⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-13 更新
Locality-aware Gaussian Compression for Fast and High-quality Rendering
Authors:Seungjoo Shin, Jaesik Park, Sunghyun Cho
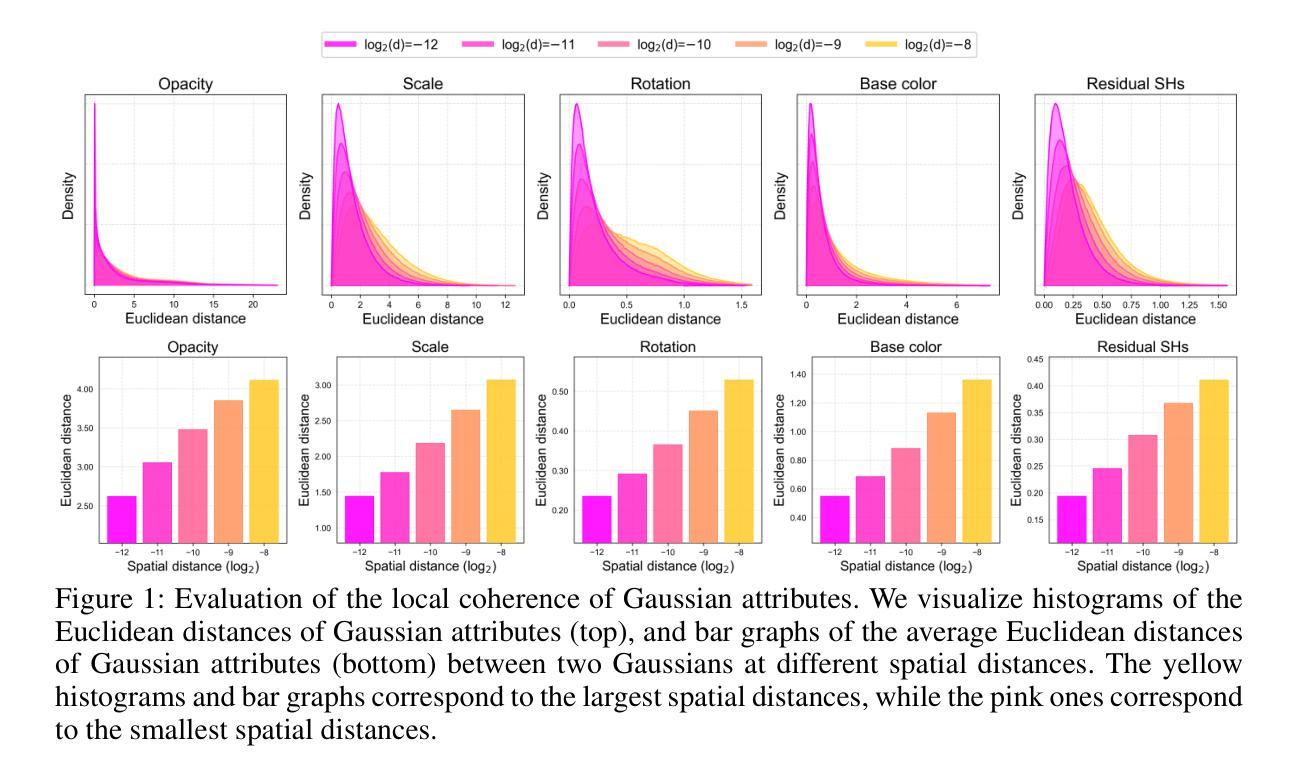
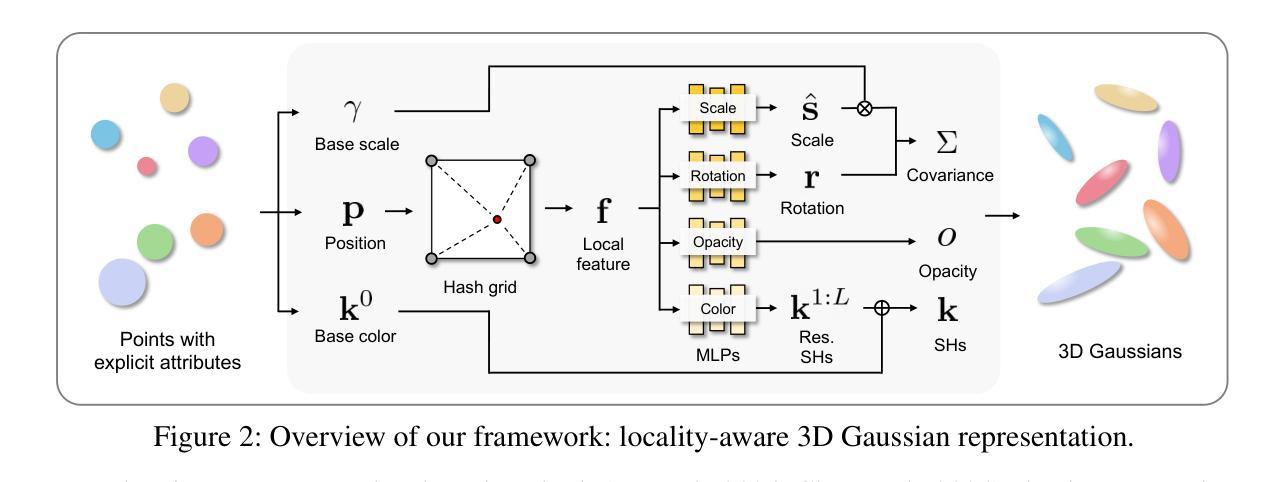
We present LocoGS, a locality-aware 3D Gaussian Splatting (3DGS) framework that exploits the spatial coherence of 3D Gaussians for compact modeling of volumetric scenes. To this end, we first analyze the local coherence of 3D Gaussian attributes, and propose a novel locality-aware 3D Gaussian representation that effectively encodes locally-coherent Gaussian attributes using a neural field representation with a minimal storage requirement. On top of the novel representation, LocoGS is carefully designed with additional components such as dense initialization, an adaptive spherical harmonics bandwidth scheme and different encoding schemes for different Gaussian attributes to maximize compression performance. Experimental results demonstrate that our approach outperforms the rendering quality of existing compact Gaussian representations for representative real-world 3D datasets while achieving from 54.6$\times$ to 96.6$\times$ compressed storage size and from 2.1$\times$ to 2.4$\times$ rendering speed than 3DGS. Even our approach also demonstrates an averaged 2.4$\times$ higher rendering speed than the state-of-the-art compression method with comparable compression performance.
我们提出了LocoGS,这是一个基于局部感知的3D高斯混合(3DGS)框架,它利用3D高斯的空间连贯性对体积场景进行紧凑建模。为此,我们首先分析了3D高斯属性的局部连贯性,并提出了一种新型的局部感知的3D高斯表示方法,该方法使用具有最小存储要求的神经网络场表示法有效地编码局部连贯的高斯属性。在新型表示法的基础上,LocoGS经过精心设计,增加了密集初始化、自适应球面谐波带宽方案以及针对不同高斯属性的不同编码方案等组件,以最大化压缩性能。实验结果表明,我们的方法在具有代表性的真实世界3D数据集上,其渲染质量超过了现有紧凑高斯表示方法的渲染质量,同时实现了从54.6倍到96.6倍的压缩存储大小,以及从2.1倍到2.4倍的渲染速度提升。相较于具有相近压缩性能的当前顶尖压缩方法,我们的方法还表现出了平均高出2.4倍的渲染速度。
论文及项目相关链接
PDF 28 pages, 15 figures, and 14 tables
Summary
该文章介绍了LocoGS,一个基于空间感知的3D高斯融合(3DGS)框架。它通过利用局部一致性的3D高斯模型,实现对体积场景的有效建模。文章提出一种新型的局部感知的3D高斯表示方法,使用神经网络场表示技术,以最小的存储需求有效地编码局部一致的Gaussian属性。此外,LocoGS还通过密集初始化、自适应球面谐波带宽方案以及不同高斯属性的编码方案进行设计,以最大化压缩性能。实验结果表明,该方法的渲染质量优于现有紧凑高斯表示方法,在真实世界数据集上实现了较高的压缩存储和渲染速度提升。
Key Takeaways
- LocoGS是一个基于空间感知的3D高斯融合(3DGS)框架,旨在实现对体积场景的紧凑建模。
- 该方法利用局部一致的3D高斯模型,提出一种新型的局部感知的3D高斯表示方法。
- LocoGS使用神经网络场表示技术,以最小的存储需求有效地编码局部一致的Gaussian属性。
- LocoGS通过密集初始化、自适应球面谐波带宽方案以及不同高斯属性的编码方案进行设计,以提高压缩性能。
- 实验结果表明,LocoGS的渲染质量优于现有方法,实现了较高的压缩存储提升,压缩比从54.6倍到96.6倍不等。
- LocoGS的渲染速度也有所提升,相比现有先进压缩方法,即使在相近的压缩性能下,平均渲染速度提高了2.4倍。
点此查看论文截图

Arc2Avatar: Generating Expressive 3D Avatars from a Single Image via ID Guidance
Authors:Dimitrios Gerogiannis, Foivos Paraperas Papantoniou, Rolandos Alexandros Potamias, Alexandros Lattas, Stefanos Zafeiriou
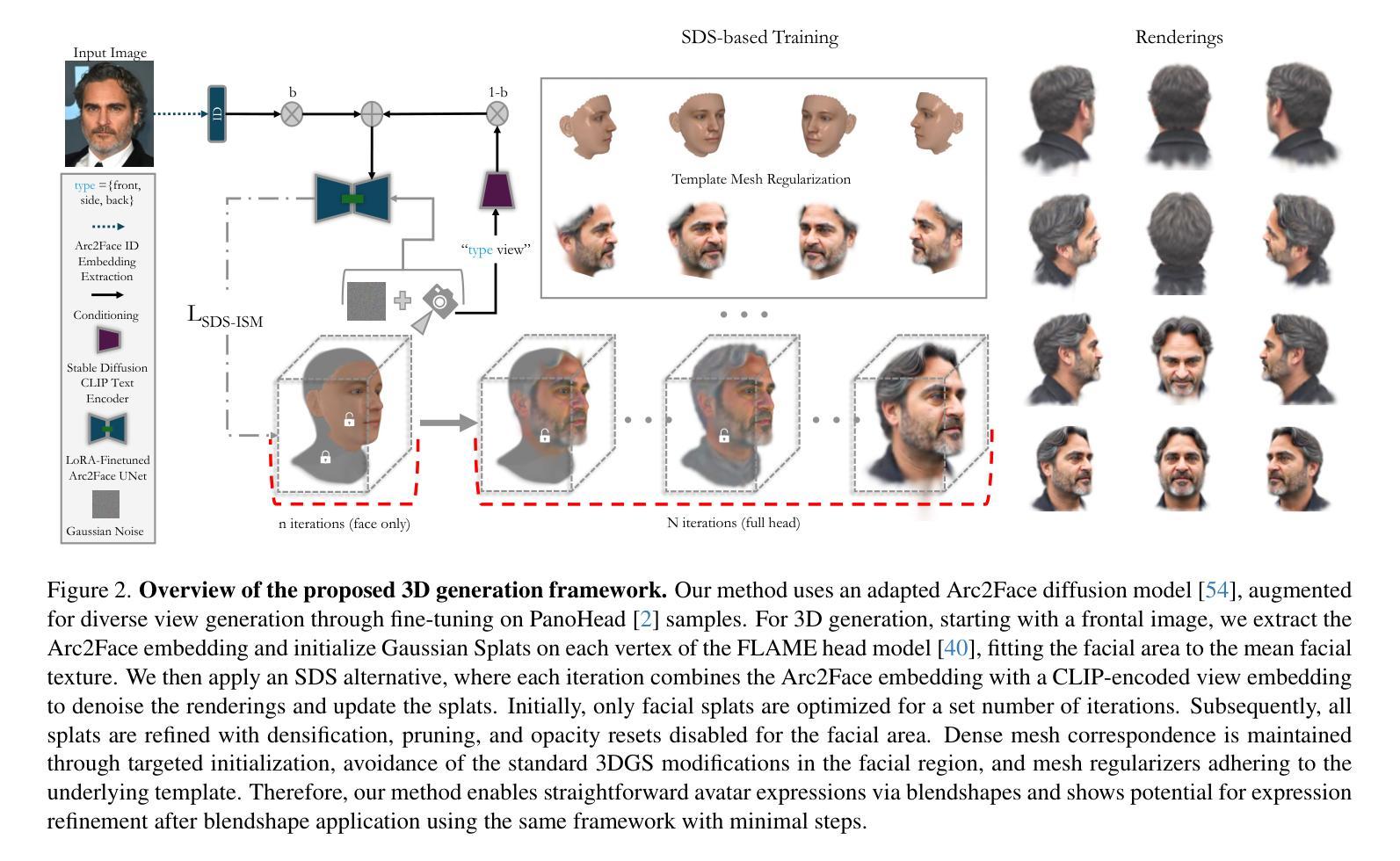
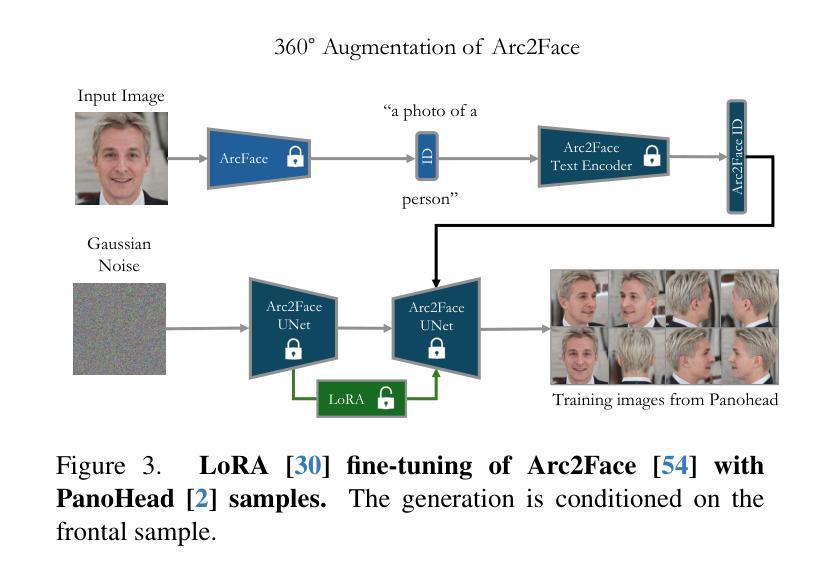
Inspired by the effectiveness of 3D Gaussian Splatting (3DGS) in reconstructing detailed 3D scenes within multi-view setups and the emergence of large 2D human foundation models, we introduce Arc2Avatar, the first SDS-based method utilizing a human face foundation model as guidance with just a single image as input. To achieve that, we extend such a model for diverse-view human head generation by fine-tuning on synthetic data and modifying its conditioning. Our avatars maintain a dense correspondence with a human face mesh template, allowing blendshape-based expression generation. This is achieved through a modified 3DGS approach, connectivity regularizers, and a strategic initialization tailored for our task. Additionally, we propose an optional efficient SDS-based correction step to refine the blendshape expressions, enhancing realism and diversity. Experiments demonstrate that Arc2Avatar achieves state-of-the-art realism and identity preservation, effectively addressing color issues by allowing the use of very low guidance, enabled by our strong identity prior and initialization strategy, without compromising detail.
受3D高斯平铺(3DGS)在多视角设置下重建详细3D场景的有效性,以及大型二维人类基础模型的出现的启发,我们引入了Arc2Avatar。Arc2Avatar是基于SDS的第一个方法,仅使用单幅图像作为输入,并利用人类面部基础模型作为指导。为了实现这一点,我们通过微调合成数据并修改其条件,将该模型扩展到多视角的人头生成。我们的角色与一个人脸网格模板保持密集的对应关系,允许基于blendshape的表情生成。这是通过一个改进的3DGS方法、连接正则器和针对我们的任务量身定制的战略初始化来实现的。此外,我们提出了一种可选的基于SDS的校正步骤,以优化blendshape表情,提高真实感和多样性。实验表明,Arc2Avatar达到了最先进的真实感和身份保留效果,通过我们的强大身份先验和初始化策略,允许使用非常低的指导来解决颜色问题,在不损害细节的情况下增强了效果。
论文及项目相关链接
Summary
Arc2Avatar是首个基于SDS的方法,利用单张图像和人脸基础模型指导,通过改进3DGS方法,实现多角度生成逼真的人脸头像。此方法维持了与人脸网格模板的密集对应关系,并通过修正步骤提高表情的真实性和多样性。
Key Takeaways
- Arc2Avatar利用SDS方法结合单张图像和人脸基础模型指导,实现多角度生成逼真的人脸头像。
- Arc2Avatar使用改进后的3DGS方法,实现了与模板人脸网格的密集对应关系。
- 通过添加连接正则化和针对任务的策略初始化,实现了表情生成。
- Arc2Avatar具有高效的SDS修正步骤,可增强表情的真实性和多样性。
- Arc2Avatar达到了先进水平的真实性和身份保留能力。
- Arc2Avatar通过强大的身份先验知识和初始化策略,解决了色彩问题,在低指导情况下也能使用。
点此查看论文截图

Scaffold-SLAM: Structured 3D Gaussians for Simultaneous Localization and Photorealistic Mapping
Authors:Wen Tianci, Liu Zhiang, Lu Biao, Fang Yongchun
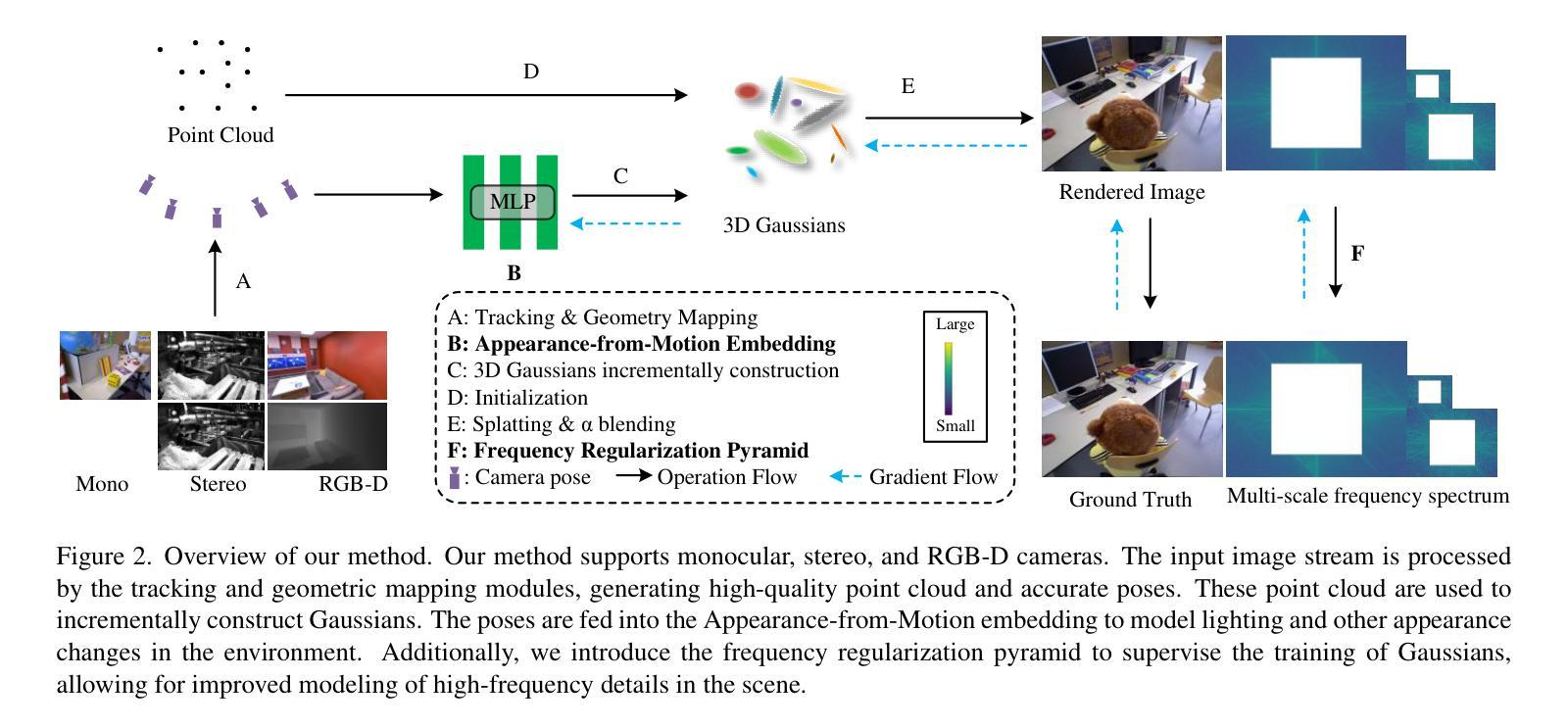
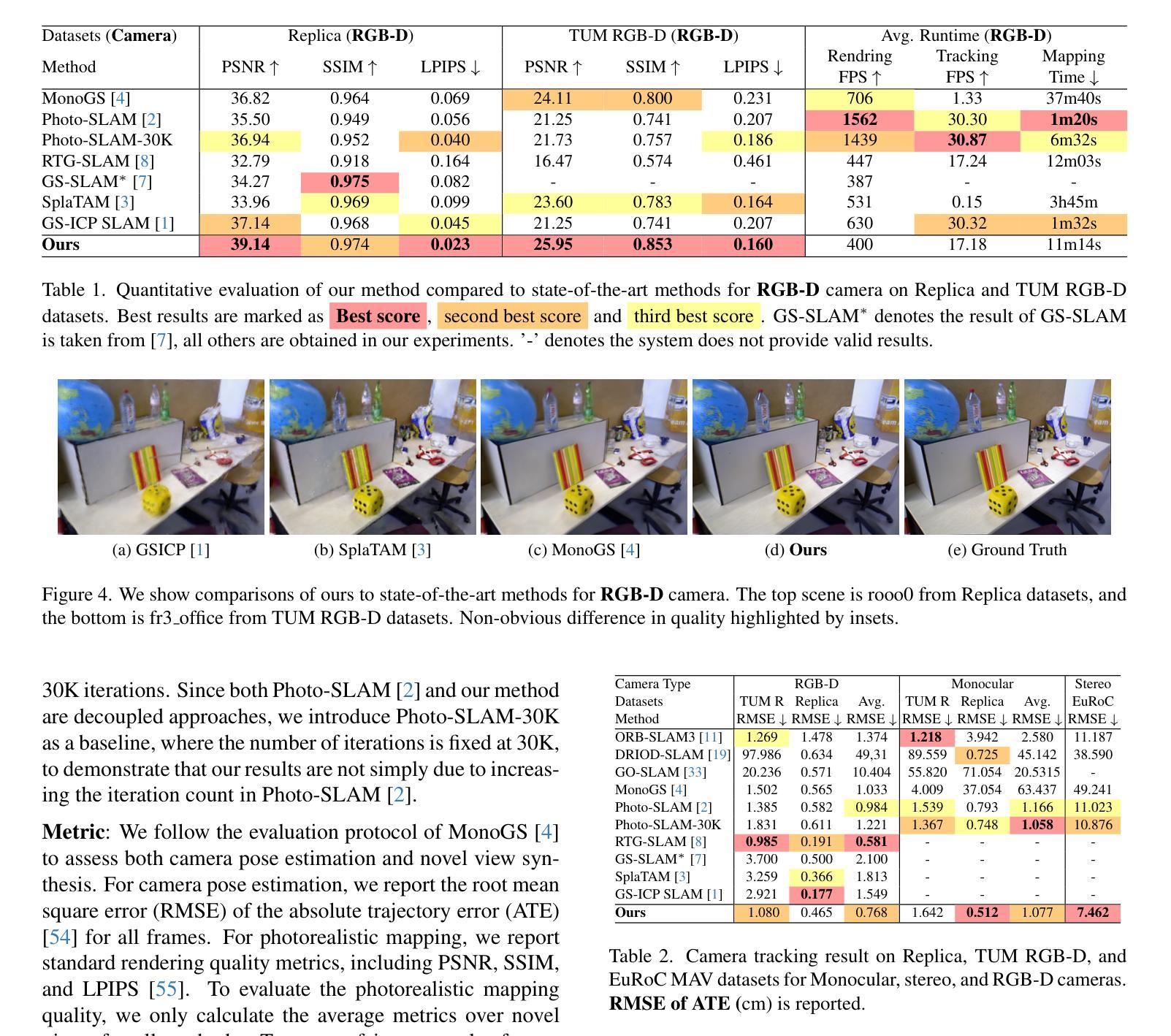
3D Gaussian Splatting (3DGS) has recently revolutionized novel view synthesis in the Simultaneous Localization and Mapping (SLAM). However, existing SLAM methods utilizing 3DGS have failed to provide high-quality novel view rendering for monocular, stereo, and RGB-D cameras simultaneously. Notably, some methods perform well for RGB-D cameras but suffer significant degradation in rendering quality for monocular cameras. In this paper, we present Scaffold-SLAM, which delivers simultaneous localization and high-quality photorealistic mapping across monocular, stereo, and RGB-D cameras. We introduce two key innovations to achieve this state-of-the-art visual quality. First, we propose Appearance-from-Motion embedding, enabling 3D Gaussians to better model image appearance variations across different camera poses. Second, we introduce a frequency regularization pyramid to guide the distribution of Gaussians, allowing the model to effectively capture finer details in the scene. Extensive experiments on monocular, stereo, and RGB-D datasets demonstrate that Scaffold-SLAM significantly outperforms state-of-the-art methods in photorealistic mapping quality, e.g., PSNR is 16.76% higher in the TUM RGB-D datasets for monocular cameras.
3D高斯贴图(3DGS)最近为同时定位与地图构建(SLAM)中的新视角合成带来了革命性的变革。然而,现有的利用3DGS的SLAM方法未能同时为单目相机、立体相机和RGB-D相机提供高质量的新视角渲染。值得注意的是,一些方法为RGB-D相机提供了良好的表现,但在单目相机上的渲染质量却出现了显著下降。在本文中,我们提出了Scaffold-SLAM,它能够在单目相机、立体相机和RGB-D相机上同时进行定位和高质量的照片级地图构建。我们引入了两种关键创新技术,以实现最先进的视觉质量。首先,我们提出了运动嵌入的外观技术,使3D高斯能够更好地对不同相机姿态下的图像外观变化进行建模。其次,我们引入了一个频率正则化金字塔来引导高斯的分布,使模型能够有效地捕捉场景中的细节。在单目相机、立体相机和RGB-D数据集上的大量实验表明,Scaffold-SLAM在照片级地图构建质量上显著优于最先进的方法,例如在TUM RGB-D数据集中,对于单目相机,PSNR提高了16.76%。
论文及项目相关链接
PDF 12 pages, 6 figures
Summary
本文介绍了基于三维高斯分裂(3DGS)技术的支架SLAM(Scaffold-SLAM),实现了对单目、立体和RGB-D相机的同步定位和高品质超现实主义映射。引入了两项关键创新技术:利用动态生成图像的嵌入技术以及频率正则化金字塔来引导高斯分布,有效提升模型的细节捕捉能力,从而实现更佳的视觉质量。实验表明,与现有技术相比,Scaffold-SLAM在单目、立体和RGB-D数据集上的超现实主义映射质量显著提高。
Key Takeaways
- 介绍了Scaffold-SLAM技术,该技术结合了三维高斯分裂(3DGS)实现了针对单目、立体和RGB-D相机的同步定位和高质量超现实主义地图生成。
- 提出“Appearance-from-Motion”嵌入技术,使三维高斯能更好地模拟不同相机视角下的图像外观变化。
- 引入频率正则化金字塔,指导高斯分布,使得模型更有效地捕捉场景的细节。
- 进行了大量实验验证,涉及多种数据集。实验证明,与当前的技术相比,Scaffold-SLAM的映射质量显著更优。例如在TUM RGB-D数据集中PSNR提高了16.76%。
点此查看论文截图


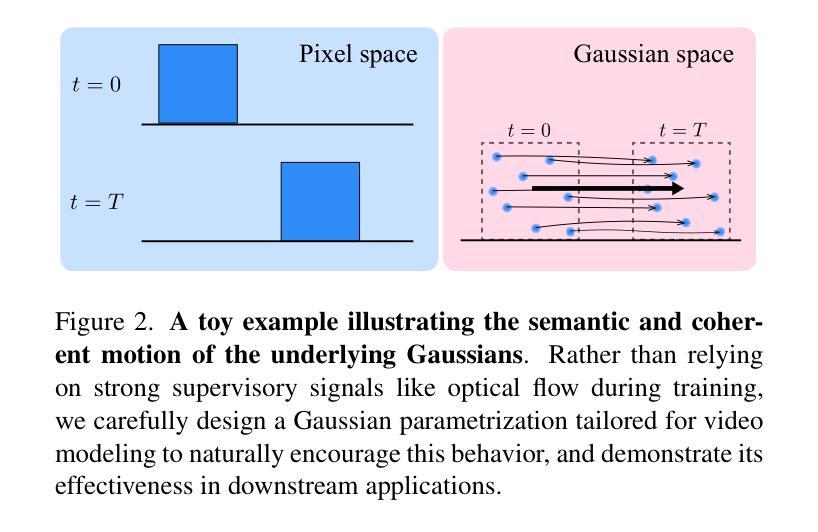
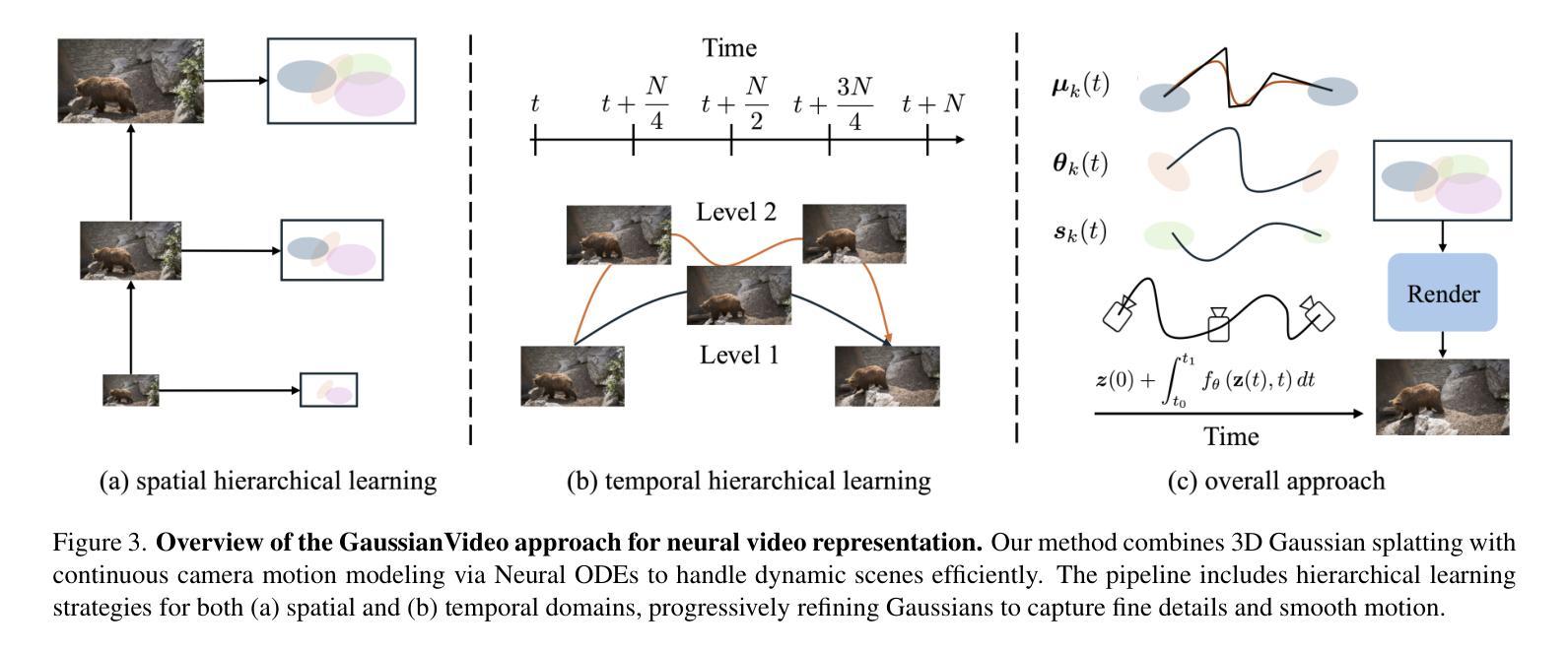
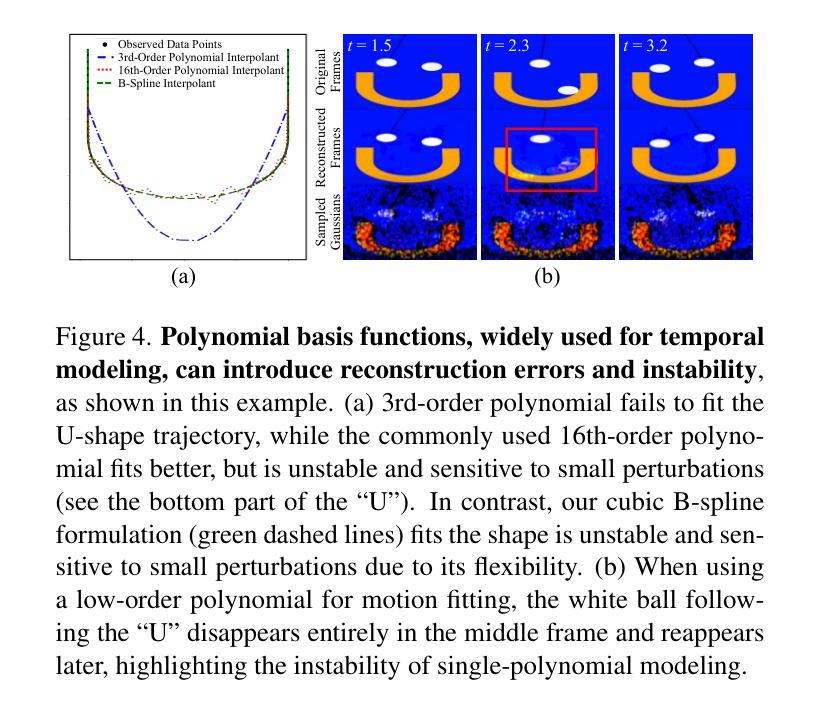
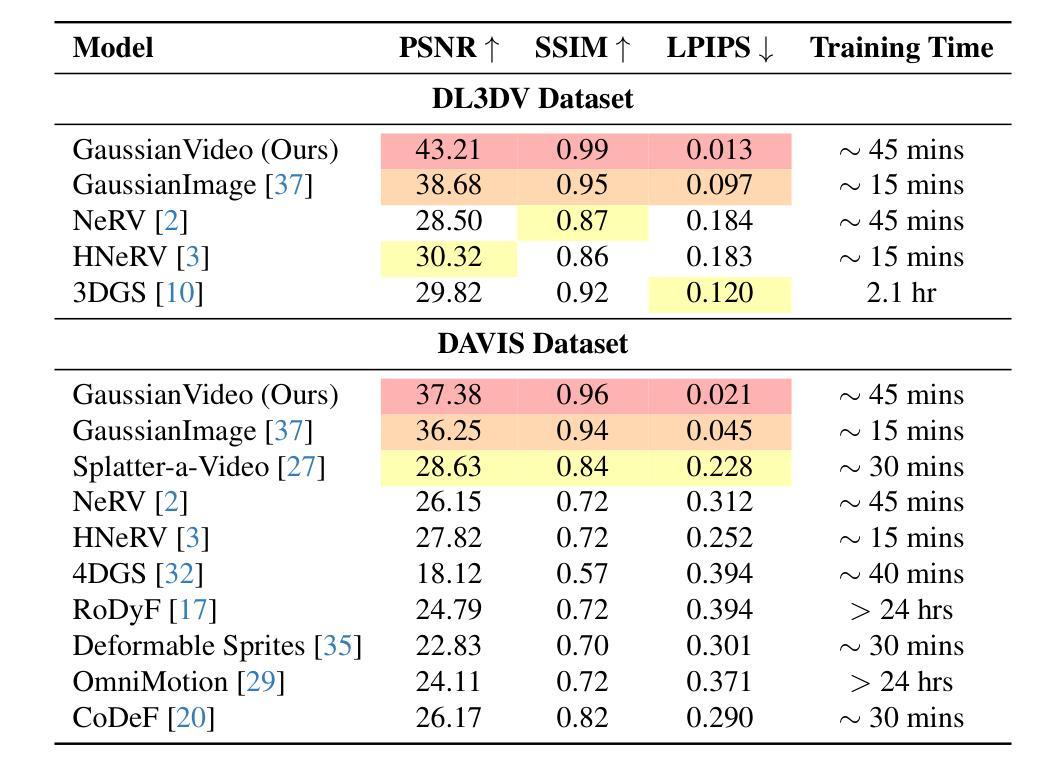
GaussianVideo: Efficient Video Representation via Hierarchical Gaussian Splatting
Authors:Andrew Bond, Jui-Hsien Wang, Long Mai, Erkut Erdem, Aykut Erdem
Efficient neural representations for dynamic video scenes are critical for applications ranging from video compression to interactive simulations. Yet, existing methods often face challenges related to high memory usage, lengthy training times, and temporal consistency. To address these issues, we introduce a novel neural video representation that combines 3D Gaussian splatting with continuous camera motion modeling. By leveraging Neural ODEs, our approach learns smooth camera trajectories while maintaining an explicit 3D scene representation through Gaussians. Additionally, we introduce a spatiotemporal hierarchical learning strategy, progressively refining spatial and temporal features to enhance reconstruction quality and accelerate convergence. This memory-efficient approach achieves high-quality rendering at impressive speeds. Experimental results show that our hierarchical learning, combined with robust camera motion modeling, captures complex dynamic scenes with strong temporal consistency, achieving state-of-the-art performance across diverse video datasets in both high- and low-motion scenarios.
对于从视频压缩到交互式模拟等应用而言,为动态视频场景设计高效的神经表示至关重要。然而,现有方法常常面临与内存使用高、训练时间长和时序一致性差相关的挑战。为了解决这些问题,我们引入了一种新型神经视频表示方法,它将3D高斯喷绘与连续相机运动建模相结合。通过利用神经常微分方程,我们的方法在学会平滑相机轨迹的同时,通过高斯分布维持了明确的3D场景表示。此外,我们还引入了一种时空分层学习策略,逐步优化空间和时间特征,以提高重建质量和加速收敛。这种内存高效的方法能以令人印象深刻的速度实现高质量渲染。实验结果表明,我们的分层学习与稳健的相机运动建模相结合,能捕获具有强时序一致性的复杂动态场景,在高和低运动场景的各种视频数据集上均达到最先进的性能。
论文及项目相关链接
PDF 10 pages, 10 figures
总结
针对动态视频场景的高效神经表示对于视频压缩到交互模拟等应用至关重要。然而,现有方法常面临内存使用高、训练时间长和时序一致性差等问题。为解决这些问题,我们提出了一种结合三维高斯涂抹和连续相机运动建模的新型神经视频表示方法。通过利用神经常微分方程,我们的方法在学习平滑相机轨迹的同时,通过高斯分布显式表示三维场景。此外,我们还引入了一种时空分层学习策略,逐步优化空间和时间特征,以提高重建质量和加速收敛。这种内存高效的方法以令人印象深刻的速度实现了高质量渲染。实验结果表明,我们的分层学习与稳健的相机运动建模相结合,能够捕捉复杂的动态场景,具有较强的时序一致性,在高低运动场景的多种视频数据集上均达到了最先进的性能。
关键见解
- 高效神经表示对于动态视频场景的处理至关重要,对于从视频压缩到交互模拟的各种应用都有重要意义。
- 现有方法在处理动态视频场景时面临诸多挑战,如高内存使用、训练时间长和时序一致性差等。
- 提出了一种新型神经视频表示方法,结合三维高斯涂抹和连续相机运动建模,解决上述问题。
- 利用神经常微分方程学习平滑相机轨迹,同时利用高斯分布显式表示三维场景。
- 引入了一种新的时空分层学习策略,逐步优化空间和时间特征,以提高重建质量和加速模型收敛。
- 所提出的方法在内存使用上更加高效,实现了高质量的视频渲染速度。
点此查看论文截图


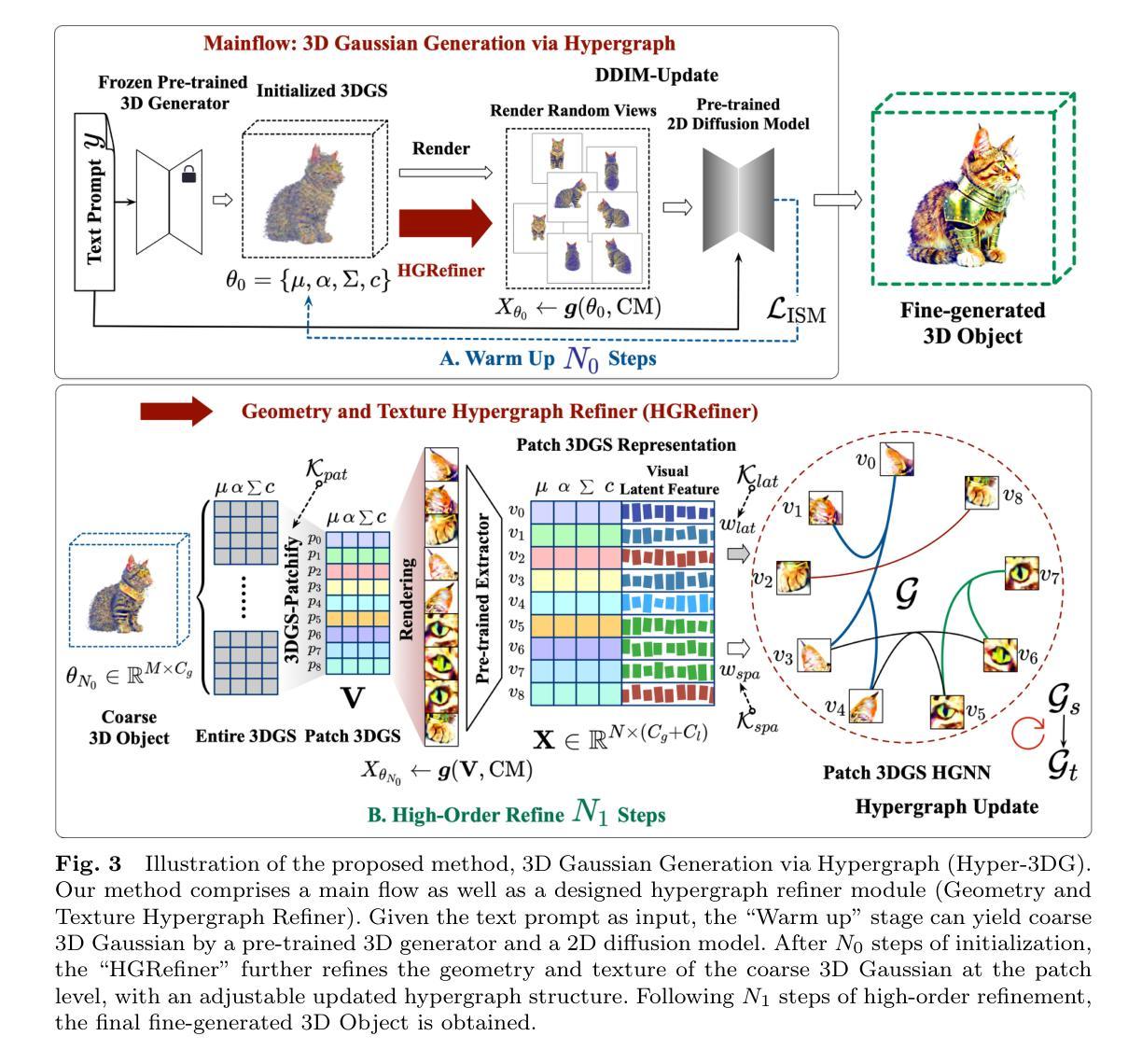
Hyper-3DG: Text-to-3D Gaussian Generation via Hypergraph
Authors:Donglin Di, Jiahui Yang, Chaofan Luo, Zhou Xue, Wei Chen, Xun Yang, Yue Gao
Text-to-3D generation represents an exciting field that has seen rapid advancements, facilitating the transformation of textual descriptions into detailed 3D models. However, current progress often neglects the intricate high-order correlation of geometry and texture within 3D objects, leading to challenges such as over-smoothness, over-saturation and the Janus problem. In this work, we propose a method named 3D Gaussian Generation via Hypergraph (Hyper-3DG)'', designed to capture the sophisticated high-order correlations present within 3D objects. Our framework is anchored by a well-established mainflow and an essential module, named Geometry and Texture Hypergraph Refiner (HGRefiner)’’. This module not only refines the representation of 3D Gaussians but also accelerates the update process of these 3D Gaussians by conducting the Patch-3DGS Hypergraph Learning on both explicit attributes and latent visual features. Our framework allows for the production of finely generated 3D objects within a cohesive optimization, effectively circumventing degradation. Extensive experimentation has shown that our proposed method significantly enhances the quality of 3D generation while incurring no additional computational overhead for the underlying framework. (Project code: https://github.com/yjhboy/Hyper3DG)
文本到3D生成是一个激动人心的领域,该领域经历了快速发展,推动了文本描述向详细3D模型的转换。然而,当前进展往往忽视了3D对象内部几何和纹理之间复杂的高阶相关性,从而面临过度平滑、过度饱和和Janus问题等挑战。在这项工作中,我们提出了一种名为“通过超图进行3D高斯生成(Hyper-3DG)”的方法,旨在捕捉3D对象内部存在的高级高阶相关性。我们的框架以主流和核心模块为基础,这个核心模块被称为“几何和纹理超图细化器(HGRefiner)”。此模块不仅细化了对3D高斯的表现,还通过进行Patch-3DGS超图学习对明确属性和潜在视觉特征进行加速更新和优化,以此提升这些更新过的模型。我们的框架能够在整体优化中生成精细的3D对象,有效避免了质量下降的问题。大量实验表明,我们提出的方法显著提高了三维生成的质量,并且对底层框架没有额外的计算开销。(项目代码:https://github.com/yjhboy/Hyper3DG)
论文及项目相关链接
PDF Accepted by IJCV
Summary
文本到三维生成领域发展迅速,但存在忽视三维物体几何和纹理高阶相关性的问题,导致生成模型过于平滑、过于饱和和Janus问题。本研究提出一种名为“Hyper-3DG”的方法,通过超图捕捉三维物体内部的高阶相关性。其核心框架包括主流程和名为“HGRefiner”的模块,可细化三维高斯表示并加速其更新过程。该方法显著提高三维生成质量,且对底层框架无额外计算开销。
Key Takeaways
- 文本到三维生成领域发展迅速,但存在挑战,如忽视三维物体几何和纹理的高阶相关性。
- 提出一种名为“Hyper-3DG”的方法,通过超图技术捕捉三维物体内部的高阶相关性。
- “HGRefiner”模块不仅细化三维高斯表示,还通过Patch-3DGS超图学习加速三维高斯的更新过程。
- 方法对显式属性和潜在视觉特征进行超图学习。
- 实验表明,该方法显著提高三维生成质量,同时不增加底层框架的计算开销。
点此查看论文截图