⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-06 更新
L3D-Pose: Lifting Pose for 3D Avatars from a Single Camera in the Wild
Authors:Soumyaratna Debnath, Harish Katti, Shashikant Verma, Shanmuganathan Raman
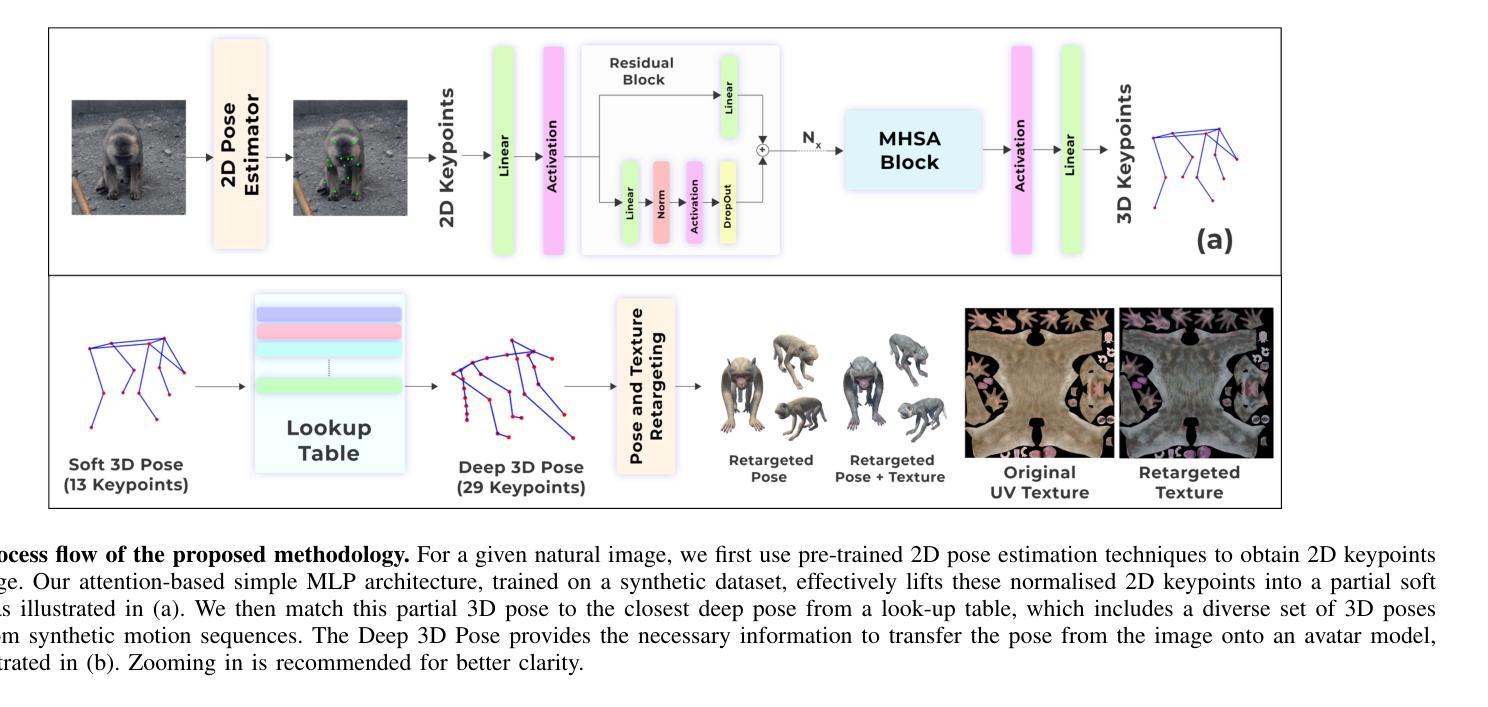
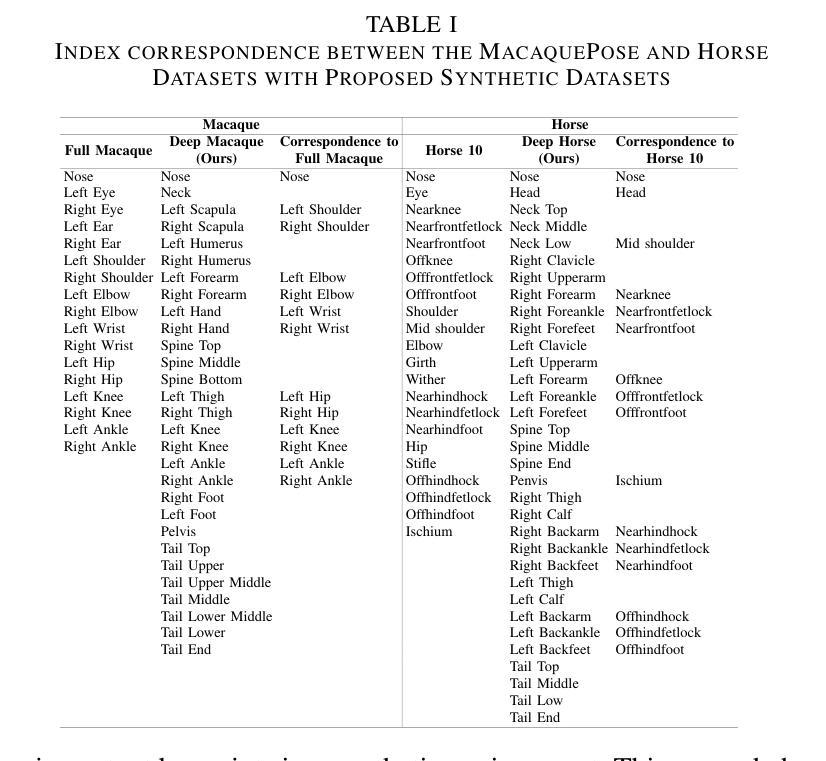
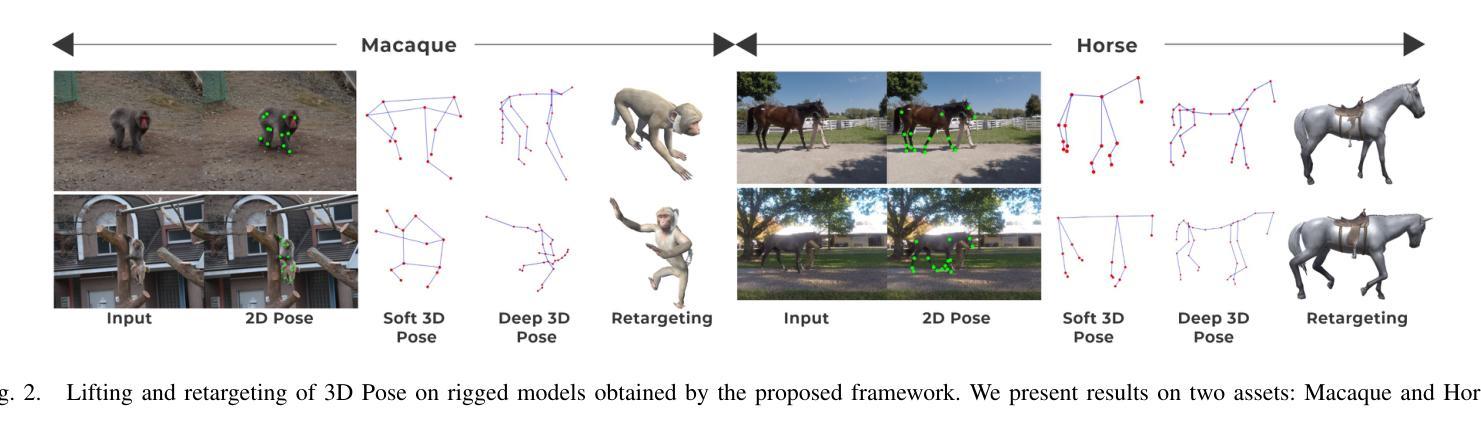
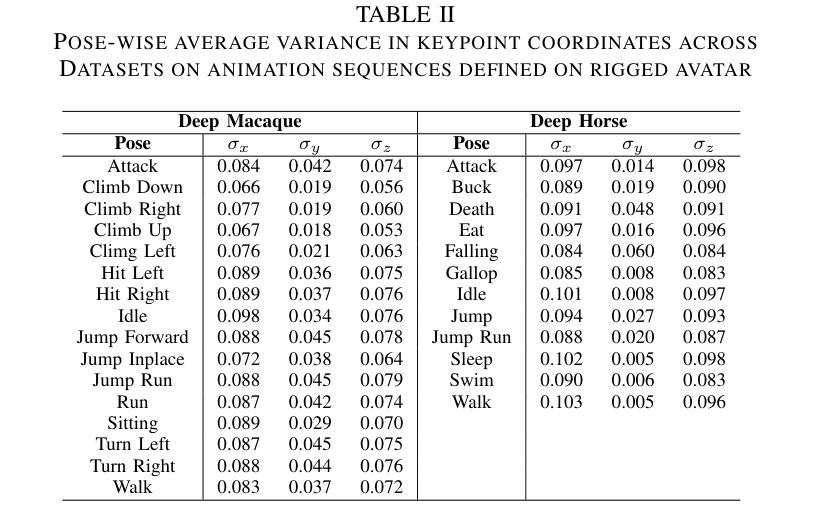
While 2D pose estimation has advanced our ability to interpret body movements in animals and primates, it is limited by the lack of depth information, constraining its application range. 3D pose estimation provides a more comprehensive solution by incorporating spatial depth, yet creating extensive 3D pose datasets for animals is challenging due to their dynamic and unpredictable behaviours in natural settings. To address this, we propose a hybrid approach that utilizes rigged avatars and the pipeline to generate synthetic datasets to acquire the necessary 3D annotations for training. Our method introduces a simple attention-based MLP network for converting 2D poses to 3D, designed to be independent of the input image to ensure scalability for poses in natural environments. Additionally, we identify that existing anatomical keypoint detectors are insufficient for accurate pose retargeting onto arbitrary avatars. To overcome this, we present a lookup table based on a deep pose estimation method using a synthetic collection of diverse actions rigged avatars perform. Our experiments demonstrate the effectiveness and efficiency of this lookup table-based retargeting approach. Overall, we propose a comprehensive framework with systematically synthesized datasets for lifting poses from 2D to 3D and then utilize this to re-target motion from wild settings onto arbitrary avatars.
二维姿态估计虽然已经提高了我们对动物和灵长类动物动作的理解能力,但由于缺乏深度信息,其应用范围受到限制。三维姿态估计通过结合空间深度提供了更全面的解决方案,然而,为动物创建广泛的三维姿态数据集具有挑战性,因为它们在自然环境中的行为和动作是动态且不可预测的。为了解决这一问题,我们提出了一种混合方法,利用刚体化身和管道生成合成数据集来获取必要的三维注释以进行训练。我们的方法引入了一个基于简单注意力机制的MLP网络,将二维姿态转换为三维,设计该网络独立于输入图像,以确保对自然环境中的姿态的可扩展性。此外,我们发现现有的解剖关键点检测器在将姿态重新定位到任意化身时并不准确。为了克服这一点,我们提出了一种基于深度姿态估计方法的查找表,该表使用合成集合中多样化的动作刚体化身表现。我们的实验证明了基于查找表的重新定位方法的有效性和效率。总的来说,我们提出了一个综合框架,通过系统地合成数据集来提升从二维到三维的姿态估计能力,然后将其应用于将野生环境中的动作重新定位到任意化身上。
论文及项目相关链接
PDF 2025 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2025)
Summary
本文提出一种混合方法,利用动画角色模型和合成数据集生成必要的3D注释进行训练,以解决动物在自然环境中的动态和不可预测行为所带来的挑战。文章还介绍了一种基于注意力的简单多层感知器网络,用于将二维姿态转换为三维姿态。此外,文章还提出了一种基于深度姿态估计方法的查找表,用于解决现有解剖关键点检测器对准确姿态重定向的不足。整体而言,本文构建了一个从二维到三维的系统性综合框架,并将姿态从野外环境中转移到任意角色模型上。
Key Takeaways
关键点概览如下:
- 提出了一种利用动画角色模型和合成数据集进行训练的新方法来解决动物在自然环境中的动态行为带来的挑战。
- 介绍了一种基于注意力的简单多层感知器网络(MLP),用于将二维姿态转换为三维姿态。该网络独立于输入图像,确保了其在自然环境中姿态的可扩展性。
- 现有的解剖关键点检测器对于准确地将姿态重定向到任意动画角色模型上是不足的。因此提出了基于深度姿态估计方法的查找表来解决这个问题。
- 通过实验验证了查找表为基础的重定向方法的有效性和效率。
- 该研究构建了从二维到三维的系统性综合框架,用于提升姿态估计的精度和范围。
- 该方法可用于将野外环境中的运动转移到任意角色模型上,增强了虚拟世界与现实世界的互动可能性。
点此查看论文截图