⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-03 更新
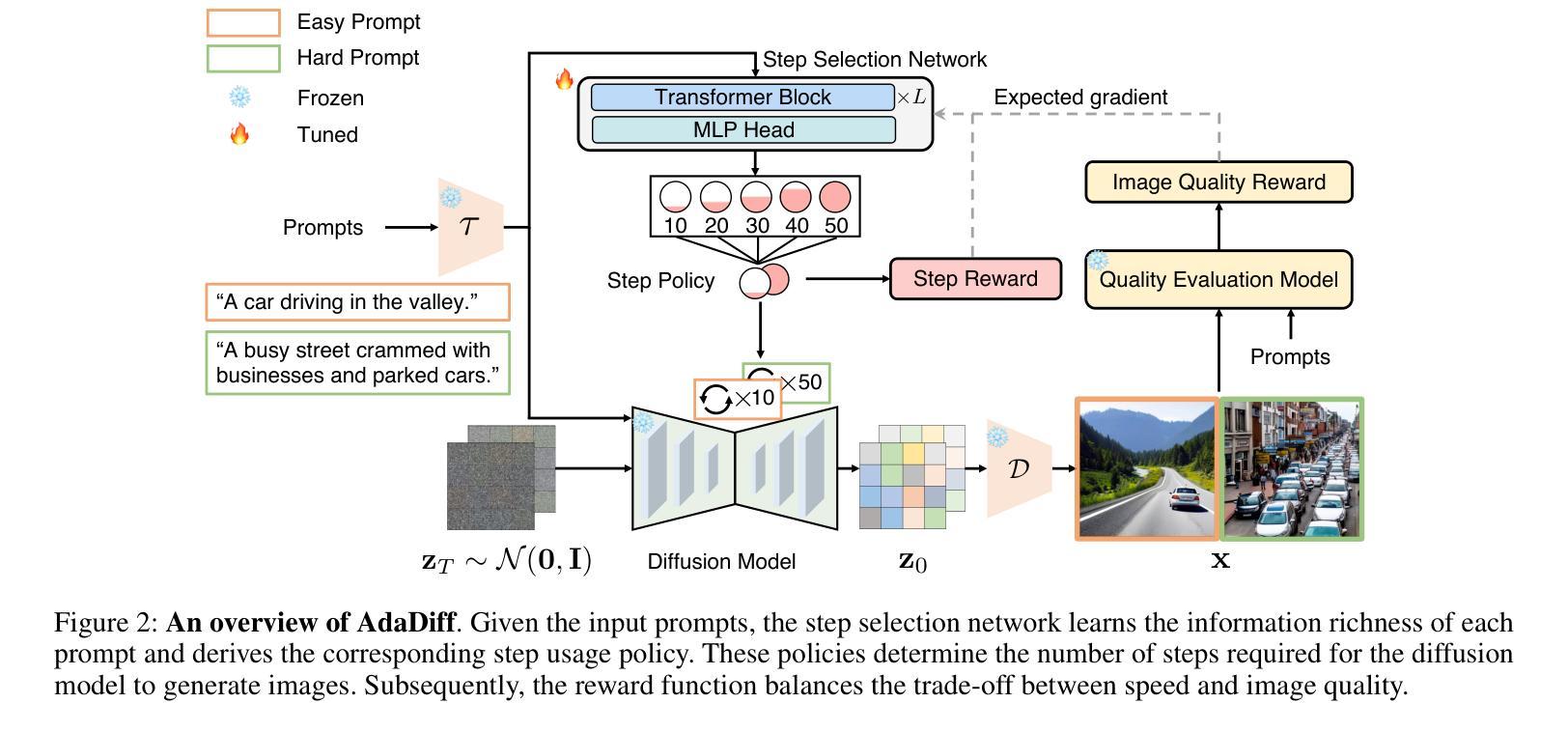
AdaDiff: Adaptive Step Selection for Fast Diffusion Models
Authors:Hui Zhang, Zuxuan Wu, Zhen Xing, Jie Shao, Yu-Gang Jiang
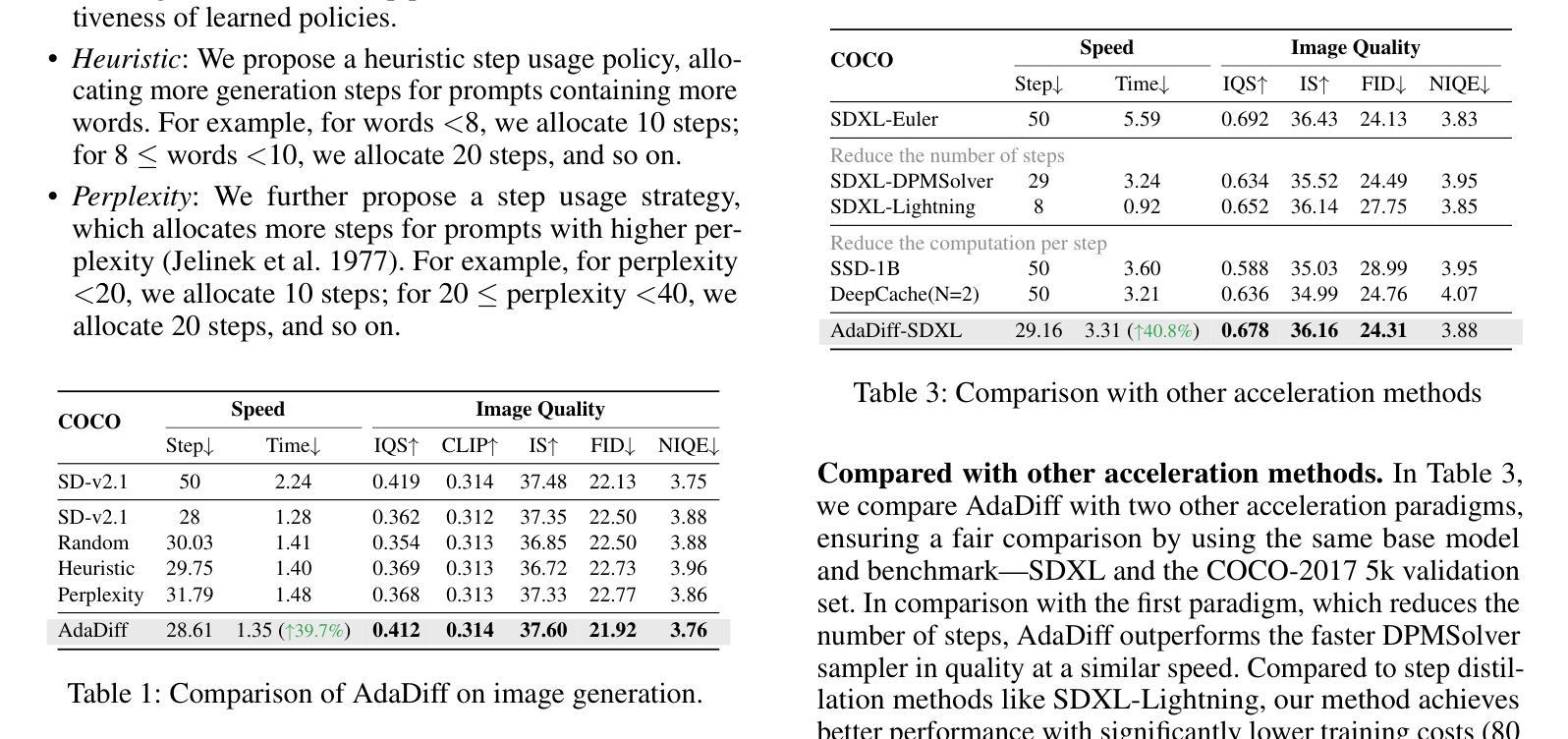
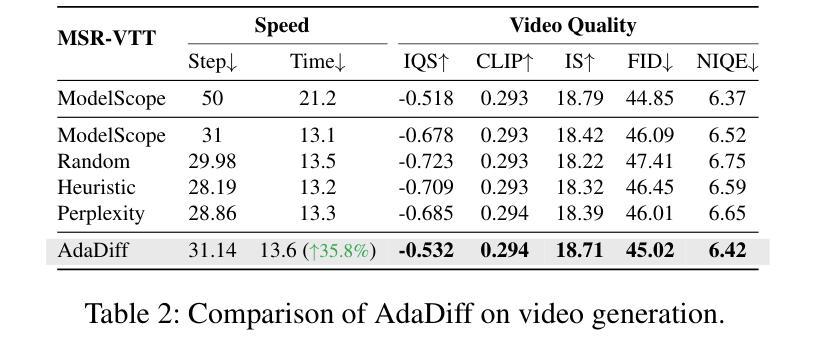
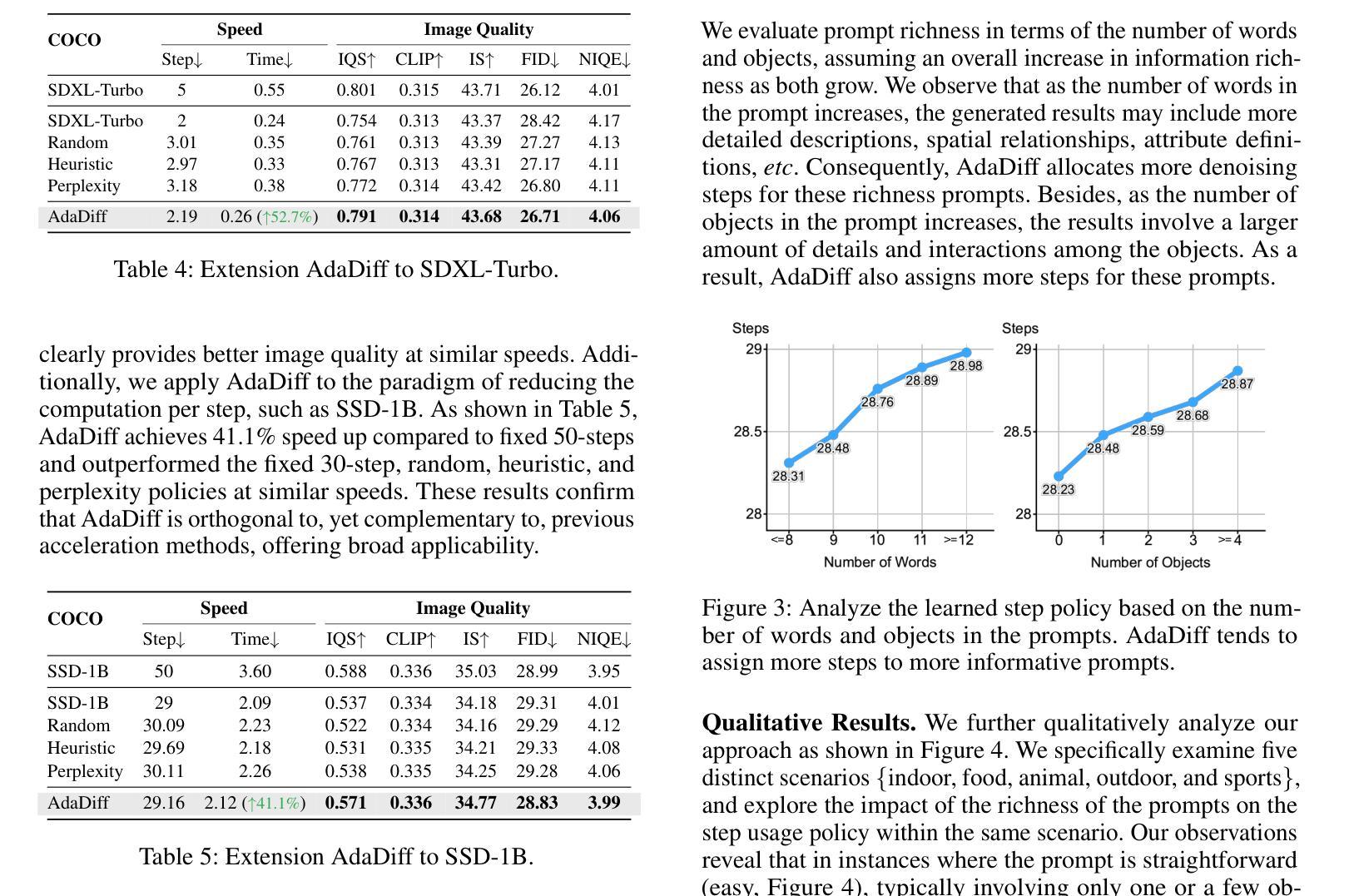
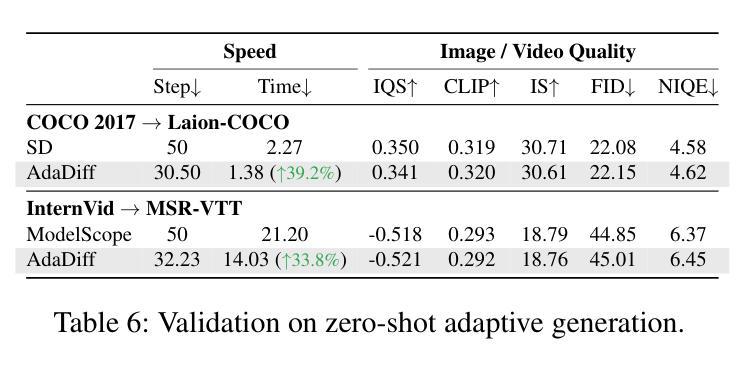
Diffusion models, as a type of generative model, have achieved impressive results in generating images and videos conditioned on textual conditions. However, the generation process of diffusion models involves denoising dozens of steps to produce photorealistic images/videos, which is computationally expensive. Unlike previous methods that design ``one-size-fits-all’’ approaches for speed up, we argue denoising steps should be sample-specific conditioned on the richness of input texts. To this end, we introduce AdaDiff, a lightweight framework designed to learn instance-specific step usage policies, which are then used by the diffusion model for generation. AdaDiff is optimized using a policy gradient method to maximize a carefully designed reward function, balancing inference time and generation quality. We conduct experiments on three image generation and two video generation benchmarks and demonstrate that our approach achieves similar visual quality compared to the baseline using a fixed 50 denoising steps while reducing inference time by at least 33%, going as high as 40%. Furthermore, our method can be used on top of other acceleration methods to provide further speed benefits. Lastly, qualitative analysis shows that AdaDiff allocates more steps to more informative prompts and fewer steps to simpler prompts.
扩散模型作为一种生成模型,在根据文本条件生成图像和视频方面取得了令人印象深刻的结果。然而,扩散模型的生成过程包括去噪的多个步骤,以产生逼真的图像/视频,这在计算上是昂贵的。与以前为加速而设计的“一刀切”方法不同,我们认为去噪步骤应该是根据输入文本的丰富性对样本进行特定条件设定的。为此,我们引入了AdaDiff,一个轻量级的框架,旨在学习实例特定的步骤使用策略,然后由扩散模型用于生成。AdaDiff使用策略梯度方法进行优化,以最大化精心设计的奖励函数,在推理时间和生成质量之间取得平衡。我们在三个图像生成和两个视频生成基准测试上进行了实验,结果表明,我们的方法在使用固定的50步去噪的情况下,实现了与基线相似的视觉质量,同时至少减少了33%的推理时间,最高可达40%。此外,我们的方法可以在其他加速方法之上使用,以提供进一步的加速效益。最后,定性分析表明AdaDiff为更富有信息的提示分配更多步骤,为更简单的提示分配较少步骤。
论文及项目相关链接
PDF Accepted by AAAI 2025
Summary
本文介绍了扩散模型在生成图像和视频方面的出色表现,但其生成过程涉及数十步去噪,计算成本较高。为此,提出了一种轻量级的框架AdaDiff,通过实例特定的步骤使用策略来加速扩散模型的生成过程。AdaDiff使用策略梯度方法进行优化,以最大化精心设计奖励函数,平衡推理时间和生成质量。实验结果表明,该方法在保持视觉质量的同时,将推理时间减少了至少33%,最高可达40%。此外,该方法可与其他加速方法结合使用,以进一步提高速度效益。
Key Takeaways
- 扩散模型在生成图像和视频方面表现出色,但需要大量计算资源。
- AdaDiff框架旨在加速扩散模型的生成过程。
- AdaDiff通过实例特定的步骤使用策略进行优化。
- AdaDiff使用策略梯度方法和精心设计奖励函数进行最优化。
- AdaDiff能够在保持视觉质量的同时减少推理时间。
- AdaDiff可与其他加速方法结合使用,提供进一步的速度效益。
点此查看论文截图

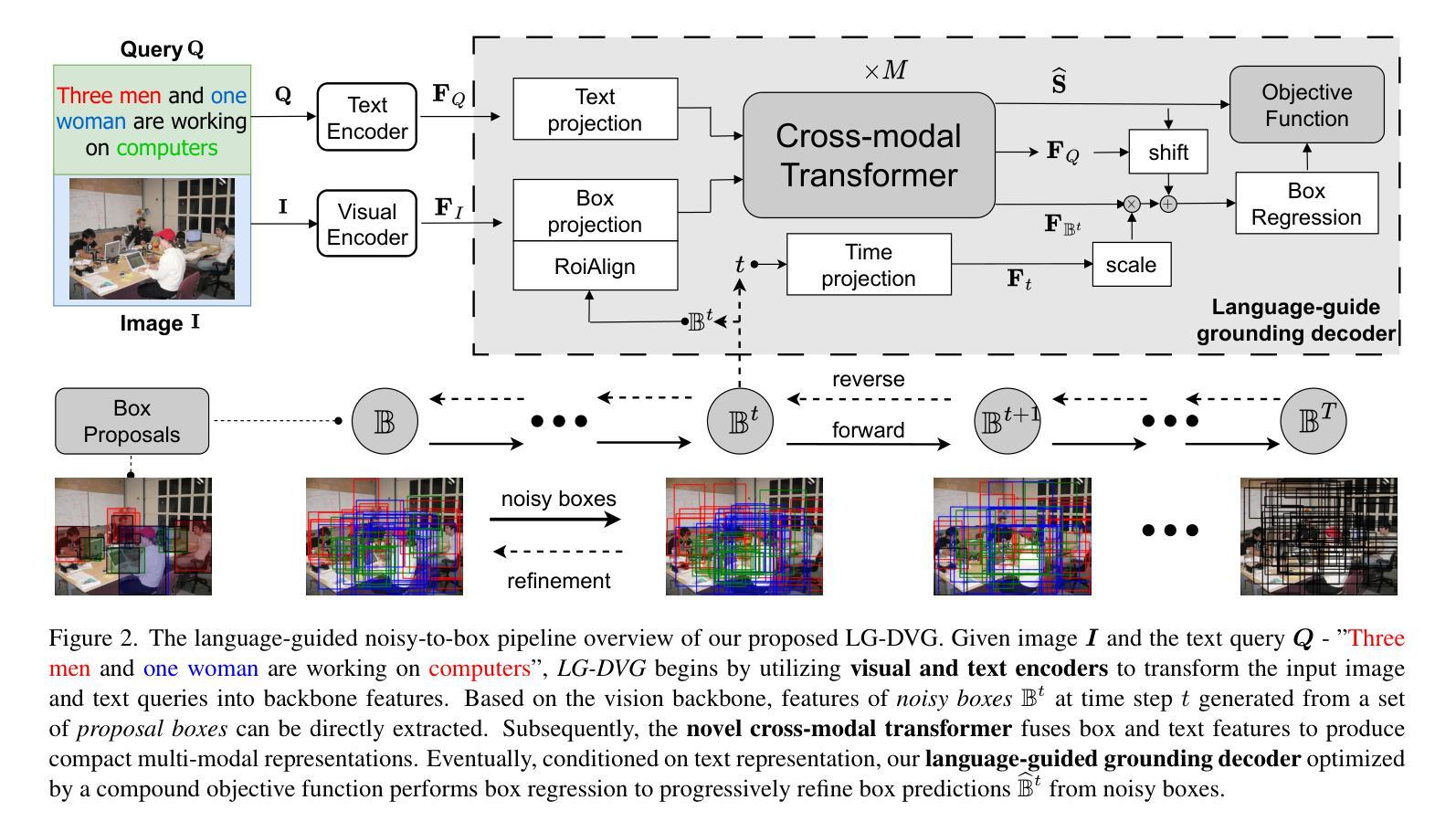
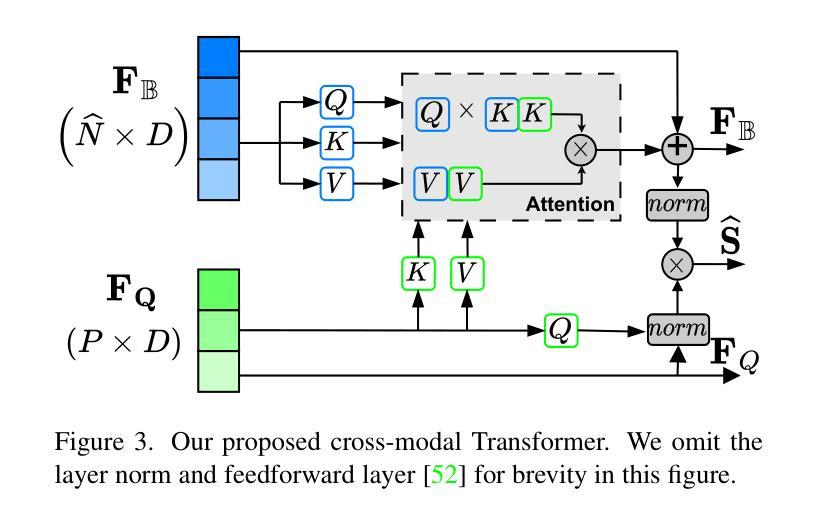
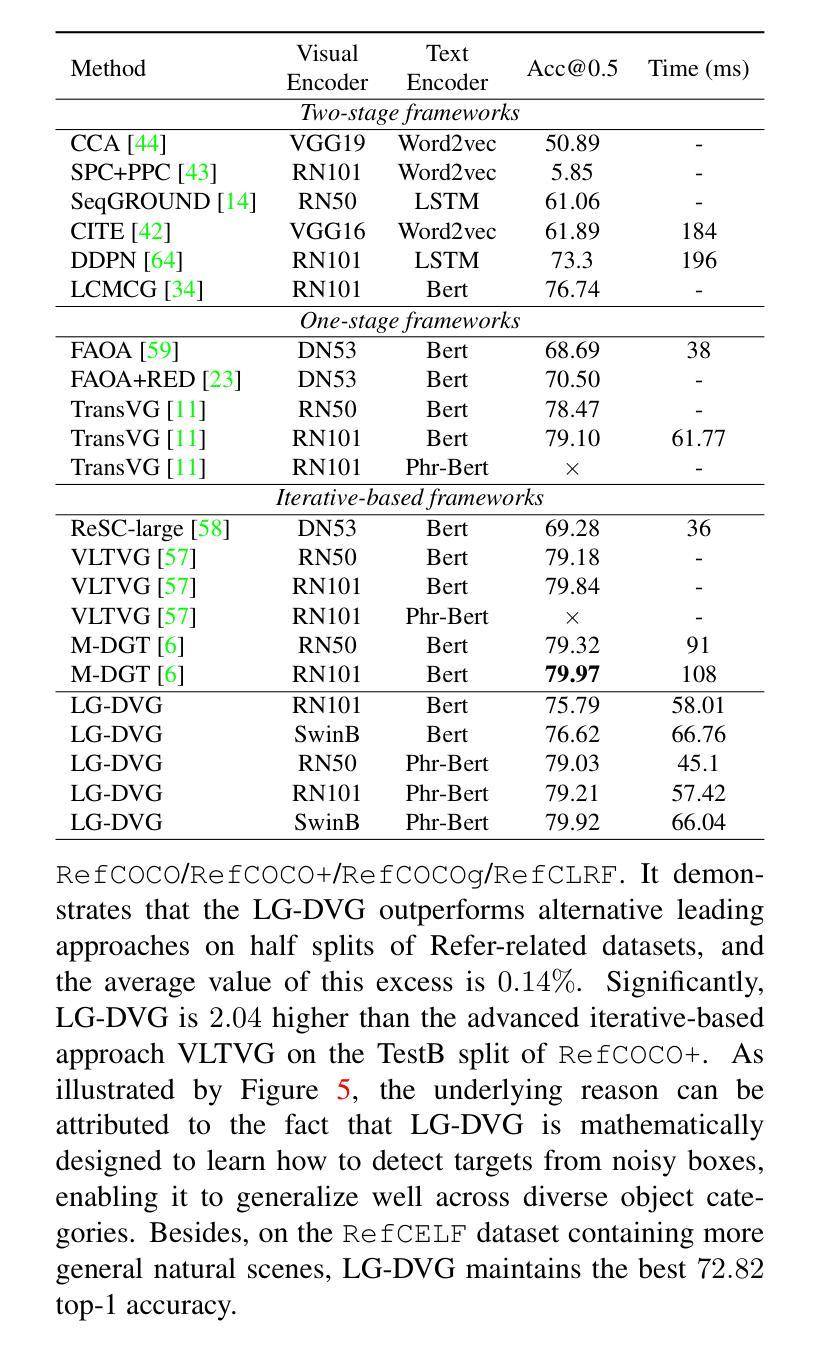
Language-Guided Diffusion Model for Visual Grounding
Authors:Sijia Chen, Baochun Li
Visual grounding (VG) tasks involve explicit cross-modal alignment, as semantically corresponding image regions are to be located for the language phrases provided. Existing approaches complete such visual-text reasoning in a single-step manner. Their performance causes high demands on large-scale anchors and over-designed multi-modal fusion modules based on human priors, leading to complicated frameworks that may be difficult to train and overfit to specific scenarios. Even worse, such once-for-all reasoning mechanisms are incapable of refining boxes continuously to enhance query-region matching. In contrast, in this paper, we formulate an iterative reasoning process by denoising diffusion modeling. Specifically, we propose a language-guided diffusion framework for visual grounding, LG-DVG, which trains the model to progressively reason queried object boxes by denoising a set of noisy boxes with the language guide. To achieve this, LG-DVG gradually perturbs query-aligned ground truth boxes to noisy ones and reverses this process step by step, conditional on query semantics. Extensive experiments for our proposed framework on five widely used datasets validate the superior performance of solving visual grounding, a cross-modal alignment task, in a generative way. The source codes are available at https://github.com/iQua/vgbase/tree/main/examples/DiffusionVG.
视觉定位(VG)任务涉及明确的跨模态对齐,需要为提供的语言短语定位语义对应的图像区域。现有方法以单步方式完成此类视觉文本推理。它们的性能对大规模锚点以及基于人类先验知识设计的复杂的多模态融合模块提出了高要求,导致框架复杂,可能难以训练和适应特定场景。更糟糕的是,这种一次性的推理机制无法持续调整框以改进查询区域匹配。相比之下,本文通过去噪扩散建模制定了一个迭代推理过程。具体来说,我们提出了一种用于视觉定位的语言引导扩散框架(LG-DVG),该框架训练模型通过去噪一组噪声框和语言指南逐步推理查询对象框。为实现这一点,LG-DVG将查询对齐的地面真实框逐渐扰动为噪声框,并根据查询语义逐步反转这一过程。在五个广泛使用的数据集上对我们提出的框架进行了大量实验,验证了其在解决跨模态对齐任务的视觉定位方面的优越性能。源代码可在https://github.com/iQua/vgbase/tree/main/examples/DiffusionVG处获取。
论文及项目相关链接
PDF 20 pages, 16 figures
Summary
本文提出一种基于去噪扩散模型的语言引导视觉定位框架(LG-DVG),用于视觉定位任务。该框架采用迭代推理过程,通过去噪一系列噪声框来逐步推理查询对象框,实现跨模态对齐。实验验证其在多个数据集上的优越性。
Key Takeaways
- 视觉定位任务涉及明确的多模态对齐,要求找到与语言短语对应的图像区域。
- 现有方法采用一次性完成视觉文本推理的方式,需要大规模锚点和复杂的多模态融合模块,难以训练和适应特定场景。
- 提出的LG-DVG框架采用基于去噪扩散模型的迭代推理过程,逐步推理查询对象框。
- LG-DVG通过语言引导逐步将查询对齐的真实框扰动成噪声框,并逐步反转这一过程,实现跨模态对齐。
- 广泛实验验证LG-DVG在多个数据集上解决视觉定位任务的优越性。
- LG-DVG框架可在https://github.com/iQua/vgbase/tree/main/examples/DiffusionVG获取源代码。
点此查看论文截图