⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-10 更新
Hidden Entity Detection from GitHub Leveraging Large Language Models
Authors:Lu Gan, Martin Blum, Danilo Dessi, Brigitte Mathiak, Ralf Schenkel, Stefan Dietze
Named entity recognition is an important task when constructing knowledge bases from unstructured data sources. Whereas entity detection methods mostly rely on extensive training data, Large Language Models (LLMs) have paved the way towards approaches that rely on zero-shot learning (ZSL) or few-shot learning (FSL) by taking advantage of the capabilities LLMs acquired during pretraining. Specifically, in very specialized scenarios where large-scale training data is not available, ZSL / FSL opens new opportunities. This paper follows this recent trend and investigates the potential of leveraging Large Language Models (LLMs) in such scenarios to automatically detect datasets and software within textual content from GitHub repositories. While existing methods focused solely on named entities, this study aims to broaden the scope by incorporating resources such as repositories and online hubs where entities are also represented by URLs. The study explores different FSL prompt learning approaches to enhance the LLMs’ ability to identify dataset and software mentions within repository texts. Through analyses of LLM effectiveness and learning strategies, this paper offers insights into the potential of advanced language models for automated entity detection.
从非结构化数据源构建知识库时,命名实体识别是一项重要任务。实体检测方法大多依赖于大量的训练数据,而大型语言模型(LLM)的出现为依赖于零样本学习(ZSL)或少样本学习(FSL)的方法铺平了道路。它们通过利用大型语言模型在预训练期间获得的能力来实现这一点。特别地,在无法使用大规模训练数据的高度专业化场景中,ZSL/FSL带来了新的机会。本文遵循这一最新趋势,探讨了在这种场景中利用大型语言模型(LLM)自动检测GitHub存储库中的数据集和软件资源的潜力。现有的方法只专注于命名实体,而本研究旨在通过整合存储库和在线中心等资源(其中实体也以URL形式表示)来扩大范围。该研究探索了不同的FSL提示学习方法来提高LLM在存储库文本中识别数据集和软件提及的能力。通过对LLM的有效性和学习策略的分析,本文提供了对高级语言模型在自动实体检测方面的潜力的深刻见解。
论文及项目相关链接
PDF accepted by KDD2024 workshop DL4KG
Summary:
大规模语言模型(LLM)可在缺乏大规模训练数据的情况下,利用零样本学习(ZSL)或少样本学习(FSL)技术在构建知识库时自动检测GitHub存储库中的数据集和软件。本文主要探索使用LLM来自动检测文本内容中的数据集和软件,不仅关注命名实体识别,还融入资源如存储库和在线中心,其中实体通过URL表示。通过探索不同的FSL提示学习方法,增强LLM在存储库文本中识别数据集和软件的能力。通过对LLM的效果和学习策略的分析,为自动化实体检测提供深入见解。
Key Takeaways:
- 大型语言模型(LLM)能够在缺乏大规模训练数据的情况下,利用零样本学习(ZSL)或少样本学习(FSL)技术识别GitHub存储库中的实体。
- 现有方法主要关注命名实体识别,而本文研究扩大了范围,纳入如存储库和在线中心等资源的考虑。
- 研究探索了不同的FSL提示学习方法来增强LLM在存储库文本中识别数据集和软件的能力。
- 该研究通过对LLM的有效性和学习策略的分析,为自动化实体检测提供了见解。
- 借助LLM的技术可以在一定程度上简化并改进数据集合和软件包的检测与识别。
- URL的引入增强了实体识别的准确性,因为许多数据集和软件的引用都包含URL链接。
点此查看论文截图



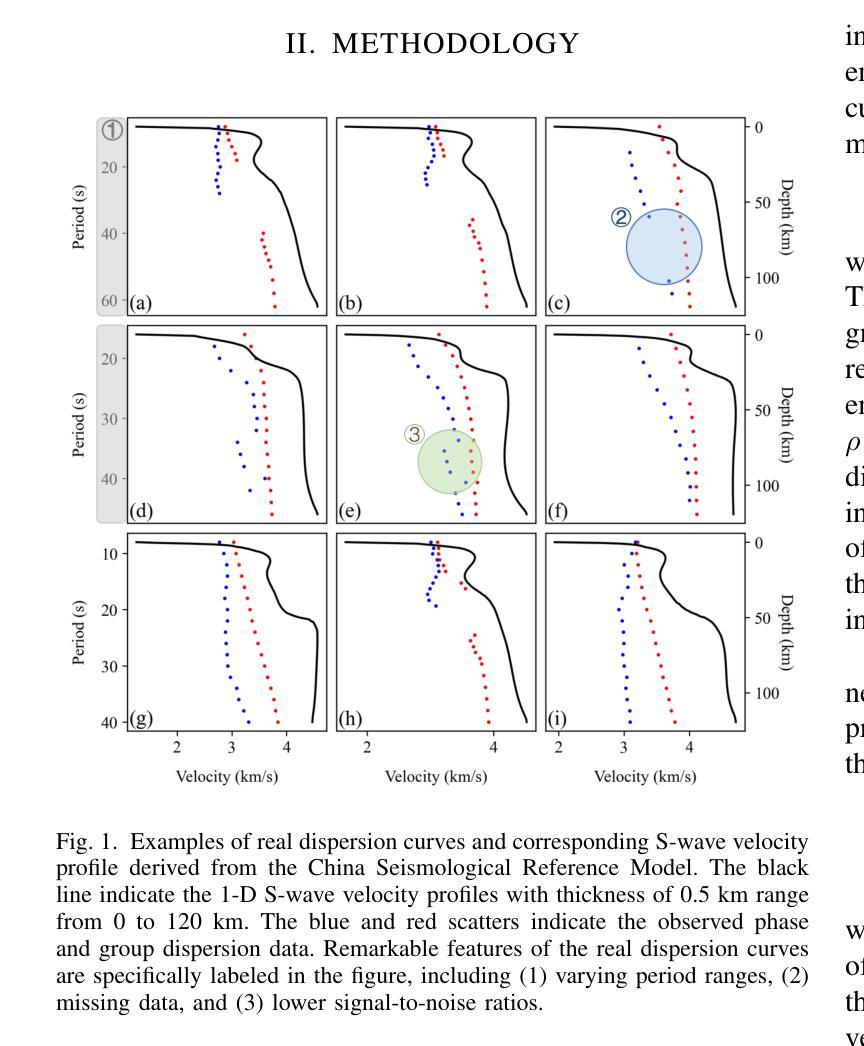
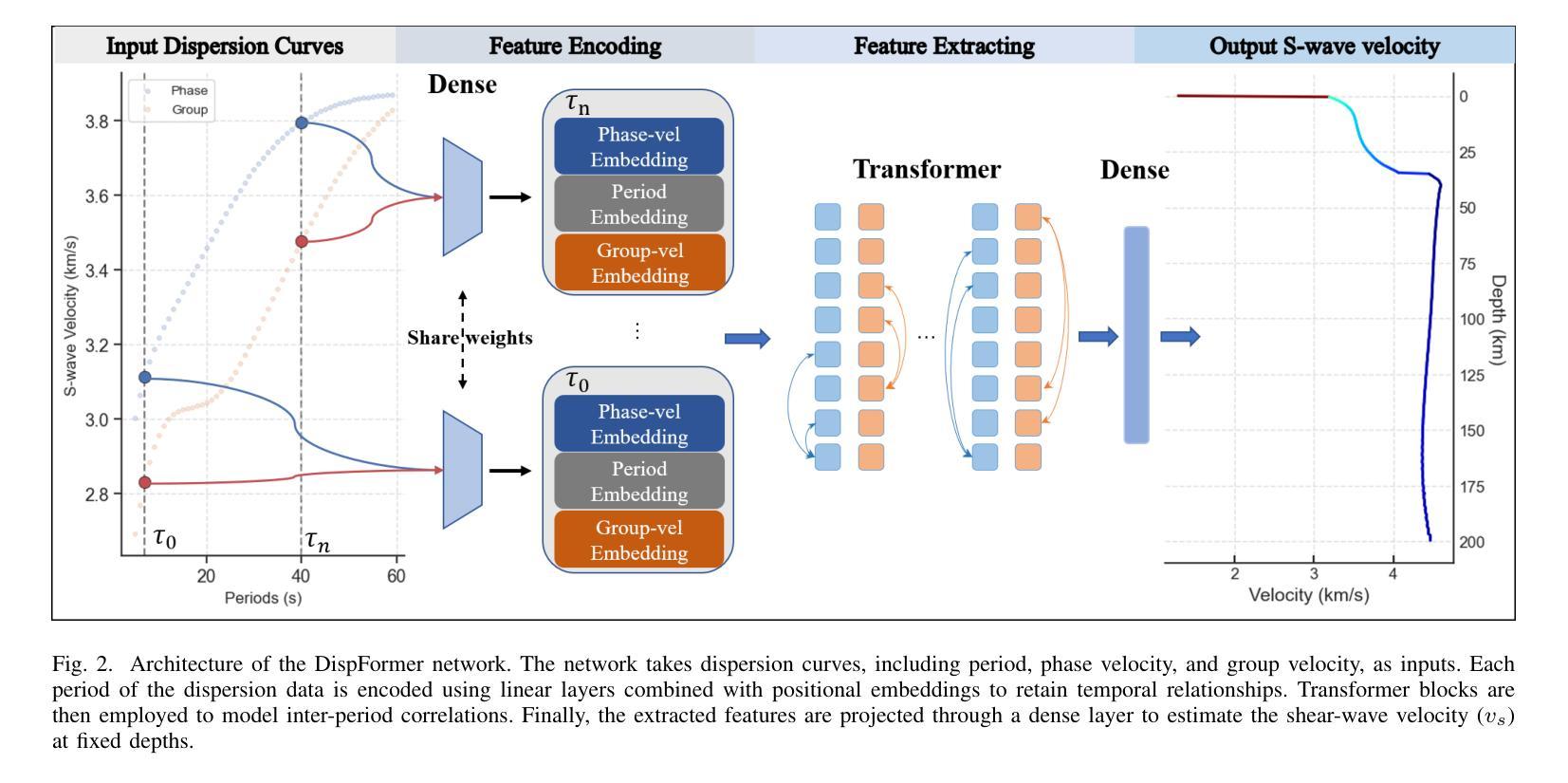
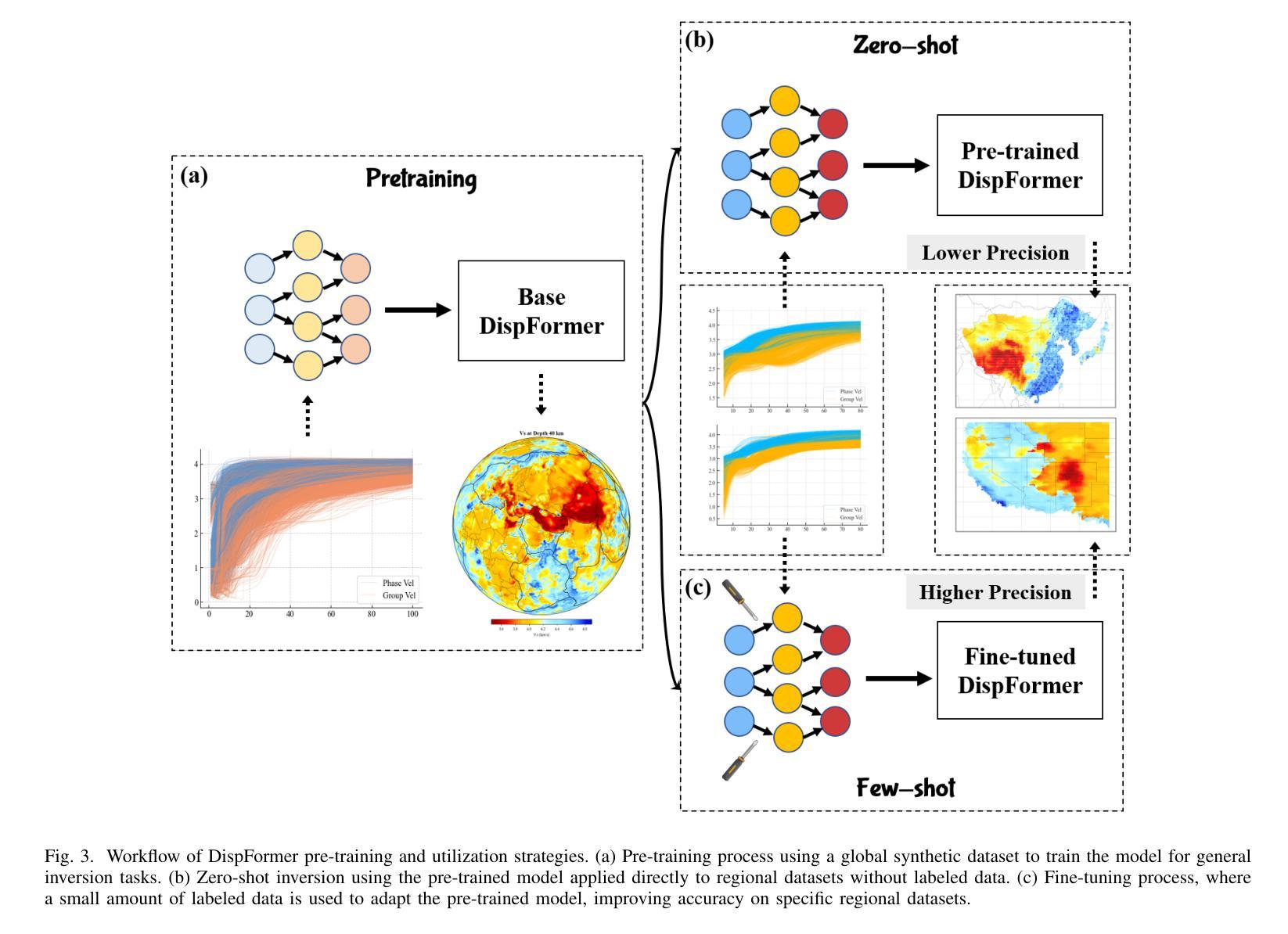
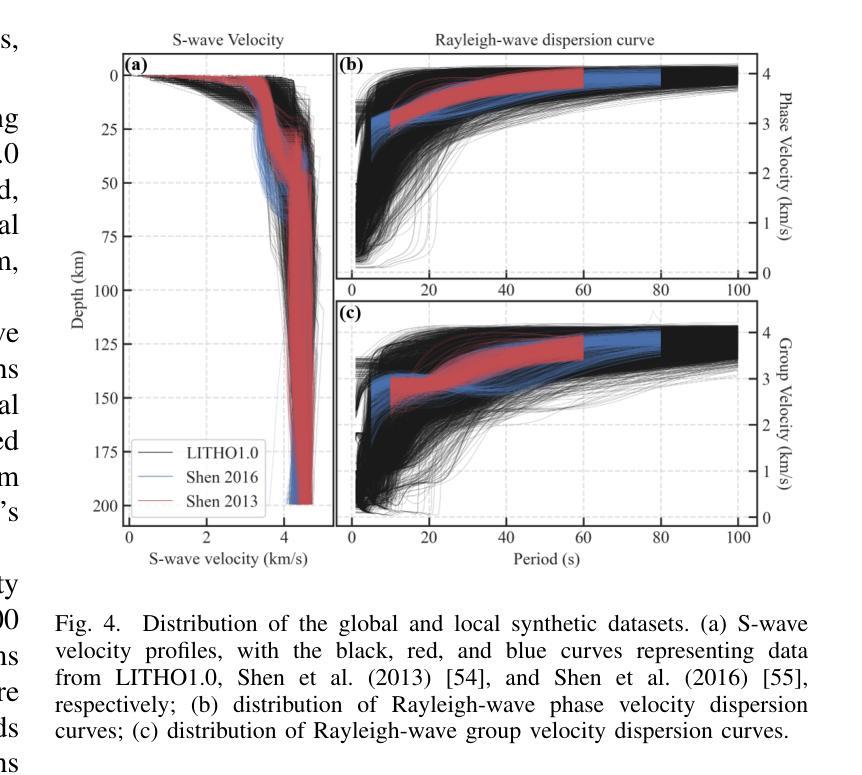
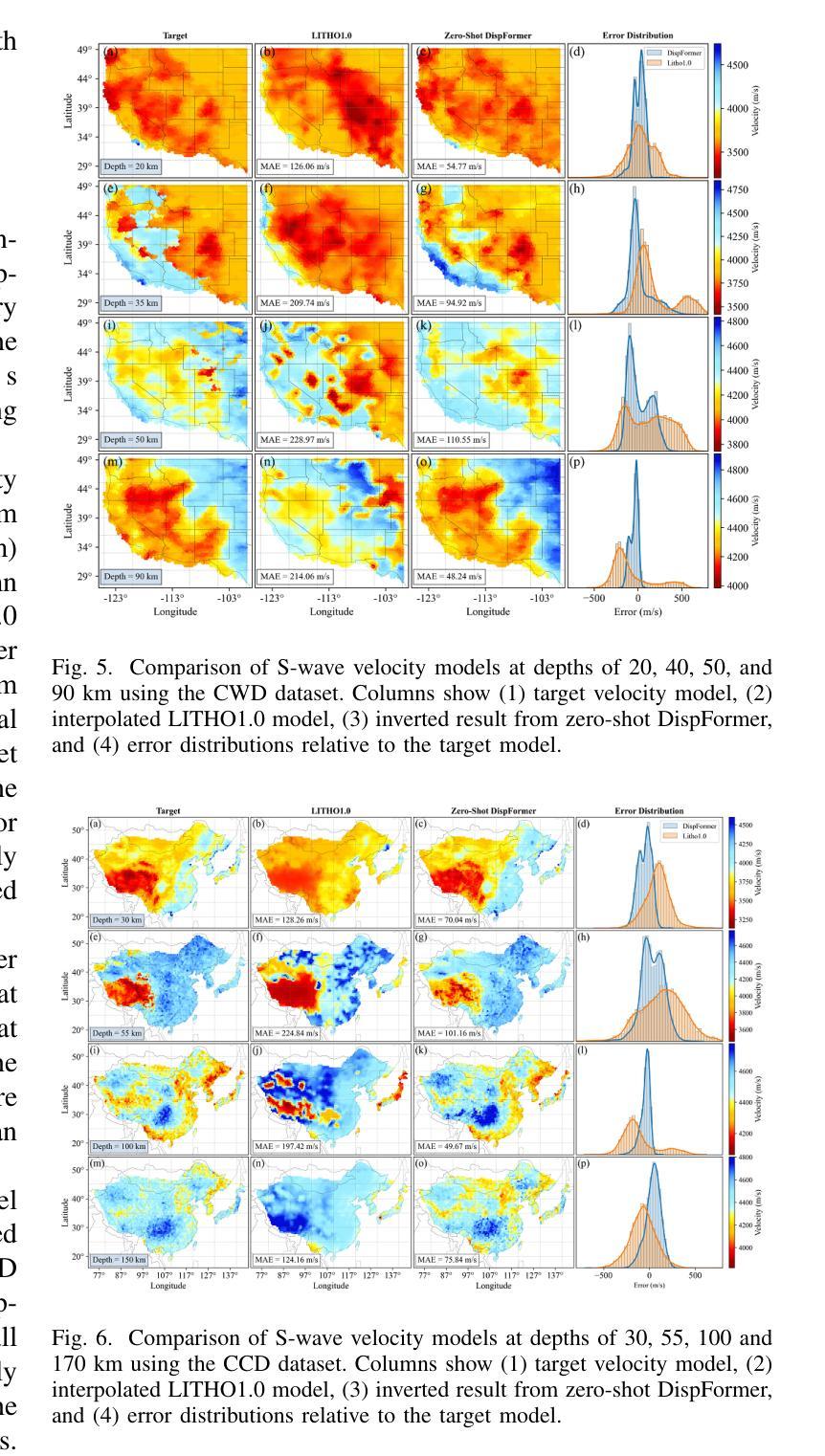
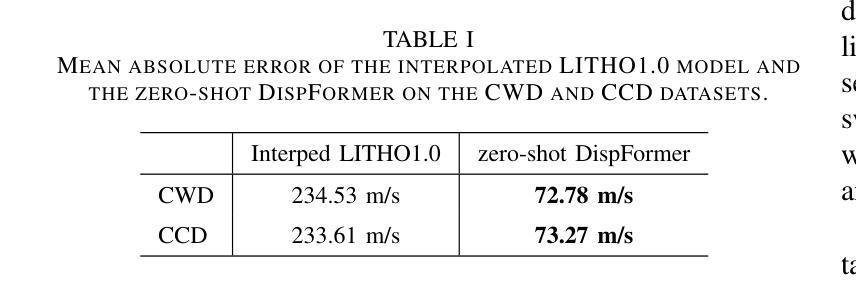
DispFormer: Pretrained Transformer for Flexible Dispersion Curve Inversion from Global Synthesis to Regional Applications
Authors:Feng Liu, Bao Deng, Rui Su, Lei Bai, Wanli Ouyang
Surface wave dispersion curve inversion is essential for estimating subsurface Shear-wave velocity ($v_s$), yet traditional methods often struggle to balance computational efficiency with inversion accuracy. While deep learning approaches show promise, previous studies typically require large amounts of labeled data and struggle with real-world datasets that have varying period ranges, missing data, and low signal-to-noise ratios. This study proposes DispFormer, a transformer-based neural network for inverting the $v_s$ profile from Rayleigh-wave phase and group dispersion curves. DispFormer processes dispersion data at each period independently, thereby allowing it to handle data of varying lengths without requiring network modifications or alignment between training and testing data. The performance is demonstrated by pre-training it on a global synthetic dataset and testing it on two regional synthetic datasets using zero-shot and few-shot strategies. Results indicate that zero-shot DispFormer, even without any labeled data, produces inversion profiles that match well with the ground truth, providing a deployable initial model generator to assist traditional methods. When labeled data is available, few-shot DispFormer outperforms traditional methods with only a small number of labels. Furthermore, real-world tests indicate that DispFormer effectively handles varying length data, and yields lower data residuals than reference models. These findings demonstrate that DispFormer provides a robust foundation model for dispersion curve inversion and is a promising approach for broader applications.
表面波弥散曲线反演对于估计地下剪切波速度(v_s)至关重要,但传统方法往往在计算效率和反演精度之间难以取得平衡。虽然深度学习方法显示出潜力,但之前的研究通常需要大量标记数据,并且在处理具有不同周期范围、缺失数据和低信噪比的真实世界数据集时面临困难。本研究提出了DispFormer,这是一个基于转换器的神经网络,用于从瑞利波相位和群弥散曲线反演v_s剖面。DispFormer独立处理每个周期的弥散数据,因此能够处理不同长度的数据,而无需对网络和训练和测试数据进行修改或对齐。通过在全球合成数据集上进行预训练,并在两个区域合成数据集上使用零样本和少样本策略进行测试,验证了其性能。结果表明,零样本DispFormer即使没有标记数据也能产生与真实情况匹配良好的反演剖面,为传统方法提供了一个可部署的初始模型生成器。当有标记数据时,少样本DispFormer仅需少量标签就能超越传统方法。此外,真实世界测试表明,DispFormer有效处理不同长度的数据,并且产生的数据残差低于参考模型。这些发现表明,DispFormer为弥散曲线反演提供了稳健的基础模型,是更广泛应用的有前途的方法。
论文及项目相关链接
PDF 11 pages, 11 figures, related codes and data are available at https://github.com/liufeng2317/DispFormer
Summary
本文提出了一种基于变压器的神经网络DispFormer,用于从Rayleigh波相位和群速度色散曲线反演地下剪切波速度($v_s$)分布。DispFormer能够处理不同长度的数据,且无需修改网络结构或训练与测试数据对齐。通过全球合成数据集进行预训练,并在两个区域合成数据集上采用零样本和少样本策略进行测试,结果显示零样本DispFormer即使没有标记数据也能生成与真实情况匹配的反演剖面,为传统方法提供了可部署的初始模型生成器。当使用少量标记数据时,少样本DispFormer表现优于传统方法。此外,实际测试表明,DispFormer能有效处理不同长度的数据,并产生较低的数据残差。总之,DispFormer为色散曲线反演提供了稳健的基础模型,在更广领域具有广阔的应用前景。
Key Takeaways
- DispFormer是一种基于神经网络的变压器架构,用于反演地下剪切波速度($v_s$)。
- DispFormer能够处理不同长度的数据,无需调整网络结构或数据对齐。
- 通过全球合成数据集预训练的DispFormer,在零样本状态下表现出良好的反演性能。
- 当使用少量标记数据时,少样本DispFormer优于传统方法。
- DispFormer在实际测试中表现出色,能有效处理不同长度的数据并产生较低的数据残差。
- DispFormer为色散曲线反演提供了稳健的基础模型。
点此查看论文截图

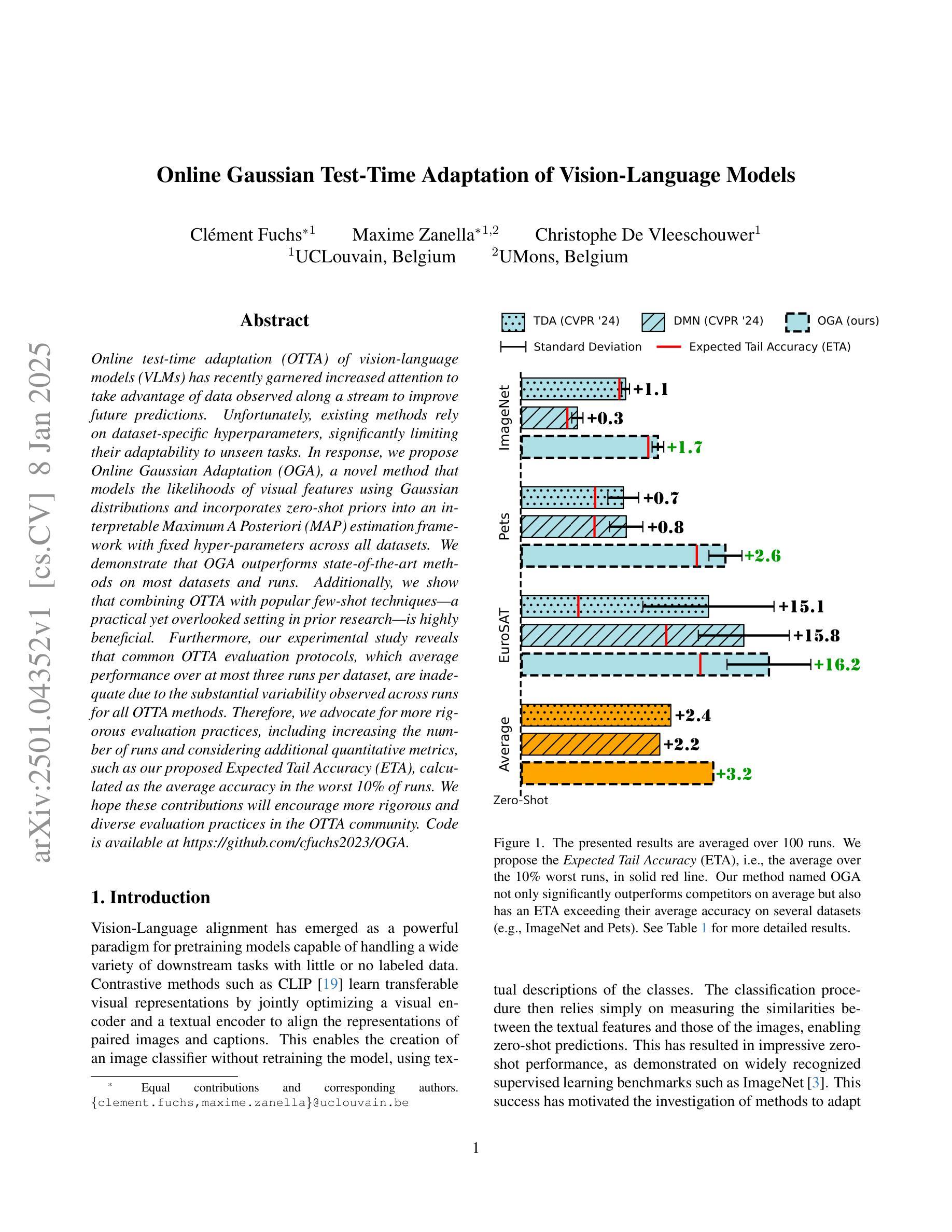
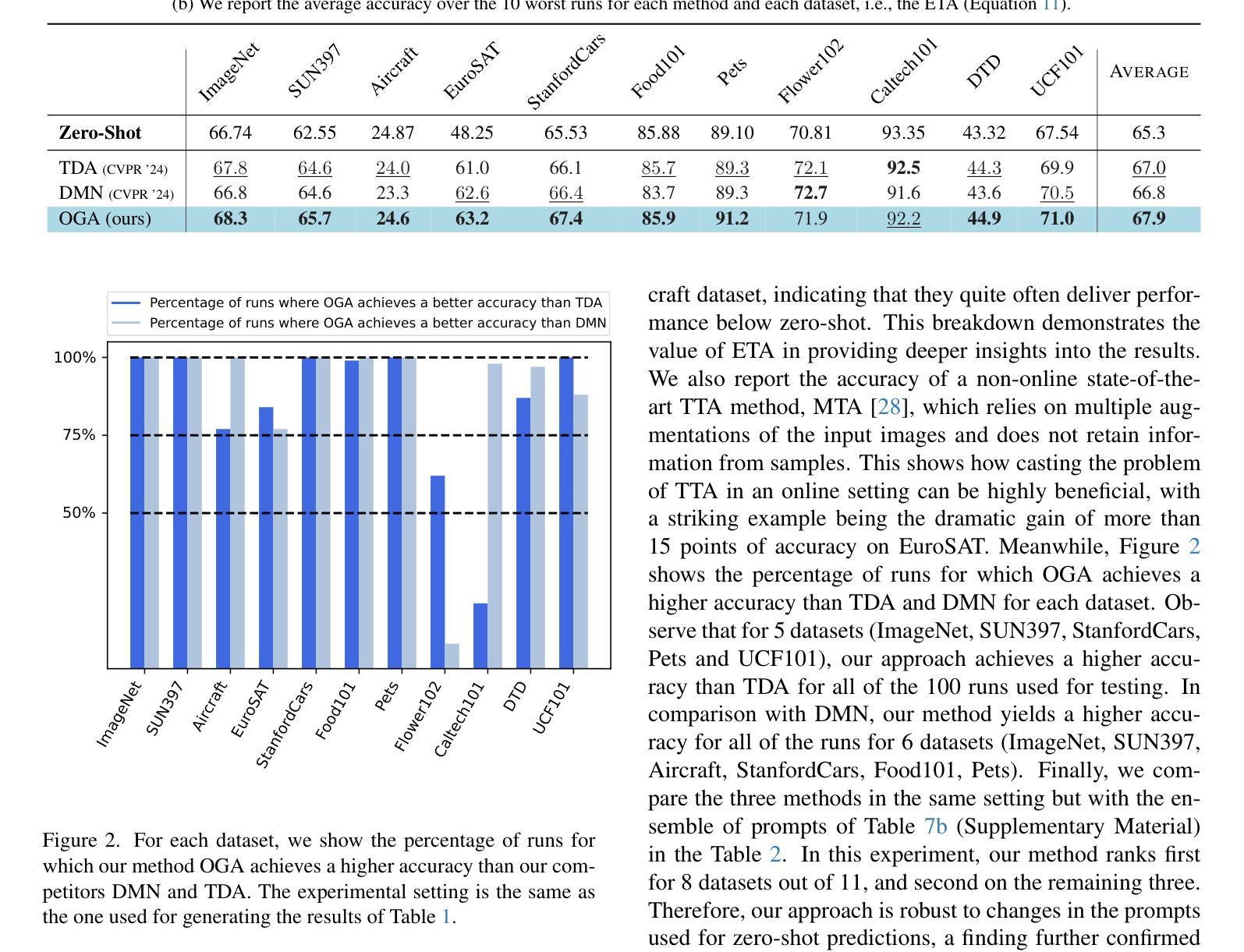
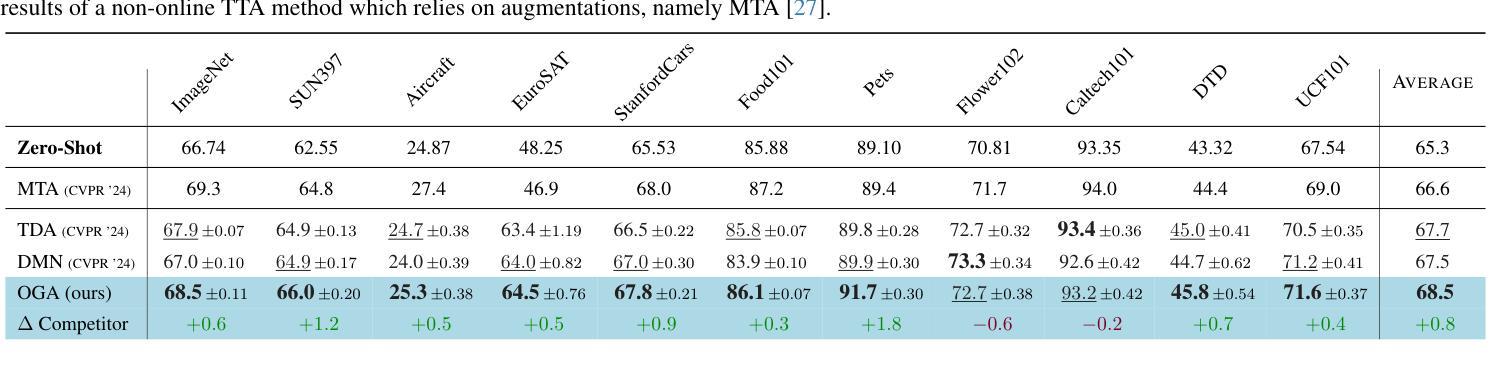
Online Gaussian Test-Time Adaptation of Vision-Language Models
Authors:Clément Fuchs, Maxime Zanella, Christophe De Vleeschouwer
Online test-time adaptation (OTTA) of vision-language models (VLMs) has recently garnered increased attention to take advantage of data observed along a stream to improve future predictions. Unfortunately, existing methods rely on dataset-specific hyperparameters, significantly limiting their adaptability to unseen tasks. In response, we propose Online Gaussian Adaptation (OGA), a novel method that models the likelihoods of visual features using Gaussian distributions and incorporates zero-shot priors into an interpretable Maximum A Posteriori (MAP) estimation framework with fixed hyper-parameters across all datasets. We demonstrate that OGA outperforms state-of-the-art methods on most datasets and runs. Additionally, we show that combining OTTA with popular few-shot techniques (a practical yet overlooked setting in prior research) is highly beneficial. Furthermore, our experimental study reveals that common OTTA evaluation protocols, which average performance over at most three runs per dataset, are inadequate due to the substantial variability observed across runs for all OTTA methods. Therefore, we advocate for more rigorous evaluation practices, including increasing the number of runs and considering additional quantitative metrics, such as our proposed Expected Tail Accuracy (ETA), calculated as the average accuracy in the worst 10% of runs. We hope these contributions will encourage more rigorous and diverse evaluation practices in the OTTA community. Code is available at https://github.com/cfuchs2023/OGA .
在线测试时间适应(OTTA)视觉语言模型(VLMs)最近引起了人们的广泛关注,利用观察到的数据流来改善未来的预测。然而,现有方法依赖于特定数据集的超参数,极大地限制了它们对未见任务的适应能力。作为回应,我们提出了在线高斯适应(OGA),这是一种新型方法,利用高斯分布对视觉特征的概率进行建模,并将零样本先验融入可解释的最大后验(MAP)估计框架中,该框架在所有数据集上都具有固定的超参数。我们证明OGA在大多数数据集和运行中的表现都优于最新技术。此外,我们还展示了将OTTA与流行的少量镜头技术相结合(这在先前的研究中是一个实用但被忽视的设置)是非常有益的。此外,我们的实验研究表明,常见的OTTA评估协议(在每个数据集上平均运行最多三次的性能)是不充分的,因为所有OTTA方法在运行之间的观察值都有很大差异。因此,我们提倡更严格的评估实践,包括增加运行次数并考虑额外的定量指标,如我们提出的预期尾部精度(ETA),计算为在最差的10%运行中平均精度的值。我们希望这些贡献将鼓励OTTA社区采用更严格和多样化的评估实践。代码可在https://github.com/cfuchs2023/OGA找到。
论文及项目相关链接
Summary
本文提出了在线高斯适应(OGA)方法,该方法利用高斯分布对视觉特征进行建模,并将零样本先验纳入可解释的最大后验估计框架中。此方法在所有数据集上都使用固定的超参数,提高了对不同任务的适应性。实验表明,OGA在大多数数据集和运行中的表现优于现有方法。此外,结合在线测试时间适应(OTTA)和流行的少样本技术,效果更佳。作者对现有的OTTA评估协议提出质疑,认为现有的评估协议不足够全面和可靠,建议采用更严格的评估方法和更多定量指标来评价模型性能。
Key Takeaways
- OGA方法利用高斯分布建模视觉特征,提高了模型的适应性和预测性能。
- OGA在所有数据集上使用固定超参数,增强了其泛化能力。
- OGA在大多数数据集上的表现优于现有方法。
- 结合OTTA和少样本技术能进一步提升模型性能。
- 现有的OTTA评估协议存在不足,需要更严格的评估方法和更多定量指标来全面评价模型性能。
- 作者提出了一种新的评估指标——预期尾部准确率(ETA),用于更准确地衡量模型在不同运行中的性能稳定性。
点此查看论文截图
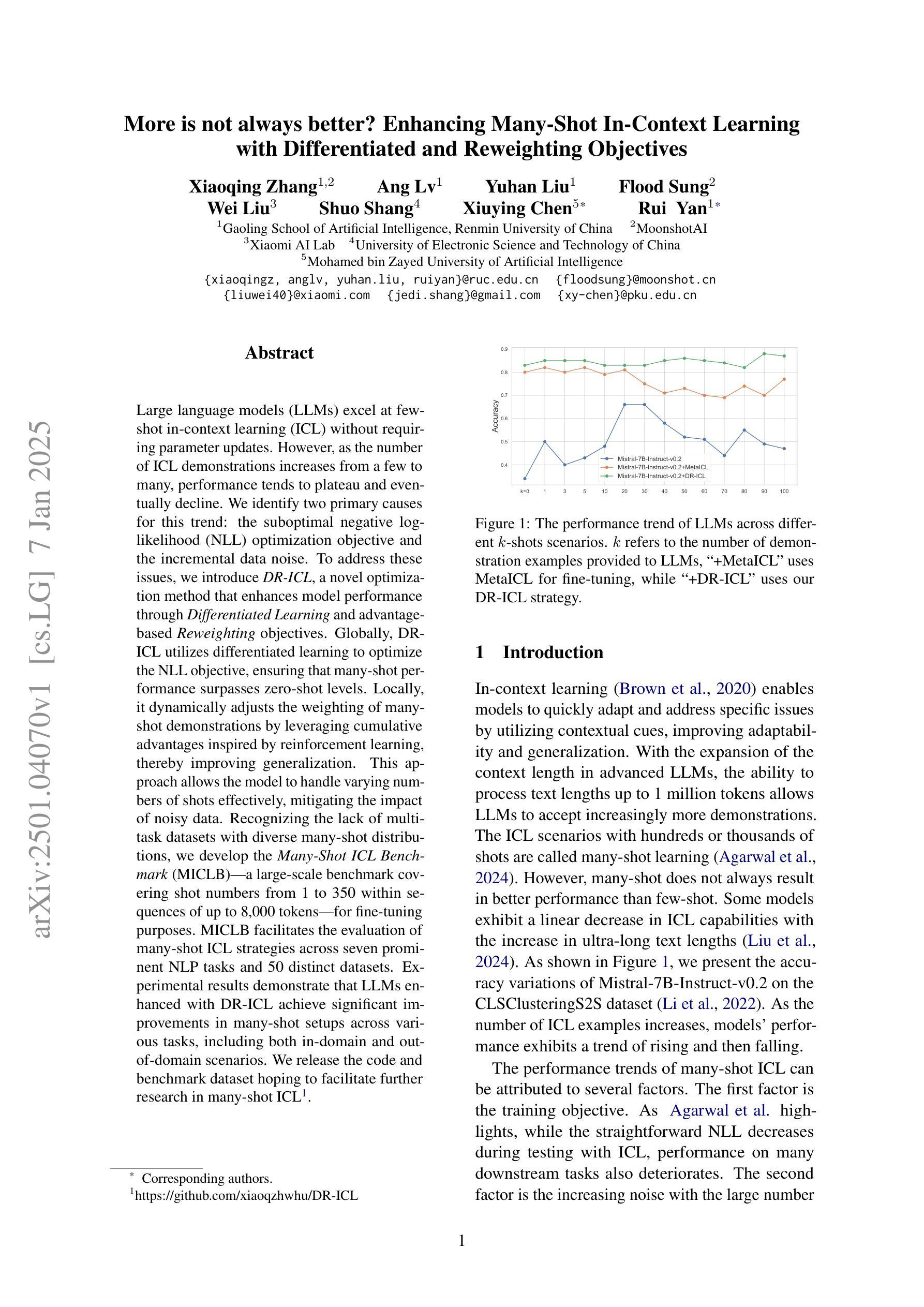
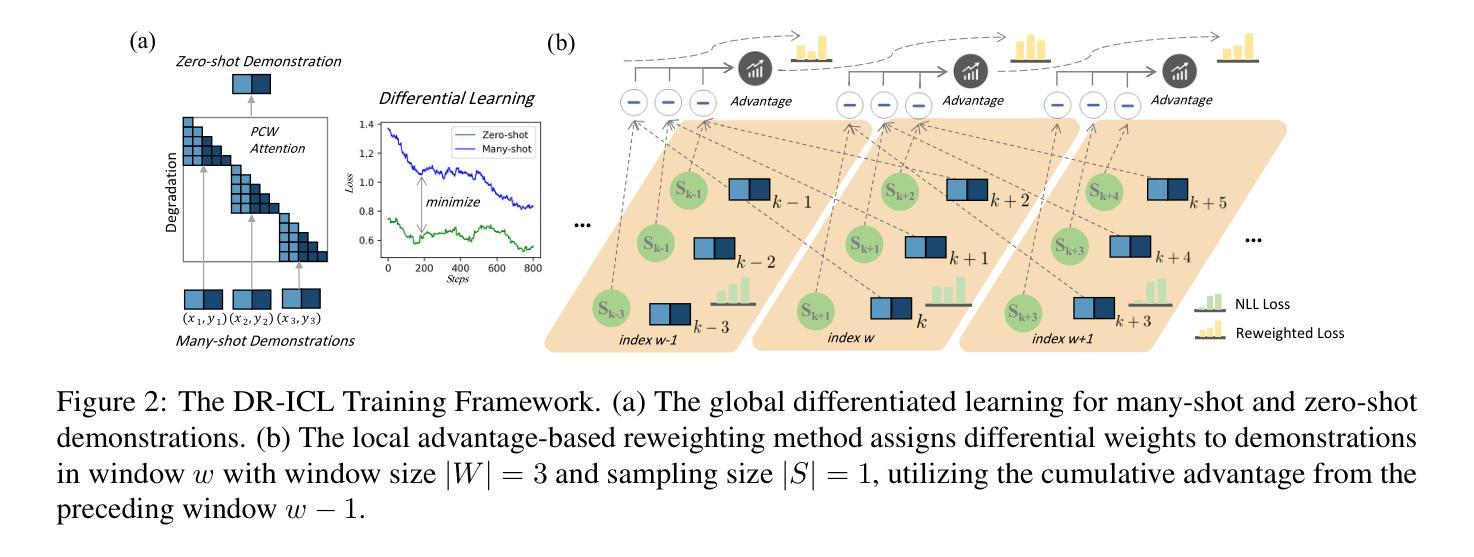
More is not always better? Enhancing Many-Shot In-Context Learning with Differentiated and Reweighting Objectives
Authors:Xiaoqing Zhang, Ang Lv, Yuhan Liu, Flood Sung, Wei Liu, Shuo Shang, Xiuying Chen, Rui Yan
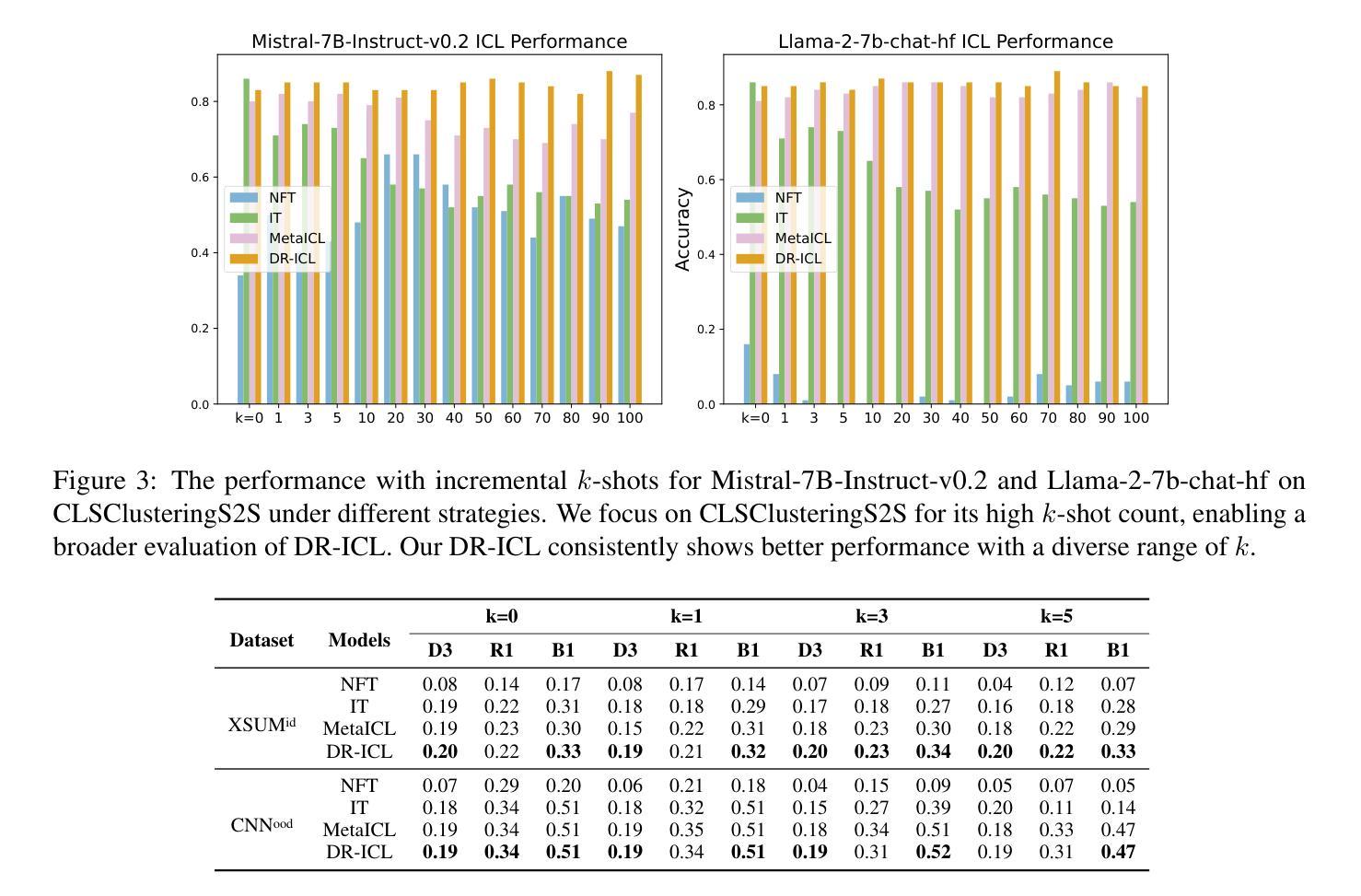
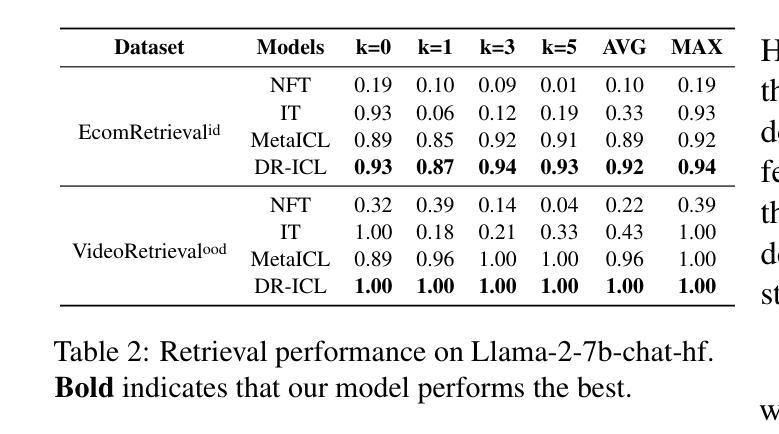
Large language models (LLMs) excel at few-shot in-context learning (ICL) without requiring parameter updates. However, as the number of ICL demonstrations increases from a few to many, performance tends to plateau and eventually decline. We identify two primary causes for this trend: the suboptimal negative log-likelihood (NLL) optimization objective and the incremental data noise. To address these issues, we introduce DR-ICL, a novel optimization method that enhances model performance through Differentiated Learning and advantage-based Reweighting objectives. Globally, DR-ICL utilizes differentiated learning to optimize the NLL objective, ensuring that many-shot performance surpasses zero-shot levels. Locally, it dynamically adjusts the weighting of many-shot demonstrations by leveraging cumulative advantages inspired by reinforcement learning, thereby improving generalization. This approach allows the model to handle varying numbers of shots effectively, mitigating the impact of noisy data. Recognizing the lack of multi-task datasets with diverse many-shot distributions, we develop the Many-Shot ICL Benchmark (MICLB)-a large-scale benchmark covering shot numbers from 1 to 350 within sequences of up to 8,000 tokens-for fine-tuning purposes. MICLB facilitates the evaluation of many-shot ICL strategies across seven prominent NLP tasks and 50 distinct datasets. Experimental results demonstrate that LLMs enhanced with DR-ICL achieve significant improvements in many-shot setups across various tasks, including both in-domain and out-of-domain scenarios. We release the code and benchmark dataset hoping to facilitate further research in many-shot ICL.
大型语言模型(LLM)在不需更新参数的情况下,擅长进行少量上下文学习(ICL)。然而,随着ICL演示的数量从几个增加到许多,性能往往达到峰值并最终下降。我们确定了这一趋势的两个主要原因:次优的负对数似然(NLL)优化目标和增量数据噪声。为了解决这些问题,我们引入了DR-ICL这一新型优化方法,它通过差异化学习和基于优势的重加权目标来提高模型性能。从全局角度看,DR-ICL通过优化NLL目标进行差异化学习,确保多镜头性能超越零镜头水平。从局部角度看,它利用强化学习得到的累积优势动态调整多镜头演示的权重,从而提高泛化能力。这种方法使模型能够有效地处理不同数量的镜头,减轻噪声数据的影响。由于缺少具有多种多镜头分布的多任务数据集,我们开发了多镜头ICL基准测试(MICLB)——一个大规模基准测试,涵盖从1到350的射击次数,序列中的令牌数高达8000个——用于微调目的。MICLB便于在七个主要NLP任务和五十个不同数据集上评估多镜头ICL策略的效果。实验结果表明,采用DR-ICL增强的大型语言模型在各种任务的多镜头设置中取得了显著改进,包括域内和域外场景。我们发布代码和基准数据集,希望能进一步推动多镜头ICL的研究。
论文及项目相关链接
PDF 13 pages, 8 figures, 11 tables
摘要
大语言模型在不需要参数更新的少量上下文学习场景中表现出色,但随着上下文学习示例从几个增加到多个,性能往往会达到峰值并最终下降。研究团队针对这一问题提出了DR-ICL这一新型优化方法,通过差异化学习和基于优势的加权优化目标来提升模型性能。该方法通过差异化学习优化负对数似然目标,确保多示例性能超越零示例水平。同时,它还会根据强化学习的累积优势动态调整多示例演示的权重,从而提高模型的泛化能力。这种方法使模型能够更有效地处理不同数量的示例,减轻噪声数据的影响。此外,为了解决多任务数据集缺乏多样多变的多示例分布问题,研究团队开发了一个大规模基准测试平台——多示例上下文学习基准(MICLB),涵盖了从1到350个示例,序列长度高达8000个标记的多种场景,用于精细调整目的。MICLB能够在七个主要NLP任务和五十个不同数据集上评估多示例上下文学习策略。实验结果表明,采用DR-ICL增强的大语言模型在各种任务的多示例设置中都取得了显著改进,包括域内和域外场景。我们公开了代码和基准数据集,希望进一步推动多示例上下文学习领域的研究。
关键见解
- 大语言模型在不需要参数更新的少量上下文学习中表现出色,但随着示例数量增加,性能会下降。
- 性能下降的主要原因包括次优的负对数似然优化目标和增加的数据噪声。
- DR-ICL是一种新型优化方法,通过差异化学习和基于优势的加权来优化模型性能。
- DR-ICL能够在全球范围内优化负对数似然目标,并在局部通过借鉴强化学习的累积优势动态调整多示例演示的权重。
- DR-ICL允许模型有效处理不同数量的示例,并减轻噪声数据的影响。
- 为了促进多示例上下文学习研究,研究团队开发了一个大规模基准测试平台——多示例上下文学习基准(MICLB),涵盖多种NLP任务和数据集。
点此查看论文截图

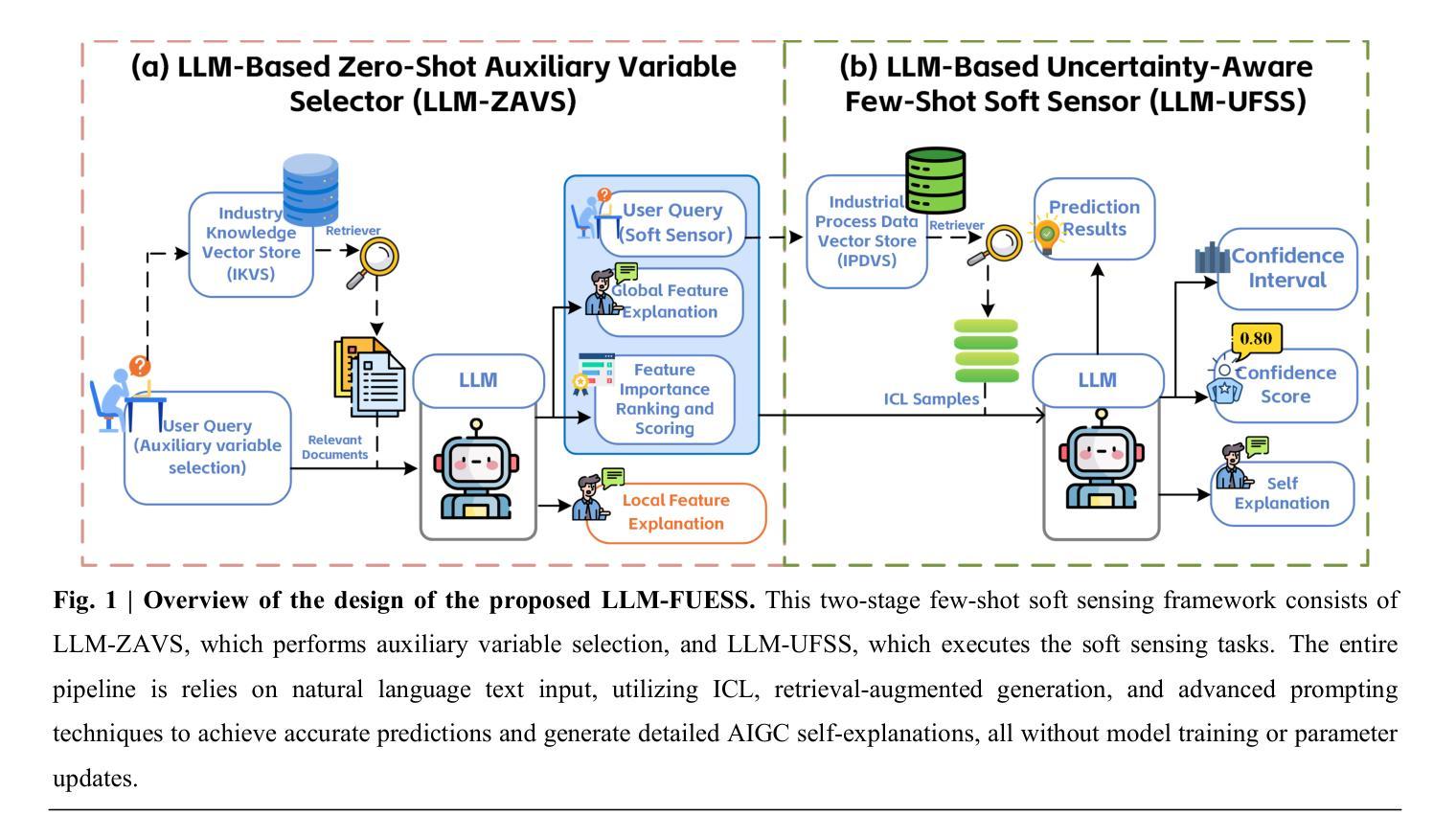
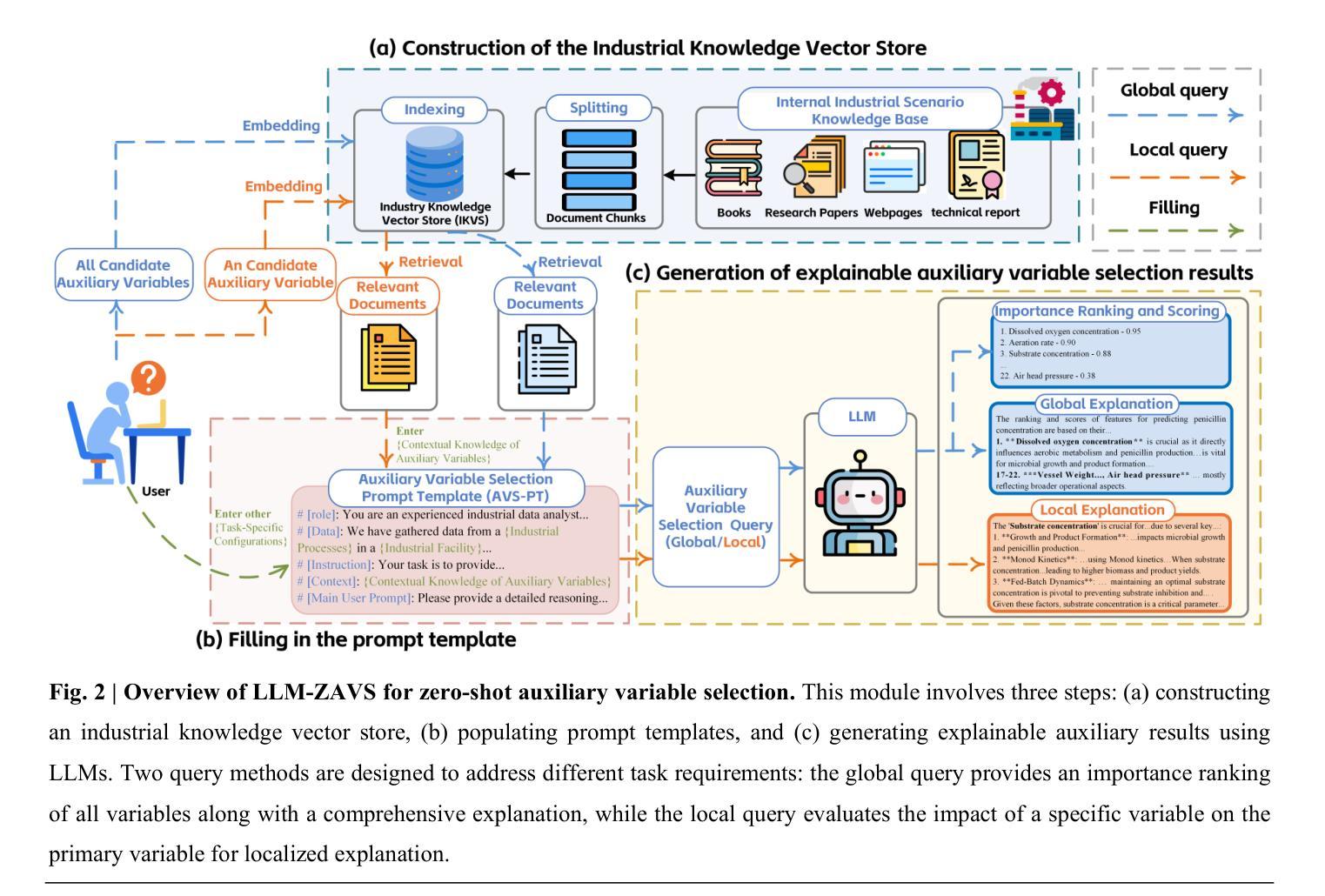
A Soft Sensor Method with Uncertainty-Awareness and Self-Explanation Based on Large Language Models Enhanced by Domain Knowledge Retrieval
Authors:Shuo Tong, Han Liu, Runyuan Guo, Wenqing Wang, Xueqiong Tian, Lingyun Wei, Lin Zhang, Huayong Wu, Ding Liu, Youmin Zhang
Data-driven soft sensors are crucial in predicting key performance indicators in industrial systems. However, current methods predominantly rely on the supervised learning paradigms of parameter updating, which inherently faces challenges such as high development costs, poor robustness, training instability, and lack of interpretability. Recently, large language models (LLMs) have demonstrated significant potential across various domains, notably through In-Context Learning (ICL), which enables high-performance task execution with minimal input-label demonstrations and no prior training. This paper aims to replace supervised learning with the emerging ICL paradigm for soft sensor modeling to address existing challenges and explore new avenues for advancement. To achieve this, we propose a novel framework called the Few-shot Uncertainty-aware and self-Explaining Soft Sensor (LLM-FUESS), which includes the Zero-shot Auxiliary Variable Selector (LLM-ZAVS) and the Uncertainty-aware Few-shot Soft Sensor (LLM-UFSS). The LLM-ZAVS retrieves from the Industrial Knowledge Vector Storage to enhance LLMs’ domain-specific knowledge, enabling zero-shot auxiliary variable selection. In the LLM-UFSS, we utilize text-based context demonstrations of structured data to prompt LLMs to execute ICL for predicting and propose a context sample retrieval augmentation strategy to improve performance. Additionally, we explored LLMs’ AIGC and probabilistic characteristics to propose self-explanation and uncertainty quantification methods for constructing a trustworthy soft sensor. Extensive experiments demonstrate that our method achieved state-of-the-art predictive performance, strong robustness, and flexibility, effectively mitigates training instability found in traditional methods. To the best of our knowledge, this is the first work to establish soft sensor utilizing LLMs.
数据驱动软传感器在工业系统中预测关键性能指标方面发挥着重要作用。然而,当前的方法主要依赖于参数更新的监督学习模式,这固有地面临着高开发成本、鲁棒性差、训练不稳定和缺乏可解释性等挑战。最近,大型语言模型(LLM)在各个领域表现出了巨大的潜力,尤其是通过上下文学习(ICL),它能够在少量输入标签演示的情况下实现高性能的任务执行,无需预先训练。
论文及项目相关链接
Summary
数据驱动型软传感器对预测工业系统关键性能指标至关重要。然而,当前方法主要依赖参数更新的监督学习模式,这固有地面临高开发成本、鲁棒性差、训练不稳定和缺乏可解释性等挑战。近期,大型语言模型(LLM)在各个领域展现出巨大潜力,尤其是在无需事先训练的情境学习(ICL)方面。本文旨在将新兴的ICL范式应用于软传感器建模,以应对现有挑战并探索新的进步途径。为此,我们提出了一种名为Few-shot Uncertainty-aware and self-Explaining Soft Sensor(LLM-FUESS)的新框架,包括Zero-shot Auxiliary Variable Selector(LLM-ZAVS)和Uncertainty-aware Few-shot Soft Sensor(LLM-UFSS)。LLM-ZAVS从工业知识向量存储中检索以增强LLM的领域特定知识,实现零辅助变量选择。在LLM-UFSS中,我们利用结构化数据的文本上下文演示来提示LLM执行ICL进行预测,并提出一种上下文样本检索增强策略来提高性能。此外,我们还探索了LLM的自解释和不确定性量化方法,以构建可信赖的软传感器。大量实验表明,我们的方法达到了先进的预测性能、强大的鲁棒性和灵活性,有效地解决了传统方法中的训练不稳定问题。据我们所知,这是首次利用LLM建立软传感器的工作。
Key Takeaways
- 数据驱动型软传感器在预测工业系统关键性能指标方面扮演重要角色。
- 当前软传感器方法主要基于监督学习,存在高成本、缺乏鲁棒性、训练不稳定和缺乏可解释性问题。
- 大型语言模型(LLM)和情境学习(ICL)在软传感器建模中具有巨大潜力。
- 论文提出了Few-shot Uncertainty-aware and self-Explaining Soft Sensor(LLM-FUESS)框架,结合LLM-ZAVS和LLM-UFSS,以改进软传感器性能。
- LLM-ZAVS利用工业知识向量存储增强LLM的领域特定知识,实现零辅助变量选择。
- LLM-UFSS利用文本上下文演示和上下文样本检索增强策略,提高预测性能。
点此查看论文截图

CaT-BENCH: Benchmarking Language Model Understanding of Causal and Temporal Dependencies in Plans
Authors:Yash Kumar Lal, Vanya Cohen, Nathanael Chambers, Niranjan Balasubramanian, Raymond Mooney
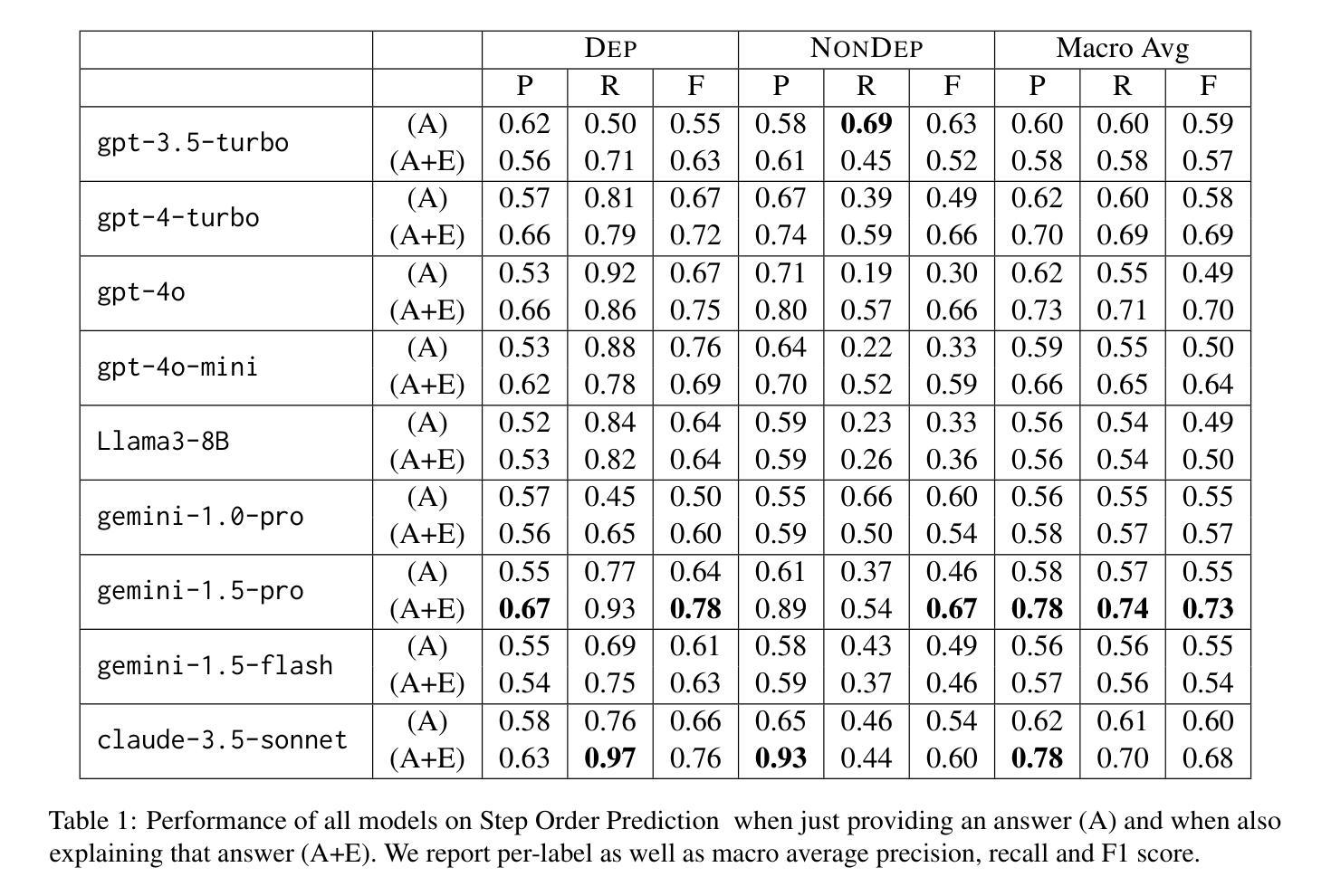
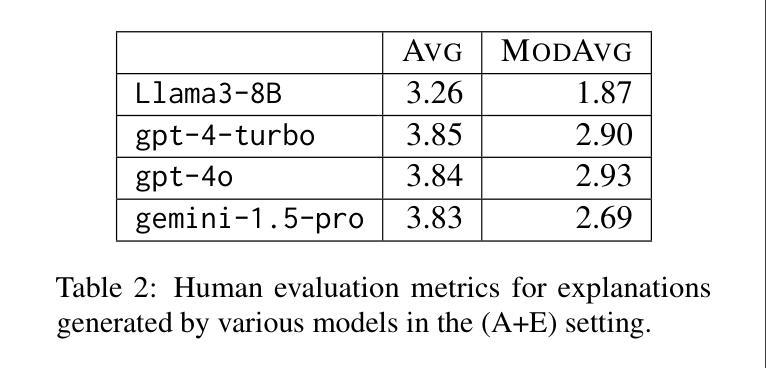
Understanding the abilities of LLMs to reason about natural language plans, such as instructional text and recipes, is critical to reliably using them in decision-making systems. A fundamental aspect of plans is the temporal order in which their steps needs to be executed, which reflects the underlying causal dependencies between them. We introduce CaT-Bench, a benchmark of Step Order Prediction questions, which test whether a step must necessarily occur before or after another in cooking recipe plans. We use this to evaluate how well frontier LLMs understand causal and temporal dependencies. We find that SOTA LLMs are underwhelming (best zero-shot is only 0.59 in F1), and are biased towards predicting dependence more often, perhaps relying on temporal order of steps as a heuristic. While prompting for explanations and using few-shot examples improve performance, the best F1 result is only 0.73. Further, human evaluation of explanations along with answer correctness show that, on average, humans do not agree with model reasoning. Surprisingly, we also find that explaining after answering leads to better performance than normal chain-of-thought prompting, and LLM answers are not consistent across questions about the same step pairs. Overall, results show that LLMs’ ability to detect dependence between steps has significant room for improvement.
理解大型语言模型(LLM)在决策系统推理中针对自然语言计划(如说明性文本和食谱)的能力对于可靠地使用它们至关重要。计划的一个基本方面是按照其步骤需要执行的时序顺序,这反映了它们之间的潜在因果依赖关系。我们引入了CaT-Bench,一个步骤顺序预测问题的基准测试,测试烹饪食谱计划中某个步骤是否必须在另一个步骤之前或之后发生。我们使用它来评估前沿LLM对因果和时间依赖关系的理解程度。我们发现,最先进的LLM表现令人失望(最佳零样本的F1分数仅为0.59),并且偏向于更频繁地预测依赖性,或许依赖步骤的时间顺序作为启发式方法。虽然提示解释和使用少量示例可以提高性能,但最佳F1结果仅为0.73。此外,通过对解释和答案正确性的人类评估显示,平均而言,人类并不认同模型的推理。令人惊讶的是,我们还发现,在回答问题后解释比正常思维链提示导致更好的性能,并且LLM对同一步骤对的答案并不一致。总体而言,结果表明LLM检测步骤之间依赖性的能力仍有很大提升空间。
论文及项目相关链接
PDF Accepted to EMNLP 2024 Main Conference
Summary
大型语言模型(LLMs)理解和处理自然语言计划(如指令文本和食谱)的能力对于在决策系统中可靠使用它们至关重要。计划的一个基本方面是步骤执行的时序顺序,这反映了它们之间的潜在因果依赖关系。本文介绍了CaT-Bench,一个步骤顺序预测问题的基准测试,用于测试LLMs在烹饪食谱计划中理解因果和时间依赖关系的能力。研究发现,现有最前沿的LLMs表现令人失望(最佳零样本F1分数仅为0.59),且倾向于过度预测依赖性,可能依赖步骤的时序顺序作为启发式。虽然提示解释和使用少量样本可以提高性能,但最佳F1结果仅为0.73。此外,对解释和答案正确性的人类评估显示,LLMs的推理平均而言并不符合人类的理解。令人惊讶的是,我们还发现先答题再解释的模式比传统的思考链提示更有效,并且对于同一步骤对的各种问题,LLM的答案并不一致。总体而言,LLMs在检测步骤间依赖关系的能力方面仍有很大的提升空间。
Key Takeaways
- LLMs在处理自然语言计划方面的能力对于在决策系统中的使用至关重要。
- CaT-Bench基准测试用于评估LLMs在理解烹饪食谱计划中的因果和时间依赖关系。
- 当前LLMs在步骤顺序预测方面的表现不佳,最佳F1分数仅为0.73。
- LLMs倾向于过度预测步骤之间的依赖性,可能依赖时序启发式。
- 提示解释和使用少量样本可以提高LLMs的性能,但仍存在改进空间。
- 人类评估显示LLMs的推理并不符合人类的理解。
点此查看论文截图

Rho-1: Not All Tokens Are What You Need
Authors:Zhenghao Lin, Zhibin Gou, Yeyun Gong, Xiao Liu, Yelong Shen, Ruochen Xu, Chen Lin, Yujiu Yang, Jian Jiao, Nan Duan, Weizhu Chen
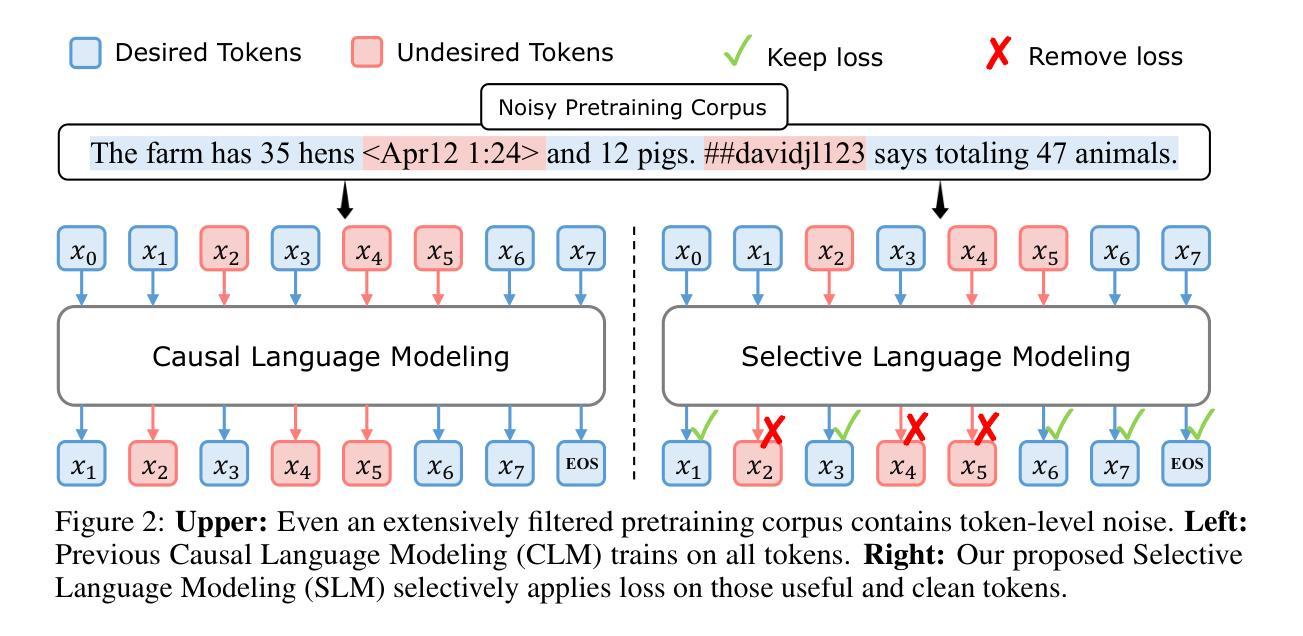
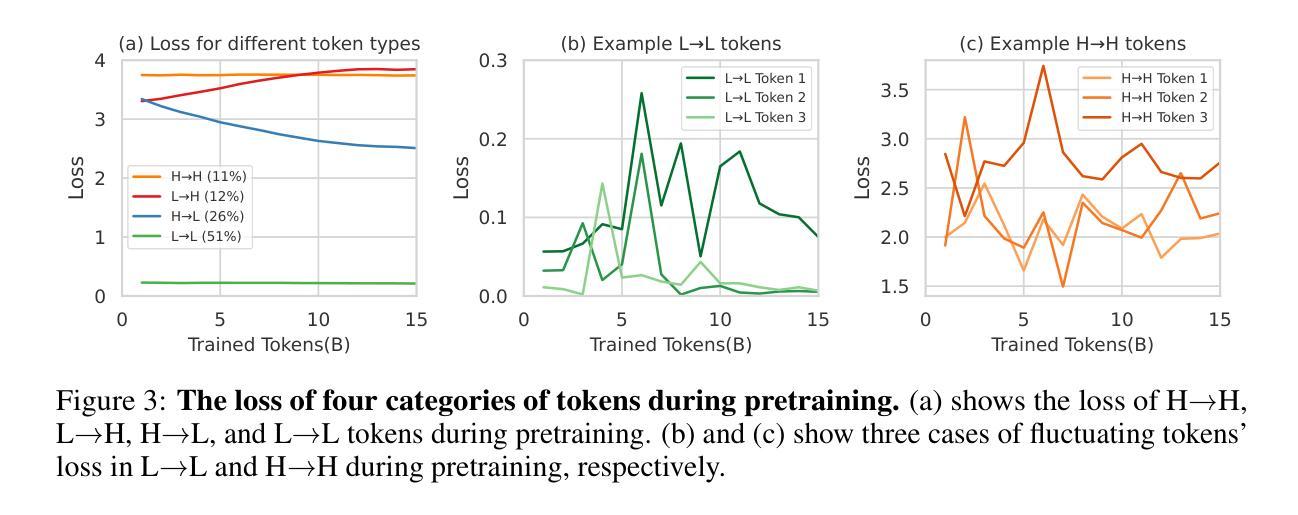
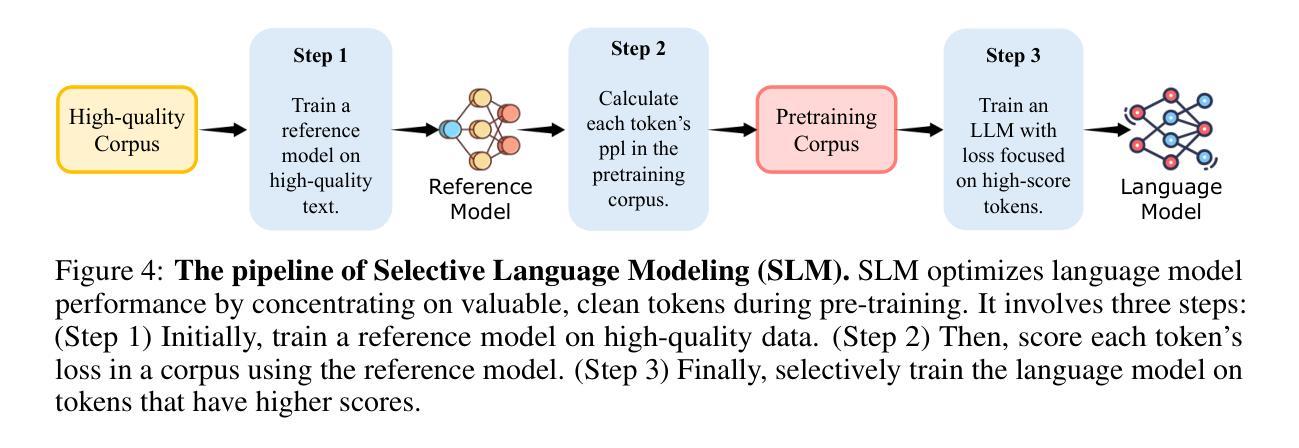
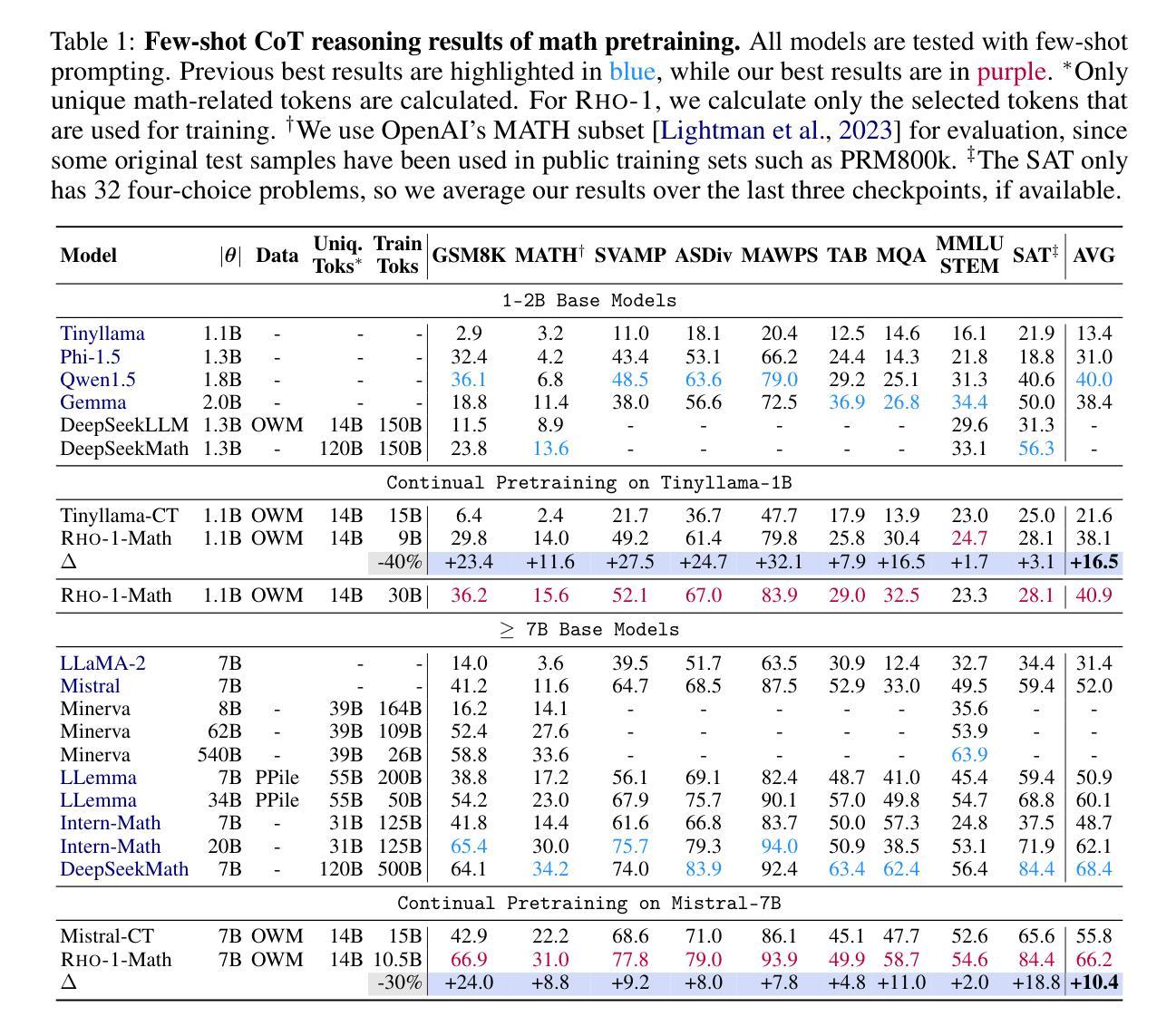
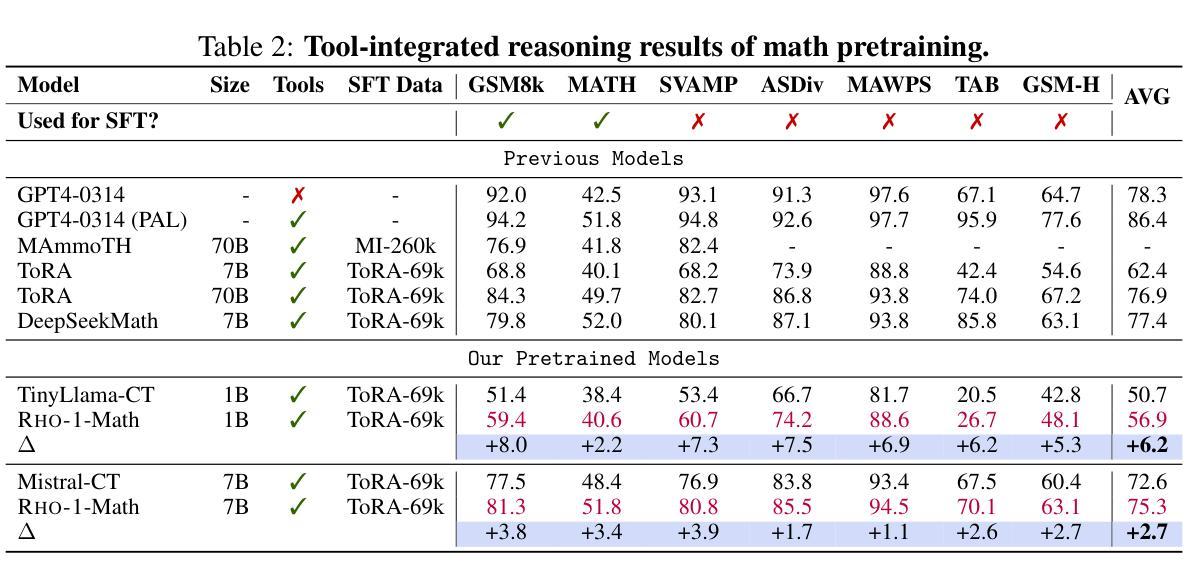
Previous language model pre-training methods have uniformly applied a next-token prediction loss to all training tokens. Challenging this norm, we posit that “9l training”. Our initial analysis examines token-level training dynamics of language model, revealing distinct loss patterns for different tokens. Leveraging these insights, we introduce a new language model called Rho-1. Unlike traditional LMs that learn to predict every next token in a corpus, Rho-1 employs Selective Language Modeling (SLM), which selectively trains on useful tokens that aligned with the desired distribution. This approach involves scoring pretraining tokens using a reference model, and then training the language model with a focused loss on tokens with higher scores. When continual pretraining on 15B OpenWebMath corpus, Rho-1 yields an absolute improvement in few-shot accuracy of up to 30% in 9 math tasks. After fine-tuning, Rho-1-1B and 7B achieved state-of-the-art results of 40.6% and 51.8% on MATH dataset, respectively - matching DeepSeekMath with only 3% of the pretraining tokens. Furthermore, when continual pretraining on 80B general tokens, Rho-1 achieves 6.8% average enhancement across 15 diverse tasks, increasing both efficiency and performance of the language model pre-training.
之前的语言模型预训练方法都是将所有训练令牌统一应用下一个令牌预测损失。我们挑战这一常规,提出“9l训练”方法。我们的初步分析研究了语言模型的令牌级训练动态,揭示了不同令牌的不同损失模式。基于这些见解,我们引入了一种名为Rho-1的新语言模型。不同于传统LMs学习预测语料库中的每个下一个令牌,Rho-1采用选择性语言建模(Selective Language Modeling,SLM),只针对与所需分布对齐的有用令牌进行选择性训练。这种方法涉及使用参考模型为预训练令牌打分,然后针对得分较高的令牌使用有针对性的损失来训练语言模型。在连续预训练15B OpenWebMath语料库时,Rho-1在9个数学任务中的小样本精度提高了高达30%。经过微调后,Rho-1-1B和7B在MATH数据集上达到了最新的最好成绩,分别为40.6%和51.8%,分别匹配了DeepSeekMath只有其预训练令牌的3%。此外,在对80B通用令牌进行连续预训练时,Rho-1在15个不同任务上平均提高了6.8%的性能,提高了语言模型预训练的效率与性能。
论文及项目相关链接
PDF First two authors equal contribution
Summary
该文挑战了传统语言模型预训练的方式,提出一种名为Rho-1的新型语言模型。该模型采用选择性语言建模(SLM)方法,只针对有用且符合期望分布的令牌进行训练。通过评分预训练令牌并使用有针对性的损失函数对高分令牌进行训练,在持续预训练时提高了模型的效率和性能。在多个任务中,Rho-1的预训练令牌数量相较于其他模型大大减少,但仍取得了显著的准确性提升。
Key Takeaways
- 传统语言模型预训练采用对所有令牌应用下一个令牌预测损失的方法,而本文提出挑战并引入选择性语言建模(SLM)。
- Rho-1模型使用参考模型对预训练令牌进行评分,只针对高分令牌进行有针对性的损失训练。
- Rho-1模型在持续预训练时,相较于其他模型使用更少的预训练令牌数量。
- Rho-1在多个数学任务中实现了高达30%的少样本准确性提升。
- Rho-1在MATH数据集上的表现达到或超越了现有技术,即使只使用少量预训练令牌。
- Rho-1在多种任务上平均提高了模型的效率和性能,平均提升幅度达到6.8%。
- Rho-1模型的引入为语言模型的预训练提供了新的视角和方法论基础。
点此查看论文截图

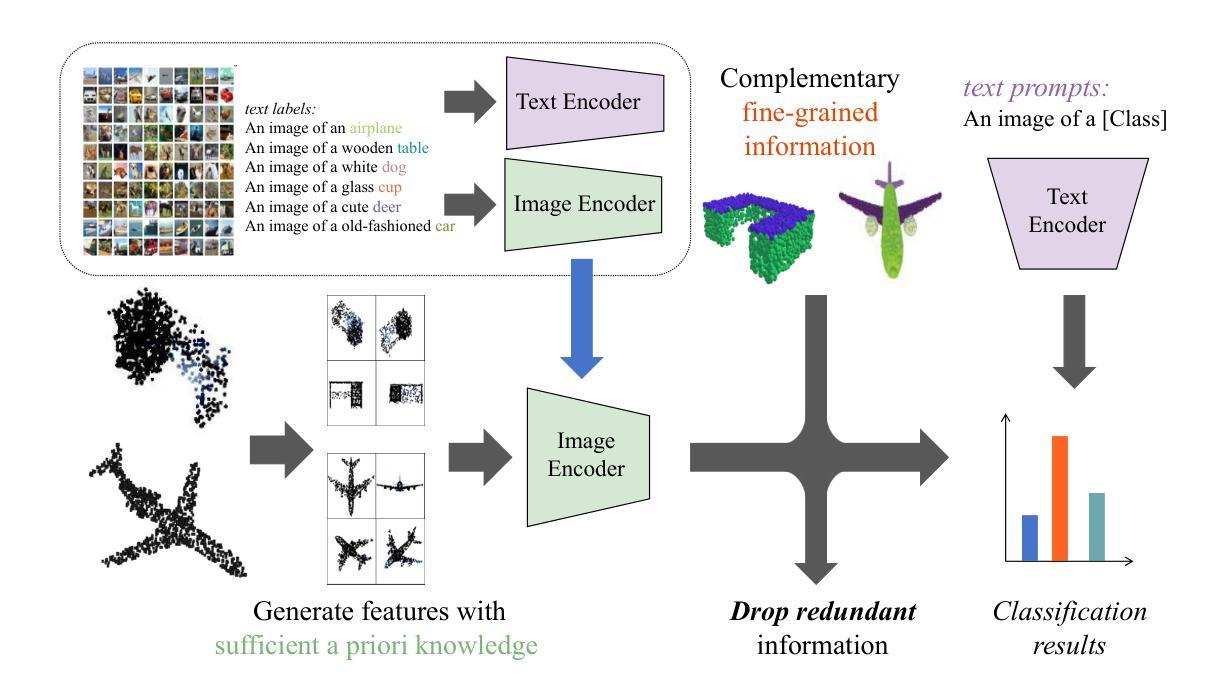
FILP-3D: Enhancing 3D Few-shot Class-incremental Learning with Pre-trained Vision-Language Models
Authors:Wan Xu, Tianyu Huang, Tianyu Qu, Guanglei Yang, Yiwen Guo, Wangmeng Zuo
Few-shot class-incremental learning (FSCIL) aims to mitigate the catastrophic forgetting issue when a model is incrementally trained on limited data. However, many of these works lack effective exploration of prior knowledge, rendering them unable to effectively address the domain gap issue in the context of 3D FSCIL, thereby leading to catastrophic forgetting. The Contrastive Vision-Language Pre-Training (CLIP) model serves as a highly suitable backbone for addressing the challenges of 3D FSCIL due to its abundant shape-related prior knowledge. Unfortunately, its direct application to 3D FSCIL still faces the incompatibility between 3D data representation and the 2D features, primarily manifested as feature space misalignment and significant noise. To address the above challenges, we introduce the FILP-3D framework with two novel components: the Redundant Feature Eliminator (RFE) for feature space misalignment and the Spatial Noise Compensator (SNC) for significant noise. RFE aligns the feature spaces of input point clouds and their embeddings by performing a unique dimensionality reduction on the feature space of pre-trained models (PTMs), effectively eliminating redundant information without compromising semantic integrity. On the other hand, SNC is a graph-based 3D model designed to capture robust geometric information within point clouds, thereby augmenting the knowledge lost due to projection, particularly when processing real-world scanned data. Moreover, traditional accuracy metrics are proven to be biased due to the imbalance in existing 3D datasets. Therefore we propose 3D FSCIL benchmark FSCIL3D-XL and novel evaluation metrics that offer a more nuanced assessment of a 3D FSCIL model. Experimental results on both established and our proposed benchmarks demonstrate that our approach significantly outperforms existing state-of-the-art methods.
少量类别增量学习(FSCIL)旨在解决模型在有限数据上逐步训练时出现的灾难性遗忘问题。然而,这些工作中的许多缺乏对先验知识的有效探索,导致它们无法有效解决3D FSCIL中的领域差距问题,从而导致灾难性遗忘。对比视觉语言预训练(CLIP)模型由于其丰富的形状相关先验知识,成为应对3D FSCIL挑战的理想骨干网。然而,其直接应用于3D FSCIL仍然面临3D数据表示与2D特征之间的不兼容问题,主要表现为特征空间不对齐和显著噪声。为了解决上述挑战,我们引入了FILP-3D框架,其中包括两个新组件:用于特征空间不对齐的冗余特征消除器(RFE)和用于显著噪声的空间噪声补偿器(SNC)。RFE通过对预训练模型(PTM)的特征空间进行独特的降维操作,对齐输入点云及其嵌入的特征空间,有效地消除了冗余信息,同时不损害语义完整性。另一方面,SNC是一个基于图的3D模型,旨在捕获点云中的稳健几何信息,从而弥补因投影而丢失的知识,特别是在处理现实世界扫描数据时。此外,由于现有3D数据集的不平衡,传统准确性指标被证明是有偏见的。因此,我们提出了3D FSCIL基准测试FSCIL3D-XL和新的评估指标,为3D FSCIL模型提供更微妙的评估。在既定基准测试和我们提出的基准测试上的实验结果都表明,我们的方法显著优于现有最先进的方法。
论文及项目相关链接
Summary
针对few-shot类增量学习(FSCIL)中的灾难性遗忘问题,文章提出了使用对比视觉语言预训练(CLIP)模型的FILP-3D框架。该框架引入了两个新组件:用于特征空间不对齐的冗余特征消除器(RFE)和用于显著噪声的空间噪声补偿器(SNC)。同时,为解决传统准确率度量在3D数据集上的偏见问题,文章提出了FSCIL3D-XL基准测试和新型评估指标。实验结果表明,该方法在现有和传统基准测试上的表现均显著优于现有技术。
Key Takeaways
- Few-shot类增量学习(FSCIL)面临灾难性遗忘问题,需要探索先前知识来解决。
- 对比视觉语言预训练(CLIP)模型因其丰富的形状相关先验知识,适合解决3D FSCIL的挑战。
- FILP-3D框架通过引入冗余特征消除器(RFE)和空间噪声补偿器(SNC)来解决3D数据表示与2D特征之间的不兼容问题。
- RFE通过对预训练模型的特征空间进行独特的降维操作,消除了冗余信息,同时保持语义完整性。
- SNC是一个基于图的3D模型,旨在捕捉点云中的稳健几何信息,从而弥补因投影而丢失的知识。
- 传统准确率度量在3D数据集上存在偏见,因此提出了FSCIL3D-XL基准测试和新型评估指标,以提供更细致的评估。
点此查看论文截图