⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-13 更新
OVO-Bench: How Far is Your Video-LLMs from Real-World Online Video Understanding?
Authors:Yifei Li, Junbo Niu, Ziyang Miao, Chunjiang Ge, Yuanhang Zhou, Qihao He, Xiaoyi Dong, Haodong Duan, Shuangrui Ding, Rui Qian, Pan Zhang, Yuhang Zang, Yuhang Cao, Conghui He, Jiaqi Wang
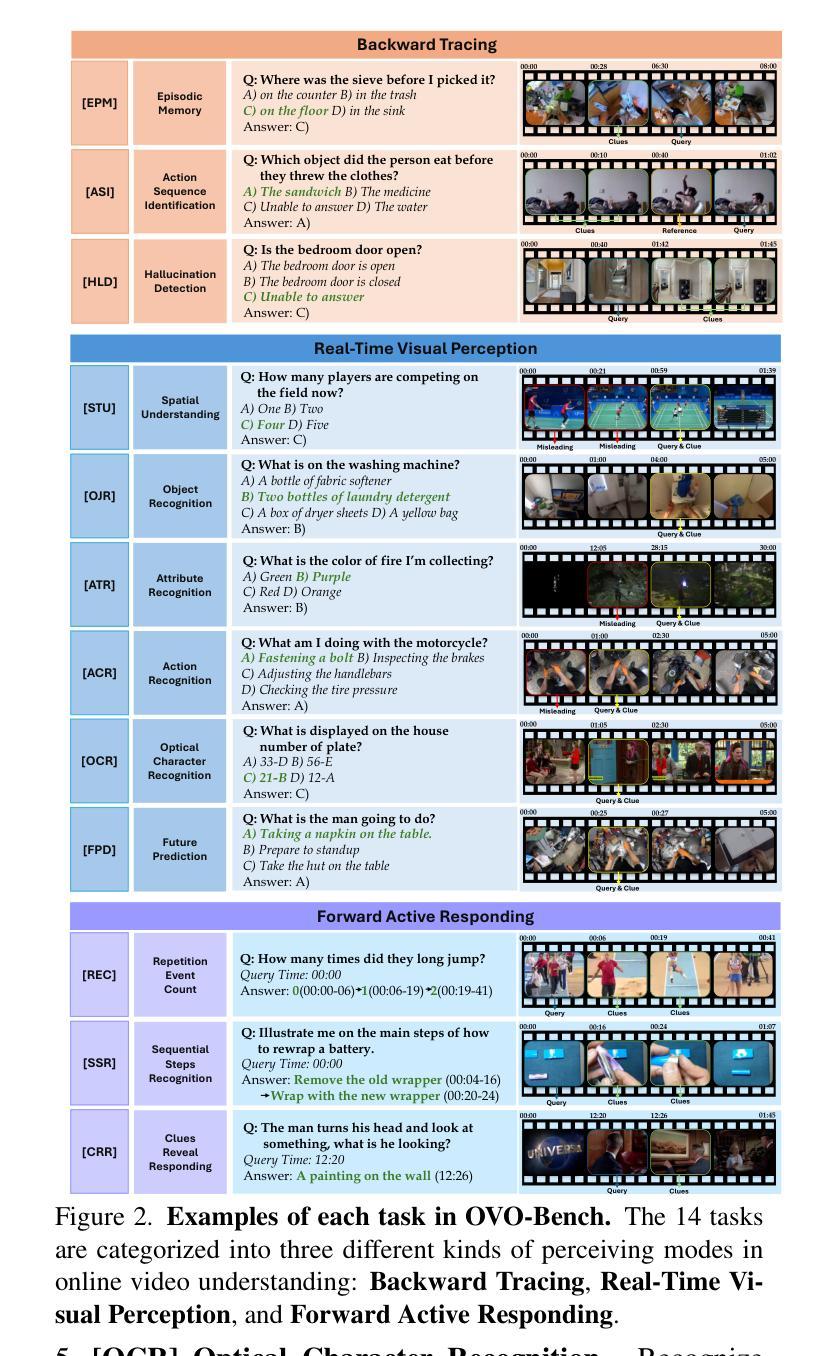
Temporal Awareness, the ability to reason dynamically based on the timestamp when a question is raised, is the key distinction between offline and online video LLMs. Unlike offline models, which rely on complete videos for static, post hoc analysis, online models process video streams incrementally and dynamically adapt their responses based on the timestamp at which the question is posed. Despite its significance, temporal awareness has not been adequately evaluated in existing benchmarks. To fill this gap, we present OVO-Bench (Online-VideO-Benchmark), a novel video benchmark that emphasizes the importance of timestamps for advanced online video understanding capability benchmarking. OVO-Bench evaluates the ability of video LLMs to reason and respond to events occurring at specific timestamps under three distinct scenarios: (1) Backward tracing: trace back to past events to answer the question. (2) Real-time understanding: understand and respond to events as they unfold at the current timestamp. (3) Forward active responding: delay the response until sufficient future information becomes available to answer the question accurately. OVO-Bench comprises 12 tasks, featuring 644 unique videos and approximately human-curated 2,800 fine-grained meta-annotations with precise timestamps. We combine automated generation pipelines with human curation. With these high-quality samples, we further developed an evaluation pipeline to systematically query video LLMs along the video timeline. Evaluations of nine Video-LLMs reveal that, despite advancements on traditional benchmarks, current models struggle with online video understanding, showing a significant gap compared to human agents. We hope OVO-Bench will drive progress in video LLMs and inspire future research in online video reasoning. Our benchmark and code can be accessed at https://github.com/JoeLeelyf/OVO-Bench.
时间感知能力是区分离线与在线视频LLM的关键区别,它能够在基于提出问题的时间戳进行动态推理。与依赖完整视频进行静态、事后分析的离线模型不同,在线模型会逐步处理视频流,并根据提出问题的时间戳动态调整其响应。尽管时间感知能力非常重要,但在现有的基准测试中并未得到足够评估。为了填补这一空白,我们推出了OVO-Bench(在线视频基准测试),这是一个新的视频基准测试,它强调时间戳对于高级在线视频理解能力基准测试的重要性。OVO-Bench评估视频LLM在三种不同场景下对发生在特定时间戳的事件进行推理和响应的能力:1)向后追溯:追溯过去的事件来回答问题。2)实时理解:理解并响应当前时间戳上发生的事件。3)向前主动响应:延迟响应,直到未来有足够的信息来准确回答问题。OVO-Bench包含12项任务,包含644个独特视频和约经人工精细标注的2800个带有精确时间戳的元注释。我们结合自动化生成管道和人工精编。通过这些高质量的样本,我们进一步开发了一个评估管道,可以系统地沿着视频时间线查询视频LLM。对九个视频LLM的评估表明,尽管在传统基准测试上取得了进展,但当前模型在在线视频理解方面仍然面临困难,与人类代理相比存在明显差距。我们希望OVO-Bench将推动视频LLM的进展,并激发未来在线视频推理的研究灵感。我们的基准测试和代码可在https://github.com/JoeLeelyf/OVO-Bench访问。
论文及项目相关链接
PDF 28 pages
Summary
本文介绍了时序感知能力在线上视频LLM中的重要性,这是区分线上和线下视频LLM的关键区别。线上模型能够处理视频流并动态适应响应,而线下模型则依赖于完整视频进行静态分析。为填补现有基准测试对时序感知能力评估的不足,本文提出了OVO-Bench基准测试,强调时间戳在高级在线视频能力评估中的重要性。OVO-Bench评估视频LLM在特定时间戳发生的事件的推理和响应能力,包括三种场景:回溯、实时理解和未来主动响应。该基准测试包含高质量样本和评估流程,以系统地查询视频LLM沿视频时间线的表现。对现有九个视频LLM的评估显示,尽管在传统基准测试上有所进展,但当前模型在线上视频理解方面仍存在显著差距。
Key Takeaways
- 时序感知能力是线上视频LLM与线下模型的关键区别,使线上模型能够处理视频流并动态响应。
- 现有基准测试对时序感知能力的评估不足,需要新的评估方法。
- OVO-Bench基准测试强调时间戳在在线视频理解中的重要性,评估视频LLM在特定场景下的表现。
- OVO-Bench包含三种场景:回溯、实时理解和未来主动响应。
- 该基准测试采用高质量样本和评估流程,以系统地查询视频LLM的表现。
- 对九个视频LLM的评估显示,尽管在传统基准测试上有进展,但线上视频理解仍存在显著差距。
点此查看论文截图

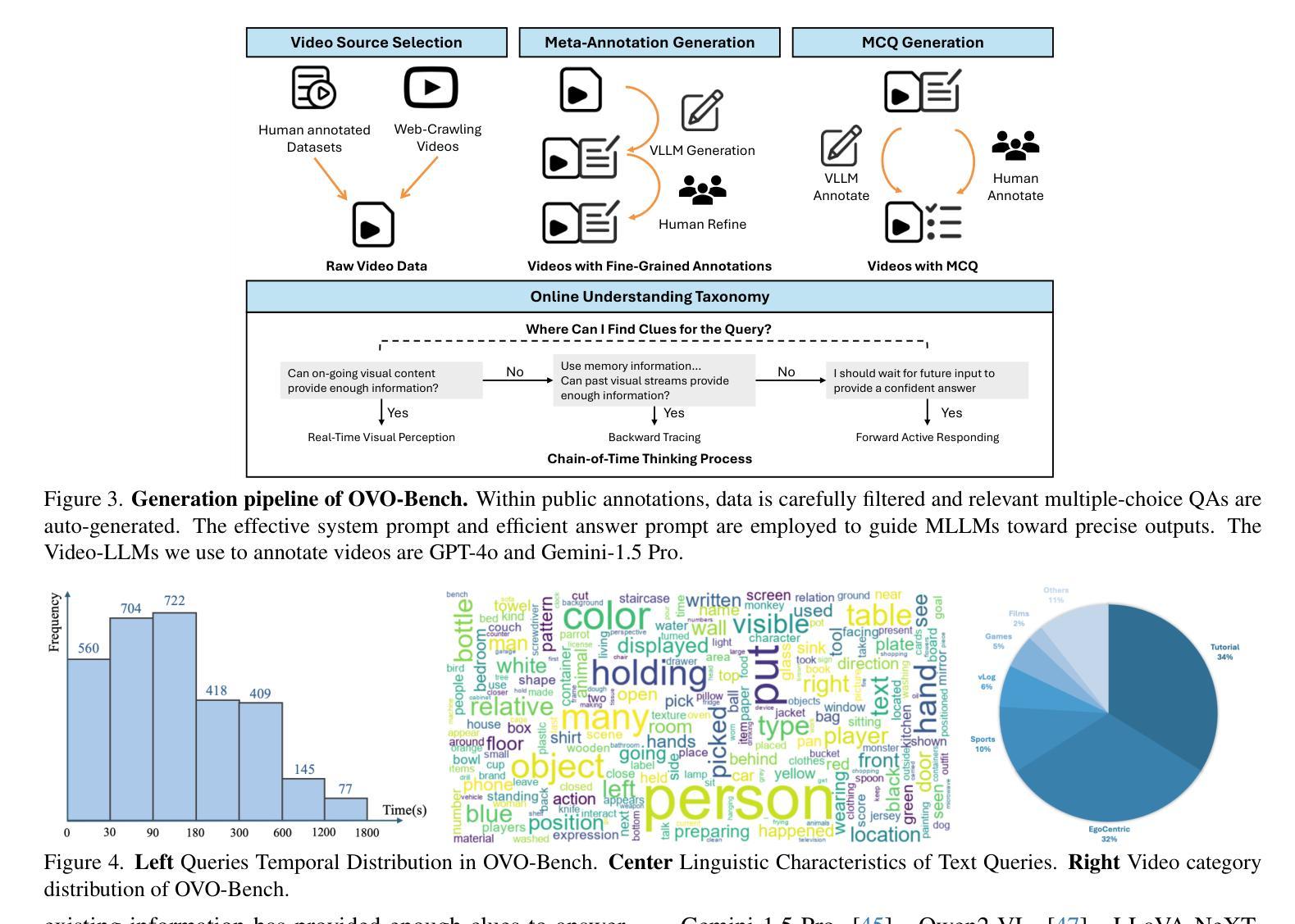
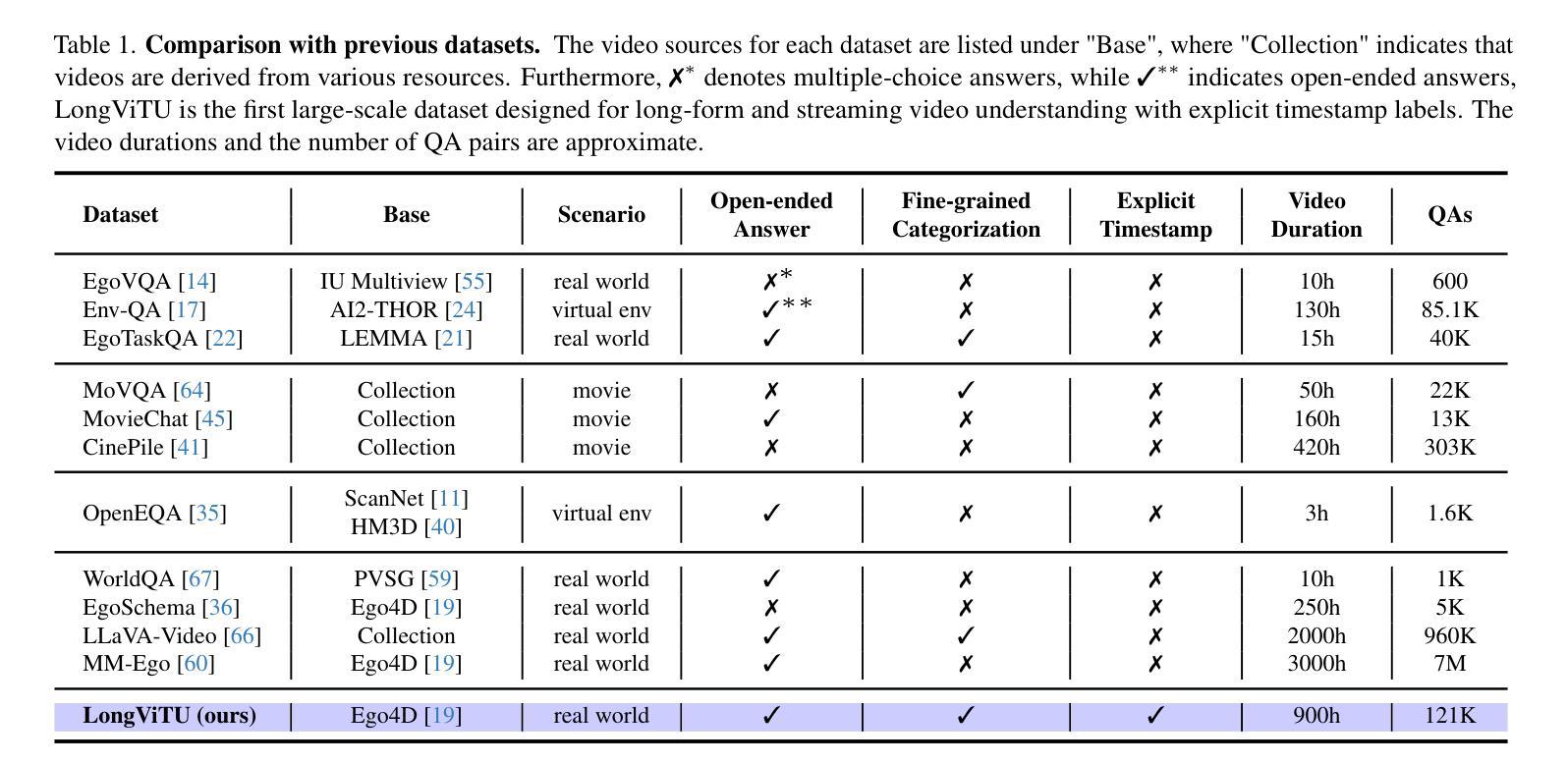
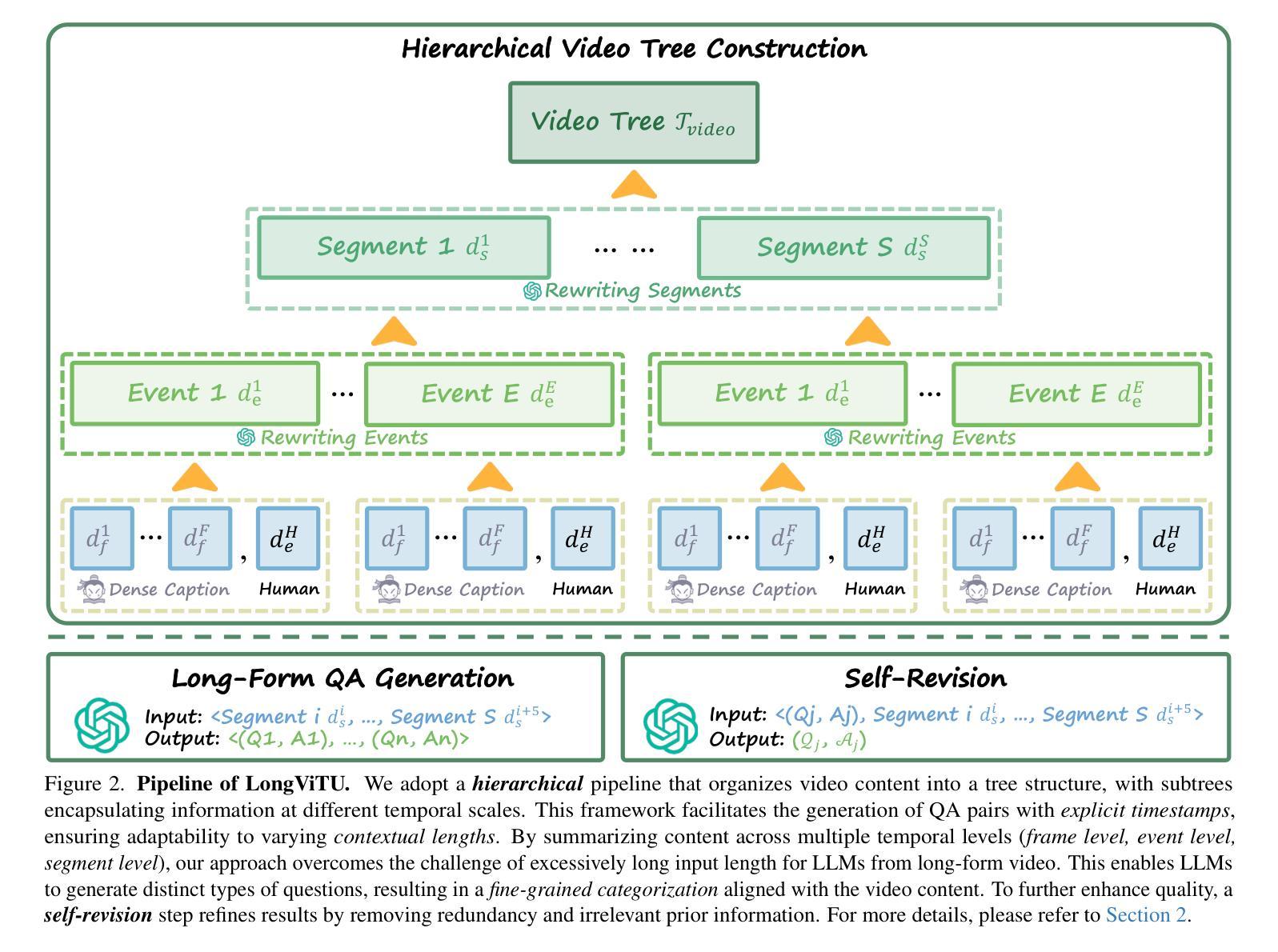
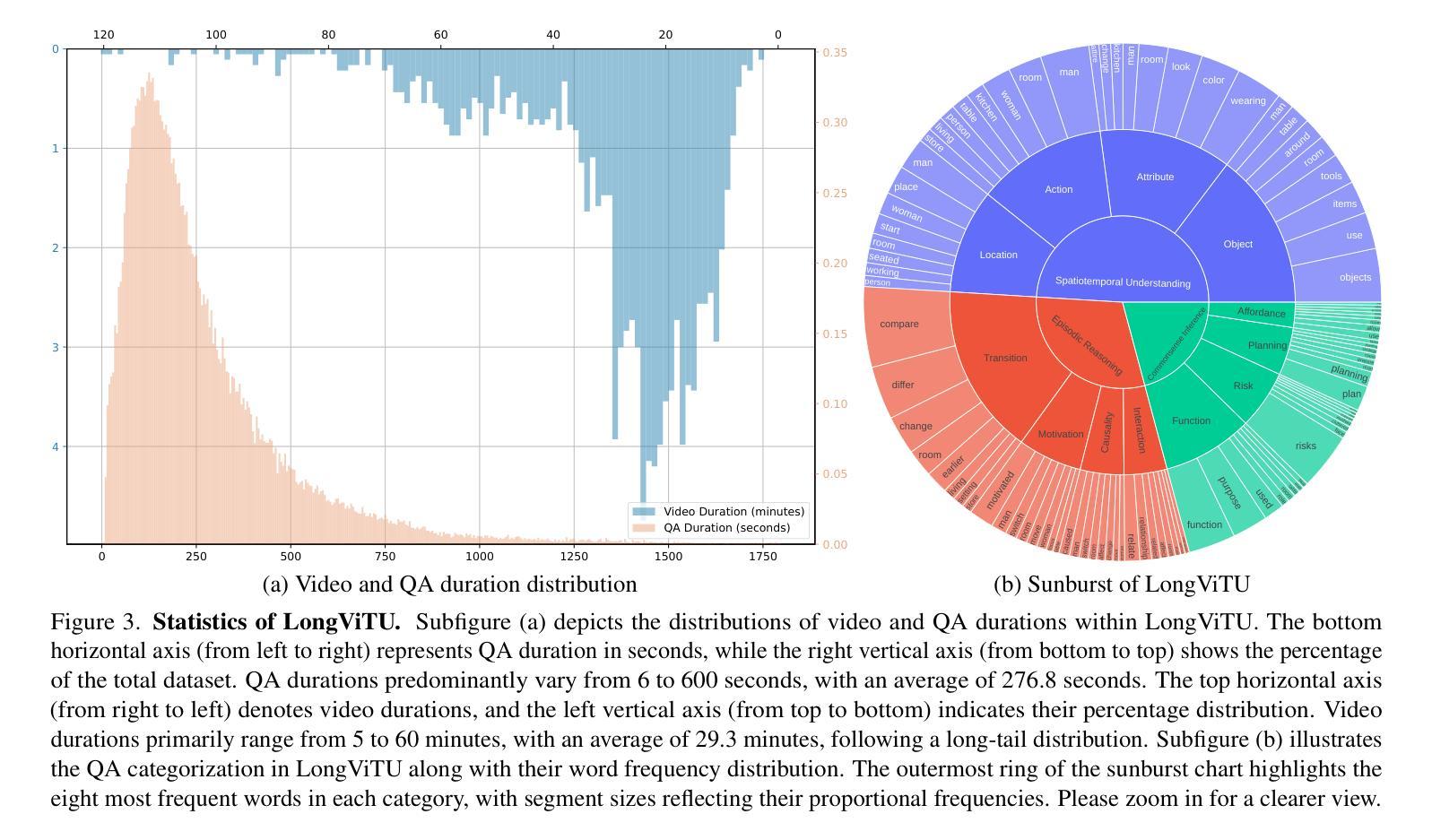
LongViTU: Instruction Tuning for Long-Form Video Understanding
Authors:Rujie Wu, Xiaojian Ma, Hai Ci, Yue Fan, Yuxuan Wang, Haozhe Zhao, Qing Li, Yizhou Wang
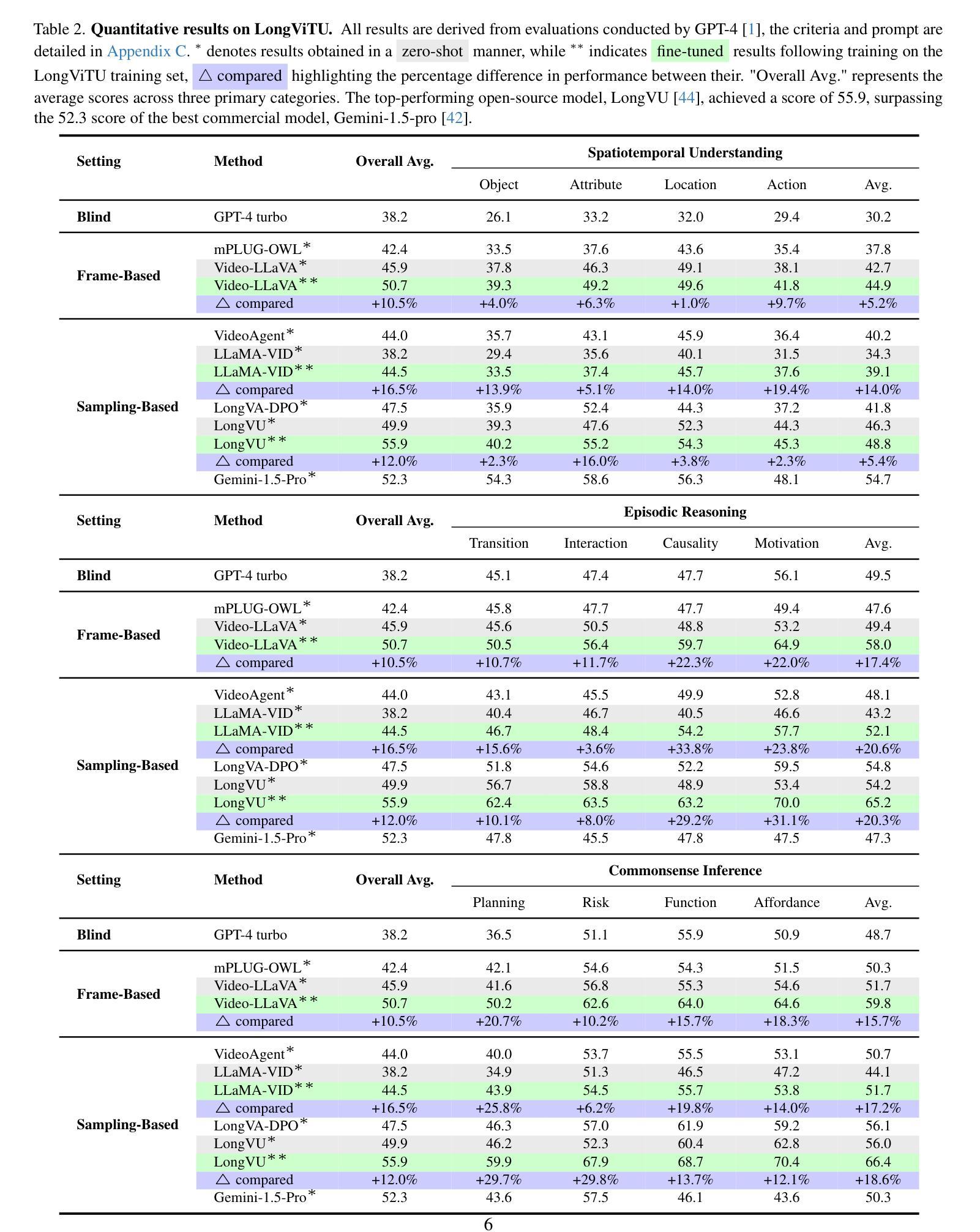
This paper introduce LongViTU, a large-scale (~121k QA pairs, ~900h videos), automatically generated dataset for long-form video understanding. We developed a systematic approach that organizes videos into a hierarchical tree structure and incorporates self-revision mechanisms to ensure high-quality QA pairs. Each QA pair in LongViTU features: 1) long-term context (average certificate length of 4.6 minutes); 2) rich knowledge and condensed reasoning (commonsense, causality, planning, etc.); and 3) explicit timestamp labels for relevant events. LongViTU also serves as a benchmark for instruction following in long-form and streaming video understanding. We evaluate the open-source state-of-the-art long video understanding model, LongVU, and the commercial model, Gemini-1.5-Pro, on our benchmark. They achieve GPT-4 scores of 49.9 and 52.3, respectively, underscoring the substantial challenge posed by our benchmark. Further supervised fine-tuning (SFT) on LongVU led to performance improvements of 12.0% on our benchmark, 2.2% on the in-distribution (ID) benchmark EgoSchema, 1.0%, 2.2% and 1.2% on the out-of-distribution (OOD) benchmarks VideoMME (Long), WorldQA and OpenEQA, respectively. These outcomes demonstrate LongViTU’s high data quality and robust OOD generalizability.
本文介绍了LongViTU,这是一个大规模(
121k个问答对,900小时视频)的自动生成的长期视频理解数据集。我们开发了一种系统方法,将视频组织成层次树结构,并融入自我修正机制,以确保高质量的问答对。LongViTU中的每个问答对都具有以下特点:1)长期上下文(平均证书长度为4.6分钟);2)丰富的知识和浓缩的推理(常识、因果、规划等);3)相关事件有明确的时间戳标签。LongViTU还为长视频和流媒体视频理解中的指令遵循提供了基准测试。我们在基准测试上评估了开源的先进长视频理解模型LongVU和商用模型Gemini-1.5-Pro。它们在我们的基准测试上分别达到了GPT-4的49.9分和52.3分,凸显出我们的基准测试所带来的巨大挑战。对LongVU进行进一步的监督微调(SFT)后,在我们的基准测试上的性能提高了12.0%,在内部分布(ID)基准EgoSchema上提高了2.2%,在外部分布(OOD)基准VideoMME(Long)、WorldQA和OpenEQA上分别提高了1.0%、2.2%和1.2%。这些结果证明了LongViTU的高数据质量和稳健的OOD泛化能力。
论文及项目相关链接
摘要
本文介绍了LongViTU,一个大规模自动生成的用于长视频理解的数据集。该数据集组织视频为层次树结构,并引入自我修正机制确保高质量的问答对。LongViTU的每个问答对具有长期上下文、丰富知识和推理,并为相关事件提供明确的时间戳标签。此外,LongViTU还为长视频理解和流媒体理解提供了基准测试。我们在基准测试上评估了开源先进的长视频理解模型LongVU和商业模型Gemini-1.5-Pro,它们分别达到了GPT-4的49.9分和52.3分,突显出我们的基准测试具有较大挑战性。进一步对LongVU进行有监督微调(SFT)后,在我们的基准测试上的性能提高了12.0%,在内部分布(ID)基准EgoSchema上提高了2.2%,在外部分布(OOD)基准VideoMME(Long)、WorldQA和OpenEQA上分别提高了1.0%、2.2%和1.2%。这些结果表明LongViTU数据的高质量和强大的泛化能力。
关键见解
- LongViTU是一个大规模自动生成的用于长视频理解的数据集。
- 系统性地组织视频为层次树结构,并引入自我修正机制确保问答对质量。
- LongViTU问答对具有长期上下文、丰富知识和推理,包含时间戳标签。
- 提供长视频理解和流媒体理解的基准测试。
- 评估显示,先进模型在LongViTU基准测试上表现有挑战性。
- 对LongVU模型进行有监督微调后,性能显著提高。
- LongViTU表现出高数据质量和强大的泛化能力。
点此查看论文截图

GPT4Scene: Understand 3D Scenes from Videos with Vision-Language Models
Authors:Zhangyang Qi, Zhixiong Zhang, Ye Fang, Jiaqi Wang, Hengshuang Zhao
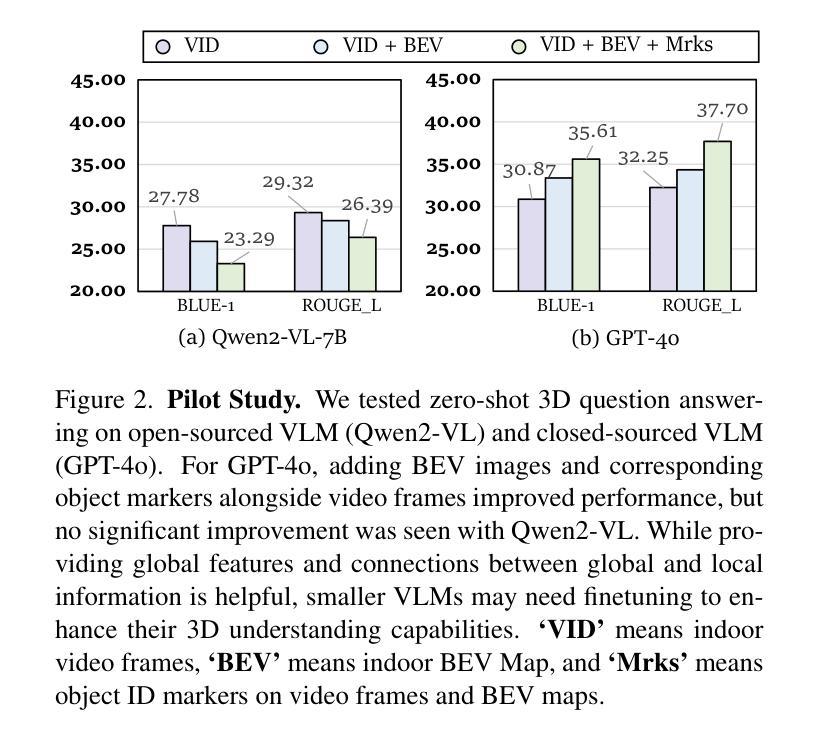
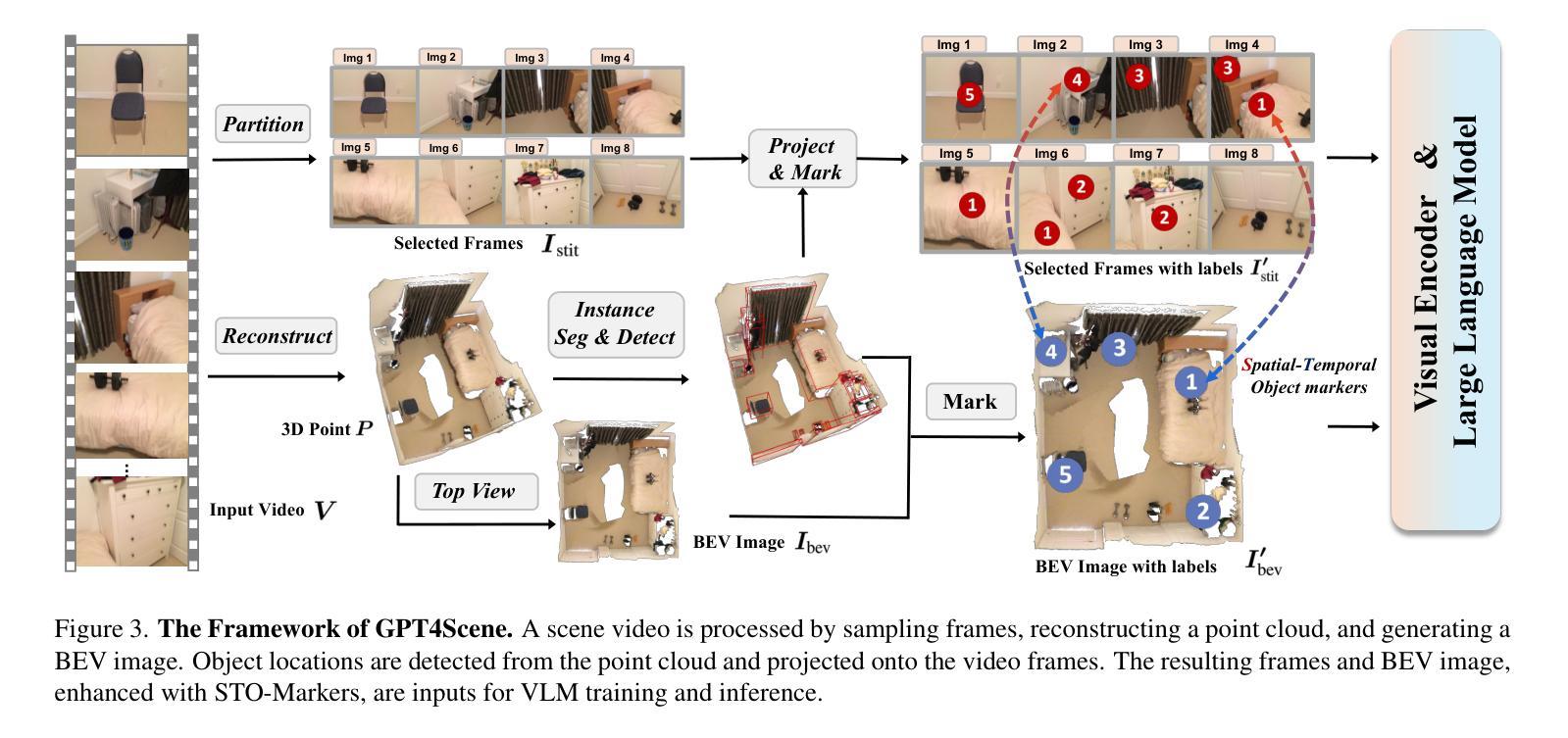
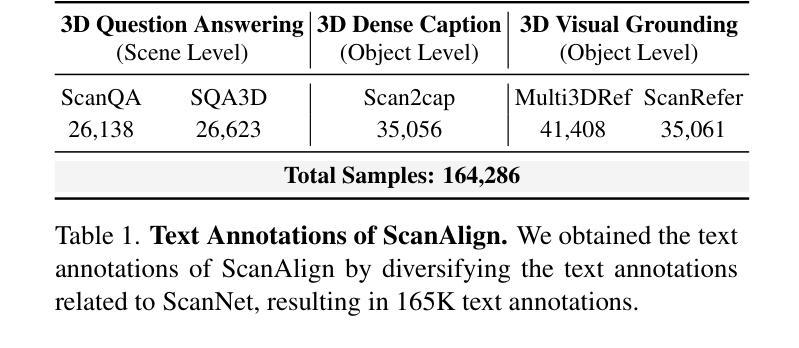
In recent years, 2D Vision-Language Models (VLMs) have made significant strides in image-text understanding tasks. However, their performance in 3D spatial comprehension, which is critical for embodied intelligence, remains limited. Recent advances have leveraged 3D point clouds and multi-view images as inputs, yielding promising results. However, we propose exploring a purely vision-based solution inspired by human perception, which merely relies on visual cues for 3D spatial understanding. This paper empirically investigates the limitations of VLMs in 3D spatial knowledge, revealing that their primary shortcoming lies in the lack of global-local correspondence between the scene and individual frames. To address this, we introduce GPT4Scene, a novel visual prompting paradigm in VLM training and inference that helps build the global-local relationship, significantly improving the 3D spatial understanding of indoor scenes. Specifically, GPT4Scene constructs a 3D Bird’s Eye View (BEV) image from the video and marks consistent object IDs across both frames and the BEV image. The model then inputs the concatenated BEV image and video frames with markers. In zero-shot evaluations, GPT4Scene improves performance over closed-source VLMs like GPT-4o. Additionally, we prepare a processed video dataset consisting of 165K text annotation to fine-tune open-source VLMs, achieving state-of-the-art performance on all 3D understanding tasks. Surprisingly, after training with the GPT4Scene paradigm, VLMs consistently improve during inference, even without visual prompting and BEV image as explicit correspondence. It demonstrates that the proposed paradigm helps VLMs develop an intrinsic ability to understand 3D scenes, which paves the way for a noninvasive approach to extending pre-trained VLMs for 3D scene understanding.
近年来,二维视觉语言模型(VLMs)在图像文本理解任务中取得了显著进展。然而,它们在三维空间理解方面的表现,对于体现智能至关重要,仍然有限。最近的进展利用三维点云和多视角图像作为输入,取得了有前景的结果。然而,我们提出探索一种纯粹基于视觉的解决方案,该方案受到人类感知的启发,仅依赖视觉线索进行三维空间理解。本文经验性地研究了VLMs在三维空间知识方面的局限性,发现它们的主要缺点在于场景与单个帧之间缺乏全局局部对应关系。为了解决这一问题,我们引入了GPT4Scene,这是一种新型的视觉提示范式,应用于VLM训练和推理,有助于建立全局局部关系,显著提高对室内场景的三维空间理解。具体而言,GPT4Scene从视频构建三维鸟瞰图(BEV)图像,并在帧和BEV图像上标记一致的对象ID。然后,模型将拼接的BEV图像和视频帧(带有标记)作为输入。在零样本评估中,GPT4Scene改进了如GPT-4o等封闭源VLM的性能。此外,我们准备了一个处理过的视频数据集,包含16.5万条文本注释,以微调开源VLMs,在所有三维理解任务上达到最新性能水平。令人惊讶的是,在用GPT4Scene范式训练后,即使在推理过程中没有视觉提示和BEV图像作为明确的对应关系,VLMs的表现在持续提高。这表明所提出的范式有助于VLMs发展内在理解三维场景的能力,这为扩展预训练的VLMs以进行三维场景理解提供了非侵入式方法。
论文及项目相关链接
PDF Project page: https://gpt4scene.github.io/
摘要
近年来,二维视觉语言模型(VLMs)在图像文本理解任务上取得了显著进展。然而,对于体现人工智能体潜能的3D空间理解,其表现仍然有限。虽然已有研究利用3D点云和多视角图像作为输入,取得了有前景的结果,但本文提出一种基于纯粹视觉的解决方案,仅依靠视觉线索进行3D空间理解。本文实证探讨了VLMs在3D空间知识方面的局限性,发现其主要缺陷在于场景与个体帧之间缺乏全局-局部对应关系。为解决这一问题,我们提出了GPT4Scene,这是一种新的视觉提示范式,在VLM训练和推理过程中有助于建立全局-局部关系,显著提高对室内场景的3D空间理解能力。GPT4Scene通过构建视频的3D鸟瞰图(BEV)并标记帧和BEV图像中的一致对象ID来实现这一目标。模型将拼接的BEV图像和带标记的视频帧作为输入。在零样本评估中,GPT4Scene的性能超过了如GPT-4o等封闭源代码的VLMs。此外,我们还准备了一个包含16.5万文本注解的处理过的视频数据集,以微调开源VLMs,在所有3D理解任务上实现卓越性能。令人惊讶的是,经过GPT4Scene范式训练后,即使在不需要视觉提示和BEV图像作为明确对应的情况下,VLMs的推理性能也持续提高。这表明所提出的范式有助于VLMs培养对3D场景的内在理解能力,为扩展预训练VLMs进行3D场景理解提供了无创方法。
Key Takeaways
- 2D VLMs在图像文本理解上的显著进展但在关键的3D空间理解上表现有限。
- 当前研究倾向于利用3D点云和多视角图像作为输入来提高性能。
- 论文提出了一种基于视觉的纯解决方案GPT4Scene来处理3D空间理解问题。它依赖视觉线索来感知和理解空间信息。
点此查看论文截图