⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-10 更新
Boosting Salient Object Detection with Knowledge Distillated from Large Foundation Models
Authors:Miaoyang He, Shuyong Gao, Tsui Qin Mok, Weifeng Ge, Wengqiang Zhang
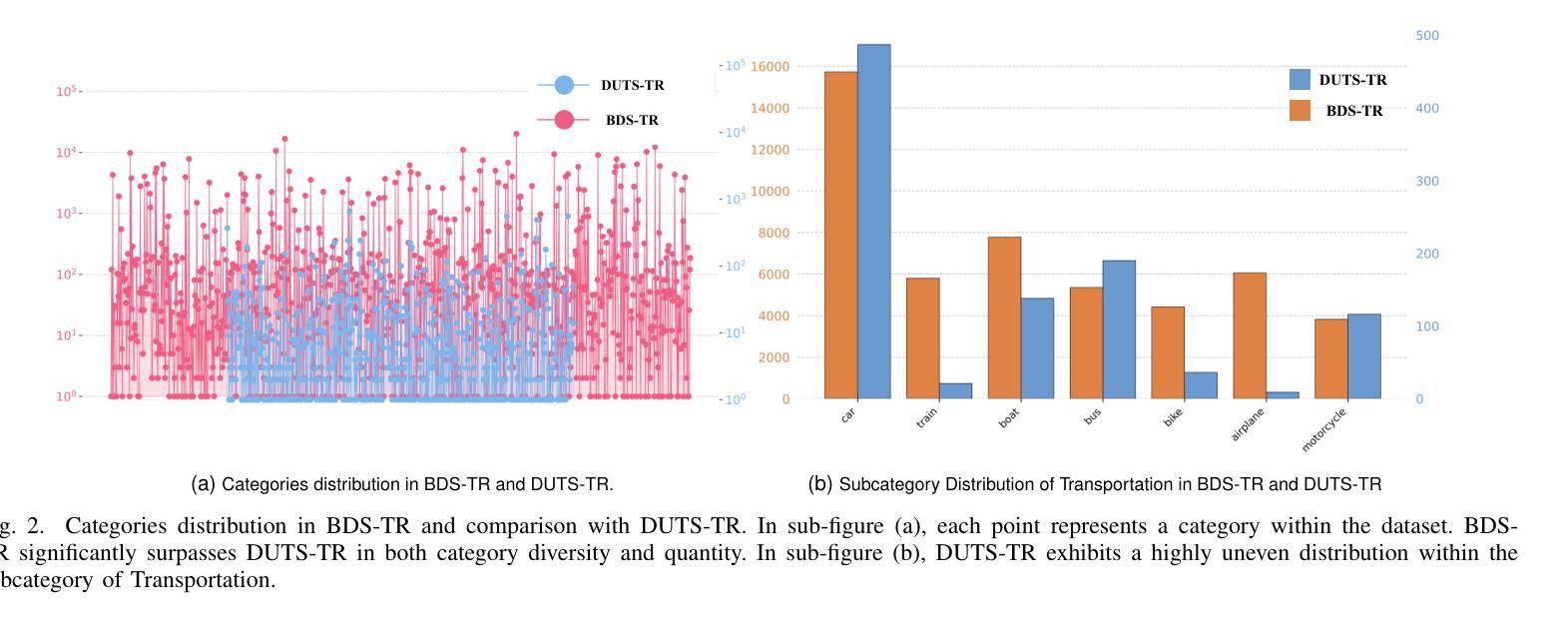
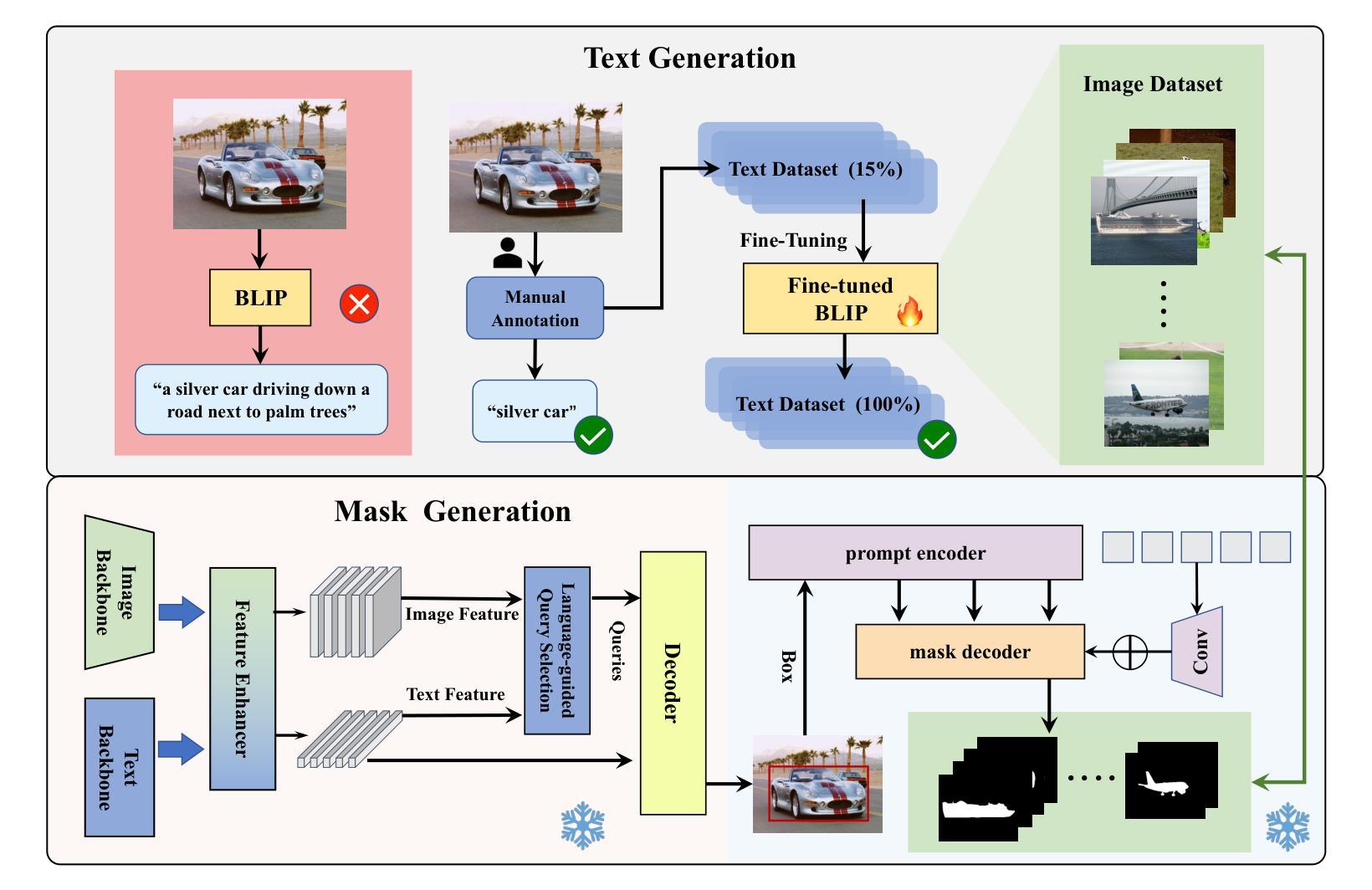
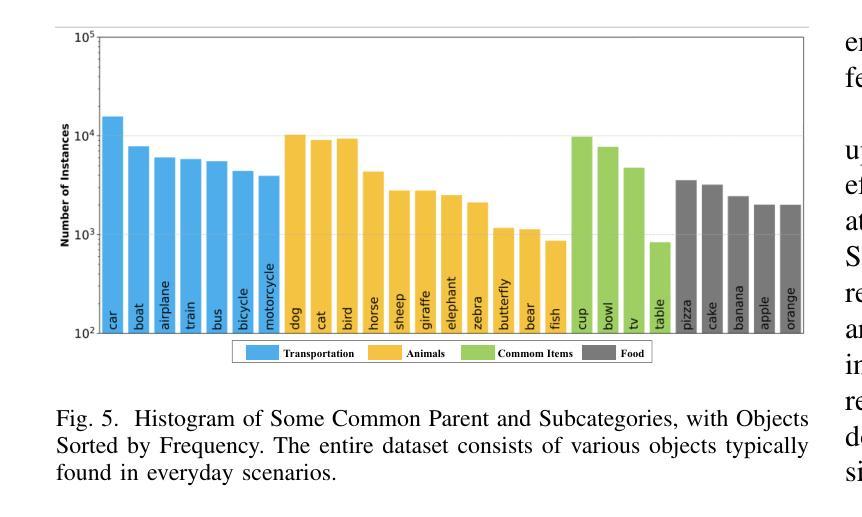
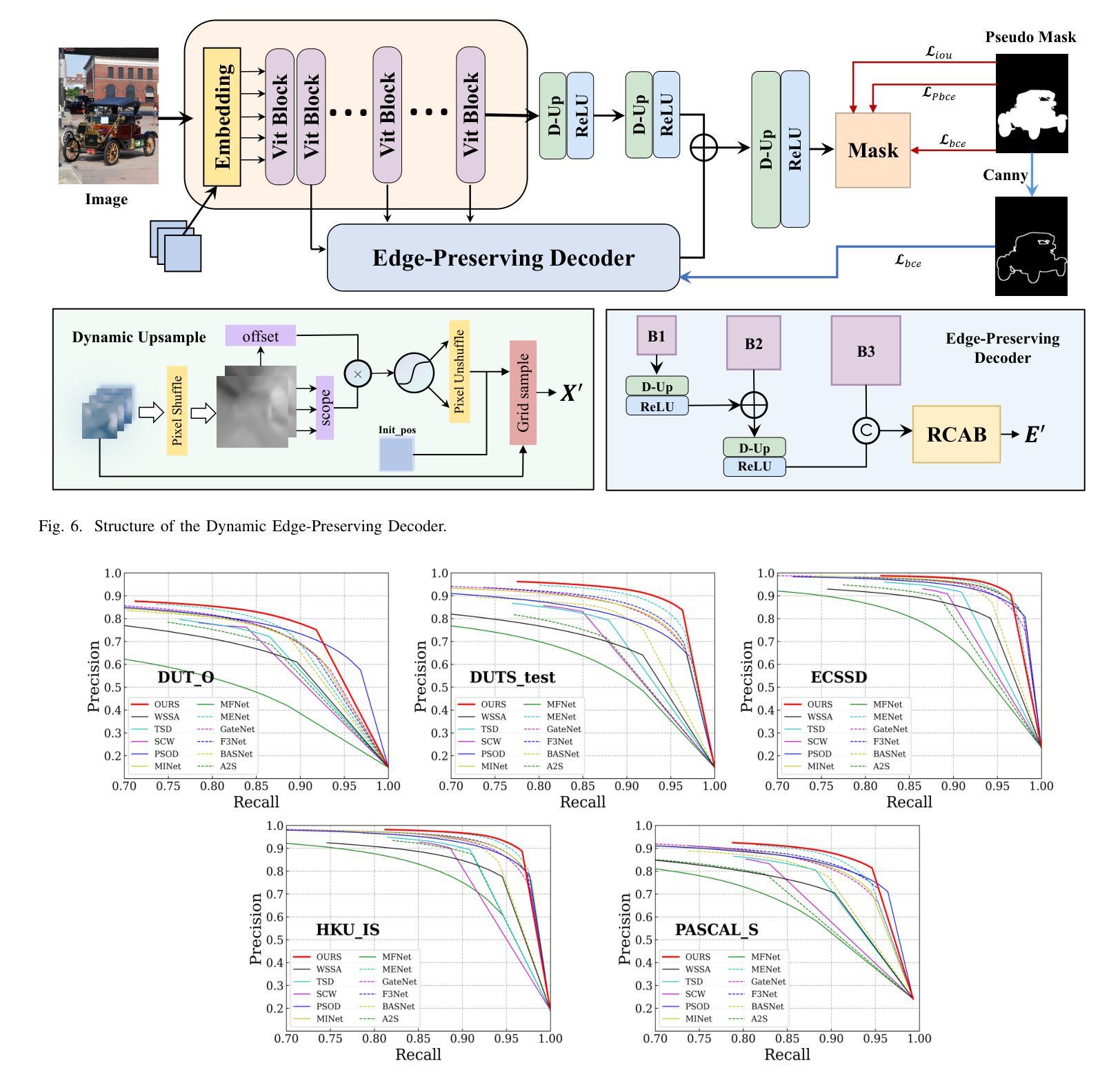
Salient Object Detection (SOD) aims to identify and segment prominent regions within a scene. Traditional models rely on manually annotated pseudo labels with precise pixel-level accuracy, which is time-consuming. We developed a low-cost, high-precision annotation method by leveraging large foundation models to address the challenges. Specifically, we use a weakly supervised approach to guide large models in generating pseudo-labels through textual prompts. Since large models do not effectively focus on the salient regions of images, we manually annotate a subset of text to fine-tune the model. Based on this approach, which enables precise and rapid generation of pseudo-labels, we introduce a new dataset, BDS-TR. Compared to the previous DUTS-TR dataset, BDS-TR is more prominent in scale and encompasses a wider variety of categories and scenes. This expansion will enhance our model’s applicability across a broader range of scenarios and provide a more comprehensive foundational dataset for future SOD research. Additionally, we present an edge decoder based on dynamic upsampling, which focuses on object edges while gradually recovering image feature resolution. Comprehensive experiments on five benchmark datasets demonstrate that our method significantly outperforms state-of-the-art approaches and also surpasses several existing fully-supervised SOD methods. The code and results will be made available.
显著性目标检测(SOD)旨在识别和分割场景内的突出区域。传统模型依赖于具有精确像素级精度的手动注释伪标签,这是非常耗时的。我们通过利用大型基础模型来解决这一挑战,开发了一种低成本、高精度的注释方法。具体来说,我们采用一种弱监督的方法,通过文本提示引导大型模型生成伪标签。由于大型模型并不能有效地关注图像的显著区域,我们对一部分文本进行了手动注释,以微调模型。基于这种能够精确快速地生成伪标签的方法,我们引入了一个新的数据集BDS-TR。与之前的DUTS-TR数据集相比,BDS-TR在规模上更为突出,涵盖了更广泛的类别和场景。这种扩展将提高我们的模型在更广泛场景中的适用性,并为未来的SOD研究提供更全面的基础数据集。此外,我们提出了一种基于动态上采样的边缘解码器,它专注于目标边缘,同时逐渐恢复图像特征分辨率。在五套基准数据集上的综合实验表明,我们的方法显著优于最新技术,并且也超越了几种现有的完全监督的SOD方法。代码和结果将一并公开。
论文及项目相关链接
Summary
一种新型的显著性目标检测(SOD)方法,通过利用大型基础模型,实现了低成本、高精度的标注方法。该方法采用弱监督方式生成伪标签,并通过手动标注部分文本对模型进行微调。此外,还引入了一个新数据集BDS-TR,并设计了一种基于动态上采样的边缘解码器,该方法关注目标边缘并逐步恢复图像特征分辨率。实验表明,该方法显著优于现有技术,并超越了一些全监督的SOD方法。
Key Takeaways
- 该方法利用大型基础模型,实现了低成本、高精度的显著性目标检测标注。
- 通过弱监督方式生成伪标签,并结合手动标注的文本对模型进行微调。
- 引入了一个新的数据集BDS-TR,规模更大,涵盖更广泛的类别和场景。
- 提出了基于动态上采样的边缘解码器,关注目标边缘并逐步恢复图像特征分辨率。
- 该方法显著提高了显著性目标检测的精度和效率。
- 在多个基准数据集上的实验验证了该方法的有效性。
点此查看论文截图


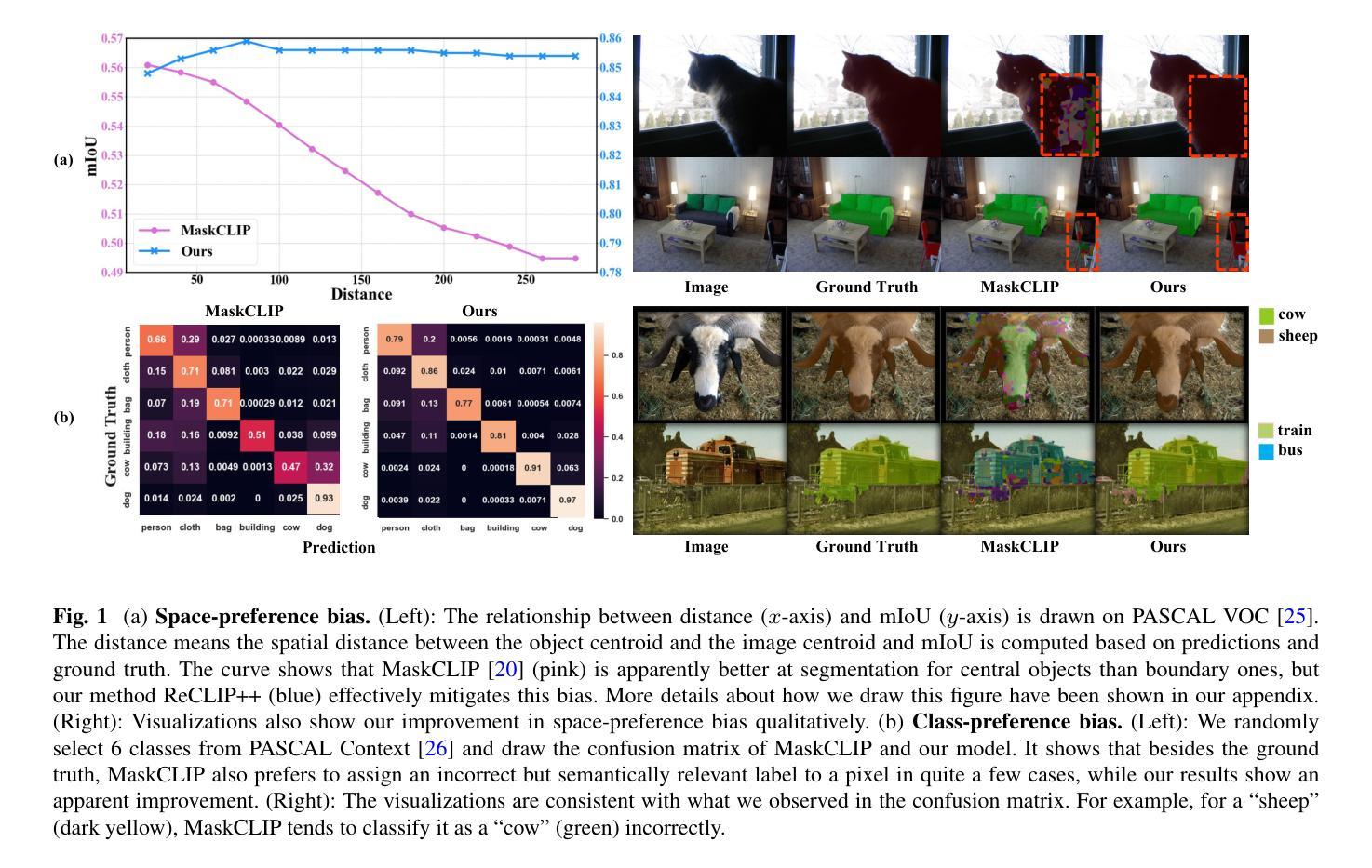
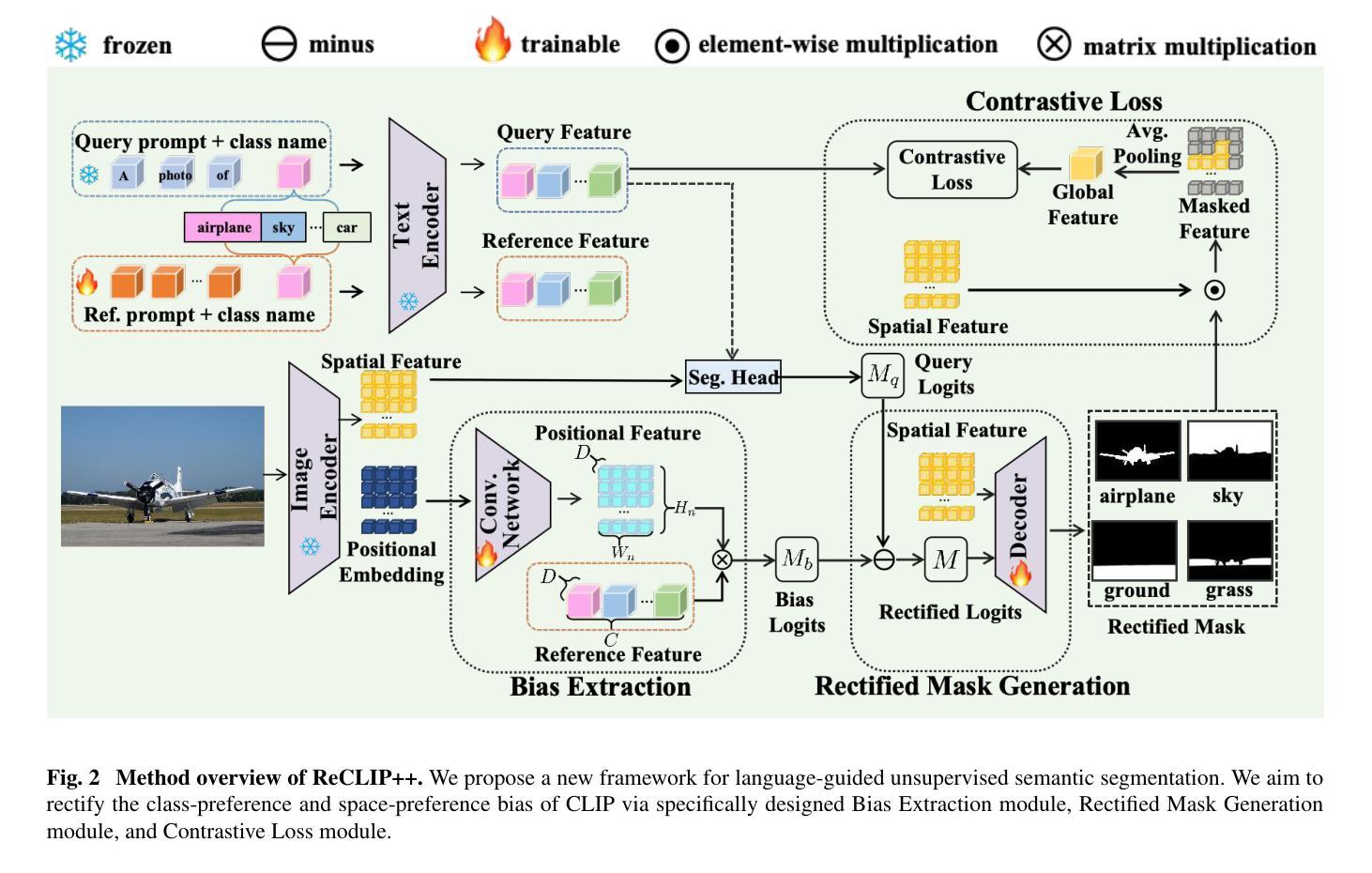
ReCLIP++: Learn to Rectify the Bias of CLIP for Unsupervised Semantic Segmentation
Authors:Jingyun Wang, Guoliang Kang
Recent works utilize CLIP to perform the challenging unsupervised semantic segmentation task where only images without annotations are available. However, we observe that when adopting CLIP to such a pixel-level understanding task, unexpected bias (including class-preference bias and space-preference bias) occurs. Previous works don’t explicitly model the bias, which largely constrains the segmentation performance. In this paper, we propose to explicitly model and rectify the bias existing in CLIP to facilitate the unsupervised semantic segmentation task. Specifically, we design a learnable “Reference” prompt to encode class-preference bias and a projection of the positional embedding in the vision transformer to encode space-preference bias respectively. To avoid interference, two kinds of biases are firstly independently encoded into different features, i.e., the Reference feature and the positional feature. Via a matrix multiplication between the Reference feature and the positional feature, a bias logit map is generated to explicitly represent two kinds of biases. Then we rectify the logits of CLIP via a simple element-wise subtraction. To make the rectified results smoother and more contextual, we design a mask decoder which takes the feature of CLIP and the rectified logits as input and outputs a rectified segmentation mask with the help of Gumbel-Softmax operation. A contrastive loss based on the masked visual features and the text features of different classes is imposed, which makes the bias modeling and rectification process meaningful and effective. Extensive experiments on various benchmarks including PASCAL VOC, PASCAL Context, ADE20K, Cityscapes, and COCO Stuff demonstrate that our method performs favorably against previous state-of-the-arts. The implementation is available at: https://github.com/dogehhh/ReCLIP.
最近的工作利用CLIP来执行具有挑战性的无监督语义分割任务,该任务仅提供没有注释的图像。然而,我们观察到,在将CLIP应用于这种像素级的理解任务时,会出现意想不到的偏见(包括类别偏好偏见和空间偏好偏见)。以前的工作没有显式地建模偏见,这极大地限制了分割性能。在本文中,我们提出显式地建模并纠正CLIP中存在的偏见,以促进无监督语义分割任务。具体来说,我们设计了一个可学习的“参考”提示来编码类别偏好偏见,并设计了一种在视觉变压器中的位置嵌入投影来编码空间偏好偏见。为了避免干扰,我们将这两种偏见首先独立地编码为不同的特征,即参考特征和位置特征。通过参考特征与位置特征之间的矩阵乘法,生成一个偏差逻辑图,显式表示两种偏差。然后我们通过简单的元素减法来纠正CLIP的逻辑值。为了使校正结果更平滑、更具上下文性,我们设计了一个掩码解码器,它接受CLIP的特征和校正后的逻辑值作为输入,并借助Gumbel-Softmax操作输出校正后的分割掩码。基于掩码视觉特征和不同类别文本特征的对比损失被施加,这使得偏差建模和校正过程有意义且有效。在包括PASCAL VOC、PASCAL Context、ADE20K、Cityscapes和COCO Stuff等各种基准测试上的广泛实验表明,我们的方法与以前的最先进方法相比表现良好。实现细节可在https://github.com/dogehhh/ReCLIP找到。
论文及项目相关链接
PDF Extended version of our CVPR 24 paper
Summary
基于CLIP的无监督语义分割任务中,存在类偏好和空间偏好等偏见问题。本文提出显式建模并纠正CLIP中的偏见,通过设计可学习的“参考”提示和位置嵌入投影来分别编码类偏好和空间偏好偏见。通过矩阵乘法生成偏见逻辑图,以显式表示两种偏见。通过简单的元素级减法纠正CLIP的逻辑。设计掩膜解码器使修正结果更平滑、更具上下文性。基于对比损失进行掩膜视觉特征和不同类别文本特征的对比,使偏见建模和修正过程有意义且有效。在多个数据集上的实验表明,该方法优于先前的方法。
Key Takeaways
- 利用CLIP进行无监督语义分割任务时存在偏见问题。
- 本文首次提出显式建模并纠正CLIP中的类偏好和空间偏好偏见。
- 通过设计“参考”提示和位置嵌入投影来分别编码两种偏见。
- 通过矩阵乘法生成偏见逻辑图,然后通过元素级减法纠正CLIP的逻辑。
- 设计的掩膜解码器使修正结果更平滑、更具上下文性。
- 对比损失用于确保偏见建模和修正过程的有效性。
点此查看论文截图