⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-14 更新
UV-Attack: Physical-World Adversarial Attacks for Person Detection via Dynamic-NeRF-based UV Mapping
Authors:Yanjie Li, Wenxuan Zhang, Kaisheng Liang, Bin Xiao
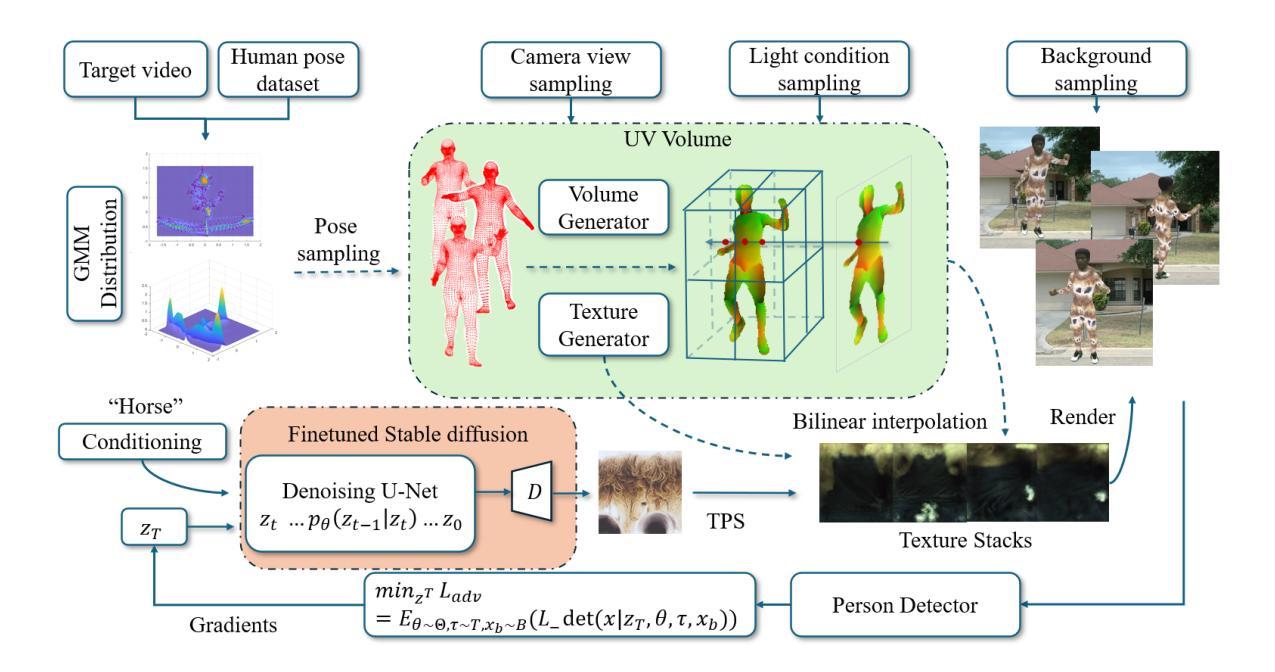
In recent research, adversarial attacks on person detectors using patches or static 3D model-based texture modifications have struggled with low success rates due to the flexible nature of human movement. Modeling the 3D deformations caused by various actions has been a major challenge. Fortunately, advancements in Neural Radiance Fields (NeRF) for dynamic human modeling offer new possibilities. In this paper, we introduce UV-Attack, a groundbreaking approach that achieves high success rates even with extensive and unseen human actions. We address the challenge above by leveraging dynamic-NeRF-based UV mapping. UV-Attack can generate human images across diverse actions and viewpoints, and even create novel actions by sampling from the SMPL parameter space. While dynamic NeRF models are capable of modeling human bodies, modifying clothing textures is challenging because they are embedded in neural network parameters. To tackle this, UV-Attack generates UV maps instead of RGB images and modifies the texture stacks. This approach enables real-time texture edits and makes the attack more practical. We also propose a novel Expectation over Pose Transformation loss (EoPT) to improve the evasion success rate on unseen poses and views. Our experiments show that UV-Attack achieves a 92.75% attack success rate against the FastRCNN model across varied poses in dynamic video settings, significantly outperforming the state-of-the-art AdvCamou attack, which only had a 28.50% ASR. Moreover, we achieve 49.5% ASR on the latest YOLOv8 detector in black-box settings. This work highlights the potential of dynamic NeRF-based UV mapping for creating more effective adversarial attacks on person detectors, addressing key challenges in modeling human movement and texture modification.
在最近的研究中,使用补丁或基于静态3D模型的纹理修改对抗人员检测器的攻击由于人类运动的灵活性而具有较低的成功率。对由各种动作引起的3D变形进行建模一直是一个巨大的挑战。幸运的是,神经网络辐射场(NeRF)在动态人体建模方面的进展提供了新的可能性。在本文中,我们介绍了UV-Attack,这是一种突破性的方法,即使面对广泛且未见的人类动作,也能实现较高的成功率。我们通过利用动态NeRF的UV映射来解决上述挑战。UV-Attack可以生成各种动作和视角的人类图像,甚至可以通过采样SMPL参数空间来创建新的动作。虽然动态NeRF模型能够对人体进行建模,但修改衣物纹理却具有挑战性,因为它们嵌入在神经网络参数中。为了解决这个问题,UV-Attack生成UV地图而不是RGB图像,并修改纹理堆栈。这种方法使实时纹理编辑成为可能,并使攻击更加实用。我们还提出了一种新型的姿态变换期望损失(EoPT),以提高在未见姿态和视角上的躲避成功率。我们的实验表明,在动态视频设置中,针对各种姿态的FastRCNN模型,UV-Attack的攻击成功率达到了92.75%,显著优于最先进的AdvCamou攻击,其攻击成功率仅为28.5%。此外,我们在黑箱设置下实现了对最新YOLOv8检测器的49.5%攻击成功率。这项工作突出了动态NeRF的UV映射在创建针对人员检测器的更有效对抗攻击方面的潜力,解决了建模人类运动和纹理修改方面的关键挑战。
论文及项目相关链接
PDF 23 pages, 22 figures, submitted to ICLR2025
摘要
基于NeRF的动态人体建模对抗攻击新方法
UV-Attack利用动态NeRF的UV映射技术,生成各种动作和视角的人体图像,并成功实现高成功率对抗攻击。通过采样SMPL参数空间,甚至可以创建新动作。面临嵌入神经网络参数的衣物纹理修改挑战时,UV-Attack生成UV地图代替RGB图像并修改纹理堆栈,实现实时纹理编辑。此外,提出期望姿态转换损失(EoPT)来提高未见姿态和视角的躲避成功率。实验显示,UV-Attack在动态视频设置中对FastRCNN模型的攻击成功率为92.75%,显著优于仅具有28.50%攻击成功率的AdvCamou攻击。此外,在针对最新YOLOv8检测器的黑箱设置中实现了49.5%的攻击成功率。这项工作展示了动态NeRF的UV映射在创建更有效的人体检测对抗攻击方面的潜力。
关键见解
- 静态3D模型纹理修改或补丁对动态人体检测的对抗攻击成功率较低。
- 动态NeRF建模为人体动作提供了新模型化方法,提高了对抗攻击的成功率。
- UV-Attack利用动态NeRF的UV映射技术生成不同动作和视角的人体图像。
- 通过采样SMPL参数空间,UV-Attack可以创造新动作。
- UV-Attack生成UV地图而不是RGB图像以修改纹理,实现实时纹理编辑。
- 提出期望姿态转换损失(EoPT)提高未见姿态和视角的躲避成功率。
- UV-Attack在动态视频设置和黑箱设置中对最新人体检测模型表现出高攻击成功率。
点此查看论文截图



The GAN is dead; long live the GAN! A Modern GAN Baseline
Authors:Yiwen Huang, Aaron Gokaslan, Volodymyr Kuleshov, James Tompkin
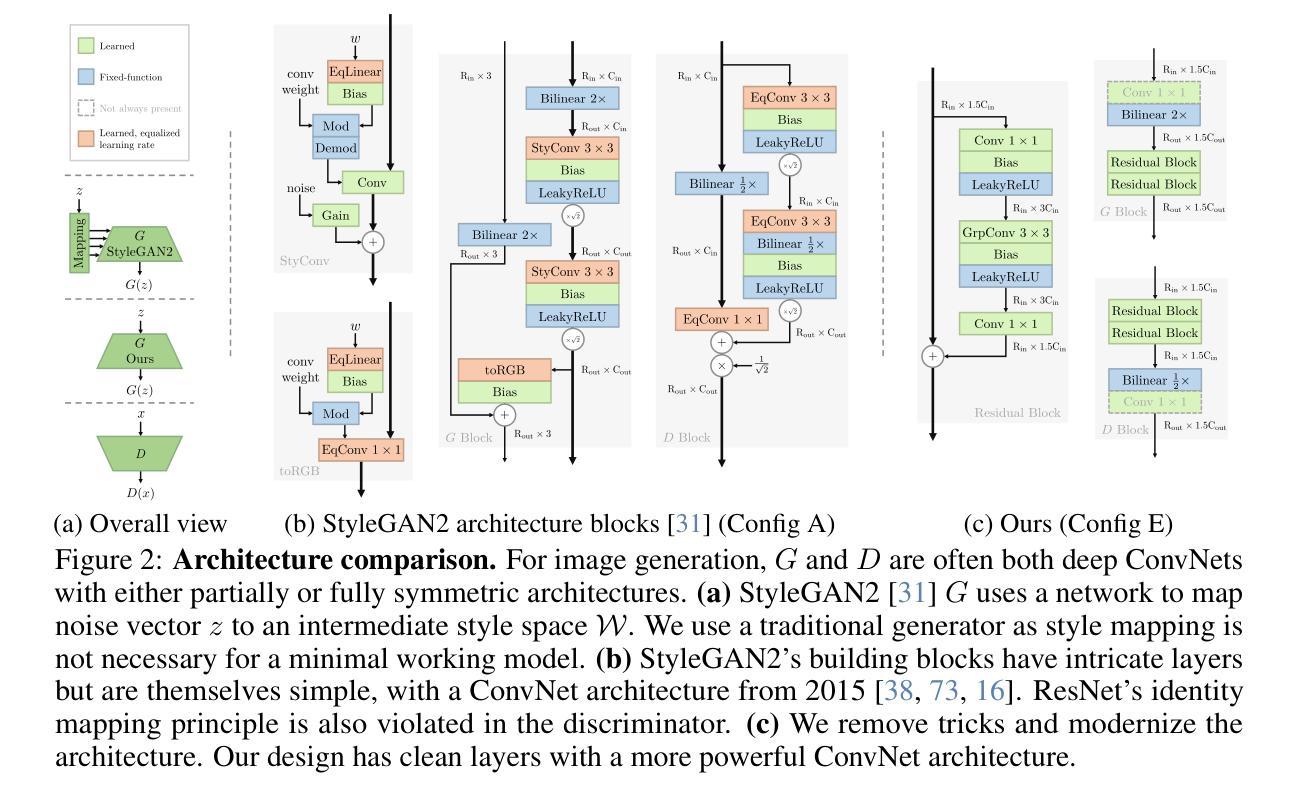
There is a widely-spread claim that GANs are difficult to train, and GAN architectures in the literature are littered with empirical tricks. We provide evidence against this claim and build a modern GAN baseline in a more principled manner. First, we derive a well-behaved regularized relativistic GAN loss that addresses issues of mode dropping and non-convergence that were previously tackled via a bag of ad-hoc tricks. We analyze our loss mathematically and prove that it admits local convergence guarantees, unlike most existing relativistic losses. Second, our new loss allows us to discard all ad-hoc tricks and replace outdated backbones used in common GANs with modern architectures. Using StyleGAN2 as an example, we present a roadmap of simplification and modernization that results in a new minimalist baseline – R3GAN. Despite being simple, our approach surpasses StyleGAN2 on FFHQ, ImageNet, CIFAR, and Stacked MNIST datasets, and compares favorably against state-of-the-art GANs and diffusion models.
有一种普遍的观点认为生成对抗网络(GANs)难以训练,文献中的GAN架构充斥着经验性的技巧。我们针对这一观点提供证据,并以更有原则的方式构建了一个现代GAN基准模型。首先,我们推导出了一个表现良好的正则化相对GAN损失,解决了模式丢失和非收敛的问题,这些问题之前是通过一系列即兴技巧来解决的。我们从数学上分析我们的损失,并证明它与大多数现有的相对论损失不同,具有局部收敛性保证。其次,我们的新损失允许我们放弃所有即兴技巧,并用现代架构替代通用GAN中使用的过时主干。以StyleGAN2为例,我们提出了一个简化与现代化的路线图,从而形成了新的极简基准模型——R3GAN。尽管我们的方法很简单,但在FFHQ、ImageNet、CIFAR和堆叠MNIST数据集上,它超越了StyleGAN2,并与最先进的GAN和扩散模型相比表现良好。
论文及项目相关链接
PDF Accepted to NeurIPS 2024. Code available at https://github.com/brownvc/R3GAN/
Summary
本文反驳了GAN难以训练的观点,并以更原则性的方式构建了一个现代GAN基准模型。首先,我们推导出一个表现良好的正则化相对GAN损失,解决了之前通过一系列临时技巧处理的模式丢失和非收敛问题。其次,我们的新损失允许我们摒弃所有临时技巧,并用现代架构取代通用GAN中使用的过时主干。以StyleGAN2为例,我们提出了简化与现代化的路线图,从而形成了新的极简基线——R3GAN。尽管方法简单,但我们的方法在FFHQ、ImageNet、CIFAR和堆叠MNIST数据集上超越了StyleGAN2,并与最先进的GAN和扩散模型相比具有竞争力。
Key Takeaways
- 本文反驳了GAN难以训练的观点,提出以更原则性的方式构建现代GAN模型。
- 推导出一个表现良好的正则化相对GAN损失,解决模式丢失和非收敛问题。
- 新的损失函数使丢弃所有临时技巧成为可能,可以用现代架构取代通用GAN中的过时主干。
- 通过StyleGAN2的示例展示了简化与现代化的路线图。
- 提出了新的极简基线模型R3GAN。
- R3GAN在多个数据集上表现超越State-of-the-art GANs和扩散模型。
点此查看论文截图



Patch-GAN Transfer Learning with Reconstructive Models for Cloud Removal
Authors:Wanli Ma, Oktay Karakus, Paul L. Rosin
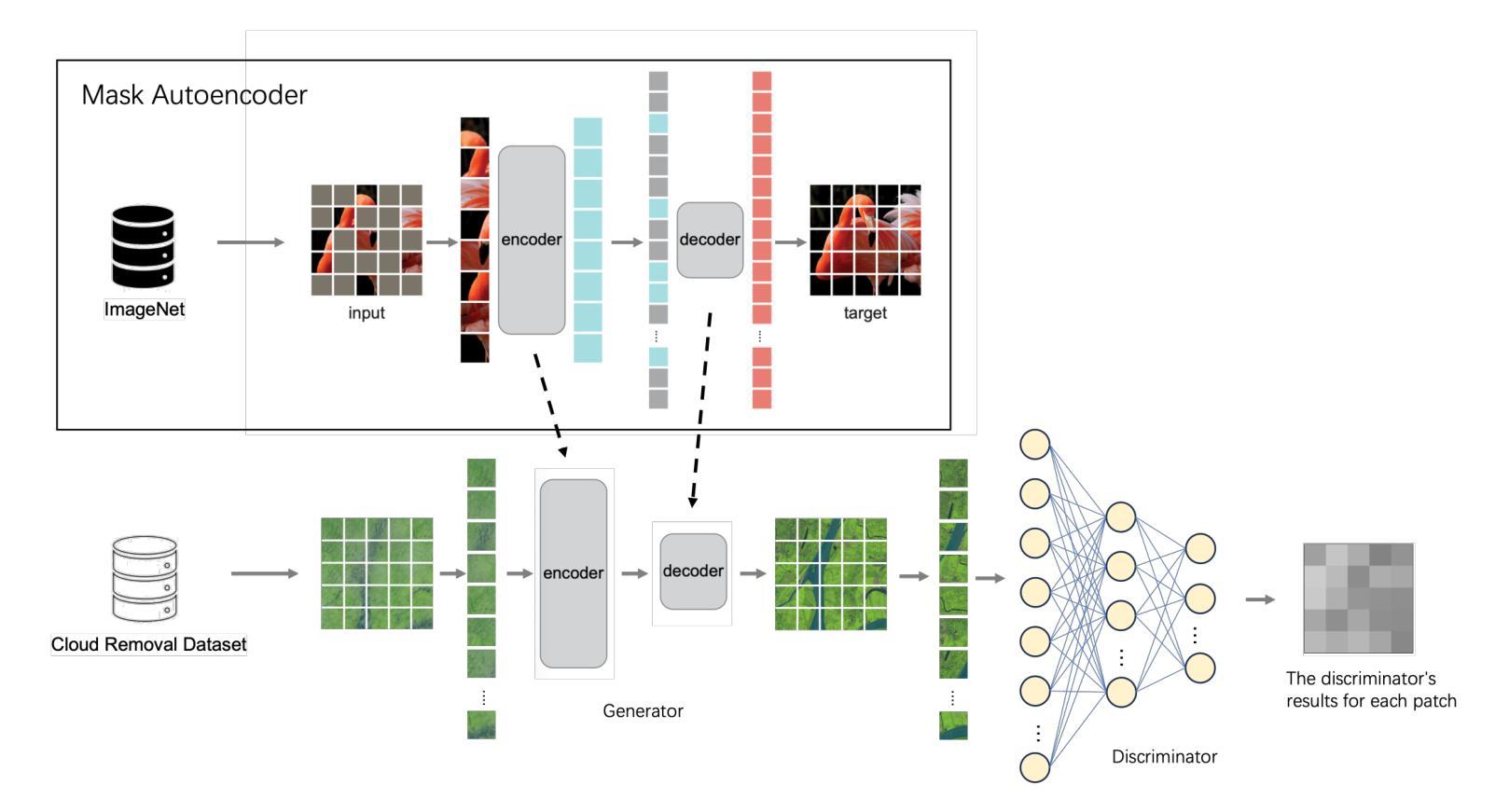
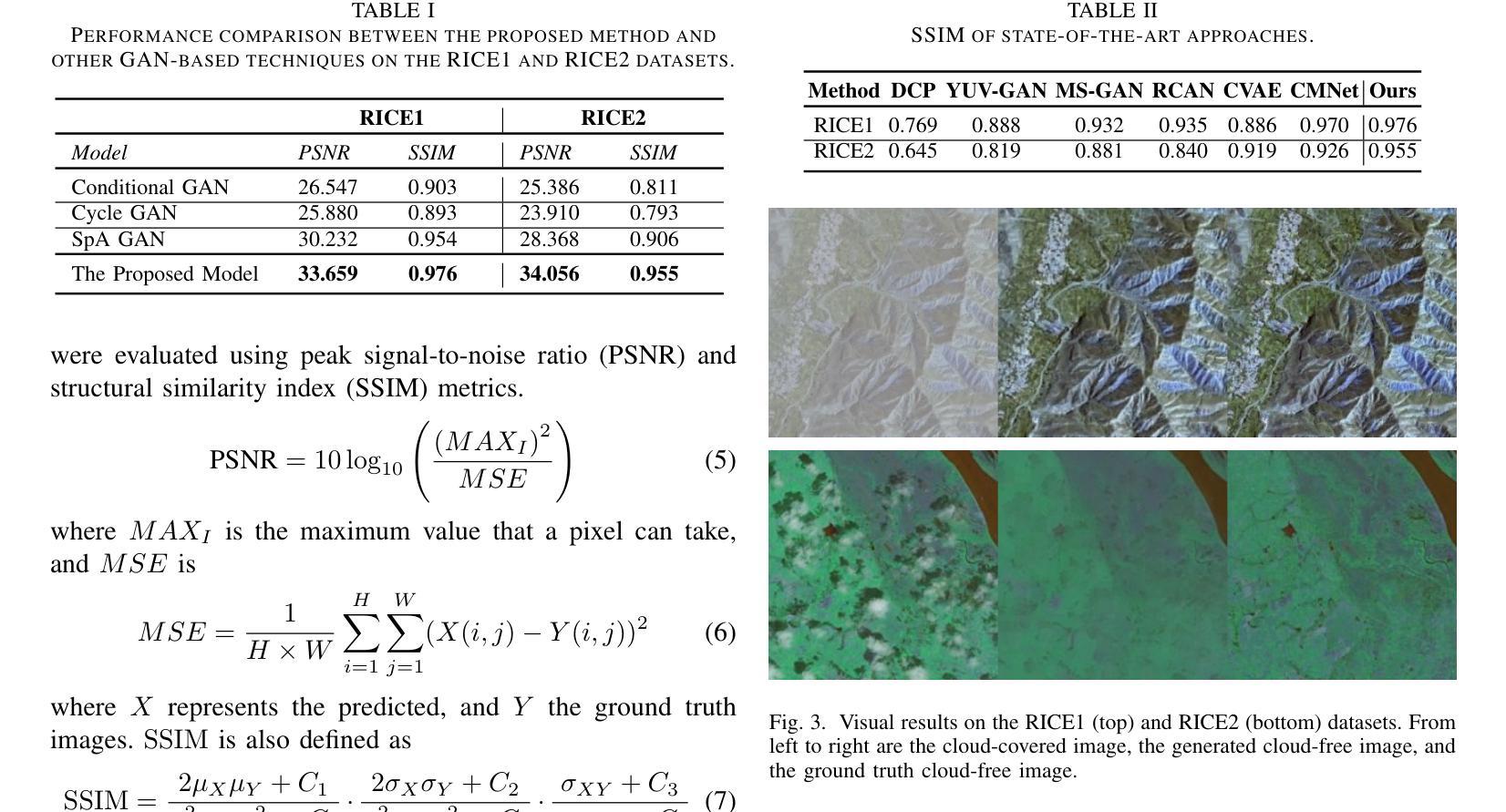
Cloud removal plays a crucial role in enhancing remote sensing image analysis, yet accurately reconstructing cloud-obscured regions remains a significant challenge. Recent advancements in generative models have made the generation of realistic images increasingly accessible, offering new opportunities for this task. Given the conceptual alignment between image generation and cloud removal tasks, generative models present a promising approach for addressing cloud removal in remote sensing. In this work, we propose a deep transfer learning approach built on a generative adversarial network (GAN) framework to explore the potential of the novel masked autoencoder (MAE) image reconstruction model in cloud removal. Due to the complexity of remote sensing imagery, we further propose using a patch-wise discriminator to determine whether each patch of the image is real or not. The proposed reconstructive transfer learning approach demonstrates significant improvements in cloud removal performance compared to other GAN-based methods. Additionally, whilst direct comparisons with some of the state-of-the-art cloud removal techniques are limited due to unclear details regarding their train/test data splits, the proposed model achieves competitive results based on available benchmarks.
云去除在增强遥感图像分析方面发挥着至关重要的作用,然而,准确重建云遮挡区域仍然是一个巨大的挑战。最近生成模型的进步使得生成真实图像变得越来越容易,为这项任务提供了新的机会。鉴于图像生成和云去除任务之间的概念一致性,生成模型为解决遥感中的云去除问题提供了一种有前途的方法。在这项工作中,我们提出了一种基于生成对抗网络(GAN)框架的深度迁移学习方法,以探索新型掩码自动编码器(MAE)图像重建模型在云去除中的潜力。由于遥感图像的复杂性,我们进一步提出使用局部判别器来确定图像的每个局部是否真实。与基于GAN的其他方法相比,所提出的重建迁移学习方法在云去除性能上显示出显着提高。虽然由于训练/测试数据分割的细节不明确,无法直接与某些最先进的云去除技术进行比较,但基于可用的基准测试,所提出模型取得了具有竞争力的结果。
论文及项目相关链接
Summary
本文探讨了云移除技术在遥感图像分析中的重要性及其所面临的挑战。为解决这一问题,提出了一种基于生成对抗网络(GAN)框架的深度迁移学习方法,并探索了新型掩码自编码器(MAE)图像重建模型在云移除中的潜力。为提高性能,还引入了基于补丁的鉴别器来判断图像补丁的真实性。相较于其他GAN方法,该重建迁移学习方法在云移除性能上取得了显著改进,并在现有基准测试中取得了有竞争力的结果。
Key Takeaways
- 云移除在遥感图像分析中至关重要,但重建云遮挡区域是一大挑战。
- 生成模型的发展为云移除任务提供了新的机会。
- 本文提出了一种基于生成对抗网络(GAN)框架的深度迁移学习方法来进行云移除。
- 引入了新型掩码自编码器(MAE)图像重建模型以增强性能。
- 采用基于补丁的鉴别器来提高图像的真实性判断。
- 该方法在云移除性能上较其他GAN方法有显著改进。
点此查看论文截图


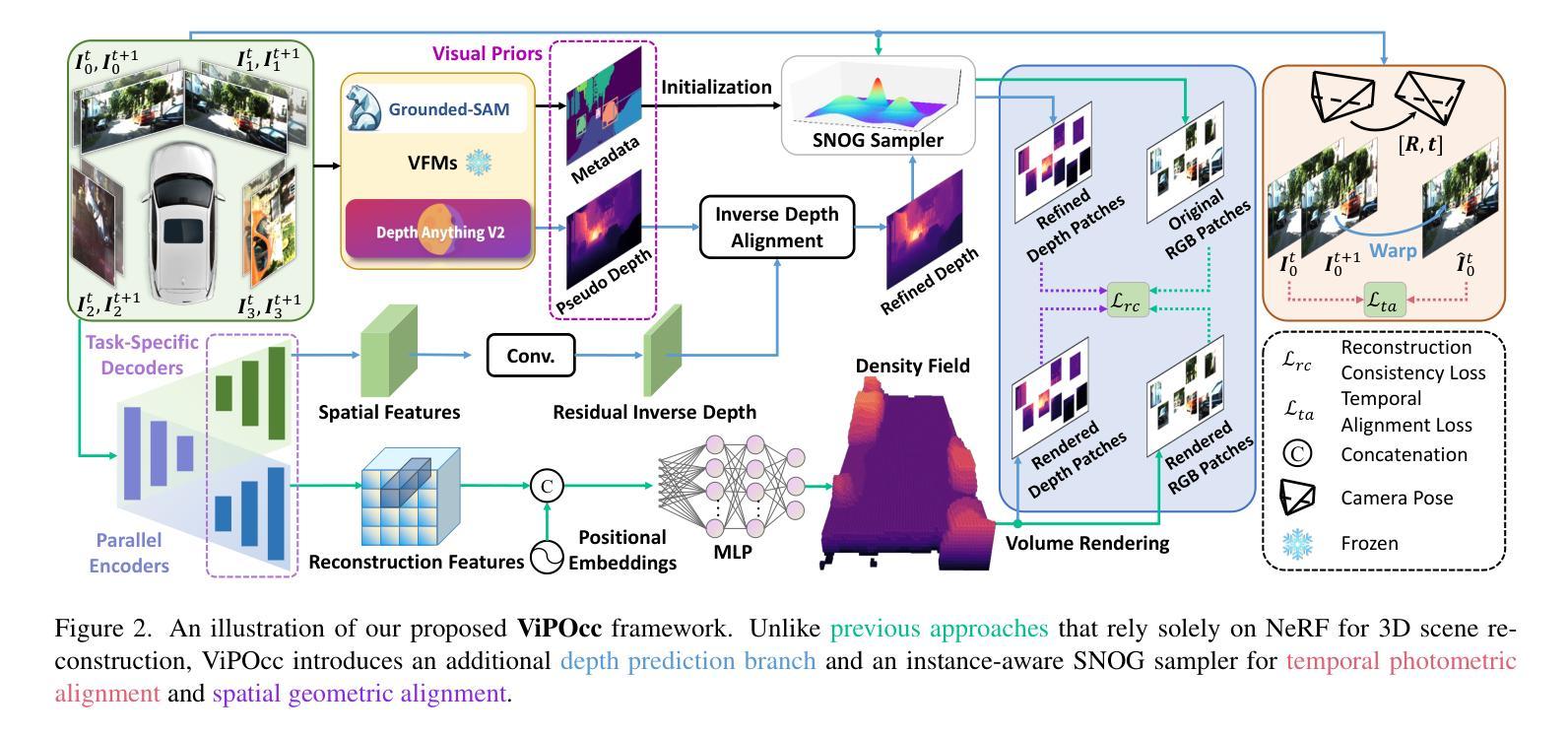
ViPOcc: Leveraging Visual Priors from Vision Foundation Models for Single-View 3D Occupancy Prediction
Authors:Yi Feng, Yu Han, Xijing Zhang, Tanghui Li, Yanting Zhang, Rui Fan
Inferring the 3D structure of a scene from a single image is an ill-posed and challenging problem in the field of vision-centric autonomous driving. Existing methods usually employ neural radiance fields to produce voxelized 3D occupancy, lacking instance-level semantic reasoning and temporal photometric consistency. In this paper, we propose ViPOcc, which leverages the visual priors from vision foundation models (VFMs) for fine-grained 3D occupancy prediction. Unlike previous works that solely employ volume rendering for RGB and depth image reconstruction, we introduce a metric depth estimation branch, in which an inverse depth alignment module is proposed to bridge the domain gap in depth distribution between VFM predictions and the ground truth. The recovered metric depth is then utilized in temporal photometric alignment and spatial geometric alignment to ensure accurate and consistent 3D occupancy prediction. Additionally, we also propose a semantic-guided non-overlapping Gaussian mixture sampler for efficient, instance-aware ray sampling, which addresses the redundant and imbalanced sampling issue that still exists in previous state-of-the-art methods. Extensive experiments demonstrate the superior performance of ViPOcc in both 3D occupancy prediction and depth estimation tasks on the KITTI-360 and KITTI Raw datasets. Our code is available at: \url{https://mias.group/ViPOcc}.
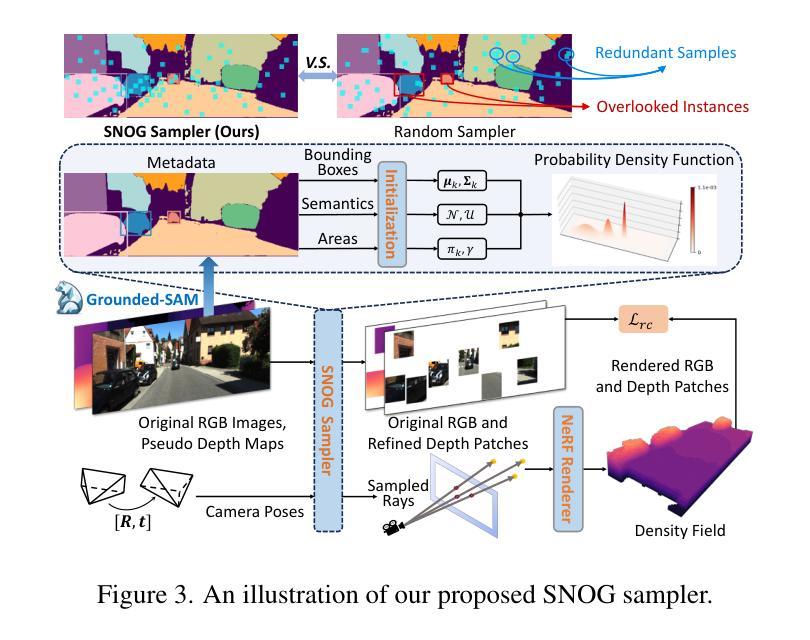
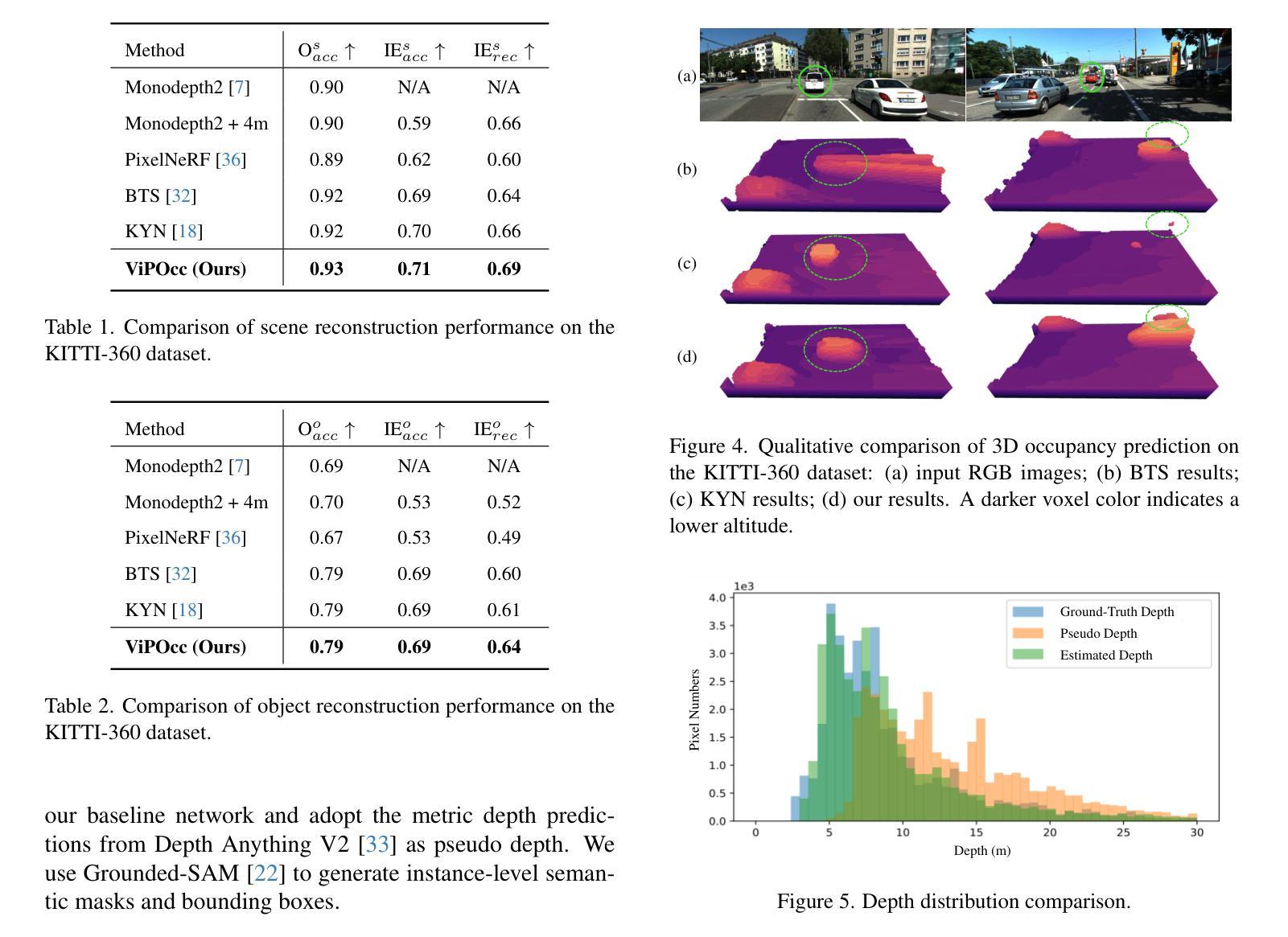
从单幅图像推断场景的三维结构是视觉自主驾驶领域中一个不适定且具有挑战性的问题。现有方法通常采用神经辐射场来生成体素化的三维占用信息,但缺乏实例级别的语义推理和时间上的光度一致性。在本文中,我们提出了ViPOcc,它利用视觉先验知识(视觉基础模型(VFM))来进行精细粒度的三维占用预测。与仅使用体积渲染进行RGB和深度图像重建的先前工作不同,我们引入了一个度量深度估计分支,并提出一个逆深度对齐模块来弥合视觉基础模型预测和真实值之间深度分布的域差距。然后,恢复的度量深度被用于时间光度对齐和空间几何对齐,以确保准确且一致的三维占用预测。此外,我们还提出了一种语义引导的非重叠高斯混合采样器,用于高效、实例感知的射线采样,解决了先前最先进的方法中仍然存在的冗余和不平衡采样问题。大量实验表明,ViPOcc在KITTI-360和KITTI Raw数据集上的三维占用预测和深度估计任务中都表现出卓越的性能。我们的代码可在:https://mias.group/ViPOcc获取。
论文及项目相关链接
PDF accepted to AAAI25
Summary
本文提出一种基于视觉先验的精细粒度三维占用预测方法ViPOcc,该方法利用视觉基础模型(VFMs)进行单图像的三维场景结构推断。不同于仅使用体积渲染进行RGB和深度图像重建的方法,ViPOcc引入了度量深度估计分支,并提出反向深度对齐模块来缩小VFM预测与真实值之间的深度分布域差距。同时,本文还提出一种语义引导的非重叠高斯混合采样器,用于高效、实例感知的射线采样,解决先前先进方法中仍存在的冗余和不平衡采样问题。在KITTI-360和KITTI Raw数据集上的实验表明,ViPOcc在三维占用预测和深度估计任务上均表现出卓越性能。
Key Takeaways
- ViPOcc利用视觉基础模型(VFMs)进行精细粒度的三维占用预测。
- 引入了度量深度估计分支以提高深度预测的准确性。
- 反向深度对齐模块缩小了VFM预测与真实深度之间的域差距。
- 提出语义引导的非重叠高斯混合采样器,解决冗余和不平衡采样问题。
- 方法在KITTI-360和KITTI Raw数据集上的实验表现出卓越性能。
- ViPOcc能确保准确且一致的三维占用预测。
点此查看论文截图

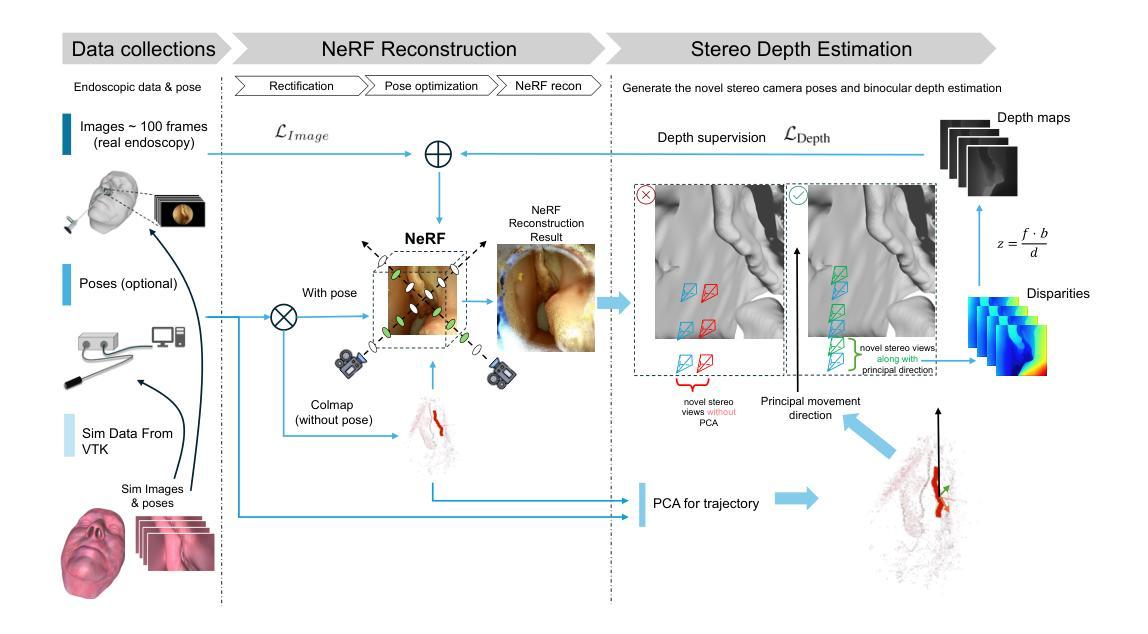
EndoPerfect: A Hybrid NeRF-Stereo Vision Approach Pioneering Monocular Depth Estimation and 3D Reconstruction in Endoscopy
Authors:Pengcheng Chen, Wenhao Li, Nicole Gunderson, Jeremy Ruthberg, Randall Bly, Zhenglong Sun, Waleed M. Abuzeid, Eric J. Seibel
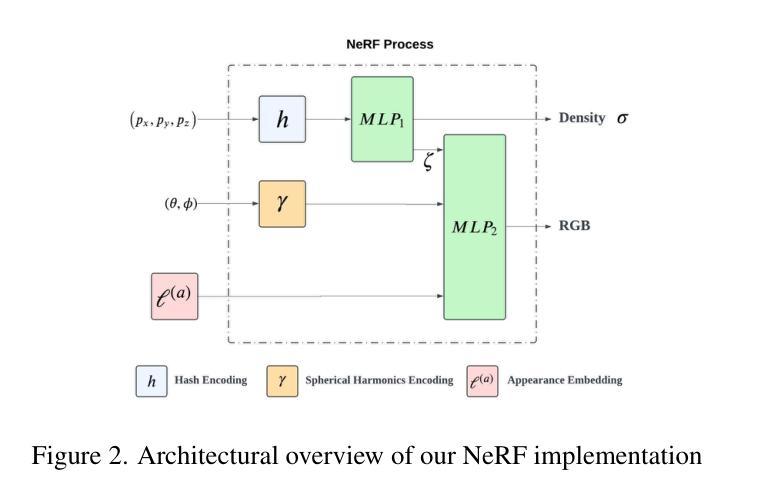
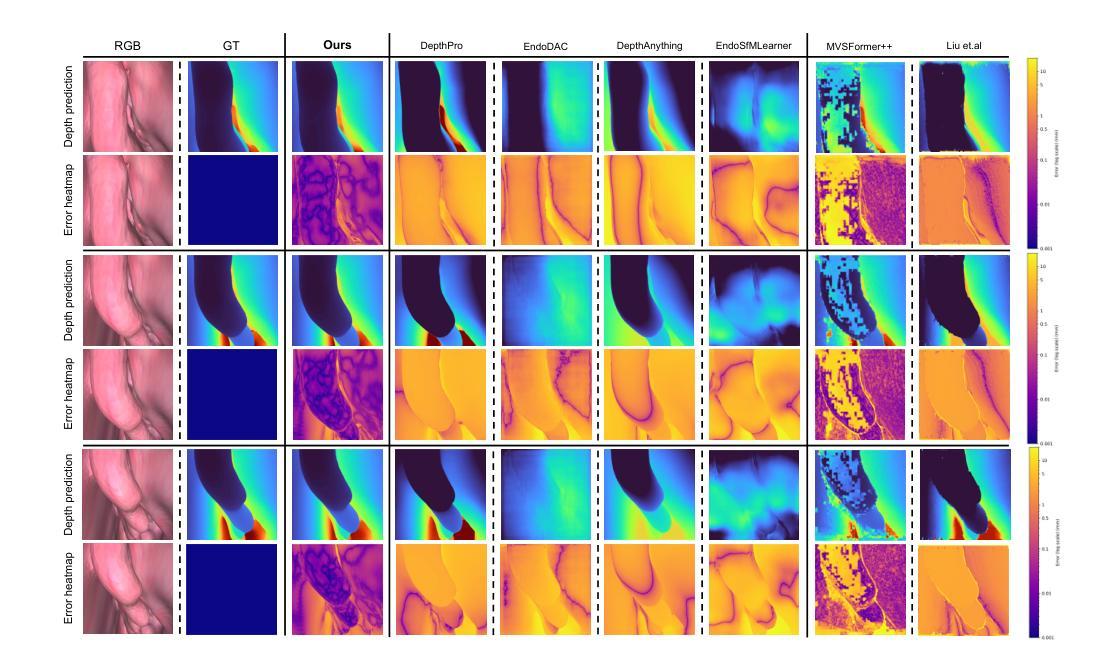
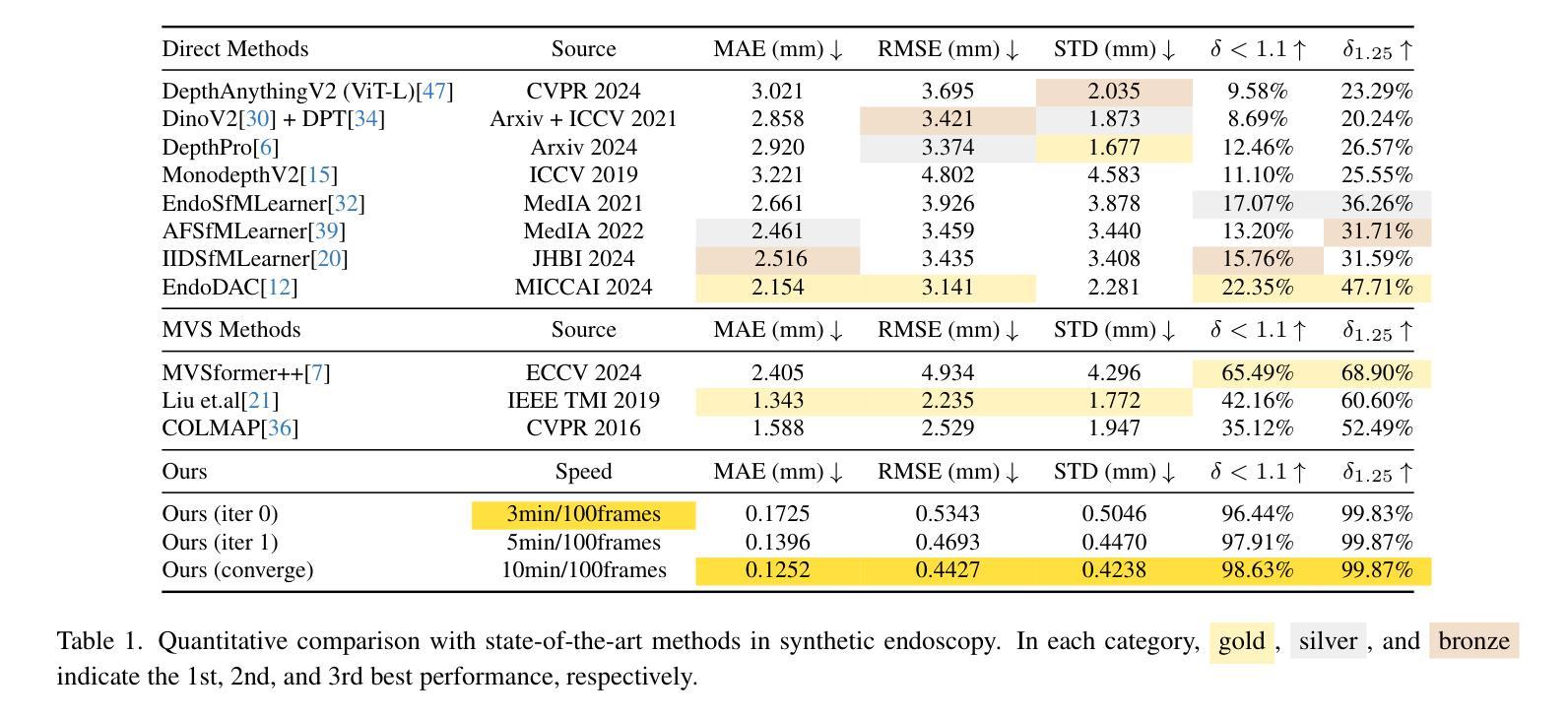
3D reconstruction in endoscopic sinus surgery (ESS) demands exceptional accuracy, with the mean error and standard deviation necessitating within the range of a single CT slice (0.625 mm), as the critical structures in the nasal cavity are situated within submillimeter distances from surgical instruments. This poses a formidable challenge when using conventional monocular endoscopes. Depth estimation is crucial for 3D reconstruction, yet existing depth estimation methodologies either suffer from inherent accuracy limitations or, in the case of learning-based approaches, perform poorly when applied to ESS despite succeeding on their original datasets. In this study, we present a novel, highly generalizable method that combines Neural Radiance Fields (NeRF) and stereo depth estimation for 3D reconstruction that can derive metric monocular depth. Our approach begins with an initial NeRF reconstruction yielding a coarse 3D scene, the subsequent creation of binocular pairs within coarse 3D scene, and generation of depth maps through stereo vision, These depth maps are used to supervise subsequent NeRF iteration, progressively refining NeRF and binocular depth, the refinement process continues until the depth maps converged. This recursive process generates high-accuracy depth maps from monocular endoscopic video. Evaluation in synthetic endoscopy shows a depth accuracy of 0.125 $\pm$ 0.443 mm, well within the 0.625 mm threshold. Further clinical experiments with real endoscopic data demonstrate a mean distance to CT mesh of 0.269 mm, representing the highest accuracy among monocular 3D reconstruction methods in ESS.
在内镜鼻窦手术(ESS)的3D重建中,需要极高的准确性,平均误差和标准偏差必须在单个CT切片(0.625毫米)的范围内,因为鼻腔内的关键结构距离手术器械在亚毫米之内。这在使用传统的单目内窥镜时构成了一个巨大的挑战。深度估计是3D重建中的关键,但现有的深度估计方法要么存在固有的准确性限制,要么在应用于ESS时表现不佳,尽管它们在原始数据集上表现成功。在这项研究中,我们提出了一种新颖且高度通用的方法,结合了神经辐射场(NeRF)和立体深度估计进行3D重建,可以推导单目深度度量。我们的方法首先通过初始NeRF重建得到一个粗略的3D场景,然后在粗略的3D场景内创建双目配对,并通过立体视觉生成深度图。这些深度图用于监督随后的NeRF迭代,逐步优化NeRF和双目深度。优化过程将继续进行,直到深度图收敛。这种递归过程可以从单目内窥镜视频中生成高精度的深度图。在合成内窥镜评估中的深度准确性为0.125±0.443毫米,远低于0.625毫米的阈值。使用真实内窥镜数据的进一步临床实验表明,到CT网格的平均距离为0.269毫米,代表了ESS中单目3D重建方法中的最高精度。
论文及项目相关链接
Summary
本文介绍了一种结合Neural Radiance Fields(NeRF)和立体深度估计的3D重建新方法,用于内窥镜鼻窦手术(ESS)中的单目深度推导。该方法通过递归过程生成高精度深度图,从单目内窥镜视频中提取深度信息,并在合成内窥镜和真实内窥镜数据上取得了较高准确性。
Key Takeaways
- 3D重建在内窥镜鼻窦手术(ESS)中需要极高精度,因为鼻腔内的关键结构距离手术器械仅有几毫米。
- 现有深度估计方法在内窥镜手术中面临精度挑战。
- 本研究提出了一种结合NeRF和立体深度估计的新方法,用于单目深度推导的3D重建。
- 该方法首先进行初始NeRF重建,生成粗略的3D场景,然后创建双目对并生成深度图,用于监督随后的NeRF迭代。
- 通过递归过程,该方法能够生成高精度的深度图,从单目内窥镜视频中提取深度信息。
- 在合成内窥镜数据上的实验表明,该方法的深度精度达到了0.125±0.443mm,远优于传统方法。
点此查看论文截图