⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-13 更新
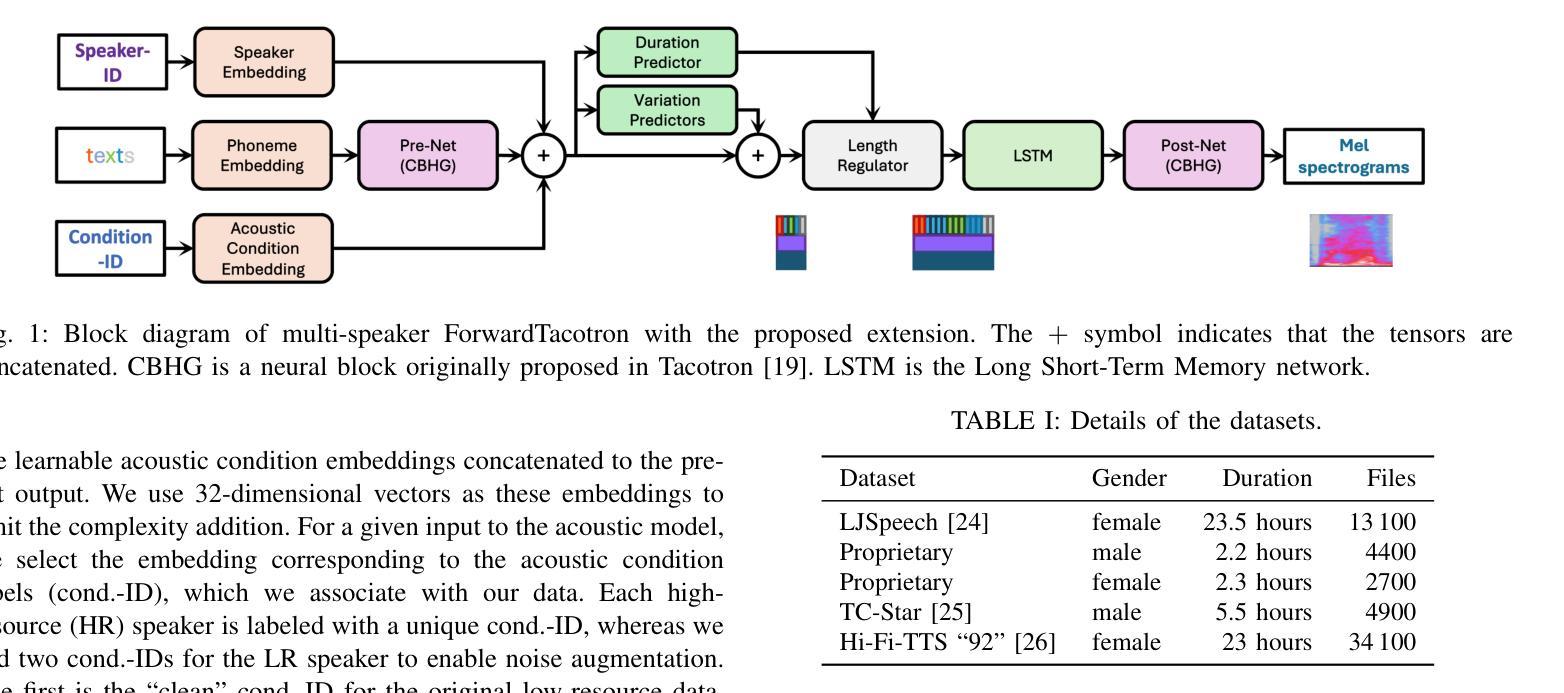
Low-Resource Text-to-Speech Synthesis Using Noise-Augmented Training of ForwardTacotron
Authors:Kishor Kayyar Lakshminarayana, Frank Zalkow, Christian Dittmar, Nicola Pia, Emanuel A. P. Habets
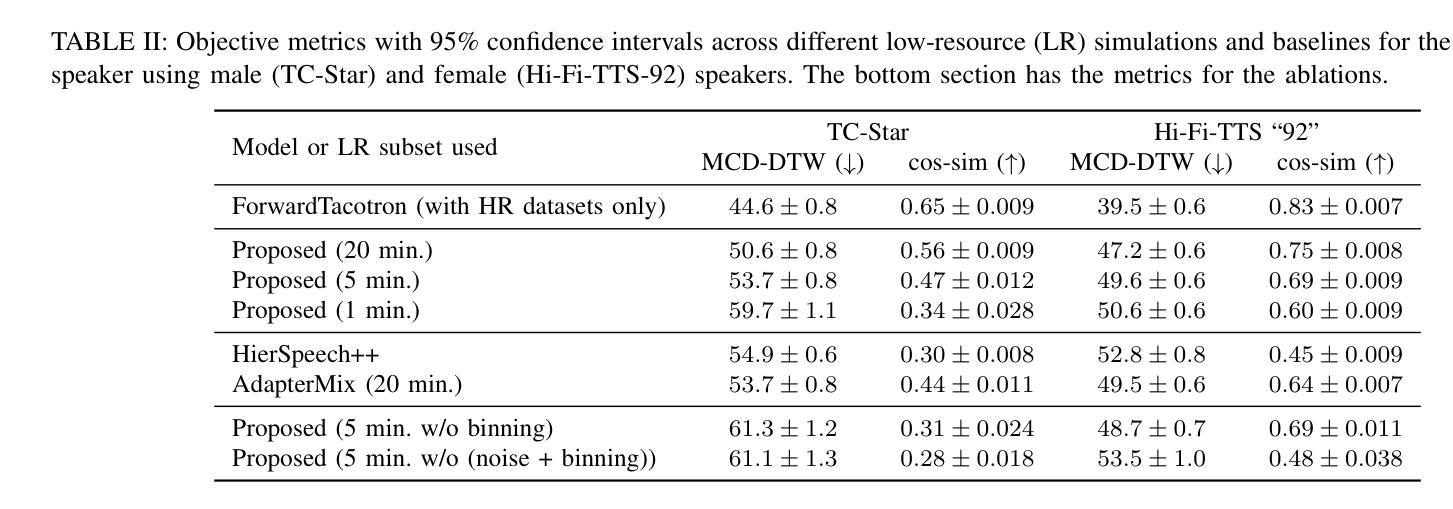
In recent years, several text-to-speech systems have been proposed to synthesize natural speech in zero-shot, few-shot, and low-resource scenarios. However, these methods typically require training with data from many different speakers. The speech quality across the speaker set typically is diverse and imposes an upper limit on the quality achievable for the low-resource speaker. In the current work, we achieve high-quality speech synthesis using as little as five minutes of speech from the desired speaker by augmenting the low-resource speaker data with noise and employing multiple sampling techniques during training. Our method requires only four high-quality, high-resource speakers, which are easy to obtain and use in practice. Our low-complexity method achieves improved speaker similarity compared to the state-of-the-art zero-shot method HierSpeech++ and the recent low-resource method AdapterMix while maintaining comparable naturalness. Our proposed approach can also reduce the data requirements for speech synthesis for new speakers and languages.
近年来,已有多种文本到语音系统被提出,可在零样本、小样本文本资源稀缺的场景下合成自然语音。然而,这些方法通常需要使用来自许多不同发言人的数据进行训练。发言人集中的语音质量各不相同,并对低资源发言人的语音质量设定了上限。在目前的工作中,我们通过使用目标发言人的五分钟的语音来实现高质量的语音合成,通过使用噪声来增强低资源语音数据并在训练过程中采用多种采样技术。我们的方法只需要四个高质量、高资源的发言人,在实践中易于获取和使用。我们的低复杂度方法在提高说话人相似度方面优于最新的零样本方法HierSpeech++和最近的低资源方法AdapterMix,同时保持相当的自然度。我们提出的方法还可以降低新发言人和新语言的语音合成对数据的要求。
论文及项目相关链接
PDF Accepted for publication at the 2025 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2025) to be held at Hyderabad, India
Summary
近年来,针对零样本、少样本和低资源场景的文本到语音系统被相继提出。然而,这些方法通常需要大量不同说话人的数据进行训练,语音质量因说话人的不同而各异,并对低资源说话人的语音质量设置了上限。当前工作中,我们通过将低资源说话人的数据增加噪声并采用多重采样技术进行训练,仅使用五分钟的目标说话人的语音即可实现高质量的语音合成。该方法仅需四个高质量、高资源的说话人,易于在实际操作中获得和使用。相比最新的零样本方法HierSpeech++和近期的低资源方法AdapterMix,我们的方法在保持自然性的同时,提高了说话人相似性。此外,该方法还可降低新说话人和新语言合成所需的数据要求。
Key Takeaways
- 近年提出的文本到语音系统主要在零样本、少样本和低资源场景下进行合成,但存在对大量不同说话人数据的需求。
- 语音质量因说话人的不同而存在差异,对低资源说话人的语音质量设置了上限。
- 提出了一种新方法,仅使用五分钟目标说话人的语音和通过增加噪声及多重采样技术即可实现高质量语音合成。
- 方法仅需四个高质量、高资源的说话人,易于获取并在实践中使用。
- 与现有方法相比,该方法在保持自然性的同时,提高了说话人相似性。
- 该方法降低了新说话人和新语言合成所需的数据要求。
点此查看论文截图

Language-Inspired Relation Transfer for Few-shot Class-Incremental Learning
Authors:Yifan Zhao, Jia Li, Zeyin Song, Yonghong Tian
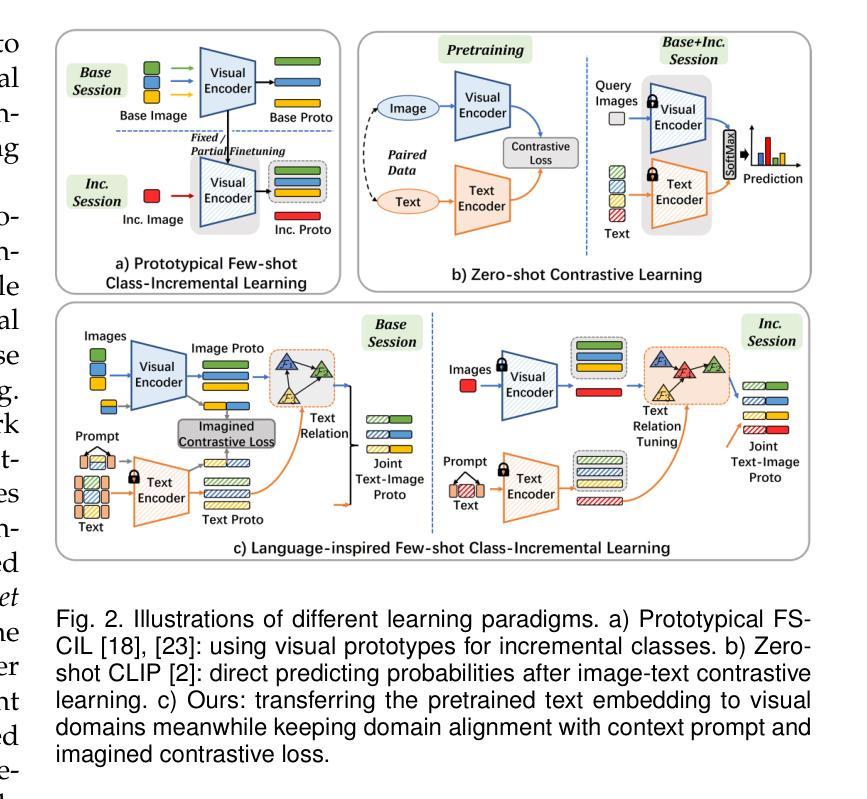
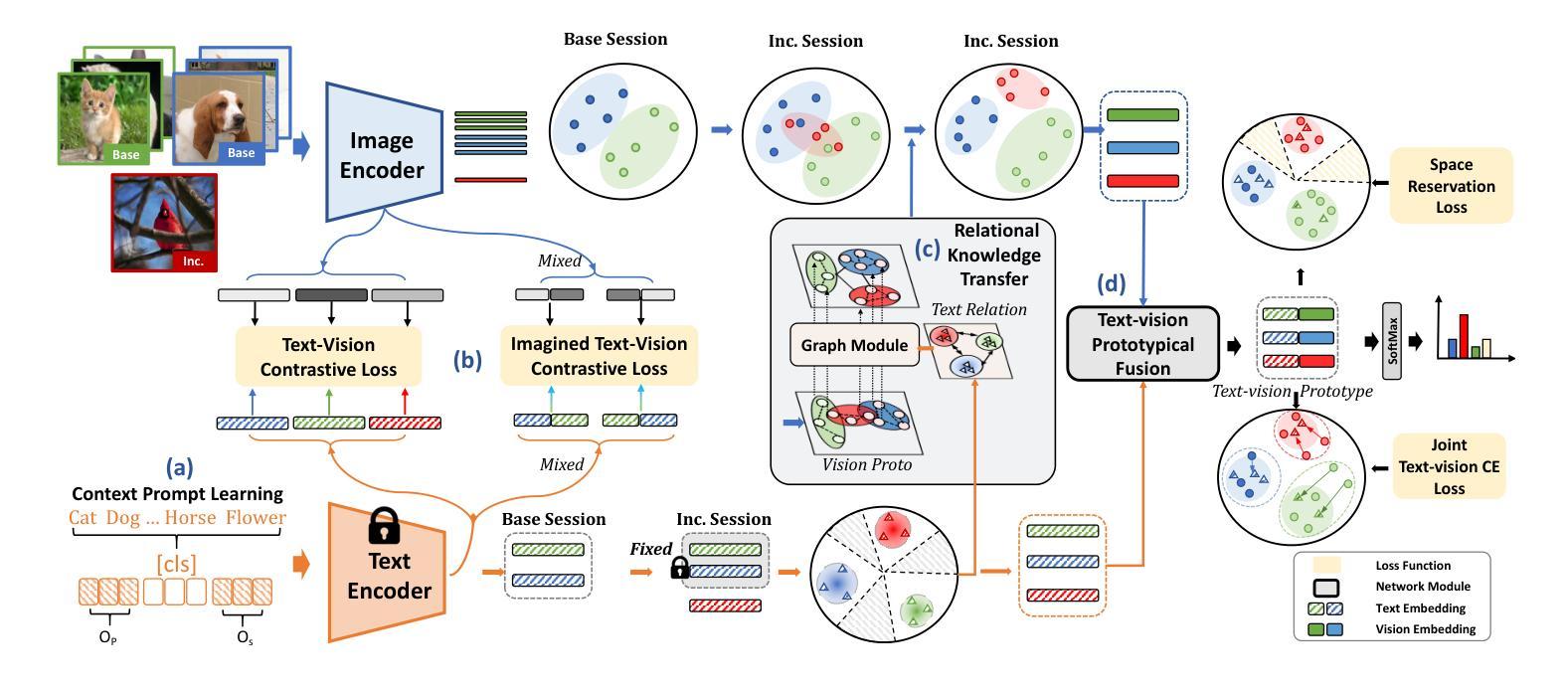
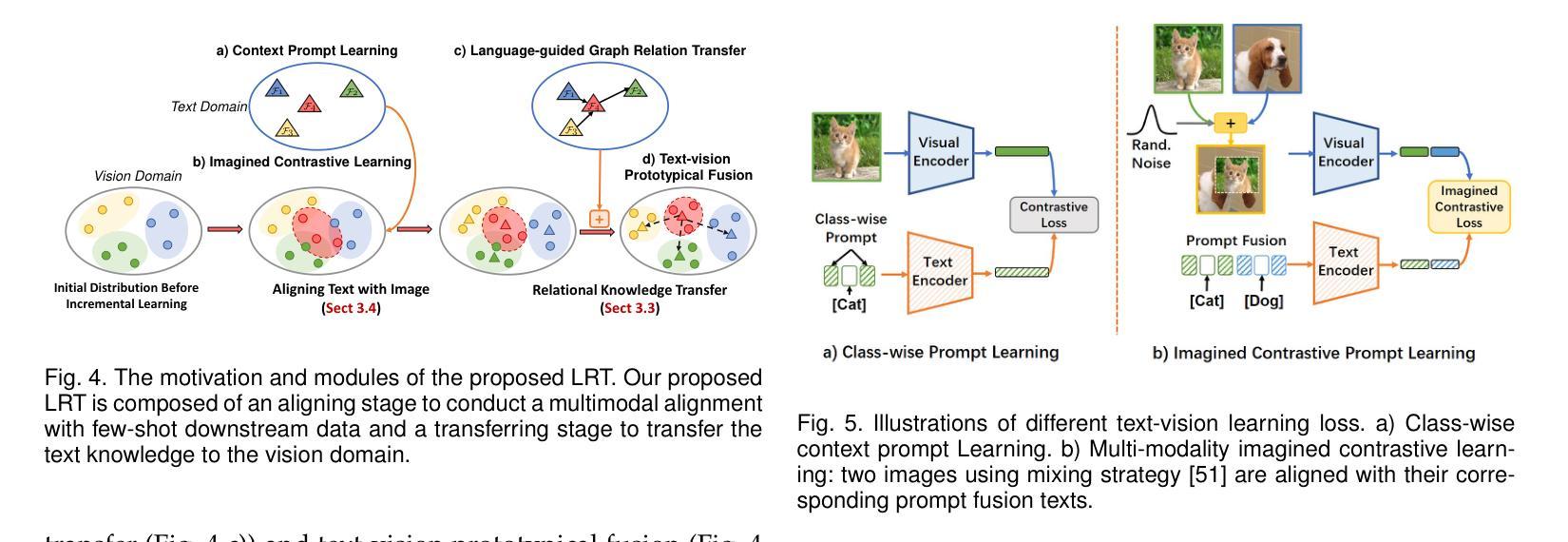
Depicting novel classes with language descriptions by observing few-shot samples is inherent in human-learning systems. This lifelong learning capability helps to distinguish new knowledge from old ones through the increase of open-world learning, namely Few-Shot Class-Incremental Learning (FSCIL). Existing works to solve this problem mainly rely on the careful tuning of visual encoders, which shows an evident trade-off between the base knowledge and incremental ones. Motivated by human learning systems, we propose a new Language-inspired Relation Transfer (LRT) paradigm to understand objects by joint visual clues and text depictions, composed of two major steps. We first transfer the pretrained text knowledge to the visual domains by proposing a graph relation transformation module and then fuse the visual and language embedding by a text-vision prototypical fusion module. Second, to mitigate the domain gap caused by visual finetuning, we propose context prompt learning for fast domain alignment and imagined contrastive learning to alleviate the insufficient text data during alignment. With collaborative learning of domain alignments and text-image transfer, our proposed LRT outperforms the state-of-the-art models by over $13%$ and $7%$ on the final session of mini-ImageNet and CIFAR-100 FSCIL benchmarks.
通过观察少数样本并用语言描述来描绘新型类别,是人类学习系统的固有特性。这种终身学习能力有助于通过开放世界学习的增加来区分新旧知识,即所谓的Few-Shot Class-Incremental Learning(FSCIL)。现有解决此问题的研究主要依赖于视觉编码器的仔细调整,这显示出基础知识和增量知识之间的明显权衡。受人类学习系统的启发,我们提出了一种新的语言启发关系转移(LRT)范式,通过联合视觉线索和文本描述来理解对象,包括两个主要步骤。首先,我们通过提出图关系转换模块将预训练的文本知识转移到视觉领域,然后通过文本视觉原型融合模块融合视觉和语言嵌入。其次,为了缓解由于视觉微调造成的领域差距,我们提出了上下文提示学习进行快速领域对齐和想象对比学习,以缓解对齐过程中的文本数据不足。通过领域对齐和文本图像传输的协作学习,我们提出的LRT在mini-ImageNet和CIFAR-100 FSCIL基准测试的最后一期比最先进的模型高出超过13%和7%。
论文及项目相关链接
PDF Accepted by IEEE TPAMI
Summary
本文探讨了基于人类学习系统的少样本类增量学习(FSCIL)问题。针对现有方法主要依赖视觉编码器的调整,存在基础知识与增量知识之间的权衡问题,提出一种新的语言启发关系转移(LRT)范式。该范式通过两个主要步骤理解和识别对象:一是通过图关系转换模块将预训练的文本知识转移到视觉领域,然后通过文本-视觉原型融合模块融合视觉和文本嵌入。二是为了减少因视觉微调导致的领域差距,提出了上下文提示学习和想象对比学习。实验结果表明,所提出的LRT在mini-ImageNet和CIFAR-100的FSCIL基准测试中,相较于现有模型有显著提升。
Key Takeaways
- 人类学习系统能够通过对少样本的观察,通过语言描述来描绘新型类别,这为Few-Shot Class-Incremental Learning(FSCIL)提供了启示。
- 现有解决FSCIL问题的方法主要依赖视觉编码器的调整,存在基础知识和增量知识的权衡问题。
- 提出的Language-inspired Relation Transfer(LRT)范式通过结合视觉线索和文本描述来理解对象。
- LRT范式包括两个主要步骤:将预训练的文本知识转移到视觉领域,然后融合视觉和文本嵌入。
- 为减少因视觉微调导致的领域差距,提出了上下文提示学习和想象对比学习。
- 实验结果表明,LRT在FSCIL任务上的性能超过现有模型。
点此查看论文截图

Enhancing Unsupervised Graph Few-shot Learning via Set Functions and Optimal Transport
Authors:Yonghao Liu, Fausto Giunchiglia, Ximing Li, Lan Huang, Xiaoyue Feng, Renchu Guan
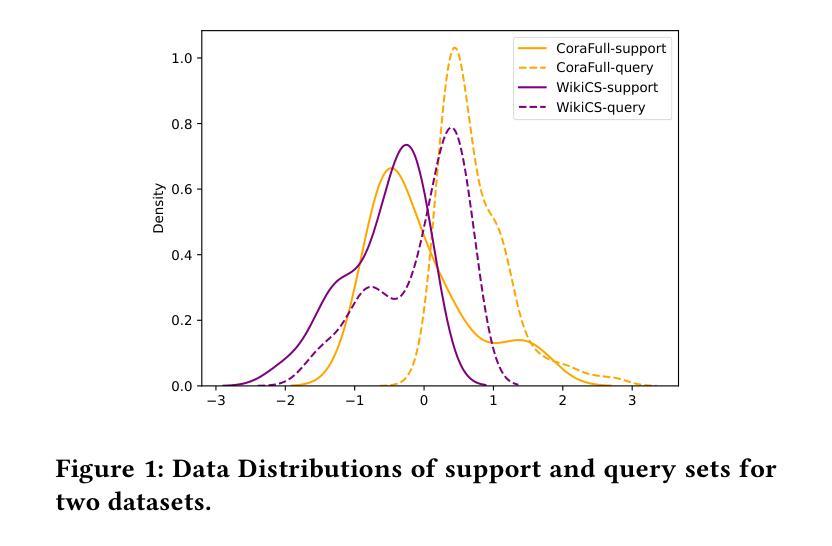
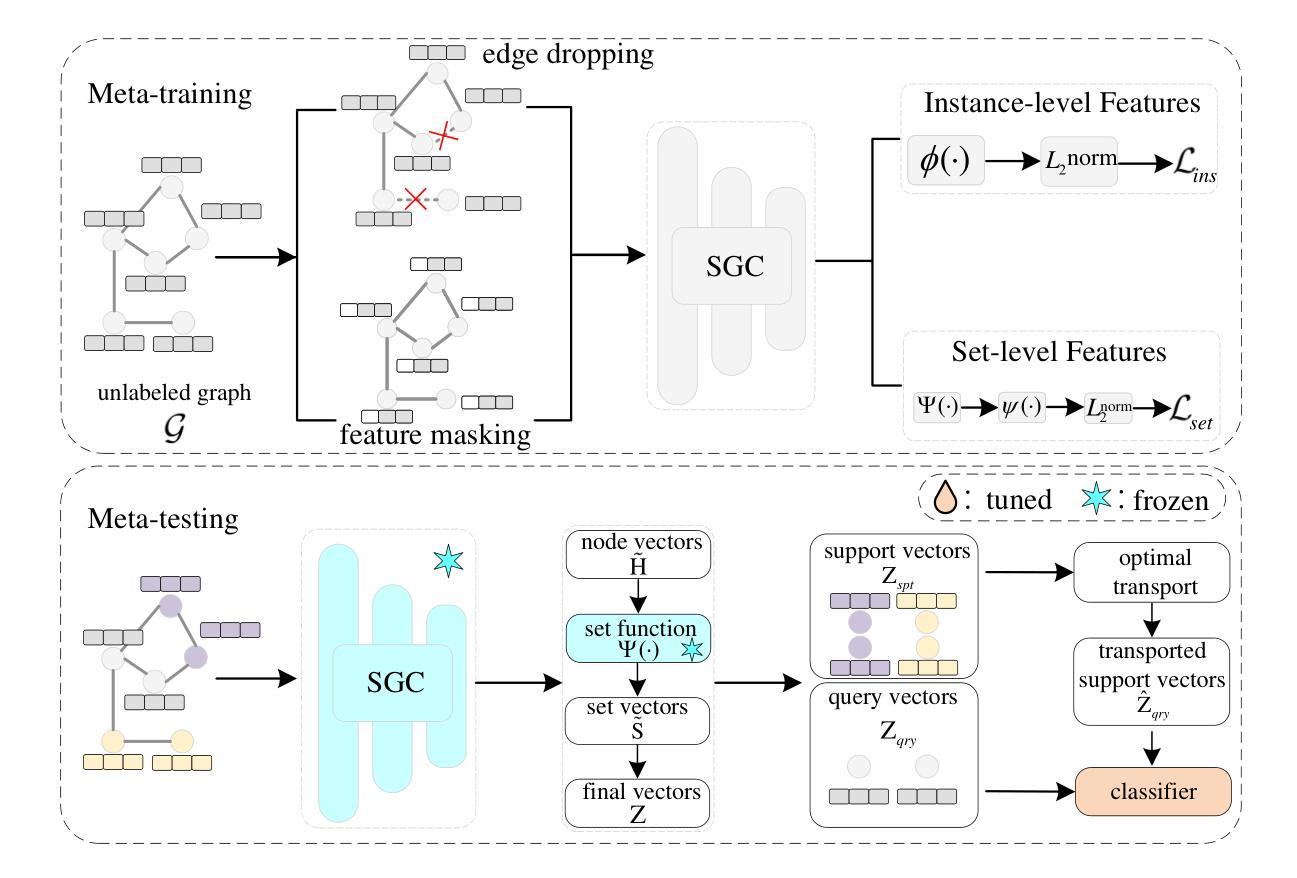
Graph few-shot learning has garnered significant attention for its ability to rapidly adapt to downstream tasks with limited labeled data, sparking considerable interest among researchers. Recent advancements in graph few-shot learning models have exhibited superior performance across diverse applications. Despite their successes, several limitations still exist. First, existing models in the meta-training phase predominantly focus on instance-level features within tasks, neglecting crucial set-level features essential for distinguishing between different categories. Second, these models often utilize query sets directly on classifiers trained with support sets containing only a few labeled examples, overlooking potential distribution shifts between these sets and leading to suboptimal performance. Finally, previous models typically require necessitate abundant labeled data from base classes to extract transferable knowledge, which is typically infeasible in real-world scenarios. To address these issues, we propose a novel model named STAR, which leverages Set funcTions and optimAl tRansport for enhancing unsupervised graph few-shot learning. Specifically, STAR utilizes expressive set functions to obtain set-level features in an unsupervised manner and employs optimal transport principles to align the distributions of support and query sets, thereby mitigating distribution shift effects. Theoretical analysis demonstrates that STAR can capture more task-relevant information and enhance generalization capabilities. Empirically, extensive experiments across multiple datasets validate the effectiveness of STAR. Our code can be found here.
图少量学习(Graph Few-Shot Learning)因其能够在有限标记数据下迅速适应下游任务的能力而受到广泛关注,引发了研究人员的极大兴趣。最近的图少量学习模型的进展在各种应用中表现出了卓越的性能。尽管取得了成功,但仍存在一些局限性。首先,现有模型在元训练阶段主要关注任务内的实例级特征,而忽略了对于区分不同类别至关重要的集合级特征。其次,这些模型通常直接在由支持集(仅包含少量标记示例)训练的分类器上使用查询集,忽视了这些集合之间潜在的分布偏移,导致性能不佳。最后,以前的模型通常需要来自基类的丰富标记数据来提取可转移知识,这在现实场景中通常不可行。为了解决这些问题,我们提出了一种新型模型STAR,它利用集合函数和最优传输(Set funcTions and optimAl tRansport)来提高无监督图少量学习的性能。具体来说,STAR使用表达性强的集合函数以无监督的方式获取集合级特征,并采用最优传输原理来对齐支持集和查询集的分布,从而减轻分布偏移的影响。理论分析表明,STAR能够捕获更多任务相关信息并提高泛化能力。在多个数据集上的大量实验验证了STAR的有效性。我们的代码可以在这里找到。
论文及项目相关链接
PDF KDD2025
Summary
本文介绍了图少样本学习的重要性及其在面对下游任务时的优势。尽管现有模型在多个应用领域表现出卓越性能,但它们仍面临一些局限性。为此,提出了一种名为STAR的新型模型,该模型利用集合函数和最佳传输技术,以无监督的方式解决图少样本学习问题。通过理论分析验证,STAR能更好地捕捉任务相关信息并提升泛化能力。在多个数据集上的实验证明了STAR的有效性。
Key Takeaways
- 图少样本学习能迅速适应下游任务,具有有限标记数据的优势。
- 现有模型主要关注实例级特征,忽视了集合级特征的重要性。
- 模型在元训练阶段直接使用查询集进行训练可能导致性能下降。
- 模型通常依赖于大量的基本类别的标记数据来提取可转移知识,这在现实世界中通常不可行。
- 提出的STAR模型利用集合函数以无监督方式获取集合级特征。
- STAR采用最佳传输原则来对齐支持集和查询集分布,减少分布偏移的影响。
点此查看论文截图

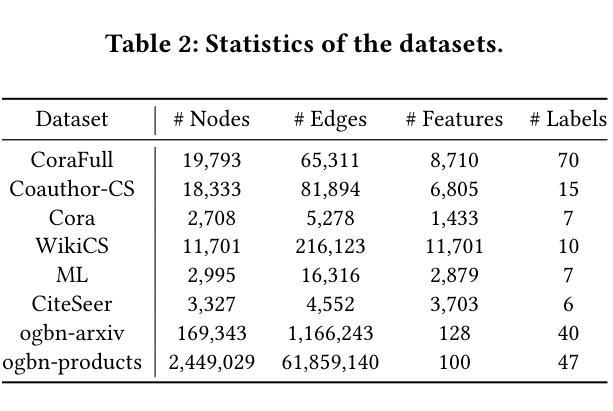
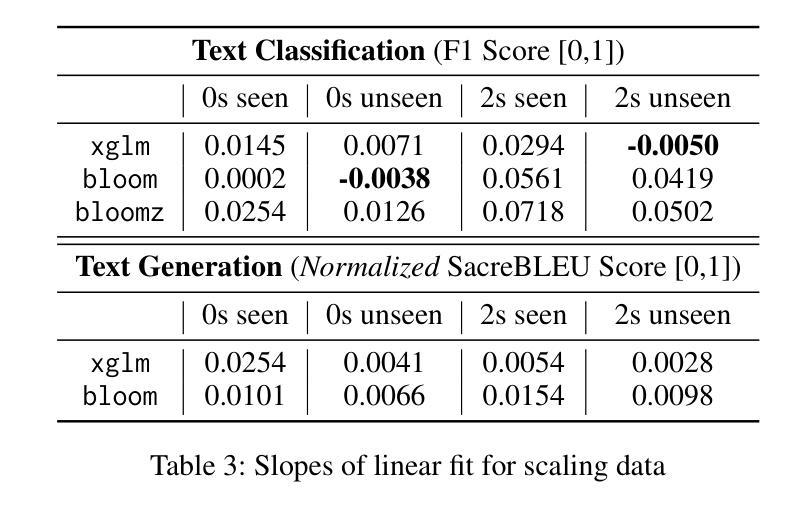
The Impact of Model Scaling on Seen and Unseen Language Performance
Authors:Rhitabrat Pokharel, Sina Bagheri Nezhad, Ameeta Agrawal, Suresh Singh
The rapid advancement of Large Language Models (LLMs), particularly those trained on multilingual corpora, has intensified the need for a deeper understanding of their performance across a diverse range of languages and model sizes. Our research addresses this critical need by studying the performance and scaling behavior of multilingual LLMs in text classification and machine translation tasks across 204 languages. We systematically examine both seen and unseen languages across three model families of varying sizes in zero-shot and few-shot settings. Our findings show significant differences in scaling behavior between zero-shot and two-shot scenarios, with striking disparities in performance between seen and unseen languages. Model scale has little effect on zero-shot performance, which remains mostly flat. However, in two-shot settings, larger models show clear linear improvements in multilingual text classification. For translation tasks, however, only the instruction-tuned model showed clear benefits from scaling. Our analysis also suggests that overall resource levels, not just the proportions of pretraining languages, are better predictors of model performance, shedding light on what drives multilingual LLM effectiveness.
随着大型语言模型(LLM)的快速发展,特别是在多语言语料库上训练的模型,我们需要更深入地理解其在多种语言和不同模型规模上的性能。我们的研究通过研究和比较不同大小模型家族在204种语言的文本分类和机器翻译任务中的性能和扩展行为来应对这一迫切需求。我们在零样本和少样本环境中,系统研究了可见语言和未见语言在不同模型上的表现。我们发现零样本和两样本场景中的扩展行为存在显著差异,并且在可见语言和未见语言之间表现出惊人的表现差异。模型规模对零样本表现几乎没有影响,基本上保持稳定。然而,在两样本环境中,大型模型在跨语言文本分类中显示出明显的线性改进。但对于翻译任务来说,只有指令调优模型才能从扩展中明显受益。我们的分析还表明,整体资源水平,而非预训练语言的比例更能预测模型性能,这揭示了推动多语言LLM有效性的因素。
论文及项目相关链接
PDF Accepted at SEAS Workshop at AAAI25
Summary
多语言大型语言模型(LLM)在文本分类和机器翻译任务中的性能和扩展行为研究。研究涉及三个不同规模的模型家族,在零样本和少样本场景下对204种语言的性能进行了系统评估。发现零样本和两样本场景下的扩展行为存在显著差异,不同语言和模型规模下的性能差异明显。模型规模对零样本性能影响较小,而在两样本场景下,大型模型在跨语言文本分类中的表现呈现线性提升。对于翻译任务,只有经过指令调优的模型才能从扩展中获得明显优势。整体资源水平而非预训练语言的比例能更好地预测模型性能。
Key Takeaways
- 多语言大型语言模型(LLM)在文本分类和机器翻译任务中的性能需深入研究。
- 零样本和少样本场景下的模型表现存在显著差距。
- 模型规模对零样本性能影响较小,但在两样本场景下,大型模型在跨语言文本分类中有线性提升。
- 对于机器翻译任务,只有经过指令调优的模型能从扩展中获得优势。
- 整体资源水平是预测模型性能的关键因素。
- 不同语言和模型之间的性能差异明显,需要针对不同语言和任务进行优化。
点此查看论文截图



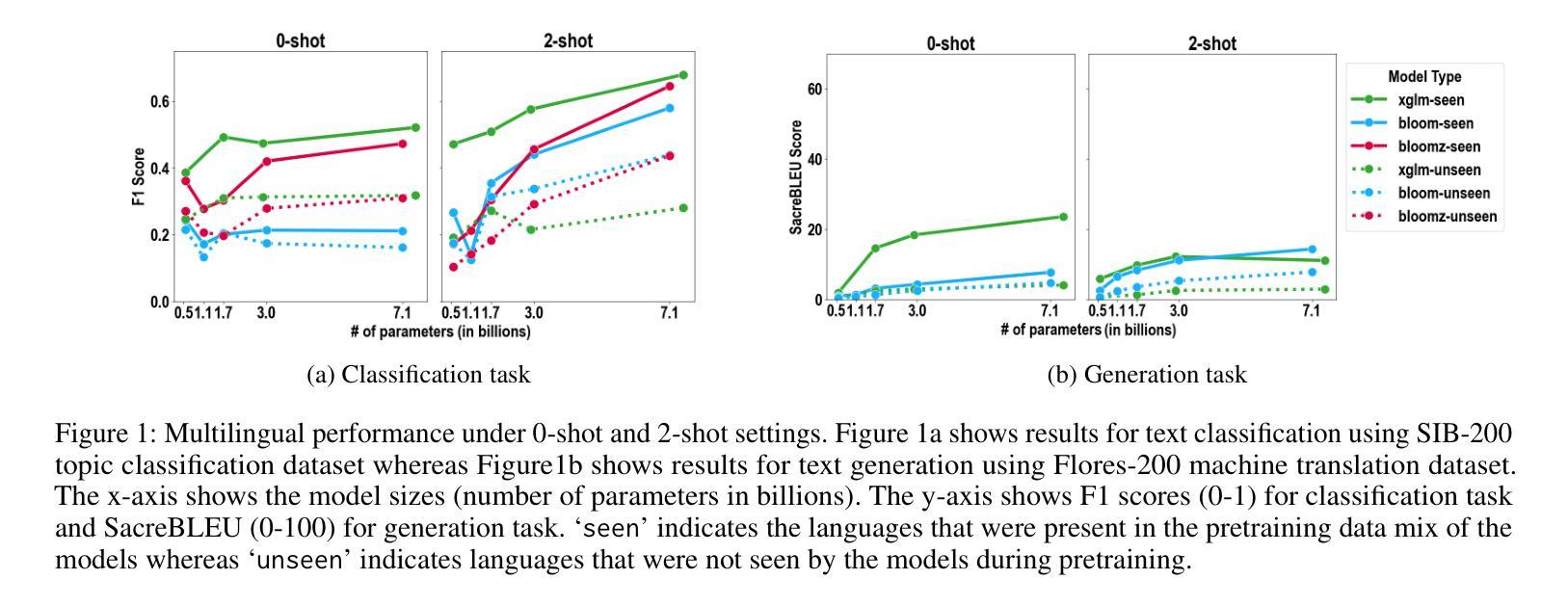
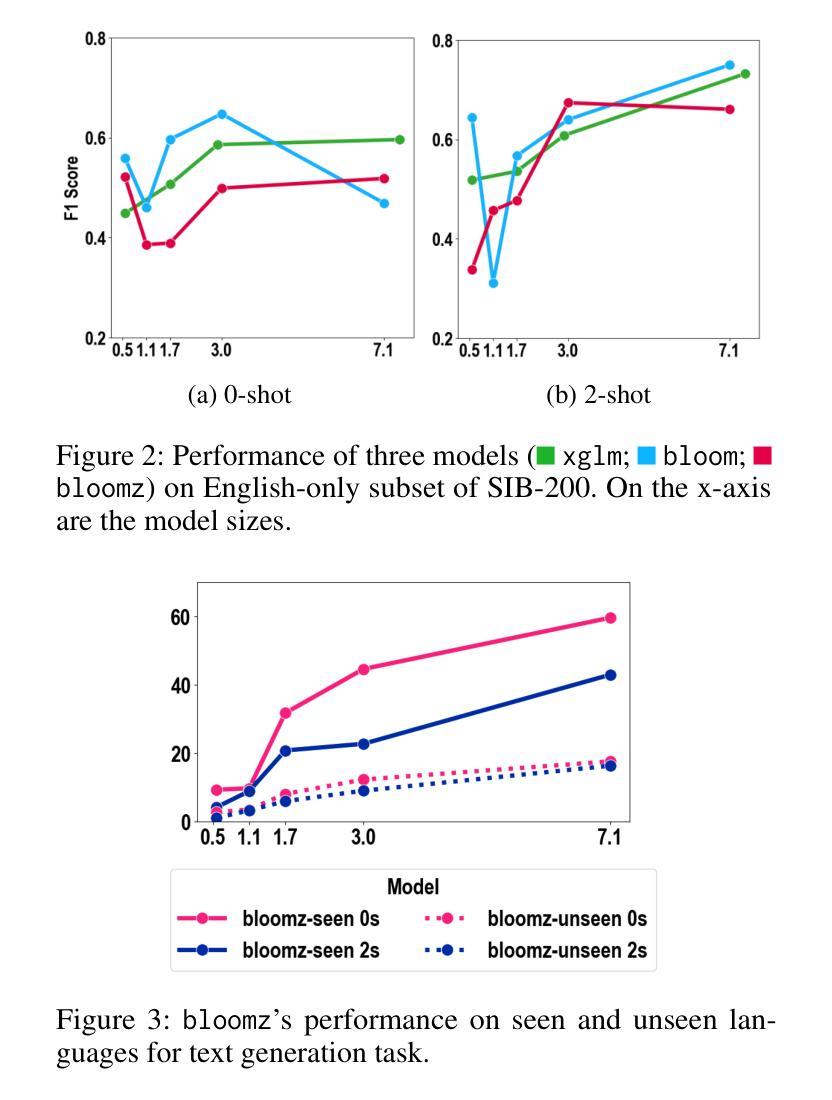
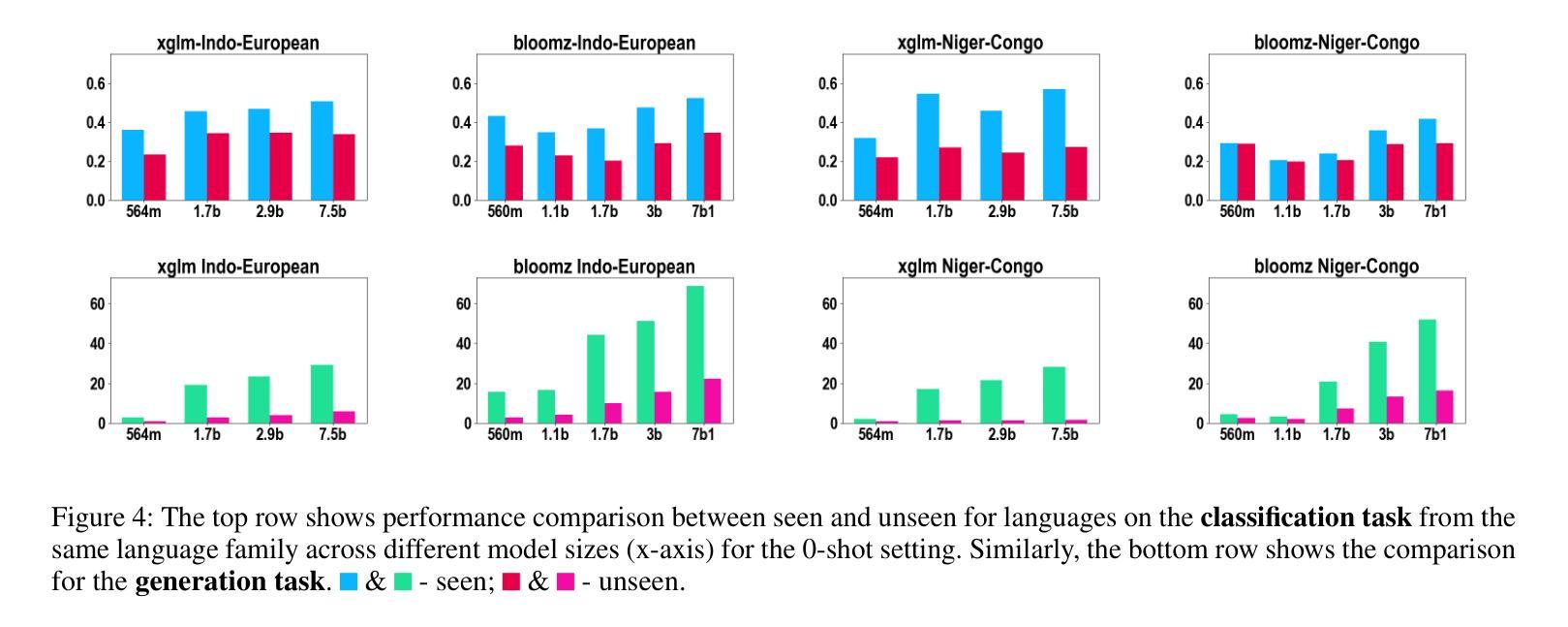
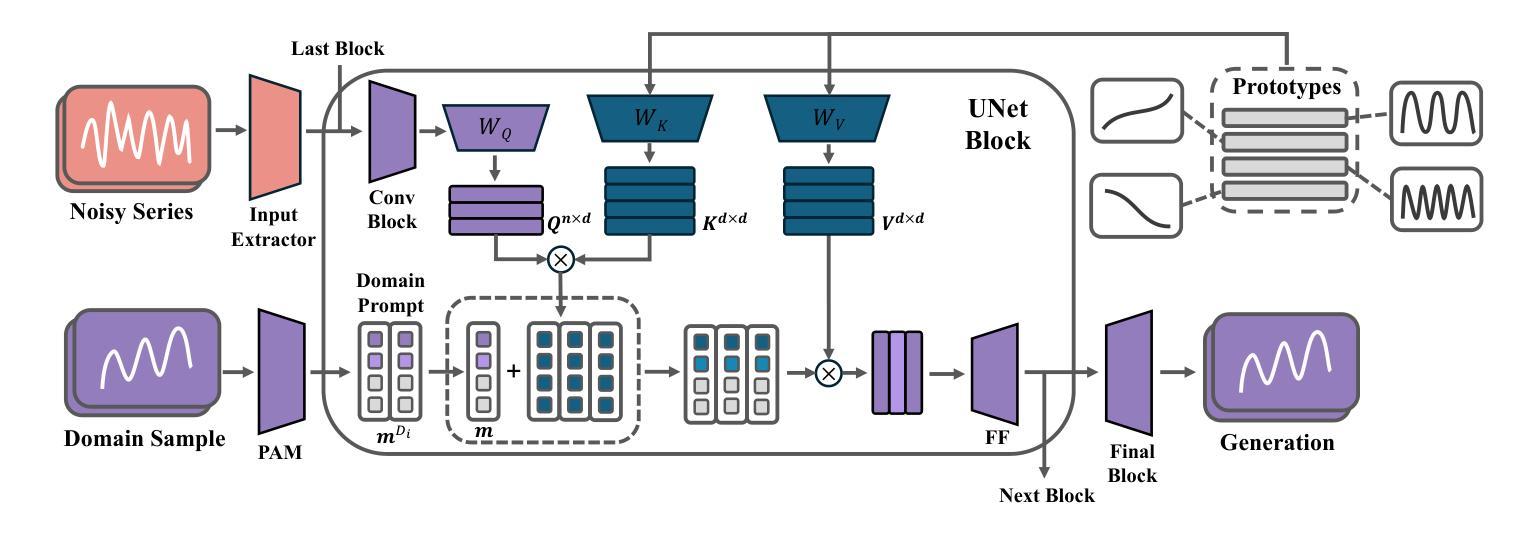
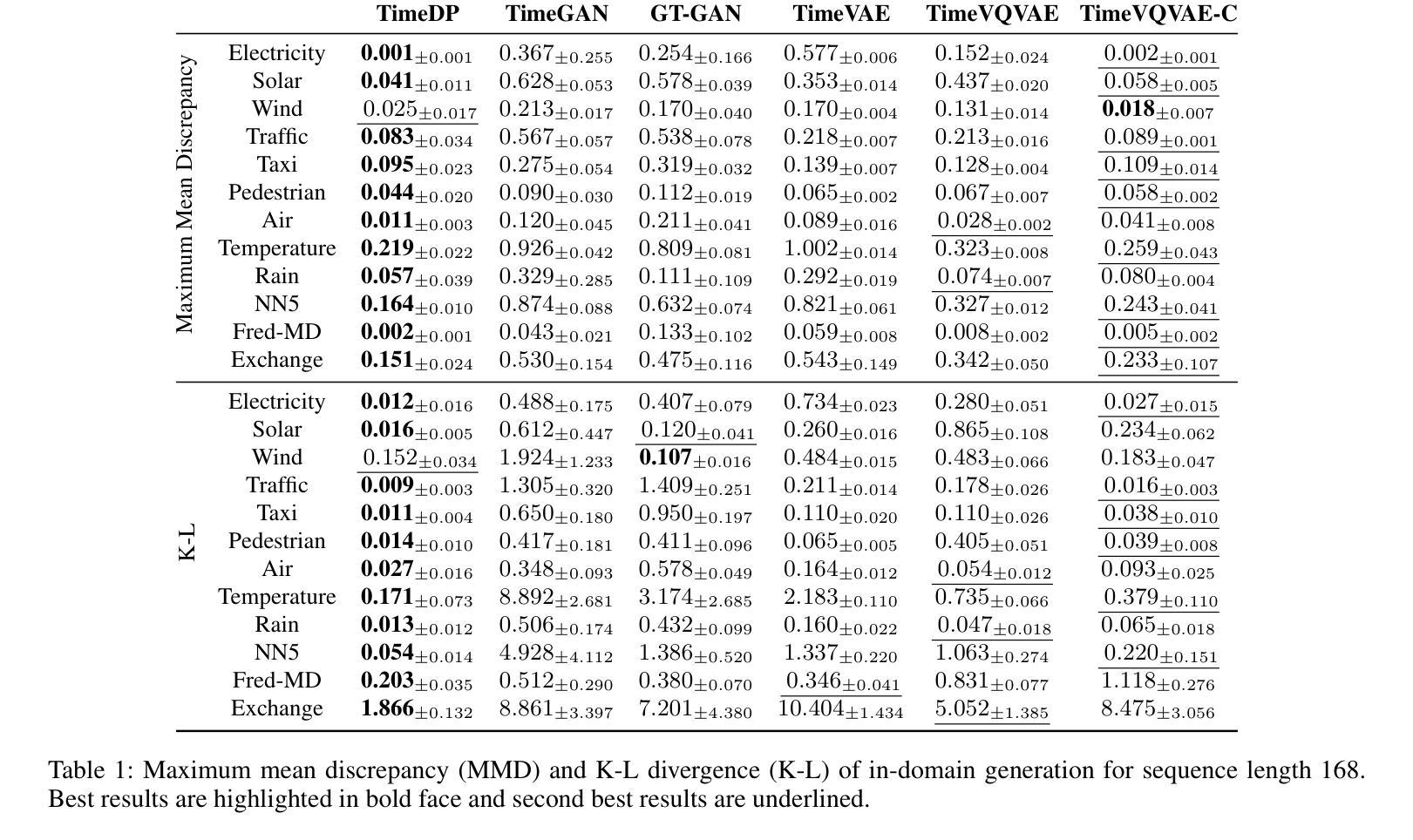
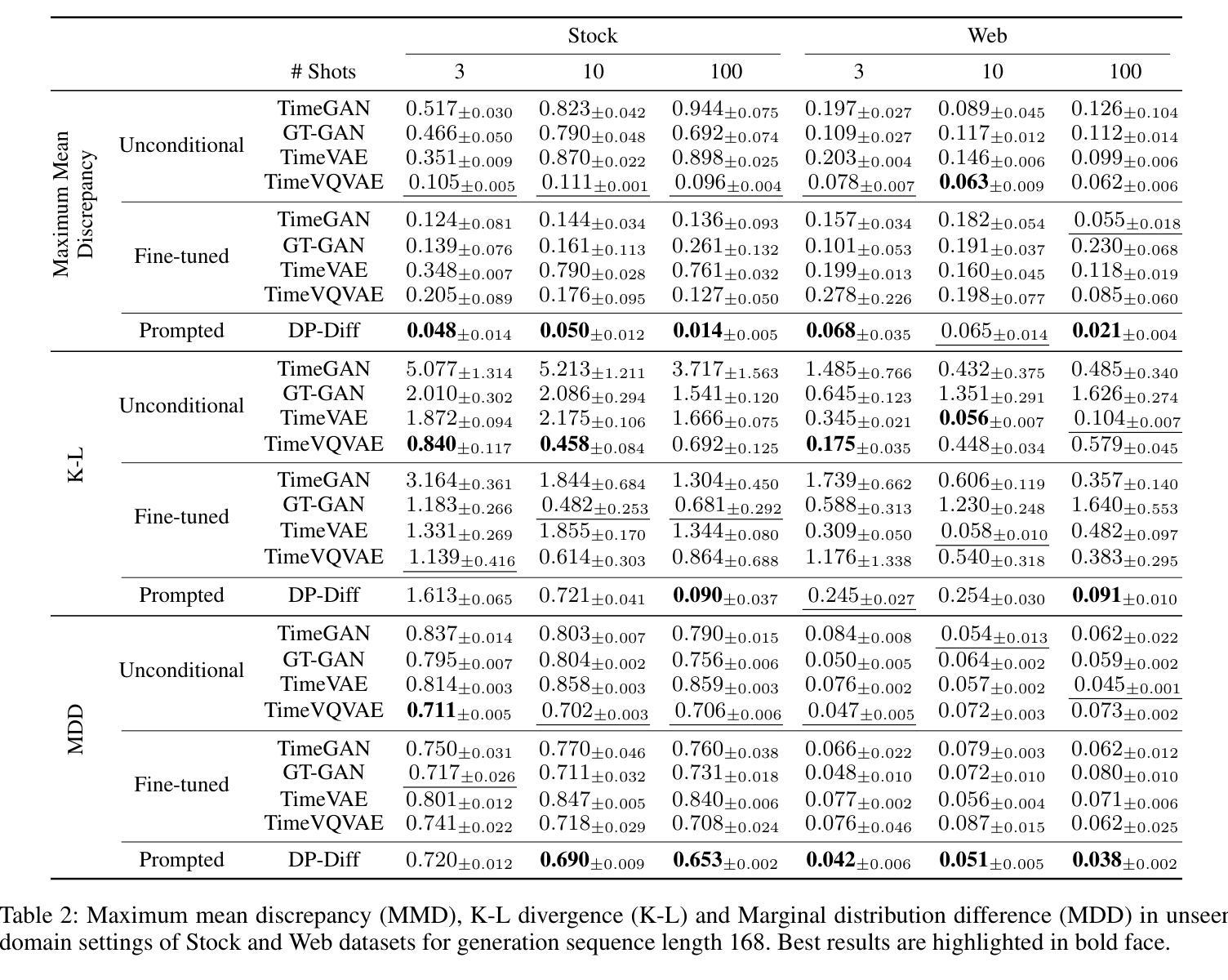
TimeDP: Learning to Generate Multi-Domain Time Series with Domain Prompts
Authors:Yu-Hao Huang, Chang Xu, Yueying Wu, Wu-Jun Li, Jiang Bian
Time series generation models are crucial for applications like data augmentation and privacy preservation. Most existing time series generation models are typically designed to generate data from one specified domain. While leveraging data from other domain for better generalization is proved to work in other application areas, this approach remains challenging for time series modeling due to the large divergence in patterns among different real world time series categories. In this paper, we propose a multi-domain time series diffusion model with domain prompts, named TimeDP. In TimeDP, we utilize a time series semantic prototype module which defines time series prototypes to represent time series basis, each prototype vector serving as “word” representing some elementary time series feature. A prototype assignment module is applied to extract the extract domain specific prototype weights, for learning domain prompts as generation condition. During sampling, we extract “domain prompt” with few-shot samples from the target domain and use the domain prompts as condition to generate time series samples. Experiments demonstrate that our method outperforms baselines to provide the state-of-the-art in-domain generation quality and strong unseen domain generation capability.
时间序列生成模型在数据增强和隐私保护等应用中发挥着重要作用。大多数现有的时间序列生成模型通常被设计用来从特定领域生成数据。虽然利用其他领域的数据以实现更好的泛化在其他应用领域已被证明是有效的,但由于不同现实世界时间序列类别之间模式存在巨大差异,这种方法在时间序列建模中仍然具有挑战性。在本文中,我们提出了一种带有领域提示的多领域时间序列扩散模型,名为TimeDP。在TimeDP中,我们利用时间序列语义原型模块来定义时间序列原型以表示时间序列基础,每个原型向量都作为代表某些基本时间序列特征的“单词”。应用原型分配模块来提取领域特定的原型权重,作为生成条件的领域提示进行学习。在采样过程中,我们从目标领域提取少量样本的“领域提示”,并将领域提示作为条件来生成时间序列样本。实验表明,我们的方法在领域内生成质量和未见领域的生成能力方面均超过了基线方法,达到了最新水平。
论文及项目相关链接
PDF AAAI 2025
Summary
本文提出一种名为TimeDP的多域时间序列扩散模型,通过引入时间序列语义原型模块和原型分配模块,实现跨域生成时间序列数据。该模型能够提取特定域的时间序列原型权重,将其作为生成条件进行学习,从而在采样过程中利用来自目标域的少量样本提取“域提示”,并作为条件生成时间序列样本。实验表明,该方法在领域内生成质量和未见领域的生成能力上具有优越性。
Key Takeaways
- 时间序列生成模型在数据增强和隐私保护等应用中具有重要意义。
- 现有时间序列生成模型通常局限于特定领域的数据生成。
- 跨域生成时间序列数据具有挑战性,因为不同现实世界时间序列类别之间存在模式差异。
- TimeDP模型通过引入时间序列语义原型模块和原型分配模块实现多域时间序列生成。
- TimeDP模型能够提取特定域的时间序列原型权重,作为生成条件进行学习。
- 在采样过程中,TimeDP模型利用来自目标域的少量样本提取“域提示”。
点此查看论文截图

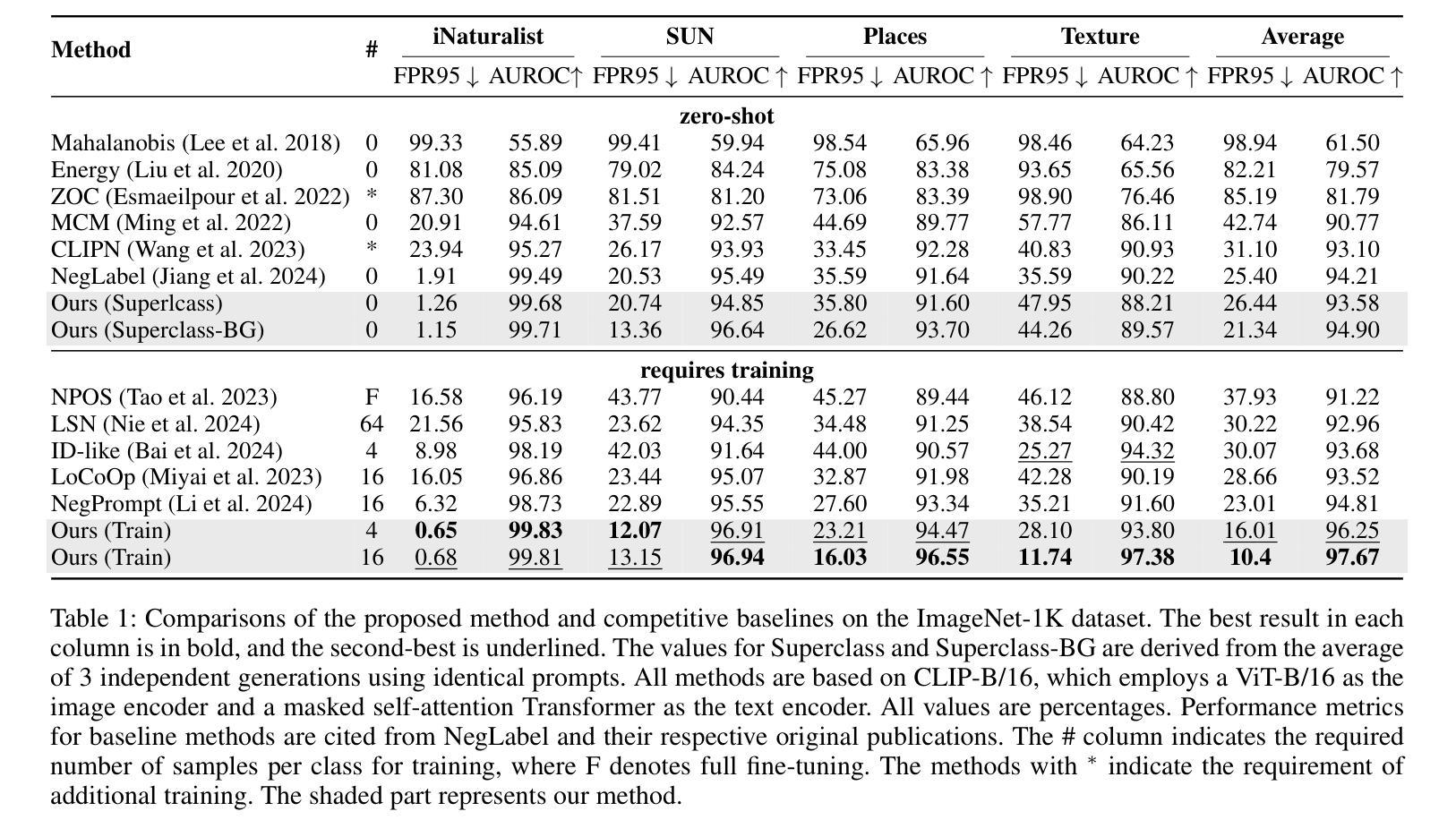
Harnessing Large Language and Vision-Language Models for Robust Out-of-Distribution Detection
Authors:Pei-Kang Lee, Jun-Cheng Chen, Ja-Ling Wu
Out-of-distribution (OOD) detection has seen significant advancements with zero-shot approaches by leveraging the powerful Vision-Language Models (VLMs) such as CLIP. However, prior research works have predominantly focused on enhancing Far-OOD performance, while potentially compromising Near-OOD efficacy, as observed from our pilot study. To address this issue, we propose a novel strategy to enhance zero-shot OOD detection performances for both Far-OOD and Near-OOD scenarios by innovatively harnessing Large Language Models (LLMs) and VLMs. Our approach first exploit an LLM to generate superclasses of the ID labels and their corresponding background descriptions followed by feature extraction using CLIP. We then isolate the core semantic features for ID data by subtracting background features from the superclass features. The refined representation facilitates the selection of more appropriate negative labels for OOD data from a comprehensive candidate label set of WordNet, thereby enhancing the performance of zero-shot OOD detection in both scenarios. Furthermore, we introduce novel few-shot prompt tuning and visual prompt tuning to adapt the proposed framework to better align with the target distribution. Experimental results demonstrate that the proposed approach consistently outperforms current state-of-the-art methods across multiple benchmarks, with an improvement of up to 2.9% in AUROC and a reduction of up to 12.6% in FPR95. Additionally, our method exhibits superior robustness against covariate shift across different domains, further highlighting its effectiveness in real-world scenarios.
非分布内(OOD)检测利用强大的视觉语言模型(VLMs)如CLIP的零样本方法取得了重大进展。然而,先前的研究工作主要集中在提高远OOD性能上,可能会损害近OOD的效果,从我们的初步研究中可以观察到这一点。为了解决这个问题,我们提出了一种新的策略,通过创新性地利用大型语言模型(LLMs)和VLMs,提高零样本的远OOD和近OOD场景的性能。我们的方法首先利用LLM生成ID标签的超类及其相应的背景描述,然后使用CLIP进行特征提取。接下来,我们通过从超类特征中减去背景特征来分离ID数据的核心语义特征。这种精炼的表示有助于从WordNet的综合候选标签集中为OOD数据选择更合适的负标签,从而提高两种场景下的零样本OOD检测性能。此外,我们引入了新型的小样本提示调整和视觉提示调整,以适应框架以更好地与目标分布对齐。实验结果表明,所提出的方法在多基准测试中始终优于当前最先进的方法,在AUROC上提高了高达2.9%,在FPR9ud下减少了高达12.6%。此外,我们的方法在应对不同领域的协变量变化方面表现出更强的稳健性,进一步突显其在现实世界场景中的有效性。
论文及项目相关链接
PDF 9 pages, 4 figures
摘要
基于CLIP的视觉语言模型和大型语言模型,提出一种改进策略以提高零样本模式下的离群值检测性能,针对远近两类离群数据都进行了改进。该研究使用语言模型生成标签和背景描述,提取特征后,通过减去背景特征得到精炼表示,选择更合适的负标签用于离群值数据。此外,引入少样本提示调整和视觉提示调整以适应目标分布。实验结果表明,该方法在多个基准测试中均优于当前先进技术,在AUROC上提高了高达2.9%,在FPR95上降低了高达12.6%。此方法对不同域的协变量偏移具有良好的稳健性,显示出其在真实场景中的有效性。
关键见解
一、利用视觉语言模型和大型语言模型结合的策略来提高零样本模式下的离群值检测性能。
二、生成标签和背景描述并使用特征提取,通过精炼表示选择更合适的负标签用于离群值数据。
三、引入少样本提示调整和视觉提示调整以适应目标分布,提高检测性能。
四、实验结果表明该方法在多个基准测试中表现优异,包括AUROC和FPR95等指标。
五、该方法对不同的协变量偏移具有良好的稳健性,适用于真实场景。
六、研究强调了结合语言模型和视觉模型的策略对于解决离群值检测问题的重要性。
点此查看论文截图


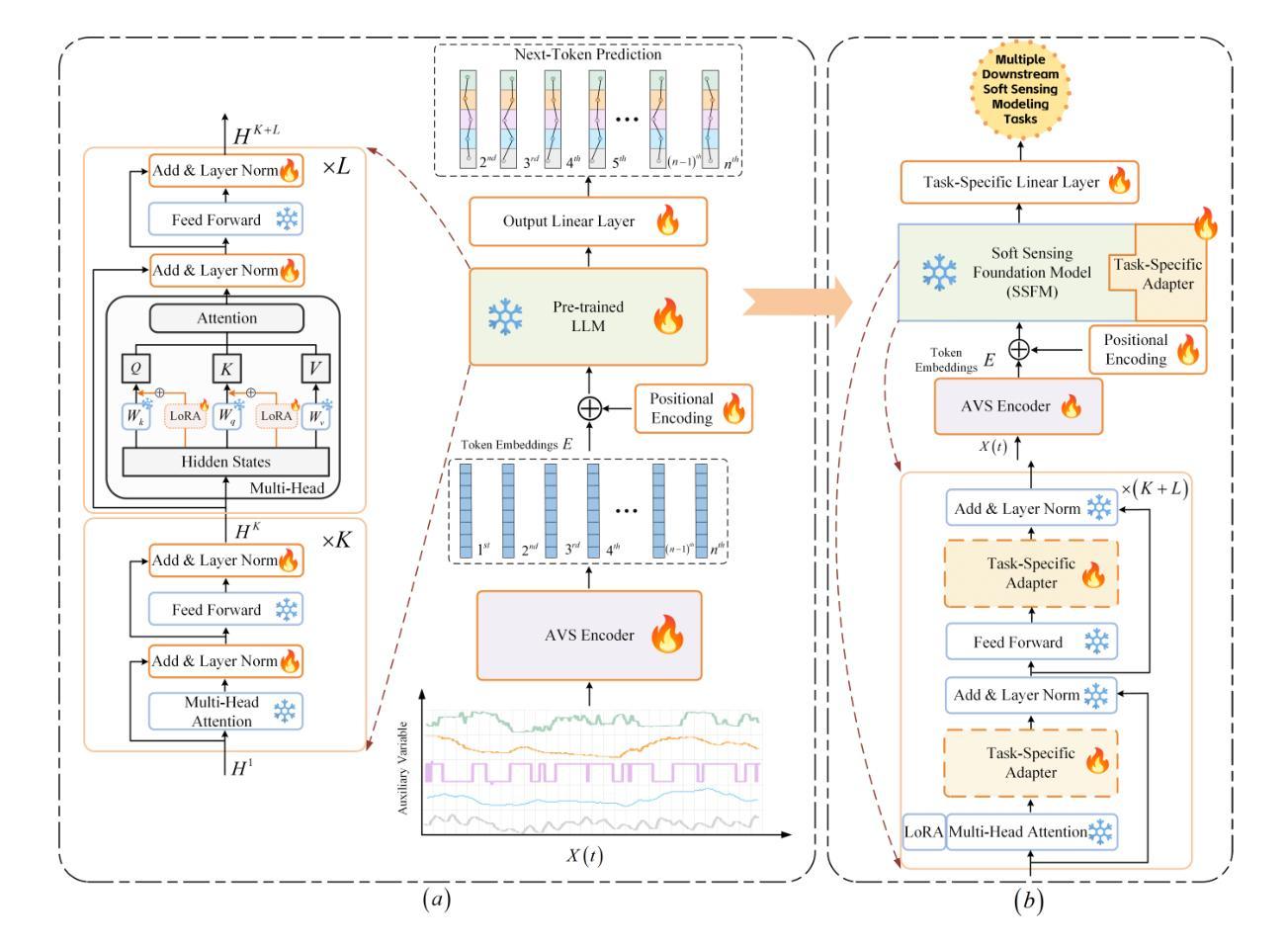
A Text-Based Knowledge-Embedded Soft Sensing Modeling Approach for General Industrial Process Tasks Based on Large Language Model
Authors:Shuo Tong, Han Liu, Runyuan Guo, Xueqiong Tian, Wenqing Wang, Ding Liu, Youmin Zhang
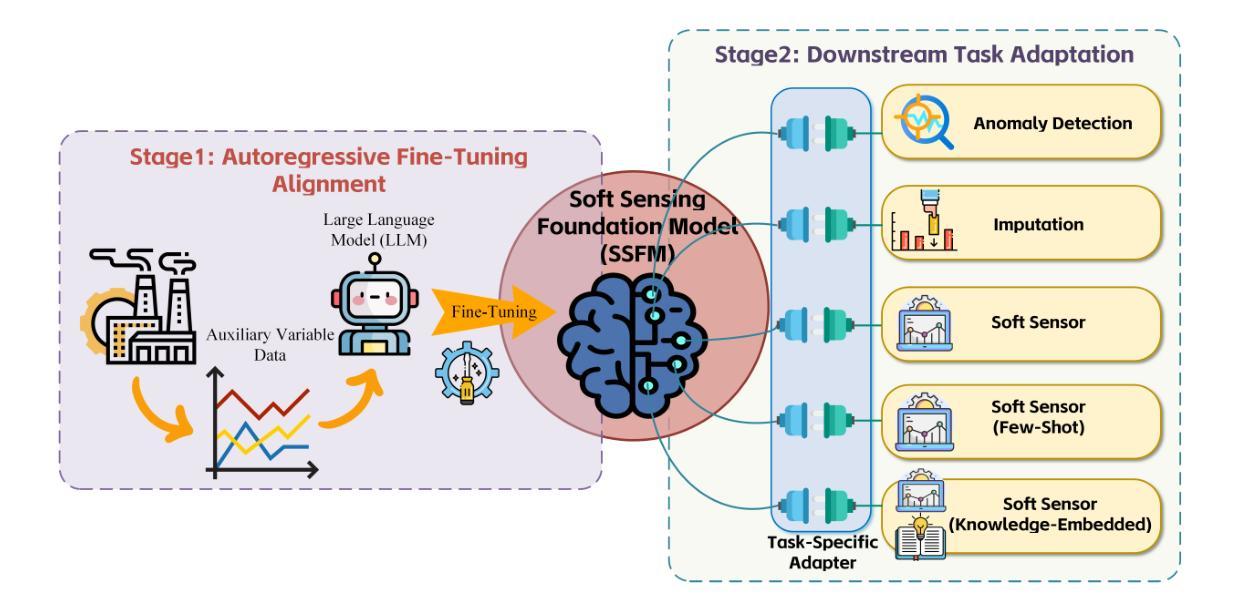
Data-driven soft sensors (DDSS) have become mainstream methods for predicting key performance indicators in process industries. However, DDSS development requires complex and costly customized designs tailored to various tasks during the modeling process. Moreover, DDSS are constrained to a single structured data modality, limiting their ability to incorporate additional contextual knowledge. Furthermore, DDSSs’ limited representation learning leads to weak predictive performance with scarce data. To address these challenges, we propose a general framework named LLM-TKESS (large language model for text-based knowledge-embedded soft sensing), harnessing the powerful general problem-solving capabilities, cross-modal knowledge transfer abilities, and few-shot capabilities of LLM for enhanced soft sensing modeling. Specifically, an auxiliary variable series encoder (AVS Encoder) is proposed to unleash LLM’s potential for capturing temporal relationships within series and spatial semantic relationships among auxiliary variables. Then, we propose a two-stage fine-tuning alignment strategy: in the first stage, employing parameter-efficient fine-tuning through autoregressive training adjusts LLM to rapidly accommodate process variable data, resulting in a soft sensing foundation model (SSFM). Subsequently, by training adapters, we adapt the SSFM to various downstream tasks without modifying its architecture. Then, we propose two text-based knowledge-embedded soft sensors, integrating new natural language modalities to overcome the limitations of pure structured data models. Furthermore, benefiting from LLM’s pre-existing world knowledge, our model demonstrates outstanding predictive capabilities in small sample conditions. Using the thermal deformation of air preheater rotor as a case study, we validate through extensive experiments that LLM-TKESS exhibits outstanding performance.
数据驱动软传感器(DDSS)已成为流程工业预测关键绩效指标的主流方法。然而,DDSS开发需要在建模过程中对多种任务进行定制化的复杂且昂贵的设计。此外,DDSS受限于单一的结构化数据模态,无法融入额外的上下文知识。而且,DDSS的有限表示学习导致在数据稀缺时的预测性能较弱。
为了解决这些挑战,我们提出了一种名为LLM-TKESS(基于文本知识嵌入软感知的大型语言模型)的通用框架,利用LLM的强大通用问题解决能力、跨模态知识迁移能力和小样本能力,增强软感知建模。具体来说,我们提出了一种辅助变量序列编码器(AVS编码器),以释放LLM捕捉序列内的时间关系和辅助变量之间的空间语义关系的潜力。
论文及项目相关链接
Summary
数据驱动软传感器(DDSS)已成为流程工业中预测关键性能指标的主流方法,但其开发过程中需要针对各种任务进行复杂且成本高昂的定制设计。针对DDSS在数据稀缺、单一数据模态和有限表示学习方面的局限性,提出一种通用框架LLM-TKESS(大型语言模型文本知识嵌入软传感),利用大型语言模型的通用问题解决能力、跨模态知识迁移能力和小样本学习能力,增强软传感建模。通过辅助变量序列编码器和两阶段精细调整对齐策略,结合自然语言模态数据,LLM-TKESS展现出卓越的预测性能。
Key Takeaways
- 数据驱动软传感器(DDSS)是流程工业中预测关键性能指标的主流方法,但存在开发复杂、成本高和局限性。
- LLM-TKESS框架利用大型语言模型的通用问题解决能力和跨模态知识迁移能力,以改进DDSS的弱点。
- LLM-TKESS通过辅助变量序列编码器(AVS Encoder)捕捉时间序列和空间语义关系。
- 两阶段精细调整对齐策略,使LLM适应过程变量数据,并快速建立软传感基础模型(SSFM)。
- LLM-TKESS通过训练适配器适应各种下游任务,同时保持模型结构不变。
- 结合自然语言模态数据,克服纯结构化数据模型的局限性。
点此查看论文截图



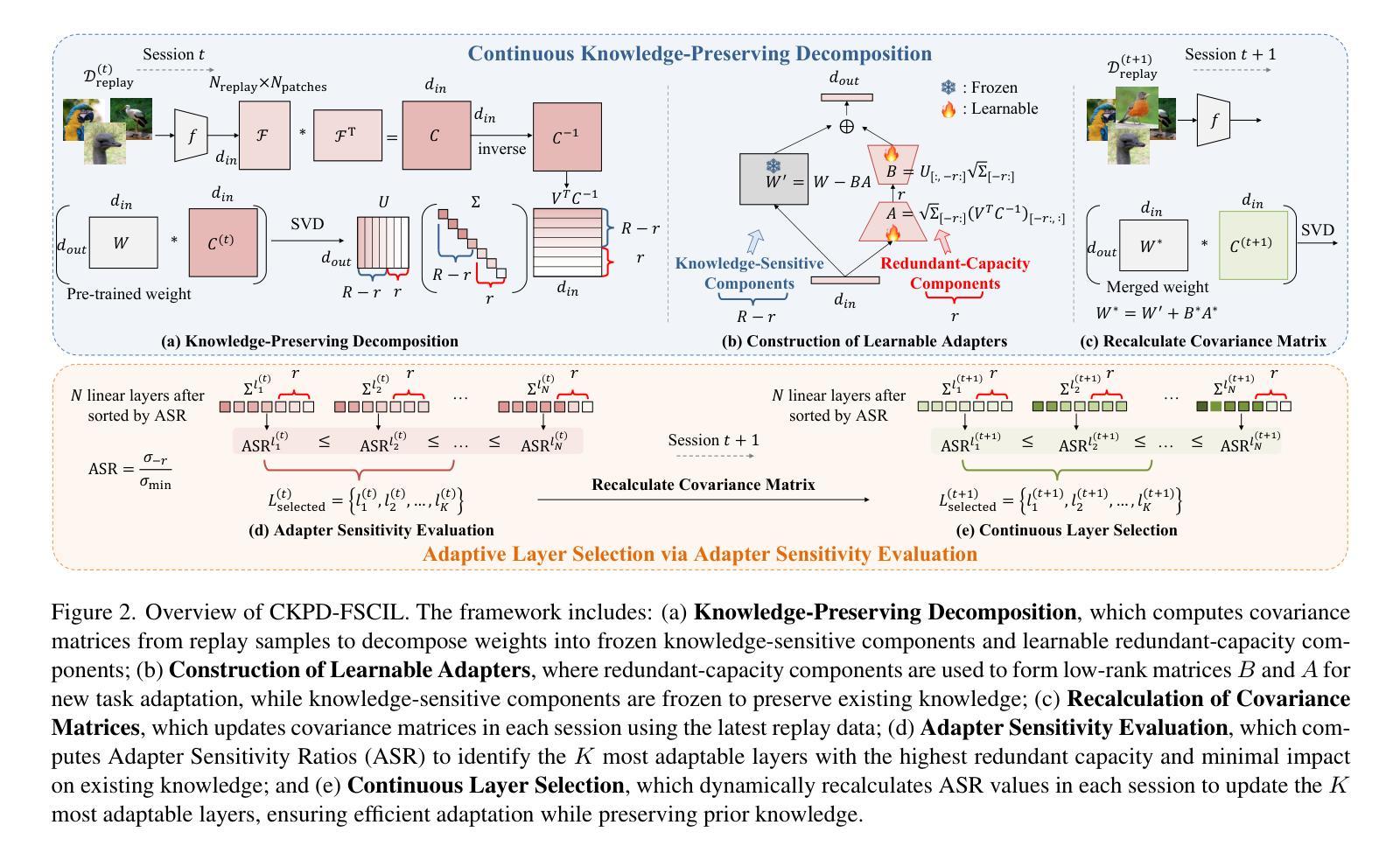
Continuous Knowledge-Preserving Decomposition for Few-Shot Continual Learning
Authors:Xiaojie Li, Yibo Yang, Jianlong Wu, David A. Clifton, Yue Yu, Bernard Ghanem, Min Zhang
Few-shot class-incremental learning (FSCIL) involves learning new classes from limited data while retaining prior knowledge, and often results in catastrophic forgetting. Existing methods either freeze backbone networks to preserve knowledge, which limits adaptability, or rely on additional modules or prompts, introducing inference overhead. To this end, we propose Continuous Knowledge-Preserving Decomposition for FSCIL (CKPD-FSCIL), a framework that decomposes a model’s weights into two parts: one that compacts existing knowledge (knowledge-sensitive components) and another that carries redundant capacity to accommodate new abilities (redundant-capacity components). The decomposition is guided by a covariance matrix from replay samples, ensuring principal components align with classification abilities. During adaptation, we freeze the knowledge-sensitive components and only adapt the redundant-capacity components, fostering plasticity while minimizing interference without changing the architecture or increasing overhead. Additionally, CKPD introduces an adaptive layer selection strategy to identify layers with redundant capacity, dynamically allocating adapters. Experiments on multiple benchmarks show that CKPD-FSCIL outperforms state-of-the-art methods.
少量样本类增量学习(FSCIL)涉及从有限数据中学习新类别的同时保留先前知识,这常常导致灾难性遗忘。现有方法要么冻结主干网络以保留知识,从而限制了适应性,要么依赖于附加模块或提示,增加了推理开销。为此,我们提出了面向FSCIL的持续知识保留分解(CKPD-FSCIL)框架,该框架将模型的权重分解为两部分:一部分是压缩现有知识(知识敏感组件),另一部分是具有容纳新能力剩余容量(剩余容量组件)。分解由回放样本的协方差矩阵引导,确保主成分与分类能力对齐。在适应过程中,我们冻结知识敏感组件,只适应剩余容量组件,促进可塑性,同时最小化干扰,而不改变架构或增加开销。此外,CKPD引入了一种自适应层选择策略,以识别具有剩余容量的层,并动态分配适配器。在多个基准测试上的实验表明,CKPD-FSCIL优于最新方法。
论文及项目相关链接
PDF Code: https://github.com/xiaojieli0903/CKPD-FSCIL
Summary
模型权重分解方法CKPD-FSCIL解决少量类别增量学习中的灾难性遗忘问题。通过分解模型权重为知识敏感组件和冗余容量组件,确保在适应新类别时保留现有知识。采用由回放样本的协方差矩阵引导的分解方法,确保主成分与分类能力对齐。冻结知识敏感组件,仅适应冗余容量组件,促进可塑性并最小化干扰,且无需改变架构或增加额外开销。CKPD还引入了自适应层选择策略来识别具有冗余容量的层,并动态分配适配器。CKPD-FSCIL在多个基准测试上的表现优于现有方法。
Key Takeaways
- CKPD-FSCIL解决了少量类别增量学习中的灾难性遗忘问题。
- 通过将模型权重分解为知识敏感组件和冗余容量组件,CKPD-FSCIL能够在适应新类别时保留现有知识。
- 分解方法由回放样本的协方差矩阵引导,确保主成分与分类能力对齐。
- 在适应过程中,CKPD-FSCIL通过冻结知识敏感组件并仅适应冗余容量组件,以促进可塑性并最小化干扰。
- CKPD-FSCIL方法不需要改变模型架构或增加额外开销。
- CKPD引入了自适应层选择策略,能够识别具有冗余容量的层。
点此查看论文截图

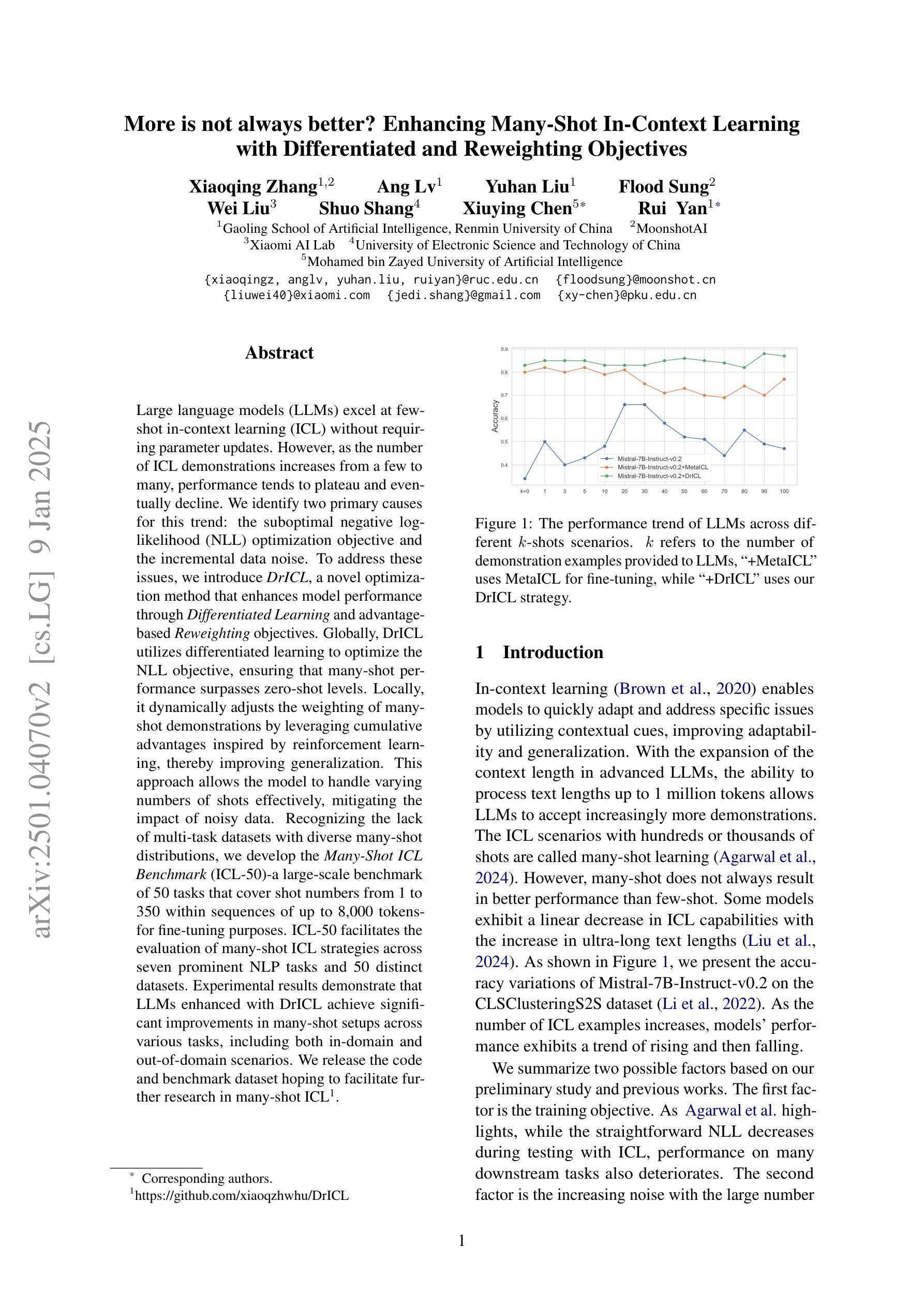
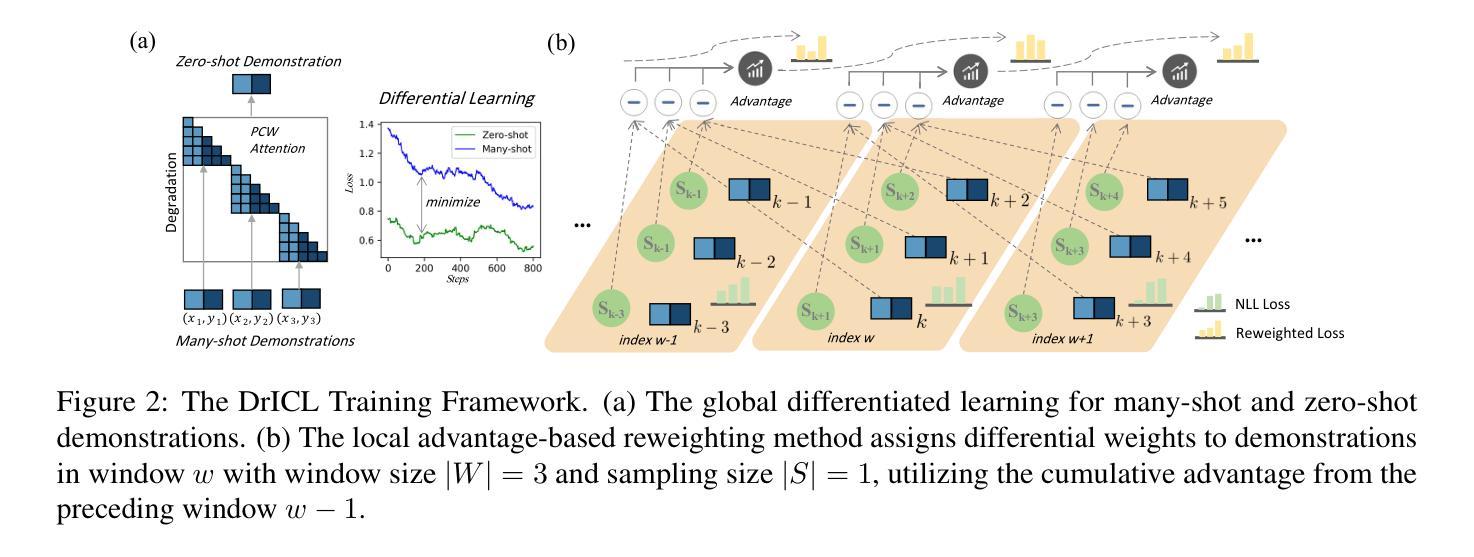
More is not always better? Enhancing Many-Shot In-Context Learning with Differentiated and Reweighting Objectives
Authors:Xiaoqing Zhang, Ang Lv, Yuhan Liu, Flood Sung, Wei Liu, Shuo Shang, Xiuying Chen, Rui Yan
Large language models (LLMs) excel at few-shot in-context learning (ICL) without requiring parameter updates. However, as the number of ICL demonstrations increases from a few to many, performance tends to plateau and eventually decline. We identify two primary causes for this trend: the suboptimal negative log-likelihood (NLL) optimization objective and the incremental data noise. To address these issues, we introduce DrICL, a novel optimization method that enhances model performance through Differentiated Learning and advantage-based Reweighting objectives. Globally, DrICL utilizes differentiated learning to optimize the NLL objective, ensuring that many-shot performance surpasses zero-shot levels. Locally, it dynamically adjusts the weighting of many-shot demonstrations by leveraging cumulative advantages inspired by reinforcement learning, thereby improving generalization. This approach allows the model to handle varying numbers of shots effectively, mitigating the impact of noisy data. Recognizing the lack of multi-task datasets with diverse many-shot distributions, we develop the Many-Shot ICL Benchmark (ICL-50)-a large-scale benchmark of 50 tasks that cover shot numbers from 1 to 350 within sequences of up to 8,000 tokens-for fine-tuning purposes. ICL-50 facilitates the evaluation of many-shot ICL strategies across seven prominent NLP tasks and 50 distinct datasets. Experimental results demonstrate that LLMs enhanced with DrICL achieve significant improvements in many-shot setups across various tasks, including both in-domain and out-of-domain scenarios. We release the code and benchmark dataset hoping to facilitate further research in many-shot ICL.
大型语言模型(LLM)在不需更新参数的情况下,擅长于少量样本上下文学习(ICL)。然而,随着ICL演示样本的数量从少数增加到多数,性能往往达到平台期并最终下降。我们确定了导致这一趋势的两个主要原因:次优的负对数似然(NLL)优化目标和增量数据噪声。为了解决这些问题,我们引入了DrICL,这是一种新型优化方法,通过差异化学习和基于优势的重加权目标来提高模型性能。全局上,DrICL通过差异化学习来优化NLL目标,确保多次射击的性能超过零次射击水平。局部上,它受强化学习的启发,利用累积优势动态调整多次射击演示的权重,从而提高泛化能力。这种方法使模型能够有效地处理不同数量的样本,减轻噪声数据的影响。认识到缺乏具有多种多样多次射击分布的多任务数据集,我们开发了多次射击ICL基准测试(ICL-50)——一个大规模基准测试,包含50个任务,涵盖从1到350的射击次数,序列中的令牌高达8000个,用于微调目的。ICL-50有助于评估跨七个突出NLP任务和50个不同数据集的多次射击ICL策略。实验结果表明,使用DrICL增强的大型语言模型在各种任务的多镜头设置中实现了显着改进,包括域内和域外场景。我们发布代码和基准数据集,希望促进多镜头ICL的进一步研究。
论文及项目相关链接
PDF 13 pages, 8 figures, 11 tables
摘要
大型语言模型在无需参数更新的少样本上下文学习(ICL)中表现出色,但随着上下文学习示例从少数增加到多数,性能往往达到平台期并最终下降。研究指出这一现象主要由次优的负对数似然优化目标和递增的数据噪声引起。为解决这些问题,提出DrICL这一新型优化方法,通过差异化学习和基于优势的重加权目标来提升模型性能。DrICL全局优化负对数似然目标,确保多示例性能超越零示例水平;局部则通过借鉴强化学习的累积优势动态调整多示例演示的权重,提升模型的泛化能力。此方法使模型有效应对不同样本量,缓解数据噪声影响。研究认识到缺乏多样多示例分布的多任务数据集,于是开发出大型基准测试ICL-50,包含50个任务、涵盖1至350个示例、序列长达8000个符号,用于微调目的。ICL-50能在七个显著的自然语言处理任务和50个不同数据集上评估多示例ICL策略。实验结果显示,采用DrICL增强的大型语言模型在各种任务的多示例设置中取得了显著改进,包括域内和域外场景。研究公布了代码和基准测试数据集,希望能进一步推动多示例ICL的研究。
关键见解
- 大型语言模型在少样本上下文学习中表现优异,但随着示例数量增加,性能可能下降。
- 性能下降的主要原因包括次优的负对数似然优化目标和数据噪声的递增。
- 引入DrICL方法,通过差异化学习和基于优势的重加权来优化模型性能。
- DrICL能在多示例场景下提升模型性能,并超越零示例水平。
- 开发出大型基准测试ICL-50,用于评估多示例ICL策略在多个自然语言处理任务和数据集上的性能。
- 采用DrICL的大型语言模型在多示例设置中取得了显著改进,包括在域内和域外场景。
点此查看论文截图

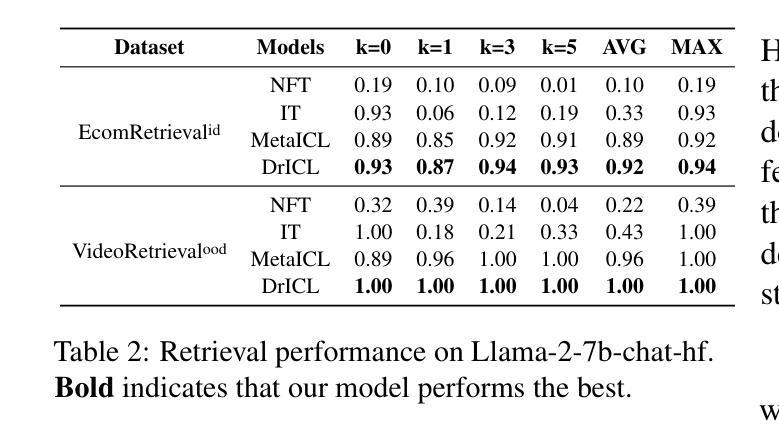
Literature Meets Data: A Synergistic Approach to Hypothesis Generation
Authors:Haokun Liu, Yangqiaoyu Zhou, Mingxuan Li, Chenfei Yuan, Chenhao Tan
AI holds promise for transforming scientific processes, including hypothesis generation. Prior work on hypothesis generation can be broadly categorized into theory-driven and data-driven approaches. While both have proven effective in generating novel and plausible hypotheses, it remains an open question whether they can complement each other. To address this, we develop the first method that combines literature-based insights with data to perform LLM-powered hypothesis generation. We apply our method on five different datasets and demonstrate that integrating literature and data outperforms other baselines (8.97% over few-shot, 15.75% over literature-based alone, and 3.37% over data-driven alone). Additionally, we conduct the first human evaluation to assess the utility of LLM-generated hypotheses in assisting human decision-making on two challenging tasks: deception detection and AI generated content detection. Our results show that human accuracy improves significantly by 7.44% and 14.19% on these tasks, respectively. These findings suggest that integrating literature-based and data-driven approaches provides a comprehensive and nuanced framework for hypothesis generation and could open new avenues for scientific inquiry.
人工智能(AI)有望改变科学过程,包括假设生成。关于假设生成的前期工作可以大致分为理论驱动和数据驱动的方法。虽然这两种方法在生成新颖且合理的假设方面都被证明是有效的,但它们是否能相互补充仍然是一个悬而未决的问题。为了解决这个问题,我们开发了一种结合文献见解和数据的方法,利用大型语言模型(LLM)进行假设生成。我们在五个不同的数据集上应用了我们提出的方法,并证明整合文献和数据的方法优于其他基准测试(在少样本情况下高出8.97%,在仅基于文献的情况下高出15.75%,在仅数据驱动的情况下高出3.37%)。此外,我们还进行了首次人类评估,以评估大型语言模型生成的假设在协助人类进行两项具有挑战性的任务时的效用:欺骗检测和AI生成内容检测。我们的结果表明,在这些任务上,人类准确率分别提高了7.44%和14.19%。这些发现表明,整合基于文献和基于数据驱动的方法为假设生成提供了一个全面而微妙的框架,并可能为科学探索开辟新的途径。
论文及项目相关链接
PDF 37 pages, 9 figures, code link: https://github.com/ChicagoHAI/hypothesis-generation
Summary
基于文本的信息,人工智能在融合文献和大数据的基础上,可以通过LLM驱动的方法生成假设,既提升了假设生成的效果,又有助于改善人类在欺骗检测和AI生成内容检测任务上的准确性。该方法的出现为科学过程带来了变革的承诺,特别是在假设生成方面。
Key Takeaways
- AI具有改变科学过程的潜力,特别是在假设生成方面。
- 假设生成方法可分为理论驱动和数据驱动两大类,但两者互补性尚待研究。
- 提出了一种结合文献和数据的LLM驱动假设生成方法,该方法在五组不同数据集上的表现均超过其他基准测试。
- 人类在欺骗检测和AI生成内容检测任务上,借助LLM生成的假设,准确性得到显著提高。
- 综合文献和大数据的方法为假设生成提供了全面而细致的框架。
- 该方法可能开启新的科学探索途径。
点此查看论文截图

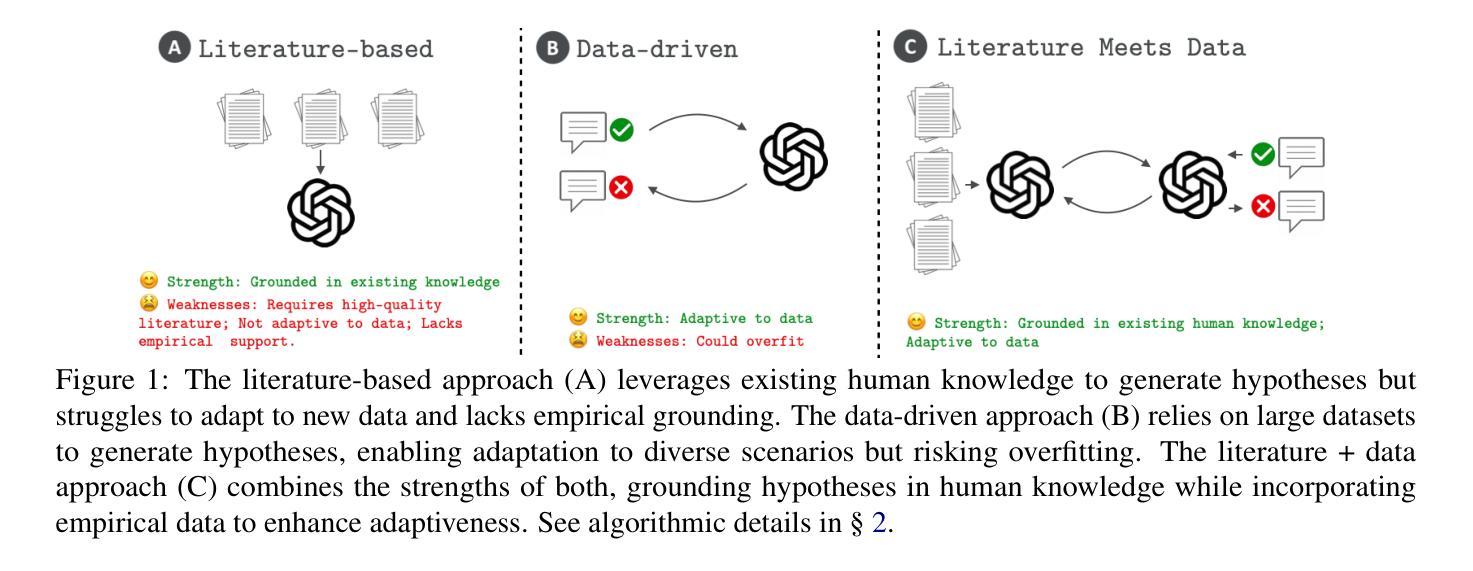
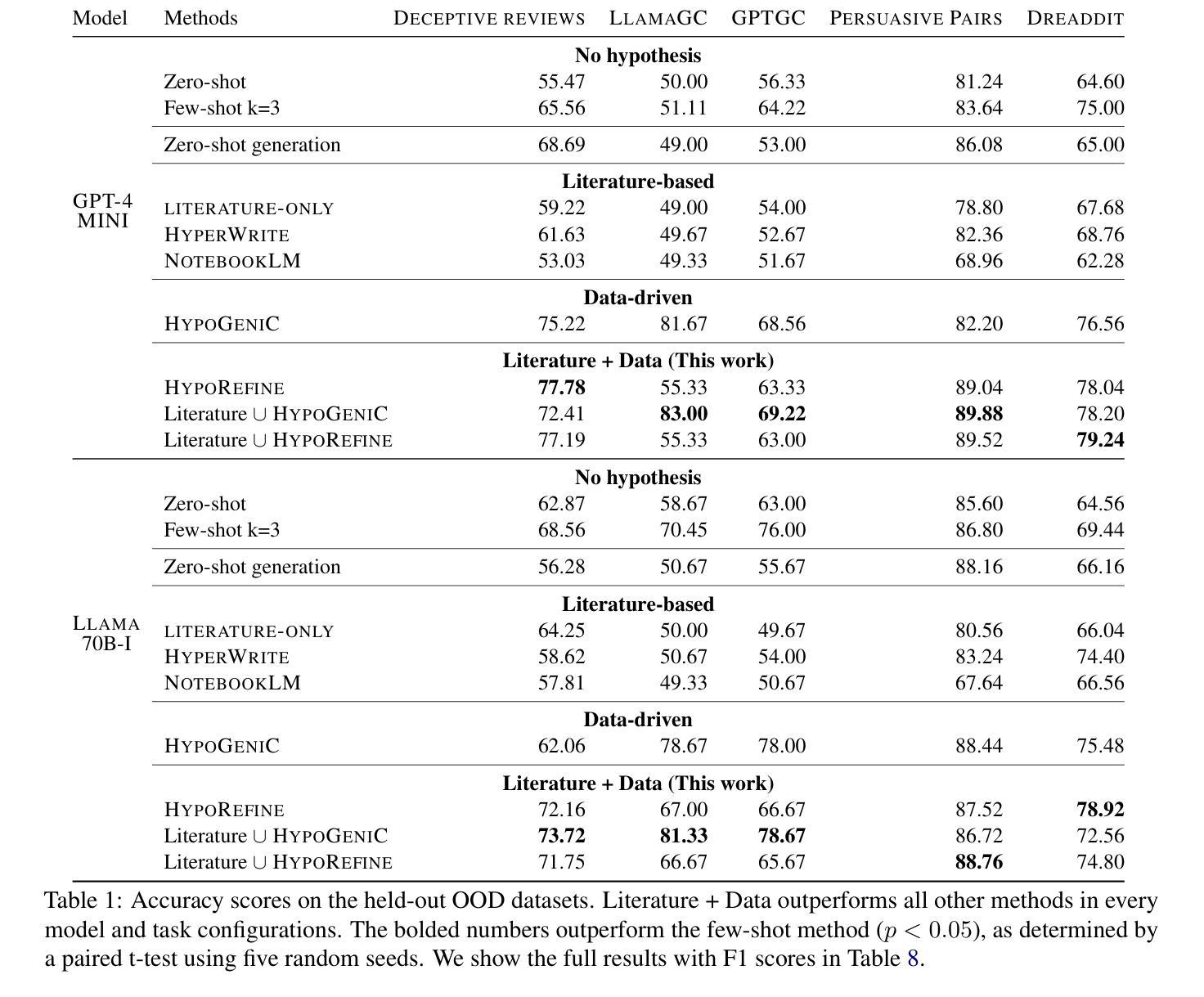
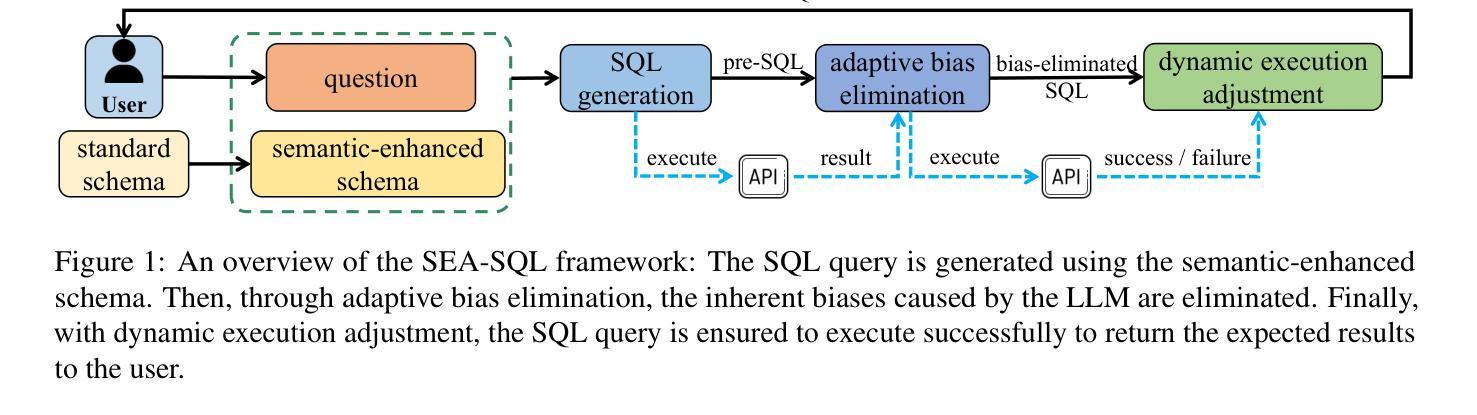
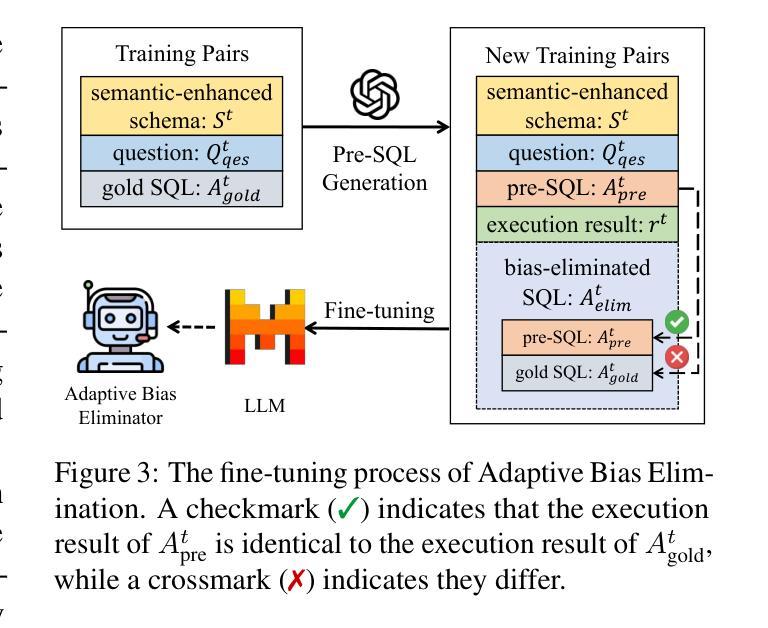
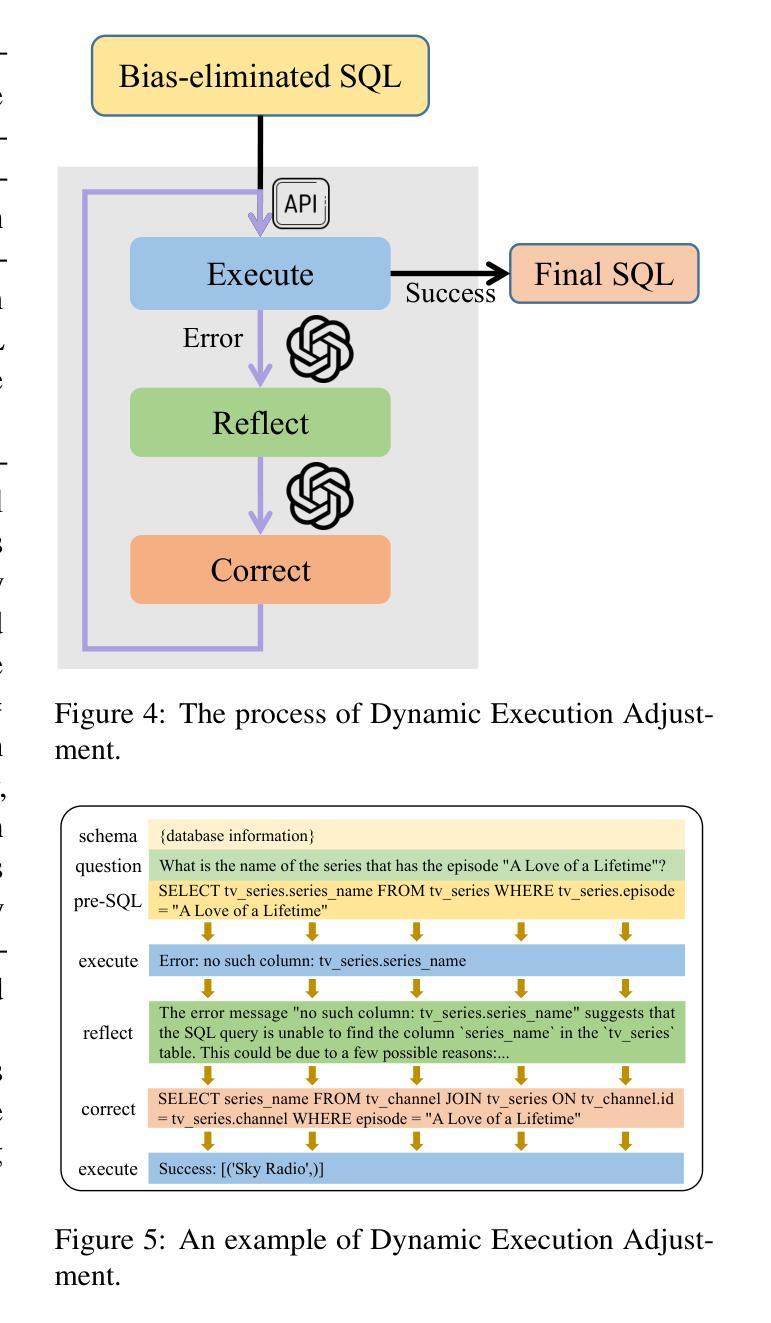
SEA-SQL: Semantic-Enhanced Text-to-SQL with Adaptive Refinement
Authors:Chaofan Li, Yingxia Shao, Yawen Li, Zheng Liu
Recent advancements in large language models (LLMs) have significantly contributed to the progress of the Text-to-SQL task. A common requirement in many of these works is the post-correction of SQL queries. However, the majority of this process entails analyzing error cases to develop prompts with rules that eliminate model bias. And there is an absence of execution verification for SQL queries. In addition, the prevalent techniques primarily depend on GPT-4 and few-shot prompts, resulting in expensive costs. To investigate the effective methods for SQL refinement in a cost-efficient manner, we introduce Semantic-Enhanced Text-to-SQL with Adaptive Refinement (SEA-SQL), which includes Adaptive Bias Elimination and Dynamic Execution Adjustment, aims to improve performance while minimizing resource expenditure with zero-shot prompts. Specifically, SEA-SQL employs a semantic-enhanced schema to augment database information and optimize SQL queries. During the SQL query generation, a fine-tuned adaptive bias eliminator is applied to mitigate inherent biases caused by the LLM. The dynamic execution adjustment is utilized to guarantee the executability of the bias eliminated SQL query. We conduct experiments on the Spider and BIRD datasets to demonstrate the effectiveness of this framework. The results demonstrate that SEA-SQL achieves state-of-the-art performance in the GPT3.5 scenario with 9%-58% of the generation cost. Furthermore, SEA-SQL is comparable to GPT-4 with only 0.9%-5.3% of the generation cost.
最近大型语言模型(LLM)的进展对Text-to-SQL任务产生了重大推动。许多研究中的一项常见要求是SQL查询的后修正。然而,这个过程的大部分涉及分析错误情况,以制定规则提示来消除模型偏见。此外,缺乏对SQL查询的执行验证。此外,主流技术主要依赖于GPT-4和少量提示,导致成本高昂。为了以成本效益高的方式研究SQL精炼的有效方法,我们引入了带有自适应精炼的语义增强文本到SQL(SEA-SQL),包括自适应偏差消除和动态执行调整,旨在提高性能,同时以零提示的方式最小化资源支出。具体来说,SEA-SQL采用语义增强架构来增强数据库信息并优化SQL查询。在生成SQL查询时,应用了微调的自适应偏差消除器,以减轻LLM引起的固有偏差。动态执行调整用于保证偏差消除后的SQL查询的可执行性。我们在Spider和BIRD数据集上进行了实验,以证明该框架的有效性。结果表明,在GPT3.5场景中,SEA-SQL达到了最先进的性能,生成成本降低了9%~58%。此外,SEA-SQL与GPT-4相比,生成成本仅增加了0.9%~5.3%。
论文及项目相关链接
PDF The article has been accepted by Frontiers of Computer Science (FCS), with the DOI: {10.1007/s11704-025-41136-3}
Summary
大型语言模型(LLM)在文本到SQL任务中的最新进展已经取得了显著贡献。然而,大多数方法都需要对SQL查询进行后修正,这主要涉及到分析错误情况并制定规则提示以消除模型偏见。此外,缺乏SQL查询的执行验证。本文介绍了一种成本效益高的SQL精炼有效方法——语义增强文本到SQL自适应精炼(SEA-SQL),旨在提高性能的同时最小化资源消耗,采用零镜头提示。SEA-SQL采用语义增强模式来增强数据库信息并优化SQL查询。在SQL查询生成过程中,应用了精细调整的自适应偏见消除器来减轻LLM引起的固有偏见。动态执行调整可确保消除偏见的SQL查询的可执行性。在Spider和BIRD数据集上的实验表明,SEA-SQL在GPT3.5场景中实现了最先进的性能,生成成本降低了9%-58%。此外,SEA-SQL与GPT-4相比,生成成本仅增加了0.9%-5.3%。
Key Takeaways
- 文本描述了大型语言模型(LLM)在文本到SQL任务中的应用进展及挑战。
- 介绍了SEA-SQL方法,该方法旨在通过自适应精炼技术提高SQL查询的性能和成本效益。
- SEA-SQL采用语义增强模式来优化数据库信息和SQL查询。
- 自适应偏见消除器的应用是SEA-SQL的一个重要特点,能够减轻LLM的固有偏见。
- 动态执行调整确保消除偏见的SQL查询的可执行性。
- 在Spider和BIRD数据集上的实验表明,SEA-SQL在GPT3.5场景中表现优异,与GPT-4相比具有较低的成本增加。
点此查看论文截图