⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-07 更新
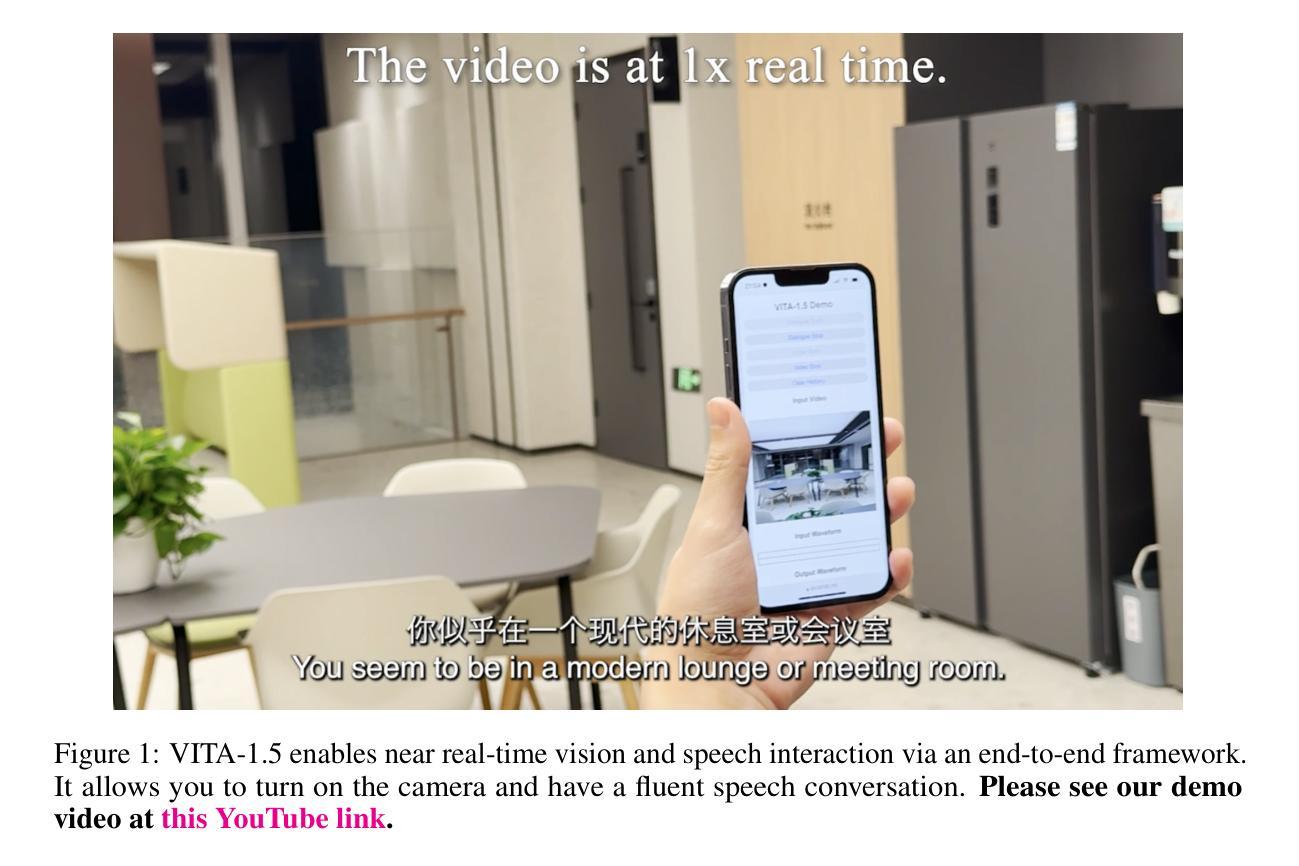
VITA-1.5: Towards GPT-4o Level Real-Time Vision and Speech Interaction
Authors:Chaoyou Fu, Haojia Lin, Xiong Wang, Yi-Fan Zhang, Yunhang Shen, Xiaoyu Liu, Yangze Li, Zuwei Long, Heting Gao, Ke Li, Xiawu Zheng, Rongrong Ji, Xing Sun, Caifeng Shan, Ran He
Recent Multimodal Large Language Models (MLLMs) have typically focused on integrating visual and textual modalities, with less emphasis placed on the role of speech in enhancing interaction. However, speech plays a crucial role in multimodal dialogue systems, and implementing high-performance in both vision and speech tasks remains a significant challenge due to the fundamental modality differences. In this paper, we propose a carefully designed multi-stage training methodology that progressively trains LLM to understand both visual and speech information, ultimately enabling fluent vision and speech interaction. Our approach not only preserves strong vision-language capacity, but also enables efficient speech-to-speech dialogue capabilities without separate ASR and TTS modules, significantly accelerating multimodal end-to-end response speed. By comparing our method against state-of-the-art counterparts across benchmarks for image, video, and speech tasks, we demonstrate that our model is equipped with both strong visual and speech capabilities, making near real-time vision and speech interaction.
最近的多模态大型语言模型(MLLMs)主要关注视觉和文本模态的融合,对语音在增强交互中的作用重视不够。然而,语音在多模态对话系统中起着至关重要的作用,由于基本模态差异的存在,在视觉和语音任务中实现高性能仍然是一个巨大的挑战。在本文中,我们提出了一种精心设计的多阶段训练方法论,逐步训练大型语言模型以理解视觉和语音信息,最终使流畅的视觉和语音交互成为可能。我们的方法不仅保留了强大的视觉语言功能,而且能够在没有单独的自动语音识别(ASR)和文本到语音(TTS)模块的情况下实现高效的语音对话功能,从而显著加快多模态端到端的响应速度。通过与图像、视频和语音任务的最新前沿技术进行比较,我们证明了我们的模型具有强大的视觉和语音功能,能够实现近乎实时的视觉和语音交互。
论文及项目相关链接
PDF https://github.com/VITA-MLLM/VITA
Summary
本文提出了一个精心设计的多阶段训练策略,该策略旨在使大型语言模型逐步理解视觉和语音信息,实现流畅的视觉和语音交互。该方法不仅保留了强大的视觉语言功能,还实现了高效的语音对话能力,无需单独的ASR和TTS模块,从而大大加快了多模态端到端响应速度。实验证明,该模型在图像、视频和语音任务上均表现出强大的视觉和语音能力,可实现近实时的视觉和语音交互。
Key Takeaways
- 多模态大型语言模型在集成视觉和文本模态时,通常忽略了语音在增强交互中的作用。
- 语音在多媒体对话系统中起关键作用。
- 实现视觉和语音任务的高性能是一个重大挑战,因为这两种模态存在根本上的差异。
- 提出了一种多阶段训练策略,使大型语言模型逐步理解视觉和语音信息。
- 该方法不仅保持了强大的视觉语言功能,还实现了高效的语音对话能力。
- 通过去除ASR和TTS模块,显著加速了多模态端到端的响应速度。
点此查看论文截图

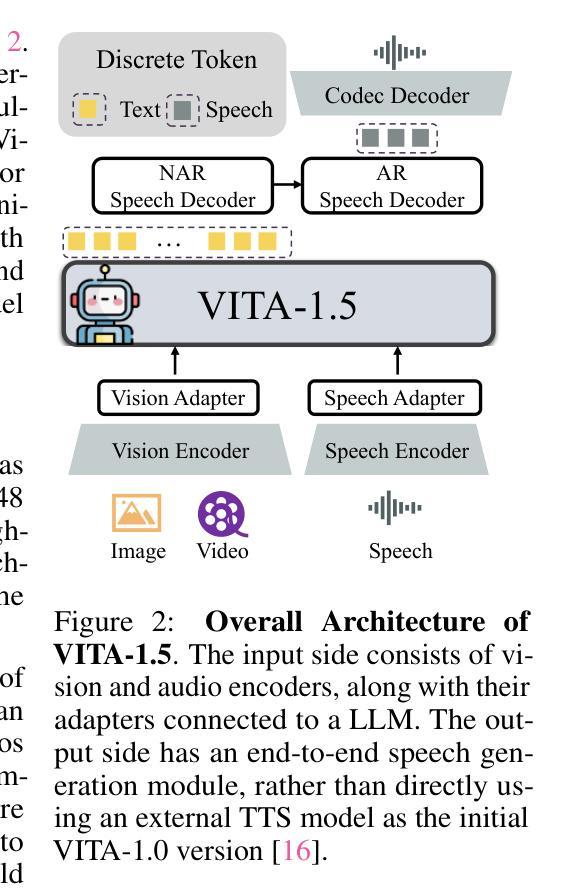
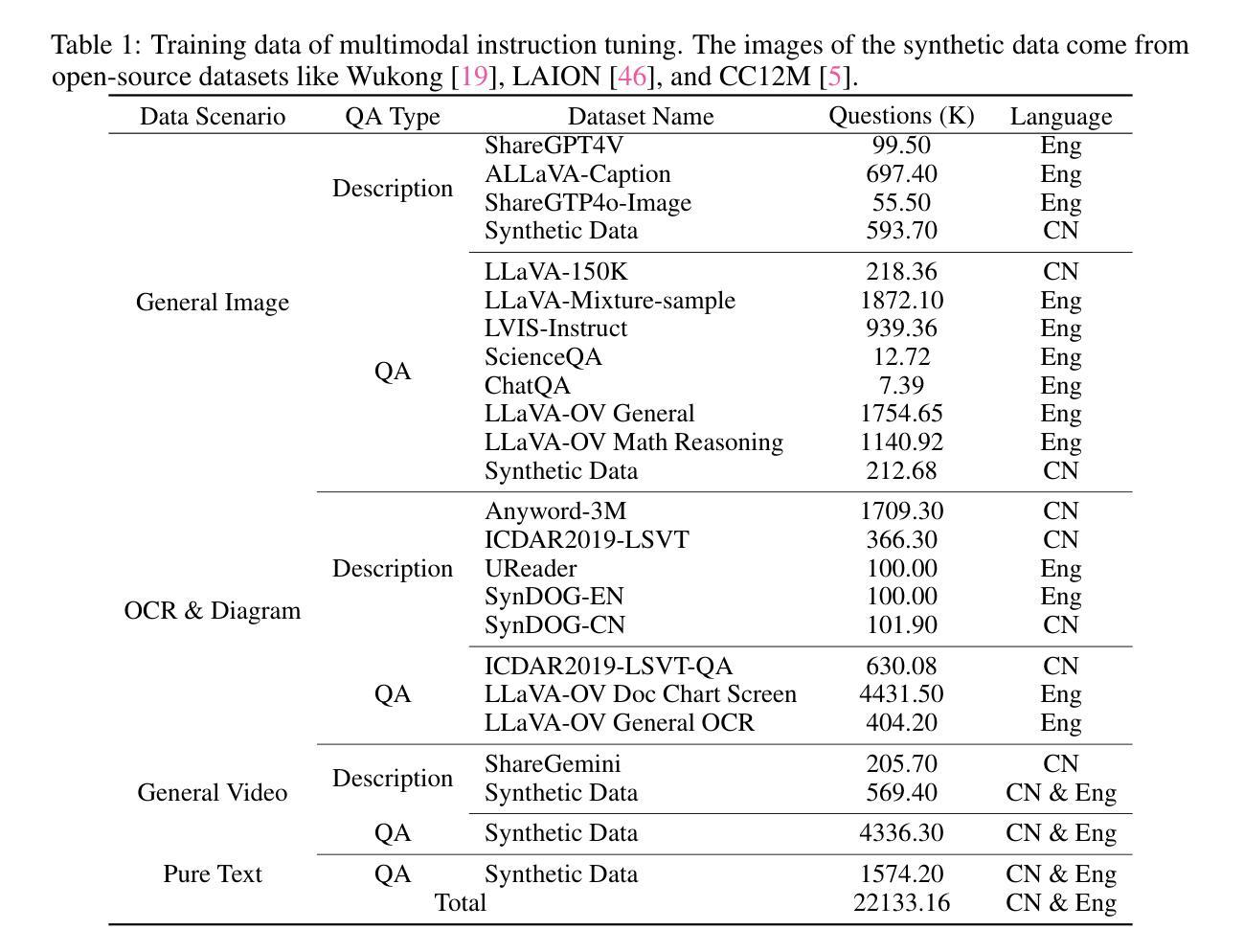
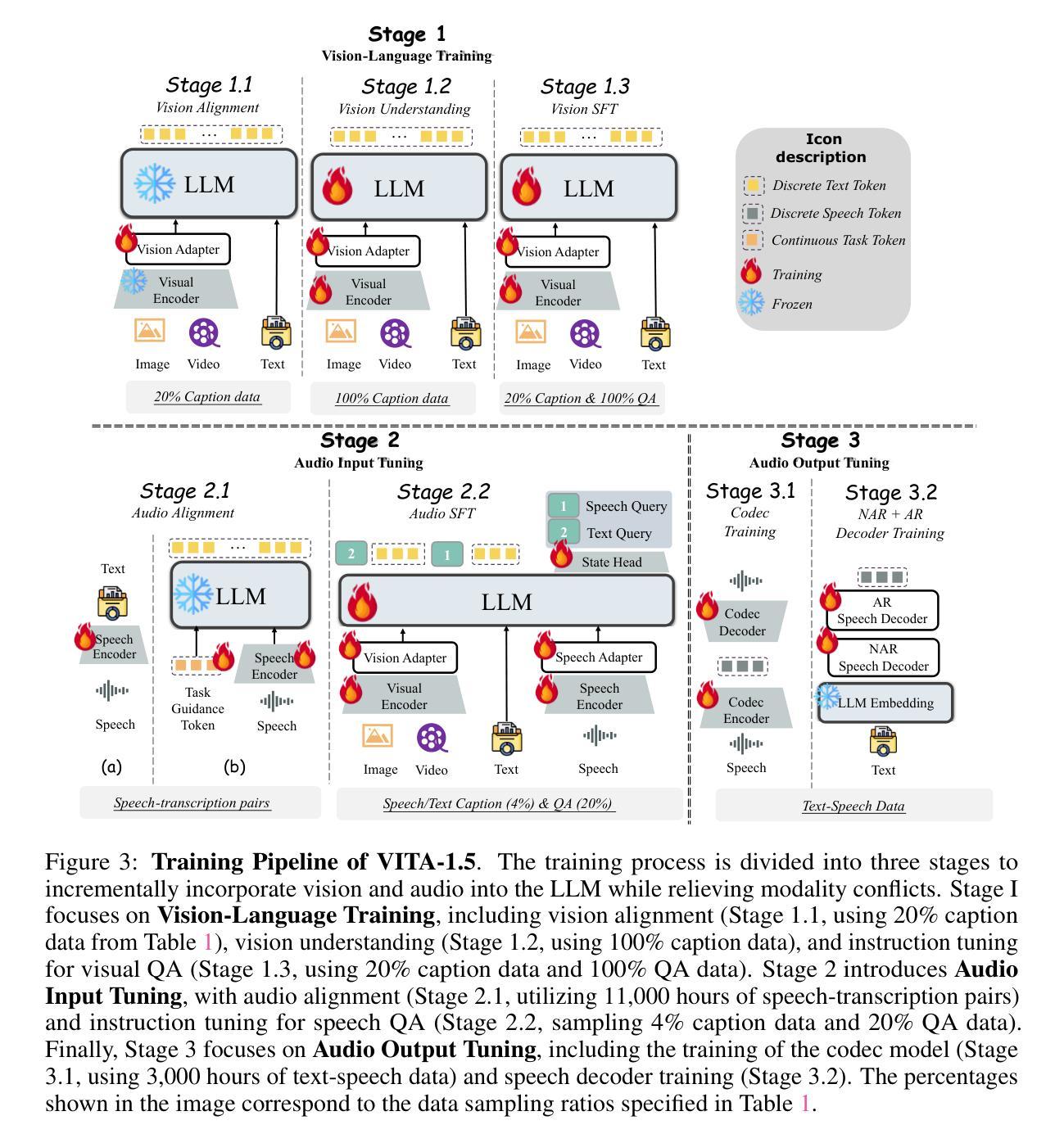
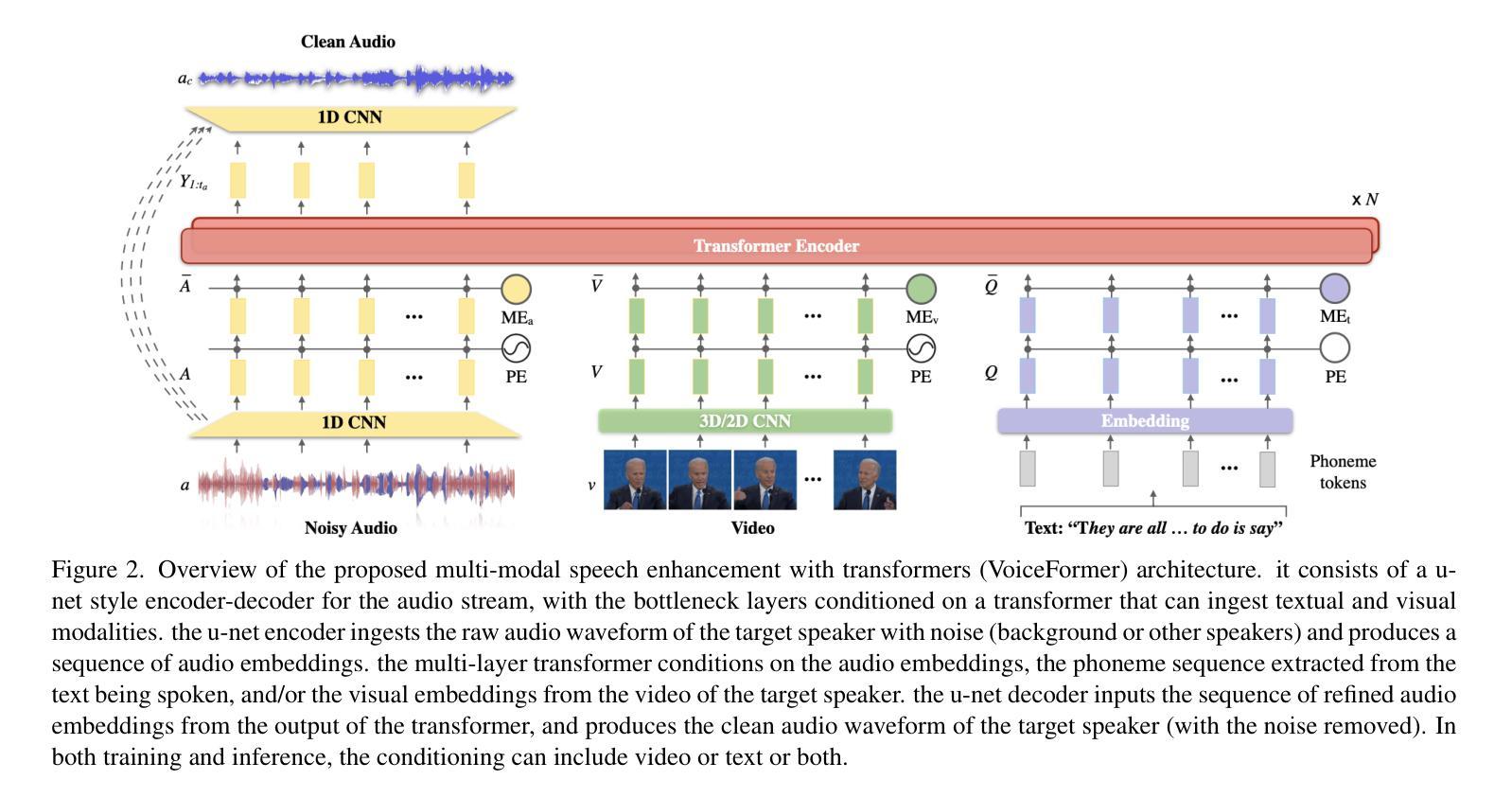
Reading to Listen at the Cocktail Party: Multi-Modal Speech Separation
Authors:Akam Rahimi, Triantafyllos Afouras, Andrew Zisserman
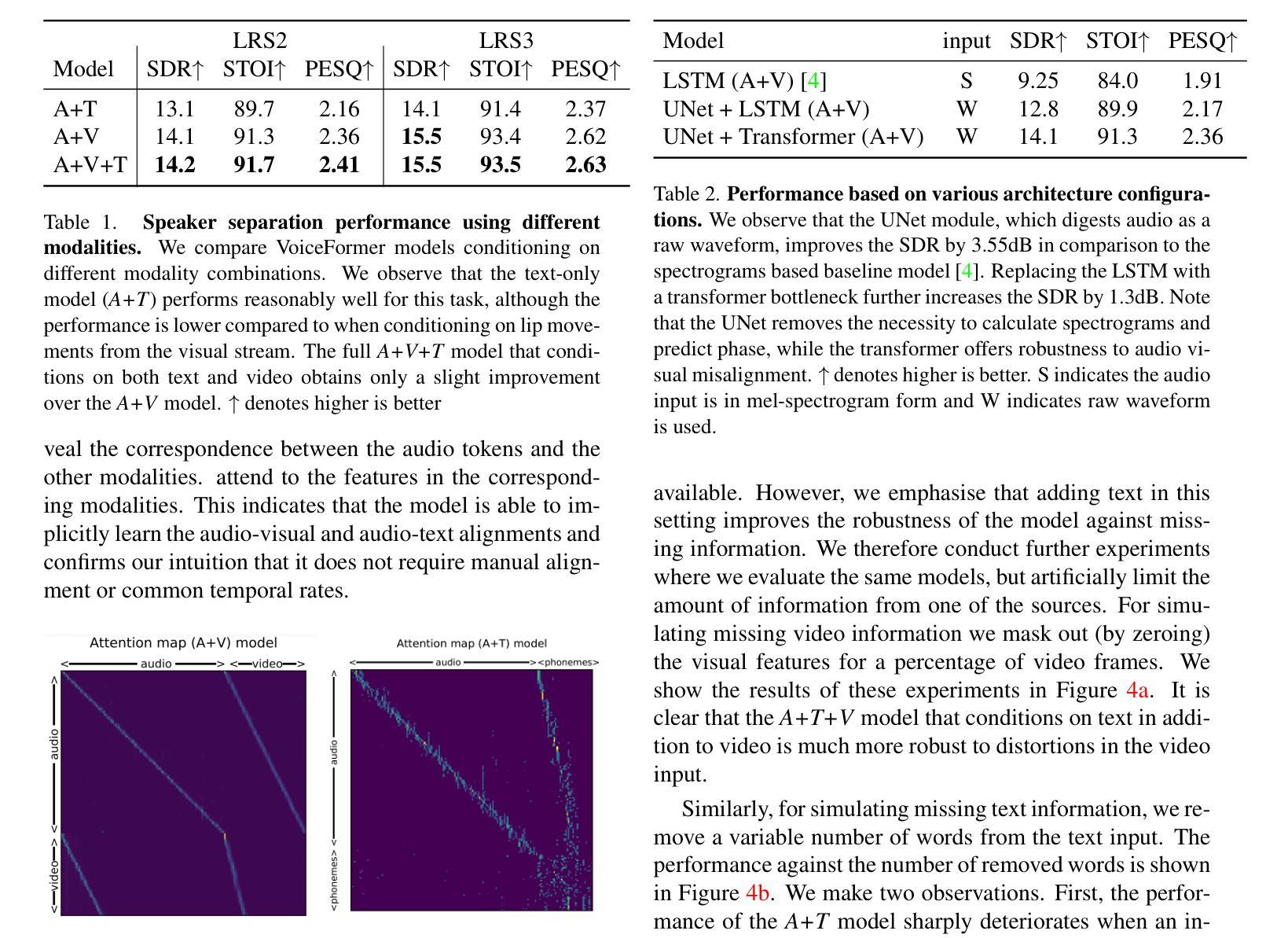
The goal of this paper is speech separation and enhancement in multi-speaker and noisy environments using a combination of different modalities. Previous works have shown good performance when conditioning on temporal or static visual evidence such as synchronised lip movements or face identity. In this paper, we present a unified framework for multi-modal speech separation and enhancement based on synchronous or asynchronous cues. To that end we make the following contributions: (i) we design a modern Transformer-based architecture tailored to fuse different modalities to solve the speech separation task in the raw waveform domain; (ii) we propose conditioning on the textual content of a sentence alone or in combination with visual information; (iii) we demonstrate the robustness of our model to audio-visual synchronisation offsets; and, (iv) we obtain state-of-the-art performance on the well-established benchmark datasets LRS2 and LRS3.
本文的目标是在多说话人和嘈杂的环境中进行语音分离和增强,结合使用不同的模式。以前的工作在基于时间或静态视觉证据(如同步的唇部动作或面部身份)的条件下表现出良好的性能。在本文中,我们提出了一种基于同步或异步线索的多模式语音分离和增强的统一框架。为此,我们做出了以下贡献:(i)我们设计了一种基于现代Transformer的架构,该架构专门用于融合不同的模式,以解决原始波形域中的语音分离任务;(ii)我们提出根据句子本身的文本内容或结合视觉信息进行条件处理;(iii)我们证明了我们的模型对视听同步偏移的鲁棒性;(iv)我们在公认的基准数据集LRS2和LRS3上获得了最先进的性能。
论文及项目相关链接
总结
本文旨在利用多模态技术在多说话人和噪声环境下实现语音分离与增强。通过同步或异步线索,提出了一种统一的多模态语音分离与增强框架。主要贡献包括:设计了一种基于Transformer的架构,融合不同模态以解决原始波形域中的语音分离任务;提出仅对句子文本内容进行条件处理,或与视觉信息相结合;验证了模型对音视频同步偏移的稳健性;在LRS2和LRS3标准数据集上取得了业界领先性能。
关键见解
- 论文旨在利用多模态技术在多说话人和噪声环境下实现语音分离与增强。
- 提出了一种统一的多模态语音分离与增强框架,基于同步或异步线索。
- 设计了一种基于Transformer的架构,用于融合不同模态以解决语音分离任务。
- 可以对句子文本内容进行条件处理,也可与视觉信息结合。
- 模型对音视频同步偏移具有稳健性。
- 在LRS2和LRS3标准数据集上取得了业界领先性能。
- 论文展示了多模态技术在解决语音分离任务中的潜力和优势。
点此查看论文截图

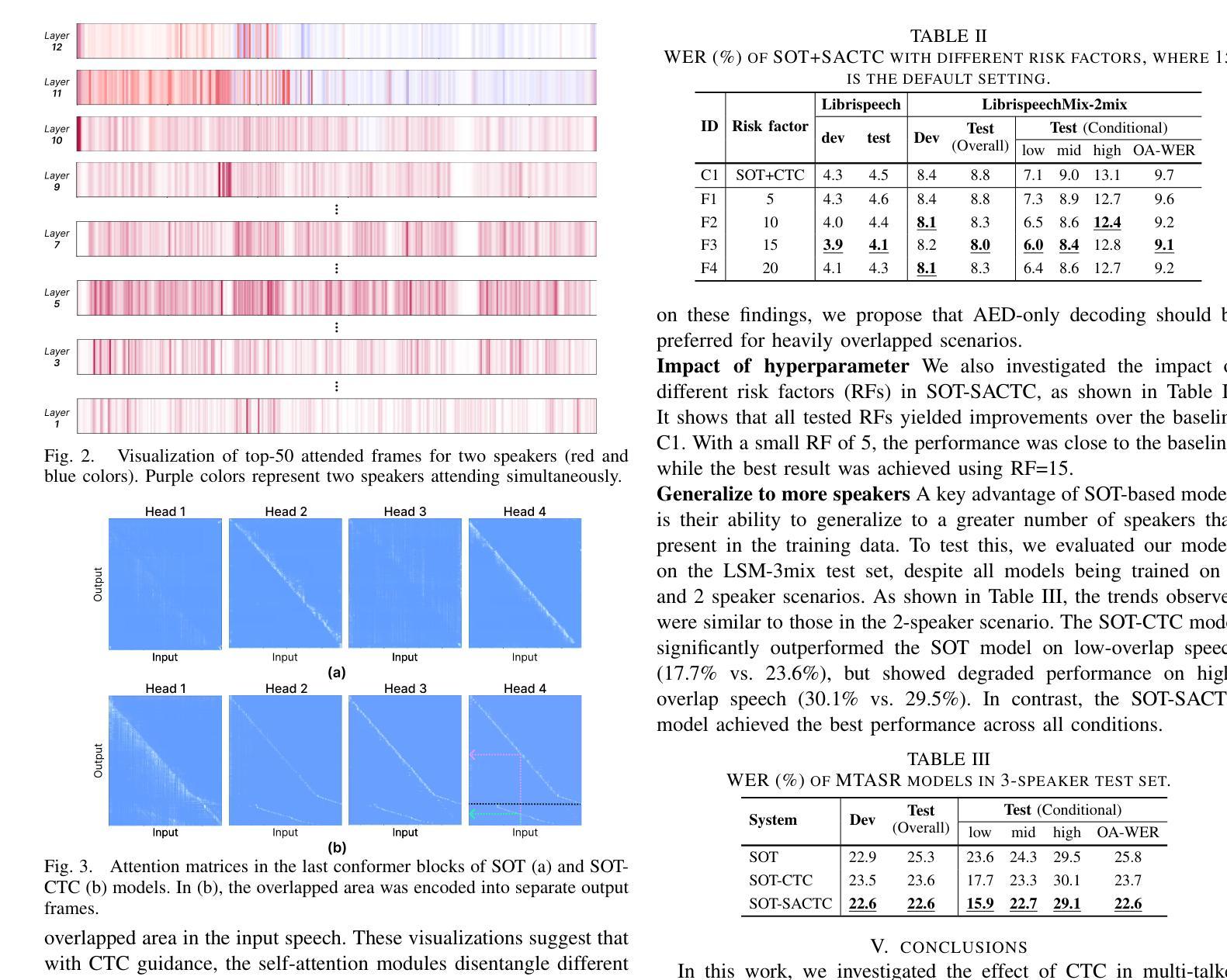
Speech Retrieval-Augmented Generation without Automatic Speech Recognition
Authors:Do June Min, Karel Mundnich, Andy Lapastora, Erfan Soltanmohammadi, Srikanth Ronanki, Kyu Han
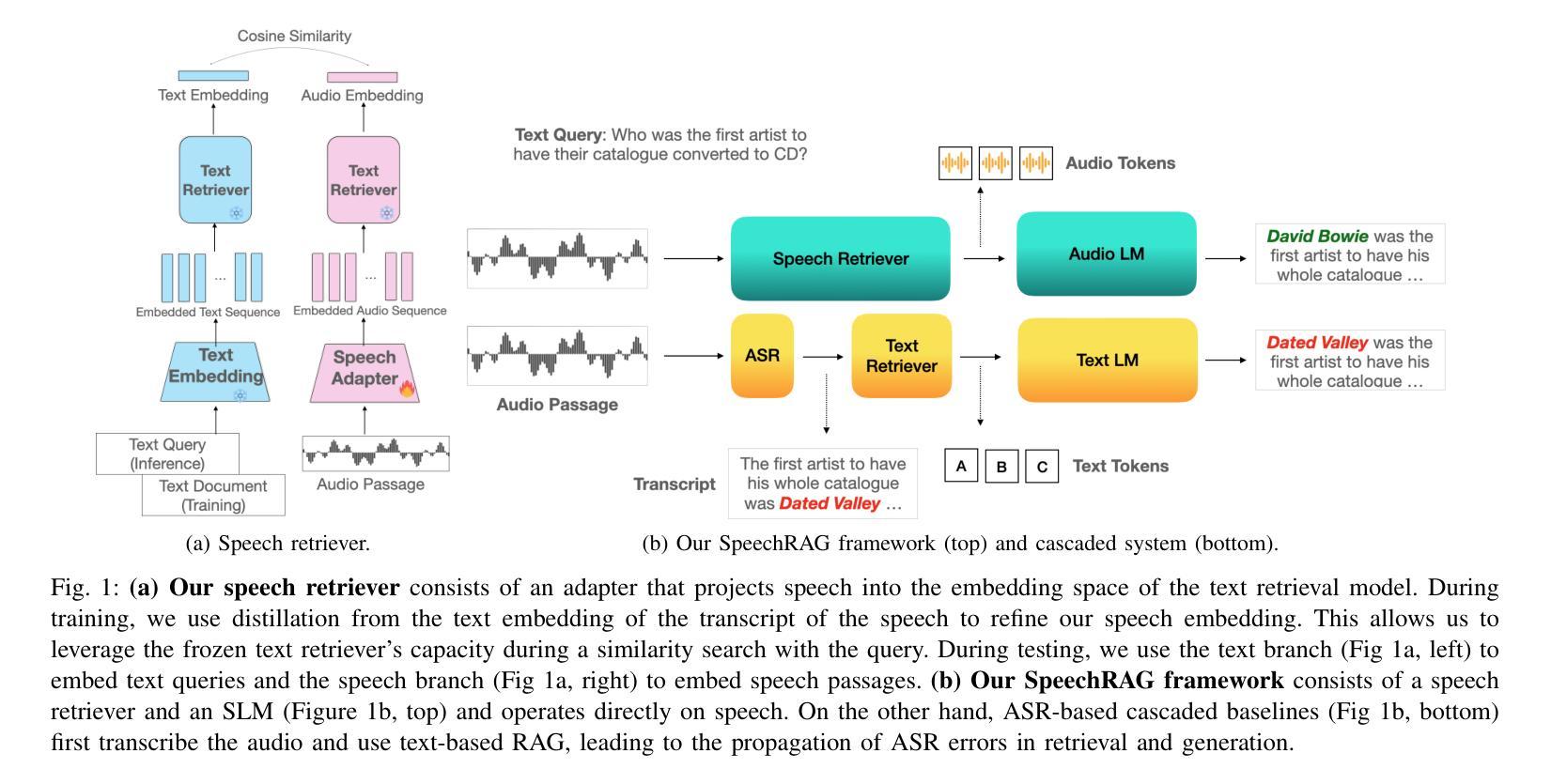
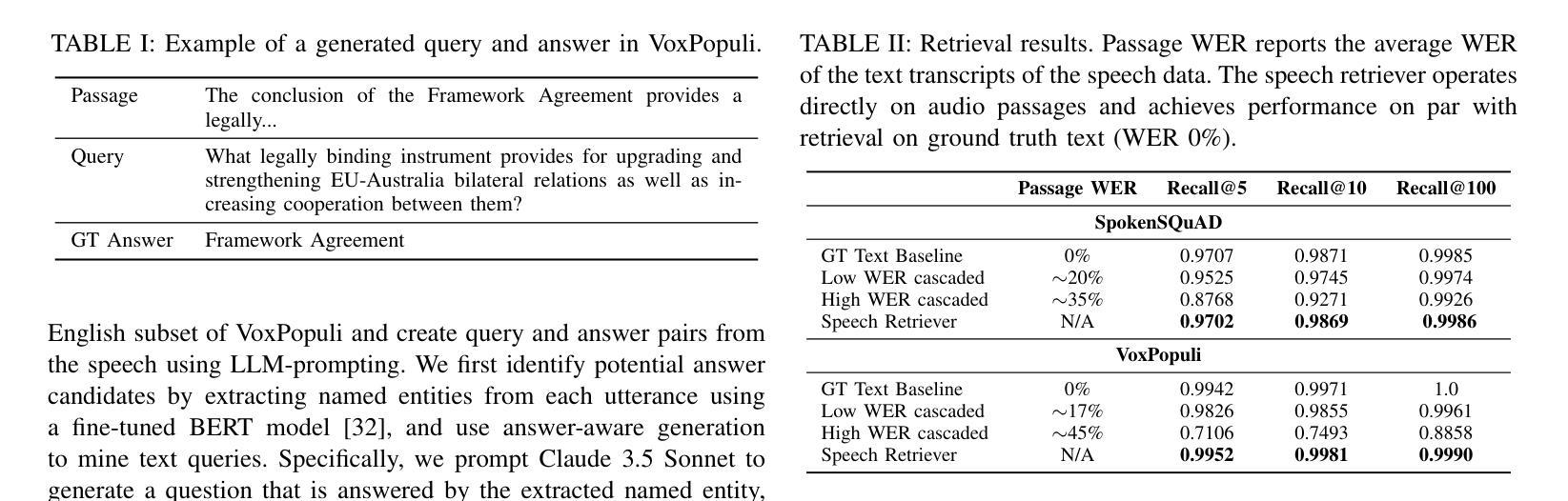
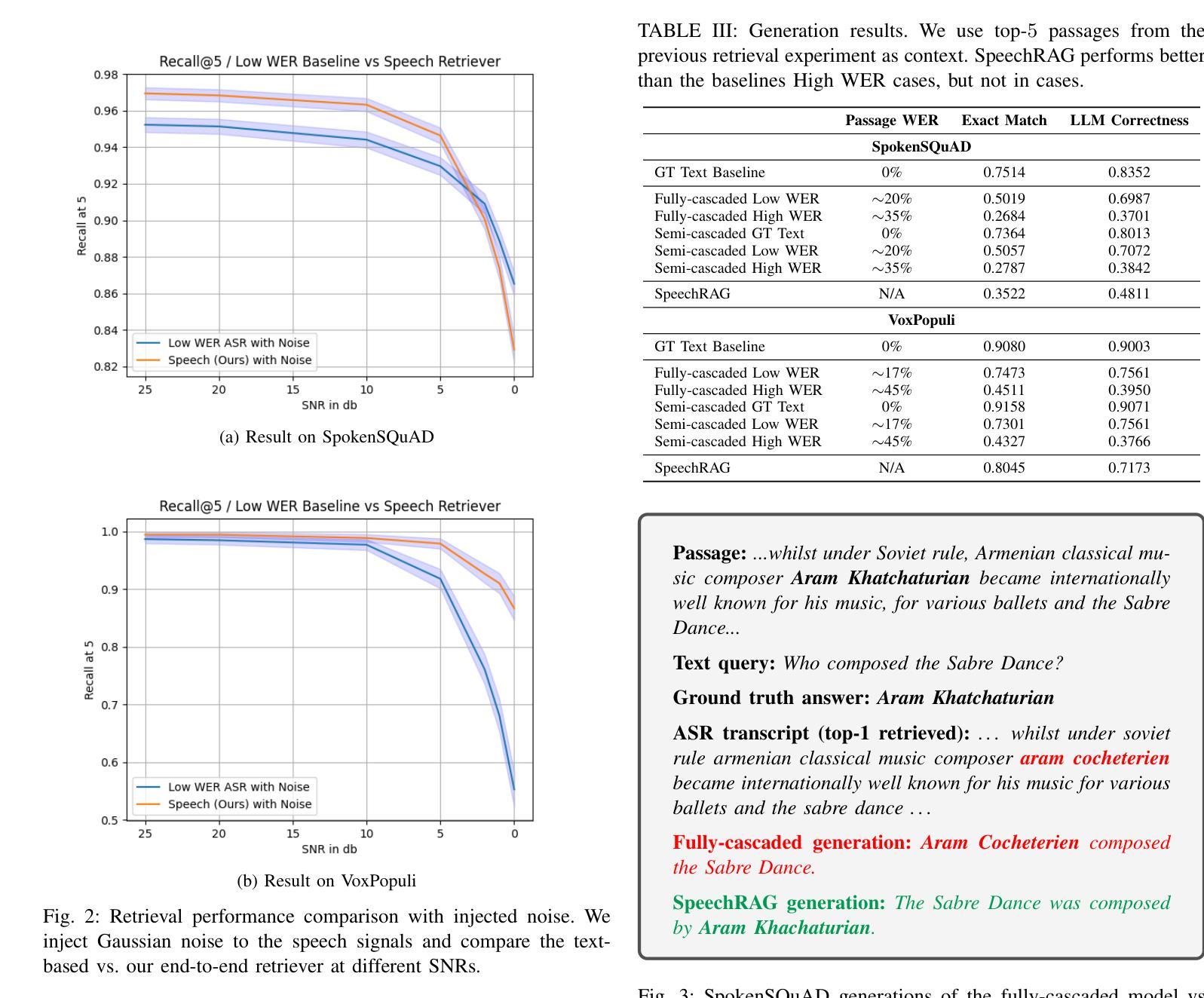
One common approach for question answering over speech data is to first transcribe speech using automatic speech recognition (ASR) and then employ text-based retrieval-augmented generation (RAG) on the transcriptions. While this cascaded pipeline has proven effective in many practical settings, ASR errors can propagate to the retrieval and generation steps. To overcome this limitation, we introduce SpeechRAG, a novel framework designed for open-question answering over spoken data. Our proposed approach fine-tunes a pre-trained speech encoder into a speech adapter fed into a frozen large language model (LLM)–based retrieval model. By aligning the embedding spaces of text and speech, our speech retriever directly retrieves audio passages from text-based queries, leveraging the retrieval capacity of the frozen text retriever. Our retrieval experiments on spoken question answering datasets show that direct speech retrieval does not degrade over the text-based baseline, and outperforms the cascaded systems using ASR. For generation, we use a speech language model (SLM) as a generator, conditioned on audio passages rather than transcripts. Without fine-tuning of the SLM, this approach outperforms cascaded text-based models when there is high WER in the transcripts.
对于语音数据的问题回答,一种常见的方法是先使用自动语音识别(ASR)进行语音转录,然后在转录结果上运用基于文本的检索增强生成(RAG)。虽然这种级联管道在许多实际环境中已被证明是有效的,但ASR错误可能会传播到检索和生成步骤。为了克服这一限制,我们引入了SpeechRAG,这是一个专为开放式问题回答设计的语音数据框架。我们提出的方法对预训练的语音编码器进行微调,使其适应于基于冻结的大型语言模型(LLM)的检索模型的语音适配器。通过对文本和语音的嵌入空间进行对齐,我们的语音检索器能够直接从基于文本的查询中检索音频片段,利用冻结文本检索器的检索能力。我们在语音问答数据集上的检索实验表明,直接语音检索并不亚于基于文本的基线,并且优于使用ASR的级联系统。对于生成部分,我们使用语音语言模型(SLM)作为生成器,以音频片段为条件,而不是文本。在不微调SLM的情况下,当转录中的词错误率(WER)较高时,这种方法优于级联的基于文本模型。
论文及项目相关链接
PDF ICASSP 2025
Summary:
提出了一种名为SpeechRAG的新框架,用于开放式问答对话的语音数据。它通过微调预训练的语音编码器并将其输入到基于大型语言模型的检索模型中,实现直接语音检索。该框架通过对文本和语音嵌入空间的对齐,使得从文本查询中直接检索语音片段成为可能。实验表明,相较于级联系统和仅使用文本基线的方法,SpeechRAG在语音问答数据集上的表现不逊色,且在转录文字错误率较高时表现更优。
Key Takeaways:
- SpeechRAG是一个为开放式问答设计的语音数据问答框架。
- 它通过微调预训练的语音编码器并将其输入到基于大型语言模型的检索模型中,实现直接语音检索。
- SpeechRAG通过对文本和语音嵌入空间的对齐,允许从文本查询中直接检索语音片段。
- 相比级联系统和仅使用文本基线的方法,SpeechRAG在语音问答数据集上的表现优异。
- 当转录文字错误率较高时,SpeechRAG的表现优于级联的文本基线模型。
- SpeechRAG采用了基于音频片段的条件生成方法,未对语言模型进行微调。
点此查看论文截图

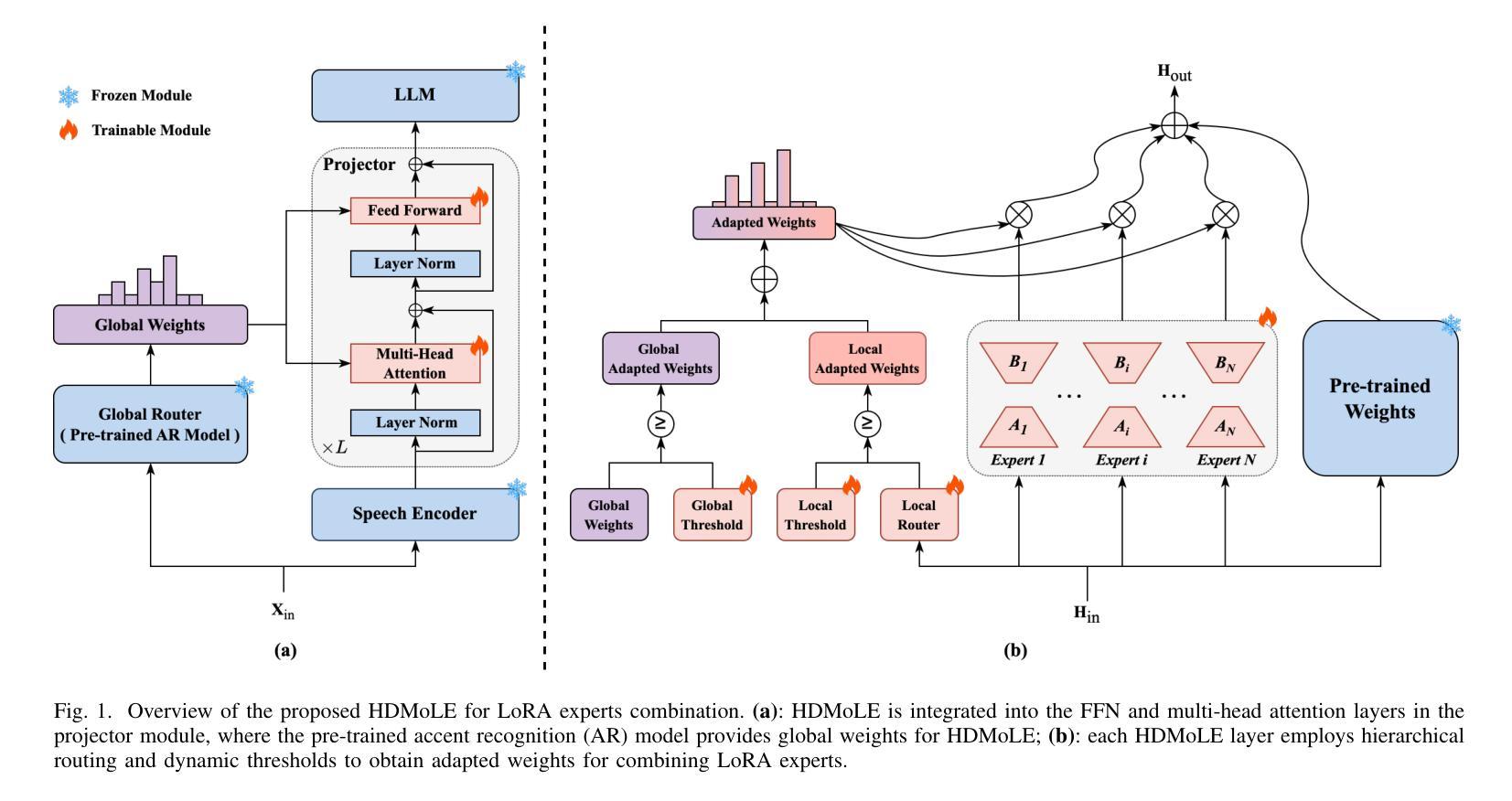
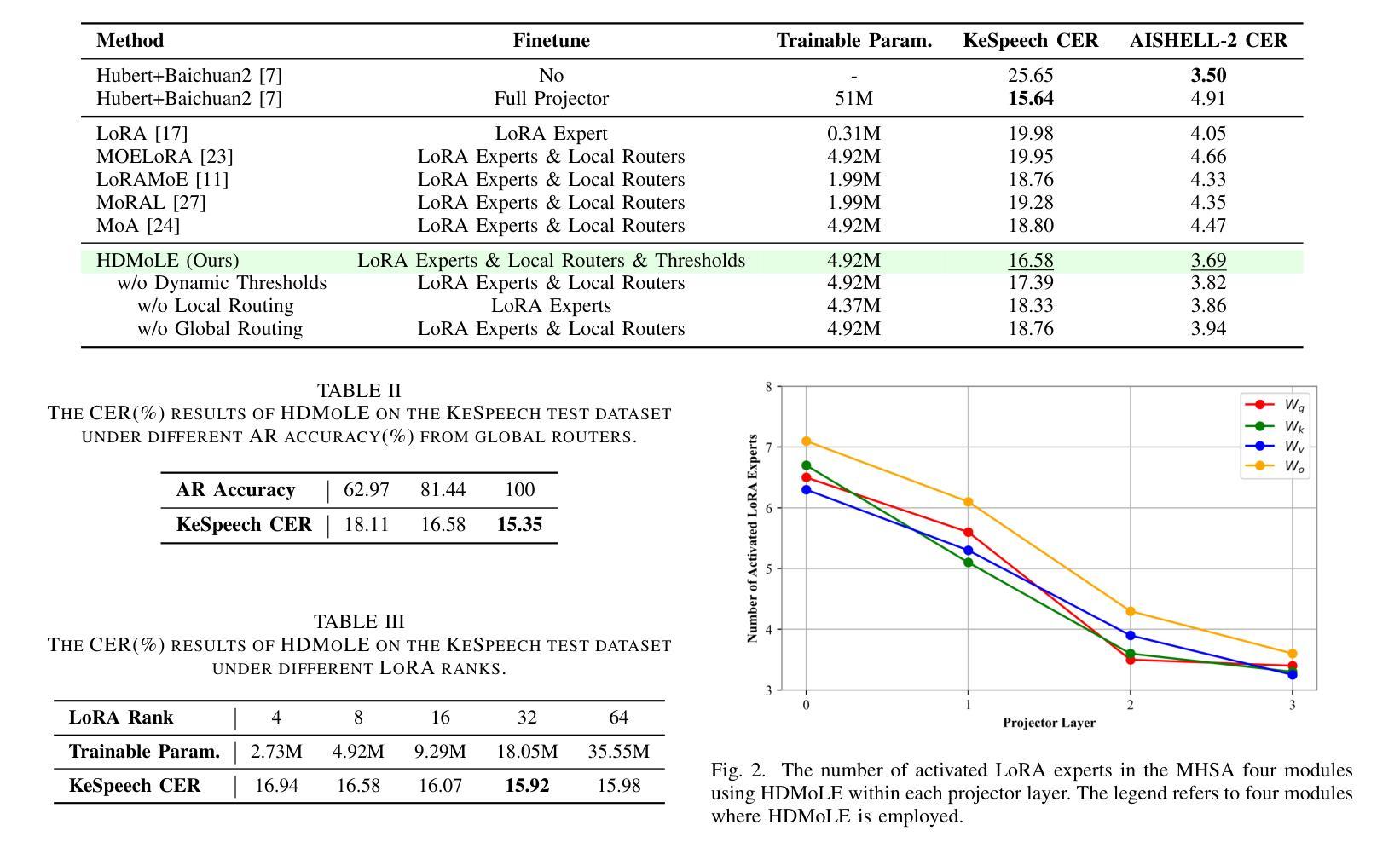
HDMoLE: Mixture of LoRA Experts with Hierarchical Routing and Dynamic Thresholds for Fine-Tuning LLM-based ASR Models
Authors:Bingshen Mu, Kun Wei, Qijie Shao, Yong Xu, Lei Xie
Recent advancements in integrating Large Language Models (LLM) with automatic speech recognition (ASR) have performed remarkably in general domains. While supervised fine-tuning (SFT) of all model parameters is often employed to adapt pre-trained LLM-based ASR models to specific domains, it imposes high computational costs and notably reduces their performance in general domains. In this paper, we propose a novel parameter-efficient multi-domain fine-tuning method for adapting pre-trained LLM-based ASR models to multi-accent domains without catastrophic forgetting named \textit{HDMoLE}, which leverages hierarchical routing and dynamic thresholds based on combining low-rank adaptation (LoRA) with the mixer of experts (MoE) and can be generalized to any linear layer. Hierarchical routing establishes a clear correspondence between LoRA experts and accent domains, improving cross-domain collaboration among the LoRA experts. Unlike the static Top-K strategy for activating LoRA experts, dynamic thresholds can adaptively activate varying numbers of LoRA experts at each MoE layer. Experiments on the multi-accent and standard Mandarin datasets demonstrate the efficacy of HDMoLE. Applying HDMoLE to an LLM-based ASR model projector module achieves similar performance to full fine-tuning in the target multi-accent domains while using only 9.6% of the trainable parameters required for full fine-tuning and minimal degradation in the source general domain.
最近,将大型语言模型(LLM)与自动语音识别(ASR)相结合的进展在通用领域取得了显著的效果。虽然通常通过监督微调(SFT)所有模型参数来适应基于预训练LLM的ASR模型到特定领域,但这样做带来了很高的计算成本并降低了它们在通用领域的性能。在本文中,我们提出了一种新颖的跨多领域参数高效微调方法,名为HDMoLE,该方法无需灾难性遗忘即可将基于预训练LLM的ASR模型适应于多口音领域。HDMoLE结合了层次路由和基于低秩适应(LoRA)与专家混合器(MoE)的动态阈值技术,并可推广至任何线性层。层次路由建立了LoRA专家和口音领域之间的明确对应关系,改进了跨领域的LoRA专家之间的协作。与静态Top-K策略激活LoRA专家不同,动态阈值可以自适应激活每个MoE层的不同数量的LoRA专家。在多口音和标准普通话数据集上的实验证明了HDMoLE的有效性。将HDMoLE应用于基于LLM的ASR模型的投影模块,在目标多口音领域实现了与完全微调相似的性能,同时仅使用9.6%的微调所需的可训练参数,并且在源通用领域的性能几乎没有下降。
论文及项目相关链接
PDF Accepted by ICASSP 2025
摘要
适应预训练的大型语言模型(LLM)为基础的自动语音识别(ASR)模型到特定领域时,通常采用监督微调(SFT)所有模型参数的方法。然而,这带来了较高的计算成本,且在一般领域中的性能会显著降低。本文提出了一种新的参数高效多领域微调方法,名为HDMoLE,用于适应预训练LLM为基础的ASR模型到多口音领域,而不会发生灾难性遗忘。该方法结合了低秩适应(LoRA)与专家混合(MoE),采用层次路由和动态阈值,可以推广到任何线性层。层次路由建立了LoRA专家与口音领域之间的清晰对应关系,改善了跨领域的LoRA专家协作。动态阈值可以自适应地激活不同数量的LoRA专家,不同于静态Top-K策略。在多口音和标准普通话数据集上的实验证明了HDMoLE的有效性。将HDMoLE应用于LLM为基础的ASR模型的投影模块,在目标多口音领域中实现了与全微调相似的性能,同时仅使用9.6%的微调所需的可训练参数,且在源一般领域中的性能下降微乎其微。
关键见解
- 提出了一种新的参数高效多领域微调方法HDMoLE,用于适应预训练的大型语言模型为基础的自动语音识别模型到多口音领域。
- HDMoLE结合了低秩适应(LoRA)与专家混合(MoE),并采用层次路由和动态阈值技术,提高了跨领域协作和模型性能。
- 与传统的监督微调方法相比,HDMoLE在保持目标领域性能的同时,显著减少了计算成本和模型参数的使用。
- 通过在多个口音和标准普通话数据集上进行实验,证明了HDMoLE的有效性。
- HDMoLE在目标多口音领域中的性能与全微调相似,同时保持了对源一般领域的性能影响最小化。
- HDMoLE中的动态阈值可以自适应地激活不同数量的LoRA专家,提高了模型的灵活性和适应性。
点此查看论文截图

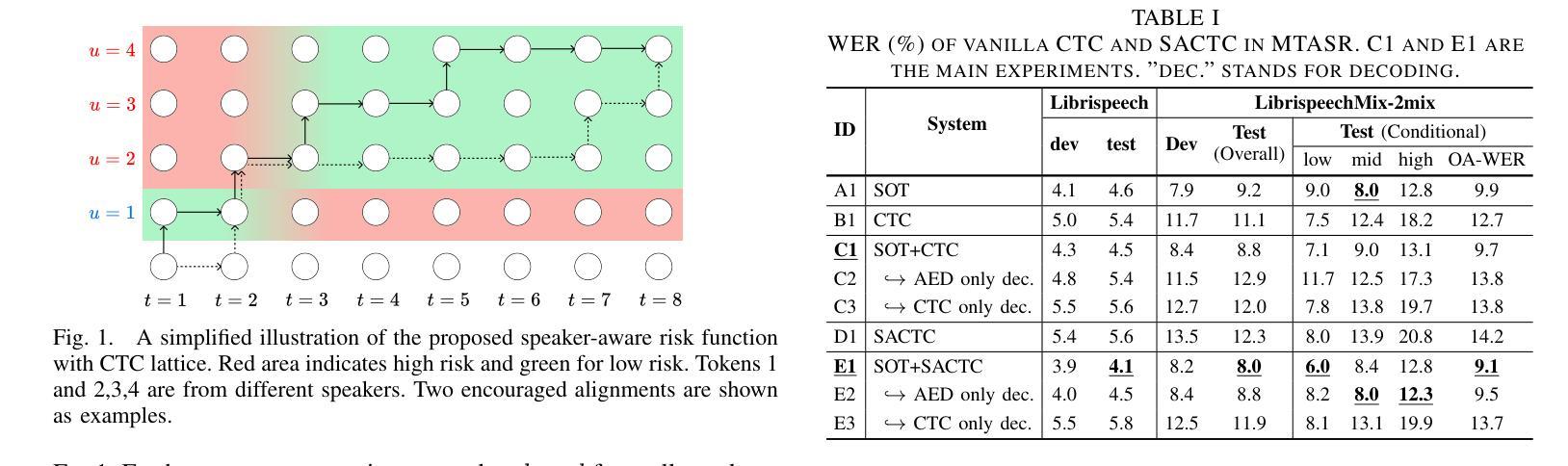
Disentangling Speakers in Multi-Talker Speech Recognition with Speaker-Aware CTC
Authors:Jiawen Kang, Lingwei Meng, Mingyu Cui, Yuejiao Wang, Xixin Wu, Xunying Liu, Helen Meng
Multi-talker speech recognition (MTASR) faces unique challenges in disentangling and transcribing overlapping speech. To address these challenges, this paper investigates the role of Connectionist Temporal Classification (CTC) in speaker disentanglement when incorporated with Serialized Output Training (SOT) for MTASR. Our visualization reveals that CTC guides the encoder to represent different speakers in distinct temporal regions of acoustic embeddings. Leveraging this insight, we propose a novel Speaker-Aware CTC (SACTC) training objective, based on the Bayes risk CTC framework. SACTC is a tailored CTC variant for multi-talker scenarios, it explicitly models speaker disentanglement by constraining the encoder to represent different speakers’ tokens at specific time frames. When integrated with SOT, the SOT-SACTC model consistently outperforms standard SOT-CTC across various degrees of speech overlap. Specifically, we observe relative word error rate reductions of 10% overall and 15% on low-overlap speech. This work represents an initial exploration of CTC-based enhancements for MTASR tasks, offering a new perspective on speaker disentanglement in multi-talker speech recognition. The code is available at https://github.com/kjw11/Speaker-Aware-CTC.
多任务语音识别的挑战在于解析和转录重叠的语音内容。为了应对这些挑战,这篇论文研究了Connectionist Temporal Classification(CTC)在结合Serialized Output Training(SOT)进行多任务语音识别时的说话人解析作用。我们的可视化结果显示,CTC引导编码器在不同的时间区域表示不同的说话人,以形成声学嵌入。利用这一发现,我们提出了基于Bayes风险CTC框架的Speaker-Aware CTC(SACTC)训练目标。SACTC是为多任务对话场景量身定制的CTC变体,它通过约束编码器在特定时间帧上表示不同说话人的标记来显式建模说话人的解析。当与SOT结合时,SOT-SACTC模型在各种程度的语音重叠情况下均优于标准的SOT-CTC。具体来说,我们观察到整体相对词错误率降低了10%,在低重叠语音上降低了15%。这项工作代表了基于CTC的多任务语音识别任务的初步探索,为解析多任务语音中的说话人提供了新的视角。代码可在 https://github.com/kjw11/Speaker-Aware-CTC 中获取。
论文及项目相关链接
PDF Accepted by ICASSP2025
Summary
本文研究了在多说话人语音识别(MTASR)中,结合连接时序分类(CTC)和序列化输出训练(SOT)在解决说话人解纠缠和语音转录方面的挑战。通过可视化发现,CTC指导编码器在不同的时间区域表示不同的说话人,形成不同的声学嵌入。基于此,提出了针对多说话人场景的Speaker-Aware CTC(SACTC)训练目标。SACTC在CTC基础上增加了对说话人解纠缠的建模,通过约束编码器在特定时间帧表示不同说话人的标记。结合SOT后,SACTC模型在各种程度的语音重叠情况下均优于标准SOT-CTC模型。相对字词错误率总体降低10%,在低重叠语音上降低15%。这为MTASR任务的CTC增强研究提供了新视角。
Key Takeaways
- 多说话人语音识别(MTASR)面临解纠缠和转录重叠语音的独特挑战。
- 连接时序分类(CTC)在说话人解纠缠中起到关键作用,能指导编码器在不同时间区域表示不同说话人。
- 提出了基于Bayes风险CTC框架的Speaker-Aware CTC(SACTC)训练目标。
- SACTC是专为多说话人场景设计的CTC变体,能显式建模说话人的解纠缠。
- 结合序列化输出训练(SOT),SACTC模型在各种语音重叠情况下表现优异,相对字词错误率有所降低。
- 研究为MTASR任务的CTC增强提供了新视角。
点此查看论文截图