⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-10 更新
GLoG-CSUnet: Enhancing Vision Transformers with Adaptable Radiomic Features for Medical Image Segmentation
Authors:Niloufar Eghbali, Hassan Bagher-Ebadian, Tuka Alhanai, Mohammad M. Ghassemi
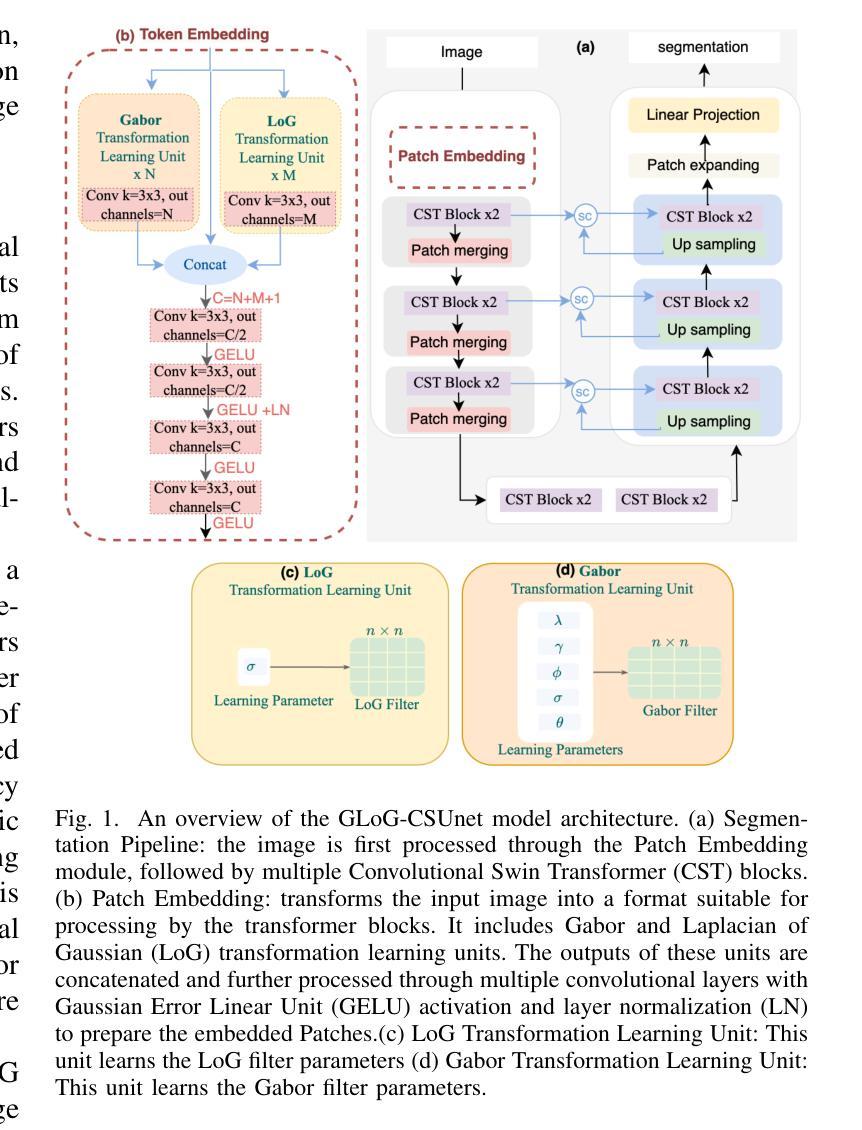
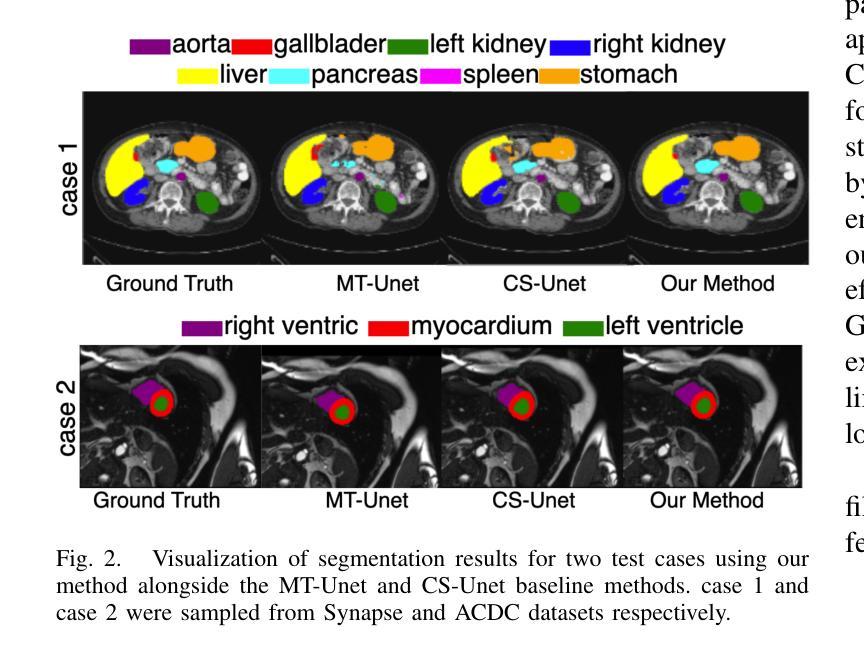
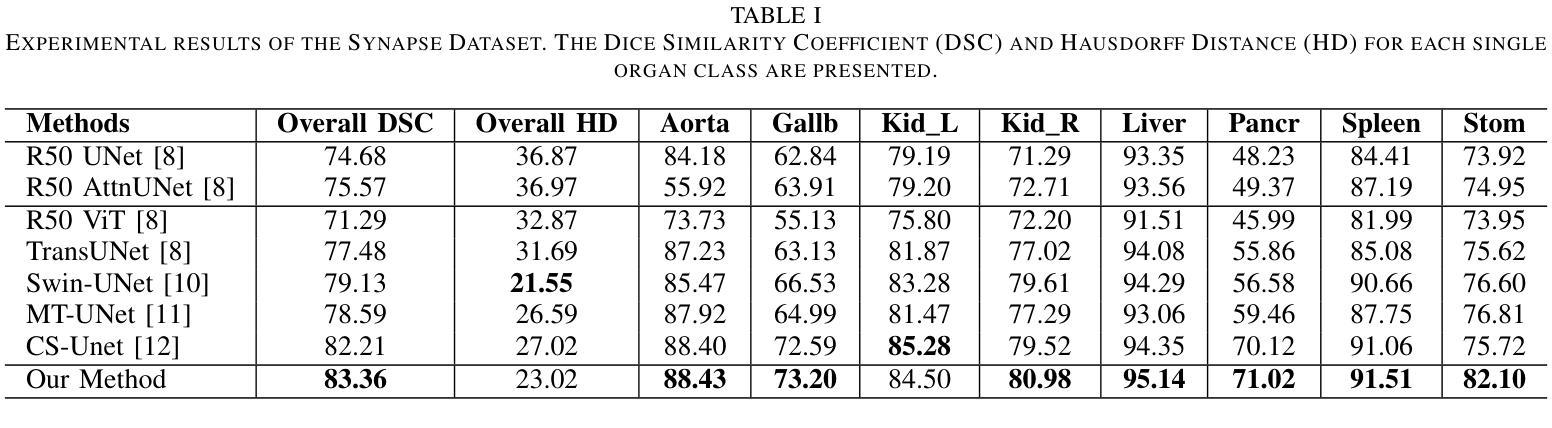
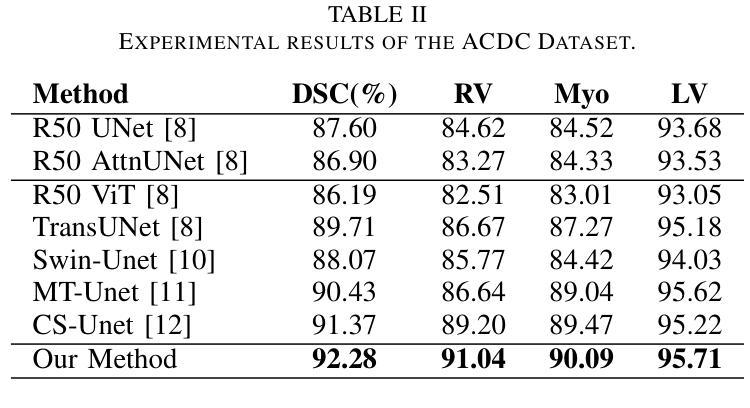
Vision Transformers (ViTs) have shown promise in medical image semantic segmentation (MISS) by capturing long-range correlations. However, ViTs often struggle to model local spatial information effectively, which is essential for accurately segmenting fine anatomical details, particularly when applied to small datasets without extensive pre-training. We introduce Gabor and Laplacian of Gaussian Convolutional Swin Network (GLoG-CSUnet), a novel architecture enhancing Transformer-based models by incorporating learnable radiomic features. This approach integrates dynamically adaptive Gabor and Laplacian of Gaussian (LoG) filters to capture texture, edge, and boundary information, enhancing the feature representation processed by the Transformer model. Our method uniquely combines the long-range dependency modeling of Transformers with the texture analysis capabilities of Gabor and LoG features. Evaluated on the Synapse multi-organ and ACDC cardiac segmentation datasets, GLoG-CSUnet demonstrates significant improvements over state-of-the-art models, achieving a 1.14% increase in Dice score for Synapse and 0.99% for ACDC, with minimal computational overhead (only 15 and 30 additional parameters, respectively). GLoG-CSUnet’s flexible design allows integration with various base models, offering a promising approach for incorporating radiomics-inspired feature extraction in Transformer architectures for medical image analysis. The code implementation is available on GitHub at: https://github.com/HAAIL/GLoG-CSUnet.
视觉Transformer(ViT)通过捕捉长程相关性在医学图像语义分割(MISS)中显示出潜力。然而,ViT在建模局部空间信息时往往效果不佳,这对于准确分割精细的解剖细节至关重要,尤其是在未进行广泛预训练的情况下应用于小规模数据集时。我们引入了Gabor和Gaussian的Laplacian卷积Swin网络(GLoG-CSUnet),这是一种新型架构,通过融入可学习的放射学特征来增强基于Transformer的模型。该方法结合了动态自适应的Gabor和Gaussian的Laplacian(LoG)滤波器,以捕获纹理、边缘和边界信息,增强Transformer模型处理的特征表示。我们的方法独特地结合了Transformer的长程依赖建模与Gabor和LoG特征的纹理分析能力。在Synapse多器官和ACDC心脏分割数据集上进行评估,GLoG-CSUnet在最新模型上实现了显著改进,Synapse的Dice得分增加了1.14%,ACDC增加了0.99%,且计算开销极小(仅分别增加了15和30个额外参数)。GLoG-CSUnet的设计灵活,可与各种基础模型集成,为在Transformer架构中融入放射学启发特征提取的医学图像分析提供了有前景的方法。代码实现可在GitHub上找到:https://github.com/HAAIL/GLoG-CSUnet。
论文及项目相关链接
Summary
一篇关于Vision Transformers(ViTs)在医学图像语义分割(MISS)中应用的研究论文。论文介绍了GLoG-CSUnet这一新型架构,它通过引入可学习的放射学特征,增强了基于Transformer的模型。该架构结合了Gabor和Laplacian of Gaussian(LoG)滤波器,以捕获纹理、边缘和边界信息,从而提高Transformer模型的特征表示能力。在Synapse多器官和ACDC心脏分割数据集上的评估显示,GLoG-CSUnet较现有模型有显著改进,Dice得分分别提高了1.14%和0.99%,且计算开销较小。
Key Takeaways
- Vision Transformers (ViTs) 在医学图像语义分割(MISS)中有应用潜力,但面临局部空间信息建模的挑战。
- GLoG-CSUnet是一种新型架构,旨在增强基于Transformer的模型,通过引入可学习的放射学特征来提升性能。
- GLoG-CSUnet结合了Gabor和LoG滤波器,以捕获纹理、边缘和边界信息,优化特征表示。
- GLoG-CSUnet在Synapse多器官和ACDC心脏分割数据集上的表现优于现有模型,Dice得分有显著提高。
- GLoG-CSUnet的设计具有灵活性,可与其他基础模型集成。
- 该方法展示了在Transformer架构中融入放射学特征提取的潜力。
- GLoG-CSUnet的代码实现已公开在GitHub上。
点此查看论文截图

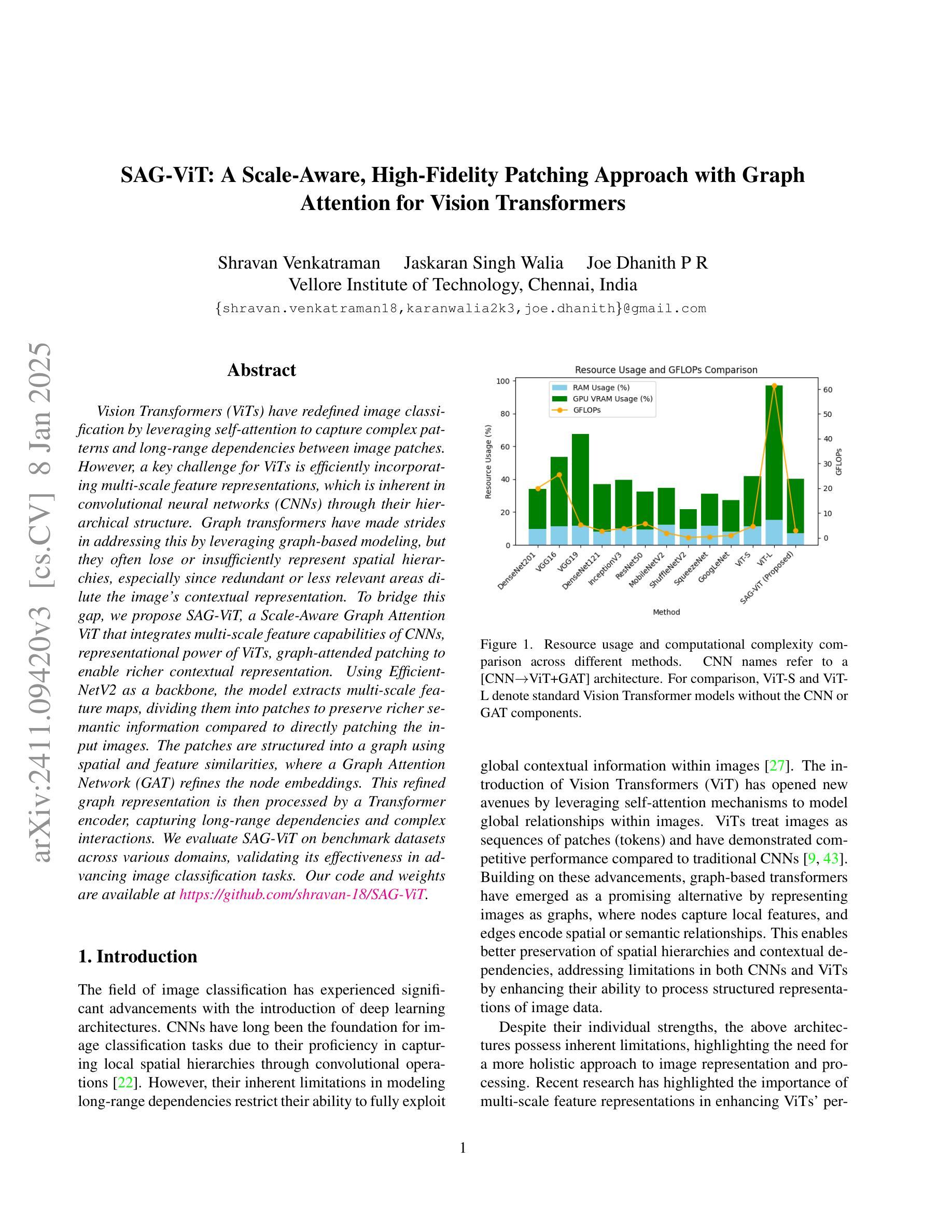
SAG-ViT: A Scale-Aware, High-Fidelity Patching Approach with Graph Attention for Vision Transformers
Authors:Shravan Venkatraman, Jaskaran Singh Walia, Joe Dhanith P R
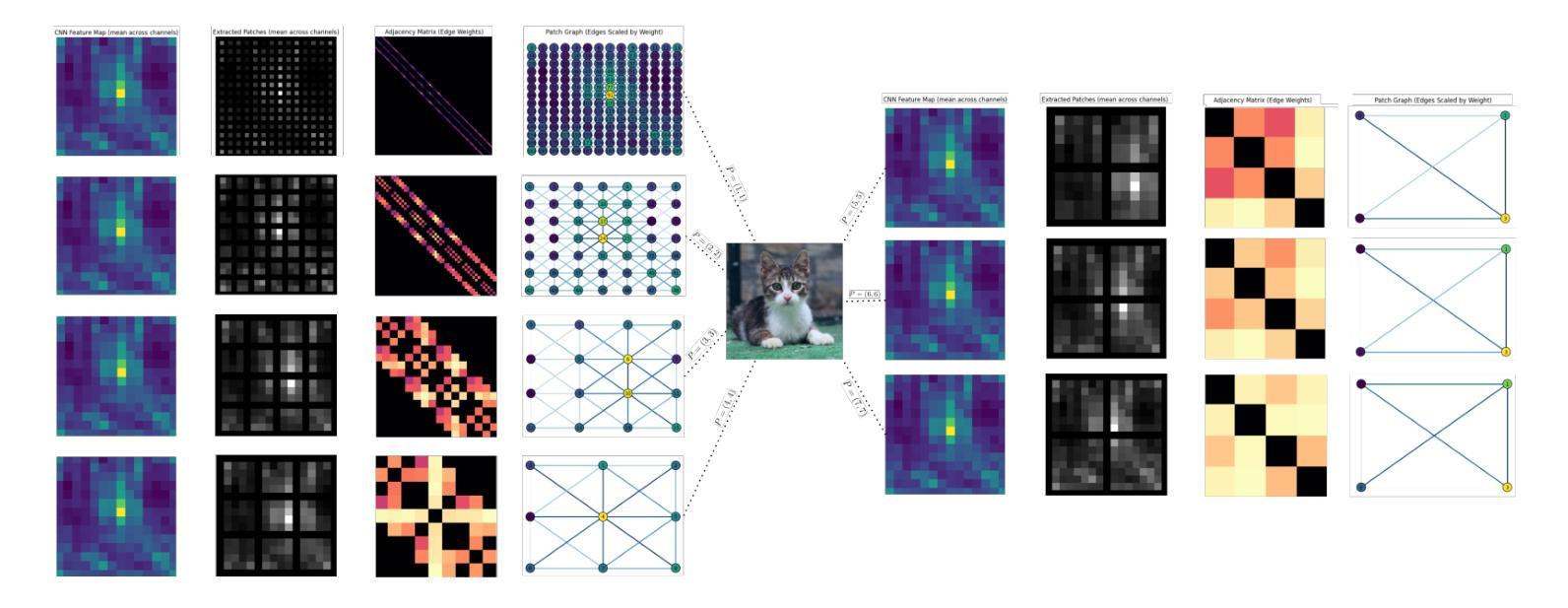
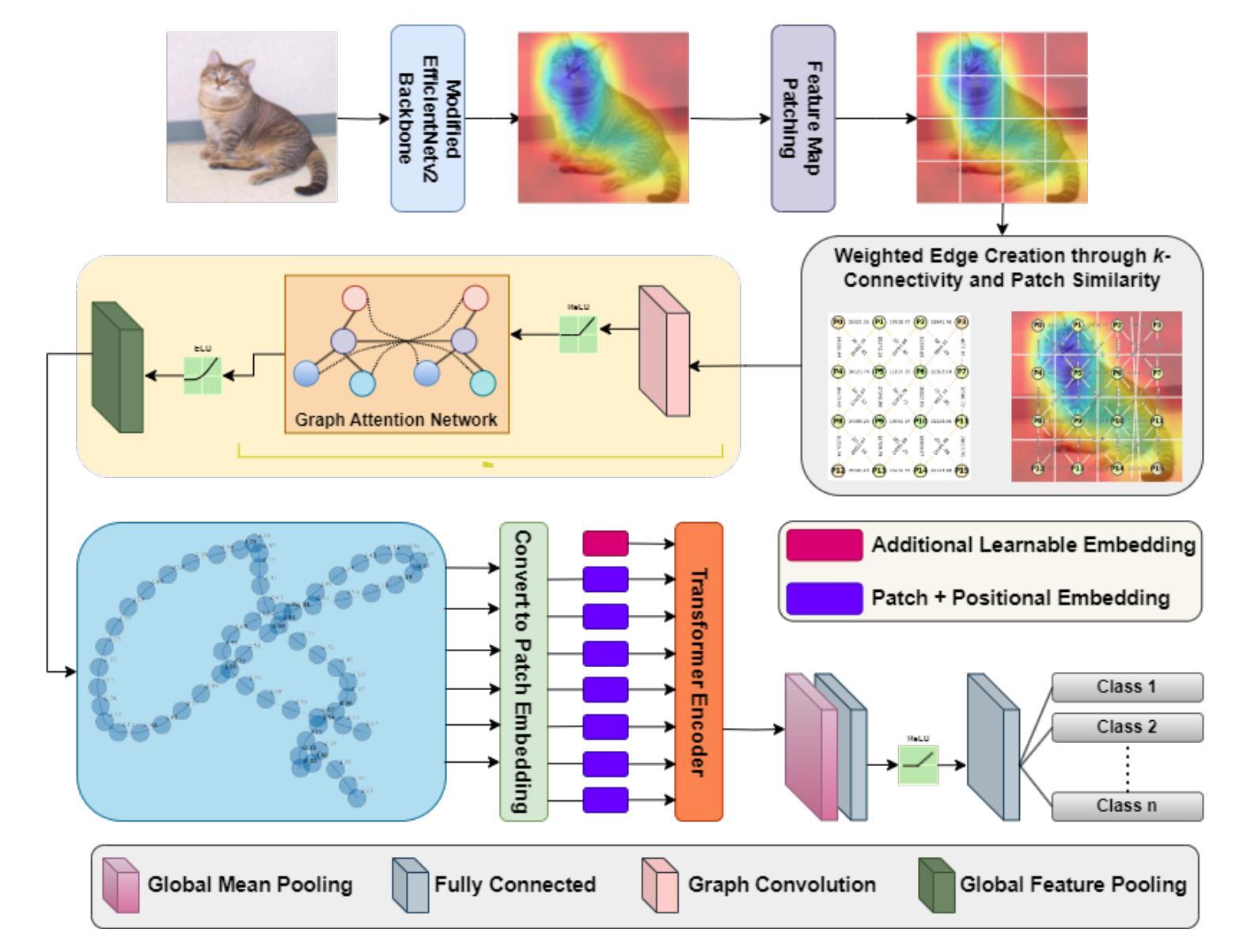
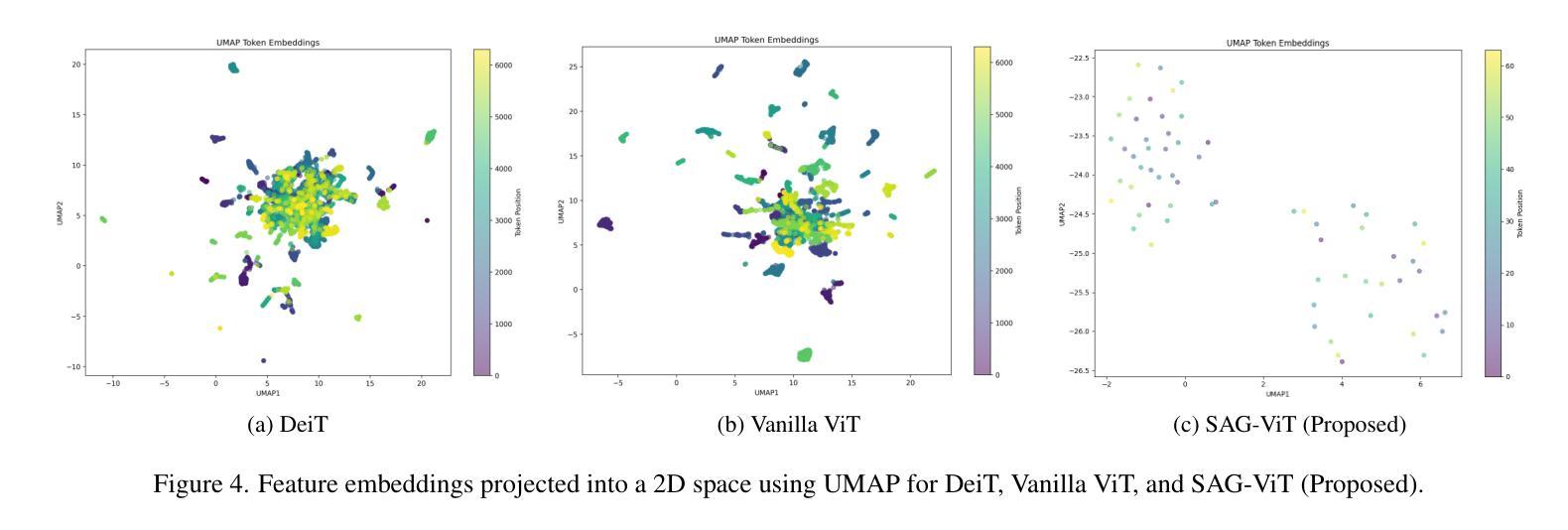
Vision Transformers (ViTs) have redefined image classification by leveraging self-attention to capture complex patterns and long-range dependencies between image patches. However, a key challenge for ViTs is efficiently incorporating multi-scale feature representations, which is inherent in convolutional neural networks (CNNs) through their hierarchical structure. Graph transformers have made strides in addressing this by leveraging graph-based modeling, but they often lose or insufficiently represent spatial hierarchies, especially since redundant or less relevant areas dilute the image’s contextual representation. To bridge this gap, we propose SAG-ViT, a Scale-Aware Graph Attention ViT that integrates multi-scale feature capabilities of CNNs, representational power of ViTs, graph-attended patching to enable richer contextual representation. Using EfficientNetV2 as a backbone, the model extracts multi-scale feature maps, dividing them into patches to preserve richer semantic information compared to directly patching the input images. The patches are structured into a graph using spatial and feature similarities, where a Graph Attention Network (GAT) refines the node embeddings. This refined graph representation is then processed by a Transformer encoder, capturing long-range dependencies and complex interactions. We evaluate SAG-ViT on benchmark datasets across various domains, validating its effectiveness in advancing image classification tasks. Our code and weights are available at https://github.com/shravan-18/SAG-ViT.
Vision Transformers(ViTs)通过利用自注意力机制来捕捉图像补丁之间的复杂模式和长距离依赖关系,从而重新定义了图像分类。然而,ViTs的关键挑战在于如何有效地融入多尺度特征表示,而这一点是卷积神经网络(CNNs)所固有的,得益于其分层结构。图变压器通过利用基于图的建模在这方面取得了进展,但它们往往会丢失或不足以表示空间层次结构,尤其是因为冗余或不太相关的区域会稀释图像的上下文表示。为了弥补这一差距,我们提出了SAG-ViT,这是一种融合CNN的多尺度特征能力、ViTs的表示能力以及图注意力修补的Scale-Aware Graph Attention ViT,以实现更丰富的上下文表示。我们以EfficientNetV2作为骨干网,该模型提取多尺度特征图,将它们分成补丁,以保留比直接修补输入图像更丰富的语义信息。这些补丁使用空间特征和相似性构建成图,其中图注意力网络(GAT)对节点嵌入进行细化。然后,这个精细的图表示被Transformer编码器处理,捕捉长距离依赖关系和复杂交互。我们在各种领域的基准数据集上评估了SAG-ViT,验证了其在推进图像分类任务方面的有效性。我们的代码和权重可在https://github.com/shravan-1-地着王宪亚续找转期车世2向冲冲们表现超越量。(我们的代码和权重可在 https://github.com/shravan-18/SAG-ViT 找到。)
论文及项目相关链接
PDF 14 pages, 8 figures, 9 tables
Summary
ViTs通过利用自注意力机制捕捉图像补丁之间的复杂模式和长距离依赖关系,从而重新定义了图像分类。然而,ViTs面临的关键挑战是有效地结合多尺度特征表示,这在卷积神经网络(CNN)中是通过其层次结构固有的。为解决这一挑战,我们提出了SAG-ViT,这是一种结合CNN多尺度特征能力、ViT表征能力和图注意补丁技术以丰富上下文表示的尺度感知图注意ViT。我们以EfficientNetV2作为骨干网,提取多尺度特征图并将其划分为补丁,以保存丰富的语义信息。这些补丁被结构化成一个图,利用空间特征和相似性,通过图注意力网络(GAT)精炼节点嵌入。然后,精炼的图表示被传递给Transformer编码器,捕捉长距离依赖关系和复杂交互。我们在各种领域的基准数据集上评估了SAG-ViT的有效性,验证了其在图像分类任务上的进步。我们的代码和权重可在https://github.com/shravan-18/SAG-ViT找到。
Key Takeaways
- ViTs利用自注意力机制进行图像分类,但面临结合多尺度特征表示的挑战。
- SAG-ViT结合了CNN的多尺度特征能力、ViT的表征能力和图注意补丁技术。
- EfficientNetV2作为骨干网用于提取多尺度特征图,再划分为补丁以保存丰富的语义信息。
- 图注意力网络(GAT)用于精炼由补丁构成的图中的节点嵌入。
- 精炼的图表示通过Transformer编码器处理,捕捉长距离依赖关系和复杂交互。
- SAG-ViT在多个基准数据集上的表现验证了其在图像分类任务上的有效性。
点此查看论文截图