⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-09 更新
Sa2VA: Marrying SAM2 with LLaVA for Dense Grounded Understanding of Images and Videos
Authors:Haobo Yuan, Xiangtai Li, Tao Zhang, Zilong Huang, Shilin Xu, Shunping Ji, Yunhai Tong, Lu Qi, Jiashi Feng, Ming-Hsuan Yang
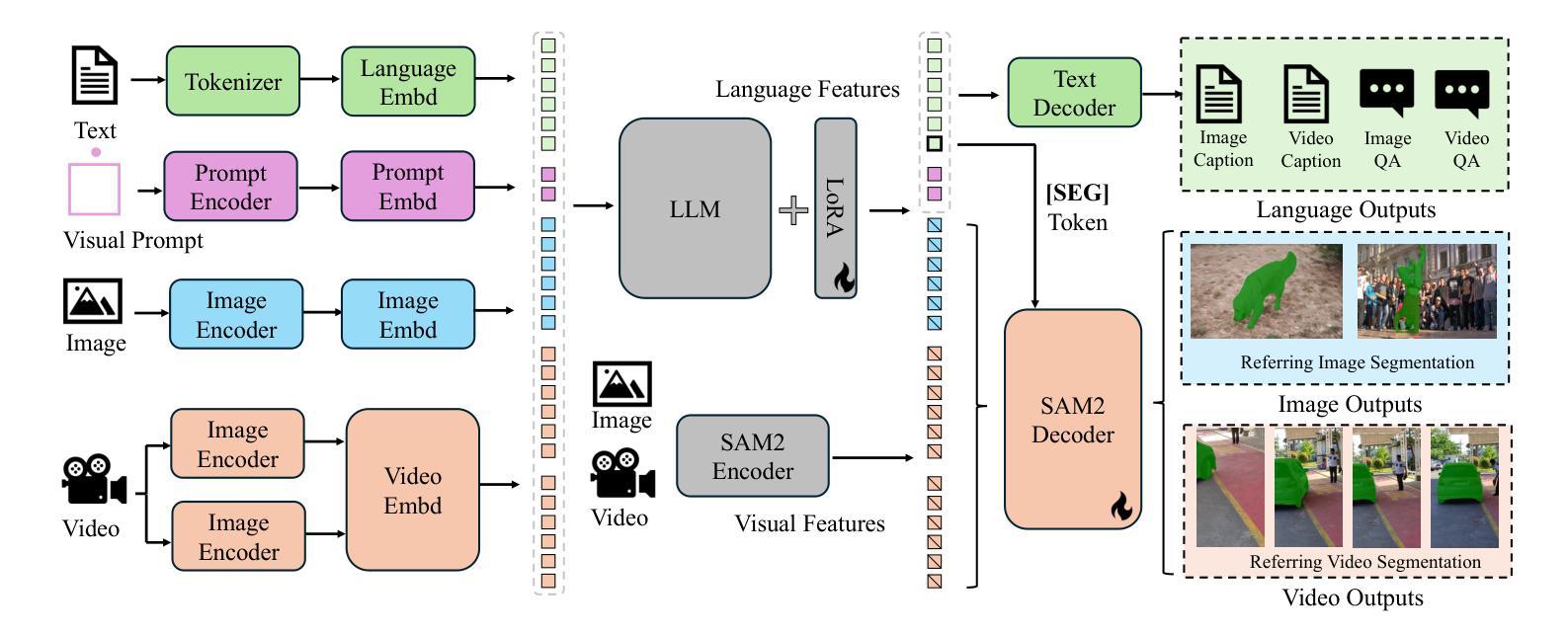
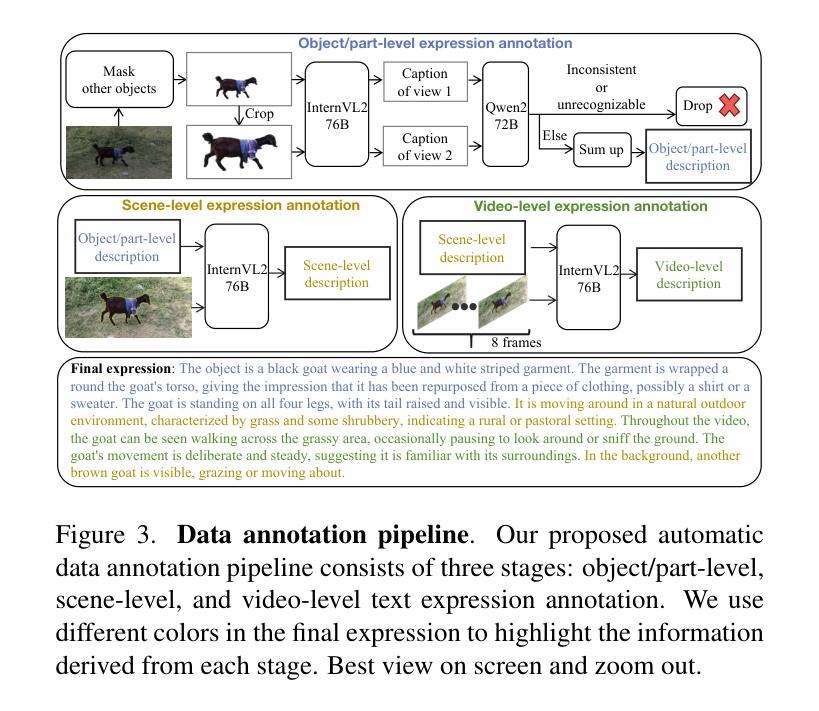
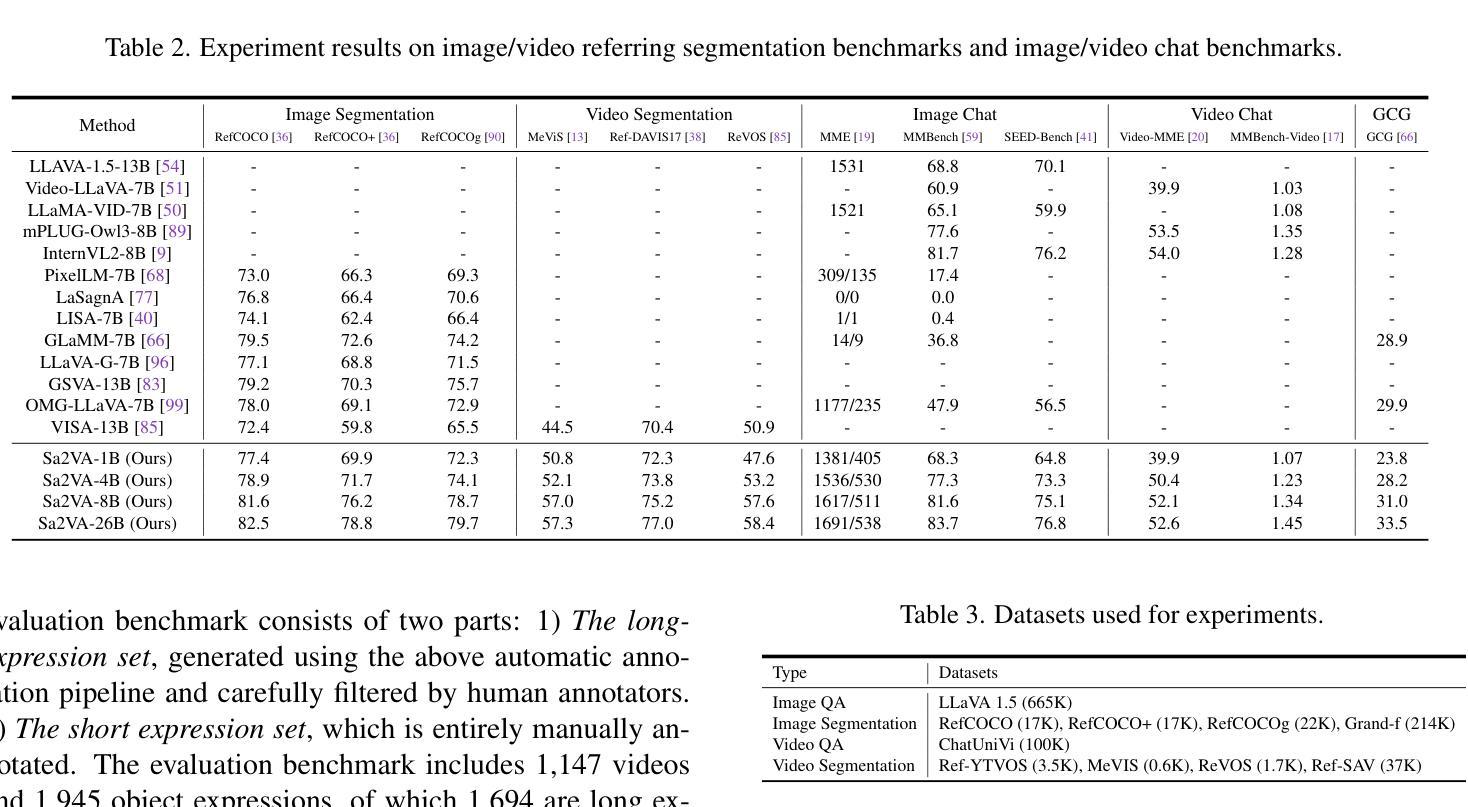
This work presents Sa2VA, the first unified model for dense grounded understanding of both images and videos. Unlike existing multi-modal large language models, which are often limited to specific modalities and tasks, Sa2VA supports a wide range of image and video tasks, including referring segmentation and conversation, with minimal one-shot instruction tuning. Sa2VA combines SAM-2, a foundation video segmentation model, with LLaVA, an advanced vision-language model, and unifies text, image, and video into a shared LLM token space. Using the LLM, Sa2VA generates instruction tokens that guide SAM-2 in producing precise masks, enabling a grounded, multi-modal understanding of both static and dynamic visual content. Additionally, we introduce Ref-SAV, an auto-labeled dataset containing over 72k object expressions in complex video scenes, designed to boost model performance. We also manually validate 2k video objects in the Ref-SAV datasets to benchmark referring video object segmentation in complex environments. Experiments show that Sa2VA achieves state-of-the-art across multiple tasks, particularly in referring video object segmentation, highlighting its potential for complex real-world applications.
本文介绍了Sa2VA,这是首个统一模型,用于密集地对图像和视频进行理解。不同于现有的多模态大型语言模型,这些模型通常仅限于特定的模态和任务,而Sa2VA则支持广泛的图像和视频任务,包括引用分割和对话,并且只需最少的单次指令调整。Sa2VA结合了SAM-2(基础视频分割模型)和LLaVA(先进的视觉语言模型),并将文本、图像和视频统一到共享的LLM令牌空间中。使用LLM,Sa2VA生成指令令牌,指导SAM-2生成精确蒙版,实现对静态和动态视觉内容的接地多模态理解。此外,我们还引入了Ref-SAV,这是一个自动标记的数据集,包含超过7.2万个复杂视频场景中的对象表达式,旨在提高模型性能。我们还手动验证了Ref-SAV数据集中的2千个视频对象,以基准测试复杂环境中的引用视频对象分割。实验表明,Sa2VA在多个任务上均达到了最新水平,特别是在引用视频对象分割方面表现突出,凸显其在复杂现实世界应用中的潜力。
论文及项目相关链接
PDF Project page: https://lxtgh.github.io/project/sa2va
Summary
本文主要介绍了Sa2VA模型,该模型为图像和视频提供了稠密的基础理解。不同于现有的多模态大型语言模型,Sa2VA支持广泛的图像和视频任务,包括引用分割和对话等,只需一次指令调整即可应对。它通过结合SAM-2基础视频分割模型和LLaVA高级视觉语言模型,并将文本、图像和视频统一到共享的大型语言模型标记空间中,实现了对静态和动态视觉内容的扎实多模态理解。此外,本文还介绍了用于提升模型性能的Ref-SAV数据集。实验表明,Sa2VA在多任务中均达到了业界最佳水平,特别是在视频对象分割方面表现出巨大的潜力。
Key Takeaways
- Sa2VA是首个统一模型,能稠密地理解图像和视频。
- 它支持广泛的图像和视频任务,包括引用分割和对话等。
- Sa2VA结合了SAM-2基础视频分割模型和LLaVA高级视觉语言模型。
- Sa2VA将文本、图像和视频统一到共享的大型语言模型标记空间中。
- Sa2VA通过生成指令标记来指导SAM-2产生精确的面罩,实现对静态和动态视觉内容的理解。
- 引入了Ref-SAV数据集,包含超过7万多个复杂视频场景中的对象表达,用于提升模型性能。
点此查看论文截图