⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-10 更新
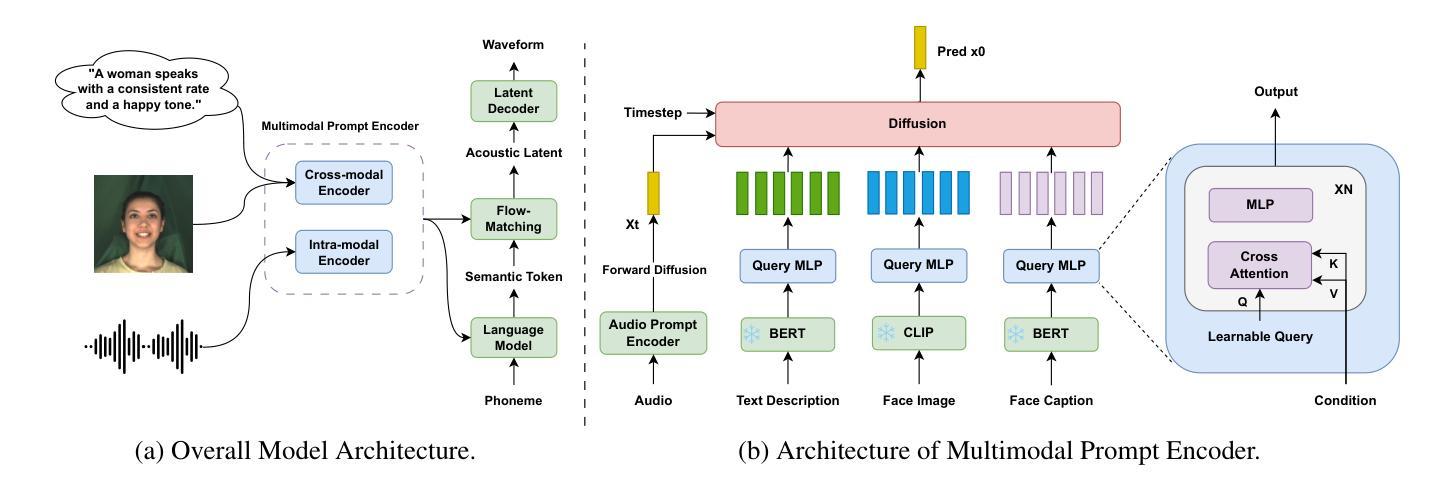
FleSpeech: Flexibly Controllable Speech Generation with Various Prompts
Authors:Hanzhao Li, Yuke Li, Xinsheng Wang, Jingbin Hu, Qicong Xie, Shan Yang, Lei Xie
Controllable speech generation methods typically rely on single or fixed prompts, hindering creativity and flexibility. These limitations make it difficult to meet specific user needs in certain scenarios, such as adjusting the style while preserving a selected speaker’s timbre, or choosing a style and generating a voice that matches a character’s visual appearance. To overcome these challenges, we propose \textit{FleSpeech}, a novel multi-stage speech generation framework that allows for more flexible manipulation of speech attributes by integrating various forms of control. FleSpeech employs a multimodal prompt encoder that processes and unifies different text, audio, and visual prompts into a cohesive representation. This approach enhances the adaptability of speech synthesis and supports creative and precise control over the generated speech. Additionally, we develop a data collection pipeline for multimodal datasets to facilitate further research and applications in this field. Comprehensive subjective and objective experiments demonstrate the effectiveness of FleSpeech. Audio samples are available at https://kkksuper.github.io/FleSpeech/
传统的可控语音生成方法通常依赖于单一或固定的提示,这限制了创造性和灵活性。这些局限使得在某些场景下难以满足特定用户的需求,例如在保留选定演讲者音质的同时调整风格,或者选择风格并生成与角色视觉外观相匹配的语音。为了克服这些挑战,我们提出了FleSpeech,这是一个新型的多阶段语音生成框架,通过整合各种控制形式,允许更灵活地操作语音属性。FleSpeech采用多模态提示编码器,处理和统一不同的文本、音频和视觉提示,形成连贯的表示。这种方法增强了语音合成的适应性,支持对生成的语音进行创造性和精确的控制。此外,我们还为开发多模态数据集的数据收集管道,以促进该领域的进一步研究和应用。综合的主观和客观实验证明了FleSpeech的有效性。音频样本可在https://kkksuper.github.io/FleSpeech/找到。
论文及项目相关链接
PDF 14 pages, 3 figures
Summary
文本主要提出了一种新型的多阶段语音生成框架——FleSpeech,该框架解决了传统可控语音生成方法中的限制,如单一或固定的提示方式。FleSpeech通过整合多种形式的控制,实现了语音属性的灵活操控,能够处理并统一文本、音频和视觉提示,从而增强语音合成的适应性并支持对生成语音的创造性与精确控制。此外,还介绍了FleSpeech的多模态数据集收集流程。
Key Takeaways
- FleSpeech解决了传统可控语音生成方法的局限性,如单一或固定的提示方式。
- FleSpeech采用多阶段框架,实现更灵活的语音属性操控。
- FleSpeech能够处理并统一文本、音频和视觉提示,增强语音合成的适应性。
- FleSpeech支持创造性与精确控制生成的语音。
- FleSpeech采用多模态数据集收集流程,有助于该领域的研究与应用。
- FleSpeech的有效性通过主观和客观实验得到了验证。
点此查看论文截图

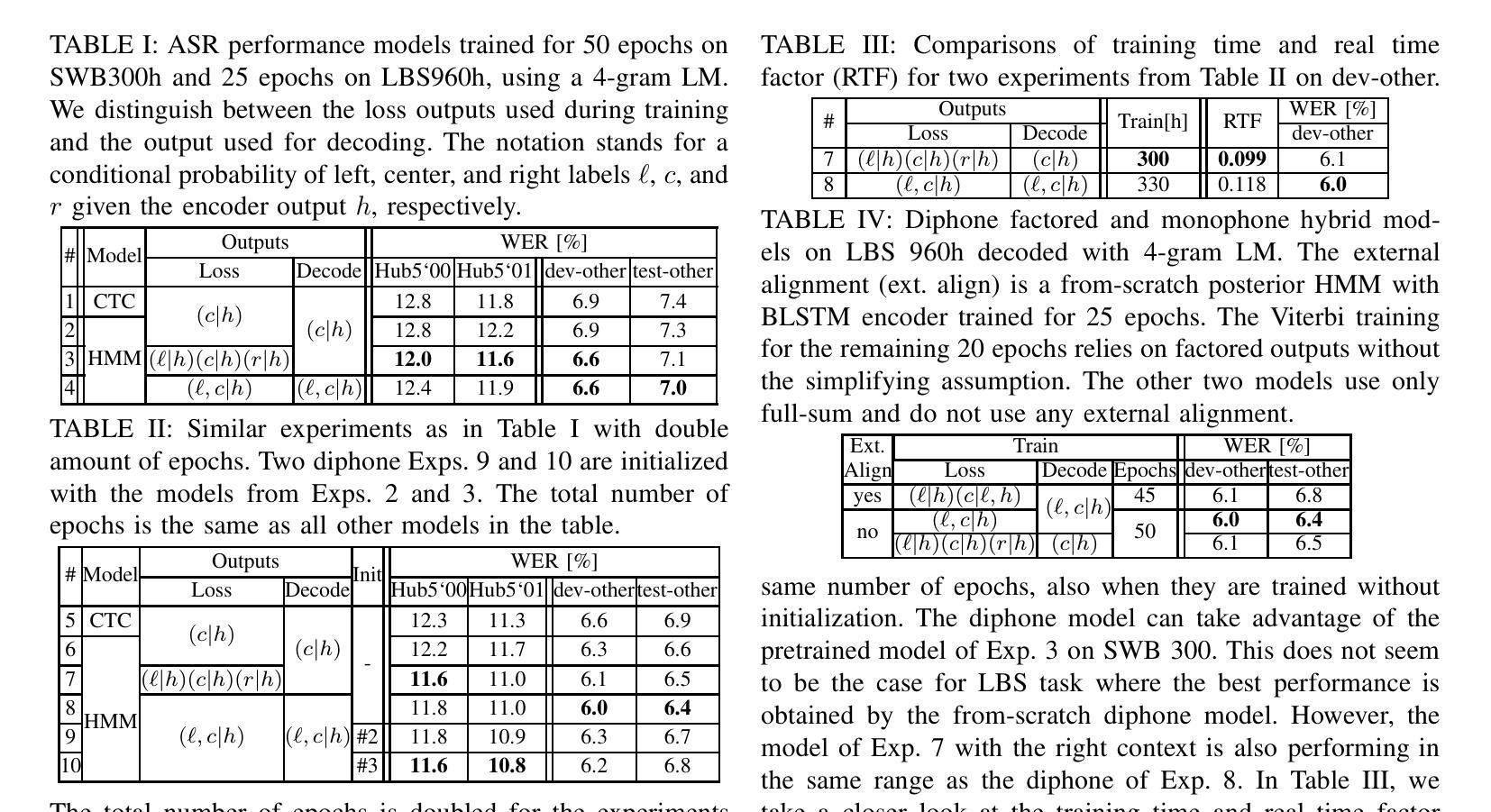
Right Label Context in End-to-End Training of Time-Synchronous ASR Models
Authors:Tina Raissi, Ralf Schlter, Hermann Ney
Current time-synchronous sequence-to-sequence automatic speech recognition (ASR) models are trained by using sequence level cross-entropy that sums over all alignments. Due to the discriminative formulation, incorporating the right label context into the training criterion’s gradient causes normalization problems and is not mathematically well-defined. The classic hybrid neural network hidden Markov model (NN-HMM) with its inherent generative formulation enables conditioning on the right label context. However, due to the HMM state-tying the identity of the right label context is never modeled explicitly. In this work, we propose a factored loss with auxiliary left and right label contexts that sums over all alignments. We show that the inclusion of the right label context is particularly beneficial when training data resources are limited. Moreover, we also show that it is possible to build a factored hybrid HMM system by relying exclusively on the full-sum criterion. Experiments were conducted on Switchboard 300h and LibriSpeech 960h.
当前的时间同步序列到序列自动语音识别(ASR)模型是通过使用序列级别的交叉熵(对所有对齐进行求和)来进行训练的。由于采用判别式公式,将正确的标签上下文纳入训练标准的梯度中会导致归一化问题,并且在数学上定义不明确。经典的混合神经网络隐马尔可夫模型(NN-HMM)凭借其内在的生成式公式,能够实现基于正确的标签上下文进行条件设置。然而,由于HMM的状态绑定,正确的标签上下文的身份从未被显式建模。在这项工作中,我们提出了一种带有辅助的左和右标签上下文的分解损失函数,对所有对齐进行求和。我们表明,在训练数据资源有限的情况下,引入正确的标签上下文特别有益。此外,我们还表明,仅依赖全和准则来构建分解混合HMM系统也是可能的。实验在Switchboard 300小时和LibriSpeech 960小时数据集上进行。
论文及项目相关链接
PDF Accepted for presentation at ICASSP 2025
Summary
当前时序同步的序列到序列语音识别模型使用序列级别的交叉熵进行训练,该交叉熵对所有对齐进行求和。由于判别式公式的问题,将正确的标签上下文纳入训练标准的梯度中会导致归一化问题,且在数学上未明确定义。经典的混合神经网络隐马尔可夫模型(NN-HMM)具有其固有的生成式表述,可以基于正确的标签上下文进行条件处理。但由于HMM的状态绑定,并未明确建模正确的标签上下文的身份。在这项工作中,我们提出了一种带有辅助左右标签上下文的分解损失,该损失对所有对齐进行求和。我们表明,在训练数据资源有限的情况下,引入正确的标签上下文特别有益。此外,我们还展示了仅依靠全和准则来构建分解混合HMM系统的可能性。
Key Takeaways
- 当前ASR模型使用序列级别交叉熵进行训练,对所有对齐求和。
- 判别式公式将正确的标签上下文纳入训练标准的梯度会引发问题。
- 经典的NN-HMM模型可以基于正确的标签上下文进行条件处理,但未明确建模其身份。
- 提出了一种带有辅助左右标签上下文的分解损失。
- 引入正确的标签上下文在训练数据有限的情况下特别有益。
- 仅依靠全和准则可以构建分解混合HMM系统。
- 实验在Switchboard 300h和LibriSpeech 960h数据集上进行。
点此查看论文截图

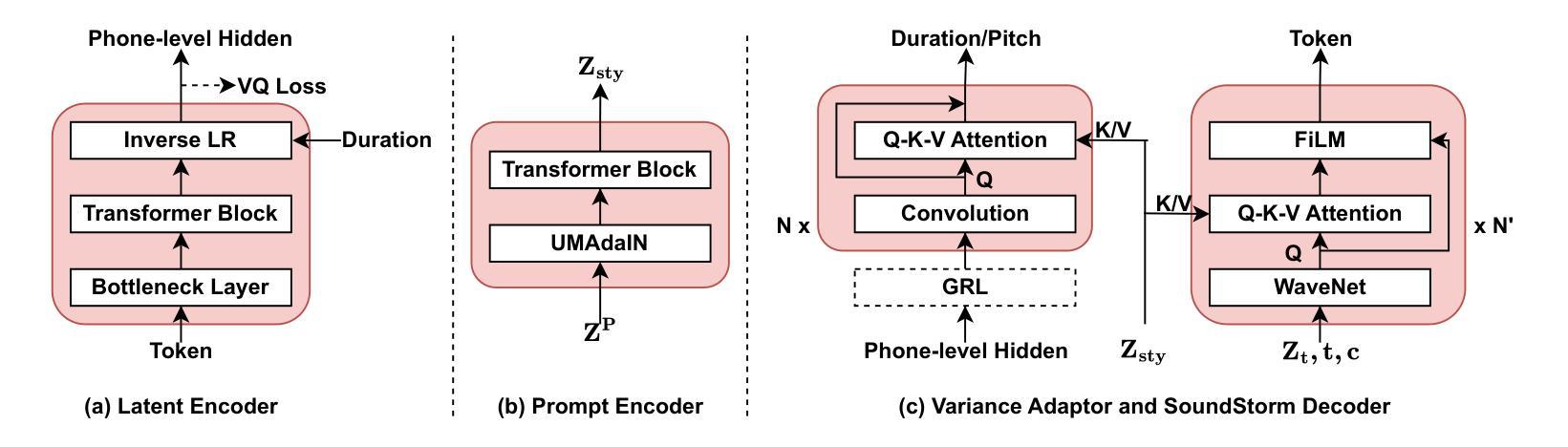
ZSVC: Zero-shot Style Voice Conversion with Disentangled Latent Diffusion Models and Adversarial Training
Authors:Xinfa Zhu, Lei He, Yujia Xiao, Xi Wang, Xu Tan, Sheng Zhao, Lei Xie
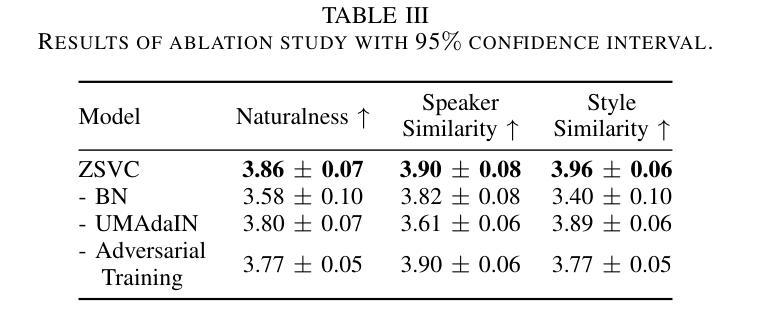
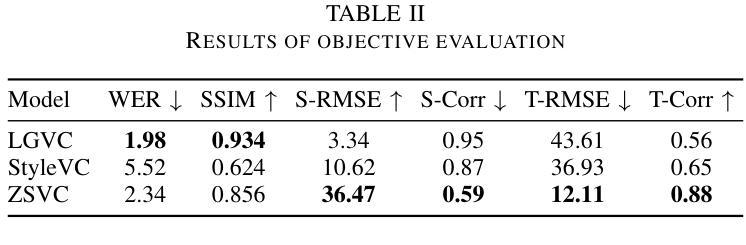
Style voice conversion aims to transform the speaking style of source speech into a desired style while keeping the original speaker’s identity. However, previous style voice conversion approaches primarily focus on well-defined domains such as emotional aspects, limiting their practical applications. In this study, we present ZSVC, a novel Zero-shot Style Voice Conversion approach that utilizes a speech codec and a latent diffusion model with speech prompting mechanism to facilitate in-context learning for speaking style conversion. To disentangle speaking style and speaker timbre, we introduce information bottleneck to filter speaking style in the source speech and employ Uncertainty Modeling Adaptive Instance Normalization (UMAdaIN) to perturb the speaker timbre in the style prompt. Moreover, we propose a novel adversarial training strategy to enhance in-context learning and improve style similarity. Experiments conducted on 44,000 hours of speech data demonstrate the superior performance of ZSVC in generating speech with diverse speaking styles in zero-shot scenarios.
风格语音转换旨在将源语音的讲话风格转换为所需的风格,同时保持原始说话者的身份。然而,以前的风格语音转换方法主要集中在情绪等方面等定义明确的领域,限制了其实际应用。本研究提出了ZSVC,这是一种利用语音编解码器和带有语音提示机制的潜在扩散模型的新型零风格语音转换方法,以促进说话风格转换的上下文学习。为了解开说话风格和说话者音色,我们引入信息瓶颈来过滤源语音中的说话风格,并采用不确定性建模自适应实例归一化(UMAdaIN)来扰动风格提示中的说话者音色。此外,我们提出了一种新型对抗训练策略,以增强上下文学习并提高风格相似性。在44000小时语音数据进行的实验表明,ZSVC在零样本场景下生成具有多种说话风格的语音方面表现出卓越性能。
论文及项目相关链接
PDF 5 pages, 3 figures, accepted by ICASSP 2025
Summary
文本主要介绍了零样本风格语音转换方法(ZSVC)。该方法利用语音编解码器和潜在扩散模型,结合说话风格提示,进行风格语音转换。研究提出了信息瓶颈和不确定性建模自适应实例归一化(UMAdaIN)等技术来处理说话风格和发音特性的转换问题。通过提出的对抗训练策略,提高在零样本场景下的风格相似性和学习表现。
Key Takeaways
- ZSVC是一种零样本风格语音转换方法,专注于转换源语音的说话风格为期望的风格,同时保持原始说话者的身份。
- 利用语音编解码器和潜在扩散模型进行说话风格转换。
- 采用信息瓶颈技术来分离说话风格和发音特性。
- 使用UMAdaIN技术来干扰说话风格提示中的发音特性。
- 提出对抗训练策略以提高零样本场景下的风格相似性和学习表现。
点此查看论文截图

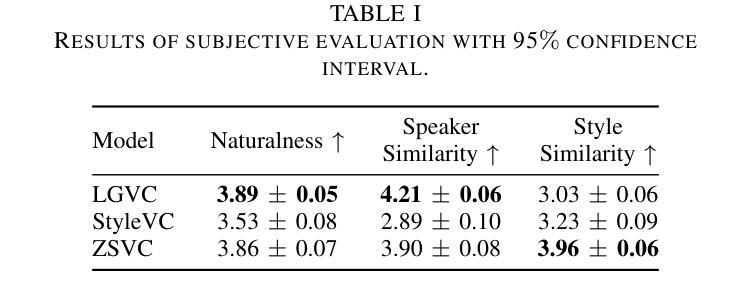

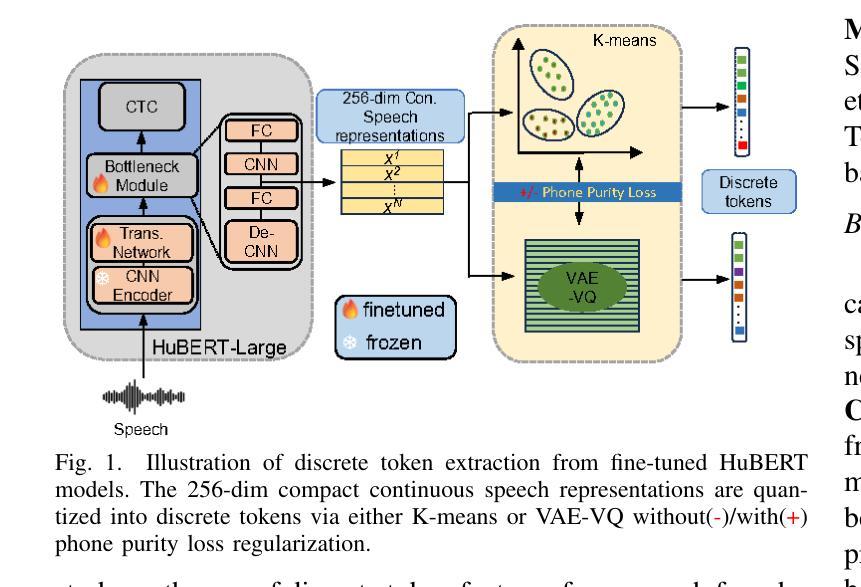
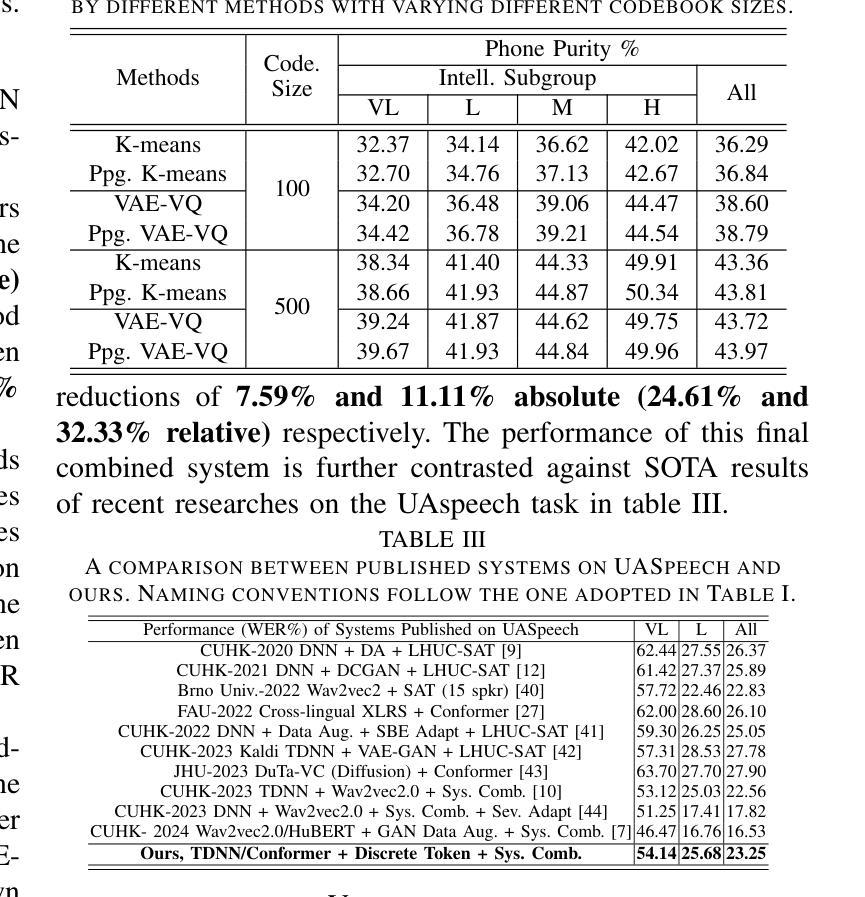
Phone-purity Guided Discrete Tokens for Dysarthric Speech Recognition
Authors:Huimeng Wang, Xurong Xie, Mengzhe Geng, Shujie Hu, Haoning Xu, Youjun Chen, Zhaoqing Li, Jiajun Deng, Xunying Liu
Discrete tokens extracted provide efficient and domain adaptable speech features. Their application to disordered speech that exhibits articulation imprecision and large mismatch against normal voice remains unexplored. To improve their phonetic discrimination that is weakened during unsupervised K-means or vector quantization of continuous features, this paper proposes novel phone-purity guided (PPG) discrete tokens for dysarthric speech recognition. Phonetic label supervision is used to regularize maximum likelihood and reconstruction error costs used in standard K-means and VAE-VQ based discrete token extraction. Experiments conducted on the UASpeech corpus suggest that the proposed PPG discrete token features extracted from HuBERT consistently outperform hybrid TDNN and End-to-End (E2E) Conformer systems using non-PPG based K-means or VAE-VQ tokens across varying codebook sizes by statistically significant word error rate (WER) reductions up to 0.99% and 1.77% absolute (3.21% and 4.82% relative) respectively on the UASpeech test set of 16 dysarthric speakers. The lowest WER of 23.25% was obtained by combining systems using different token features. Consistent improvements on the phone purity metric were also achieved. T-SNE visualization further demonstrates sharper decision boundaries were produced between K-means/VAE-VQ clusters after introducing phone-purity guidance.
提取的离散令牌提供高效且适应于特定领域的语音特征。它们在针对发音不精确以及与正常声音存在较大差异的混乱语音中的应用尚未得到探索。为了提高在连续特征的无监督K-means或向量量化过程中被削弱的语音辨别能力,本文提出了用于口齿不清的语音识别的新型电话纯净度引导(PPG)离散令牌。语音标签监督用于规范最大似然和重建误差成本,这些成本用于基于标准K-means和VAE-VQ的离散令牌提取。在UASpeech语料库上进行的实验表明,从HuBERT中提取的PPG离散令牌特征始终优于使用非PPG的K-means或VAE-VQ令牌的混合TDNN和端到端(E2E)Conformer系统。在UASpeech的16位口齿不清的说话者的测试集上,通过统计显著的字错误率(WER)减少高达绝对值的0.99%和1.77%(相对值分别为3.21%和4.82%)。通过将使用不同令牌特征的系统进行组合,获得了最低的WER为23.25%。在电话纯净度指标方面也取得了持续的改进。T-SNE可视化进一步证明了引入电话纯净度指导后,K-means/VAE-VQ集群之间的决策边界更加清晰。
论文及项目相关链接
PDF ICASSP 2025
Summary
离散语音特征提取技术对于语音领域具有高效性和适应性。针对发音不精确、与正常语音存在较大差异的障碍性语音,本文提出一种新型的电话纯净度引导(PPG)离散令牌技术用于识别。通过利用语音标签监督来规范最大似然和重建误差成本,改善传统的K均值和基于VAE-VQ的离散令牌提取中的语音辨识问题。在UASpeech语料库上的实验表明,采用PPG离散令牌特征的HuBERT系统优于混合TDNN和端到端(E2E)Conformer系统,在代码本大小不同的情况下,相对字词错误率(WER)绝对降低达1.77%,相对降低达4.82%。结合不同令牌特征的系统可获得最低WER为23.25%。同时,电话纯净度指标也有显著提高。T-SNE可视化进一步证明引入电话纯净度指导后,K均值/ VAE-VQ集群之间的决策边界更加清晰。
Key Takeaways
- 离散语音特征提取技术对于语音领域具有高效性和适应性。
- 针对障碍性语音(如发音不精确等),本文提出了一种电话纯净度引导(PPG)离散令牌技术用于识别。
- 通过语音标签监督改善传统的K均值和基于VAE-VQ的离散令牌提取中的语音辨识问题。
- 在UASpeech语料库的实验中,采用PPG离散令牌特征的HuBERT系统表现优异,相对于其他系统有明显降低的字词错误率(WER)。
- 结合不同令牌特征的系统可以获得更低的WER。
- 电话纯净度指标显著提高,证明PPG离散令牌技术对于语音识别的有效性。
点此查看论文截图


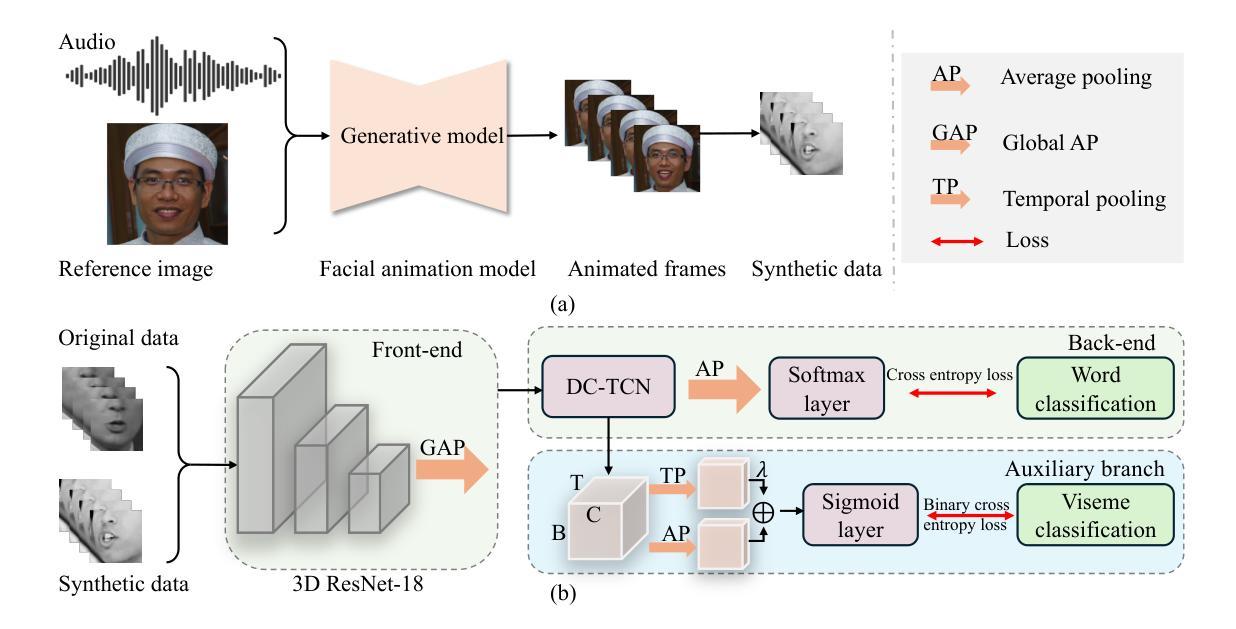
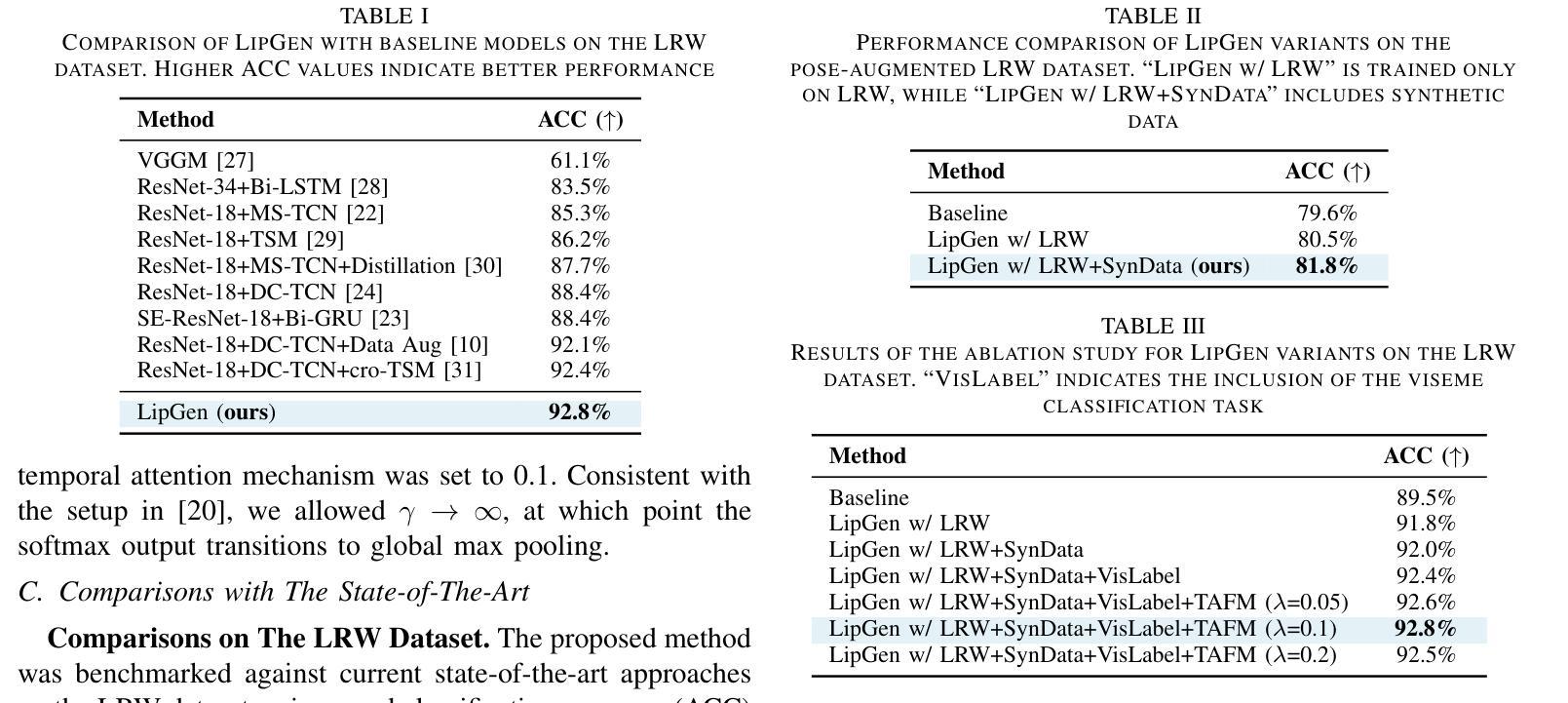
LipGen: Viseme-Guided Lip Video Generation for Enhancing Visual Speech Recognition
Authors:Bowen Hao, Dongliang Zhou, Xiaojie Li, Xingyu Zhang, Liang Xie, Jianlong Wu, Erwei Yin
Visual speech recognition (VSR), commonly known as lip reading, has garnered significant attention due to its wide-ranging practical applications. The advent of deep learning techniques and advancements in hardware capabilities have significantly enhanced the performance of lip reading models. Despite these advancements, existing datasets predominantly feature stable video recordings with limited variability in lip movements. This limitation results in models that are highly sensitive to variations encountered in real-world scenarios. To address this issue, we propose a novel framework, LipGen, which aims to improve model robustness by leveraging speech-driven synthetic visual data, thereby mitigating the constraints of current datasets. Additionally, we introduce an auxiliary task that incorporates viseme classification alongside attention mechanisms. This approach facilitates the efficient integration of temporal information, directing the model’s focus toward the relevant segments of speech, thereby enhancing discriminative capabilities. Our method demonstrates superior performance compared to the current state-of-the-art on the lip reading in the wild (LRW) dataset and exhibits even more pronounced advantages under challenging conditions.
视觉语音识别(VSR),也称为唇读,由于其广泛的实际应用而备受关注。深度学习技术的出现和硬件能力的进步极大地提高了唇读模型的性能。尽管有这些进步,现有数据集主要以稳定的视频录制为主,唇动变化有限。这一局限性导致模型对现实场景中遇到的变动非常敏感。为了解决这一问题,我们提出了一个新型框架LipGen,旨在利用语音驱动合成视觉数据,提高模型的稳健性,从而缓解当前数据集的约束。此外,我们引入了一个辅助任务,结合viseme分类和注意力机制。这种方法有助于有效地整合时间信息,引导模型关注语音的相关片段,从而提高辨别能力。我们的方法在唇读领域的LRW数据集上展现了卓越的性能,并在具有挑战性的条件下表现出更为明显的优势。
论文及项目相关链接
PDF This paper has been accepted for presentation at ICASSP 2025
Summary
视觉语音识别(VSR),俗称唇读技术,因其广泛的实践应用而备受关注。随着深度学习技术的发展和硬件能力的进步,唇读模型的性能得到了显著提升。然而,现有数据集主要以稳定的视频录制为主,唇动变化有限,导致模型对真实场景中的变化高度敏感。为解决这一问题,我们提出了LipGen这一新型框架,旨在利用语音驱动合成视觉数据,提升模型的稳健性,以缓解当前数据集的约束。此外,我们还引入了一项辅助任务,结合viseme分类和注意力机制,以高效地整合时序信息,引导模型关注于语音的关键片段,从而提升其辨别能力。相较于现有的唇读技术,我们的方法在唇读野(LRW)数据集上表现出卓越的性能,并在具有挑战性的环境下优势更为明显。
Key Takeaways
- 视觉语音识别(VSR)技术因其实用性受到广泛关注。
- 现有数据集主要依赖稳定视频录制,限制了模型的适应性。
- LipGen框架旨在提高模型稳健性,通过利用语音驱动的合成视觉数据缓解数据约束。
- 引入viseme分类和注意力机制的辅助任务,以提高模型的辨别能力。
- 方法在唇读野(LRW)数据集上表现优越。
- 在具有挑战性的环境下,该方法较现有技术更具优势。
点此查看论文截图


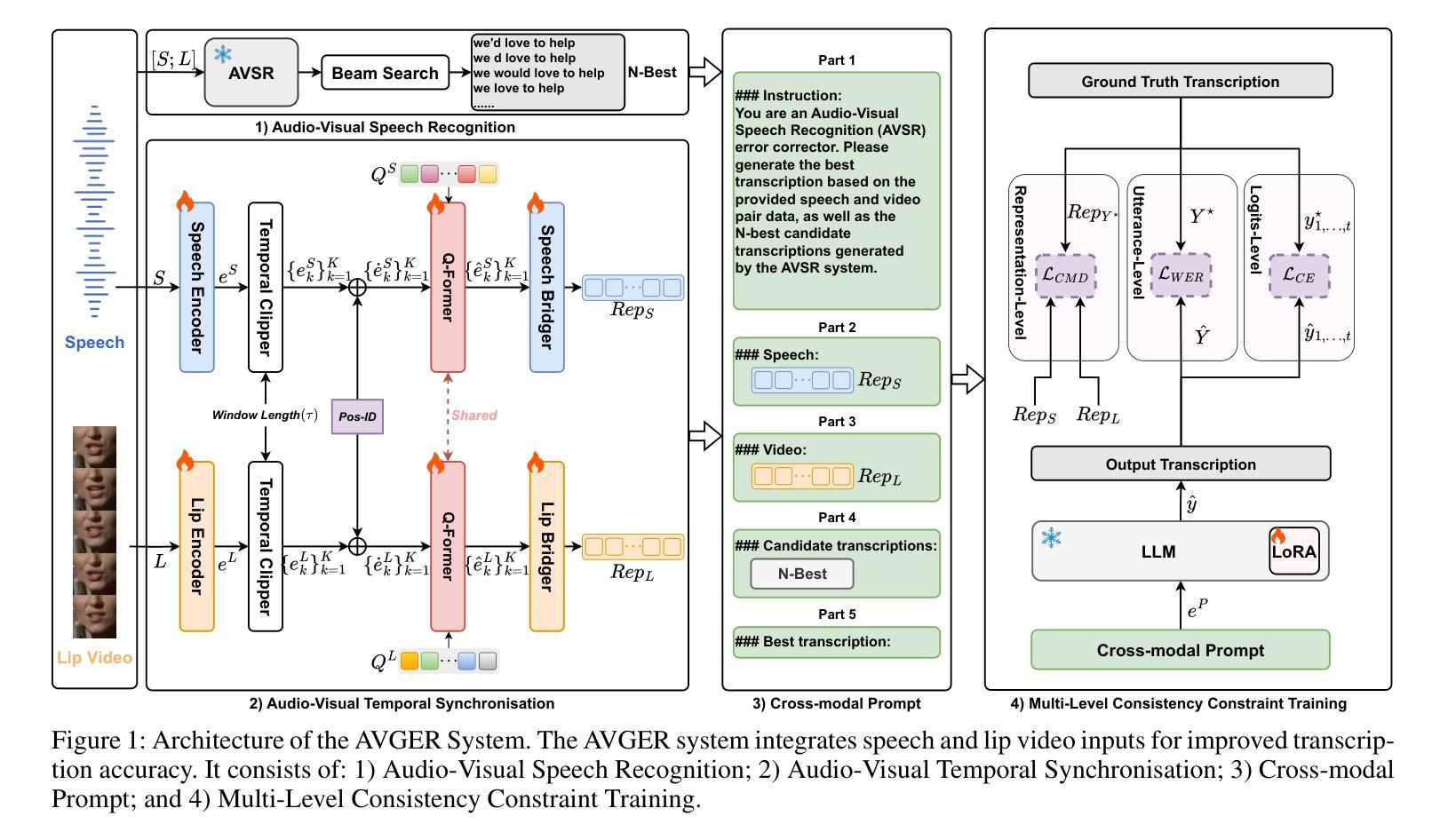
Listening and Seeing Again: Generative Error Correction for Audio-Visual Speech Recognition
Authors:Rui Liu, Hongyu Yuan, Haizhou Li
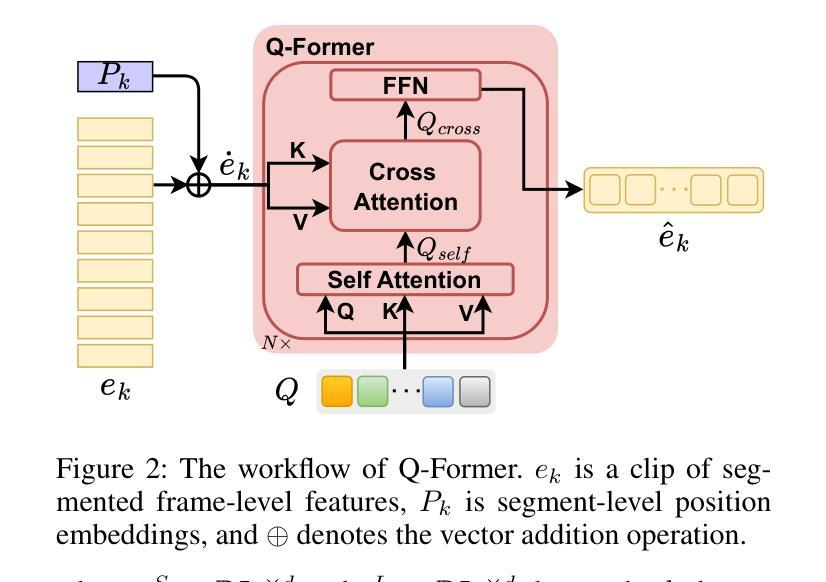
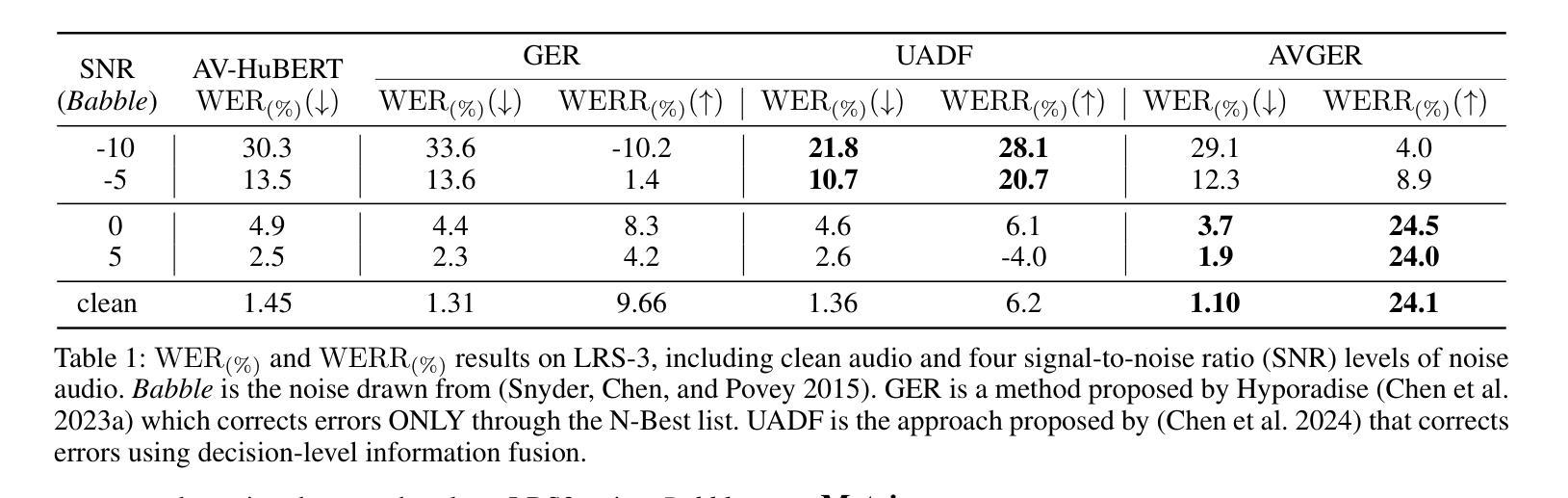
Unlike traditional Automatic Speech Recognition (ASR), Audio-Visual Speech Recognition (AVSR) takes audio and visual signals simultaneously to infer the transcription. Recent studies have shown that Large Language Models (LLMs) can be effectively used for Generative Error Correction (GER) in ASR by predicting the best transcription from ASR-generated N-best hypotheses. However, these LLMs lack the ability to simultaneously understand audio and visual, making the GER approach challenging to apply in AVSR. In this work, we propose a novel GER paradigm for AVSR, termed AVGER, that follows the concept of ``listening and seeing again’’. Specifically, we first use the powerful AVSR system to read the audio and visual signals to get the N-Best hypotheses, and then use the Q-former-based Multimodal Synchronous Encoder to read the audio and visual information again and convert them into an audio and video compression representation respectively that can be understood by LLM. Afterward, the audio-visual compression representation and the N-Best hypothesis together constitute a Cross-modal Prompt to guide the LLM in producing the best transcription. In addition, we also proposed a Multi-Level Consistency Constraint training criterion, including logits-level, utterance-level and representations-level, to improve the correction accuracy while enhancing the interpretability of audio and visual compression representations. The experimental results on the LRS3 dataset show that our method outperforms current mainstream AVSR systems. The proposed AVGER can reduce the Word Error Rate (WER) by 24% compared to them. Code and models can be found at: https://github.com/CircleRedRain/AVGER.
与传统的自动语音识别(ASR)不同,视听语音识别(AVSR)同时处理音频和视觉信号来进行转录。最近的研究表明,大型语言模型(LLM)可以通过预测ASR生成的N-best假设中的最佳转录,有效地用于自动语音识别中的生成错误校正(GER)。然而,这些LLM无法同时理解音频和视觉信号,使得在AVSR中应用GER方法具有挑战性。在这项工作中,我们提出了一种新型的AVSR的GER方法,称为AVGER,它遵循“再次聆听和观看”的概念。具体来说,我们首先使用强大的AVSR系统读取音频和视觉信号,以获得N-best假设,然后使用基于Q-former的多模态同步编码器再次读取音频和视觉信息,并将它们转换为LLM可以理解的音频和视频压缩表示形式。之后,视听压缩表示和N-best假设共同构成一个跨模态提示,引导LLM生成最佳转录。此外,我们还提出了多级别一致性约束训练准则,包括logits级别、话语级别和表示级别,以提高校正准确性,同时增强视听压缩表示的可解释性。在LRS3数据集上的实验结果表明,我们的方法优于当前主流的AVSR系统。与它们相比,所提出的AVGER可以将单词错误率(WER)降低24%。代码和模型可在https://github.com/CircleRedRain/AVGER找到。
论文及项目相关链接
摘要
本文提出了一种针对音频视觉语音识别(AVSR)的生成式误差校正(AVGER)新方法。该方法结合音频和视觉信号,利用强大的AVSR系统获取N-best假设,再通过Q-former基多模态同步编码器对音频和视觉信息进行二次处理,转化为可被大型语言模型(LLM)理解的音频视觉压缩表示。此外,还提出了多级别一致性约束训练准则,以提高校正精度并增强音频和视觉压缩表示的可解释性。在LRS3数据集上的实验结果表明,该方法优于主流AVSR系统,可降低24%的单词错误率。
关键见解
- AVGER方法结合了音频和视觉信号进行语音识别,提高了识别的准确性。
- 利用强大的AVSR系统获取N-best假设,为生成式误差校正(GER)提供了更丰富的信息。
- Q-former基多模态同步编码器能够将音频和视觉信息转化为可理解的压缩表示,便于LLM进行处理。
- 提出多级别一致性约束训练准则,旨在提高校正精度并增强音频和视觉表示的可解释性。
- AVGER方法在LRS3数据集上的表现优于主流AVSR系统。
- AVGER方法可降低单词错误率(WER)24%,显示出其在实际应用中的有效性。
- 研究的代码和模型可在https://github.com/CircleRedRain/AVGER找到。
点此查看论文截图

Samba-ASR: State-Of-The-Art Speech Recognition Leveraging Structured State-Space Models
Authors:Syed Abdul Gaffar Shakhadri, Kruthika KR, Kartik Basavaraj Angadi
We propose Samba ASR,the first state of the art Automatic Speech Recognition(ASR)model leveraging the novel Mamba architecture as both encoder and decoder,built on the foundation of state space models(SSMs).Unlike transformerbased ASR models,which rely on self-attention mechanisms to capture dependencies,Samba ASR effectively models both local and global temporal dependencies using efficient statespace dynamics,achieving remarkable performance gains.By addressing the limitations of transformers,such as quadratic scaling with input length and difficulty in handling longrange dependencies,Samba ASR achieves superior accuracy and efficiency.Experimental results demonstrate that Samba ASR surpasses existing opensource transformerbased ASR models across various standard benchmarks,establishing it as the new state of theart in ASR.Extensive evaluations on the benchmark dataset show significant improvements in Word Error Rate(WER),with competitive performance even in lowresource scenarios.Furthermore,the inherent computational efficiency and parameter optimization of the Mamba architecture make Samba ASR a scalable and robust solution for diverse ASR tasks.Our contributions include the development of a new Samba ASR architecture for automatic speech recognition(ASR),demonstrating the superiority of structured statespace models(SSMs)over transformer based models for speech sequence processing.We provide a comprehensive evaluation on public benchmarks,showcasing stateoftheart(SOTA)performance,and present an indepth analysis of computational efficiency,robustness to noise,and sequence generalization.This work highlights the viability of Mamba SSMs as a transformerfree alternative for efficient and accurate ASR.By leveraging the advancements of statespace modeling,Samba ASR redefines ASR performance standards and sets a new benchmark for future research in this field.
我们提出了Samba ASR,这是首款结合新型Mamba架构作为编码器和解码器的先进自动语音识别(ASR)模型,它建立在状态空间模型(SSMs)的基础上。不同于依赖自注意力机制捕获依赖关系的基于变压器的ASR模型,Samba ASR使用高效的状态空间动力学有效地对局部和全局时间依赖关系进行建模,实现了显著的性能提升。通过解决变压器模型的局限性,如输入长度的二次扩展和处理长距离依赖关系的困难,Samba ASR在准确性和效率上更胜一筹。实验结果表明,Samba ASR在各种标准基准测试中超越了现有的开源基于变压器的ASR模型,成为ASR领域的新技术前沿。在基准数据集上的广泛评估显示,其在词错误率(WER)方面取得了显著改进,即使在资源匮乏的场景中也具有竞争力。此外,Mamba架构的固有计算效率和参数优化使Samba ASR成为适用于各种ASR任务的可扩展和稳健的解决方案。我们的贡献包括为自动语音识别(ASR)开发新的Samba ASR架构,证明结构化状态空间模型(SSMs)在语音序列处理方面优于基于变压器的模型。我们在公共基准测试上进行了全面评估,展示了其处于行业顶尖的性能表现,并对计算效率、抗噪声干扰的鲁棒性和序列泛化能力进行了深入分析。这项工作突出了Mamba SSMs作为无变压器的高效准确ASR的替代方案的可行性。通过利用状态空间建模的进展,Samba ASR重新定义了ASR的性能标准,并为该领域的未来研究设定了新的基准。
论文及项目相关链接
Summary
Samba ASR是一款利用Mamba架构的自动语音识别(ASR)模型,它在状态空间模型(SSMs)的基础上实现了本地和全局时间依赖性的有效建模。与传统基于变压器的ASR模型相比,Samba ASR通过解决输入长度和长距离依赖性问题,实现了更高的准确性和效率。实验结果表明,Samba ASR在各种标准基准测试中超过了现有的开源基于变压器的ASR模型,且在低资源场景中表现出竞争力。此外,Mamba架构的计算效率和参数优化使Samba ASR成为多样化的ASR任务的可扩展和稳健解决方案。此研究展示了状态空间模型在语音识别领域的优越性,为未来的研究设定了新的基准。
Key Takeaways
- Samba ASR是一个基于状态空间模型的自动语音识别(ASR)模型。
- 它采用Mamba架构,既作为编码器也作为解码器。
- 与基于变压器的ASR模型相比,Samba ASR通过建模本地和全局时间依赖性实现了更高的性能。
- Samba ASR解决了基于变压器的模型的局限性,如输入长度的二次扩展和长距离依赖性的处理困难。
- 实验结果显示,Samba ASR在多种基准测试中超越了现有的开源基于变压器的ASR模型。
- Samba ASR在低资源场景中表现出竞争力,且具有良好的计算效率和参数优化。
点此查看论文截图

A Lightweight and Real-Time Binaural Speech Enhancement Model with Spatial Cues Preservation
Authors:Jingyuan Wang, Jie Zhang, Shihao Chen, Miao Sun
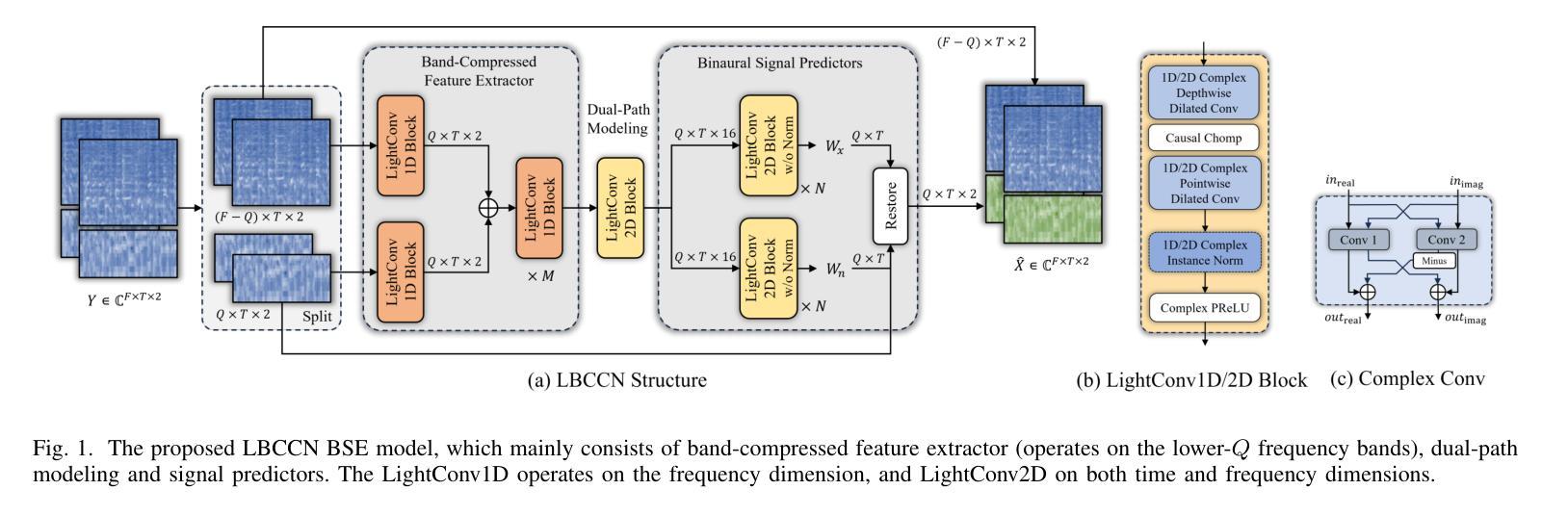
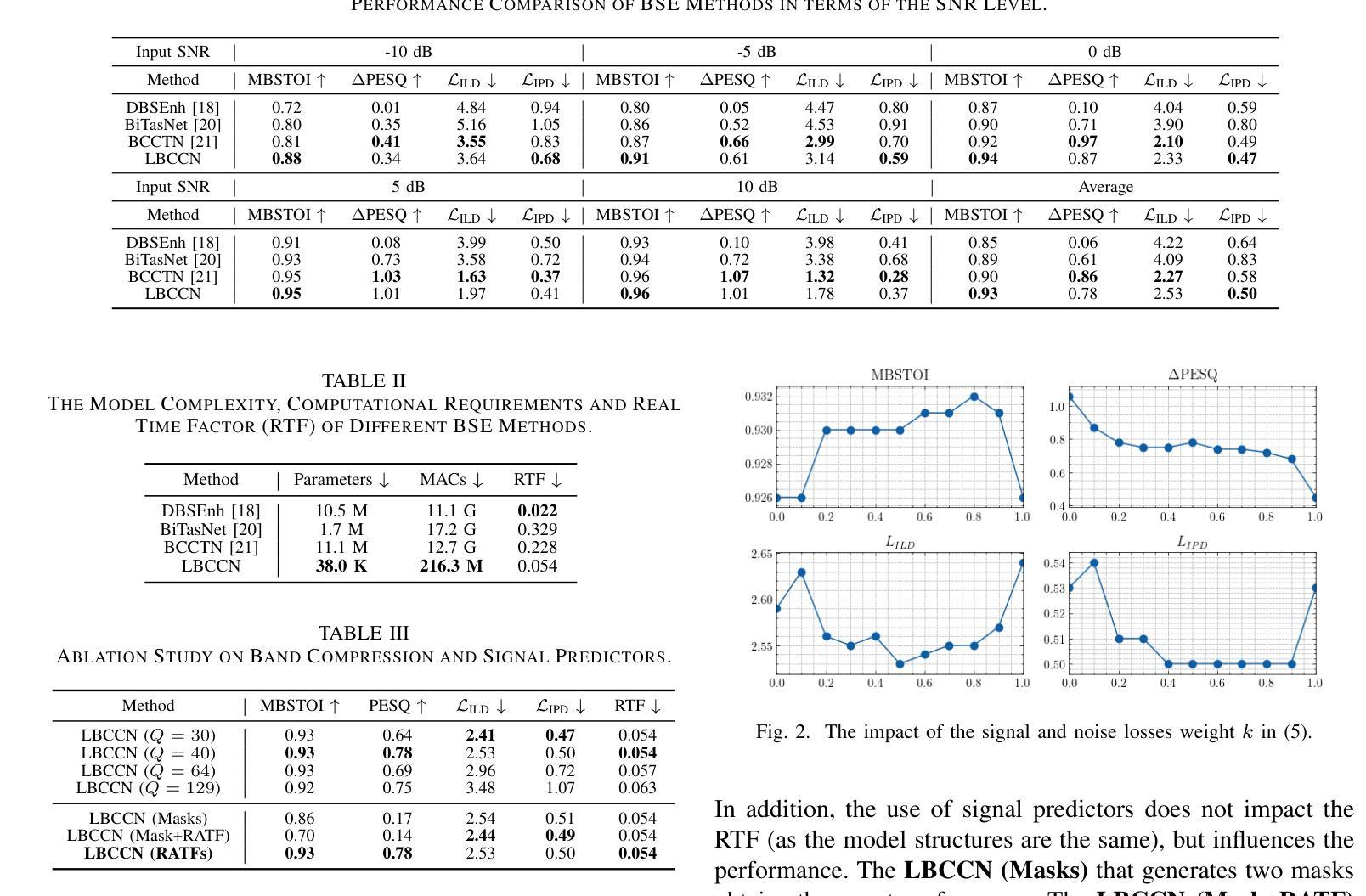
Binaural speech enhancement (BSE) aims to jointly improve the speech quality and intelligibility of noisy signals received by hearing devices and preserve the spatial cues of the target for natural listening. Existing methods often suffer from the compromise between noise reduction (NR) capacity and spatial cues preservation (SCP) accuracy and a high computational demand in complex acoustic scenes. In this work, we present a learning-based lightweight binaural complex convolutional network (LBCCN), which excels in NR by filtering low-frequency bands and keeping the rest. Additionally, our approach explicitly incorporates the estimation of interchannel relative acoustic transfer function to ensure the spatial cues fidelity and speech clarity. Results show that the proposed LBCCN can achieve a comparable NR performance to state-of-the-art methods under fixed-speaker conditions, but with a much lower computational cost and a certain degree of SCP capability. The reproducible code and audio examples are available at https://github.com/jywanng/LBCCN.
双耳语音增强(BSE)旨在共同提高听力设备接收到的噪声信号的质量和语音清晰度,并保留目标的空间线索以实现自然聆听。现有方法经常在噪声降低(NR)能力和空间线索保留(SCP)准确性之间做出妥协,并且在复杂的声学场景中计算需求较高。在这项工作中,我们提出了一种基于学习的轻量级双耳复杂卷积网络(LBCCN),它通过过滤低频带实现出色的NR效果并保持其余部分。此外,我们的方法明确地结合了通道间相对声学传递函数的估计,以确保空间线索的保真度和语音清晰度。结果表明,在固定说话人条件下,所提出的LBCCN的NR性能可与最先进的方法相媲美,但计算成本更低,并且具有一定的SCP能力。可复用的代码和音频示例可在https://github.com/jywanng/LBCCN找到。
论文及项目相关链接
Summary
本文介绍了基于学习的轻量化双耳复杂卷积网络(LBCCN)在噪声环境下的语音增强技术。该技术旨在提高语音质量和可懂度,同时保留目标的空间线索以实现自然聆听体验。通过过滤低频带并保持其余部分实现降噪,同时估计通道间相对声学传输函数以确保空间线索保真和语音清晰度。与现有方法相比,LBCCN在固定说话人条件下具有相当的降噪性能,但计算成本更低,并具有一定的空间线索保留能力。
Key Takeaways
- Binaural speech enhancement (BSE)旨在提高噪声信号的语音质量和可懂度,同时保留自然聆听时的空间线索。
- 现有方法常常在噪声减少(NR)能力、空间线索保留(SCP)精度以及复杂声学场景中的计算需求之间面临权衡。
- 提出的基于学习的轻量化双耳复杂卷积网络(LBCCN)通过过滤低频带进行降噪,并估计通道间相对声学传输函数以确保空间线索的保真和语音清晰度。
- LBCCN具有与最新技术相当的降噪性能,但在固定说话人条件下计算成本更低。
- LBCCN还具有一定的空间线索保留能力。
- 可复用的代码和音频示例可在指定链接找到。
点此查看论文截图

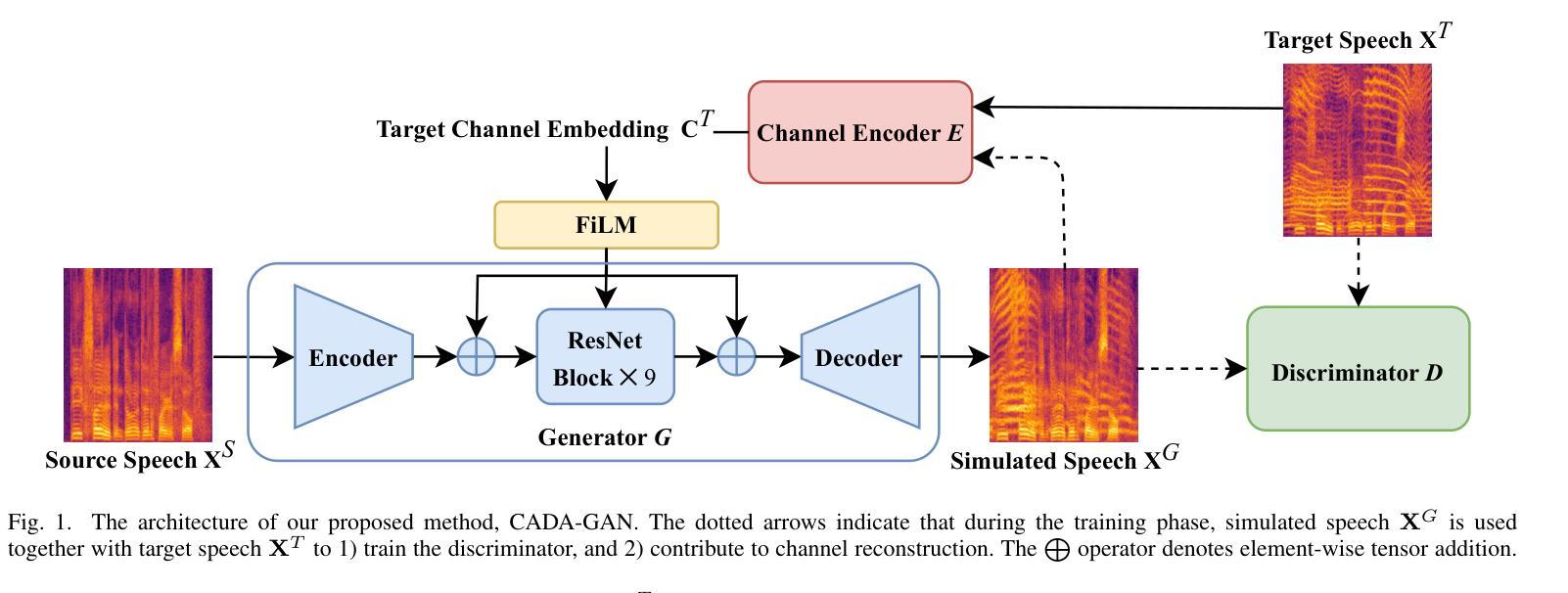
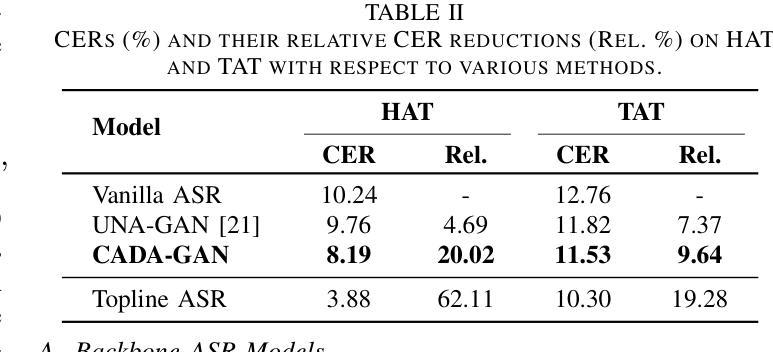
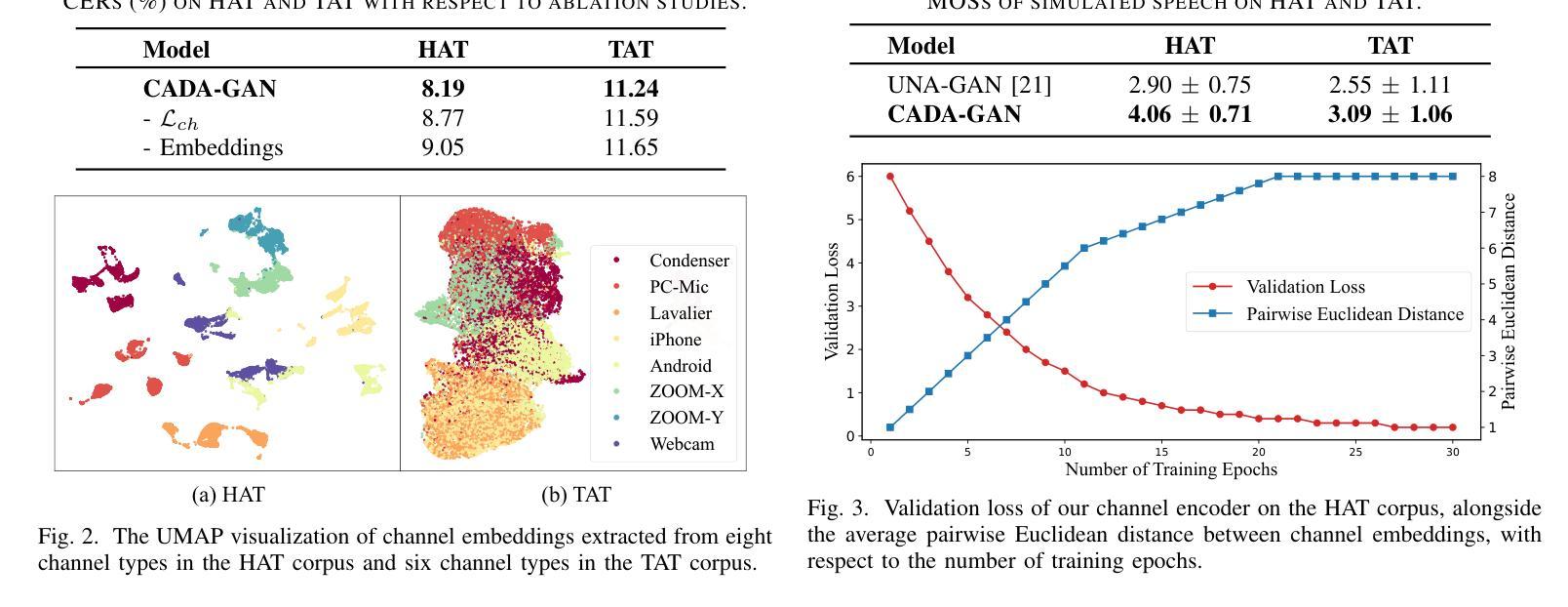
Channel-Aware Domain-Adaptive Generative Adversarial Network for Robust Speech Recognition
Authors:Chien-Chun Wang, Li-Wei Chen, Cheng-Kang Chou, Hung-Shin Lee, Berlin Chen, Hsin-Min Wang
While pre-trained automatic speech recognition (ASR) systems demonstrate impressive performance on matched domains, their performance often degrades when confronted with channel mismatch stemming from unseen recording environments and conditions. To mitigate this issue, we propose a novel channel-aware data simulation method for robust ASR training. Our method harnesses the synergistic power of channel-extractive techniques and generative adversarial networks (GANs). We first train a channel encoder capable of extracting embeddings from arbitrary audio. On top of this, channel embeddings are extracted using a minimal amount of target-domain data and used to guide a GAN-based speech synthesizer. This synthesizer generates speech that faithfully preserves the phonetic content of the input while mimicking the channel characteristics of the target domain. We evaluate our method on the challenging Hakka Across Taiwan (HAT) and Taiwanese Across Taiwan (TAT) corpora, achieving relative character error rate (CER) reductions of 20.02% and 9.64%, respectively, compared to the baselines. These results highlight the efficacy of our channel-aware data simulation method for bridging the gap between source- and target-domain acoustics.
预训练的自动语音识别(ASR)系统在匹配领域上表现出令人印象深刻的性能,但当面临由未见过的录音环境和条件导致的通道不匹配问题时,它们的性能往往会下降。为了缓解这个问题,我们提出了一种用于稳健ASR训练的新型通道感知数据仿真方法。我们的方法结合了通道提取技术和生成对抗网络(GANs)的协同力量。首先,我们训练一个能够从任意音频中提取嵌入的通道编码器。在此基础上,使用少量目标域数据提取通道嵌入,并用于指导基于GAN的语音合成器。该合成器生成的语音忠实保留了输入语音的语音内容,同时模仿目标域的通道特性。我们在具有挑战性的客家话(HAT)和台湾话(TAT)语料库上评估了我们的方法,与基线相比,相对字符错误率(CER)分别降低了20.02%和9.64%。这些结果凸显了我们的通道感知数据仿真方法在弥合源域和目标域声学之间的差距方面的有效性。
论文及项目相关链接
PDF Accepted to ICASSP 2025
Summary
本文提出一种新颖的通道感知数据仿真方法,用于增强自动语音识别(ASR)系统的鲁棒性训练。该方法结合了通道提取技术和生成对抗网络(GANs)的优势,通过训练通道编码器提取任意音频的嵌入信息,并使用少量目标域数据提取通道嵌入来引导基于GAN的语音合成器。合成器生成的语音既保留了输入语音的语音内容,又模仿了目标域的通道特性。在挑战性的客家话跨台湾(HAT)和台湾跨台湾(TAT)语料库上的评估结果表明,与基线相比,字符错误率(CER)分别降低了20.02%和9.64%,凸显了该通道感知数据仿真方法在弥合源域和目标域声学差异方面的有效性。
Key Takeaways
- 通道感知数据仿真方法用于增强ASR系统的鲁棒性训练。
- 结合了通道提取技术和生成对抗网络(GANs)。
- 通过训练通道编码器提取任意音频的嵌入信息。
- 使用少量目标域数据提取通道嵌入来引导GAN-based语音合成器。
- 合成器生成的语音既保留输入语音内容,又模仿目标域的通道特性。
- 在客家话跨台湾(HAT)和台湾跨台湾(TAT)语料库上进行了评估。
点此查看论文截图

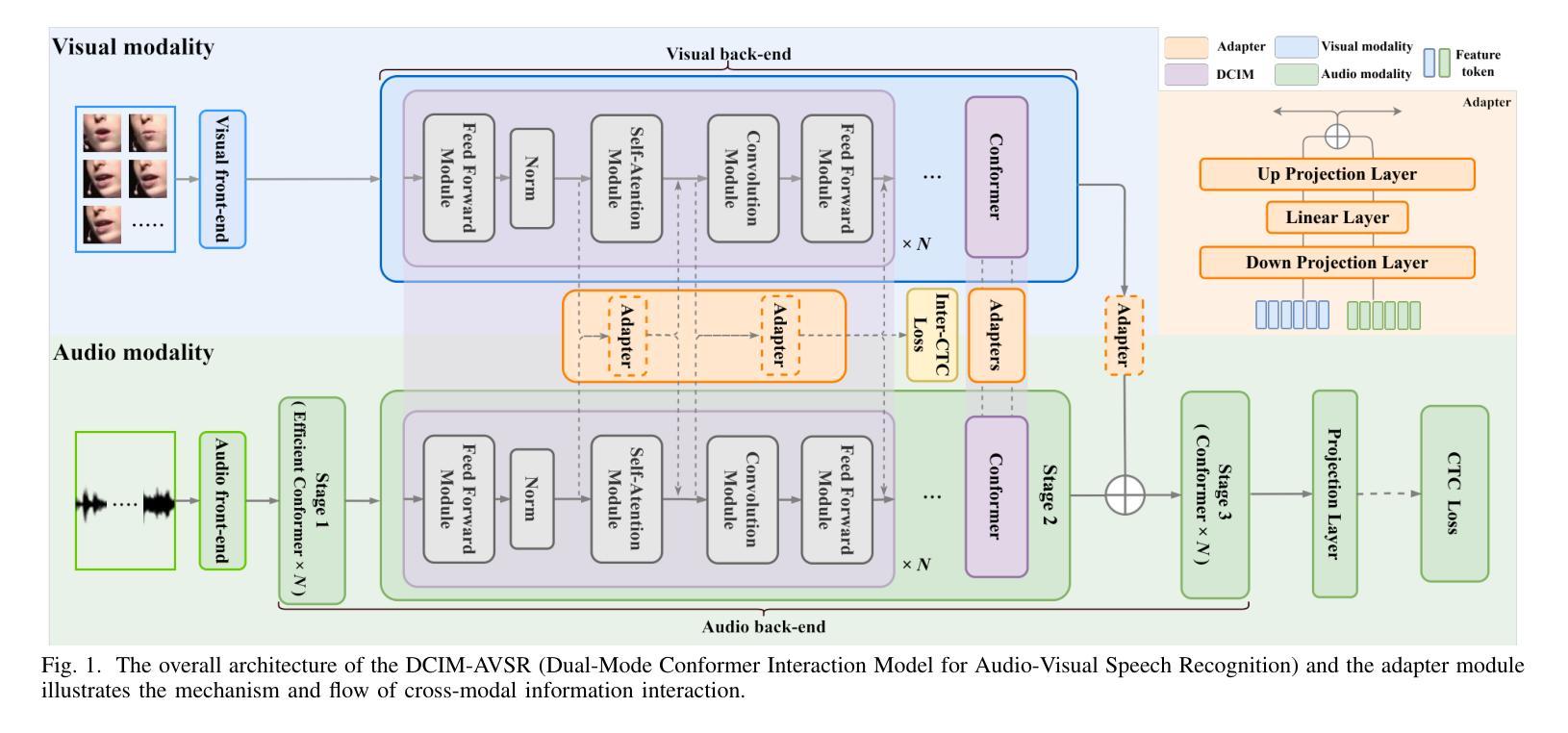
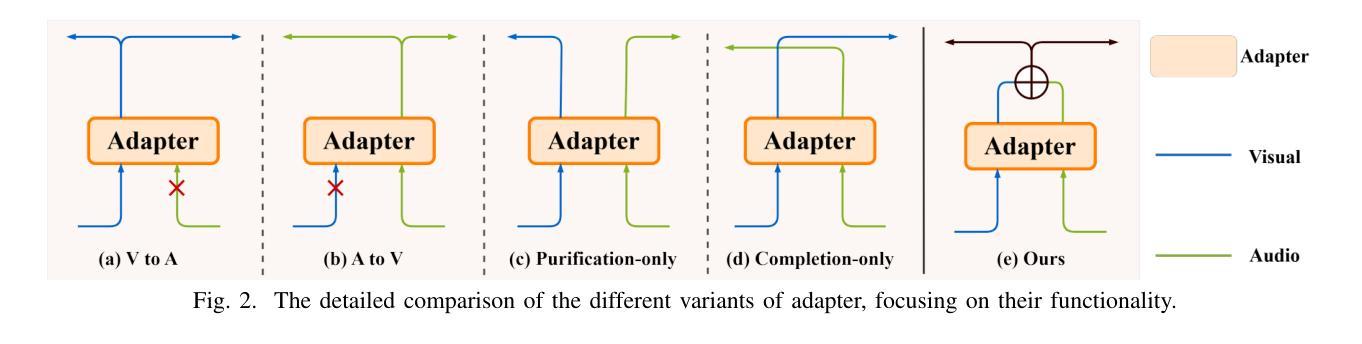
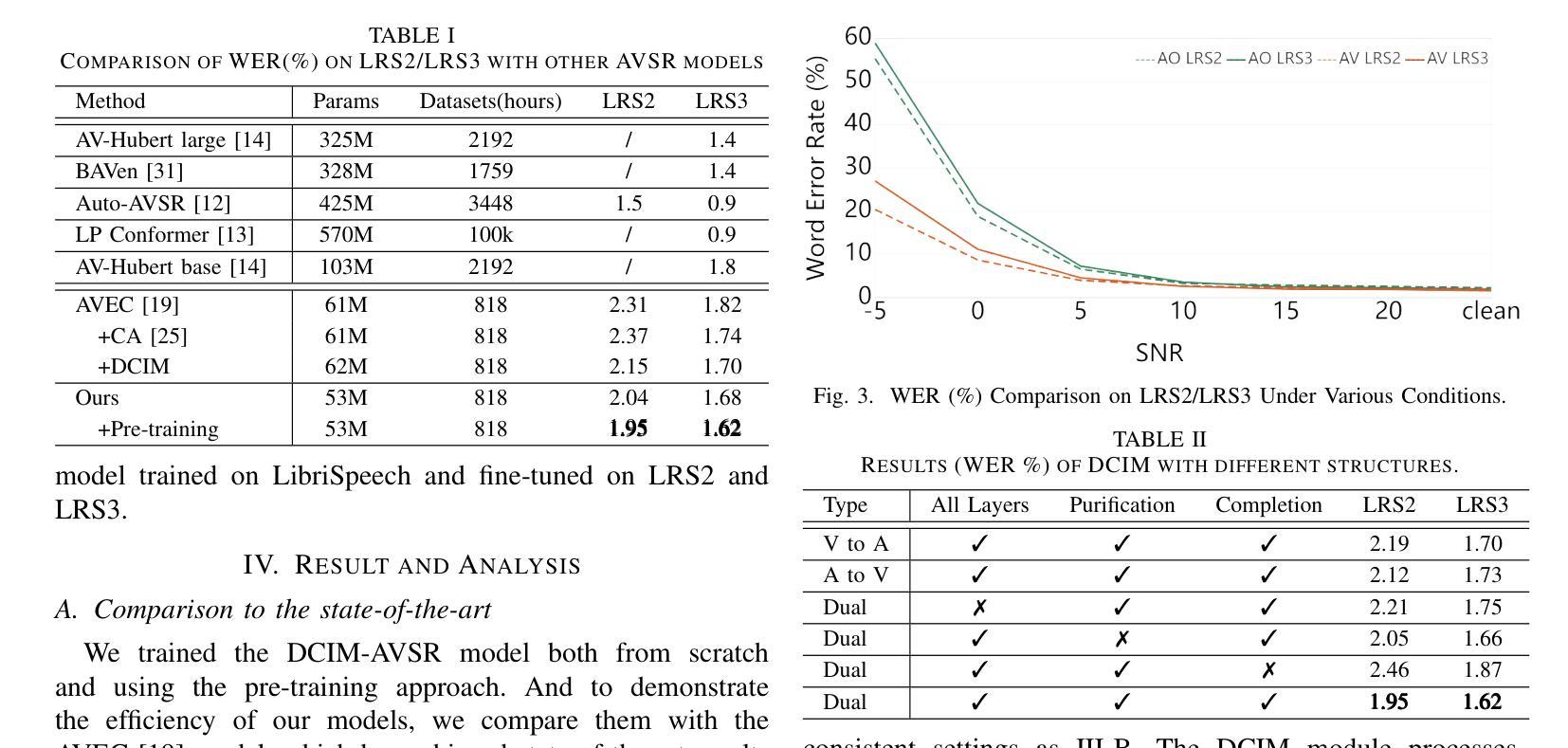
DCIM-AVSR : Efficient Audio-Visual Speech Recognition via Dual Conformer Interaction Module
Authors:Xinyu Wang, Haotian Jiang, Haolin Huang, Yu Fang, Mengjie Xu, Qian Wang
Speech recognition is the technology that enables machines to interpret and process human speech, converting spoken language into text or commands. This technology is essential for applications such as virtual assistants, transcription services, and communication tools. The Audio-Visual Speech Recognition (AVSR) model enhances traditional speech recognition, particularly in noisy environments, by incorporating visual modalities like lip movements and facial expressions. While traditional AVSR models trained on large-scale datasets with numerous parameters can achieve remarkable accuracy, often surpassing human performance, they also come with high training costs and deployment challenges. To address these issues, we introduce an efficient AVSR model that reduces the number of parameters through the integration of a Dual Conformer Interaction Module (DCIM). In addition, we propose a pre-training method that further optimizes model performance by selectively updating parameters, leading to significant improvements in efficiency. Unlike conventional models that require the system to independently learn the hierarchical relationship between audio and visual modalities, our approach incorporates this distinction directly into the model architecture. This design enhances both efficiency and performance, resulting in a more practical and effective solution for AVSR tasks.
语音识别是一项能够使机器解释和处理人类语音的技术,它将口语转化为文本或命令。对于虚拟助理、转录服务和通信工具等应用程序而言,这项技术至关重要。视听语音识别(AVSR)模型通过融入诸如嘴唇动作和面部表情等视觉模式,增强了传统语音识别的性能,特别是在嘈杂的环境中。虽然经过大规模数据集训练的传统AVSR模型具有许多参数,可以获得惊人的准确性,甚至超越人类表现,但它们也带来了高昂的训练成本和部署挑战。为了解决这些问题,我们引入了一个高效的AVSR模型,通过集成双卷积交互模块(DCIM)减少了参数数量。此外,我们还提出了一种预训练方法,通过选择性更新参数进一步优化模型性能,从而在效率上取得了显着提高。不同于传统模型需要系统独立学习音频和视觉模态之间的层次关系,我们的方法直接将这种区别纳入模型架构中。这种设计提高了效率和性能,为AVSR任务提供了更实用、更有效的解决方案。
论文及项目相关链接
PDF Accepted to ICASSP 2025
摘要
该文本介绍了一种改进的视听语音识别模型,通过引入双转换器交互模块和预训练方法来优化性能和效率,使其在嘈杂环境中实现高效、准确的语音识别。
关键要点
- 该模型通过引入双转换器交互模块来减少参数数量,提高了视听语音识别的效率。
- 提出了一种预训练方法,通过选择性更新参数来优化模型性能。
- 该模型将视听模态的层次关系直接融入模型架构中,增强了效率和性能。
- 改进后的模型在嘈杂环境中实现高效、准确的语音识别。
- 该模型减少了训练成本,提高了部署效率。
- 该模型提高了视听语音识别的实用性和有效性。
点此查看论文截图

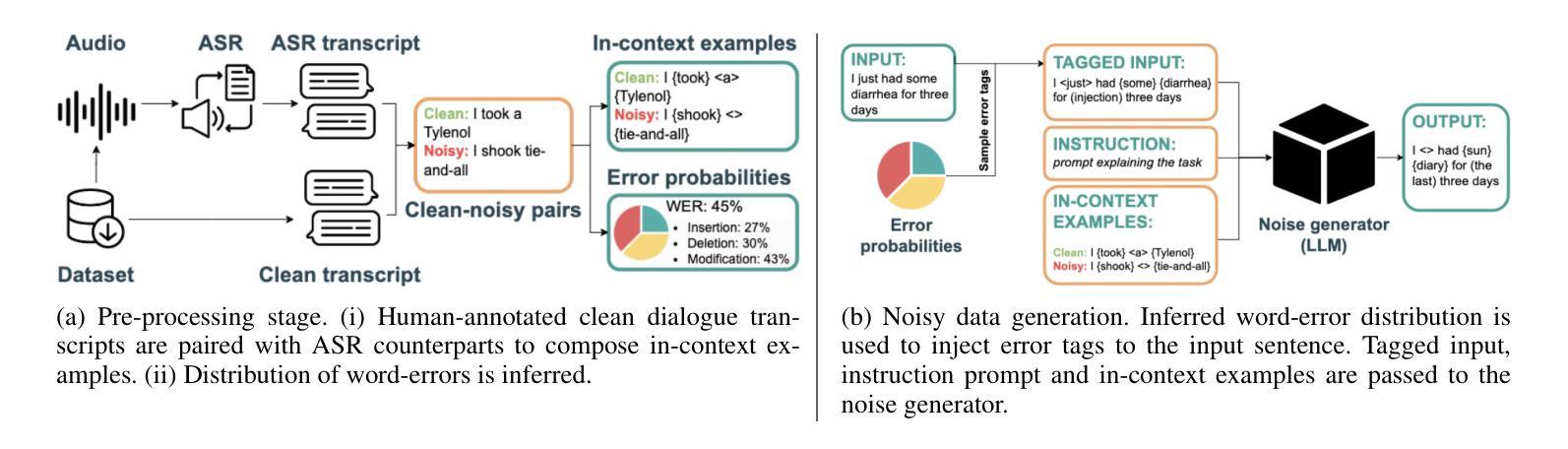
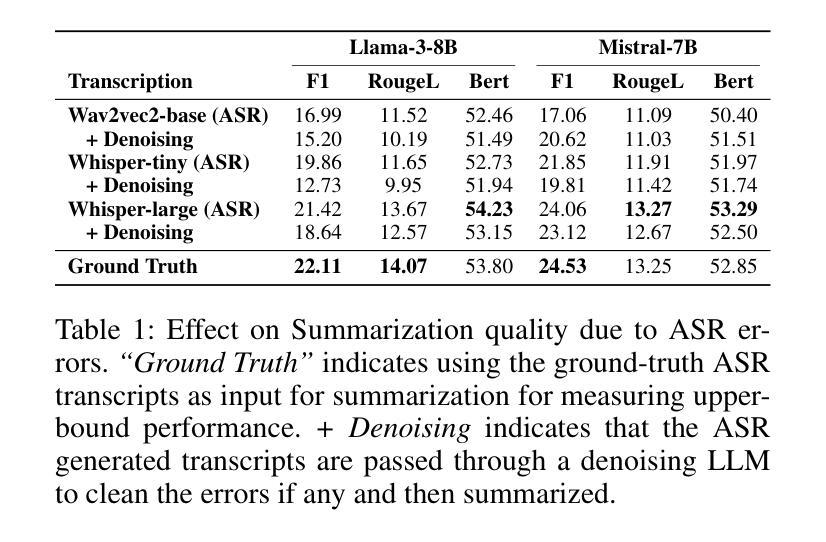
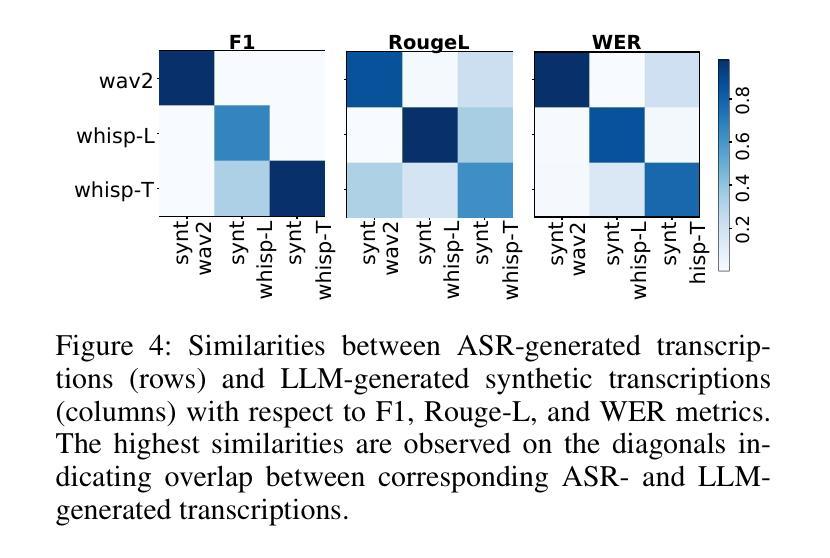
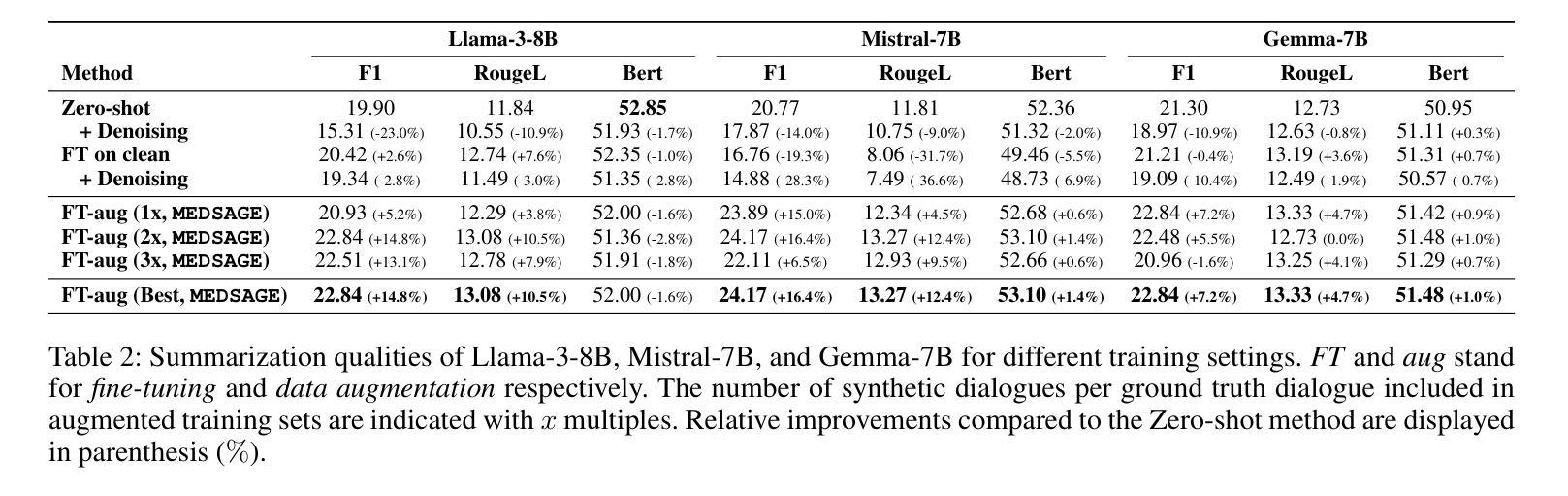
MEDSAGE: Enhancing Robustness of Medical Dialogue Summarization to ASR Errors with LLM-generated Synthetic Dialogues
Authors:Kuluhan Binici, Abhinav Ramesh Kashyap, Viktor Schlegel, Andy T. Liu, Vijay Prakash Dwivedi, Thanh-Tung Nguyen, Xiaoxue Gao, Nancy F. Chen, Stefan Winkler
Automatic Speech Recognition (ASR) systems are pivotal in transcribing speech into text, yet the errors they introduce can significantly degrade the performance of downstream tasks like summarization. This issue is particularly pronounced in clinical dialogue summarization, a low-resource domain where supervised data for fine-tuning is scarce, necessitating the use of ASR models as black-box solutions. Employing conventional data augmentation for enhancing the noise robustness of summarization models is not feasible either due to the unavailability of sufficient medical dialogue audio recordings and corresponding ASR transcripts. To address this challenge, we propose MEDSAGE, an approach for generating synthetic samples for data augmentation using Large Language Models (LLMs). Specifically, we leverage the in-context learning capabilities of LLMs and instruct them to generate ASR-like errors based on a few available medical dialogue examples with audio recordings. Experimental results show that LLMs can effectively model ASR noise, and incorporating this noisy data into the training process significantly improves the robustness and accuracy of medical dialogue summarization systems. This approach addresses the challenges of noisy ASR outputs in critical applications, offering a robust solution to enhance the reliability of clinical dialogue summarization.
自动语音识别(ASR)系统在将语音转录为文本方面起着至关重要的作用,但它们引入的错误会显著影响下游任务(如摘要)的性能。这一问题在临床对话摘要中尤为突出,这是一个资源匮乏的领域,缺乏微调所需的大量监督数据,因此需要使用ASR模型作为黑箱解决方案。由于缺少足够的医学对话音频录音和相应的ASR转录,因此采用传统数据增强方法来提高摘要模型的抗噪性能并不可行。为了解决这一挑战,我们提出了MEDSAGE方法,这是一种利用大型语言模型(LLM)生成合成样本进行数据增强的方法。具体来说,我们利用LLM的上下文学习能力,以少量可用的医学对话例子(带有音频录音)为基础,指导它们生成类似ASR的错误。实验结果表明,LLM可以有效地模拟ASR噪声,将这种嘈杂的数据纳入训练过程,可以显著提高医学对话摘要系统的稳健性和准确性。该方法解决了关键应用中ASR输出噪声的问题,为提高临床对话摘要的可靠性提供了稳健的解决方案。
论文及项目相关链接
PDF Accepted by the Thirty-Ninth AAAI Conference on Artificial Intelligence (AAAI-25)
Summary
自动语音识别(ASR)系统对将语音转化为文本具有关键作用,但其产生的错误会对下游任务如摘要的生成性能产生严重影响。特别是在临床对话摘要这一资源匮乏的领域,由于缺少精细调整所需的监督数据,必须依赖ASR模型作为黑箱解决方案。由于缺少足够的医疗对话音频录音和相应的ASR转录,使用传统数据增强方法提高摘要模型的抗噪声能力并不可行。为解决这一挑战,我们提出MEDSAGE方法,利用大型语言模型(LLM)生成合成样本进行数据增强。我们利用LLM的上下文学习能力,根据少量可用的带音频录音的医疗对话示例,指导它们生成类似ASR的错误。实验结果表明,LLM可以有效模拟ASR噪声,将这类噪声数据纳入训练过程,能显著提高医疗对话摘要系统的稳健性和准确性。该方法解决了噪声ASR输出在关键应用中的挑战,为提高临床对话摘要的可靠性提供了稳健的解决方案。
Key Takeaways
- ASR系统在转录语音为文本时的重要性及其可能产生的错误对下游任务的影响。
- 临床对话摘要是一个资源匮乏的领域,需要解决ASR模型的挑战。
- 传统数据增强方法因缺乏医疗对话音频录音和相应的ASR转录而不可行。
- MEDSAGE方法利用大型语言模型生成合成样本进行数据增强。
- LLMs可以有效地模拟ASR噪声。
- 将噪声数据纳入训练过程可以提高医疗对话摘要系统的稳健性和准确性。
点此查看论文截图




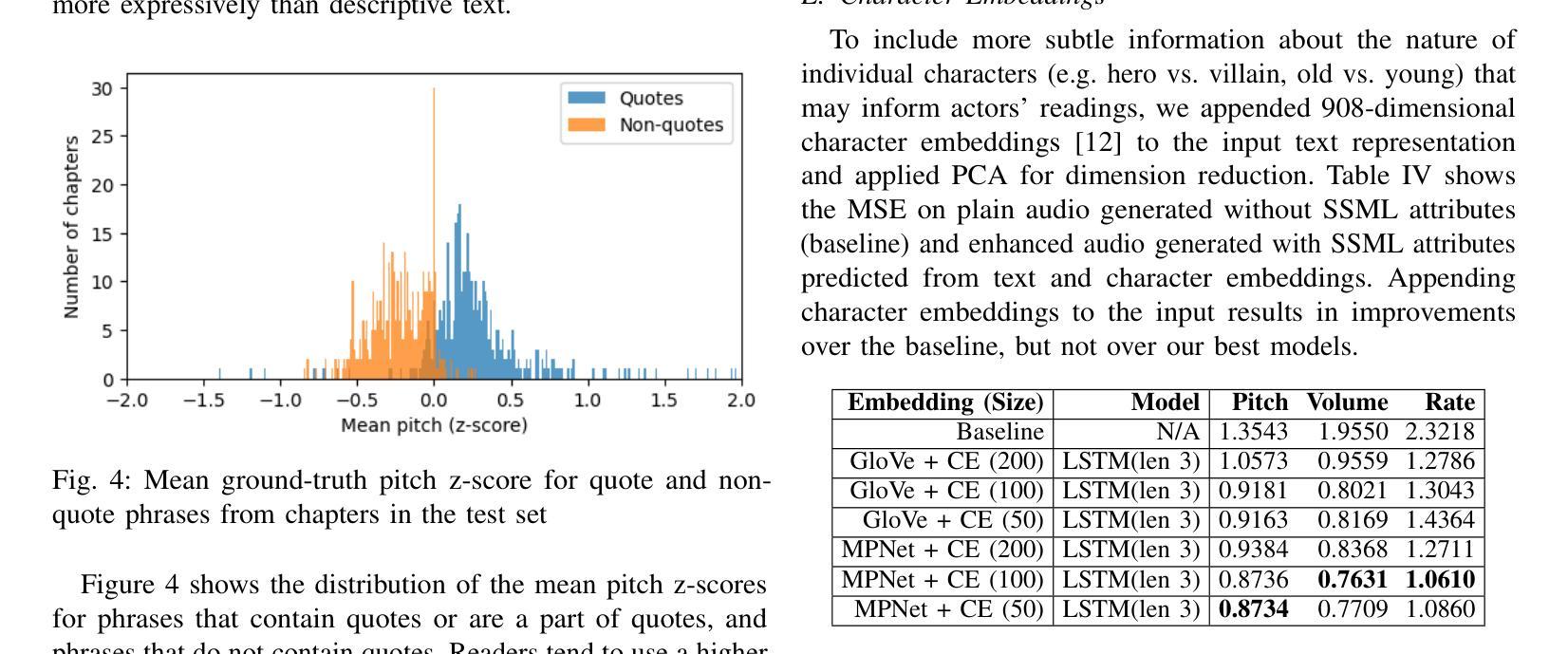
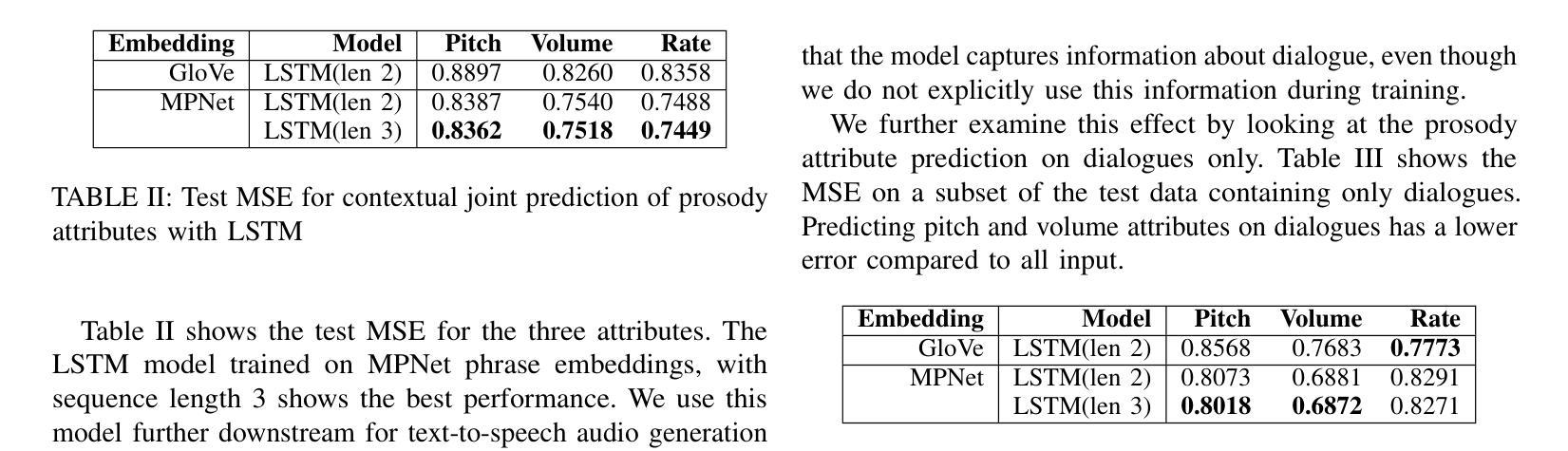
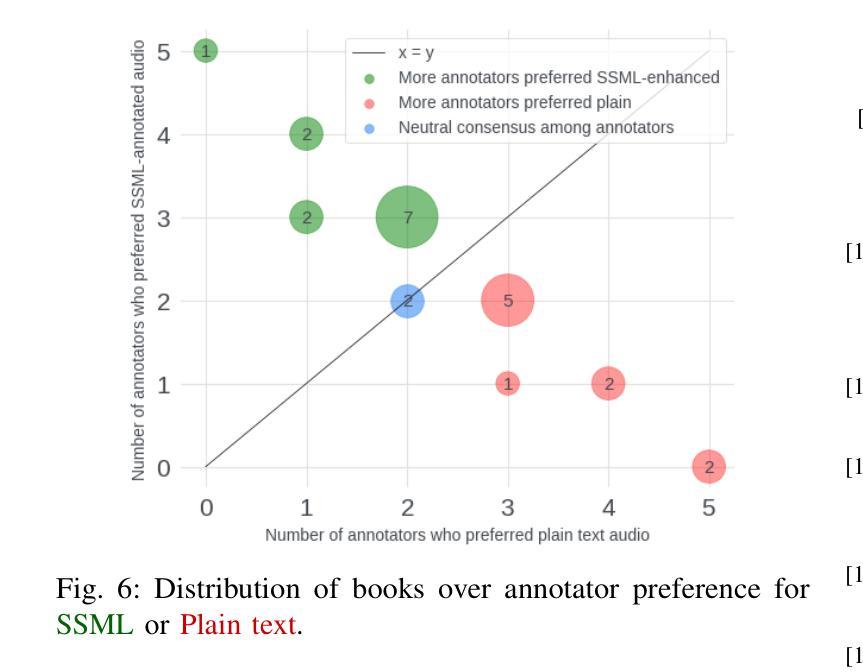
Prosody Analysis of Audiobooks
Authors:Charuta Pethe, Bach Pham, Felix D Childress, Yunting Yin, Steven Skiena
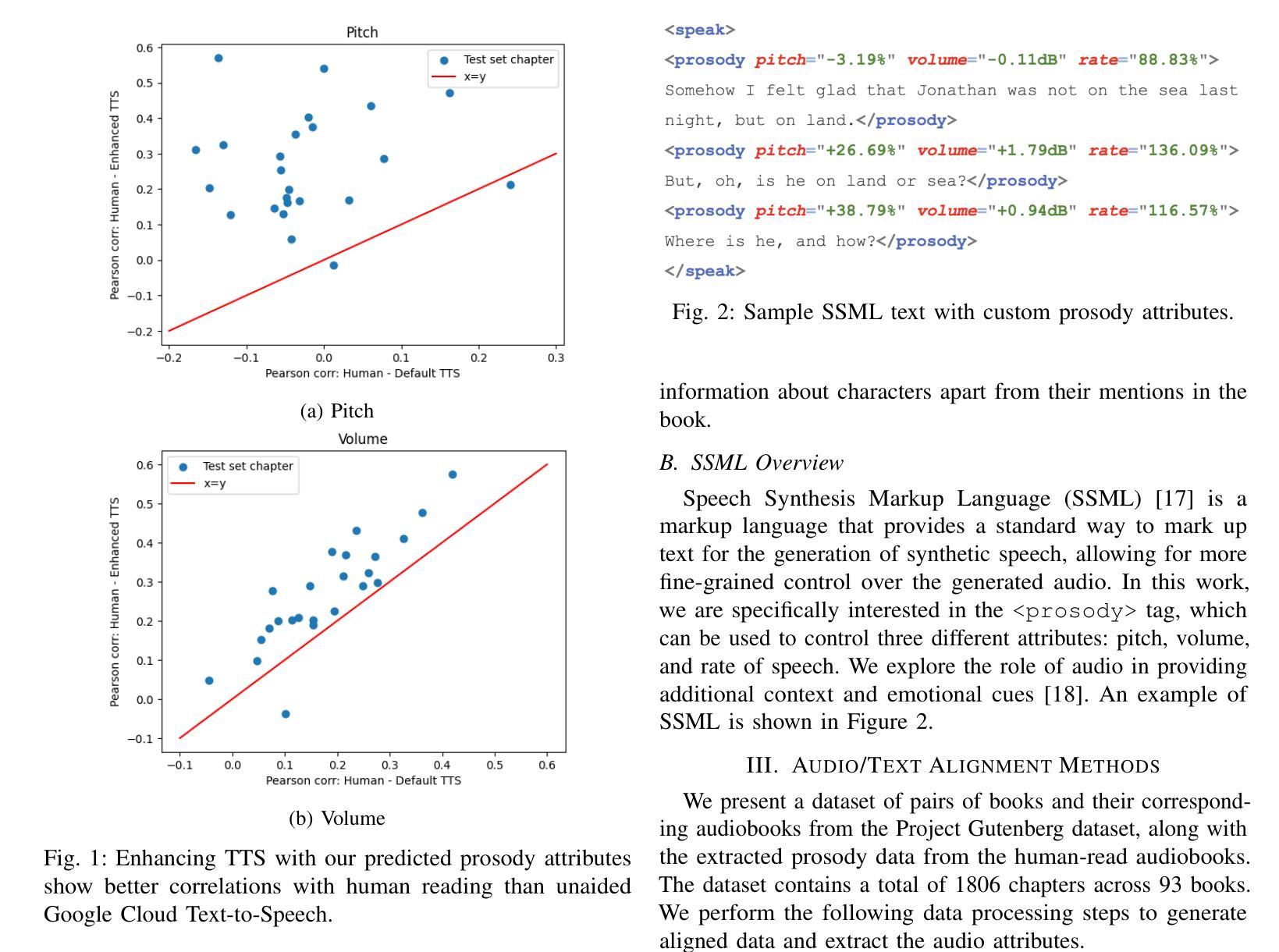
Recent advances in text-to-speech have made it possible to generate natural-sounding audio from text. However, audiobook narrations involve dramatic vocalizations and intonations by the reader, with greater reliance on emotions, dialogues, and descriptions in the narrative. Using our dataset of 93 aligned book-audiobook pairs, we present improved models for prosody prediction properties (pitch, volume, and rate of speech) from narrative text using language modeling. Our predicted prosody attributes correlate much better with human audiobook readings than results from a state-of-the-art commercial TTS system: our predicted pitch shows a higher correlation with human reading for 22 out of the 24 books, while our predicted volume attribute proves more similar to human reading for 23 out of the 24 books. Finally, we present a human evaluation study to quantify the extent that people prefer prosody-enhanced audiobook readings over commercial text-to-speech systems.
近期文本转语音(TTS)技术的进步使得从文本生成自然声音的音频成为可能。然而,有声书的叙述涉及读者的大胆发声和语调变化,更加依赖于叙述中的情感、对话和描述。使用我们93本已对齐的书籍与有声书的数据集,我们提出了采用语言建模来预测叙述文本中的韵律属性(音调、音量和语速)的改进模型。我们的预测韵律属性与人类有声书阅读之间的相关性要好于最先进商业TTS系统的结果:在我们预测的音调方面,有22本图书与人的阅读高度相关;预测音量属性方面,有23本图书与人的阅读高度相似。最后,我们进行了一项人类评估研究,量化人们对于带韵律增强功能的有声书阅读与商业文本转语音系统偏好程度如何。
论文及项目相关链接
PDF Accepted to IEEE ICSC 2025
Summary
随着文本转语音技术的最新进展,从文本生成自然音频已成为可能。针对有声书朗读中需要更多情感和叙述性的特点,本文使用包含93个对齐的书籍-有声书对数据集,提出了改进的语言模型来预测语调属性(音调、音量和语速)。预测结果与真人朗读高度一致,相较于先进的商业文本转语音系统有更好的表现。并进行了人类评估实验,定量研究了人们对于有语调增强功能的有声书阅读的偏好。
Key Takeaways
- 文本转语音技术现在可以生成自然的音频。
- 有声书朗读涉及更多的情感和叙述性元素。
- 使用语言模型对语调属性(音调、音量和语速)进行预测改进。
- 对比商业文本转语音系统,改进模型的预测结果更接近真人朗读。
- 在预测音调方面,改进模型在22本书中的表现优于真人朗读。
- 在预测音量方面,改进模型在大多数书籍中的表现接近真人朗读。
点此查看论文截图