⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-09 更新
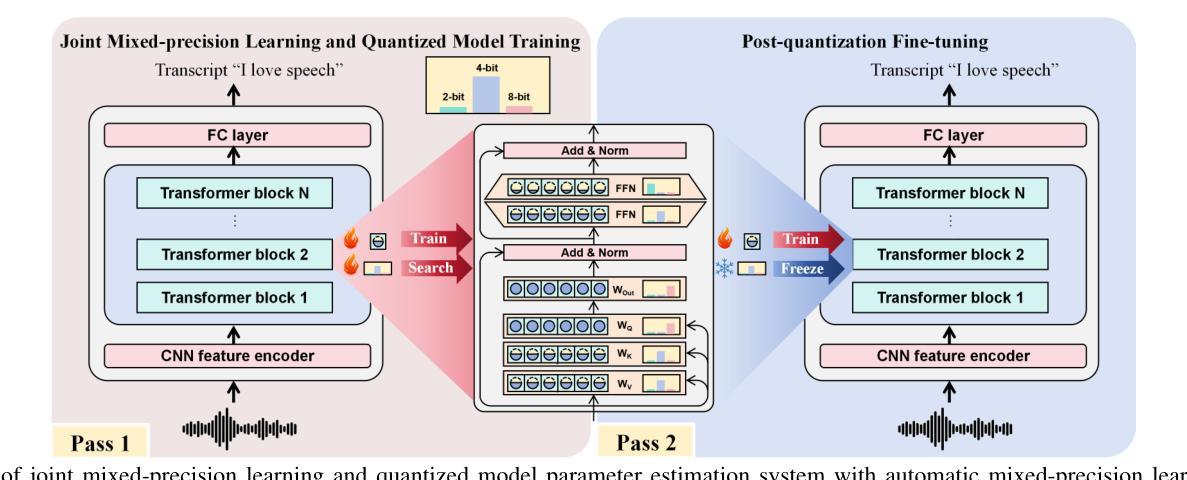
Effective and Efficient Mixed Precision Quantization of Speech Foundation Models
Authors:Haoning Xu, Zhaoqing Li, Zengrui Jin, Huimeng Wang, Youjun Chen, Guinan Li, Mengzhe Geng, Shujie Hu, Jiajun Deng, Xunying Liu
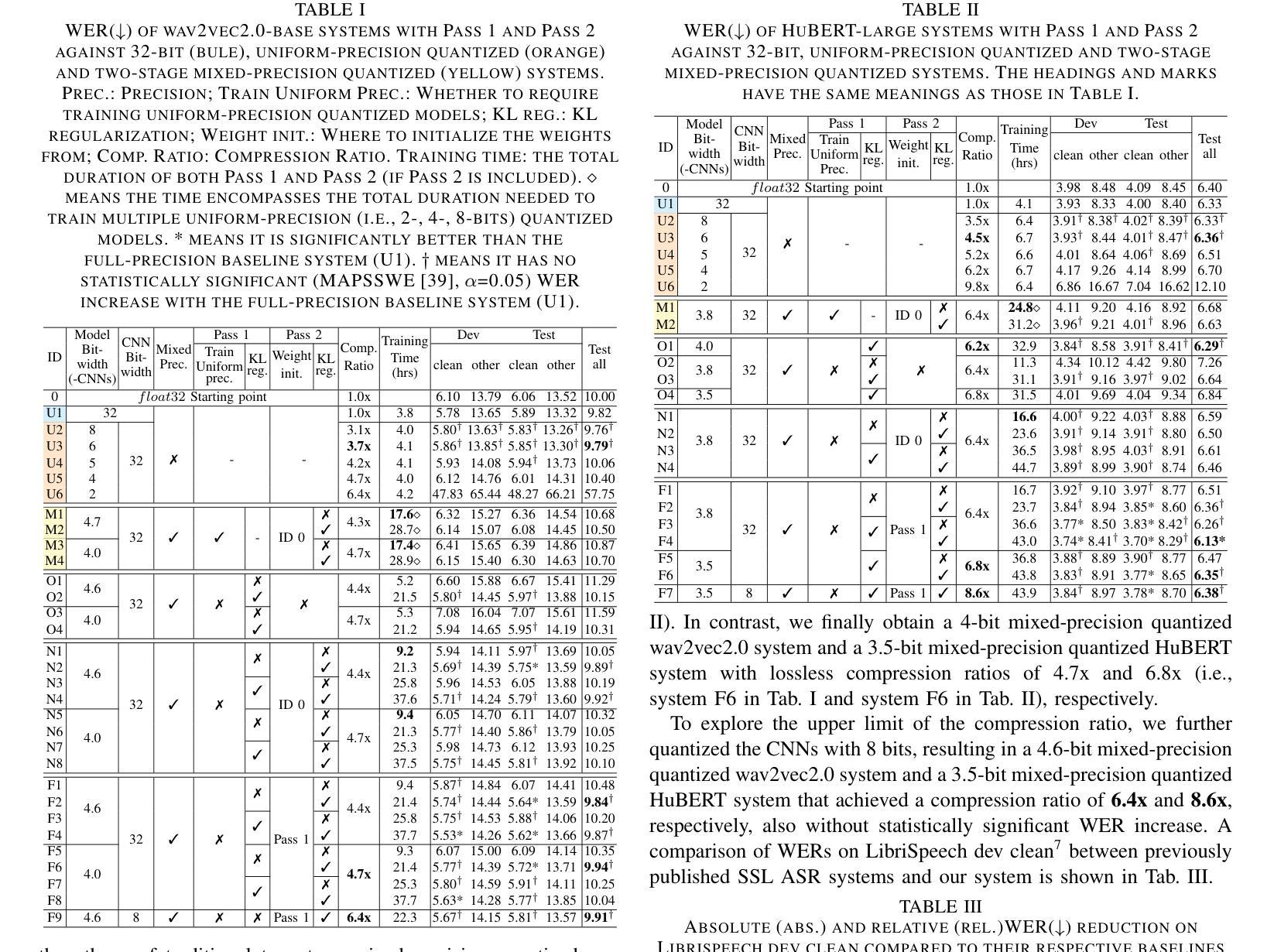
This paper presents a novel mixed-precision quantization approach for speech foundation models that tightly integrates mixed-precision learning and quantized model parameter estimation into one single model compression stage. Experiments conducted on LibriSpeech dataset with fine-tuned wav2vec2.0-base and HuBERT-large models suggest the resulting mixed-precision quantized models increased the lossless compression ratio by factors up to 1.7x and 1.9x over the respective uniform-precision and two-stage mixed-precision quantized baselines that perform precision learning and model parameters quantization in separate and disjointed stages, while incurring no statistically word error rate (WER) increase over the 32-bit full-precision models. The system compression time of wav2vec2.0-base and HuBERT-large models is reduced by up to 1.9 and 1.5 times over the two-stage mixed-precision baselines, while both produce lower WERs. The best-performing 3.5-bit mixed-precision quantized HuBERT-large model produces a lossless compression ratio of 8.6x over the 32-bit full-precision system.
本文提出了一种用于语音基础模型的新型混合精度量化方法,该方法将混合精度学习和量化模型参数估计紧密集成到一个单一的模型压缩阶段中。在LibriSpeech数据集上进行的实验,对fine-tuned的wav2vec2.0-base和HuBERT-large模型显示,所得混合精度量化模型相对于各自的均匀精度和两阶段混合精度量化基线,无损压缩比提高了最高达1.7倍和1.9倍。这些基线在不同的阶段进行精度学习和模型参数量化,彼此独立。同时,相对于32位全精度模型,混合精度量化模型没有产生统计上的词错误率(WER)增加。对于wav2vec2.0-base和HuBERT-large模型的系统压缩时间,相对于两阶段混合精度基线减少了最多达1.9倍和1.5倍,同时两者都产生了更低的WER。表现最佳的3.5位混合精度量化HuBERT-large模型相对于32位全精度系统实现了8.6倍的无损压缩比。
论文及项目相关链接
PDF To appear at IEEE ICASSP 2025
Summary
本文介绍了一种新颖的混合精度量化方法,用于语音基础模型。该方法将混合精度学习和量化模型参数估计紧密集成到一个单一的模型压缩阶段。实验表明,该方法的压缩比例最高可达均匀精度方法的1.7倍和两阶段混合精度量化方法的1.9倍,且并未导致单词错误率(WER)的显著提高。此外,此方法还能有效减少模型的系统压缩时间。对于最好的表现的混合精度量化的HuBERT-large模型,相对于32位全精度系统,其无损压缩比例达到了惊人的8.6倍。
Key Takeaways
- 该论文提出了一种新的混合精度量化方法,结合了混合精度学习与模型参数量化的单一压缩阶段。
- 在LibriSpeech数据集上进行的实验验证了这种方法的效率,无损压缩比例显著提高。
- 对比均匀精度方法和两阶段混合精度量化方法,新方法表现出更高的压缩效率和更低的WER。
- 对于HuBERT-large模型,最佳表现的混合精度量化模型实现了高达8.6倍的无损压缩比例。
- 该方法减少了模型的系统压缩时间。
- 新方法在提高压缩效率的同时,未增加统计上的WER。
点此查看论文截图

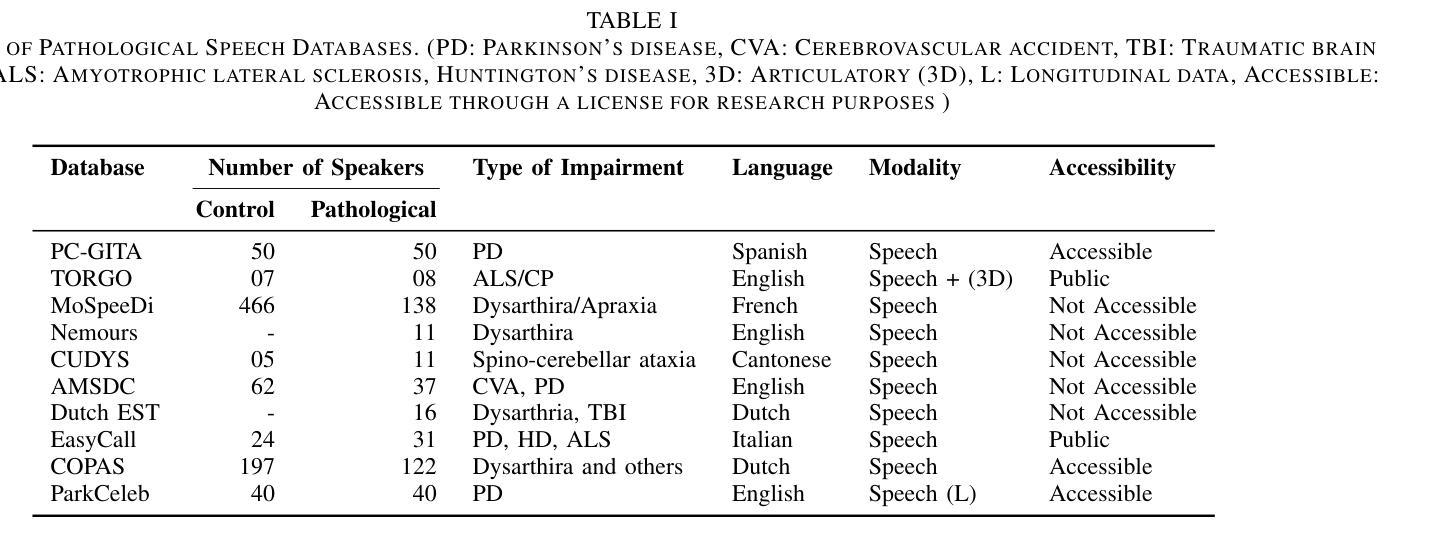
Deep Learning for Pathological Speech: A Survey
Authors:Shakeel A. Sheikh, Md. Sahidullah, Ina Kodrasi
Advancements in spoken language technologies for neurodegenerative speech disorders are crucial for meeting both clinical and technological needs. This overview paper is vital for advancing the field, as it presents a comprehensive review of state-of-the-art methods in pathological speech detection, automatic speech recognition, pathological speech intelligibility enhancement, intelligibility and severity assessment, and data augmentation approaches for pathological speech. It also high-lights key challenges, such as ensuring robustness, privacy, and interpretability. The paper concludes by exploring promising future directions, including the adoption of multimodal approaches and the integration of graph neural networks and large language models to further advance speech technology for neurodegenerative speech disorders
自然语言技术针对神经退行性疾病言语障碍的进步对于满足临床和技术需求至关重要。这篇综述文章对推进该领域至关重要,因为它全面回顾了病理性言语检测、自动语音识别、病理性言语清晰度增强、清晰度和严重性评估以及病理性言语数据增强方法的最新方法。它还强调了关键挑战,如确保稳健性、隐私性和可解释性。文章最后探讨了有前景的未来方向,包括采用多模式方法和整合图神经网络和大型语言模型,以进一步推动针对神经退行性疾病的言语技术的提升。
论文及项目相关链接
PDF Submitted to IEEE JSTSP Special Issue on Modelling and Processing Language and Speech in Neurodegenerative Disorders
Summary
随着神经退行性疾病导致的言语障碍的日益普遍,针对此领域的口语技术进展尤为重要。本文全面综述了当前最先进的方法,包括病理性言语检测、自动语音识别、病理性言语清晰度提升等,同时强调了鲁棒性、隐私和可解释性等关键挑战。未来研究方向包括采用多模态方法和集成图神经网络和大型语言模型等。
Key Takeaways
- 神经退行性疾病导致的言语障碍需要先进的口语技术来满足临床和技术需求。
- 论文全面综述了病理性言语检测、自动语音识别等领域的最新方法。
- 论文强调了提高技术鲁棒性、保护隐私和增强可解释性等方面的关键挑战。
- 多模态方法在未来的口语技术发展中具有潜力。
- 图神经网络和大型语言模型的集成有望进一步提高神经退行性疾病的口语技术水平。
- 论文强调了数据扩充方法在病理性言语研究中的重要性。
点此查看论文截图


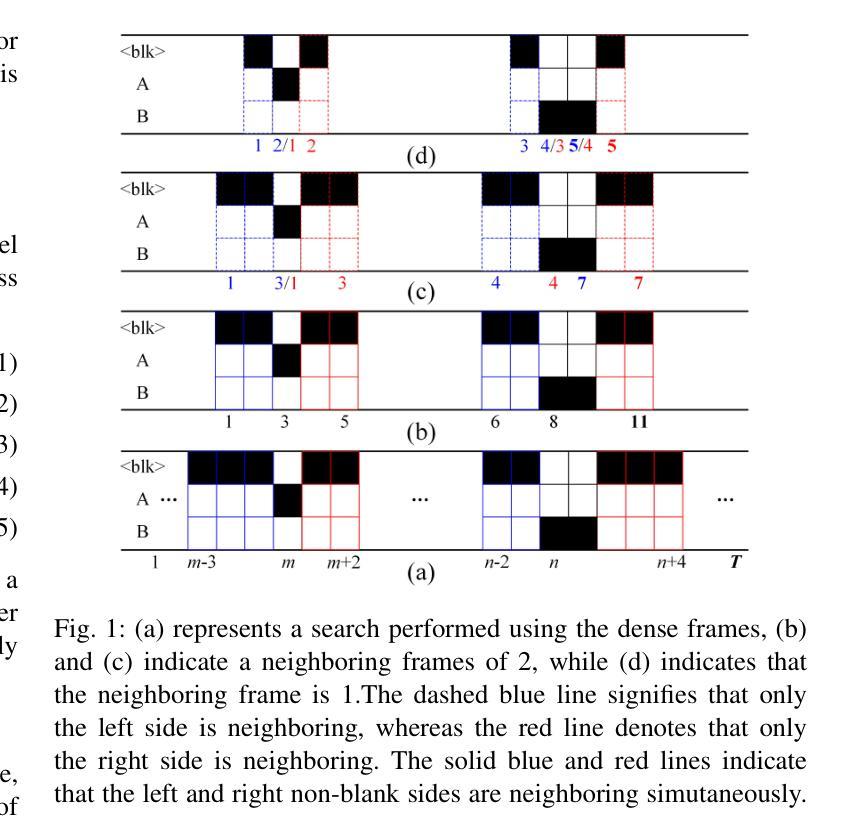
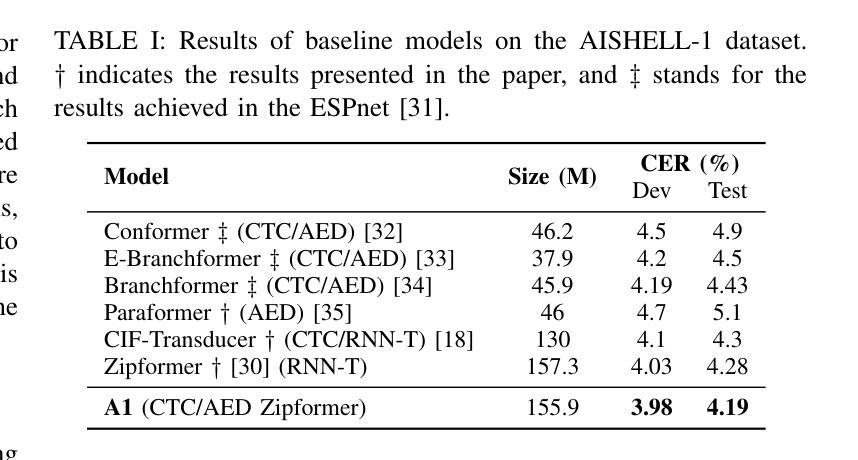
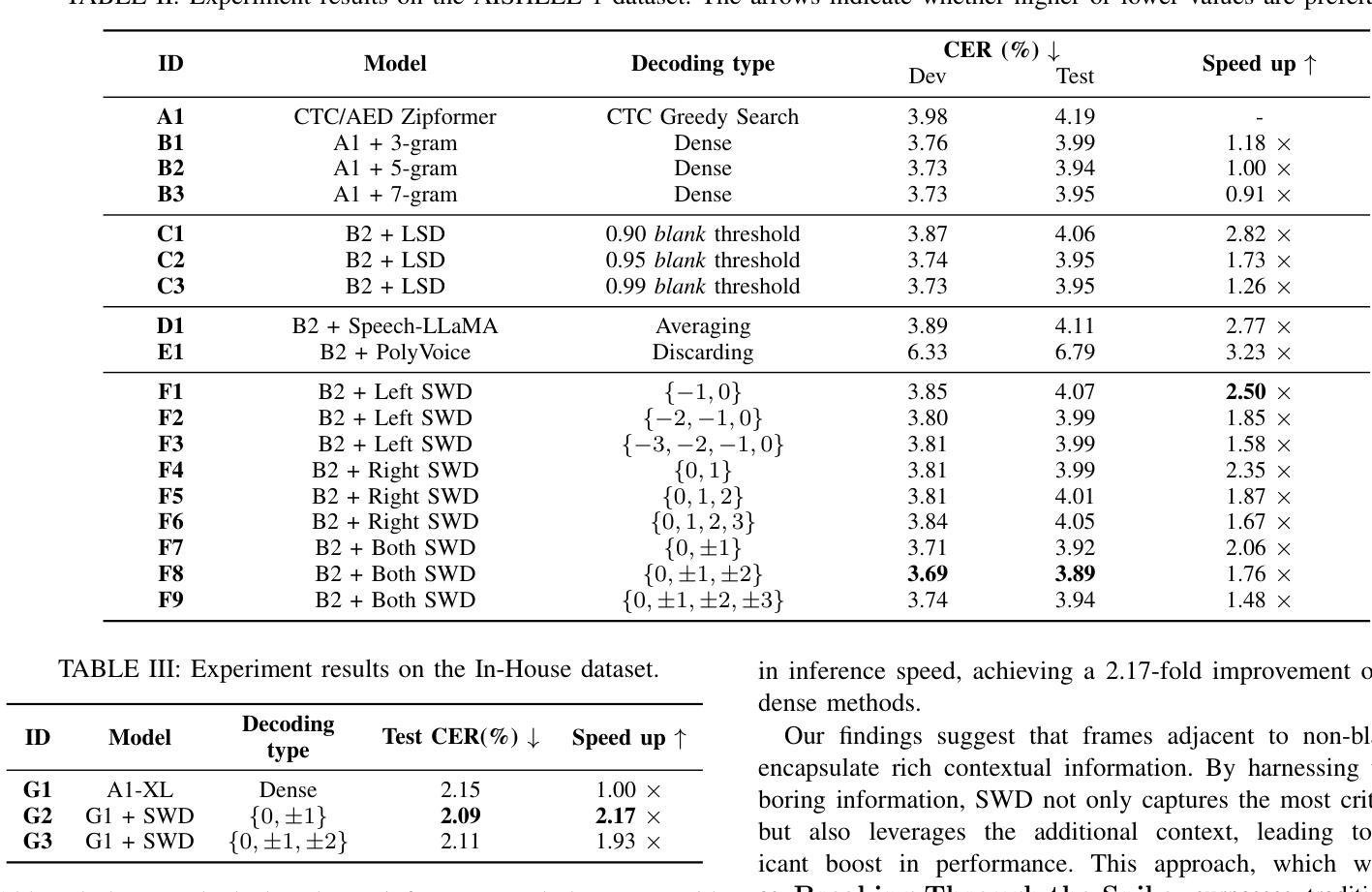
Breaking Through the Spike: Spike Window Decoding for Accelerated and Precise Automatic Speech Recognition
Authors:Wei Zhang, Tian-Hao Zhang, Chao Luo, Hui Zhou, Chao Yang, Xinyuan Qian, Xu-Cheng Yin
Recently, end-to-end automatic speech recognition has become the mainstream approach in both industry and academia. To optimize system performance in specific scenarios, the Weighted Finite-State Transducer (WFST) is extensively used to integrate acoustic and language models, leveraging its capacity to implicitly fuse language models within static graphs, thereby ensuring robust recognition while also facilitating rapid error correction. However, WFST necessitates a frame-by-frame search of CTC posterior probabilities through autoregression, which significantly hampers inference speed. In this work, we thoroughly investigate the spike property of CTC outputs and further propose the conjecture that adjacent frames to non-blank spikes carry semantic information beneficial to the model. Building on this, we propose the Spike Window Decoding algorithm, which greatly improves the inference speed by making the number of frames decoded in WFST linearly related to the number of spiking frames in the CTC output, while guaranteeing the recognition performance. Our method achieves SOTA recognition accuracy with significantly accelerates decoding speed, proven across both AISHELL-1 and large-scale In-House datasets, establishing a pioneering approach for integrating CTC output with WFST.
最近,端到端的自动语音识别已成为业界和学术界的主流方法。为了优化特定场景的系统性能,广泛采用加权有限状态转换器(WFST)来整合声学模型和语言模型,利用其隐式融合静态图内语言模型的能力,从而确保稳健的识别并促进快速错误纠正。然而,WFST需要通过自回归对CTC后验概率进行逐帧搜索,这显著阻碍了推理速度。在这项工作中,我们深入研究了CTC输出的突发特性,并进一步提出了猜想,即非空白突发的相邻帧携带对模型有益的语义信息。在此基础上,我们提出了突发窗口解码算法,通过使WFST中解码的帧数线性相关于CTC输出中的突发帧数,大大提高了推理速度,同时保证识别性能。我们的方法在AI壳牌语音1号语料库以及大规模内部数据集中均实现了最先进的识别精度和显著加速的解码速度,为整合CTC输出和WFST建立了开创性的方法。
论文及项目相关链接
PDF Accepted by ICASSP 2025
Summary
本文探讨了端到端的自动语音识别技术在特定场景下的优化问题。文章指出,尽管加权有限状态转换器(WFST)能够融合声学模型和语言模型,保证识别的稳健性和错误修正的迅速性,但其需要进行帧到帧的CTC后验概率搜索,严重影响了推理速度。研究提出了Spike Window解码算法,通过基于CTC输出中的Spike属性进行解码,在保证识别性能的同时,极大地提高了推理速度。该算法在AISHELL-1和大规模内部数据集上实现了最先进的识别精度和快速解码速度。
Key Takeaways
- 端到端的自动语音识别技术已成为行业与学术界的主流。
- 加权有限状态转换器(WFST)能够融合声学模型和语言模型,确保稳健的识别并促进快速错误修正。
- WFST的帧到帧搜索限制了推理速度。
- 研究提出了Spike Window解码算法,该算法基于CTC输出的Spike属性进行解码。
- Spike Window解码算法在保证识别性能的同时,显著提高了解码速度。
- 该方法在AISHELL-1和大规模内部数据集上实现了最先进的识别精度。
点此查看论文截图

Samba-ASR: State-Of-The-Art Speech Recognition Leveraging Structured State-Space Models
Authors:Syed Abdul Gaffar Shakhadri, Kruthika KR, Kartik Basavaraj Angadi
We propose Samba ASR,the first state of the art Automatic Speech Recognition(ASR)model leveraging the novel Mamba architecture as both encoder and decoder,built on the foundation of state space models(SSMs).Unlike transformerbased ASR models,which rely on self-attention mechanisms to capture dependencies,Samba ASR effectively models both local and global temporal dependencies using efficient statespace dynamics,achieving remarkable performance gains.By addressing the limitations of transformers,such as quadratic scaling with input length and difficulty in handling longrange dependencies,Samba ASR achieves superior accuracy and efficiency.Experimental results demonstrate that Samba ASR surpasses existing opensource transformerbased ASR models across various standard benchmarks,establishing it as the new state of theart in ASR.Extensive evaluations on the benchmark dataset show significant improvements in Word Error Rate(WER),with competitive performance even in lowresource scenarios.Furthermore,the inherent computational efficiency and parameter optimization of the Mamba architecture make Samba ASR a scalable and robust solution for diverse ASR tasks.Our contributions include the development of a new Samba ASR architecture for automatic speech recognition(ASR),demonstrating the superiority of structured statespace models(SSMs)over transformer based models for speech sequence processing.We provide a comprehensive evaluation on public benchmarks,showcasing stateoftheart(SOTA)performance,and present an indepth analysis of computational efficiency,robustness to noise,and sequence generalization.This work highlights the viability of Mamba SSMs as a transformerfree alternative for efficient and accurate ASR.By leveraging the advancements of statespace modeling,Samba ASR redefines ASR performance standards and sets a new benchmark for future research in this field.
我们提出Samba ASR,这是一个利用新型Mamba架构作为编解码器的最先进的语音识别(ASR)模型。它建立在状态空间模型(SSMs)的基础上。不同于依赖自注意力机制捕捉依赖性的基于变压器的ASR模型,Samba ASR使用高效的状态空间动力学有效地对局部和全局时间依赖性进行建模,实现了显著的性能提升。通过解决变压器模型的局限性,如输入长度的二次扩展和难以处理长距离依赖关系,Samba ASR在准确性方面更胜一筹,且效率更高。实验结果表明,Samba ASR在各种标准基准测试中超越了现有的开源基于变压器的ASR模型,成为ASR领域的新技术标杆。在基准数据集上的全面评估显示,其在词错误率(WER)方面取得了显著的改进,即使在资源有限的情况下也表现出竞争力。此外,Mamba架构的固有计算效率和参数优化使得Samba ASR成为各种ASR任务的可扩展和稳健解决方案。我们的贡献包括为自动语音识别(ASR)开发新的Samba ASR架构,证明了结构化状态空间模型(SSMs)在语音序列处理方面优于基于变压器的模型。我们在公共基准测试上进行了全面评估,展示了其卓越的性能,并深入分析了其计算效率、对噪声的鲁棒性和序列泛化能力。这项工作强调了Mamba SSMs作为无变压器的高效准确ASR的可行性。通过利用状态空间建模的进展,Samba ASR重新定义了ASR的性能标准,并为该领域的未来研究设定了新的基准。
论文及项目相关链接
摘要
本文提出一种新型的自动语音识别(ASR)模型——Samba ASR,它采用新颖的Mamba架构作为编码器和解码器,建立在状态空间模型(SSMs)的基础上。与其他基于变压器的ASR模型不同,Samba ASR通过状态空间动态有效地建模局部和全局时间依赖性,实现了显著的性能提升。实验结果表明,Samba ASR在各项标准基准测试中超越了现有的开源基于变压器的ASR模型,成为ASR领域的新技术领先者。它在基准数据集上的词错误率(WER)有显著改善,甚至在低资源场景中也有竞争力。此外,Mamba架构的固有计算效率和参数优化使Samba ASR成为多样化ASR任务的可扩展和稳健解决方案。本研究贡献包括为自动语音识别(ASR)开发新的Samba ASR架构,展示结构化状态空间模型(SSMs)在语音序列处理方面优于基于变压器的模型。我们在公共基准测试上进行了全面评估,展示了其卓越性能,并深入分析了其计算效率、对噪声的鲁棒性和序列泛化能力。这项工作证明了Mamba SSMs作为无变压器的高效、准确ASR的可行性。通过利用状态空间建模的进步,Samba ASR重新定义了ASR的性能标准,为这一领域未来的研究设定了新的基准。
关键见解
- Samba ASR是基于状态空间模型(SSMs)的自动语音识别(ASR)模型,采用Mamba架构作为编码器和解码器。
- 与基于变压器的ASR模型不同,Samba ASR通过状态空间动态建模局部和全局时间依赖性,实现性能提升。
- Samba ASR在各项标准基准测试中表现出卓越性能,超越了现有的开源基于变压器的ASR模型。
- 它在基准数据集上的词错误率(WER)显著改善,且在低资源场景中也有竞争力。
- Mamba架构的固有计算效率和参数优化使Samba ASR适用于多样化ASR任务。
- 深入研究展示结构化状态空间模型(SSMs)在语音序列处理方面的优势,为ASR设定了新的性能标准。
点此查看论文截图

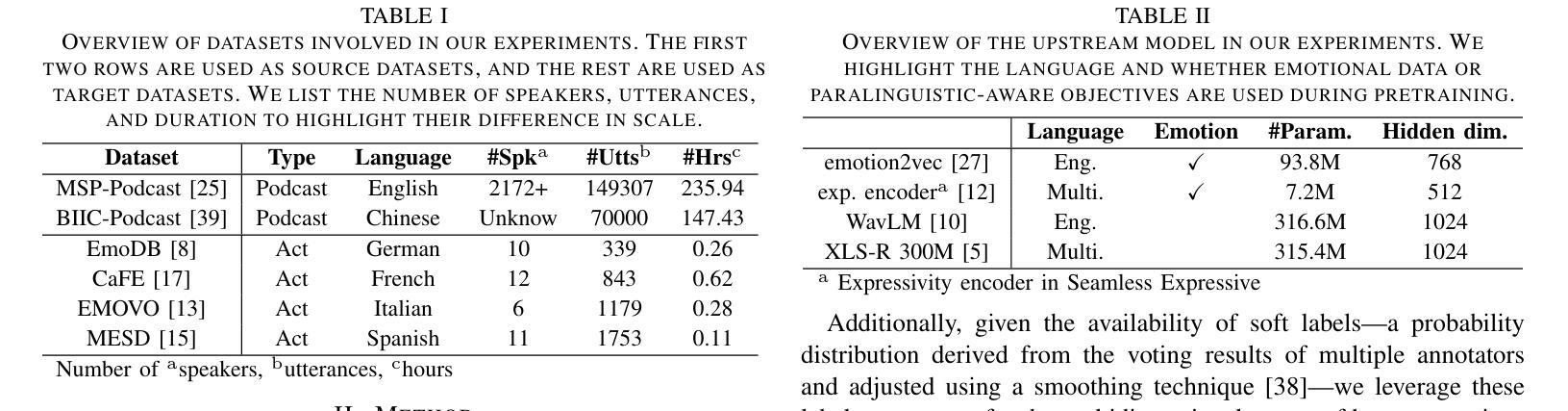
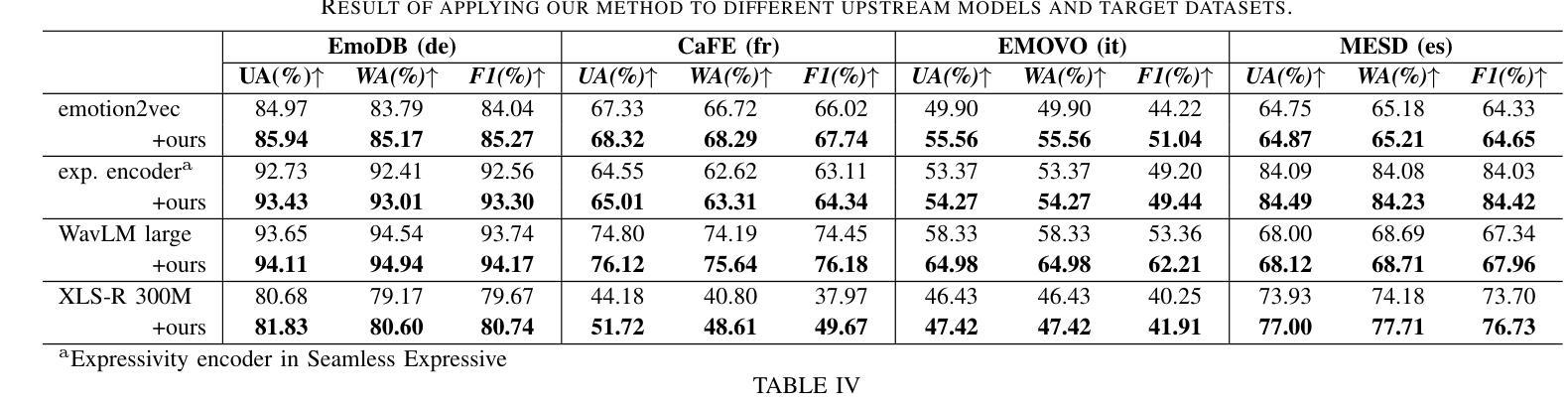
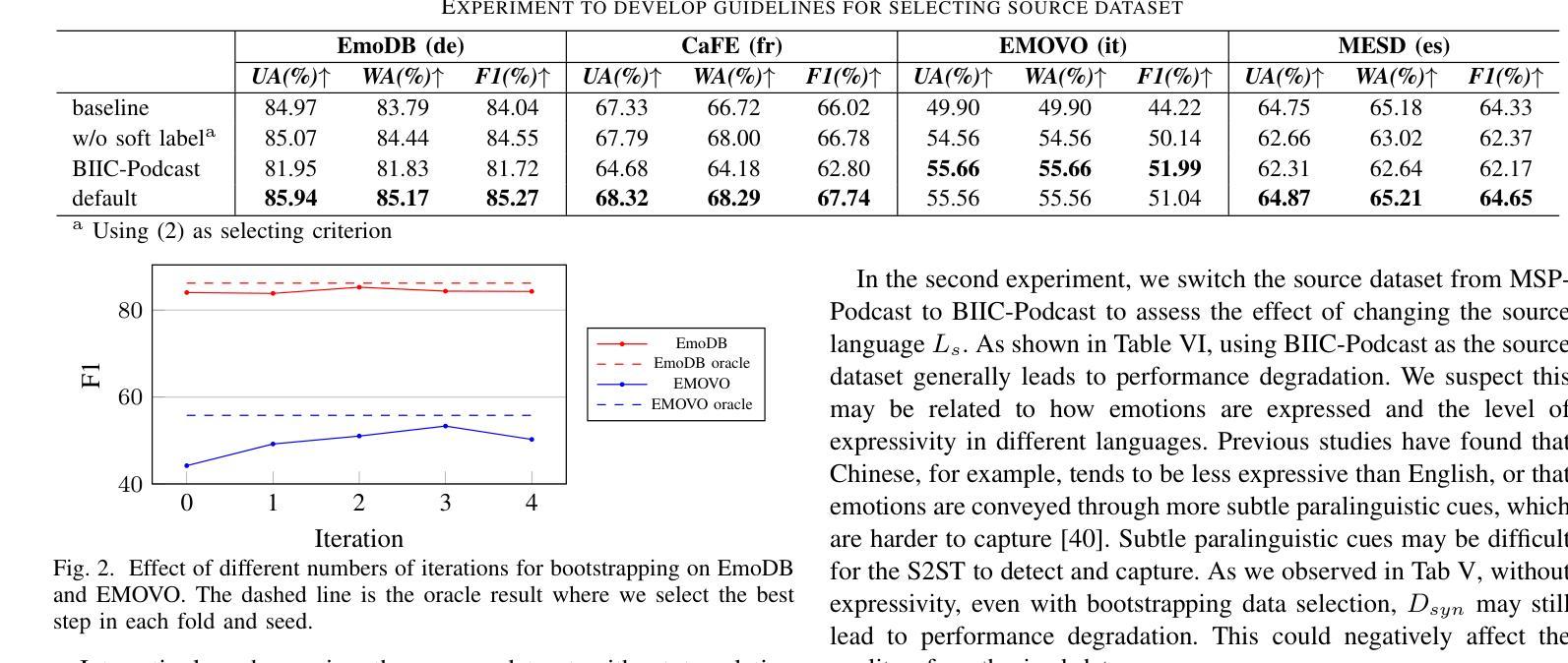
Improving Speech Emotion Recognition in Under-Resourced Languages via Speech-to-Speech Translation with Bootstrapping Data Selection
Authors:Hsi-Che Lin, Yi-Cheng Lin, Huang-Cheng Chou, Hung-yi Lee
Speech Emotion Recognition (SER) is a crucial component in developing general-purpose AI agents capable of natural human-computer interaction. However, building robust multilingual SER systems remains challenging due to the scarcity of labeled data in languages other than English and Chinese. In this paper, we propose an approach to enhance SER performance in low SER resource languages by leveraging data from high-resource languages. Specifically, we employ expressive Speech-to-Speech translation (S2ST) combined with a novel bootstrapping data selection pipeline to generate labeled data in the target language. Extensive experiments demonstrate that our method is both effective and generalizable across different upstream models and languages. Our results suggest that this approach can facilitate the development of more scalable and robust multilingual SER systems.
语音情绪识别(SER)是开发能够与人类进行自然交互的通用人工智能代理的关键组成部分。然而,由于除英语和中文之外的其他语言的标记数据稀缺,构建稳健的多语言SER系统仍然是一个挑战。在本文中,我们提出了一种方法,通过利用高资源语言的数据来提高低资源语言SER的性能。具体来说,我们采用表达性语音到语音翻译(S2ST)结合一种新的自举数据选择管道,以在目标语言中生成标记数据。广泛的实验表明,我们的方法既有效又可在不同的上游模型和语言中通用化。我们的结果表明,这种方法可以促进更可扩展和稳健的多语言SER系统的发展。
论文及项目相关链接
PDF 5 pages, 2 figures, Accepted to ICASSP 2025
Summary
本文提出了通过利用高资源语言的数据来提高低资源语言语音情感识别性能的方法。具体而言,通过采用表现力强的语音到语音翻译结合新颖的自举数据选择流程,在目标语言中生成标记数据。实验证明该方法有效且可跨不同上游模型和语言进行推广,有助于开发更可扩展和稳健的多语种语音情感识别系统。
Key Takeaways
- 语音情感识别是开发通用人工智能代理实现自然人机交互的关键技术。
- 构建多语种语音情感识别系统面临的主要挑战是除英语和中文以外其他语言的标记数据稀缺。
- 本文提出利用高资源语言的数据来提升低资源语言语音情感识别的性能。
- 采用表达性强的语音到语音翻译技术结合自举数据选择流程,在目标语言中生成标记数据。
- 实验证明该方法既有效,又可在不同上游模型和语言间推广。
- 此方法有助于开发更可扩展和稳健的多语种语音情感识别系统。
点此查看论文截图



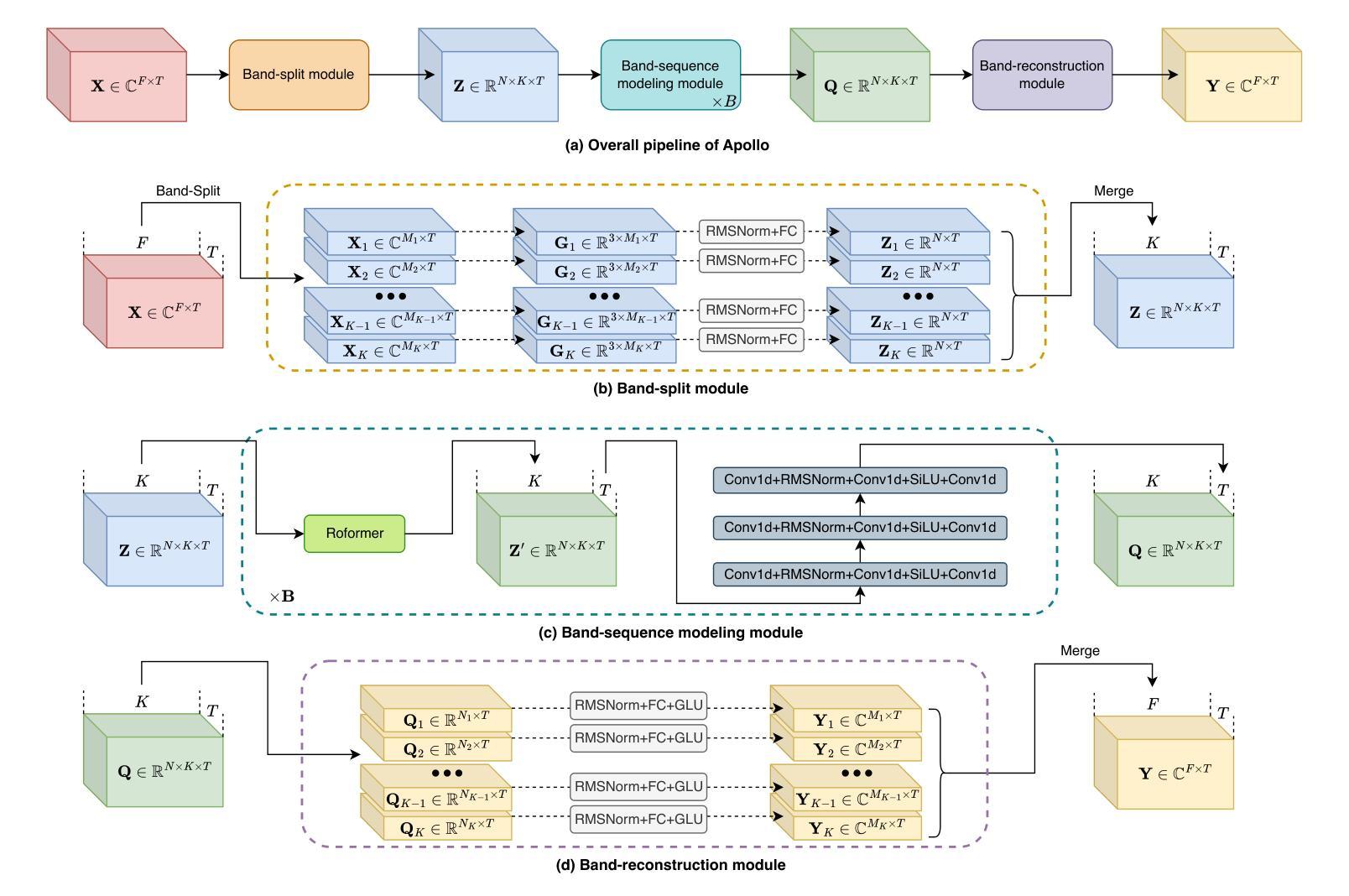
Apollo: Band-sequence Modeling for High-Quality Audio Restoration
Authors:Kai Li, Yi Luo
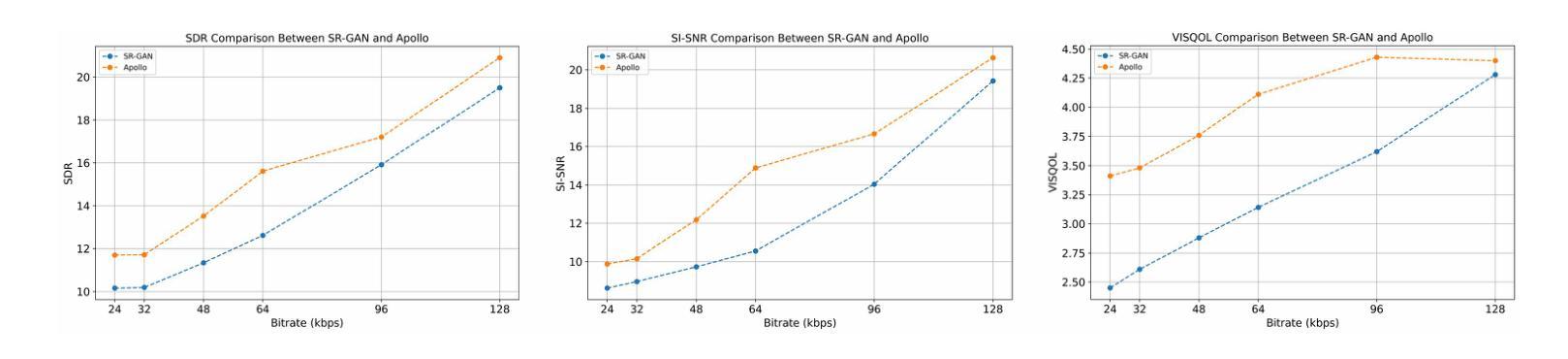
Audio restoration has become increasingly significant in modern society, not only due to the demand for high-quality auditory experiences enabled by advanced playback devices, but also because the growing capabilities of generative audio models necessitate high-fidelity audio. Typically, audio restoration is defined as a task of predicting undistorted audio from damaged input, often trained using a GAN framework to balance perception and distortion. Since audio degradation is primarily concentrated in mid- and high-frequency ranges, especially due to codecs, a key challenge lies in designing a generator capable of preserving low-frequency information while accurately reconstructing high-quality mid- and high-frequency content. Inspired by recent advancements in high-sample-rate music separation, speech enhancement, and audio codec models, we propose Apollo, a generative model designed for high-sample-rate audio restoration. Apollo employs an explicit frequency band split module to model the relationships between different frequency bands, allowing for more coherent and higher-quality restored audio. Evaluated on the MUSDB18-HQ and MoisesDB datasets, Apollo consistently outperforms existing SR-GAN models across various bit rates and music genres, particularly excelling in complex scenarios involving mixtures of multiple instruments and vocals. Apollo significantly improves music restoration quality while maintaining computational efficiency. The source code for Apollo is publicly available at https://github.com/JusperLee/Apollo.
音频修复在现代社会变得越来越重要,这不仅仅是因为先进播放设备带来的对高质量听觉体验的需求,也因为生成式音频模型的日益强大的能力需要高保真音频。通常,音频修复被定义为从损坏的输入预测无损音频的任务,通常使用生成对抗网络(GAN)框架进行训练,以平衡感知和失真。由于音频退化主要集中在中频和高频范围内,特别是在编解码器中,一个关键挑战在于设计一种生成器,能够保留低频信息,同时准确重建高质量的中频和高频内容。受高采样率音乐分离、语音增强和音频编解码器模型的最新进展的启发,我们提出了Apollo,这是一个用于高采样率音频修复的生成模型。Apollo采用明确的频带分割模块来模拟不同频带之间的关系,从而生成更连贯、更高质量的修复音频。在MUSDB18-HQ和MoisesDB数据集上评估,Apollo在各种比特率和音乐风格上均优于现有的SR-GAN模型,特别是在涉及多种乐器和人声混合的复杂场景中表现尤为出色。Apollo在提升音乐修复质量的同时保持了计算效率。Apollo的源代码可在https://github.com/JusperLee/Apollo公开获取。
论文及项目相关链接
PDF Accepted by ICASSP 2025, Demo Page: https://cslikai.cn/Apollo
摘要
随着现代社会对高质量听觉体验的需求日益增长,音频修复技术变得尤为重要。音频修复的任务在于从损坏的输入中预测无损音频,通常使用生成对抗网络(GAN)框架进行训练,以平衡感知和失真。针对音频降质主要集中在中高频范围的问题,尤其是编码器的降质,设计出一个能够保存低频信息并准确重建高质量中高频内容的生成器成为一大挑战。受高采样率音乐分离、语音增强和音频编码模型最新进展的启发,我们提出了Apollo,一个用于高采样率音频修复的生成模型。Apollo采用明确的频带分割模块,模拟不同频带之间的关系,从而生成更为连贯和高质量的音频。在MUSDB18-HQ和MoisesDB数据集上的评估结果表明,Apollo在各种比特率和音乐类型上均优于现有的SR-GAN模型,特别是在涉及多种乐器和人声混合的复杂场景中表现尤为出色。Apollo在提升音乐修复质量的同时,也保持了计算效率。Apollo的源代码已公开在https://github.com/JusperLee/Apollo。
关键见解
- 音频修复在现代社会中具有重要性,以满足高质量听觉体验的需求。
- 音频修复的任务是预测从损坏输入中的无损音频,通常使用GAN框架进行训练。
- 音频降质主要集中在中高频范围,设计能够保存低频信息并重建中高频内容的生成器是挑战之一。
- Apollo是一个用于高采样率音频修复的生成模型,采用频带分割模块来提高音频质量。
- Apollo在多个数据集上的表现优于现有SR-GAN模型,尤其在复杂场景中表现突出。
- Apollo在提高音乐修复质量的同时,也保持了计算效率。
点此查看论文截图



The Faetar Benchmark: Speech Recognition in a Very Under-Resourced Language
Authors:Michael Ong, Sean Robertson, Leo Peckham, Alba Jorquera Jimenez de Aberasturi, Paula Arkhangorodsky, Robin Huo, Aman Sakhardande, Mark Hallap, Naomi Nagy, Ewan Dunbar
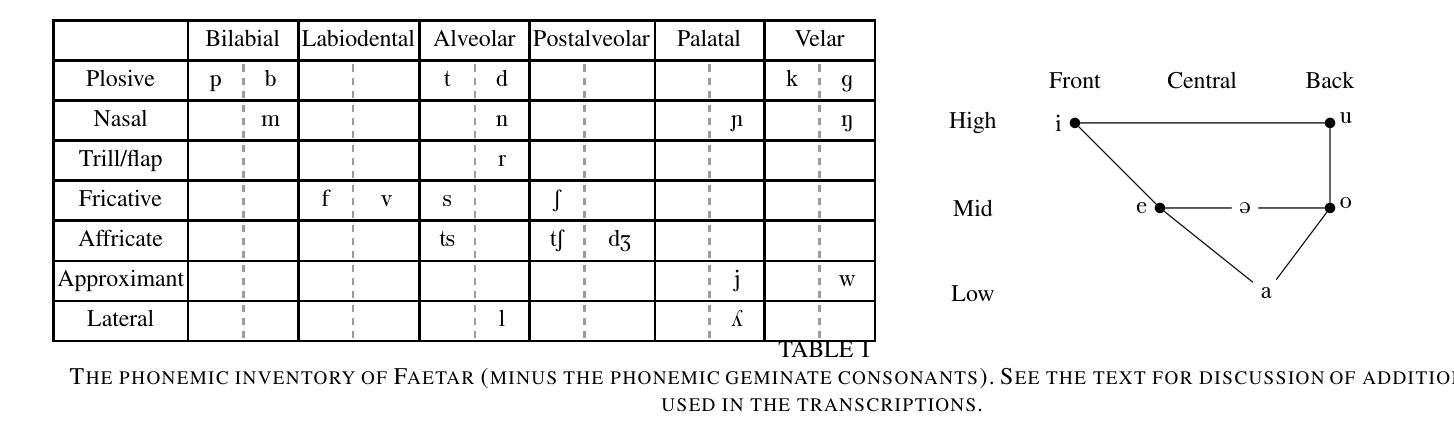
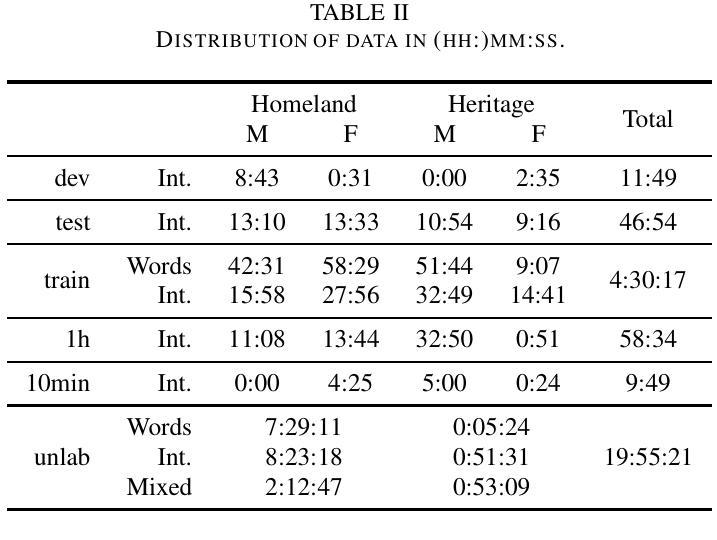
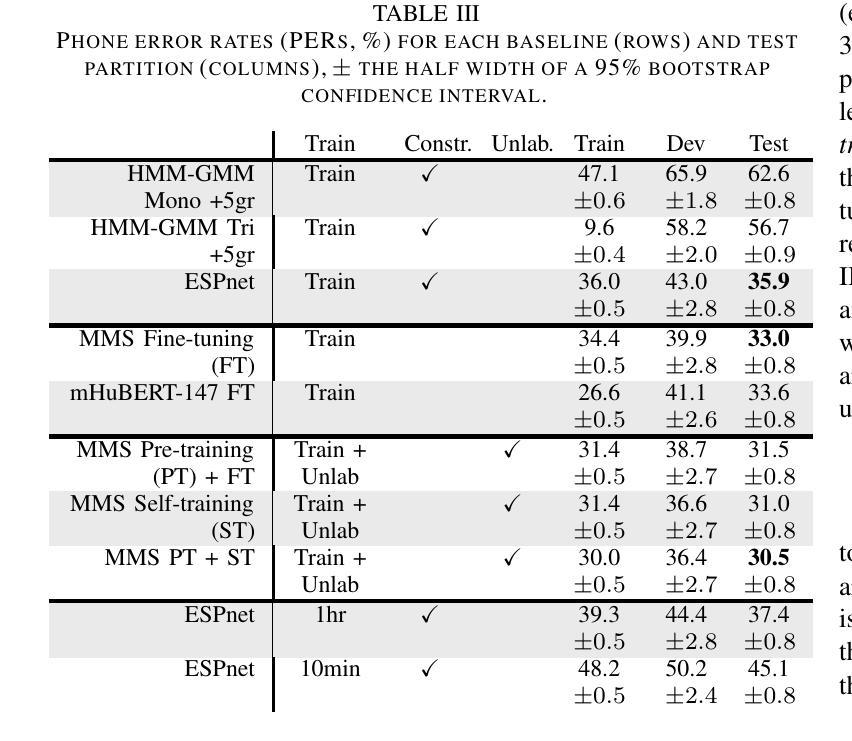
We introduce the Faetar Automatic Speech Recognition Benchmark, a benchmark corpus designed to push the limits of current approaches to low-resource speech recognition. Faetar, a Franco-Proven\c{c}al variety spoken primarily in Italy, has no standard orthography, has virtually no existing textual or speech resources other than what is included in the benchmark, and is quite different from other forms of Franco-Proven\c{c}al. The corpus comes from field recordings, most of which are noisy, for which only 5 hrs have matching transcriptions, and for which forced alignment is of variable quality. The corpus contains an additional 20 hrs of unlabelled speech. We report baseline results from state-of-the-art multilingual speech foundation models with a best phone error rate of 30.4%, using a pipeline that continues pre-training on the foundation model using the unlabelled set.
我们介绍了Faetar自动语音识别基准测试,这是一个基准测试语料库,旨在推动当前方法在资源匮乏语音识别方面的极限。Faetar是一种主要在意大利使用的法罗-普罗旺斯方言,它没有标准的正字法,除了基准测试中包含的内容外,几乎没有现有的文本或语音资源,而且与其他形式的法罗-普罗旺斯方言有很大的不同。该语料库来自现场录音,其中大部分是嘈杂的,只有5小时的语音有匹配的转录,而且其强制对齐的质量也是时好时坏。语料库还包含额外的20小时未标注的语音。我们报告了使用最先进的多语言语音基础模型的基线结果,最佳语音错误率为30.4%,使用在基础模型上继续使用未标注集进行预训练的管道。
论文及项目相关链接
总结
本文介绍了Faetar自动语音识别基准测试集,这是一个为挑战当前低资源语音识别方法而设计的基准测试集。Faetar是一种主要在意大利使用的法意混合方言,没有标准的正字法,除了基准测试集中包含的之外,几乎没有现有的文本或语音资源,并且与其他形式的法意混合方言有很大差异。该语料库来自现场录音,其中大部分是嘈杂的,只有5小时的录音有匹配的转录文本,强制对齐的质量不一。此外,语料库还包含20小时的未标记语音。报告了使用前沿的多语言语音基础模型的基线结果,最佳音素错误率为30.4%,使用在基础模型上继续对未标记集进行预训练的管道。
要点
- Faetar自动语音识别基准测试集是为了挑战低资源语音识别方法而设计的。
- Faetar是一种特殊的法意混合方言,缺乏标准正字法,资源匮乏。
- 该语料库主要来自现场录音,部分语音环境嘈杂。
- 只有5小时的语音有匹配的转录文本,强制对齐的质量存在差异。
- 语料库还包含20小时的未标记语音。
- 报告了使用前沿多语言语音基础模型的基线结果。
点此查看论文截图

Neural Speech and Audio Coding: Modern AI Technology Meets Traditional Codecs
Authors:Minje Kim, Jan Skoglund
This paper explores the integration of model-based and data-driven approaches within the realm of neural speech and audio coding systems. It highlights the challenges posed by the subjective evaluation processes of speech and audio codecs and discusses the limitations of purely data-driven approaches, which often require inefficiently large architectures to match the performance of model-based methods. The study presents hybrid systems as a viable solution, offering significant improvements to the performance of conventional codecs through meticulously chosen design enhancements. Specifically, it introduces a neural network-based signal enhancer designed to post-process existing codecs’ output, along with the autoencoder-based end-to-end models and LPCNet–hybrid systems that combine linear predictive coding (LPC) with neural networks. Furthermore, the paper delves into predictive models operating within custom feature spaces (TF-Codec) or predefined transform domains (MDCTNet) and examines the use of psychoacoustically calibrated loss functions to train end-to-end neural audio codecs. Through these investigations, the paper demonstrates the potential of hybrid systems to advance the field of speech and audio coding by bridging the gap between traditional model-based approaches and modern data-driven techniques.
本文探讨了神经网络语音和音频编码系统中基于模型和基于数据的方法的融合。文章重点介绍了语音和音频编解码器的主观评估过程所面临的挑战,并讨论了纯数据驱动方法的局限性,这些方法通常需要构建庞大且低效的架构才能达到基于模型的方法的性能。该研究提出了混合系统作为一个可行的解决方案,通过精心选择的设计增强措施,对常规编解码器的性能进行了重大改进。具体来说,它引入了一种基于神经网络的信号增强器,用于对现有的编解码器输出进行后处理,以及基于自编码器的端到端模型和LPCNet混合系统,该系统将线性预测编码(LPC)与神经网络相结合。此外,文章还深入研究了在自定义特征空间(TF-Codec)或预定义变换域(MDCTNet)内运行的预测模型,并探讨了使用心理声学校准损失函数来训练端到端神经音频编解码器。通过这些研究,文章展示了混合系统在缩小传统基于模型的方法和现代基于数据的技术之间的差距方面所具有的发展潜力,从而推动语音和音频编码领域的发展。
论文及项目相关链接
PDF Published in IEEE Signal Processing Magazine
Summary
本文探讨了神经语音和音频编码系统中基于模型和数据驱动方法的融合。文章指出了语音和音频编码主观评估过程所带来的挑战,并讨论了纯粹数据驱动方法的局限性,这些方法通常需要构建庞大的架构才能达到基于模型的方法的性能。研究提出混合系统作为解决方案,通过精心设计改进,对传统编码器的性能进行了显着提高。特别是,它引入了一种基于神经网络的信号增强器,用于对现有编码器的输出进行后处理,以及基于自编码器的端到端模型和LPCNet混合系统,结合线性预测编码(LPC)与神经网络。此外,本文还研究了在自定义特征空间(TF-Codec)或预定义变换域(MDCTNet)内运行的预测模型,并探讨了使用心理声学校准损失函数来训练端到端神经音频编码器的潜力。本文通过混合系统的研究,展示了其缩小传统基于模型的方法和现代数据驱动技术之间差距,推动语音和音频编码领域发展的潜力。
Key Takeaways
- 探讨了模型与数据驱动方法在神经语音和音频编码中的融合。
- 强调了语音和音频编码主观评估过程的挑战。
- 指出纯粹数据驱动方法的局限性以及为何需要混合系统。
- 介绍了基于神经网络的信号增强器及其作用。
- 探讨了结合线性预测编码(LPC)与神经网络的混合系统(LPCNet)。
- 研究了在自定义特征空间或预定义变换域内运行的预测模型。
点此查看论文截图

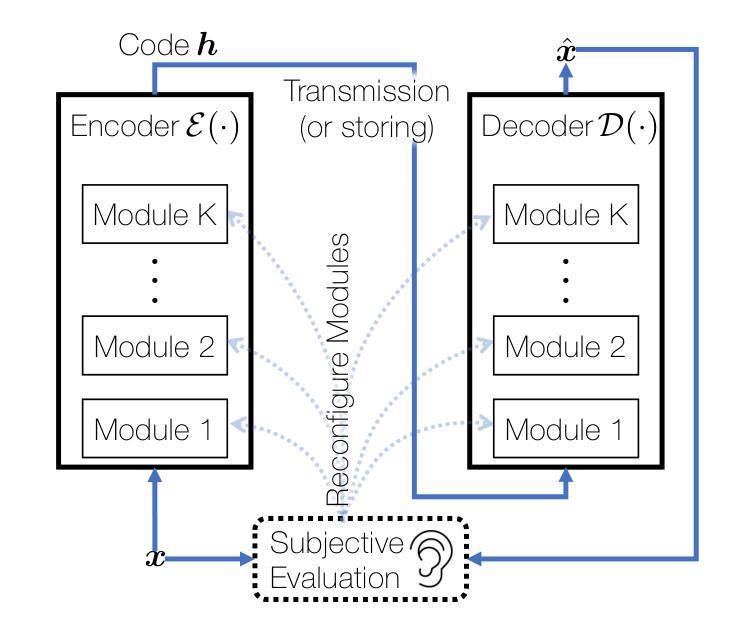
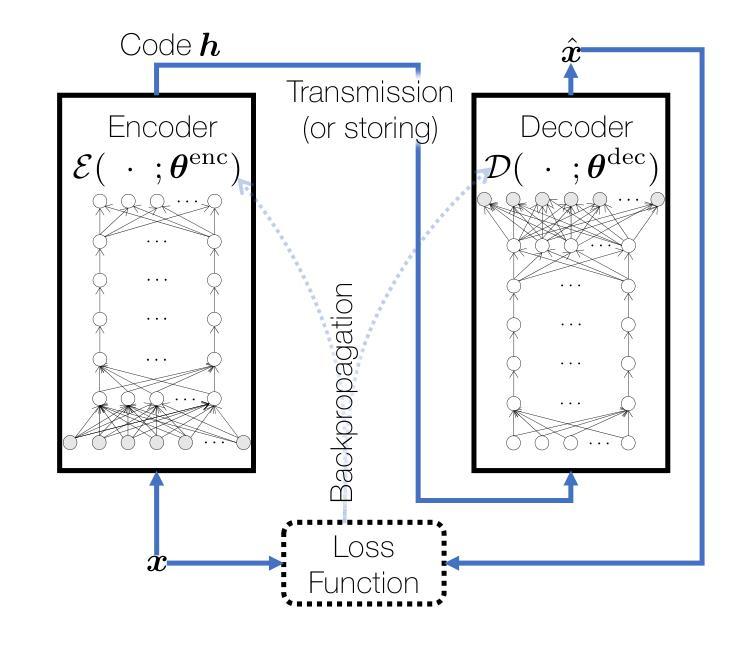
Continuously Learning New Words in Automatic Speech Recognition
Authors:Christian Huber, Alexander Waibel
Despite recent advances, Automatic Speech Recognition (ASR) systems are still far from perfect. Typical errors include acronyms, named entities, and domain-specific special words for which little or no labeled data is available. To address the problem of recognizing these words, we propose a self-supervised continual learning approach: Given the audio of a lecture talk with the corresponding slides, we bias the model towards decoding new words from the slides by using a memory-enhanced ASR model from the literature. Then, we perform inference on the talk, collecting utterances that contain detected new words into an adaptation data set. Continual learning is then performed by training adaptation weights added to the model on this data set. The whole procedure is iterated for many talks. We show that with this approach, we obtain increasing performance on the new words when they occur more frequently (more than 80% recall) while preserving the general performance of the model.
尽管最近取得了进展,但自动语音识别(ASR)系统仍然远非完美。典型的错误包括缩写词、命名实体和特定领域的特殊词汇,这些词汇很少或几乎没有相应的标记数据。为了解决识别这些词汇的问题,我们提出了一种自监督的连续学习方法:给定带有相应幻灯片的讲座音频,我们通过使用文献中的记忆增强ASR模型,偏向模型以从幻灯片中解码新词汇。然后,我们对讲座进行推理,收集包含检测到的新词汇的片段,形成一个适应数据集。通过在此数据集上训练模型的附加适应权重,连续学习得以进行。整个过程多次迭代讲座内容。我们表明,通过这种方法,当新词汇出现得更频繁时,我们在这些词汇上的性能有所提高(召回率超过80%),同时保持模型的整体性能。
论文及项目相关链接
PDF Accepted at ICASSP 2025
Summary
这篇文本主要讨论的是自动语音识别(ASR)系统存在的问题及其改进方法。针对ASR系统在识别缩写、命名实体和特定领域特殊词汇时出现的典型错误,提出了一种基于自监督的持续学习方法。该方法利用带有相应幻灯片的讲座音频,通过增强记忆的ASR模型,偏向解码幻灯片中的新词汇。然后,对讲座进行推理,收集包含检测到的新词汇的片段,形成一个适应数据集。通过在此数据集上训练模型的适应权重,实现持续学习。该方法能够提高模型对新词的识别性能,并且随着新词出现频率的增加,召回率超过80%,同时保持模型的总体性能。
Key Takeaways
- 自动语音识别(ASR)系统仍存在识别缩写、命名实体和特定领域特殊词汇的挑战。
- 提出了一种基于自监督的持续学习方法来解决这些问题。
- 方法利用讲座音频和相应幻灯片,通过增强记忆的ASR模型偏向解码幻灯片中的新词汇。
- 通过收集包含新词汇的片段形成适应数据集,并进行持续学习。
- 该方法能够提高模型对新词的识别性能。
- 随着新词出现频率的增加,召回率超过80%。
点此查看论文截图

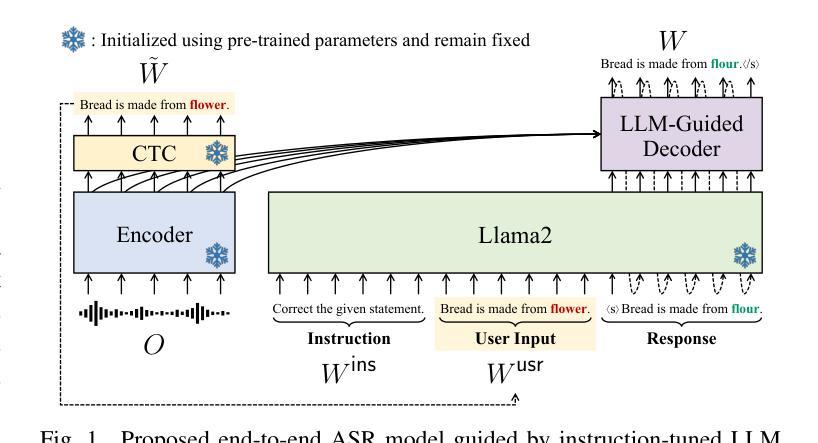
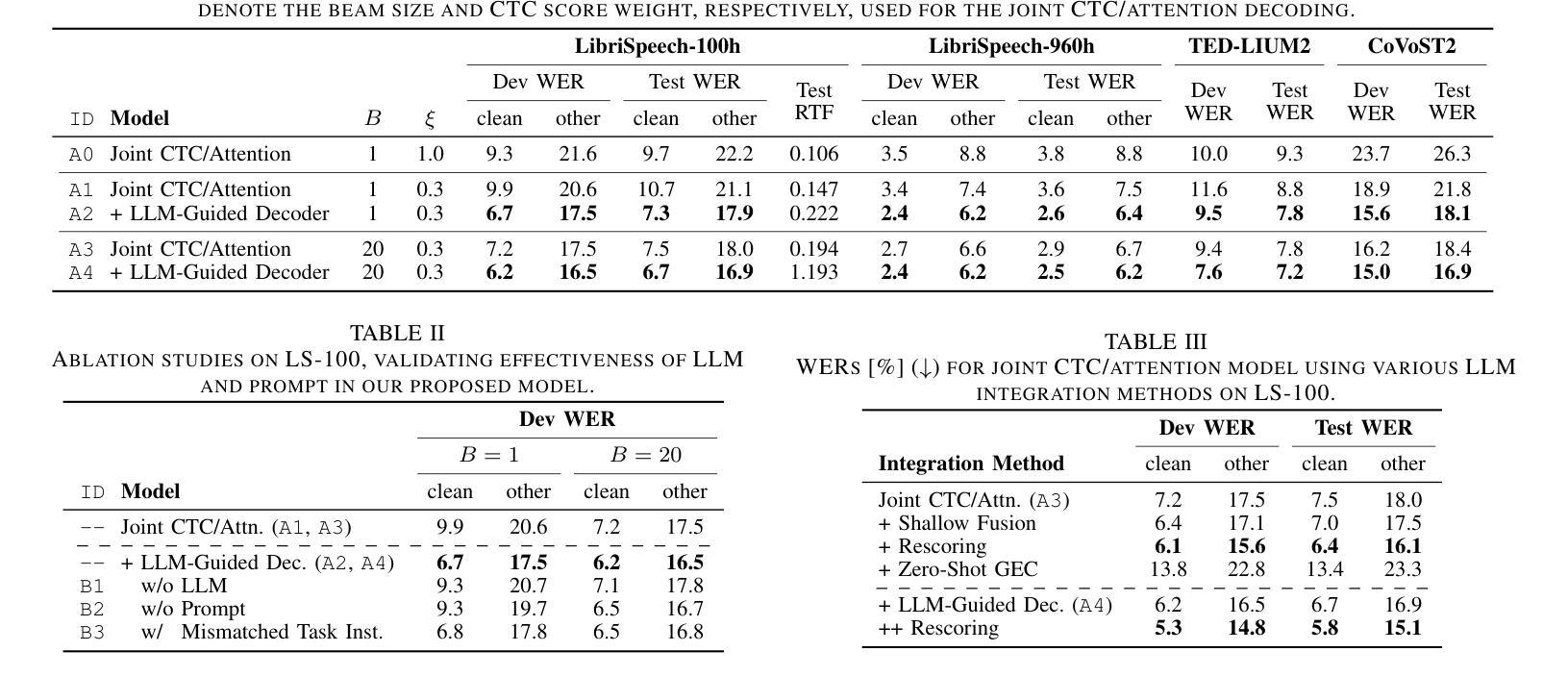
Harnessing the Zero-Shot Power of Instruction-Tuned Large Language Model in End-to-End Speech Recognition
Authors:Yosuke Higuchi, Tetsuji Ogawa, Tetsunori Kobayashi
We propose to utilize an instruction-tuned large language model (LLM) for guiding the text generation process in automatic speech recognition (ASR). Modern large language models (LLMs) are adept at performing various text generation tasks through zero-shot learning, prompted with instructions designed for specific objectives. This paper explores the potential of LLMs to derive linguistic information that can facilitate text generation in end-to-end ASR models. Specifically, we instruct an LLM to correct grammatical errors in an ASR hypothesis and use the LLM-derived representations to refine the output further. The proposed model is built on the joint CTC and attention architecture, with the LLM serving as a front-end feature extractor for the decoder. The ASR hypothesis, subject to correction, is obtained from the encoder via CTC decoding and fed into the LLM along with a specific instruction. The decoder subsequently takes as input the LLM output to perform token predictions, combining acoustic information from the encoder and the powerful linguistic information provided by the LLM. Experimental results show that the proposed LLM-guided model achieves a relative gain of approximately 13% in word error rates across major benchmarks.
我们提议在自动语音识别(ASR)的文本生成过程中,利用经过指令训练的大型语言模型(LLM)进行引导。现代大型语言模型(LLM)擅长通过零样本学习完成各种文本生成任务,这些任务通过针对特定目标的指令来提示。本文探讨了LLM在端到端ASR模型中用于促进文本生成的潜力。具体来说,我们指导LLM纠正ASR假设中的语法错误,并使用LLM生成的表示来进一步完善输出。所提出的模型建立在连接时序分类(CTC)和注意力架构之上,LLM作为解码器的前端特征提取器。需要纠正的ASR假设是通过CTC解码从编码器获得的,并与特定指令一起输入到LLM中。解码器随后以LLM输出作为输入来进行令牌预测,结合编码器提供的音频信息和LLM提供的强大的语言信息。实验结果表明,所提出的LLM引导模型在主要基准测试上实现了约13%的词错误率相对增益。
论文及项目相关链接
PDF Accepted to ICASSP2025
Summary
利用指令优化的大型语言模型(LLM)指导自动语音识别(ASR)中的文本生成过程。LLM能够通过零样本学习执行各种文本生成任务,通过为特定目标设计的指令进行提示。本文探讨了LLM在端到端ASR模型中用于文本生成的潜力。具体来说,我们指导LLM纠正ASR假设中的语法错误,并使用LLM生成的表示来进一步完善输出。提出的模型建立在联合CTC和注意力架构上,LLM作为解码器的前端特征提取器。ASR假设(需进行纠正)由编码器通过CTC解码获得,并与特定指令一起输入LLM。解码器随后以LLM输出作为输入进行令牌预测,结合编码器的声音信息和LLM提供的强大语言信息。实验结果表明,所提出的LLM指导模型在主要基准测试上相对提高了约13%的单词错误率。
Key Takeaways
- 大型语言模型(LLM)可以用于指导自动语音识别(ASR)中的文本生成过程。
- LLM能够通过零样本学习执行文本生成任务,并通过特定指令进行优化。
- LLM在端到端ASR模型中的潜力在于纠正ASR假设中的语法错误并进一步完善输出。
- 提出的模型结合CTC和注意力架构,其中LLM作为解码器的前端特征提取器。
- ASR假设通过CTC解码获得,并与指令一起输入LLM进行进一步处理。
- LLM的输出与编码器的声音信息结合,用于解码器的令牌预测。
点此查看论文截图