⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-06 更新
Reconstruction vs. Generation: Taming Optimization Dilemma in Latent Diffusion Models
Authors:Jingfeng Yao, Xinggang Wang
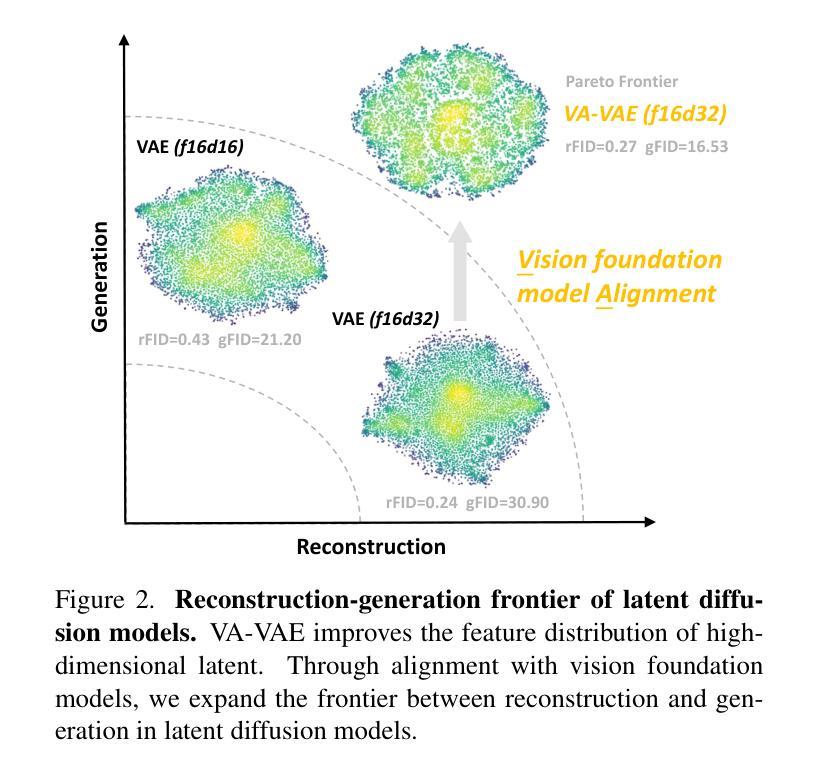
Latent diffusion models with Transformer architectures excel at generating high-fidelity images. However, recent studies reveal an optimization dilemma in this two-stage design: while increasing the per-token feature dimension in visual tokenizers improves reconstruction quality, it requires substantially larger diffusion models and more training iterations to achieve comparable generation performance. Consequently, existing systems often settle for sub-optimal solutions, either producing visual artifacts due to information loss within tokenizers or failing to converge fully due to expensive computation costs. We argue that this dilemma stems from the inherent difficulty in learning unconstrained high-dimensional latent spaces. To address this, we propose aligning the latent space with pre-trained vision foundation models when training the visual tokenizers. Our proposed VA-VAE (Vision foundation model Aligned Variational AutoEncoder) significantly expands the reconstruction-generation frontier of latent diffusion models, enabling faster convergence of Diffusion Transformers (DiT) in high-dimensional latent spaces. To exploit the full potential of VA-VAE, we build an enhanced DiT baseline with improved training strategies and architecture designs, termed LightningDiT. The integrated system achieves state-of-the-art (SOTA) performance on ImageNet 256x256 generation with an FID score of 1.35 while demonstrating remarkable training efficiency by reaching an FID score of 2.11 in just 64 epochs–representing an over 21 times convergence speedup compared to the original DiT. Models and codes are available at: https://github.com/hustvl/LightningDiT.
基于Transformer架构的潜在扩散模型在生成高保真图像方面表现出色。然而,最近的研究揭示了这种两阶段设计中的一个优化困境:虽然增加视觉分词器中的每令牌特征维度可以提高重建质量,但要实现相当的生成性能,需要大幅扩展扩散模型的规模并增加训练迭代次数。因此,现有系统通常选择次优解决方案,要么由于分词器中的信息丢失而产生视觉伪影,要么由于计算成本高昂而无法完全收敛。我们认为,这种困境源于学习无约束的高维潜在空间的固有困难。为解决这一问题,我们建议在训练视觉分词器时,将其潜在空间与预训练的视觉基础模型进行对齐。我们提出的VA-VAE(与预训练视觉基础模型对齐的变分自动编码器)显著扩展了潜在扩散模型的重建-生成边界,使扩散Transformer(DiT)在高维潜在空间中更快收敛。为了充分发挥VA-VAE的潜力,我们建立了增强的DiT基线,采用了改进的训练策略和架构设计,称为LightningDiT。集成系统在ImageNet 256x256生成任务上实现了最新性能,FID得分为1.35,同时显示出显著的训练效率,仅在64个周期内就达到了2.11的FID得分,与原始DiT相比,实现了超过21倍的收敛速度提升。模型和代码可通过https://github.com/hustvl/LightningDiT获取。
论文及项目相关链接
PDF Models and codes are available at: https://github.com/hustvl/LightningDiT
Summary
本文探讨了基于Transformer架构的潜在扩散模型在高保真图像生成方面的优势。研究揭示了优化中的困境:虽然增加视觉标记器中的每令牌特征维度可以提高重建质量,但这需要更大的扩散模型和更多的训练迭代来达到相应的生成性能。为此,文章提出了与预训练视觉基础模型对齐训练视觉标记器的方法,并推出了VA-VAE(与视觉基础模型对齐的变分自编码器)。此外,为了充分利用VA-VAE的潜力,文章还建立了增强的DiT基线,名为LightningDiT。它在ImageNet 256x256生成任务上取得了最新技术性能,并在仅64个周期内就达到了令人印象深刻的训练效率。
Key Takeaways
- 潜在扩散模型能生成高保真图像,但存在优化困境。
- 增加视觉标记器中的每令牌特征维度能提高重建质量,但要求更大的模型和更多训练迭代。
- 扩散模型面临学习无约束高维潜在空间的困难。
- 提出VA-VAE(与视觉基础模型对齐的变分自编码器)来解决这一问题。
- VA-VAE显著扩展了潜在扩散模型的重建-生成边界。
- 建立了增强的DiT基线,名为LightningDiT,以充分利用VA-VAE的潜力。
- LightningDiT在ImageNet 256x256生成任务上取得最新技术性能,并在训练效率方面实现显著改进。
点此查看论文截图

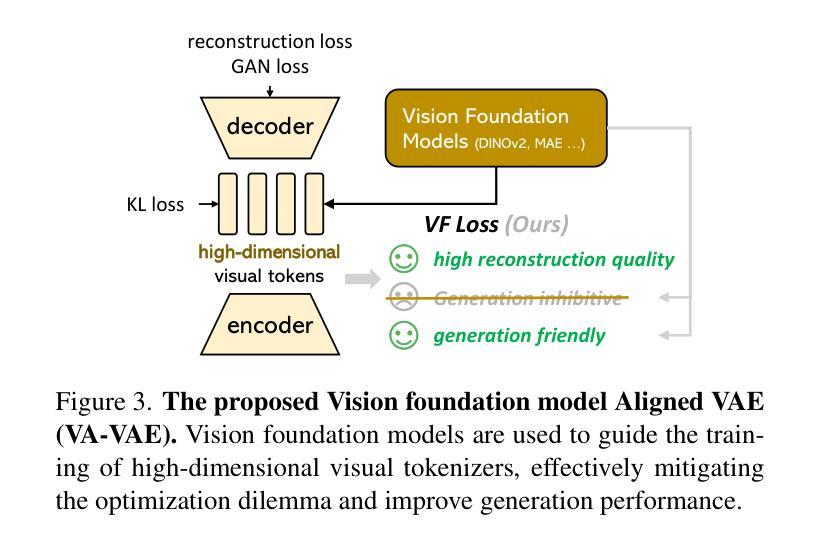
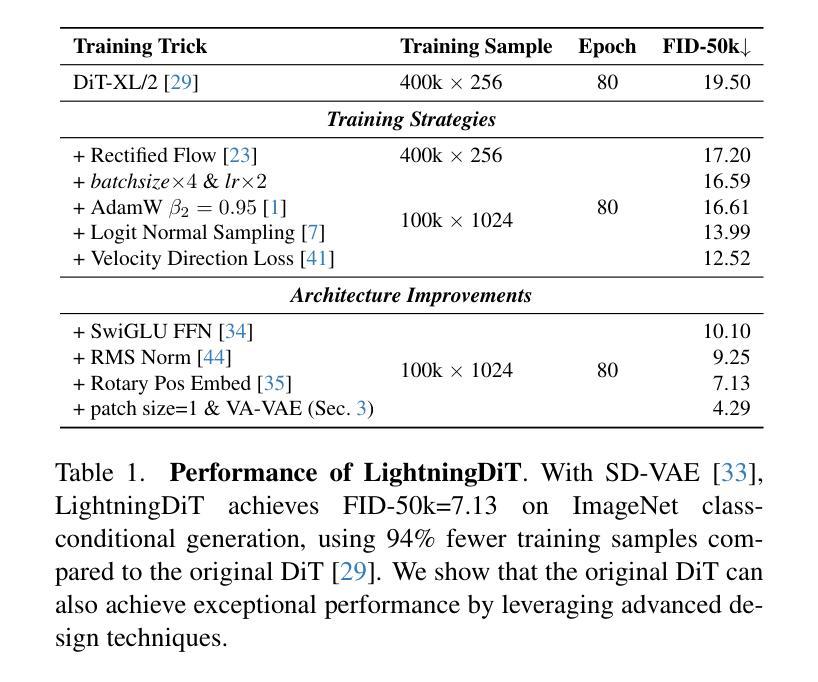
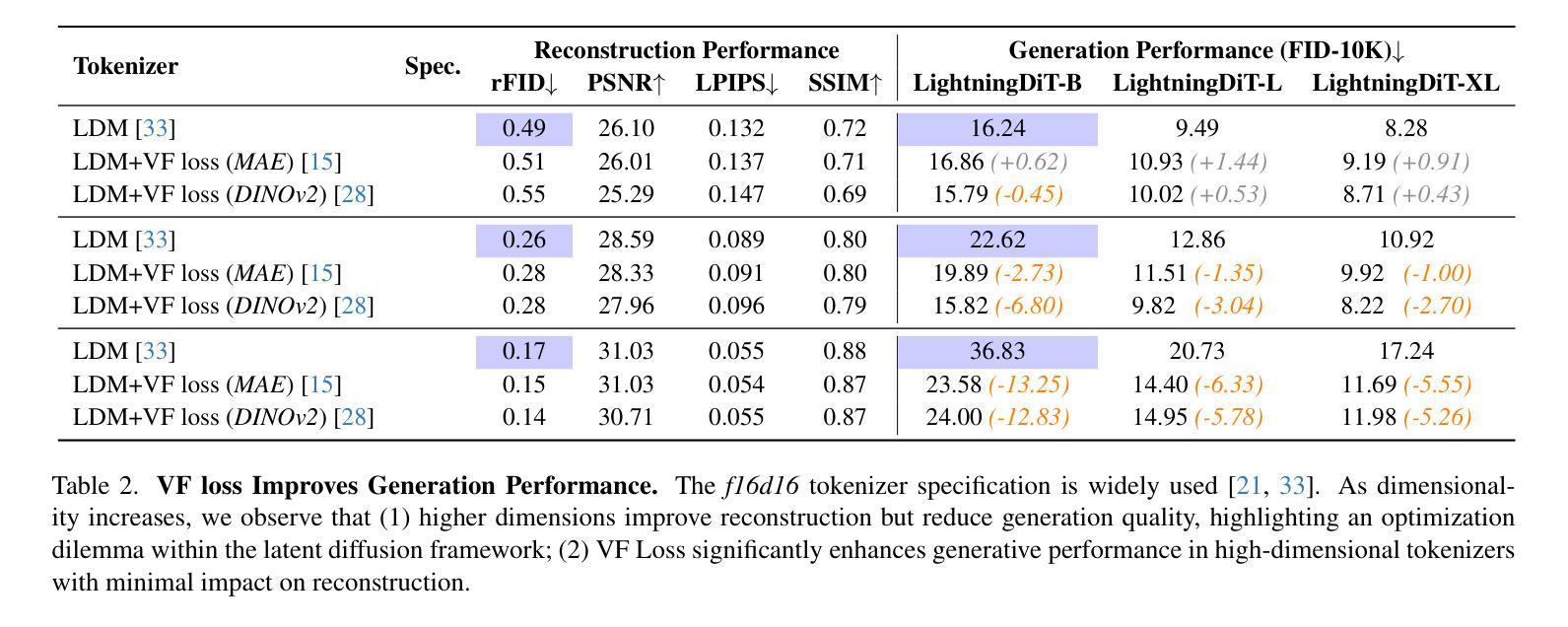
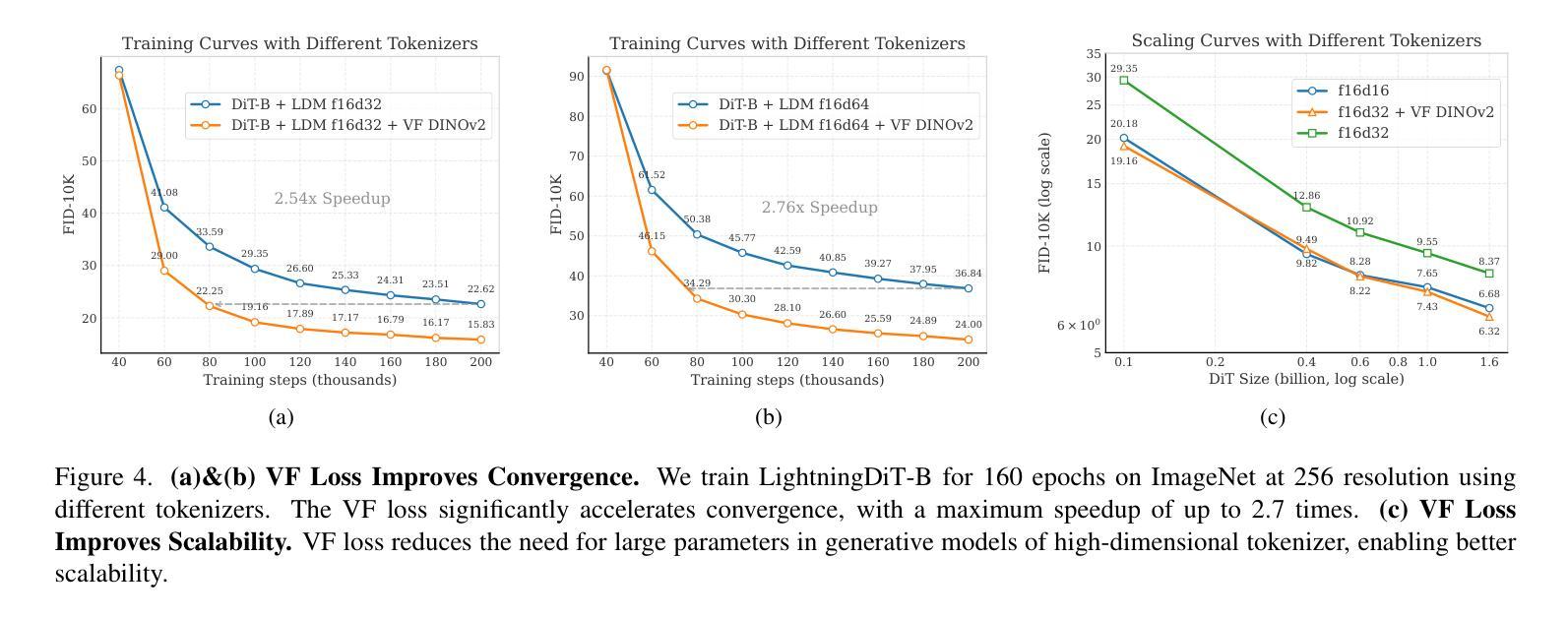
Test-time Controllable Image Generation by Explicit Spatial Constraint Enforcement
Authors:Z. Zhang, B. Liu, J. Bao, L. Chen, S. Zhu, J. Yu
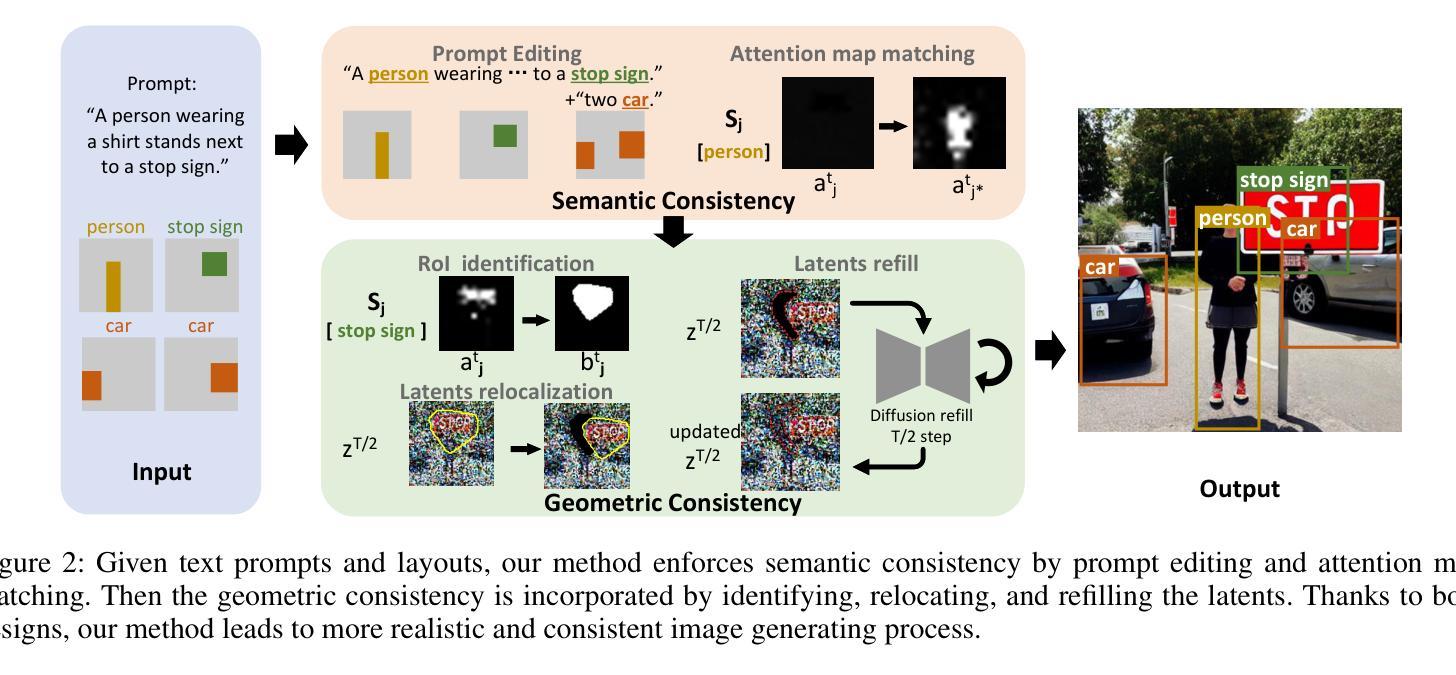
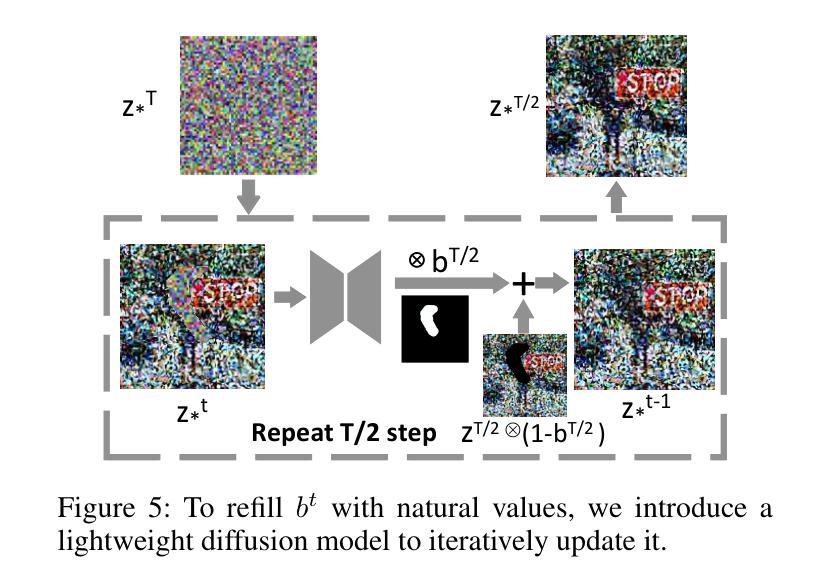
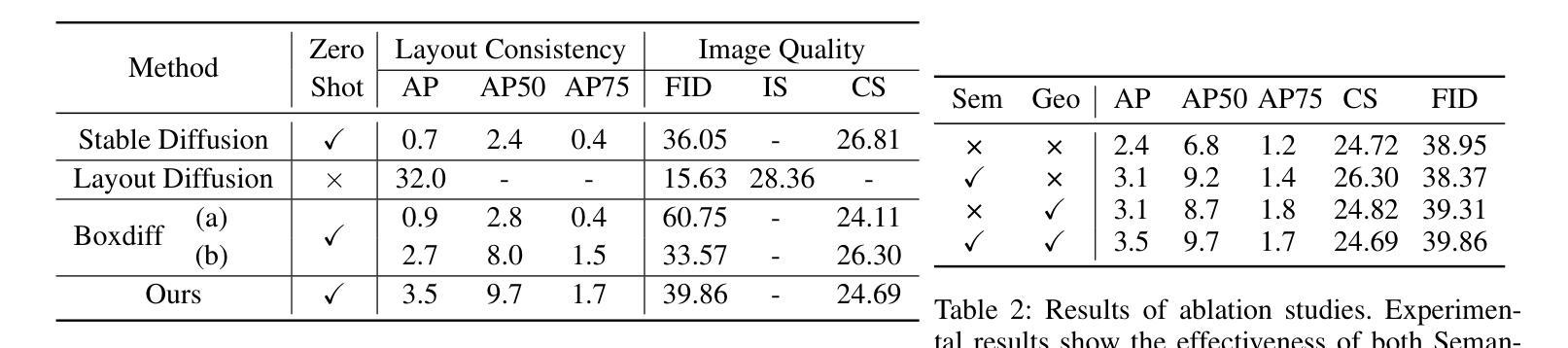
Recent text-to-image generation favors various forms of spatial conditions, e.g., masks, bounding boxes, and key points. However, the majority of the prior art requires form-specific annotations to fine-tune the original model, leading to poor test-time generalizability. Meanwhile, existing training-free methods work well only with simplified prompts and spatial conditions. In this work, we propose a novel yet generic test-time controllable generation method that aims at natural text prompts and complex conditions. Specifically, we decouple spatial conditions into semantic and geometric conditions and then enforce their consistency during the image-generation process individually. As for the former, we target bridging the gap between the semantic condition and text prompts, as well as the gap between such condition and the attention map from diffusion models. To achieve this, we propose to first complete the prompt w.r.t. semantic condition, and then remove the negative impact of distracting prompt words by measuring their statistics in attention maps as well as distances in word space w.r.t. this condition. To further cope with the complex geometric conditions, we introduce a geometric transform module, in which Region-of-Interests will be identified in attention maps and further used to translate category-wise latents w.r.t. geometric condition. More importantly, we propose a diffusion-based latents-refill method to explicitly remove the impact of latents at the RoI, reducing the artifacts on generated images. Experiments on Coco-stuff dataset showcase 30$%$ relative boost compared to SOTA training-free methods on layout consistency evaluation metrics.
最近文本到图像生成技术更倾向于各种空间条件形式,例如遮罩、边界框和关键点。然而,大多数先前技术需要特定形式的标注来微调原始模型,导致测试时泛化能力较差。同时,现有的无训练方法仅适用于简化提示和简单的空间条件。在这项工作中,我们提出了一种新型且通用的测试时间可控生成方法,旨在处理自然语言文本提示和复杂条件。具体来说,我们将空间条件分为语义和几何条件,然后在图像生成过程中单独强制执行它们的一致性。对于前者,我们的目标是缩小语义条件和文本提示之间的差距,以及这种条件与扩散模型的注意力图之间的差距。为实现这一目标,我们提出首先根据语义条件完成提示,然后通过测量注意力图中的统计数据和与此条件相关的词空间距离来消除干扰提示词的不利影响。为了应对复杂的几何条件,我们引入了一个几何变换模块,该模块将在注意力图中识别感兴趣区域,并进一步用于根据几何条件转换类别潜在变量。更重要的是,我们提出了一种基于扩散的潜在变量填充方法,以明确消除感兴趣区域潜在变量的影响,减少生成图像上的伪影。在Coco-stuff数据集上的实验表明,与最先进的无训练方法相比,在布局一致性评估指标上相对提升了30%。
论文及项目相关链接
摘要
本文主要研究文本到图像生成中的空间条件控制。针对现有技术对特定形式标注的依赖以及测试时通用性较差的问题,提出了一种新的通用测试时间可控生成方法。该方法将空间条件解耦为语义和几何条件,并在图像生成过程中分别实施一致性约束。通过针对语义条件和几何条件的处理,提高了文本提示和自然条件下图像生成的衔接性。在Coco-stuff数据集上的实验表明,与现有无训练方法相比,在布局一致性评估指标上相对提升了30%。
关键见解
- 文本到图像生成领域开始重视空间条件控制,如掩码、边界框和关键点等。
- 当前大多数技术需要对原始模型进行特定形式的标注微调,导致测试时的通用性较差。
- 提出了一种新的通用测试时间可控生成方法,适用于自然文本提示和复杂条件。
- 方法将空间条件解耦为语义和几何条件,并分别实施一致性约束。
- 通过处理语义条件来缩小文本提示与注意力图的差距。
- 引入几何转换模块以处理复杂的几何条件,通过识别关注区域(Region-of-Interests)来调整类别特定的潜在变量。
- 提出了一种基于扩散的潜在变量填充方法,以明确消除关注区域中潜在变量的影响,减少生成图像的伪影。
点此查看论文截图


Conditional Consistency Guided Image Translation and Enhancement
Authors:A. V. Subramanyam, Amil Bhagat, Milind Jain
Consistency models have emerged as a promising alternative to diffusion models, offering high-quality generative capabilities through single-step sample generation. However, their application to multi-domain image translation tasks, such as cross-modal translation and low-light image enhancement remains largely unexplored. In this paper, we introduce Conditional Consistency Models (CCMs) for multi-domain image translation by incorporating additional conditional inputs. We implement these modifications by introducing task-specific conditional inputs that guide the denoising process, ensuring that the generated outputs retain structural and contextual information from the corresponding input domain. We evaluate CCMs on 10 different datasets demonstrating their effectiveness in producing high-quality translated images across multiple domains. Code is available at https://github.com/amilbhagat/Conditional-Consistency-Models.
一致性模型作为扩散模型的具有前景的替代方案已经崭露头角,它通过单步样本生成提供高质量的生成能力。然而,它们在多域图像翻译任务中的应用,如跨模态翻译和低光图像增强,仍然在很大程度上未被探索。在本文中,我们通过引入额外的条件输入,介绍了用于多域图像翻译的条件一致性模型(CCM)。我们通过引入任务特定的条件输入来实现这些修改,引导去噪过程,确保生成的输出保留对应输入域的结构和上下文信息。我们在10个不同的数据集上评估了CCM,证明了它们在多个领域生成高质量翻译图像的有效性。代码可在https://github.com/amilbhagat/Conditional-Consistency-Models找到。
论文及项目相关链接
PDF 6 pages, 5 figures, 4 tables, ICME conference 2025
Summary
条件一致性模型(CCM)是一种新兴的技术,为扩散模型提供了有前景的替代方案。该技术通过单步样本生成实现了高质量生成能力,并在多领域图像翻译任务中表现出巨大潜力。通过引入额外的条件输入,CCM能够确保生成的输出保留输入领域的结构和上下文信息。本文在十个不同的数据集上评估了CCM的有效性,证明了其在多领域图像翻译中生成高质量图像的能力。
Key Takeaways
- 条件一致性模型(CCM)是一种新兴技术,可作为扩散模型的替代方案。
- CCM通过单步样本生成实现高质量生成能力。
- CCM在多领域图像翻译任务中具有巨大潜力。
- CCM通过引入额外的条件输入,确保生成的输出保留输入领域的结构和上下文信息。
- CCM在多个数据集上进行了评估,证明了其有效性。
- CCM生成的图像质量高。
点此查看论文截图



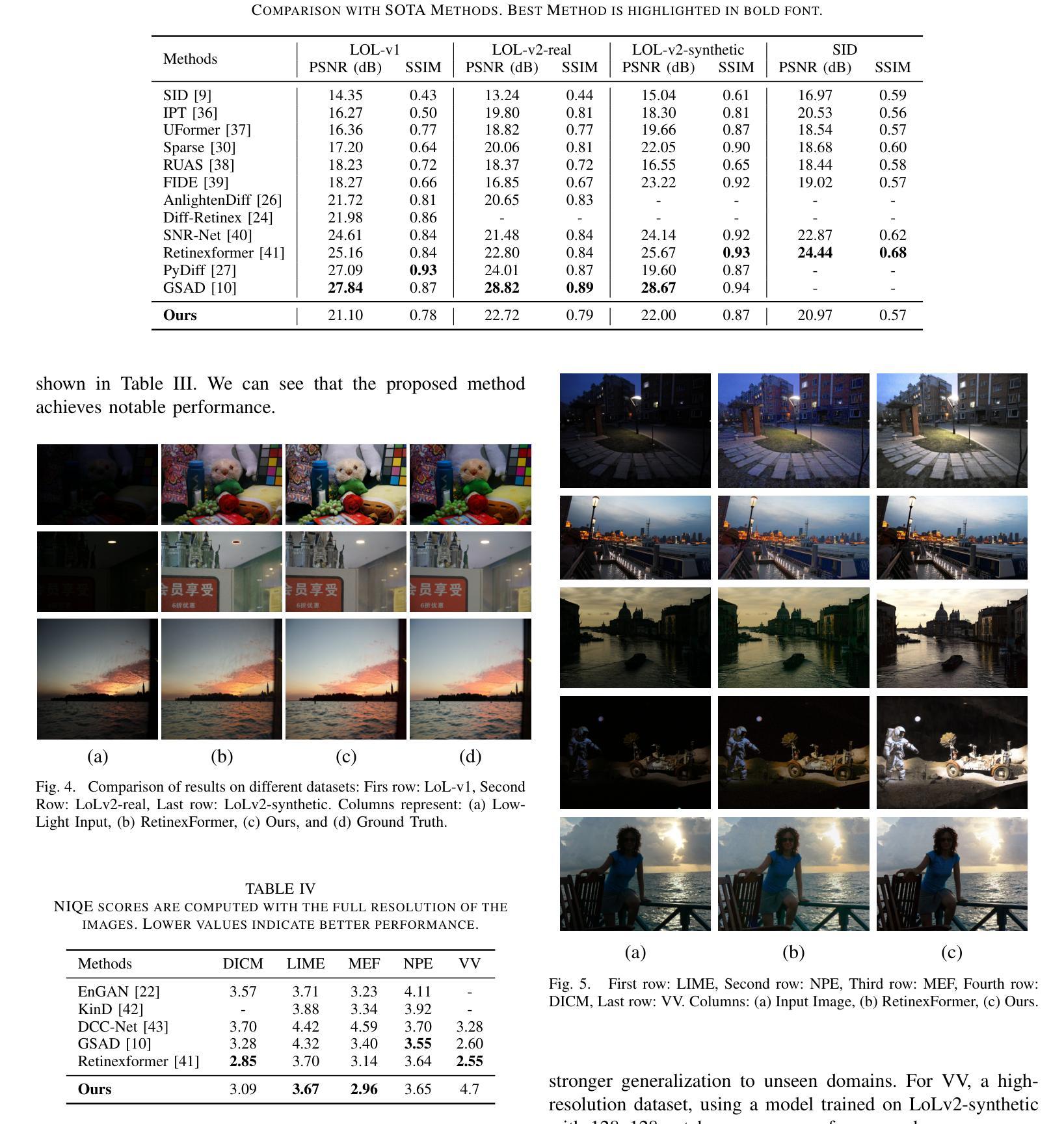
Semantics-Guided Diffusion for Deep Joint Source-Channel Coding in Wireless Image Transmission
Authors:Maojun Zhang, Haotian Wu, Guangxu Zhu, Richeng Jin, Xiaoming Chen, Deniz Gündüz
Joint source-channel coding (JSCC) offers a promising avenue for enhancing transmission efficiency by jointly incorporating source and channel statistics into the system design. A key advancement in this area is the deep joint source and channel coding (DeepJSCC) technique that designs a direct mapping of input signals to channel symbols parameterized by a neural network, which can be trained for arbitrary channel models and semantic quality metrics. This paper advances the DeepJSCC framework toward a semantics-aligned, high-fidelity transmission approach, called semantics-guided diffusion DeepJSCC (SGD-JSCC). Existing schemes that integrate diffusion models (DMs) with JSCC face challenges in transforming random generation into accurate reconstruction and adapting to varying channel conditions. SGD-JSCC incorporates two key innovations: (1) utilizing some inherent information that contributes to the semantics of an image, such as text description or edge map, to guide the diffusion denoising process; and (2) enabling seamless adaptability to varying channel conditions with the help of a semantics-guided DM for channel denoising. The DM is guided by diverse semantic information and integrates seamlessly with DeepJSCC. In a slow fading channel, SGD-JSCC dynamically adapts to the instantaneous signal-to-noise ratio (SNR) directly estimated from the channel output, thereby eliminating the need for additional pilot transmissions for channel estimation. In a fast fading channel, we introduce a training-free denoising strategy, allowing SGD-JSCC to effectively adjust to fluctuations in channel gains. Numerical results demonstrate that, guided by semantic information and leveraging the powerful DM, our method outperforms existing DeepJSCC schemes, delivering satisfactory reconstruction performance even at extremely poor channel conditions.
联合源信道编码(JSCC)通过将源和信道统计信息共同纳入系统设计,为提高传输效率提供了有前景的途径。该领域的一个关键进展是深度联合源和信道编码(DeepJSCC)技术,该技术设计了一种直接将输入信号映射到由神经网络参数化的信道符号的方法,可以针对任意信道模型和语义质量指标进行训练。本文推进了DeepJSCC框架,朝着语义对齐、高保真传输方法发展,称为语义引导扩散DeepJSCC(SGD-JSCC)。现有将扩散模型(DMs)与JSCC相结合的方案面临着将随机生成转化为精确重建以及适应不同信道条件的挑战。SGD-JSCC有两个关键创新点:(1)利用构成图像语义的固有信息,如文本描述或边缘图,来指导扩散去噪过程;(2)借助语义引导的DM进行信道去噪,实现对不同信道条件的无缝适应。DM在多种语义信息的引导下,与DeepJSCC无缝集成。在慢衰减信道中,SGD-JSCC能够直接从信道输出估计瞬时信噪比(SNR),从而无需额外的导频传输来进行信道估计。在快衰减信道中,我们引入了一种无训练的去噪策略,使SGD-JSCC能够有效地适应信道增益的波动。数值结果表明,在语义信息的指导下,利用强大的DM,我们的方法在极差的信道条件下仍能实现出色的重建性能,超越了现有的DeepJSCC方案。
论文及项目相关链接
PDF 13 pages, submitted to IEEE for possible publication
Summary
本文介绍了语义引导扩散深度联合源信道编码(SGD-JSCC)技术,该技术利用图像内在语义信息引导扩散去噪过程,适应不同的信道条件,从而提高语义对齐的高保真传输效率。它结合了扩散模型(DMs)和DeepJSCC技术的优点,通过在语义引导下动态适应不同的信道条件来实现高效传输。
Key Takeaways
- JSCC技术结合了源和信道统计信息,有助于提高传输效率。
- DeepJSCC技术是设计输入信号到信道符号的直接映射的关键进展,可通过神经网络进行训练。
- SGD-JSCC技术利用图像内在语义信息(如文本描述或边缘映射)来指导扩散去噪过程。
- SGD-JSCC利用语义引导DM无缝适应不同的信道条件。
- 在慢衰落信道中,SGD-JSCC通过直接从信道输出估计瞬时信噪比来动态适应,从而消除了对额外试点传输进行信道估计的需求。
- 在快衰落信道中,SGD-JSCC引入了一种无训练的去噪策略,能够有效地适应信道增益的波动。
点此查看论文截图

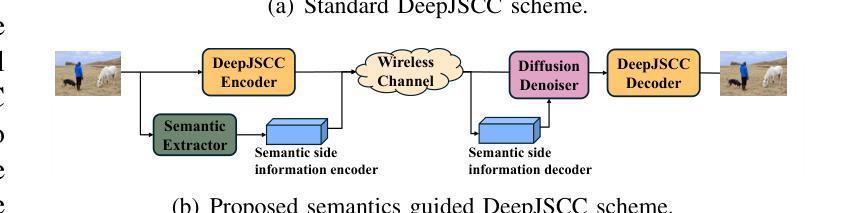
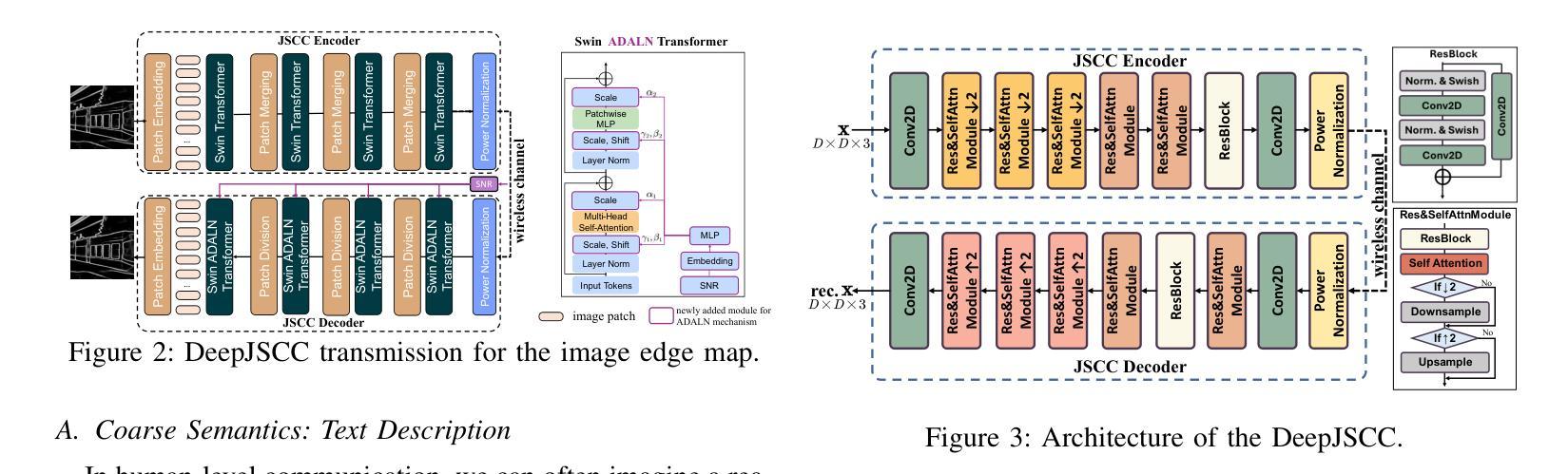
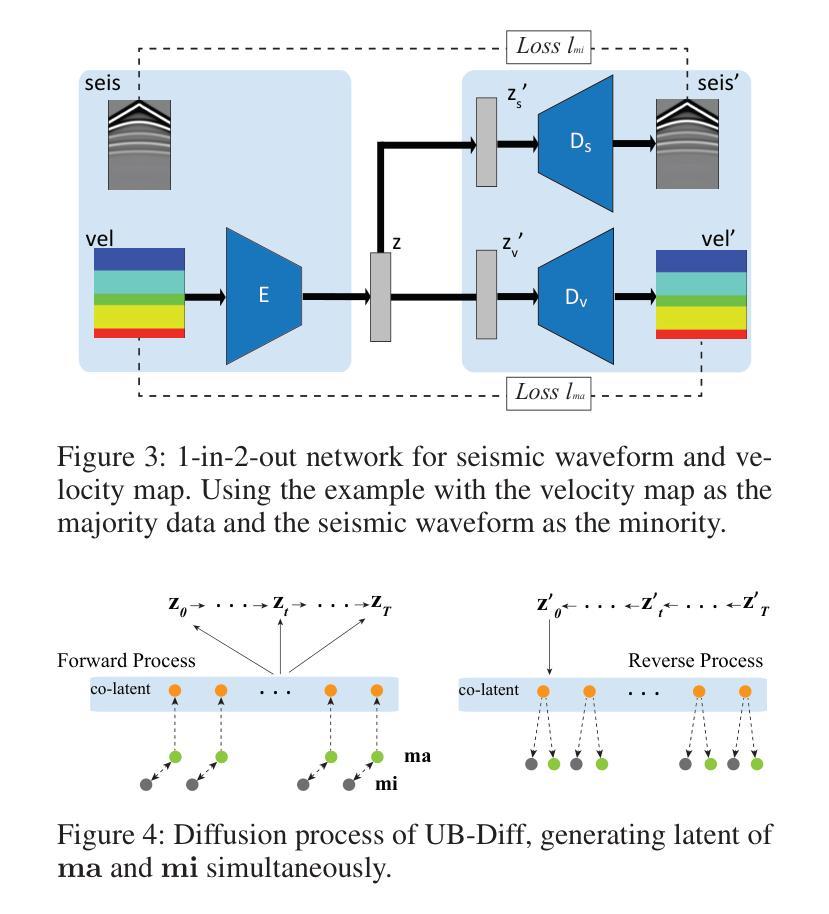
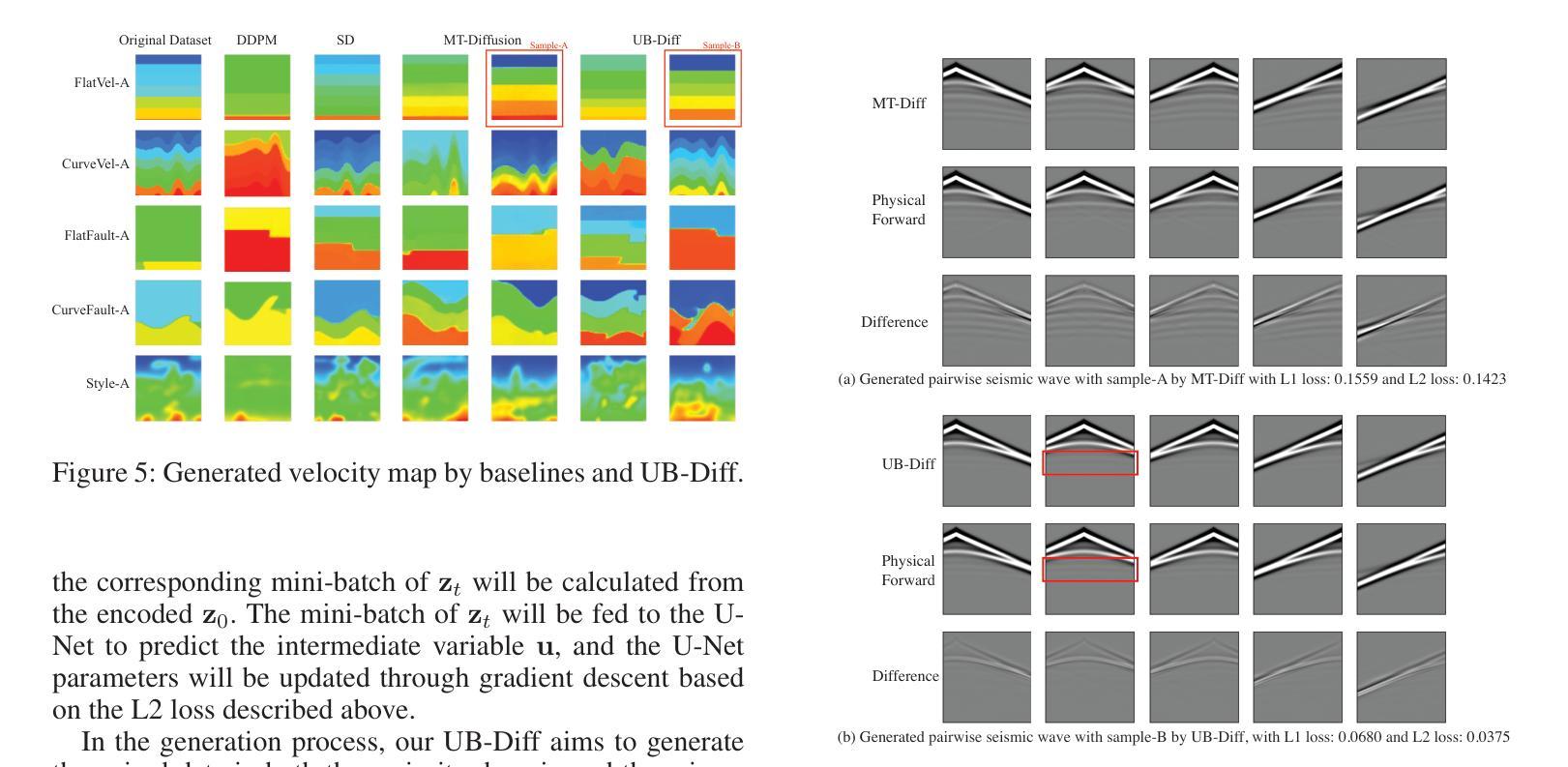
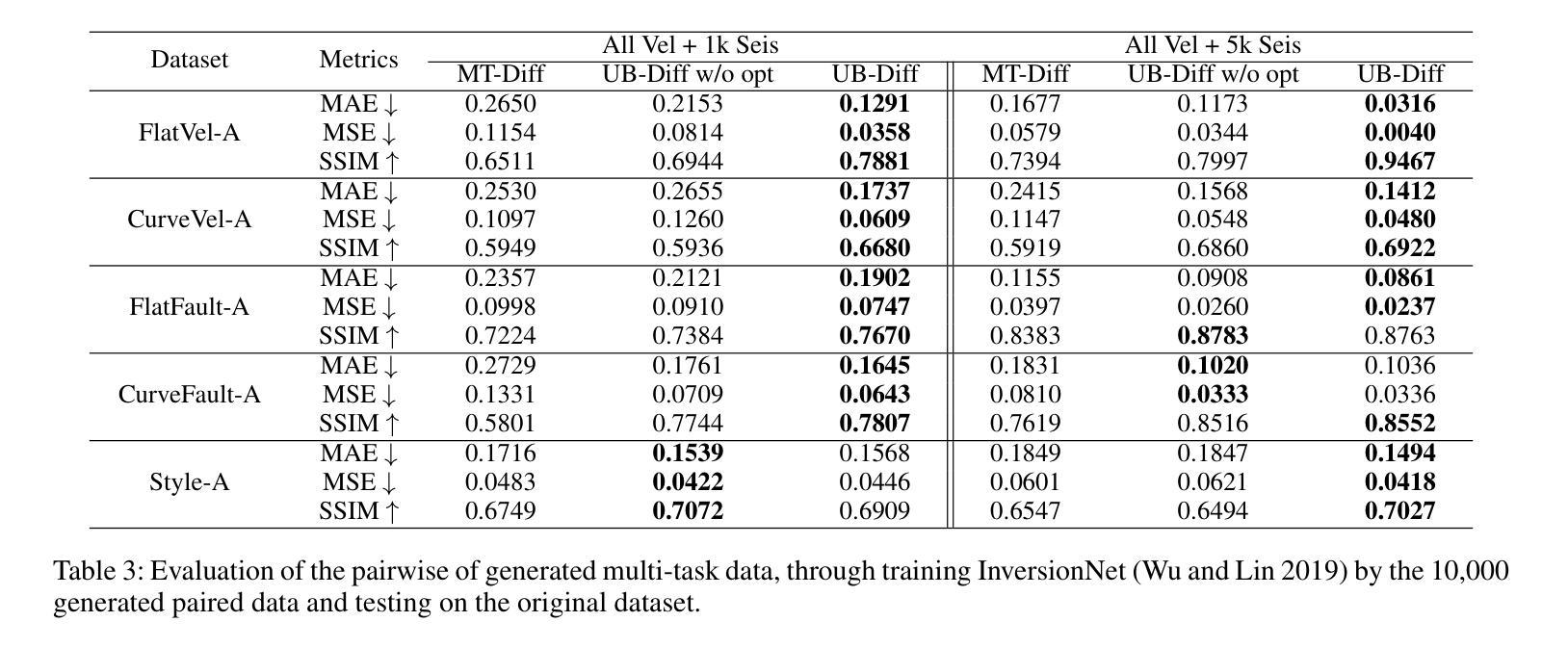
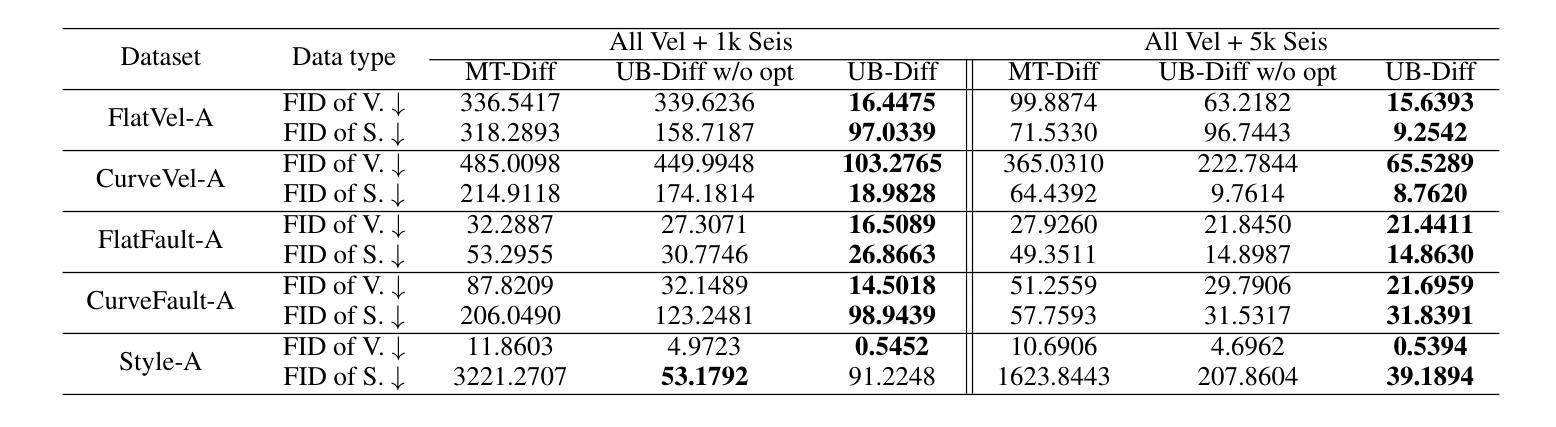
A Novel Diffusion Model for Pairwise Geoscience Data Generation with Unbalanced Training Dataset
Authors:Junhuan Yang, Yuzhou Zhang, Yi Sheng, Youzuo Lin, Lei Yang
Recently, the advent of generative AI technologies has made transformational impacts on our daily lives, yet its application in scientific applications remains in its early stages. Data scarcity is a major, well-known barrier in data-driven scientific computing, so physics-guided generative AI holds significant promise. In scientific computing, most tasks study the conversion of multiple data modalities to describe physical phenomena, for example, spatial and waveform in seismic imaging, time and frequency in signal processing, and temporal and spectral in climate modeling; as such, multi-modal pairwise data generation is highly required instead of single-modal data generation, which is usually used in natural images (e.g., faces, scenery). Moreover, in real-world applications, the unbalance of available data in terms of modalities commonly exists; for example, the spatial data (i.e., velocity maps) in seismic imaging can be easily simulated, but real-world seismic waveform is largely lacking. While the most recent efforts enable the powerful diffusion model to generate multi-modal data, how to leverage the unbalanced available data is still unclear. In this work, we use seismic imaging in subsurface geophysics as a vehicle to present ``UB-Diff’’, a novel diffusion model for multi-modal paired scientific data generation. One major innovation is a one-in-two-out encoder-decoder network structure, which can ensure pairwise data is obtained from a co-latent representation. Then, the co-latent representation will be used by the diffusion process for pairwise data generation. Experimental results on the OpenFWI dataset show that UB-Diff significantly outperforms existing techniques in terms of Fr'{e}chet Inception Distance (FID) score and pairwise evaluation, indicating the generation of reliable and useful multi-modal pairwise data.
最近,生成式人工智能技术的出现对我们的日常生活产生了变革性的影响,然而其在科学应用中的使用仍处于早期阶段。数据稀缺是数据驱动的科学计算中一个主要且众所周知的障碍,因此,物理指导的生成式人工智能具有巨大的潜力。在科学计算中,大多数任务研究多种数据模态的转换,以描述物理现象,例如地震成像中的空间和波形、信号处理中的时间和频率以及气候建模中的时间和光谱;因此,多模态配对数据生成的需求非常高,而不是通常在自然图像(例如面部、风景)中使用的单模态数据生成。此外,在真实世界应用中,不同模态的数据可用量通常存在不平衡的情况;例如,地震成像中的空间数据(即速度图)可以很容易地模拟,但真实世界的地震波形却非常缺乏。尽管最近的努力使强大的扩散模型能够生成多模态数据,但如何利用不平衡的可用数据仍然不清楚。在这项工作中,我们以地下地球物理学中的地震成像为例,介绍了一种名为UB-Diff的新型多模态配对科学数据生成扩散模型。一个主要的创新点在于采用一进两出的编码器-解码器网络结构,可以确保从协同潜在表示中获得配对数据。然后,扩散过程将使用协同潜在表示来进行配对数据生成。在OpenFWI数据集上的实验结果表明,UB-Diff在Fr’echet Inception Distance(FID)得分和配对评估方面显著优于现有技术,证明其生成可靠且有用的多模态配对数据的能力。
论文及项目相关链接
PDF Accepted at AAAI 2025. This is the preprint version. Keywords: Multi-modal generation, diffuison models, scientific data generation, unbalanced modalities
摘要
生成式AI技术在科学应用中的潜力巨大,尤其在多模态数据生成方面。本研究针对地震成像等科学计算中的多模态数据转换任务,提出了一种新的扩散模型UB-Diff,用于多模态配对科学数据生成。该模型采用一进两出的编码器-解码器网络结构,确保从协同潜在表示中获得配对数据,并通过扩散过程进行配对数据生成。实验结果表明,UB-Diff在OpenFWI数据集上的表现显著优于现有技术,生成可靠且有用的多模态配对数据。
关键见解
- 生成式AI技术在科学应用中的潜力巨大,特别是在多模态数据生成方面。
- 在科学计算中,多模态数据转换任务普遍存在,例如地震成像、信号处理和气候建模。
- 提出了一种新的扩散模型UB-Diff,用于多模态配对科学数据生成。
- UB-Diff采用一进两出的编码器-解码器网络结构,确保从协同潜在表示中获得配对数据。
- 实验结果表明,UB-Diff在生成多模态配对数据方面显著优于现有技术。
- 利用地震成像等实际应用场景验证了UB-Diff模型的实用性。
- 该模型的引入对于解决科学计算中数据稀缺的问题具有重大意义。
点此查看论文截图


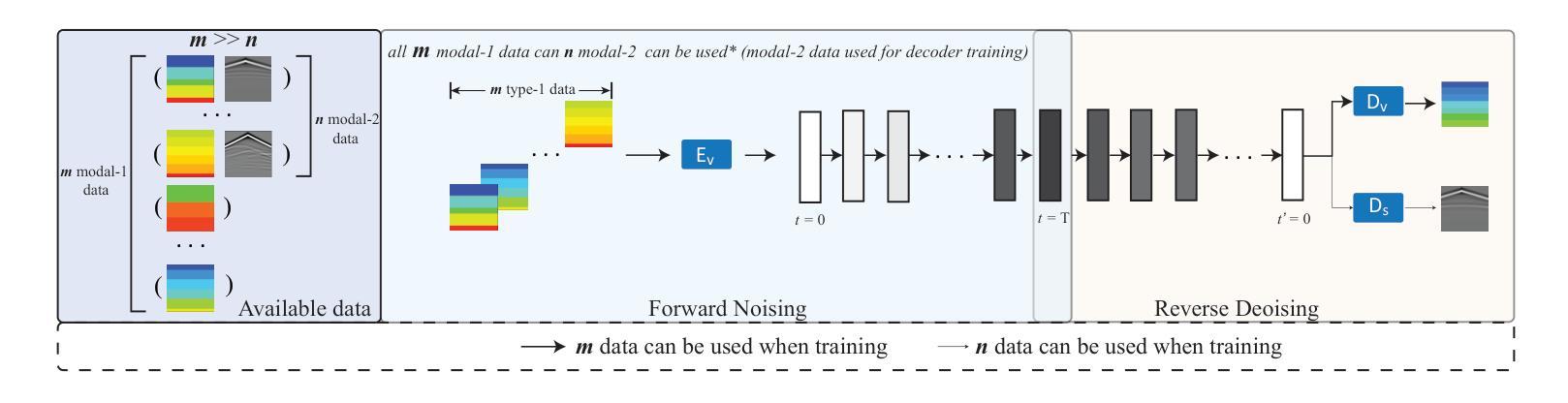
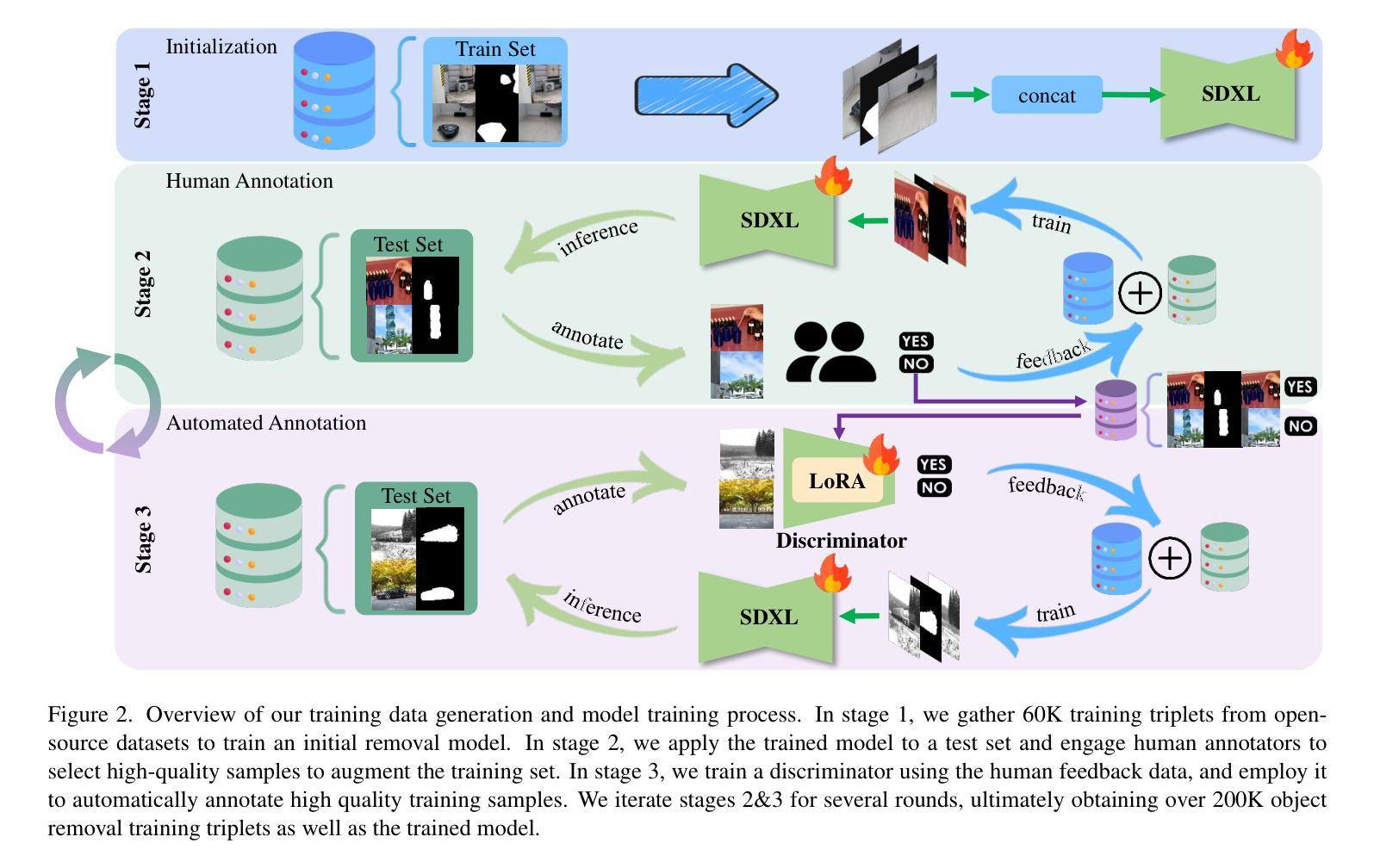
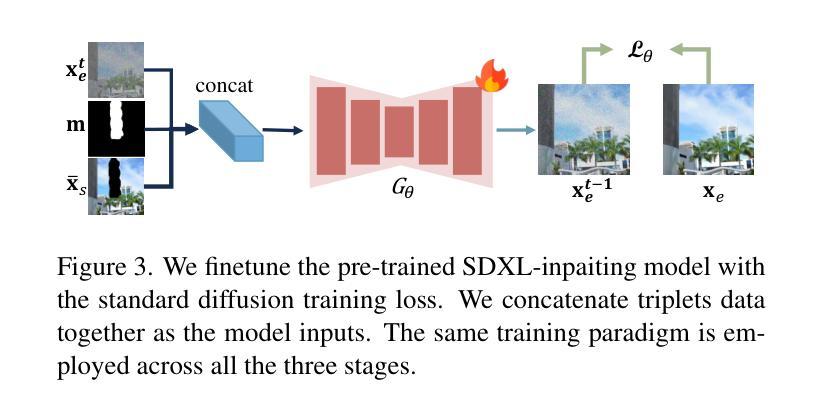
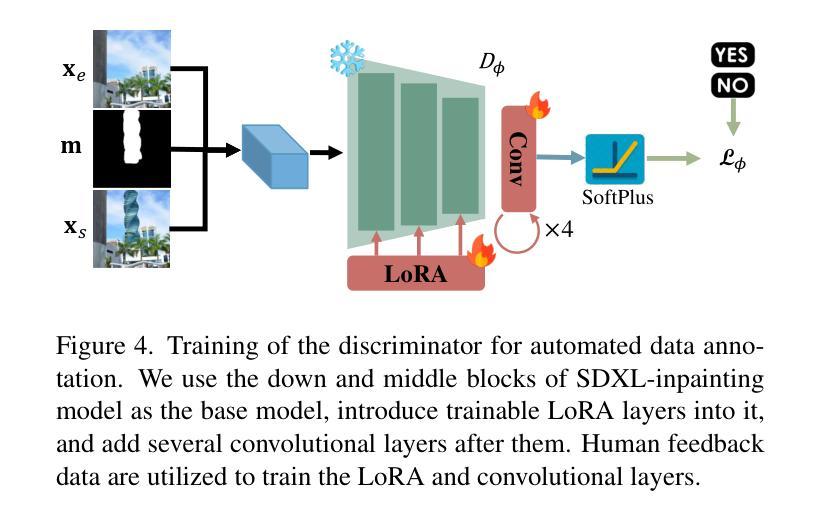
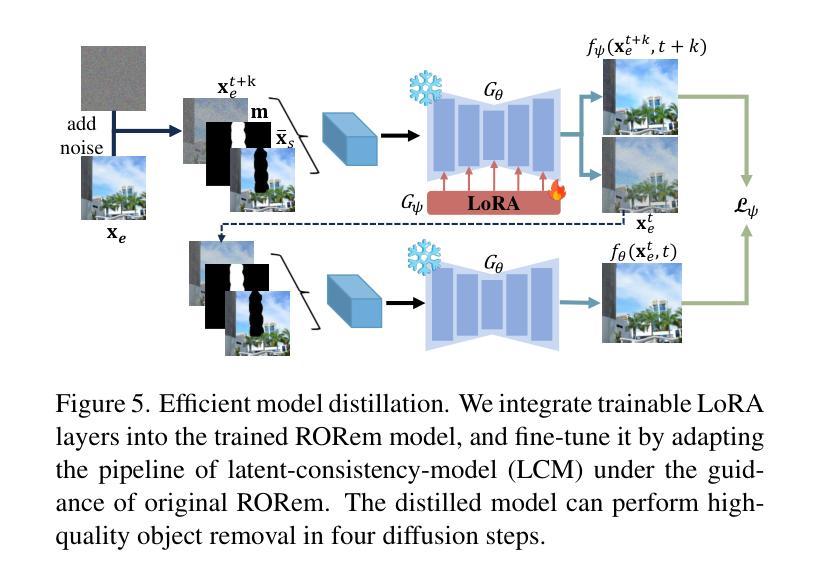
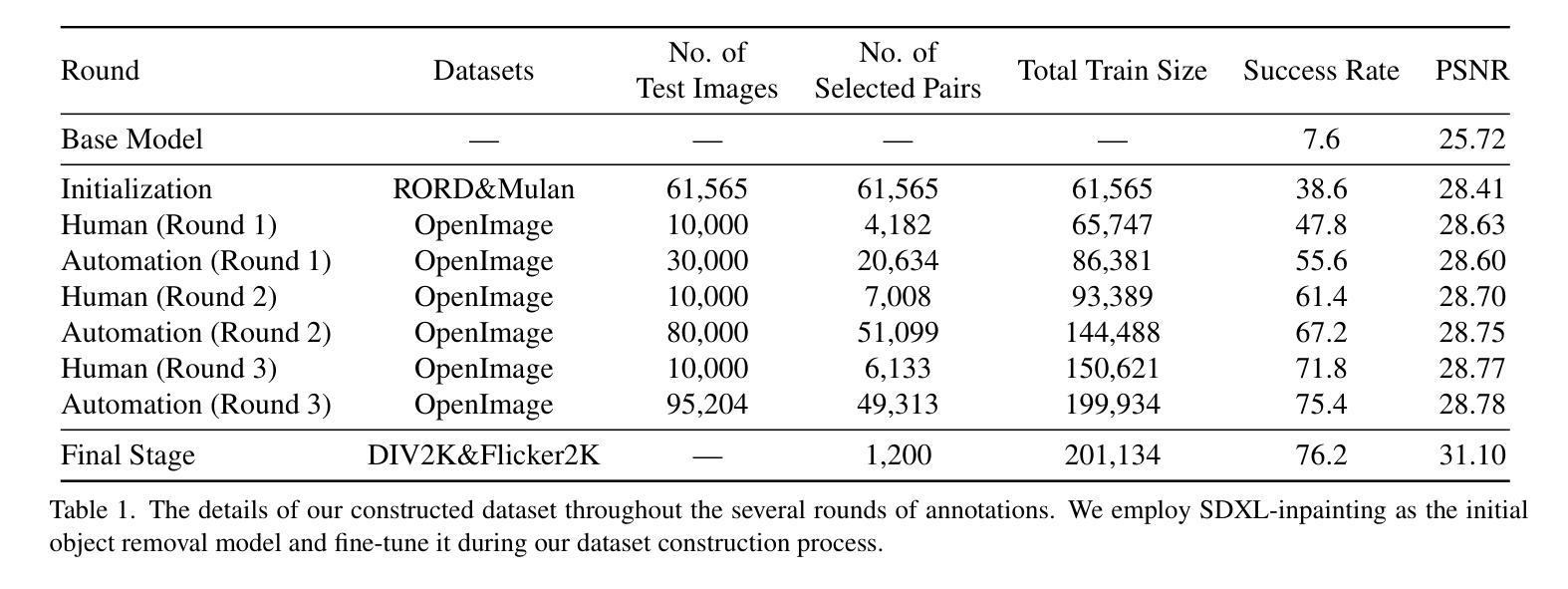
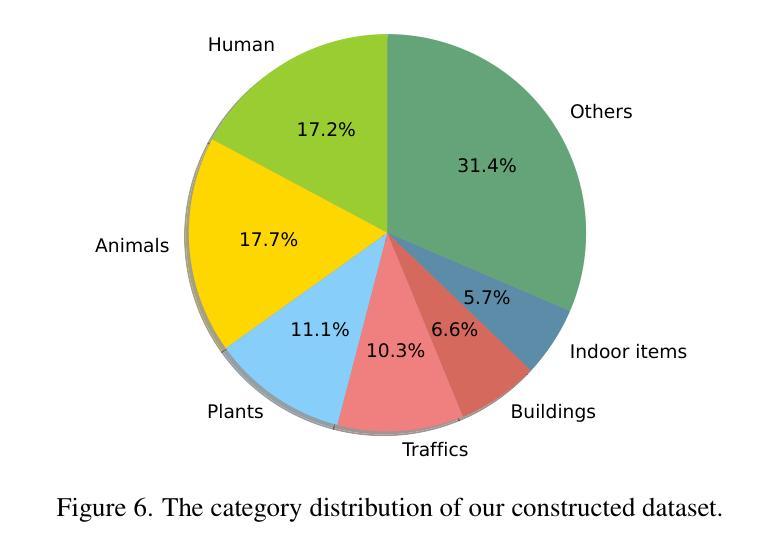
RORem: Training a Robust Object Remover with Human-in-the-Loop
Authors:Ruibin Li, Tao Yang, Song Guo, Lei Zhang
Despite the significant advancements, existing object removal methods struggle with incomplete removal, incorrect content synthesis and blurry synthesized regions, resulting in low success rates. Such issues are mainly caused by the lack of high-quality paired training data, as well as the self-supervised training paradigm adopted in these methods, which forces the model to in-paint the masked regions, leading to ambiguity between synthesizing the masked objects and restoring the background. To address these issues, we propose a semi-supervised learning strategy with human-in-the-loop to create high-quality paired training data, aiming to train a Robust Object Remover (RORem). We first collect 60K training pairs from open-source datasets to train an initial object removal model for generating removal samples, and then utilize human feedback to select a set of high-quality object removal pairs, with which we train a discriminator to automate the following training data generation process. By iterating this process for several rounds, we finally obtain a substantial object removal dataset with over 200K pairs. Fine-tuning the pre-trained stable diffusion model with this dataset, we obtain our RORem, which demonstrates state-of-the-art object removal performance in terms of both reliability and image quality. Particularly, RORem improves the object removal success rate over previous methods by more than 18%. The dataset, source code and trained model are available at https://github.com/leeruibin/RORem.
尽管取得了重大进展,但现有的物体去除方法在去除不完整、内容合成不准确以及合成区域模糊等方面仍存在困难,导致成功率较低。这些问题主要是由于缺乏高质量配对训练数据以及这些方法所采用的自监督训练范式导致的。自监督训练范式迫使模型对遮挡区域进行填充,导致合成遮挡物体和恢复背景之间存在模糊性。为了解决这些问题,我们提出了一种半监督学习策略,并结合人工参与,以创建高质量配对训练数据,旨在训练一个稳健物体去除器(RORem)。我们首先从公开数据源收集6万对训练样本,训练初始物体去除模型以生成去除样本,然后利用人工反馈选择高质量物体去除对,再用其训练判别器,以自动化后续训练数据生成过程。经过几轮迭代,我们最终获得了一个包含超过20万对样本的物体去除数据集。我们使用此数据集对预训练的稳定扩散模型进行微调,得到了我们的RORem。它在可靠性和图像质量方面实现了最先进的物体去除性能。特别是,RORem在成功率上较以前的方法提高了18%以上。数据集、源代码和训练好的模型可在https://github.com/leeruibin/RORem获得。
论文及项目相关链接
Summary
本文提出一种半监督学习策略,结合人工参与,创建高质量配对训练数据,旨在训练一个稳健的对象移除器(RORem)。通过迭代收集训练样本并利用人类反馈选择高质量的对象移除配对,训练判别器自动化后续训练数据生成过程。最终获得大量对象移除数据集,并用其微调预训练的稳定扩散模型,得到性能卓越的RORem,在可靠性和图像质量方面均表现出卓越的对象移除性能,成功率较之前的方法提高超过18%。
Key Takeaways
- 现有对象移除方法存在不完整移除、错误内容合成和合成区域模糊等问题,导致低成功率。
- 主要问题源于缺乏高质量配对训练数据和采用的自监督训练范式。
- 提出一种半监督学习策略,结合人工参与创建高质量配对训练数据,以训练稳健的对象移除器(RORem)。
- 通过迭代过程收集训练样本并利用人类反馈选择高质量对象移除配对,训练判别器自动化后续数据生成。
- 最终获得大量对象移除数据集,并用其微调预训练的稳定扩散模型。
- RORem在对象移除方面表现出卓越性能,成功率高,且图像质量良好。
点此查看论文截图

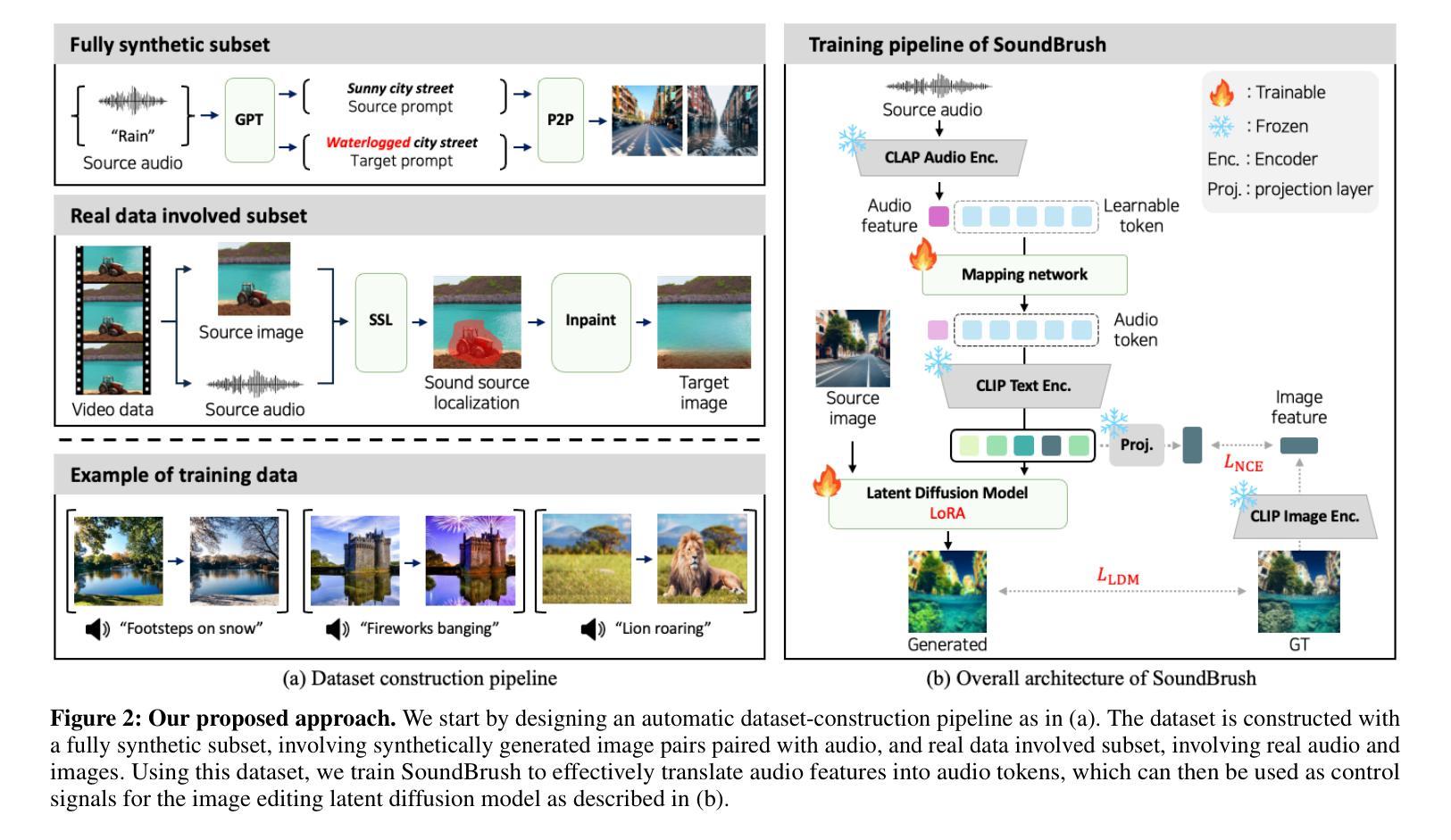
SoundBrush: Sound as a Brush for Visual Scene Editing
Authors:Kim Sung-Bin, Kim Jun-Seong, Junseok Ko, Yewon Kim, Tae-Hyun Oh
We propose SoundBrush, a model that uses sound as a brush to edit and manipulate visual scenes. We extend the generative capabilities of the Latent Diffusion Model (LDM) to incorporate audio information for editing visual scenes. Inspired by existing image-editing works, we frame this task as a supervised learning problem and leverage various off-the-shelf models to construct a sound-paired visual scene dataset for training. This richly generated dataset enables SoundBrush to learn to map audio features into the textual space of the LDM, allowing for visual scene editing guided by diverse in-the-wild sound. Unlike existing methods, SoundBrush can accurately manipulate the overall scenery or even insert sounding objects to best match the audio inputs while preserving the original content. Furthermore, by integrating with novel view synthesis techniques, our framework can be extended to edit 3D scenes, facilitating sound-driven 3D scene manipulation. Demos are available at https://soundbrush.github.io/.
我们提出了SoundBrush模型,该模型将声音作为画笔来编辑和操作视觉场景。我们扩展了潜在扩散模型(Latent Diffusion Model,LDM)的生成能力,以融入音频信息来编辑视觉场景。受到现有图像编辑作品的启发,我们将此任务定位为监督学习问题,并利用各种现成的模型构建声音配对视觉场景数据集来进行训练。这个丰富生成的数据集使SoundBrush学会将音频特征映射到LDM的文本空间,从而实现由各种野外声音引导的视觉场景编辑。与现有方法不同,SoundBrush能够准确地操作整体风景,甚至插入声音对象以最佳方式匹配音频输入,同时保留原始内容。此外,通过结合新颖视图合成技术,我们的框架可以扩展到编辑3D场景,实现声音驱动的3D场景操作。演示视频可在https://soundbrush.github.io/查看。
论文及项目相关链接
PDF AAAI 2025
Summary
我们提出了SoundBrush模型,它利用声音作为画笔来编辑和操作视觉场景。该模型扩展了潜在扩散模型(Latent Diffusion Model,LDM)的生成能力,以融入音频信息来编辑视觉场景。我们受到现有图像编辑工作的启发,将此任务构建为监督学习问题,并利用各种现成的模型构建了一个用于训练的声音配对视觉场景数据集。这个丰富生成的数据集使SoundBrush能够学习将音频特征映射到LDM的文本空间,从而实现由各种自然声音引导的视觉场景编辑。与现有方法不同,SoundBrush能够准确地操作整体风景,甚至插入与声音最匹配的对象,同时保留原始内容。此外,通过与新颖视图合成技术相结合,我们的框架可扩展到编辑3D场景,实现声音驱动的3D场景操作。
Key Takeaways
- SoundBrush模型利用声音作为画笔编辑视觉场景,扩展了Latent Diffusion Model(LDM)的生成能力。
- 该模型通过构建声音配对视觉场景数据集进行训练,实现音频信息与视觉场景的融合。
- SoundBrush能够准确操作整体风景和插入与音频匹配的对象,同时保留原始内容。
- SoundBrush模型具有先进的音频特征映射到文本空间的能力。
- 该模型可以与新颖视图合成技术结合,编辑3D场景,实现声音驱动的3D场景操作。
- SoundBrush模型在视觉场景编辑方面表现出高度的创造性和灵活性。
点此查看论文截图



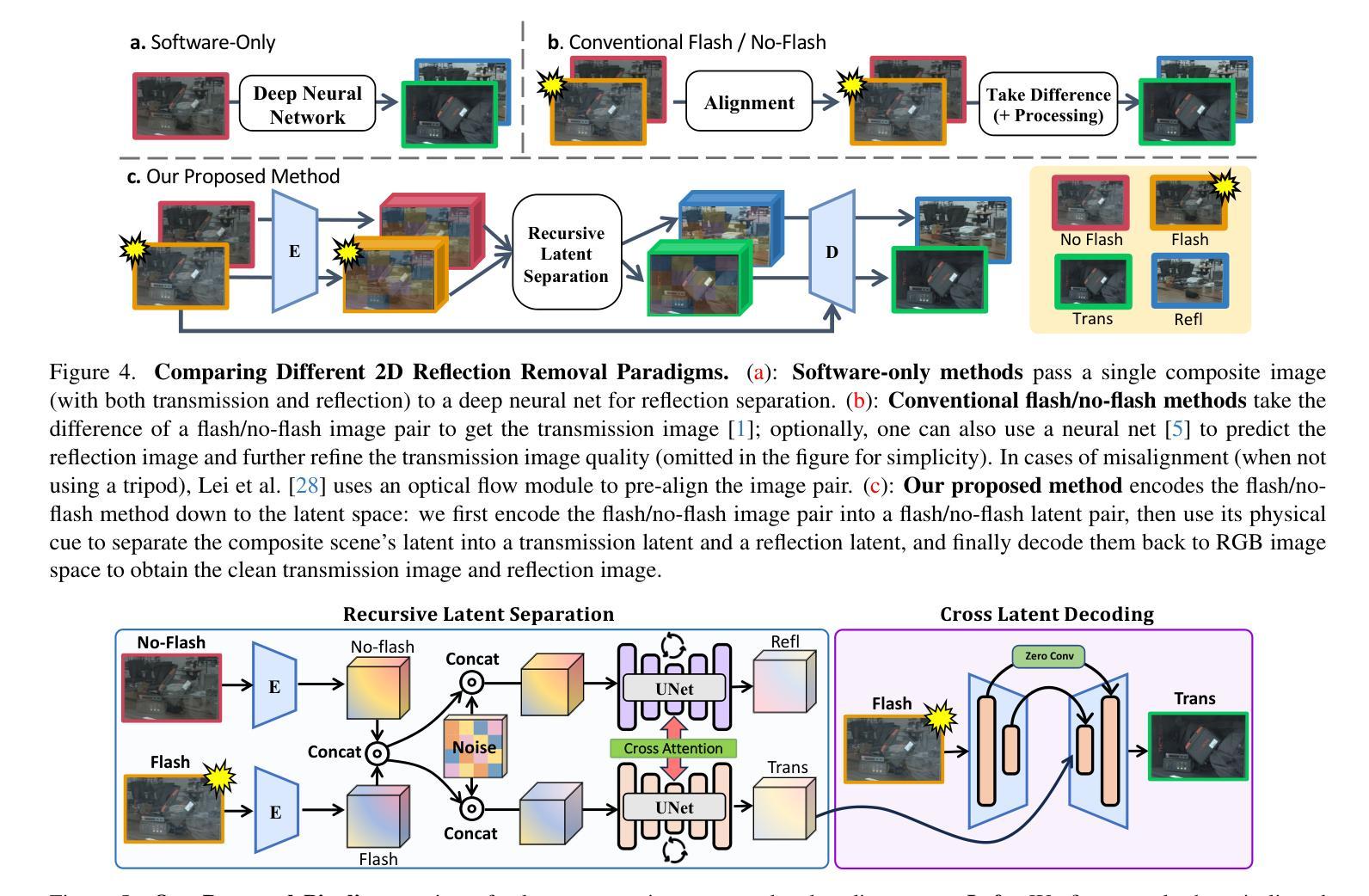
Flash-Split: 2D Reflection Removal with Flash Cues and Latent Diffusion Separation
Authors:Tianfu Wang, Mingyang Xie, Haoming Cai, Sachin Shah, Christopher A. Metzler
Transparent surfaces, such as glass, create complex reflections that obscure images and challenge downstream computer vision applications. We introduce Flash-Split, a robust framework for separating transmitted and reflected light using a single (potentially misaligned) pair of flash/no-flash images. Our core idea is to perform latent-space reflection separation while leveraging the flash cues. Specifically, Flash-Split consists of two stages. Stage 1 separates apart the reflection latent and transmission latent via a dual-branch diffusion model conditioned on an encoded flash/no-flash latent pair, effectively mitigating the flash/no-flash misalignment issue. Stage 2 restores high-resolution, faithful details to the separated latents, via a cross-latent decoding process conditioned on the original images before separation. By validating Flash-Split on challenging real-world scenes, we demonstrate state-of-the-art reflection separation performance and significantly outperform the baseline methods.
透明表面,如玻璃,会产生复杂的反射,从而掩盖图像并给下游计算机视觉应用带来挑战。我们引入了Flash-Split,这是一个使用一对(可能未对齐的)闪光/无闪光图像来分离透射光和反射光的稳健框架。我们的核心思想是在利用闪光线索的同时,在潜在空间进行反射分离。具体来说,Flash-Split分为两个阶段。第一阶段通过基于编码的闪光/无闪光潜在对条件的双分支扩散模型,分离反射潜在和传输潜在,有效地缓解了闪光/无闪光不对齐的问题。第二阶段通过基于分离前的原始图像条件的跨潜在解码过程,对分离的潜在恢复高分辨率、忠实的细节。我们通过在实际挑战场景中对Flash-Split进行验证,证明了其在反射分离方面的卓越性能,并显著优于基准方法。
论文及项目相关链接
Summary
本文介绍了Flash-Split框架,该框架利用一对闪光/无闪光图像在潜在空间进行反射分离,有效分离传输光和反射光。该框架分为两个阶段:第一阶段通过双分支扩散模型对闪光/无闪光潜在对进行条件处理,有效缓解闪光/无闪光图像的对齐问题;第二阶段通过跨潜在解码过程恢复分离后的潜在的高分辨率真实细节。Flash-Split在具有挑战性的真实场景中表现优异,实现了最先进的反射分离性能。
Key Takeaways
- Flash-Split框架用于分离透明表面上的传输光和反射光。
- 利用闪光/无闪光图像对进行潜在空间反射分离。
- 第一阶段通过双分支扩散模型处理闪光/无闪光潜在对,解决对齐问题。
- 第二阶段通过跨潜在解码恢复高分辨率真实细节。
- Flash-Split在真实场景中的反射分离性能达到最新水平。
- 该方法显著优于现有基准方法。
点此查看论文截图




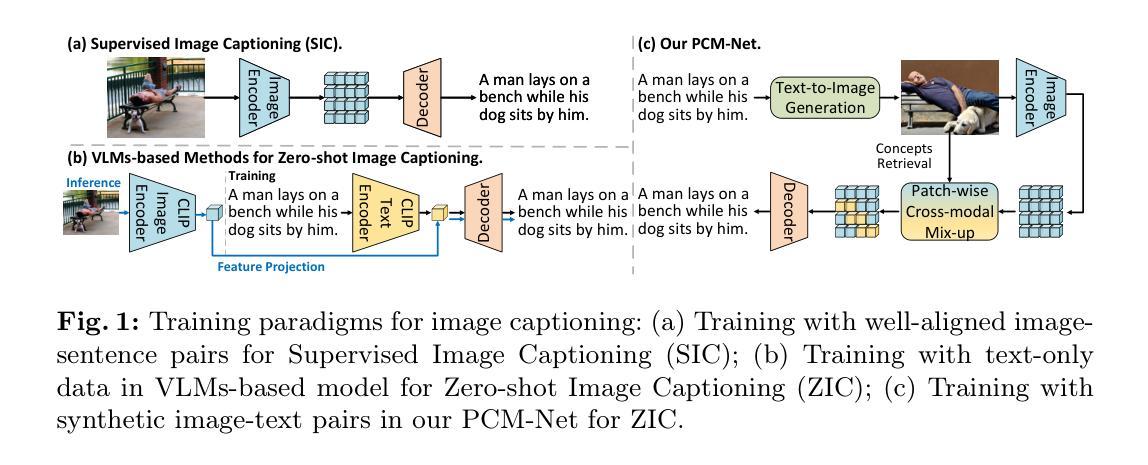
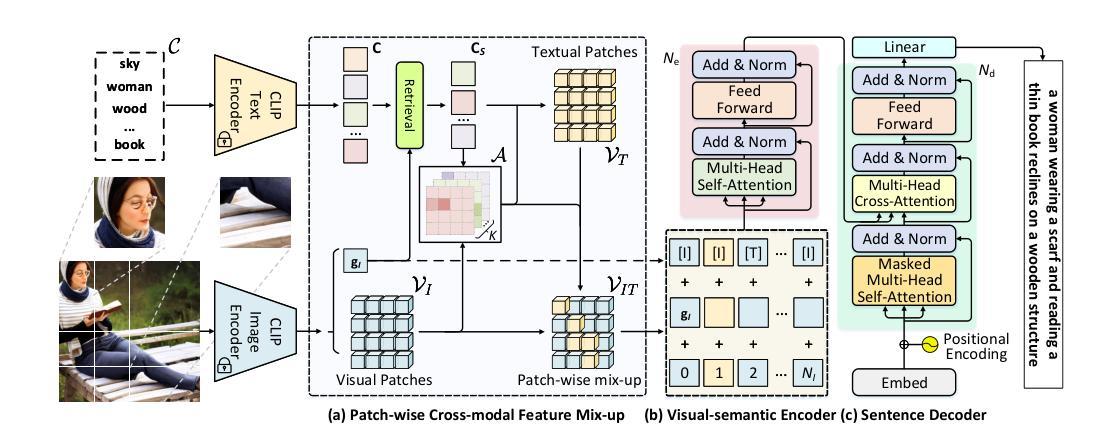
Unleashing Text-to-Image Diffusion Prior for Zero-Shot Image Captioning
Authors:Jianjie Luo, Jingwen Chen, Yehao Li, Yingwei Pan, Jianlin Feng, Hongyang Chao, Ting Yao
Recently, zero-shot image captioning has gained increasing attention, where only text data is available for training. The remarkable progress in text-to-image diffusion model presents the potential to resolve this task by employing synthetic image-caption pairs generated by this pre-trained prior. Nonetheless, the defective details in the salient regions of the synthetic images introduce semantic misalignment between the synthetic image and text, leading to compromised results. To address this challenge, we propose a novel Patch-wise Cross-modal feature Mix-up (PCM) mechanism to adaptively mitigate the unfaithful contents in a fine-grained manner during training, which can be integrated into most of encoder-decoder frameworks, introducing our PCM-Net. Specifically, for each input image, salient visual concepts in the image are first detected considering the image-text similarity in CLIP space. Next, the patch-wise visual features of the input image are selectively fused with the textual features of the salient visual concepts, leading to a mixed-up feature map with less defective content. Finally, a visual-semantic encoder is exploited to refine the derived feature map, which is further incorporated into the sentence decoder for caption generation. Additionally, to facilitate the model training with synthetic data, a novel CLIP-weighted cross-entropy loss is devised to prioritize the high-quality image-text pairs over the low-quality counterparts. Extensive experiments on MSCOCO and Flickr30k datasets demonstrate the superiority of our PCM-Net compared with state-of-the-art VLMs-based approaches. It is noteworthy that our PCM-Net ranks first in both in-domain and cross-domain zero-shot image captioning. The synthetic dataset SynthImgCap and code are available at https://jianjieluo.github.io/SynthImgCap.
最近,零样本图像描述(zero-shot image captioning)越来越受到关注,这项任务仅使用文本数据进行训练。文本到图像扩散模型的显著进展表明,可以通过利用由此预训练先验生成的合成图像-描述对来解决此任务。然而,合成图像的关键区域的缺陷细节会导致合成图像与文本之间的语义不匹配,从而产生妥协结果。为了应对这一挑战,我们提出了一种新颖的Patch-wise Cross-modal feature Mix-up(PCM)机制,以在训练期间以精细的方式自适应地减轻不真实的内容。该机制可以集成到大多数编码器-解码器框架中,从而推出我们的PCM-Net。具体来说,首先会考虑CLIP空间中的图像-文本相似性来检测输入图像中的关键视觉概念。接下来,输入图像的块级视觉特征会选择性地与关键视觉概念的文本特征融合,从而产生具有较少缺陷内容的混合特征图。最后,利用视觉语义编码器来优化派生特征图,并进一步将其融入句子解码器以生成描述。此外,为了使用合成数据进行模型训练的便利,设计了一种新颖的CLIP加权交叉熵损失,以优先对待高质量图像-文本对优于低质量对。在MSCOCO和Flickr30k数据集上的大量实验表明,我们的PCM-Net优于基于最新VLMs的方法。值得注意的是,我们的PCM-Net在域内和跨域的零样本图像描述中都排名第一。合成数据集SynthImgCap和代码可在https://jianjieluo.github.io/SynthImgCap上找到。
论文及项目相关链接
PDF ECCV 2024
Summary
本文关注零样本图像描述任务,利用文本数据训练模型生成图像描述。针对合成图像在显著区域存在的细节缺陷导致的语义对齐问题,提出一种新颖的Patch-wise Cross-modal feature Mix-up(PCM)机制,以精细方式自适应减轻不真实内容。通过结合图像和文本特征,生成混合特征图并优化视觉语义编码器,用于生成描述。同时,引入CLIP加权交叉熵损失以优化合成数据训练。实验证明,该方法在MSCOCO和Flickr30k数据集上优于其他前沿方法,特别是在零样本图像描述任务中表现突出。相关数据集和代码已公开分享。
Key Takeaways
- 关注零样本图像描述任务,借助文本数据训练模型。
- 提出新颖的Patch-wise Cross-modal feature Mix-up(PCM)机制,自适应减轻合成图像中的不真实内容。
- 结合图像和文本特征生成混合特征图,并优化视觉语义编码器进行描述生成。
- 引入CLIP加权交叉熵损失,以优化合成数据的模型训练。
- 实验证明该方法在MSCOCO和Flickr30k数据集上表现优异。
- PCM-Net在零样本图像描述任务中排名第一,无论是针对目标域还是跨域。
点此查看论文截图

diffIRM: A Diffusion-Augmented Invariant Risk Minimization Framework for Spatiotemporal Prediction over Graphs
Authors:Zhaobin Mo, Haotian Xiang, Xuan Di
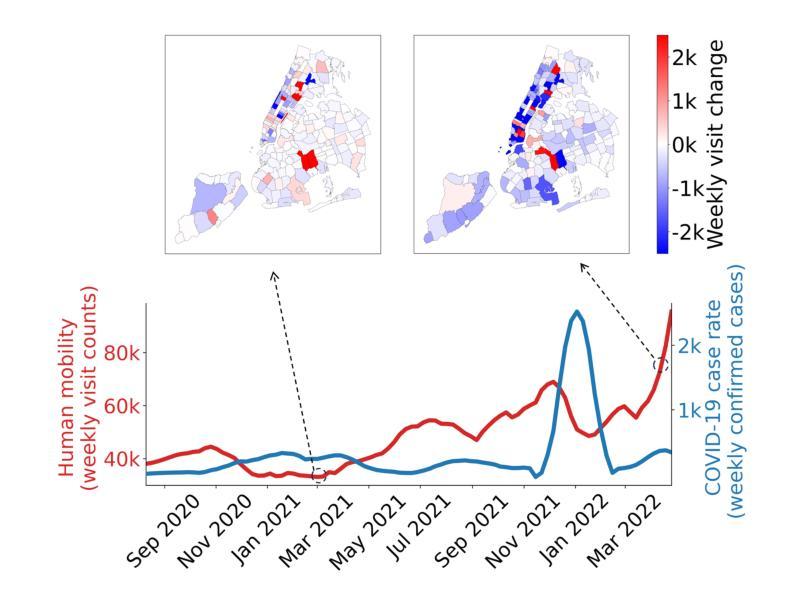
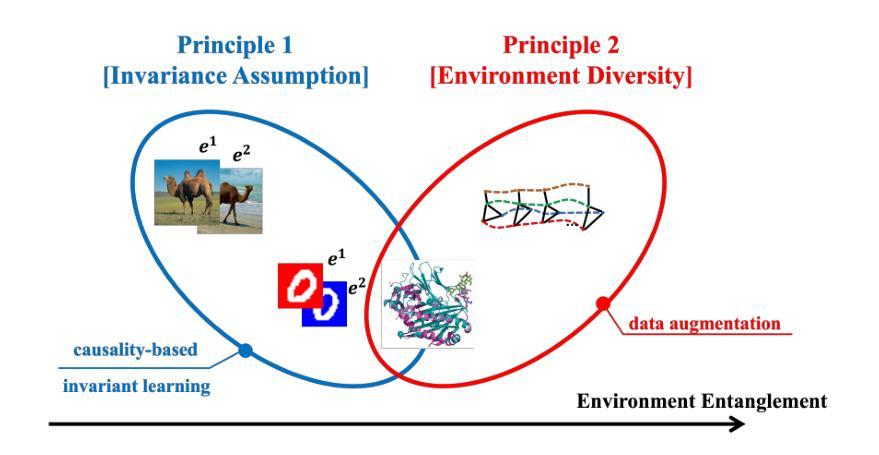
Spatiotemporal prediction over graphs (STPG) is challenging, because real-world data suffers from the Out-of-Distribution (OOD) generalization problem, where test data follow different distributions from training ones. To address this issue, Invariant Risk Minimization (IRM) has emerged as a promising approach for learning invariant representations across different environments. However, IRM and its variants are originally designed for Euclidean data like images, and may not generalize well to graph-structure data such as spatiotemporal graphs due to spatial correlations in graphs. To overcome the challenge posed by graph-structure data, the existing graph OOD methods adhere to the principles of invariance existence, or environment diversity. However, there is little research that combines both principles in the STPG problem. A combination of the two is crucial for efficiently distinguishing between invariant features and spurious ones. In this study, we fill in this research gap and propose a diffusion-augmented invariant risk minimization (diffIRM) framework that combines these two principles for the STPG problem. Our diffIRM contains two processes: i) data augmentation and ii) invariant learning. In the data augmentation process, a causal mask generator identifies causal features and a graph-based diffusion model acts as an environment augmentor to generate augmented spatiotemporal graph data. In the invariant learning process, an invariance penalty is designed using the augmented data, and then serves as a regularizer for training the spatiotemporal prediction model. The real-world experiment uses three human mobility datasets, i.e. SafeGraph, PeMS04, and PeMS08. Our proposed diffIRM outperforms baselines.
时空图数据预测(STPG)是一项具有挑战性的任务,因为现实世界的数据面临着分布外(OOD)泛化问题,即测试数据与训练数据的分布不同。为了解决这一问题,不变风险最小化(IRM)作为一种在不同环境中学习不变表示的有前途的方法而出现。然而,IRM及其变体最初是为欧几里得数据(如图像)设计的,可能由于图的空间相关性而不能很好地推广到图结构数据(如时空图)。为了克服图结构数据带来的挑战,现有的图OOD方法坚持不变性存在和环境多样性的原则。然而,在STPG问题中很少有研究将两者结合起来。两者的结合对于有效地区分不变特征和虚假特征至关重要。本研究填补了这一研究空白,提出了一种结合这两个原则的时空图数据预测扩散增强不变风险最小化(diffIRM)框架。我们的diffIRM包含两个过程:i)数据增强和ii)。在数据增强过程中,因果掩码生成器识别因果特征,基于图的扩散模型作为环境增强器生成增强的时空图数据。在不变学习过程中,使用增强数据设计不变性惩罚,并将其作为时空预测模型的训练正则化器。使用SafeGraph、PeMS04和PeMS08三个人类移动数据集进行的现实世界实验表明,我们提出的diffIRM优于基线方法。
论文及项目相关链接
Summary
时空图预测面临来自真实数据的分布外泛化问题。为解决这一问题,研究提出融合因果特征识别与扩散模型的扩散增强不变风险最小化框架,以更有效地进行数据不变特征的鉴别。框架包括数据增强与不变学习两部分。在现实世界的实验数据集上进行验证,所提方法表现优于基线模型。
Key Takeaways
- 时空图预测面临分布外泛化问题,即测试数据与训练数据分布不同的问题。
- 不变风险最小化(IRM)及其变体在应对图结构数据时存在挑战,因为它们可能无法很好地推广到时空图等图形结构数据。
- 本研究通过融合不变存在原则和环境多样性原则来解决时空图的STPG问题。这是现有研究中尚未得到充分关注的领域。
- 提出一种名为“扩散增强不变风险最小化”(diffIRM)的框架来解决这个问题,包括数据增强和不变学习两个过程。
- 在数据增强过程中,使用因果掩码生成器识别因果特征,并使用基于图的扩散模型作为环境增强器来生成增强的时空图数据。
- 在不变学习过程中,使用增强数据设计不变性惩罚,作为训练时空预测模型的规则化器。
点此查看论文截图