⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-14 更新
Real-Time Textless Dialogue Generation
Authors:Long Mai, Julie Carson-Berndsen
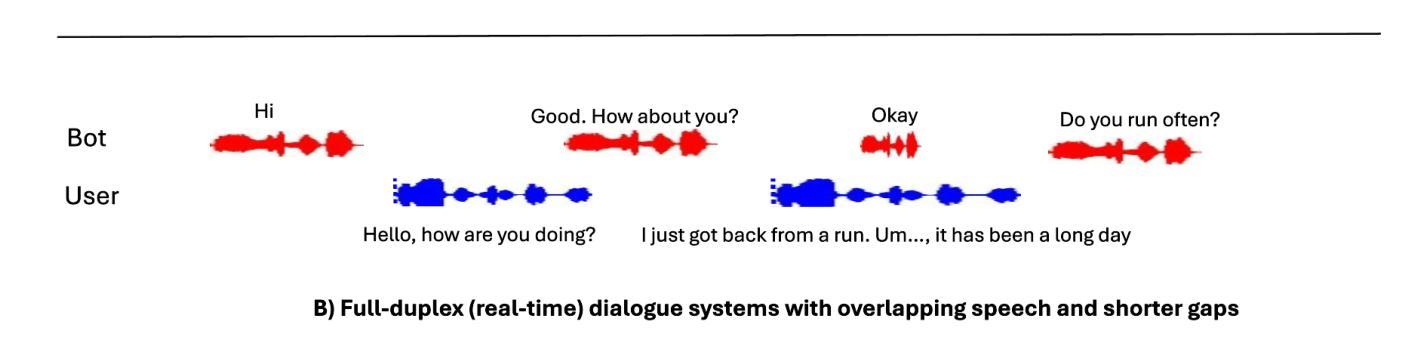
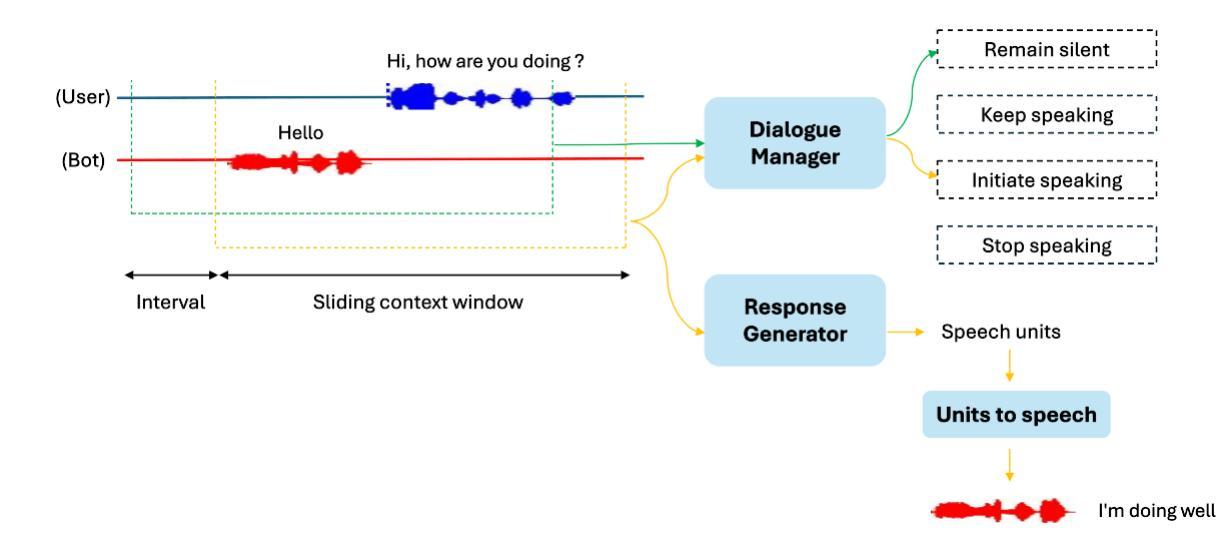
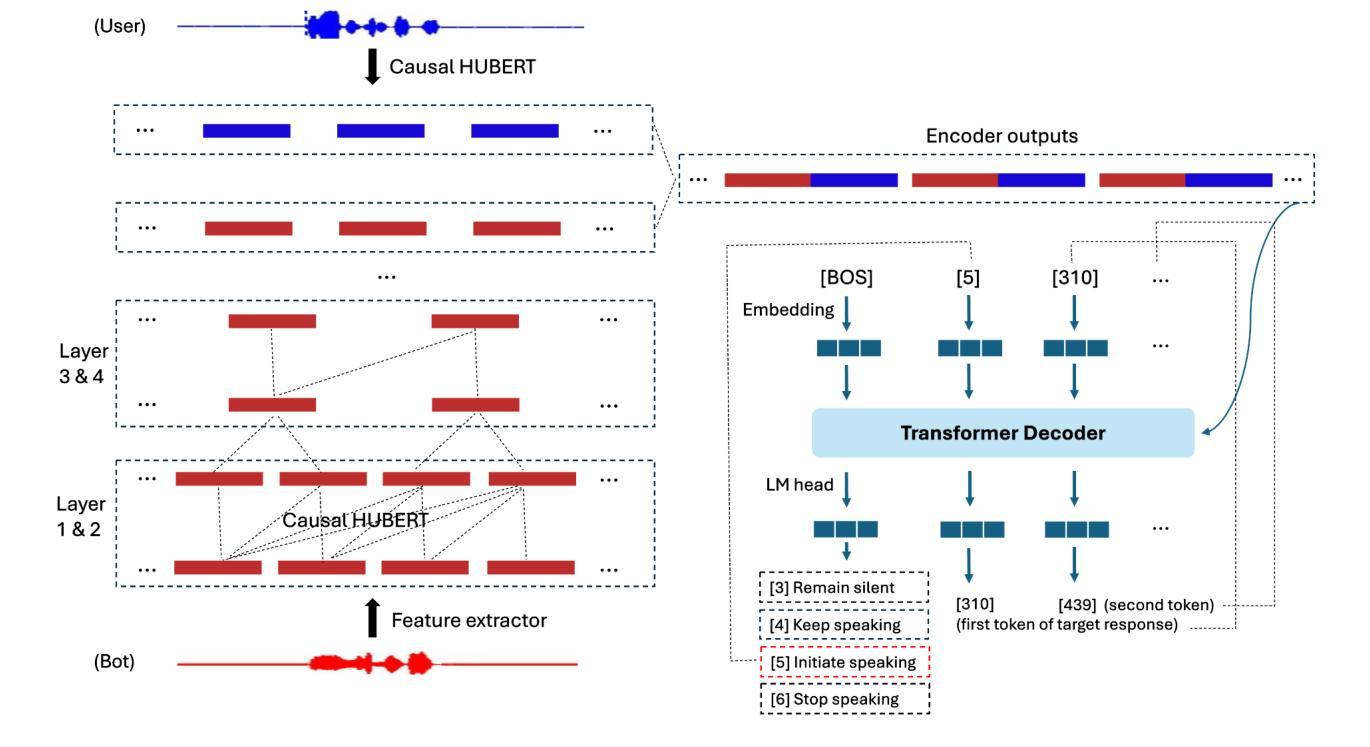
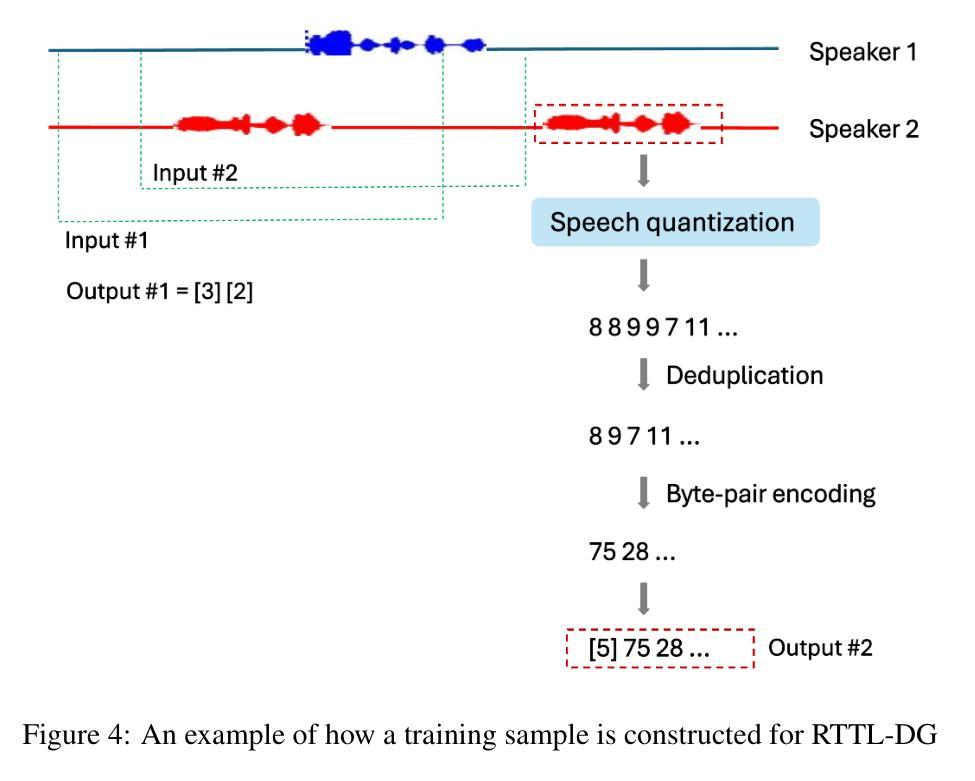
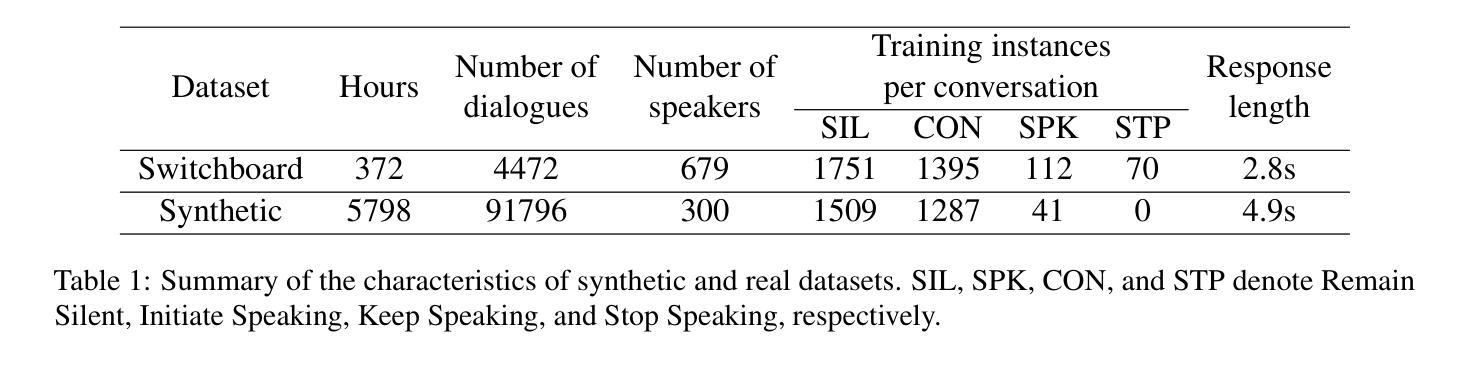
Recent advancements in large language models (LLMs) have led to significant progress in text-based dialogue systems. These systems can now generate high-quality responses that are accurate and coherent across a wide range of topics and tasks. However, spoken dialogue systems still lag behind in terms of naturalness. They tend to produce robotic interactions, with issues such as slow response times, overly generic or cautious replies, and a lack of natural rhythm and fluid turn-taking. This shortcoming is largely due to the over-reliance on the traditional cascaded design, which involve separate, sequential components, as well as the use of text as an intermediate representation. This paper propose a real-time, textless spoken dialogue generation model (RTTL-DG) that aims to overcome these challenges. Our system enables fluid turn-taking and generates responses with minimal delay by processing streaming spoken conversation directly. Additionally, our model incorporates backchannels, filters, laughter, and other paralinguistic signals, which are often absent in cascaded dialogue systems, to create more natural and human-like interactions. The implementations and generated samples are available in our repository: https://github.com/mailong25/rts2s-dg
近年来,大型语言模型(LLM)的进展为基于文本的对话系统带来了巨大的进步。这些系统现在能够生成高质量、准确且连贯的响应,涵盖广泛的主题和任务。然而,在口语对话系统方面,自然性仍然有所欠缺。它们往往产生机械式的交互,存在响应速度慢、回复过于通用或谨慎,以及缺乏自然的节奏和流畅的会话转换等问题。这一缺陷在很大程度上是由于过度依赖传统的级联设计,该设计包含单独的、顺序的组件,以及使用文本作为中间表示形式。本文提出了一种实时、无文本口语对话生成模型(RTTL-DG),旨在克服这些挑战。我们的系统通过直接处理流式口语会话,实现了流畅的会话转换和最小化延迟的响应。此外,我们的模型还融入了反馈通道、过滤器、笑声等其他副语言信号,这些信号通常缺失于级联对话系统,从而创造更加自然和人性化的交互。相关实现和生成的样本可在我们的仓库中找到:https://github.com/mailong25/rts2s-dg 。
论文及项目相关链接
Summary
大型语言模型(LLM)的进步推动了文本对话系统的显著发展,但口语对话系统仍显生硬。本文提出一种实时、非文本口语对话生成模型(RTTL-DG),旨在克服现有挑战。该模型直接处理流式口语对话,实现流畅的话语转换,减少延迟,并融入背道信号等副语言信号,创建更自然、人性化的交互。
Key Takeaways
- 大型语言模型的进步已显著推动文本对话系统的发展。
- 口语对话系统仍面临自然性不足的问题,如反应迟缓、回复过于通用或谨慎,缺乏自然节奏和流畅的会话转换。
- 传统级联设计在口语对话系统中的局限性,包括各组件的分离和顺序性,以及使用文本作为中间表示形式的问题。
- RTTL-DG模型旨在克服现有挑战,通过直接处理流式口语对话实现更自然的交互。
- RTTL-DG模型实现流畅的话语转换和减少延迟。
- RTTL-DG模型融入副语言信号(如背道信号),提升交互的自然性和人性化程度。
点此查看论文截图

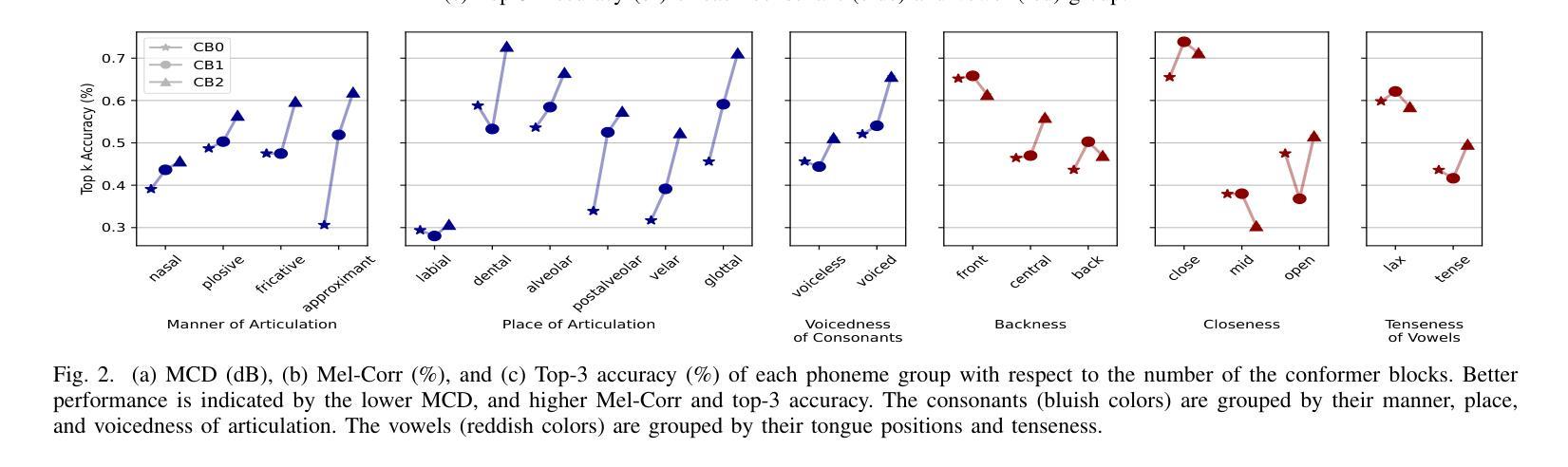
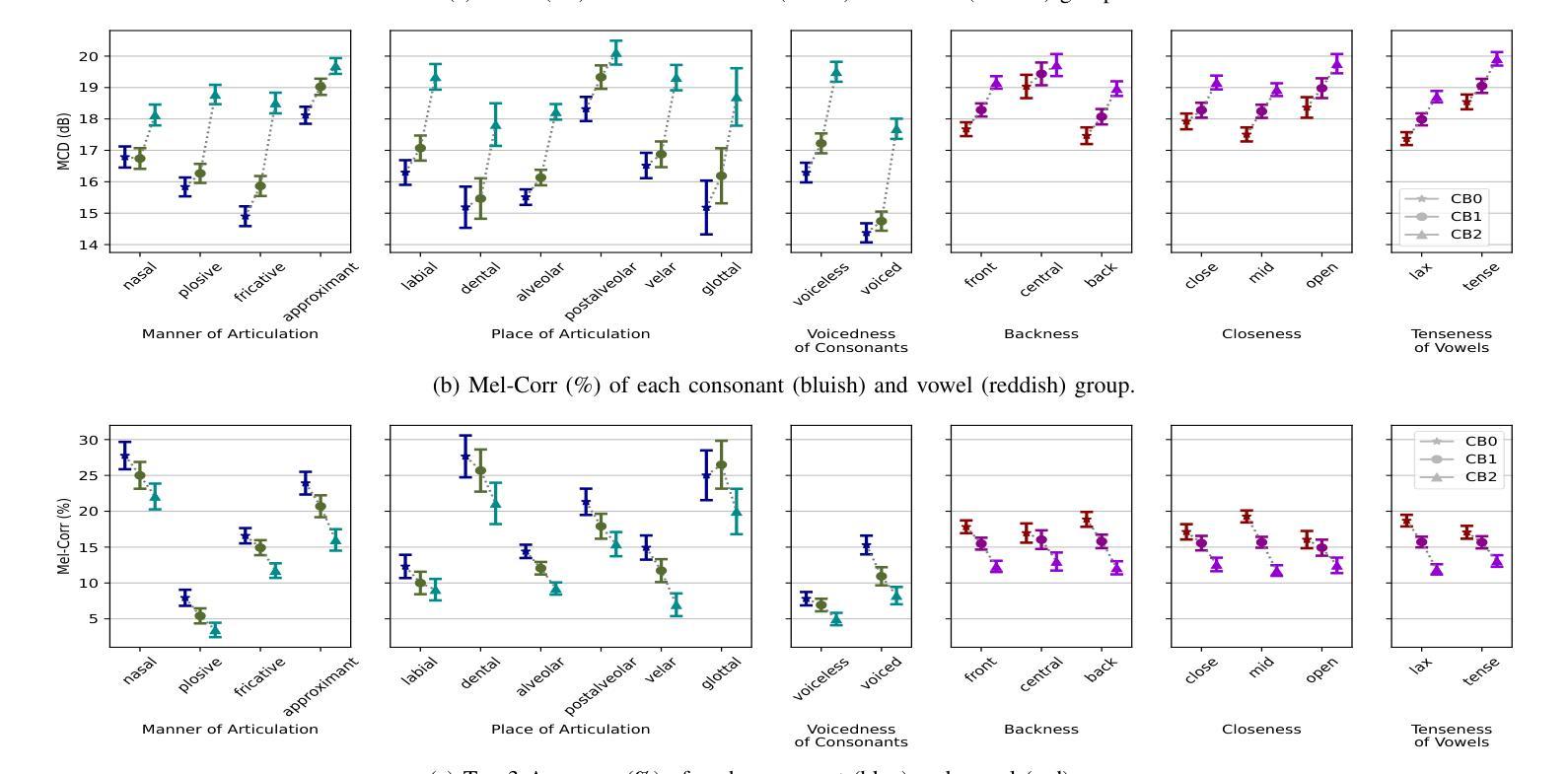
Enhancing Listened Speech Decoding from EEG via Parallel Phoneme Sequence Prediction
Authors:Jihwan Lee, Tiantian Feng, Aditya Kommineni, Sudarsana Reddy Kadiri, Shrikanth Narayanan
Brain-computer interfaces (BCI) offer numerous human-centered application possibilities, particularly affecting people with neurological disorders. Text or speech decoding from brain activities is a relevant domain that could augment the quality of life for people with impaired speech perception. We propose a novel approach to enhance listened speech decoding from electroencephalography (EEG) signals by utilizing an auxiliary phoneme predictor that simultaneously decodes textual phoneme sequences. The proposed model architecture consists of three main parts: EEG module, speech module, and phoneme predictor. The EEG module learns to properly represent EEG signals into EEG embeddings. The speech module generates speech waveforms from the EEG embeddings. The phoneme predictor outputs the decoded phoneme sequences in text modality. Our proposed approach allows users to obtain decoded listened speech from EEG signals in both modalities (speech waveforms and textual phoneme sequences) simultaneously, eliminating the need for a concatenated sequential pipeline for each modality. The proposed approach also outperforms previous methods in both modalities. The source code and speech samples are publicly available.
脑机接口(BCI)提供了许多以人类为中心的应用可能性,尤其对神经障碍患者具有重要影响。从脑活动中解码文本或语音是一个相关领域,这可能增强语音感知受损人士的生活质量。我们提出了一种利用辅助音素预测器增强从脑电图(EEG)信号中解码的语音解码的新方法,该预测器可同时解码文本音素序列。所提出的模型架构由三个主要部分组成:EEG模块、语音模块和音素预测器。EEG模块学习将EEG信号适当地表示为EEG嵌入。语音模块从EEG嵌入生成语音波形。音素预测器输出解码的文本模式中的音素序列。我们提出的方法允许用户同时从EEG信号中获得两种模式的解码语音(语音波形和文本音素序列),而无需为每个模态使用串联的连续管道。该方法在两个模态上的表现均优于以前的方法。源代码和语音样本可公开访问。
论文及项目相关链接
PDF ICASSP 2025
Summary
本文介绍了一种利用脑机接口(BCI)技术增强听语音解码的新方法,通过脑电图(EEG)信号同时解码语音波形和文本音素序列。新方法包括EEG模块、语音模块和音素预测器三部分,可让用户同时获得两种模式的解码听语音,即语音波形和文本音素序列。该方法在两种模式下均优于以前的方法。
Key Takeaways
- BCI技术在神经障碍患者的生活质量的提高方面具有巨大的潜力,特别是在文本或语音解码方面。
- 文章提出了一种新方法,使用辅助音素预测器从EEG信号中增强听语音解码。
- 新方法包括EEG模块、语音模块和音素预测器三个主要部分。
- 用户可以同时获得语音波形和文本音素序列两种模式的解码听语音。
- 该方法在两种模式下均表现出优于以前的方法的性能。
- 公开可用源代码和语音样本。
点此查看论文截图