⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-06 更新
AltGen: AI-Driven Alt Text Generation for Enhancing EPUB Accessibility
Authors:Yixian Shen, Hang Zhang, Yanxin Shen, Lun Wang, Chuanqi Shi, Shaoshuai Du, Yiyi Tao
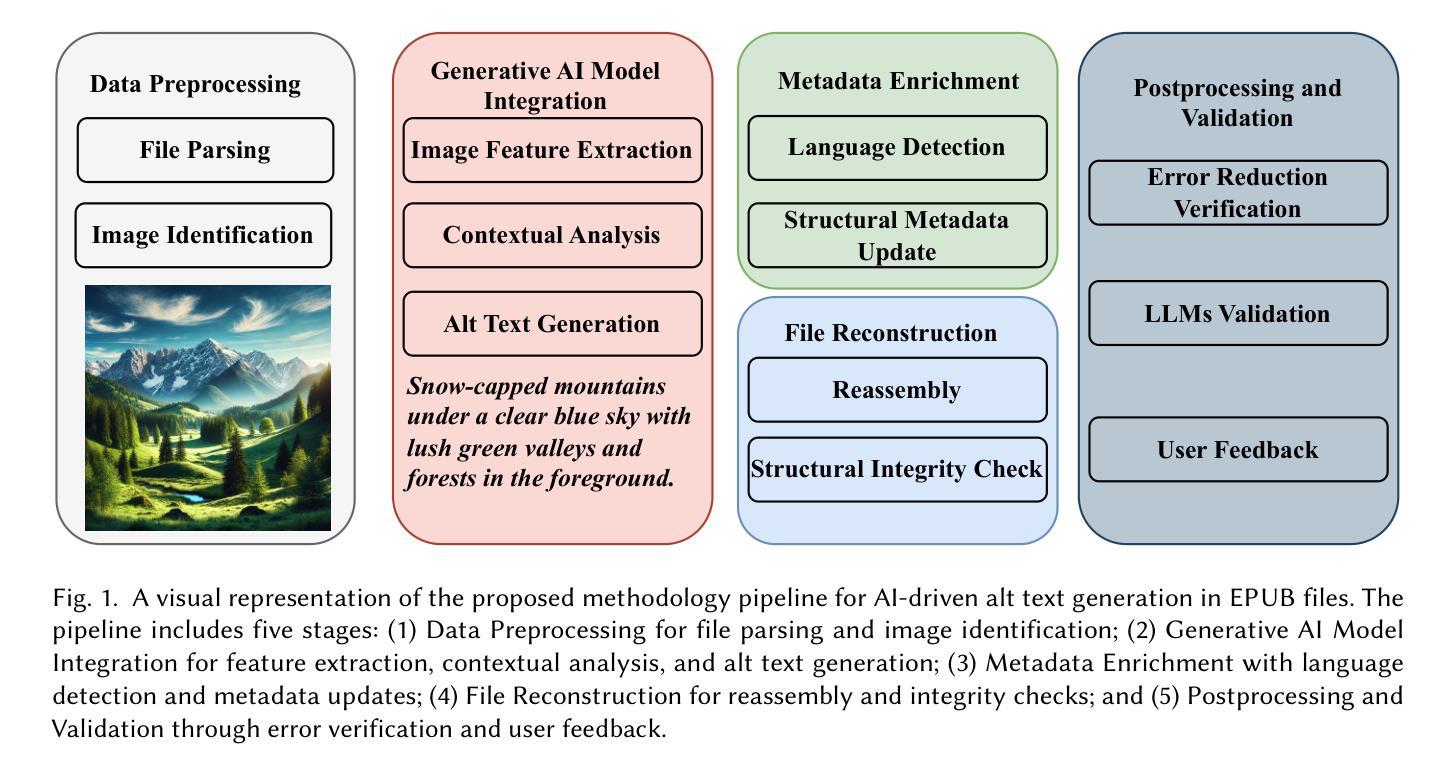
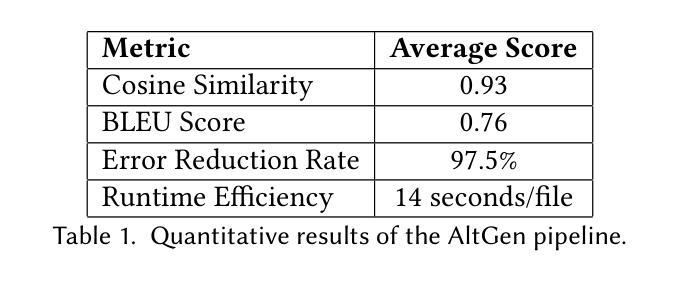
Digital accessibility is a cornerstone of inclusive content delivery, yet many EPUB files fail to meet fundamental accessibility standards, particularly in providing descriptive alt text for images. Alt text plays a critical role in enabling visually impaired users to understand visual content through assistive technologies. However, generating high-quality alt text at scale is a resource-intensive process, creating significant challenges for organizations aiming to ensure accessibility compliance. This paper introduces AltGen, a novel AI-driven pipeline designed to automate the generation of alt text for images in EPUB files. By integrating state-of-the-art generative models, including advanced transformer-based architectures, AltGen achieves contextually relevant and linguistically coherent alt text descriptions. The pipeline encompasses multiple stages, starting with data preprocessing to extract and prepare relevant content, followed by visual analysis using computer vision models such as CLIP and ViT. The extracted visual features are enriched with contextual information from surrounding text, enabling the fine-tuned language models to generate descriptive and accurate alt text. Validation of the generated output employs both quantitative metrics, such as cosine similarity and BLEU scores, and qualitative feedback from visually impaired users. Experimental results demonstrate the efficacy of AltGen across diverse datasets, achieving a 97.5% reduction in accessibility errors and high scores in similarity and linguistic fidelity metrics. User studies highlight the practical impact of AltGen, with participants reporting significant improvements in document usability and comprehension. Furthermore, comparative analyses reveal that AltGen outperforms existing approaches in terms of accuracy, relevance, and scalability.
数字无障碍性是包容性内容交付的基石,然而许多EPUB文件未能达到基本无障碍标准,尤其是在为图像提供描述性alt文本方面。Alt文本对于视力受损用户通过辅助技术理解视觉内容起着至关重要的作用。然而,大规模生成高质量的alt文本是一个资源密集型的过程,对于旨在确保符合无障碍性标准的组织来说,这构成了重大挑战。本文介绍了AltGen,这是一种新型的AI驱动管道,旨在自动化EPUB文件中图像的alt文本生成。通过集成最先进的生成模型,包括先进的基于变压器的架构,AltGen实现了与上下文相关且语言连贯的alt文本描述。该管道包括多个阶段,从数据预处理中提取和准备相关内容开始,然后使用计算机视觉模型(如CLIP和ViT)进行视觉分析。从周围文本中提取的视觉特征通过上下文信息得到丰富,使微调后的语言模型能够生成描述性和准确的alt文本。对生成输出的验证采用定量指标(如余弦相似度和BLEU分数)和视力受损用户的定性反馈。实验结果表明,AltGen在多种数据集上的有效性,在访问性错误方面减少了97.5%,并且在相似性和语言忠实度指标上获得了高分。用户研究表明,AltGen具有实际影响力,参与者的报告显著提高了文档的可用性和理解力。此外,比较分析表明,AltGen在准确性、相关性和可扩展性方面优于现有方法。
论文及项目相关链接
Summary
本文介绍了一种名为AltGen的新颖AI驱动管道,用于自动生成EPUB文件中图像的alt文本,以提高数字内容的可访问性。通过集成先进的生成模型,包括基于transformer的架构,AltGen能够生成与上下文相关且在语言上连贯的alt文本描述。该方法包括数据预处理、视觉分析等多个阶段,并利用计算机视觉模型和视觉特征生成丰富信息,进而结合周围文本提供的信息来优化生成的alt文本质量。实验验证和用户研究均显示AltGen的有效性和实用性。它能有效地解决EPUB文件中的图像alt文本缺失问题,提高文档的可访问性和可用性。相较于现有方法,AltGen在准确性、相关性和可扩展性方面表现更优。
Key Takeaways
以下是关于文本的关键见解:
- AltGen是一个创新的AI驱动管道,旨在自动生成EPUB文件中图像的alt文本,以增强内容的可访问性。
- AltGen集成了先进的生成模型(包括基于transformer的架构),能够生成与上下文相关且在语言上连贯的alt文本描述。
- AltGen的管道包括多个阶段,从数据预处理到视觉分析,利用计算机视觉模型和视觉特征生成丰富信息。
- AltGen能有效解决EPUB文件中图像alt文本缺失的问题,实验结果显示其在多种数据集上表现良好,并显著减少了可访问性错误。
- 用户研究证实AltGen的实际影响,参与者反馈表明其在文档可用性和理解方面显著提高。
点此查看论文截图

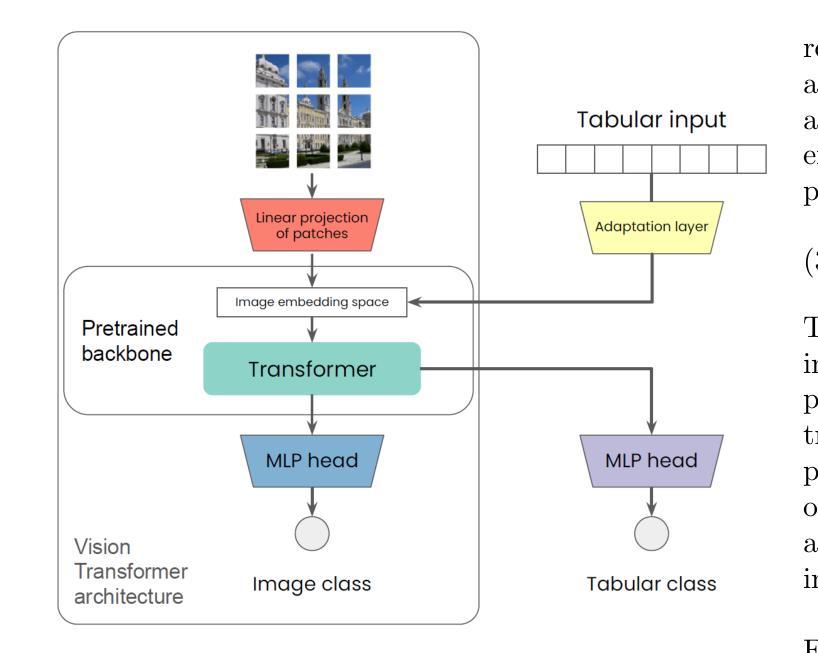
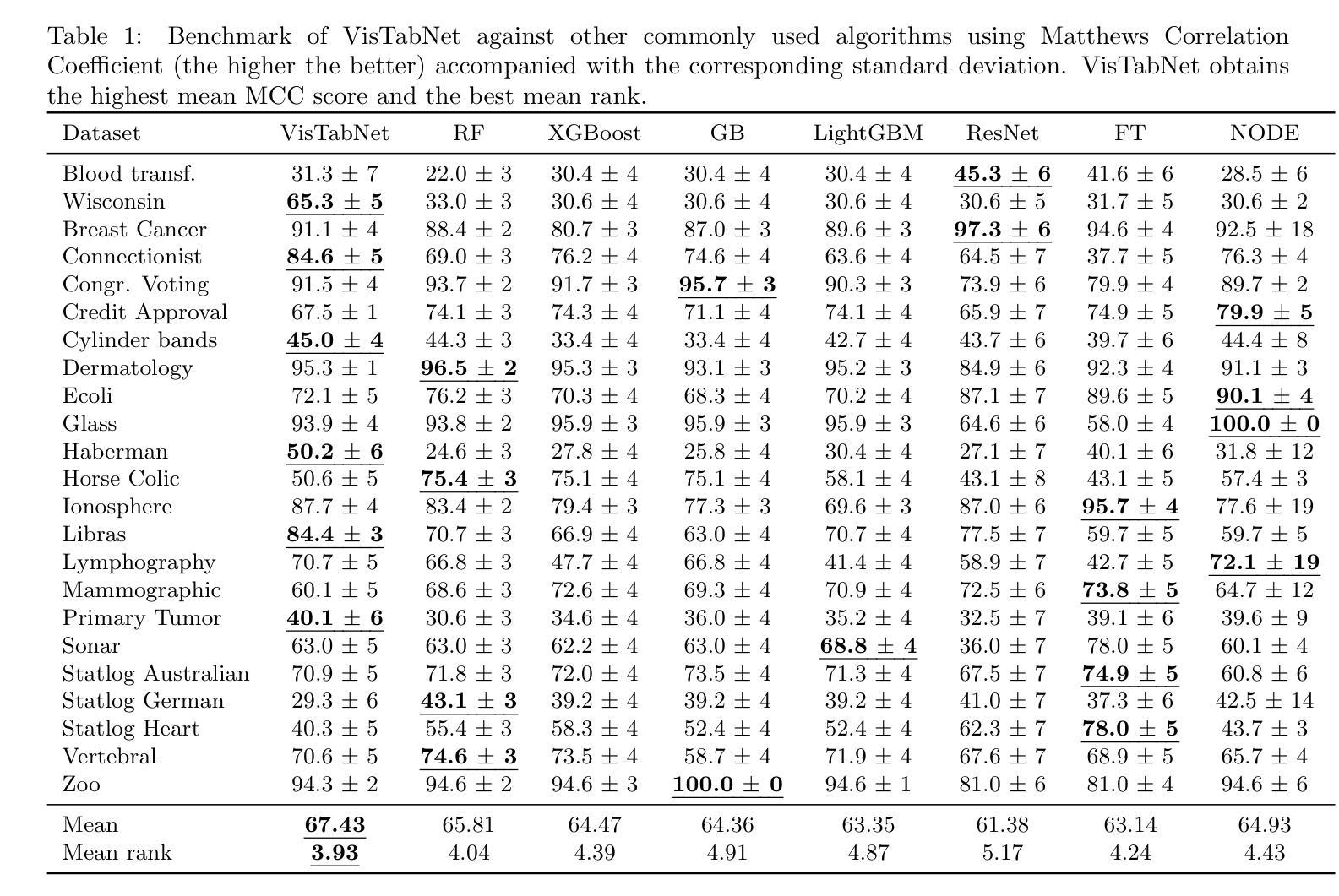
VisTabNet: Adapting Vision Transformers for Tabular Data
Authors:Witold Wydmański, Ulvi Movsum-zada, Jacek Tabor, Marek Śmieja
Although deep learning models have had great success in natural language processing and computer vision, we do not observe comparable improvements in the case of tabular data, which is still the most common data type used in biological, industrial and financial applications. In particular, it is challenging to transfer large-scale pre-trained models to downstream tasks defined on small tabular datasets. To address this, we propose VisTabNet – a cross-modal transfer learning method, which allows for adapting Vision Transformer (ViT) with pre-trained weights to process tabular data. By projecting tabular inputs to patch embeddings acceptable by ViT, we can directly apply a pre-trained Transformer Encoder to tabular inputs. This approach eliminates the conceptual cost of designing a suitable architecture for processing tabular data, while reducing the computational cost of training the model from scratch. Experimental results on multiple small tabular datasets (less than 1k samples) demonstrate VisTabNet’s superiority, outperforming both traditional ensemble methods and recent deep learning models. The proposed method goes beyond conventional transfer learning practice and shows that pre-trained image models can be transferred to solve tabular problems, extending the boundaries of transfer learning.
尽管深度学习模型在自然语言处理和计算机视觉领域取得了巨大成功,但在处理表格数据的情况下,我们并未观察到相应的改进。表格数据仍然是生物、工业和财务应用中最常用的数据类型。特别是,将大规模预训练模型转移到在小型表格数据集上定义的下游任务是一项挑战。为了解决这一问题,我们提出了VisTabNet——一种跨模态迁移学习方法,它允许使用预训练权重对Vision Transformer(ViT)进行适配以处理表格数据。通过将表格输入投影到ViT可接受的补丁嵌入,我们可以直接将预训练的Transformer编码器应用于表格输入。这种方法消除了为处理表格数据而设计合适架构的概念成本,同时降低了从头开始训练模型的计算成本。在多个小型表格数据集(少于1k样本)上的实验结果证明了VisTabNet的优越性,它超越了传统的集成方法以及最近的深度学习模型。所提出的方法超越了传统的迁移学习实践,并表明预训练的图像模型可以转移到解决表格问题,从而扩展了迁移学习的边界。
论文及项目相关链接
Summary
VisTabNet是一种跨模态迁移学习方法,可将预训练的Vision Transformer(ViT)模型应用于处理表格数据。该方法通过投影表格输入到ViT可接受的补丁嵌入,可直接应用预训练的Transformer编码器处理表格数据。这种方法在多个小型表格数据集上的实验结果证明了其优越性,超越了传统的集成方法和最近的深度学习模型。此方法突破了传统的迁移学习实践,展示了预训练的图像模型可以转移到解决表格问题,扩展了迁移学习的边界。
Key Takeaways
- 尽管深度学习模型在自然语言处理和计算机视觉方面取得了巨大成功,但在处理表格数据时并未出现相应的改进。
- 表格数据仍是生物、工业和财务应用中最常用的数据类型。
- 将预训练的Vision Transformer(ViT)模型应用于处理表格数据具有挑战性。
- VisTabNet是一种跨模态迁移学习方法,旨在解决上述问题。
- VisTabNet通过将表格输入投影到ViT可接受的补丁嵌入,直接应用预训练的Transformer编码器处理表格数据。
- VisTabNet在多个小型表格数据集上的实验结果证明了其优越性,超越了传统方法和最近的深度学习模型。
点此查看论文截图