⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-10 更新
Disentangled Clothed Avatar Generation with Layered Representation
Authors:Weitian Zhang, Sijing Wu, Manwen Liao, Yichao Yan
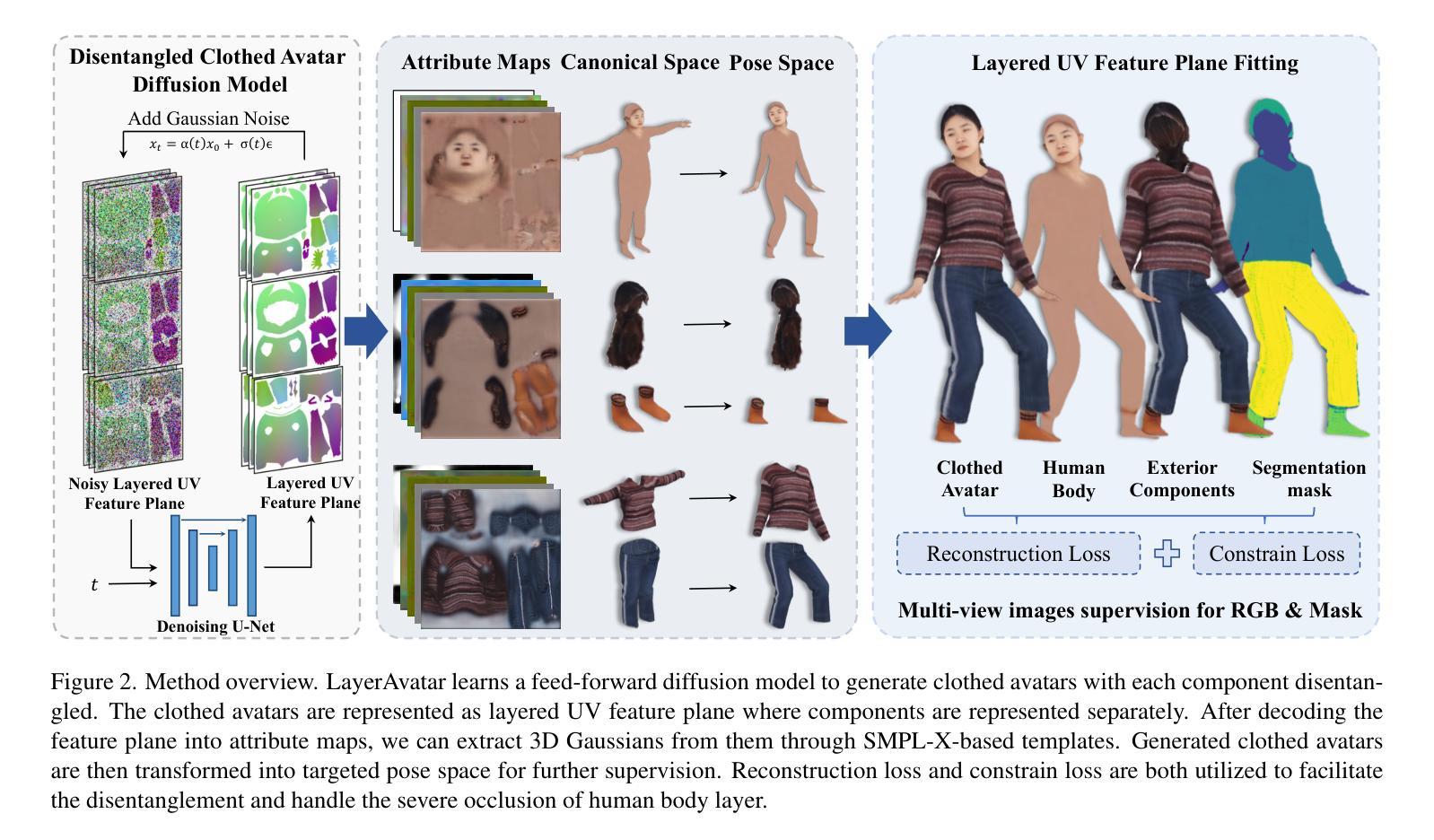
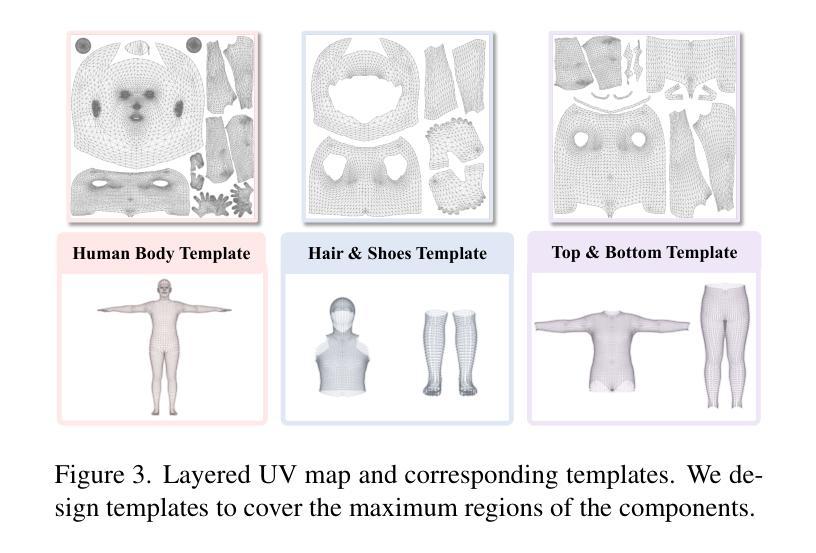
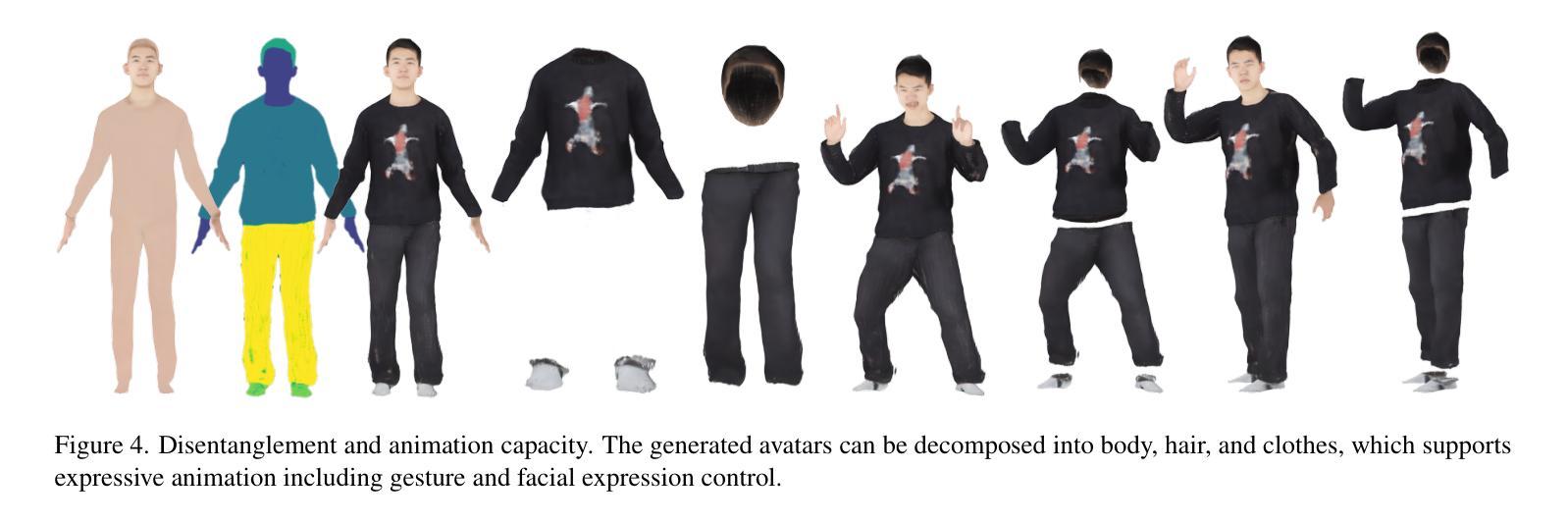
Clothed avatar generation has wide applications in virtual and augmented reality, filmmaking, and more. Previous methods have achieved success in generating diverse digital avatars, however, generating avatars with disentangled components (\eg, body, hair, and clothes) has long been a challenge. In this paper, we propose LayerAvatar, the first feed-forward diffusion-based method for generating component-disentangled clothed avatars. To achieve this, we first propose a layered UV feature plane representation, where components are distributed in different layers of the Gaussian-based UV feature plane with corresponding semantic labels. This representation supports high-resolution and real-time rendering, as well as expressive animation including controllable gestures and facial expressions. Based on the well-designed representation, we train a single-stage diffusion model and introduce constrain terms to address the severe occlusion problem of the innermost human body layer. Extensive experiments demonstrate the impressive performances of our method in generating disentangled clothed avatars, and we further explore its applications in component transfer. The project page is available at: https://olivia23333.github.io/LayerAvatar/
衣物虚拟角色的生成在虚拟和增强现实、电影制作等领域有广泛的应用。先前的方法已经成功生成了各种数字虚拟角色,然而,生成具有分离组件(例如身体、头发和衣物)的虚拟角色一直是一个挑战。在本文中,我们提出了LayerAvatar,这是一种基于前馈扩散的方法,用于生成组件分离的穿衣虚拟角色。为了实现这一点,我们首先提出了一种分层UV特征平面表示法,其中组件根据相应的语义标签分布在基于高斯分布的UV特征平面的不同层中。这种表示法支持高分辨率和实时渲染,以及包括可控手势和面部表情在内的生动动画。基于这种精心设计的设计表示法,我们训练了一个单阶段扩散模型,并引入了约束项来解决最内层人体层的严重遮挡问题。大量实验证明了我们方法在生成分离的穿衣虚拟角色方面的出色表现,并进一步探索了其在组件转移中的应用。项目页面可通过以下链接访问:https://olivia23333.github.io/LayerAvatar/
论文及项目相关链接
PDF project page: https://olivia23333.github.io/LayerAvatar/
Summary
高性能服装化数字虚拟人物生成技术在虚拟与增强现实、影视制作等领域具有广泛应用。本论文提出了一种名为LayerAvatar的新型前馈扩散方法,用于生成组件分离的服装化虚拟人物。通过设计基于高斯UV特征平面的分层表示方法,实现了高质量、实时渲染及表情动作的可控性。针对人体内部层遮挡问题,论文引入约束项训练单阶段扩散模型。实验证明,该方法在生成分离服装化虚拟人物方面具有显著优势,并在组件转换应用中展现潜力。详情访问项目网页:https://olivia23333.github.io/LayerAvatar/。
Key Takeaways
- LayerAvatar是一种前馈扩散方法,用于生成组件分离的服装化虚拟人物。
- 采用基于高斯UV特征平面的分层表示方法,实现高质量、实时渲染及表情动作的可控性。
- 通过引入约束项解决了人体内部层遮挡问题。
- 实验证明该方法在生成分离服装化虚拟人物方面具有显著优势。
- LayerAvatar方法支持服装化虚拟人物的组件转换应用。
- LayerAvatar在虚拟与增强现实、影视制作等领域有广泛应用潜力。
点此查看论文截图