⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-13 更新
LlamaV-o1: Rethinking Step-by-step Visual Reasoning in LLMs
Authors:Omkar Thawakar, Dinura Dissanayake, Ketan More, Ritesh Thawkar, Ahmed Heakl, Noor Ahsan, Yuhao Li, Mohammed Zumri, Jean Lahoud, Rao Muhammad Anwer, Hisham Cholakkal, Ivan Laptev, Mubarak Shah, Fahad Shahbaz Khan, Salman Khan
Reasoning is a fundamental capability for solving complex multi-step problems, particularly in visual contexts where sequential step-wise understanding is essential. Existing approaches lack a comprehensive framework for evaluating visual reasoning and do not emphasize step-wise problem-solving. To this end, we propose a comprehensive framework for advancing step-by-step visual reasoning in large language models (LMMs) through three key contributions. First, we introduce a visual reasoning benchmark specifically designed to evaluate multi-step reasoning tasks. The benchmark presents a diverse set of challenges with eight different categories ranging from complex visual perception to scientific reasoning with over 4k reasoning steps in total, enabling robust evaluation of LLMs’ abilities to perform accurate and interpretable visual reasoning across multiple steps. Second, we propose a novel metric that assesses visual reasoning quality at the granularity of individual steps, emphasizing both correctness and logical coherence. The proposed metric offers deeper insights into reasoning performance compared to traditional end-task accuracy metrics. Third, we present a new multimodal visual reasoning model, named LlamaV-o1, trained using a multi-step curriculum learning approach, where tasks are progressively organized to facilitate incremental skill acquisition and problem-solving. The proposed LlamaV-o1 is designed for multi-step reasoning and learns step-by-step through a structured training paradigm. Extensive experiments show that our LlamaV-o1 outperforms existing open-source models and performs favorably against close-source proprietary models. Compared to the recent Llava-CoT, our LlamaV-o1 achieves an average score of 67.3 with an absolute gain of 3.8% across six benchmarks while being 5 times faster during inference scaling. Our benchmark, model, and code are publicly available.
推理是解决复杂多步骤问题的基本能力,特别是在需要连续步骤理解的视觉环境中尤为重要。现有方法缺乏评估视觉推理的综合框架,并不强调逐步解决问题。为此,我们通过三项关键贡献,提出了推进大型语言模型(LLM)的逐步视觉推理的综合框架。首先,我们引入了一个专门设计用于评估多步骤推理任务的视觉推理基准测试。该基准测试涵盖了一系列从复杂视觉感知到科学推理的八个不同类别的挑战,总共包含超过4000个推理步骤,能够稳健地评估LLM在多个步骤中进行准确和可解释的视觉推理的能力。其次,我们提出了一种新的指标,该指标在单个步骤的粒度上评估视觉推理的质量,强调正确性和逻辑连贯性。与传统的任务结束准确性指标相比,所提出的指标提供了对推理性能的更深入见解。第三,我们提出了一种名为LlamaV-o1的新型多模态视觉推理模型,采用多步骤课程学习法进行训练,任务按进度组织,便于逐步掌握技能和解决问题。提出的LlamaV-o1旨在进行多步骤推理,并通过结构化训练范式进行逐步学习。大量实验表明,我们的LlamaV-o1性能优于现有开源模型,并在多个基准测试中表现良好。与最近的Llava-CoT相比,我们的LlamaV-o1在六个基准测试中平均得分67.3,绝对提升3.8%,同时推理缩放速度提高5倍。我们的基准测试、模型和代码均已公开可用。
论文及项目相关链接
PDF 15 pages, 5 Figures
摘要
本文提出一个全面的框架,以推进大型语言模型(LMMs)的逐步视觉推理能力,主要通过三个关键贡献实现。首先,引入专门设计用于评估多步骤推理任务的视觉推理基准测试。该基准测试包含从复杂视觉感知到科学推理的八个不同类别,包含超过4000个推理步骤,能够稳健地评估LLMs在多步骤内的准确和可解释视觉推理能力。其次,提出一种新型评估指标,该指标在单个步骤的粒度上评估视觉推理质量,强调正确性和逻辑连贯性,相比传统的任务完成度评估指标,提供更深入的推理性能洞察。最后,提出一种名为LlamaV-o1的新型多模态视觉推理模型,采用多步骤课程学习法进行训练,任务按进度组织,促进逐步技能获取和问题解决。LlamaV-o1专为多步骤推理设计,通过结构化训练范式进行逐步学习。实验显示,LlamaV-o1在公开数据集上表现优于现有开源模型,并且在六个基准测试中相对于最近的Llava-CoT模型取得平均得分67.3的优异成绩,同时推理速度提升5倍。
关键见解
- 提出一种针对大型语言模型(LMMs)的新的综合框架,旨在推进逐步视觉推理能力。
- 引入视觉推理基准测试,用于评估多步骤推理任务性能,包括多个类别和超过4000个推理步骤。
- 提出一种新型的视觉推理质量评估指标,关注于步骤级别的正确性和逻辑连贯性。
- 开发了一种新型多模态视觉推理模型LlamaV-o1,用于多步骤推理,并采用结构化训练范式进行训练。
- 实验显示LlamaV-o1模型在多个基准测试中表现优越,相较于其他模型有明显的性能提升。
- LlamaV-o1模型具有高效的推理速度,相较于其他模型提升了5倍。
- 公开提供了基准测试、模型和代码。
点此查看论文截图





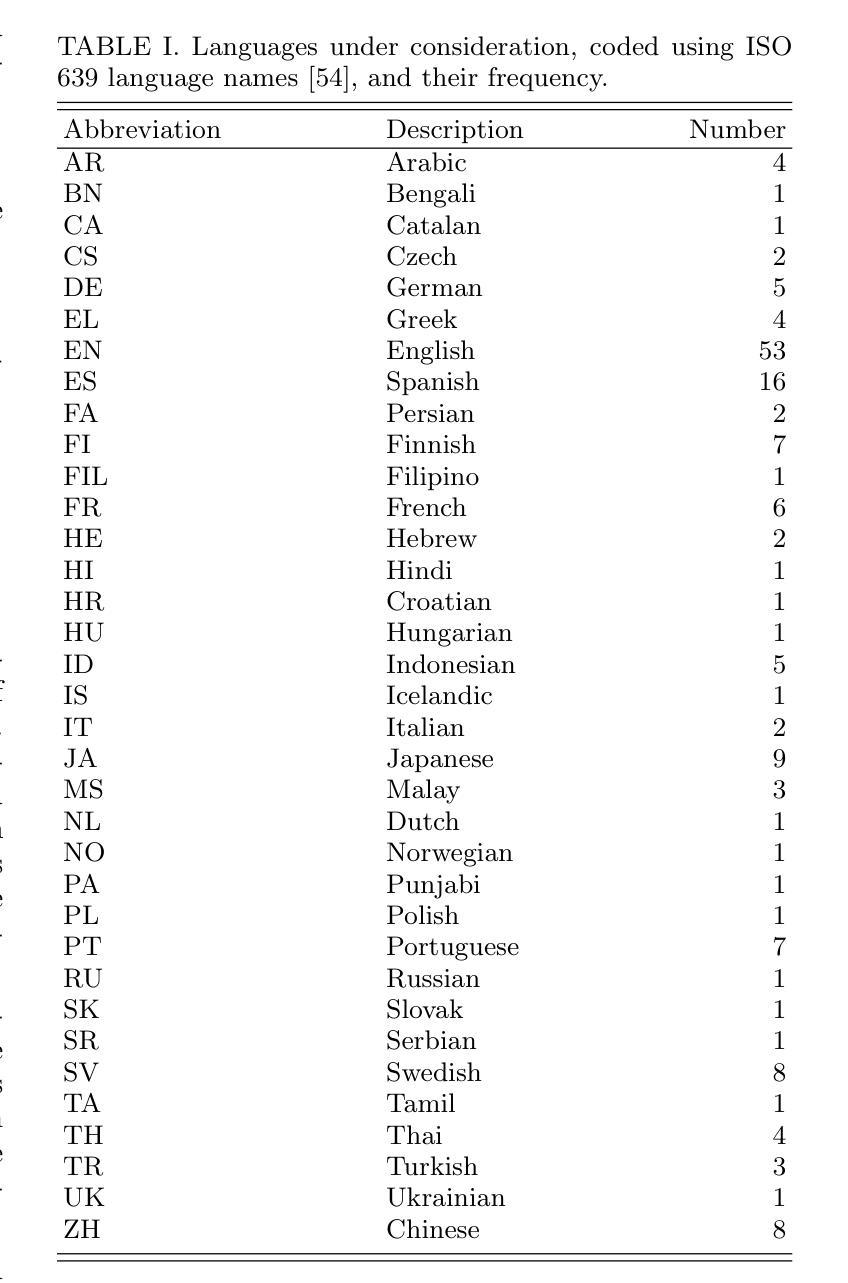
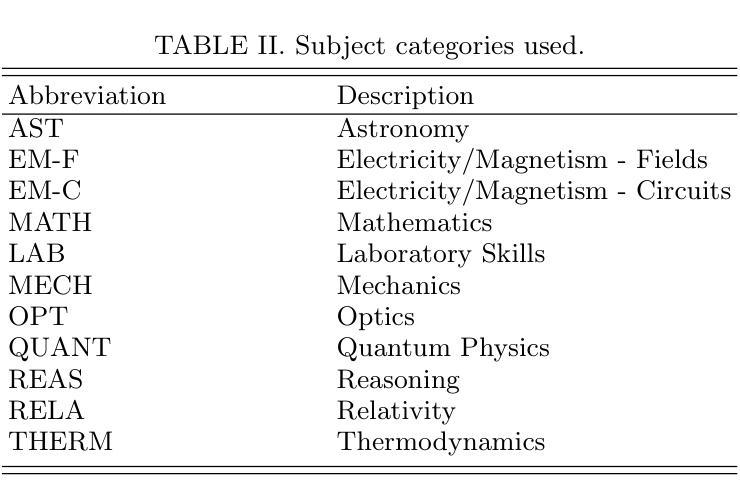
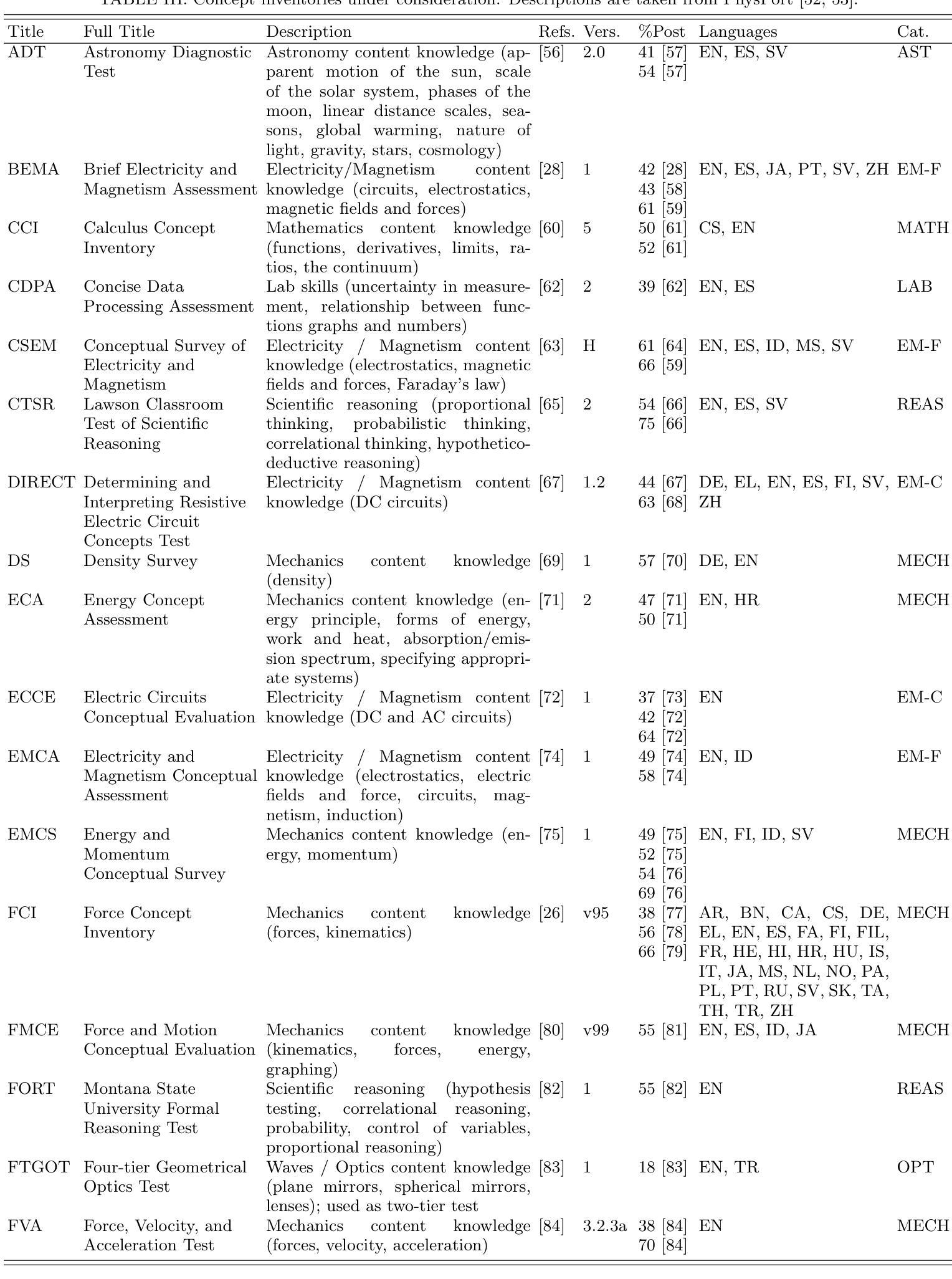
Multilingual Performance of a Multimodal Artificial Intelligence System on Multisubject Physics Concept Inventories
Authors:Gerd Kortemeyer, Marina Babayeva, Giulia Polverini, Bor Gregorcic, Ralf Widenhorn
We investigate the multilingual and multimodal performance of a large language model-based artificial intelligence (AI) system, GPT-4o, on a diverse set of physics concept inventories spanning multiple languages and subject areas. The inventories taken from the PhysPort website cover the classical physics topics of mechanics, electromagnetism, optics, and thermodynamics as well as relativity, quantum mechanics, astronomy, mathematics, and laboratory skills. Unlike previous text-only studies, we uploaded the inventories as images mirroring what a student would see on paper, assessing the system’s multimodal functionality. The AI is prompted in English and autonomously chooses the language of its response - either remaining in the nominal language of the test, switching entirely to English, or mixing languages - revealing adaptive behavior dependent on linguistic complexity and data availability. Our results indicate some variation in performance across subject areas, with laboratory skills standing out as the area of poorest performance. Furthermore, the AI’s performance on questions that require visual interpretation of images is worse than on purely text-based questions. Questions that are difficult for the AI tend to be that way invariably of the inventory language. We also find large variations in performance across languages, with some appearing to benefit substantially from language switching, a phenomenon similar to code-switching ofhuman speakers. Overall, comparing the obtained AI results to the existing literature, we find that the AI system outperforms average undergraduate students post-instruction in all subject areas but laboratory skills.
我们研究了一个基于大型语言模型的人工智能系统GPT-4o在多语言、多模式环境下的性能表现。该系统的测试范围涵盖多个语言和学科领域的物理概念清单,这些清单来自PhysPort网站,涵盖了经典物理学的力学、电磁学、光学、热力学话题,还包括相对论、量子力学、天文学、数学和实验技能。与以往仅针对文本的研究不同,我们将清单以图像的形式上传,模拟学生在纸上看到的内容,评估系统的多模式功能。该系统的提示语为英语,并且能够独立选择回应的语言,可以选择保持在测试的指定语言、完全切换到英语或混合使用多种语言,根据语言复杂性和数据可用性展现出适应性的行为。我们的研究结果显示,不同学科领域的表现存在一定差异,实验技能是表现较差的领域。此外,对于需要图像视觉解释的问题,AI的表现不如基于纯文本的问题。对于AI而言,难以回答的问题往往与清单的语言有关。我们还发现不同语言之间的性能差异很大,有些语言在切换时会大大受益,这种现象类似于人类说话者的代码转换。总体而言,将人工智能的结果与现有文献进行比较,我们发现该AI系统在所有学科领域中的表现超过了平均本科生的表现,但在实验技能方面除外。
论文及项目相关链接
Summary
研究团队对基于大型语言模型的AI系统GPT-4o在多语言、多模态环境下的物理概念库表现进行了调查。测试涵盖了多个语言和主题的物理概念库,包括经典物理、相对论、量子力学、天文学、数学和实验技能等领域。研究通过上传图像形式的题库来评估AI的多模态功能,模拟学生纸上作答的场景。AI在英语提示下可自主选择回答语言,展现出了根据语言复杂度和数据可用性的自适应行为。结果显示,不同主题领域的表现有所差异,实验技能领域表现最差。此外,对于需要图像解读的问题,AI的表现较纯文本问题更差。困难问题的共性在于题库语言。不同语言间的表现存在显著差异,部分语言切换有助于提升表现,类似于人类的语言切换现象。总体而言,相较于现有文献中的大学生,AI系统在大部分领域表现更佳,唯独在实验技能方面还有待提高。
Key Takeaways
- GPT-4o在多语言和多模态环境下的物理概念库表现被研究。
- 测试涵盖了多个语言和主题的物理概念,包括经典物理和其他多个领域。
- AI在多模态环境下进行评估,可以自主选择回答语言,展示出自适应行为。
- AI在不同主题领域的表现存在差异,实验技能领域表现最差。
- AI在解读图像类问题上的表现较纯文本问题更差。
- 困难问题的共性在于题库语言。
- AI在语言切换方面的表现存在显著差异,部分语言切换有助于提高表现。
点此查看论文截图


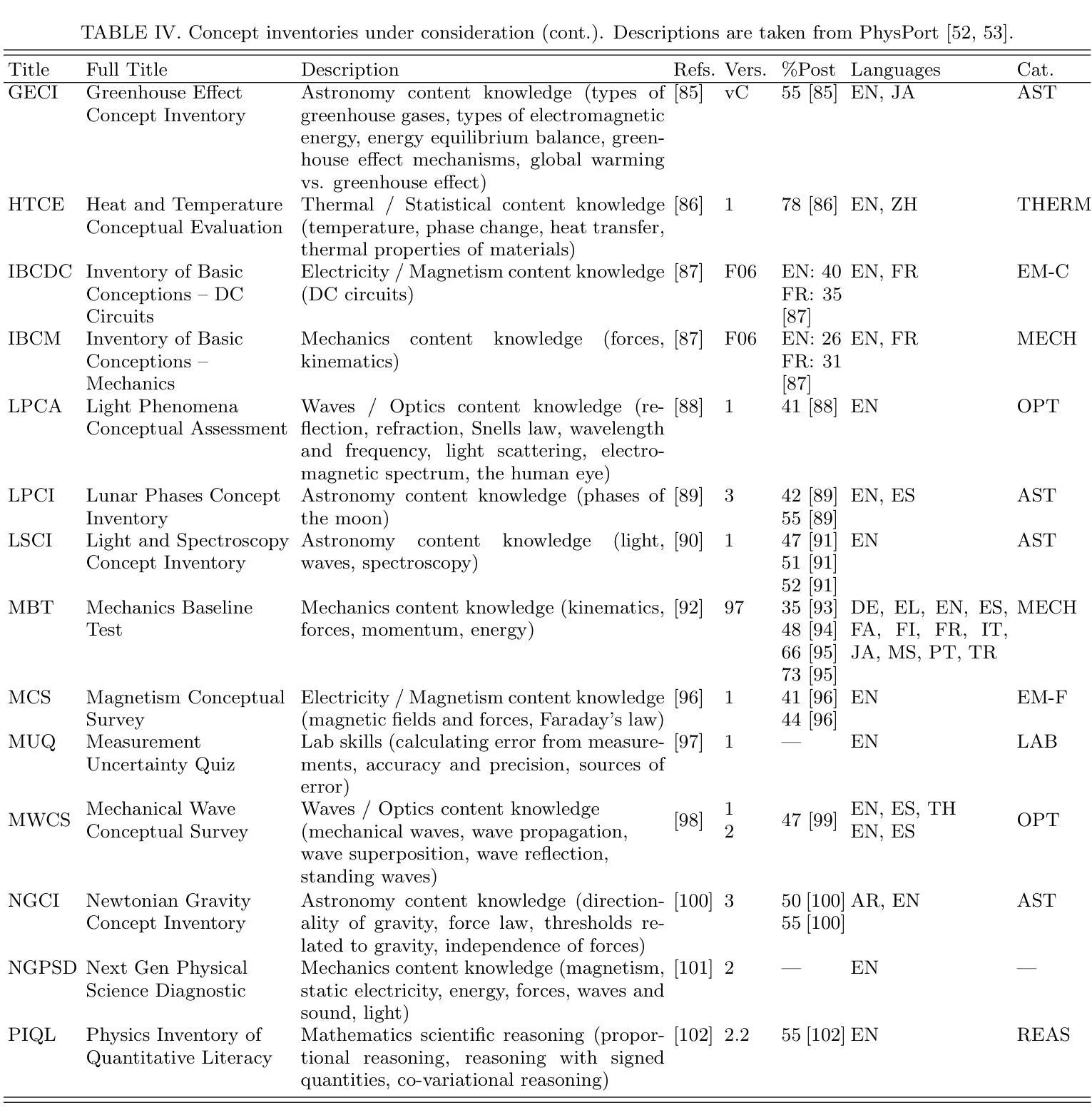
Supervision policies can shape long-term risk management in general-purpose AI models
Authors:Manuel Cebrian, Emilia Gomez, David Fernandez Llorca
The rapid proliferation and deployment of General-Purpose AI (GPAI) models, including large language models (LLMs), present unprecedented challenges for AI supervisory entities. We hypothesize that these entities will need to navigate an emergent ecosystem of risk and incident reporting, likely to exceed their supervision capacity. To investigate this, we develop a simulation framework parameterized by features extracted from the diverse landscape of risk, incident, or hazard reporting ecosystems, including community-driven platforms, crowdsourcing initiatives, and expert assessments. We evaluate four supervision policies: non-prioritized (first-come, first-served), random selection, priority-based (addressing the highest-priority risks first), and diversity-prioritized (balancing high-priority risks with comprehensive coverage across risk types). Our results indicate that while priority-based and diversity-prioritized policies are more effective at mitigating high-impact risks, particularly those identified by experts, they may inadvertently neglect systemic issues reported by the broader community. This oversight can create feedback loops that amplify certain types of reporting while discouraging others, leading to a skewed perception of the overall risk landscape. We validate our simulation results with several real-world datasets, including one with over a million ChatGPT interactions, of which more than 150,000 conversations were identified as risky. This validation underscores the complex trade-offs inherent in AI risk supervision and highlights how the choice of risk management policies can shape the future landscape of AI risks across diverse GPAI models used in society.
通用人工智能(GPAI)模型,包括大型语言模型(LLM)的快速扩散和部署,给人工智能监管实体带来了前所未有的挑战。我们假设这些实体需要在一个新兴的充满风险和事故报告的环境中导航,这个环境可能会超出其监管能力。为了调查这一点,我们开发了一个模拟框架,该框架通过从多样化的风险、事故或危害报告生态系统提取的特征进行参数化设置,这些生态系统包括社区驱动的平台、众包倡议和专家评估。我们评估了四种监管政策:非优先(先到先得)、随机选择、基于优先级的(先解决最高风险的问题)和优先考虑多样性的(平衡高风险与不同类型风险的全面覆盖)。我们的结果表明,虽然基于优先级和优先考虑多样性的政策在缓解高风险方面更为有效,尤其是专家所识别的高风险,但它们可能会无意中忽视社区报告的更为广泛的问题。这种监督疏忽可能会产生反馈循环,放大某些类型的报告,同时遏制其他类型的报告,从而导致对整体风险景观的偏颇认识。我们通过多个现实世界的数据集验证了模拟结果的有效性,其中包括一个包含超过一百万次的ChatGPT交互的数据集,其中超过15万次对话被识别为具有风险。这一验证强调了人工智能风险监管固有的复杂权衡,并突出了风险管理政策的选择如何塑造社会使用的各种GPAI模型的人工智能风险未来格局。
论文及项目相关链接
PDF 24 pages, 14 figures
Summary
本文探讨了通用人工智能(GPAI)模型,特别是大型语言模型(LLM)的迅速发展和部署给人工智能监管机构带来的挑战。为应对挑战,本文建立了一个模拟框架,评估了四种监管政策的效果,发现优先处理高风险问题并兼顾风险类型多样性的政策能有效缓解高风险影响,但可能忽视社区反映的系统性问题,造成反馈循环并扭曲整体风险认知。研究通过包括百万次ChatGPT交互在内的真实数据集验证了模拟结果。
Key Takeaways
- 通用人工智能模型(GPAI)的快速部署给AI监管机构带来挑战。
- 需要建立一个应对风险的模拟框架。
- 四种监管政策模拟评估发现优先处理高风险并兼顾风险多样性的政策更有效。
- 优先处理高风险的政策可能忽视社区反映的系统性问题。
- 忽视社区反馈可能形成反馈循环并扭曲整体风险认知。
- 模拟结果通过真实数据集验证,包括百万次ChatGPT交互数据。
点此查看论文截图

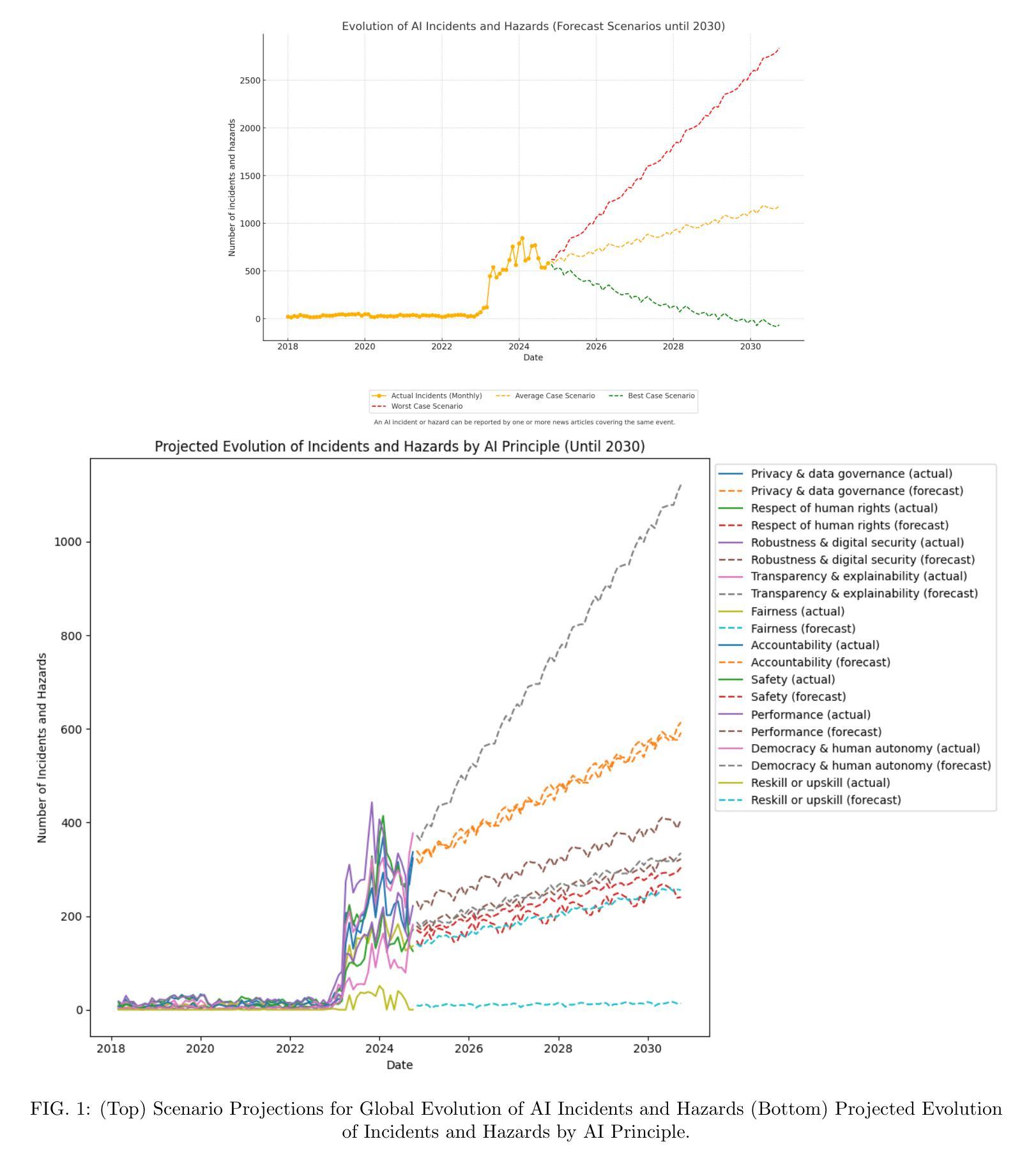

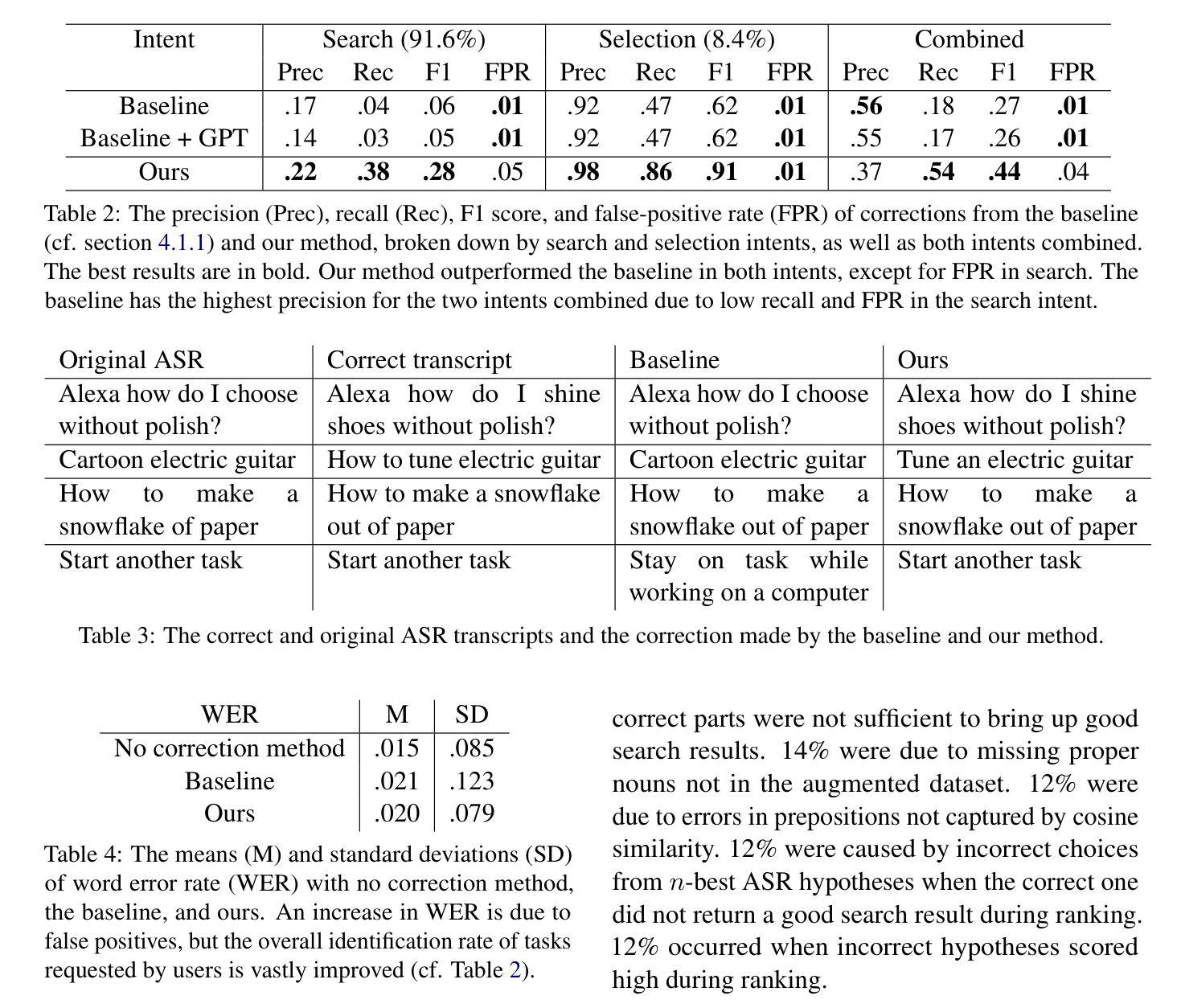
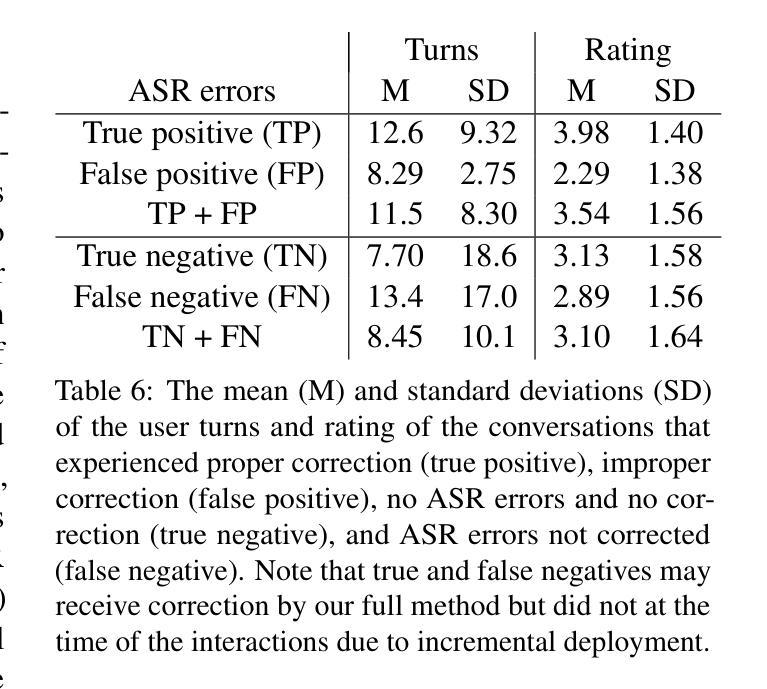
Contextual ASR Error Handling with LLMs Augmentation for Goal-Oriented Conversational AI
Authors:Yuya Asano, Sabit Hassan, Paras Sharma, Anthony Sicilia, Katherine Atwell, Diane Litman, Malihe Alikhani
General-purpose automatic speech recognition (ASR) systems do not always perform well in goal-oriented dialogue. Existing ASR correction methods rely on prior user data or named entities. We extend correction to tasks that have no prior user data and exhibit linguistic flexibility such as lexical and syntactic variations. We propose a novel context augmentation with a large language model and a ranking strategy that incorporates contextual information from the dialogue states of a goal-oriented conversational AI and its tasks. Our method ranks (1) n-best ASR hypotheses by their lexical and semantic similarity with context and (2) context by phonetic correspondence with ASR hypotheses. Evaluated in home improvement and cooking domains with real-world users, our method improves recall and F1 of correction by 34% and 16%, respectively, while maintaining precision and false positive rate. Users rated .8-1 point (out of 5) higher when our correction method worked properly, with no decrease due to false positives.
通用自动语音识别(ASR)系统在面向目标的对话中并不总是表现良好。现有的ASR校正方法依赖于用户先前数据或命名实体。我们将校正扩展到没有用户先前数据且表现出语言灵活性的任务,例如词汇和句法变化。我们提出了一种新型上下文扩充方法,使用大型语言模型和排名策略,该策略结合了面向目标对话AI的会话状态及其任务中的上下文信息。我们的方法通过(1)词汇和语义与上下文的相似度对最佳ASR假设进行排名,(2)通过音韵与ASR假设的对应来排名上下文。在家庭改善和烹饪领域进行现实世界用户评估显示,我们的方法将召回率和校正F1值分别提高了34%和16%,同时保持了精确度和误报率。用户评价(在正常工作情况下)比原先提高了0.8-1分(满分5分),并且没有因为误报而降低评分。
论文及项目相关链接
PDF Accepted to COLING 2025 Industry Track
Summary
自动语音识别(ASR)系统在目标导向对话中的表现并不总是理想。现有ASR校正方法依赖于用户先验数据或命名实体。我们将其扩展到没有用户先验数据且表现出语言灵活性的任务中,如词汇和句法变化。我们提出了一种新的上下文扩充方法,结合大型语言模型和排名策略,该策略融入了目标导向对话AI的对话状态和任务中的上下文信息。我们的方法通过(1)词法和语义相似性对ASR假设进行排名,并与上下文对比;(2)通过音素对应与ASR假设进行排名。在家庭改善和烹饪领域进行真实用户评估,我们的方法将校正的召回率和F1值分别提高了34%和16%,同时保持精确度和误报率。用户对我们的校正方法给予了更高的评价。
Key Takeaways
- ASR系统在目标导向对话中的表现有待提高。
- 现有ASR校正方法主要依赖于用户先验数据或命名实体,存在局限性。
- 本文提出了一种新的上下文扩充方法,用于扩展ASR校正到没有用户先验数据的任务。
- 该方法结合大型语言模型和排名策略,考虑了对话状态和任务的上下文信息。
- 方法通过词法和语义相似性对ASR假设进行排名,同时考虑了与上下文的对比以及音素对应。
- 在真实用户评估中,该方法显著提高了校正的召回率和F1值。
点此查看论文截图



From Conversation to Automation: Leveraging Large Language Models to Analyze Strategies in Problem Solving Therapy
Authors:Elham Aghakhani, Lu Wang, Karla T. Washington, George Demiris, Jina Huh-Yoo, Rezvaneh Rezapour
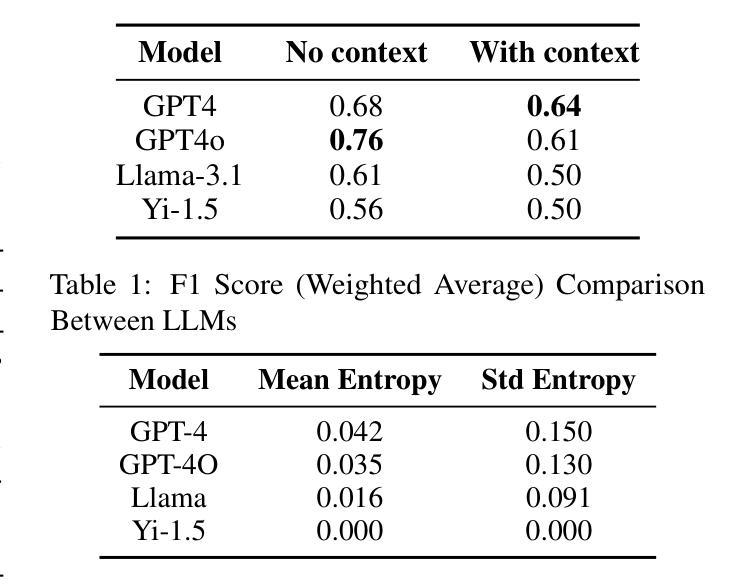
Problem-solving therapy (PST) is a structured psychological approach that helps individuals manage stress and resolve personal issues by guiding them through problem identification, solution brainstorming, decision-making, and outcome evaluation. As mental health care increasingly integrates technologies like chatbots and large language models (LLMs), understanding how PST can be effectively automated is important. This study leverages anonymized therapy transcripts to analyze and classify therapeutic interventions using various LLMs and transformer-based models. Our results show that GPT-4o achieved the highest accuracy (0.76) in identifying PST strategies, outperforming other models. Additionally, we introduced a new dimension of communication strategies that enhances the current PST framework, offering deeper insights into therapist-client interactions. This research demonstrates the potential of LLMs to automate complex therapeutic dialogue analysis, providing a scalable, efficient tool for mental health interventions. Our annotation framework can enhance the accessibility, effectiveness, and personalization of PST, supporting therapists in real-time with more precise, targeted interventions.
问题解决疗法(PST)是一种结构化心理方法,通过引导个人识别问题、集思广益找解决方案、做出决定和评估结果,帮助他们管理压力并解决个人问题。随着心理健康护理越来越多地整合聊天机器人和大型语言模型(LLM)等技术,了解如何有效地自动化PST非常重要。本研究使用匿名治疗记录来分析并利用各种LLM和基于转换器的模型对治疗干预进行分类。我们的结果表明,GPT-4o在识别PST策略方面达到了最高准确率(0.76),优于其他模型。此外,我们引入了增强当前PST框架的沟通策略新维度,为治疗师与客户的互动提供了更深入的了解。该研究展示了LLM自动化复杂治疗对话分析的潜力,为心理健康干预提供了可扩展、高效的工具。我们的注释框架可以提高PST的普及性、有效性和个性化程度,为治疗师提供实时支持,进行更精确、有针对性的干预。
论文及项目相关链接
PDF 16 pages
Summary
PST(问题解决疗法)是一种结构化心理方法,通过引导个人识别问题、解决难题、进行决策评估和成果评估来帮助个人应对压力和解决个人问题。随着精神卫生护理越来越多地融入聊天机器人等大型语言模型技术,理解如何有效地自动化PST变得至关重要。本研究使用匿名治疗记录分析并分类治疗干预措施,涉及多种大型语言模型和基于转换器的模型。结果表明GPT-4o在识别PST策略方面取得了最高精确度(准确率为0.76),超越了其他模型。此外,研究引入了新的沟通策略维度,增强了当前的PST框架,提供了对治疗师与患者互动的深入了解。该研究展示了大型语言模型在自动化复杂的治疗对话分析方面的潜力,提供了一种用于精神健康干预的可扩展高效工具。其注释框架可以提升PST的便捷性、效果和个性化程度,支持治疗师进行更精确、有针对性的干预措施。
Key Takeaways
- 问题解决疗法(PST)是一种结构化的心理方法,用以引导个人面对和解决自己的问题。
- 随着科技的进步,特别是大型语言模型(LLM)的融入,PST的自动化成为研究焦点。
- 研究利用匿名治疗记录来分析和分类治疗干预措施,包括使用多种大型语言模型和基于转换器的模型。
- GPT-4o模型在识别PST策略方面表现最佳,准确率为0.76。
- 研究引入了新的沟通策略维度,增强了我们对治疗师与患者交流的理解。
- 大型语言模型在自动化治疗对话分析方面具有潜力,可为精神健康干预提供高效工具。
点此查看论文截图

Hermit Kingdom Through the Lens of Multiple Perspectives: A Case Study of LLM Hallucination on North Korea
Authors:Eunjung Cho, Won Ik Cho, Soomin Seo
Hallucination in large language models (LLMs) remains a significant challenge for their safe deployment, particularly due to its potential to spread misinformation. Most existing solutions address this challenge by focusing on aligning the models with credible sources or by improving how models communicate their confidence (or lack thereof) in their outputs. While these measures may be effective in most contexts, they may fall short in scenarios requiring more nuanced approaches, especially in situations where access to accurate data is limited or determining credible sources is challenging. In this study, we take North Korea - a country characterised by an extreme lack of reliable sources and the prevalence of sensationalist falsehoods - as a case study. We explore and evaluate how some of the best-performing multilingual LLMs and specific language-based models generate information about North Korea in three languages spoken in countries with significant geo-political interests: English (United States, United Kingdom), Korean (South Korea), and Mandarin Chinese (China). Our findings reveal significant differences, suggesting that the choice of model and language can lead to vastly different understandings of North Korea, which has important implications given the global security challenges the country poses.
大型语言模型(LLM)中的幻觉仍是其安全部署的一大挑战,尤其是因为其传播误导信息的可能性。现有的解决方案大多侧重于通过将模型与可靠来源对齐或改进模型如何传达其输出中的信心(或缺乏信心)来解决这一挑战。虽然这些措施在大多数情况下可能有效,但在需要更微妙方法的情况下可能会失效,特别是在无法获得准确数据或确定可靠来源具有挑战性的情况下。在这项研究中,我们以朝鲜为例——一个以极度缺乏可靠信息和流行耸人听闻的虚假信息为特点的国家。我们探索并评估了一些表现最佳的多语言LLM和基于特定语言的模型如何生成关于朝鲜的信息,包括三种在具有重大地缘政治利益的国家中使用的语言:英语(美国、英国)、韩语(韩国)和中文普通话(中国)。我们的研究结果显示了显著差异,这表明所选模型和语言的不同可能导致对朝鲜的理解大相径庭,考虑到朝鲜对全球安全带来的挑战,这一发现具有重要意义。
论文及项目相关链接
PDF Accepted at COLING 2025
Summary
大型语言模型(LLM)中的幻觉现象对模型的安全部署构成重大挑战,特别是其传播错误信息的潜力。现有解决方案主要通过与可靠数据源对齐模型或改进模型对输出的信心沟通来解决此问题。这些措施虽然适用于大多数情况,但在需要更精细处理的情况下可能不足够有效,特别是在无法获得准确数据或难以确定可靠数据源的情况下。本研究以朝鲜为例,这是一个缺乏可靠信息源且流行耸人听闻的虚假信息的国家。我们探索并评估了一些表现最好的多语言LLM和基于特定语言的模型如何用英语(美国、英国)、韩语(韩国)和中文普通话(中国)三种语言生成有关朝鲜的信息。研究结果显示显著的语言差异,显示所选模型和语言的不同可能导致对朝鲜的理解存在巨大差异,这对全球安全挑战具有重要意义。
Key Takeaways
- 大型语言模型(LLM)中的幻觉现象可能对模型的部署产生安全隐患,特别是在传播错误信息方面。
- 当前解决方案主要通过与可靠数据源对齐模型或提高模型对输出信心的展现来应对挑战。
- 在缺乏准确数据或难以确定可靠信息源的情境中,现有解决方案可能效果有限。
- 研究以朝鲜为案例,揭示语言模型在生成关于该国的信息时存在的差异。
- 不同语言和模型的选择可能导致对朝鲜理解的不同,这在全球安全问题上具有重要影响。
- 跨语言和模型的差异在特定地区的误解和误判中可能起到关键作用。
点此查看论文截图

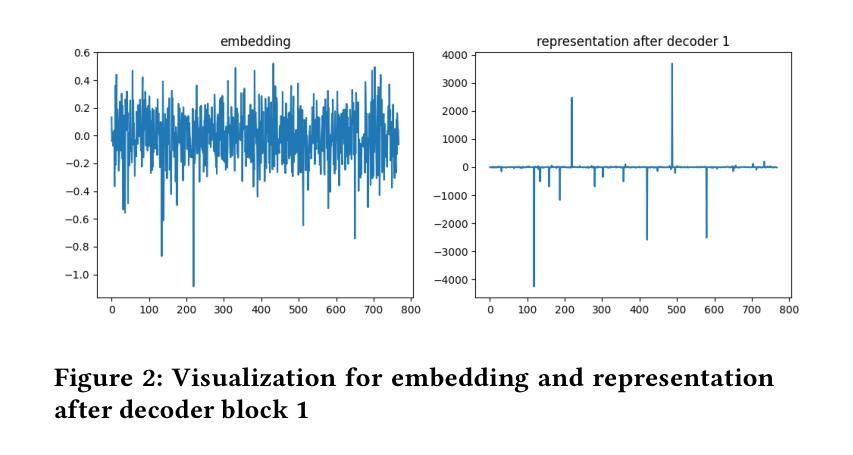
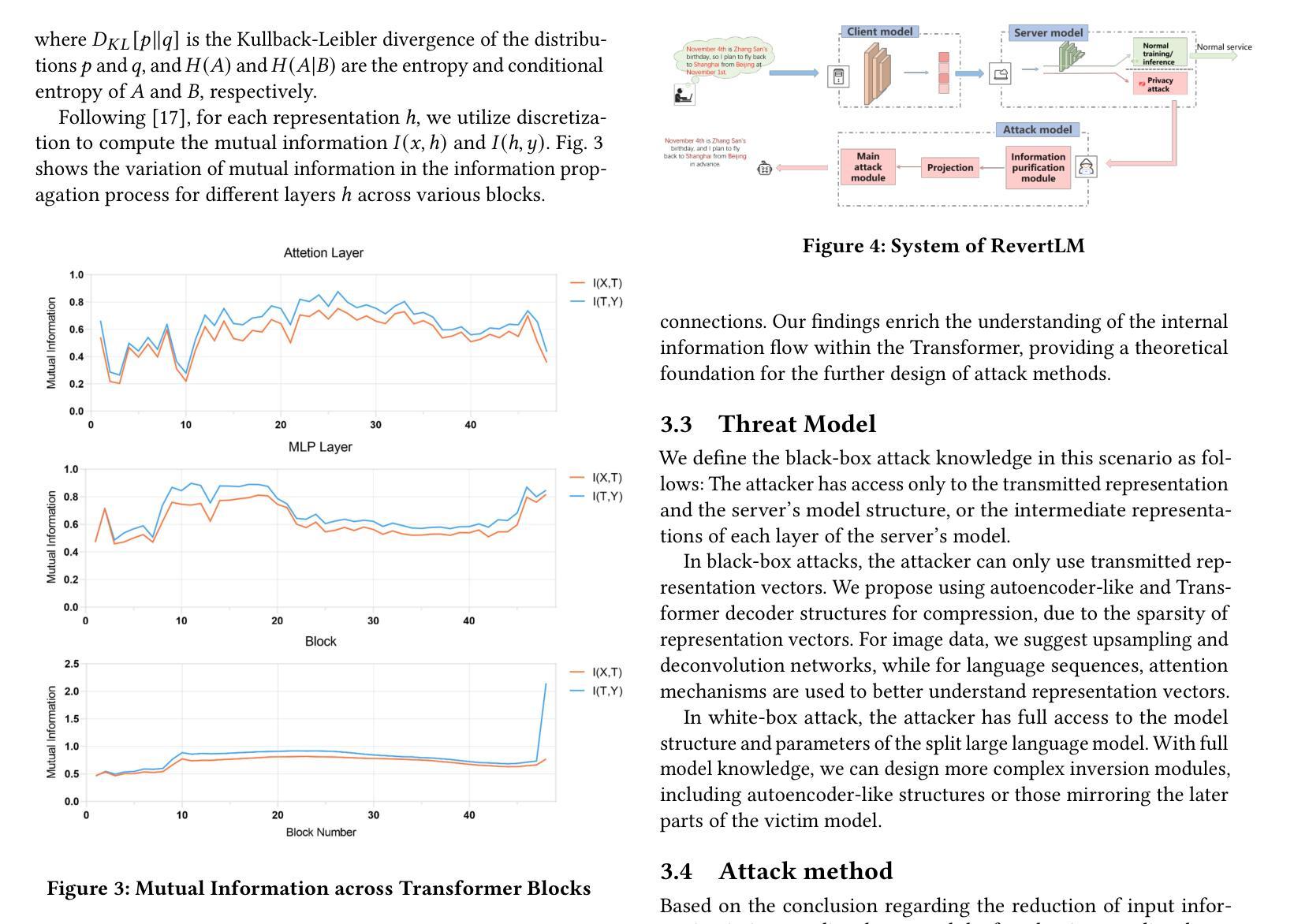
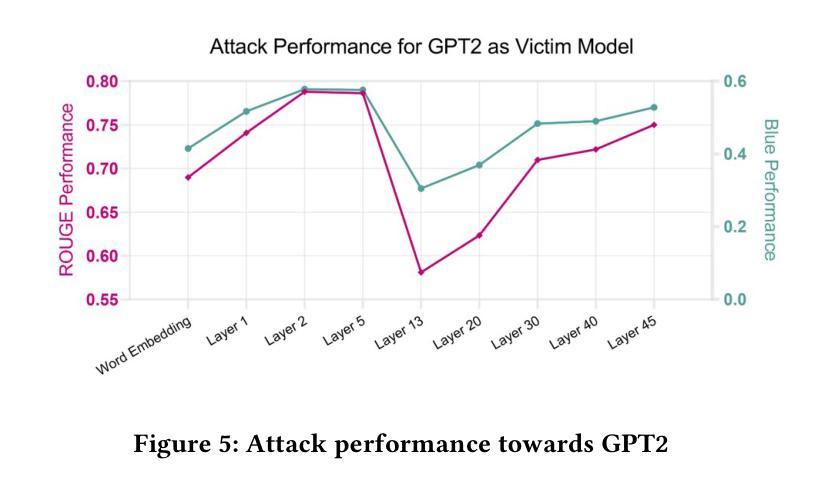
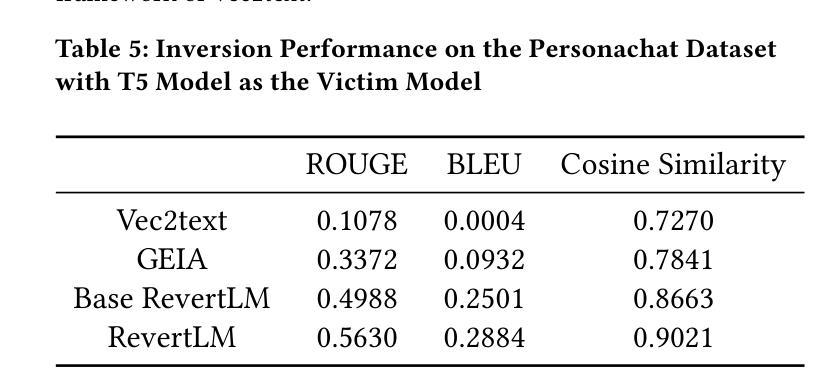
Model Inversion in Split Learning for Personalized LLMs: New Insights from Information Bottleneck Theory
Authors:Yunmeng Shu, Shaofeng Li, Tian Dong, Yan Meng, Haojin Zhu
Personalized Large Language Models (LLMs) have become increasingly prevalent, showcasing the impressive capabilities of models like GPT-4. This trend has also catalyzed extensive research on deploying LLMs on mobile devices. Feasible approaches for such edge-cloud deployment include using split learning. However, previous research has largely overlooked the privacy leakage associated with intermediate representations transmitted from devices to servers. This work is the first to identify model inversion attacks in the split learning framework for LLMs, emphasizing the necessity of secure defense. For the first time, we introduce mutual information entropy to understand the information propagation of Transformer-based LLMs and assess privacy attack performance for LLM blocks. To address the issue of representations being sparser and containing less information than embeddings, we propose a two-stage attack system in which the first part projects representations into the embedding space, and the second part uses a generative model to recover text from these embeddings. This design breaks down the complexity and achieves attack scores of 38%-75% in various scenarios, with an over 60% improvement over the SOTA. This work comprehensively highlights the potential privacy risks during the deployment of personalized LLMs on the edge side.
个性化大型语言模型(LLM)越来越普遍,GPT-4等模型的出色表现引人注目。这一趋势也推动了在移动设备上部署LLM的广泛研究。对于这种边缘云部署的可行方法包括使用分割学习。然而,之前的研究在很大程度上忽视了从设备到服务器传输的中间表示形式所关联的隐私泄露问题。本工作是首次在分割学习框架中识别LLM的模型反转攻击,并强调安全防御的必要性。我们首次引入互信息熵来了解基于Transformer的LLM的信息传播情况,并评估LLM块的隐私攻击性能。为了解决表示稀疏且包含的信息少于嵌入的问题,我们提出了一个两阶段的攻击系统,其中第一阶段将表示投影到嵌入空间,第二阶段使用生成模型从这些嵌入中恢复文本。这种设计降低了复杂性,在各种场景下实现了38%-75%的攻击得分,比现有技术提高了60%以上。本工作全面突出了在边缘侧部署个性化LLM期间可能存在的潜在隐私风险。
论文及项目相关链接
PDF 8 pages
Summary
该文本研究了在移动设备上部署个性化大型语言模型(LLMs)时的隐私问题。介绍了一种新颖的基于互信息熵的攻击方式,并提出了一种两阶段攻击系统以解决现有研究中忽视的中间表示传输隐私问题。该设计能够突破复杂场景,实现在不同场景下的攻击得分达到38%-75%,比现有技术高出超过60%。这项研究全面强调了边缘侧部署个性化LLMs时的潜在隐私风险。
Key Takeaways
- 大型语言模型(LLMs)在移动设备上的部署越来越普遍,但中间表示传输隐私问题尚未得到充分关注。
- 提出了一种新颖的模型逆攻击方式,强调了在部署个性化LLMs时的隐私泄露风险。
- 使用互信息熵来理解和评估Transformer-based LLMs的信息传播以及隐私攻击性能。
- 引入了创新的攻击系统,分为两个阶段,将中间表示投影到嵌入空间,并使用生成模型从这些嵌入中恢复文本。
- 该攻击系统的设计能够降低复杂性,并在不同场景下实现较高的攻击得分。这一设计与现有技术的改进幅度超过了60%。
- 本研究的重要性在于其指出个性化LLMs在边缘侧部署时面临的潜在隐私风险,并提供了相应的安全防御方法。这为未来相关研究的推进指明了方向。
点此查看论文截图



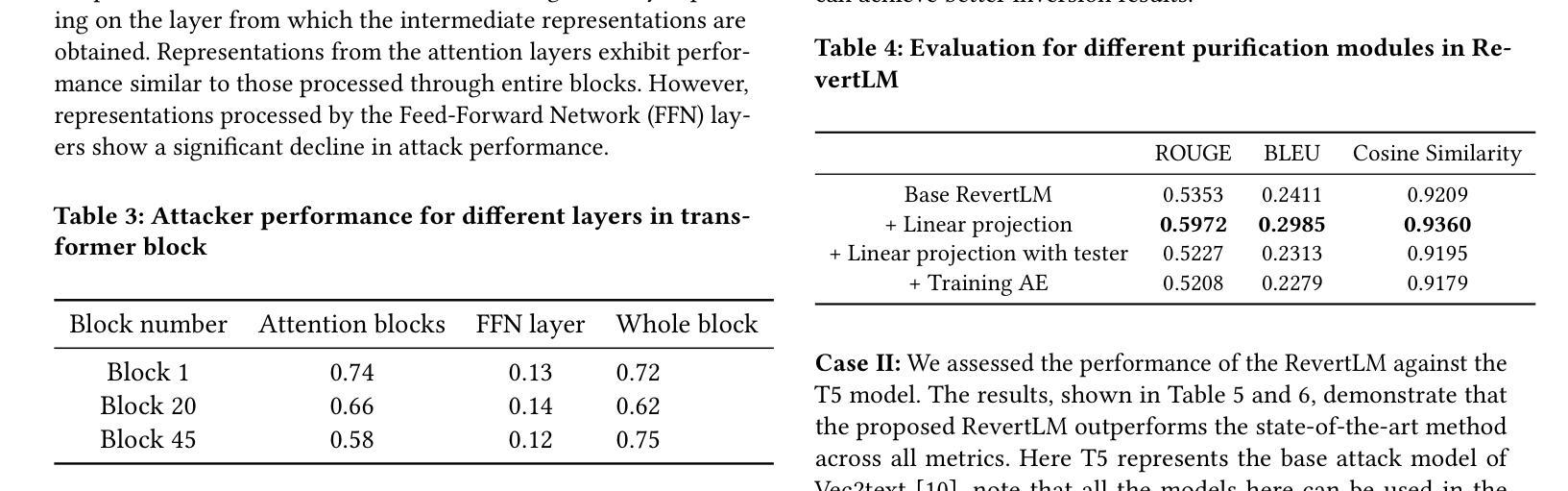
Valley2: Exploring Multimodal Models with Scalable Vision-Language Design
Authors:Ziheng Wu, Zhenghao Chen, Ruipu Luo, Can Zhang, Yuan Gao, Zhentao He, Xian Wang, Haoran Lin, Minghui Qiu
Recently, vision-language models have made remarkable progress, demonstrating outstanding capabilities in various tasks such as image captioning and video understanding. We introduce Valley2, a novel multimodal large language model designed to enhance performance across all domains and extend the boundaries of practical applications in e-commerce and short video scenarios. Notably, Valley2 achieves state-of-the-art (SOTA) performance on e-commerce benchmarks, surpassing open-source models of similar size by a large margin (79.66 vs. 72.76). Additionally, Valley2 ranks second on the OpenCompass leaderboard among models with fewer than 10B parameters, with an impressive average score of 67.4. The code and model weights are open-sourced at https://github.com/bytedance/Valley.
最近,视觉语言模型在图像标注和视频理解等任务中取得了显著的进步,并展示了出色的能力。我们推出了Valley2,这是一款新型的多模态大型语言模型,旨在提高所有领域的性能,并扩展在电子商务和短视频场景中的实际应用边界。值得注意的是,Valley2在电子商务基准测试上达到了最先进的性能,以较大幅度超越了类似规模的开源模型(79.66对72.76)。此外,在少于10B参数的模型中,Valley2在OpenCompass排行榜上名列第二,平均得分令人印象深刻,达到67.4分。代码和模型权重已公开在https://github.com/bytedance/Valley。
论文及项目相关链接
Summary
山谷模型2(Valley2)是一款全新的多模态大型语言模型,适用于电子商务和短视频场景,表现出卓越的性能。在电子商务领域的标杆测试中,山谷模型2已达到最前沿的技术性能表现,远超同量级开源模型;并且在参数数量少于十亿的大型模型竞赛中名列第二。模型权重与代码已在GitHub上开源。
Key Takeaways
- Valley2是一种多模态大型语言模型,适用于电子商务和短视频场景。
- 在电子商务领域的标杆测试中,其表现已达到了前沿技术(State-of-the-art)的水平。
- 对比于相似的开源模型,山谷模型2的性能大幅超越现有模型(79.66 vs. 72.76)。
- 在参数数量少于十亿的模型中,山谷模型排名第二。其平均得分达到了令人印象深刻的67.4分。
- Valley模型的代码和权重已在GitHub上开源,便于其他研究者使用和改进。
点此查看论文截图



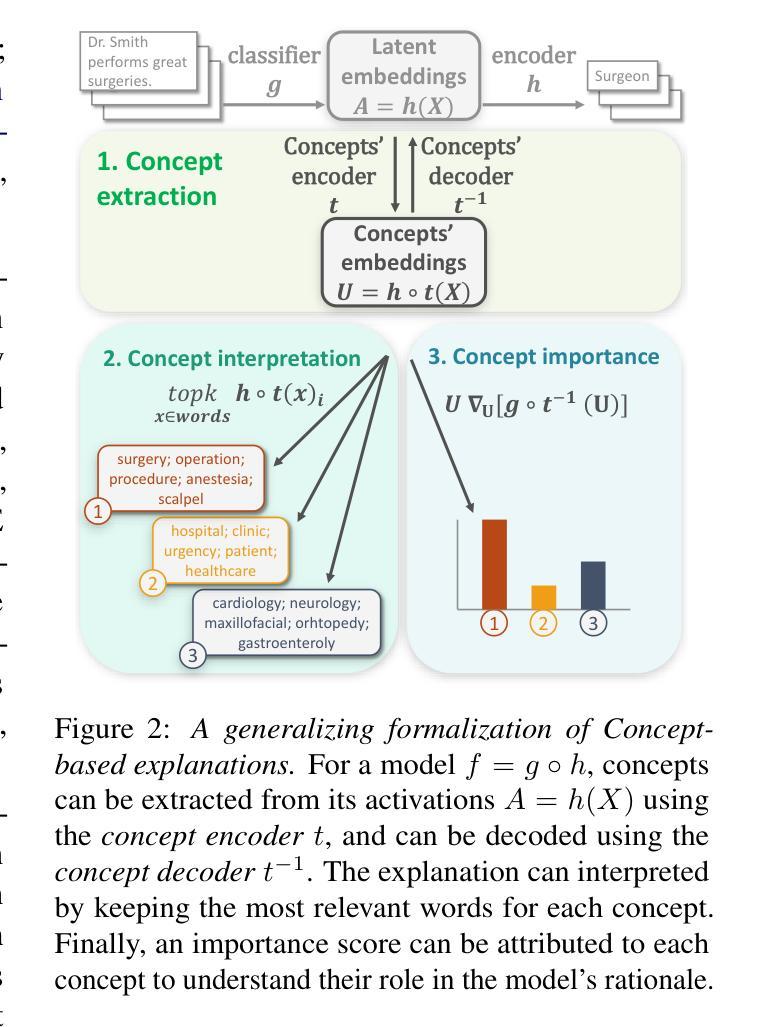
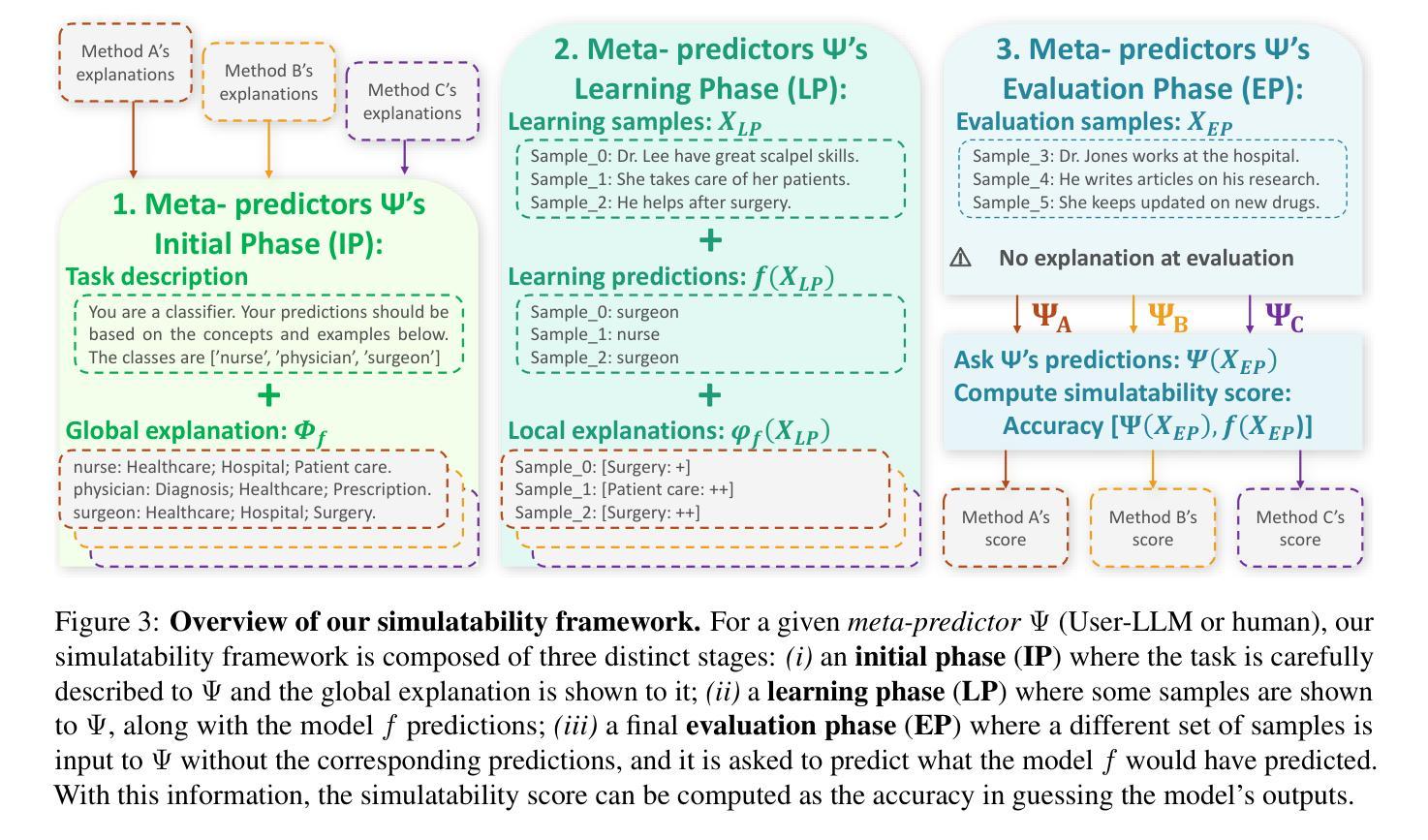
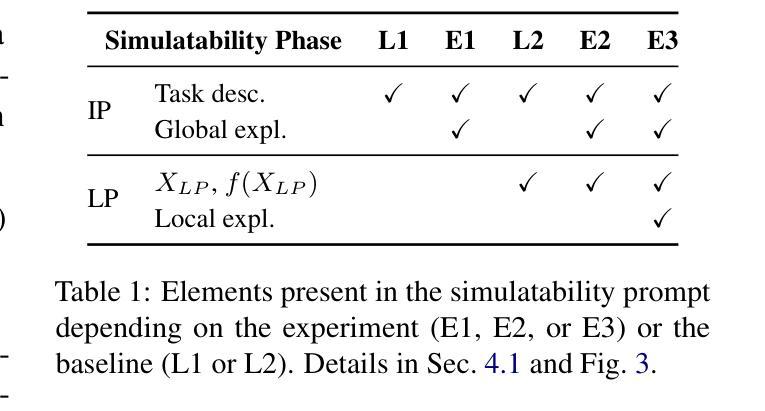
ConSim: Measuring Concept-Based Explanations’ Effectiveness with Automated Simulatability
Authors:Antonin Poché, Alon Jacovi, Agustin Martin Picard, Victor Boutin, Fanny Jourdan
Concept-based explanations work by mapping complex model computations to human-understandable concepts. Evaluating such explanations is very difficult, as it includes not only the quality of the induced space of possible concepts but also how effectively the chosen concepts are communicated to users. Existing evaluation metrics often focus solely on the former, neglecting the latter. We introduce an evaluation framework for measuring concept explanations via automated simulatability: a simulator’s ability to predict the explained model’s outputs based on the provided explanations. This approach accounts for both the concept space and its interpretation in an end-to-end evaluation. Human studies for simulatability are notoriously difficult to enact, particularly at the scale of a wide, comprehensive empirical evaluation (which is the subject of this work). We propose using large language models (LLMs) as simulators to approximate the evaluation and report various analyses to make such approximations reliable. Our method allows for scalable and consistent evaluation across various models and datasets. We report a comprehensive empirical evaluation using this framework and show that LLMs provide consistent rankings of explanation methods. Code available at https://github.com/AnonymousConSim/ConSim
基于概念的解释是通过将复杂的模型计算映射到人类可理解的概念来工作的。评估这种解释是非常困难的,因为它不仅包括可能的概念空间的质量,还包括所选择的概念如何有效地传达给用户。现有的评估指标往往只关注前者,而忽视了后者。我们引入了一个评估框架,通过自动化模拟性来衡量概念解释:模拟器根据提供的解释预测解释模型的输出的能力。这种方法既考虑概念空间,又考虑其端到端的最终解释。进行模拟性研究对人类来说尤其困难,特别是在广泛而全面的经验评估的尺度上(这是本文的主题)。我们建议使用大型语言模型(LLM)作为模拟器来近似评估,并报告各种分析使这些近似值可靠。我们的方法允许在多种模型和数据集上进行可扩展和一致性的评估。我们使用该框架报告了全面的经验评估,并证明了LLM对解释方法提供了一致的排名。代码可在https://github.com/AnonymousConSim/ConSim找到。
论文及项目相关链接
Summary
概念解释通过映射复杂模型计算到人类可理解的概念来实现。评估此类解释非常困难,因为它不仅包括可能概念空间的质量,还包括所选择概念向用户传达的有效性。现有评估指标往往只关注前者而忽略了后者。我们通过自动模拟能力引入了一个评估框架,即模拟器根据提供的解释预测解释模型输出的能力。这种方法同时考虑了概念空间及其解释,进行了端到端的评估。进行模拟能力的人类研究是众所周知的困难,特别是在广泛而全面的经验评估中更是如此。我们提议使用大型语言模型(LLM)作为模拟器进行近似评估,并报告了各种分析以确保此类近似的可靠性。我们的方法允许对各种模型和数据集进行可扩展和一致的评估。我们使用该框架进行了全面的经验评估,并展示了LLM对解释方法的一致排名。
Key Takeaways
- 概念解释通过将复杂模型计算映射到人类可理解的概念来工作。
- 评估概念解释不仅涉及可能概念空间的质量,还包括如何有效地向用户传达所选概念。
- 现有评估指标主要关注概念空间的质量,忽略了向用户传达概念的有效性。
- 引入了一个基于自动模拟能力的评估框架,以全面考虑概念空间和其解释。
- 使用大型语言模型(LLM)作为模拟器进行近似评估。
- LLM在评估不同解释方法时提供了一致的排名。
点此查看论文截图

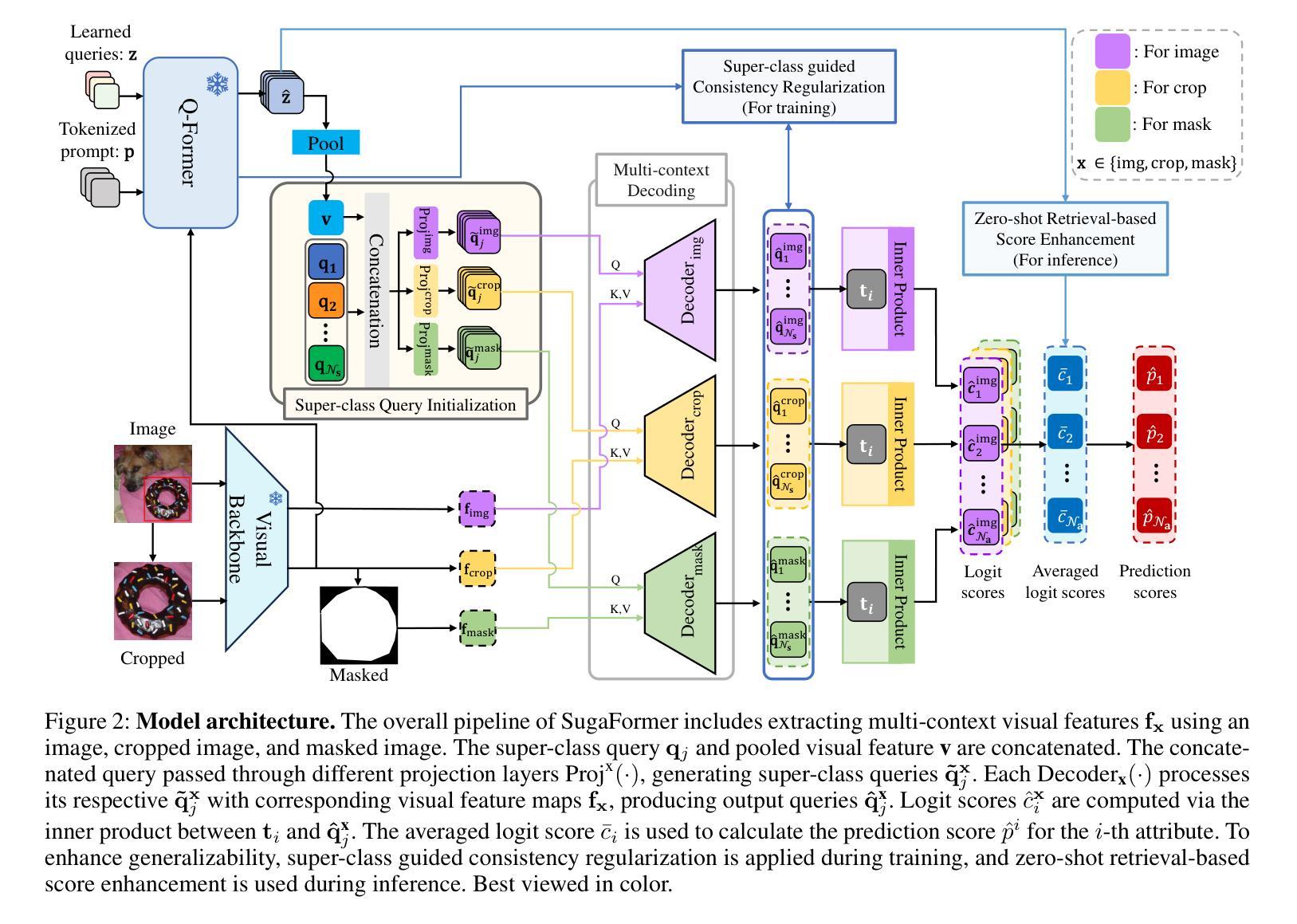
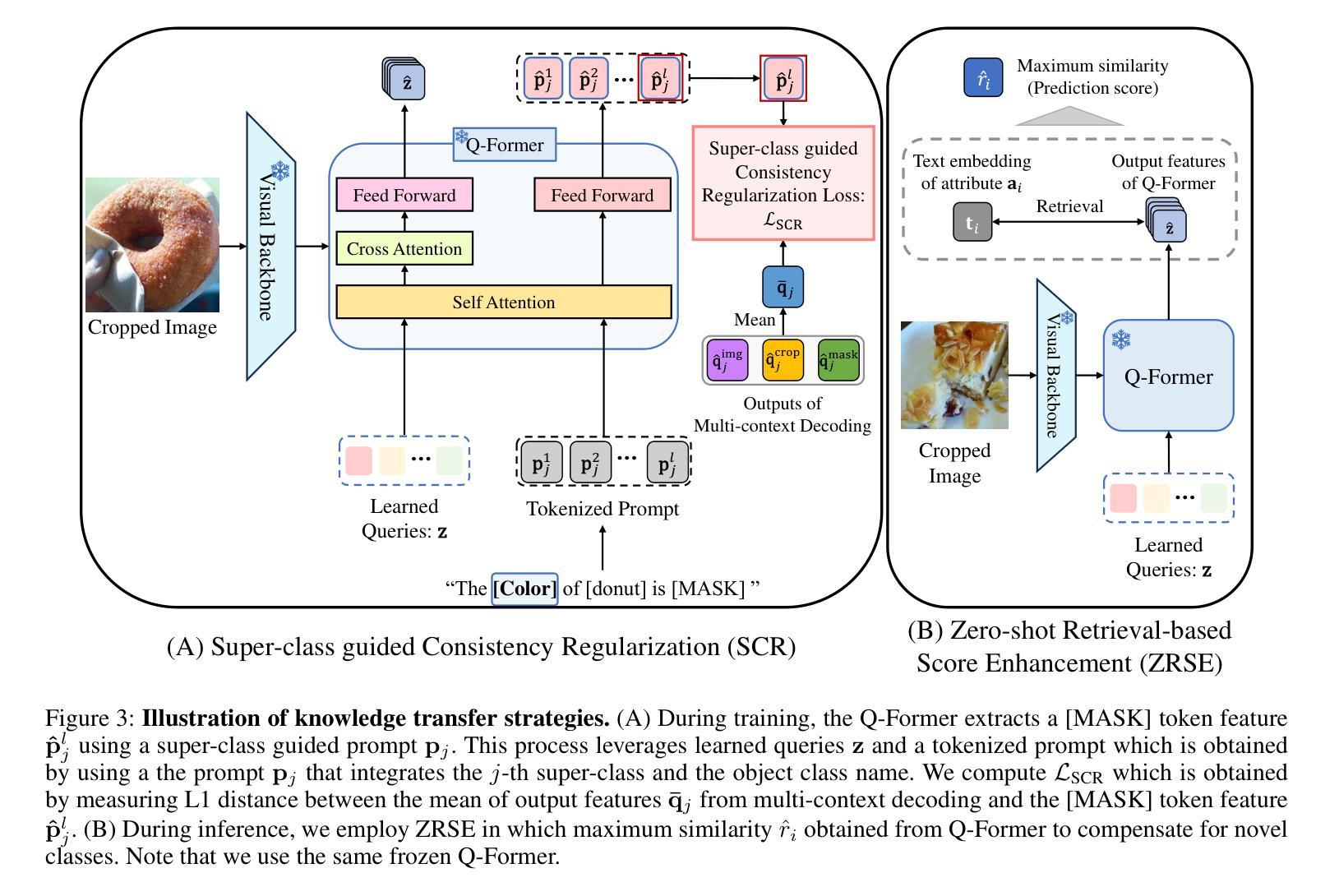
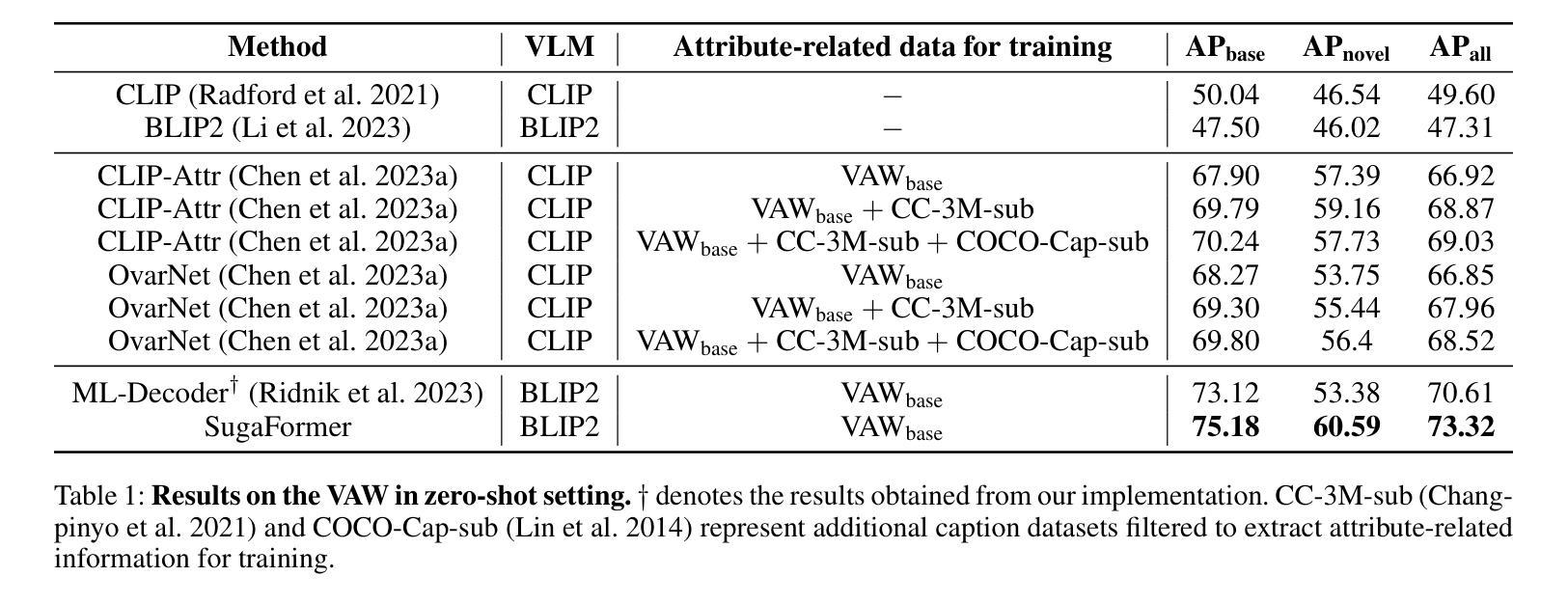
Super-class guided Transformer for Zero-Shot Attribute Classification
Authors:Sehyung Kim, Chanhyeong Yang, Jihwan Park, Taehoon Song, Hyunwoo J. Kim
Attribute classification is crucial for identifying specific characteristics within image regions. Vision-Language Models (VLMs) have been effective in zero-shot tasks by leveraging their general knowledge from large-scale datasets. Recent studies demonstrate that transformer-based models with class-wise queries can effectively address zero-shot multi-label classification. However, poor utilization of the relationship between seen and unseen attributes makes the model lack generalizability. Additionally, attribute classification generally involves many attributes, making maintaining the model’s scalability difficult. To address these issues, we propose Super-class guided transFormer (SugaFormer), a novel framework that leverages super-classes to enhance scalability and generalizability for zero-shot attribute classification. SugaFormer employs Super-class Query Initialization (SQI) to reduce the number of queries, utilizing common semantic information from super-classes, and incorporates Multi-context Decoding (MD) to handle diverse visual cues. To strengthen generalizability, we introduce two knowledge transfer strategies that utilize VLMs. During training, Super-class guided Consistency Regularization (SCR) aligns SugaFormer’s features with VLMs using region-specific prompts, and during inference, Zero-shot Retrieval-based Score Enhancement (ZRSE) refines predictions for unseen attributes. Extensive experiments demonstrate that SugaFormer achieves state-of-the-art performance across three widely-used attribute classification benchmarks under zero-shot, and cross-dataset transfer settings. Our code is available at https://github.com/mlvlab/SugaFormer.
属性分类对于识别图像区域内的特定特征至关重要。视觉语言模型(VLMs)通过利用大规模数据集的一般知识,在零样本任务中表现出了有效性。最近的研究表明,基于带有类别查询的transformer模型可以有效地解决零样本多标签分类问题。然而,对可见和不可见属性之间关系的利用不足使得模型的通用性较差。此外,属性分类通常涉及许多属性,使得保持模型的可扩展性变得困难。为了解决这些问题,我们提出了Super-class guided transFormer(SugaFormer)这一新框架,该框架利用超类来增强零样本属性分类的可扩展性和通用性。SugaFormer采用Super-class Query Initialization(SQI)来减少查询数量,利用超类的通用语义信息,并结合Multi-context Decoding(MD)来处理各种视觉线索。为了加强通用性,我们引入了两种利用VLMs的知识转移策略。在训练过程中,Super-class guided Consistency Regularization(SCR)通过区域特定的提示使SugaFormer的特征与VLMs对齐,在推理过程中,Zero-shot Retrieval-based Score Enhancement(ZRSE)完善了未见属性的预测。大量实验表明,SugaFormer在三个广泛使用的属性分类基准测试中实现了零样本和跨数据集迁移设置的最新性能。我们的代码位于https://github.com/mlvlab/SugaFormer。
论文及项目相关链接
PDF AAAI25
Summary
本文提出一种名为Super-class guided transFormer(SugaFormer)的新框架,用于解决零样本属性分类中的可伸缩性和泛化性问题。它通过利用超类信息,采用Super-class Query Initialization(SQI)减少查询数量,并结合Multi-context Decoding(MD)处理多样化的视觉线索。此外,通过引入两种利用视觉语言模型(VLMs)的知识转移策略,即Super-class guided Consistency Regularization(SCR)和Zero-shot Retrieval-based Score Enhancement(ZRSE),提高了模型的泛化能力。在三个广泛使用的属性分类基准测试上,SugaFormer在零样本和跨数据集传输设置下实现了最先进的性能。
Key Takeaways
- 属性分类在识别图像区域特定特征中至关重要。
- 视觉语言模型(VLMs)在零样本任务中通过利用大规模数据集的一般知识已经展现出有效性。
- 最近的研究表明,基于类查询的transformer模型可以有效地解决零样本多标签分类问题。
- SugaFormer框架通过利用超类信息来解决属性分类中的可伸缩性和泛化性问题。
- Super-class Query Initialization(SQI)减少了查询数量,而Multi-context Decoding(MD)处理多样化的视觉线索。
- SugaFormer引入两种知识转移策略来利用VLMs,提高模型的泛化能力。
- SugaFormer在多个基准测试上实现了最先进的性能,包括零样本和跨数据集传输设置。
点此查看论文截图

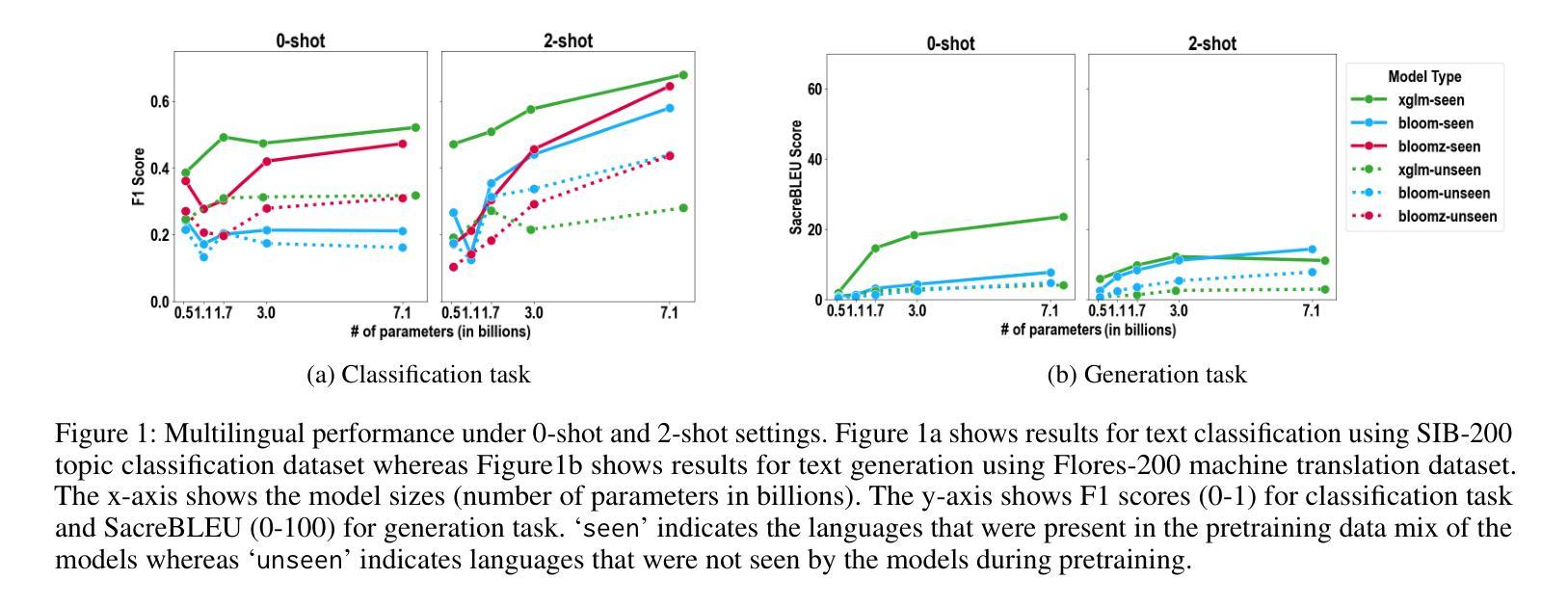
The Impact of Model Scaling on Seen and Unseen Language Performance
Authors:Rhitabrat Pokharel, Sina Bagheri Nezhad, Ameeta Agrawal, Suresh Singh
The rapid advancement of Large Language Models (LLMs), particularly those trained on multilingual corpora, has intensified the need for a deeper understanding of their performance across a diverse range of languages and model sizes. Our research addresses this critical need by studying the performance and scaling behavior of multilingual LLMs in text classification and machine translation tasks across 204 languages. We systematically examine both seen and unseen languages across three model families of varying sizes in zero-shot and few-shot settings. Our findings show significant differences in scaling behavior between zero-shot and two-shot scenarios, with striking disparities in performance between seen and unseen languages. Model scale has little effect on zero-shot performance, which remains mostly flat. However, in two-shot settings, larger models show clear linear improvements in multilingual text classification. For translation tasks, however, only the instruction-tuned model showed clear benefits from scaling. Our analysis also suggests that overall resource levels, not just the proportions of pretraining languages, are better predictors of model performance, shedding light on what drives multilingual LLM effectiveness.
随着大型语言模型(LLM)的快速发展,尤其是那些在多语种语料库上训练的模型,对跨多种语言和不同模型规模的性能进行更深入理解的必要性日益凸显。我们的研究通过研究和评估多语种LLM在文本分类和机器翻译任务中在204种语言中的性能和扩展行为来应对这一迫切需求。我们在零样本和少样本环境下,系统性地研究了三个不同规模的模型家族在已知和未知语言上的表现。我们的研究结果表明,零样本和两样本场景中的扩展行为存在明显差异,已知和未知语言之间的性能差异也很显著。在零样本场景下,模型规模对性能的影响微乎其微,基本保持平稳。然而,在两样本设置中,较大的模型在多语种文本分类中显示出明显的线性改进。然而,对于翻译任务,只有经过指令调整的模型才能从扩展中受益明显。我们的分析还表明,总体而言,资源水平,而不仅仅是预训练语言的比例,更能预测模型的性能,这为我们了解多语种LLM效果的原因提供了新的见解。
论文及项目相关链接
PDF Accepted at SEAS Workshop at AAAI25
Summary
多语言大型语言模型(LLM)在文本分类和机器翻译方面的性能研究至关重要。本研究系统地研究了不同规模模型在多语言环境下的表现与扩展性,涵盖了204种语言,涉及零样本和少量样本场景。研究发现,零样本和两样本场景下的扩展性行为存在显著差异,且在可见语言和不可见语言间的性能表现有显著差异。模型规模对零样本性能影响较小,而在两样本环境中,大型模型在跨语言文本分类上表现出清晰的线性改进。然而,对于翻译任务,只有经过指令调优的模型在扩展时显示出明显优势。总体而言,资源水平而非预训练语言的比例能更好地预测模型性能。
Key Takeaways
- 多语言LLM在文本分类和机器翻译方面的性能研究非常重要。
- 研究涉及多种语言环境和不同规模的模型。
- 零样本和两样本场景下的模型扩展性行为存在显著差异。
- 模型规模对零样本性能影响较小,而在两样本环境中,大型模型在跨语言文本分类上表现更好。
- 对于翻译任务,只有经过指令调优的模型在扩展时显示出优势。
- 资源水平而非预训练语言的比例是模型性能更好的预测指标。
点此查看论文截图



Centurio: On Drivers of Multilingual Ability of Large Vision-Language Model
Authors:Gregor Geigle, Florian Schneider, Carolin Holtermann, Chris Biemann, Radu Timofte, Anne Lauscher, Goran Glavaš
Most Large Vision-Language Models (LVLMs) to date are trained predominantly on English data, which makes them struggle to understand non-English input and fail to generate output in the desired target language. Existing efforts mitigate these issues by adding multilingual training data, but do so in a largely ad-hoc manner, lacking insight into how different training mixes tip the scale for different groups of languages. In this work, we present a comprehensive investigation into the training strategies for massively multilingual LVLMs. First, we conduct a series of multi-stage experiments spanning 13 downstream vision-language tasks and 43 languages, systematically examining: (1) the number of training languages that can be included without degrading English performance and (2) optimal language distributions of pre-training as well as (3) instruction-tuning data. Further, we (4) investigate how to improve multilingual text-in-image understanding, and introduce a new benchmark for the task. Surprisingly, our analysis reveals that one can (i) include as many as 100 training languages simultaneously (ii) with as little as 25-50% of non-English data, to greatly improve multilingual performance while retaining strong English performance. We further find that (iii) including non-English OCR data in pre-training and instruction-tuning is paramount for improving multilingual text-in-image understanding. Finally, we put all our findings together and train Centurio, a 100-language LVLM, offering state-of-the-art performance in an evaluation covering 14 tasks and 56 languages.
迄今为止,大多数大型视觉语言模型(LVLMs)主要接受英语数据的训练,这使得它们难以理解和处理非英语输入,并且无法生成目标语言的输出。现有的努力通过添加多语言训练数据来缓解这些问题,但这样做在很大程度上是临时性的,缺乏对不同训练组合如何影响不同语言群体的认识。在这项工作中,我们对大规模多语言LVLM的训练策略进行了全面的研究。首先,我们进行了一系列跨13个下游视觉语言任务和43种语言的多阶段实验,系统地研究了:(1)在不影响英语性能的情况下可以包含多少种训练语言;(2)预训练的最优语言分布以及(3)指令微调数据的优化。此外,我们还(4)研究了如何改进多语言文本图像理解,并引入了该任务的新的基准测试。令人惊讶的是,我们的分析表明,人们可以同时包含多达100种训练语言(ii)只需使用25-50%的非英语数据,就可以在保持强大的英语性能的同时,大大提高多语言能力。我们进一步发现,(iii)在预训练和指令微调中包含非英语OCR数据对于提高多语言文本图像理解至关重要。最后,我们将所有发现结合起来,训练了Centurio,这是一个100种语言的LVLM,在涵盖14项任务和56种语言的评估中表现出卓越的性能。
论文及项目相关链接
Summary
本文研究了大规模多语言视觉语言模型(LVLMs)的训练策略。通过一系列实验,探讨了同时训练多种语言时如何平衡英语性能与其他语言性能的问题,并发现可以同时包含多达100种训练语言,只需使用25%~50%的非英语数据即可在保持英语性能的同时大幅提升多语言能力。同时,研究还发现包含非英语OCR数据的预训练和指令微调对于提高多语言文本图像理解至关重要。最终,基于这些发现,训练出了一个支持100种语言的LVLM模型Centurio,在涵盖多种任务和语言的评估中表现出卓越性能。
Key Takeaways
- 大规模视觉语言模型(LVLMs)在应对非英语输入和生成目标语言输出时存在挑战。
- 通过一系列实验,系统研究了多语言训练策略,包括训练语言数量、预训练及指令微调数据的语言分布。
- 研究发现可以同时包含多达100种训练语言,且只需使用部分非英语数据即可在保持英语性能的同时提升多语言能力。
- 包含非英语OCR数据的预训练和指令微调对于提高多语言文本图像理解至关重要。
- 基于上述发现,开发出一种支持100种语言的LVLM模型Centurio。
- Centurio在涵盖多种任务和语言的评估中表现出卓越性能。
点此查看论文截图


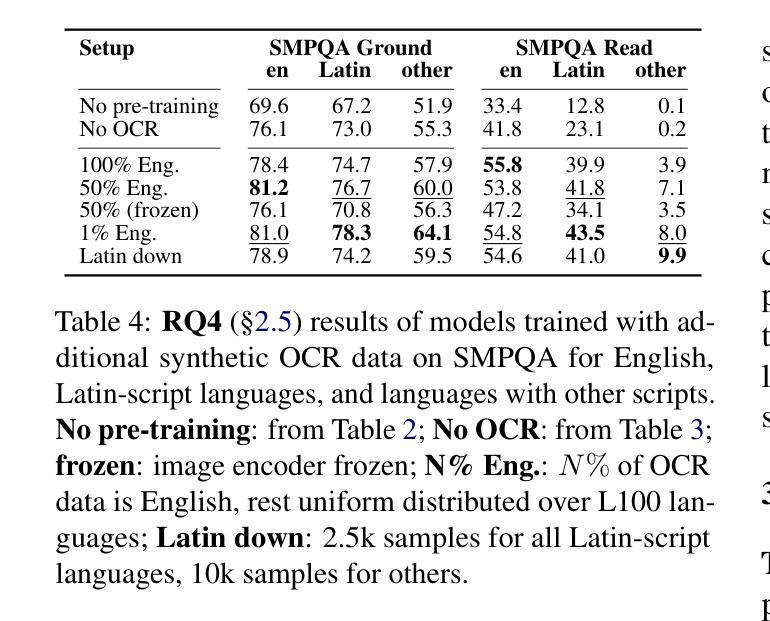
On the Generalizability of Transformer Models to Code Completions of Different Lengths
Authors:Nathan Cooper, Rosalia Tufano, Gabriele Bavota, Denys Poshyvanyk
The programming landscape is nowadays being reshaped by the advent of Large Language Models (LLMs) able to automate code-related tasks related to code implementation (e.g., code completion) and comprehension (e.g., code summarization). Such a paradigm shift comes with a number of implications related to how software will be written, maintained, and evolved. Also, these LLMs are extremely expensive to train, posing questions on their sustainability over time. Given their training cost, their ability to generalize, namely their ability to work on task instances different from those on which they have been trained, is an aspect worth being investigated. Previous work already showed that transformer models can successfully support code completion in a cross-project setting. However, it is unclear whether LLM are able to generalize to inputs having lengths not seen during training. For example, it is known that training a model on short instances allows to substantially reduce the training cost. However, the extent to which such a model would provide good performance on sequences having lengths not seen during training is not known. Many recent works in Natural Language Processing (NLP) tackled this problem in the context of decoder-only LLMs, i.e., xPOS and ALiBi. To assess if these solutions extend to encoder-decoder LLMs usually adopted in the code-related tasks, we present a large empirical study evaluating this generalization property of these and other encoding schemes proposed in the literature, namely Sinusoidal, xPOS, ALiBi, and T5. We found that none of these solutions successfully generalize to unseen lengths and that the only safe solution is to ensure the representativeness in the training set of all lengths likely to be encountered at inference time.
当前,编程领域正在被大型语言模型(LLM)重塑。这些模型能够自动化与代码实现(例如代码补全)和理解(例如代码摘要)相关的任务。这种范式转变带来了一系列关于软件如何编写、维护和演进的启示。此外,训练这些LLM需要极高的成本,这引发了它们是否可持续发展的质疑。考虑到它们的训练成本,它们在任务实例上的泛化能力——尤其是处理不同于训练实例的任务——是一个值得调查的方面。之前的工作已经表明,transformer模型可以在跨项目环境中成功支持代码补全。然而,尚不清楚LLM是否能够泛化到训练过程中未见长度的输入。例如,已知在短实例上训练模型可以大大减少训练成本。但是,这种模型在处理训练期间未见长度的序列方面的表现程度尚不清楚。自然语言处理(NLP)领域的许多最新工作都在针对仅解码器LLM的情境解决了这个问题,例如xPOS和ALiBi。为了评估这些解决方案是否适用于代码中通常采用编码器-解码器LLM的任务,我们进行了一项大型实证研究,评估了这些解决方案以及文献中提出的其他编码方案的泛化属性,包括正弦、xPOS、ALiBi和T5。我们发现这些解决方案都不适用于未见长度的泛化,唯一安全的解决方案是确保训练集中的代表性能够涵盖所有可能在推理时遇到的长度。
论文及项目相关链接
PDF Accepted for publication at ICSME 2024
Summary
大型语言模型(LLM)正在重塑编程领域,能够自动化与代码实现和理解相关的任务,如代码补全和代码摘要。然而,LLM的训练成本极高,其可持续性问题备受关注。LLM的泛化能力,即在新任务上表现的能力,特别是在训练时未见过的序列长度上,是一个值得研究的问题。研究表明,训练模型在短实例上可能降低训练成本,但对于未见过长度的序列性能表现尚不清楚。本研究对编码方案进行了大规模实证研究,包括正弦、xPOS、ALiBi和T5等方案,发现这些方案均不能成功泛化到未见过的长度,唯一安全的解决方案是确保训练集中涵盖所有可能在推理时遇到的长度。
Key Takeaways
- 大型语言模型(LLM)正在改变编程领域,实现自动化代码任务。
- LLM的训练成本高昂,其可持续性受到关注。
- LLM的泛化能力,即在新的、与训练数据不同的任务上的表现,是一个重要研究领域。
- 现有研究主要关注解码器LLM的泛化能力。
- 在编码方案的研究中,包括正弦、xPOS、ALiBi和T5等方案在代码相关任务中的泛化性能表现不一。
- 目前没有解决方案能够成功泛化到未见过的长度。
点此查看论文截图

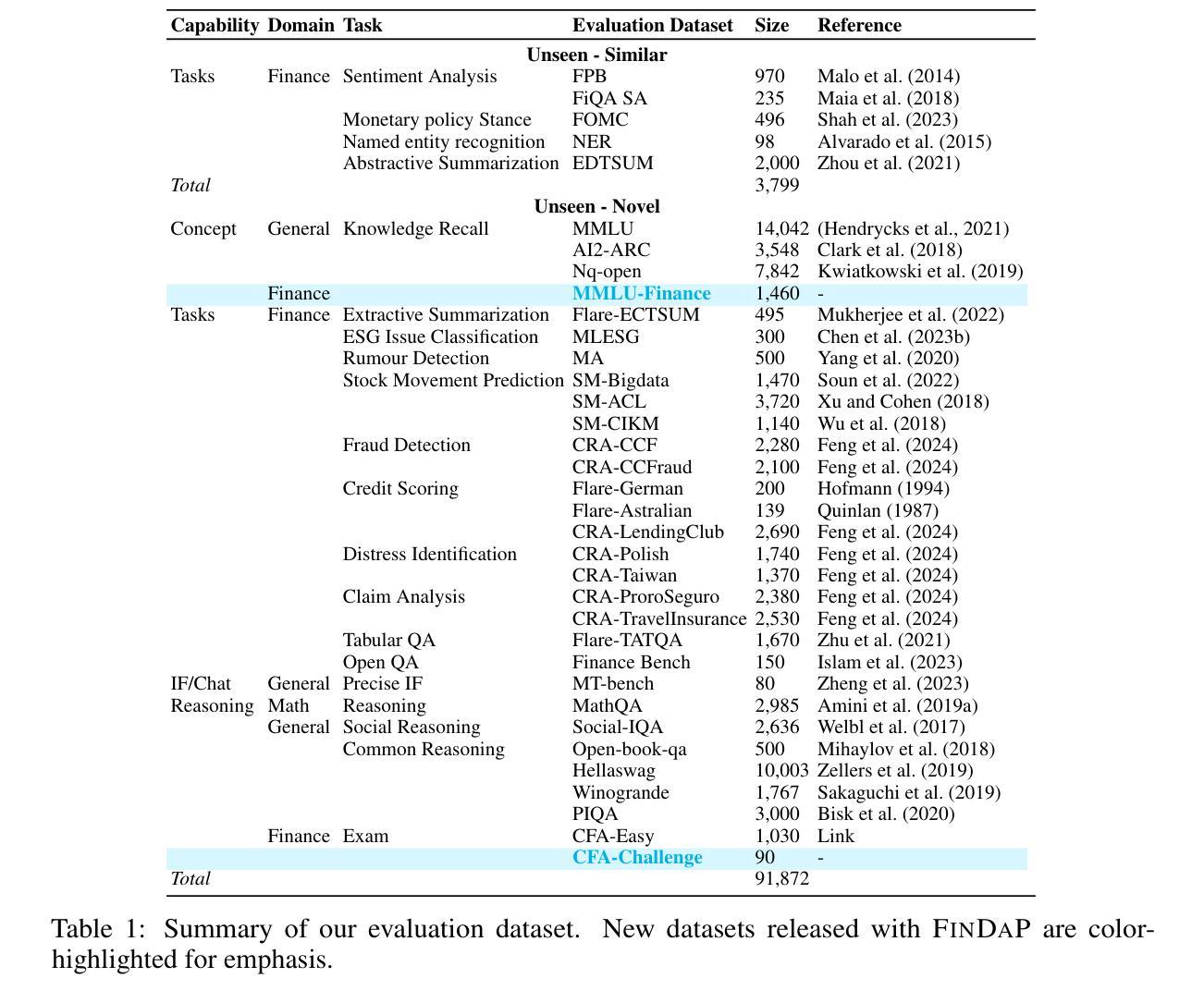
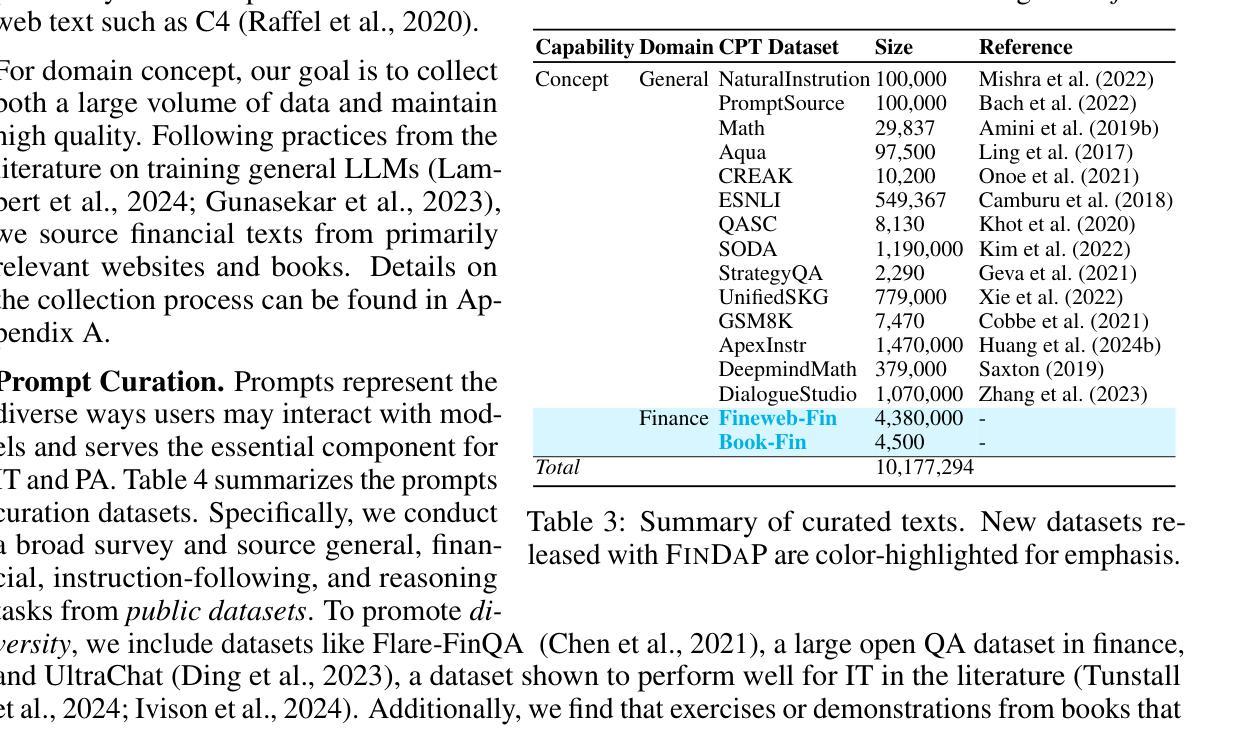
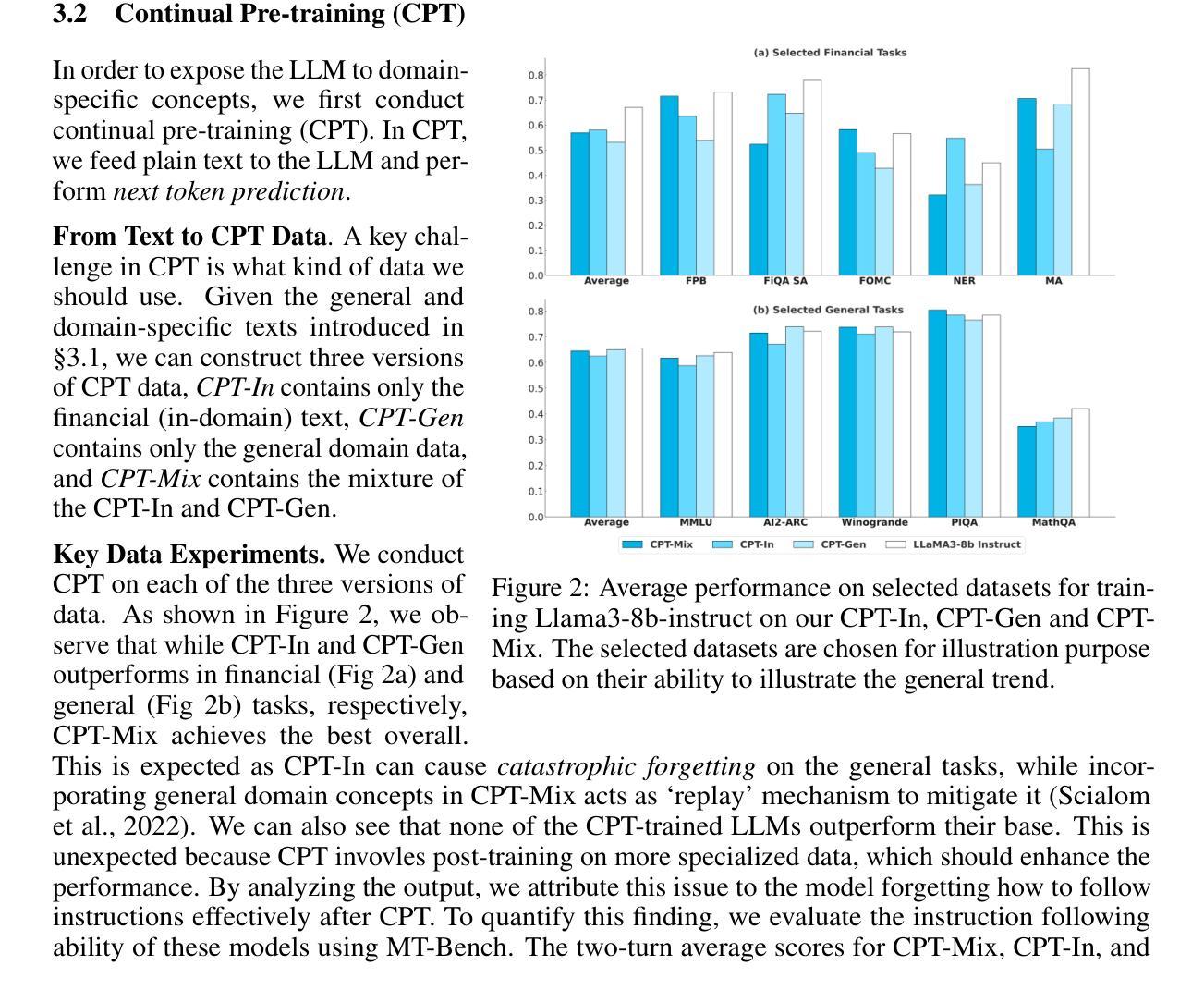
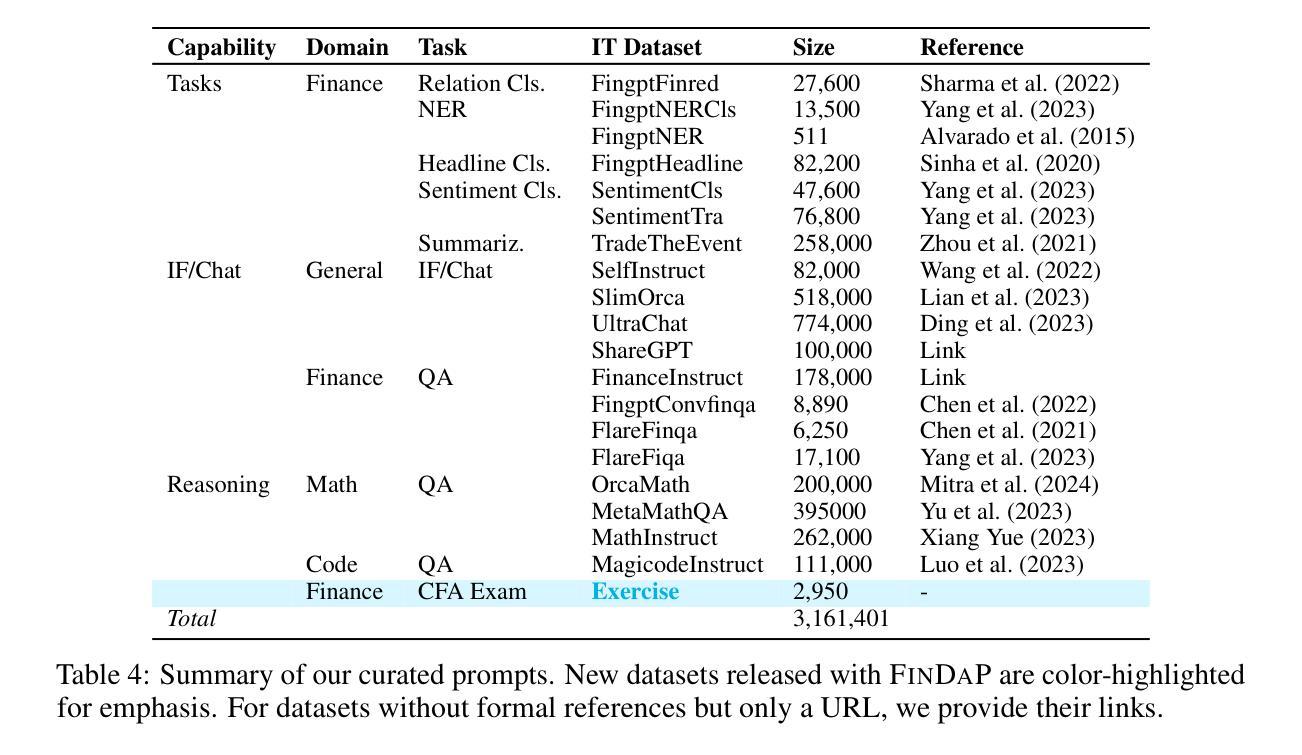
Demystifying Domain-adaptive Post-training for Financial LLMs
Authors:Zixuan Ke, Yifei Ming, Xuan-Phi Nguyen, Caiming Xiong, Shafiq Joty
Domain-adaptive post-training of large language models (LLMs) has emerged as a promising approach for specialized domains such as medicine and finance. However, significant challenges remain in identifying optimal adaptation criteria and training strategies across varying data and model configurations. To address these challenges, we introduce FINDAP, a systematic and fine-grained investigation into domain-adaptive post-training of LLMs for the finance domain. Our approach begins by identifying the core capabilities required for the target domain and designing a comprehensive evaluation suite aligned with these needs. We then analyze the effectiveness of key post-training stages, including continual pretraining, instruction tuning, and preference alignment. Building on these insights, we propose an effective training recipe centered on a novel preference data distillation method, which leverages process signals from a generative reward model. The resulting model, Llama-Fin, achieves state-of-the-art performance across a wide range of financial tasks. Our analysis also highlights how each post-training stage contributes to distinct capabilities, uncovering specific challenges and effective solutions, providing valuable insights for domain adaptation of LLMs. Project page: https://github.com/SalesforceAIResearch/FinDap
针对特定领域的语言模型(LLM)的后训练在当今的医学、金融等专业化领域展现出了巨大的潜力。然而,在不同数据和模型配置下确定最佳适应标准和训练策略仍然面临重大挑战。为了应对这些挑战,我们引入了FINDAP,这是一个针对金融领域LLM领域自适应后训练的全面而精细的研究。我们的方法首先确定目标领域所需的核心能力,并设计一套符合这些需求的综合评估套件。然后分析关键后训练阶段的有效性,包括连续预训练、指令调整和偏好对齐等。基于这些见解,我们提出了一种以新型偏好数据蒸馏方法为中心的有效训练配方,该方法利用来自生成奖励模型的过程信号。因此得到的模型Llama-Fin在广泛的金融任务上达到了最先进的性能。我们的分析还强调了每个后训练阶段对独特能力的贡献,揭示了特定的挑战和有效的解决方案,为LLM的领域适应提供了宝贵的见解。项目页面:https://github.com/SalesforceAIResearch/FinDap
论文及项目相关链接
Summary
领域自适应的后期训练大型语言模型(LLM)在医学和金融等特定领域具有巨大的潜力。本文介绍了一种新的方法FINDAP,通过系统地精细研究LLM的领域自适应后期训练,特别是在金融领域的应用。通过识别目标领域所需的核心能力,并设计与之相符的综合评估套件,分析关键后期训练阶段的效果,包括持续预训练、指令调整和偏好对齐等。基于这些见解,提出了一种以新型偏好数据蒸馏方法为中心的有效训练配方,该方法利用生成奖励模型的流程信号。最终模型Llama-Fin在广泛的金融任务上实现了卓越的性能。本文分析还指出了每个后期训练阶段对不同能力的贡献,揭示了特定挑战和有效解决方案,为LLM的领域自适应提供了宝贵见解。
Key Takeaways
- 领域自适应的后期训练大型语言模型(LLM)在特定领域如医学和金融中有广泛应用前景。
- FINDAP方法通过系统地研究LLM的领域自适应后期训练,为金融领域提供了一种新的解决方案。
- 通过识别目标领域所需的核心能力,并设计相应的综合评估套件,以评估模型性能。
- 分析了关键后期训练阶段的效果,包括持续预训练、指令调整和偏好对齐等。
- 提出了以偏好数据蒸馏方法为中心的有效训练配方,该方法利用生成奖励模型的流程信号。
- 最终模型Llama-Fin在广泛的金融任务上实现了卓越性能。
点此查看论文截图


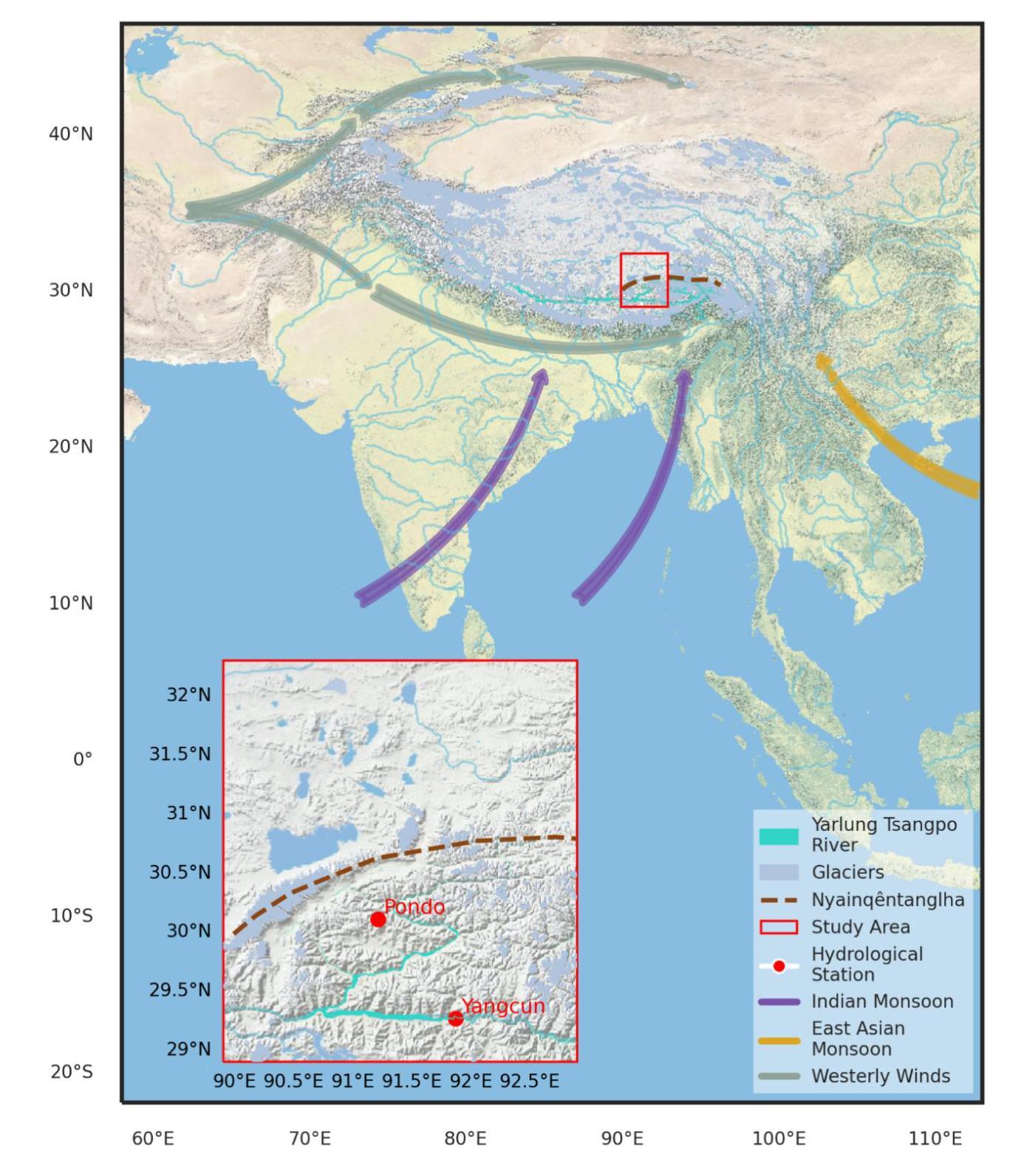
AI-Driven Reinvention of Hydrological Modeling for Accurate Predictions and Interpretation to Transform Earth System Modeling
Authors:Cuihui Xia, Lei Yue, Deliang Chen, Yuyang Li, Hongqiang Yang, Ancheng Xue, Zhiqiang Li, Qing He, Guoqing Zhang, Dambaru Ballab Kattel, Lei Lei, Ming Zhou
Traditional equation-driven hydrological models often struggle to accurately predict streamflow in challenging regional Earth systems like the Tibetan Plateau, while hybrid and existing algorithm-driven models face difficulties in interpreting hydrological behaviors. This work introduces HydroTrace, an algorithm-driven, data-agnostic model that substantially outperforms these approaches, achieving a Nash-Sutcliffe Efficiency of 98% and demonstrating strong generalization on unseen data. Moreover, HydroTrace leverages advanced attention mechanisms to capture spatial-temporal variations and feature-specific impacts, enabling the quantification and spatial resolution of streamflow partitioning as well as the interpretation of hydrological behaviors such as glacier-snow-streamflow interactions and monsoon dynamics. Additionally, a large language model (LLM)-based application allows users to easily understand and apply HydroTrace’s insights for practical purposes. These advancements position HydroTrace as a transformative tool in hydrological and broader Earth system modeling, offering enhanced prediction accuracy and interpretability.
传统基于方程的水文模型在面临具有挑战性的区域地球系统(如青藏高原)时,往往难以准确预测径流。而混合和现有算法驱动模型在解释水文行为方面则面临困难。本文介绍了HydroTrace,这是一种算法驱动、数据自主模型,相较于这些方法具有显著优势,实现了高达98%的Nash-Sutcliffe效率,并在未见数据上表现出强大的泛化能力。此外,HydroTrace利用先进的注意力机制来捕捉时空变化和特征特定影响,实现了径流分配的定量化和空间分辨率,并解释了水文行为,如冰川-雪-径流相互作用和季风动力学。另外,基于大型语言模型(LLM)的应用程序允许用户轻松理解和应用HydroTrace的见解以解决实际问题。这些进步使HydroTrace在水文和更广泛的地球系统建模中成为一种变革性工具,提高了预测精度和可解释性。
论文及项目相关链接
Summary
本文介绍了HydroTrace模型,这是一种算法驱动、数据无关的水文模型,适用于像青藏高原这样的具有挑战性的区域地球系统。该模型能够捕捉时空变化和特征特定影响,具有高预测准确率和出色的泛化能力。此外,HydroTrace还利用大型语言模型(LLM)使公众更容易理解和应用其见解,为水文和更广泛的地球系统建模提供了先进工具。
Key Takeaways
- HydroTrace是一种算法驱动、数据无关的水文模型,适用于具有挑战性的区域地球系统。
- HydroTrace通过利用先进的注意力机制来捕捉时空变化和特征特定影响,从而实现高预测准确率和泛化能力。
- HydroTrace实现了高达98%的Nash-Sutcliffe效率,显著优于传统和混合模型。
- HydroTrace能够量化并解析径流的时空分布和空间分辨率,解释如冰川-雪-径流相互作用和季风动态等水文行为。
- HydroTrace利用大型语言模型(LLM)使得公众更容易理解和应用其见解。
- HydroTrace在实用性和准确性方面为水文模型带来了新的可能性,并对广泛的地球系统建模具有重大意义。
点此查看论文截图


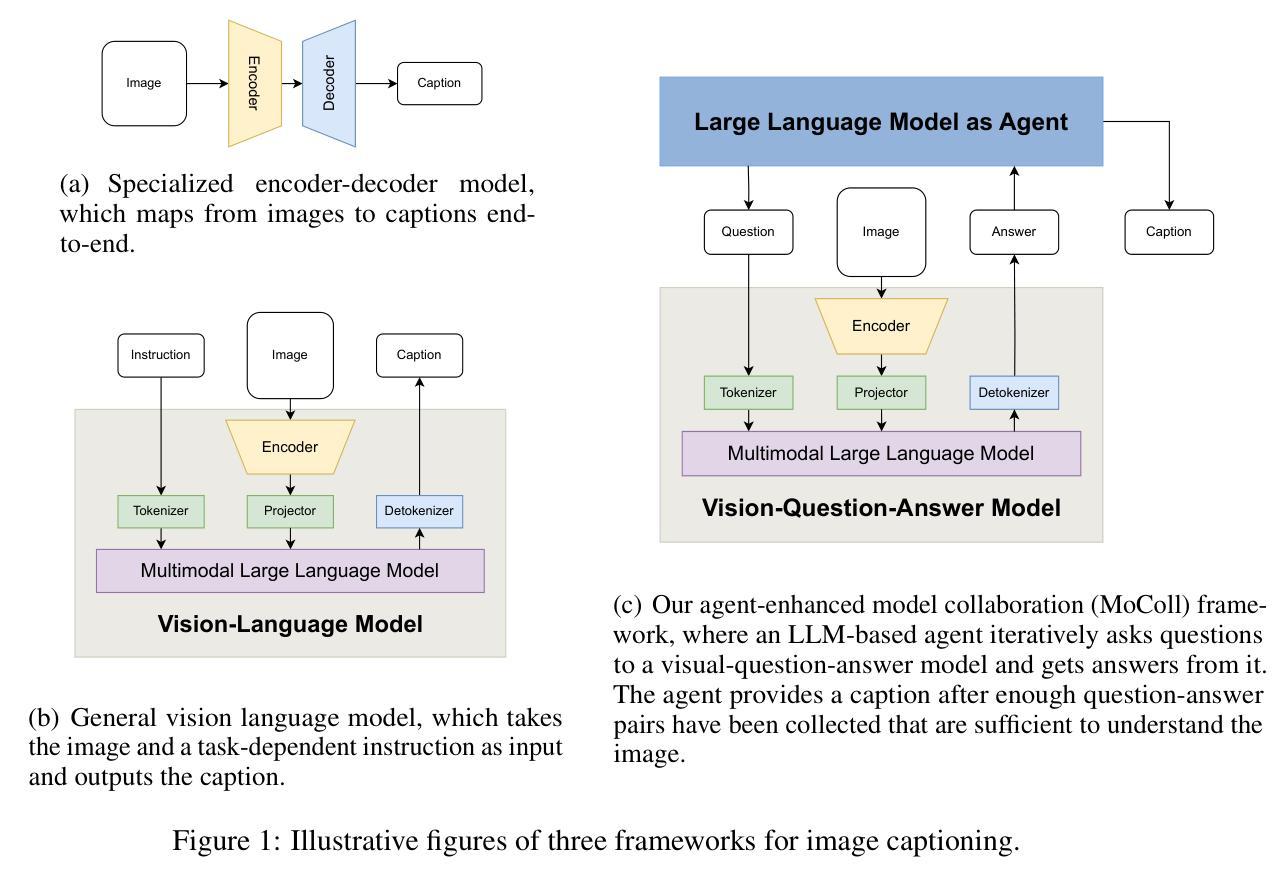
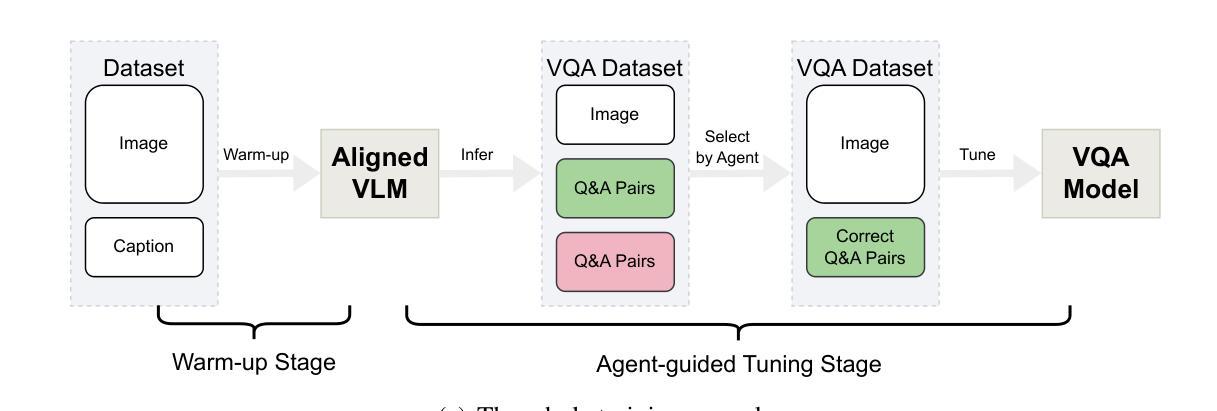
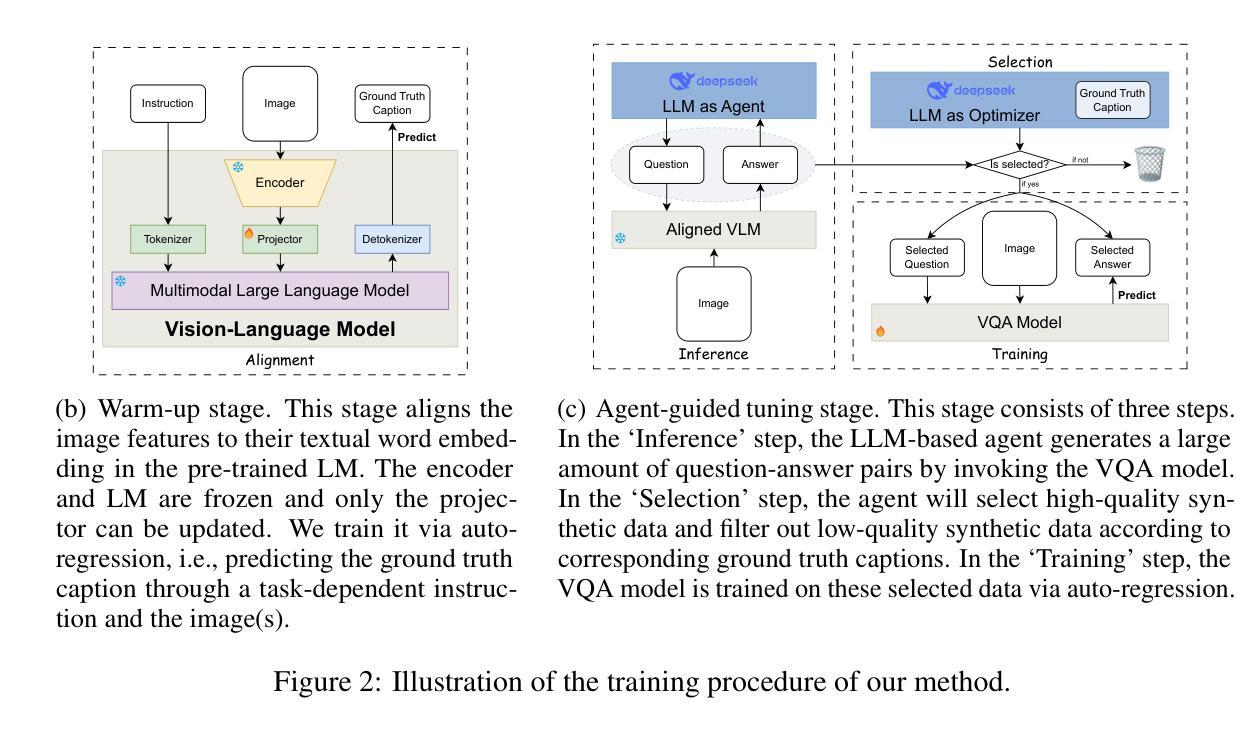
MoColl: Agent-Based Specific and General Model Collaboration for Image Captioning
Authors:Pu Yang, Bin Dong
Image captioning is a critical task at the intersection of computer vision and natural language processing, with wide-ranging applications across various domains. For complex tasks such as diagnostic report generation, deep learning models require not only domain-specific image-caption datasets but also the incorporation of relevant general knowledge to provide contextual accuracy. Existing approaches exhibit inherent limitations: specialized models excel in capturing domain-specific details but lack generalization, while vision-language models (VLMs) built on large language models (LLMs) leverage general knowledge but struggle with domain-specific adaptation. To address these limitations, this paper proposes a novel agent-enhanced model collaboration framework, which we call MoColl, designed to effectively integrate domain-specific and general knowledge. Specifically, our approach is to decompose complex image captioning tasks into a series of interconnected question-answer subtasks. A trainable visual question answering (VQA) model is employed as a specialized tool to focus on domain-specific visual analysis, answering task-specific questions based on image content. Concurrently, an LLM-based agent with general knowledge formulates these questions and synthesizes the resulting question-answer pairs into coherent captions. Beyond its role in leveraging the VQA model, the agent further guides its training to enhance its domain-specific capabilities. Experimental results on radiology report generation validate the effectiveness of the proposed framework, demonstrating significant improvements in the quality of generated reports.
图像标注是计算机视觉和自然语言处理领域的交叉任务,具有广泛的应用范围,涵盖各个领域。对于生成诊断报告等复杂任务,深度学习模型不仅需要特定领域的图像标注数据集,还需要融入相关的通用知识来提供上下文准确性。现有方法存在固有的局限性:特定领域的模型擅长捕捉特定细节,但缺乏泛化能力;而基于大型语言模型的视觉语言模型(VLM)利用通用知识,但在特定领域的适应性方面却遇到困难。为了克服这些局限性,本文提出了一种新型代理增强模型协作框架,我们称之为MoColl,旨在有效地整合特定领域知识和通用知识。具体来说,我们的方法是将复杂的图像标注任务分解为一系列相互关联的问答子任务。采用可训练的视觉问答(VQA)模型作为专用工具,专注于特定领域的视觉分析,根据图像内容回答特定任务的问题。同时,一个基于大型语言模型的代理利用通用知识来制定这些问题,并将得到的问题答案对合成连贯的标注。除了发挥对VQA模型的利用作用外,该代理还进一步指导其训练,以增强其特定领域的能力。在放射学报告生成方面的实验结果验证了所提框架的有效性,显示出生成的报告质量显著提高。
论文及项目相关链接
Summary
图像描述是计算机视觉和自然语言处理领域的重要任务,广泛应用于各个领域。针对诊断报告生成等复杂任务,深度学习模型不仅需要特定的图像描述数据集,还需要融入相关的通用知识以提高上下文准确性。现有方法存在局限性:特定模型擅长捕捉特定领域的细节,但缺乏泛化能力;而基于大型语言模型的视觉语言模型(VLMs)虽然可以利用通用知识,但在特定领域的适应性方面却遇到困难。本文提出了一种新的代理增强模型协作框架(MoColl),旨在有效整合特定领域和通用知识。具体来说,本文方法是将复杂的图像描述任务分解为一系列相互关联的问答子任务。采用可训练的视觉问答(VQA)模型作为特定工具,专注于特定领域的视觉分析,根据图像内容回答特定任务问题。同时,具有通用知识的LLM基于代理制定这些问题,并将结果问题答案对合成连贯的描述。除了发挥在VQA模型中的作用外,代理还进一步指导其训练,增强其在特定领域的能力。在放射学报告生成方面的实验验证了所提框架的有效性,显示出生成的报告质量显著提高。
Key Takeaways
- 图像描述是计算机视觉和自然语言处理的重要交叉任务,具有广泛的应用领域。
- 深度学习模型在图像描述任务中需要特定的图像描述数据集和通用知识。
- 现有方法存在局限性:特定模型缺乏泛化能力,而基于大型语言模型的视觉语言模型在特定领域的适应性方面面临挑战。
- 本文提出了一种新的代理增强模型协作框架(MoColl),以整合特定领域和通用知识。
- MoColl框架将图像描述任务分解为一系列相互关联的问答子任务。
- 采用可训练的视觉问答(VQA)模型回答特定任务问题,同时利用具有通用知识的LLM代理制定问题和合成描述。
点此查看论文截图

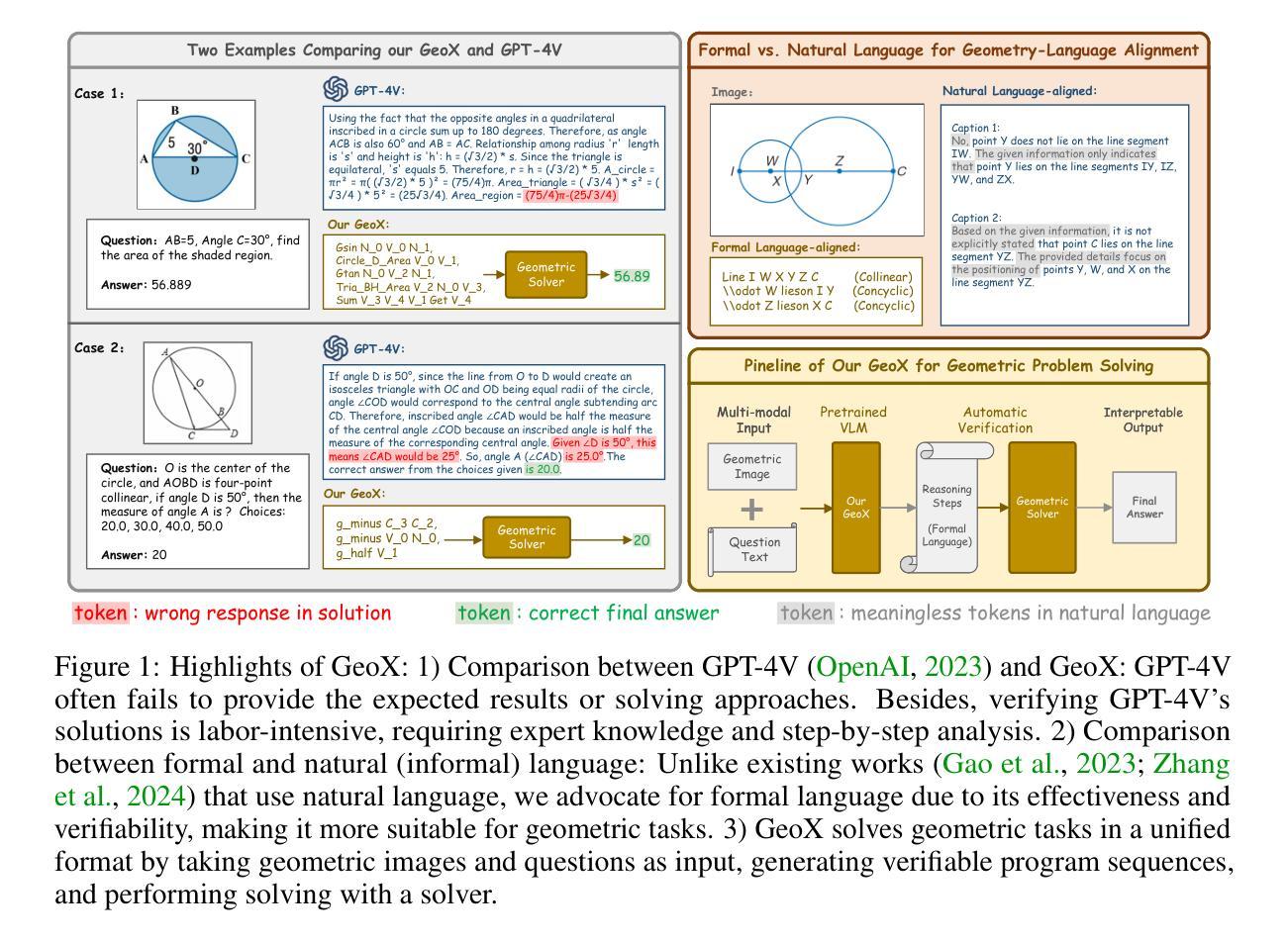
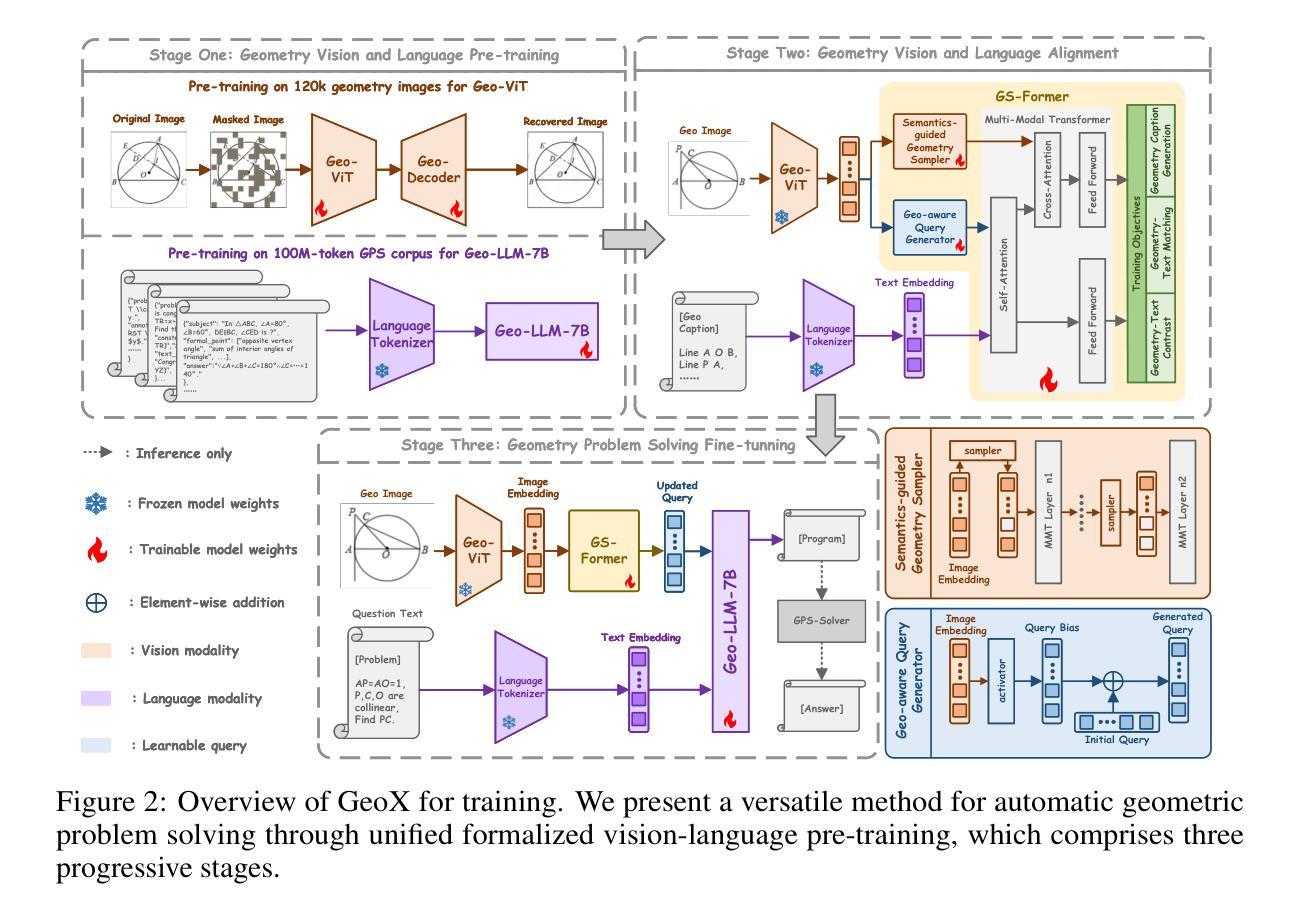
GeoX: Geometric Problem Solving Through Unified Formalized Vision-Language Pre-training
Authors:Renqiu Xia, Mingsheng Li, Hancheng Ye, Wenjie Wu, Hongbin Zhou, Jiakang Yuan, Tianshuo Peng, Xinyu Cai, Xiangchao Yan, Bin Wang, Conghui He, Botian Shi, Tao Chen, Junchi Yan, Bo Zhang
Despite their proficiency in general tasks, Multi-modal Large Language Models (MLLMs) struggle with automatic Geometry Problem Solving (GPS), which demands understanding diagrams, interpreting symbols, and performing complex reasoning. This limitation arises from their pre-training on natural images and texts, along with the lack of automated verification in the problem-solving process. Besides, current geometric specialists are limited by their task-specific designs, making them less effective for broader geometric problems. To this end, we present GeoX, a multi-modal large model focusing on geometric understanding and reasoning tasks. Given the significant differences between geometric diagram-symbol and natural image-text, we introduce unimodal pre-training to develop a diagram encoder and symbol decoder, enhancing the understanding of geometric images and corpora. Furthermore, we introduce geometry-language alignment, an effective pre-training paradigm that bridges the modality gap between unimodal geometric experts. We propose a Generator-And-Sampler Transformer (GS-Former) to generate discriminative queries and eliminate uninformative representations from unevenly distributed geometric signals. Finally, GeoX benefits from visual instruction tuning, empowering it to take geometric images and questions as input and generate verifiable solutions. Experiments show that GeoX outperforms both generalists and geometric specialists on publicly recognized benchmarks, such as GeoQA, UniGeo, Geometry3K, and PGPS9k.
尽管多模态大型语言模型(MLLMs)在一般任务上表现熟练,但在自动几何问题求解(GPS)方面却面临挑战。GPS需要理解图表、解释符号和进行复杂推理。这一局限性源于它们对自然图像和文本的预训练,以及问题解决过程中缺乏自动验证。此外,当前的几何专家受限于其特定任务的设计,使得他们对更广泛的几何问题处理效率较低。为此,我们推出了专注于几何理解和推理任务的GeoX多模态大型模型。考虑到几何图形符号与几何图像文本之间的显著差异,我们引入了单模态预训练来开发图表编码器和符号解码器,提高对几何图像和语料的理解。此外,我们还引入了几何语言对齐的有效预训练模式,它弥合了单模态几何专家之间的模态差距。我们提出了一种生成器和采样器Transformer(GS-Former),以生成区分性查询并消除不均匀分布的几何信号中的无用表示。最后,GeoX得益于视觉指令微调,能够接收几何图像和问题作为输入,并生成可验证的解决方案。实验表明,GeoX在公认的基准测试上表现优于通用模型和几何专家模型,如GeoQA、UniGeo、Geometry3K和PGPS9k等。
论文及项目相关链接
PDF Our code is available at https://github.com/Alpha-Innovator/GeoX
Summary:尽管多模态大型语言模型(MLLMs)在一般任务上表现出色,但在自动几何问题求解(GPS)方面存在困难,这要求理解图表、解释符号和进行复杂推理。其局限性源于对自然图像和文本的预训练,以及问题求解过程中缺乏自动验证。为解决这些问题,提出GeoX模型,专注于几何理解和推理任务。通过引入单模态预训练、几何语言对齐和生成采样变压器(GS-Former)等方法,提高几何图像和语料的理解能力,缩小模态间的差距。实验表明,GeoX在公认的基准测试上优于通用模型和几何专家。
Key Takeaways:
- 多模态大型语言模型(MLLMs)在自动几何问题求解(GPS)方面存在困难。
- 局限性的原因是模型预训练主要基于自然图像和文本,缺乏针对几何问题的专门训练。
- GeoX模型旨在解决这一问题,通过引入单模态预训练、几何语言对齐等方法提升对几何图像和语料的理解。
- GeoX模型采用生成采样变压器(GS-Former)来生成判别性查询并消除不均匀分布的几何信号中的非信息表示。
- GeoX模型通过视觉指令调整,可以接收几何图像和问题作为输入,并生成可验证的解决方案。
- 实验结果显示,GeoX在多个公认的基准测试上表现优于通用模型和几何专家。
点此查看论文截图

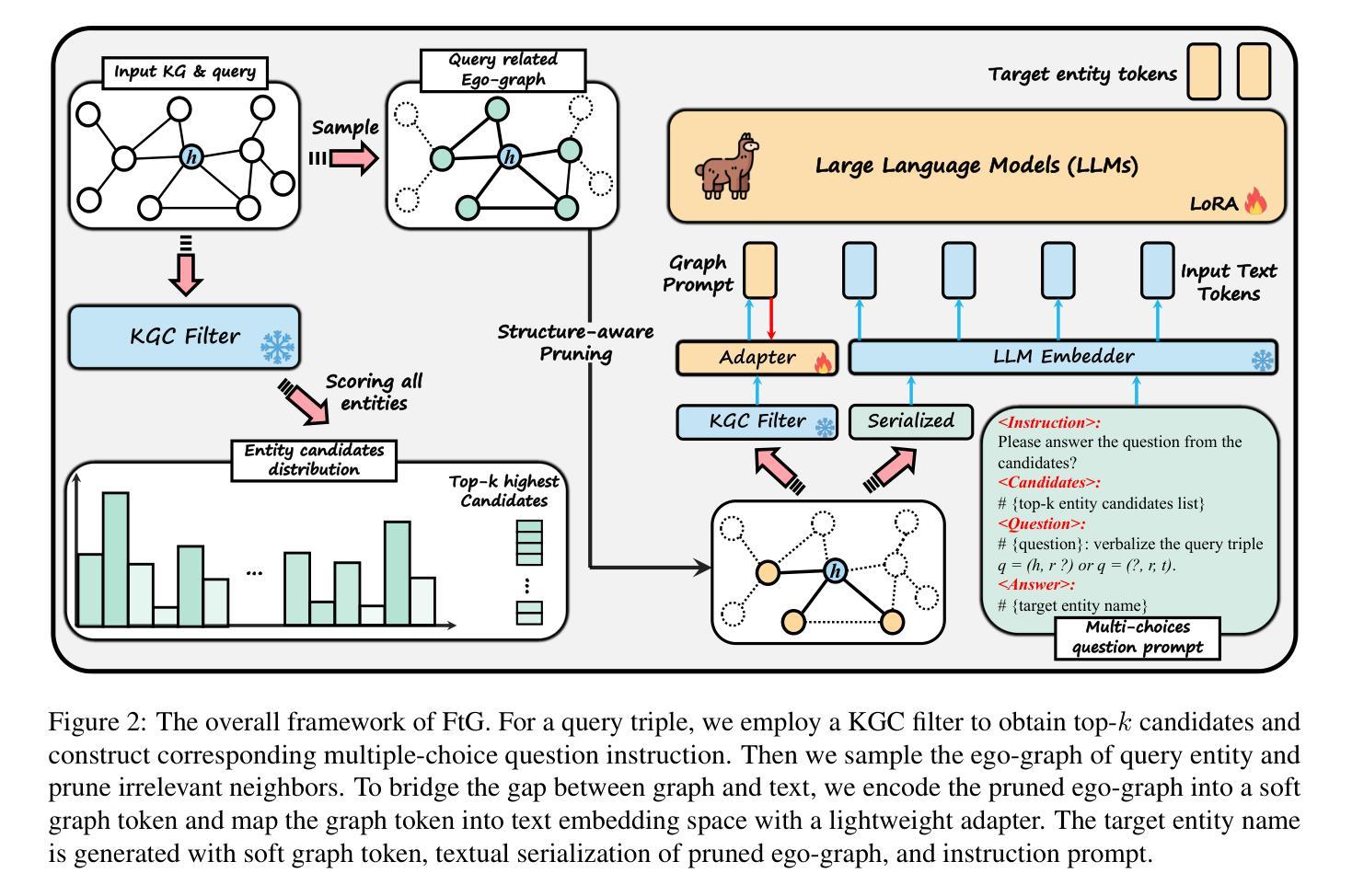
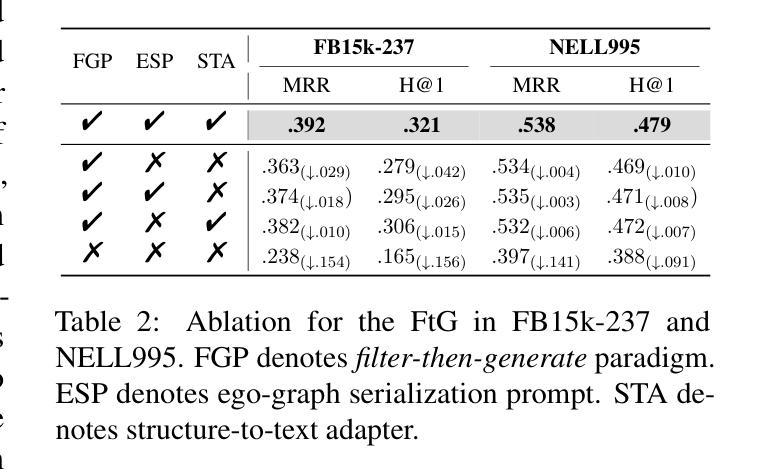
Filter-then-Generate: Large Language Models with Structure-Text Adapter for Knowledge Graph Completion
Authors:Ben Liu, Jihai Zhang, Fangquan Lin, Cheng Yang, Min Peng
Large Language Models (LLMs) present massive inherent knowledge and superior semantic comprehension capability, which have revolutionized various tasks in natural language processing. Despite their success, a critical gap remains in enabling LLMs to perform knowledge graph completion (KGC). Empirical evidence suggests that LLMs consistently perform worse than conventional KGC approaches, even through sophisticated prompt design or tailored instruction-tuning. Fundamentally, applying LLMs on KGC introduces several critical challenges, including a vast set of entity candidates, hallucination issue of LLMs, and under-exploitation of the graph structure. To address these challenges, we propose a novel instruction-tuning-based method, namely FtG. Specifically, we present a \textit{filter-then-generate} paradigm and formulate the KGC task into a multiple-choice question format. In this way, we can harness the capability of LLMs while mitigating the issue casused by hallucinations. Moreover, we devise a flexible ego-graph serialization prompt and employ a structure-text adapter to couple structure and text information in a contextualized manner. Experimental results demonstrate that FtG achieves substantial performance gain compared to existing state-of-the-art methods. The instruction dataset and code are available at \url{https://github.com/LB0828/FtG}.
大规模语言模型(LLM)拥有庞大的内在知识和卓越语义理解能力,已经彻底改变了自然语言处理的各项任务。尽管取得了成功,但在知识图谱补全(KGC)方面,LLM仍存在明显差距。经验证据表明,即使通过复杂提示设计或针对指令调整,LLM的表现始终逊于传统KGC方法。根本原因在于,将LLM应用于KGC面临几个关键挑战,包括大量的实体候选对象、LLM的幻觉问题以及对图结构的利用不足。为了解决这些挑战,我们提出了一种基于指令调整的新方法,称为FtG。具体来说,我们提出了一个“过滤然后生成”的模式,并将KGC任务制定为多选问题格式。通过这种方式,我们可以在减轻幻觉问题影响的同时,利用LLM的能力。此外,我们设计了一个灵活的自我图序列化提示,并采用了结构文本适配器,以语境化的方式将结构和文本信息进行结合。实验结果表明,与现有最先进的方法相比,FtG实现了显著的性能提升。指令数据集和代码可通过以下网址获得:https://github.com/LB0b28/FtG。
论文及项目相关链接
PDF COLING 2025 Main Conference
Summary
大规模语言模型(LLM)具有巨大的内在知识和高级的语义理解能力,已经彻底改变了自然语言处理的各项任务。然而,在知识图谱补全(KGC)方面,LLM的应用仍存在显著差距。尽管通过精心设计的提示或指令调整,LLM的表现仍然不及传统的KGC方法。在KGC任务中应用LLM面临实体候选集规模大、LLM的幻觉问题以及图形结构利用不足等挑战。为解决这些问题,我们提出了一种基于指令调整的方法FtG,并采用了“过滤-生成”的模式,将KGC任务转化为多选问题形式。此外,我们还设计了灵活的自我图序列化提示,并采用结构文本适配器以语境化的方式结合结构和文本信息。实验结果表明,FtG相较于现有先进方法取得了显著的性能提升。
Key Takeaways
- LLM具有强大的内在知识和语义理解能力,但其在知识图谱补全(KGC)方面的应用仍存在挑战。
- LLM在KGC方面的挑战包括实体候选集规模大、LLM的幻觉问题以及图形结构利用不足。
- 为解决上述挑战,提出了基于指令调整的方法FtG。
- FtG采用“过滤-生成”模式,将KGC任务转化为多选问题形式以利用LLM的优势并缓解幻觉问题。
- FtG设计了灵活的自我图序列化提示,以更好地适应KGC任务。
- FtG采用结构文本适配器结合结构和文本信息,提高模型性能。
点此查看论文截图


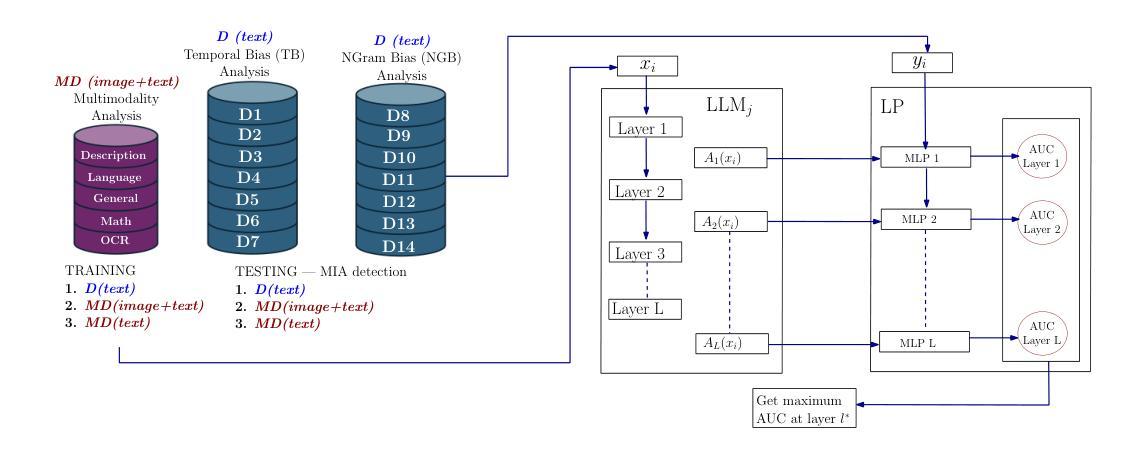
LUMIA: Linear probing for Unimodal and MultiModal Membership Inference Attacks leveraging internal LLM states
Authors:Luis Ibanez-Lissen, Lorena Gonzalez-Manzano, Jose Maria de Fuentes, Nicolas Anciaux, Joaquin Garcia-Alfaro
Large Language Models (LLMs) are increasingly used in a variety of applications, but concerns around membership inference have grown in parallel. Previous efforts focus on black-to-grey-box models, thus neglecting the potential benefit from internal LLM information. To address this, we propose the use of Linear Probes (LPs) as a method to detect Membership Inference Attacks (MIAs) by examining internal activations of LLMs. Our approach, dubbed LUMIA, applies LPs layer-by-layer to get fine-grained data on the model inner workings. We test this method across several model architectures, sizes and datasets, including unimodal and multimodal tasks. In unimodal MIA, LUMIA achieves an average gain of 15.71 % in Area Under the Curve (AUC) over previous techniques. Remarkably, LUMIA reaches AUC>60% in 65.33% of cases – an increment of 46.80% against the state of the art. Furthermore, our approach reveals key insights, such as the model layers where MIAs are most detectable. In multimodal models, LPs indicate that visual inputs can significantly contribute to detect MIAs – AUC>60% is reached in 85.90% of experiments.
大型语言模型(LLM)在各种应用中越来越广泛,但关于成员推理的担忧也在日益增长。之前的努力主要集中在黑箱到灰箱模型上,从而忽视了内部LLM信息的潜在价值。为了解决这个问题,我们提出了一种使用线性探针(LPs)的方法,通过检查LLM的内部激活来检测成员推理攻击(MIA)。我们的方法称为LUMIA,它通过逐层应用LPs来获得关于模型内部工作机制的细粒度数据。我们在多种模型架构、规模和数据集上测试了此方法,包括单模态和多模态任务。在单模态MIA中,与传统的技术相比,平均增益提高了AUC(曲线下面积)的百分比达到平均增加百分比为百分之五点七十一(AUC提高了百分之五点七十一)。值得注意的是,在百分之六十五点三三的案例中,Lumia的AUC超过了百分之六十(AUC> 60%),相比之前最高水平的案例有了四十六点八的提高。此外,我们的方法揭示了一些重要见解,比如最能检测到MIA的模型层。在多模态模型中,LPs表明视觉输入可以大大有助于检测MIA——在百分之八十五点九的实验中达到AUC> 60%。
论文及项目相关链接
Summary
LLM内部信息用于检测成员推理攻击的新方法——LUMIA技术提出利用线性探头(LPs)进行探究内部活动实现更精细的检测。该技术能适用于不同模型架构、大小和数据集,包括单模态和多模态任务,可提升成员推理攻击检测的准确性。
Key Takeaways
- LLMs在多种应用中的使用日益普及,成员推理攻击的检测变得越来越重要。
- LUMIA技术利用线性探头(LPs)通过检查LLM的内部活动来检测成员推理攻击(MIAs)。
- LUMIA能够在不同的模型架构、大小和单模态任务上实现更精细的检测,平均提升AUC值达15.71%。
点此查看论文截图

Separating Tongue from Thought: Activation Patching Reveals Language-Agnostic Concept Representations in Transformers
Authors:Clément Dumas, Chris Wendler, Veniamin Veselovsky, Giovanni Monea, Robert West
A central question in multilingual language modeling is whether large language models (LLMs) develop a universal concept representation, disentangled from specific languages. In this paper, we address this question by analyzing latent representations (latents) during a word translation task in transformer-based LLMs. We strategically extract latents from a source translation prompt and insert them into the forward pass on a target translation prompt. By doing so, we find that the output language is encoded in the latent at an earlier layer than the concept to be translated. Building on this insight, we conduct two key experiments. First, we demonstrate that we can change the concept without changing the language and vice versa through activation patching alone. Second, we show that patching with the mean over latents across different languages does not impair and instead improves the models’ performance in translating the concept. Our results provide evidence for the existence of language-agnostic concept representations within the investigated models.
在多语言语言建模中的一个核心问题是大型语言模型(LLM)是否脱离了特定语言,发展出了一种通用的概念表示。在本文中,我们通过分析基于transformer的LLM在单词翻译任务中的潜在表示(latents),来解决这个问题。我们策略性地从源翻译提示中提取潜在因素,并将其插入到目标翻译提示的前向传递中。通过这样做,我们发现输出语言比要翻译的概念更早地编码在潜在因素中。基于这一发现,我们进行了两项关键实验。首先,我们证明可以通过仅使用激活补丁来改变概念而不改变语言,反之亦然。其次,我们展示了通过不同语言的潜在因素平均值进行补丁并不会损害模型的性能,反而能提高其在翻译概念方面的表现。我们的结果提供了证据,证明在所研究的模型中存在与语言无关的概念表示。
论文及项目相关链接
PDF 18 pages, 14 figures, previous version published under the title “How Do Llamas Process Multilingual Text? A Latent Exploration through Activation Patching” at the ICML 2024 mechanistic interpretability workshop at https://openreview.net/forum?id=0ku2hIm4BS
Summary:
本文研究了基于Transformer的大型语言模型(LLM)在词翻译任务中的潜在表示,并发现语言模型中存在与特定语言无关的概念表示。通过分析和修改这些潜在表示,实验证明可以在不改变概念的情况下改变输出语言,同时也表明用不同语言的平均潜在表示进行修补可以提高模型的翻译性能。
Key Takeaways:
- 大型语言模型(LLM)在词翻译任务中的潜在表示是研究的重点。
- 通过分析发现,输出语言被编码在翻译要翻译的概念的早期层中。
- 通过激活补丁技术,可以在不改变概念的情况下改变输出语言,反之亦然。
- 使用不同语言的平均潜在表示进行补丁可以提高模型的翻译性能。
- 实验证明语言模型中存在与特定语言无关的概念表示。
- 语言模型的潜代表结构揭示了一种潜在的普遍概念表示方式。
点此查看论文截图