⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-07 更新
Conditional Consistency Guided Image Translation and Enhancement
Authors:Amil Bhagat, Milind Jain, A. V. Subramanyam
Consistency models have emerged as a promising alternative to diffusion models, offering high-quality generative capabilities through single-step sample generation. However, their application to multi-domain image translation tasks, such as cross-modal translation and low-light image enhancement remains largely unexplored. In this paper, we introduce Conditional Consistency Models (CCMs) for multi-domain image translation by incorporating additional conditional inputs. We implement these modifications by introducing task-specific conditional inputs that guide the denoising process, ensuring that the generated outputs retain structural and contextual information from the corresponding input domain. We evaluate CCMs on 10 different datasets demonstrating their effectiveness in producing high-quality translated images across multiple domains. Code is available at https://github.com/amilbhagat/Conditional-Consistency-Models.
一致性模型已成为扩散模型的一个前景广阔的替代方案,它通过单步采样生成提供高质量生成能力。然而,它们在多域图像翻译任务(如跨模态翻译和低光图像增强)的应用仍然很少被探索。在本文中,我们通过引入额外的条件输入,介绍了用于多域图像翻译的条件一致性模型(CCM)。我们通过引入特定任务的条件输入来实现这些修改,引导去噪过程,确保生成的输出保留来自相应输入域的结构和上下文信息。我们在10个不同的数据集上评估CCM,证明了它们在多个领域生成高质量翻译图像的有效性。代码可在https://github.com/amilbhagat/Conditional-Consistency-Models找到。
论文及项目相关链接
PDF 6 pages, 5 figures, 4 tables, The first two authors contributed equally
Summary
本文介绍了条件一致性模型(CCM)在多域图像翻译领域的应用。通过引入额外的条件输入,CCM模型实现了对单一步骤样本生成的高质量生成能力,尤其适用于跨模态翻译和低光图像增强等任务。该模型能够在不同数据集上生成高质量的多域翻译图像。
Key Takeaways
- 条件一致性模型(CCM)是一种新兴的多域图像翻译方法,具有前景。
- CCM通过引入额外的条件输入,实现了对单一步骤样本生成的高质量生成能力。
- CCM特别适用于跨模态翻译和低光图像增强等任务。
- CCM通过任务特定的条件输入引导去噪过程,确保生成的输出保留输入域的结构和上下文信息。
- CCM在多个数据集上的实验证明了其生成高质量翻译图像的有效性。
- CCM模型的代码已公开发布在GitHub上。
点此查看论文截图



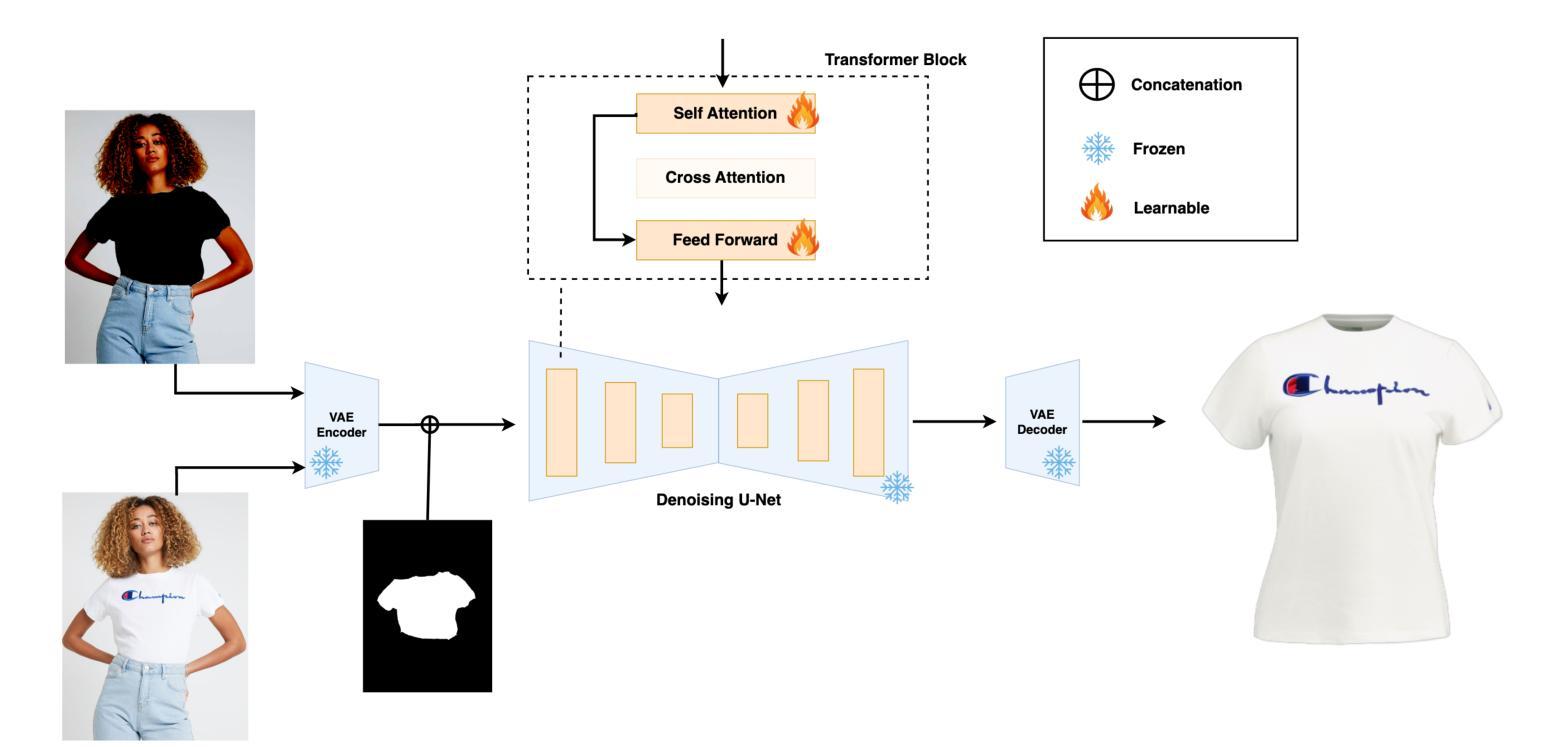
TryOffAnyone: Tiled Cloth Generation from a Dressed Person
Authors:Ioannis Xarchakos, Theodoros Koukopoulos
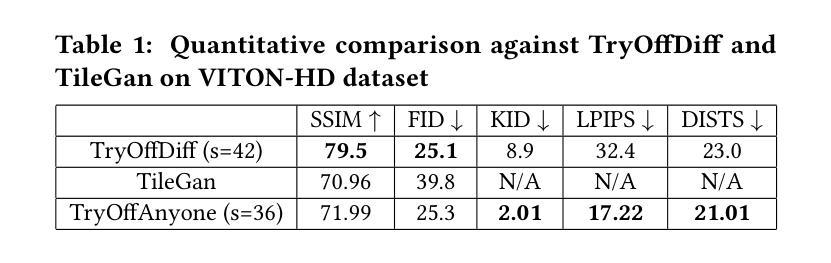
The fashion industry is increasingly leveraging computer vision and deep learning technologies to enhance online shopping experiences and operational efficiencies. In this paper, we address the challenge of generating high-fidelity tiled garment images essential for personalized recommendations, outfit composition, and virtual try-on systems from photos of garments worn by models. Inspired by the success of Latent Diffusion Models (LDMs) in image-to-image translation, we propose a novel approach utilizing a fine-tuned StableDiffusion model. Our method features a streamlined single-stage network design, which integrates garmentspecific masks to isolate and process target clothing items effectively. By simplifying the network architecture through selective training of transformer blocks and removing unnecessary crossattention layers, we significantly reduce computational complexity while achieving state-of-the-art performance on benchmark datasets like VITON-HD. Experimental results demonstrate the effectiveness of our approach in producing high-quality tiled garment images for both full-body and half-body inputs. Code and model are available at: https://github.com/ixarchakos/try-off-anyone
时尚产业正越来越多地利用计算机视觉和深度学习技术,以提升在线购物体验和运营效率。本文解决了一个挑战,即使用模特穿着服装的照片生成高质量的分块服装图像,这对于个性化推荐、服装搭配和虚拟试穿系统至关重要。受潜在扩散模型(Latent Diffusion Models,简称LDM)在图像到图像翻译中的成功的启发,我们提出了一种利用微调过的StableDiffusion模型的新方法。我们的方法采用简洁的单阶段网络设计,通过集成特定的服装蒙版来有效地隔离和处理目标服装项目。通过选择性训练变压器块并删除不必要的交叉注意力层来简化网络架构,我们在降低计算复杂性的同时,在VITON-HD等基准数据集上实现了最先进的性能。实验结果表明,我们的方法在生成全身和半身输入的高质量分块服装图像方面非常有效。代码和模型可在https://github.com/ixarchakos/try-off-anyone找到。
论文及项目相关链接
Summary
时尚产业正借助计算机视觉和深度学习技术来提升在线购物体验和运营效率。本文解决生成高质量平铺服装图片的问题,这对个性化推荐、搭配组合和虚拟试衣系统至关重要。文章提出一种利用微调StableDiffusion模型的新方法,采用简洁的单阶段网络设计,集成服装特定掩膜有效处理目标服装。该方法在简化网络架构的同时,通过选择性训练变压器块和移除不必要的交叉注意力层,显著降低了计算复杂度,并在VITON-HD等基准数据集上实现了卓越性能。
Key Takeaways
- 时尚产业结合计算机视觉和深度学习技术以提升在线购物体验与运营效率。
- 文章聚焦于生成高质量平铺服装图片的挑战性问题,这对个性化推荐、搭配组合和虚拟试衣系统至关重要。
- 采用StableDiffusion模型的新方法,通过简洁的单阶段网络设计解决生成高质量服装图片的问题。
- 集成服装特定掩膜以有效处理目标服装,提高图像生成的质量。
- 方法通过选择性训练和优化网络架构降低计算复杂度,提升效率。
- 该方法在基准数据集VITON-HD上实现卓越性能。
点此查看论文截图