⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-02 更新
DEGSTalk: Decomposed Per-Embedding Gaussian Fields for Hair-Preserving Talking Face Synthesis
Authors:Kaijun Deng, Dezhi Zheng, Jindong Xie, Jinbao Wang, Weicheng Xie, Linlin Shen, Siyang Song
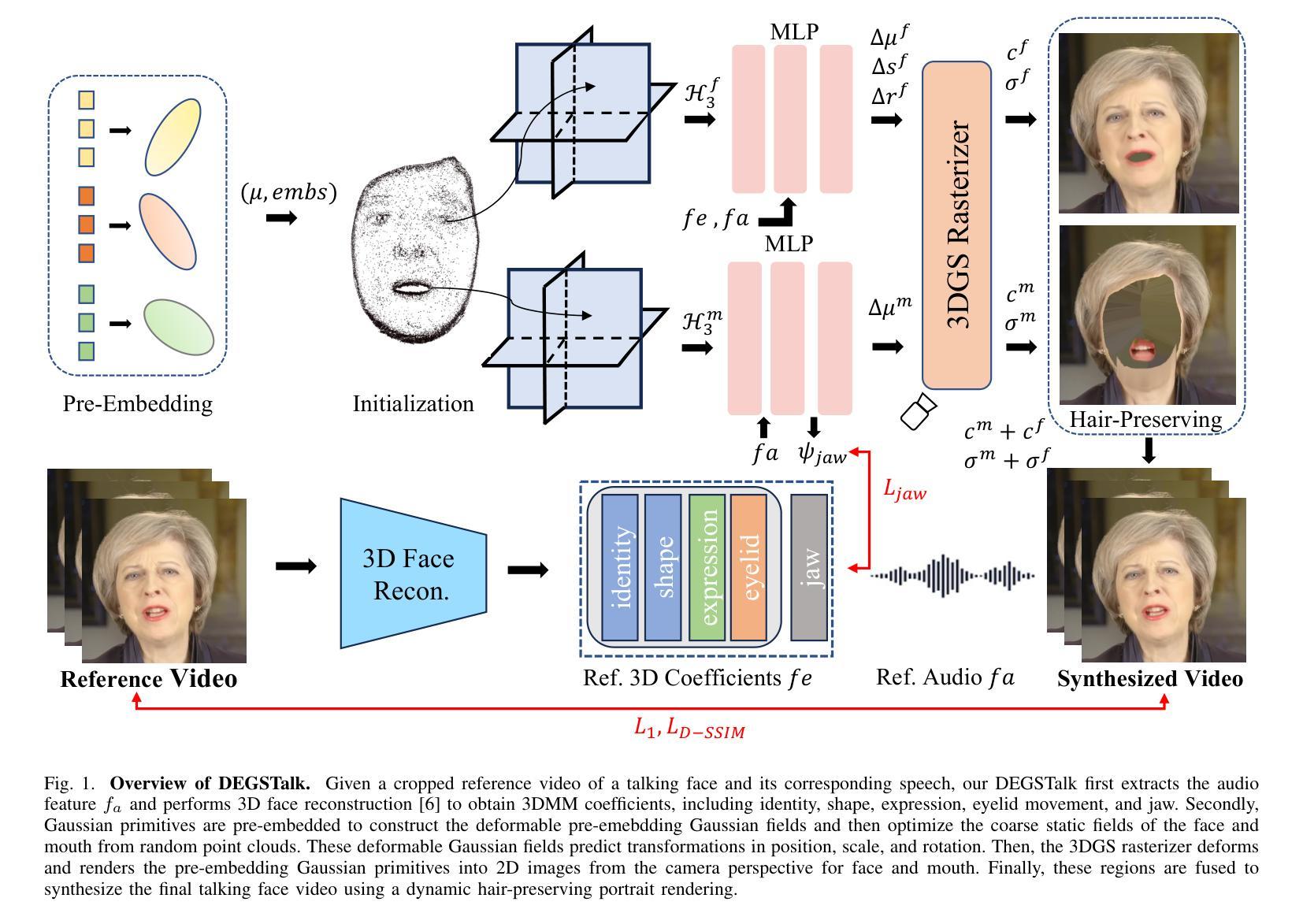
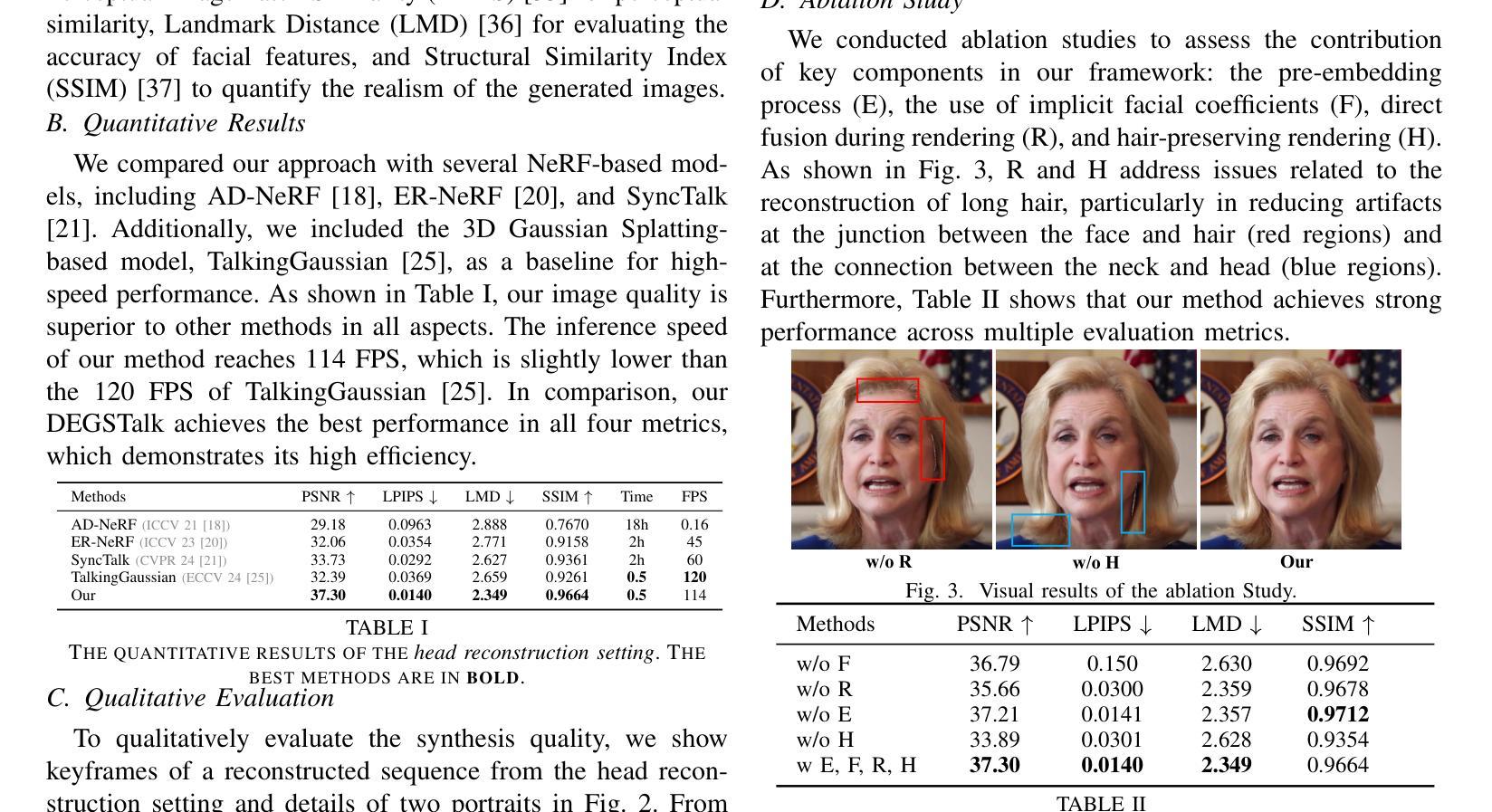
Accurately synthesizing talking face videos and capturing fine facial features for individuals with long hair presents a significant challenge. To tackle these challenges in existing methods, we propose a decomposed per-embedding Gaussian fields (DEGSTalk), a 3D Gaussian Splatting (3DGS)-based talking face synthesis method for generating realistic talking faces with long hairs. Our DEGSTalk employs Deformable Pre-Embedding Gaussian Fields, which dynamically adjust pre-embedding Gaussian primitives using implicit expression coefficients. This enables precise capture of dynamic facial regions and subtle expressions. Additionally, we propose a Dynamic Hair-Preserving Portrait Rendering technique to enhance the realism of long hair motions in the synthesized videos. Results show that DEGSTalk achieves improved realism and synthesis quality compared to existing approaches, particularly in handling complex facial dynamics and hair preservation. Our code will be publicly available at https://github.com/CVI-SZU/DEGSTalk.
准确合成说话人脸视频并为长发个体捕捉精细面部特征是一项重大挑战。为了应对现有方法中的这些挑战,我们提出了一种基于可变形预嵌入高斯场(DEGSTalk)的说话人脸合成方法,该方法使用基于三维高斯填充(3DGS)的方法生成具有长发的真实说话人脸。我们的DEGSTalk采用可变形预嵌入高斯场,使用隐式表达式系数动态调整预嵌入高斯基本体,从而能够精确捕捉动态面部区域和微妙表情。此外,我们还提出了一种动态保发肖像渲染技术,以提高合成视频中长发运动的真实感。结果表明,与现有方法相比,DEGSTalk在实现真实感和合成质量方面有所提高,特别是在处理复杂的面部动态和头发保留方面。我们的代码将在https://github.com/CVI-SZU/DEGSTalk公开可用。
论文及项目相关链接
PDF Accepted by ICASSP 2025
Summary
本文提出了一种基于三维高斯投影(3DGS)的说话人脸合成方法,称为分解嵌入高斯场(DEGSTalk)。该方法可生成具有长发的真实感说话人脸。它通过可变形预嵌入高斯场动态调整预嵌入高斯原始数据,使用隐式表达式系数捕捉面部动态区域和微妙表情。此外,还提出了一种动态保持头发渲染技术,提高了合成视频中长发动作的真实感。与现有方法相比,DEGSTalk在处理复杂的面部动态和保持头发方面实现了更高的真实感和合成质量。
Key Takeaways
- 说话人脸合成中,处理长发和捕捉面部细微特征是重大挑战。
- DEGSTalk方法采用三维高斯投影技术生成真实感的说话人脸。
- DEGSTalk使用可变形预嵌入高斯场动态调整预嵌入数据以适应面部动作。
- 提出的动态保持头发渲染技术提高了合成视频中长发动作的真实感。
- DEGSTalk方法特别擅长处理复杂的面部动态和头发保持问题。
- 该方法的代码将在公开平台上发布,便于他人使用和验证。
点此查看论文截图


UniAvatar: Taming Lifelike Audio-Driven Talking Head Generation with Comprehensive Motion and Lighting Control
Authors:Wenzhang Sun, Xiang Li, Donglin Di, Zhuding Liang, Qiyuan Zhang, Hao Li, Wei Chen, Jianxun Cui
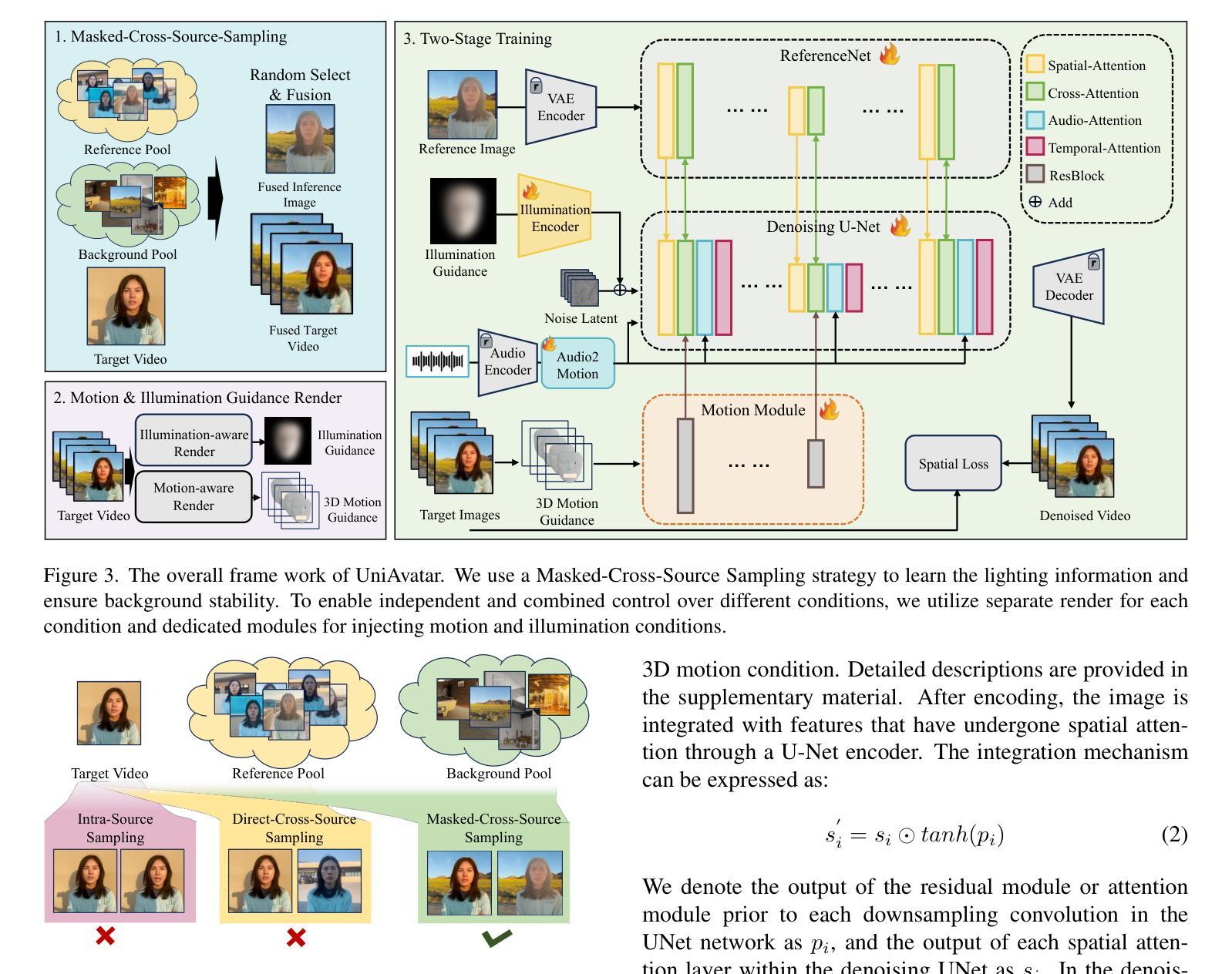
Recently, animating portrait images using audio input is a popular task. Creating lifelike talking head videos requires flexible and natural movements, including facial and head dynamics, camera motion, realistic light and shadow effects. Existing methods struggle to offer comprehensive, multifaceted control over these aspects. In this work, we introduce UniAvatar, a designed method that provides extensive control over a wide range of motion and illumination conditions. Specifically, we use the FLAME model to render all motion information onto a single image, maintaining the integrity of 3D motion details while enabling fine-grained, pixel-level control. Beyond motion, this approach also allows for comprehensive global illumination control. We design independent modules to manage both 3D motion and illumination, permitting separate and combined control. Extensive experiments demonstrate that our method outperforms others in both broad-range motion control and lighting control. Additionally, to enhance the diversity of motion and environmental contexts in current datasets, we collect and plan to publicly release two datasets, DH-FaceDrasMvVid-100 and DH-FaceReliVid-200, which capture significant head movements during speech and various lighting scenarios.
近期,使用音频输入来驱动人物肖像图像进行动画设计是一项热门任务。创建逼真的对话头部视频需要灵活和自然的动作,包括面部和头部动态、相机运动、真实的光影效果。现有方法难以在各方面提供全面、多元的控制。在这项工作中,我们引入了UniAvatar方法,该方法可对广泛的运动和照明条件进行全面控制。具体来说,我们使用FLAME模型将所有运动信息渲染到单张图像上,这样既保持了3D运动细节的完整性,又实现了精细的像素级控制。除了运动控制外,我们的方法还允许进行全面的全局照明控制。我们设计了独立的模块来管理3D运动和照明,以实现单独和组合控制。大量实验表明,我们的方法在广泛的运动控制和照明控制方面都优于其他方法。此外,为了提高当前数据集中运动和环境上下文的多样性,我们收集和计划公开两个数据集,即DH-FaceDrasMvVid-100和DH-FaceReliVid-200。这两个数据集捕捉了演讲过程中的重要头部运动和多种照明场景。
论文及项目相关链接
Summary
新一代动画肖像技术UniAvatar能够全面控制图像动作和照明条件,实现逼真说话头动画。通过运用FLAME模型将全部动作信息渲染至单张图像上,在维持3D动作细节完整性的同时实现精细像素级控制。此外,该技术还提供全面的全局照明控制,独立管理3D动作和照明,可同时或分别进行操作。实验证明,该方法在动作控制和照明控制方面都优于其他技术。同时,为了提升现有数据集中的动作和环境上下文多样性,收集并计划公开两个数据集DH-FaceDrasMvVid-100和DH-FaceReliVid-200,用于捕捉言语过程中的大幅头部运动和不同光照场景。
Key Takeaways
- UniAvatar技术能全面控制图像动作和照明条件,实现逼真说话头动画。
- 利用FLAME模型将动作信息渲染至单张图像,维持3D动作细节完整性,同时实现精细像素级控制。
- 提供全面的全局照明控制,允许对动作和照明进行独立或同时操作。
- 在动作控制和照明控制方面优于其他技术。
- 收集并计划公开两个数据集以提升动作和环境上下文的多样性。
- DH-FaceDrasMvVid-100数据集捕捉言语过程中的大幅头部运动。
点此查看论文截图





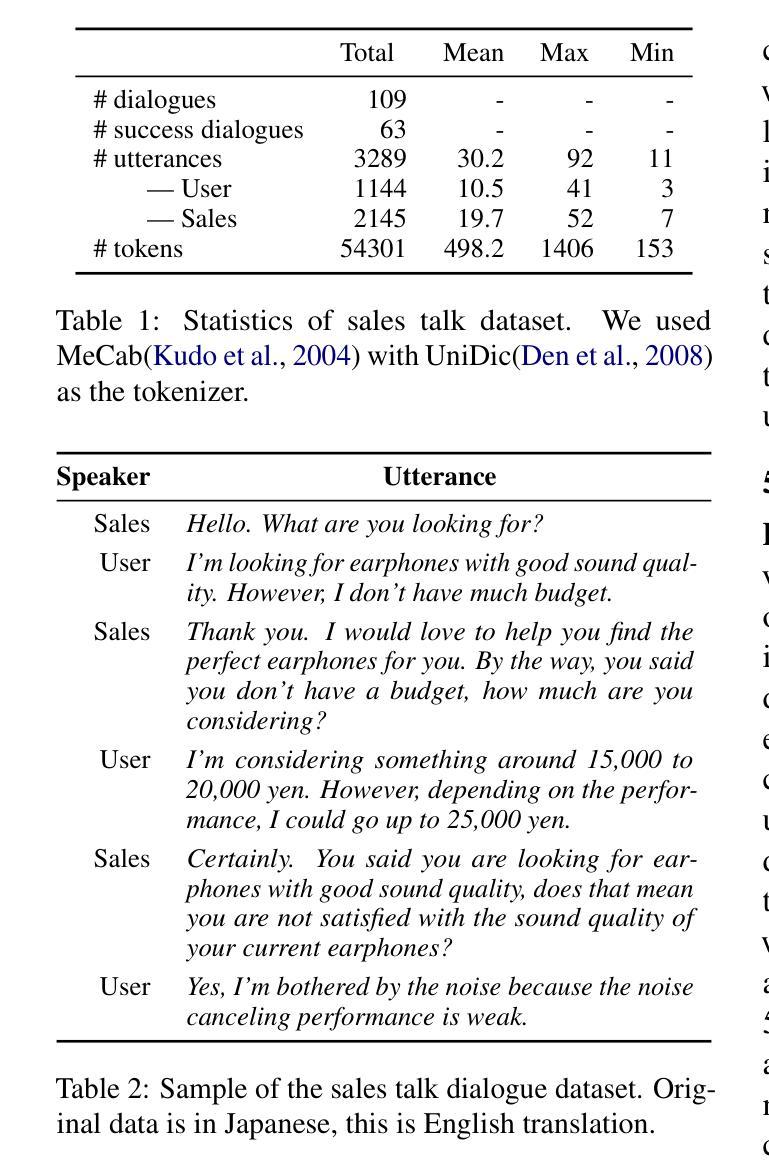
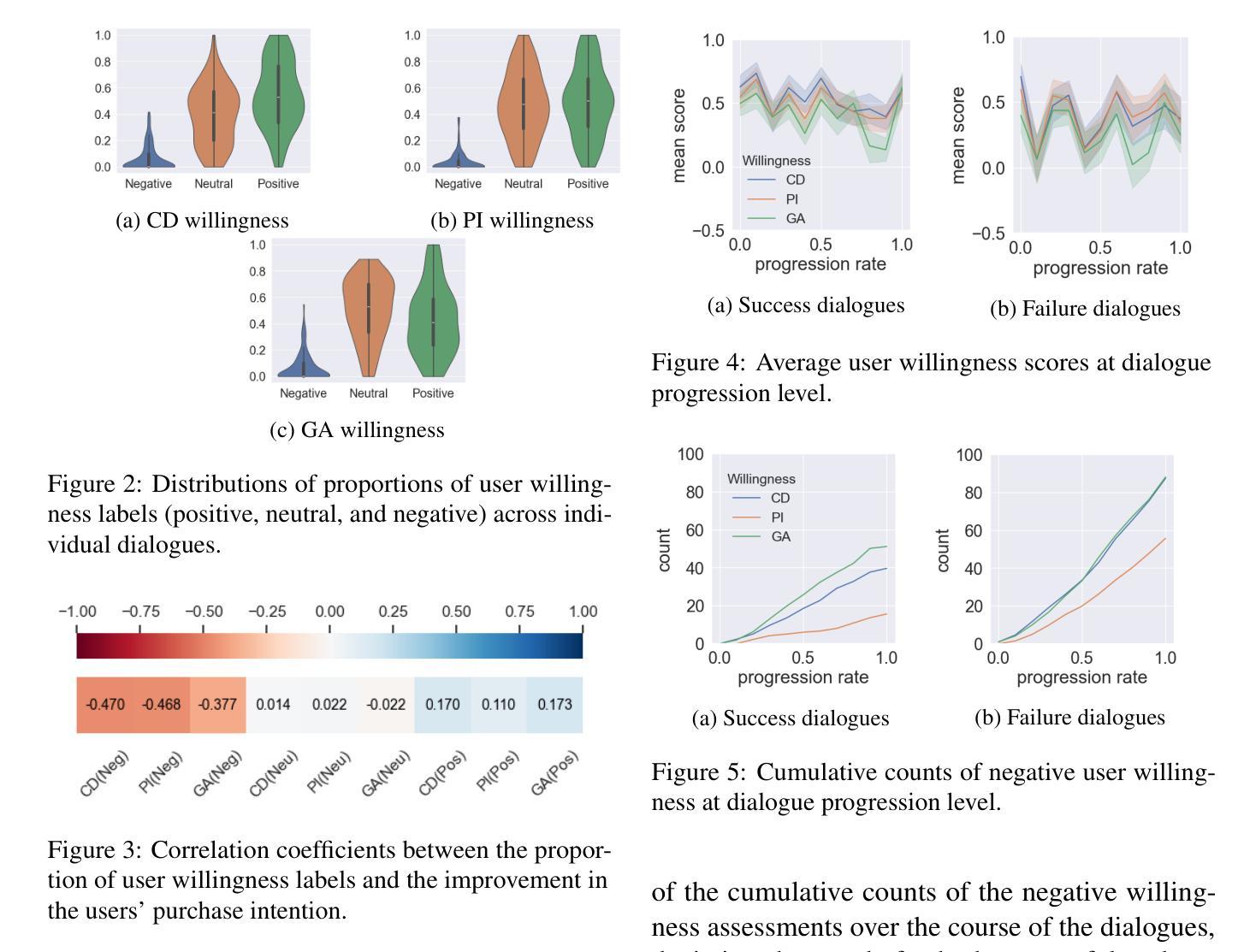
User Willingness-aware Sales Talk Dataset
Authors:Asahi Hentona, Jun Baba, Shiki Sato, Reina Akama
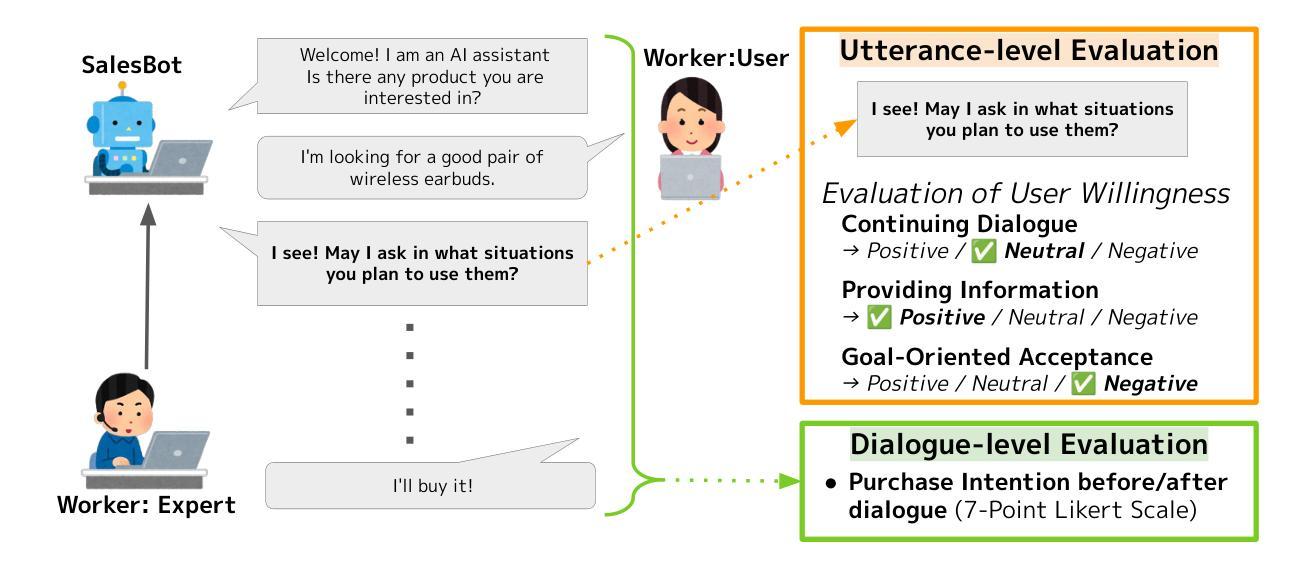
User willingness is a crucial element in the sales talk process that affects the achievement of the salesperson’s or sales system’s objectives. Despite the importance of user willingness, to the best of our knowledge, no previous study has addressed the development of automated sales talk dialogue systems that explicitly consider user willingness. A major barrier is the lack of sales talk datasets with reliable user willingness data. Thus, in this study, we developed a user willingness-aware sales talk collection by leveraging the ecological validity concept, which is discussed in the field of human-computer interaction. Our approach focused on three types of user willingness essential in real sales interactions. We created a dialogue environment that closely resembles real-world scenarios to elicit natural user willingness, with participants evaluating their willingness at the utterance level from multiple perspectives. We analyzed the collected data to gain insights into practical user willingness-aware sales talk strategies. In addition, as a practical application of the constructed dataset, we developed and evaluated a sales dialogue system aimed at enhancing the user’s intent to purchase.
用户意愿是销售对话过程中至关重要的元素,影响销售人员或销售系统目标的实现。尽管用户意愿非常重要,但据我们所知,目前没有研究专注于考虑用户意愿的自动化销售对话系统的开发。一个主要障碍是缺乏具有可靠用户意愿数据的销售对话数据集。因此,在研究中,我们利用人机交互领域中讨论过的生态效度概念,开发了一个考虑用户意愿的销售对话数据集。我们的方法侧重于真实销售互动中三种重要的用户意愿类型。我们创建了一个与真实世界场景非常相似的对话环境,以激发用户的自然意愿,参与者可以从多个角度评价其在话语层面的意愿。我们分析了收集的数据,以深入了解实际用户意愿感知的销售对话策略。此外,作为所构建数据集的实际应用,我们开发并评估了一个旨在增强用户购买意愿的销售对话系统。
论文及项目相关链接
PDF 12 pages, Accepted to COLING2025
Summary
用户意愿是销售对话过程中影响销售人员或销售系统目标实现的关键因素。本研究首次考虑用户意愿,开发自动化销售对话系统。通过利用人机交互领域中的生态效度概念,构建了一个用户意愿感知的销售对话数据集。重点关注真实销售互动中的三种用户意愿类型,创建一个模拟真实场景对话环境,激发自然用户意愿,并从多个角度评价参与者的意愿水平。分析数据,了解实践中的用户意愿感知销售策略。同时,利用构建的数据集开发评估了一个旨在增强用户购买意向的销售对话系统。
Key Takeaways
- 用户意愿对销售对话过程至关重要,影响销售人员或系统的目标实现。
- 现有研究中缺乏考虑用户意愿的自动化销售对话系统。
- 利用生态效度概念构建用户意愿感知的销售对话数据集。
- 关注真实销售互动中的三种关键用户意愿类型。
- 创建模拟真实场景对话环境,从多个角度评估参与者的意愿水平。
- 分析数据以获取关于用户意愿感知销售策略的实用见解。
点此查看论文截图

Towards Expressive Video Dubbing with Multiscale Multimodal Context Interaction
Authors:Yuan Zhao, Rui Liu, Gaoxiang Cong
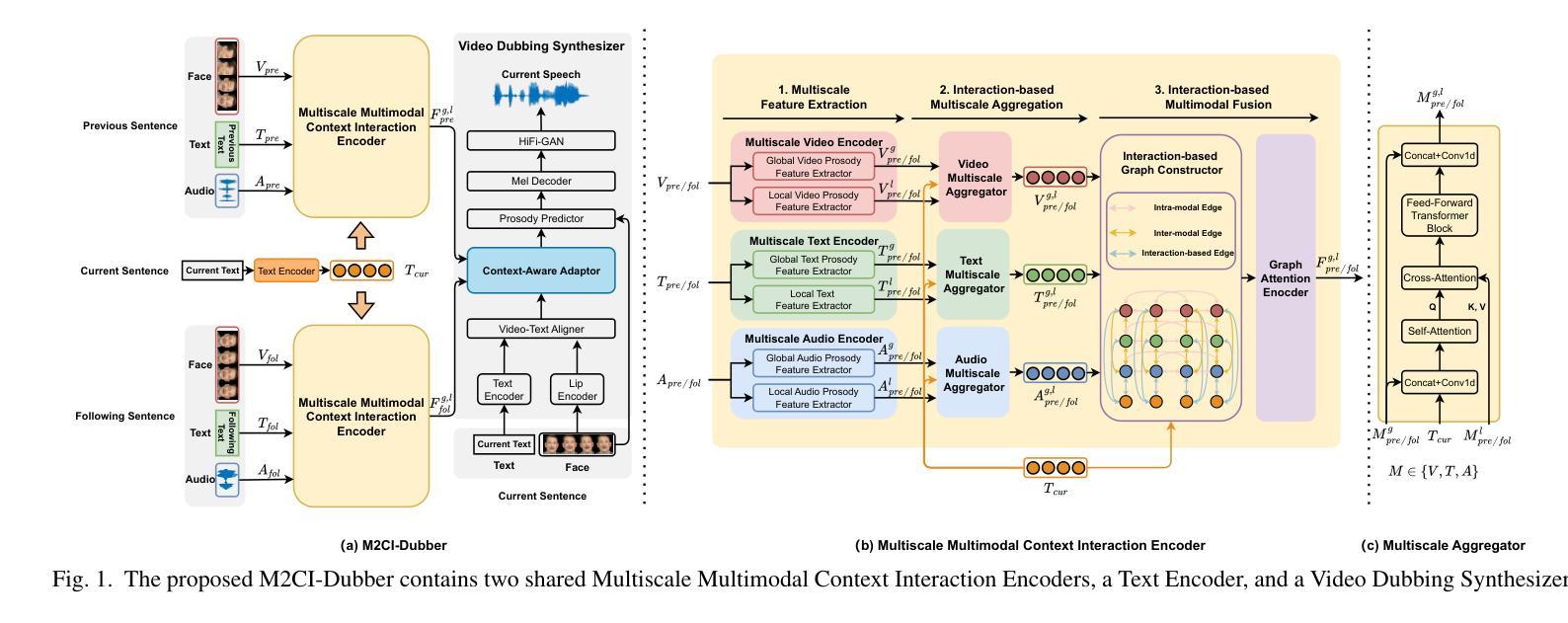
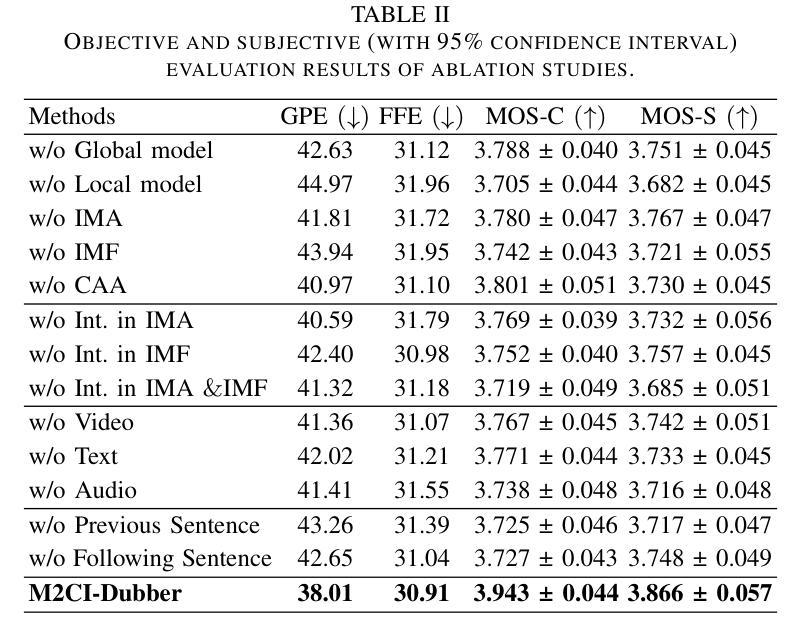
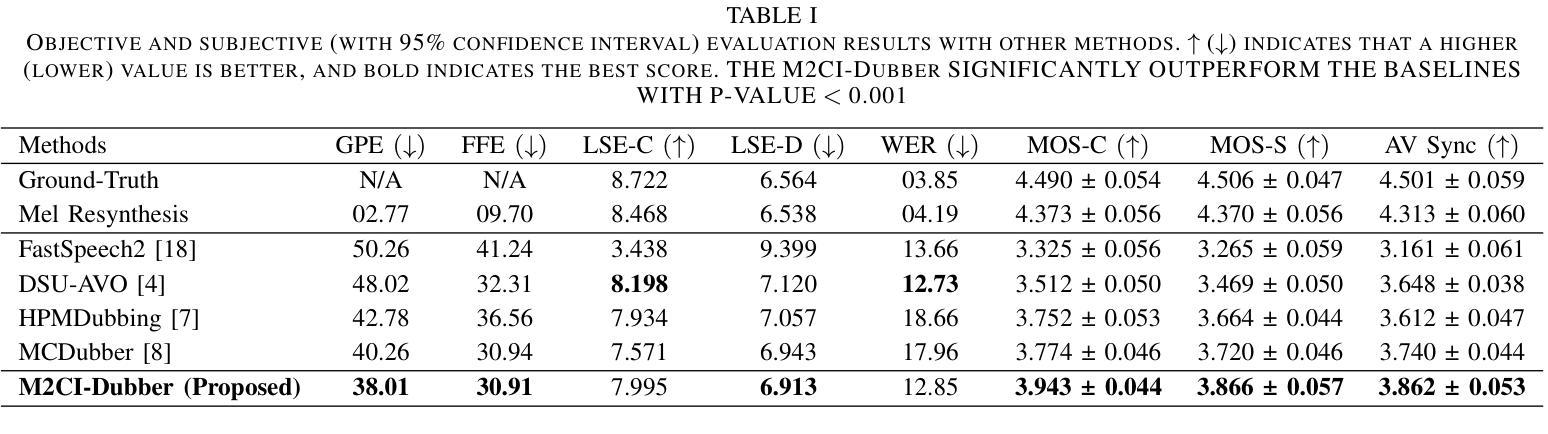
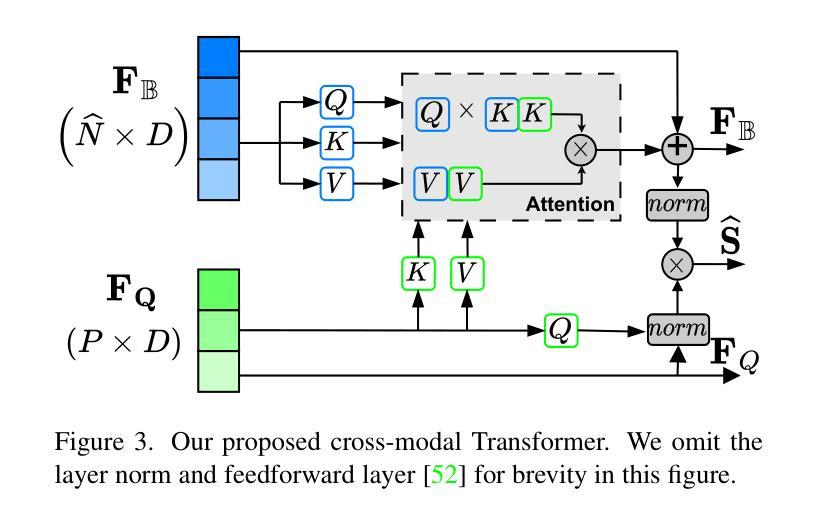
Automatic Video Dubbing (AVD) generates speech aligned with lip motion and facial emotion from scripts. Recent research focuses on modeling multimodal context to enhance prosody expressiveness but overlooks two key issues: 1) Multiscale prosody expression attributes in the context influence the current sentence’s prosody. 2) Prosody cues in context interact with the current sentence, impacting the final prosody expressiveness. To tackle these challenges, we propose M2CI-Dubber, a Multiscale Multimodal Context Interaction scheme for AVD. This scheme includes two shared M2CI encoders to model the multiscale multimodal context and facilitate its deep interaction with the current sentence. By extracting global and local features for each modality in the context, utilizing attention-based mechanisms for aggregation and interaction, and employing an interaction-based graph attention network for fusion, the proposed approach enhances the prosody expressiveness of synthesized speech for the current sentence. Experiments on the Chem dataset show our model outperforms baselines in dubbing expressiveness. The code and demos are available at \textcolor[rgb]{0.93,0.0,0.47}{https://github.com/AI-S2-Lab/M2CI-Dubber}.
自动视频配音(AVD)根据剧本生成与唇部动作和面部情绪对齐的语音。最近的研究主要集中在构建多模态上下文以提高语调表现力,但忽略了两个关键问题:1)上下文中的多尺度语调表达属性会影响当前句子的语调。2)上下文中的语调线索与当前句子相互作用,影响最终的语调表现力。为了解决这些挑战,我们提出了M2CI-Dubber,这是一种用于AVD的多尺度多模态上下文交互方案。该方案包括两个共享的M2CI编码器,用于对多尺度多模态上下文进行建模,并促进其与当前句子的深度交互。通过提取上下文中每种模态的全局和局部特征,利用基于注意力的机制进行聚合和交互,并采用基于交互的图注意力网络进行融合,所提出的方法提高了当前句子合成语音的语调表现力。在Chem数据集上的实验表明,我们的模型在配音表现力方面超过了基线。代码和演示可在https://github.com/AI-S2-Lab/M2CI-Dubber上找到。
论文及项目相关链接
PDF Accepted by ICSSP 2025
Summary
自动视频配音(AVD)技术能够根据脚本生成与唇部动作和面部表情对齐的语音。针对当前研究中存在的多尺度语音情感表达属性及上下文交互影响语音情感表达的问题,提出了M2CI-Dubber方案。该方案通过构建多尺度多模态上下文交互模型,采用共享M2CI编码器对上下文的多尺度多模态信息进行建模,并促进其与当前句子的深度交互。通过提取上下文中每种模态的全局和局部特征,利用基于注意力的机制进行聚合和交互,并采用基于交互的图注意力网络进行融合,提高了合成语音的情感表达能力。在Chem数据集上的实验表明,该模型在配音表现力方面优于基准模型。
Key Takeaways
- AVD技术能自动为视频生成配音,并与唇部动作和面部表情对齐。
- 当前AVD研究主要集中在建模多模态上下文以增强语音的情感表现力。
- 存在两个关键问题需要解决:多尺度语音情感表达属性在上下文中的影响和上下文中的语音情感线索与当前句子的交互。
- 提出M2CI-Dubber方案,通过构建多尺度多模态上下文交互模型来解决这些问题。
- M2CI-Dubber采用共享M2CI编码器来建模上下文的多尺度多模态信息,并促进其与当前句子的深度交互。
- 通过提取上下文中每种模态的全局和局部特征,利用基于注意力的机制进行特征聚合和交互。
点此查看论文截图