⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-10 更新
EpiCoder: Encompassing Diversity and Complexity in Code Generation
Authors:Yaoxiang Wang, Haoling Li, Xin Zhang, Jie Wu, Xiao Liu, Wenxiang Hu, Zhongxin Guo, Yangyu Huang, Ying Xin, Yujiu Yang, Jinsong Su, Qi Chen, Scarlett Li
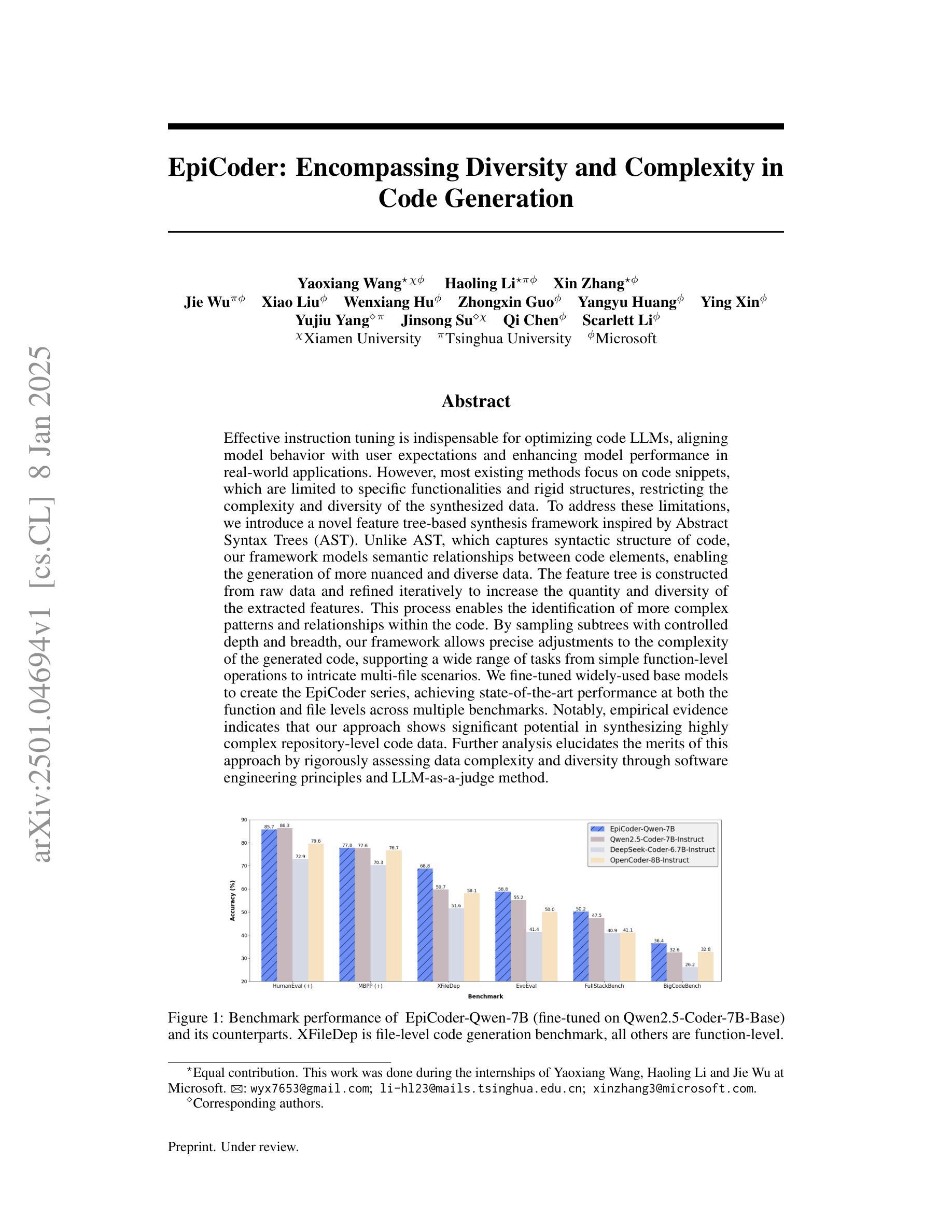
Effective instruction tuning is indispensable for optimizing code LLMs, aligning model behavior with user expectations and enhancing model performance in real-world applications. However, most existing methods focus on code snippets, which are limited to specific functionalities and rigid structures, restricting the complexity and diversity of the synthesized data. To address these limitations, we introduce a novel feature tree-based synthesis framework inspired by Abstract Syntax Trees (AST). Unlike AST, which captures syntactic structure of code, our framework models semantic relationships between code elements, enabling the generation of more nuanced and diverse data. The feature tree is constructed from raw data and refined iteratively to increase the quantity and diversity of the extracted features. This process enables the identification of more complex patterns and relationships within the code. By sampling subtrees with controlled depth and breadth, our framework allows precise adjustments to the complexity of the generated code, supporting a wide range of tasks from simple function-level operations to intricate multi-file scenarios. We fine-tuned widely-used base models to create the EpiCoder series, achieving state-of-the-art performance at both the function and file levels across multiple benchmarks. Notably, empirical evidence indicates that our approach shows significant potential in synthesizing highly complex repository-level code data. Further analysis elucidates the merits of this approach by rigorously assessing data complexity and diversity through software engineering principles and LLM-as-a-judge method.
对代码LLM进行优化调整是不可或缺的,这能使模型行为与用户期望相符,提高模型在现实世界应用中的性能。然而,大多数现有方法主要关注代码片段,这局限于特定功能和固定结构,从而限制了合成数据的复杂性和多样性。为了解决这个问题,我们受到抽象语法树(AST)的启发,引入了一种新的基于特征树的合成框架。不同于AST捕捉代码的语法结构,我们的框架对代码元素之间的语义关系进行建模,从而能够生成更微妙和多样化的数据。特征树是根据原始数据构建的,并经过迭代优化来增加提取特征的数量和多样性。这个过程能够识别代码内部更复杂的模式和关系。通过控制深度和广度来采样子树,我们的框架可以对生成的代码的复杂性进行精确调整,支持从简单的函数级操作到复杂的多文件场景的各种任务。我们微调了广泛使用的基准模型,创建了EpiCoder系列,在多个基准测试中实现了函数和文件级别的最先进的性能。值得注意的是,经验证据表明我们的方法在合成高度复杂的仓库级代码数据方面显示出巨大潜力。进一步的分析通过软件工程原理和LLM评估方法严格地评估数据的复杂性和多样性,阐明了该方法的优点。
论文及项目相关链接
PDF 40 pages, 11 figures
Summary
该文本介绍了针对代码LLM的优化指令调整的重要性,以及如何通过新型特征树合成框架解决现有方法的局限性。该框架通过建模代码元素间的语义关系,生成更为细致和多样的数据。通过构建特征树并迭代优化,能识别更复杂的代码模式和关系。通过控制子树的深度和广度采样,该框架支持从简单函数级操作到复杂多文件场景的各种任务。经验证据表明,该方法在合成高度复杂的仓库级代码数据方面显示出巨大潜力。
Key Takeaways
- 代码LLM的优化指令调整对于模型性能优化和用户期望对齐至关重要。
- 现有方法主要关注代码片段,存在局限性,难以处理复杂和多样化的合成数据。
- 新型特征树合成框架通过建模代码元素间的语义关系,解决了这一问题,生成更细致和多样的数据。
- 特征树的构建和迭代优化有助于识别更复杂的代码模式和关系。
- 该框架支持通过控制子树的深度和广度采样,适应不同复杂度的任务。
- EpiCoder系列模型通过微调广泛使用的基准模型,实现了函数和文件级别多个基准测试的最新性能。
点此查看论文截图
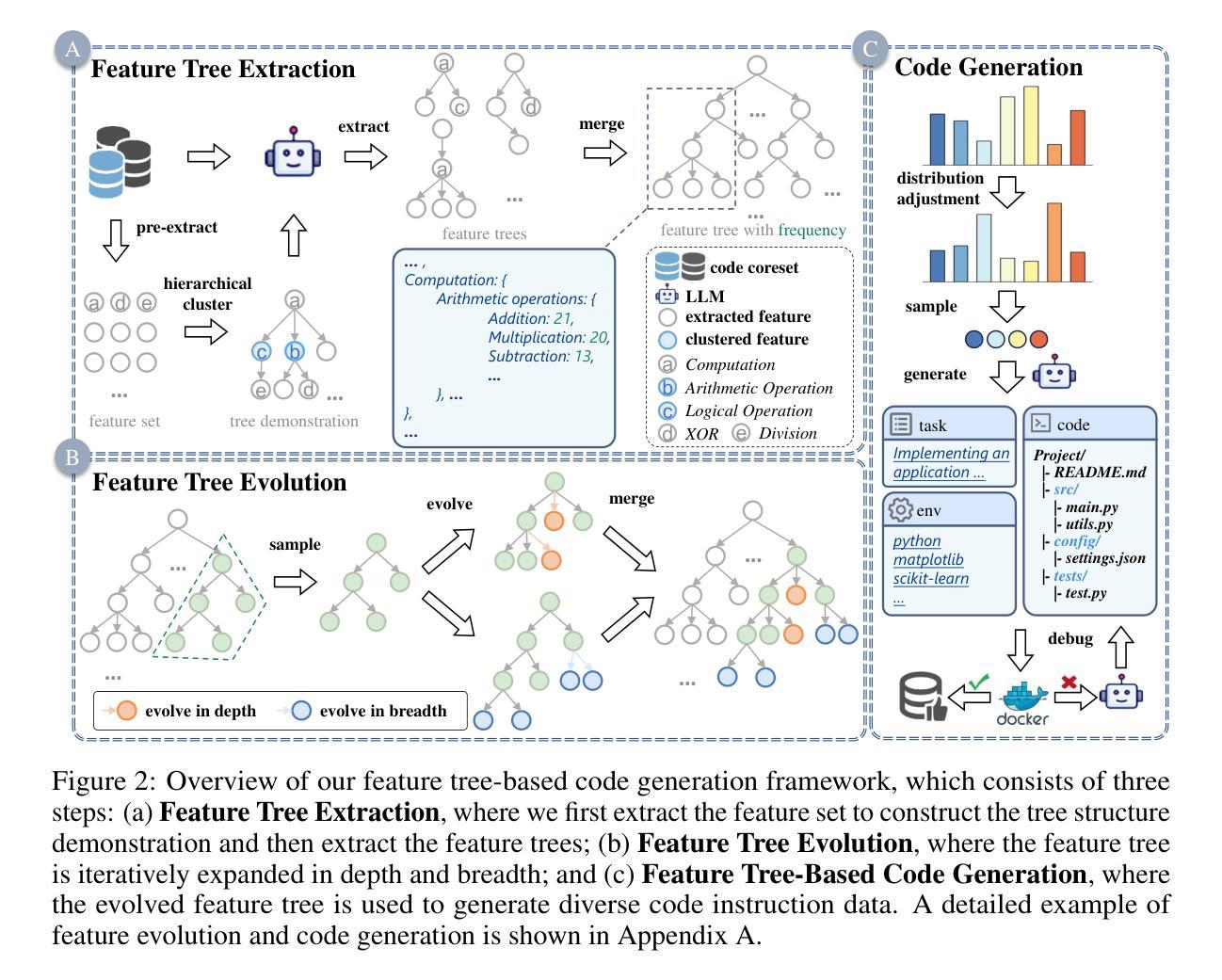



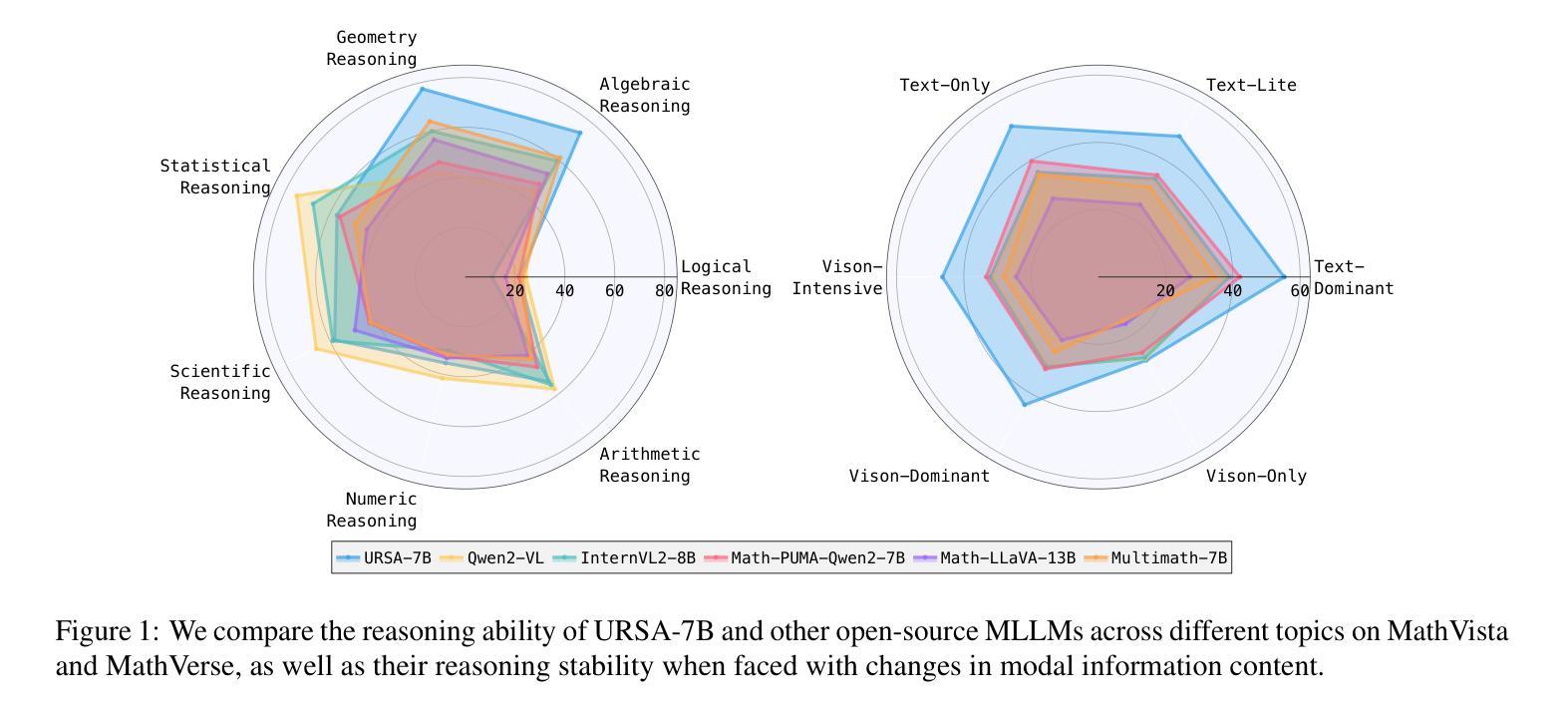
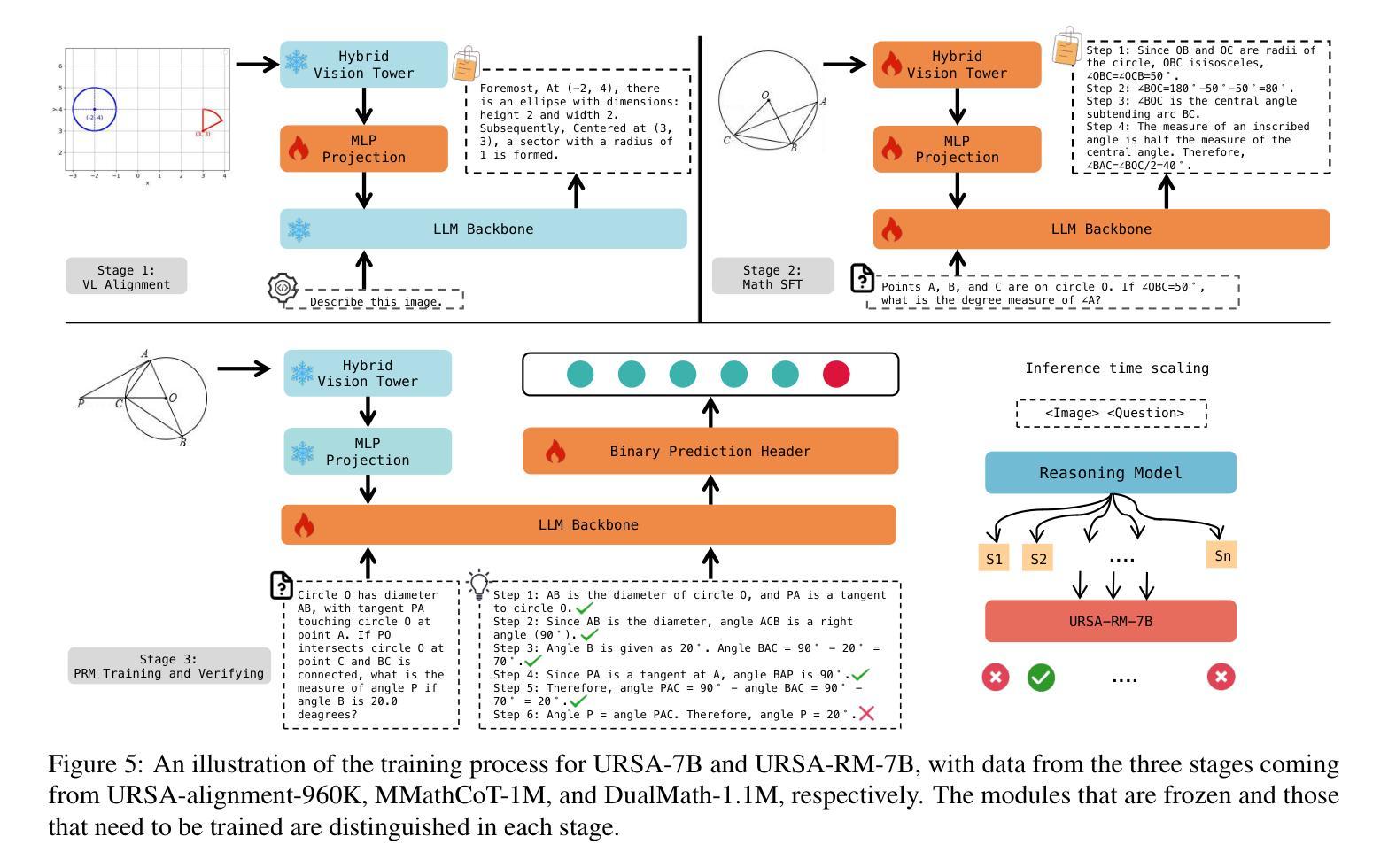
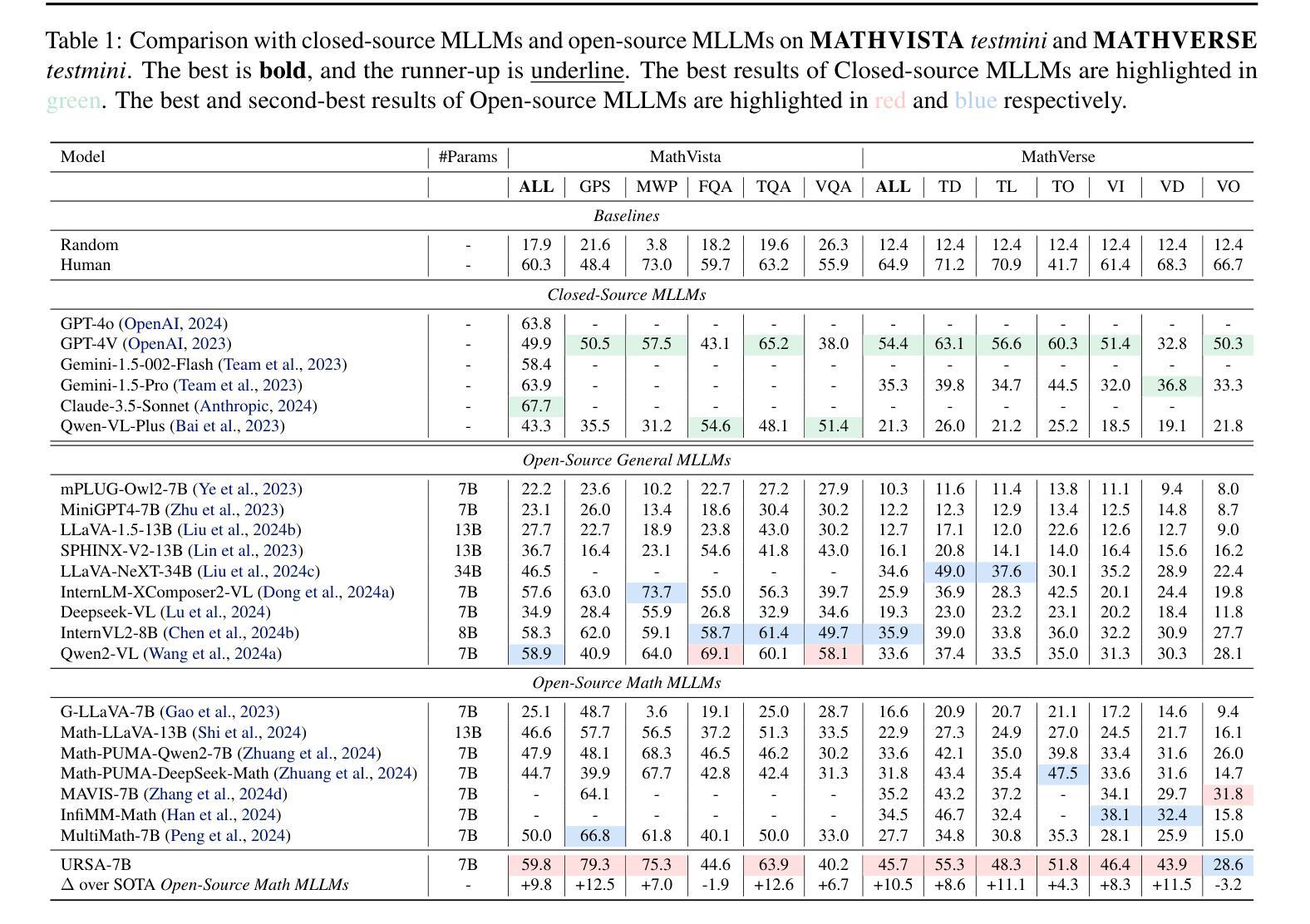
URSA: Understanding and Verifying Chain-of-thought Reasoning in Multimodal Mathematics
Authors:Ruilin Luo, Zhuofan Zheng, Yifan Wang, Yiyao Yu, Xinzhe Ni, Zicheng Lin, Jin Zeng, Yujiu Yang
Chain-of-thought (CoT) reasoning has been widely applied in the mathematical reasoning of Large Language Models (LLMs). Recently, the introduction of derivative process supervision on CoT trajectories has sparked discussions on enhancing scaling capabilities during test time, thereby boosting the potential of these models. However, in multimodal mathematical reasoning, the scarcity of high-quality CoT training data has hindered existing models from achieving high-precision CoT reasoning and has limited the realization of reasoning potential during test time. In this work, we propose a three-module synthesis strategy that integrates CoT distillation, trajectory-format rewriting, and format unification. It results in a high-quality CoT reasoning instruction fine-tuning dataset in multimodal mathematics, MMathCoT-1M. We comprehensively validate the state-of-the-art (SOTA) performance of the trained URSA-7B model on multiple multimodal mathematical benchmarks. For test-time scaling, we introduce a data synthesis strategy that automatically generates process annotation datasets, known as DualMath-1.1M, focusing on both interpretation and logic. By further training URSA-7B on DualMath-1.1M, we transition from CoT reasoning capabilities to robust supervision abilities. The trained URSA-RM-7B acts as a verifier, effectively enhancing the performance of URSA-7B at test time. URSA-RM-7B also demonstrates excellent out-of-distribution (OOD) verifying capabilities, showcasing its generalization. Model weights, training data and code will be open-sourced.
思维链(CoT)推理已在大型语言模型(LLM)的数学推理中得到广泛应用。最近,对思维链轨迹的派生过程监督的讨论引发了关于提高测试时的扩展能力的兴趣,从而提高了这些模型的潜力。然而,在多模态数学推理中,高质量思维链训练数据的稀缺阻碍了现有模型实现高精度思维链推理,并限制了测试时推理潜力的实现。在这项工作中,我们提出了一种三模块合成策略,该策略集成了思维链蒸馏、轨迹格式重写和格式统一。这导致在多模态数学中产生了高质量的思维链推理指令微调数据集MMathCoT-1M。我们全面验证了训练后的URSA-7B模型在多个多模态数学基准测试上的最新性能。为了测试时的扩展能力,我们引入了一种数据合成策略,该策略可以自动生成名为DualMath-1.1M的过程注释数据集,侧重于解释和逻辑。通过对URSA-7B在DualMath-1.1M上进行进一步训练,我们从思维链推理能力转变为强大的监督能力。经过训练的URSA-RM-7B充当验证器,有效提高URSA-7B在测试时的性能。此外,URSA-RM-7B还展示了出色的离群验证能力,展示了其泛化能力。模型的权重、训练数据和代码将开源。
论文及项目相关链接
PDF 27 pages, 10 tables, 17 figures. The training data has been released. The code and model are currently undergoing internal review. They will be made available soon. Project url: https://ursa-math.github.io
Summary
本文介绍了在多模态数学推理中,通过引入链式思维(CoT)推理和衍生过程监督,提高大型语言模型(LLM)的测试时扩展能力的方法。针对高质量CoT训练数据的稀缺问题,提出了一个三模块合成策略,包括CoT蒸馏、轨迹格式重写和格式统一,并创建了MMathCoT-1M高质量CoT推理指令微调数据集。此外,还介绍了一种数据合成策略,自动生成过程注解数据集DualMath-1.1M,并用于进一步提高模型的监督能力。经过在多个多模态数学基准测试上的验证,URSA-RM-7B模型表现出优异的性能,包括测试时扩展能力、验证能力和泛化能力。
Key Takeaways
- 链式思维(CoT)推理被广泛应用于大型语言模型(LLM)的数学推理中。
- 衍生过程监督有助于提高模型的测试时扩展能力。
- 高质量CoT训练数据的稀缺限制了多模态数学推理模型的精度和潜力。
- 提出了一个三模块合成策略来创建高质量的CoT推理指令微调数据集MMathCoT-1M。
- 引入了一种数据合成策略,自动生成过程注解数据集DualMath-1.1M,以提高模型的监督能力。
- URSA-RM-7B模型在多个多模态数学基准测试上表现出优异的性能。
点此查看论文截图




Towards System 2 Reasoning in LLMs: Learning How to Think With Meta Chain-of-Though
Authors:Violet Xiang, Charlie Snell, Kanishk Gandhi, Alon Albalak, Anikait Singh, Chase Blagden, Duy Phung, Rafael Rafailov, Nathan Lile, Dakota Mahan, Louis Castricato, Jan-Philipp Franken, Nick Haber, Chelsea Finn
We propose a novel framework, Meta Chain-of-Thought (Meta-CoT), which extends traditional Chain-of-Thought (CoT) by explicitly modeling the underlying reasoning required to arrive at a particular CoT. We present empirical evidence from state-of-the-art models exhibiting behaviors consistent with in-context search, and explore methods for producing Meta-CoT via process supervision, synthetic data generation, and search algorithms. Finally, we outline a concrete pipeline for training a model to produce Meta-CoTs, incorporating instruction tuning with linearized search traces and reinforcement learning post-training. Finally, we discuss open research questions, including scaling laws, verifier roles, and the potential for discovering novel reasoning algorithms. This work provides a theoretical and practical roadmap to enable Meta-CoT in LLMs, paving the way for more powerful and human-like reasoning in artificial intelligence.
我们提出了一种新的框架,即元思维链(Meta-CoT),它通过对到达特定思维链(CoT)所需的基本推理进行显式建模,从而扩展了传统的思维链(CoT)。我们提供了来自表现出与上下文搜索一致的行为的先进模型的实证证据,并探索了通过过程监督、合成数据生成和搜索算法产生元思维链的方法。最后,我们概述了训练模型产生元思维链的具体流程,包括利用线性化搜索轨迹进行指令调整以及强化学习后训练。最后,我们讨论了开放的研究问题,包括规模定律、验证器角色和发现新型推理算法的可能性。这项工作在理论与实践上为大型语言模型实现元思维链铺平了道路,为人工智能中更强大、更人性化的推理能力奠定了基础。
论文及项目相关链接
Summary
本文提出了一个新颖框架——Meta Chain-of-Thought(Meta-CoT),它通过明确建模到达特定Chain-of-Thought(CoT)所需的底层推理,扩展了传统CoT。本文通过实证证据展示了先进模型与上下文搜索一致的行为,并探索了通过过程监督、合成数据生成和搜索算法产生Meta-CoT的方法。此外,文章概述了训练模型以产生Meta-CoTs的具体流程,包括使用线性化搜索轨迹的指令微调以及强化学习后训练。最后,本文讨论了开放研究问题,包括规模法则、验证器角色以及发现新型推理算法的可能性。本研究为在大型语言模型中实现Meta-CoT提供了理论和实践路线图,为人工智能中更强大、更人性化的推理铺平了道路。
Key Takeaways
- 提出了Meta Chain-of-Thought(Meta-CoT)框架,扩展了传统CoT,通过明确建模底层推理来提升模型推理能力。
- 通过实证证据展示了先进模型与上下文搜索一致的行为。
- 探讨了产生Meta-CoT的三种方法:过程监督、合成数据生成和搜索算法。
- 提供了训练模型以产生Meta-CoTs的具体流程,包括指令微调、线性化搜索轨迹和强化学习后训练。
- 强调了规模法则、验证器角色以及发现新型推理算法等开放研究问题的重要性。
- Meta-CoT框架有助于实现更强大、更人性化的AI推理。
点此查看论文截图

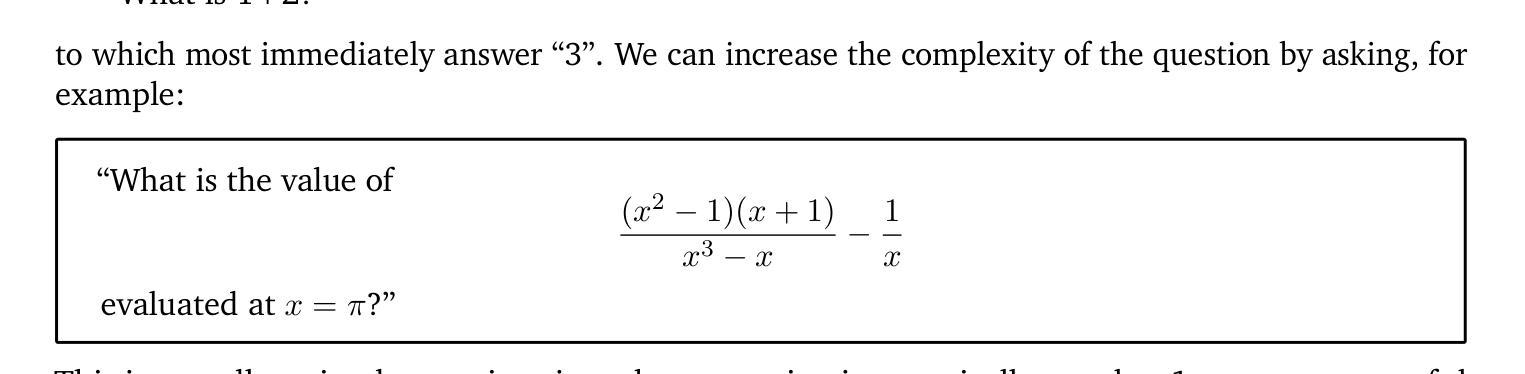

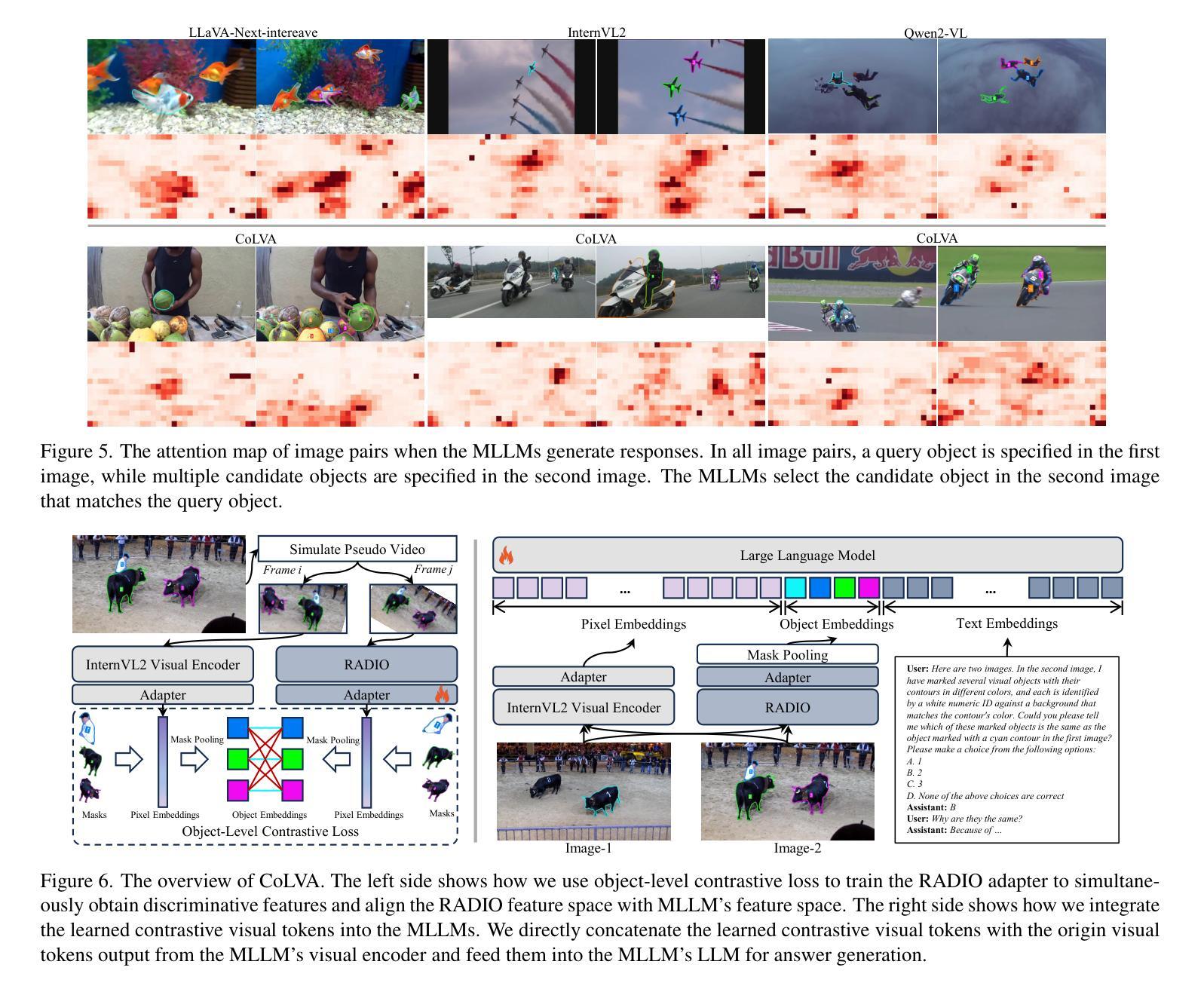
Are They the Same? Exploring Visual Correspondence Shortcomings of Multimodal LLMs
Authors:Yikang Zhou, Tao Zhang, Shilin Xu, Shihao Chen, Qianyu Zhou, Yunhai Tong, Shunping Ji, Jiangning Zhang, Xiangtai Li, Lu Qi
Recent advancements in multimodal models have shown a strong ability in visual perception, reasoning abilities, and vision-language understanding. However, studies on visual matching ability are missing, where finding the visual correspondence of objects is essential in vision research. Our research reveals that the matching capabilities in recent multimodal LLMs (MLLMs) still exhibit systematic shortcomings, even with current strong MLLMs models, GPT-4o. In particular, we construct a Multimodal Visual Matching (MMVM) benchmark to fairly benchmark over 30 different MLLMs. The MMVM benchmark is built from 15 open-source datasets and Internet videos with manual annotation. We categorize the data samples of MMVM benchmark into eight aspects based on the required cues and capabilities to more comprehensively evaluate and analyze current MLLMs. In addition, we have designed an automatic annotation pipeline to generate the MMVM SFT dataset, including 220K visual matching data with reasoning annotation. Finally, we present CoLVA, a novel contrastive MLLM with two novel technical designs: fine-grained vision expert with object-level contrastive learning and instruction augmentation strategy. CoLVA achieves 51.06% overall accuracy (OA) on the MMVM benchmark, surpassing GPT-4o and baseline by 8.41% and 23.58% OA, respectively. The results show the effectiveness of our MMVM SFT dataset and our novel technical designs. Code, benchmark, dataset, and models are available at https://github.com/zhouyiks/CoLVA.
近期多模态模型的进展显示出强大的视觉感知、推理能力和视觉语言理解。然而,关于视觉匹配能力的研究仍有所缺失,视觉研究中找到物体的视觉对应物至关重要。我们的研究发现,即使在现有的强大LLM模型GPT-4o中,最近的多模态LLM(MLLMs)的匹配能力仍然表现出系统性的不足。特别是,我们建立了一个多模态视觉匹配(MMVM)基准测试,可以对超过30种不同的MLLM进行公平的比较。MMVM基准测试由包含手动注释的15个开源数据集和互联网视频构建而成。我们根据所需线索和能力将MMVM基准测试的数据样本分为八个方面,以更全面地对当前LLM进行评估和分析。此外,我们还设计了一个自动注释管道来生成MMVM SFT数据集,其中包括带有推理注释的22万视觉匹配数据。最后,我们提出了CoLVA,这是一种新型对比MLLM,具有两项新颖的技术设计:具有对象级对比学习的精细视觉专家和指令增强策略。CoLVA在MMVM基准测试中实现了整体准确度为百分之五十一,超过GPT-4o和基线模型分别为百分之八点四一和百分之二十三点五八。结果表明我们的MMVM SFT数据集和新颖的技术设计的有效性。代码、基准测试、数据集和模型均可在https://github.com/zhouyiks/CoLVA找到。
论文及项目相关链接
PDF project page: https://zhouyiks.github.io/projects/CoLVA/
Summary
最新多模态模型在视觉感知、推理能力和视觉语言理解方面表现出强大能力,但在视觉匹配能力方面存在系统性短板。研究构建了多模态视觉匹配(MMVM)基准测试,包含超过30种不同的多模态大型语言模型。MMVM基准测试包含手动标注的开放源数据集和互联网视频数据样本。此外,设计了自动标注管道生成MMVM SFT数据集,包含带有推理标注的22万视觉匹配数据。最后,提出一种新型对比多模态大型语言模型CoLVA,具有精细视觉专家和对象级对比学习以及指令增强策略等技术特点,在MMVM基准测试中实现了较高的准确率。
Key Takeaways
- 多模态模型在视觉感知、推理和视觉语言理解方面取得显著进展,但视觉匹配能力的研究仍然缺失。
- 视觉匹配在视觉研究中至关重要,涉及找到对象的视觉对应关系。
- 现有大型多模态语言模型(LLMs)在匹配能力上仍有系统性不足。
- 构建了一个多模态视觉匹配(MMVM)基准测试,用于评估超过30种不同的LLMs。
- MMVM基准测试包含手动标注的开放源数据集和互联网视频数据样本,分为八个方面进行全面评估和分析。
- 设计了自动标注管道生成MMVM SFT数据集,包含带有推理标注的22万视觉匹配数据样本。
点此查看论文截图


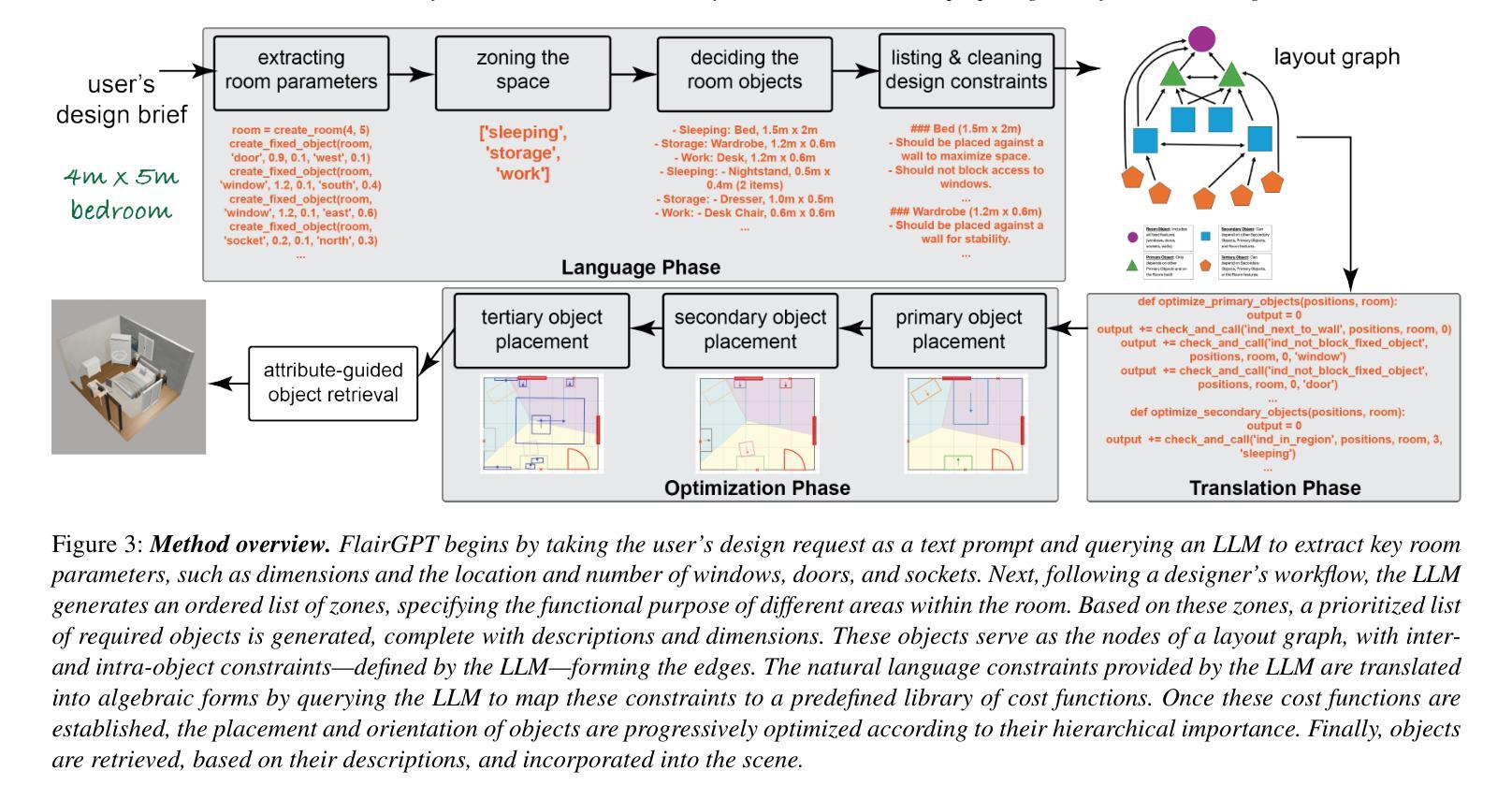
FlairGPT: Repurposing LLMs for Interior Designs
Authors:Gabrielle Littlefair, Niladri Shekhar Dutt, Niloy J. Mitra
Interior design involves the careful selection and arrangement of objects to create an aesthetically pleasing, functional, and harmonized space that aligns with the client’s design brief. This task is particularly challenging, as a successful design must not only incorporate all the necessary objects in a cohesive style, but also ensure they are arranged in a way that maximizes accessibility, while adhering to a variety of affordability and usage considerations. Data-driven solutions have been proposed, but these are typically room- or domain-specific and lack explainability in their design design considerations used in producing the final layout. In this paper, we investigate if large language models (LLMs) can be directly utilized for interior design. While we find that LLMs are not yet capable of generating complete layouts, they can be effectively leveraged in a structured manner, inspired by the workflow of interior designers. By systematically probing LLMs, we can reliably generate a list of objects along with relevant constraints that guide their placement. We translate this information into a design layout graph, which is then solved using an off-the-shelf constrained optimization setup to generate the final layouts. We benchmark our algorithm in various design configurations against existing LLM-based methods and human designs, and evaluate the results using a variety of quantitative and qualitative metrics along with user studies. In summary, we demonstrate that LLMs, when used in a structured manner, can effectively generate diverse high-quality layouts, making them a viable solution for creating large-scale virtual scenes. Project webpage at https://flairgpt.github.io/
室内设计涉及对象的精心选择和布置,以创造一个美观、实用、和谐的空间,这个空间要符合客户的设计简报。这一任务特别具有挑战性,因为一个成功的设计不仅要以协调的风格融入所有必需的对象,还要确保它们的布置方式能最大限度地提高可访问性,同时考虑到各种经济性和使用方面的因素。数据驱动解决方案已经被提出,但这些解决方案通常是针对特定房间或领域的,并且在设计考虑因素中缺乏可解释性,无法用于生成最终布局。在本文中,我们调查了是否可以直接使用大型语言模型(LLM)进行室内设计。虽然我们发现LLM目前还不能生成完整的布局,但可以通过受室内设计师工作流程启发的结构化方式有效地利用它们。通过系统地探测LLM,我们可以可靠地生成对象列表以及指导其放置的相关约束。我们将这些信息转化为设计布局图,然后使用现成的约束优化设置来解决,以生成最终的布局。我们在各种设计配置中对我们的算法进行了基准测试,对象包括现有的LLM方法和人工设计,并使用各种定量和定性指标以及用户研究来评估结果。总之,我们证明了当LLM以结构化的方式使用时,可以有效地生成多样化的高质量布局,使其成为创建大规模虚拟场景的一种可行解决方案。项目网页地址是https://flairgpt.github.io/。
论文及项目相关链接
PDF Accepted at EUROGRAPHICS 2025
Summary:
室内设计涉及精心选择和安排物品,以创造一个美观、实用、和谐的空间,符合客户的设计需求。本文探索了大型语言模型(LLM)在室内设计中的应用潜力。虽然LLM尚不能生成完整的布局,但可以通过系统查询生成物品列表和相关约束,指导物品的摆放。这些信息被转化为设计布局图,然后使用现成的约束优化设置生成最终布局。本文评估了算法在各种设计配置中的表现,并与现有LLM方法和人类设计进行了比较。总体而言,当以结构化的方式使用时,LLM可以有效地生成多样化的高质量布局。
Key Takeaways:
- 室内设计涉及选择物品并安排其布局以创造美观、实用且符合客户设计需求的和谐空间。
- 大型语言模型(LLM)在室内设计中有应用潜力。
- LLM尚不能生成完整的布局设计,但可通过系统查询生成物品列表和相关约束。
- LLM生成的信息被转化为设计布局图,然后使用约束优化设置生成最终布局。
- 算法在各种设计配置中的表现得到了评估,并与现有方法和人类设计进行了比较。
- LLM可以有效地生成多样化的高质量布局。
点此查看论文截图





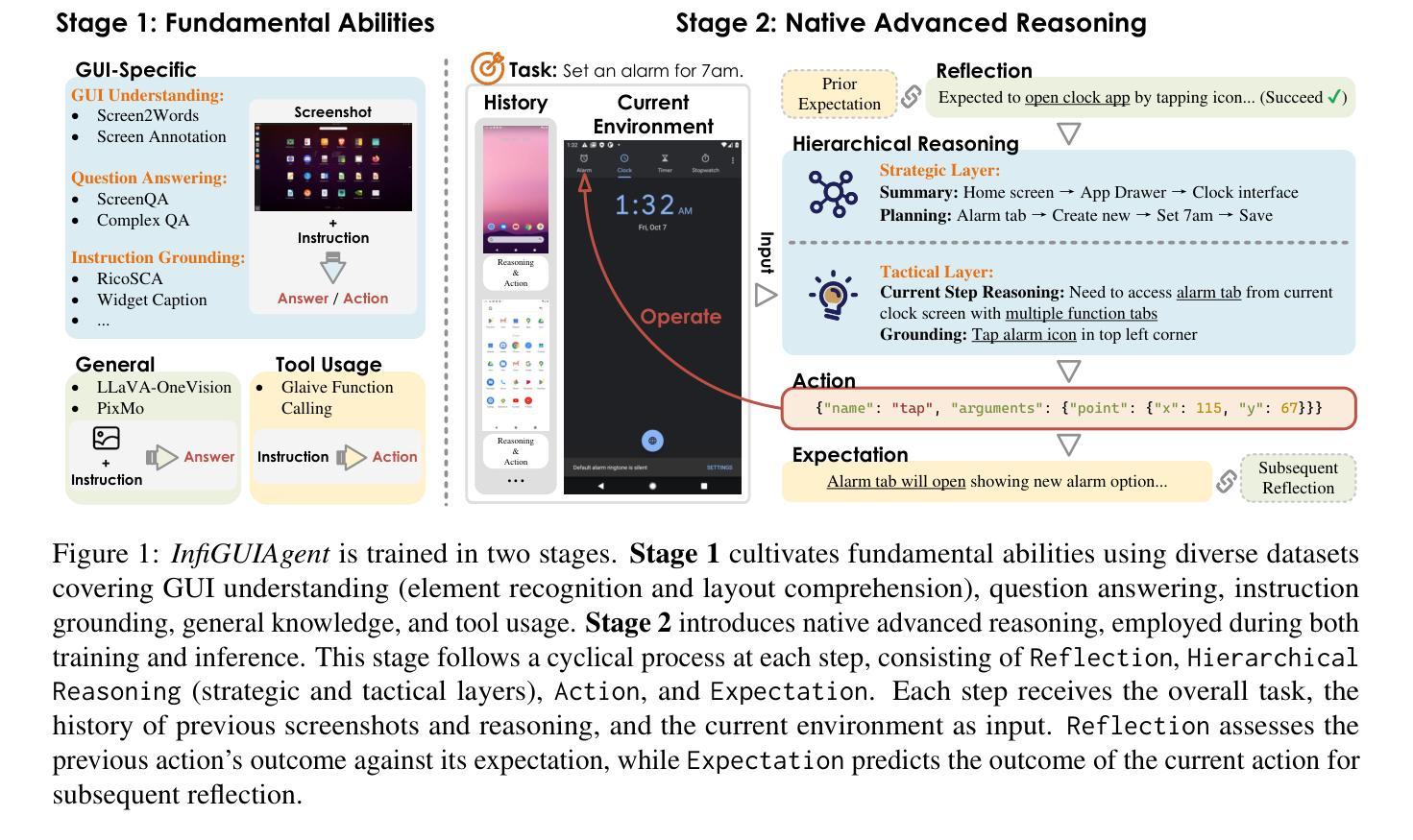
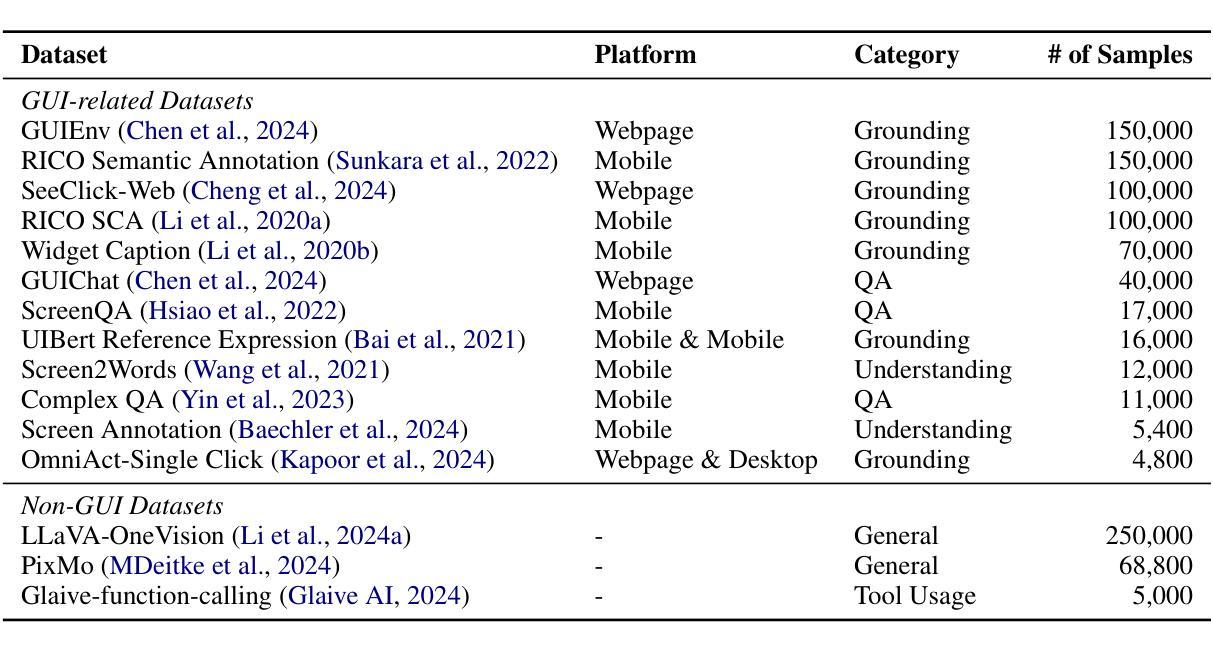
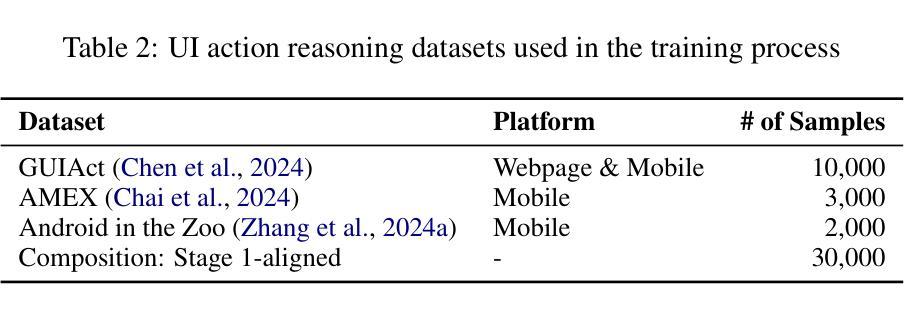
InfiGUIAgent: A Multimodal Generalist GUI Agent with Native Reasoning and Reflection
Authors:Yuhang Liu, Pengxiang Li, Zishu Wei, Congkai Xie, Xueyu Hu, Xinchen Xu, Shengyu Zhang, Xiaotian Han, Hongxia Yang, Fei Wu
Graphical User Interface (GUI) Agents, powered by multimodal large language models (MLLMs), have shown great potential for task automation on computing devices such as computers and mobile phones. However, existing agents face challenges in multi-step reasoning and reliance on textual annotations, limiting their effectiveness. We introduce \textit{InfiGUIAgent}, an MLLM-based GUI Agent trained with a two-stage supervised fine-tuning pipeline. Stage 1 enhances fundamental skills such as GUI understanding and grounding, while Stage 2 integrates hierarchical reasoning and expectation-reflection reasoning skills using synthesized data to enable native reasoning abilities of the agents. \textit{InfiGUIAgent} achieves competitive performance on several GUI benchmarks, highlighting the impact of native reasoning skills in enhancing GUI interaction for automation tasks. Resources are available at \url{https://github.com/Reallm-Labs/InfiGUIAgent}.
图形用户界面(GUI)代理,在多模态大型语言模型(MLLMs)的驱动下,已显示出在计算机和移动电话等计算设备上实现任务自动化的巨大潜力。然而,现有的代理面临多步推理和依赖文本注释的挑战,这限制了它们的有效性。我们介绍了基于MLLM的GUI代理\text{InfiGUIAgent},它通过两阶段监督微调管道进行训练。第一阶段增强基本能力,如GUI理解和定位能力;第二阶段利用合成数据集成分层推理和期望反映推理能力,以实现代理的固有推理能力。\text{InfiGUIAgent}在多个GUI基准测试中表现出良好的性能,突显了固有推理能力在提高GUI交互以完成自动化任务方面的作用。相关资源可通过以下网址获取:\url{https://github.com/Reallm-Labs/InfiGUIAgent}。
论文及项目相关链接
PDF 14 pages, 7 figures, work in progress
Summary
GUI用户界面(GUI)Agent由多模态大型语言模型(MLLMs)驱动,在自动完成计算机和移动电话等计算设备的任务方面显示出巨大潜力。然而,现有代理面临多步推理和依赖文本注释的挑战,限制了其有效性。本研究推出名为InfiGUIAgent的新型GUI Agent,该代理通过两个阶段进行监督精细调整管道进行训练。第一阶段提升理解GUI和基本接地技能,第二阶段集成层次推理和期望反射推理技能,并利用合成数据实现代理的本地推理能力。InfiGUIAgent在多个GUI基准测试中表现优异,突显了本地推理技能在提高自动化任务的GUI交互能力中的重要作用。GitHub资源库地址为:[链接地址](https://github.com/Reallm-Labs/InfiGUIAgent)。
Key Takeaways
- GUI用户界面(GUI)Agent在自动化任务中展现潜力。
- 多模态大型语言模型(MLLMs)驱动这些代理的能力显著。
- 当前GUI Agent面临多步推理和依赖文本注释的挑战。
- InfiGUIAgent是一种新型的GUI Agent,通过两个阶段监督精细调整管道进行训练。
- 第一阶段关注基本技能的增强,如理解GUI和基本接地技能。
- 第二阶段集成层次推理和期望反射推理技能,并利用合成数据实现本地推理能力。
点此查看论文截图

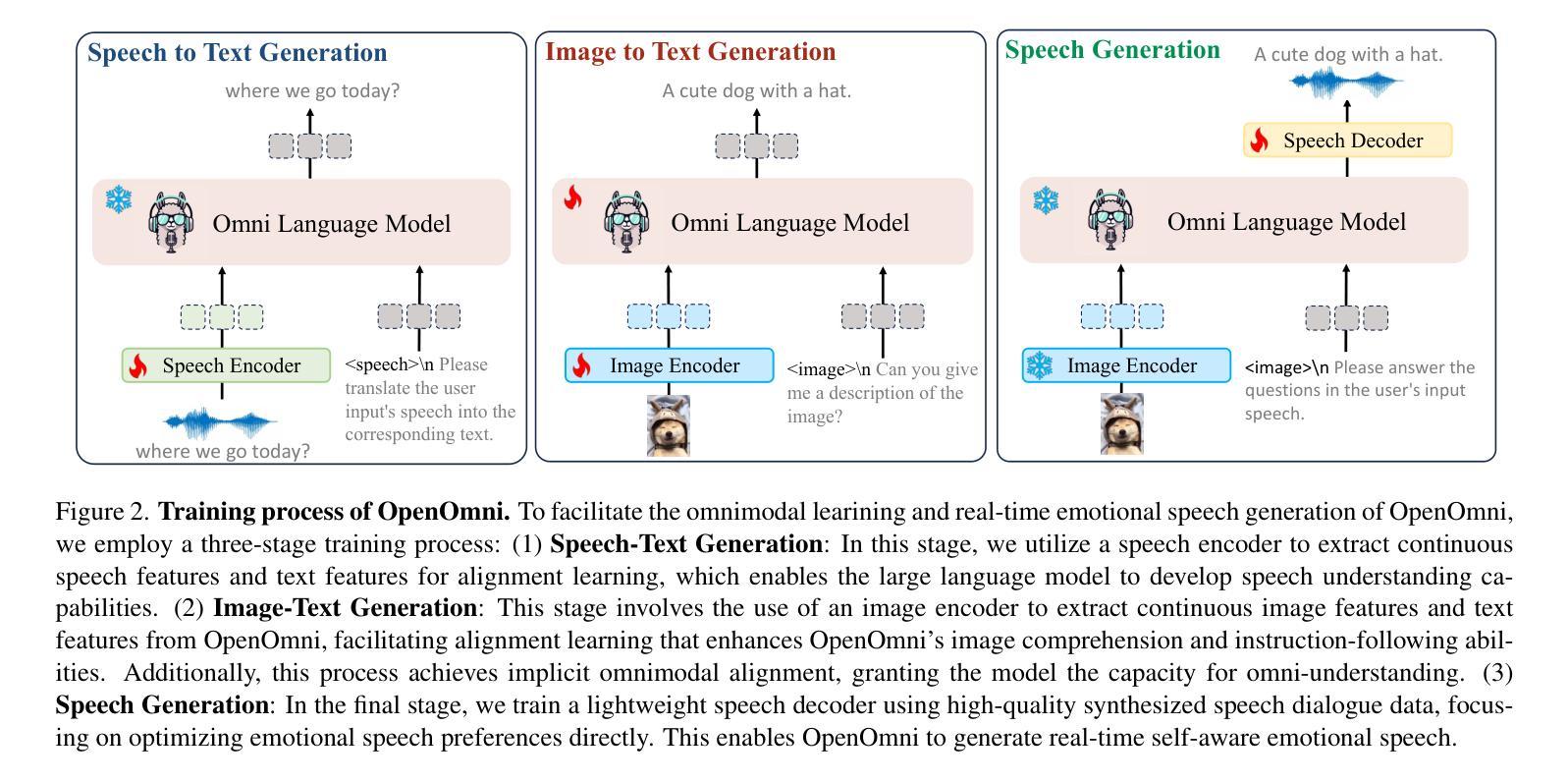
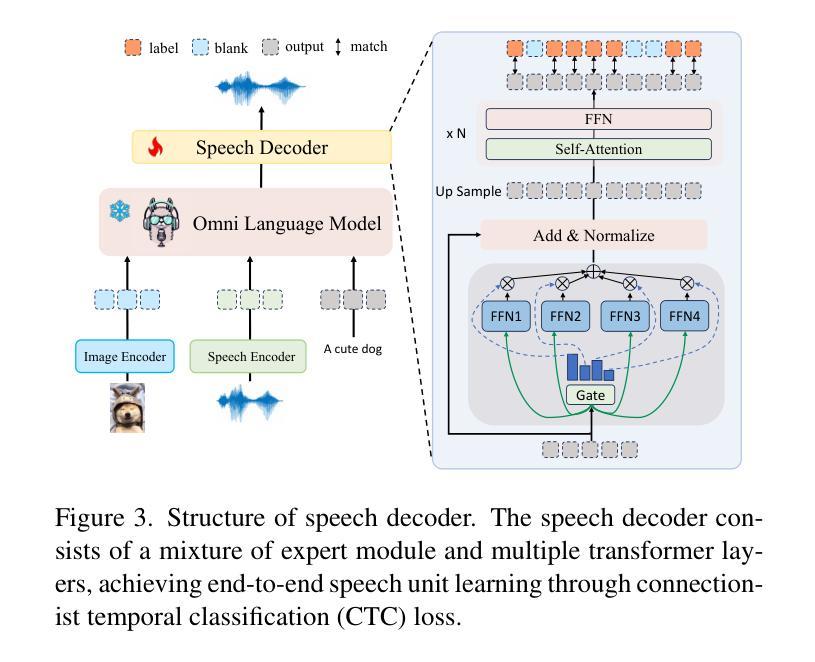
OpenOmni: Large Language Models Pivot Zero-shot Omnimodal Alignment across Language with Real-time Self-Aware Emotional Speech Synthesis
Authors:Run Luo, Ting-En Lin, Haonan Zhang, Yuchuan Wu, Xiong Liu, Min Yang, Yongbin Li, Longze Chen, Jiaming Li, Lei Zhang, Yangyi Chen, Hamid Alinejad-Rokny, Fei Huang
Recent advancements in omnimodal learning have been achieved in understanding and generation across images, text, and speech, though mainly within proprietary models. Limited omnimodal datasets and the inherent challenges associated with real-time emotional speech generation have hindered open-source progress. To address these issues, we propose openomni, a two-stage training method combining omnimodal alignment and speech generation to develop a state-of-the-art omnimodal large language model. In the alignment phase, a pre-trained speech model is further trained on text-image tasks to generalize from vision to speech in a (near) zero-shot manner, outperforming models trained on tri-modal datasets. In the speech generation phase, a lightweight decoder facilitates real-time emotional speech through training on speech tasks and preference learning. Experiments demonstrate that openomni consistently improves across omnimodal, vision-language, and speech-language evaluations, enabling natural, emotion-rich dialogues and real-time emotional speech generation.
尽管主要在专有模型内,多模态学习在图像、文本和语音的理解和生成方面取得了最新进展。然而,有限的多模态数据集和实时情感语音生成所固有的挑战阻碍了开源进展。为了解决这些问题,我们提出了openomni,这是一种结合多模态对齐和语音生成的两阶段训练方法,以开发先进的多模态大型语言模型。在对齐阶段,预训练的语音模型进一步在文本图像任务上进行训练,以(接近)零样本的方式从视觉推广到语音,优于在三元模态数据集上训练的模型。在语音生成阶段,一个轻量级的解码器通过语音任务和偏好学习进行训练,便于实时情感语音生成。实验表明,openomni在多模态、视觉语言和语音语言评估中均有所提高,可实现自然、情感丰富的对话和实时情感语音生成。
论文及项目相关链接
Summary
随着近期多模态学习在图像、文本和语音方面的理解与发展取得进步,主要集中在专有模型上。针对多模态数据集稀缺以及实时情绪语音生成面临的固有挑战,本文提出一种名为“openomni”的两阶段训练方法,通过多模态对齐和语音生成,以开发先进的多模态大型语言模型。首先进行对齐训练,在文本图像任务上进一步训练预训练语音模型,实现零样本或接近零样本的跨模态泛化能力,并超越三模态数据集训练的模型。其次进行语音生成训练,通过语音任务和偏好学习训练轻量级解码器,实现实时情绪语音生成。实验证明,openomni在多模态、视觉语言和语音语言评估中表现优异,可实现自然、情感丰富的对话和实时情绪语音生成。
Key Takeaways
列出如下要点作为关键收获点:
- Openomni是一个两阶段训练的多模态语言模型方法,用于实现先进的图像、文本和语音之间的理解和生成。
- 对齐阶段利用预训练的语音模型进行文本图像任务训练,实现了从视觉到语音的零样本泛化能力。
- 对比其他模型在三模态数据集上的训练结果,此方法表现出了出色的性能。
- 在语音生成阶段,通过轻量级解码器进行实时情绪语音生成训练。
- 该方法通过偏好学习优化实时情绪语音生成效果。
- 实验结果表明,openomni在多模态、视觉语言和语音语言评估中有优异表现。
点此查看论文截图

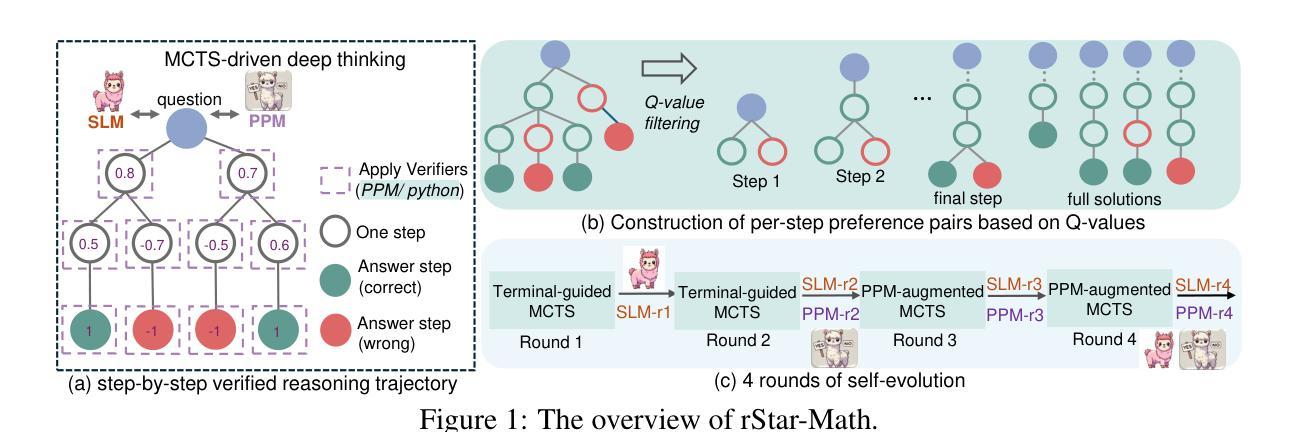
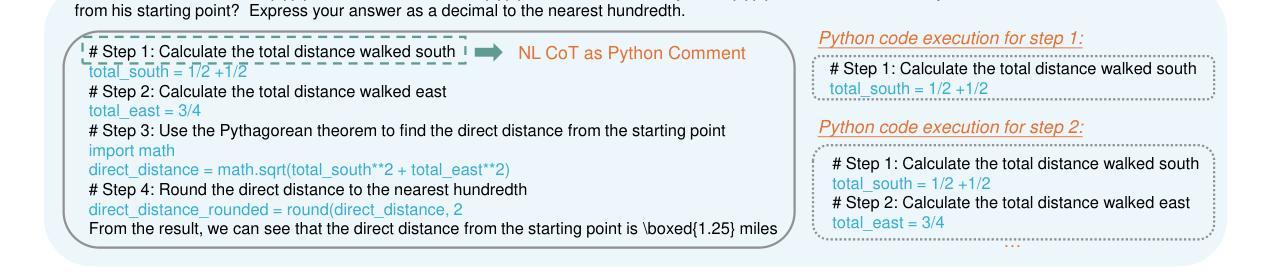
rStar-Math: Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking
Authors:Xinyu Guan, Li Lyna Zhang, Yifei Liu, Ning Shang, Youran Sun, Yi Zhu, Fan Yang, Mao Yang
We present rStar-Math to demonstrate that small language models (SLMs) can rival or even surpass the math reasoning capability of OpenAI o1, without distillation from superior models. rStar-Math achieves this by exercising “deep thinking” through Monte Carlo Tree Search (MCTS), where a math policy SLM performs test-time search guided by an SLM-based process reward model. rStar-Math introduces three innovations to tackle the challenges in training the two SLMs: (1) a novel code-augmented CoT data sythesis method, which performs extensive MCTS rollouts to generate step-by-step verified reasoning trajectories used to train the policy SLM; (2) a novel process reward model training method that avoids na"ive step-level score annotation, yielding a more effective process preference model (PPM); (3) a self-evolution recipe in which the policy SLM and PPM are built from scratch and iteratively evolved to improve reasoning capabilities. Through 4 rounds of self-evolution with millions of synthesized solutions for 747k math problems, rStar-Math boosts SLMs’ math reasoning to state-of-the-art levels. On the MATH benchmark, it improves Qwen2.5-Math-7B from 58.8% to 90.0% and Phi3-mini-3.8B from 41.4% to 86.4%, surpassing o1-preview by +4.5% and +0.9%. On the USA Math Olympiad (AIME), rStar-Math solves an average of 53.3% (8/15) of problems, ranking among the top 20% the brightest high school math students. Code and data will be available at https://github.com/microsoft/rStar.
我们推出rStar-Math,以证明小型语言模型(SLM)可以在无需高级模型蒸馏的情况下,与OpenAI o1的数学推理能力相抗衡,甚至实现超越。rStar-Math通过蒙特卡洛树搜索(MCTS)进行“深度思考”来实现这一点,其中数学策略SLM在测试时进行搜索,由基于SLM的流程奖励模型进行引导。rStar-Math针对训练两个SLM的挑战,提出了三项创新:(1)一种新型代码增强CoT数据合成方法,它执行大量的MCTS回合制模拟,以生成用于训练策略SLM的经过逐步验证的推理轨迹;(2)一种新型流程奖励模型训练方法,避免了简单的步骤级评分注释,从而产生了更有效的流程偏好模型(PPM);(3)一种自我进化方法,其中策略SLM和PPM从零开始构建,并通过迭代进化来提高推理能力。通过为747k数学问题合成数百万解决方案来进行四轮自我进化,rStar-Math推动了SLM的数学推理能力达到最新水平。在MATH基准测试中,它将Qwen2.5-Math-7B从58.8%提高到90.0%,将Phi3-mini-3.8B从41.4%提高到86.4%,超过了o1-preview的+4.5%和+0.9%。在美国数学奥林匹克竞赛(AIME)中,rStar-Math平均解决了8/15的问题,位列前20%,相当于顶尖高中生数学水平。相关代码和数据将在https://github.com/microsoft/rStar上发布。
论文及项目相关链接
Summary
rStar-Math展示了小型语言模型(SLM)可以通过Monte Carlo树搜索(MCTS)的“深度思考”方式,在不需要高级模型蒸馏的情况下,达到甚至超越OpenAI在数学推理方面的能力。rStar-Math通过三项创新解决训练两个SLM所面临的挑战:一种新型的代码增强CoT数据合成方法、一种新型过程奖励模型训练方法以及一种自我进化策略。经过多轮自我进化,以及为747k数学问题合成数百万解决方案,rStar-Math将SLM的数学推理能力提升至最新水平。在MATH基准测试中,其将Qwen2.5-Math-7B与Phi3-mini-3.8B的表现从之前的百分比提升到了较高的准确率。此外,它在USA Math Olympiad(AIME)上平均解决了8个问题中的大约一半,表现优于大多数高中生。更多信息和资源可在GitHub的rStar项目中获取。
Key Takeaways
- rStar-Math展示了小型语言模型在数学推理方面的强大能力,可匹敌甚至超越OpenAI o1模型。
- rStar-Math通过Monte Carlo树搜索实现深度思考,无需高级模型蒸馏。
- rStar-Math引入三项创新来解决训练语言模型的挑战,包括数据合成、过程奖励模型训练和自我进化策略。
- 通过自我进化与大量合成解决方案,rStar-Math提升了语言模型的数学推理能力至最新水平。
- 在MATH基准测试中,rStar-Math显著提高了两个模型的性能表现。
- rStar-Math在MATH Olympiad上表现优异,平均解决半数以上问题,展现出高水准的数学推理能力。
点此查看论文截图

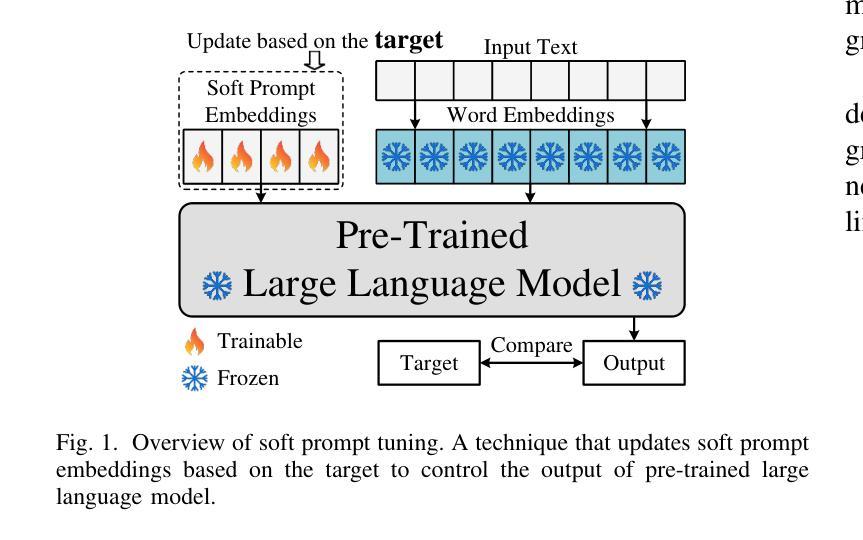
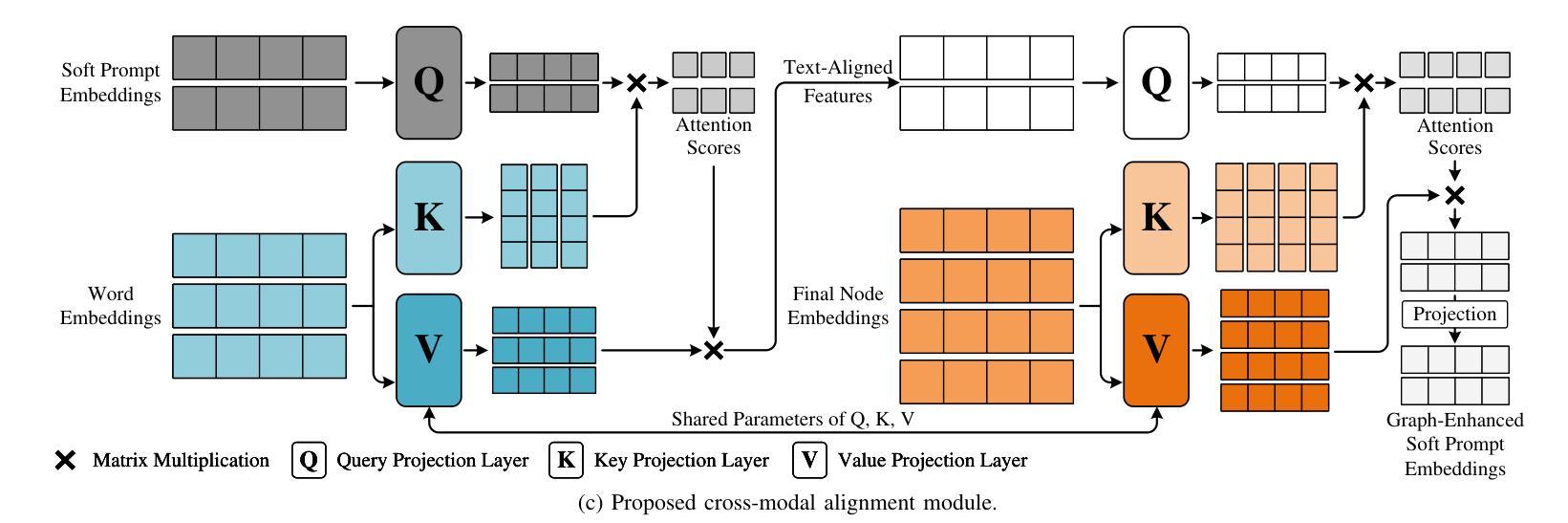
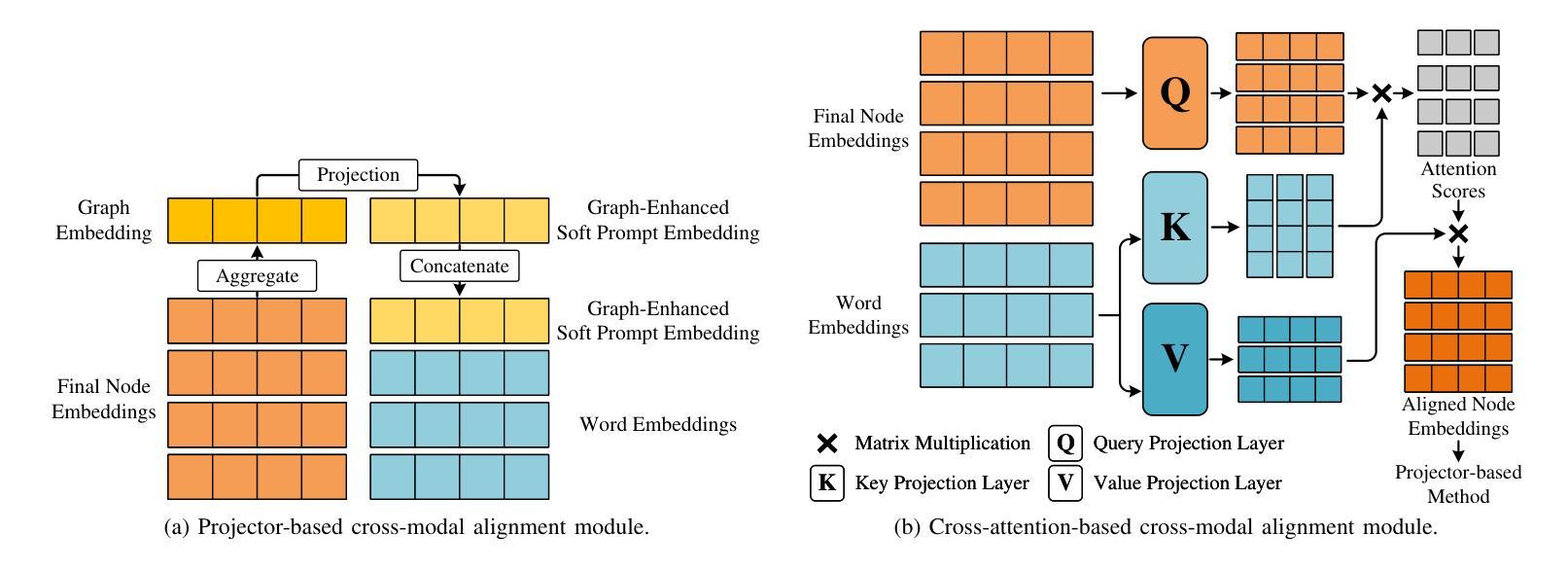
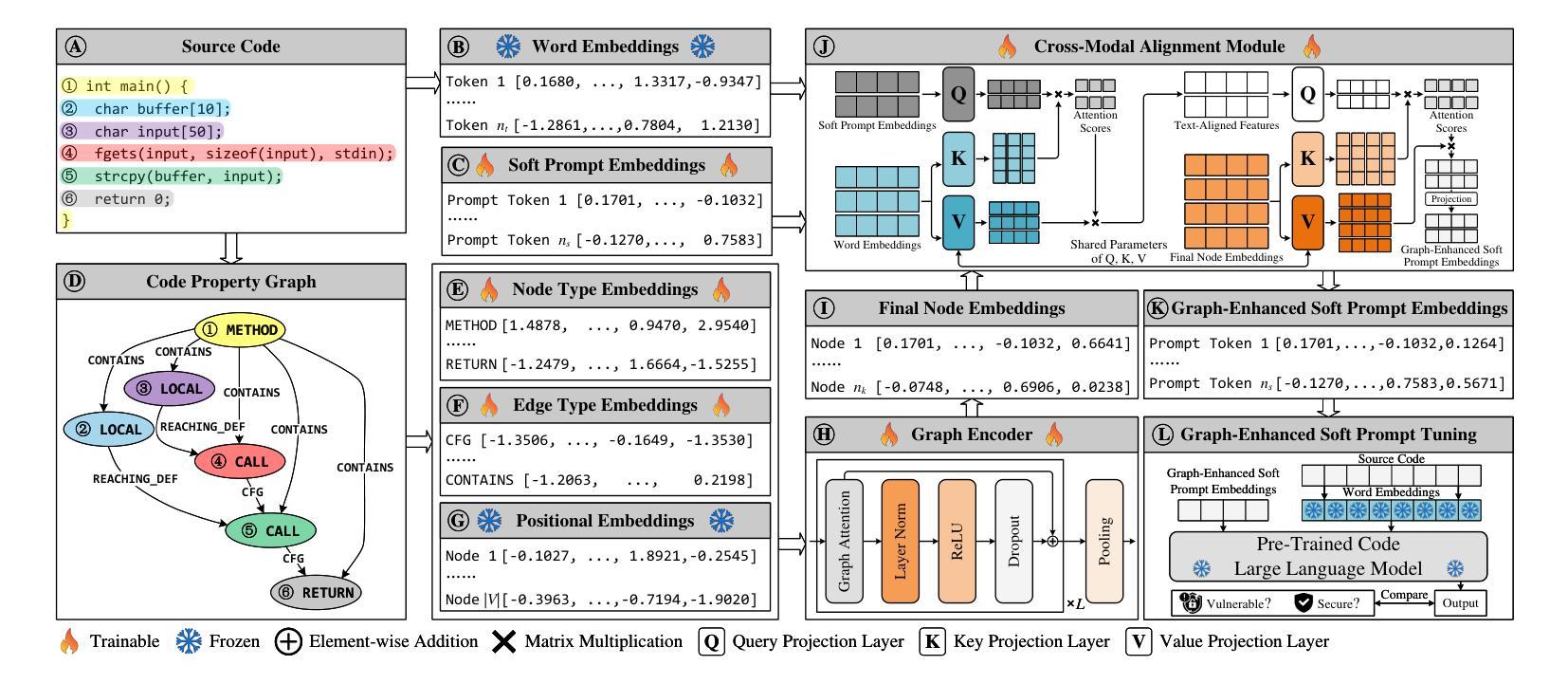
CGP-Tuning: Structure-Aware Soft Prompt Tuning for Code Vulnerability Detection
Authors:Ruijun Feng, Hammond Pearce, Pietro Liguori, Yulei Sui
Large language models (LLMs) have been proposed as powerful tools for detecting software vulnerabilities, where task-specific fine-tuning is typically employed to provide vulnerability-specific knowledge to the LLMs for this purpose. However, traditional full-parameter fine-tuning is inefficient for modern, complex LLMs, which contain billions of parameters. Soft prompt tuning has been suggested as a more efficient alternative for fine-tuning LLMs in general cases. However, pure soft prompt tuning treats source code as plain text, losing structural information inherent in source code. Meanwhile, graph-enhanced soft prompt tuning methods, which aim to address this issue, are unable to preserve the rich semantic information within code graphs, as they are primarily designed for general graph-related tasks and focus more on adjacency information. They also fail to ensure computational efficiency while accounting for graph-text interactions. This paper, therefore, introduces a new code graph-enhanced, structure-aware soft prompt tuning method for vulnerability detection, referred to as CGP-Tuning. It employs innovative type-aware embeddings to capture the rich semantic information within code graphs, along with a novel and efficient cross-modal alignment module that achieves linear computational cost while incorporating graph-text interactions. The proposed CGP-Tuning is evaluated on the latest DiverseVul dataset and the most recent open-source code LLMs, CodeLlama and CodeGemma. Experimental results demonstrate that CGP-Tuning outperforms the best state-of-the-art method by an average of 3.5 percentage points in accuracy, without compromising its vulnerability detection capabilities for long source code.
大型语言模型(LLM)已被提议作为检测软件漏洞的强大工具。通常,会采用特定任务的微调(fine-tuning)来为LLM提供针对漏洞的特定知识。然而,对于包含数十亿参数的现代复杂LLM,传统全参数微调是不高效的。一般情况下,软提示调整(soft prompt tuning)被建议为一种更高效的LLM微调替代方案。然而,纯软提示调整将源代码视为纯文本,从而失去了源代码中固有的结构信息。同时,旨在解决这个问题的图增强软提示调整方法无法保留代码图中的丰富语义信息,因为它们主要针对一般图相关任务而设计,更侧重于邻接信息。它们也未能确保计算效率,同时考虑图文交互。因此,本文介绍了一种新的用于漏洞检测的代码图增强、结构感知软提示调整方法,称为CGP-Tuning。它采用创新的类型感知嵌入来捕获代码图中的丰富语义信息,以及一个高效的新型跨模态对齐模块,该模块在计算成本为线性的同时实现了图文交互。提出的CGP-Tuning在最新的DiverseVul数据集和最新的开源代码LLM(CodeLlama和CodeGemma)上进行了评估。实验结果表明,CGP-Tuning在准确率上平均优于现有最佳方法3.5个百分点,同时对于长源代码的漏洞检测能力不妥协。
论文及项目相关链接
PDF 14 pages, 5 figures
Summary
大型语言模型(LLM)在检测软件漏洞方面具有潜力,通常通过特定任务微调来提供漏洞特定知识。然而,对于现代复杂的LLM,传统全参数微调效率低下。软提示调作为一种更高效的LLM微调方法被提出,但纯软提示调将源代码视为纯文本,丢失了源代码的内在结构信息。本文提出了一种新的代码图增强结构感知软提示调方法,称为CGP-Tuning,用于漏洞检测。它采用类型感知嵌入捕捉代码图中的丰富语义信息,以及高效跨模态对齐模块,实现线性计算成本并融入图文本交互。在最新的DiverseVul数据集和开源代码LLM上的实验结果表明,CGP-Tuning在准确率上平均超出最佳现有方法3.5个百分点,且对长源代码的漏洞检测能力不受影响。
Key Takeaways
- LLMs具备检测软件漏洞的潜力,通过特定任务微调提供漏洞特定知识。
- 传统全参数微调对于现代复杂的LLM效率低下。
- 软提示调方法被视为更高效的LLM微调替代方案,但存在处理源代码时丢失结构信息的问题。
- CGP-Tuning是一种新的代码图增强结构感知软提示调方法,旨在解决上述问题。
- CGP-Tuning采用类型感知嵌入和高效跨模态对齐模块。
- CGP-Tuning在最新的数据集和LLM上表现优异,准确率超过现有方法。
点此查看论文截图

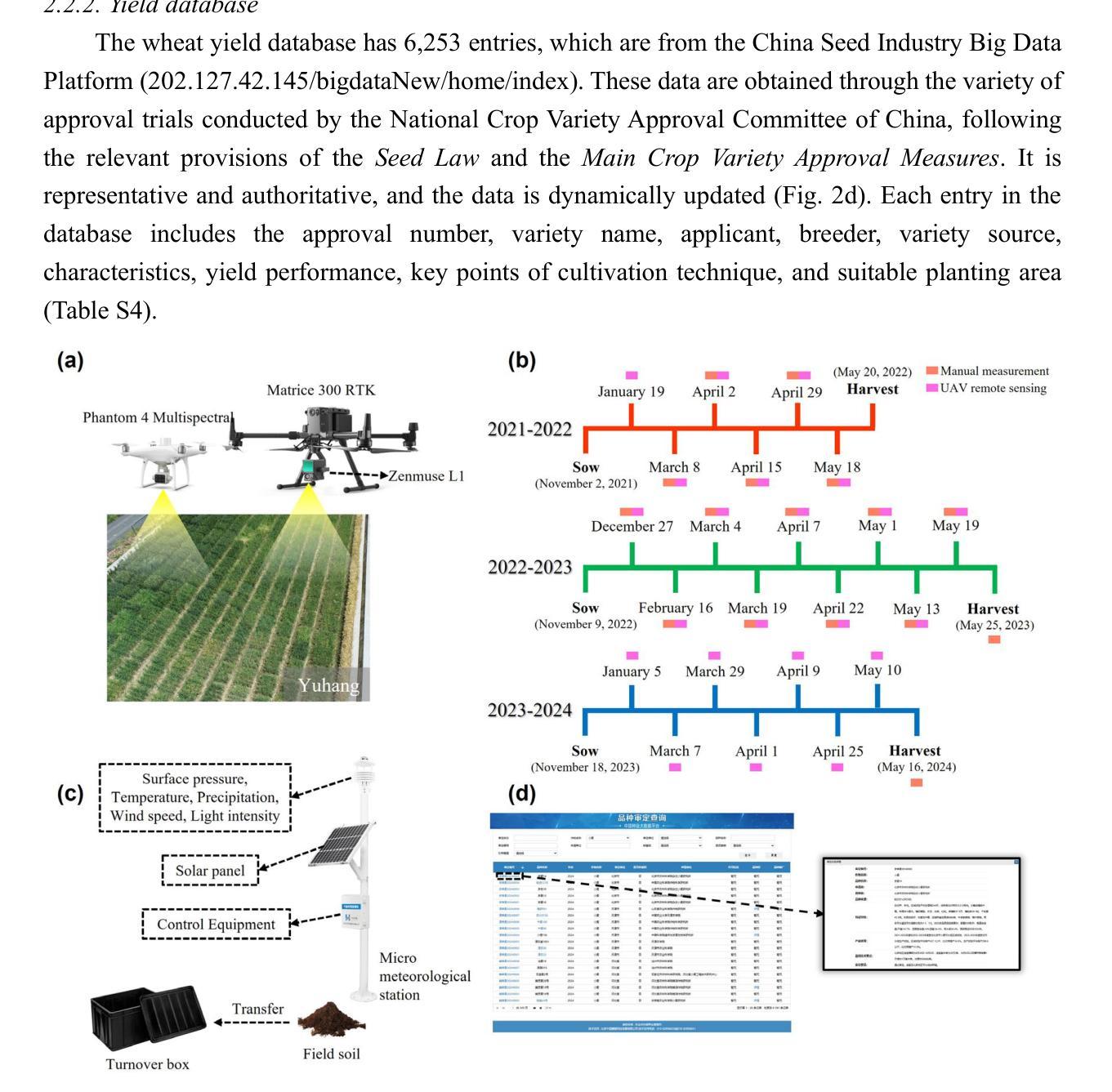
Integrating remote sensing data assimilation, deep learning and large language model for interactive wheat breeding yield prediction
Authors:Guofeng Yang, Nanfei Jin, Wenjie Ai, Zhonghua Zheng, Yuhong He, Yong He
Yield is one of the core goals of crop breeding. By predicting the potential yield of different breeding materials, breeders can screen these materials at various growth stages to select the best performing. Based on unmanned aerial vehicle remote sensing technology, high-throughput crop phenotyping data in breeding areas is collected to provide data support for the breeding decisions of breeders. However, the accuracy of current yield predictions still requires improvement, and the usability and user-friendliness of yield forecasting tools remain suboptimal. To address these challenges, this study introduces a hybrid method and tool for crop yield prediction, designed to allow breeders to interactively and accurately predict wheat yield by chatting with a large language model (LLM). First, the newly designed data assimilation algorithm is used to assimilate the leaf area index into the WOFOST model. Then, selected outputs from the assimilation process, along with remote sensing inversion results, are used to drive the time-series temporal fusion transformer model for wheat yield prediction. Finally, based on this hybrid method and leveraging an LLM with retrieval augmented generation technology, we developed an interactive yield prediction Web tool that is user-friendly and supports sustainable data updates. This tool integrates multi-source data to assist breeding decision-making. This study aims to accelerate the identification of high-yield materials in the breeding process, enhance breeding efficiency, and enable more scientific and smart breeding decisions.
产量是作物育种的核心目标之一。通过预测不同育种材料的潜在产量,育种家可以在各个生长阶段对这些材料进行筛选,以选择表现最佳的品种。基于无人机遥感技术,收集育种区的高通量作物表型数据,为育种家的育种决策提供了数据支持。然而,当前产量预测的准确度仍有待提高,产量预测工具的使用性和友好性也不尽如人意。本研究为了解决这些挑战,引入了一种用于作物产量预测的混合方法和工具,设计该工具的目的是让育种家通过与大语言模型(LLM)聊天,以交互方式准确预测小麦产量。首先,使用新设计的数据同化算法将叶面积指数同化到WOFOST模型中。然后,将同化过程选择的输出与遥感反演结果相结合,用于驱动时间序列时间融合变压器模型进行小麦产量预测。最后,基于这种混合方法,并利用具有检索增强生成技术的大语言模型(LLM),我们开发了一个交互式的产量预测网络工具,该工具友好且支持可持续数据更新。该工具整合了多源数据,辅助育种决策。本研究旨在加快育种过程中高产量材料的识别,提高育种效率,并做出更科学和智能的育种决策。
论文及项目相关链接
摘要
基于无人机遥感技术的高通量作物表型数据为育种决策提供了数据支持。本研究引入了一种混合方法和工具,旨在通过大型语言模型(LLM)与育种者进行交互,准确预测小麦产量。该工具采用新的数据同化算法将叶片指数融入WOFOST模型中,利用同化过程和遥感反演结果驱动时间序列时序融合器模型预测小麦产量。此外,还开发了一个交互式在线产量预测工具,整合多源数据辅助育种决策,旨在加速育种过程中高产材料的识别,提高育种效率,使育种决策更加科学和智能化。
关键见解
- 利用无人机遥感技术收集育种区域的高通量作物表型数据,为育种决策提供支持。
- 当前产量预测的准确性和用户友好性有待提高。
- 引入混合方法,通过大型语言模型(LLM)实现与育种者的交互式产量预测。
- 采用新的数据同化算法将叶片指数融入WOFOST模型以提高预测准确性。
- 结合同化过程和遥感反演结果,利用时间序列融合器模型进行小麦产量预测。
- 开发了一个用户友好的在线产量预测工具,支持可持续数据更新,整合多源数据辅助育种决策。
点此查看论文截图



Hidden Entity Detection from GitHub Leveraging Large Language Models
Authors:Lu Gan, Martin Blum, Danilo Dessi, Brigitte Mathiak, Ralf Schenkel, Stefan Dietze
Named entity recognition is an important task when constructing knowledge bases from unstructured data sources. Whereas entity detection methods mostly rely on extensive training data, Large Language Models (LLMs) have paved the way towards approaches that rely on zero-shot learning (ZSL) or few-shot learning (FSL) by taking advantage of the capabilities LLMs acquired during pretraining. Specifically, in very specialized scenarios where large-scale training data is not available, ZSL / FSL opens new opportunities. This paper follows this recent trend and investigates the potential of leveraging Large Language Models (LLMs) in such scenarios to automatically detect datasets and software within textual content from GitHub repositories. While existing methods focused solely on named entities, this study aims to broaden the scope by incorporating resources such as repositories and online hubs where entities are also represented by URLs. The study explores different FSL prompt learning approaches to enhance the LLMs’ ability to identify dataset and software mentions within repository texts. Through analyses of LLM effectiveness and learning strategies, this paper offers insights into the potential of advanced language models for automated entity detection.
从非结构化数据源构建知识库时,实体识别是一项重要任务。虽然实体检测方法大多依赖于大量的训练数据,但大型语言模型(LLM)开辟了依赖零样本学习(ZSL)或少样本学习(FSL)的方法的道路,利用LLM在预训练期间获得的能力。特别地,在无法使用大规模训练数据的专业场景中,ZSL/FSL带来了新的机会。本文遵循这一最新趋势,探讨了利用大型语言模型(LLM)在GitHub仓库的文本内容中自动检测数据集和软件工具的潜力。虽然现有方法只关注命名实体,但本研究旨在通过引入仓库和在线中心等资源(其中实体也以URL表示)来扩大范围。该研究探索了不同的FSL提示学习方法,以提高LLM在仓库文本中识别数据集和软件提及的能力。通过对LLM的有效性和学习策略的分析,本文提供了对高级语言模型在自动实体检测方面的潜力的见解。
论文及项目相关链接
PDF accepted by KDD2024 workshop DL4KG
摘要
命名实体识别是从非结构化数据源构建知识库时的重要任务。传统的实体检测方法主要依赖于大量的训练数据,然而,大型语言模型(LLM)的出现为那些依靠零样本学习(ZSL)或少样本学习(FSL)的方法铺平了道路。特别是当大规模训练数据无法获取时,ZSL/FSL显得尤为重要。本文遵循这一最新趋势,探讨了利用大型语言模型(LLM)在GitHub存储库中自动检测数据集和软件的技术潜力。现有的方法主要集中在命名实体上,而本研究旨在通过引入资源(如存储库和在线中心),其中实体也由URL表示,从而扩大范围。该研究探索了不同的FSL提示学习方法,以提高LLM在存储库文本中识别数据集和软件提及的能力。通过对LLM的效果和学习策略的分析,本文提供了高级语言模型在自动实体检测方面的潜力的见解。
要点摘要
- 大型语言模型(LLMs)在知识库构建中起到重要作用,特别是在零样本学习(ZSL)和少样本学习(FSL)环境下。
- 当大规模训练数据不可获取时,LLMs的潜力在特殊场景中尤为突出。
- 现有方法主要关注命名实体的识别,而本研究扩展了这一范围,考虑了包括URL在内的其他资源表示实体。
- 本研究探讨了不同的FSL提示学习方法以增强LLM识别数据集和软件提及的能力。
- 通过GitHub存储库文本进行实体检测是一个新颖且富有挑战性的研究领域。
- LLMs在自动实体检测方面的潜力巨大,特别是在处理复杂的文本数据时。
点此查看论文截图



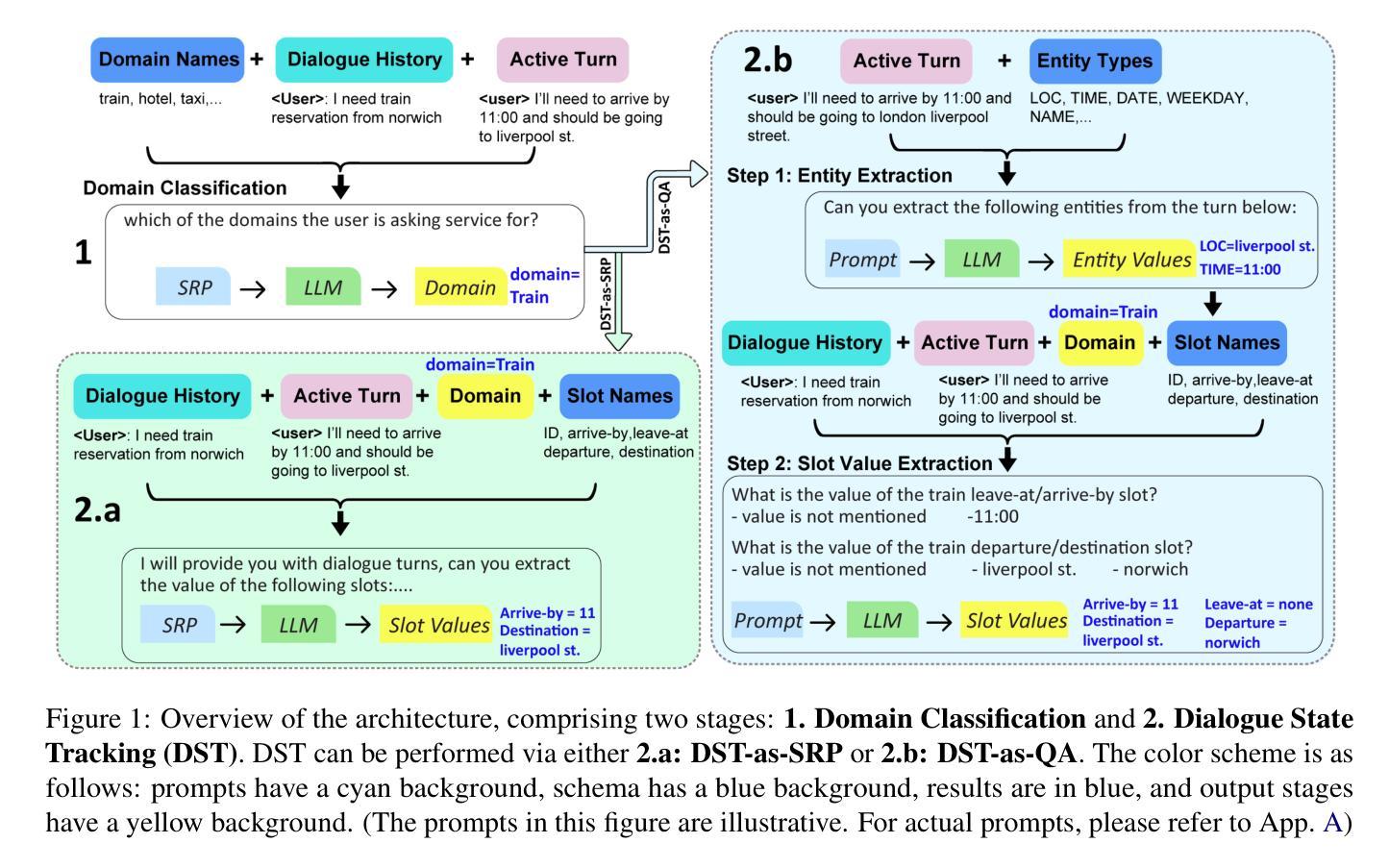
A Zero-Shot Open-Vocabulary Pipeline for Dialogue Understanding
Authors:Abdulfattah Safa, Gözde Gül Şahin
Dialogue State Tracking (DST) is crucial for understanding user needs and executing appropriate system actions in task-oriented dialogues. Majority of existing DST methods are designed to work within predefined ontologies and assume the availability of gold domain labels, struggling with adapting to new slots values. While Large Language Models (LLMs)-based systems show promising zero-shot DST performance, they either require extensive computational resources or they underperform existing fully-trained systems, limiting their practicality. To address these limitations, we propose a zero-shot, open-vocabulary system that integrates domain classification and DST in a single pipeline. Our approach includes reformulating DST as a question-answering task for less capable models and employing self-refining prompts for more adaptable ones. Our system does not rely on fixed slot values defined in the ontology allowing the system to adapt dynamically. We compare our approach with existing SOTA, and show that it provides up to 20% better Joint Goal Accuracy (JGA) over previous methods on datasets like Multi-WOZ 2.1, with up to 90% fewer requests to the LLM API.
对话状态跟踪(DST)对于理解用户需求和在执行任务导向型对话中执行适当的系统操作至关重要。现有的大多数DST方法都是为预定义的类设计工作的,并假定有黄金领域标签可用,难以适应新的插槽值。虽然基于大型语言模型(LLM)的系统显示出有前景的零射击DST性能,但它们要么需要大量的计算资源,要么它们的表现低于现有的完全训练的系统,从而限制了其实用性。为了解决这些局限性,我们提出了一种零射、开放词汇的系统,它将领域分类和DST集成在一个单一的管道中。我们的方法包括将DST重新表述为一个问答任务,以供能力较差的模型使用,并为适应性更强的模型使用自我完善提示。我们的系统不依赖于本体论中定义的固定插槽值,允许系统动态适应。我们将我们的方法与现有的最佳技术进行比较,并证明它在Multi-WOZ 2.1等数据集上提供了高达20%的联合目标准确率(JGA),而且对LLM API的请求减少了高达90%。
论文及项目相关链接
摘要
对话状态追踪(DST)在任务导向型对话中理解用户需求并执行适当系统操作至关重要。现有的DST方法大多在预设的本体论内设计,并假定黄金领域标签的可用性,难以适应新槽位值。大型语言模型(LLM)为基础的系统展现出有前景的零样本DST性能,但它们需要庞大的计算资源或性能低于现有的完全训练系统,限制了实用性。为解决这个问题,我们提出了一个零样本、开放词汇的系统,将领域分类和DST整合在一个单一管道中。我们的方法包括将DST重新构建为对较弱模型的问题回答任务,并为更灵活的模型采用自我修正提示。我们的系统不依赖于本体论中定义的固定槽值,使系统能够动态适应。我们将方法与现有最佳技术进行了比较,并证明在Multi-WOZ 2.1等数据集上,与以前的方法相比,联合目标准确率(JGA)提高了高达20%,对LLM API的请求减少了高达90%。
关键见解
- 对话状态追踪(DST)在任务导向对话中很重要,需要理解用户需求并实施相应系统操作。
- 现有DST方法大多基于预设本体论设计,难以适应新槽位值。
- 大型语言模型(LLM)在零样本DST性能上表现有前景,但需要大量计算资源或性能可能低于完全训练的系统。
- 提出了一种零样本、开放词汇的系统,集成领域分类和DST在一个单一管道中。
- 将DST重新构建为问题回答任务,适用于较弱模型。
- 采用自我修正提示,适应更灵活的模型。
- 系统不依赖固定的槽位值,能够动态适应。在Multi-WOZ 2.1数据集上,与以前的方法相比,联合目标准确率提高了高达20%,对LLM API的请求减少了高达90%。
点此查看论文截图

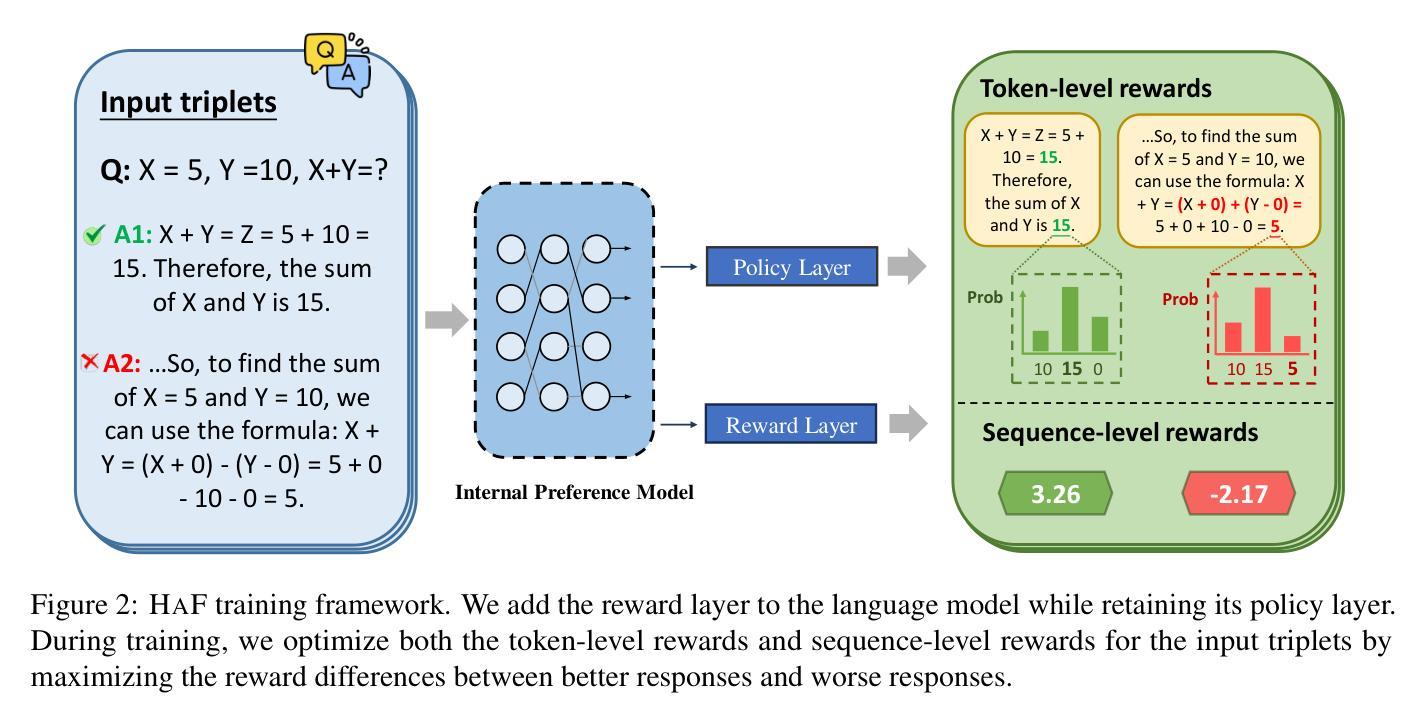
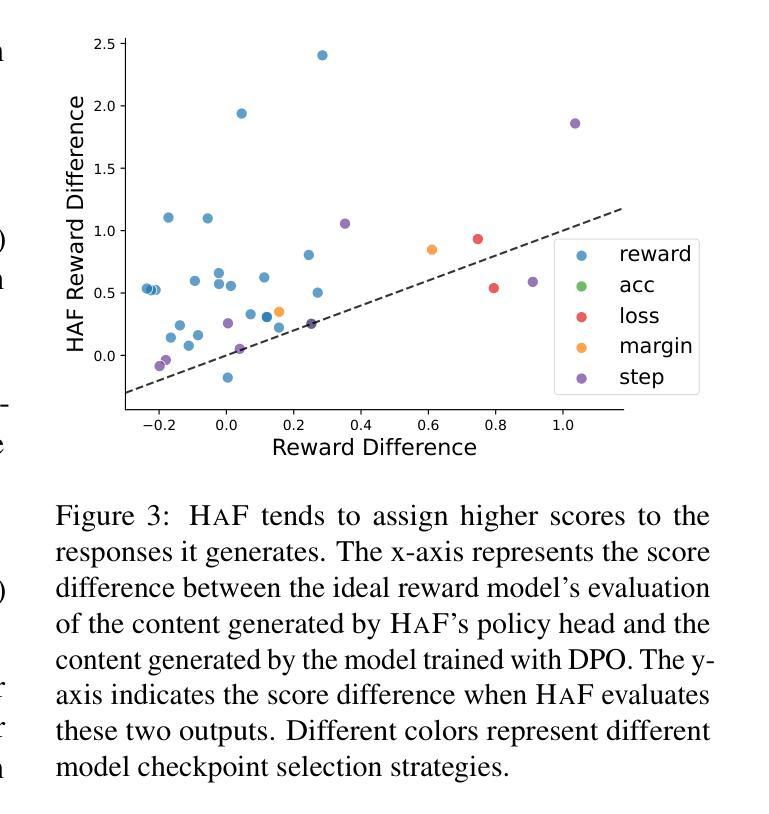
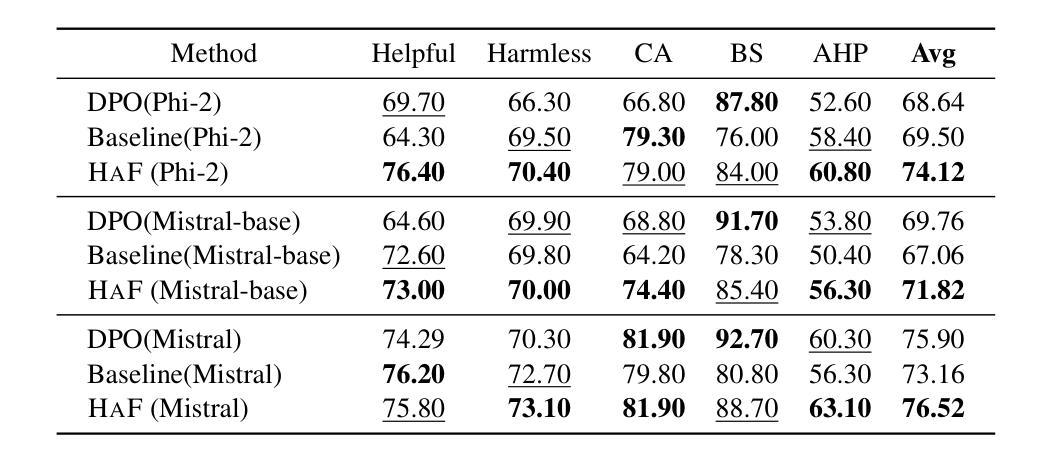
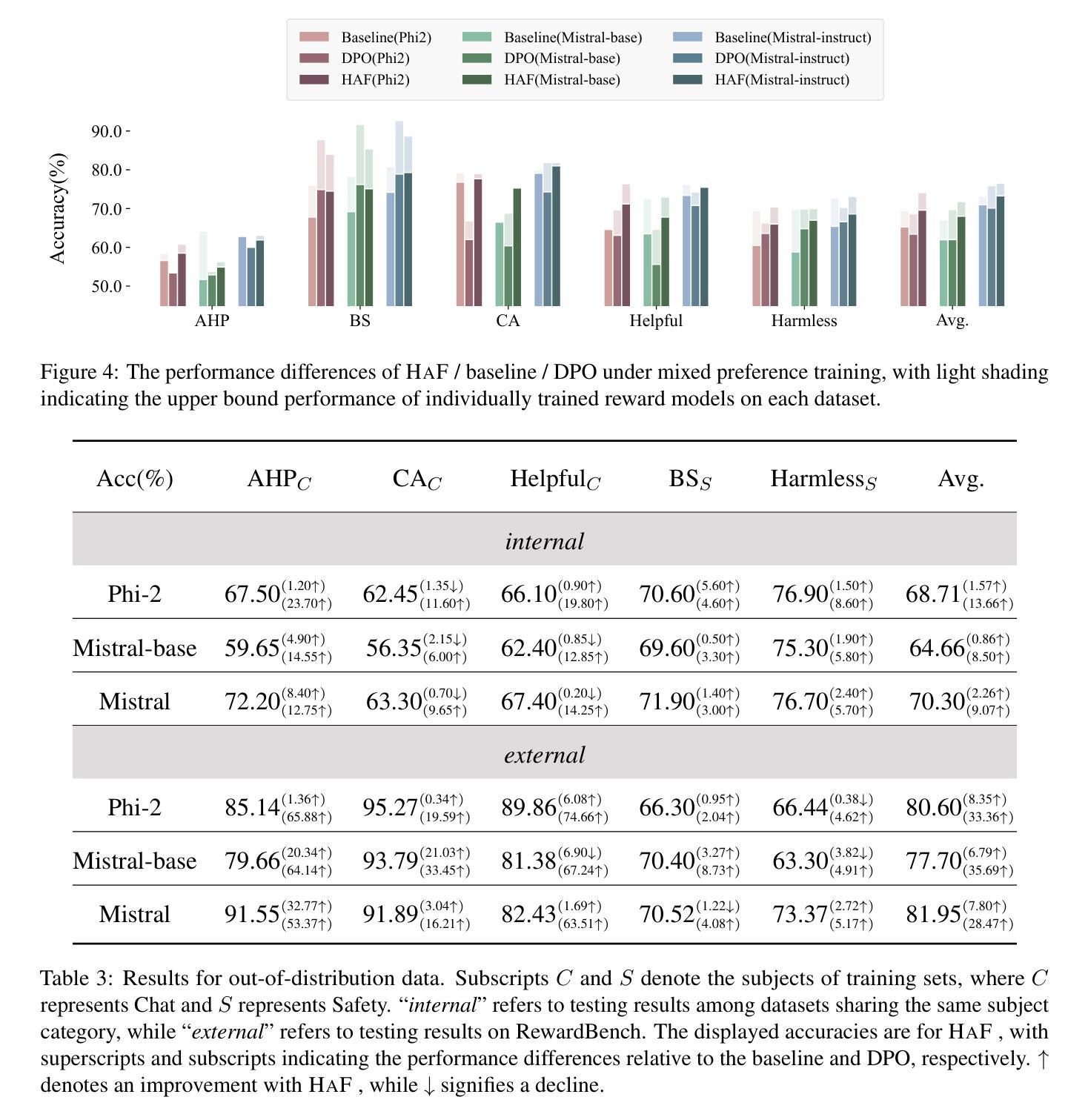
HAF-RM: A Hybrid Alignment Framework for Reward Model Training
Authors:Shujun Liu, Xiaoyu Shen, Yuhang Lai, Siyuan Wang, Shengbin Yue, Zengfeng Huang, Xuanjing Huang, Zhongyu Wei
The reward model has become increasingly important in alignment, assessment, and data construction for large language models (LLMs). Most existing researchers focus on enhancing reward models through data improvements, following the conventional training framework for reward models that directly optimizes the predicted rewards. In this paper, we propose a hybrid alignment framework HaF-RM for reward model training by introducing an additional constraint on token-level policy probabilities in addition to the reward score. It can simultaneously supervise the internal preference model at the token level and optimize the mapping layer of the reward model at the sequence level. Experiment results on five datasets sufficiently show the validity and effectiveness of our proposed hybrid framework for training a high-quality reward model. By decoupling the reward modeling procedure and incorporating hybrid supervision, our HaF-RM framework offers a principled and effective approach to enhancing the performance and alignment of reward models, a critical component in the responsible development of powerful language models. We release our code at https://haf-rm.github.io.
奖励模型在大规模语言模型(LLM)的对齐、评估和数据构建中变得越来越重要。大多数现有研究人员主要通过数据改进来优化奖励模型,遵循传统的奖励模型训练框架,直接优化预测的奖励。在本文中,我们提出了一种用于奖励模型训练的混合对齐框架HaF-RM,除了奖励分数之外,还引入了token级策略概率的额外约束。它可以同时监督token级别的内部偏好模型,并优化序列级别的奖励模型的映射层。在五个数据集上的实验结果表明,我们提出的混合框架用于训练高质量奖励模型是有效和高效的。通过解耦奖励建模过程并融入混合监督,我们的HaF-RM框架提供了一种有原则且有效的方法来提高奖励模型的性能和对齐性,这是强大语言模型负责任发展的重要组成部分。我们将在https://haf-rm.github.io发布我们的代码。
论文及项目相关链接
Summary
本文提出一种名为HaF-RM的混合对齐框架,用于训练大型语言模型的奖励模型。该框架在传统的奖励模型训练框架的基础上,引入了额外的标记级策略概率约束,可以同时监督内部偏好模型的标记级优化和奖励模型的序列级映射层优化。实验结果表明,该混合框架能有效提高奖励模型的质量和性能。
Key Takeaways
- 奖励模型在大语言模型中对齐、评估和数据处理方面变得日益重要。
- 现有研究主要通过数据改进来优化奖励模型。
- 本文提出一种名为HaF-RM的混合对齐框架,用于训练奖励模型。
- HaF-RM框架引入额外的标记级策略概率约束。
- 该框架能同时监督内部偏好模型的标记级优化和奖励模型的序列级映射层优化。
- 在五个数据集上的实验验证了HaF-RM框架的有效性和高效性。
点此查看论文截图


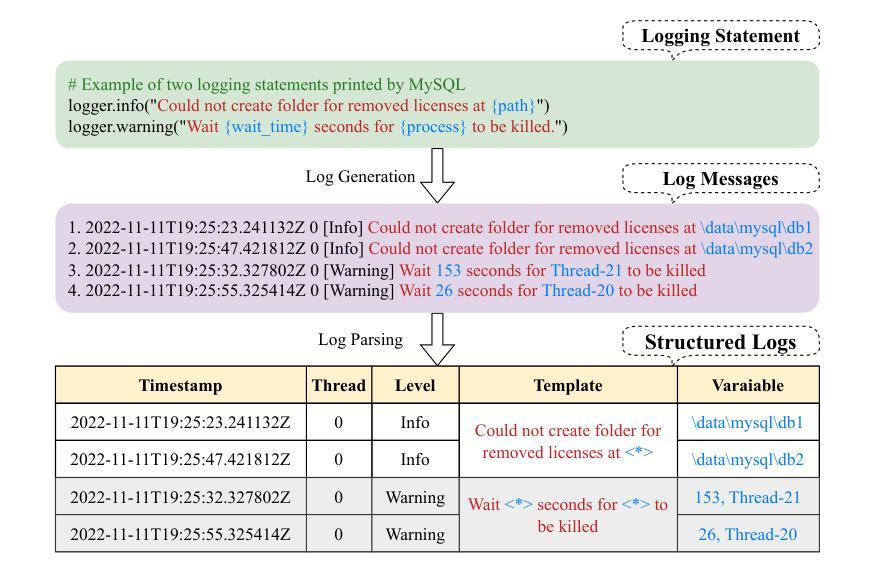
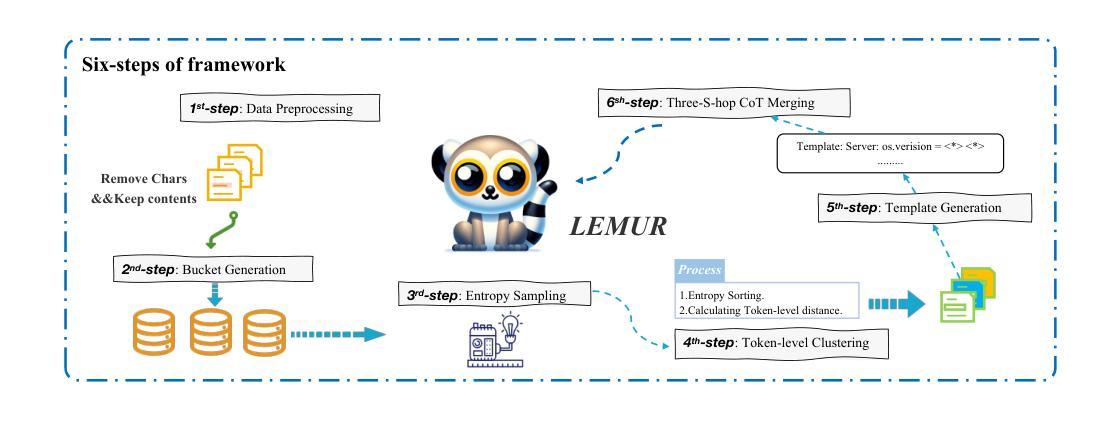
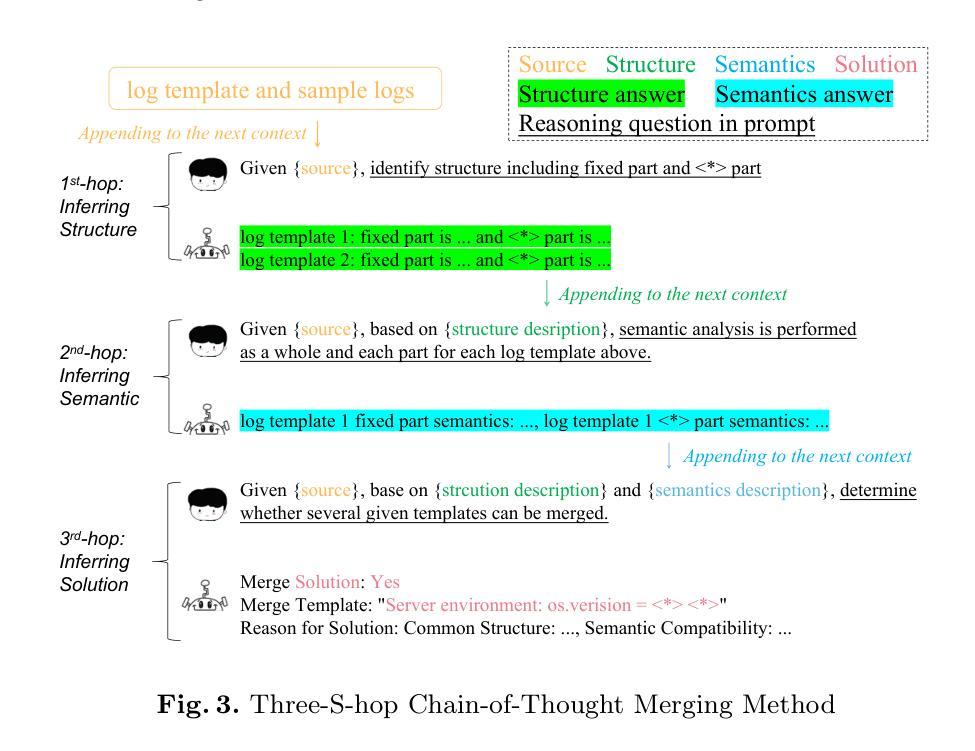
Lemur: Log Parsing with Entropy Sampling and Chain-of-Thought Merging
Authors:Wei Zhang, Hongcheng Guo, Anjie Le, Jian Yang, Jiaheng Liu, Zhoujun Li
Logs produced by extensive software systems are integral to monitoring system behaviors. Advanced log analysis facilitates the detection, alerting, and diagnosis of system faults. Log parsing, which entails transforming raw log messages into structured templates, constitutes a critical phase in the automation of log analytics. Existing log parsers fail to identify the correct templates due to reliance on human-made rules. Besides, These methods focus on statistical features while ignoring semantic information in log messages. To address these challenges, we introduce a cutting-edge \textbf{L}og parsing framework with \textbf{E}ntropy sampling and Chain-of-Thought \textbf{M}erging (Lemur). Specifically, to discard the tedious manual rules. We propose a novel sampling method inspired by information entropy, which efficiently clusters typical logs. Furthermore, to enhance the merging of log templates, we design a chain-of-thought method for large language models (LLMs). LLMs exhibit exceptional semantic comprehension, deftly distinguishing between parameters and invariant tokens. We have conducted experiments on large-scale public datasets. Extensive evaluation demonstrates that Lemur achieves the state-of-the-art performance and impressive efficiency. The Code is available at https://github.com/zwpride/lemur.
日志记录由广泛的软件系统生成,对于监控系统行为至关重要。先进的日志分析有助于检测、预警和诊断系统故障。日志解析是将原始日志消息转换为结构化模板的过程,是日志分析自动化的关键阶段。现有的日志解析器由于依赖人工规则而无法识别正确的模板。此外,这些方法侧重于统计特征,而忽略了日志消息中的语义信息。为了解决这些挑战,我们引入了一种先进的日志解析框架,采用熵采样和思维链合并(Lemur)。具体来说,为了摒弃繁琐的人工规则,我们提出了一种受信息熵启发的新型采样方法,该方法可以有效地对典型日志进行聚类。此外,为了提高日志模板的合并效率,我们为大语言模型(LLM)设计了一种思维链方法。LLM表现出卓越的理解能力,能够区分参数和不变令牌。我们在大规模公共数据集上进行了实验。广泛评估表明,Lemur达到了最先进的性能,并且效率令人印象深刻。代码可在https://github.com/zwpride/lemur获取。
论文及项目相关链接
Summary
日志分析是监测软件系统行为的重要手段,其中日志解析是自动化日志分析的关键环节。现有日志解析方法依赖人工规则,忽视语义信息,难以准确识别日志模板。本文提出一种基于信息熵采样和链式合并思想的先进日志解析框架(Lemur),通过信息熵采样方法高效聚类典型日志,采用链式合并策略提升日志模板合并效果,在大规模公共数据集上实现了卓越的性能和效率。
Key Takeaways
- 日志分析在系统故障检测、预警和诊断中发挥着重要作用。
- 日志解析是自动化日志分析的核心环节,需要将原始日志消息转换为结构化模板。
- 现有日志解析方法存在依赖人工规则、难以准确识别日志模板的问题。
- 提出的Lemur框架采用信息熵采样方法,能够高效聚类典型日志。
- Lemur利用链式合并策略,提升了日志模板的合并效果。
- Lemur在大规模公共数据集上实现了卓越的性能和效率。
点此查看论文截图

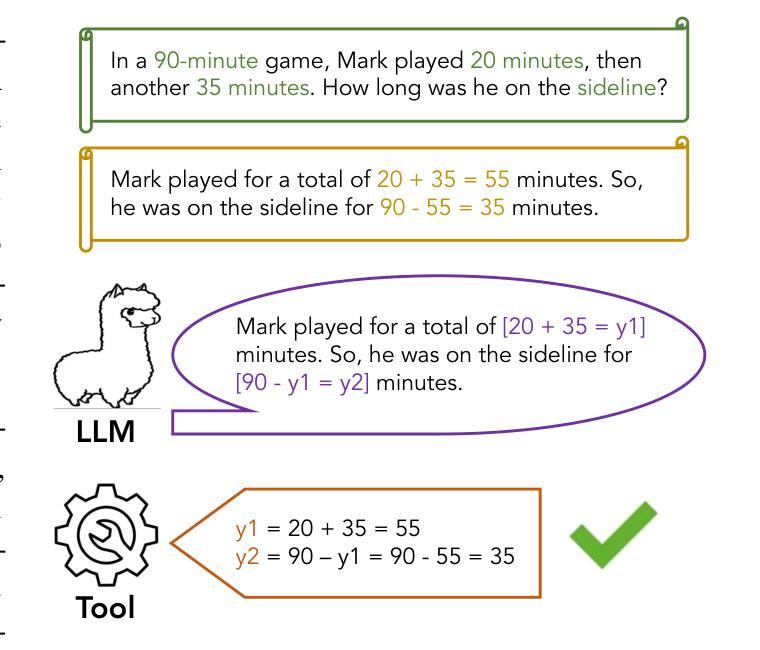
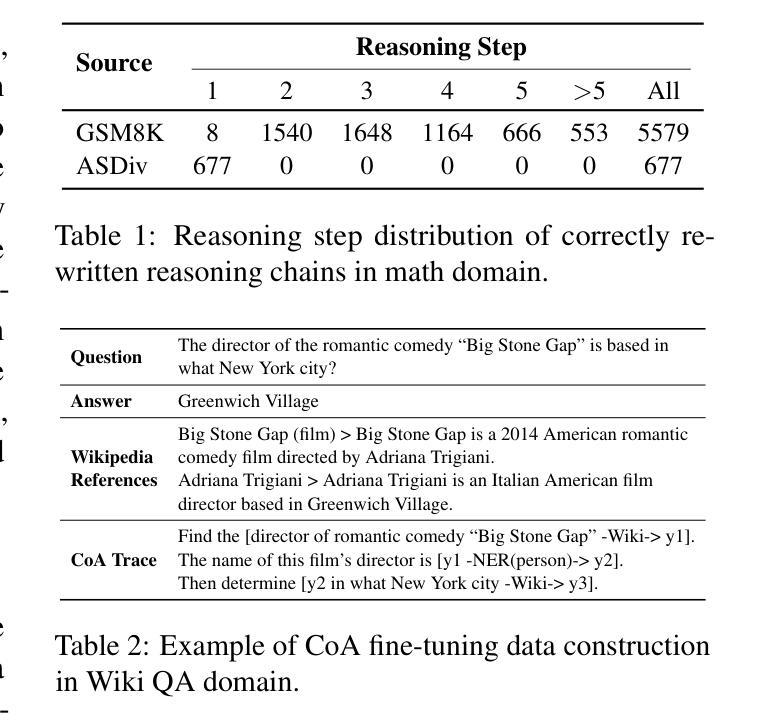
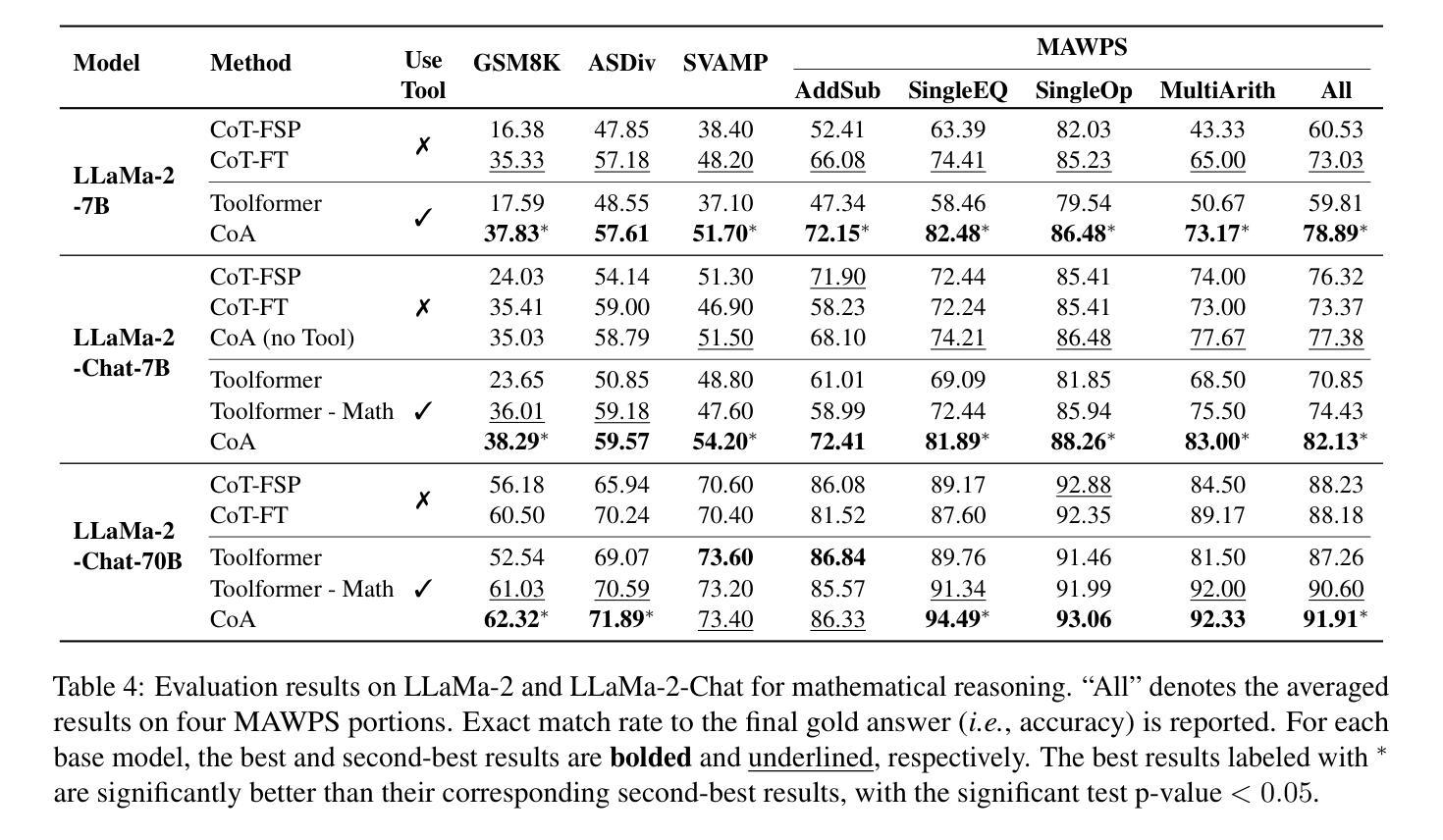
Efficient Tool Use with Chain-of-Abstraction Reasoning
Authors:Silin Gao, Jane Dwivedi-Yu, Ping Yu, Xiaoqing Ellen Tan, Ramakanth Pasunuru, Olga Golovneva, Koustuv Sinha, Asli Celikyilmaz, Antoine Bosselut, Tianlu Wang
To achieve faithful reasoning that aligns with human expectations, large language models (LLMs) need to ground their reasoning to real-world knowledge (e.g., web facts, math and physical rules). Tools help LLMs access this external knowledge, but there remains challenges for fine-tuning LLM agents (e.g., Toolformer) to invoke tools in multi-step reasoning problems, where inter-connected tool calls require holistic and efficient tool usage planning. In this work, we propose a new method for LLMs to better leverage tools in multi-step reasoning. Our method, Chain-of-Abstraction (CoA), trains LLMs to first decode reasoning chains with abstract placeholders, and then call domain tools to reify each reasoning chain by filling in specific knowledge. This planning with abstract chains enables LLMs to learn more general reasoning strategies, which are robust to shifts of domain knowledge (e.g., math results) relevant to different reasoning questions. It also allows LLMs to perform decoding and calling of external tools in parallel, which avoids the inference delay caused by waiting for tool responses. In mathematical reasoning and Wiki QA domains, we show that our method consistently outperforms previous chain-of-thought and tool-augmented baselines on both in-distribution and out-of-distribution test sets, with an average ~6% absolute QA accuracy improvement. LLM agents trained with our method also show more efficient tool use, with inference speed being on average ~1.4x faster than baseline tool-augmented LLMs.
为了实现与人类期望相符的忠实推理,大型语言模型(LLM)需要将他们的推理基于现实世界的知识(如网络事实、数学和物理规则)。工具帮助LLM访问外部知识,但在微调LLM代理(如Toolformer)以在需要整体和高效工具使用规划的跨步骤推理问题中调用工具时仍存在挑战。在这项工作中,我们提出了一种新方法,使LLM能够更好地在跨步骤推理中利用工具。我们的方法称为抽象链法(Chain-of-Abstraction,CoA),它训练LLM首先通过抽象占位符解码推理链,然后通过调用领域工具来具体化每个推理链,填充特定知识。这种抽象链的规划使LLM能够学习更通用的推理策略,这些策略对不同推理问题的领域知识变化具有稳健性(如数学结果的变化)。它还允许LLM并行执行解码和调用外部工具,从而避免了等待工具响应而导致的推理延迟。在数学推理和Wiki QA领域,我们证明了我们的方法在各种分布内和分布外的测试集上均优于之前的思维链和工具增强基线方法,平均问答准确性提高了约6%。使用我们的方法进行训练的LLM代理还显示出更有效的工具使用,推理速度平均比基线工具增强LLM快约1.4倍。
论文及项目相关链接
摘要
大型语言模型(LLM)要实现符合人类期望的忠实推理,需要将其推理基础建立在现实世界知识上,如网络事实、数学和物理规则等。尽管有工具帮助LLM访问这些外部知识,但在微调LLM代理以在具有互联工具调用的多步骤推理问题中调用工具时,仍存在挑战。在本研究中,我们提出了一种新方法,使LLM更好地在多步骤推理中利用工具。我们的方法——抽象链(Chain-of-Abstraction,CoA)——训练LLM首先解码带有抽象占位符的推理链,然后调用领域工具来填充具体知识以具体化每个推理链。这种抽象链的规划使LLM能够学习更通用的推理策略,这些策略对不同推理问题的领域知识变化具有稳健性。此外,它还允许LLM并行进行解码和调用外部工具,从而避免了因等待工具响应而造成的推理延迟。在数学推理和Wiki QA领域,我们的方法在各种测试集上均优于之前的思考链和工具增强基线,平均问答准确性提高约6%。使用我们方法训练的LLM代理还表现出更有效的工具使用,推理速度平均比基线工具增强LLM快约1.4倍。
关键见解
- 大型语言模型(LLM)需要基于现实世界知识(如网络事实、数学和物理规则)进行推理,以符合人类期望。
- 在多步骤推理中调用互联工具存在挑战,需要微调LLM代理以更好地利用工具。
- 提出的抽象链(CoA)方法允许LLM解码带有抽象占位符的推理链,然后调用领域工具填充具体知识。
- 抽象链规划使LLM能够学习更通用的推理策略,对领域知识变化具有稳健性。
- CoA方法提高了LLM在数学推理和Wiki QA领域的性能,平均问答准确性提高约6%。
- 使用CoA方法训练的LLM代理表现出更有效的工具使用。
点此查看论文截图


Harnessing the Zero-Shot Power of Instruction-Tuned Large Language Model in End-to-End Speech Recognition
Authors:Yosuke Higuchi, Tetsuji Ogawa, Tetsunori Kobayashi
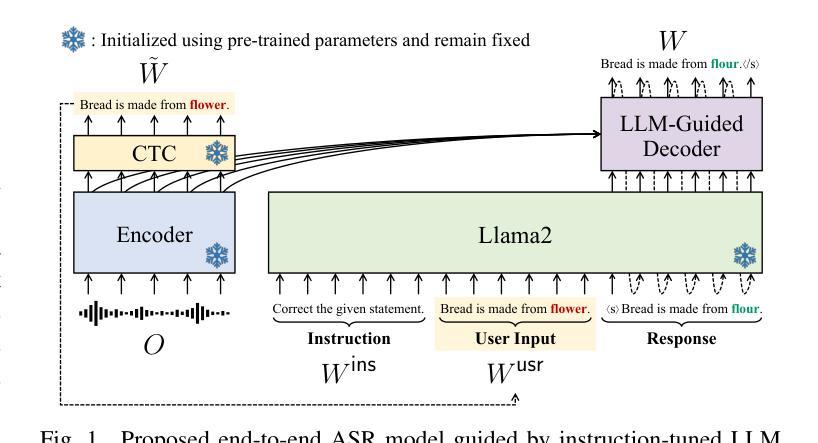
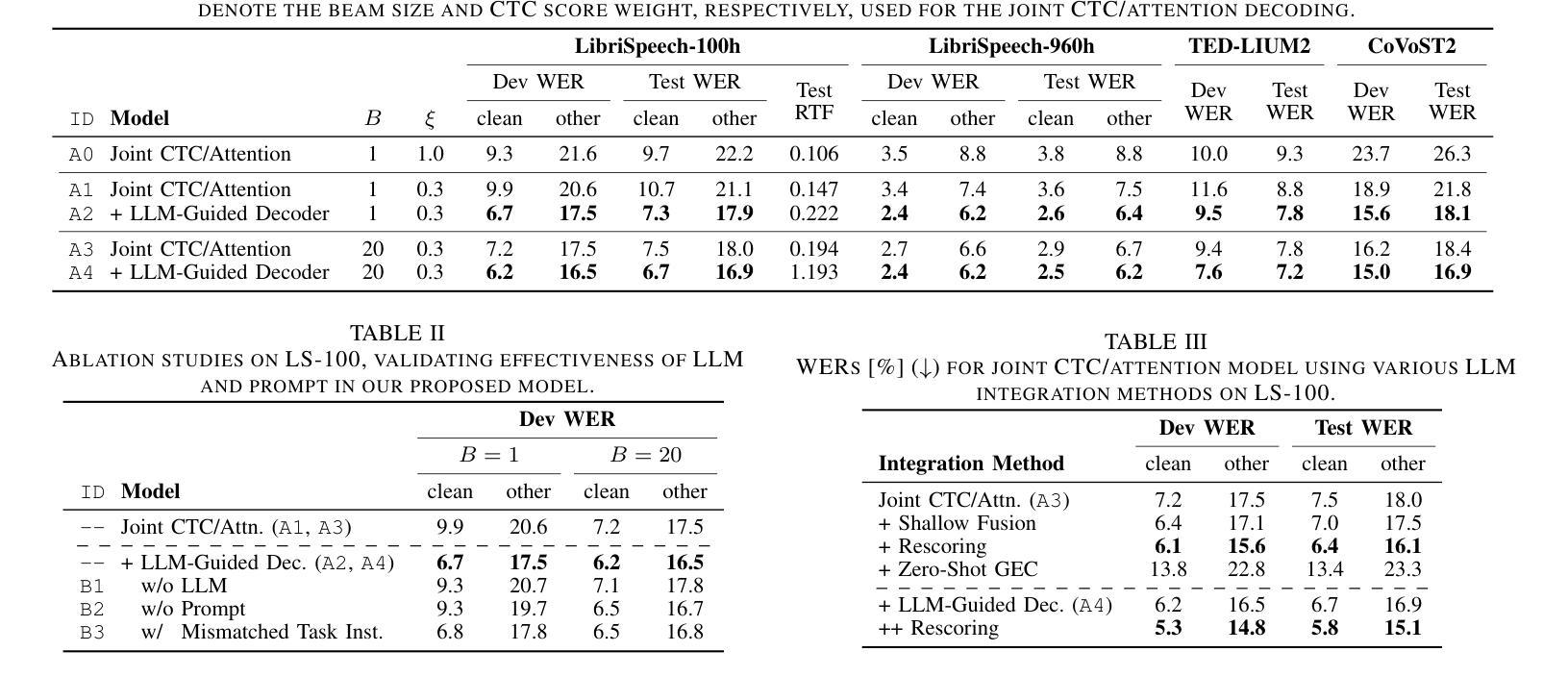
We propose to utilize an instruction-tuned large language model (LLM) for guiding the text generation process in automatic speech recognition (ASR). Modern large language models (LLMs) are adept at performing various text generation tasks through zero-shot learning, prompted with instructions designed for specific objectives. This paper explores the potential of LLMs to derive linguistic information that can facilitate text generation in end-to-end ASR models. Specifically, we instruct an LLM to correct grammatical errors in an ASR hypothesis and use the LLM-derived representations to refine the output further. The proposed model is built on the joint CTC and attention architecture, with the LLM serving as a front-end feature extractor for the decoder. The ASR hypothesis, subject to correction, is obtained from the encoder via CTC decoding and fed into the LLM along with a specific instruction. The decoder subsequently takes as input the LLM output to perform token predictions, combining acoustic information from the encoder and the powerful linguistic information provided by the LLM. Experimental results show that the proposed LLM-guided model achieves a relative gain of approximately 13% in word error rates across major benchmarks.
我们提议利用经过指令训练的的大型语言模型(LLM)来指导自动语音识别(ASR)中的文本生成过程。现代大型语言模型(LLM)擅长通过零样本学习完成各种文本生成任务,这些任务通过针对特定目标设计的指令来提示。本文探讨了LLM在端到端ASR模型中用于文本生成的潜力。具体来说,我们指令LLM来纠正ASR假设中的语法错误,并使用LLM生成的表示来进一步改进输出。所提出的模型基于CTC和注意力架构的联合构建,LLM作为解码器前端特征提取器。需要纠正的ASR假设是通过CTC解码从编码器获得的,并与特定指令一起输入到LLM中。随后,解码器以LLM输出作为输入来进行令牌预测,结合来自编码器的声音信息和LLM提供的强大语言信息。实验结果表明,所提出的LLM引导模型在主要基准测试上取得了约13%的相对词错误率收益。
论文及项目相关链接
PDF Accepted to ICASSP2025
Summary
利用指令微调的大型语言模型(LLM)指导自动语音识别(ASR)中的文本生成过程。现代LLM通过零样本学习完成各种文本生成任务,通过为特定目标设计指令来执行。本文探索了LLM在端到端ASR模型中用于文本生成的潜力。具体地,我们指示LLM纠正ASR假设中的语法错误,并使用LLM生成的表示来进一步完善输出。提出的模型建立在联合CTC和注意力架构上,LLM作为解码器的前端特征提取器。ASR假设经过修正后,通过CTC解码从编码器获得,并与特定指令一起输入LLM。解码器随后以LLM输出作为输入进行令牌预测,结合编码器的声音信息和LLM提供的强大语言信息。实验结果表明,所提出的LLM引导模型在主要基准测试上的词错误率相对提高了约13%。
Key Takeaways
- 利用指令微调的大型语言模型(LLM)可以指导自动语音识别(ASR)中的文本生成。
- LLM具备零样本学习能力,可以通过特定指令完成各种文本生成任务。
- LLM在端到端ASR模型中的潜力在于其能纠正ASR假设中的语法错误并改善输出。
- 提出的模型结合CTC解码和注意力架构,其中LLM作为解码器的前端特征提取器。
- ASR假设经过修正后,通过特定指令输入LLM,并结合声学信息进行令牌预测。
- LLM引导的模型在主要基准测试上实现了相对较高的性能提升,词错误率降低了约13%。
点此查看论文截图