⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-08 更新
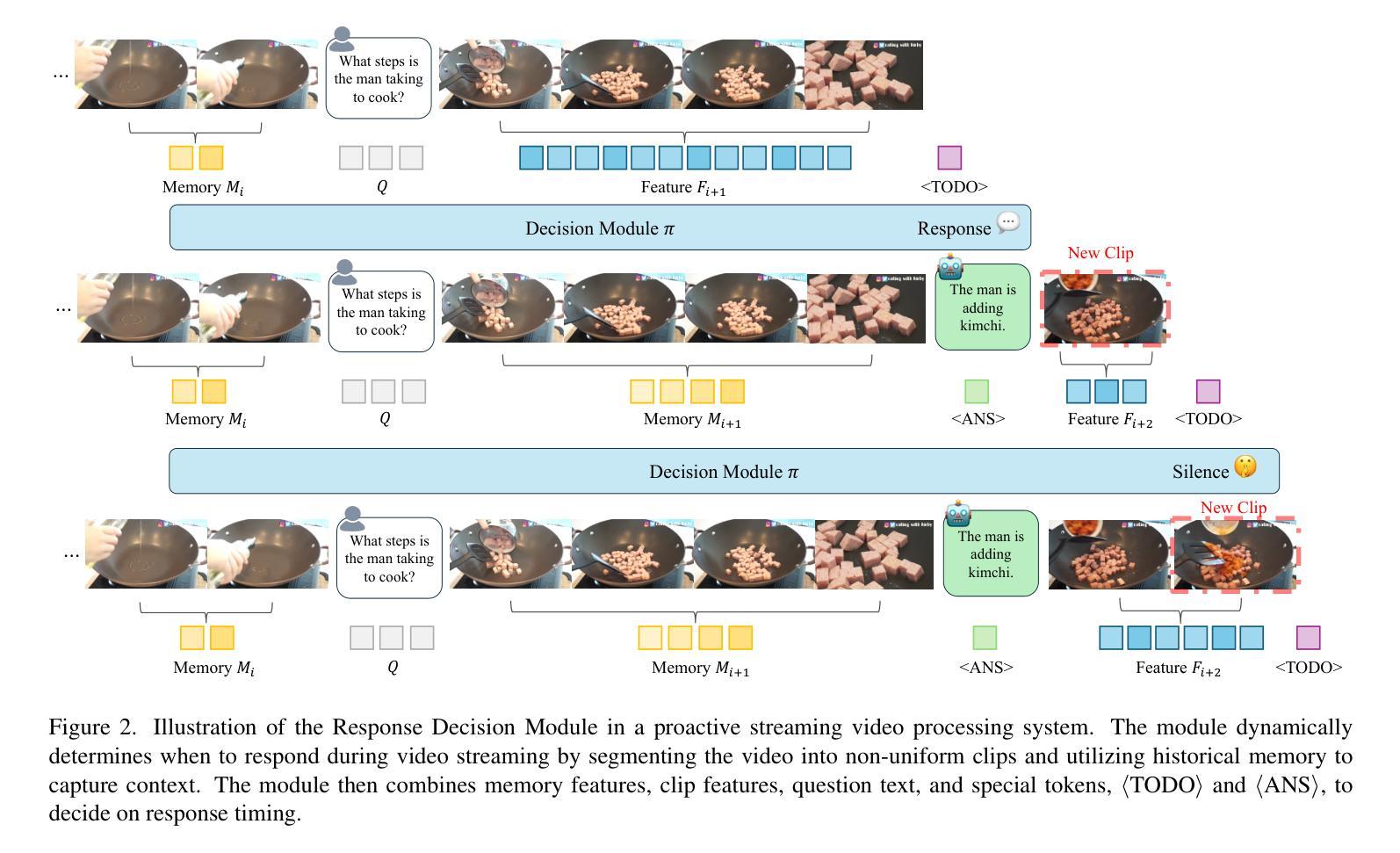
Dispider: Enabling Video LLMs with Active Real-Time Interaction via Disentangled Perception, Decision, and Reaction
Authors:Rui Qian, Shuangrui Ding, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Yuhang Cao, Dahua Lin, Jiaqi Wang
Active Real-time interaction with video LLMs introduces a new paradigm for human-computer interaction, where the model not only understands user intent but also responds while continuously processing streaming video on the fly. Unlike offline video LLMs, which analyze the entire video before answering questions, active real-time interaction requires three capabilities: 1) Perception: real-time video monitoring and interaction capturing. 2) Decision: raising proactive interaction in proper situations, 3) Reaction: continuous interaction with users. However, inherent conflicts exist among the desired capabilities. The Decision and Reaction require a contrary Perception scale and grain, and the autoregressive decoding blocks the real-time Perception and Decision during the Reaction. To unify the conflicted capabilities within a harmonious system, we present Dispider, a system that disentangles Perception, Decision, and Reaction. Dispider features a lightweight proactive streaming video processing module that tracks the video stream and identifies optimal moments for interaction. Once the interaction is triggered, an asynchronous interaction module provides detailed responses, while the processing module continues to monitor the video in the meantime. Our disentangled and asynchronous design ensures timely, contextually accurate, and computationally efficient responses, making Dispider ideal for active real-time interaction for long-duration video streams. Experiments show that Dispider not only maintains strong performance in conventional video QA tasks, but also significantly surpasses previous online models in streaming scenario responses, thereby validating the effectiveness of our architecture. The code and model are released at \url{https://github.com/Mark12Ding/Dispider}.
主动实时与视频LLM(大型预训练模型)交互为人机交互引入了一种新的范式。在这种范式中,模型不仅能够理解用户的意图,还能够在实时处理流式视频的同时进行响应。与离线视频LLM不同,后者在分析整个视频后才回答问题,主动实时交互需要三种能力:1)感知:实时视频监控和交互捕获。2)决策:在适当的情境下主动发起交互。3)反应:与用户持续交互。然而,所期望的能力之间存在固有的冲突。决策和反应需要相反的感知规模和粒度,而自回归解码在反应期间阻碍了实时感知和决策。为了在一个和谐系统中统一这些冲突的能力,我们提出了Dispider系统,它能够解开感知、决策和反应。Dispider采用了一个轻量级的主动流式视频处理模块,该模块跟踪视频流并识别交互的最佳时刻。一旦触发交互,异步交互模块会提供详细的响应,同时处理模块继续监控视频。我们的解耦和异步设计确保了及时、上下文准确和计算高效的响应,使Dispider成为适合长时间流式视频的主动实时交互的理想选择。实验表明,Dispider不仅在传统的视频问答任务中保持强大的性能,而且在流式场景响应中显著超越了以前的在线模型,从而验证了我们的架构的有效性。代码和模型已发布在[https://github.com/Mark12Ding/Dispider]。
论文及项目相关链接
Summary
实时主动交互为视频LLM引入了一种新的人机交互模式,该模式要求模型不仅理解用户意图,而且在处理流式视频的同时做出响应。为实现这种模式,需要解决感知、决策和反应三个核心问题。为解决这些核心问题存在的内在冲突,我们提出了Dispider系统,该系统实现了感知、决策和反应的分离和解耦。实验表明,Dispider不仅在传统视频问答任务中表现优异,而且在流媒体场景响应中显著超越了之前的在线模型,验证了其架构的有效性。
Key Takeaways
- 实时主动交互为视频LLM开启了新的人机交互模式。
- 这种模式要求模型具备理解用户意图、处理流式视频并做出响应的能力。
- 实现这种模式需要解决感知、决策和反应三个核心问题。
- 感知、决策和反应之间存在内在冲突。
- Dispider系统通过解耦这些能力,实现了感知、决策和反应的分离。
- 实验表明,Dispider在传统视频问答任务和流媒体场景响应中都表现出色。
点此查看论文截图

Sentiment-enhanced Graph-based Sarcasm Explanation in Dialogue
Authors:Kun Ouyang, Liqiang Jing, Xuemeng Song, Meng Liu, Yupeng Hu, Liqiang Nie
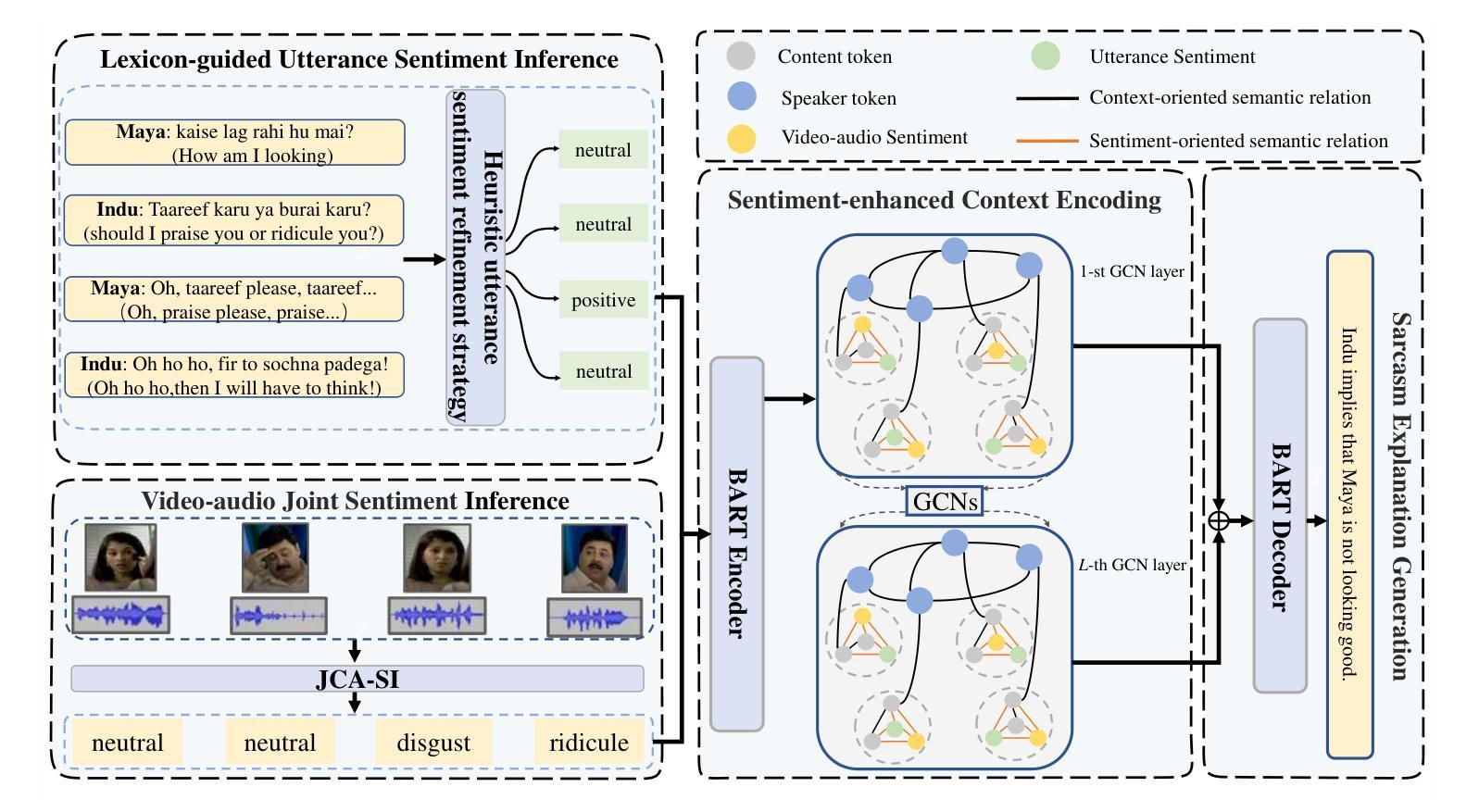
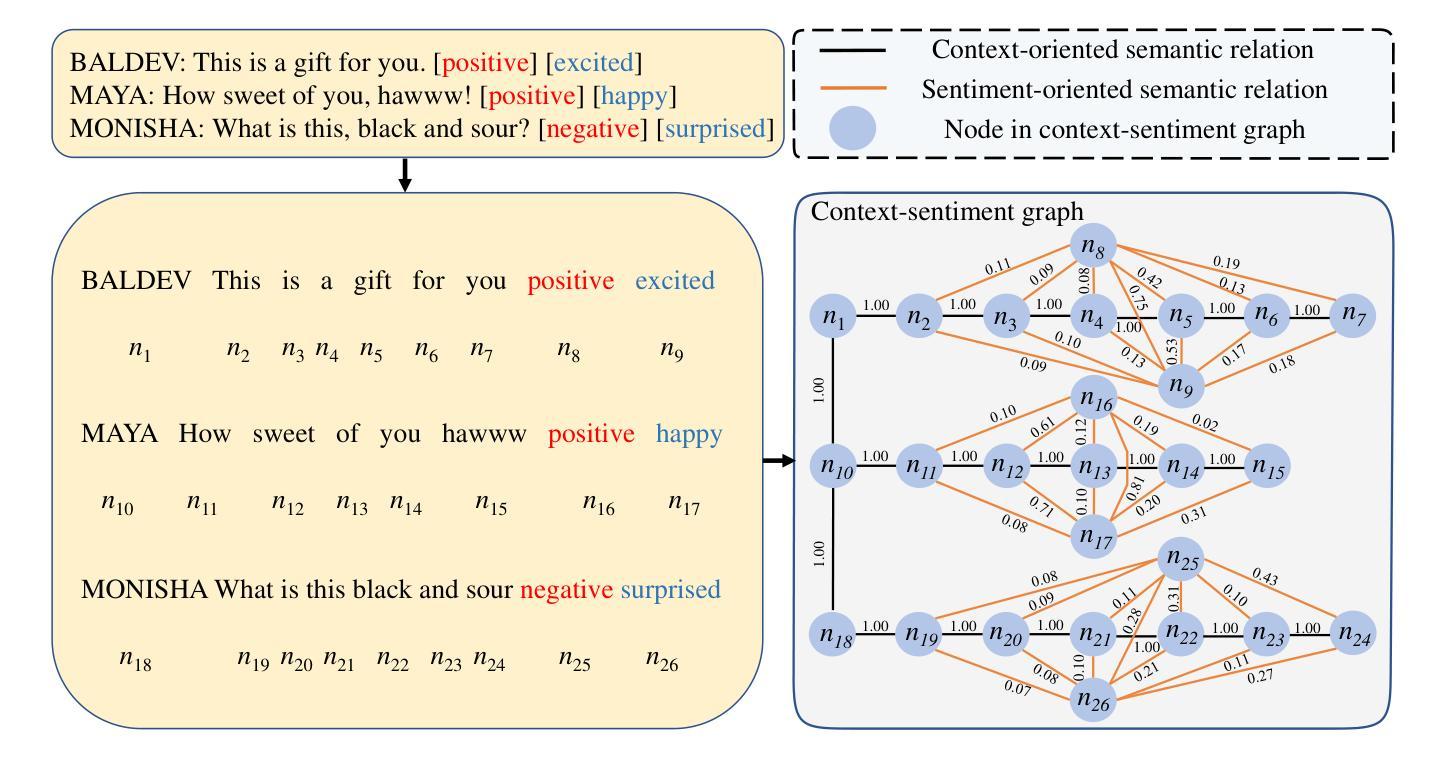
Sarcasm Explanation in Dialogue (SED) is a new yet challenging task, which aims to generate a natural language explanation for the given sarcastic dialogue that involves multiple modalities (\ie utterance, video, and audio). Although existing studies have achieved great success based on the generative pretrained language model BART, they overlook exploiting the sentiments residing in the utterance, video and audio, which play important roles in reflecting sarcasm that essentially involves subtle sentiment contrasts. Nevertheless, it is non-trivial to incorporate sentiments for boosting SED performance, due to three main challenges: 1) diverse effects of utterance tokens on sentiments; 2) gap between video-audio sentiment signals and the embedding space of BART; and 3) various relations among utterances, utterance sentiments, and video-audio sentiments. To tackle these challenges, we propose a novel sEntiment-enhanceD Graph-based multimodal sarcasm Explanation framework, named EDGE. In particular, we first propose a lexicon-guided utterance sentiment inference module, where a heuristic utterance sentiment refinement strategy is devised. We then develop a module named Joint Cross Attention-based Sentiment Inference (JCA-SI) by extending the multimodal sentiment analysis model JCA to derive the joint sentiment label for each video-audio clip. Thereafter, we devise a context-sentiment graph to comprehensively model the semantic relations among the utterances, utterance sentiments, and video-audio sentiments, to facilitate sarcasm explanation generation. Extensive experiments on the publicly released dataset WITS verify the superiority of our model over cutting-edge methods.
对话中的讽刺解释(SED)是一项新颖且充满挑战的任务,旨在针对给定的包含多种模式(即话语、视频和音频)的讽刺对话生成自然语言解释。尽管现有研究基于生成式预训练语言模型BART取得了巨大成功,但它们忽视了话语、视频和音频中存在的情感,这些情感在反映本质上涉及微妙情感对比的讽刺方面发挥着重要作用。然而,由于三个主要挑战,融入情感来提升SED性能并不简单:1)话语标记对情感的多样影响;2)视频-音频情感信号与BART嵌入空间之间的鸿沟;3)话语、话语情感和视频-音频情感之间的各种关系。为了应对这些挑战,我们提出了一种新的情感增强图基多模式讽刺解释框架,名为EDGE。具体而言,我们首先提出了词典引导的话语情感推断模块,其中设计了一种启发式话语情感优化策略。然后,我们通过扩展多模式情感分析模型JCA,开发了名为联合跨注意力情感推断(JCA-SI)的模块,以得出每个视频-音频片段的联合情感标签。之后,我们设计了一个上下文情感图,以全面建模话语、话语情感和视频-音频情感之间的语义关系,以促进讽刺解释的产生。在公开发布的数据集WITS上进行的广泛实验证明了我们模型相较于前沿方法的优越性。
论文及项目相关链接
PDF This paper got accepted by IEEE TMM
Summary
该文本介绍了对话中的讽刺解释(SED)这一新任务,旨在针对给定的讽刺对话生成自然语言解释,该对话涉及多种模态(如话语、视频和音频)。现有研究虽然基于生成式预训练语言模型BART取得了很大成功,但忽略了话语、视频和音频中的情感,这些情感在反映涉及微妙情感对比的讽刺中起着重要作用。为了结合情感来提升SED性能,文章提出了面临的挑战和解决方法,并介绍了一种新型的基于情感增强的图模型——边缘(EDGE)。实验验证表明该模型在公开数据集上的性能优于前沿方法。
Key Takeaways
- 对话中的讽刺解释(SED)是涉及多种模态(如话语、视频和音频)的新挑战任务。
- 现有研究忽略了话语、视频和音频中的情感因素,这对反映讽刺至关重要。
- 存在三大挑战来结合情感提升SED性能:话语对不同情感的复杂影响、视频音频情感信号与BART嵌入空间的差距以及不同因素之间的关系。
- 提出了基于情感增强的图模型——边缘(EDGE)来解决这些挑战。
- EDGE模型包括一个词典引导的话语情感推断模块和一个基于联合交叉注意力的情感推断模块(JCA-SI)。这两个模块分别用于优化和改进情感推断。
- EDGE模型通过构建上下文情感图,全面建模了不同话语、话语情感和视频音频情感之间的语义关系,有助于生成讽刺解释。
点此查看论文截图