⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-06 更新
RingFormer: A Neural Vocoder with Ring Attention and Convolution-Augmented Transformer
Authors:Seongho Hong, Yong-Hoon Choi
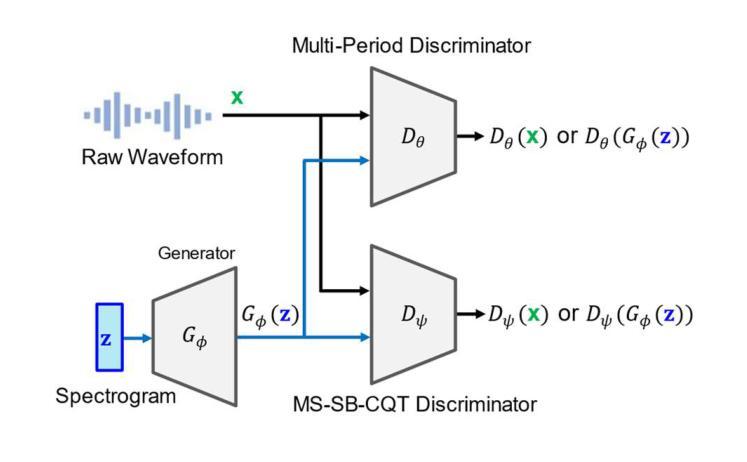
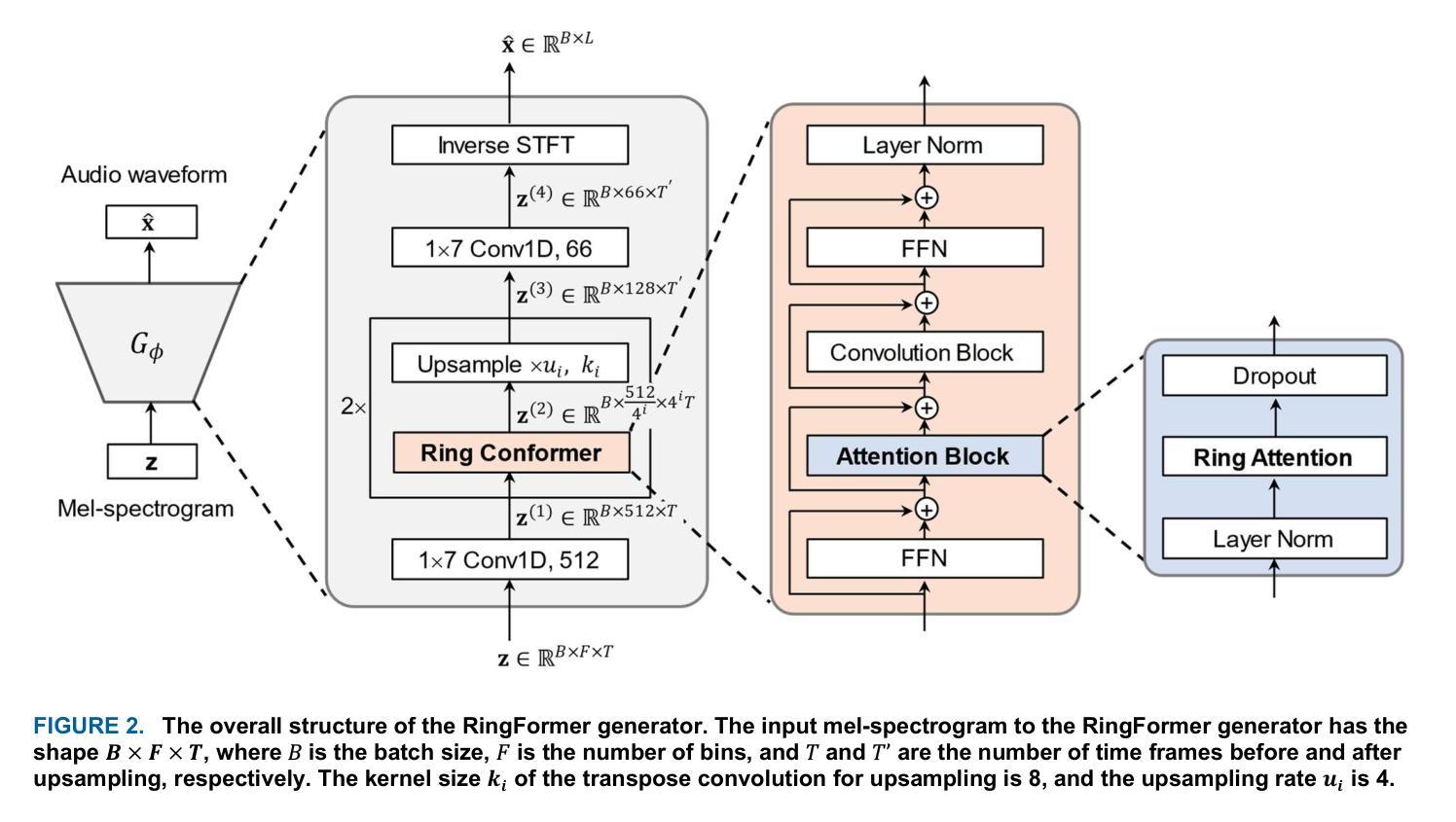
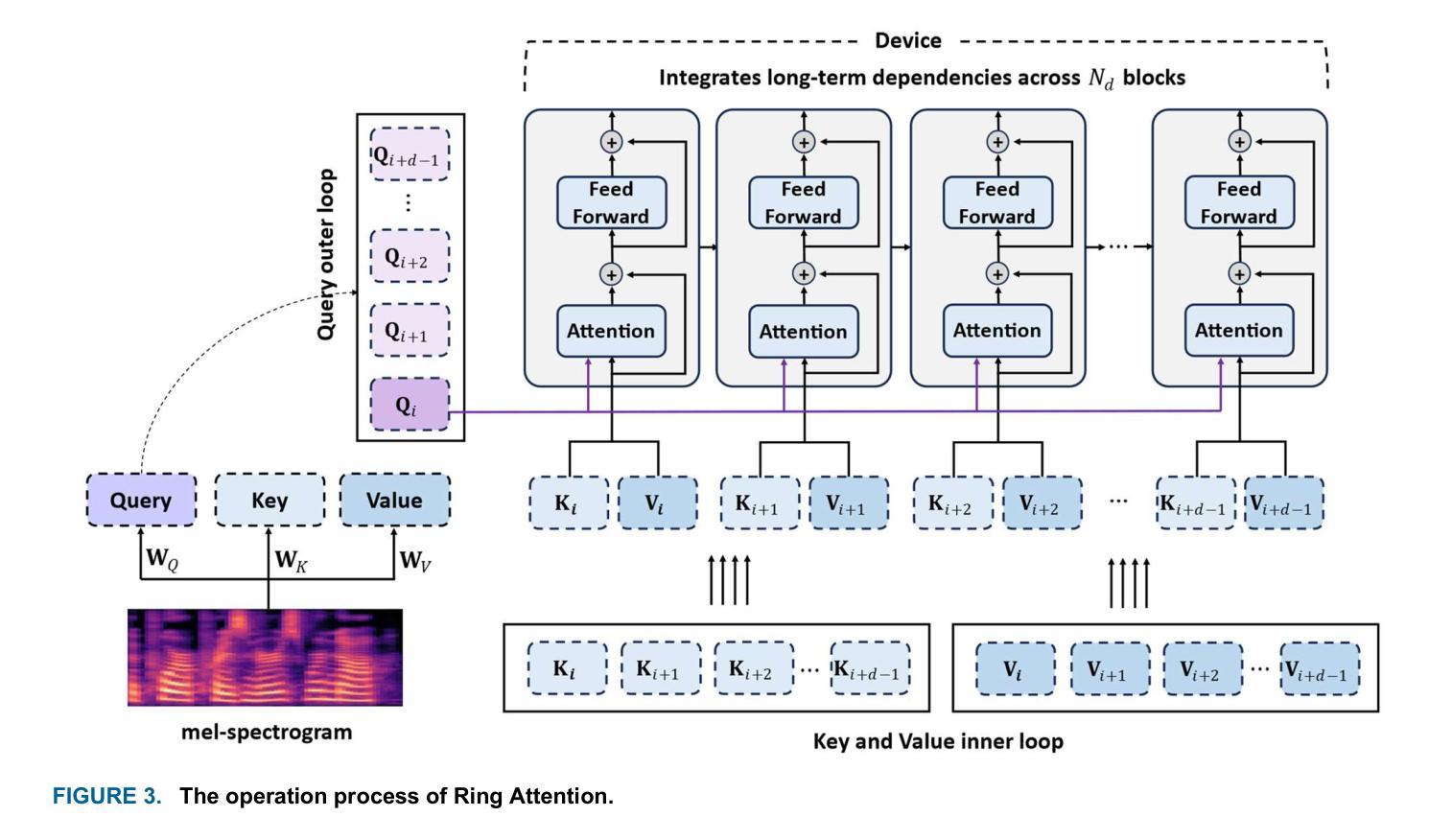
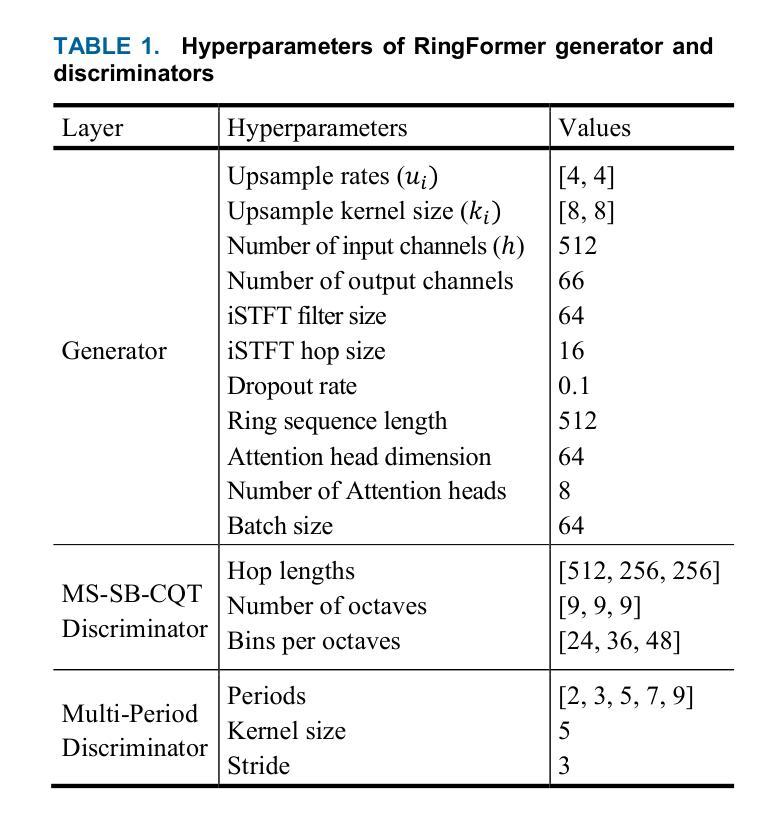
While transformers demonstrate outstanding performance across various audio tasks, their application to neural vocoders remains challenging. Neural vocoders require the generation of long audio signals at the sample level, which demands high temporal resolution. This results in significant computational costs for attention map generation and limits their ability to efficiently process both global and local information. Additionally, the sequential nature of sample generation in neural vocoders poses difficulties for real-time processing, making the direct adoption of transformers impractical. To address these challenges, we propose RingFormer, a neural vocoder that incorporates the ring attention mechanism into a lightweight transformer variant, the convolution-augmented transformer (Conformer). Ring attention effectively captures local details while integrating global information, making it well-suited for processing long sequences and enabling real-time audio generation. RingFormer is trained using adversarial training with two discriminators. The proposed model is applied to the decoder of the text-to-speech model VITS and compared with state-of-the-art vocoders such as HiFi-GAN, iSTFT-Net, and BigVGAN under identical conditions using various objective and subjective metrics. Experimental results show that RingFormer achieves comparable or superior performance to existing models, particularly excelling in real-time audio generation. Our code and audio samples are available on GitHub.
尽管Transformer在各种音频任务中表现出卓越的性能,但它们在神经vocoder中的应用仍然具有挑战性。神经vocoder需要在样本级别生成长的音频信号,这要求高的时间分辨率。这会导致注意力图生成的计算成本显著增加,并限制它们有效处理全局和局部信息的能力。此外,神经vocoder中样本生成的顺序性给实时处理带来了困难,使得直接采用Transformer变得不切实际。为了解决这些挑战,我们提出了RingFormer,这是一种结合了环形注意力机制的轻量级Transformer变体——卷积增强Transformer(Conformer)的神经vocoder。环形注意力机制可以有效地捕捉局部细节,同时整合全局信息,非常适合处理长序列并实现实时音频生成。RingFormer使用两个鉴别器进行对抗训练。所提出的模型应用于文本到语音模型的解码器VITS,并与最先进的vocoder(如HiFi-GAN、iSTFT-Net和BigVGAN)在相同条件下进行比较,使用各种客观和主观指标进行评估。实验结果表明,RingFormer在实时音频生成方面达到了与现有模型相当或更高的性能。我们的代码和音频样本可在GitHub上找到。
论文及项目相关链接
Summary
本文探讨了神经网络编码器在音频生成任务中的应用,提出一种名为RingFormer的新型神经网络编码器,结合了环形注意力机制和轻量级Transformer变体(Conformer)。RingFormer能有效捕捉局部细节并整合全局信息,适合处理长序列数据并可实现实时音频生成。在文本转语音模型VITS的解码器上应用此模型,并与现有先进的vocoder进行了比较,结果显示RingFormer在实时音频生成方面表现优异。
Key Takeaways
- 神经网络编码器在音频生成任务中应用具有挑战,需生成长音频信号和高时空分辨率。
- RingFormer模型结合了环形注意力机制和Conformer,适用于处理长序列数据。
- Ring attention能有效捕捉局部细节并整合全局信息。
- RingFormer通过对抗训练与两个鉴别器进行训练。
- RingFormer在文本转语音模型VITS的解码器上应用,并实现了实时音频生成。
- 与HiFi-GAN、iSTFT-Net和BigVGAN等先进vocoder比较,RingFormer表现优异。
点此查看论文截图

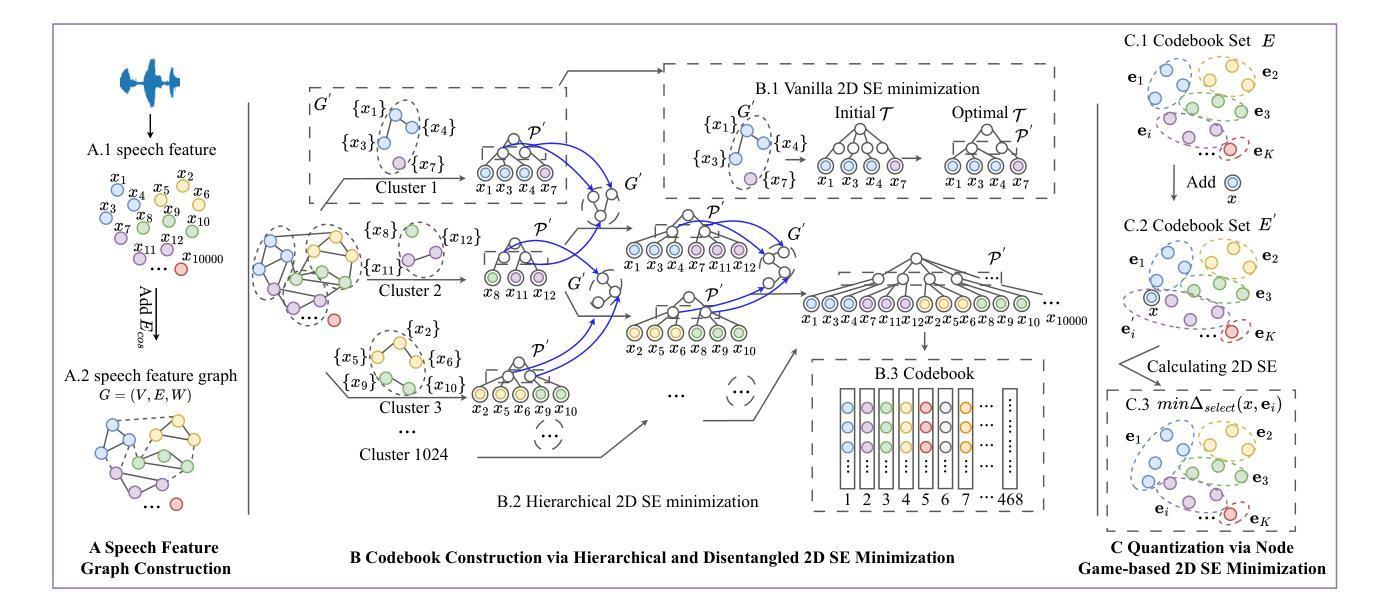
SECodec: Structural Entropy-based Compressive Speech Representation Codec for Speech Language Models
Authors:Linqin Wang, Yaping Liu, Zhengtao Yu, Shengxiang Gao, Cunli Mao, Yuxin Huang, Wenjun Wang, Ling Dong
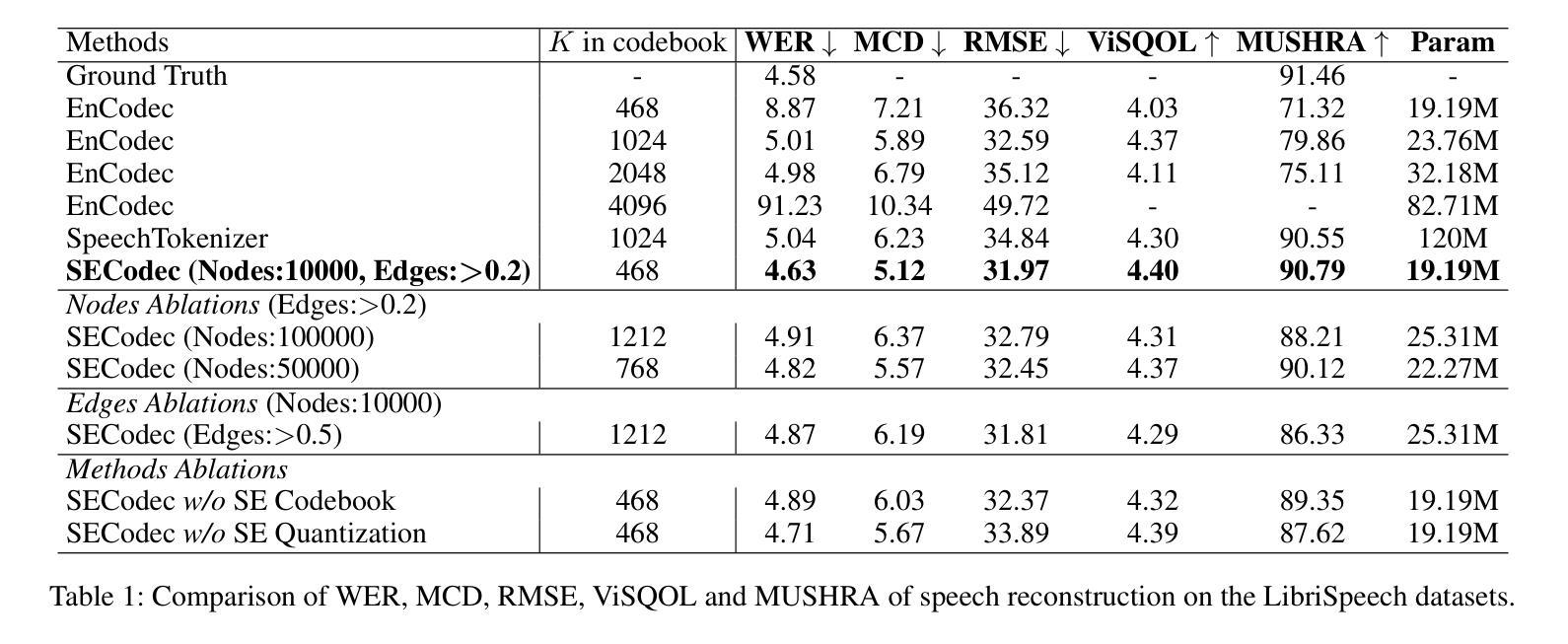
With the rapid advancement of large language models (LLMs), discrete speech representations have become crucial for integrating speech into LLMs. Existing methods for speech representation discretization rely on a predefined codebook size and Euclidean distance-based quantization. However, 1) the size of codebook is a critical parameter that affects both codec performance and downstream task training efficiency. 2) The Euclidean distance-based quantization may lead to audio distortion when the size of the codebook is controlled within a reasonable range. In fact, in the field of information compression, structural information and entropy guidance are crucial, but previous methods have largely overlooked these factors. Therefore, we address the above issues from an information-theoretic perspective, we present SECodec, a novel speech representation codec based on structural entropy (SE) for building speech language models. Specifically, we first model speech as a graph, clustering the speech features nodes within the graph and extracting the corresponding codebook by hierarchically and disentangledly minimizing 2D SE. Then, to address the issue of audio distortion, we propose a new quantization method. This method still adheres to the 2D SE minimization principle, adaptively selecting the most suitable token corresponding to the cluster for each incoming original speech node. Furthermore, we develop a Structural Entropy-based Speech Language Model (SESLM) that leverages SECodec. Experimental results demonstrate that SECodec performs comparably to EnCodec in speech reconstruction, and SESLM surpasses VALL-E in zero-shot text-to-speech tasks. Code, demo speeches, speech feature graph, SE codebook, and models are available at https://github.com/wlq2019/SECodec.
随着大型语言模型(LLM)的快速发展,离散语音表示对于将语音集成到LLM中变得至关重要。现有的语音表示离散化方法依赖于预设的码本大小和基于欧几里得距离的量化。然而,1)码本的大小是一个影响编码性能以及下游任务训练效率的关键参数。2)当码本大小控制在合理范围内时,基于欧几里得距离的量化可能导致音频失真。事实上,在信息压缩领域,结构信息和熵指导至关重要,但之前的方法大多忽略了这些因素。因此,我们从信息理论的角度解决上述问题,提出SECodec,这是一种基于结构熵(SE)构建语音语言模型的新型语音表示编码。具体来说,我们首先将语音建模为图,在图中对语音特征节点进行聚类,并通过层次化、分解地最小化二维SE来提取相应的码本。然后,为了解决音频失真问题,我们提出了一种新的量化方法。该方法仍然遵循二维SE最小化原则,自适应地为每个传入原始语音节点选择最匹配的标记(token)。此外,我们开发了一种基于结构熵的语音语言模型(SESLM),该模型利用SECodec。实验结果表明,SECodec在语音重建方面的表现与EnCodec相当,SESLM在零样本文本到语音任务上超过了VALL-E。相关代码、演示语音、语音特征图、SE码本和模型均可在https://github.com/wlq2019/SECodec找到。
论文及项目相关链接
PDF Accepted to the Thirty-Ninth AAAI Conference on Artificial Intelligence (AAAI-25)
摘要
随着大型语言模型(LLMs)的快速发展,离散语音表示对于将语音融入LLMs中变得至关重要。现有语音表示离散化方法依赖于预设的码本大小和基于欧几里得距离的量化。然而,码本大小是影响编解码器性能和下游任务训练效率的关键参数。此外,基于欧几里得距离的量化在控制码本大小在合理范围内时可能导致音频失真。本文从信息理论角度解决上述问题,提出SECodec,一种基于结构熵(SE)的新型语音表示编解码器,用于构建语音语言模型。通过建模语音为图,在图中聚类语音特征节点并提取相应的码本,我们最小化二维SE来生成码本。为解决音频失真问题,我们提出了一种新的量化方法,仍遵循二维SE最小化原则,自适应地为每个输入的原始语音节点选择最匹配的标记。此外,我们开发了基于结构熵的语音语言模型SESLM,利用SECodec。实验结果表明,SECodec在语音重建方面与EnCodec表现相当,SESLM在零样本文本到语音任务中超越了VALL-E。相关代码、演示语音、语音特征图、SE码本和模型可在https://github.com/wlq2019/SECodec找到。
要点
- 离散语音表示对于将语音融入大型语言模型至关重要。
- 现有方法依赖于预设码本大小和基于欧几里得距离的量化,存在音频失真问题。
- 提出SECodec编解码器,从信息理论角度解决上述问题,利用结构熵建模语音。
- SECodec通过最小化二维结构熵生成码本,解决音频失真问题。
- 开发基于结构熵的语音语言模型SESLM。
- 实验显示SECodec在语音重建方面表现良好,SESLM在文本到语音任务中表现优异。
点此查看论文截图