⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-08 更新
Make Imagination Clearer! Stable Diffusion-based Visual Imagination for Multimodal Machine Translation
Authors:Andong Chen, Yuchen Song, Kehai Chen, Muyun Yang, Tiejun Zhao, Min Zhang
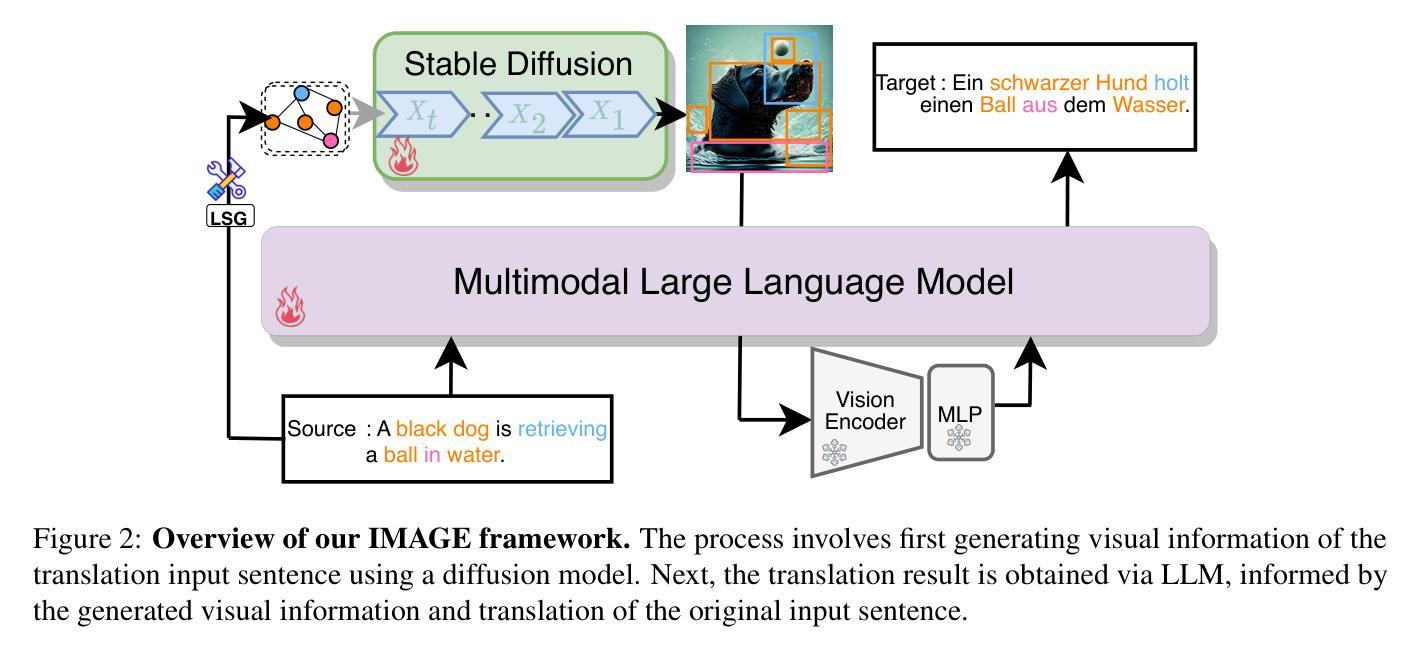
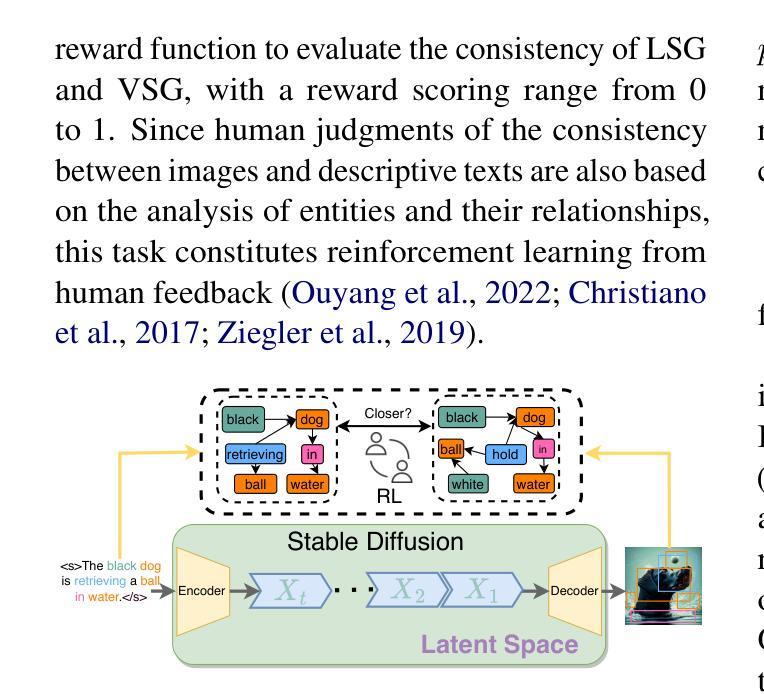
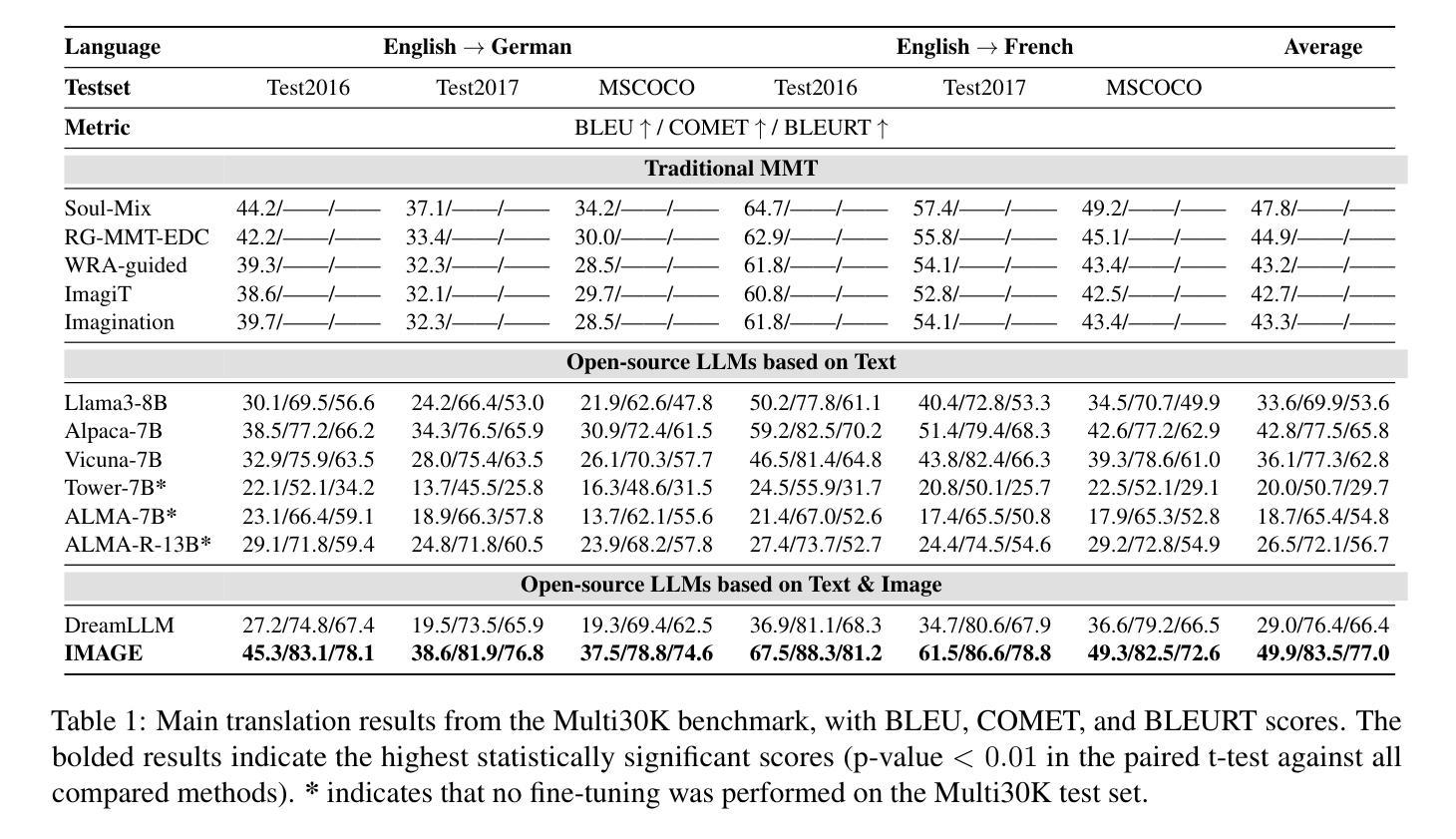
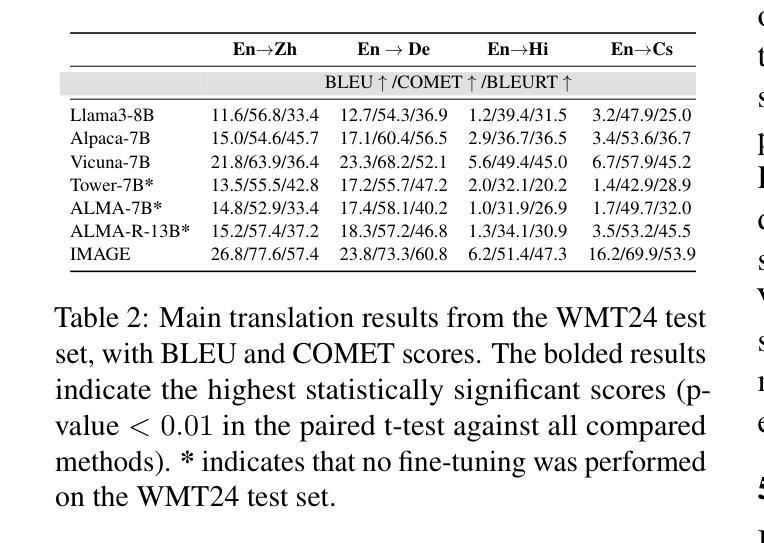
Visual information has been introduced for enhancing machine translation (MT), and its effectiveness heavily relies on the availability of large amounts of bilingual parallel sentence pairs with manual image annotations. In this paper, we introduce a stable diffusion-based imagination network into a multimodal large language model (MLLM) to explicitly generate an image for each source sentence, thereby advancing the multimodel MT. Particularly, we build heuristic human feedback with reinforcement learning to ensure the consistency of the generated image with the source sentence without the supervision of image annotation, which breaks the bottleneck of using visual information in MT. Furthermore, the proposed method enables imaginative visual information to be integrated into large-scale text-only MT in addition to multimodal MT. Experimental results show that our model significantly outperforms existing multimodal MT and text-only MT, especially achieving an average improvement of more than 14 BLEU points on Multi30K multimodal MT benchmarks.
将视觉信息引入以增强机器翻译的效果,其有效性在很大程度上依赖于大量带有手动图像注释的双语平行句子对。在本文中,我们将基于稳定扩散的想象网络引入多模态大型语言模型(MLLM)中,为每句源语言生成明确的图像,从而促进多模态机器翻译的发展。特别地,我们借助强化学习与启发式人类反馈,确保生成图像与源句子的一致性,无需图像注释的监督,从而突破了机器翻译中使用视觉信息的瓶颈。此外,该方法除了多模态机器翻译外,还可以将富有想象力的视觉信息整合到大规模的纯文本机器翻译中。实验结果表明,我们的模型在现有的多模态机器翻译和纯文本机器翻译中都表现得更为出色,特别是在Multi30K多模态机器翻译基准测试中,平均提高了超过14个BLEU点。
论文及项目相关链接
PDF Work in progress
Summary
本文引入了一种基于稳定扩散的想象网络,将其融入多模态大型语言模型(MLLM)中,为每句源文本明确生成对应的图像,从而推动多模态机器翻译的发展。该研究通过强化学习与启发式人类反馈的结合,确保生成图像与源文本的的一致性,无需图像注解的监督,打破了机器翻译中使用视觉信息的瓶颈。此外,该方法不仅适用于多模态机器翻译,还能将想象性的视觉信息融入大规模的纯文本机器翻译中。实验结果表明,该模型在多模态MT基准测试上的表现显著优于现有技术,特别是在Multi30K多模态MT基准测试上的BLEU得分平均提高了14分以上。
Key Takeaways
- 引入稳定扩散基于想象的网络到多模态大型语言模型(MLLM),为源句子明确生成对应的图像。
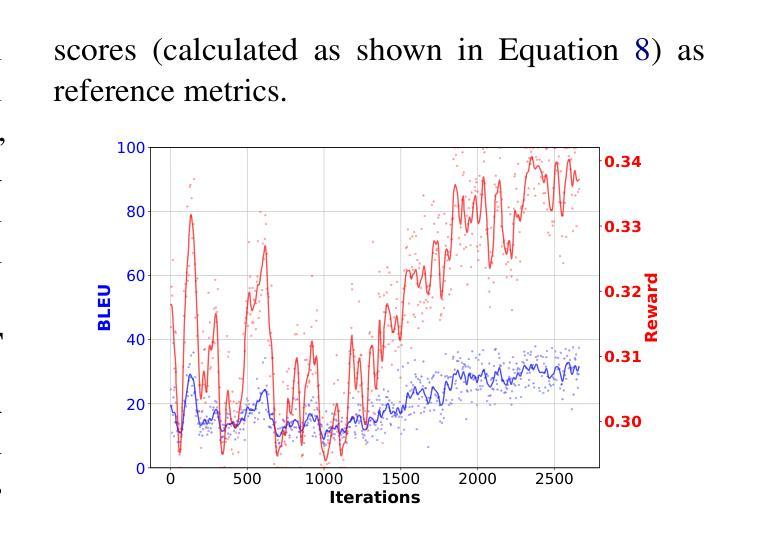
- 通过结合强化学习与启发式人类反馈,确保生成图像与源文本的一致性。
- 该方法无需图像注解的监督,打破了机器翻译中使用视觉信息的瓶颈。
- 想象性视觉信息可融入大规模的纯文本机器翻译。
- 模型在多模态机器翻译上的表现显著优于现有技术。
- 在Multi30K多模态MT基准测试上,模型的BLEU得分平均提高了14分以上。
点此查看论文截图