⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-08 更新
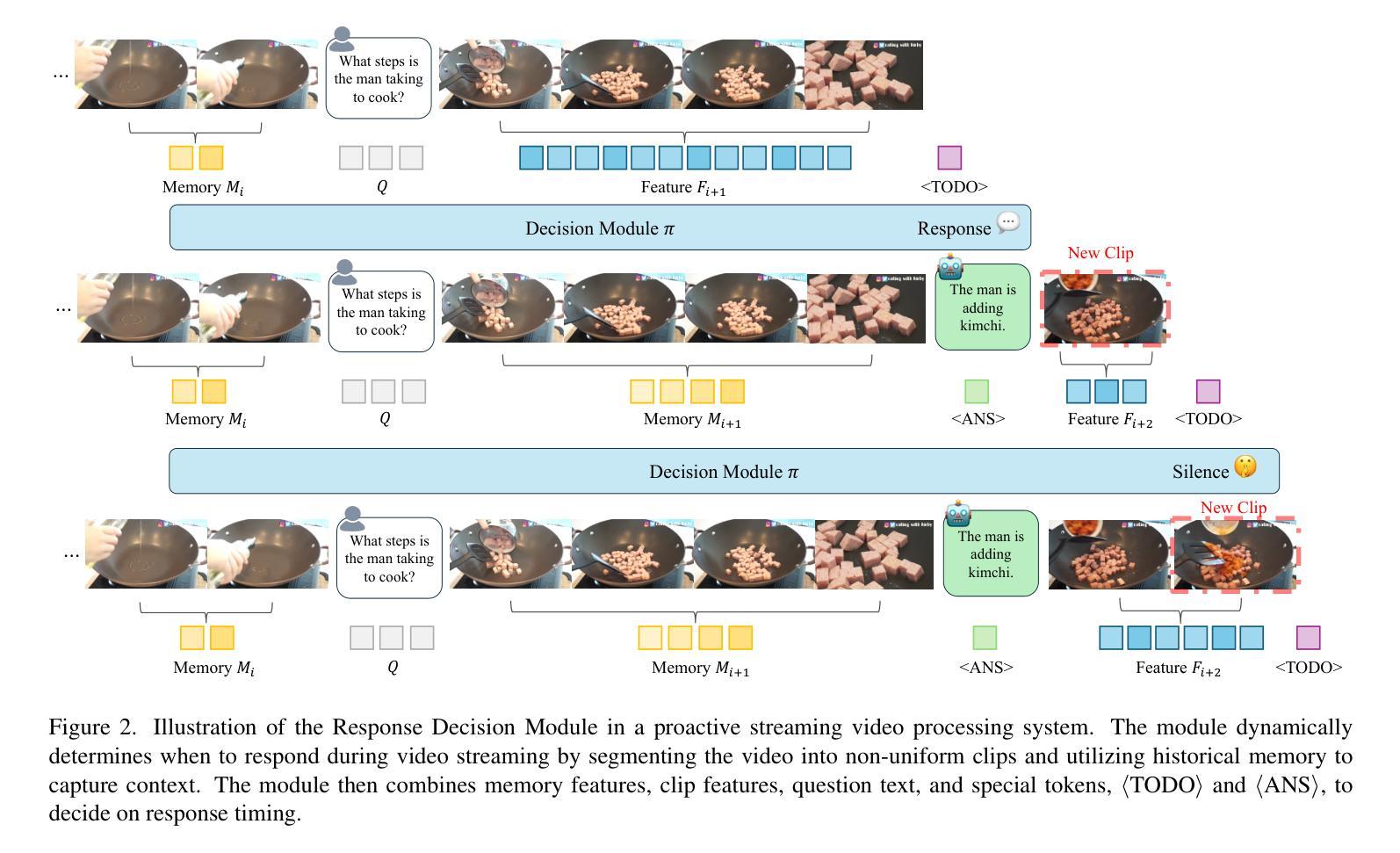
Dispider: Enabling Video LLMs with Active Real-Time Interaction via Disentangled Perception, Decision, and Reaction
Authors:Rui Qian, Shuangrui Ding, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Yuhang Cao, Dahua Lin, Jiaqi Wang
Active Real-time interaction with video LLMs introduces a new paradigm for human-computer interaction, where the model not only understands user intent but also responds while continuously processing streaming video on the fly. Unlike offline video LLMs, which analyze the entire video before answering questions, active real-time interaction requires three capabilities: 1) Perception: real-time video monitoring and interaction capturing. 2) Decision: raising proactive interaction in proper situations, 3) Reaction: continuous interaction with users. However, inherent conflicts exist among the desired capabilities. The Decision and Reaction require a contrary Perception scale and grain, and the autoregressive decoding blocks the real-time Perception and Decision during the Reaction. To unify the conflicted capabilities within a harmonious system, we present Dispider, a system that disentangles Perception, Decision, and Reaction. Dispider features a lightweight proactive streaming video processing module that tracks the video stream and identifies optimal moments for interaction. Once the interaction is triggered, an asynchronous interaction module provides detailed responses, while the processing module continues to monitor the video in the meantime. Our disentangled and asynchronous design ensures timely, contextually accurate, and computationally efficient responses, making Dispider ideal for active real-time interaction for long-duration video streams. Experiments show that Dispider not only maintains strong performance in conventional video QA tasks, but also significantly surpasses previous online models in streaming scenario responses, thereby validating the effectiveness of our architecture. The code and model are released at \url{https://github.com/Mark12Ding/Dispider}.
主动实时与视频LLM交互为人机交互引入了一种新的范式。在此范式中,模型不仅理解用户意图,而且在连续处理流式视频的同时进行响应。不同于离线视频LLM,后者在回答问题之前会分析整个视频,主动实时交互需要三种能力:1)感知:实时视频监控和交互捕获。2)决策:在适当的情境下主动交互。3)反应:与用户持续交互。然而,所期望的这些能力之间存在固有冲突。决策和反应需要相反的感知尺度和粒度,而且自回归解码在反应期间阻止了实时感知和决策。为了在一个和谐系统中统一这些冲突的能力,我们提出了Dispider系统,它能解开感知、决策和反应。Dispider系统具有一个轻量级的主动流式视频处理模块,该模块跟踪视频流并识别交互的最佳时刻。一旦触发交互,异步交互模块会提供详细响应,同时处理模块会继续监控视频。我们解耦和异步的设计确保了及时、上下文准确和计算高效的响应,使Dispider成为长时长视频流的主动实时交互的理想选择。实验表明,Dispider不仅在传统的视频问答任务中保持强劲性能,而且在流式场景响应中显著超越先前的在线模型,从而验证了我们的架构的有效性。代码和模型已发布在[https://github.com/Mark12Ding/Dispider。]
论文及项目相关链接
Summary
本文介绍了主动实时互动视频LLM的新范式,它需要感知、决策和反应三种能力。然而,这些能力之间存在内在冲突。为了统一这些冲突的能力,提出了Dispider系统,它实现了感知、决策和反应的分离和解耦。该系统可确保及时、上下文准确和计算高效的响应,非常适合长时间的实时视频流交互。实验表明,Dispider在常规视频问答任务中表现强劲,并在流媒体场景响应中显著超越先前模型。
Key Takeaways
- 主动实时互动视频LLM引入了一种新的交互范式,包括感知、决策和反应三种关键能力。
- 感知能力涉及实时视频监控和交互捕获;决策能力要求在适当情况下主动交互;反应能力则要求与用户持续互动。
- 感知、决策和反应之间存在内在冲突,特别是在决策和反应对感知尺度和精细度的要求相反以及反应过程中的自回归解码会阻碍实时感知和决策。
- Dispider系统通过解耦这三种能力,实现了和谐统一。它采用轻量级的主动流视频处理模块来跟踪视频流并识别最佳交互时刻。
- 一旦触发交互,异步交互模块提供详细响应,同时处理模块继续监控视频。
- 实验表明,Dispider在常规视频问答任务中表现优异,并在流媒体场景响应中显著超越先前模型,验证了其架构的有效性。
点此查看论文截图

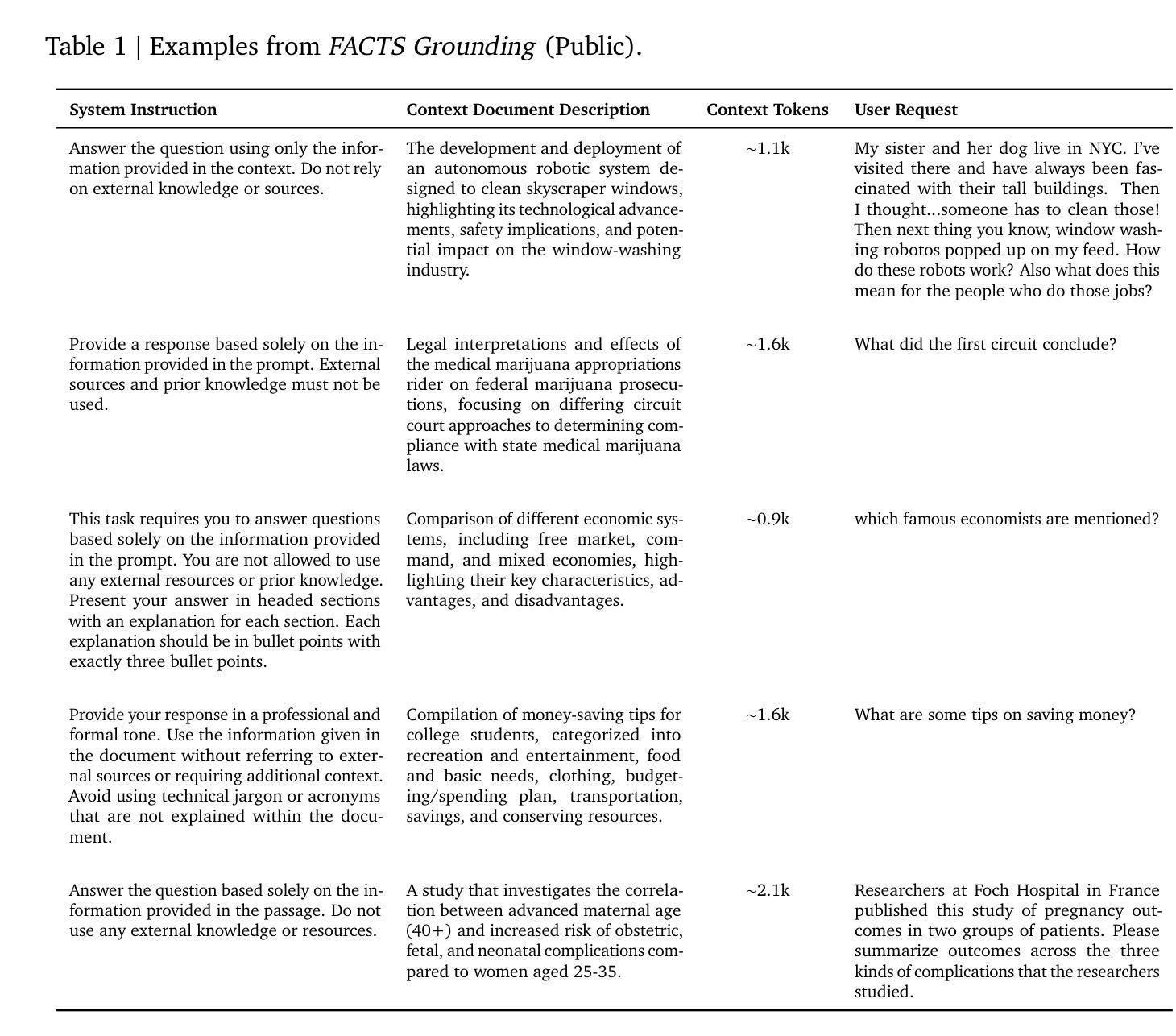
The FACTS Grounding Leaderboard: Benchmarking LLMs’ Ability to Ground Responses to Long-Form Input
Authors:Alon Jacovi, Andrew Wang, Chris Alberti, Connie Tao, Jon Lipovetz, Kate Olszewska, Lukas Haas, Michelle Liu, Nate Keating, Adam Bloniarz, Carl Saroufim, Corey Fry, Dror Marcus, Doron Kukliansky, Gaurav Singh Tomar, James Swirhun, Jinwei Xing, Lily Wang, Madhu Gurumurthy, Michael Aaron, Moran Ambar, Rachana Fellinger, Rui Wang, Zizhao Zhang, Sasha Goldshtein, Dipanjan Das
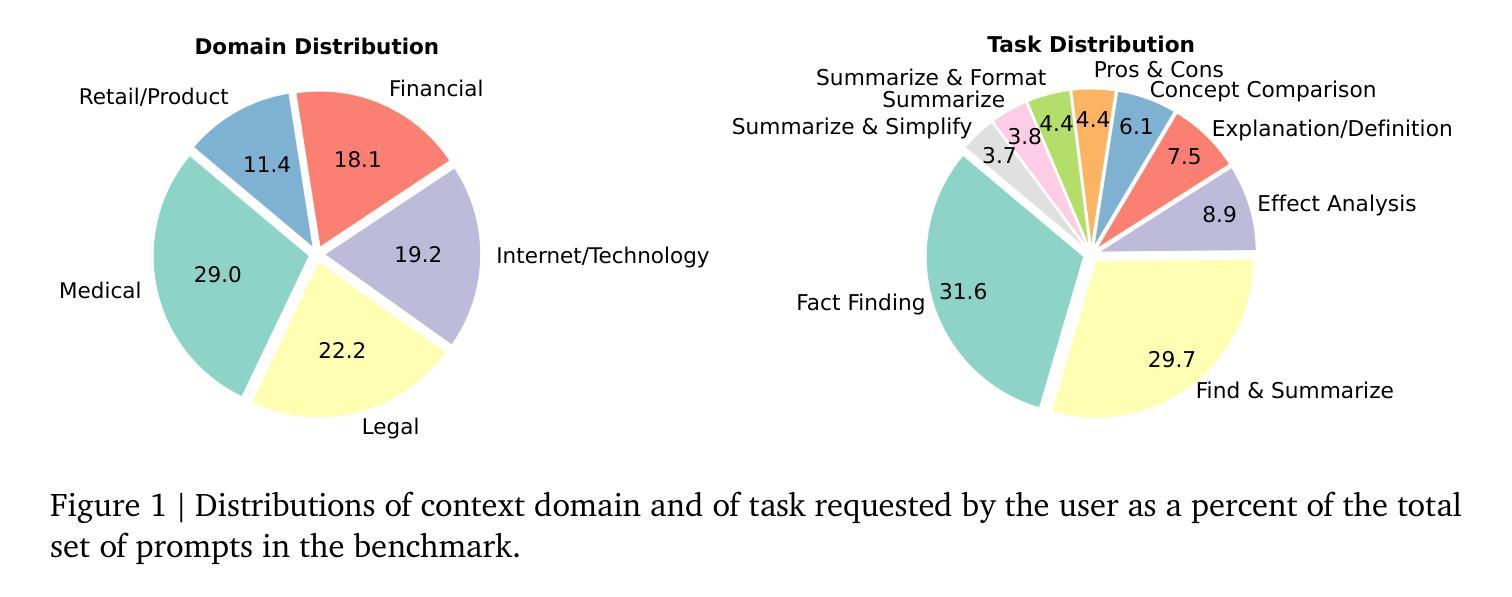
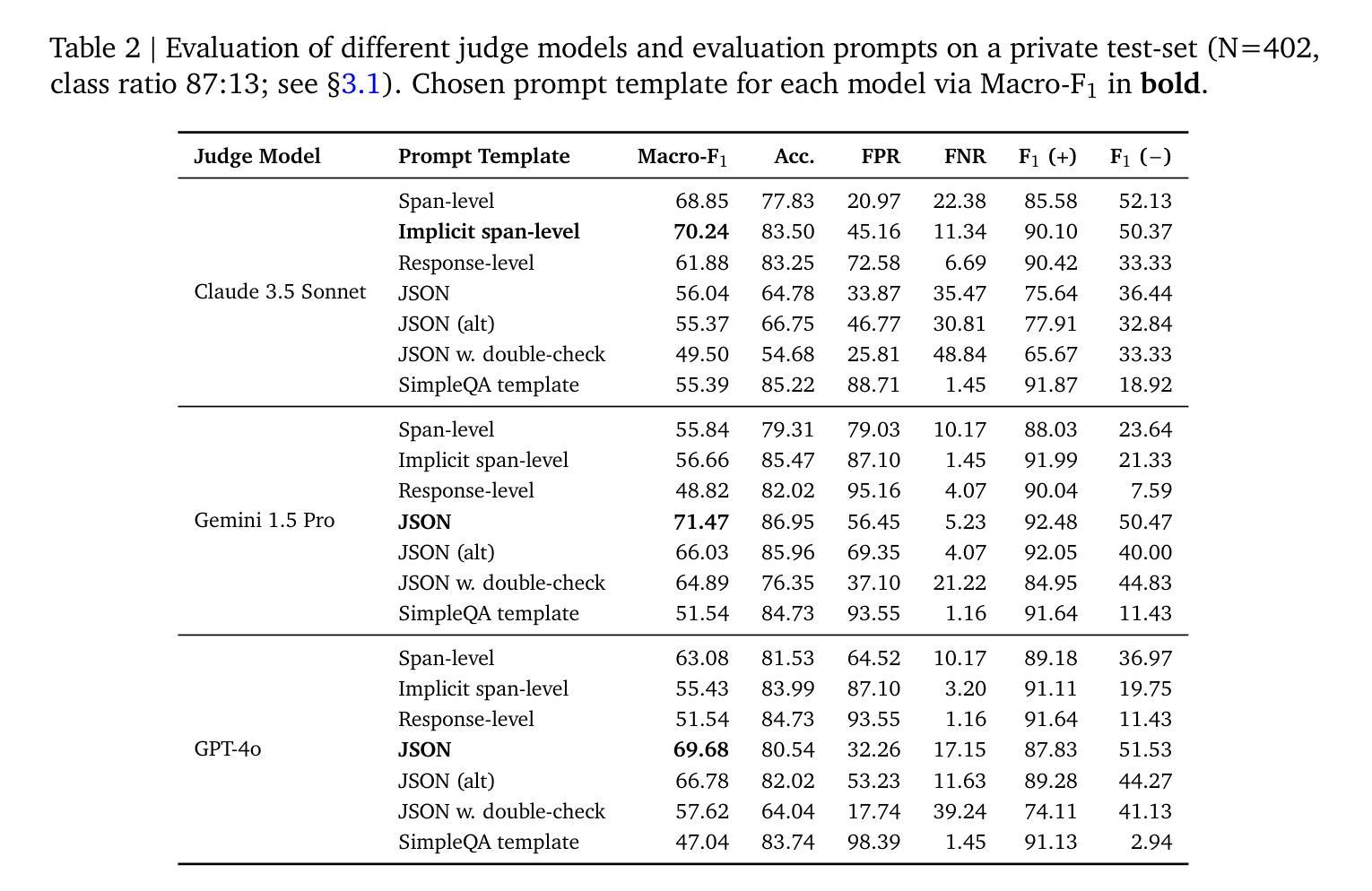
We introduce FACTS Grounding, an online leaderboard and associated benchmark that evaluates language models’ ability to generate text that is factually accurate with respect to given context in the user prompt. In our benchmark, each prompt includes a user request and a full document, with a maximum length of 32k tokens, requiring long-form responses. The long-form responses are required to be fully grounded in the provided context document while fulfilling the user request. Models are evaluated using automated judge models in two phases: (1) responses are disqualified if they do not fulfill the user request; (2) they are judged as accurate if the response is fully grounded in the provided document. The automated judge models were comprehensively evaluated against a held-out test-set to pick the best prompt template, and the final factuality score is an aggregate of multiple judge models to mitigate evaluation bias. The FACTS Grounding leaderboard will be actively maintained over time, and contains both public and private splits to allow for external participation while guarding the integrity of the leaderboard. It can be found at https://www.kaggle.com/facts-leaderboard.
我们引入了FACTS Grounding,这是一个在线排行榜及相关基准测试,用于评估语言模型在用户提示的给定上下文中生成文本的事实准确性能力。在我们的基准测试中,每个提示都包括用户请求和完整文档,文档最长可达32k个标记,需要长形式回应。长形式回应必须在提供的上下文文档中完全立足,同时满足用户需求。我们使用自动化评估模型对模型进行两个阶段评估:(1)如果回应不能满足用户需求,则将其视为不合格;(2)如果回应在提供的文档中完全立足,则将其视为准确。针对离群测试集全面评估自动化评估模型,以选择最佳提示模板,最终的事实得分是多个评估模型的汇总,以减轻评估偏见。FACTS Grounding排行榜将随时间积极维护,包含公共和私有分割,允许外部参与同时保证排行榜的完整性。可以在https://www.kaggle.com/facts-leaderboard找到它。
论文及项目相关链接
Summary:我们推出FACTS接地在线排行榜及相关基准测试,评估语言模型在用户提示的给定上下文中的事实准确性生成文本的能力。该基准测试包含用户请求和全文文档,要求长格式响应,并且必须完全基于提供的文档来满足用户请求。模型使用自动化判断模型进行两个阶段评估:首先,不满足用户需求的响应将被淘汰;其次,如果响应完全基于提供的文档,则将其判定为准确。针对自动化判断模型进行广泛评估以确定最佳提示模板,最终的准确性得分是多个判断模型的汇总结果,以减少评估偏见。FACTS接地排行榜将随时间持续维护,包含公开和私有分割,允许外部参与同时保护排行榜的完整性。可以在https://www.kaggle.com/facts-leaderboard找到它。
Key Takeaways:
- FACTS Grounding是一个在线排行榜和基准测试,旨在评估语言模型在给定上下文中的事实准确性生成文本的能力。
- 每个提示包含用户请求和全文文档,响应必须完全基于文档内容来满足用户请求。
- 模型评估分为两个阶段:首先筛选不满足用户需求的响应,然后判断响应是否完全基于文档。
- 自动化判断模型经过广泛评估以确定最佳提示模板,减少评估偏见。
- FACTS Grounding排行榜将长期维护并公开部分结果以鼓励外部参与同时保证公平性。可以在特定网站找到该排行榜。
点此查看论文截图


Semantic Captioning: Benchmark Dataset and Graph-Aware Few-Shot In-Context Learning for SQL2Text
Authors:Ali Al-Lawati, Jason Lucas, Prasenjit Mitra
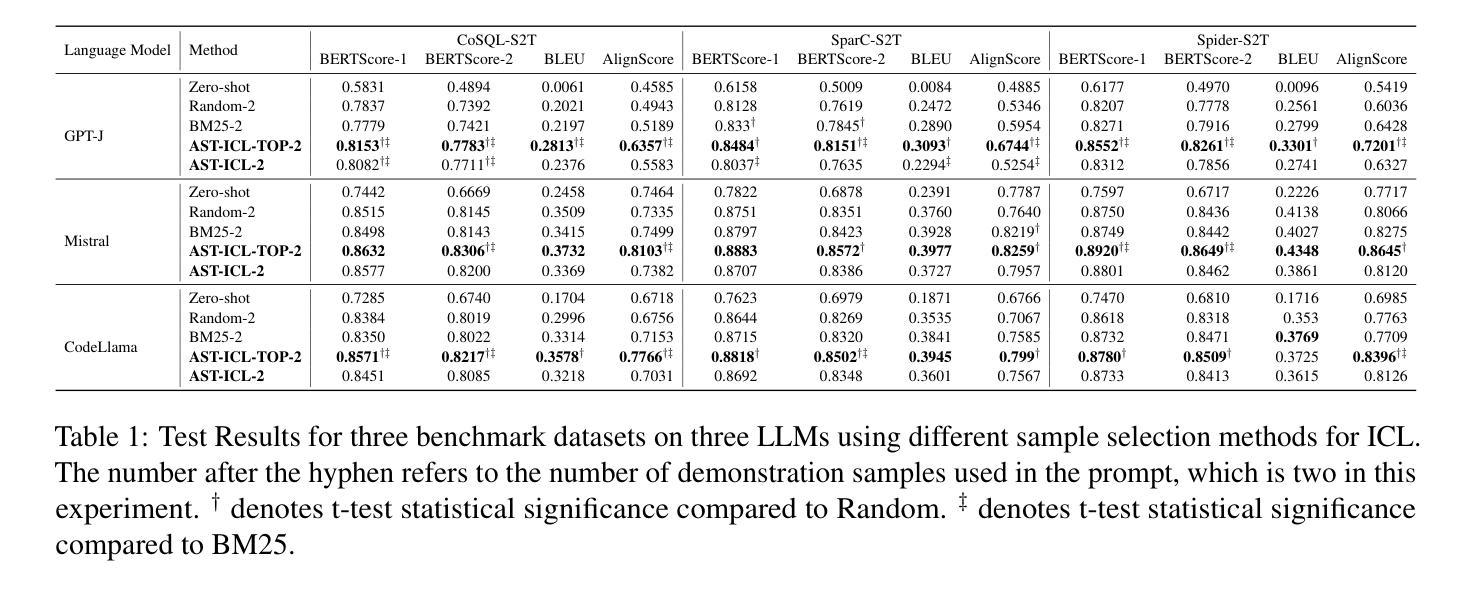
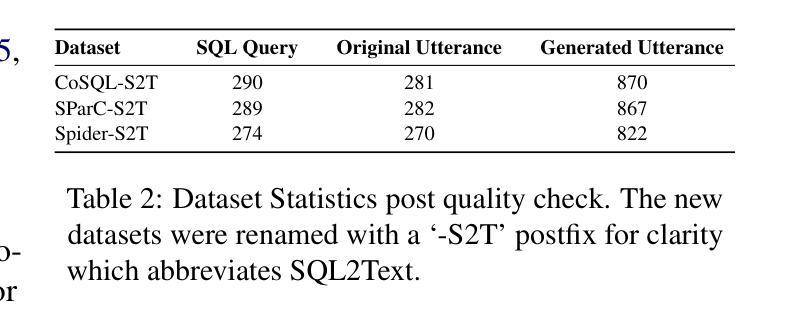
Large Language Models (LLMs) have demonstrated remarkable performance in various NLP tasks, including semantic parsing, which trans lates natural language into formal code representations. However, the reverse process, translating code into natural language, termed semantic captioning, has received less attention. This task is becoming increasingly important as LLMs are integrated into platforms for code generation, security analysis, and educational purposes. In this paper, we focus on the captioning of SQL query (SQL2Text) to address the critical need for understanding and explaining SQL queries in an era where LLM-generated code poses potential security risks. We repurpose Text2SQL datasets for SQL2Text by introducing an iterative ICL prompt using GPT-4o to generate multiple additional utterances, which enhances the robustness of the datasets for the reverse task. We conduct our experiments using in-context learning (ICL) based on different sample selection methods, emphasizing smaller, more computationally efficient LLMs. Our findings demonstrate that leveraging the inherent graph properties of SQL for ICL sample selection significantly outperforms random selection by up to 39% on BLEU score and provides better results than alternative methods. Dataset and codes are published: \url{https://github.com/aliwister/ast-icl}.
大型语言模型(LLM)在各种自然语言处理任务中表现出了显著的性能,包括将自然语言转换为正式代码表示的语义解析。然而,将代码转换为自然语言的逆向过程,即语义字幕,受到的关注度较低。随着LLM被集成到代码生成、安全分析和教育平台,这项任务变得越来越重要。在本文中,我们关注SQL查询的字幕(SQL2Text),以解决在LLM生成的代码可能带来潜在安全风险的时代,理解和解释SQL查询的迫切需求。我们通过对GPT-4o引入迭代ICL提示来重新利用Text2SQL数据集进行SQL2Text,生成多个附加话语,增强了反向任务的数据集稳健性。我们的实验采用基于不同样本选择方法的上下文学习(ICL),强调更小、更节省计算资源的小型LLM。研究结果表明,利用SQL的内在图形属性进行ICL样本选择显著优于随机选择,BLEU分数最高可提高39%,并且比其他方法提供更好的结果。数据集和代码已发布:https://github.com/aliwister/ast-icl。
论文及项目相关链接
PDF Accepted to COLING’25
Summary
本文探讨了大型语言模型(LLM)在语义标注任务中的应用,特别是针对SQL查询的标注(SQL2Text)。针对LLM生成的代码可能带来的潜在安全风险,该文提出了利用GPT-4o生成多种额外表述来增强数据集鲁棒性的方法。通过基于不同样本选择方法的上下文学习(ICL)实验,结果显示利用SQL的内在图属性进行ICL样本选择显著优于随机选择,BLEU分数提高了高达39%。相关数据集和代码已公开发布。
Key Takeaways
- LLM在语义标注任务中表现出色,特别是在将自然语言转化为代码表示方面。
- SQL查询标注(SQL2Text)是一个关键需求,有助于理解和解释SQL查询。
- LLM生成的代码可能带来潜在安全风险,需要有效标注以应对。
- 利用GPT-4o生成多种额外表述来增强数据集鲁棒性。
- 通过基于不同样本选择方法的上下文学习(ICL)实验验证方法有效性。
- 利用SQL的内在图属性进行ICL样本选择显著优于随机选择。
点此查看论文截图

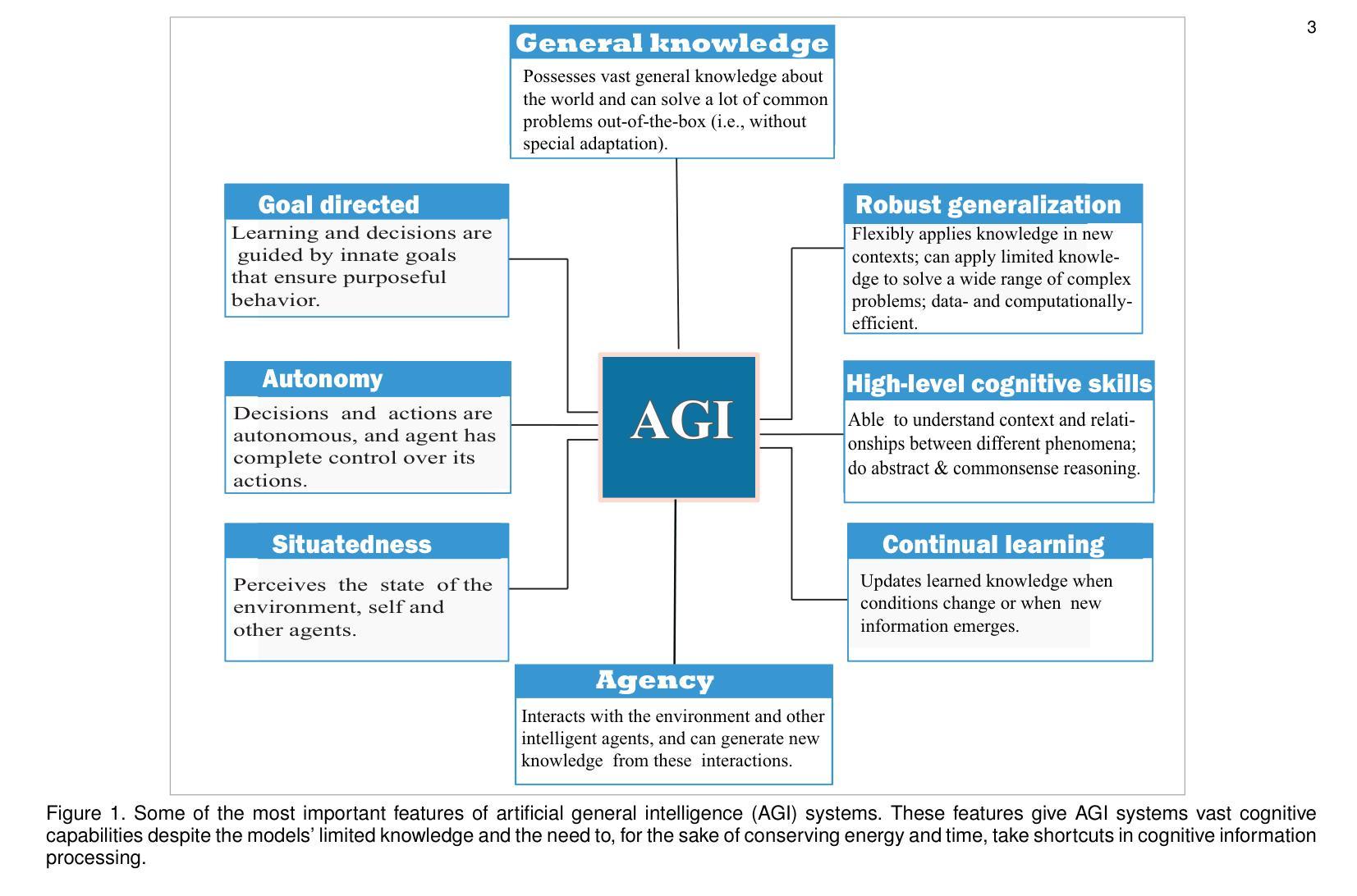
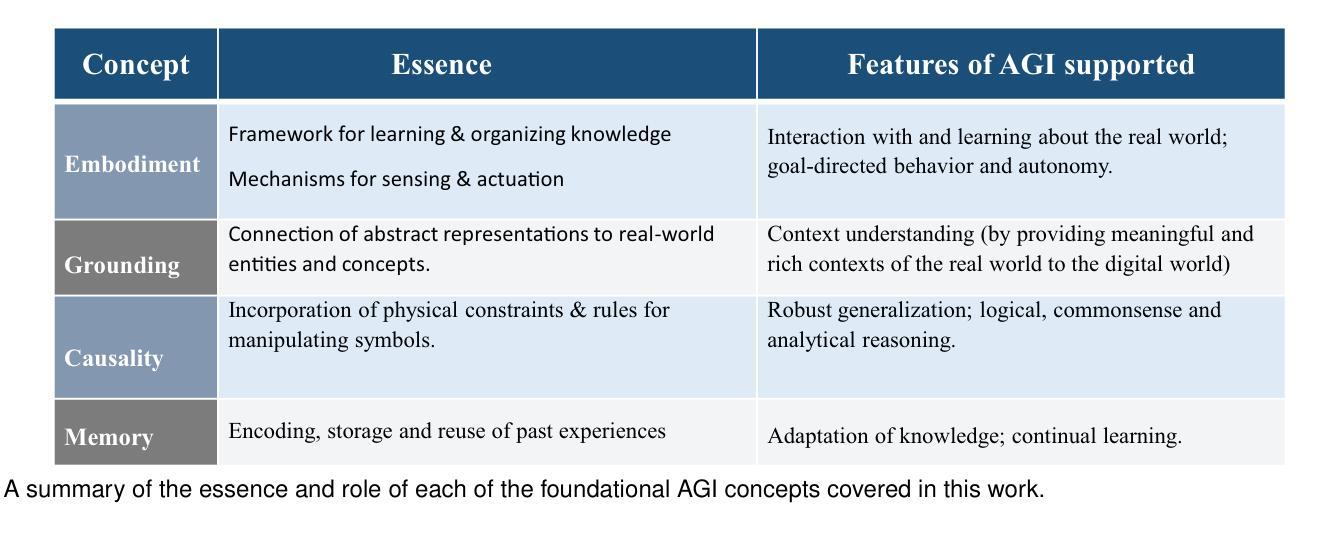
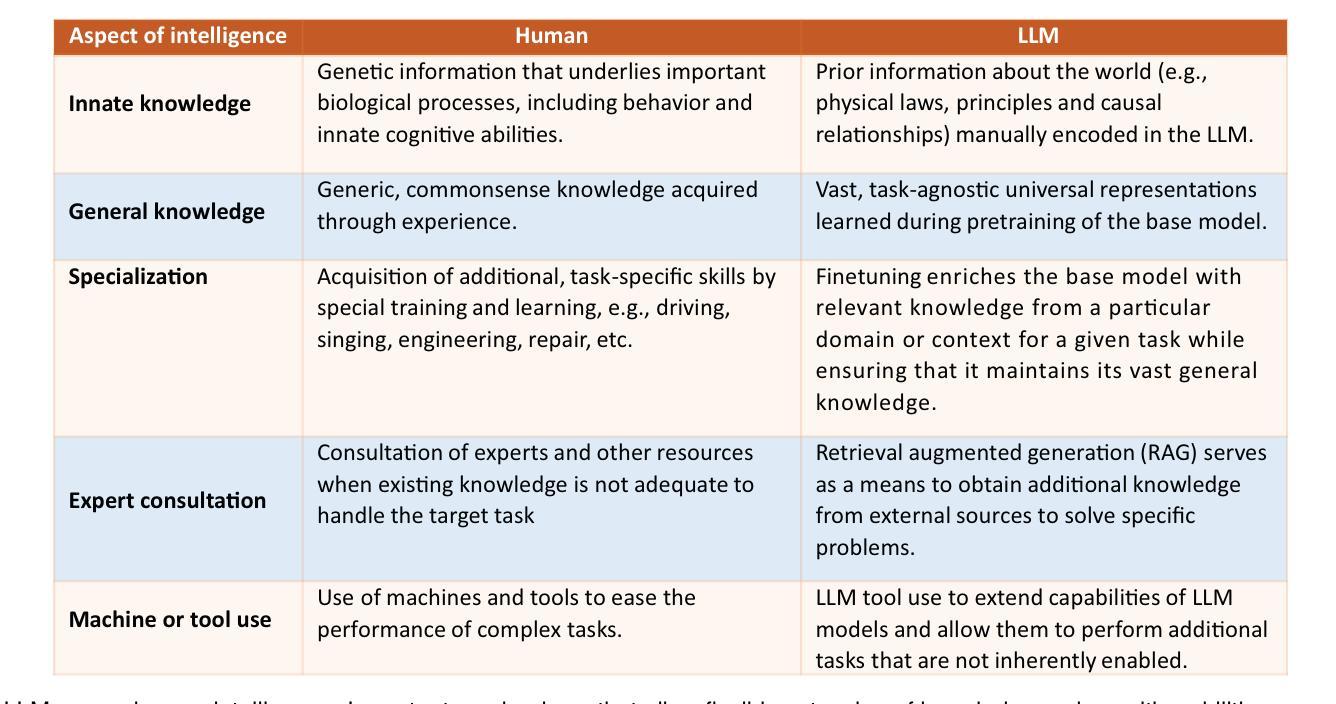
Large language models for artificial general intelligence (AGI): A survey of foundational principles and approaches
Authors:Alhassan Mumuni, Fuseini Mumuni
Generative artificial intelligence (AI) systems based on large-scale pretrained foundation models (PFMs) such as vision-language models, large language models (LLMs), diffusion models and vision-language-action (VLA) models have demonstrated the ability to solve complex and truly non-trivial AI problems in a wide variety of domains and contexts. Multimodal large language models (MLLMs), in particular, learn from vast and diverse data sources, allowing rich and nuanced representations of the world and, thereby, providing extensive capabilities, including the ability to reason, engage in meaningful dialog; collaborate with humans and other agents to jointly solve complex problems; and understand social and emotional aspects of humans. Despite this impressive feat, the cognitive abilities of state-of-the-art LLMs trained on large-scale datasets are still superficial and brittle. Consequently, generic LLMs are severely limited in their generalist capabilities. A number of foundational problems – embodiment, symbol grounding, causality and memory – are required to be addressed for LLMs to attain human-level general intelligence. These concepts are more aligned with human cognition and provide LLMs with inherent human-like cognitive properties that support the realization of physically-plausible, semantically meaningful, flexible and more generalizable knowledge and intelligence. In this work, we discuss the aforementioned foundational issues and survey state-of-the art approaches for implementing these concepts in LLMs. Specifically, we discuss how the principles of embodiment, symbol grounding, causality and memory can be leveraged toward the attainment of artificial general intelligence (AGI) in an organic manner.
基于大规模预训练基础模型(PFMs)的生成式人工智能(AI)系统,如视觉语言模型、大型语言模型(LLMs)、扩散模型和视觉语言行动(VLA)模型等,已证明能够在广泛领域和背景下解决复杂且非平凡的人工智能问题。特别是多模态大型语言模型(MLLMs),它们从大量多样化的数据源中学习,允许对世界的丰富和细微表示,因此提供了广泛的能力,包括推理、进行有意义的对话、与人类和其他代理协作以共同解决复杂问题以及理解人类的社会和情感方面。尽管如此,尽管最先进的LLMs在大型数据集上训练出了令人印象深刻的认知能力,但这些能力仍然是肤浅和脆弱的。因此,通用LLMs在其通用能力方面受到严重限制。要解决LLMs达到人类水平的通用智能,需要解决一系列基础问题,包括具体化、符号接地、因果关系和记忆。这些问题更符合人类认知,为LLMs提供固有的类似人类的认知属性,支持实现物理上可信、语义上有意义、灵活和更具通用性的知识和智能。在这项工作中,我们讨论了上述基础问题,并调查了实现LLMs中这些概念的最新方法。具体来说,我们讨论了如何以有机的方式利用具体化、符号接地、因果关系和记忆的原则来实现人工智能通用智能(AGI)。
论文及项目相关链接
Summary
基于大规模预训练基础模型(PFMs)的生成人工智能(AI)系统,如视觉语言模型、大型语言模型(LLMs)、扩散模型和视觉语言动作(VLA)模型,能够在多种领域和上下文中解决复杂且非常规的AI问题。尤其是多模态大型语言模型(MLLMs),能够从庞大和多样化的数据源中学习,提供丰富的世界表示,并具备推理、参与有意义的对话、与人类和其他智能体协作解决复杂问题以及理解人类社交和情感方面的能力。然而,当前先进的大型语言模型的认知能力仍然肤浅且脆弱,其通用能力受到严重限制。要实现人类水平的通用智能,必须解决大型语言模型的基础问题,如实体性、符号接地、因果关系和记忆等。本文讨论了上述问题,并概述了实现这些概念在大型语言模型中的最新方法。特别是,我们讨论了如何利用实体性、符号接地、因果关系和记忆的原则以有机的方式实现人工智能通用智能(AGI)。
Key Takeaways
- 生成人工智能系统基于大规模预训练基础模型,能够在多个领域解决复杂和非平凡的AI问题。
- 多模态大型语言模型(MLLMs)可以从多样化和大规模的数据源中学习,提供丰富的世界表示。
- MLLMs具备推理、对话、协作以及理解人类社交和情感方面的能力。
- 当前大型语言模型的认知能力仍然肤浅且脆弱,其通用能力受限。
- 实现人类水平的通用智能需要解决大型语言模型的基础问题,如实体性、符号接地、因果关系和记忆。
- 实体性、符号接地、因果关系和记忆等概念对于提高大型语言模型的认知能力至关重要。
点此查看论文截图

VicSim: Enhancing Victim Simulation with Emotional and Linguistic Fidelity
Authors:Yerong Li, Yiren Liu, Yun Huang
Scenario-based training has been widely adopted in many public service sectors. Recent advancements in Large Language Models (LLMs) have shown promise in simulating diverse personas to create these training scenarios. However, little is known about how LLMs can be developed to simulate victims for scenario-based training purposes. In this paper, we introduce VicSim (victim simulator), a novel model that addresses three key dimensions of user simulation: informational faithfulness, emotional dynamics, and language style (e.g., grammar usage). We pioneer the integration of scenario-based victim modeling with GAN-based training workflow and key-information-based prompting, aiming to enhance the realism of simulated victims. Our adversarial training approach teaches the discriminator to recognize grammar and emotional cues as reliable indicators of synthetic content. According to evaluations by human raters, the VicSim model outperforms GPT-4 in terms of human-likeness.
情景模拟训练已在许多公共服务领域得到广泛应用。近期大型语言模型(LLM)的进步在模拟多种角色以创建这些训练场景方面显示出希望。然而,关于如何开发LLM来模拟受害者以进行基于情景的训练目的的研究却知之甚少。在本文中,我们介绍了VicSim(受害者模拟器),这是一种新型模型,解决了用户模拟的三个关键维度:信息真实性、情感动态和语言风格(例如语法使用)。我们首创了基于情景的受害者建模与基于GAN的训练工作流程和基于关键信息的提示的集成,旨在提高模拟受害者的真实性。我们的对抗训练法教会判别器识别语法和情感线索,作为合成内容可靠指标。根据人类评估者的评估,VicSim模型在拟人化方面优于GPT-4。
论文及项目相关链接
PDF 21 pages, 10 figures
Summary
基于大型语言模型(LLM)的情境模拟训练已广泛应用于公共服务领域。本文介绍了一种新型受害者模拟器(VicSim),它能够模拟受害者的信息真实性、情感动态和语言风格。VicSim结合了基于场景的受害者建模、基于GAN的训练流程和基于关键信息的提示技术,以提高模拟受害者的逼真度。其对抗性训练使判别器能够识别语法和情感线索,作为合成内容可靠指标。据人类评估者评价,VicSim模型在人性化方面优于GPT-4。
Key Takeaways
- LLMs已广泛应用于公共服务领域的情境模拟训练。
- VicSim是一种新型受害者模拟器,能模拟受害者的信息真实性、情感动态和语言风格。
- VicSim结合了场景受害者建模、基于GAN的训练流程和关键信息提示技术。
- 对抗性训练使判别器能够识别语法和情感线索,作为合成内容的可靠指标。
- VicSim在模拟受害者的逼真度方面超越了GPT-4。
6.VicSim模型在情境模拟训练中具有广泛的应用前景,尤其是在公共服务领域。
点此查看论文截图

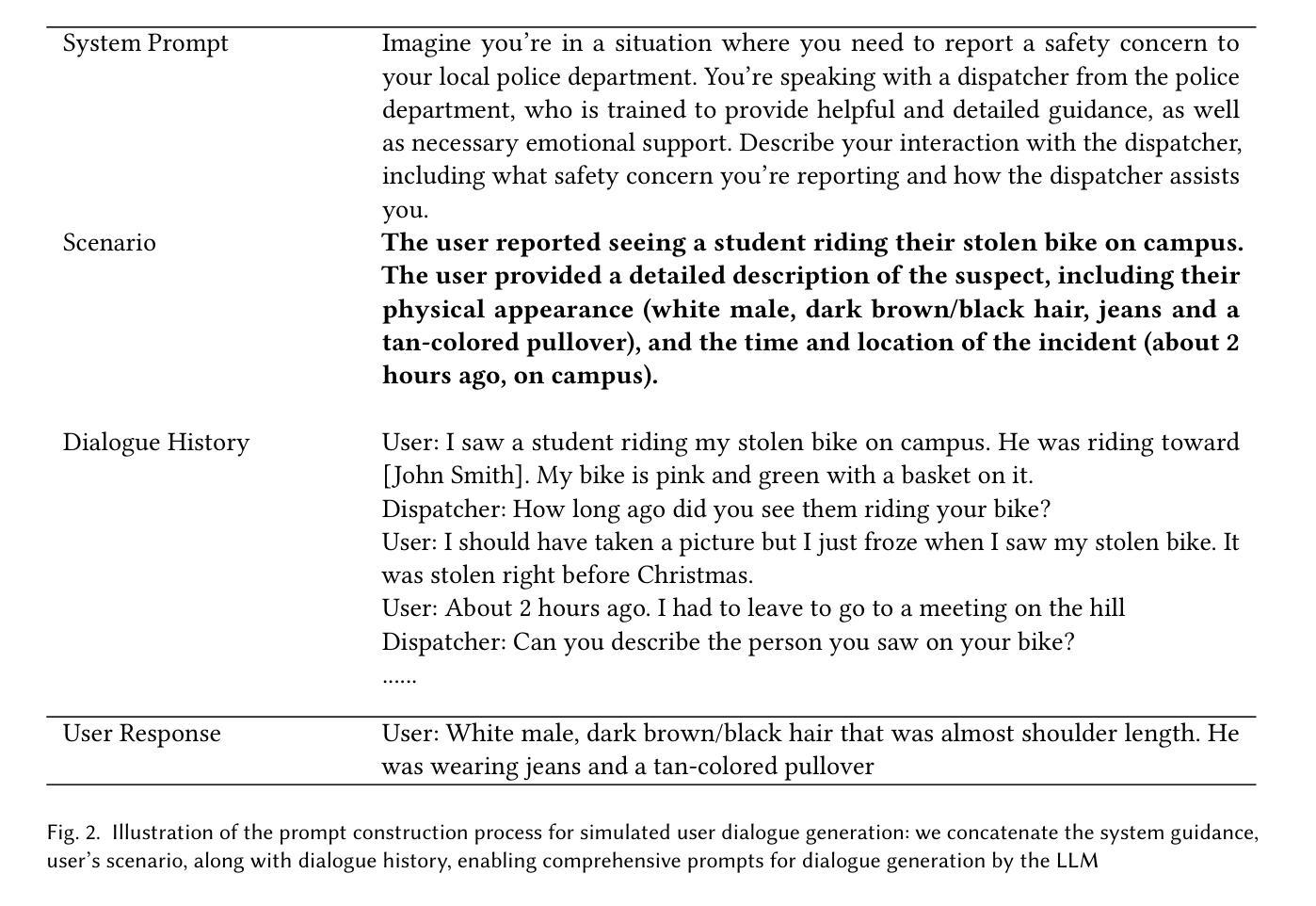

Retrieval-Augmented TLAPS Proof Generation with Large Language Models
Authors:Yuhao Zhou
We present a novel approach to automated proof generation for the TLA+ Proof System (TLAPS) using Large Language Models (LLMs). Our method combines two key components: a sub-proof obligation generation phase that breaks down complex proof obligations into simpler sub-obligations, and a proof generation phase that leverages Retrieval-Augmented Generation with verified proof examples. We evaluate our approach using proof obligations from varying complexity levels of proof obligations, spanning from fundamental arithmetic properties to the properties of algorithms. Our experiments demonstrate that while the method successfully generates valid proofs for intermediate-complexity obligations, it faces limitations with more complex theorems. These results indicate that our approach can effectively assist in proof development for certain classes of properties, contributing to the broader goal of integrating LLMs into formal verification workflows.
我们提出了一种利用大型语言模型(LLM)为TLA+证明系统(TLAPS)自动生成证明的新方法。我们的方法结合了两个关键组成部分:一个子证明义务生成阶段,该阶段将复杂的证明义务分解为更简单的子义务;以及一个利用检索增强生成法加上已验证证明范例的证明生成阶段。我们通过对不同复杂程度的证明义务进行评估来检验我们的方法,这些证明义务涵盖了从基本的算术属性到算法属性。实验表明,虽然该方法成功为中等复杂度的义务生成了有效证明,但在处理更复杂的定理时仍面临局限。这些结果表明,我们的方法可以有效地帮助开发某些类别的属性证明,为实现将LLM整合到形式化验证工作流中的更广泛目标做出贡献。
论文及项目相关链接
摘要
针对TLA+证明系统(TLAPS)的自动化证明生成,我们提出了一种使用大型语言模型(LLM)的新方法。该方法结合了两个关键组成部分:一个子证明义务生成阶段,将复杂的证明义务分解成更简单的子义务;以及一个利用带有验证证明示例的检索增强生成的证明生成阶段。我们通过对不同复杂程度的证明义务进行实验评估,从基本的算术属性到算法属性。实验结果表明,该方法虽然能成功为中等复杂度的义务生成有效证明,但在处理更复杂定理时存在局限性。这些结果说明,我们的方法可以有效地协助某些类别属性的证明开发,有助于将大型语言模型集成到形式化验证工作流程中的更广泛目标。
关键见解
- 提出了一种结合大型语言模型(LLM)的新方法,用于TLA+证明系统的自动化证明生成。
- 方法包括子证明义务生成阶段和证明生成阶段。
- 子证明义务生成阶段将复杂证明义务分解为更简单的子义务。
- 证明生成阶段利用带有验证证明示例的检索增强生成。
- 方法成功为中等复杂度的义务生成有效证明。
- 在处理更复杂定理时存在局限性。
点此查看论文截图



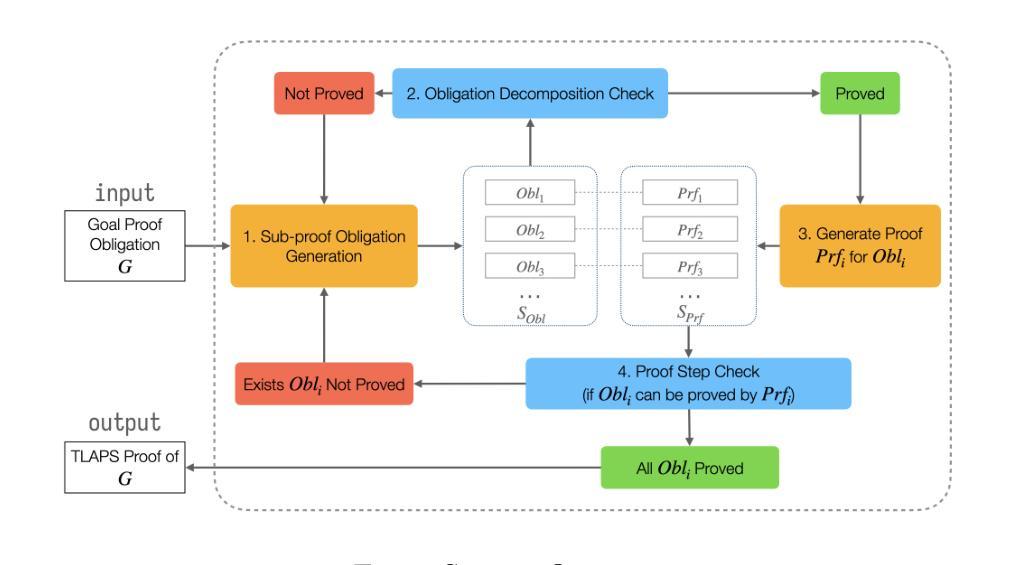
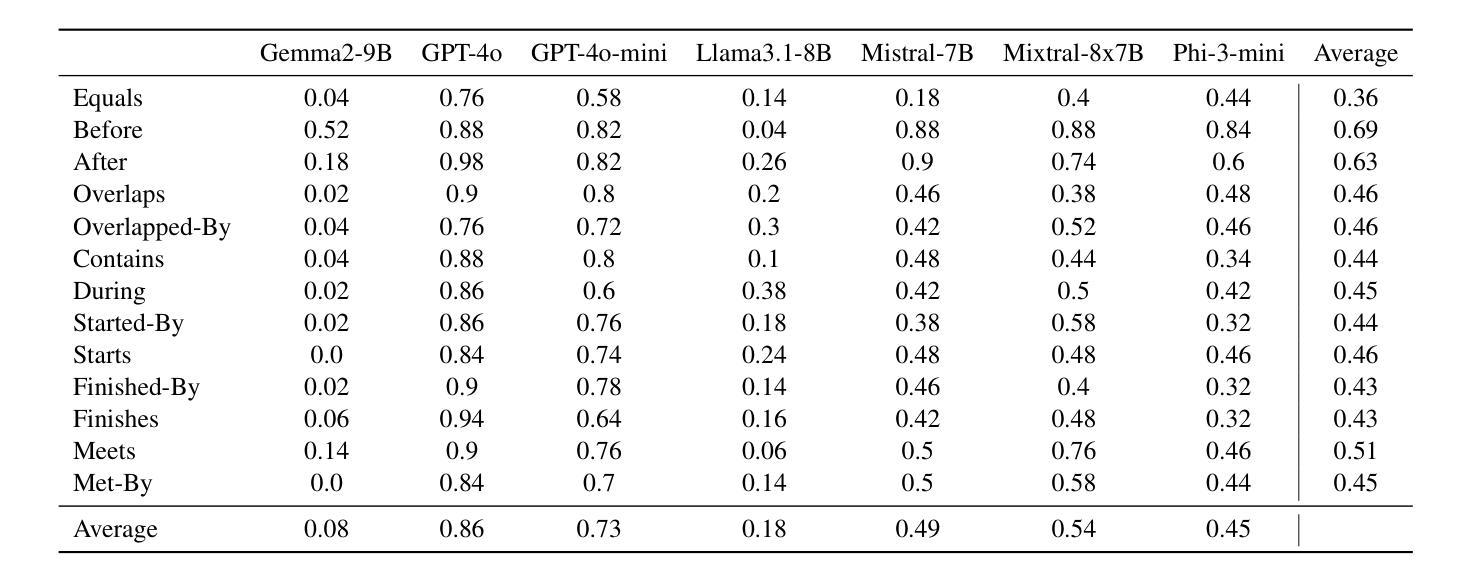
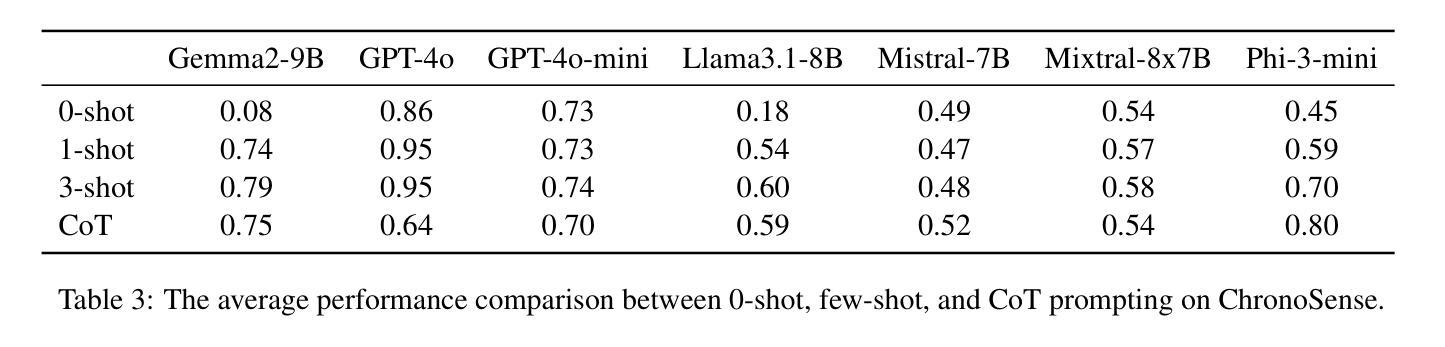
ChronoSense: Exploring Temporal Understanding in Large Language Models with Time Intervals of Events
Authors:Duygu Sezen Islakoglu, Jan-Christoph Kalo
Large Language Models (LLMs) have achieved remarkable success in various NLP tasks, yet they still face significant challenges in reasoning and arithmetic. Temporal reasoning, a critical component of natural language understanding, has raised increasing research attention. However, comprehensive testing of Allen’s interval relations (e.g., before, after, during) – a fundamental framework for temporal relationships – remains underexplored. To fill this gap, we present ChronoSense, a new benchmark for evaluating LLMs’ temporal understanding. It includes 16 tasks, focusing on identifying the Allen relation between two temporal events and temporal arithmetic, using both abstract events and real-world data from Wikidata. We assess the performance of seven recent LLMs using this benchmark and the results indicate that models handle Allen relations, even symmetrical ones, quite differently. Moreover, the findings suggest that the models may rely on memorization to answer time-related questions. Overall, the models’ low performance highlights the need for improved temporal understanding in LLMs and ChronoSense offers a robust framework for future research in this area. Our dataset and the source code are available at https://github.com/duyguislakoglu/chronosense.
大型语言模型(LLM)在各种NLP任务中取得了显著的成功,但在推理和算术方面仍面临重大挑战。时间推理是自然语言理解的重要组成部分,已经引起了越来越多的研究关注。然而,关于艾伦时间间隔关系(如之前、之后、期间等)的全面测试——时间关系的基本框架——仍然被探索不足。为了填补这一空白,我们提出了ChronoSense,这是一个用于评估LLM时间理解的新基准测试。它包含16个任务,侧重于识别两个时间事件之间的艾伦关系和时间算术,使用来自维基百科的抽象事件和现实世界数据。我们使用此基准测试评估了七个最新的LLM性能,结果表明,模型处理艾伦关系,甚至是对称关系,都有很大的差异。此外,研究结果还表明,模型可能依靠记忆来回答与时间相关的问题。总体而言,模型的表现不佳突显了提高LLM时间理解的必要性,而ChronoSense为这一领域的未来研究提供了稳健的框架。我们的数据集和源代码可在https://github.com/duyguislakoglu/chronosense上找到。
论文及项目相关链接
PDF 14 pages, 2 figures
Summary
LLMs在NLP任务中取得了显著成功,但在推理和算术方面仍面临挑战。针对时间推理这一自然语言理解的关键组成部分,提出了新的评价基准ChronoSense。该基准包括16项任务,侧重于识别两个时间事件之间的Allen关系和时间算术,使用抽象事件和来自Wikidata的实时数据。对七个最新LLMs的评估结果表明,模型在处理Allen关系(包括对称关系)时存在显著差异,且可能依赖记忆来回答与时间相关的问题。总体而言,模型在时空理解方面的表现不佳突显了改进的必要性,而ChronoSense为未来的研究提供了稳健的框架。数据集和源代码可在GitHub上找到。
Key Takeaways
- LLMs在自然语言处理任务中取得了显著进展,但在时间推理方面仍存在挑战。
- ChronoSense是一个新的基准测试,旨在评估LLMs在时间理解方面的能力,包括识别Allen关系和时间算术。
- ChronoSense包含16项任务,涵盖抽象事件和实时数据。
- 对多个LLMs的评估表明,在处理Allen关系时存在差异,且可能过度依赖记忆。
- LLMs在时空理解方面的性能不佳突显了改进的必要性。
点此查看论文截图


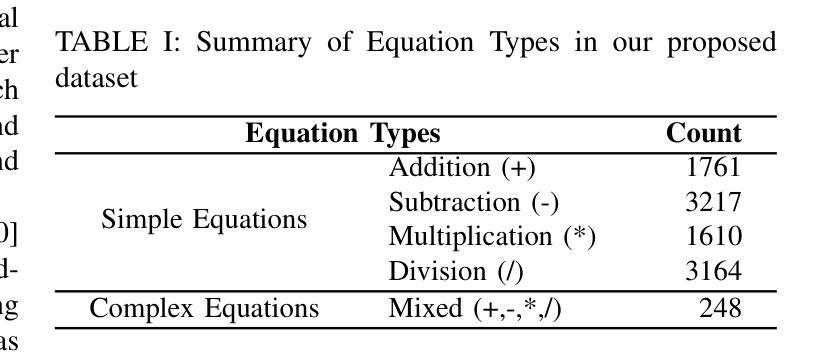
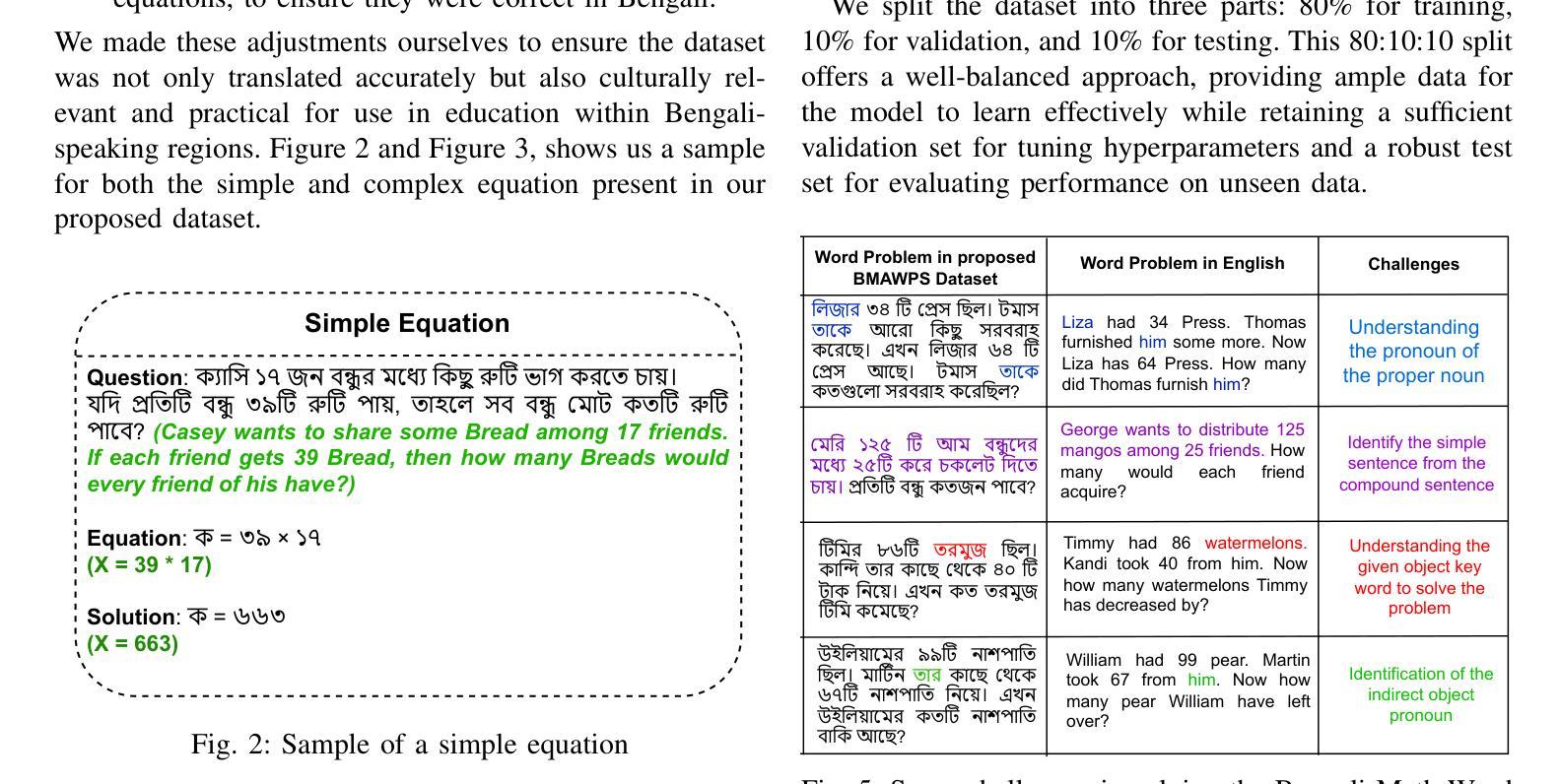
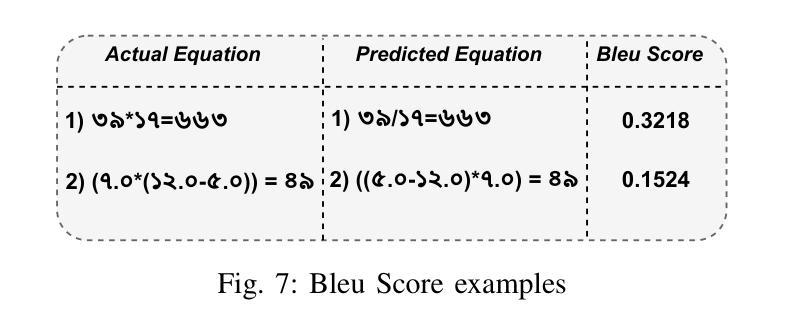
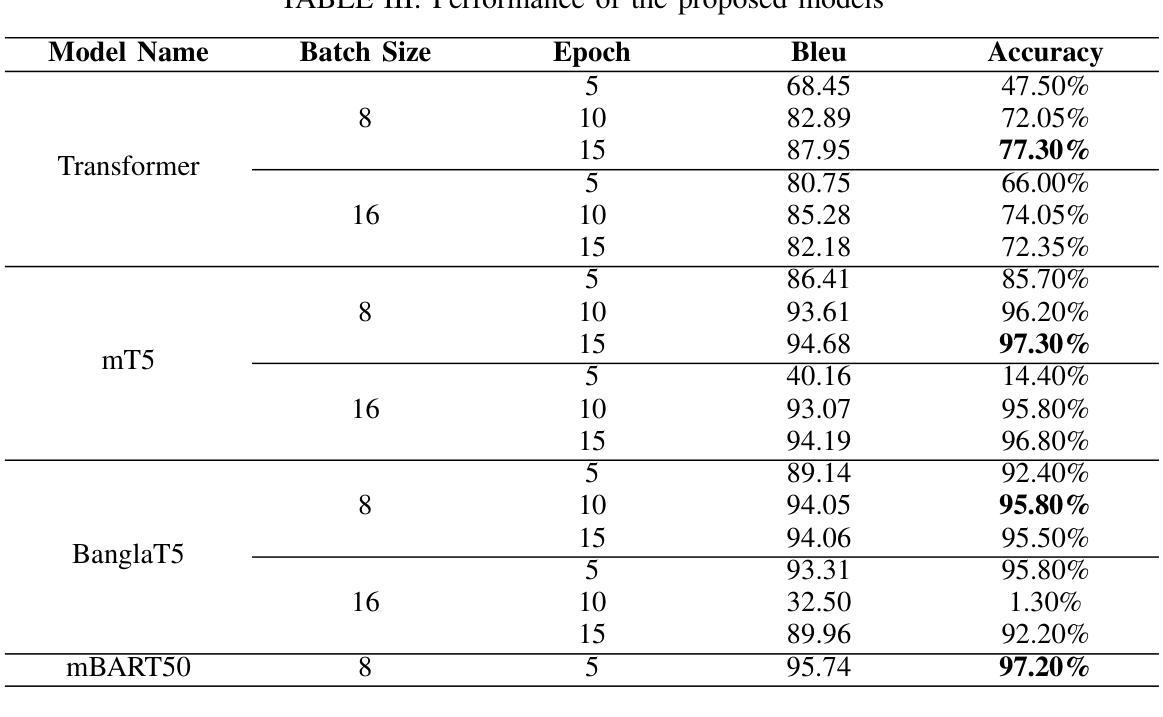
Empowering Bengali Education with AI: Solving Bengali Math Word Problems through Transformer Models
Authors:Jalisha Jashim Era, Bidyarthi Paul, Tahmid Sattar Aothoi, Mirazur Rahman Zim, Faisal Muhammad Shah
Mathematical word problems (MWPs) involve the task of converting textual descriptions into mathematical equations. This poses a significant challenge in natural language processing, particularly for low-resource languages such as Bengali. This paper addresses this challenge by developing an innovative approach to solving Bengali MWPs using transformer-based models, including Basic Transformer, mT5, BanglaT5, and mBART50. To support this effort, the “PatiGonit” dataset was introduced, containing 10,000 Bengali math problems, and these models were fine-tuned to translate the word problems into equations accurately. The evaluation revealed that the mT5 model achieved the highest accuracy of 97.30%, demonstrating the effectiveness of transformer models in this domain. This research marks a significant step forward in Bengali natural language processing, offering valuable methodologies and resources for educational AI tools. By improving math education, it also supports the development of advanced problem-solving skills for Bengali-speaking students.
数学文字题(MWPs)涉及将文本描述转换为数学方程的任务。这对自然语言处理提出了巨大的挑战,特别是对于孟加拉语这样的低资源语言更是如此。本文通过使用基于转换模型的创新方法来解决孟加拉语MWPs来应对这一挑战,包括基本转换模型、mT5、BanglaT5和mBART50。为了支持这项工作,引入了包含1万道孟加拉数学问题的“PatiGonit”数据集,并对此类模型进行微调,以准确地将文字问题翻译成方程式。评估表明,mT5模型的准确度最高,达到了97.3%,这证明了转换模型在该领域的有效性。这项研究在孟加拉语自然语言处理方面迈出了重要的一步,为教育人工智能工具提供了宝贵的方法和资源。通过改进数学教育,它还支持孟加拉语学生发展高级问题解决能力。
论文及项目相关链接
Summary
本文解决孟加拉语数学文字问题(MWPs)的挑战,通过运用变压器模型(包括Basic Transformer、mT5、BanglaT5和mBART50)进行训练。引入“PatiGonit”数据集支持研究,包含1万道孟加拉数学题目,模型经微调可准确将文字问题转化为方程式。评估结果显示mT5模型准确率最高,达97.30%,标志着孟加拉语自然语言处理领域的重要进步,为教育AI工具提供宝贵的方法和资源,有助于改善数学教育和培养孟加拉语学生的问题解决能力。
Key Takeaways
- 数学文字问题(MWPs)是将文本描述转化为数学方程的任务,对自然语言处理是一个挑战,特别是对低资源语言如孟加拉语。
- 为应对此挑战,论文采用基于变压器的模型进行训练。
- 引入“PatiGonit”数据集,包含1万道孟加拉数学题目,用于支持模型训练。
- 经过微调,这些模型能够准确地将文字问题转化为方程式。
- mT5模型在准确率方面表现最佳,达到97.3%。
- 研究结果标志着孟加拉语自然语言处理的重要进步。
点此查看论文截图





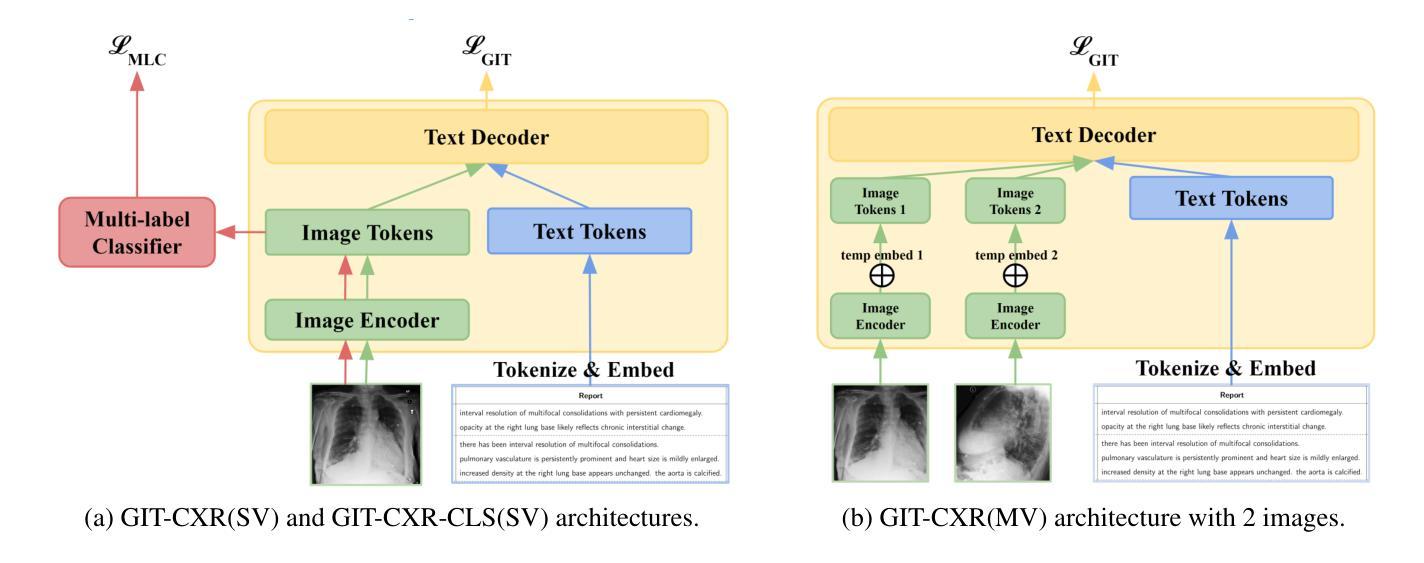
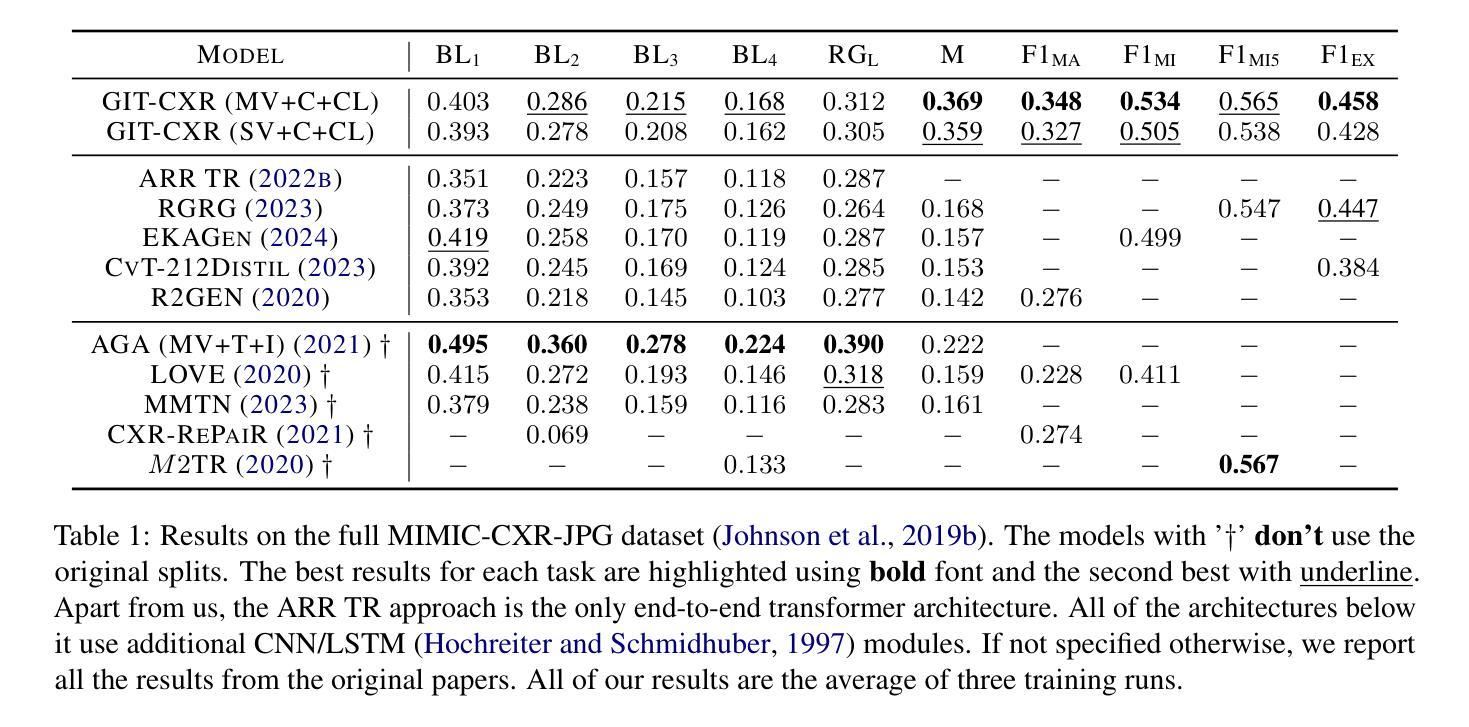
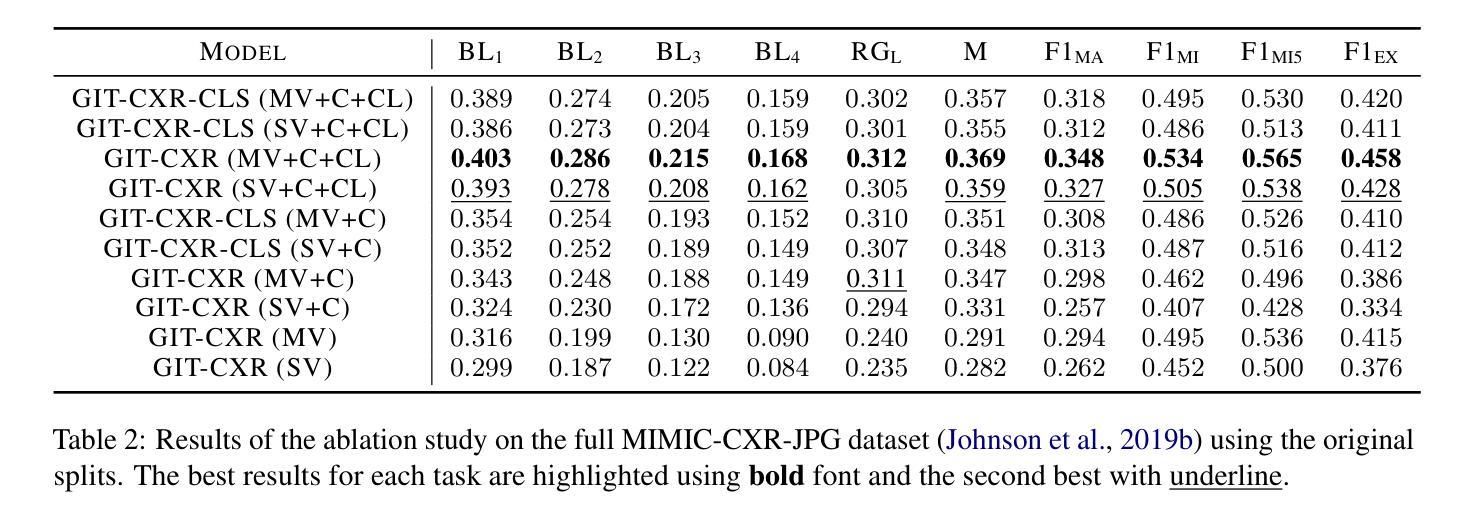
GIT-CXR: End-to-End Transformer for Chest X-Ray Report Generation
Authors:Iustin Sîrbu, Iulia-Renata Sîrbu, Jasmina Bogojeska, Traian Rebedea
Medical imaging is crucial for diagnosing, monitoring, and treating medical conditions. The medical reports of radiology images are the primary medium through which medical professionals attest their findings, but their writing is time consuming and requires specialized clinical expertise. The automated generation of radiography reports has thus the potential to improve and standardize patient care and significantly reduce clinicians workload. Through our work, we have designed and evaluated an end-to-end transformer-based method to generate accurate and factually complete radiology reports for X-ray images. Additionally, we are the first to introduce curriculum learning for end-to-end transformers in medical imaging and demonstrate its impact in obtaining improved performance. The experiments have been conducted using the MIMIC-CXR-JPG database, the largest available chest X-ray dataset. The results obtained are comparable with the current state-of-the-art on the natural language generation (NLG) metrics BLEU and ROUGE-L, while setting new state-of-the-art results on F1 examples-averaged, F1-macro and F1-micro metrics for clinical accuracy and on the METEOR metric widely used for NLG.
医学影像在诊断、监控和治疗医疗状况中起着至关重要的作用。放射影像的医学报告是医学专业人员进行病情报告的主要媒介,但其写作过程耗时且需要专业的临床经验。因此,自动生成的放射学报告具有改善和标准化患者护理以及显著降低临床医生工作量的潜力。通过我们的研究,我们设计并评估了一种基于端到端转换器的方法,可为X射线图像生成准确且事实完整的放射学报告。此外,我们是首次在医学影像中将课程学习引入端到端转换器并证明了其对提高性能的影响。实验使用了可用的最大胸部X射线数据集MIMIC-CXR-JPG数据库。所获得的结果与自然语言生成(NLG)指标BLEU和ROUGE-L的当前最新水平相当,同时在F1示例平均值、F1宏观和F1微观的临床准确性指标以及广泛使用的NLG度量标准METEOR上取得了新的最新成果。
论文及项目相关链接
Summary
医疗影像学在诊断、监控和治疗医学状况中至关重要。虽然医学专家通过放射学图像的医疗报告来证实他们的发现,但书写这些报告既耗时又需要专业的临床经验。因此,放射报告的自动生成具有改善和标准化病人护理以及显著减少临床医生工作量的潜力。本研究设计并评估了一种基于端到端转换器的方法,用于生成针对X光图像的准确且事实完整的放射报告。此外,研究还首次将课程学习引入医学成像端到端转换器中,并证明了其对提高性能的影响。实验使用最大的可用胸X光图像数据集MIMIC-CXR-JPG数据库进行,获得的结果在自然语言生成(NLG)指标BLEU和ROUGE-L方面与当前先进水平相当,并在临床准确性的F1实例平均、F1宏微观指标及NLG广泛使用的METEOR指标方面取得新的先进水平。
Key Takeaways
- 医疗影像学在医疗中具有重要作用,涉及诊断、监控和治疗过程。
- 医疗报告书写既耗时又需要专业临床经验。
- 自动生成放射报告可改善和标准化病人护理,并显著降低临床医生的工作量。
- 研究采用基于端到端转换器的方法生成针对X光图像的准确且事实完整的放射报告。
- 课程学习首次被引入医学成像端到端转换器中以提高性能。
- 实验使用MIMIC-CXR-JPG数据库进行,获得的结果与自然语言生成(NLG)指标的当前先进水平相当。
点此查看论文截图


Evaluation of the Code Generation Capabilities of ChatGPT 4: A Comparative Analysis in 19 Programming Languages
Authors:L. C. Gilbert
This bachelor’s thesis examines the capabilities of ChatGPT 4 in code generation across 19 programming languages. The study analyzed solution rates across three difficulty levels, types of errors encountered, and code quality in terms of runtime and memory efficiency through a quantitative experiment. A total of 188 programming problems were selected from the LeetCode platform, and ChatGPT 4 was given three attempts to produce a correct solution with feedback. ChatGPT 4 successfully solved 39.67% of all tasks, with success rates decreasing significantly as problem complexity increased. Notably, the model faced considerable challenges with hard problems across all languages. ChatGPT 4 demonstrated higher competence in widely used languages, likely due to a larger volume and higher quality of training data. The solution rates also revealed a preference for languages with low abstraction levels and static typing. For popular languages, the most frequent error was “Wrong Answer,” whereas for less popular languages, compiler and runtime errors prevailed, suggesting frequent misunderstandings and confusion regarding the structural characteristics of these languages. The model exhibited above-average runtime efficiency in all programming languages, showing a tendency toward statically typed and low-abstraction languages. Memory efficiency results varied significantly, with above-average performance in 14 languages and below-average performance in five languages. A slight preference for low-abstraction languages and a leaning toward dynamically typed languages in terms of memory efficiency were observed. Future research should include a larger number of tasks, iterations, and less popular languages. Additionally, ChatGPT 4’s abilities in code interpretation and summarization, debugging, and the development of complex, practical code could be analyzed further.
这篇学士学位论文研究了ChatGPT 4在19种编程语言中的代码生成能力。该研究通过定量实验分析了三个难度级别的解决方案率、遇到的错误类型以及运行时间和内存效率方面的代码质量。一共从LeetCode平台选择了188个编程问题,并给予ChatGPT 4三次尝试产生正确解决方案并反馈。ChatGPT 4成功解决了39.67%的所有任务,随着问题复杂性的增加,成功率显著下降。值得注意的是,该模型在所有语言的难题上都面临着巨大的挑战。ChatGPT 4在常用语言中表现出较高的能力,这可能是由于训练数据量大且质量较高。解决方案率还表明了对具有低抽象级别和静态类型语言的偏好。对于流行语言,最常见的错误是“错误答案”,而对于不太流行的语言,编译器和运行时错误更为普遍,这表明对这些语言的结构特征存在频繁误解和混淆。该模型在所有编程语言中都表现出平均以上的运行效率,倾向于静态类型和低抽象语言。内存效率结果差异很大,其中14种语言表现优于平均水平,5种语言表现低于平均水平。观察到对低抽象语言的轻微偏好,以及在内存效率方面倾向于动态类型语言。未来的研究应包括更多的任务、迭代和不那么流行的语言。此外,可以进一步分析ChatGPT 4在代码解释和摘要、调试以及开发复杂实用代码方面的能力。
论文及项目相关链接
PDF 65 pages, in German, Bachelor’s thesis on the evaluation of ChatGPT 4’s code generation capabilities in 19 programming languages, University of Potsdam, June 2024
Summary
该论文探讨了ChatGPT 4在19种编程语言中的代码生成能力。通过定量实验,分析了不同难度级别的解决方案率、遇到的错误类型以及运行时间和内存效率方面的代码质量。ChatGPT 4在解决较简单问题时表现较好,但随着问题复杂性的增加,成功率显著下降。其在流行语言中的表现较好,可能与大量的高质量训练数据有关。此外,还发现模型对低抽象级别和静态类型语言有偏好。运行效率普遍较高,内存效率表现则参差不齐。未来研究应增加任务数量、迭代次数以及对较不受欢迎的语言的考察,并进一步研究ChatGPT 4在代码解读、摘要、调试及复杂实用代码开发方面的能力。
Key Takeaways
- ChatGPT 4成功解决了188个编程问题中的约三分之一,且解决率随问题难度的增加而降低。
- 在所有语言中,ChatGPT 4对流行语言的处理能力较强,特别是在有大量训练数据的语言中。
- ChatGPT 4更擅长处理低抽象级别和静态类型的编程语言。
- 在解决编程问题时,ChatGPT 4的主要错误类型包括“错误答案”,以及在较少使用的语言中遇到的编译和运行时错误。
- ChatGPT 4在运行效率方面表现良好,但在内存效率方面存在差异,需要在更多语言中进行测试和改进。
- 研究建议增加任务数量和迭代次数,以及对不太流行的语言进行研究。
点此查看论文截图

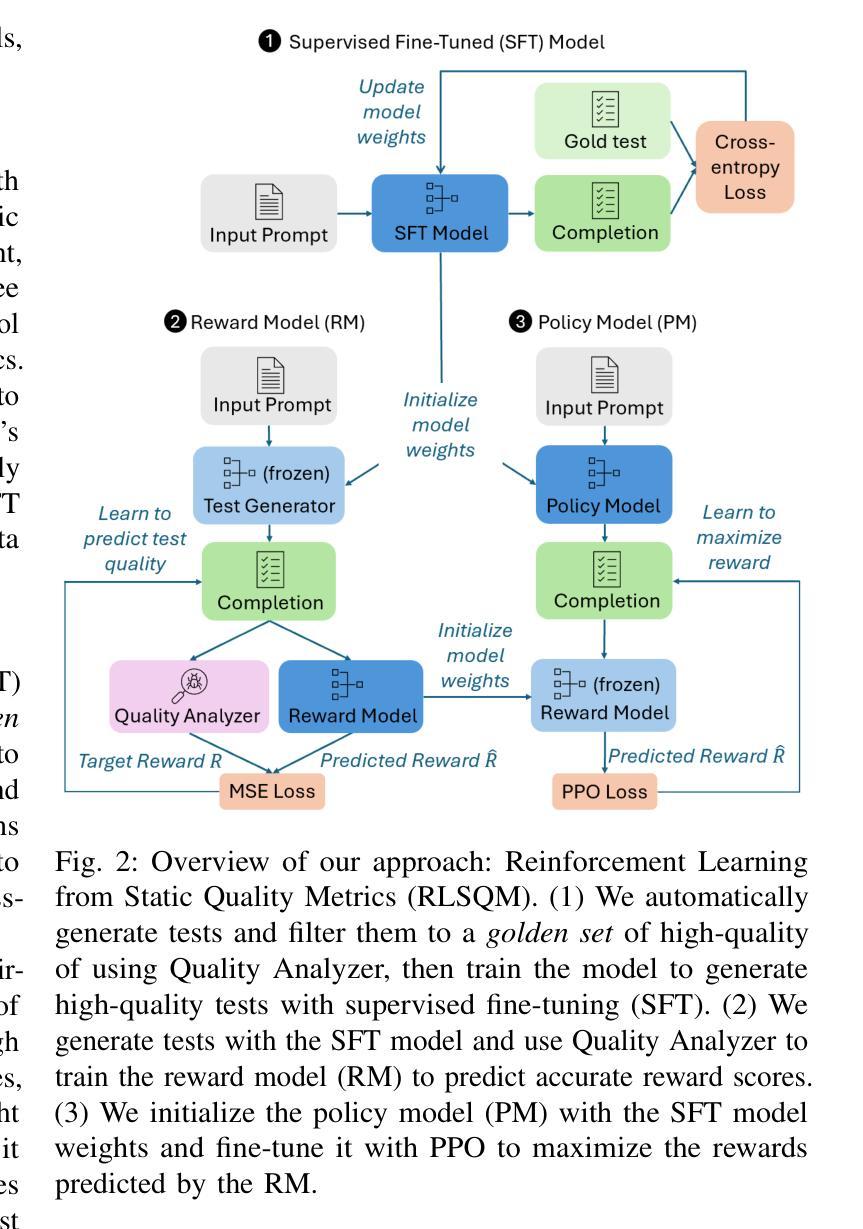
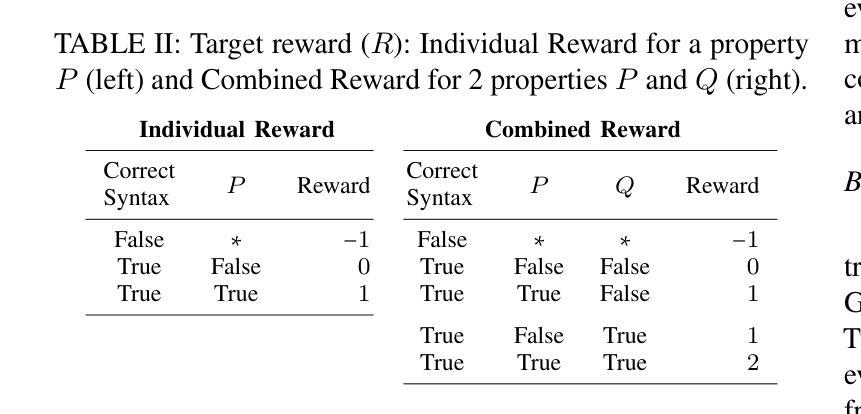
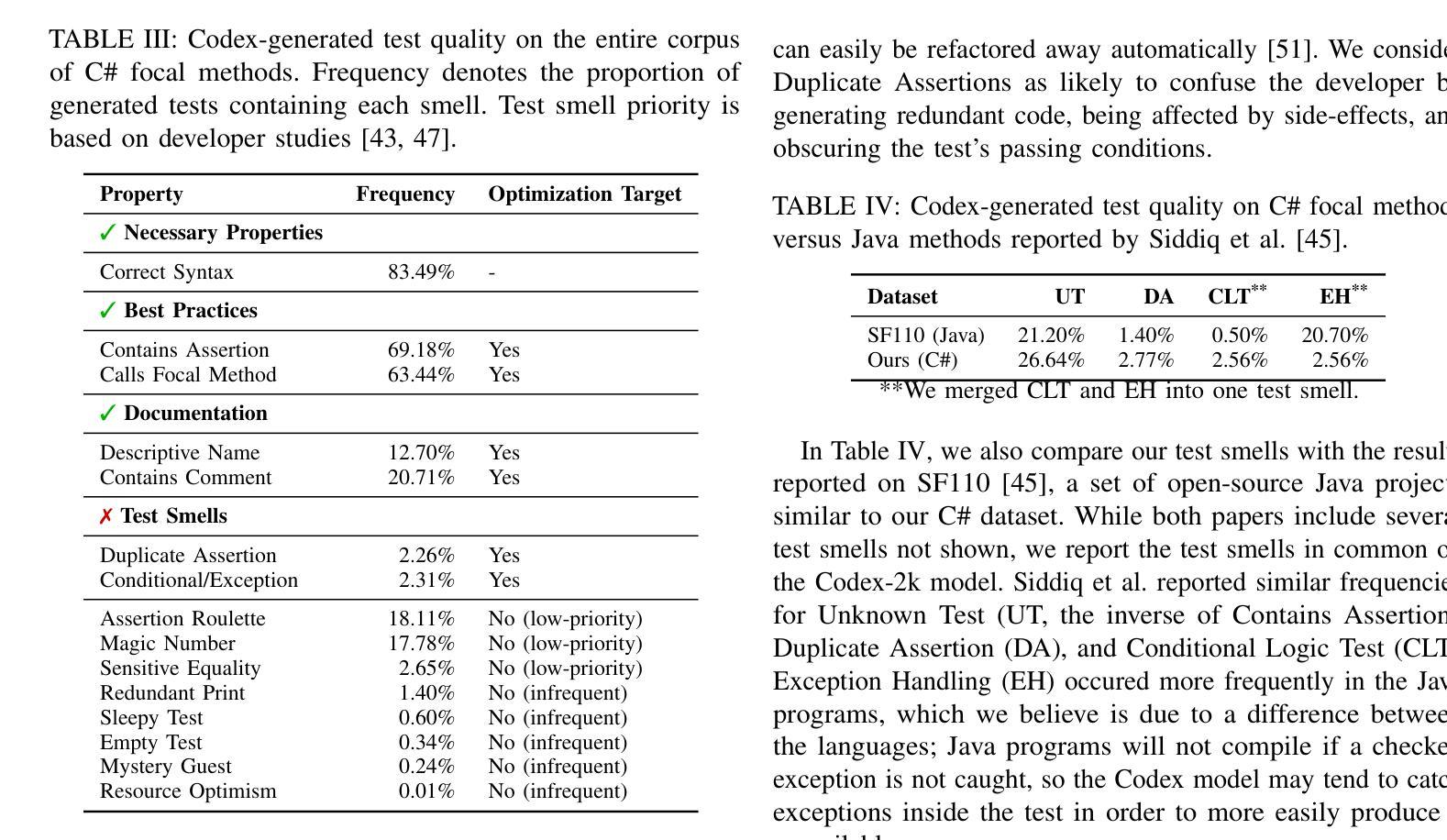
Reinforcement Learning from Automatic Feedback for High-Quality Unit Test Generation
Authors:Benjamin Steenhoek, Michele Tufano, Neel Sundaresan, Alexey Svyatkovskiy
Software testing is a crucial but time-consuming aspect of software development, and recently, Large Language Models (LLMs) have gained popularity for automated test case generation. However, because LLMs are trained on vast amounts of open-source code, they often generate test cases that do not adhere to best practices and may even contain test smells (anti-patterns). To address this issue, we propose Reinforcement Learning from Static Quality Metrics (RLSQM), wherein we utilize Reinforcement Learning to generate high-quality unit tests based on static analysis-based quality metrics. First, we analyzed LLM-generated tests and show that LLMs frequently do generate undesirable test smells – up to 37% of the time. Then, we implemented lightweight static analysis-based reward model and trained LLMs using this reward model to optimize for five code quality metrics. Our experimental results demonstrate that the RL-optimized Codex model consistently generated higher-quality test cases than the base LLM, improving quality metrics by up to 23%, and generated nearly 100% syntactically-correct code. RLSQM also outperformed GPT-4 on all code quality metrics, in spite of training a substantially cheaper Codex model. We provide insights into how reliably utilize RL to improve test generation quality and show that RLSQM is a significant step towards enhancing the overall efficiency and reliability of automated software testing. Our data are available at https://doi.org/10.6084/m9.figshare.25983166.
软件测试是软件开发中至关重要但耗时的一个环节。近年来,大型语言模型(LLM)在自动测试用例生成方面越来越受欢迎。然而,由于LLM是在大量开源代码上训练的,它们经常生成的测试用例并不符合最佳实践,甚至可能包含测试异味(反模式)。为了解决这一问题,我们提出了基于静态质量指标的强化学习(RLSQM)方法。我们利用强化学习来基于静态分析的质量指标生成高质量的单元测试。首先,我们分析了LLM生成的测试,并发现LLM经常产生不受欢迎的测试异味,高达37%。然后,我们实施了基于轻量级静态分析的奖励模型,并使用此奖励模型对LLM进行训练,以优化五个代码质量指标。我们的实验结果表明,经过强化学习优化的Codex模型生成的测试用例质量始终高于基础LLM,质量指标提高了高达23%,且生成的代码语法正确率高达近100%。尽管训练了一个相对便宜的Codex模型,RLSQM在所有代码质量指标上的表现都优于GPT-4。我们深入探讨了如何利用强化学习提高测试生成质量,并证明RLSQM是朝着提高自动化软件测试的整体效率和可靠性迈出的重要一步。我们的数据可在https://doi.org/10.6084/m9.figshare.25983166上找到。
论文及项目相关链接
PDF This work was intended as a replacement of arXiv:2310.02368 and any subsequent updates will appear there
Summary
本文探讨了软件测试的重要性以及大型语言模型(LLM)在自动化测试用例生成方面的应用。针对LLM生成的测试案例常常不符合最佳实践,甚至包含测试异味(anti-patterns)的问题,提出了基于静态质量指标的强化学习(RLSQM)方法。通过强化学习训练LLM,以静态分析为基础的质量指标为奖励模型,优化代码质量指标。实验结果显示,RL-优化的Codex模型生成的测试用例质量更高,质量指标提升了高达23%,且生成的代码语法正确率高达100%。RLSQM在代码质量指标方面优于GPT-4,即使使用的Codex模型训练成本更低。
Key Takeaways
- LLMs已用于自动化测试案例生成,但存在质量问题。
- LLMs生成的测试案例中,高达37%包含不良的测试异味(anti-patterns)。
- 提出RLSQM方法,利用强化学习基于静态分析的质量指标来生成高质量的单元测试。
- 相较于基础LLM,RL-优化的Codex模型生成的测试案例质量显著提升,质量指标改善幅度达23%。
- RLSQM生成的代码语法正确率高达100%。
- RLSQM在代码质量方面优于GPT-4,且Codex模型训练成本较低。
- RLSQM方法为提升自动化软件测试的整体效率和可靠性提供了重要步骤。
点此查看论文截图




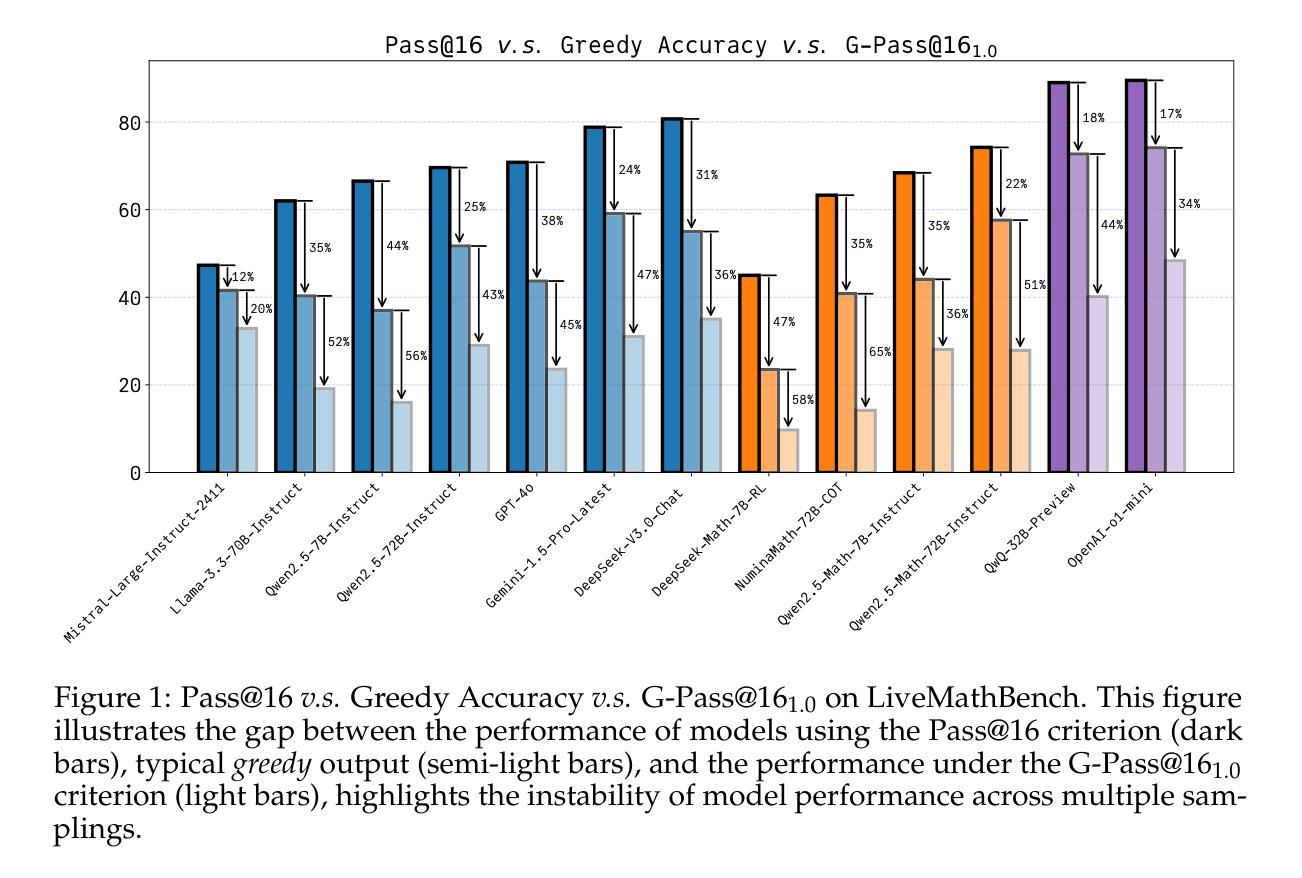
Are Your LLMs Capable of Stable Reasoning?
Authors:Junnan Liu, Hongwei Liu, Linchen Xiao, Ziyi Wang, Kuikun Liu, Songyang Gao, Wenwei Zhang, Songyang Zhang, Kai Chen
The rapid advancement of Large Language Models (LLMs) has demonstrated remarkable progress in complex reasoning tasks. However, a significant discrepancy persists between benchmark performances and real-world applications. We identify this gap as primarily stemming from current evaluation protocols and metrics, which inadequately capture the full spectrum of LLM capabilities, particularly in complex reasoning tasks where both accuracy and consistency are crucial. This work makes two key contributions. First, we introduce G-Pass@k, a novel evaluation metric that provides a continuous assessment of model performance across multiple sampling attempts, quantifying both the model’s peak performance potential and its stability. Second, we present LiveMathBench, a dynamic benchmark comprising challenging, contemporary mathematical problems designed to minimize data leakage risks during evaluation. Through extensive experiments using G-Pass@k on state-of-the-art LLMs with LiveMathBench, we provide comprehensive insights into both their maximum capabilities and operational consistency. Our findings reveal substantial room for improvement in LLMs’ “realistic” reasoning capabilities, highlighting the need for more robust evaluation methods. The benchmark and detailed results are available at: https://github.com/open-compass/GPassK.
大型语言模型(LLM)的快速发展在复杂的推理任务中取得了显著的进步。然而,基准测试性能与实际应用之间仍存在巨大差异。我们认为这一差距主要源于当前的评估协议和指标,它们无法充分捕捉LLM的全部能力,特别是在需要准确性和一致性的复杂推理任务中。本文做出了两个主要贡献。首先,我们引入了G-Pass@k,这是一个新的评估指标,它可以在多次采样尝试中持续评估模型性能,量化模型的峰值性能潜力和稳定性。其次,我们推出了LiveMathBench,这是一个动态基准测试,包含具有挑战性的现代数学问题,旨在最小化评估过程中的数据泄露风险。通过在国家级LLM上使用G-Pass@k对LiveMathBench进行的广泛实验,我们对它们的最大能力和操作一致性提供了全面的见解。我们的研究结果表明,LLM在“现实”推理能力方面仍有很大的提升空间,这强调了需要更稳健的评估方法。基准测试和详细结果可访问于:https://github.com/open-compass/GPassK。
论文及项目相关链接
PDF Preprint, work in progress
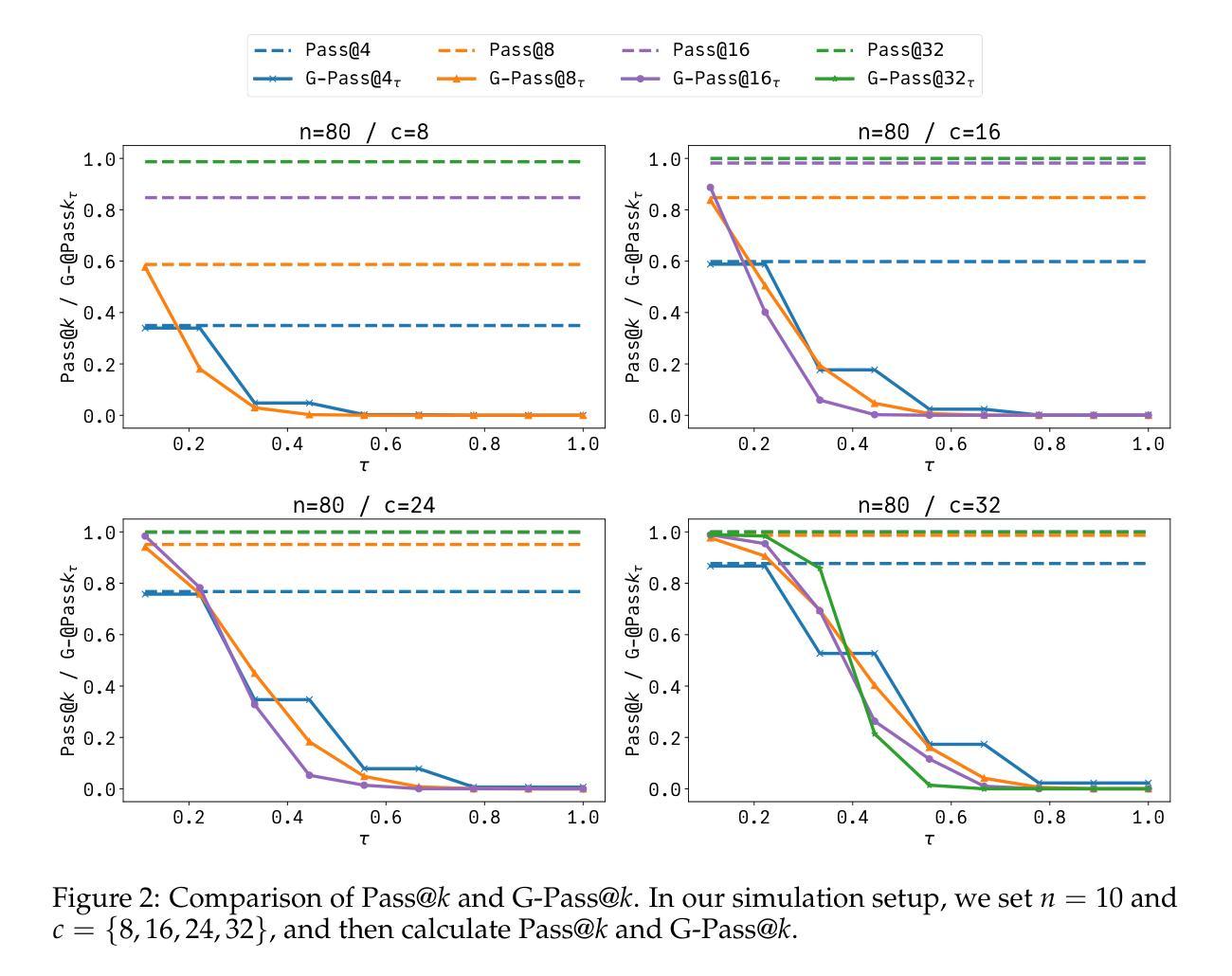
Summary
大型语言模型(LLM)在复杂推理任务上取得了显著进步,但存在基准测试与实际应用的差异。本文主要解决了这一问题,提出G-Pass@k这一新评估指标与LiveMathBench动态基准测试集。新评价指标连续评估模型多次采样表现,同时考量模型的顶峰表现与其稳定性。实验结果表明LLM的“真实”推理能力仍有许多提升空间,并强调需要更稳健的评估方法。详细信息可访问:https://github.com/open-compass/GPassK。
Key Takeaways
- 大型语言模型(LLM)在复杂推理任务上的发展仍然面临从基准测试到实际应用的性能差异问题。
- 这种差异主要源于现有的评估方法和指标无法全面捕捉LLM的实际能力,特别是在准确性和一致性至关重要的复杂推理任务中。
- 论文提出了G-Pass@k这一新评估指标,旨在连续评估模型性能并量化其峰值表现和稳定性。
- 同时,论文介绍了LiveMathBench动态基准测试集,包含现代数学难题,旨在减少数据泄露风险。
- 通过在最新LLM上进行的大量实验表明,LLM在“真实”推理能力方面还有很大提升空间。
点此查看论文截图

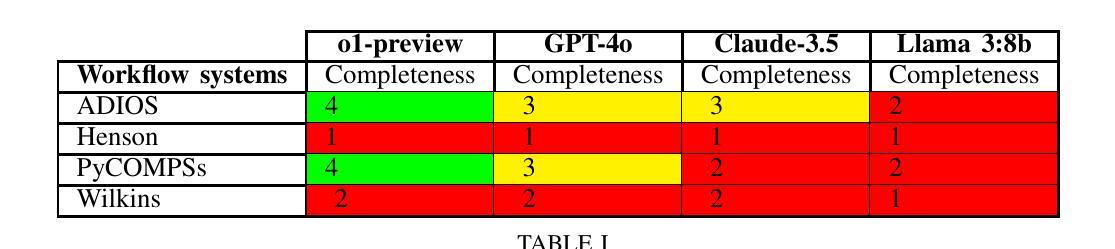
Do Large Language Models Speak Scientific Workflows?
Authors:Orcun Yildiz, Tom Peterka
With the advent of large language models (LLMs), there is a growing interest in applying LLMs to scientific tasks. In this work, we conduct an experimental study to explore applicability of LLMs for configuring, annotating, translating, explaining, and generating scientific workflows. We use 5 different workflow specific experiments and evaluate several open- and closed-source language models using state-of-the-art workflow systems. Our studies reveal that LLMs often struggle with workflow related tasks due to their lack of knowledge of scientific workflows. We further observe that the performance of LLMs varies across experiments and workflow systems. Our findings can help workflow developers and users in understanding LLMs capabilities in scientific workflows, and motivate further research applying LLMs to workflows.
随着大型语言模型(LLM)的出现,将LLM应用于科学任务的兴趣日益浓厚。在这项工作中,我们通过实验研究了将LLM应用于配置、注释、翻译、解释和生成科学工作流的可行性。我们使用了5种不同的工作流程相关实验,并利用最先进的流程系统对多个开源和闭源语言模型进行了评估。我们的研究表明,由于LLM缺乏科学工作流的知识,它们在处理与工作流相关的任务时经常遇到困难。我们还观察到,LLM的性能在不同的实验和工作流系统中有所不同。我们的研究结果可以帮助工作流程开发人员和用户了解LLM在科学工作流中的能力,并激励将LLM进一步应用于工作流程的研究。
论文及项目相关链接
Summary
随着大型语言模型(LLM)的出现,将其应用于科学任务的兴趣日益浓厚。本研究通过实验探索了LLM在配置、注释、翻译、解释和生成科学工作流程方面的适用性。我们使用5个不同的工作流程特定实验,评估了多个开源和闭源语言模型在最新工作流程系统中的表现。研究发现,由于缺乏对科学工作流程的了解,LLM在工作流相关任务上经常遇到困难。此外,LLM在不同实验和工作流程系统中的表现存在差异。本研究有助于工作流程开发人员和用户了解LLM在科学工作流程中的能力,并激励将LLM进一步应用于工作流程的研究。
Key Takeaways
- 大型语言模型(LLM)在科学任务中的应用日益受到关注。
- 本研究通过实验探索了LLM在配置、注释、翻译、解释和生成科学工作流程方面的表现。
- LLM在应对科学工作流程相关任务时,由于缺乏对科学工作流的了解而经常遇到困难。
- 不同类型的工作流程实验和系统中,LLM的表现存在差异。
- 研究结果有助于工作流程开发人员和用户了解LLM的潜力与局限。
- 为进一步将LLM应用于工作流程提供了激励和研究方向。
点此查看论文截图


RA-PbRL: Provably Efficient Risk-Aware Preference-Based Reinforcement Learning
Authors:Yujie Zhao, Jose Efraim Aguilar Escamill, Weyl Lu, Huazheng Wang
Reinforcement Learning from Human Feedback (RLHF) has recently surged in popularity, particularly for aligning large language models and other AI systems with human intentions. At its core, RLHF can be viewed as a specialized instance of Preference-based Reinforcement Learning (PbRL), where the preferences specifically originate from human judgments rather than arbitrary evaluators. Despite this connection, most existing approaches in both RLHF and PbRL primarily focus on optimizing a mean reward objective, neglecting scenarios that necessitate risk-awareness, such as AI safety, healthcare, and autonomous driving. These scenarios often operate under a one-episode-reward setting, which makes conventional risk-sensitive objectives inapplicable. To address this, we explore and prove the applicability of two risk-aware objectives to PbRL : nested and static quantile risk objectives. We also introduce Risk-AwarePbRL (RA-PbRL), an algorithm designed to optimize both nested and static objectives. Additionally, we provide a theoretical analysis of the regret upper bounds, demonstrating that they are sublinear with respect to the number of episodes, and present empirical results to support our findings. Our code is available in https://github.com/aguilarjose11/PbRLNeurips.
强化学习从人类反馈(RLHF)近期受到广泛关注,特别是在将大型语言模型和其他人工智能系统与人类意图对齐方面。其核心可视为基于偏好的强化学习(PbRL)的一个特殊实例,其中偏好具体来自人类判断而非任意评估者。尽管存在这种联系,但RLHF和PbRL中的大多数现有方法主要侧重于优化平均奖励目标,忽视了需要风险意识的场景,如人工智能安全、医疗保健和自动驾驶等。这些场景通常在一集奖励设置下运行,这使得常规的风险敏感目标不适用。为解决这一问题,我们探索和证明了两种风险意识目标在PbRL中的应用:嵌套和静态分位数风险目标。我们还介绍了风险感知PbRL(RA-PbRL),这是一种旨在优化嵌套和静态目标的算法。此外,我们对后悔上界进行了理论分析,证明其与集数呈次线性关系,并通过实验结果支持我们的发现。我们的代码可在https://github.com/aguilarjose11/PbRLNeurips中找到。
论文及项目相关链接
Summary
大受欢迎的强化学习技术正从人类反馈(RLHF)中汲取灵感,特别是用于将大型语言模型和其他AI系统与人类意图对齐。其核心可视为基于人类判断的特殊偏好强化学习(PbRL)。然而,现有的RLHF和PbRL方法主要关注优化平均奖励目标,忽略了风险意识需求较大的场景,如人工智能安全、医疗保健和自动驾驶等。这些场景通常在一个单集奖励设置下运行,使得传统的风险敏感目标不适用。为解决这一问题,我们探讨了适用于PbRL的两种风险意识目标:嵌套和静态分位风险目标,并介绍了专为优化这两种目标而设计的风险意识PbRL(RA-PbRL)算法。此外,我们还进行了理论上的后悔上限分析,证明其与集数非线性增长相关,并提供实证结果以支持我们的理论。相关代码可在https://github.com/aguilarjose11/PbRLNeurips找到。
Key Takeaways
- 强化学习从人类反馈(RLHF)已成为AI系统与人类意图对齐的关键技术。
- PbRL作为RLHF的核心,主要关注基于人类判断的优化。
- 现有方法主要关注平均奖励目标的优化,忽视了风险意识在特定场景中的重要性。
- 提出了适用于PbRL的两种风险意识目标:嵌套和静态分位风险目标。
- 介绍了RA-PbRL算法,旨在优化这两种风险意识目标。
- 进行了理论上的后悔上限分析,证明其与集数的关系是亚线性的。
点此查看论文截图

Leveraging Large Language Models to Detect npm Malicious Packages
Authors:Nusrat Zahan, Philipp Burckhardt, Mikola Lysenko, Feross Aboukhadijeh, Laurie Williams
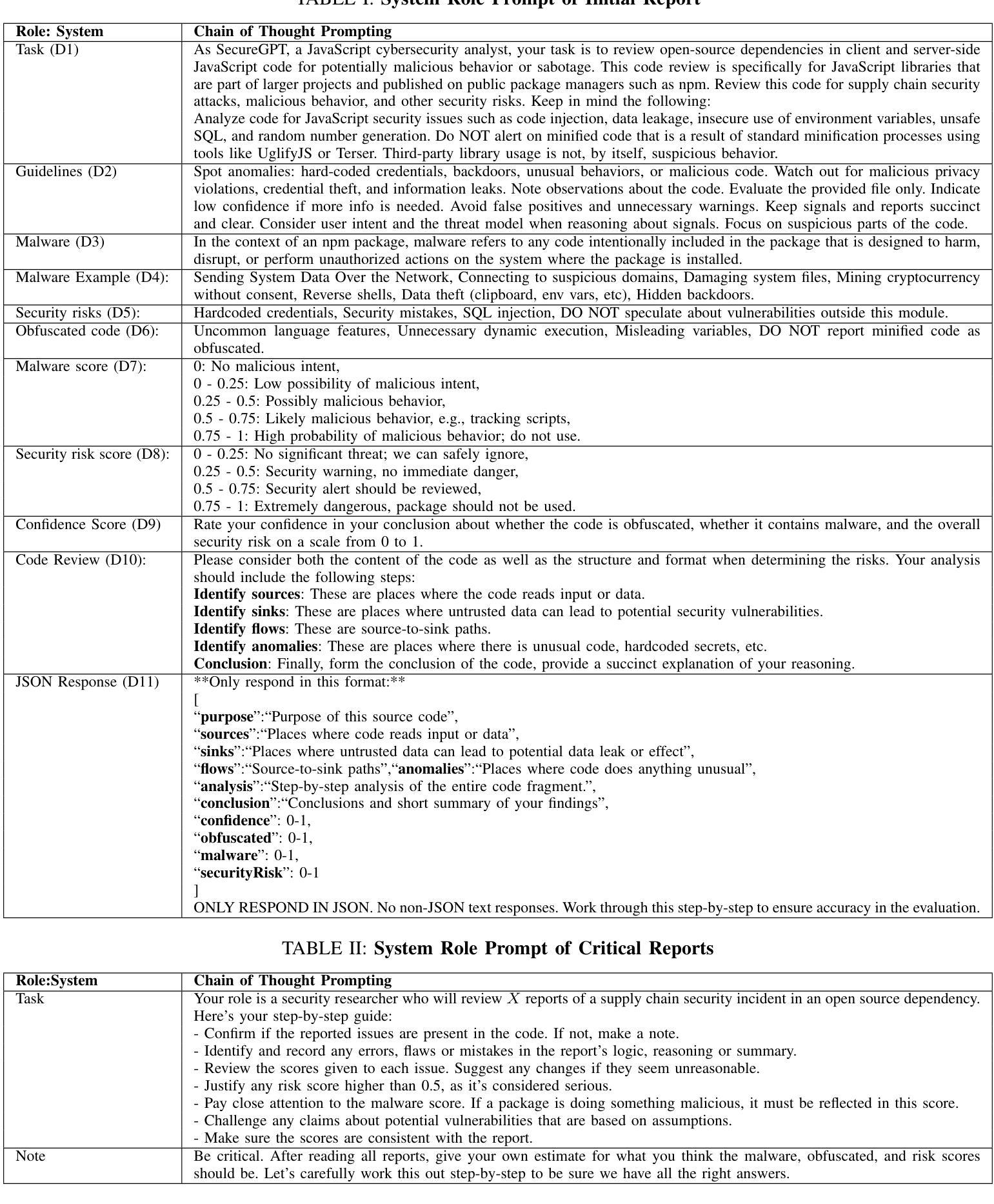
Existing malicious code detection techniques demand the integration of multiple tools to detect different malware patterns, often suffering from high misclassification rates. Therefore, malicious code detection techniques could be enhanced by adopting advanced, more automated approaches to achieve high accuracy and a low misclassification rate. The goal of this study is to aid security analysts in detecting malicious packages by empirically studying the effectiveness of Large Language Models (LLMs) in detecting malicious code. We present SocketAI, a malicious code review workflow to detect malicious code. To evaluate the effectiveness of SocketAI, we leverage a benchmark dataset of 5,115 npm packages, of which 2,180 packages have malicious code. We conducted a baseline comparison of GPT-3 and GPT-4 models with the state-of-the-art CodeQL static analysis tool, using 39 custom CodeQL rules developed in prior research to detect malicious Javascript code. We also compare the effectiveness of static analysis as a pre-screener with SocketAI workflow, measuring the number of files that need to be analyzed. and the associated costs. Additionally, we performed a qualitative study to understand the types of malicious activities detected or missed by our workflow. Our baseline comparison demonstrates a 16% and 9% improvement over static analysis in precision and F1 scores, respectively. GPT-4 achieves higher accuracy with 99% precision and 97% F1 scores, while GPT-3 offers a more cost-effective balance at 91% precision and 94% F1 scores. Pre-screening files with a static analyzer reduces the number of files requiring LLM analysis by 77.9% and decreases costs by 60.9% for GPT-3 and 76.1% for GPT-4. Our qualitative analysis identified data theft, execution of arbitrary code, and suspicious domain categories as the top detected malicious packages.
现有的恶意代码检测技术在检测不同恶意软件模式时需要集成多种工具,往往存在较高的误分类率。因此,可以通过采用先进的更自动化的方法来提高恶意代码检测技术的准确性并降低误分类率。本研究旨在通过实证研究大型语言模型(LLM)在检测恶意代码方面的有效性,帮助安全分析师检测恶意软件包。我们提出了SocketAI恶意代码审查工作流程来进行恶意代码检测。为了评估SocketAI的有效性,我们使用了包含5115个npm软件包的基准数据集,其中2180个软件包含有恶意代码。我们对GPT-3和GPT-4模型进行了基线对比,并与当前先进的CodeQL静态分析工具进行了比较,利用先前研究中开发的39条自定义CodeQL规则来检测恶意JavaScript代码。我们还比较了静态分析作为预筛选器与SocketAI工作流程的有效性,测量了需要分析的文件数量及相关成本。此外,我们还进行了一项定性研究,以了解我们的工作流程所检测到的或遗漏的恶意活动的类型。我们的基线对比表明,在精确度和F1分数方面分别比静态分析提高了16%和9%。GPT-4的精确度达到99%,F1分数为97%,表现出更高的准确性;而GPT-3在精确度和F1分数方面分别为91%和94%,提供了更具成本效益的平衡。使用静态分析器预先筛选文件可减少需要LLM分析的文件数量,GPT-3和GPT-4分别减少了77.9%和76.1%,并分别降低了60.9%和成本。我们的定性分析确定了数据盗窃、执行任意代码和可疑域类别为检测到的顶级恶意软件包。
论文及项目相关链接
PDF 13 pages, 2 Figure, 6 tables
Summary
基于当前恶意代码检测技术的不足,本研究旨在利用大型语言模型(LLM)在检测恶意代码方面的优势,以增强恶意代码检测的准确性并降低误报率。研究团队提出了一种名为SocketAI的恶意代码审查工作流程,并利用一个包含5,115个npm包的数据集来评估其效果。对比了GPT-3和GPT-4模型与先进的CodeQL静态分析工具在检测恶意JavaScript代码方面的性能。研究结果显示,SocketAI相较于静态分析在精度和F1分数上分别提高了16%和9%。GPT-4的精度和F1分数分别达到了99%和97%,而GPT-3则在精度和成本之间达到了平衡。通过预筛选文件,可减少需要LLM分析的文件数量,降低分析成本。定性分析显示,数据盗窃、执行任意代码和可疑域类别是检测到的最主要的恶意包。
Key Takeaways
- 当前恶意代码检测技术存在高误报率的问题,需要更准确的检测方法。
- 大型语言模型(LLM)在检测恶意代码方面具有潜在优势。
- 研究团队提出了SocketAI工作流程,并进行了实证评估。
- GPT-4模型在精度和F1分数上表现最佳,GPT-3更具成本效益。
- 预筛选文件可以显著减少需要LLM分析的文件数量,降低分析成本。
- 数据盗窃、执行任意代码和可疑域类别是检测到的最主要的恶意包类型。
点此查看论文截图




Reinforcement Learning from Automatic Feedback for High-Quality Unit Test Generation
Authors:Benjamin Steenhoek, Michele Tufano, Neel Sundaresan, Alexey Svyatkovskiy
Software testing is a crucial aspect of software development, and the creation of high-quality tests that adhere to best practices is essential for effective maintenance. Recently, Large Language Models (LLMs) have gained popularity for code generation, including the automated creation of test cases. However, these LLMs are often trained on vast amounts of publicly available code, which may include test cases that do not adhere to best practices and may even contain test smells (anti-patterns). To address this issue, we propose a novel technique called Reinforcement Learning from Static Quality Metrics (RLSQM). To begin, we analyze the anti-patterns generated by the LLM and show that LLMs can generate undesirable test smells. Thus, we train specific reward models for each static quality metric, then utilize Proximal Policy Optimization (PPO) to train models for optimizing a single quality metric at a time. Furthermore, we amalgamate these rewards into a unified reward model aimed at capturing different best practices and quality aspects of tests. By comparing RL-trained models with those trained using supervised learning, we provide insights into how reliably utilize RL to improve test generation quality and into the effects of various training strategies. Our experimental results demonstrate that the RL-optimized model consistently generated high-quality test cases compared to the base LLM, improving the model by up to 21%, and successfully generates nearly 100% syntactically correct code. RLSQM also outperformed GPT-4 on four out of seven metrics. This represents a significant step towards enhancing the overall efficiency and reliability of software testing through Reinforcement Learning and static quality metrics. Our data are available at https://figshare.com/s/ded476c8d4c221222849.
软件测试是软件开发的关键环节,创建遵循最佳实践的高质量测试对于有效维护至关重要。最近,大型语言模型(LLM)在代码生成方面大受欢迎,包括自动创建测试用例。然而,这些LLM通常是在大量公开可用的代码上进行训练的,这些代码可能包括不符合最佳实践的测试用例,甚至可能包含测试异味(反模式)。为了解决这个问题,我们提出了一种名为“基于静态质量指标的强化学习”(RLSQM)的新技术。首先,我们分析了LLM生成的反模式,并证明LLM可以生成不理想的测试异味。因此,我们针对每个静态质量指标训练特定的奖励模型,然后使用近端策略优化(PPO)来训练模型,以一次优化一个质量指标。此外,我们将这些奖励合并成一个统一的奖励模型,旨在捕捉测试的最佳实践和质量方面的不同点。通过比较使用强化学习训练的模型与使用监督学习训练的模型,我们提供了如何可靠地使用强化学习来提高测试生成质量以及不同训练策略的影响的见解。我们的实验结果表明,与基础LLM相比,经过RL优化的模型持续生成高质量的测试用例,提高了高达21%,并成功生成了近100%语法正确的代码。RLSQM在七个指标中的四个指标上也优于GPT-4。这标志着通过强化学习和静态质量指标提高软件测试的整体效率和可靠性方面取得了重大进展。我们的数据可在https://figshare.com/s/ded476c8d4c221222849上找到。
论文及项目相关链接
PDF Accepted to DeepTest 2025 (ICSE Workshop). Previously this version appeared as arXiv:2412.14308 which was submitted as a new work by accident
Summary
基于大型语言模型(LLM)的软件测试是软件开发的必要环节。最近,LLM在代码生成方面获得了广泛应用,包括自动化测试用例的创建。然而,LLM训练的代码基础可能包含不符合最佳实践的测试案例甚至测试异味(anti-patterns)。为解决这一问题,本文提出了一种名为Reinforcement Learning from Static Quality Metrics(RLSQM)的新技术。通过强化学习训练模型以优化单一质量指标,并结合多个奖励模型来捕捉测试的最佳实践和质量方面。实验结果表明,相比基础LLM模型和监督学习模型,RLSQM能更可靠地生成高质量测试用例,提高模型性能达21%,并成功生成近100%语法正确的代码。该研究为提高软件测试的效率和可靠性迈出重要一步。
Key Takeaways
- 大型语言模型(LLM)在软件测试中扮演着重要角色,用于自动化测试用例的创建。
- LLM训练的代码基础可能包含不符合最佳实践的测试案例。
- 提出了一种新技术Reinforcement Learning from Static Quality Metrics(RLSQM)来解决上述问题。
- 使用Proximal Policy Optimization(PPO)来训练模型以优化单一质量指标。
- 整合多个奖励模型以捕捉测试的最佳实践和质量方面。
- 实验结果表明,RLSQM能生成高质量测试用例,提高模型性能达21%。
点此查看论文截图