⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-13 更新
A Mixed-Integer Conic Program for the Multi-Agent Moving-Target Traveling Salesman Problem
Authors:Allen George Philip, Zhongqiang Ren, Sivakumar Rathinam, Howie Choset
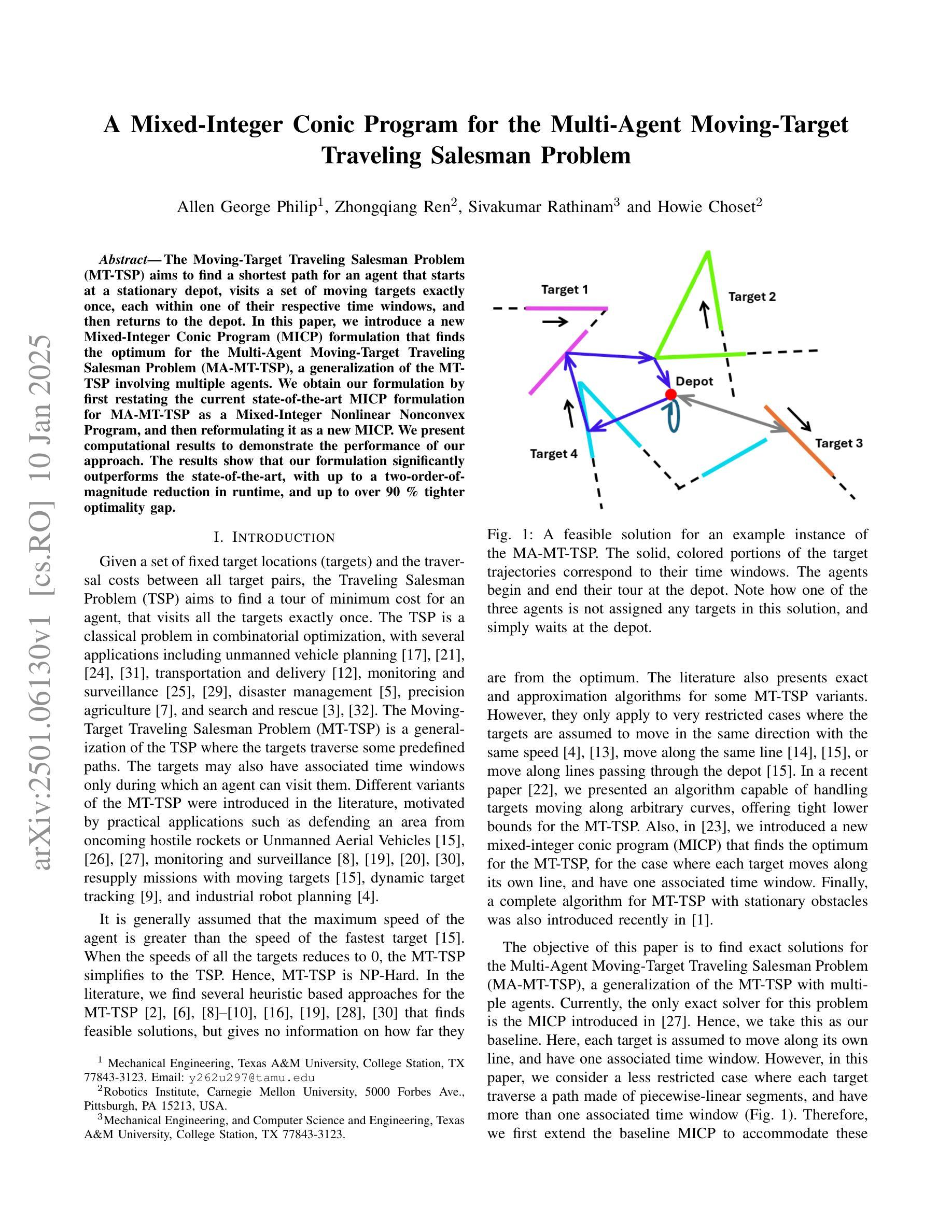
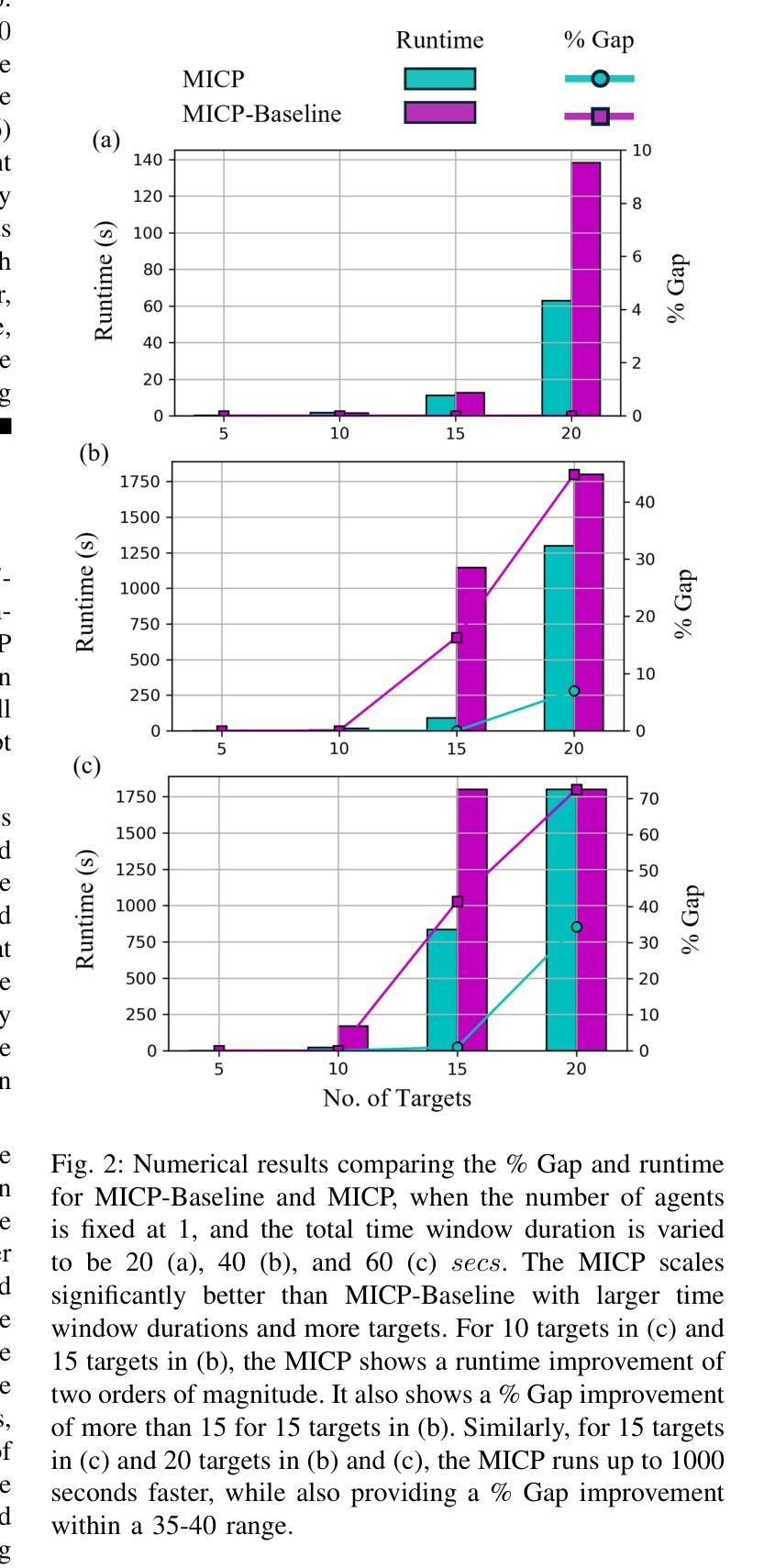
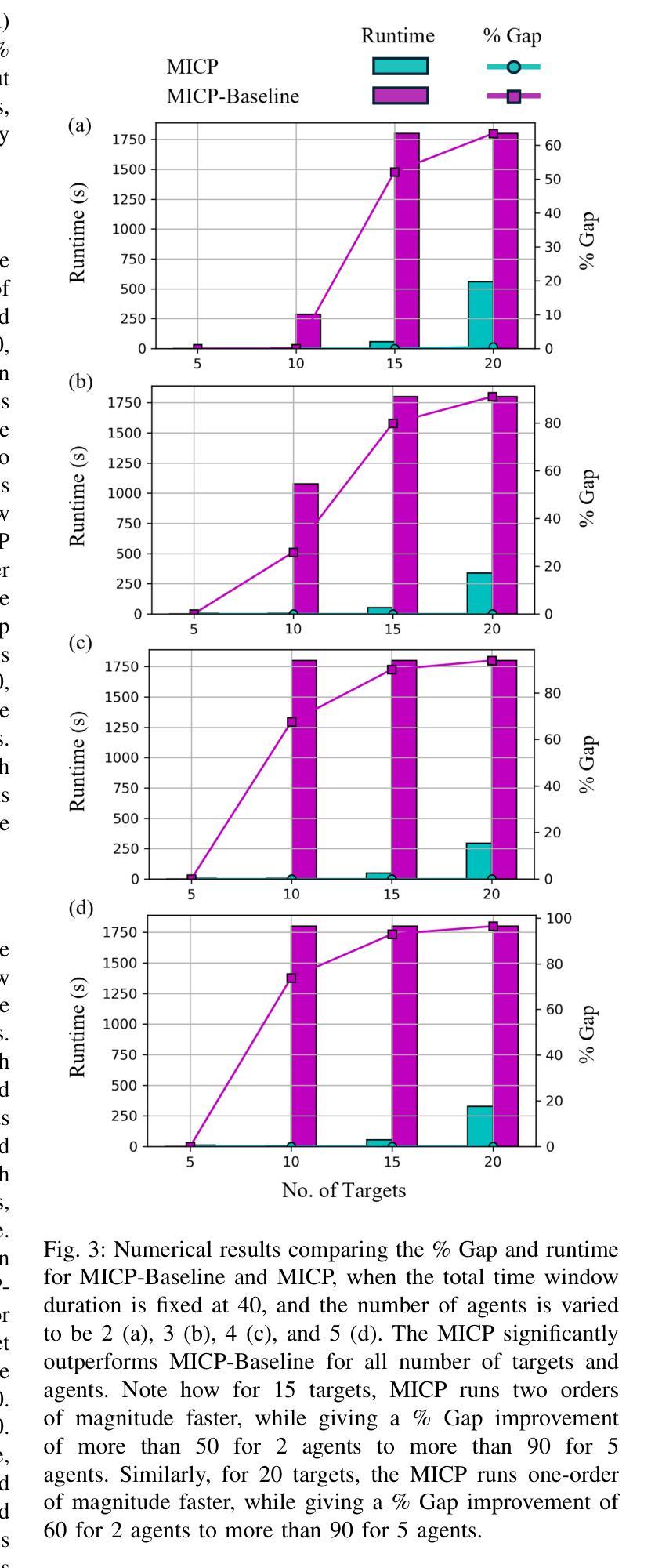
The Moving-Target Traveling Salesman Problem (MT-TSP) aims to find a shortest path for an agent that starts at a stationary depot, visits a set of moving targets exactly once, each within one of their respective time windows, and then returns to the depot. In this paper, we introduce a new Mixed-Integer Conic Program (MICP) formulation that finds the optimum for the Multi-Agent Moving-Target Traveling Salesman Problem (MA-MT-TSP), a generalization of the MT-TSP involving multiple agents. We obtain our formulation by first restating the current state-of-the-art MICP formulation for MA-MT-TSP as a Mixed-Integer Nonlinear Nonconvex Program, and then reformulating it as a new MICP. We present computational results to demonstrate the performance of our approach. The results show that our formulation significantly outperforms the state-of-the-art, with up to a two-order-of-magnitude reduction in runtime, and up to over 90% tighter optimality gap.
移动目标旅行商问题(MT-TSP)旨在为一个代理寻找最短路径,该代理从固定仓库出发,在各自的时间窗口内恰好访问一组移动目标,然后返回仓库。在本文中,我们介绍了一种新的混合整数锥规划(MICP)公式,用于求解多代理移动目标旅行商问题(MA-MT-TSP),这是MT-TSP的一个推广,涉及多个代理。我们通过首先将现有的先进MICP公式表示为MA-MT-TSP的混合整数非线性非凸规划,然后将其重新公式化为新的MICP来获得我们的公式。我们给出计算结果来证明我们的方法的性能。结果表明,我们的公式显著优于现有技术,运行时减少了两个数量级,最优间隙最多提高了90%以上。
论文及项目相关链接
PDF 7 pages, 3 figures
Summary
该文针对多代理移动目标旅行推销员问题(MA-MT-TSP)提出了一种新的混合整数锥程序(MICP)公式,该公式在寻找最优解方面表现出显著优势。通过重新表述当前最先进的MICP公式,并将其改革为新的MICP,该研究提供了一种更高效的方法来解决MT-TSP问题,即在特定时间窗口内访问移动目标并返回基地的最短路径问题。计算结果表明,该方法显著优于现有技术,运行时间最多减少两个数量级,最优间隙最多减少90%以上。
Key Takeaways
- 该文介绍了多代理移动目标旅行推销员问题(MA-MT-TSP),这是一个移动目标旅行推销员问题的扩展版本,涉及多个代理。
- 提出了一种新的混合整数锥程序(MICP)公式来解决MA-MT-TSP的最优解问题。
- 通过将现有技术最先进的MICP公式重新表述为混合整数非线性非凸程序,然后进行改革,得到新的MICP公式。
- 计算结果表明,新公式在运行时性能和最优解方面显著优于现有技术。
- 新方法在运行时间方面最多可减少两个数量级,在最优间隙方面最多可减少90%以上。
- 该研究为解决涉及移动目标和多个代理的优化问题提供了新的思路和方法。
点此查看论文截图
Scaling Safe Multi-Agent Control for Signal Temporal Logic Specifications
Authors:Joe Eappen, Zikang Xiong, Dipam Patel, Aniket Bera, Suresh Jagannathan
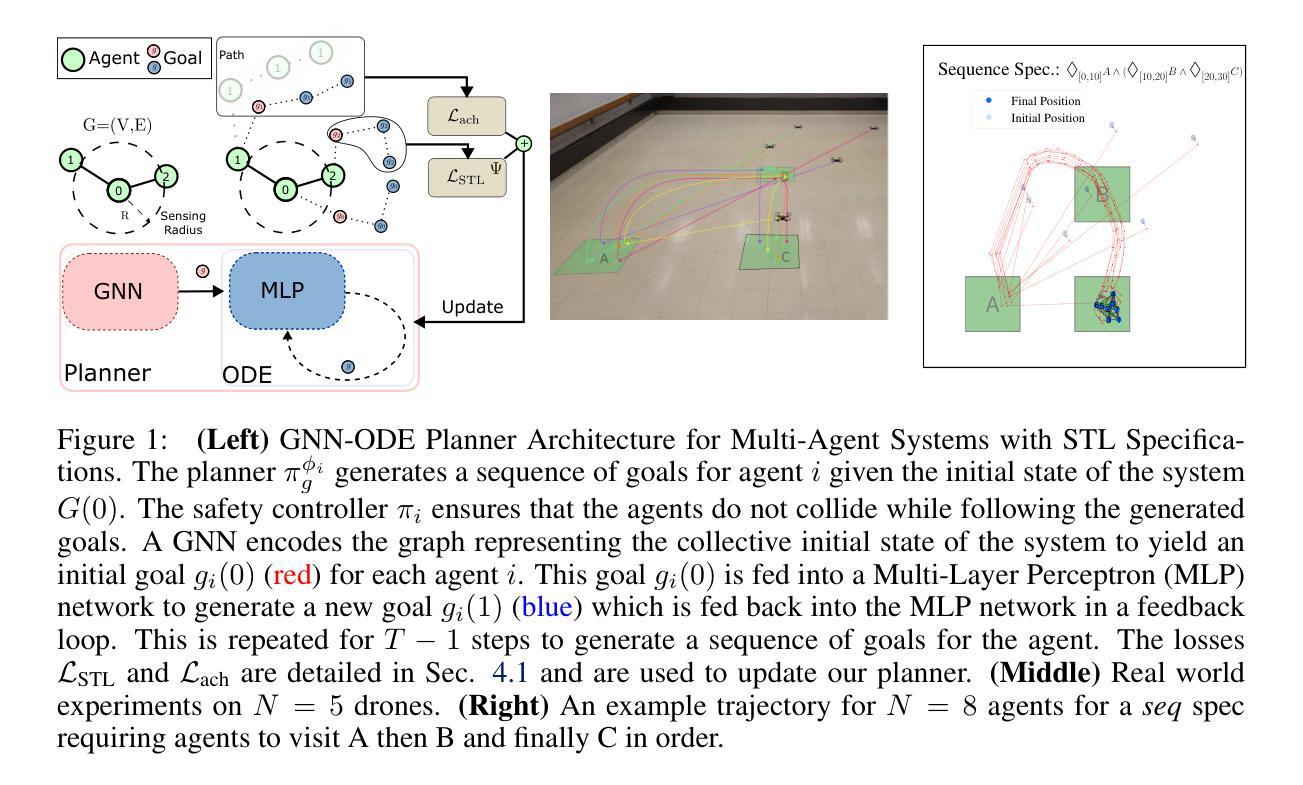
Existing methods for safe multi-agent control using logic specifications like Signal Temporal Logic (STL) often face scalability issues. This is because they rely either on single-agent perspectives or on Mixed Integer Linear Programming (MILP)-based planners, which are complex to optimize. These methods have proven to be computationally expensive and inefficient when dealing with a large number of agents. To address these limitations, we present a new scalable approach to multi-agent control in this setting. Our method treats the relationships between agents using a graph structure rather than in terms of a single-agent perspective. Moreover, it combines a multi-agent collision avoidance controller with a Graph Neural Network (GNN) based planner, models the system in a decentralized fashion, and trains on STL-based objectives to generate safe and efficient plans for multiple agents, thereby optimizing the satisfaction of complex temporal specifications while also facilitating multi-agent collision avoidance. Our experiments show that our approach significantly outperforms existing methods that use a state-of-the-art MILP-based planner in terms of scalability and performance. The project website is https://jeappen.com/mastl-gcbf-website/ and the code is at https://github.com/jeappen/mastl-gcbf .
现有使用信号时序逻辑(STL)等逻辑规范的多智能体安全控制方法常常面临可扩展性问题。这是因为它们要么依赖于单智能体的视角,要么依赖于基于混合整数线性规划(MILP)的规划器,而这些规划器在优化时较为复杂。当处理大量智能体时,这些方法在计算上被证明是昂贵且低效的。为了解决这些局限性,我们在此环境中提出了一种新的可扩展的多智能体控制方法。我们的方法使用图结构来处理智能体之间的关系,而不是从单个智能体的视角出发。此外,它将多智能体防撞控制器与基于图神经网络(GNN)的规划器相结合,以分布式方式建模系统,并在基于STL的目标上进行训练,以为多个智能体生成安全且高效的计划,从而优化复杂时序规范的满足度,同时促进多智能体的防撞。我们的实验表明,我们的方法在可扩展性和性能方面显著优于使用先进MILP规划器的现有方法。项目网站是https://jeappen.com/mastl-gcbf-website/,代码位于https://github.com/jeappen/mastl-gcbf。
论文及项目相关链接
PDF Accepted to CoRL 2024. arXiv admin note: text overlap with arXiv:2401.14554 by other authors
Summary
在现有使用信号时序逻辑(STL)等逻辑规范的多智能体控制方法中,常常面临可扩展性问题。它们依赖于单智能体视角或使用混合整数线性规划(MILP)的复杂优化。在大型系统中计算代价高且不高效。针对这些局限性,我们提出了一种新的可扩展的多智能体控制方法。该方法通过图形结构处理智能体之间的关系而非单智能体视角,结合多智能体防撞控制器与基于图神经网络(GNN)的规划器,以分散方式建模系统,并基于STL目标进行训练,生成安全有效的多智能体计划,优化复杂时序规范的满足度并促进多智能体防撞。实验表明,我们的方法大幅优于使用当前最先进MILP规划器的现有方法,在可扩展性和性能上表现优越。项目网站为:https://jeappen.com/mastl-gcbf-website/,代码库为:https://github.com/jeappen/mastl-gcbf。
Key Takeaways
- 当前多智能体控制方法使用STL等逻辑规范面临可扩展性问题。
- 现有方法依赖单智能体视角或复杂的MILP规划,计算成本高且效率低下。
- 提出一种新的多智能体控制方法,通过图形结构处理智能体关系,结合GNN规划器和防撞控制器。
- 方法以分散方式建模系统,基于STL目标进行训练,生成安全有效的计划。
- 新方法优化复杂时序规范的满足度,并促进多智能体之间的防撞。
- 实验显示新方法在可扩展性和性能上显著优于使用MILP规划器的现有方法。
点此查看论文截图

Search-o1: Agentic Search-Enhanced Large Reasoning Models
Authors:Xiaoxi Li, Guanting Dong, Jiajie Jin, Yuyao Zhang, Yujia Zhou, Yutao Zhu, Peitian Zhang, Zhicheng Dou
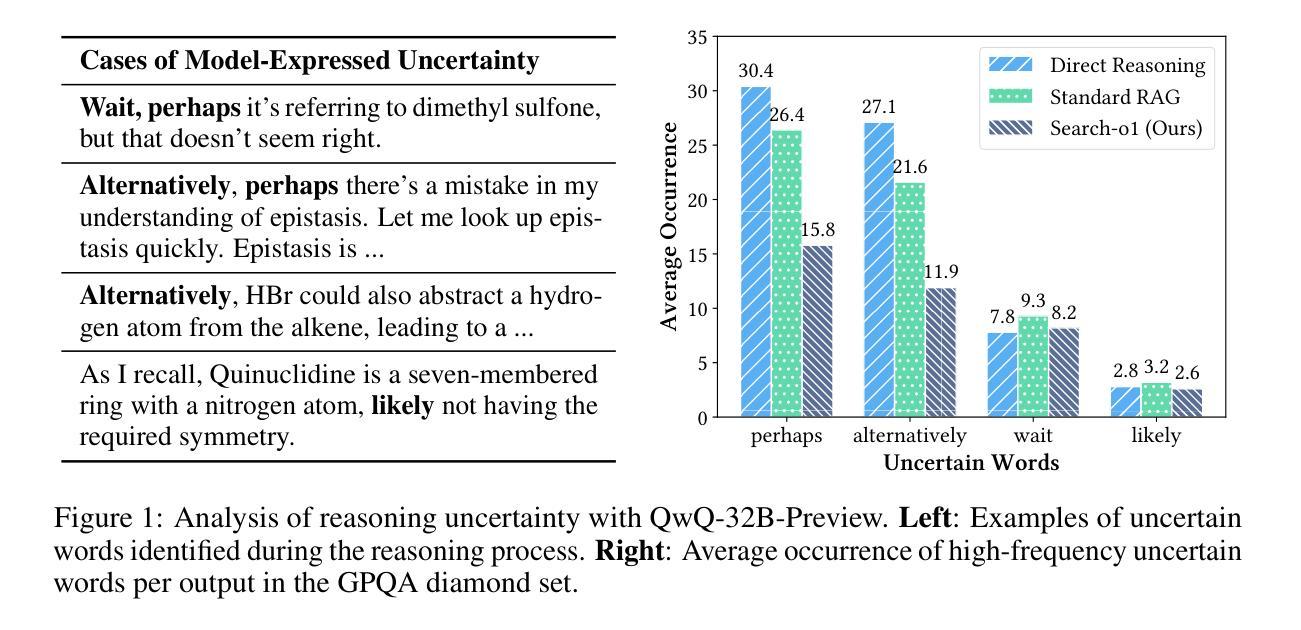
Large reasoning models (LRMs) like OpenAI-o1 have demonstrated impressive long stepwise reasoning capabilities through large-scale reinforcement learning. However, their extended reasoning processes often suffer from knowledge insufficiency, leading to frequent uncertainties and potential errors. To address this limitation, we introduce \textbf{Search-o1}, a framework that enhances LRMs with an agentic retrieval-augmented generation (RAG) mechanism and a Reason-in-Documents module for refining retrieved documents. Search-o1 integrates an agentic search workflow into the reasoning process, enabling dynamic retrieval of external knowledge when LRMs encounter uncertain knowledge points. Additionally, due to the verbose nature of retrieved documents, we design a separate Reason-in-Documents module to deeply analyze the retrieved information before injecting it into the reasoning chain, minimizing noise and preserving coherent reasoning flow. Extensive experiments on complex reasoning tasks in science, mathematics, and coding, as well as six open-domain QA benchmarks, demonstrate the strong performance of Search-o1. This approach enhances the trustworthiness and applicability of LRMs in complex reasoning tasks, paving the way for more reliable and versatile intelligent systems. The code is available at \url{https://github.com/sunnynexus/Search-o1}.
大型推理模型(如OpenAI-o1)已经通过大规模强化学习表现出了令人印象深刻的长步推理能力。然而,它们在进行扩展推理时常常会遇到知识不足的问题,导致频繁的不确定性和潜在错误。为了解决这一局限性,我们引入了Search-o1,这是一个增强大型推理模型的框架,具有基于代理的检索增强生成(RAG)机制和用于精炼检索文档的“Reason-in-Documents”模块。Search-o1将基于代理的搜索工作流程集成到推理过程中,使大型推理模型在遇到不确定知识点时能够动态检索外部知识。此外,由于检索到的文档往往冗长且繁琐,我们设计了一个单独的“Reason-in-Documents”模块来深入分析检索到的信息,然后再将其注入推理链,以最小化噪声并保持连贯的推理流程。在科学、数学和编码等领域的复杂推理任务以及六个开放领域问答基准测试上的大量实验表明,Search-o1表现出强大的性能。这种方法提高了大型推理模型在复杂推理任务中的可信度和适用性,为更可靠、更通用的智能系统铺平了道路。代码可通过以下网址获取:https://github.com/sunnynexus/Search-o1。
论文及项目相关链接
Summary
OpenAI-o1等大型推理模型在大型强化学习中展现出令人印象深刻的长期推理能力,但存在知识不足的问题,导致频繁的不确定性及潜在错误。为解决此问题,提出Search-o1框架,通过引入代理检索增强生成机制和文档内推理模块,提升LRMs的性能。Search-o1整合代理搜索流程入推理过程,使LRMs在遭遇不确定知识点时能够动态检索外部知识。同时,针对检索文档的冗长性,设计专门的文档内推理模块深入分析检索信息后注入推理链,减少噪音并保持连贯的推理流程。实验证明,Search-o1在复杂科学、数学和编码推理任务以及六个开放领域问答基准测试中表现出强大性能,提高了LRMs在复杂推理任务中的可信度和适用性。
Key Takeaways
- Large reasoning models (LRMs)如OpenAI-o1虽具有强大的长期推理能力,但存在知识不足的问题。
- Search-o1框架被引入以解决LRMs的知识不足问题,通过整合代理检索增强生成机制和文档内推理模块来提升性能。
- Search-o1允许LRMs在遭遇不确定知识点时动态检索外部知识。
- 为应对检索文档的冗长性,Search-o1设计了文档内推理模块来深入分析并减少噪音。
- Search-o1在多种复杂推理任务中表现出强大性能,包括科学、数学和编码任务。
- Search-o1在六个开放领域问答基准测试中取得良好效果。
点此查看论文截图

Knowledge Transfer in Model-Based Reinforcement Learning Agents for Efficient Multi-Task Learning
Authors:Dmytro Kuzmenko, Nadiya Shvai
We propose an efficient knowledge transfer approach for model-based reinforcement learning, addressing the challenge of deploying large world models in resource-constrained environments. Our method distills a high-capacity multi-task agent (317M parameters) into a compact 1M parameter model, achieving state-of-the-art performance on the MT30 benchmark with a normalized score of 28.45, a substantial improvement over the original 1M parameter model’s score of 18.93. This demonstrates the ability of our distillation technique to consolidate complex multi-task knowledge effectively. Additionally, we apply FP16 post-training quantization, reducing the model size by 50% while maintaining performance. Our work bridges the gap between the power of large models and practical deployment constraints, offering a scalable solution for efficient and accessible multi-task reinforcement learning in robotics and other resource-limited domains.
我们针对在资源受限环境中部署大型世界模型所面临的挑战,提出了一种高效的基于模型的知识迁移强化学习方法。我们的方法将高容量的多任务代理(含3.17亿参数)蒸馏为紧凑的含约1百万参数模型,在MT30基准测试中取得了最新性能表现,标准化得分为28.45,相对于原始含约1百万参数模型的得分18.93有显著提高。这证明了我们的蒸馏技术能够有效地整合复杂的多任务知识。此外,我们还应用了FP16训练后量化技术,将模型大小缩小了50%,同时保持了性能。我们的研究弥合了大型模型的强大能力与实际部署约束之间的鸿沟,为机器人和其他资源受限领域提供高效、可访问的多任务强化学习的可扩展解决方案。
论文及项目相关链接
PDF Preprint of an extended abstract accepted to AAMAS 2025
Summary
本文提出了一种针对模型基础强化学习的有效知识迁移方法,解决了在资源受限环境中部署大型世界模型的挑战。该方法将高容量的多任务代理(3.17亿参数)蒸馏为紧凑的1亿参数模型,在MT30基准测试上实现了最先进的性能,标准化得分为28.45,较原始的1亿参数模型的得分18.93有了显著的提升。这证明了我们的蒸馏技术能够有效地整合复杂的多任务知识。此外,我们还应用了FP16的定点训练后量化,将模型大小减少了50%,同时保持了性能。我们的研究缩小了大型模型的强大与实际应用部署约束之间的差距,为机器人和其他资源受限领域提供有效的多任务强化学习解决方案。
Key Takeaways
- 提出了一种高效的知识迁移方法用于模型基础强化学习。
- 将大型多任务代理蒸馏为紧凑模型,实现卓越性能。
- 在MT30基准测试中达到最先进的性能,得分为28.45。
- 较之原始模型,性能有所提升,得分提高近一半。
- 应用FP16定点训练后量化技术,减小模型大小50%。
- 将复杂模型的强大性能与实际部署约束相结合,提供解决方案。
点此查看论文截图


CoDe: Communication Delay-Tolerant Multi-Agent Collaboration via Dual Alignment of Intent and Timeliness
Authors:Shoucheng Song, Youfang Lin, Sheng Han, Chang Yao, Hao Wu, Shuo Wang, Kai Lv
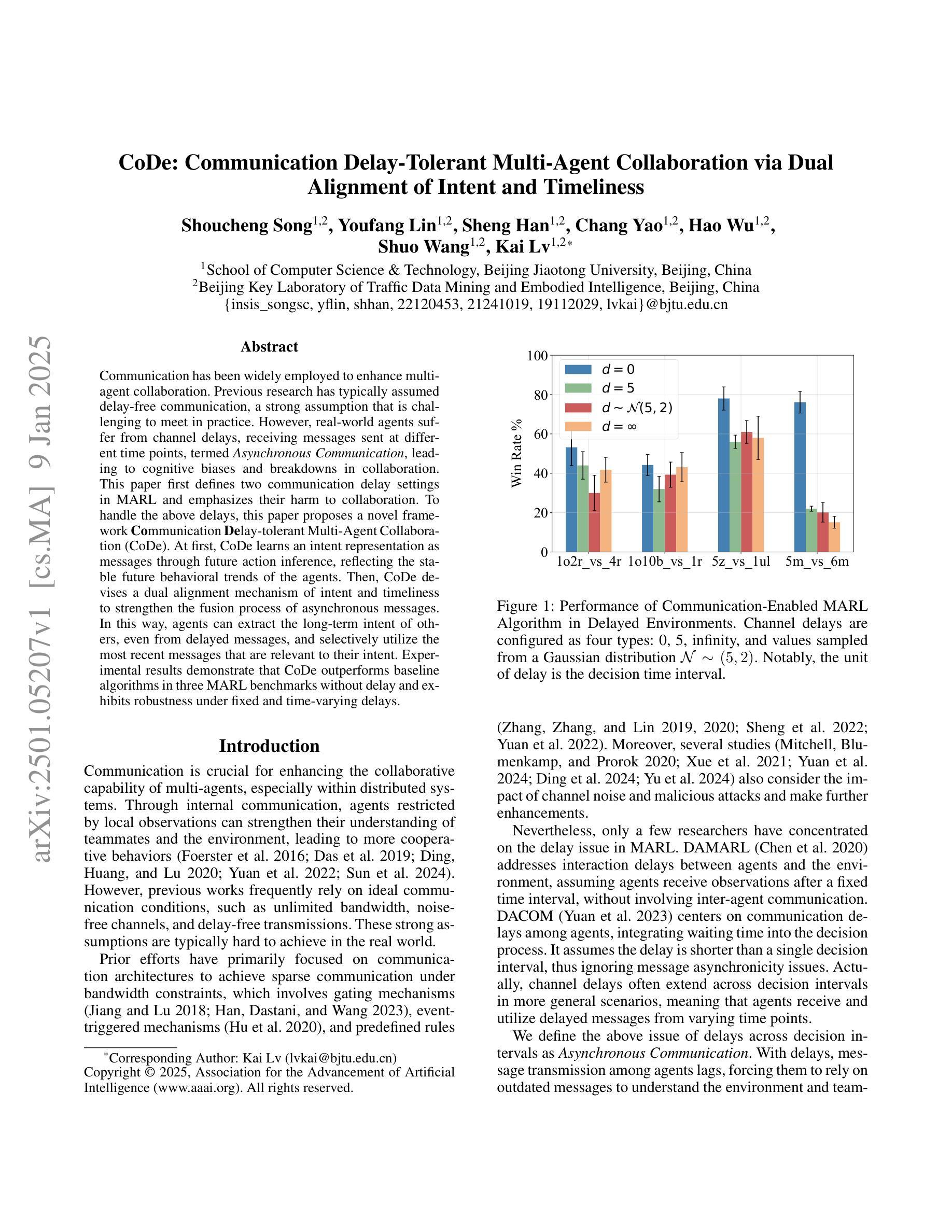
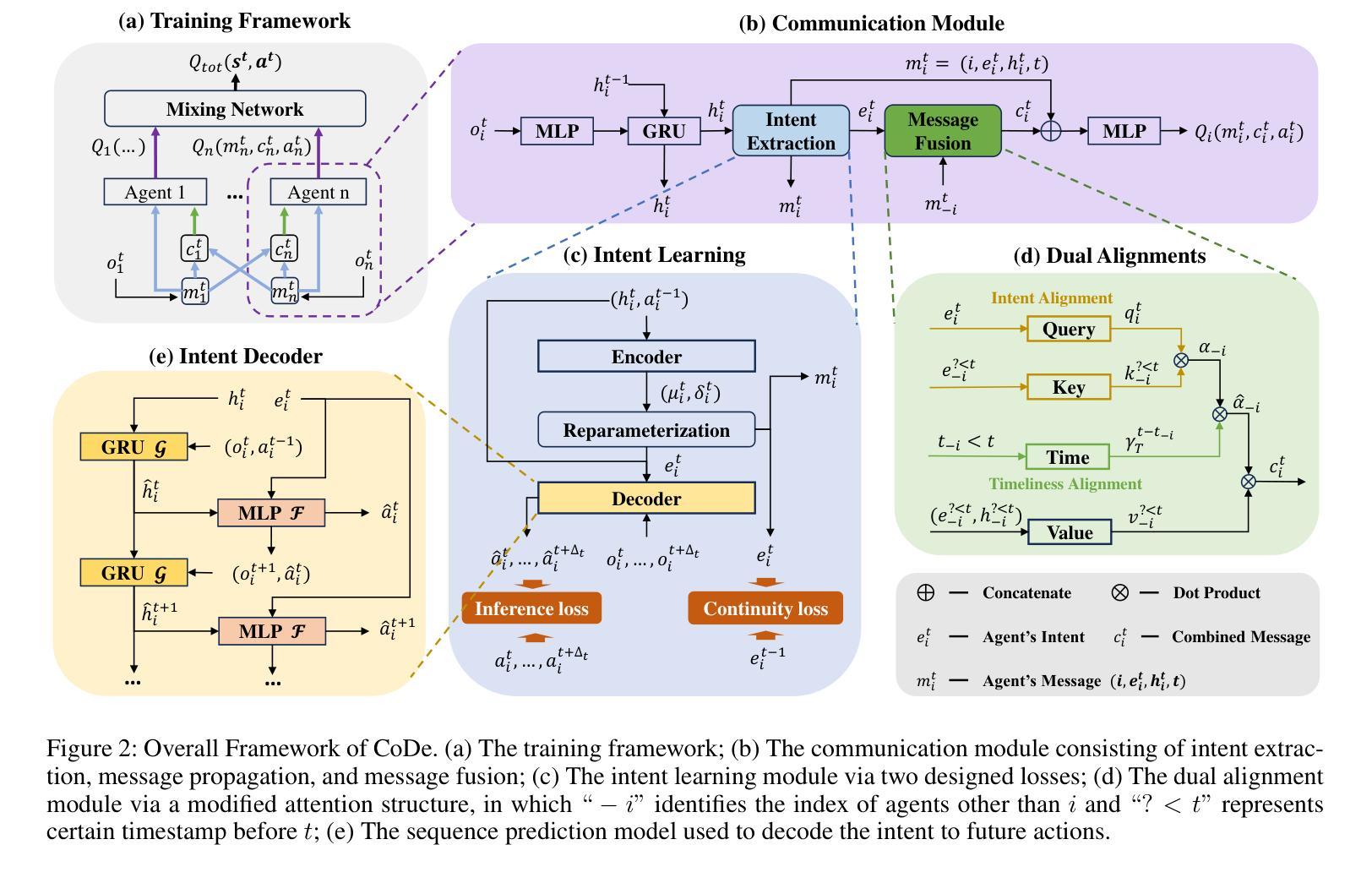
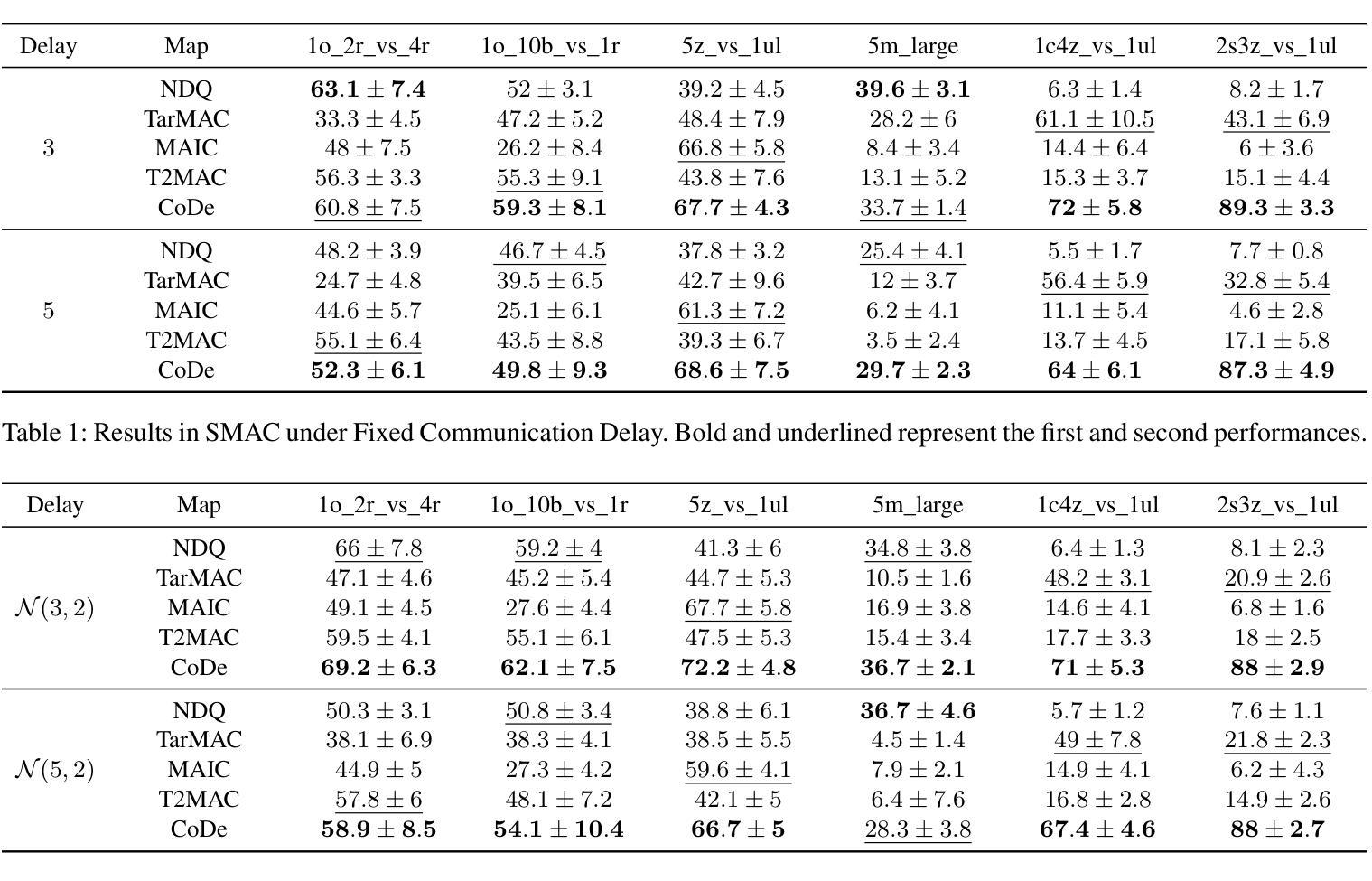
Communication has been widely employed to enhance multi-agent collaboration. Previous research has typically assumed delay-free communication, a strong assumption that is challenging to meet in practice. However, real-world agents suffer from channel delays, receiving messages sent at different time points, termed {\it{Asynchronous Communication}}, leading to cognitive biases and breakdowns in collaboration. This paper first defines two communication delay settings in MARL and emphasizes their harm to collaboration. To handle the above delays, this paper proposes a novel framework, Communication Delay-tolerant Multi-Agent Collaboration (CoDe). At first, CoDe learns an intent representation as messages through future action inference, reflecting the stable future behavioral trends of the agents. Then, CoDe devises a dual alignment mechanism of intent and timeliness to strengthen the fusion process of asynchronous messages. In this way, agents can extract the long-term intent of others, even from delayed messages, and selectively utilize the most recent messages that are relevant to their intent. Experimental results demonstrate that CoDe outperforms baseline algorithms in three MARL benchmarks without delay and exhibits robustness under fixed and time-varying delays.
通信在多智能体协作中得到了广泛应用。之前的研究通常假设通信是无延迟的,这是一个在实践中难以满足的强假设。然而,现实世界的智能体却存在通道延迟的问题,即接收在不同时间点发送的消息,这被称为“异步通信”,从而导致认知偏见和协作失灵。本文首先定义了多智能体强化学习(MARL)中的两种通信延迟设置,并强调了它们对协作的损害。为了处理上述延迟问题,本文提出了一种新型框架——通信延迟容忍多智能体协作(CoDe)。首先,CoDe通过学习意图表示作为消息,通过未来动作推断,反映智能体的稳定未来行为趋势。然后,CoDe设计了一种意图和及时性的双重对齐机制,以加强异步消息的融合过程。通过这种方式,智能体可以从延迟的消息中提取他人的长期意图,并选择性地使用与其意图最相关的最新消息。实验结果表明,CoDe在三个无延迟的MARL基准测试中优于基准算法,并在固定和时变延迟下表现出稳健性。
论文及项目相关链接
PDF AAAI 2025 Accepted
摘要
多智能体协作中引入通信增强是必要的。但以往研究常假设通信无延迟,这在实际操作中难以实现。实际场景中,智能体面临通道延迟问题,接收到的信息并非同步发送,即所谓的异步通信,可能导致认知偏差和协作失败。本文首先定义了在多智能体强化学习中的两种通信延迟设置,并强调了其对协作的危害。为解决上述问题,本文提出了一种新颖的框架——通信延迟容忍多智能体协作(CoDe)。CoDe通过未来动作推断学习意图表示作为信息,反映智能体的稳定未来行为趋势。接着,CoDe设计了一种意图与时效性的双重对齐机制,以强化异步信息的融合过程。通过这种方式,智能体可以从延迟的信息中提取他人的长期意图,并有选择地使用与其意图最相关的最新信息。实验结果表明,CoDe在三种无延迟的多智能体强化学习基准测试中优于基准算法,并在固定和时变延迟下表现出稳健性。
关键见解
- 多智能体协作中通信的重要性以及实践中的通信延迟问题被强调。
- 文中定义了两种通信延迟设置,并指出其对智能体协作的负面影响。
- 提出了一种新颖的框架CoDe,通过未来动作推断学习意图表示来解决通信延迟问题。
- CoDe设计了意图与时效性的双重对齐机制来强化异步信息的融合。
- 智能体可以从延迟信息中提取他人长期意图,并有选择地使用相关最新信息。
- 实验结果显示CoDe在多种情况下表现优越,包括无延迟和存在固定、时变延迟的多智能体强化学习环境。
点此查看论文截图

MoColl: Agent-Based Specific and General Model Collaboration for Image Captioning
Authors:Pu Yang, Bin Dong
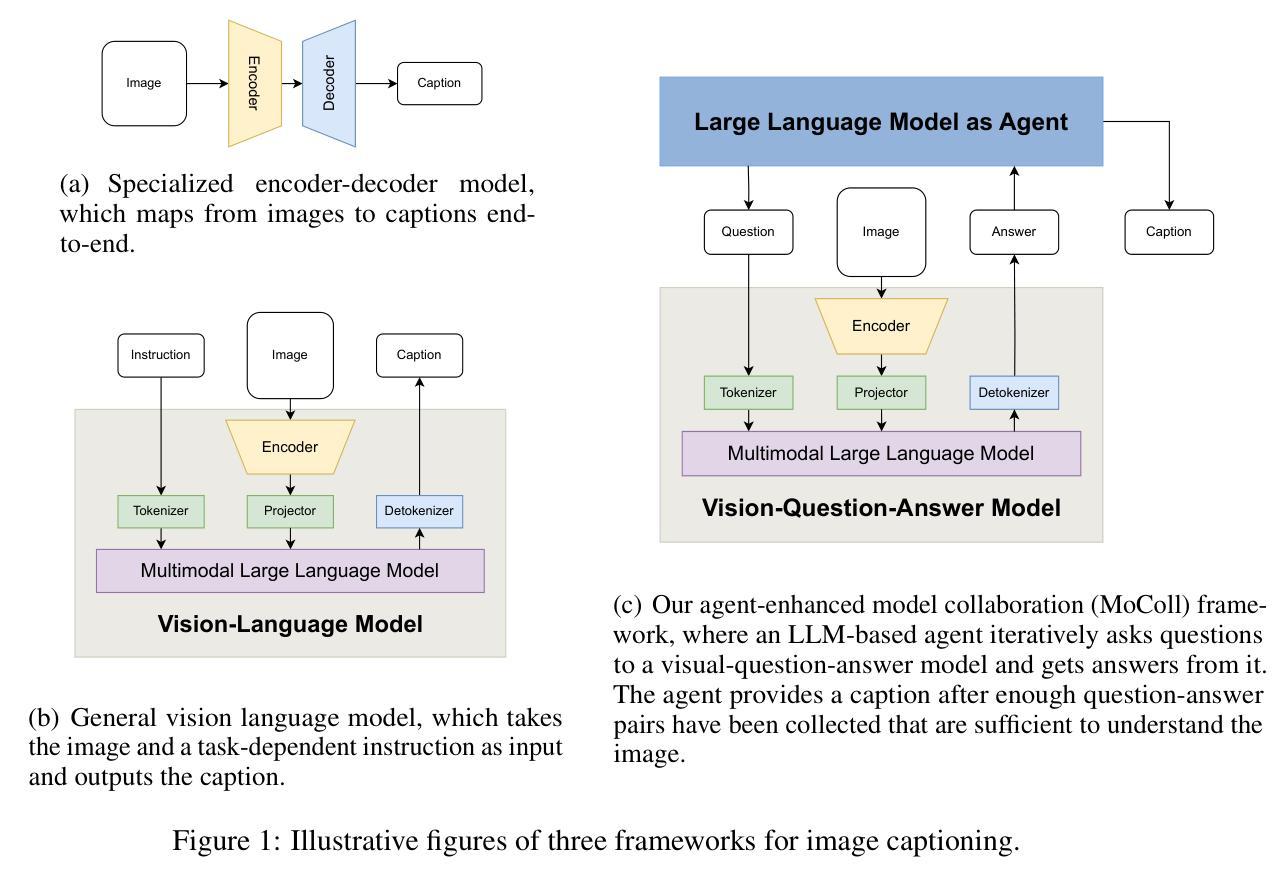
Image captioning is a critical task at the intersection of computer vision and natural language processing, with wide-ranging applications across various domains. For complex tasks such as diagnostic report generation, deep learning models require not only domain-specific image-caption datasets but also the incorporation of relevant general knowledge to provide contextual accuracy. Existing approaches exhibit inherent limitations: specialized models excel in capturing domain-specific details but lack generalization, while vision-language models (VLMs) built on large language models (LLMs) leverage general knowledge but struggle with domain-specific adaptation. To address these limitations, this paper proposes a novel agent-enhanced model collaboration framework, which we call MoColl, designed to effectively integrate domain-specific and general knowledge. Specifically, our approach is to decompose complex image captioning tasks into a series of interconnected question-answer subtasks. A trainable visual question answering (VQA) model is employed as a specialized tool to focus on domain-specific visual analysis, answering task-specific questions based on image content. Concurrently, an LLM-based agent with general knowledge formulates these questions and synthesizes the resulting question-answer pairs into coherent captions. Beyond its role in leveraging the VQA model, the agent further guides its training to enhance its domain-specific capabilities. Experimental results on radiology report generation validate the effectiveness of the proposed framework, demonstrating significant improvements in the quality of generated reports.
图像描述是计算机视觉和自然语言处理领域交汇的重要任务,其在各个领域有着广泛的应用。对于诊断报告生成等复杂任务,深度学习模型不仅需要特定领域的图像描述数据集,还需要融入相关的通用知识来提供上下文准确性。现有方法存在固有的局限性:特定领域的模型擅长捕捉特定领域的细节,但缺乏泛化能力;而基于大型语言模型的视觉语言模型(VLM)利用了一般知识,但在特定领域的适应性方面却遇到困难。为了解决这些局限性,本文提出了一种新型代理增强模型协作框架,我们称之为MoColl,旨在有效地整合特定领域知识和一般知识。具体来说,我们的方法是将复杂的图像描述任务分解为一系列相互关联的问答子任务。我们采用可训练的视觉问答(VQA)模型作为专用工具,专注于特定领域的视觉分析,根据图像内容回答特定任务的问题。同时,一个基于大型语言模型的代理利用一般知识来制定这些问题,并将得到的问题答案对合成连贯的描述。除了发挥利用VQA模型的作用外,代理还进一步引导其训练,以增强其特定领域的能力。在放射学报告生成方面的实验验证了所提框架的有效性,显示出生成的报告质量得到了显著改善。
论文及项目相关链接
Summary
图像描述是计算机视觉和自然语言处理领域的核心任务,具有广泛的应用领域。针对诊断报告生成等复杂任务,深度学习模型不仅需要特定的图像描述数据集,还需要融入相关的通用知识来提供上下文准确性。现有方法存在局限性:特定模型擅长捕捉特定领域的细节但缺乏泛化能力,而基于大型语言模型的视觉语言模型(VLMs)则利用了一般知识但难以适应特定领域。为解决这些问题,本文提出了一种新型代理增强模型协作框架MoColl,有效整合特定领域和通用知识。通过分解复杂的图像描述任务为一系列相互关联的问答子任务,采用可训练的视觉问答(VQA)模型进行特定领域的视觉分析,基于图像内容回答特定问题。同时,具有通用知识的LLM-based代理负责提出问题并合成问答对形成连贯的描述。除了引导VQA模型的应用,代理还进一步引导其训练,增强其特定领域的适应能力。在放射学报告生成方面的实验验证了该框架的有效性,显示出报告生成质量的显著提高。
Key Takeaways
- 图像描述是计算机视觉和自然语言处理的重要交叉任务,涉及广泛的应用领域。
- 深度学习模型在复杂任务中需结合特定领域的图像描述数据集和通用知识以确保上下文准确性。
- 现有方法存在局限性:特定模型缺乏泛化能力,而基于大型语言模型的视觉语言模型在特定领域适应性方面遇到困难。
- 提出了一种新的代理增强模型协作框架MoColl,整合特定领域和通用知识。
- 通过分解图像描述任务为问答子任务,利用VQA模型进行领域特定视觉分析,并结合LLM-based代理的通用知识来生成描述。
- 代理不仅引导VQA模型的应用,还参与其训练,增强模型在特定领域的适应能力。
点此查看论文截图

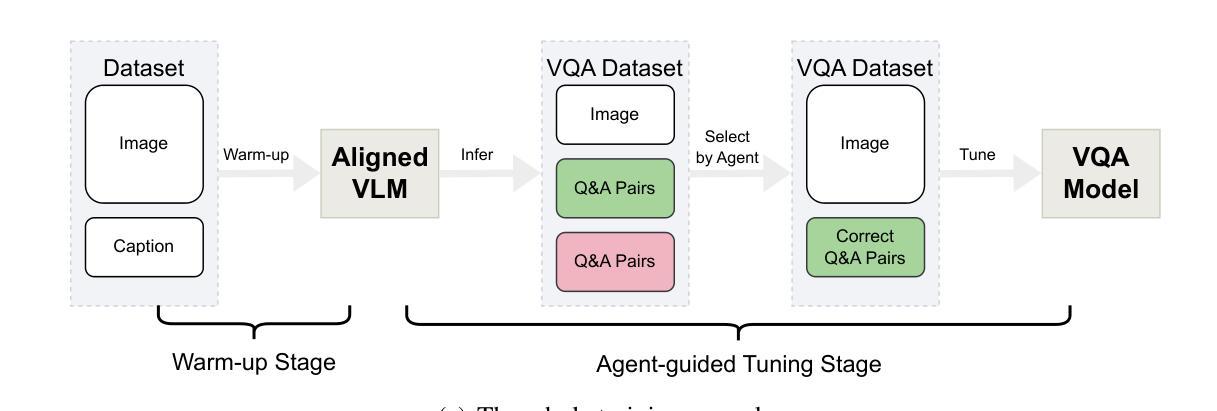
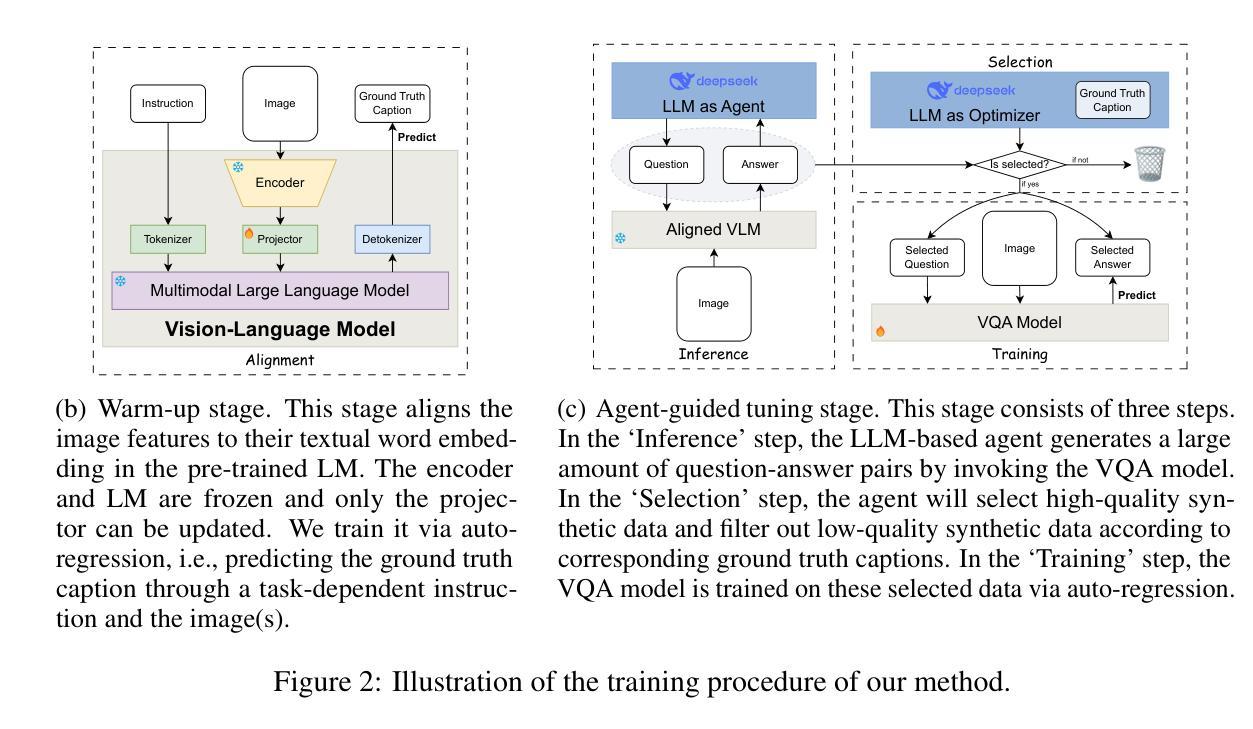
TradingAgents: Multi-Agents LLM Financial Trading Framework
Authors:Yijia Xiao, Edward Sun, Di Luo, Wei Wang
Significant progress has been made in automated problem-solving using societies of agents powered by large language models (LLMs). In finance, efforts have largely focused on single-agent systems handling specific tasks or multi-agent frameworks independently gathering data. However, multi-agent systems’ potential to replicate real-world trading firms’ collaborative dynamics remains underexplored. TradingAgents proposes a novel stock trading framework inspired by trading firms, featuring LLM-powered agents in specialized roles such as fundamental analysts, sentiment analysts, technical analysts, and traders with varied risk profiles. The framework includes Bull and Bear researcher agents assessing market conditions, a risk management team monitoring exposure, and traders synthesizing insights from debates and historical data to make informed decisions. By simulating a dynamic, collaborative trading environment, this framework aims to improve trading performance. Detailed architecture and extensive experiments reveal its superiority over baseline models, with notable improvements in cumulative returns, Sharpe ratio, and maximum drawdown, highlighting the potential of multi-agent LLM frameworks in financial trading. More details on TradingAgents are available at https://TradingAgents-AI.github.io.
在利用大型语言模型(LLM)驱动的智能体社会解决自动化问题方面,已经取得了重大进展。在金融领域,相关工作主要集中在单智能体系统处理特定任务或独立的多智能体框架收集数据上。然而,多智能体系统在模拟现实世界交易公司的合作动态方面的潜力尚未得到充分探索。《TradingAgents》项目提出了一个受交易公司启发的新型股票交易框架,该框架采用LLM驱动的智能体,担任专业角色,如基本面分析师、情绪分析师、技术分析师和具有不同风险特征的交易员。该框架包括评估市场条件的牛市和熊市研究者智能体、监控风险的团队管理智能体以及交易者综合见解的智能体基于辩论和历史数据做出明智决策的智能体。通过模拟动态的合作交易环境,这个框架旨在提高交易性能。详细的架构和广泛的实验证明其在累计回报、夏普比率和最大回撤等方面优于基线模型的表现,突显了多智能体LLM框架在金融交易中的潜力。《TradingAgents》的更多详细信息可在https://TradingAgents-AI.github.io找到。
论文及项目相关链接
PDF Multi-Agent AI in the Real World @ AAAI 2025
Summary
基于大型语言模型(LLM)的社会化代理在自动化问题求解方面取得了显著进展。金融领域主要关注单一代理系统处理特定任务或多代理框架独立收集数据。然而,多代理系统复制真实交易公司合作动力的潜力尚未得到足够研究。TradingAgents提出了一个受真实交易公司启发的新型股票交易框架,利用LLM驱动的代理完成专门任务,如基本面分析、情绪分析、技术分析以及不同风险水平的交易。该框架包括评估市场状况的Bull和Bear研究员代理、监控风险的团队管理以及根据辩论和历史数据合成信息作出决策的交粮代理等。通过模拟动态协作的交易环境,该框架旨在提高交易性能。详细的架构和广泛的实验表明其优于基准模型,在累计回报、夏普比率和最大回撤方面表现出显著的改进,突显了多代理LLM框架在金融交易中的潜力。更多详情访问:https://TradingAgents-AI.github.io。
Key Takeaways
- 多代理系统在金融领域中的应用潜力显著增长,尤其是通过模拟真实交易公司的合作动态来提高自动化问题解决的效率。
- TradingAgents框架利用大型语言模型驱动的代理完成多种金融任务,如市场分析、风险管理及交易决策等。
- 该框架受到真实交易公司的启发,模拟人类决策过程以提高交易性能。
- 通过详细架构和实验验证,TradingAgents框架表现优于基准模型,在多个关键指标上取得显著改进。
- TradingAgents框架在模拟交易环境中注重协作和动态决策过程。
- 该框架强调将人工智能与金融领域的专业知识相结合以实现更佳的金融交易结果。
点此查看论文截图

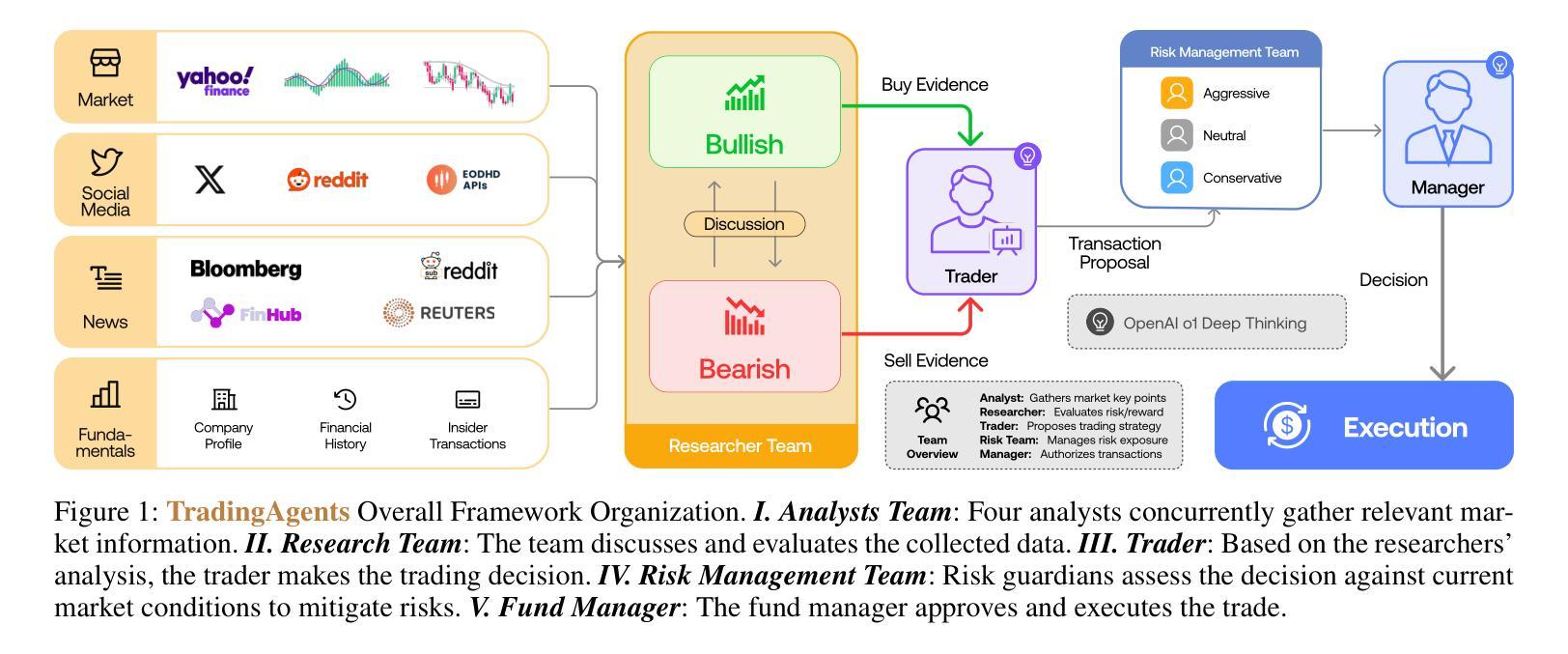



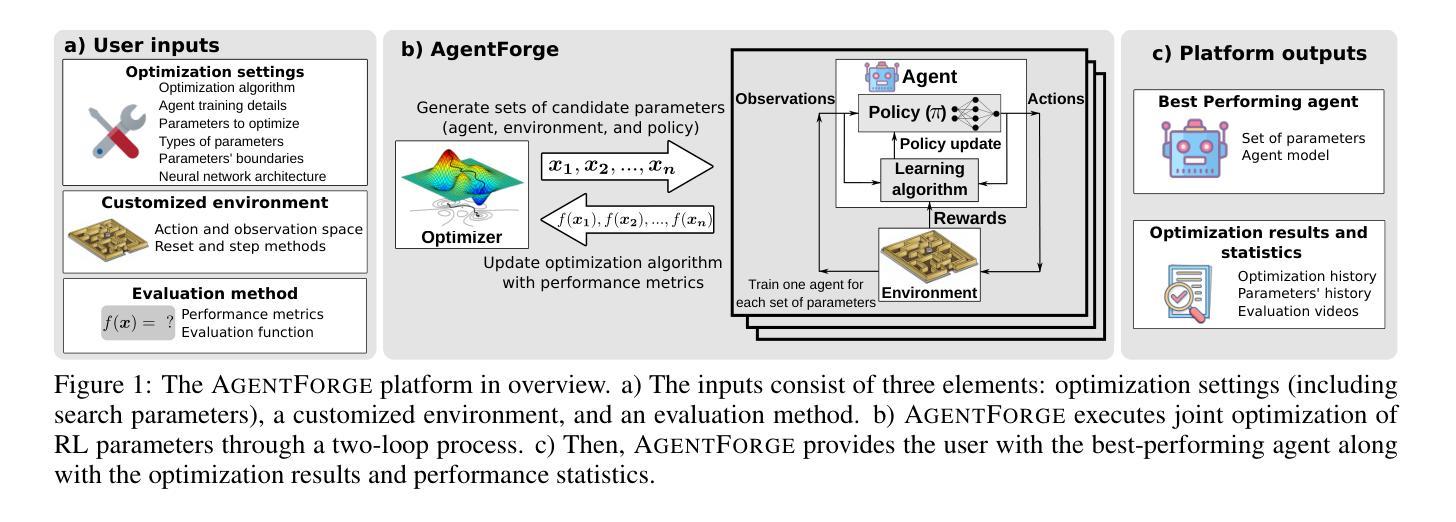
AgentForge: A Flexible Low-Code Platform for Reinforcement Learning Agent Design
Authors:Francisco Erivaldo Fernandes Junior, Antti Oulasvirta
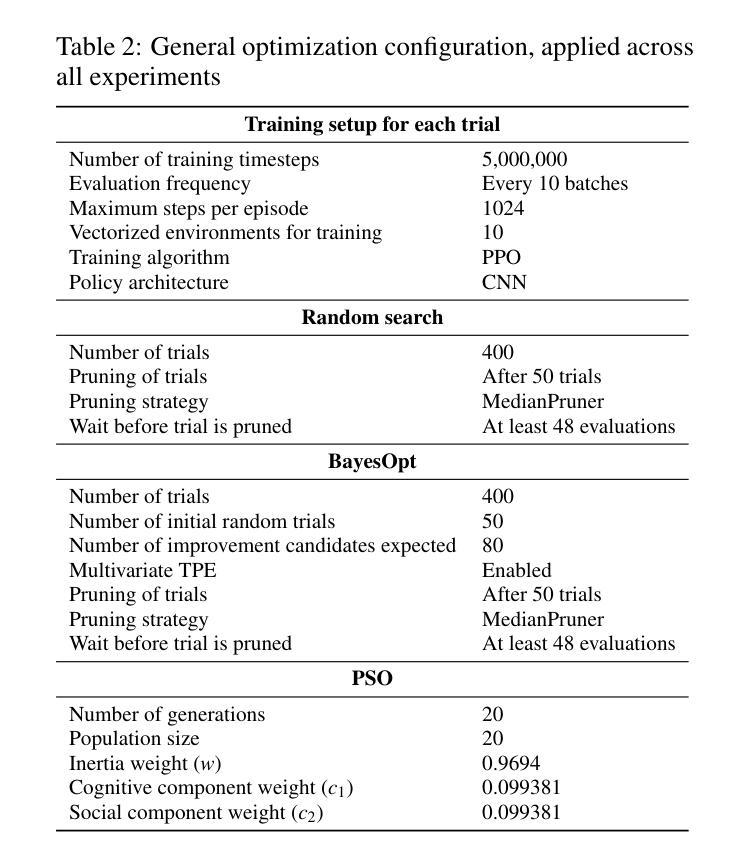
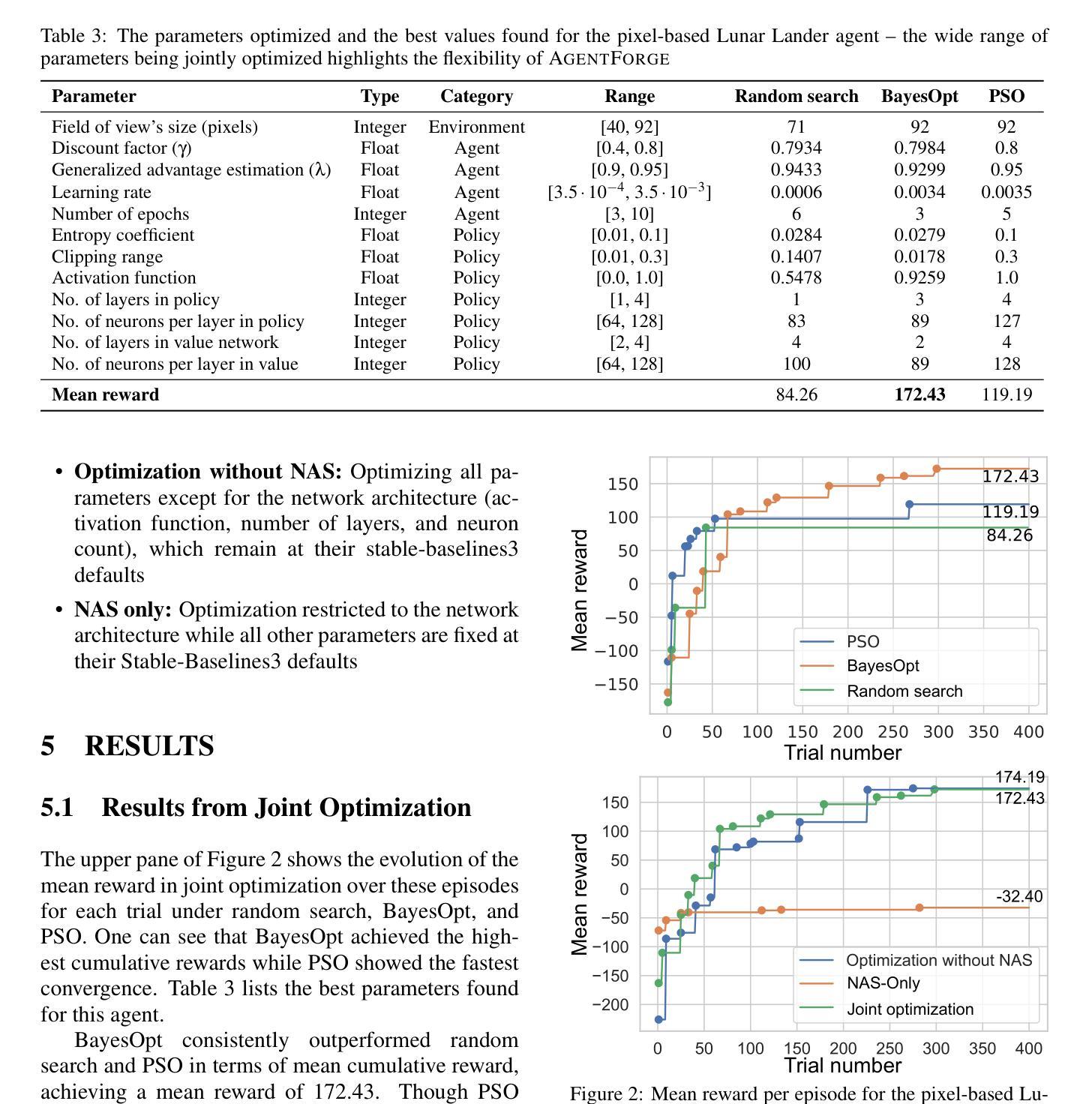
Developing a reinforcement learning (RL) agent often involves identifying values for numerous parameters, covering the policy, reward function, environment, and agent-internal architecture. Since these parameters are interrelated in complex ways, optimizing them is a black-box problem that proves especially challenging for nonexperts. Although existing optimization-as-a-service platforms (e.g., Vizier and Optuna) can handle such problems, they are impractical for RL systems, since the need for manual user mapping of each parameter to distinct components makes the effort cumbersome. It also requires understanding of the optimization process, limiting the systems’ application beyond the machine learning field and restricting access in areas such as cognitive science, which models human decision-making. To tackle these challenges, the paper presents AgentForge, a flexible low-code platform to optimize any parameter set across an RL system. Available at https://github.com/feferna/AgentForge, it allows an optimization problem to be defined in a few lines of code and handed to any of the interfaced optimizers. With AgentForge, the user can optimize the parameters either individually or jointly. The paper presents an evaluation of its performance for a challenging vision-based RL problem.
开发强化学习(RL)代理通常涉及确定许多参数的值,这些参数涵盖策略、奖励函数、环境和代理内部架构。由于这些参数以复杂的方式相互关联,因此对其进行优化是一个黑箱问题,对于非专家来说尤其具有挑战性。尽管现有的优化即服务平台(例如Vizier和Optuna)可以处理此类问题,但它们对于RL系统来说并不实用,因为需要手动将每个参数映射到不同的组件,这使得工作变得繁琐。这还需要了解优化过程,限制了系统在机器学习领域之外的应用,并限制了其在认知科学等领域的使用,认知科学模拟人类的决策过程。为了应对这些挑战,论文介绍了AgentForge,这是一个灵活的低代码平台,可以优化RL系统中的任何参数集。可在https://github.com/feferna/AgentForge上获得,它允许在几行代码中定义优化问题并将其交给任何接口优化器。使用AgentForge,用户可以单独或联合优化参数。论文对其在处理具有挑战性的基于视觉的RL问题上的性能进行了评估。
论文及项目相关链接
PDF This paper has been accepted at the 17th International Conference on Agents and Artificial Intelligence (ICAART 2025)
Summary
强化学习(RL)智能体开发涉及众多参数设定,包括策略、奖励函数、环境和智能体内部结构等。参数优化是一个黑箱问题,对非专家来说尤其具有挑战性。现有优化服务平台如Vizier和Optuna虽能解决此类问题,但在RL系统中不实用,需手动将每个参数映射到不同组件,且要求用户了解优化过程,限制了其在机器学习领域之外的应用,特别是在模拟人类决策的认知科学领域。为解决这些挑战,本文提出AgentForge,一个灵活的低代码平台,可优化RL系统中的任何参数集。用户可在几行代码中定义优化问题并交给任何接口优化器。AgentForge允许用户单独或联合优化参数。本文对其在处理具有挑战性的基于视觉的RL问题上的性能进行了评估。
Key Takeaways
- 强化学习智能体开发涉及多种参数设定,包括策略、奖励函数等,优化这些参数是一个挑战。
- 现有优化服务平台(如Vizier和Optuna)在应用于RL系统时存在不实用的问题。
- AgentForge是一个灵活的低代码平台,可以优化RL系统中的任何参数集。
- AgentForge允许用户通过简单的方式定义优化问题并将其交给优化器。
- AgentForge支持单独或联合优化参数。
- AgentForge具有广泛的应用潜力,特别是在认知科学领域模拟人类决策方面。
点此查看论文截图


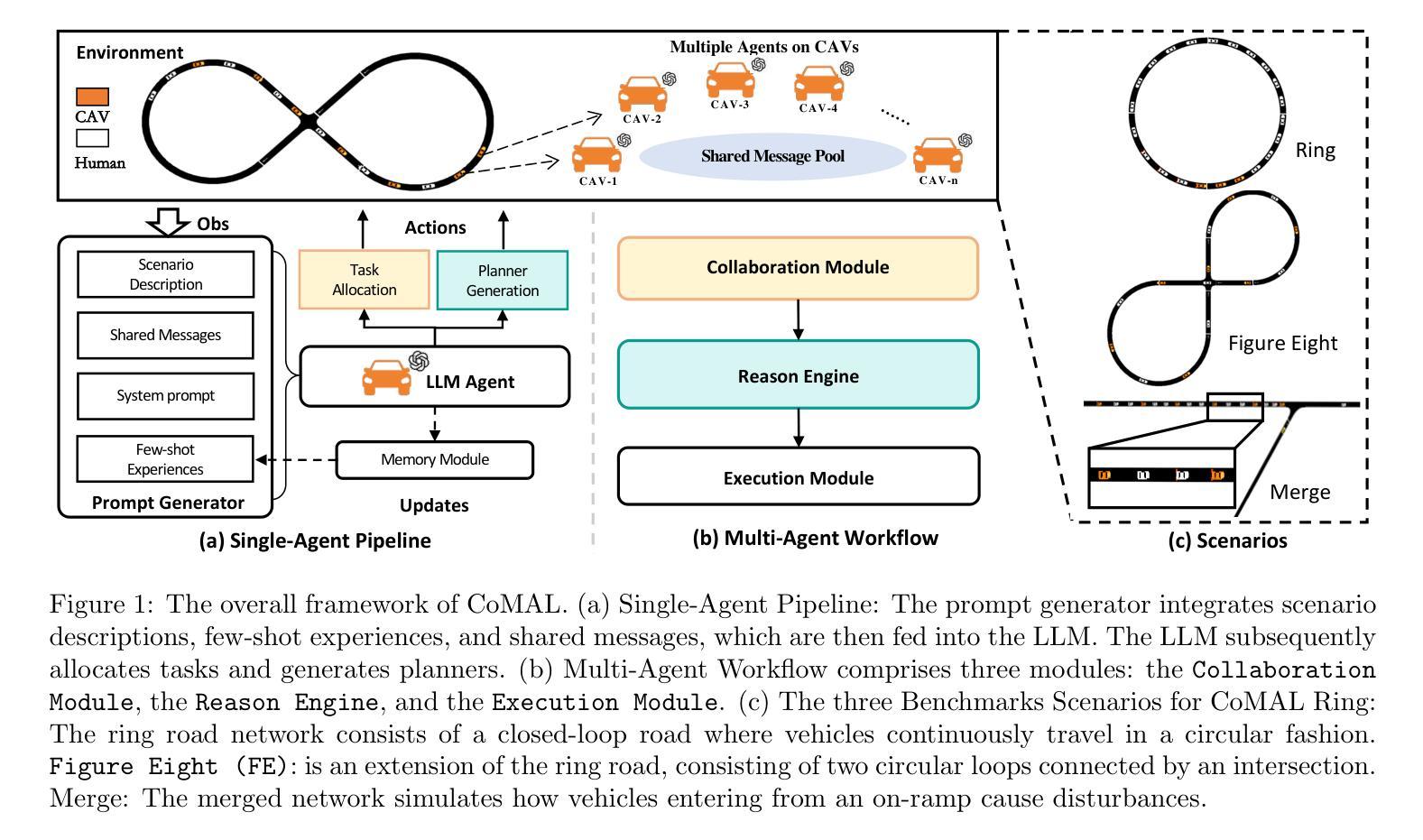
CoMAL: Collaborative Multi-Agent Large Language Models for Mixed-Autonomy Traffic
Authors:Huaiyuan Yao, Longchao Da, Vishnu Nandam, Justin Turnau, Zhiwei Liu, Linsey Pang, Hua Wei
The integration of autonomous vehicles into urban traffic has great potential to improve efficiency by reducing congestion and optimizing traffic flow systematically. In this paper, we introduce CoMAL (Collaborative Multi-Agent LLMs), a framework designed to address the mixed-autonomy traffic problem by collaboration among autonomous vehicles to optimize traffic flow. CoMAL is built upon large language models, operating in an interactive traffic simulation environment. It utilizes a Perception Module to observe surrounding agents and a Memory Module to store strategies for each agent. The overall workflow includes a Collaboration Module that encourages autonomous vehicles to discuss the effective strategy and allocate roles, a reasoning engine to determine optimal behaviors based on assigned roles, and an Execution Module that controls vehicle actions using a hybrid approach combining rule-based models. Experimental results demonstrate that CoMAL achieves superior performance on the Flow benchmark. Additionally, we evaluate the impact of different language models and compare our framework with reinforcement learning approaches. It highlights the strong cooperative capability of LLM agents and presents a promising solution to the mixed-autonomy traffic challenge. The code is available at https://github.com/Hyan-Yao/CoMAL.
将自动驾驶车辆融入城市交通具有巨大的潜力,可以通过减少拥堵并系统地优化交通流量来提高效率。在本文中,我们介绍了CoMAL(协作多智能体大型语言模型),这是一个旨在通过自动驾驶车辆之间的协作来解决混合自主交通问题的框架,以优化交通流量。CoMAL建立在大型语言模型之上,在一个交互式交通仿真环境中运行。它利用感知模块来观察周围智能体,并利用记忆模块来存储每个智能体的策略。整体工作流程包括一个协作模块,该模块鼓励自动驾驶车辆讨论有效策略并分配角色、一个推理引擎根据分配的角色确定最佳行为,以及一个执行模块,该模块使用结合基于规则模型的混合方法来控制车辆动作。实验结果表明,CoMAL在Flow基准测试中实现了卓越的性能。此外,我们还评估了不同语言模型的影响,并将我们的框架与强化学习方法进行了比较。它突出了大型语言模型智能体的强大合作能力,为解决混合自主交通挑战提供了有前景的解决方案。代码可在https://github.com/Hyan-Yao/CoMAL获取。
论文及项目相关链接
PDF 8 pages, 4 figures, accepted to SDM25
Summary
该文介绍了自主车辆与城市交通的融合具有减少拥堵、优化交通流的潜力。文章提出了基于多智能体交互的大型语言模型框架CoMAL(协作多智能体大型语言模型),用于解决混合自主交通问题。CoMAL在交互的交通仿真环境中运行,具有感知模块、记忆模块、协作模块和执行模块。它鼓励自主车辆进行策略讨论并分配角色,具有出色的协作性能。实验结果展示了它在Flow基准测试上的优越性能。
Key Takeaways
- 自主车辆与城市交通融合具有减少拥堵和优化交通流的潜力。
- CoMAL框架旨在解决混合自主交通问题,通过自主车辆间的协作优化交通流。
- CoMAL基于大型语言模型构建,在交互的交通仿真环境中运行。
- CoMAL包含感知模块、记忆模块、协作模块和执行模块。
- 协作模块鼓励自主车辆讨论有效策略并分配角色。
- 实验结果表明CoMAL在Flow基准测试上表现优越。
点此查看论文截图



LNS2+RL: Combining Multi-Agent Reinforcement Learning with Large Neighborhood Search in Multi-Agent Path Finding
Authors:Yutong Wang, Tanishq Duhan, Jiaoyang Li, Guillaume Sartoretti
Multi-Agent Path Finding (MAPF) is a critical component of logistics and warehouse management, which focuses on planning collision-free paths for a team of robots in a known environment. Recent work introduced a novel MAPF approach, LNS2, which proposed to repair a quickly obtained set of infeasible paths via iterative replanning, by relying on a fast, yet lower-quality, prioritized planning (PP) algorithm. At the same time, there has been a recent push for Multi-Agent Reinforcement Learning (MARL) based MAPF algorithms, which exhibit improved cooperation over such PP algorithms, although inevitably remaining slower. In this paper, we introduce a new MAPF algorithm, LNS2+RL, which combines the distinct yet complementary characteristics of LNS2 and MARL to effectively balance their individual limitations and get the best from both worlds. During early iterations, LNS2+RL relies on MARL for low-level replanning, which we show eliminates collisions much more than a PP algorithm. There, our MARL-based planner allows agents to reason about past and future information to gradually learn cooperative decision-making through a finely designed curriculum learning. At later stages of planning, LNS2+RL adaptively switches to PP algorithm to quickly resolve the remaining collisions, naturally trading off solution quality (number of collisions in the solution) and computational efficiency. Our comprehensive experiments on high-agent-density tasks across various team sizes, world sizes, and map structures consistently demonstrate the superior performance of LNS2+RL compared to many MAPF algorithms, including LNS2, LaCAM, EECBS, and SCRIMP. In maps with complex structures, the advantages of LNS2+RL are particularly pronounced, with LNS2+RL achieving a success rate of over 50% in nearly half of the tested tasks, while that of LaCAM, EECBS and SCRIMP falls to 0%.
多智能体路径寻找(MAPF)是物流管理和仓库管理的关键部分,它专注于在已知环境中为机器人团队规划无碰撞路径。最近的工作引入了一种新的MAPF方法LNS2,它依靠快速但质量较低的优先规划(PP)算法,通过迭代重新规划来修复快速获得的不可行路径集。与此同时,基于多智能体强化学习(MARL)的MAPF算法也备受关注,它们在合作方面表现出比PP算法更好的性能,但不可避免地速度较慢。在本文中,我们介绍了一种新的MAPF算法LNS2+RL,它结合了LNS2和MARL的独特且互补的特性,有效地平衡了各自的局限性,并取长补短。在早期迭代中,LNS2+RL依赖MARL进行低级重新规划,我们证明这消除了比PP算法更多的碰撞。我们的基于MARL的规划器允许智能体根据过去和未来信息进行推理,并通过精心设计的学习课程逐步学习合作决策。在规划后期阶段,LNS2+RL自适应切换到PP算法,快速解决剩余的碰撞问题,自然地实现了解决方案质量(解决方案中的碰撞次数)和计算效率之间的权衡。我们在各种团队规模、世界规模和地图结构的高智能体密度任务上的综合实验始终证明,LNS2+RL的性能优于许多MAPF算法,包括LNS2、LaCAM、EECBS和SCRIMP。在具有复杂结构的地图中,LNS2+RL的优势尤为突出,在将近一半的测试任务中,LNS2+RL的成功率超过50%,而LaCAM、EECBS和SCRIMP的成功率则降至0%。
论文及项目相关链接
PDF Accepted for presentation at AAAI 2025
Summary
本文介绍了新的多智能体路径规划算法LNS2+RL,该算法结合了LNS2和基于强化学习的多智能体路径规划算法(MARL)的特点。LNS2+RL在早期迭代中使用MARL进行低级重新规划,以消除碰撞为主,后期则切换到优先规划算法以提高计算效率。实验表明,LNS2+RL在多种任务场景中表现优异,尤其是在复杂结构地图中优势明显。
Key Takeaways
- LNS2+RL结合了LNS2和MARL算法的特点,旨在平衡两者优势。
- 在早期迭代中,LNS2+RL使用MARL进行低级重新规划,能有效消除碰撞。
- LNS2+RL通过精心设计的学习课程,使智能体能逐步学习合作决策。
- 在后期规划阶段,LNS2+RL自适应切换到优先规划算法以提高计算效率。
- LNS2+RL在多种任务场景中表现优异,特别是复杂结构地图中的优势更为明显。
- 与其他MAPF算法相比,如LNS2、LaCAM、EECBS和SCRIMP,LNS2+RL具有显著优势。
点此查看论文截图


GUTS: Generalized Uncertainty-Aware Thompson Sampling for Multi-Agent Active Search
Authors:Nikhil Angad Bakshi, Tejus Gupta, Ramina Ghods, Jeff Schneider
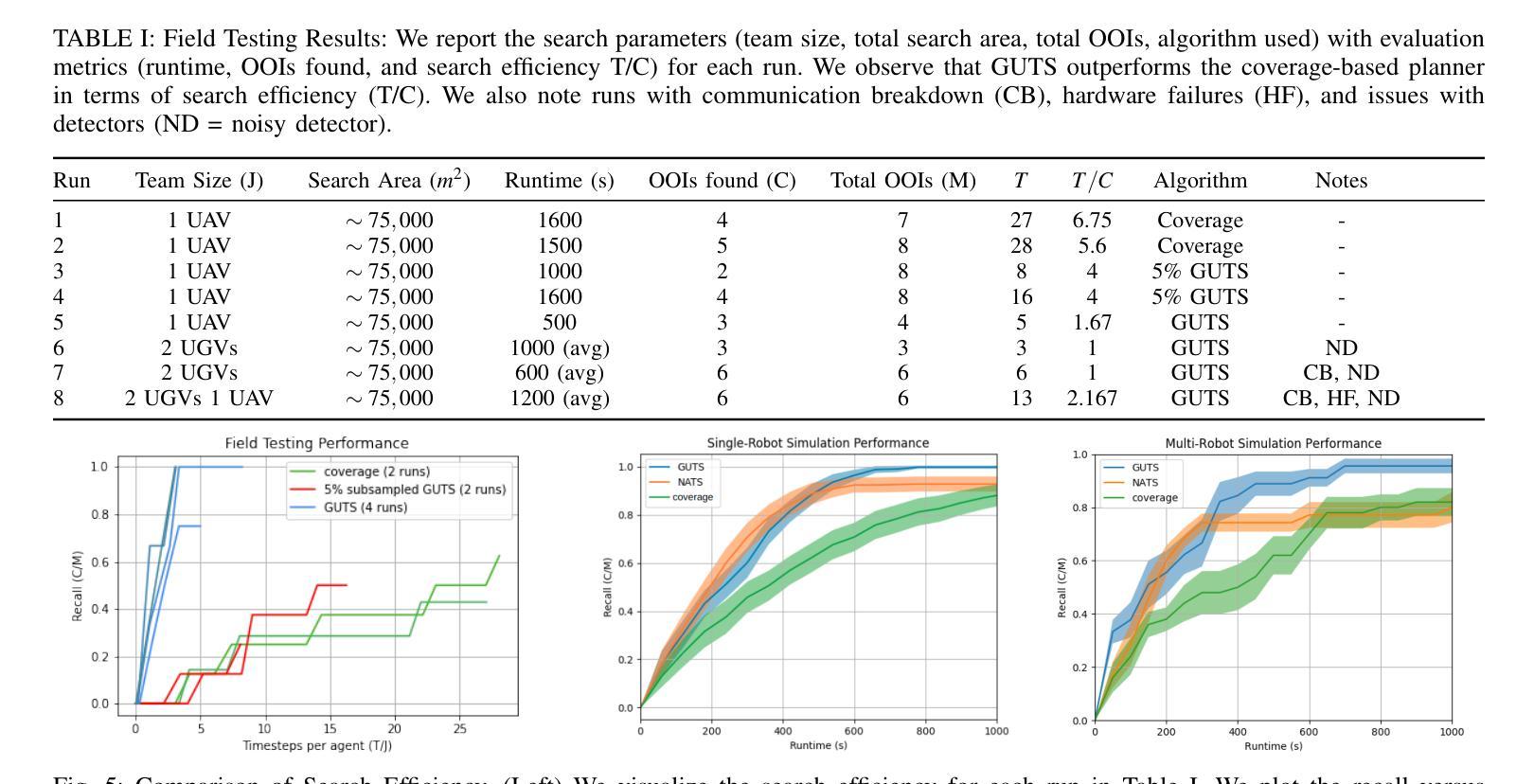
Robotic solutions for quick disaster response are essential to ensure minimal loss of life, especially when the search area is too dangerous or too vast for human rescuers. We model this problem as an asynchronous multi-agent active-search task where each robot aims to efficiently seek objects of interest (OOIs) in an unknown environment. This formulation addresses the requirement that search missions should focus on quick recovery of OOIs rather than full coverage of the search region. Previous approaches fail to accurately model sensing uncertainty, account for occlusions due to foliage or terrain, or consider the requirement for heterogeneous search teams and robustness to hardware and communication failures. We present the Generalized Uncertainty-aware Thompson Sampling (GUTS) algorithm, which addresses these issues and is suitable for deployment on heterogeneous multi-robot systems for active search in large unstructured environments. We show through simulation experiments that GUTS consistently outperforms existing methods such as parallelized Thompson Sampling and exhaustive search, recovering all OOIs in 80% of all runs. In contrast, existing approaches recover all OOIs in less than 40% of all runs. We conduct field tests using our multi-robot system in an unstructured environment with a search area of approximately 75,000 sq. m. Our system demonstrates robustness to various failure modes, achieving full recovery of OOIs (where feasible) in every field run, and significantly outperforming our baseline.
机器人快速灾害响应解决方案对于确保尽可能减少生命损失至关重要,尤其是在搜索区域对人类救援人员来说太危险或太广阔的情况下。我们将这个问题建模为异步多智能体主动搜索任务,其中每个机器人的目标是在未知环境中有效地寻找感兴趣的对象(OOIs)。这种表述解决了搜索任务应侧重于快速恢复OOIs而不是完全覆盖搜索区域的要求。以前的方法无法准确建模感知不确定性,无法考虑由于植被或地形造成的遮挡,也无法考虑对异构搜索团队的要求以及对硬件和通信故障的稳定性。我们提出了广义不确定性感知汤普森采样(GUTS)算法,该算法解决了这些问题,适用于在大型非结构化环境中进行主动搜索的异构多机器人系统部署。我们通过仿真实验表明,GUTS始终优于现有的并行汤普森采样和穷举搜索方法,在80%的运行中恢复所有OOIs。相比之下,现有方法在所有运行中恢复所有OOI的比例不到40%。我们在大约75000平方米的非结构化环境中使用我们的多机器人系统进行了现场测试。我们的系统展示了对各种故障模式的稳健性,在每次现场运行中实现了可行情况下的OOI完全恢复,并显著优于我们的基线。
论文及项目相关链接
PDF 7 pages, 5 figures, 1 table, for associated video see: https://youtu.be/K0jkzdQ_j2E , published in International Conference on Robotics and Automation (ICRA) 2023. Outstanding Deployed Systems Paper Winner
Summary
在灾难应对中,机器人解决方案能够快速反应并减少生命损失,特别是在搜索区域过于危险或广阔时。我们将这一问题建模为异步多智能体主动搜索任务,每个机器人旨在高效寻找感兴趣的对象。该建模解决了搜索任务应侧重于快速恢复感兴趣对象而非完全覆盖搜索区域的要求。针对现有方法无法准确建模感知不确定性、考虑由于植被或地形造成的遮挡或要求异构图搜索团队和硬件通信故障等问题,我们提出了广义不确定性感知的汤普森采样算法(GUTS)。模拟实验表明,GUTS在性能上始终优于并行汤普森采样和穷举搜索等现有方法,在全部运行中恢复了所有感兴趣的对象。相比之下,现有方法在所有运行中恢复所有感兴趣对象的比例不到40%。我们在大约75,000平方米的非结构化环境中使用多机器人系统进行了现场测试,系统展示了对各种故障模式的稳健性,在每次现场运行中实现了可行情况下的全部恢复对象,并显著优于基线。
Key Takeaways
- 机器人解决方案在灾难反应中的重要性:能够确保快速响应并减少生命损失,特别是在危险或广阔的搜索区域。
- 问题建模为异步多智能体主动搜索任务:机器人旨在高效寻找感兴趣的对象,满足快速恢复的要求。
- 现有方法的不足:无法准确建模感知不确定性、考虑遮挡、异构图搜索团队和硬件通信故障等问题。
- 提出的GUTS算法解决了这些问题:适用于异构多机器人系统的主动搜索,可在大型非结构化环境中部署。
- 模拟实验证明GUTS算法性能优越:相较于其他方法,在多数情况下能更高效地找到所有感兴趣的对象。
- 现场测试验证了系统的稳健性:在多机器人系统中展示了对各种故障模式的稳健性,并在可行情况下实现了全部恢复对象。
点此查看论文截图