⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-13 更新
Improving Zero-Shot Object-Level Change Detection by Incorporating Visual Correspondence
Authors:Hung Huy Nguyen, Pooyan Rahmanzadehgervi, Long Mail, Anh Totti Nguyen
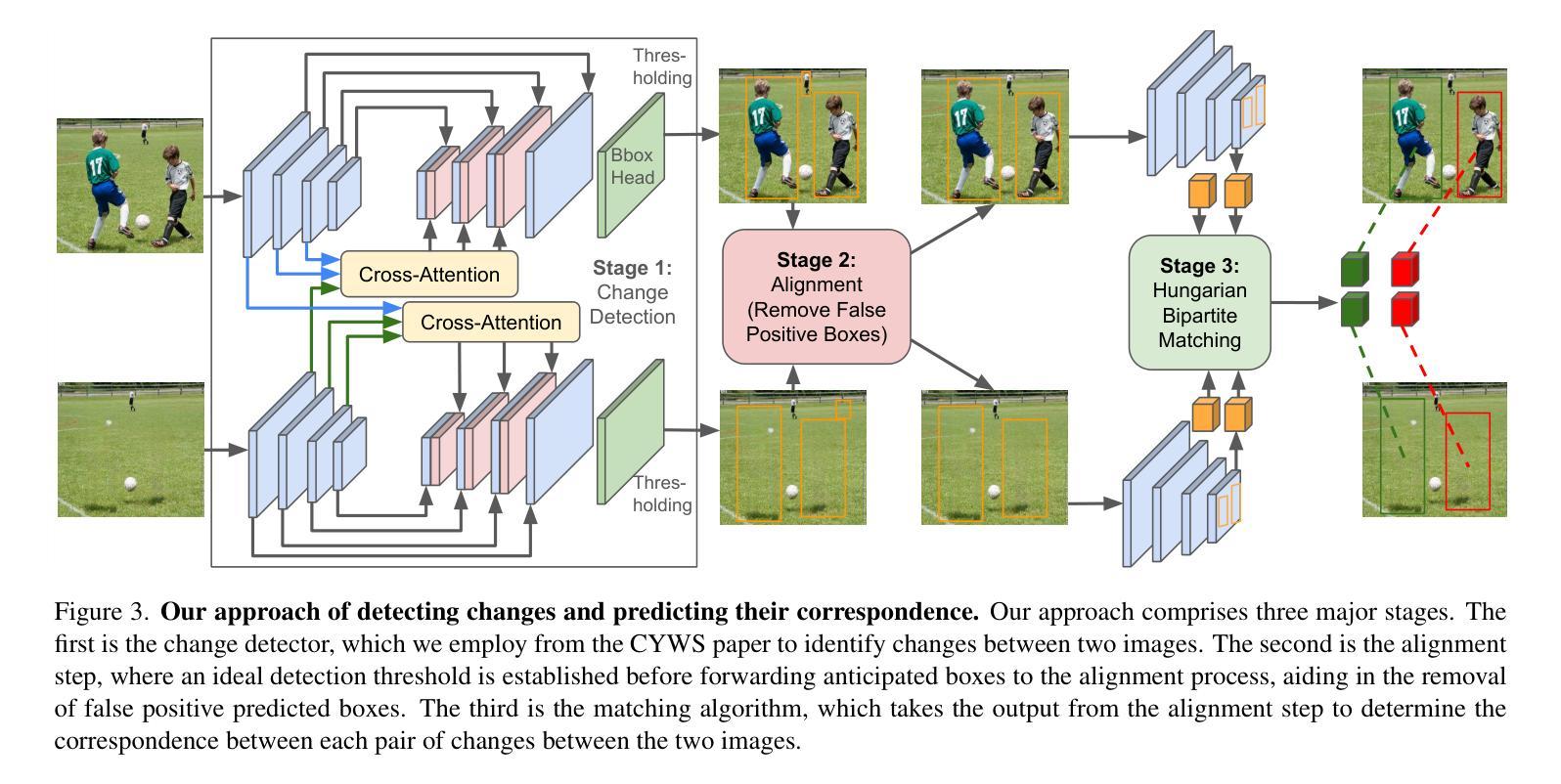
Detecting object-level changes between two images across possibly different views is a core task in many applications that involve visual inspection or camera surveillance. Existing change-detection approaches suffer from three major limitations: (1) lack of evaluation on image pairs that contain no changes, leading to unreported false positive rates; (2) lack of correspondences (\ie, localizing the regions before and after a change); and (3) poor zero-shot generalization across different domains. To address these issues, we introduce a novel method that leverages change correspondences (a) during training to improve change detection accuracy, and (b) at test time, to minimize false positives. That is, we harness the supervision labels of where an object is added or removed to supervise change detectors, improving their accuracy over previous work by a large margin. Our work is also the first to predict correspondences between pairs of detected changes using estimated homography and the Hungarian algorithm. Our model demonstrates superior performance over existing methods, achieving state-of-the-art results in change detection and change correspondence accuracy across both in-distribution and zero-shot benchmarks.
检测两张可能从不同视角拍摄的图像之间在对象级别的变化,是许多涉及视觉检查或摄像头监控的应用中的核心任务。现有的变化检测方法存在三大局限:(1)对于包含没有变化的图像对缺乏评估,导致未报告的误报率;(2)缺乏对应性(即,定位变化前后的区域);(3)在不同领域的零样本泛化能力较差。为了解决这些问题,我们引入了一种新方法,该方法利用变化对应性(a)在训练过程中提高变化检测的准确性,以及(b)在测试时,以减小误报。也就是说,我们利用一个对象添加或删除的监督标签来监督变化检测器,极大地提高了他们的工作精度,超过了以前的工作。我们的工作还首次利用估计的透视变换和匈牙利算法来预测成对的检测变化之间的对应性。我们的模型在变化检测和变化对应准确性方面都表现出卓越的性能,无论是在内部数据集还是在零样本基准测试上都达到了最新水平。
论文及项目相关链接
Summary
本文介绍了一种新的变化检测法,解决了现有方法存在的三大问题:未评估无变化图像对的误报率、缺乏对应关系和跨域零样本泛化能力弱。新方法利用变化对应关系来改进检测精度并减少误报。它使用对象添加或移除的监督标签来改善检测器的准确性,并在预测变化对应方面采用估计的透视变换和匈牙利算法。该模型在变化检测和变化对应准确性方面表现出卓越性能,达到了先进水准,无论是在内部数据集还是零样本基准测试上。
Key Takeaways
- 新方法解决了现有变化检测方法的三大主要局限:未评估无变化图像对、缺乏对应关系和跨域泛化能力弱。
- 方法利用变化对应关系在训练过程中提高检测精度,并在测试时减少误报。
- 使用对象添加或移除的监督标签来改善检测器的性能。
- 方法采用估计的透视变换和匈牙利算法来预测变化的对应关系。
- 模型在变化检测和变化对应准确性方面表现出卓越性能,达到了先进水准。
- 模型在内部数据集和零样本基准测试上都表现出良好的性能。
点此查看论文截图


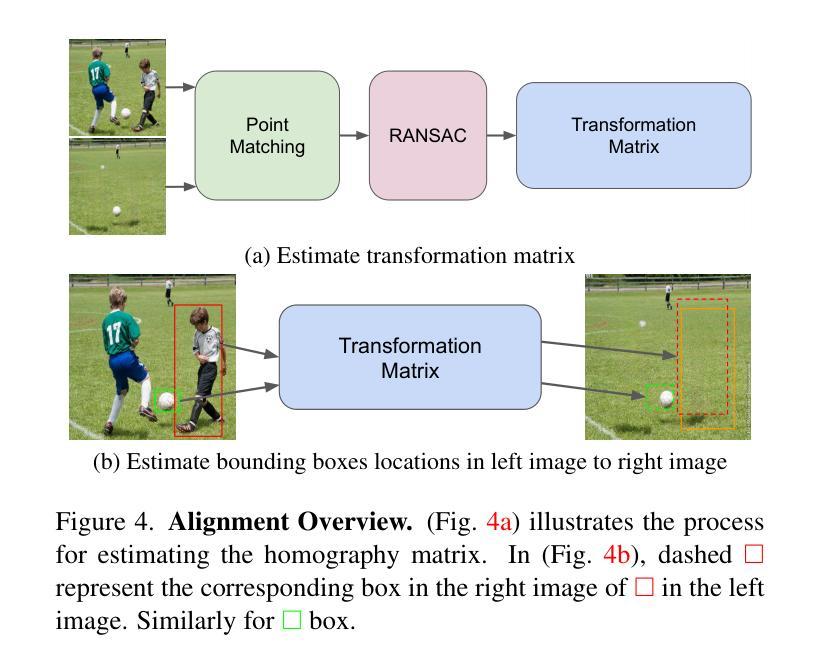
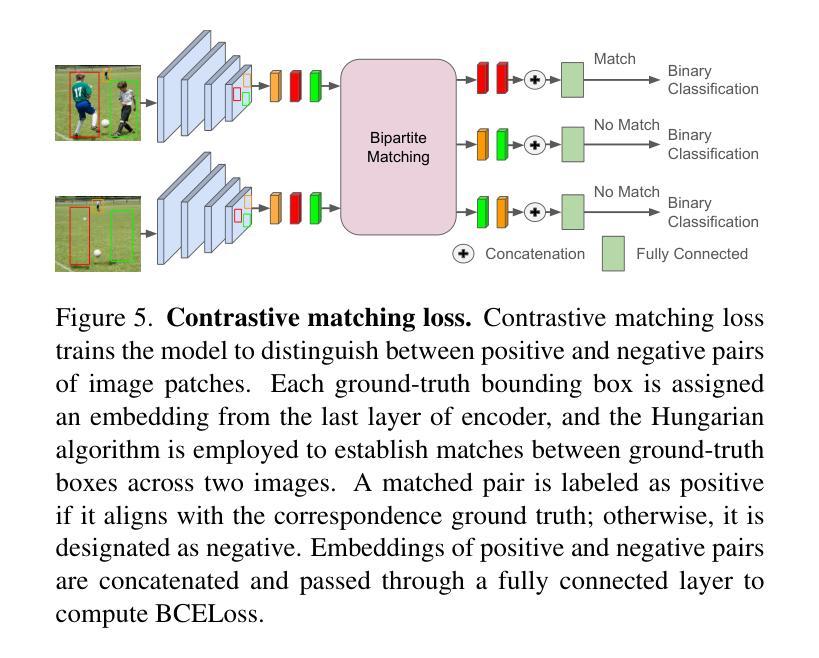
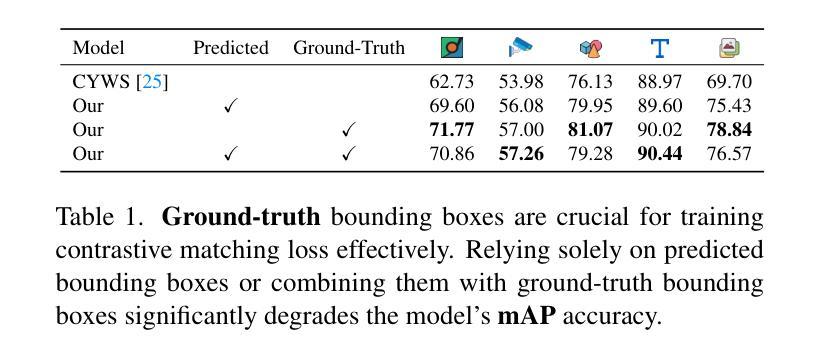

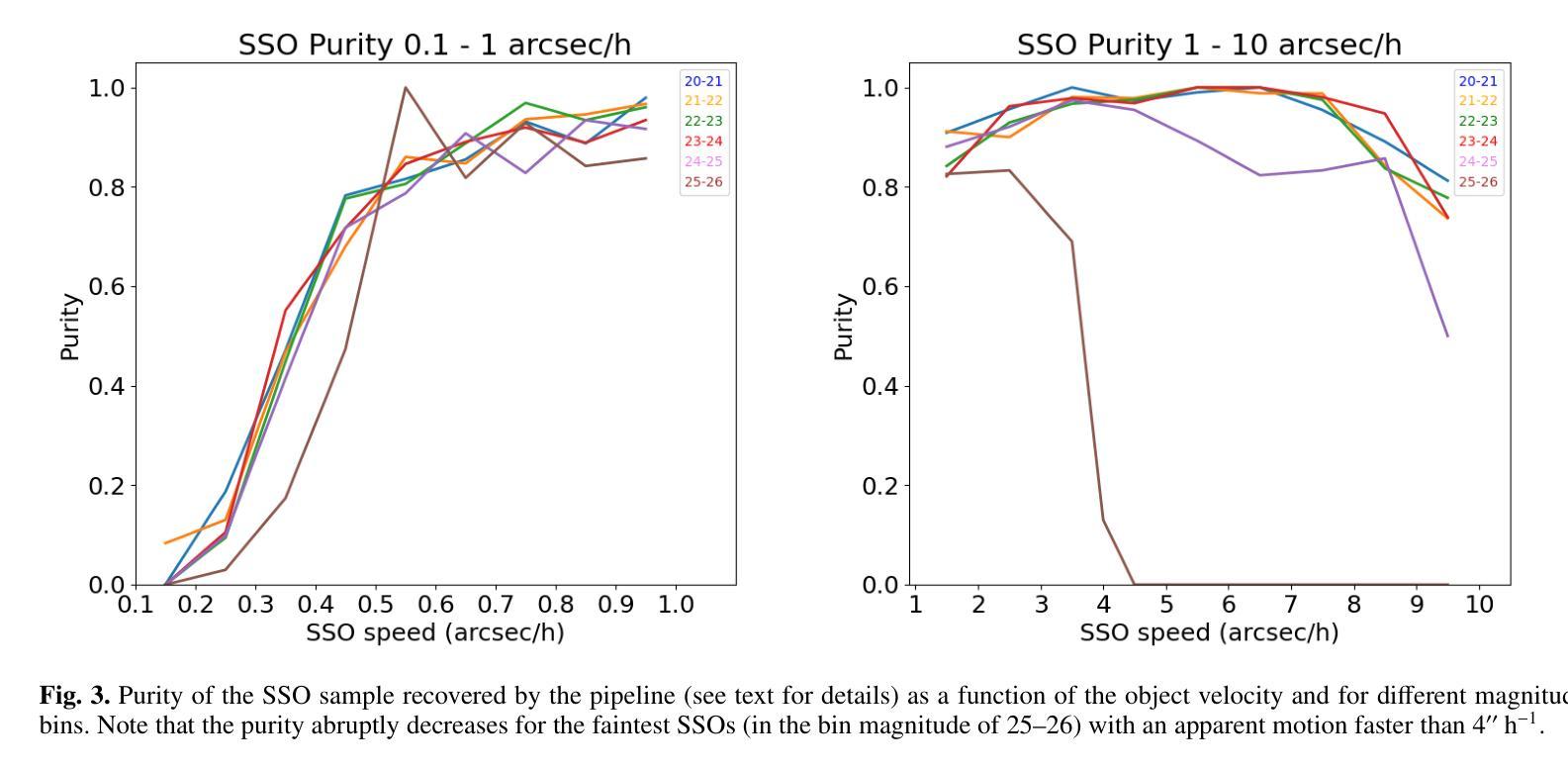
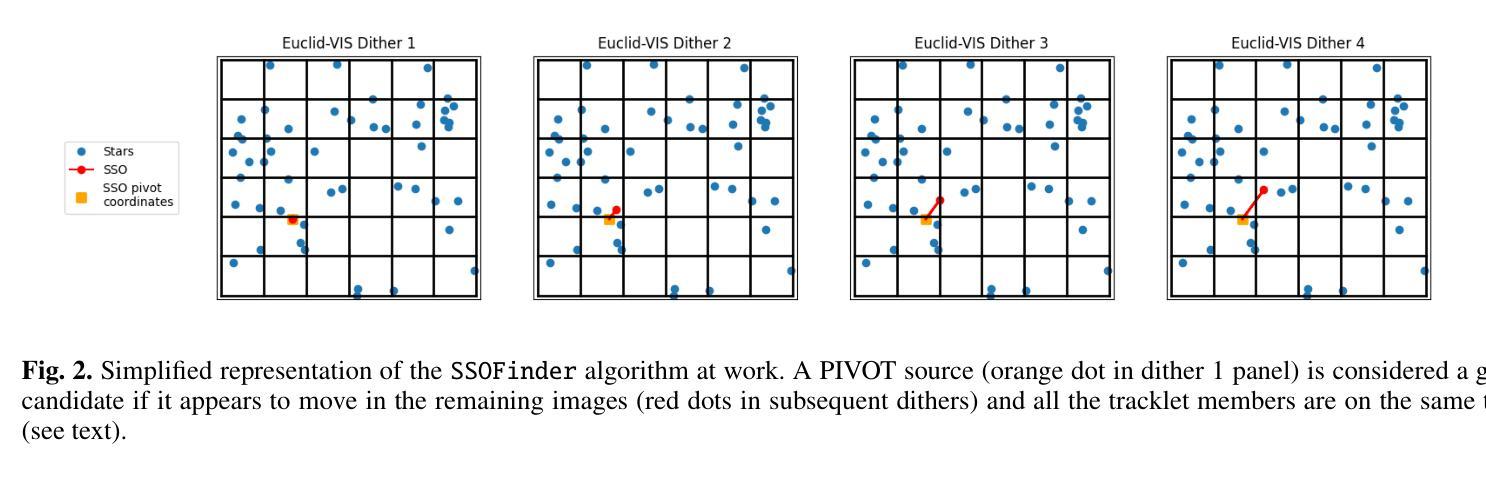
Euclid: Detecting Solar System objects in Euclid images and classifying them using Kohonen self-organising maps
Authors:A. A. Nucita, L. Conversi, A. Verdier, A. Franco, S. Sacquegna, M. Pöntinen, B. Altieri, B. Carry, F. De Paolis, F. Strafella, V. Orofino, M. Maiorano, V. Kansal, R. D. Vavrek, M. Miluzio, M. Granvik, V. Testa, N. Aghanim, S. Andreon, N. Auricchio, M. Baldi, S. Bardelli, E. Branchini, M. Brescia, J. Brinchmann, S. Camera, V. Capobianco, C. Carbone, J. Carretero, S. Casas, M. Castellano, G. Castignani, S. Cavuoti, A. Cimatti, G. Congedo, C. J. Conselice, Y. Copin, F. Courbin, H. M. Courtois, A. Da Silva, H. Degaudenzi, A. M. Di Giorgio, J. Dinis, F. Dubath, X. Dupac, S. Dusini, M. Farina, S. Farrens, S. Ferriol, M. Frailis, E. Franceschi, M. Fumana, S. Galeotta, B. Gillis, C. Giocoli, P. Gómez-Alvarez, A. Grazian, F. Grupp, S. V. H. Haugan, J. Hoar, W. Holmes, F. Hormuth, A. Hornstrup, P. Hudelot, K. Jahnke, M. Jhabvala, E. Keihänen, S. Kermiche, A. Kiessling, M. Kilbinger, R. Kohley, B. Kubik, M. Kümmel, H. Kurki-Suonio, R. Laureijs, S. Ligori, P. B. Lilje, V. Lindholm, I. Lloro, E. Maiorano, O. Mansutti, O. Marggraf, K. Markovic, N. Martinet, F. Marulli, R. Massey, D. C. Masters, E. Medinaceli, S. Mei, Y. Mellier, M. Meneghetti, G. Meylan, M. Moresco, L. Moscardini, R. Nakajima, S. -M. Niemi, C. Padilla, S. Paltani, F. Pasian, K. Pedersen, V. Pettorino, S. Pires, G. Polenta, M. Poncet, L. A. Popa, L. Pozzetti, F. Raison, R. Rebolo, A. Renzi, J. Rhodes, G. Riccio, E. Romelli, M. Roncarelli, E. Rossetti, R. Saglia, D. Sapone, B. Sartoris, M. Schirmer, P. Schneider, A. Secroun, G. Seidel, S. Serrano, C. Sirignano, G. Sirri, J. Skottfelt, L. Stanco, J. Steinwagner, P. Tallada-Crespí, A. N. Taylor, I. Tereno, R. Toledo-Moreo, F. Torradeflot, I. Tutusaus, L. Valenziano, T. Vassallo, G. Verdoes Kleijn, A. Veropalumbo, Y. Wang, J. Weller, A. Zacchei, E. Zucca, M. Bolzonella, C. Burigana, V. Scottez
The ESA Euclid mission will survey more than 14,000 deg$^2$ of the sky in visible and near-infrared wavelengths, mapping the extra-galactic sky to constrain our cosmological model of the Universe. Although the survey focusses on regions further than 15 deg from the ecliptic, it should allow for the detection of more than about $10^5$ Solar System objects (SSOs). After simulating the expected signal from SSOs in Euclid images acquired with the visible camera (VIS), we describe an automated pipeline developed to detect moving objects with an apparent velocity in the range of 0.1-10 arcsec/h, typically corresponding to sources in the outer Solar System (from Centaurs to Kuiper-belt objects). In particular, the proposed detection scheme is based on Sourcextractor software and on applying a new algorithm capable of associating moving objects amongst different catalogues. After applying a suite of filters to improve the detection quality, we study the expected purity and completeness of the SSO detections. We also show how a Kohonen self-organising neural network can be successfully trained (in an unsupervised fashion) to classify stars, galaxies, and SSOs. By implementing an early-stopping method in the training scheme, we show that the network can be used in a predictive way, allowing one to assign the probability of each detected object being a member of each considered class.
ESA的Euclid任务将在可见光和近红外波长下对超过14,000平方度的天空进行普查,以绘制天外天空地图,以限制我们对宇宙学的宇宙模型的理解。虽然这项调查的重点是远离黄道超过15度的区域,但它应能检测到超过大约10万多个太阳系物体(SSO)。在模拟了可见光相机(VIS)在Euclid图像中预期的太阳系信号后,我们描述了一个自动化管道的开发过程,该管道用于检测在可见光相机(VIS)获取的Euclid图像中明显速度为0.1至弧秒/小时范围内移动物体。尤其是,提出的检测方案基于Sourcextractor软件并采用了一种新算法,能够将不同目录中的移动物体联系起来。在应用一系列过滤器以提高检测质量后,我们研究了SSO检测的期望的纯度和完整性。我们还展示了如何使用无监督方式成功训练Kohonen自组织神经网络来分类恒星、星系和太阳系物体。通过在训练方案中实施早期停止方法,我们展示了该网络可以在预测的方式中使用,允许为每个检测到的对象分配属于每个考虑类别的概率。
论文及项目相关链接
PDF Accepted for publication on Astronomy and Astrophysics. 15 Pages, 11 Figures
Summary
ESA的Euclid任务将调查超过14,000平方度的天空,在可见光和近红外波长范围内绘制星系际空间的地图,以限制我们对宇宙学的宇宙模型。虽然调查的重点是远离黄道15度的区域,但它将检测到超过约10万颗太阳系物体(SSOs)。本文介绍了使用可见光相机(VIS)采集的Euclid图像中的预期太阳系物体信号进行仿真的自动化管道的开发,该管道可检测速度范围在0.1-10弧秒/小时之间的移动物体,通常对应于太阳系外部的来源(从Centaurs到Kuiper带物体)。通过应用一系列过滤器以提高检测质量,我们研究了SSO检测的预期纯度和完整性。我们还展示了如何成功地训练Kohonen自组织神经网络以分类恒星、星系和太阳系物体。通过实施早期停止方法,我们证明网络可以用于预测分类任务中各个对象的类别归属概率。这些工具可用于进一步完善航天领域的应用和探索活动。本文呈现了一种先进的自动化检测算法,该算法对于未来太空探测任务中的天体识别和分类具有广泛的应用前景。这一突破性的研究将有助于推进我们对太阳系和宇宙的理解。通过自动化检测流程,我们能够更有效地识别和分类太阳系物体,从而推动空间科学的发展。这一进展不仅有助于天文学领域的理论研究,更能够直接应用于未来空间探索的实际操作,进一步提升人类对太空的认识和利用能力。这为航天科技的发展开启了新的视角,预计将进一步激发创新性地探索和创新的火箭与宇航方案的设计与制定。Key Takeaways:
- ESA的Euclid任务将大范围勘测天空以推动宇宙学研究,包含太阳系外天空的区域以及对太阳系内物体的检测。
点此查看论文截图


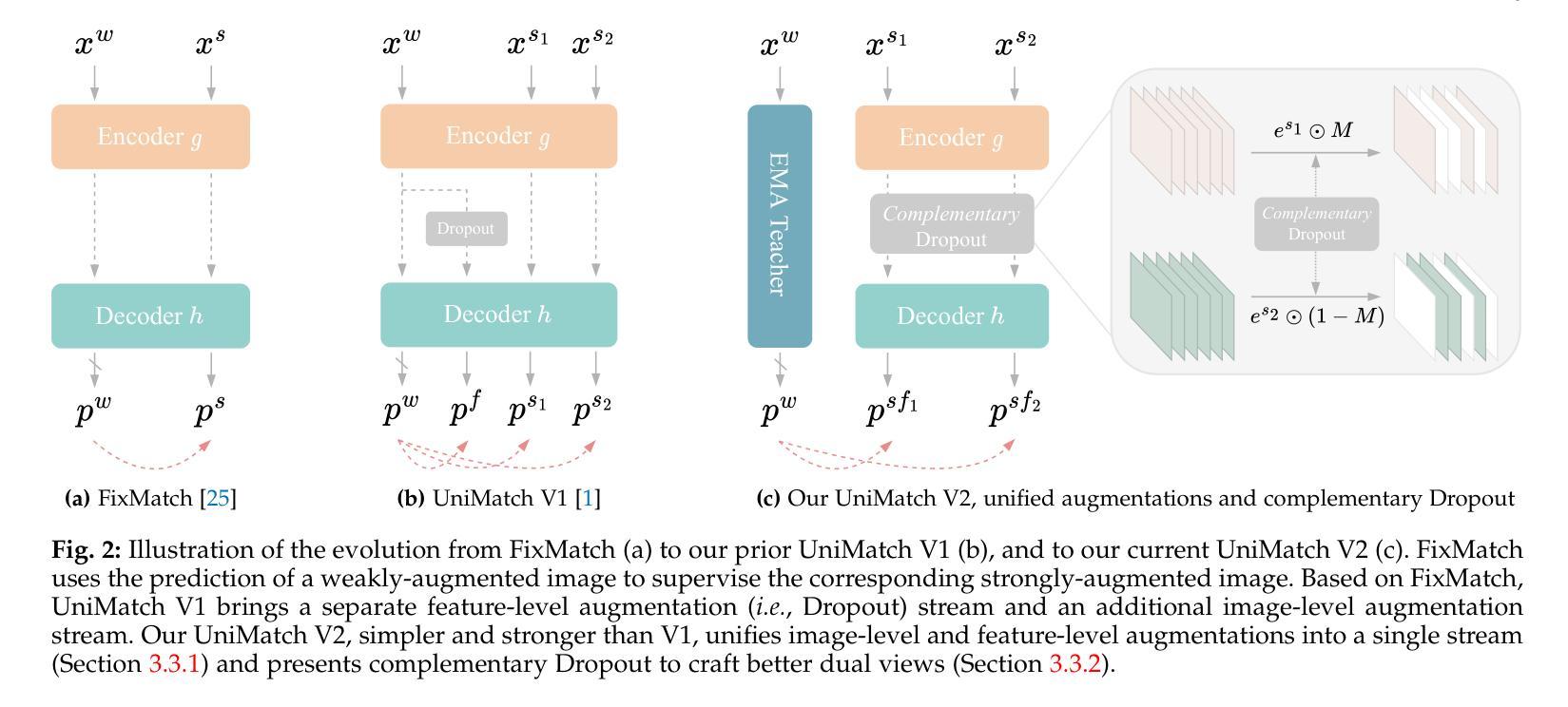
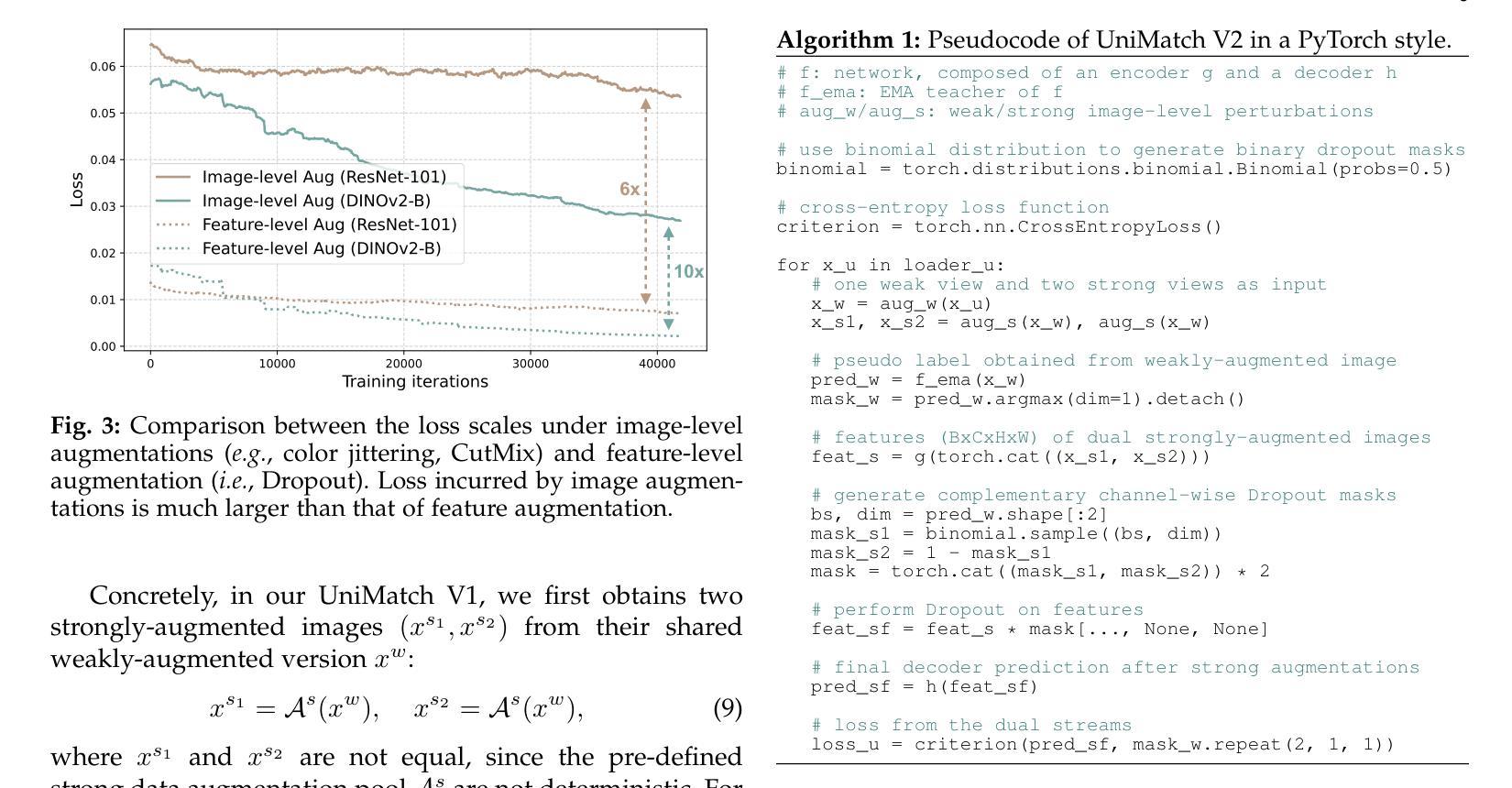
UniMatch V2: Pushing the Limit of Semi-Supervised Semantic Segmentation
Authors:Lihe Yang, Zhen Zhao, Hengshuang Zhao
Semi-supervised semantic segmentation (SSS) aims at learning rich visual knowledge from cheap unlabeled images to enhance semantic segmentation capability. Among recent works, UniMatch improves its precedents tremendously by amplifying the practice of weak-to-strong consistency regularization. Subsequent works typically follow similar pipelines and propose various delicate designs. Despite the achieved progress, strangely, even in this flourishing era of numerous powerful vision models, almost all SSS works are still sticking to 1) using outdated ResNet encoders with small-scale ImageNet-1K pre-training, and 2) evaluation on simple Pascal and Cityscapes datasets. In this work, we argue that, it is necessary to switch the baseline of SSS from ResNet-based encoders to more capable ViT-based encoders (e.g., DINOv2) that are pre-trained on massive data. A simple update on the encoder (even using 2x fewer parameters) can bring more significant improvement than careful method designs. Built on this competitive baseline, we present our upgraded and simplified UniMatch V2, inheriting the core spirit of weak-to-strong consistency from V1, but requiring less training cost and providing consistently better results. Additionally, witnessing the gradually saturated performance on Pascal and Cityscapes, we appeal that we should focus on more challenging benchmarks with complex taxonomy, such as ADE20K and COCO datasets. Code, models, and logs of all reported values, are available at https://github.com/LiheYoung/UniMatch-V2.
半监督语义分割(SSS)旨在从廉价的未标记图像中学习丰富的视觉知识,以提高语义分割能力。在近期作品中,UniMatch通过加强弱到强的一致性正则化实践,极大地改进了前人方法。后续工作通常遵循类似的流程,并提出了各种精致的设计。尽管取得了进展,但奇怪的是,即使在这个众多强大视觉模型的繁荣时代,几乎所有SSS工作仍然坚持使用1)过时的ResNet编码器进行小规模ImageNet-1K预训练,以及2)在简单的Pascal和Cityscapes数据集上进行评估。
论文及项目相关链接
PDF Accepted by TPAMI
Summary:半监督语义分割(SSS)旨在从廉价的无标签图像中学习丰富的视觉知识,以提高语义分割能力。UniMatch通过加强弱到强的一致性正则化,显著改进了先前的实践。然而,尽管近期有很多相关研究,SSS仍主要使用老旧的ResNet编码器和小规模ImageNet-1K预训练,并在简单的Pascal和Cityscapes数据集上进行评估。本文主张将SSS基线从基于ResNet的编码器转向更具能力的基于ViT的编码器(如DINOv2),并预训练在大量数据上。此外,本论文呼吁关注更复杂基准测试集(如ADE20K和COCO数据集)。代码、模型和所有报告值的日志已发布在https://github.com/LiheYoung/UniMatch-V2上。
Key Takeaways:
- UniMatch在弱到强的一致性正则化实践中表现出色,提升了先前的实践水平。
- 当前SSS研究仍主要使用老旧的ResNet编码器和小规模数据集进行训练评估,亟需改进。
- 使用更先进的ViT编码器(如DINOv2)并预训练在大量数据上可以提高SSS性能。
- UniMatch V2作为升级版,继承了V1的弱到强一致性核心精神,同时减少了训练成本,结果更为优秀。
点此查看论文截图