⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-13 更新
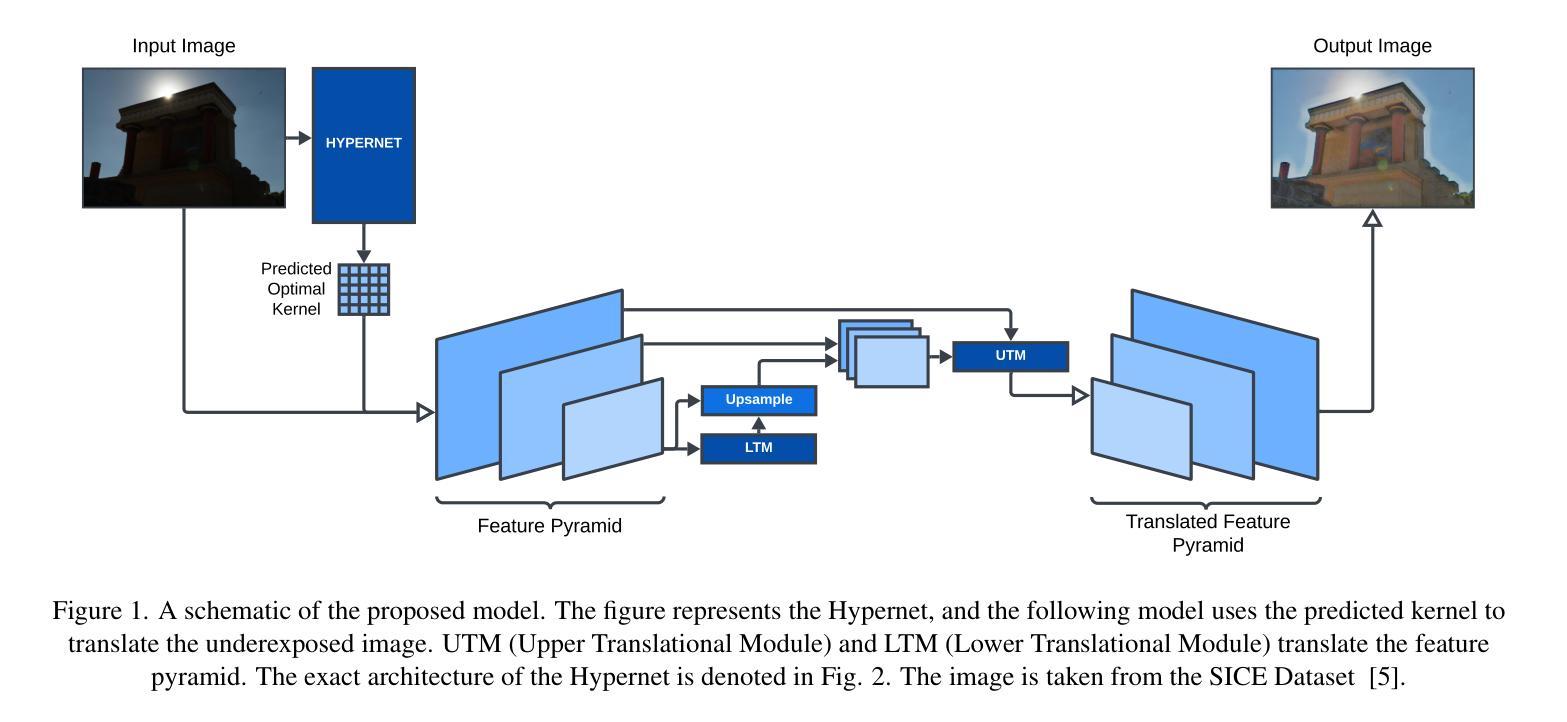
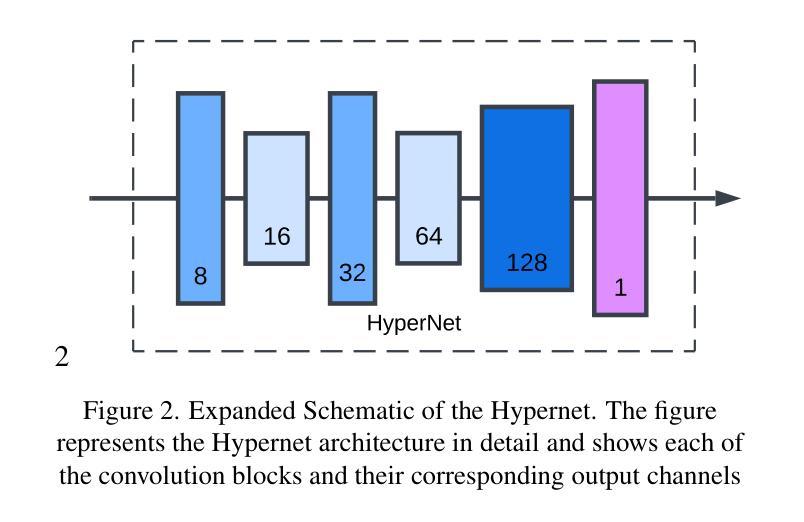
HipyrNet: Hypernet-Guided Feature Pyramid network for mixed-exposure correction
Authors:Shaurya Singh Rathore, Aravind Shenoy, Krish Didwania, Aditya Kasliwal, Ujjwal Verma
Recent advancements in image translation for enhancing mixed-exposure images have demonstrated the transformative potential of deep learning algorithms. However, addressing extreme exposure variations in images remains a significant challenge due to the inherent complexity and contrast inconsistencies across regions. Current methods often struggle to adapt effectively to these variations, resulting in suboptimal performance. In this work, we propose HipyrNet, a novel approach that integrates a HyperNetwork within a Laplacian Pyramid-based framework to tackle the challenges of mixed-exposure image enhancement. The inclusion of a HyperNetwork allows the model to adapt to these exposure variations. HyperNetworks dynamically generates weights for another network, allowing dynamic changes during deployment. In our model, the HyperNetwork employed is used to predict optimal kernels for Feature Pyramid decomposition, which enables a tailored and adaptive decomposition process for each input image. Our enhanced translational network incorporates multiscale decomposition and reconstruction, leveraging dynamic kernel prediction to capture and manipulate features across varying scales. Extensive experiments demonstrate that HipyrNet outperforms existing methods, particularly in scenarios with extreme exposure variations, achieving superior results in both qualitative and quantitative evaluations. Our approach sets a new benchmark for mixed-exposure image enhancement, paving the way for future research in adaptive image translation.
近期在图像翻译领域,对于混合曝光图像增强的技术进步展示了深度学习算法的变革潜力。然而,由于区域间的固有复杂性和对比度不一致,处理图像中的极端曝光变化仍然是一个巨大挑战。当前的方法往往难以有效适应这些变化,导致性能不佳。在这项工作中,我们提出了HipyrNet,这是一种新型方法,它在一个基于拉普拉斯金字塔的框架内集成了一个HyperNetwork,以解决混合曝光图像增强所面临的挑战。HyperNetwork的加入使模型能够适应这些曝光变化。HyperNetwork动态生成另一个网络的权重,从而在部署过程中实现动态变化。在我们的模型中,使用的HyperNetwork用于预测特征金字塔分解的最佳内核,这能够实现针对每个输入图像的定制和自适应分解过程。我们增强的翻译网络结合了多尺度分解和重建,利用动态内核预测来捕获和操作不同尺度的特征。大量实验表明,HipyrNet优于现有方法,特别是在极端曝光变化的情况下,在定性和定量评估中都取得了优越的结果。我们的方法为混合曝光图像增强设定了新的基准,为未来的自适应图像翻译研究铺平了道路。
论文及项目相关链接
Summary
本文提出一种名为HipyrNet的新型混合曝光图像增强方法,集成HyperNetwork于Laplacian金字塔框架内,以应对混合曝光图像的挑战。HyperNetwork能够动态生成权重,使模型适应曝光变化。通过预测最优核进行特征金字塔分解,实现针对每幅输入图像的定制和自适应分解过程。多尺度分解和重建的增强翻译网络,利用动态核预测,在不同尺度上捕捉和操作特征。实验显示HipyrNet在极端曝光变化场景下表现优异,为混合曝光图像增强设定新基准。
Key Takeaways
- HipyrNet集成HyperNetwork应对混合曝光图像的挑战。
- HyperNetwork能动态生成权重,增强模型对曝光变化的适应性。
- 通过预测最优核进行特征金字塔分解,实现自适应图像分解。
- 多尺度分解和重建的增强翻译网络提高性能。
- 动态核预测有助于在不同尺度上捕捉和操作特征。
- HipyrNet在极端曝光变化场景下表现优越。
点此查看论文截图


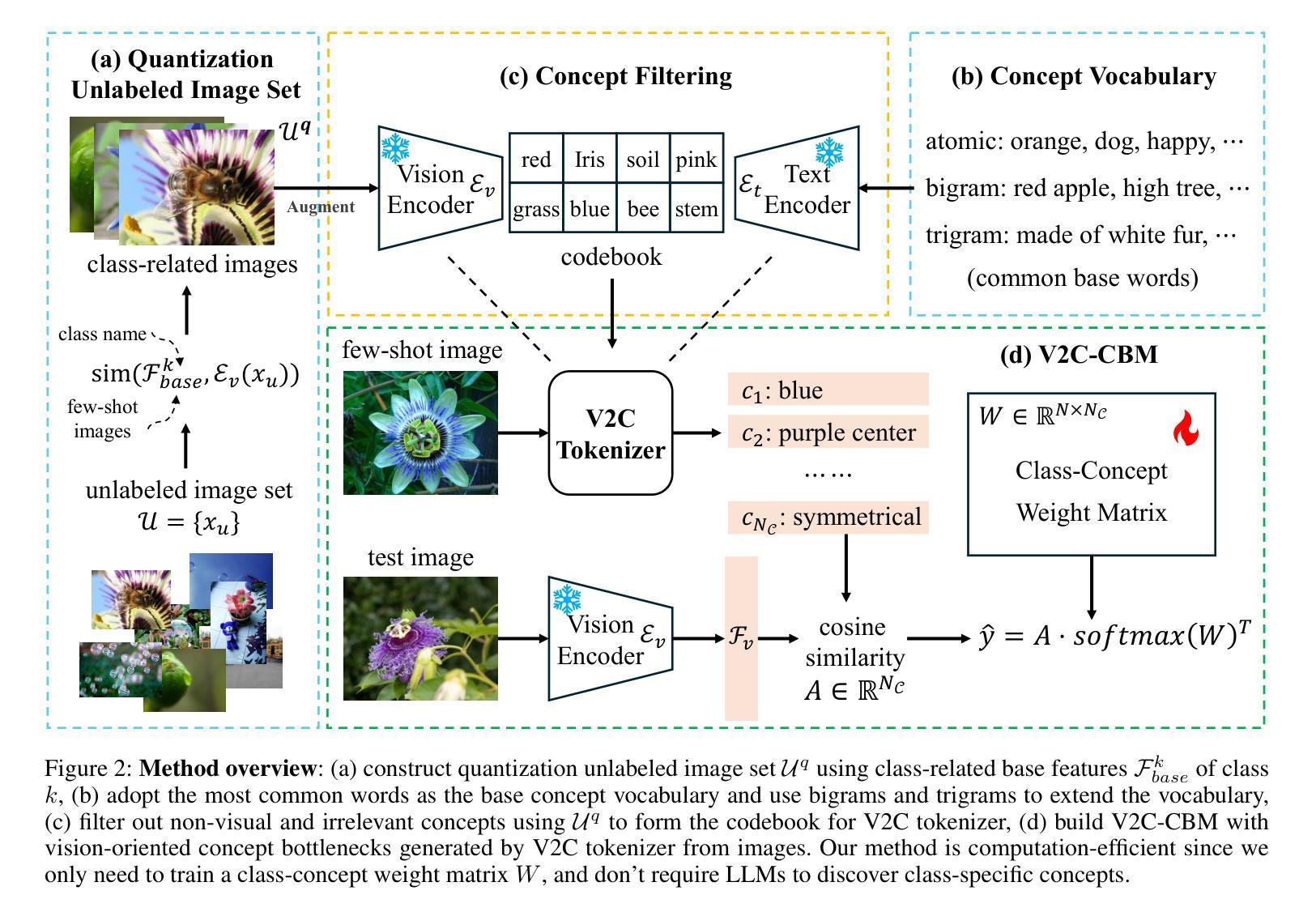
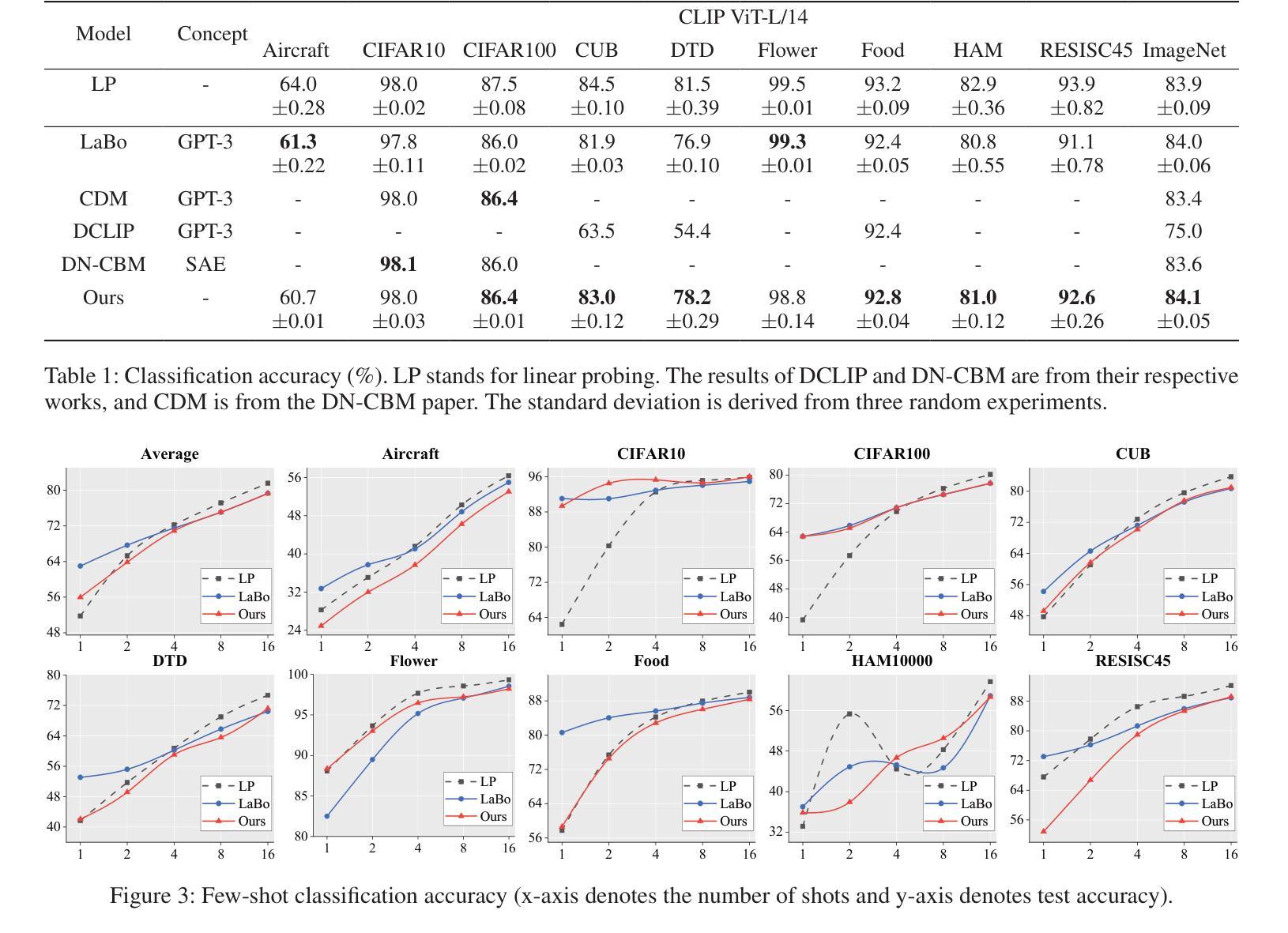
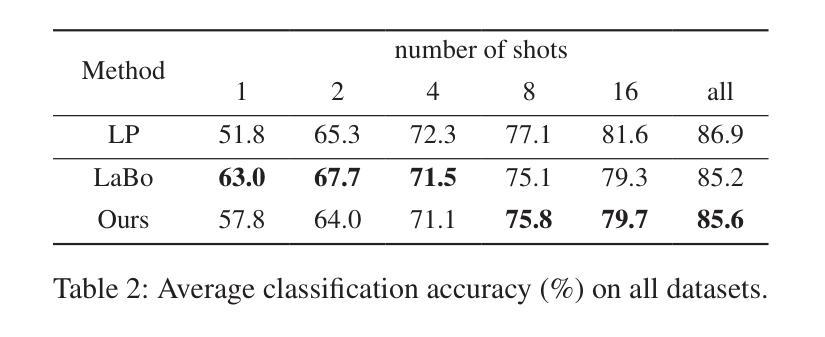
V2C-CBM: Building Concept Bottlenecks with Vision-to-Concept Tokenizer
Authors:Hangzhou He, Lei Zhu, Xinliang Zhang, Shuang Zeng, Qian Chen, Yanye Lu
Concept Bottleneck Models (CBMs) offer inherent interpretability by initially translating images into human-comprehensible concepts, followed by a linear combination of these concepts for classification. However, the annotation of concepts for visual recognition tasks requires extensive expert knowledge and labor, constraining the broad adoption of CBMs. Recent approaches have leveraged the knowledge of large language models to construct concept bottlenecks, with multimodal models like CLIP subsequently mapping image features into the concept feature space for classification. Despite this, the concepts produced by language models can be verbose and may introduce non-visual attributes, which hurts accuracy and interpretability. In this study, we investigate to avoid these issues by constructing CBMs directly from multimodal models. To this end, we adopt common words as base concept vocabulary and leverage auxiliary unlabeled images to construct a Vision-to-Concept (V2C) tokenizer that can explicitly quantize images into their most relevant visual concepts, thus creating a vision-oriented concept bottleneck tightly coupled with the multimodal model. This leads to our V2C-CBM which is training efficient and interpretable with high accuracy. Our V2C-CBM has matched or outperformed LLM-supervised CBMs on various visual classification benchmarks, validating the efficacy of our approach.
概念瓶颈模型(CBMs)通过初始时将图像翻译为人类可理解的概念,随后对这些概念进行线性组合进行分类,从而提供固有的可解释性。然而,为视觉识别任务标注概念需要丰富的专业知识和劳动力,限制了CBM的广泛应用。最近的方法利用大型语言模型的知识来构建概念瓶颈,随后的多模态模型(如CLIP)将图像特征映射到概念特征空间进行分类。尽管如此,语言模型产生的概念可能过于冗长,并可能引入非视觉属性,这会损害准确性和可解释性。在这项研究中,我们通过直接从多模态模型构建CBM来避免这些问题。为此,我们以常用词作为基础概念词汇,并利用辅助无标签图像构建视觉到概念(V2C)令牌化器,该令牌化器可以将图像显式量化为与其最相关的视觉概念,从而创建一个与多模态模型紧密耦合的面向视觉的概念瓶颈。这导致了我们的V2C-CBM,它具有高效培训、高准确性和可解释性。我们的V2C-CBM在各种视觉分类基准测试中达到了或与LLM监督的CBM相匹配甚至表现更好,验证了我们的方法的有效性。
论文及项目相关链接
PDF Accepted by AAAI2025
Summary
该研究通过构建概念瓶颈模型(CBMs)以实现图像分类的固有可解释性。该研究采用多模态模型,利用常见词汇作为基本概念词汇,结合辅助的无标签图像,构造了图像转概念(V2C)标记器,将图像量化为最相关的视觉概念,从而创建了一个与多模态模型紧密耦合的视觉导向概念瓶颈。这种方法提高了训练效率和准确性,同时在各种视觉分类基准测试中验证了其有效性。
Key Takeaways
- CBMs通过翻译图像为人类可理解的概念提供内在的可解释性。
- 最近的方法利用大型语言模型的知识构建概念瓶颈。
- 语言模型产生的概念可能冗长并引入非视觉属性,影响准确性和可解释性。
- 研究通过采用多模态模型直接构建CBMs来避免这些问题。
- 研究采用常见词汇和辅助无标签图像,构造了V2C标记器,将图像转化为视觉概念。
- V2C-CBM具有高效训练和高准确性的优点。
点此查看论文截图


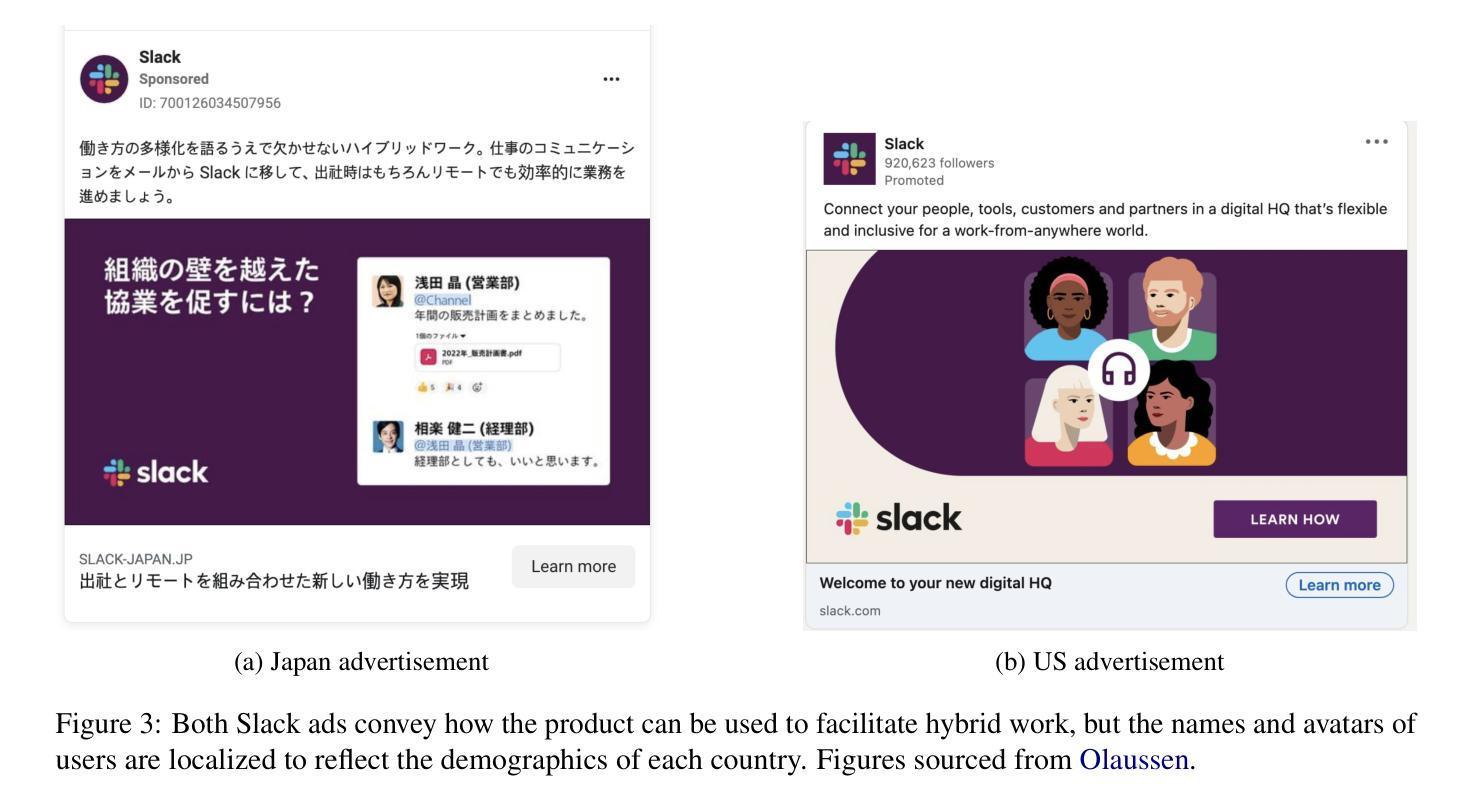
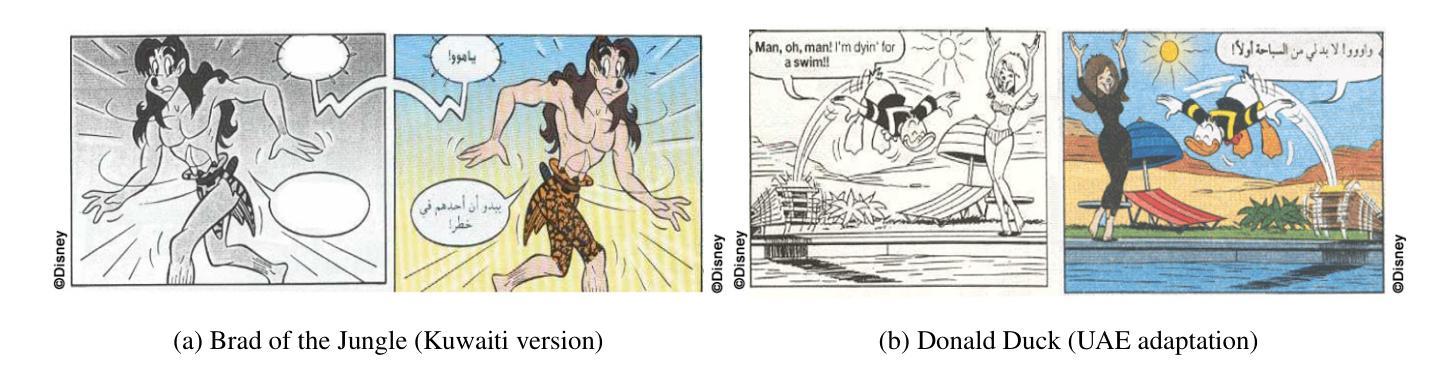
Towards Automatic Evaluation for Image Transcreation
Authors:Simran Khanuja, Vivek Iyer, Claire He, Graham Neubig
Beyond conventional paradigms of translating speech and text, recently, there has been interest in automated transcreation of images to facilitate localization of visual content across different cultures. Attempts to define this as a formal Machine Learning (ML) problem have been impeded by the lack of automatic evaluation mechanisms, with previous work relying solely on human evaluation. In this paper, we seek to close this gap by proposing a suite of automatic evaluation metrics inspired by machine translation (MT) metrics, categorized into: a) Object-based, b) Embedding-based, and c) VLM-based. Drawing on theories from translation studies and real-world transcreation practices, we identify three critical dimensions of image transcreation: cultural relevance, semantic equivalence and visual similarity, and design our metrics to evaluate systems along these axes. Our results show that proprietary VLMs best identify cultural relevance and semantic equivalence, while vision-encoder representations are adept at measuring visual similarity. Meta-evaluation across 7 countries shows our metrics agree strongly with human ratings, with average segment-level correlations ranging from 0.55-0.87. Finally, through a discussion of the merits and demerits of each metric, we offer a robust framework for automated image transcreation evaluation, grounded in both theoretical foundations and practical application. Our code can be found here: https://github.com/simran-khanuja/automatic-eval-transcreation
在超越传统的翻译语音和文本的模式之外,最近有对自动化图像创译的浓厚兴趣,以促进不同文化中的视觉内容的本地化。将其定义为正式的机器学习(ML)问题的尝试受到了缺乏自动评估机制的阻碍,以前的工作完全依赖于人为评估。在本文中,我们试图通过提出一系列受机器翻译(MT)指标启发的自动评估指标来弥补这一差距,这些指标可分为三类:a)基于对象的指标,b)基于嵌入的指标和c)基于视觉语言模型(VLM)的指标。我们借鉴翻译研究和现实世界的创译实践理论,确定了图像创译的三个关键维度:文化相关性、语义等价性和视觉相似性,并设计了这些指标以在这些轴向上评估系统。我们的结果表明,专有视觉语言模型在识别文化相关性和语义等价性方面表现最佳,而视觉编码器表示擅长测量视觉相似性。在七个国家的元评估显示,我们的指标与人类评分高度一致,平均段落水平相关性范围在0.55-0.87之间。最后,通过讨论每个指标的优点和缺点,我们提供了一个稳健的自动化图像创译评估框架,该框架既基于理论也注重实际应用。我们的代码可以在这里找到:https://github.com/simran-khanuja/automatic-eval-transcreation
论文及项目相关链接
Summary
本文提出了一套自动评估指标,以填补图像跨文化本地化过程中的自动评估机制的空白。这些指标是基于机器翻译理论构建的,分为对象基础、嵌入基础和视觉语言模型基础三类。这些指标能够评估图像转创的关键维度,包括文化相关性、语义等价性和视觉相似性。评估结果显示,基于视觉语言模型的评估指标在文化相关性和语义等价性方面表现最佳,而基于视觉编码器表示的方法在测量视觉相似性方面表现出色。此外,该研究的跨国评估表明,所提出的评估指标与人类评分高度一致,平均分段相关性在0.55至0.87之间。最后,本文讨论了各项指标的优缺点,为基于理论和实际应用的自动化图像转创评估提供了稳健框架。
Key Takeaways
- 提出了一套基于机器翻译理论的自动评估指标,用于图像转创的评估。
- 指标分为对象基础、嵌入基础和视觉语言模型基础三类,能够评估图像转创的文化相关性、语义等价性和视觉相似性。
- 基于视觉语言模型的评估指标在文化相关性和语义等价性方面表现最佳。
- 跨国评估显示,所提出的评估指标与人类评分高度一致。
- 提供了关于各项指标优缺点的讨论,为自动化图像转创评估提供了稳健框架。
- 公开了相关代码,便于他人使用和研究。
点此查看论文截图



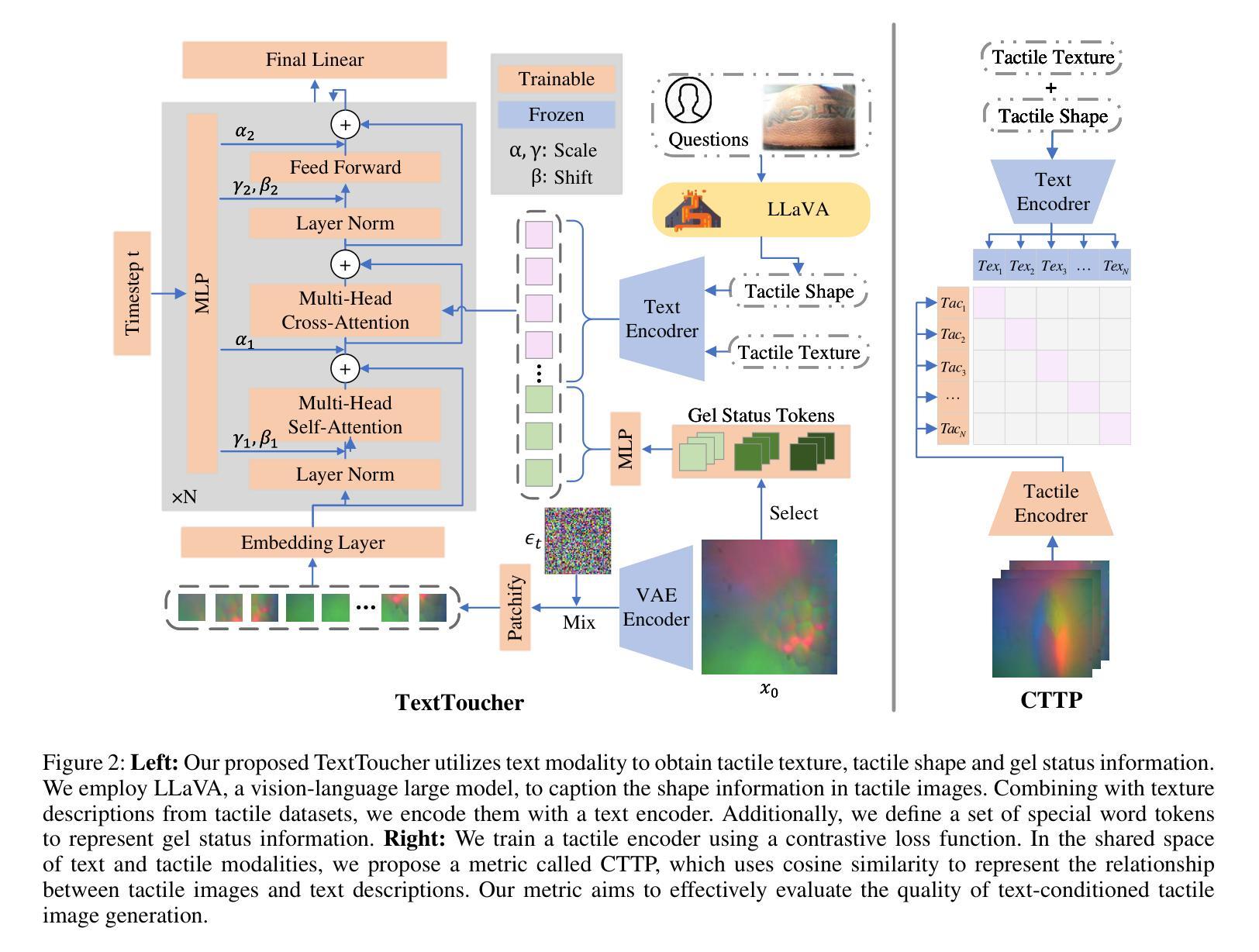
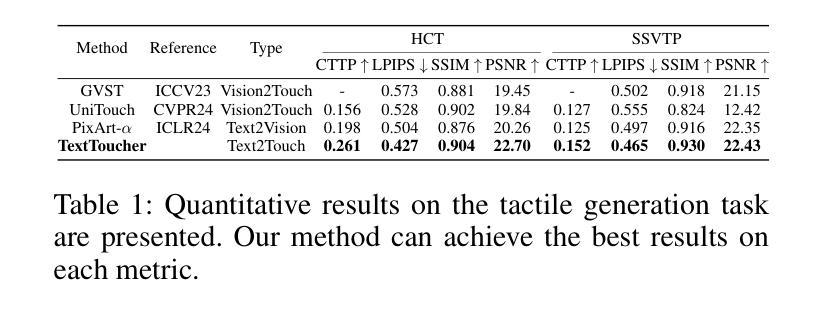
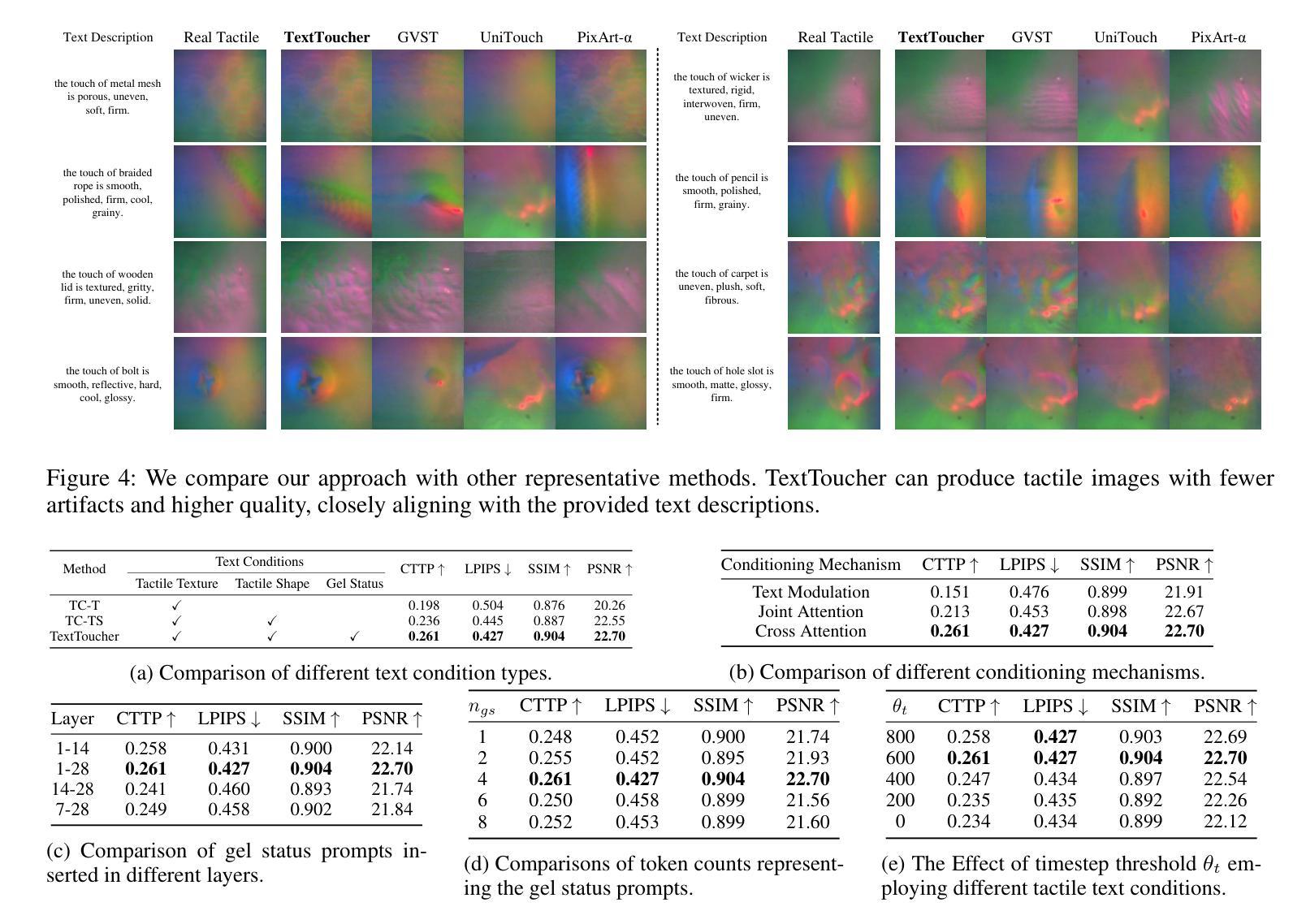
TextToucher: Fine-Grained Text-to-Touch Generation
Authors:Jiahang Tu, Hao Fu, Fengyu Yang, Hanbin Zhao, Chao Zhang, Hui Qian
Tactile sensation plays a crucial role in the development of multi-modal large models and embodied intelligence. To collect tactile data with minimal cost as possible, a series of studies have attempted to generate tactile images by vision-to-touch image translation. However, compared to text modality, visual modality-driven tactile generation cannot accurately depict human tactile sensation. In this work, we analyze the characteristics of tactile images in detail from two granularities: object-level (tactile texture, tactile shape), and sensor-level (gel status). We model these granularities of information through text descriptions and propose a fine-grained Text-to-Touch generation method (TextToucher) to generate high-quality tactile samples. Specifically, we introduce a multimodal large language model to build the text sentences about object-level tactile information and employ a set of learnable text prompts to represent the sensor-level tactile information. To better guide the tactile generation process with the built text information, we fuse the dual grains of text information and explore various dual-grain text conditioning methods within the diffusion transformer architecture. Furthermore, we propose a Contrastive Text-Touch Pre-training (CTTP) metric to precisely evaluate the quality of text-driven generated tactile data. Extensive experiments demonstrate the superiority of our TextToucher method. The source codes will be available at \url{https://github.com/TtuHamg/TextToucher}.
触觉在多模态大型模型和实体智能的发展中扮演了关键角色。为了以尽可能低的成本收集触觉数据,一系列研究尝试通过视觉到触觉图像翻译来生成触觉图像。然而,与文本模态相比,视觉模态驱动的触觉生成无法准确地描述人类的触觉感受。在这项工作中,我们从两个粒度(物体级别和传感器级别)详细分析了触觉图像的特征。在物体级别(触觉纹理、触觉形状),以及传感器级别(凝胶状态)。我们通过文本描述对这些信息进行建模,并提出了一种精细的文本到触觉生成方法(TextToucher),以生成高质量的触觉样本。具体来说,我们引入了一个多模态大型语言模型来构建关于物体级别触觉信息的文本句子,并使用一组可学习的文本提示来表示传感器级别的触觉信息。为了更好地利用构建的文本信息来指导触觉生成过程,我们融合了文本信息的双重粒度,并探索了扩散变压器架构内的各种双粒度文本调节方法。此外,我们提出了一种对比文本触摸预训练(CTTP)指标,以精确评估文本驱动生成的触觉数据的质量。大量实验证明了我们TextToucher方法的优越性。源代码将在https://github.com/TtuHamg/TextToucher上提供。
论文及项目相关链接
PDF This paper has been accepted by AAAI 2025
Summary:
触觉在构建多模态大型模型和感知智能方面发挥着关键作用。当前尝试通过视觉图像生成触觉图像存在精度问题。本研究详细分析了触觉图像的特性,并通过文本描述建立精细模型,提出一种精细文本到触感的生成方法(TextToucher),引入多模态大型语言模型构建关于物体级别的触觉信息文本,采用一系列可学习的文本提示来表示传感器级别的触觉信息。结合两种文本信息来指导触觉生成过程,并在扩散变换架构中探索各种双粒度文本调节方法。此外,提出对比文本触感预训练(CTTP)指标来精确评估文本驱动生成的触觉数据质量。实验证明TextToucher方法的优越性。
Key Takeaways:
- 触觉在多模态大型模型和感知智能发展中起关键作用。
- 视觉图像生成的触觉图像精度较低。
- 研究详细分析了触觉图像的对象级别和传感器级别特性。
- 提出一种精细的文本到触感生成方法(TextToucher)。
- 引入多模态大型语言模型构建物体级别触觉信息文本描述。
- 采用可学习文本提示表示传感器级别触觉信息。
点此查看论文截图