⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-07 更新
ACE: Anti-Editing Concept Erasure in Text-to-Image Models
Authors:Zihao Wang, Yuxiang Wei, Fan Li, Renjing Pei, Hang Xu, Wangmeng Zuo
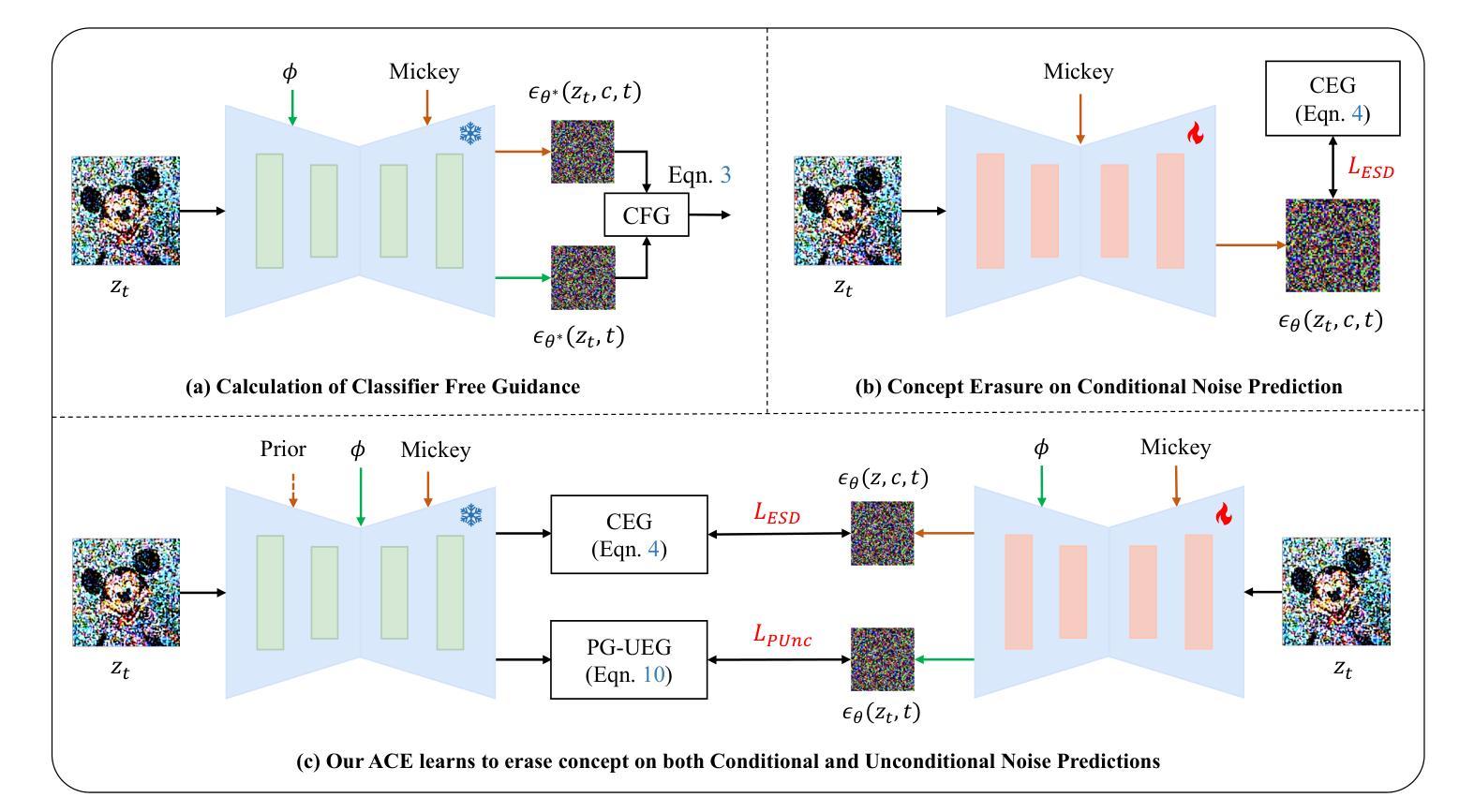
Recent advance in text-to-image diffusion models have significantly facilitated the generation of high-quality images, but also raising concerns about the illegal creation of harmful content, such as copyrighted images. Existing concept erasure methods achieve superior results in preventing the production of erased concept from prompts, but typically perform poorly in preventing undesired editing. To address this issue, we propose an Anti-Editing Concept Erasure (ACE) method, which not only erases the target concept during generation but also filters out it during editing. Specifically, we propose to inject the erasure guidance into both conditional and the unconditional noise prediction, enabling the model to effectively prevent the creation of erasure concepts during both editing and generation. Furthermore, a stochastic correction guidance is introduced during training to address the erosion of unrelated concepts. We conducted erasure editing experiments with representative editing methods (i.e., LEDITS++ and MasaCtrl) to erase IP characters, and the results indicate that our ACE effectively filters out target concepts in both types of edits. Additional experiments on erasing explicit concepts and artistic styles further demonstrate that our ACE performs favorably against state-of-the-art methods. Our code will be publicly available at https://github.com/120L020904/ACE.
近期文本到图像扩散模型的进步极大地促进了高质量图像的生成,但同时也引发了关于非法创建有害内容(如版权图像)的担忧。现有概念消除方法在防止生成被删除的概念方面取得了卓越成果,但在防止意外编辑方面表现较差。为了解决这一问题,我们提出了一种反编辑概念消除(ACE)方法,该方法不仅能在生成过程中消除目标概念,还能在编辑过程中过滤掉它。具体来说,我们提出将消除指导注入有条件和无条件的噪声预测中,使模型在编辑和生成过程中都能有效地防止创建被删除的概念。此外,在训练过程中引入了随机校正指导,以解决无关概念的侵蚀问题。我们采用具有代表性的编辑方法(即LEDITS++和MasaCtrl)进行了删除编辑实验,以删除知识产权字符,结果表明我们的ACE在两种类型的编辑中都能有效地过滤掉目标概念。关于删除明确概念和艺术风格的额外实验进一步证明,我们的ACE表现优于现有最先进的方法。我们的代码将在https://github.com/120L020904/ACE上公开提供。
论文及项目相关链接
PDF 25 pages, code available at https://github.com/120L020904/ACE
Summary
本文介绍了一种名为ACE的抗编辑概念消除方法,该方法在文本到图像扩散模型中能够消除目标概念,不仅阻止其在生成过程中出现,还能在编辑过程中过滤掉。此方法通过在条件和无条件噪声预测中注入消除指导来实现这一目标。此外,训练过程中引入了随机校正指导来解决无关概念的侵蚀问题。实验结果表明,ACE方法在去除知识产权字符、明确概念和艺术风格等方面表现出优越性能。
Key Takeaways
- ACE方法能有效防止文本到图像扩散模型中目标概念的生成和编辑过程中的出现。
- ACE方法通过在条件和无条件噪声预测中注入消除指导来实现概念消除。
- 随机校正指导的引入解决了在训练过程中无关概念的侵蚀问题。
- ACE方法在去除知识产权字符、明确概念和艺术风格等实验场景中表现出优越性能。
- ACE方法与现有先进方法相比具有竞争力。
- 该方法的代码将公开在https://github.com/120L020904/ACE。
- ACE方法对于防止有害内容的非法创建,特别是防止版权图像的生成和编辑具有重要意义。
点此查看论文截图




Conditional Consistency Guided Image Translation and Enhancement
Authors:Amil Bhagat, Milind Jain, A. V. Subramanyam
Consistency models have emerged as a promising alternative to diffusion models, offering high-quality generative capabilities through single-step sample generation. However, their application to multi-domain image translation tasks, such as cross-modal translation and low-light image enhancement remains largely unexplored. In this paper, we introduce Conditional Consistency Models (CCMs) for multi-domain image translation by incorporating additional conditional inputs. We implement these modifications by introducing task-specific conditional inputs that guide the denoising process, ensuring that the generated outputs retain structural and contextual information from the corresponding input domain. We evaluate CCMs on 10 different datasets demonstrating their effectiveness in producing high-quality translated images across multiple domains. Code is available at https://github.com/amilbhagat/Conditional-Consistency-Models.
一致性模型作为扩散模型的有前途的替代方案已经出现,它通过单步采样生成提供了高质量生成能力。然而,它们在多域图像翻译任务(如跨模态翻译和低光图像增强)的应用仍然未被充分探索。在本文中,我们通过引入额外的条件输入,介绍了用于多域图像翻译的条件一致性模型(CCM)。我们通过引入任务特定的条件输入来实现这些修改,引导去噪过程,确保生成的输出保留来自相应输入域的结构和上下文信息。我们在10个不同的数据集上评估了CCM,证明了它们在多个领域生成高质量翻译图像的有效性。代码可在https://github.com/amilbhagat/Conditional-Consistency-Models找到。
论文及项目相关链接
PDF 6 pages, 5 figures, 4 tables, The first two authors contributed equally
摘要
条件一致性模型(CCMs)通过引入附加条件输入,在多域图像翻译方面表现出良好性能。该研究将一致性模型作为扩散模型的替代方案,展现出了高质量的单步样本生成能力。本文通过任务特定的条件输入修改,将CCM应用于多域图像翻译,确保生成的输出保留了对应输入域的结构和上下文信息。在十个不同数据集上的评估证明了CCM在多个领域生成高质量翻译图像的有效性。代码已公开于GitHub上。
关键见解
- 条件一致性模型(CCMs)作为一种新兴技术,在多域图像翻译领域具有广泛应用前景。
- CCMs通过引入额外的条件输入,实现了高质量的单步样本生成能力。
- CCMs能够确保生成的图像保留输入图像的结构和上下文信息。
- CCMs在多个数据集上的表现证明了其在多域图像翻译任务中的有效性。
- CCMs具有潜力解决跨模态翻译和低光图像增强等难题。
- 研究者提供了在GitHub上的代码公开,便于他人进一步研究和应用。
点此查看论文截图



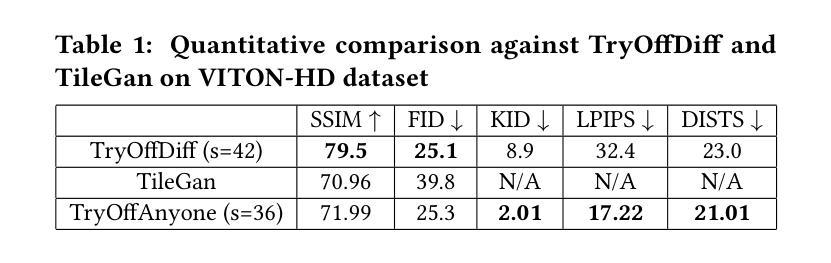
TryOffAnyone: Tiled Cloth Generation from a Dressed Person
Authors:Ioannis Xarchakos, Theodoros Koukopoulos
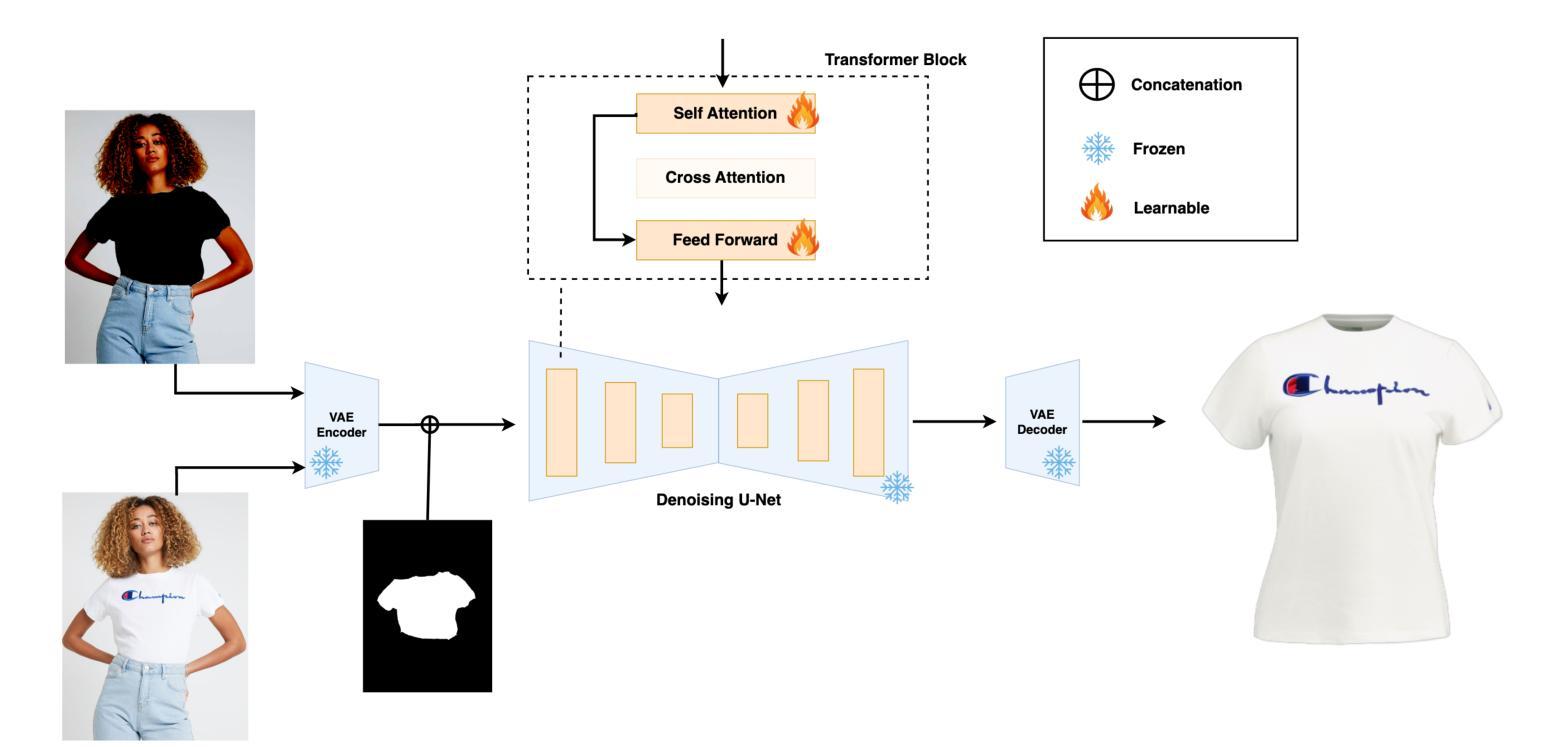
The fashion industry is increasingly leveraging computer vision and deep learning technologies to enhance online shopping experiences and operational efficiencies. In this paper, we address the challenge of generating high-fidelity tiled garment images essential for personalized recommendations, outfit composition, and virtual try-on systems from photos of garments worn by models. Inspired by the success of Latent Diffusion Models (LDMs) in image-to-image translation, we propose a novel approach utilizing a fine-tuned StableDiffusion model. Our method features a streamlined single-stage network design, which integrates garmentspecific masks to isolate and process target clothing items effectively. By simplifying the network architecture through selective training of transformer blocks and removing unnecessary crossattention layers, we significantly reduce computational complexity while achieving state-of-the-art performance on benchmark datasets like VITON-HD. Experimental results demonstrate the effectiveness of our approach in producing high-quality tiled garment images for both full-body and half-body inputs. Code and model are available at: https://github.com/ixarchakos/try-off-anyone
时尚产业正越来越多地利用计算机视觉和深度学习技术,以提升在线购物体验和运营效率。本文解决了一个挑战性问题,即从模特穿着的服装照片生成高质量的分块服装图像,这对于个性化推荐、服装搭配和虚拟试衣系统至关重要。受潜在扩散模型(Latent Diffusion Models,简称LDMs)在图到图翻译中的成功的启发,我们提出了一种利用微调过的StableDiffusion模型的新方法。我们的方法采用简化的单阶段网络设计,结合服装特定掩膜,有效地隔离和处理目标服装项目。通过选择性训练变压器块并去除不必要的交叉注意力层,我们简化了网络架构,在显著降低计算复杂性的同时,在VITON-HD等基准数据集上实现了最先进的性能。实验结果表明,我们的方法在全身体和半身输入的情况下,都能有效生成高质量的分块服装图像。代码和模型可在https://github.com/ixarchakos/try-off-anyone找到。
论文及项目相关链接
Summary:
时尚产业正利用计算机视觉和深度学习技术来提升在线购物体验和运营效率。本文解决从模特穿着的服装照片生成用于个性化推荐、搭配组合和虚拟试衣系统的高保真平铺服装图像的挑战。受潜在扩散模型(Latent Diffusion Models,简称LDMs)在图像到图像转换中的成功的启发,本文提出了一种利用精细调整的StableDiffusion模型的新方法。该方法具有简化的单阶段网络设计,通过集成服装特定掩膜来有效隔离和处理目标服装项目。通过选择性训练变压器块并去除不必要的跨注意力层,简化了网络架构,在降低计算复杂性的同时,实现了在VITON-HD等基准数据集上的最新性能。实验结果证明,该方法在生成高质量平铺服装图像方面既适用于全身输入也适用于半身输入非常有效。
Key Takeaways:
- 时尚产业正在利用计算机视觉和深度学习技术提升在线购物体验。
- 生成高保真平铺服装图像对于个性化推荐、搭配组合和虚拟试衣系统至关重要。
- 受Latent Diffusion Models(LDMs)成功的启发,提出了一种新的方法利用StableDiffusion模型生成高质量图像。
- 该方法具有简化的单阶段网络设计,并集成服装特定掩膜来隔离和处理目标服装项目。
- 通过选择性训练和优化网络架构,实现了在基准数据集上的最新性能。
- 该方法既适用于全身输入也适用于半身输入的图像生成。
- 相关的代码和模型可在https://github.com/ixarchakos/try-off-anyone上找到。
点此查看论文截图



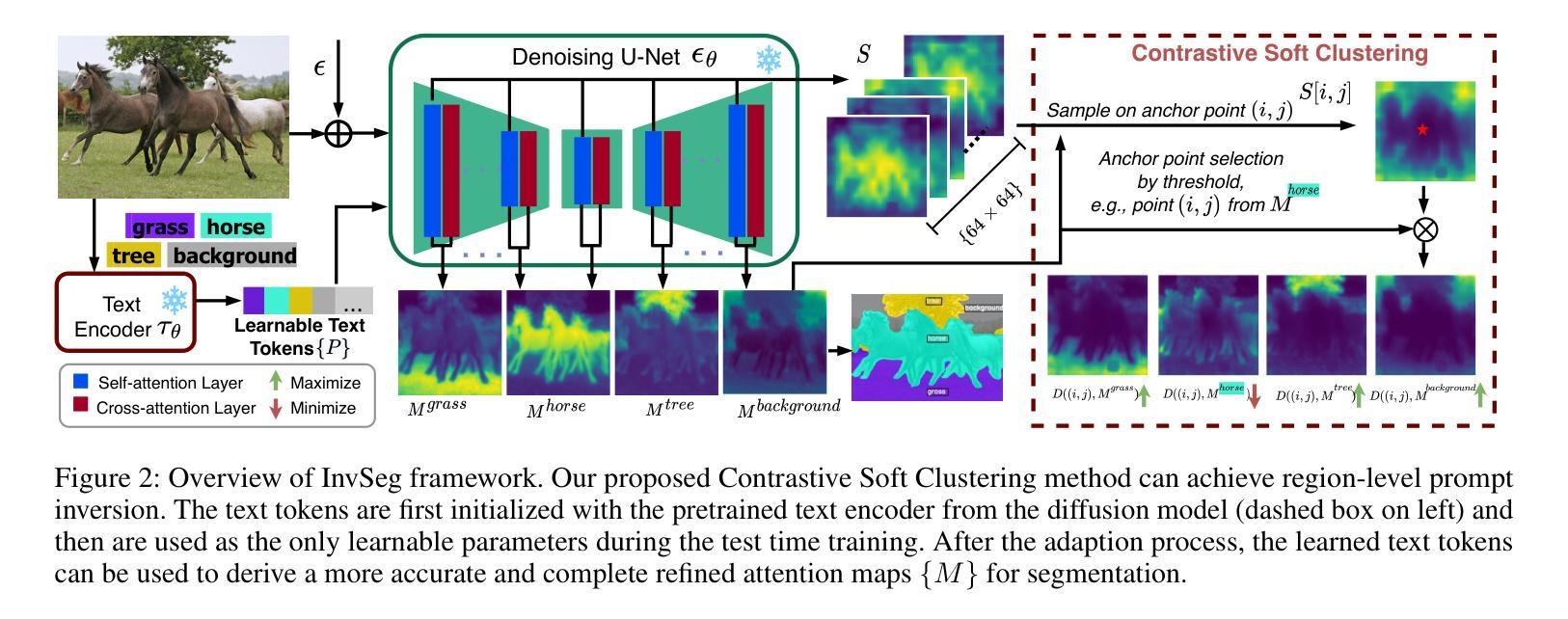
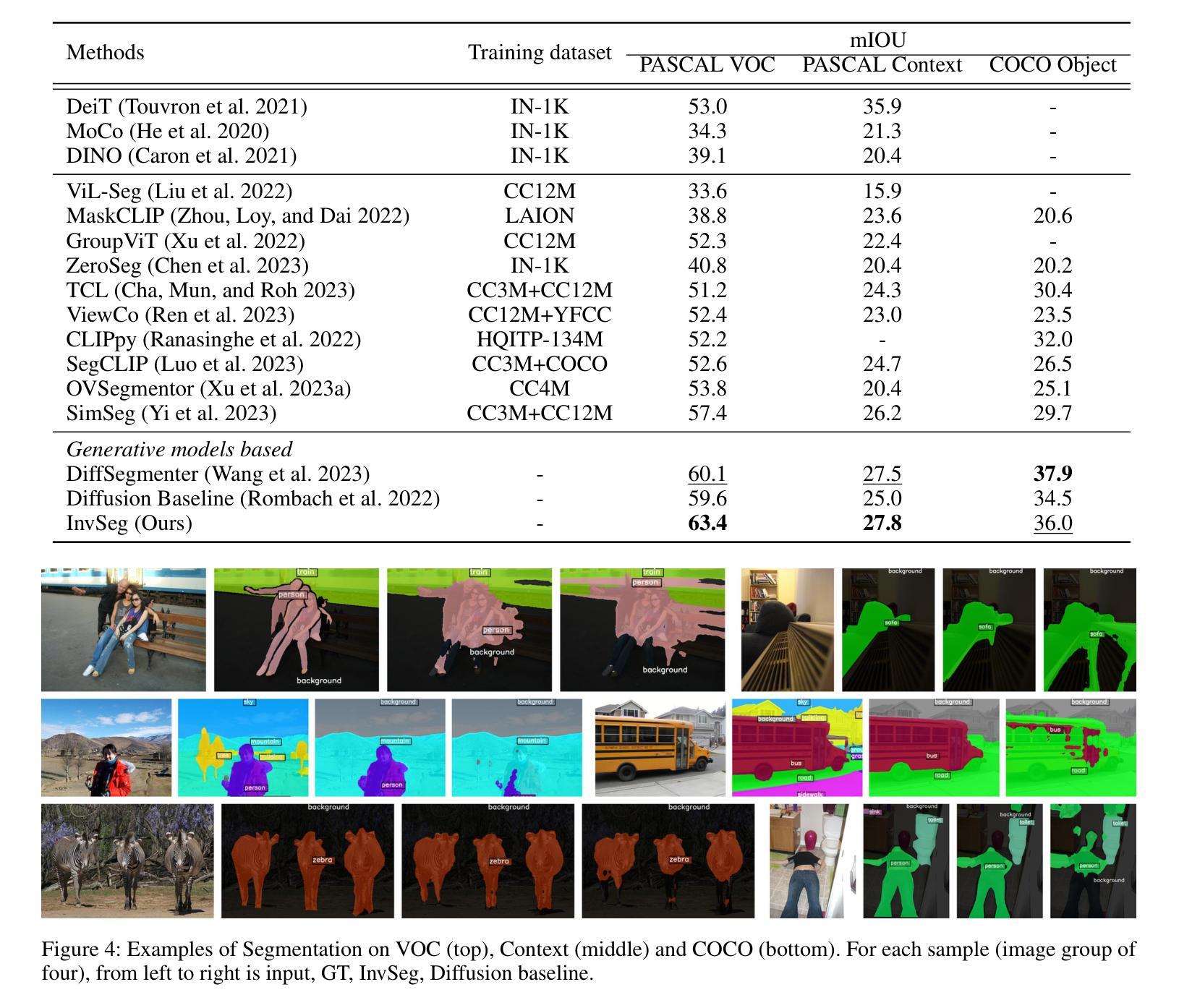
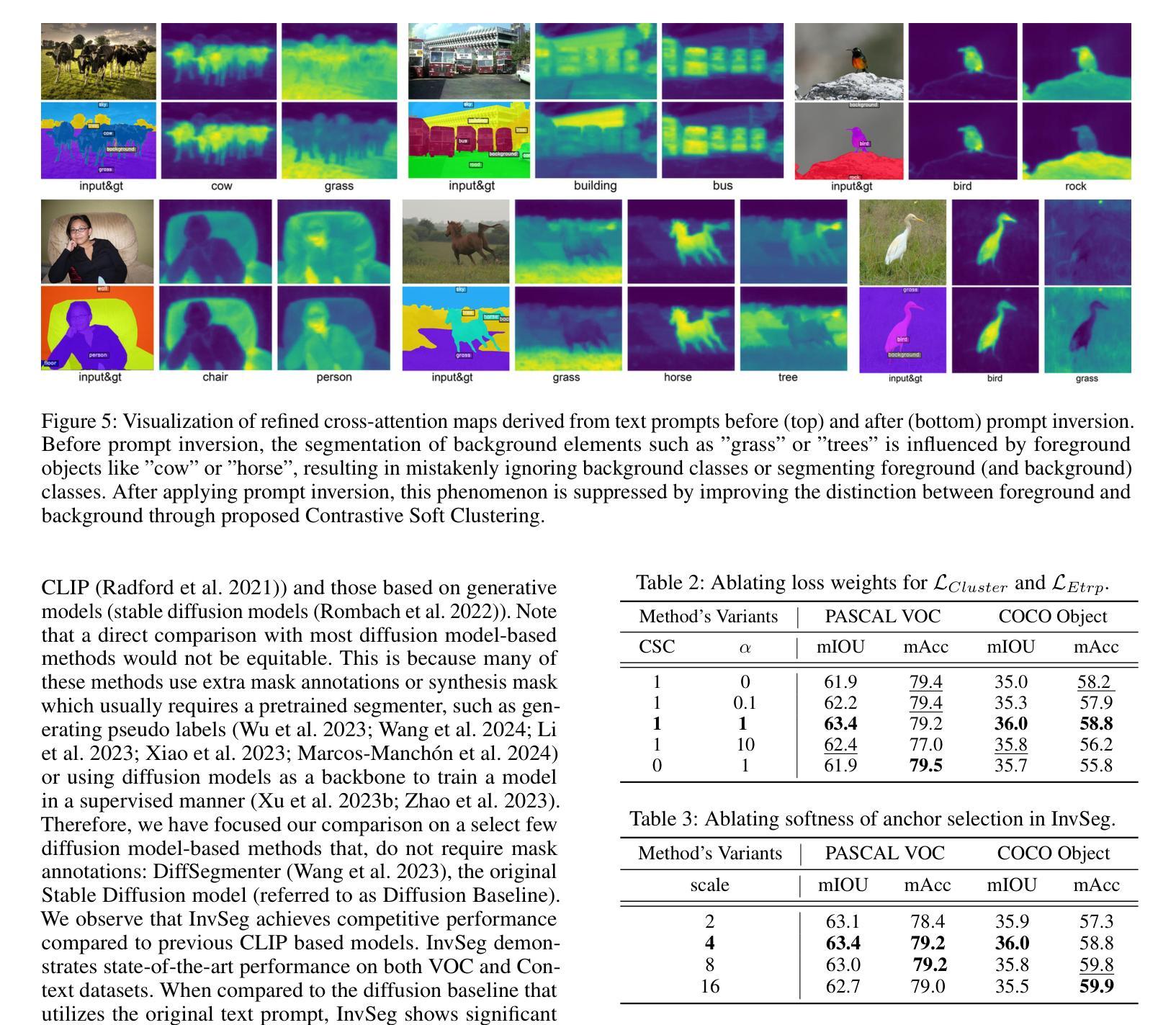
InvSeg: Test-Time Prompt Inversion for Semantic Segmentation
Authors:Jiayi Lin, Jiabo Huang, Jian Hu, Shaogang Gong
Visual-textual correlations in the attention maps derived from text-to-image diffusion models are proven beneficial to dense visual prediction tasks, e.g., semantic segmentation. However, a significant challenge arises due to the input distributional discrepancy between the context-rich sentences used for image generation and the isolated class names typically used in semantic segmentation. This discrepancy hinders diffusion models from capturing accurate visual-textual correlations. To solve this, we propose InvSeg, a test-time prompt inversion method that tackles open-vocabulary semantic segmentation by inverting image-specific visual context into text prompt embedding space, leveraging structure information derived from the diffusion model’s reconstruction process to enrich text prompts so as to associate each class with a structure-consistent mask. Specifically, we introduce Contrastive Soft Clustering (CSC) to align derived masks with the image’s structure information, softly selecting anchors for each class and calculating weighted distances to push inner-class pixels closer while separating inter-class pixels, thereby ensuring mask distinction and internal consistency. By incorporating sample-specific context, InvSeg learns context-rich text prompts in embedding space and achieves accurate semantic alignment across modalities. Experiments show that InvSeg achieves state-of-the-art performance on the PASCAL VOC, PASCAL Context and COCO Object datasets.
由文本到图像扩散模型产生的注意力图中的视觉文本相关性已证明对密集视觉预测任务(例如语义分割)有益。然而,一个重大挑战是由于用于图像生成的丰富上下文句子与通常在语义分割中使用的孤立类名之间的输入分布差异而产生的。这种差异阻碍了扩散模型捕捉准确的视觉文本相关性。
论文及项目相关链接
PDF AAAI 2025
Summary
文本-图像扩散模型的注意力映射中的视觉文本相关性对于密集的视觉预测任务(如语义分割)有益。然而,由于用于图像生成的丰富语境与语义分割中常用的孤立类名之间的输入分布差异,导致扩散模型难以捕捉准确的视觉文本相关性。为解决此问题,本文提出InvSeg方法,通过测试时的提示反转策略,利用扩散模型重建过程中提取的结构信息,将图像特定的视觉语境反转成文本提示嵌入空间,丰富文本提示,使每个类都与结构一致的掩膜相关联。通过引入对比软聚类(CSC),对齐生成的掩膜与图像的结构信息,确保掩膜区分度和内部一致性。实验表明,InvSeg在PASCAL VOC、PASCAL Context和COCO Object数据集上达到最佳性能。
Key Takeaways
- 文本-图像扩散模型的视觉文本相关性对密集视觉预测任务有益。
- 语境丰富的句子与语义分割中使用的孤立类名之间存在输入分布差异。
- 提出InvSeg方法,通过测试时的提示反转策略解决开放词汇语义分割问题。
- 利用扩散模型重建过程中的结构信息,丰富文本提示,使每个类与结构一致的掩膜相关联。
- 引入对比软聚类(CSC)对齐掩膜与图像结构信息。
- InvSeg方法能够实现跨模态的语义对齐。
点此查看论文截图


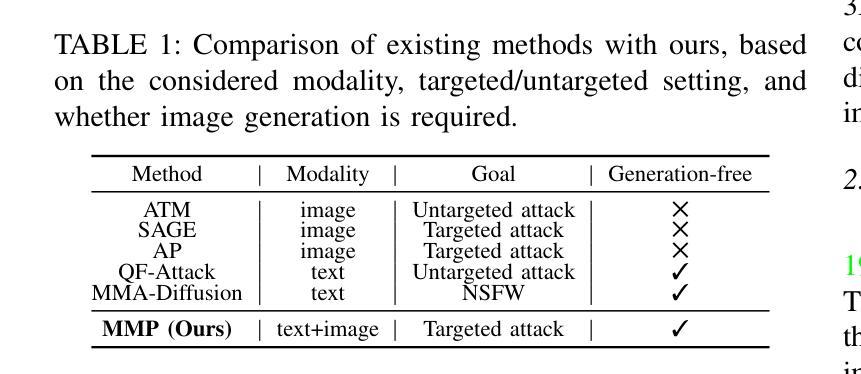
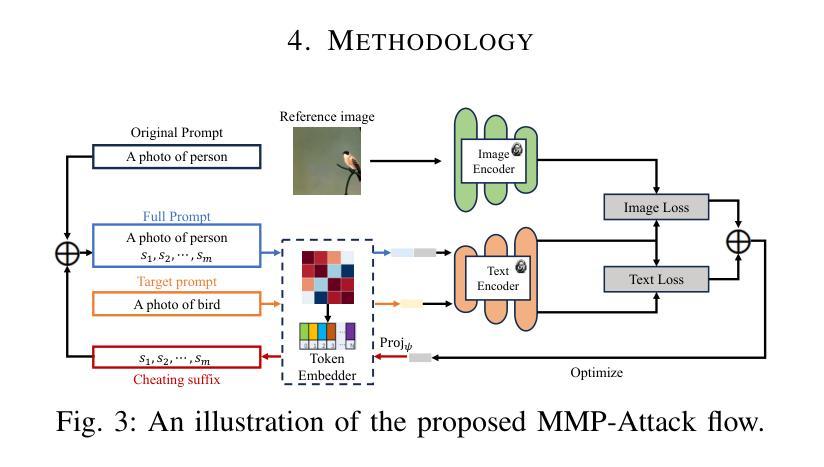
On the Multi-modal Vulnerability of Diffusion Models
Authors:Dingcheng Yang, Yang Bai, Xiaojun Jia, Yang Liu, Xiaochun Cao, Wenjian Yu
Diffusion models have been widely deployed in various image generation tasks, demonstrating an extraordinary connection between image and text modalities. Although prior studies have explored the vulnerability of diffusion models from the perspectives of text and image modalities separately, the current research landscape has not yet thoroughly investigated the vulnerabilities that arise from the integration of multiple modalities, specifically through the joint analysis of textual and visual features. In this paper, we are the first to visualize both text and image feature space embedded by diffusion models and observe a significant difference. The prompts are embedded chaotically in the text feature space, while in the image feature space they are clustered according to their subjects. These fascinating findings may underscore a potential misalignment in robustness between the two modalities that exists within diffusion models. Based on this observation, we propose MMP-Attack, which leverages multi-modal priors (MMP) to manipulate the generation results of diffusion models by appending a specific suffix to the original prompt. Specifically, our goal is to induce diffusion models to generate a specific object while simultaneously eliminating the original object. Our MMP-Attack shows a notable advantage over existing studies with superior manipulation capability and efficiency. Our code is publicly available at \url{https://github.com/ydc123/MMP-Attack}.
扩散模型已被广泛应用于各种图像生成任务,证明了图像和文本模式之间的非凡联系。尽管先前的研究已经从文本和图像模式的角度探索了扩散模型的脆弱性,但当前的研究领域尚未彻底研究由多模式集成产生的脆弱性,特别是通过文本和视觉特征的联合分析。在本文中,我们是首次可视化由扩散模型嵌入的文本和图像特征空间,并观察到显著差异。提示在文本特征空间中嵌入得混乱,而在图像特征空间中则根据主题进行聚类。这些有趣的发现可能表明扩散模型内部两个模式之间在稳健性方面存在的潜在错位。基于此观察,我们提出MMP-Attack,它利用多模式先验(MMP)通过向原始提示添加特定后缀来操纵扩散模型的生成结果。具体来说,我们的目标是在生成特定对象的同时消除原始对象。我们的MMP-Attack相较于现有研究具有显著的优势,具有更强的操控能力和效率。我们的代码公开在https://github.com/ydc123/MMP-Attack。
论文及项目相关链接
PDF Accepted at ICML2024 Workshop on Trustworthy Multi-modal Foundation Models and AI Agents (TiFA)
Summary
本文首次可视化扩散模型嵌入的文本和图像特征空间,并观察到显著差异。文本提示在文本特征空间中嵌入混乱,而图像特征空间中则根据主题进行聚类。基于此观察,提出利用多模态先验(MMP)进行扩散模型的生成结果操纵的MMP-Attack方法,通过添加特定后缀来诱导模型生成特定对象并消除原始对象。该方法相较于现有研究具有更强的操纵能力和效率。
Key Takeaways
- 扩散模型在图像生成任务中广泛应用,展示出色的图像和文本模态间的连接。
- 首次可视化扩散模型嵌入的文本和图像特征空间,发现显著差异。
- 文本提示在文本特征空间中嵌入混乱,而图像特征空间中的提示则按主题聚类。
- 扩散模型在文本和图像模态之间可能存在稳健性不一致的问题。
- 提出利用多模态先验(MMP)的MMP-Attack方法,通过添加特定后缀操纵扩散模型的生成结果。
- MMP-Attack方法的目的是诱导模型生成特定对象并消除原始对象。
点此查看论文截图