims to identify named entities from speech, playing an important role in speech processing. New named entities appear every day, however, annotating their Spoken NER data is costly. In this paper, we demonstrate that existing Spoken NER systems perform poorly when dealing with previously unseen named entities. To tackle this challenge, we propose a method for generating Spoken NER data based on a named entity dictionary (NED) to reduce costs. Specifically, we first use a large language model (LLM) to generate sentences from the sampled named entities and then use a text-to-speech (TTS) system to generate the speech. Furthermore, we introduce a noise metric to filter out noisy data. To evaluate our approach, we release a novel Spoken NER benchmark along with a corresponding NED containing 8,853 entities. Experiment results show that our method achieves state-of-the-art (SOTA) performance in the in-domain, zero-shot domain adaptation, and fully zero-shot settings. Our data will be available at https://github.com/DeepLearnXMU/HeardU.
语音命名实体识别(NER)旨在从语音中识别命名实体,在语音处理中发挥着重要作用。每天都有新的命名实体出现,然而,对它们的语音NER数据进行标注的成本很高。在本文中,我们证明了现有的语音NER系统在处理之前未见过的命名实体时表现不佳。为了应对这一挑战,我们提出了一种基于命名实体词典(NED)生成语音NER数据的方法,以降低标注成本。具体来说,我们首先使用大型语言模型(LLM)从采样的命名实体生成句子,然后使用文本到语音(TTS)系统生成语音。此外,我们还引入了一个噪声度量来过滤掉噪声数据。为了评估我们的方法,我们发布了一个新的语音NER基准测试以及一个包含8853个实体的相应NED。实验结果表明,我们的方法在域内、零样本域适应和完全零样本设置中都达到了最新技术水平。我们的数据将在https://github.com/DeepLearnXMU/HeardU上提供。
论文及项目相关链接
PDF Accepted by ICASSP 2025
Summary
语音命名实体识别(NER)旨在从语音中识别命名实体,在语音识别处理中占据重要地位。现有Spoken NER系统对于未见过的命名实体表现不佳,标注Spoken NER数据成本高昂。为解决此问题,本文提出一种基于命名实体词典(NED)生成Spoken NER数据的方法降低成本。首先使用大型语言模型(LLM)从采样命名实体生成句子,再使用文本到语音(TTS)系统生成语音。此外,引入噪声度量以过滤噪声数据。本文发布新型Spoken NER基准和包含8,853个实体的对应NED。实验结果证明该方法在领域内、零样本域适应和完全零样本设置下均达到最新技术水平。相关数据将在https://github.com/DeepLearnXMU/HeardU上提供。
Key Takeaways
- Spoken NER旨在从语音中识别命名实体,对于新出现的命名实体,现有系统表现不佳。
- 标注Spoken NER数据的成本较高,需要寻找降低成本的方法。
- 本文提出一种基于命名实体词典(NED)生成Spoken NER数据的方法,使用大型语言模型(LLM)和文本到语音(TTS)系统。
- 引入噪声度量以过滤生成的噪声数据。
- 发布了新型的Spoken NER基准和对应的包含大量实体的NED。
- 实验结果表明该方法在多个设置下达到最新技术水平。
点此查看论文截图
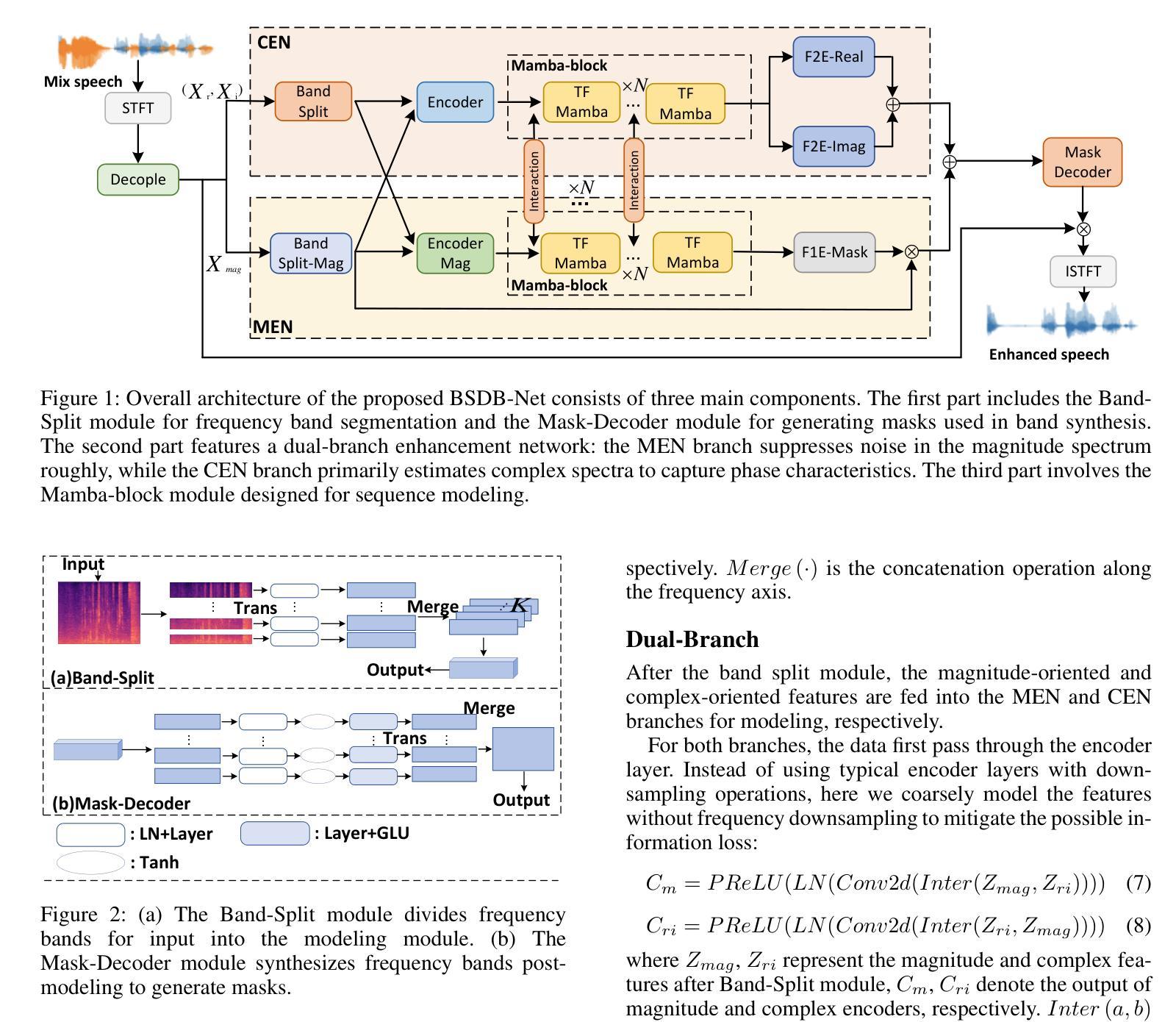
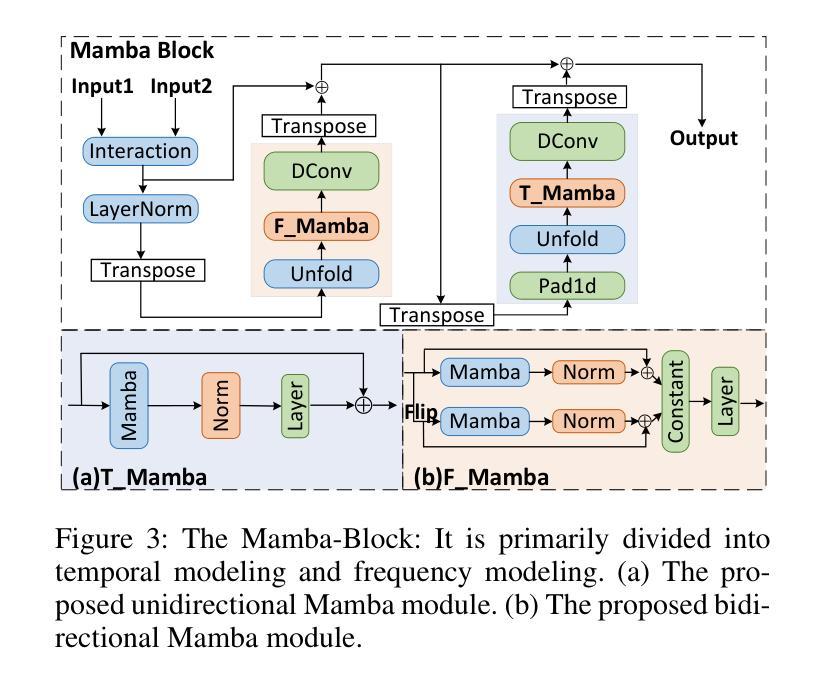
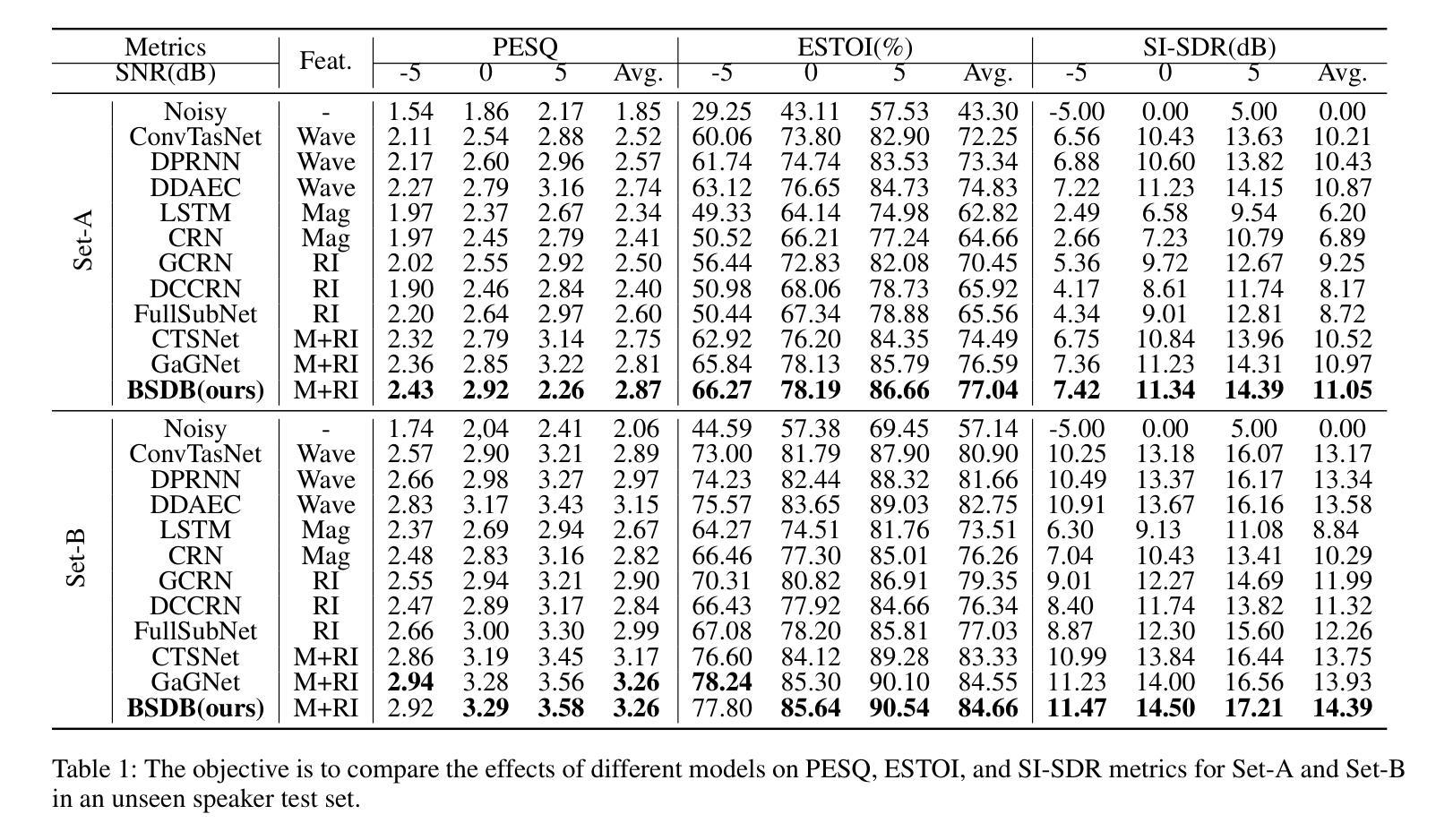
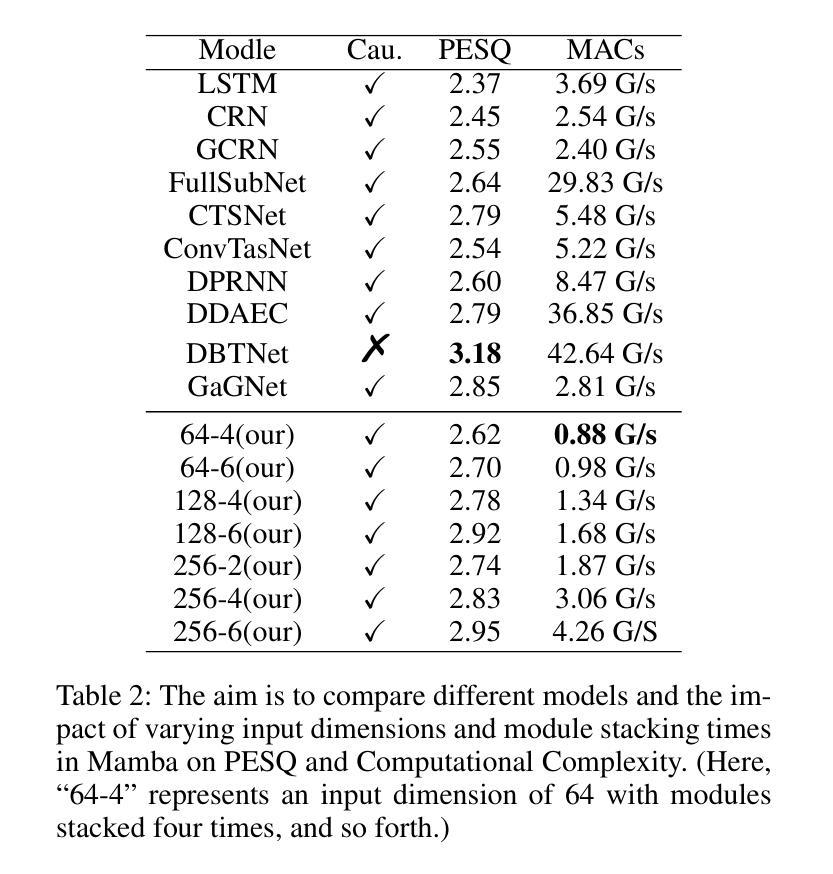
BSDB-Net: Band-Split Dual-Branch Network with Selective State Spaces Mechanism for Monaural Speech Enhancement
Authors:Cunhang Fan, Enrui Liu, Andong Li, Jianhua Tao, Jian Zhou, Jiahao Li, Chengshi Zheng, Zhao Lv
Although the complex spectrum-based speech enhancement(SE) methods have achieved significant performance, coupling amplitude and phase can lead to a compensation effect, where amplitude information is sacrificed to compensate for the phase that is harmful to SE. In addition, to further improve the performance of SE, many modules are stacked onto SE, resulting in increased model complexity that limits the application of SE. To address these problems, we proposed a dual-path network based on compressed frequency using Mamba. First, we extract amplitude and phase information through parallel dual branches. This approach leverages structured complex spectra to implicitly capture phase information and solves the compensation effect by decoupling amplitude and phase, and the network incorporates an interaction module to suppress unnecessary parts and recover missing components from the other branch. Second, to reduce network complexity, the network introduces a band-split strategy to compress the frequency dimension. To further reduce complexity while maintaining good performance, we designed a Mamba-based module that models the time and frequency dimensions under linear complexity. Finally, compared to baselines, our model achieves an average 8.3 times reduction in computational complexity while maintaining superior performance. Furthermore, it achieves a 25 times reduction in complexity compared to transformer-based models.
虽然基于复杂频谱的语音增强(SE)方法已经取得了显著的性能,但幅度和相位之间的耦合会导致补偿效应,即牺牲幅度信息来补偿对语音增强有害的相位。此外,为了进一步提高语音增强的性能,许多模块被堆叠在语音增强上,导致模型复杂度增加,限制了语音增强的应用。为了解决这些问题,我们提出了一种基于压缩频率的双路径网络。首先,我们通过并行双分支提取幅度和相位信息。这种方法利用结构化复杂光谱来隐含地捕获相位信息,并通过解耦幅度和相位来解决补偿效应。网络还包含一个交互模块,用于抑制不必要的部分并从另一个分支恢复丢失的组件。其次,为了降低网络复杂度,网络引入了一种分频策略来压缩频率维度。为了保持性能的同时进一步降低复杂度,我们设计了一个基于Mamba的模块,该模块在线性复杂度下对时间和频率维度进行建模。最后,与基线相比,我们的模型在计算复杂度上实现了平均8.3倍的降低,同时保持了优越的性能。此外,与基于变压器的模型相比,它实现了高达25倍的复杂度降低。
论文及项目相关链接
PDF Accepted by AAAI 2025
Summary
复杂谱基语音增强方法虽取得显著性能,但幅度与相位耦合会产生补偿效应,牺牲幅度信息来补偿对语音增强有害的相位。为改善语音增强性能,在语音增强上叠加了许多模块,导致模型复杂度增加。我们提出基于压缩频率的双路径网络,通过并行双分支提取幅度和相位信息,利用结构复杂谱隐式捕获相位信息,并通过解耦幅度和相位来解决补偿效应。网络引入交互模块以抑制不必要的部分并从另一分支恢复缺失的组件。为降低网络复杂度,引入频带分割策略来压缩频率维度。为进一步降低复杂度并保持良好性能,设计基于Mamba的模块,在线性复杂度下对时间和频率维度进行建模。与基线相比,我们的模型在计算复杂度上平均降低了8.3倍,同时保持优越性能,与基于变压器的模型相比,复杂度降低了25倍。
Key Takeaways
- 幅度与相位耦合可能导致补偿效应,牺牲幅度信息来补偿相位。
- 为提高语音增强性能,许多模块被叠加在SE上,导致模型复杂度增加。
- 提出基于压缩频率的双路径网络来解决幅度和相位耦合问题。
- 网络利用结构复杂谱隐式捕获相位信息,并通过解耦幅度和相位来解决补偿效应。
- 网络引入交互模块以优化性能。
- 为降低网络复杂度,采用频带分割策略和基于Mamba的模块。
点此查看论文截图

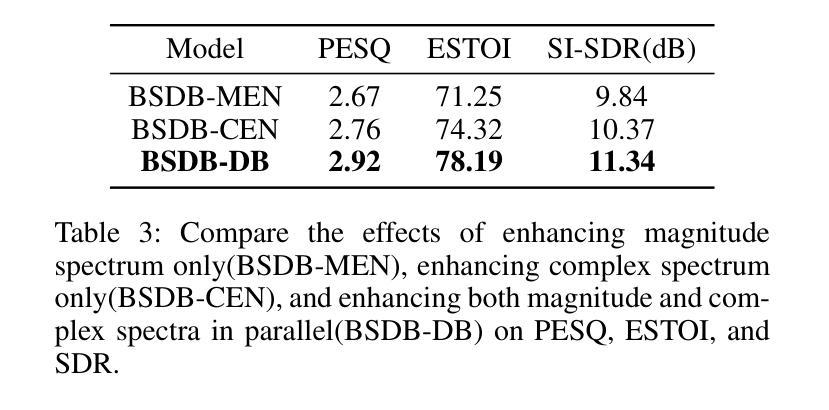
Attacking Voice Anonymization Systems with Augmented Feature and Speaker Identity Difference
Authors:Yanzhe Zhang, Zhonghao Bi, Feiyang Xiao, Xuefeng Yang, Qiaoxi Zhu, Jian Guan
This study focuses on the First VoicePrivacy Attacker Challenge within the ICASSP 2025 Signal Processing Grand Challenge, which aims to develop speaker verification systems capable of determining whether two anonymized speech signals are from the same speaker. However, differences between feature distributions of original and anonymized speech complicate this task. To address this challenge, we propose an attacker system that combines Data Augmentation enhanced feature representation and Speaker Identity Difference enhanced classifier to improve verification performance, termed DA-SID. Specifically, data augmentation strategies (i.e., data fusion and SpecAugment) are utilized to mitigate feature distribution gaps, while probabilistic linear discriminant analysis (PLDA) is employed to further enhance speaker identity difference. Our system significantly outperforms the baseline, demonstrating exceptional effectiveness and robustness against various voice anonymization systems, ultimately securing a top-5 ranking in the challenge.
本研究重点关注ICASSP 2025信号处理大赛中的首个语音隐私攻击挑战,旨在开发能够判断两个匿名语音信号是否来自同一说话人的说话人验证系统。然而,原始语音和匿名语音特征分布之间的差异使这一任务复杂化。为了应对这一挑战,我们提出了一种攻击者系统,该系统结合了数据增强增强特征表示和说话人身份差异增强分类器来提高验证性能,被称为DA-SID。具体来说,数据增强策略(即数据融合和SpecAugment)被用来缓解特征分布差距,而概率线性判别分析(PLDA)被用来进一步提高说话人的身份差异识别。我们的系统在性能上显著超越了基线系统,展现出在各种语音匿名化系统中的卓越有效性和稳健性,最终在该挑战中取得了前五的排名。
论文及项目相关链接
PDF 2 pages, submitted to ICASSP 2025 GC-7: The First VoicePrivacy Attacker Challenge (by invitation)
Summary
本研究关注ICASSP 2025信号处理大赛中的First VoicePrivacy攻击者挑战,旨在开发能够判断两个匿名语音信号是否来自同一发言人的说话人验证系统。为解决原始语音与匿名化语音特征分布差异带来的挑战,研究团队提出一种结合数据增强增强特征表示和说话人身份差异增强分类器的攻击者系统,称为DA-SID。通过使用数据融合和SpecAugment等数据增强策略,缩小特征分布差距,同时采用概率线性判别分析(PLDA)进一步强化说话人身份差异。该系统显著优于基线,对各种语音匿名化系统表现出极高的有效性和鲁棒性,最终在挑战中位列前五。
Key Takeaways
- 研究关注ICASSP 2025的VoicePrivacy攻击者挑战,主要目标是开发高效的说话人验证系统。
- 匿名化语音和原始语音的特征分布存在差异,给验证带来困难。
- 提出结合数据增强和说话人身份差异增强的系统(DA-SID)以改善验证性能。
- 数据融合和SpecAugment等数据增强策略用于缩小特征分布差距。
- 概率线性判别分析(PLDA)用于增强说话人身份差异的识别。
- 系统显著优于基线,对各种语音匿名化系统具有鲁棒性。
点此查看论文截图

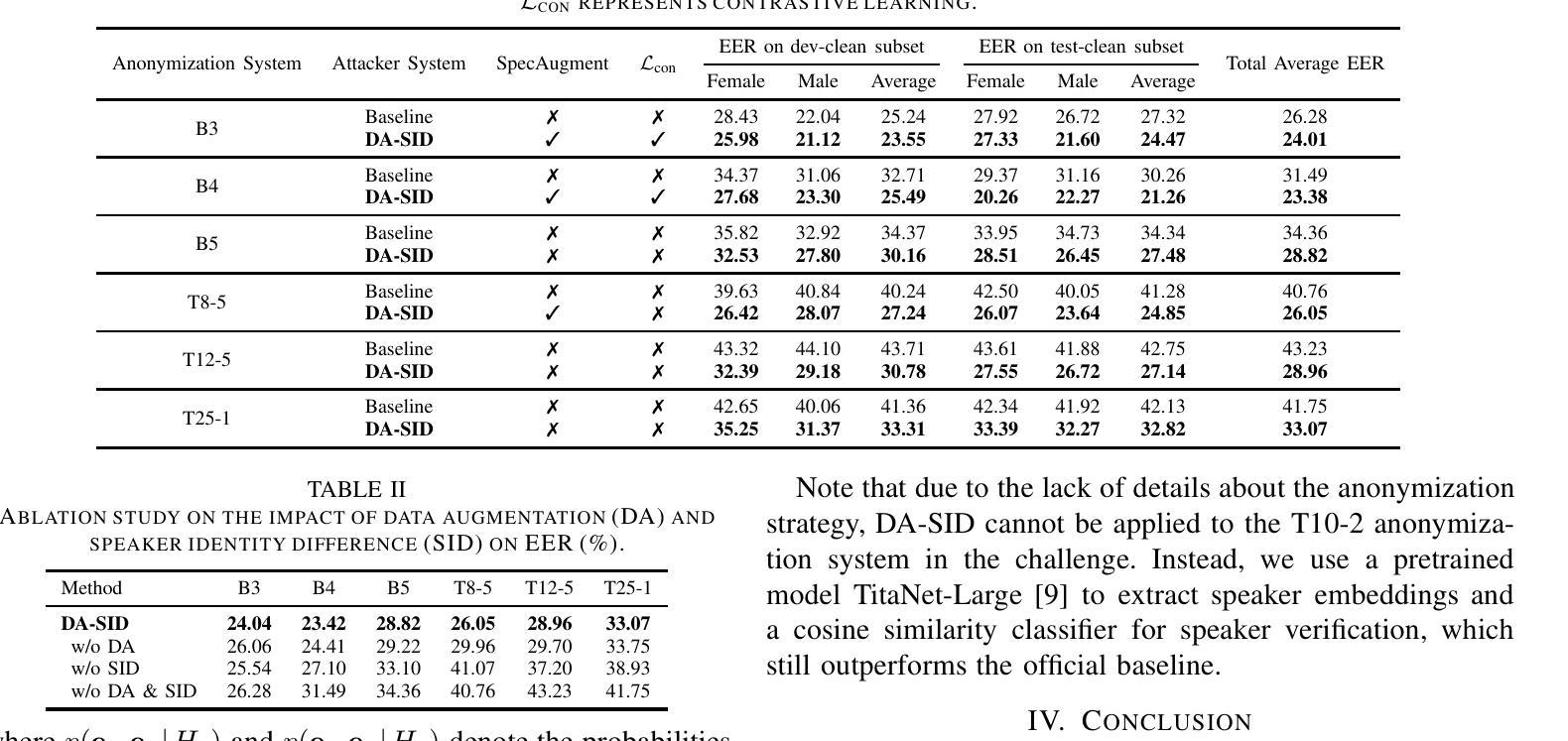
Enhancing Audiovisual Speech Recognition through Bifocal Preference Optimization
Authors:Yihan Wu, Yichen Lu, Yifan Peng, Xihua Wang, Ruihua Song, Shinji Watanabe
Audiovisual Automatic Speech Recognition (AV-ASR) aims to improve speech recognition accuracy by leveraging visual signals. It is particularly challenging in unconstrained real-world scenarios across various domains due to noisy acoustic environments, spontaneous speech, and the uncertain use of visual information. Most previous works fine-tune audio-only ASR models on audiovisual datasets, optimizing them for conventional ASR objectives. However, they often neglect visual features and common errors in unconstrained video scenarios. In this paper, we propose using a preference optimization strategy to improve speech recognition accuracy for real-world videos. First, we create preference data via simulating common errors that occurred in AV-ASR from two focals: manipulating the audio or vision input and rewriting the output transcript. Second, we propose BPO-AVASR, a Bifocal Preference Optimization method to improve AV-ASR models by leveraging both input-side and output-side preference. Extensive experiments demonstrate that our approach significantly improves speech recognition accuracy across various domains, outperforming previous state-of-the-art models on real-world video speech recognition.
视听自动语音识别(AV-ASR)旨在利用视觉信号提高语音识别精度。在跨多个领域的无约束现实场景中,由于噪声环境、自发语音和视觉信息的不确定性,它面临着巨大的挑战。之前的大多数工作都对仅使用音频的ASR模型进行微调,使其适应传统的ASR目标。然而,他们往往忽视了视觉特征和在不受约束的视频场景中的常见错误。在本文中,我们提出了一种偏好优化策略,以提高现实世界视频的语音识别精度。首先,我们通过模拟AV-ASR中发生的常见错误来创建偏好数据,这些错误主要来自于两个方面:操纵音频或视觉输入和重写输出字幕。其次,我们提出了一种双向偏好优化方法BPO-AVASR,通过利用输入和输出偏好来提高AV-ASR模型的性能。大量实验表明,我们的方法显著提高了跨多个领域的语音识别精度,在现实世界视频语音识别方面优于最新先进模型。
论文及项目相关链接
PDF Accepted by AAAI 2025
Summary
本文提出使用偏好优化策略,通过模拟AV-ASR中的常见错误并创建偏好数据,改进真实世界视频的语音识别准确性。通过操纵音频或视觉输入以及重写输出字幕,提出了基于输入和输出偏好的双焦点偏好优化方法(BPO-AVASR)。实验证明,该方法在不同领域的语音识别准确性上显著提高,优于现有最佳模型。
Key Takeaways
- Audiovisual Automatic Speech Recognition (AV-ASR)利用视觉信号提高语音识别准确性。
- 在不同的领域和不受约束的现实场景中,AV-ASR面临诸多挑战,如噪声环境、自发语言和视觉信息的不确定性。
- 大多数先前的工作是对仅使用音频的ASR模型进行微调,并优化传统的ASR目标,但忽略了视觉特征和现实视频场景中的常见错误。
- 本文通过模拟AV-ASR中的常见错误创建偏好数据,包括操纵音频或视觉输入和重写输出字幕。
- 提出了一种新的方法——BPO-AVASR(双焦点偏好优化),利用输入和输出两侧的偏好来提高AV-ASR模型的性能。
- 实验表明,该方法在真实世界的视频语音识别中显著提高了准确性,优于现有技术。
点此查看论文截图


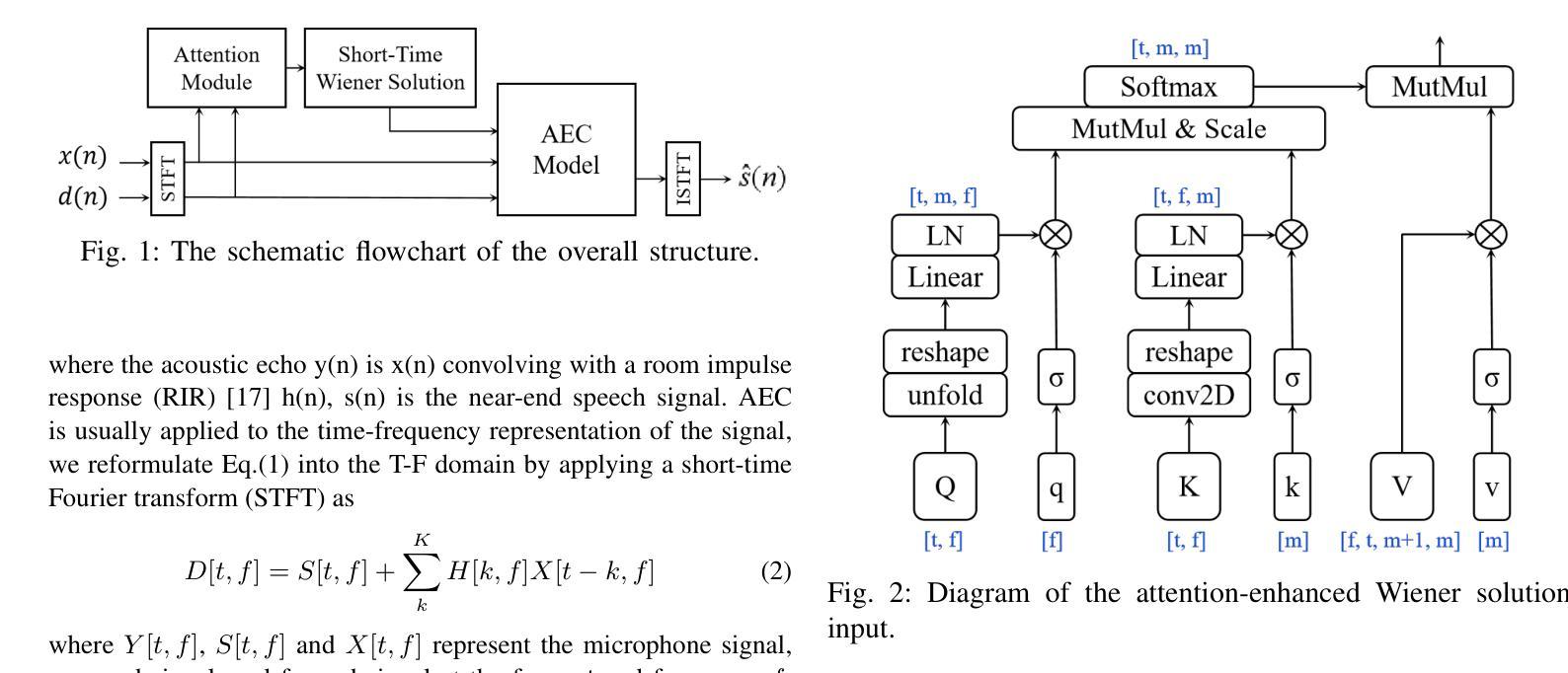
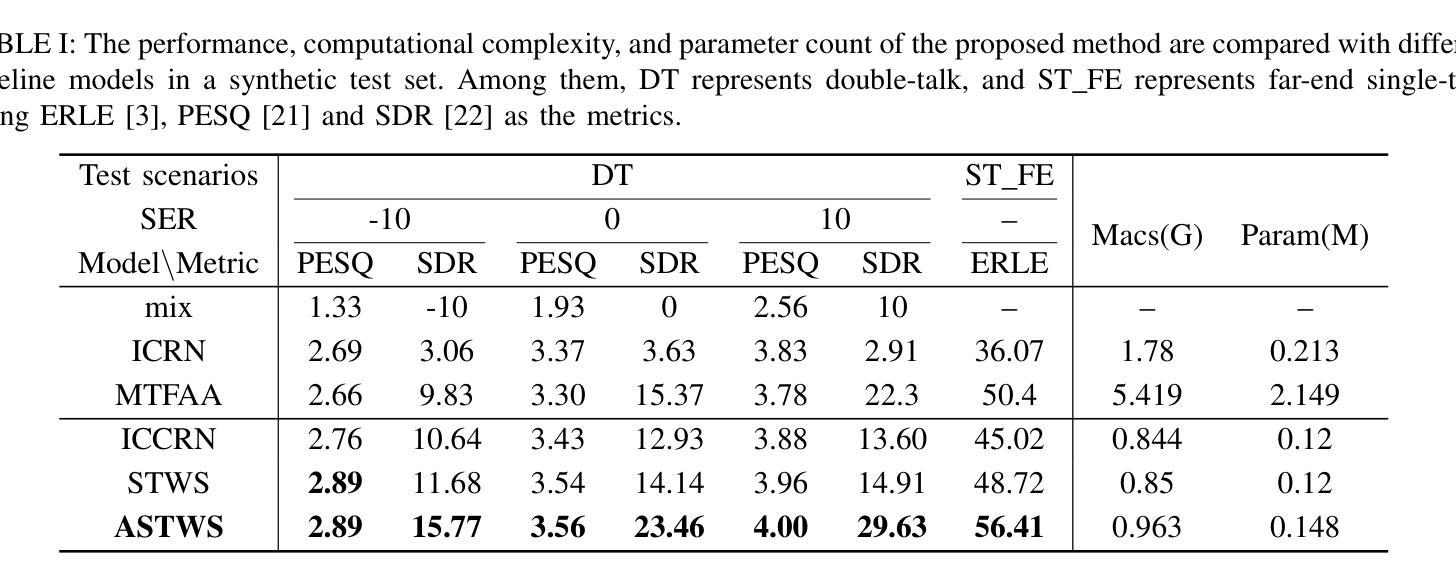
Attention-Enhanced Short-Time Wiener Solution for Acoustic Echo Cancellation
Authors:Fei Zhao, Xueliang Zhang
Acoustic Echo Cancellation (AEC) is an essential speech signal processing technology that removes echoes from microphone inputs to facilitate natural-sounding full-duplex communication. Currently, deep learning-based AEC methods primarily focus on refining model architectures, frequently neglecting the incorporation of knowledge from traditional filter theory. This paper presents an innovative approach to AEC by introducing an attention-enhanced short-time Wiener solution. Our method strategically harnesses attention mechanisms to mitigate the impact of double-talk interference, thereby optimizing the efficiency of knowledge utilization. The derivation of the short-term Wiener solution, which adapts classical Wiener solutions to finite input causality, integrates established insights from filter theory into this method. The experimental outcomes corroborate the effectiveness of our proposed approach, surpassing other baseline models in performance and generalization. The official code is available at https://github.com/ZhaoF-i/ASTWS-AEC
声学回声消除(AEC)是一项重要的语音信号处理技术和消除麦克风输入中的回声,以促进自然发声的全双工通信。目前,基于深度学习的AEC方法主要集中在改进模型架构上,往往忽略了传统滤波理论知识的融合。本文提出了一种创新的AEC方法,通过引入增强注意力短时维纳解来解决这一问题。我们的方法策略性地利用注意力机制来减轻双向通话干扰的影响,从而优化知识利用效率。短时维纳解的推导将经典的维纳解适应于有限输入因果性,将滤波理论的既定见解融入此方法。实验结果表明,我们提出的方法的有效性超越了其他基线模型在性能和泛化方面的表现。官方代码可在https://github.com/ZhaoF-i/ASTWS-AEC找到。
论文及项目相关链接
总结
本文介绍了一种基于注意力增强的短时Wiener解决方案的声学回声消除技术。该技术结合注意力机制,有效减轻双讲干扰的影响,优化知识利用效率。其将传统的Wiener解决方案进行改进,以适应有限的输入因果性,将滤波器理论的现有见解融入其中。实验结果表明,该方法在性能和泛化能力上超越了其他基线模型。
关键见解
- 本研究介绍了一种基于注意力机制的声学回声消除新技术。
- 该技术结合深度学习及传统滤波器理论,通过引入注意力机制优化知识利用效率。
- 研究人员改进了经典的Wiener解决方案,以适应有限的输入因果性。
- 实验结果证明,该技术在性能上超越了其他基线模型。
- 本技术有助于实现更自然的双向通信,提升用户体验。
- 研究人员已在GitHub上公开了相关代码,便于他人参考和进一步研发。
点此查看论文截图

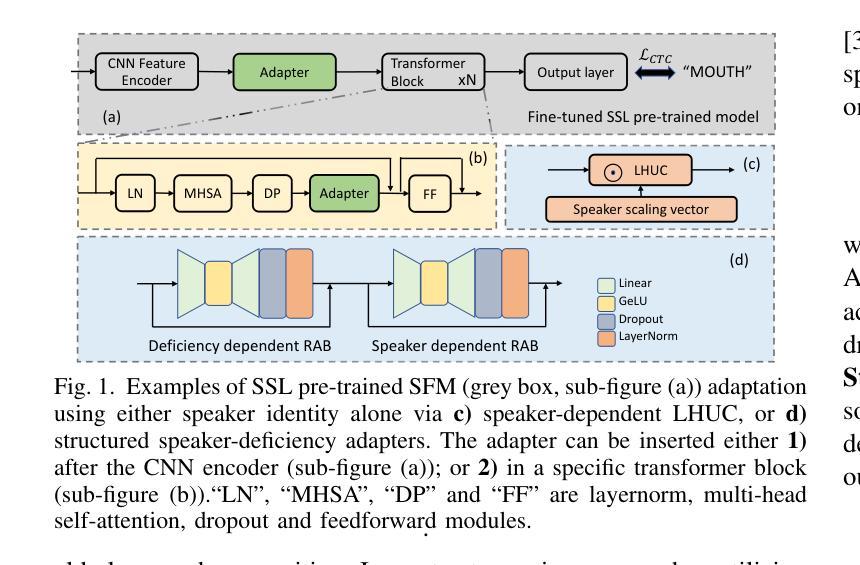
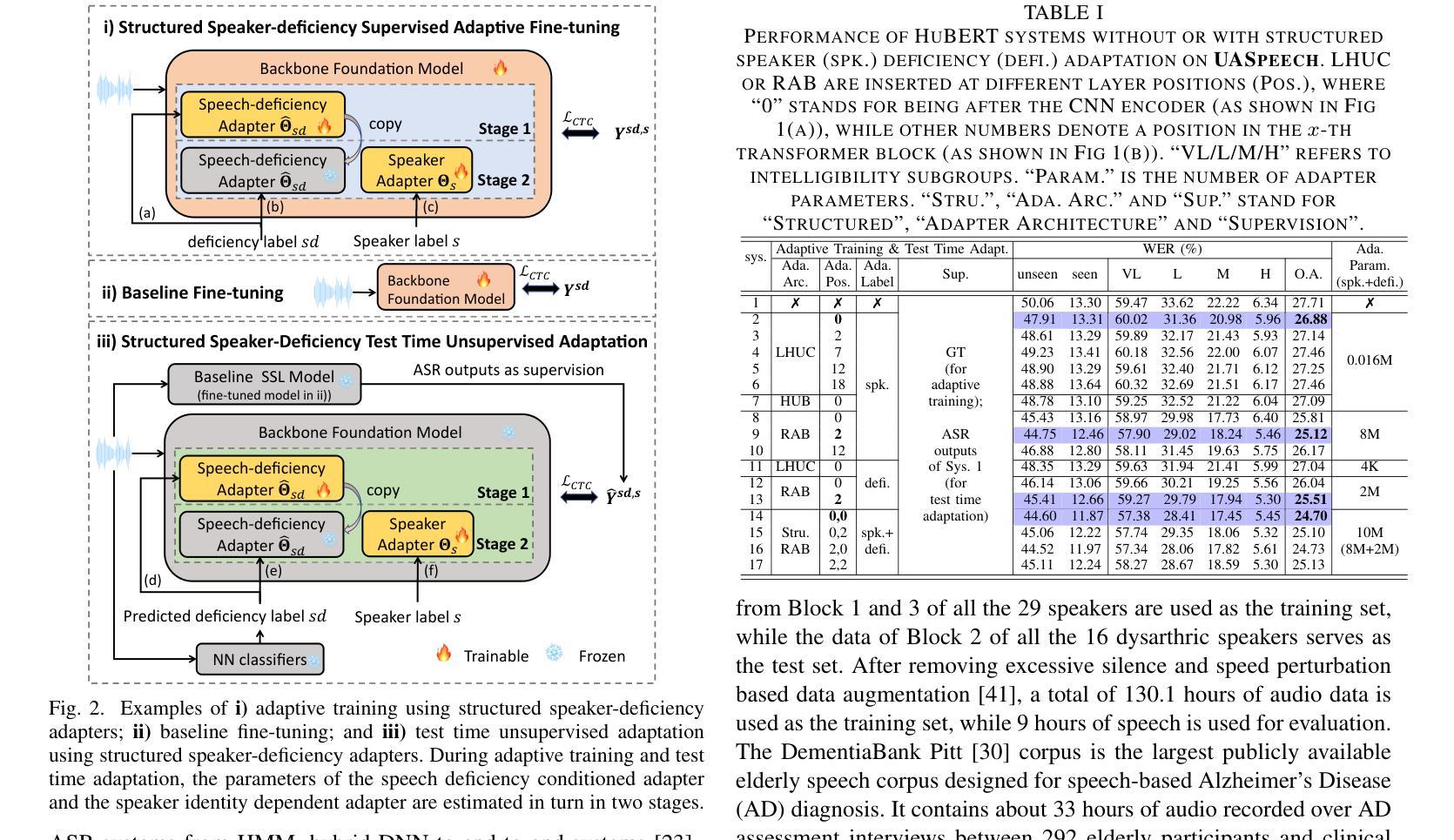
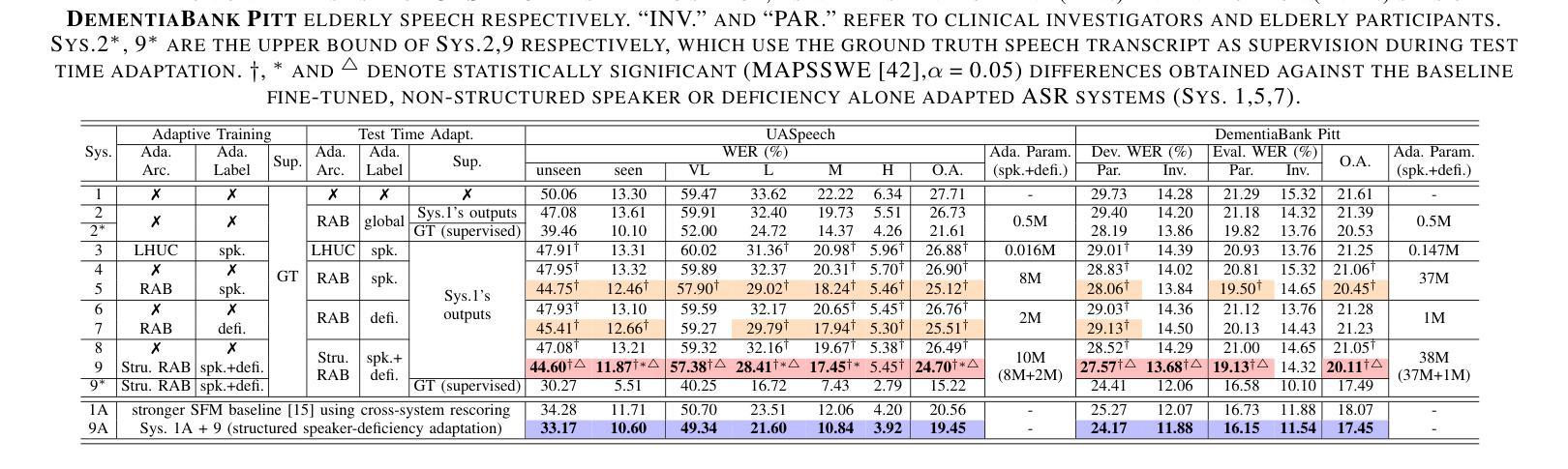
Structured Speaker-Deficiency Adaptation of Foundation Models for Dysarthric and Elderly Speech Recognition
Authors:Shujie Hu, Xurong Xie, Mengzhe Geng, Jiajun Deng, Zengrui Jin, Tianzi Wang, Mingyu Cui, Guinan Li, Zhaoqing Li, Helen Meng, Xunying Liu
Data-intensive fine-tuning of speech foundation models (SFMs) to scarce and diverse dysarthric and elderly speech leads to data bias and poor generalization to unseen speakers. This paper proposes novel structured speaker-deficiency adaptation approaches for SSL pre-trained SFMs on such data. Speaker and speech deficiency invariant SFMs were constructed in their supervised adaptive fine-tuning stage to reduce undue bias to training data speakers, and serves as a more neutral and robust starting point for test time unsupervised adaptation. Speech variability attributed to speaker identity and speech impairment severity, or aging induced neurocognitive decline, are modelled using separate adapters that can be combined together to model any seen or unseen speaker. Experiments on the UASpeech dysarthric and DementiaBank Pitt elderly speech corpora suggest structured speaker-deficiency adaptation of HuBERT and Wav2vec2-conformer models consistently outperforms baseline SFMs using either: a) no adapters; b) global adapters shared among all speakers; or c) single attribute adapters modelling speaker or deficiency labels alone by statistically significant WER reductions up to 3.01% and 1.50% absolute (10.86% and 6.94% relative) on the two tasks respectively. The lowest published WER of 19.45% (49.34% on very low intelligibility, 33.17% on unseen words) is obtained on the UASpeech test set of 16 dysarthric speakers.
针对语音基础模型(SFMs)的数据密集型精细调整,在面对稀缺且多样的言语障碍者和老年语音时,会导致数据偏差,并且对新未见说话者的泛化能力较差。本文针对此类数据,提出了新型的结构化说话者缺陷适应方法,用于SSL预训练的SFMs。在监督适应性精细调整阶段,构建了说话者和语音缺陷不变的SFMs,以减少对训练数据说话人的不必要偏见,并作为测试时间无监督适应的更中性和稳健的起点。与说话者身份、语音障碍严重程度或衰老引起的神经认知下降相关的语音变化,通过使用单独的适配器进行建模,这些适配器可以组合在一起,对任何已见或未见的说话者进行建模。在UASpeech言语障碍和DementiaBank Pitt老年语音语料库上的实验表明,对HuBERT和Wav2vec2-conformer模型进行结构化说话者缺陷适应,始终优于使用以下方法的基线SFMs:a)无适配器;b)所有说话人共享的全局适配器;c)仅对说话人或缺陷标签进行建模的单属性适配器。通过显著的WER降低,绝对降低了3.01%和1.50%(相对降低了10.86%和6.94%),在两项任务上分别实现了最佳性能。在UASpeech测试集上的最低WER为19.45%(在极低清晰度上达到49.34%,在未见词语上达到33.17%),该测试集包含16名言语障碍者。
论文及项目相关链接
摘要
数据密集型的语音基础模型(SFMs)对稀缺和多样化的言语障碍者和老年语音进行微调会导致数据偏见,并且难以推广到未见过的说话者。本文提出了针对SSL预训练SFM的新型结构化说话者缺陷适应方法。在监督自适应微调阶段,构建了说话者和语音缺陷不变的SFM,以减少对训练数据说话人的不必要偏见,并作为测试时间无监督适应的更中性和稳健的起点。语音变化归因于说话人身份、语音障碍严重程度或由衰老引起的神经认知下降,通过使用单独的适配器进行建模,这些适配器可以组合在一起,对任何已见或未见的说话者进行建模。在UASpeech言语障碍者和DementiaBank Pitt老年语音语料库上的实验表明,HuBERT和Wav2vec2-conformer模型的结构化说话者缺陷适应始终优于基线SFM使用:a)无适配器;b)所有说话人共享的全局适配器;c)单独建模说话人或缺陷标签的单属性适配器。通过显著的WER降低,绝对降低值最高达到3.01%和1.50%(相对降低分别为10.86%和6.94%)。在UASpeech测试集上的最低已发布WER为19.45%,涵盖了16位言语障碍者的测试集。
关键见解
- 数据密集型的语音基础模型(SFMs)对特定数据(如稀缺和多样化的言语障碍者和老年语音)进行微调时,易产生数据偏见,影响未见说话者的泛化能力。
- 提出新型结构化演讲者缺陷适应方法,以缓解训练数据说话人的偏见问题,并提高模型的稳健性。
- 通过在监督自适应微调阶段构建说话者和语音缺陷不变的SFM,为测试时的无监督适应提供了更中性和稳固的起点。
- 建模能够处理与说话人身份、语音障碍的严重程度以及衰老引起的神经认知下降相关的语音变化。
- 通过组合单独的适配器,模型可以适应任何已见或未见的说话者。
- 在UASpeech和DementiaBank Pitt语料库上的实验表明,结构化演讲者缺陷适应方法显著优于基线SFM。
点此查看论文截图


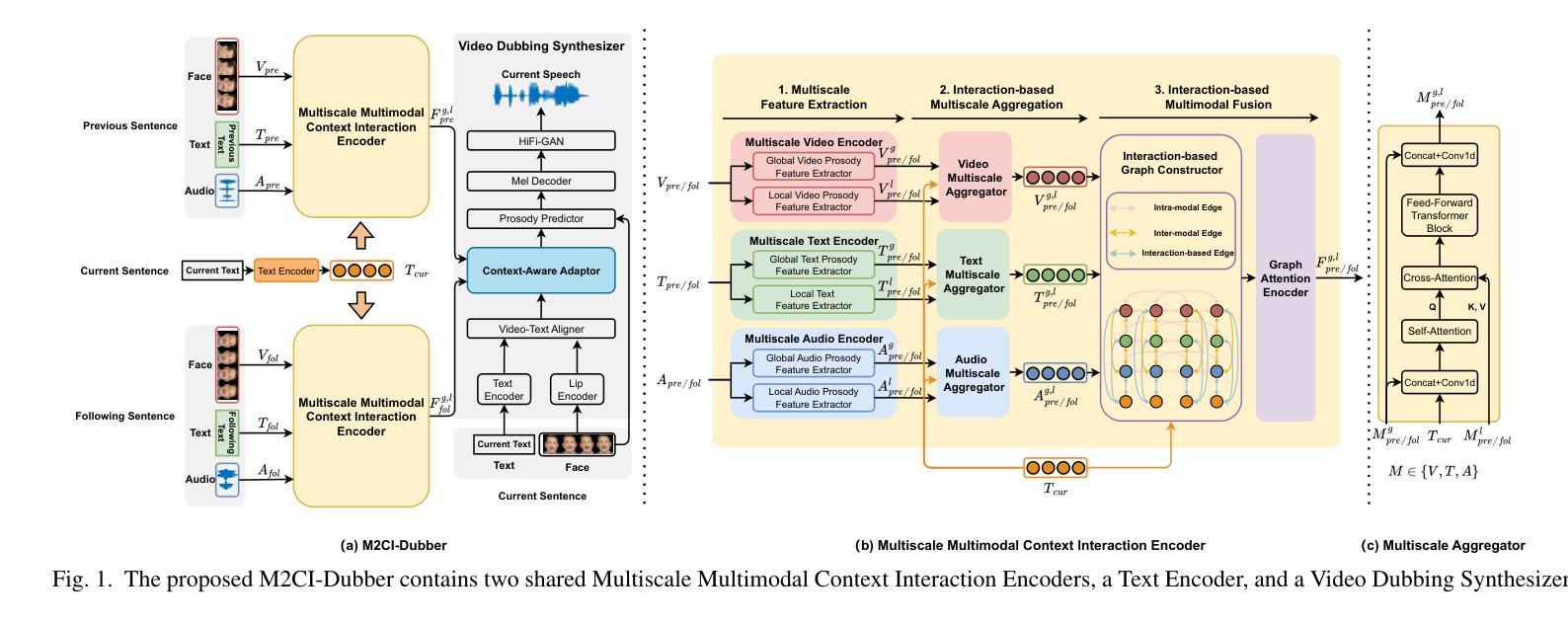
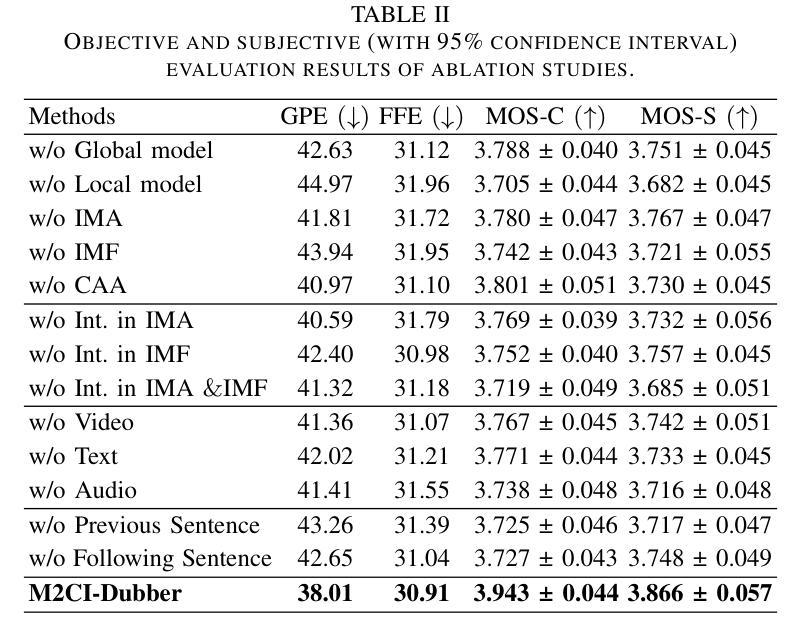
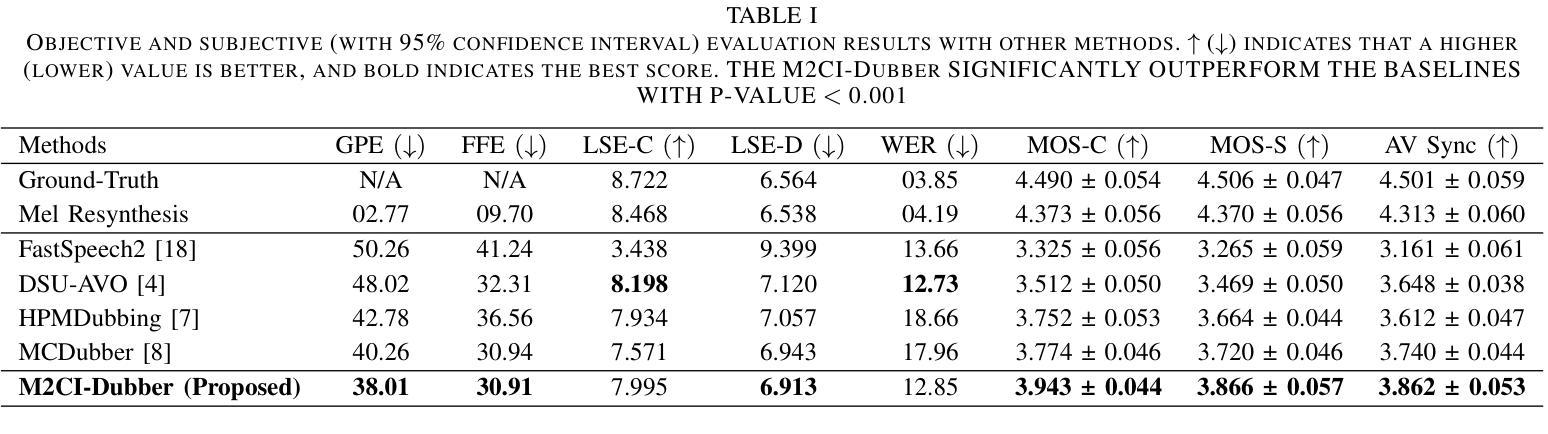
Towards Expressive Video Dubbing with Multiscale Multimodal Context Interaction
Authors:Yuan Zhao, Rui Liu, Gaoxiang Cong
Automatic Video Dubbing (AVD) generates speech aligned with lip motion and facial emotion from scripts. Recent research focuses on modeling multimodal context to enhance prosody expressiveness but overlooks two key issues: 1) Multiscale prosody expression attributes in the context influence the current sentence’s prosody. 2) Prosody cues in context interact with the current sentence, impacting the final prosody expressiveness. To tackle these challenges, we propose M2CI-Dubber, a Multiscale Multimodal Context Interaction scheme for AVD. This scheme includes two shared M2CI encoders to model the multiscale multimodal context and facilitate its deep interaction with the current sentence. By extracting global and local features for each modality in the context, utilizing attention-based mechanisms for aggregation and interaction, and employing an interaction-based graph attention network for fusion, the proposed approach enhances the prosody expressiveness of synthesized speech for the current sentence. Experiments on the Chem dataset show our model outperforms baselines in dubbing expressiveness. The code and demos are available at \textcolor[rgb]{0.93,0.0,0.47}{https://github.com/AI-S2-Lab/M2CI-Dubber}.
自动视频配音(AVD)根据脚本生成与唇部动作和面部情绪相匹配的语音。最近的研究集中在建立多模态上下文以提高韵律表达性,但忽略了两个关键问题:1)上下文中的多尺度韵律表达属性会影响当前句子的韵律。2)上下文中的韵律线索与当前句子相互作用,影响最终的韵律表达性。为了解决这些挑战,我们提出了M2CI-Dubber,这是一种用于AVD的多尺度多模态上下文交互方案。该方案包括两个共享的M2CI编码器,用于建立多尺度多模态上下文,并促进其与当前句子的深度交互。通过提取上下文中每种模态的全局和局部特征,利用基于注意力的机制进行聚合和交互,并采用基于交互的图注意力网络进行融合,所提出的方法提高了当前句子合成语音的韵律表达性。在Chem数据集上的实验表明,我们的模型在配音表达性方面优于基准模型。代码和演示可在https://github.com/AI-S2-Lab/M2CI-Dubber上找到。
论文及项目相关链接
PDF Accepted by ICSSP 2025
Summary
自动视频配音(AVD)技术能够根据脚本生成与唇部动作和面部表情相匹配的语音。然而,当前研究在模拟多模态语境以提升语调表达方面存在两个关键问题:一是多尺度语调表达属性在语境中的影响;二是语境中的语调线索与当前句子的互动。为了应对这些挑战,我们提出了M2CI-Dubber方案,这是一种多尺度多模态语境交互的AVD方案。该方案包含两个共享的M2CI编码器,用于模拟多尺度多模态语境,并与当前句子进行深度交互。通过提取语境中每种模态的全局和局部特征,利用基于注意力的机制进行聚合和互动,并采用基于交互的图注意力网络进行融合,提升了合成语音的语调表达力。在Chem数据集上的实验表明,我们的模型在配音表现力方面优于基准模型。
Key Takeaways
- AVD技术能够生成与唇部动作和面部表情匹配的语音。
- 当前研究在模拟多模态语境以提升语调表达方面存在挑战。
- M2CI-Dubber方案旨在解决多尺度语调表达和语境中的语调线索与当前句子的互动问题。
- M2CI-Dubber包含两个共享的M2CI编码器,用于模拟多尺度多模态语境。
- 通过提取全局和局部特征、利用基于注意力的机制以及图注意力网络,M2CI-Dubber提升了合成语音的语调表达力。
- 在Chem数据集上的实验表明,M2CI-Dubber模型在配音表现力方面优于其他模型。
点此查看论文截图

Neural Directed Speech Enhancement with Dual Microphone Array in High Noise Scenario
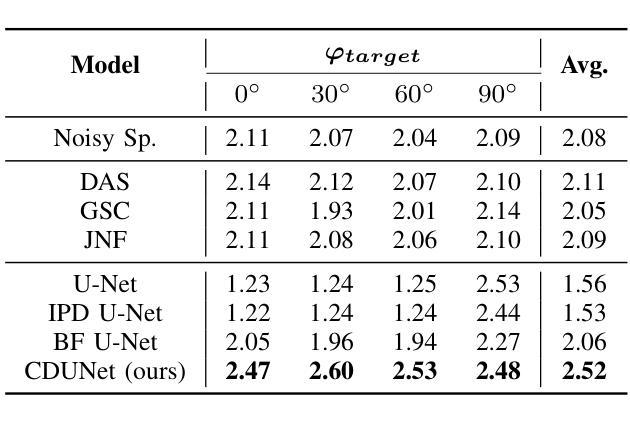
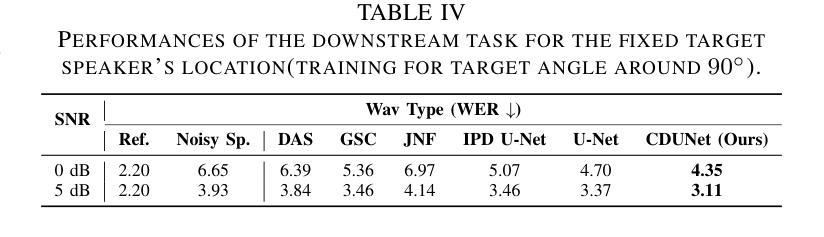
Authors:Wen Wen, Qiang Zhou, Yu Xi, Haoyu Li, Ziqi Gong, Kai Yu
In multi-speaker scenarios, leveraging spatial features is essential for enhancing target speech. While with limited microphone arrays, developing a compact multi-channel speech enhancement system remains challenging, especially in extremely low signal-to-noise ratio (SNR) conditions. To tackle this issue, we propose a triple-steering spatial selection method, a flexible framework that uses three steering vectors to guide enhancement and determine the enhancement range. Specifically, we introduce a causal-directed U-Net (CDUNet) model, which takes raw multi-channel speech and the desired enhancement width as inputs. This enables dynamic adjustment of steering vectors based on the target direction and fine-tuning of the enhancement region according to the angular separation between the target and interference signals. Our model with only a dual microphone array, excels in both speech quality and downstream task performance. It operates in real-time with minimal parameters, making it ideal for low-latency, on-device streaming applications.
在多说话人场景中,利用空间特征增强目标语音至关重要。然而,在有限的麦克风阵列下,开发紧凑的多通道语音增强系统仍然具有挑战性,特别是在信号与噪声比(SNR)极低的条件下。为了解决这个问题,我们提出了一种三向引导的空间选择方法,这是一个灵活框架,使用三个引导向量来指导增强并确定增强范围。具体来说,我们引入了一个因果导向的U-Net(CDUNet)模型,该模型以原始多通道语音和所需的增强宽度为输入。这可以根据目标方向和目标信号与干扰信号之间的角度间隔动态调整引导向量并微调增强区域。我们的模型仅使用双麦克风阵列,在语音质量和下游任务性能方面都表现出色。它以实时方式运行,参数最少,非常适合低延迟的在线流式应用。
论文及项目相关链接
PDF Accepted by ICASSP 2025
Summary:在多说话人场景中,利用空间特征增强目标语音至关重要。针对具有有限的麦克风阵列和极低信噪比条件下的挑战,提出了一种采用三个导引向量进行增强和引导的灵活框架,并引入因果导向U-Net模型,实现动态调整导引向量和精细调整增强区域。该模型仅使用双麦克风阵列,在语音质量和下游任务性能上表现出色,适用于低延迟的在线流式应用。
Key Takeaways:
- 在多说话人场景中,空间特征对于增强目标语音至关重要。
- 面对有限的麦克风阵列和极端低信噪比条件,设计灵活框架以进行多通道语音增强是一个挑战。
- 提出了一种采用三个导引向量的方法来确定增强范围。
- 引入了因果导向U-Net模型,能够根据目标方向和角度分离动态调整导引向量和增强区域。
- 该模型在仅使用双麦克风阵列的情况下,在语音质量和下游任务性能上表现出色。
- 模型可实现实时操作,参数少,适合低延迟的在线流式应用。
- 该方法为解决具有挑战性的语音增强问题提供了新的思路。
点此查看论文截图


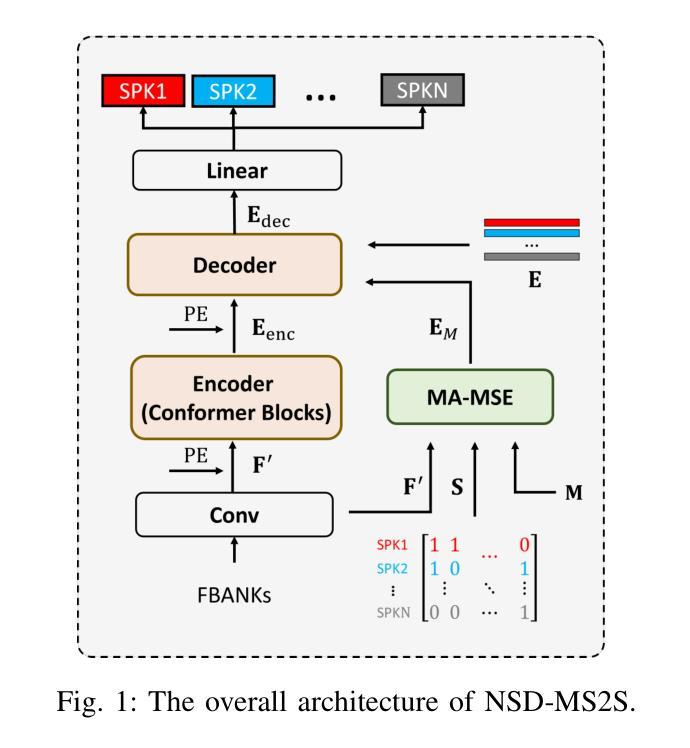
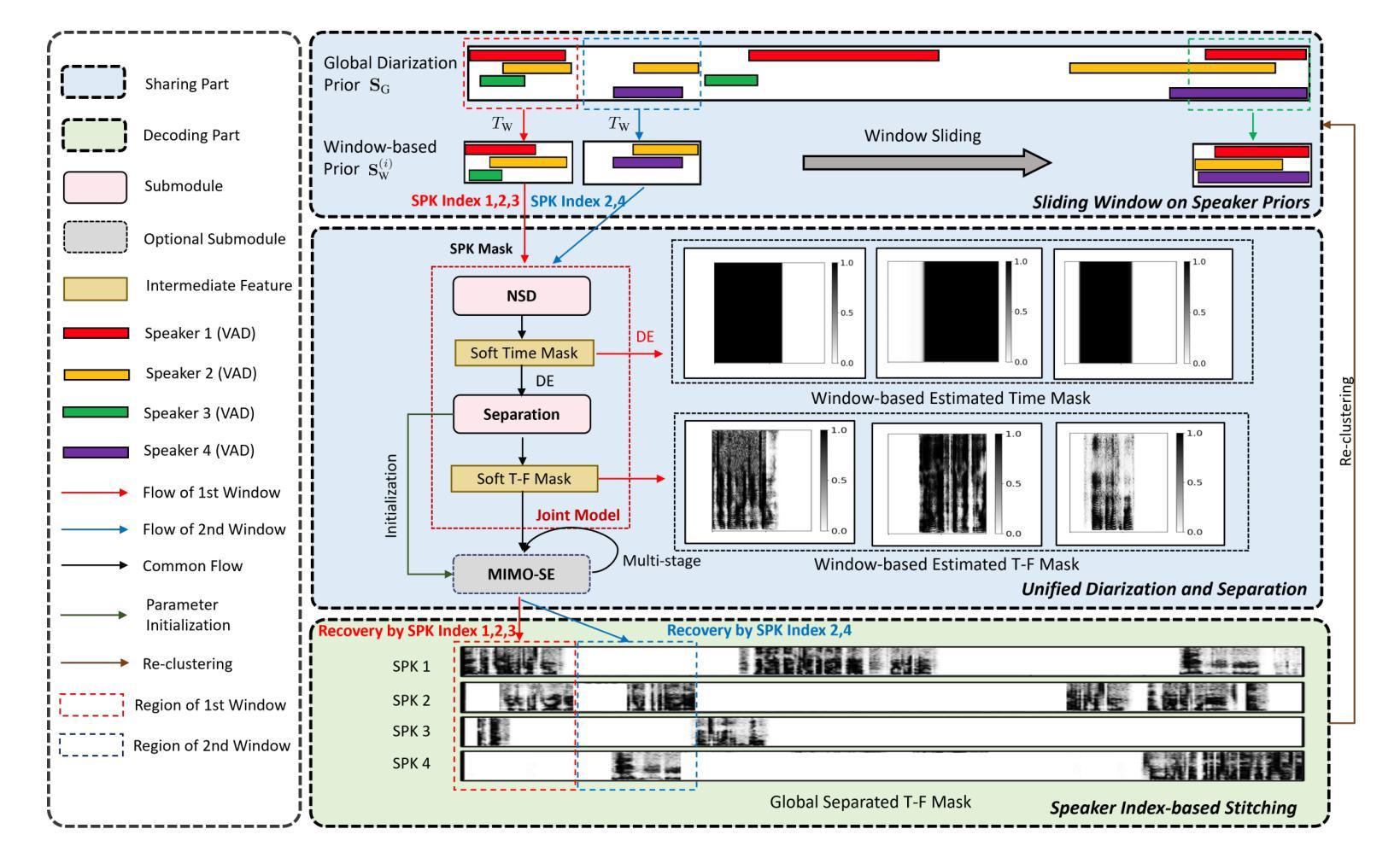
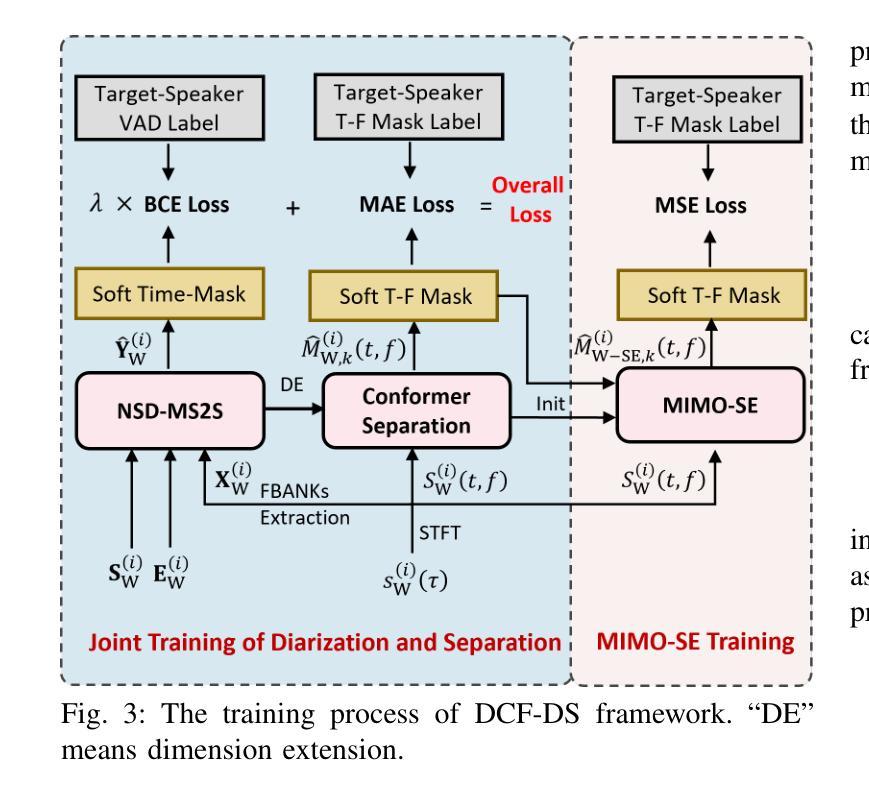
DCF-DS: Deep Cascade Fusion of Diarization and Separation for Speech Recognition under Realistic Single-Channel Conditions
Authors:Shu-Tong Niu, Jun Du, Ruo-Yu Wang, Gao-Bin Yang, Tian Gao, Jia Pan, Yu Hu
We propose a single-channel Deep Cascade Fusion of Diarization and Separation (DCF-DS) framework for back-end automatic speech recognition (ASR), combining neural speaker diarization (NSD) and speech separation (SS). First, we sequentially integrate the NSD and SS modules within a joint training framework, enabling the separation module to leverage speaker time boundaries from the diarization module effectively. Then, to complement DCF-DS training, we introduce a window-level decoding scheme that allows the DCF-DS framework to handle the sparse data convergence instability (SDCI) problem. We also explore using an NSD system trained on real datasets to provide more accurate speaker boundaries. Additionally, we incorporate an optional multi-input multi-output speech enhancement module (MIMO-SE) within the DCF-DS framework, which offers further performance gains. Finally, we enhance diarization results by re-clustering DCF-DS outputs, improving ASR accuracy. By incorporating the DCF-DS method, we achieved first place in the realistic single-channel track of the CHiME-8 NOTSOFAR-1 challenge. We also perform the evaluation on the open LibriCSS dataset, achieving a new state-of-the-art single-channel speech recognition performance.
我们提出了一种单通道深度级联融合分治与分离(DCF-DS)框架,用于后端自动语音识别(ASR),该框架结合了神经网络分治(NSD)和语音分离(SS)。首先,我们在联合训练框架中按顺序整合NSD和SS模块,使分离模块能够有效地利用分治模块中的说话人时间边界。然后,为了补充DCF-DS训练,我们引入了一种窗口级别的解码方案,该方案允许DCF-DS框架解决稀疏数据收敛不稳定(SDCI)问题。我们还探索使用在真实数据集上训练NSD系统来提供更准确的说话人边界。此外,我们在DCF-DS框架中融入了一个可选的多输入多输出语音增强模块(MIMO-SE),这带来了进一步的性能提升。最后,我们通过重新聚类DCF-DS输出结果来提升分治结果,提高ASR的准确性。通过采用DCF-DS方法,我们在CHiME-8 NOTSOFAR-1挑战的现实中单通道赛道上取得了第一名。我们还对开放的LibriCSS数据集进行了评估,实现了最新的单通道语音识别性能。
论文及项目相关链接
Summary
本文提出了一种单通道深度级联融合分治与分离(DCF-DS)框架,用于后端自动语音识别(ASR)。该框架结合了神经网络说话人分治(NSD)和语音分离(SS)。首先,在一个联合训练框架内按顺序整合NSD和SS模块,使分离模块能够有效地利用分治模块提供的说话人时间边界。其次,为了补充DCF-DS训练,引入了一种窗口级解码方案,以解决稀疏数据收敛不稳定(SDCI)问题。此外,还探索了使用在真实数据集上训练的NSD系统来提供更准确的说话人边界。同时,在DCF-DS框架中融入了一个可选的多输入多输出语音增强模块(MIMO-SE),进一步提升了性能。最后,通过对DCF-DS输出的重新聚类,优化了分治结果,提高了ASR的准确性。该框架在CHiME-8 NOTSOFAR-1挑战的现实单通道赛道中荣获第一名,并在开放的LibriCSS数据集上取得了最新的单通道语音识别性能。
Key Takeaways
- 提出了单通道Deep Cascade Fusion of Diarization and Separation(DCF-DS)框架,结合了神经网络说话人分治(NSD)和语音分离(SS)。
- 通过联合训练NSD和SS模块,使语音分离模块能够利用说话人时间边界信息。
- 引入窗口级解码方案,解决稀疏数据收敛不稳定问题。
- 使用真实数据集训练的NSD系统提供更准确的说话人边界。
- 可选融入多输入多输出语音增强模块(MIMO-SE),进一步提升性能。
- 通过重新聚类DCF-DS输出,优化分治结果,提高ASR准确性。
点此查看论文截图

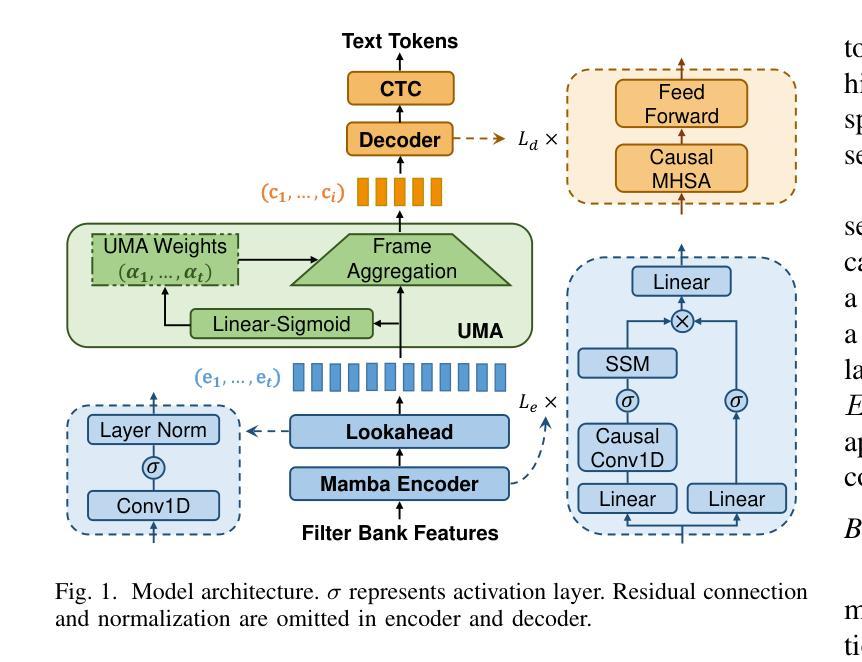
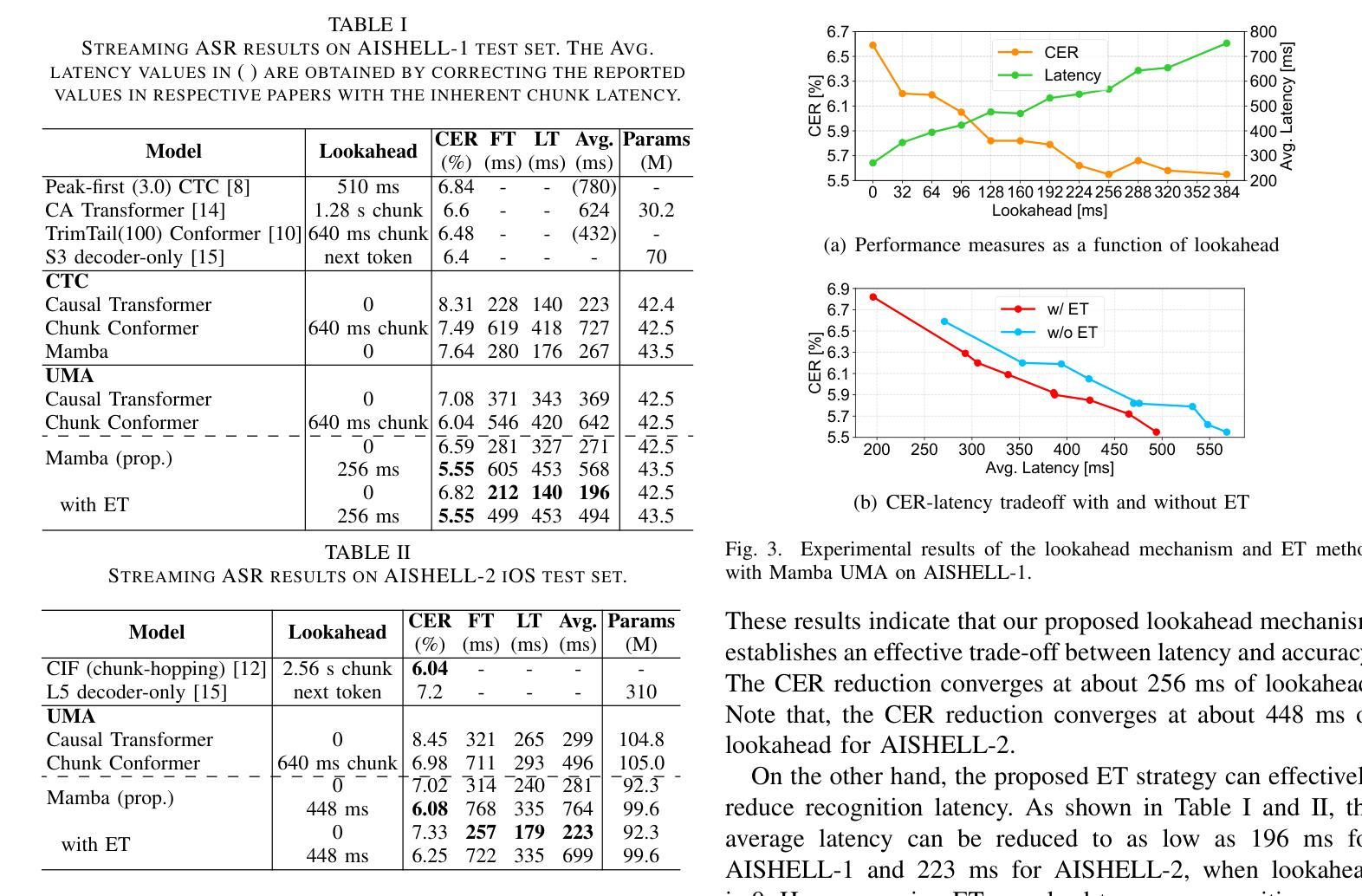
Mamba for Streaming ASR Combined with Unimodal Aggregation
Authors:Ying Fang, Xiaofei Li
This paper works on streaming automatic speech recognition (ASR). Mamba, a recently proposed state space model, has demonstrated the ability to match or surpass Transformers in various tasks while benefiting from a linear complexity advantage. We explore the efficiency of Mamba encoder for streaming ASR and propose an associated lookahead mechanism for leveraging controllable future information. Additionally, a streaming-style unimodal aggregation (UMA) method is implemented, which automatically detects token activity and streamingly triggers token output, and meanwhile aggregates feature frames for better learning token representation. Based on UMA, an early termination (ET) method is proposed to further reduce recognition latency. Experiments conducted on two Mandarin Chinese datasets demonstrate that the proposed model achieves competitive ASR performance in terms of both recognition accuracy and latency.
本文研究流式自动语音识别(ASR)。Mamba是一种最近提出的状态空间模型,在各种任务中展现出了与Transformer相匹配或更高的性能,同时得益于其线性复杂度的优势。我们探索了Mamba编码器在流式ASR中的效率,并提出了一种相关的前瞻机制,以利用可控的未来信息。此外,还实现了一种流式单模态聚合(UMA)方法,该方法可自动检测标记活动并流式触发标记输出,同时聚合特征帧以更好地学习标记表示。基于UMA,提出了一种早期终止(ET)方法,以进一步降低识别延迟。在两种中文数据集上的实验表明,该模型在识别准确性和延迟方面都取得了具有竞争力的ASR性能。
论文及项目相关链接
PDF Accepted by ICASSP 2025
Summary:
本文研究了基于流媒体的自动语音识别(ASR)。Mamba作为一种新近提出的状态空间模型,在各种任务中展现出与Transformer相匹配或更佳的性能,并且具有线性复杂度的优势。本文探索了Mamba编码器在流式ASR中的效率,并提出了一种相关的前瞻机制,以利用可控的未来信息。此外,实现了一种流式单模态聚合(UMA)方法,该方法可自动检测令牌活动并流式触发令牌输出,同时聚合特征帧以更好地学习令牌表示。基于UMA,进一步提出了早期终止(ET)方法来减少识别延迟。在两个中文数据集上的实验表明,该模型在识别准确性和延迟方面均表现出竞争力的ASR性能。
Key Takeaways:
- Mamba模型在流式ASR中展现出高效性能,可匹配或超越Transformer模型,并具备线性复杂度优势。
- 提出了利用Mamba编码器的流式ASR前瞻机制,以利用可控的未来信息。
- 实现了流式单模态聚合(UMA)方法,能自动检测令牌活动并触发流式令牌输出,同时聚合特征帧以优化学习。
- 基于UMA方法,提出了早期终止(ET)策略来进一步降低识别延迟。
- 在两个中文数据集上的实验验证了该模型在ASR性能和识别准确性方面的竞争力。
- Mamba模型在ASR任务中具有广泛的应用前景,特别是在需要高效率和低延迟的流式处理场景中。
点此查看论文截图


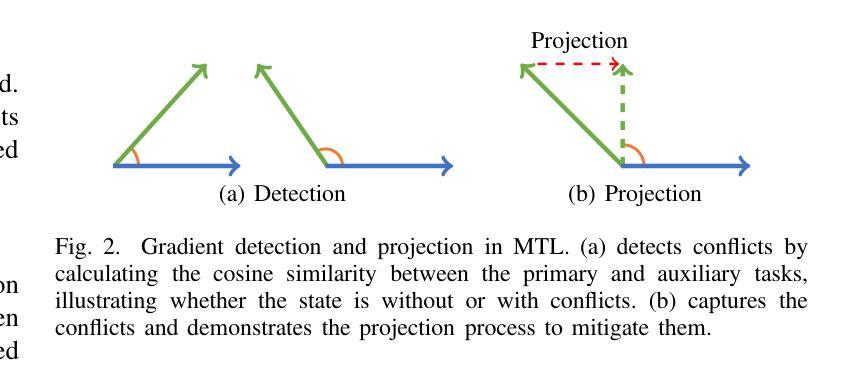
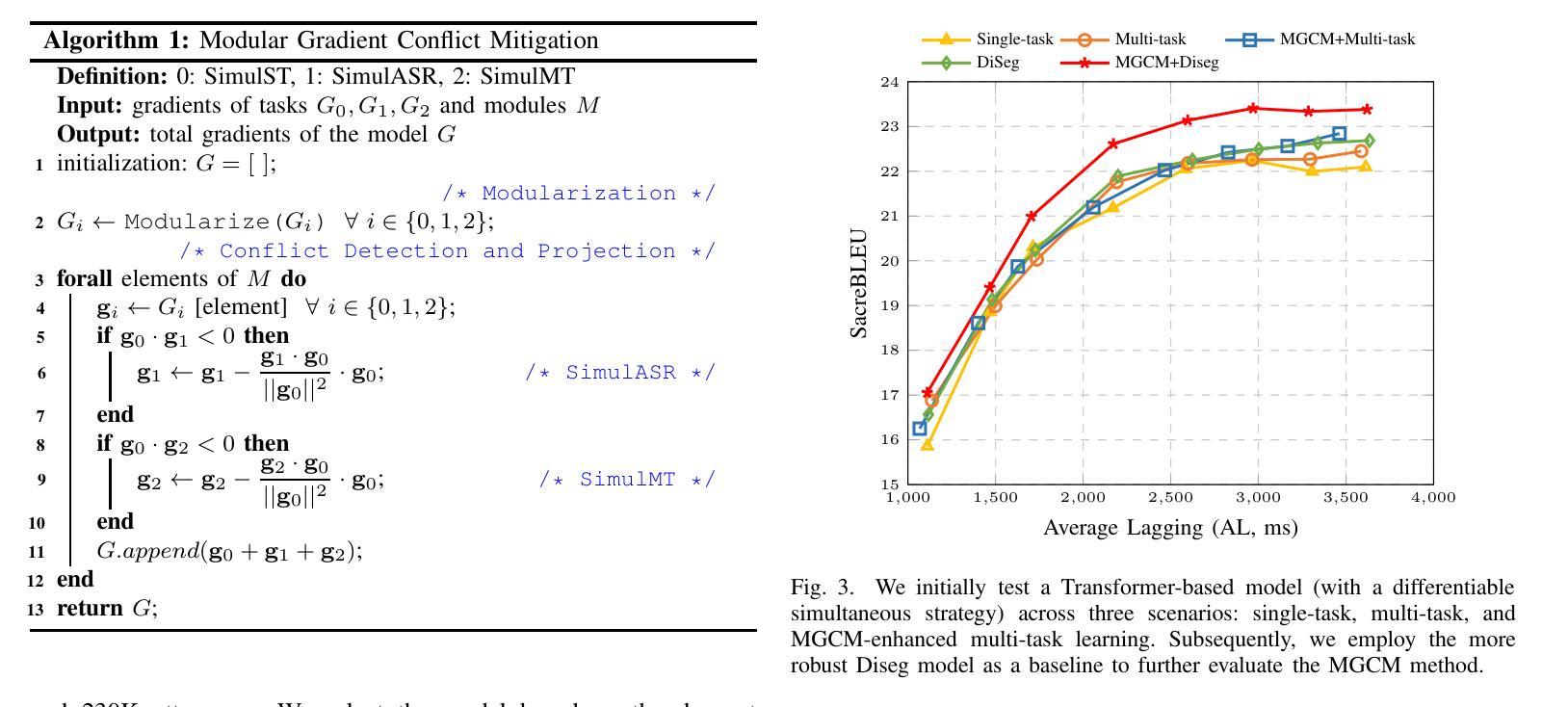
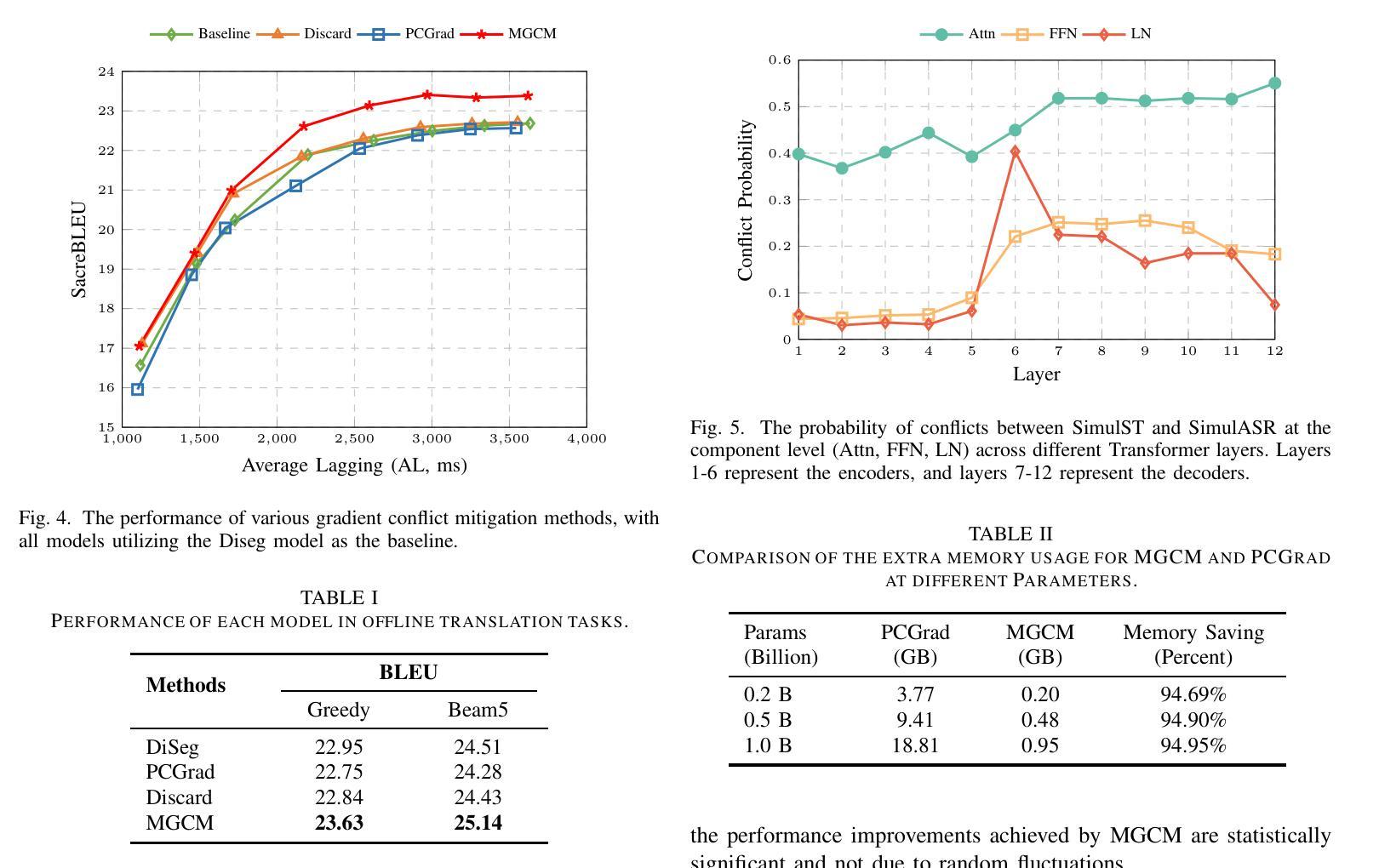
A Modular-based Strategy for Mitigating Gradient Conflicts in Simultaneous Speech Translation
Authors:Xiaoqian Liu, Yangfan Du, Jianjin Wang, Yuan Ge, Chen Xu, Tong Xiao, Guocheng Chen, Jingbo Zhu
Simultaneous Speech Translation (SimulST) involves generating target language text while continuously processing streaming speech input, presenting significant real-time challenges. Multi-task learning is often employed to enhance SimulST performance but introduces optimization conflicts between primary and auxiliary tasks, potentially compromising overall efficiency. The existing model-level conflict resolution methods are not well-suited for this task which exacerbates inefficiencies and leads to high GPU memory consumption. To address these challenges, we propose a Modular Gradient Conflict Mitigation (MGCM) strategy that detects conflicts at a finer-grained modular level and resolves them utilizing gradient projection. Experimental results demonstrate that MGCM significantly improves SimulST performance, particularly under medium and high latency conditions, achieving a 0.68 BLEU score gain in offline tasks. Additionally, MGCM reduces GPU memory consumption by over 95% compared to other conflict mitigation methods, establishing it as a robust solution for SimulST tasks.
同步语音识别翻译(SimulST)涉及在持续处理流式语音输入的同时生成目标语言文本,这带来了显著的真实时间挑战。多任务学习通常被用来提高SimulST的性能,但会在主要任务和辅助任务之间引入优化冲突,可能损害整体效率。现有的模型级冲突解决方法并不适合这项任务,这加剧了效率问题并导致GPU内存消耗过高。为了应对这些挑战,我们提出了一种模块梯度冲突缓解(MGCM)策略,它在更精细的模块级别检测并解决冲突,利用梯度投影来实现。实验结果表明,MGCM能显著提高SimulST的性能,特别是在中等和高的延迟条件下,离线任务中BLEU得分提高了0.68。此外,与其他冲突缓解方法相比,MGCM将GPU内存消耗降低了超过95%,使其成为SimulST任务的稳健解决方案。
论文及项目相关链接
PDF Accepted to ICASSP 2025
Summary
本文介绍了同步语音识别翻译(SimulST)面临的挑战,包括实时处理流式语音输入时生成目标语言文本的问题。虽然多任务学习被用来提高SimulST性能,但它引入了主要任务和辅助任务之间的优化冲突,可能损害整体效率。针对这些挑战,本文提出了一种模块化梯度冲突缓解(MGCM)策略,该策略在更精细的模块化层面检测并解决冲突,利用梯度投影来实现。实验结果表明,MGCM能显著提高SimulST性能,特别是在中等和较高的延迟条件下,在离线任务中实现了0.68的BLEU得分增益。此外,与其他冲突缓解方法相比,MGCM降低了超过95%的GPU内存消耗,成为SimulST任务的稳健解决方案。
Key Takeaways
- 同步语音识别翻译(SimulST)面临实时处理流式语音输入的挑战。
- 多任务学习在SimulST中引入优化冲突,可能影响效率。
- 模块化梯度冲突缓解(MGCM)策略能在更精细的模块化层面检测并解决冲突。
- MGCM通过梯度投影实现,可提高SimulST性能。
- 实验结果显示,MGCM在离线任务中实现了显著的BLEU得分增益。
- MGCM降低了GPU内存消耗,超过95%,比其他冲突缓解方法更有效率。
点此查看论文截图