⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-13 更新
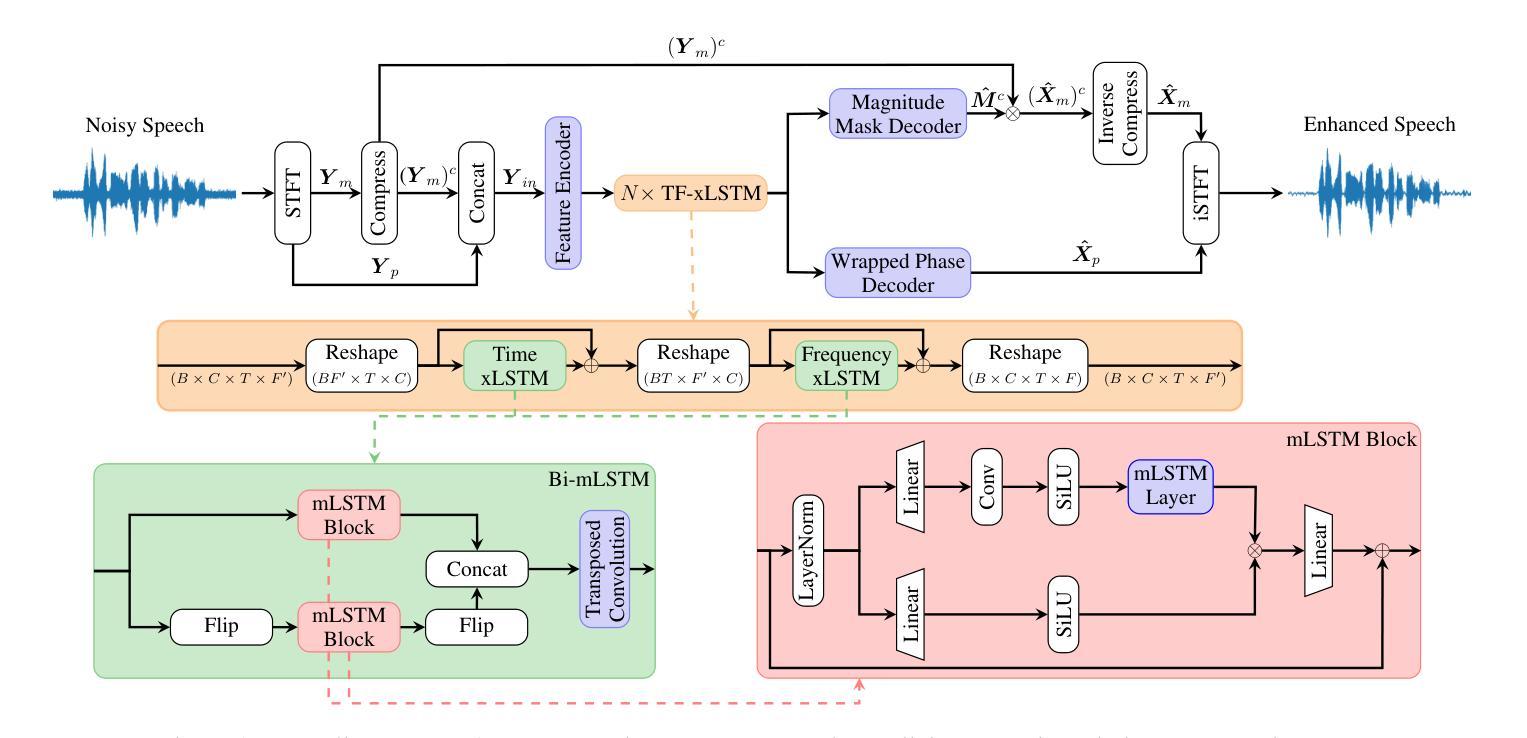
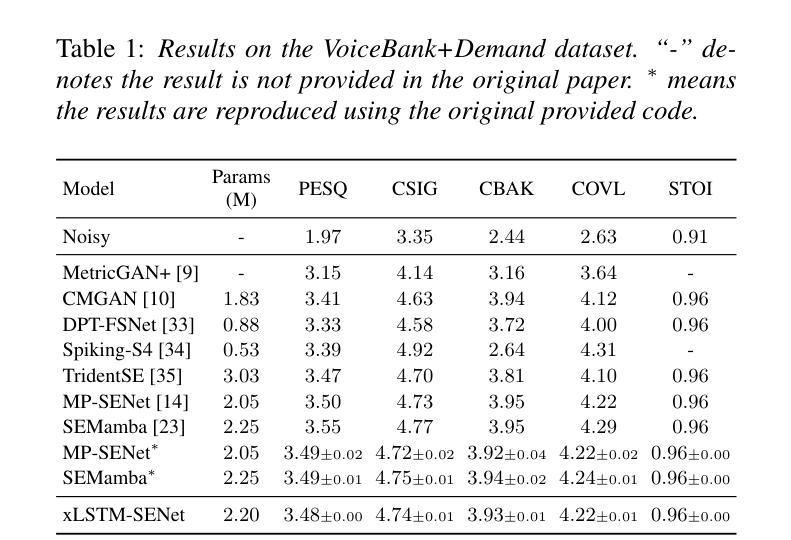
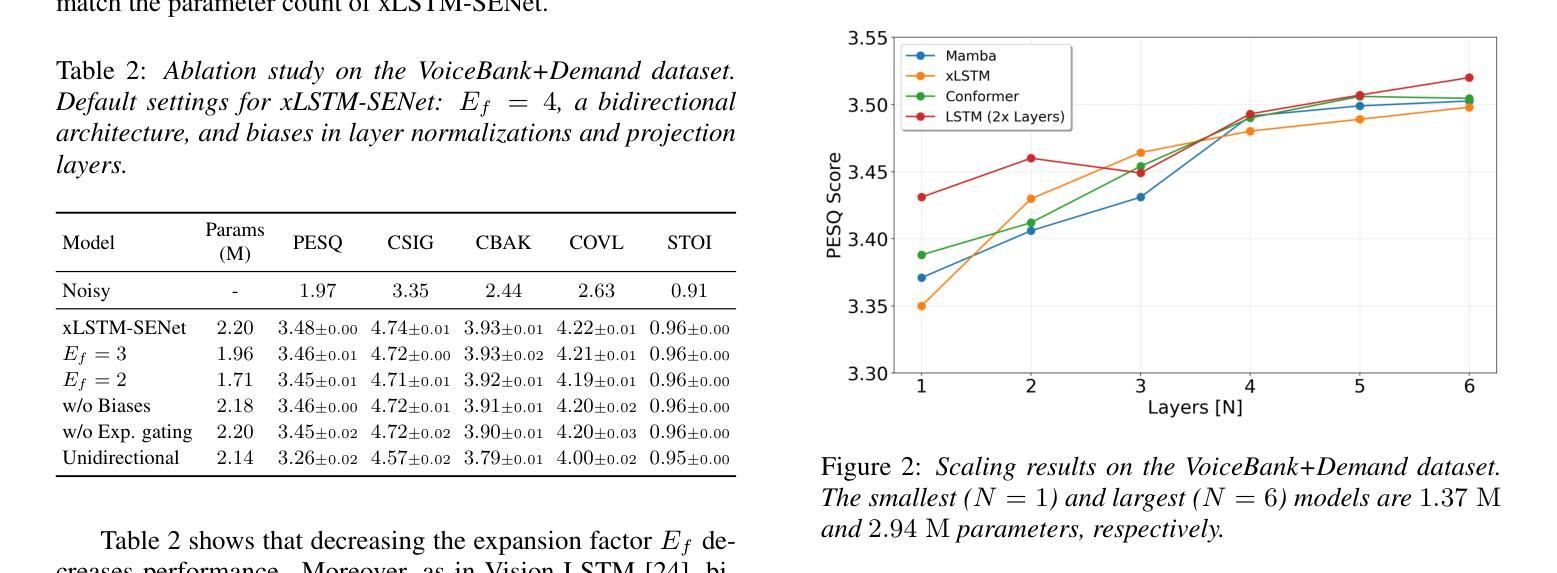
xLSTM-SENet: xLSTM for Single-Channel Speech Enhancement
Authors:Nikolai Lund Kühne, Jan Østergaard, Jesper Jensen, Zheng-Hua Tan
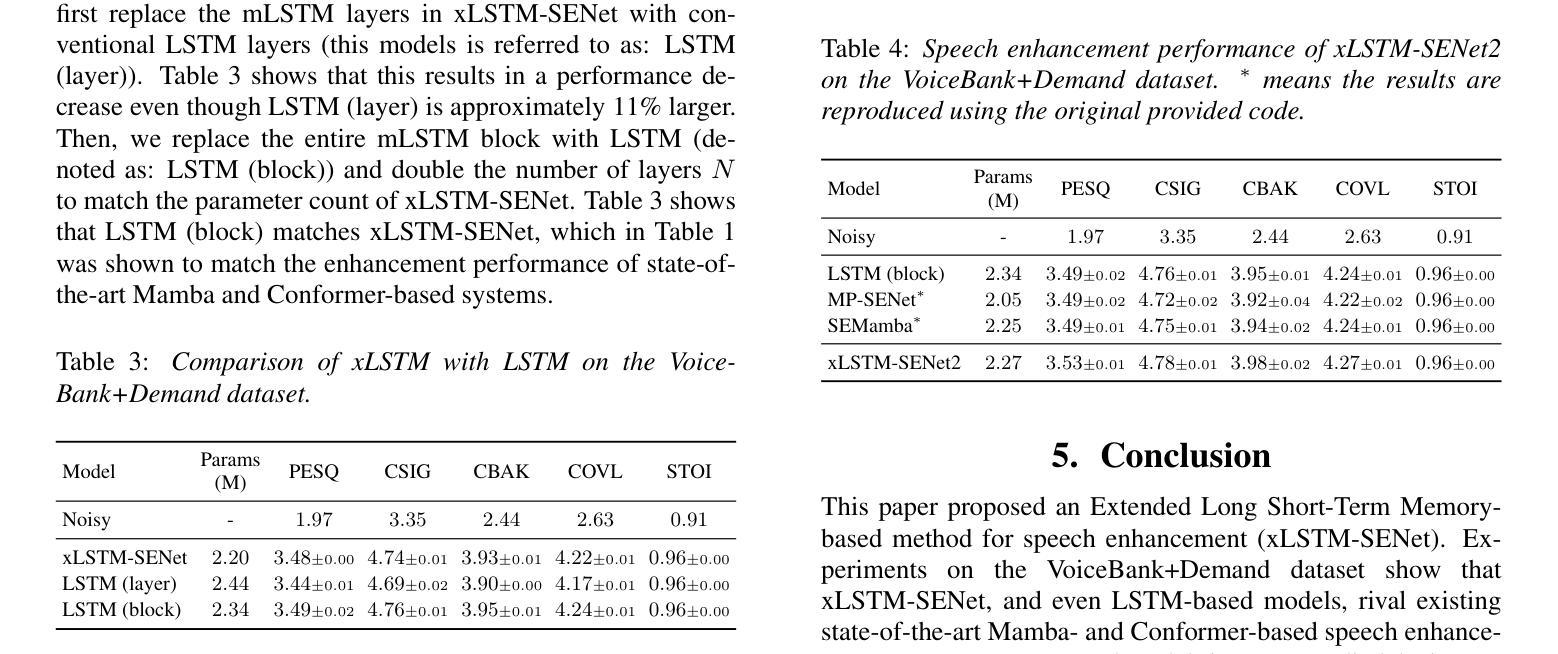
While attention-based architectures, such as Conformers, excel in speech enhancement, they face challenges such as scalability with respect to input sequence length. In contrast, the recently proposed Extended Long Short-Term Memory (xLSTM) architecture offers linear scalability. However, xLSTM-based models remain unexplored for speech enhancement. This paper introduces xLSTM-SENet, the first xLSTM-based single-channel speech enhancement system. A comparative analysis reveals that xLSTM-and notably, even LSTM-can match or outperform state-of-the-art Mamba- and Conformer-based systems across various model sizes in speech enhancement on the VoiceBank+Demand dataset. Through ablation studies, we identify key architectural design choices such as exponential gating and bidirectionality contributing to its effectiveness. Our best xLSTM-based model, xLSTM-SENet2, outperforms state-of-the-art Mamba- and Conformer-based systems on the Voicebank+DEMAND dataset.
基于注意力的架构,如Conformers,在语音增强方面表现出色,但它们面临着输入序列长度方面的可扩展性挑战。相比之下,最近提出的扩展长短期记忆(xLSTM)架构提供了线性可扩展性。然而,尚未针对语音增强探索基于xLSTM的模型。本文介绍了基于xLSTM的单通道语音增强系统xLSTM-SENet。对比分析表明,xLSTM(尤其是LSTM)在VoiceBank+Demand数据集上的语音增强方面,可以与最新的Mamba和Conformer系统相匹配或表现更优秀,且这一优势在不同模型大小中都存在。通过消融研究,我们确定了关键架构设计选择,如指数门控和双向性对其有效性有所贡献。我们最好的基于xLSTM的模型xLSTM-SENet2在Voicebank+DEMAND数据集上超越了最新的Mamba和Conformer系统。
论文及项目相关链接
Summary
xLSTM-SENet是第一篇使用扩展长短期记忆(xLSTM)的单通道语音增强系统。它解决了基于注意力架构如Conformers在语音增强上遇到的线性扩展性问题。相比现有的Mamba和Conformer系统,xLSTM-SENet在各种模型大小下的语音增强性能优异,特别是在VoiceBank+Demand数据集上。其关键设计选择,如指数门控和双向性,为其有效性做出了贡献。最佳模型xLSTM-SENet2在Voicebank+DEMAND数据集上的表现优于现有技术。
Key Takeaways
- xLSTM-SENet是基于扩展长短期记忆(xLSTM)的首个单通道语音增强系统。
- 该系统解决了基于注意力架构在语音增强方面的线性扩展性问题。
- 在VoiceBank+Demand数据集上,xLSTM-SENet的语音增强性能与现有的Mamba和Conformer系统相比表现优异。
- xLSTM-SENet的最佳模型xLSTM-SENet2的性能优于现有技术。
- 指数门控和双向性是该系统关键的设计选择。
- 该系统通过比较分析和消融研究验证了其有效性。
点此查看论文截图

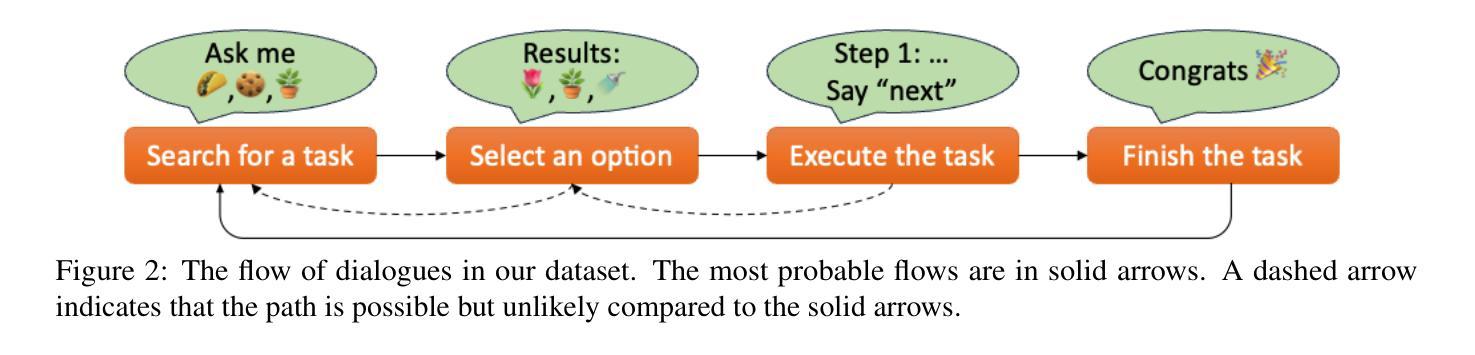
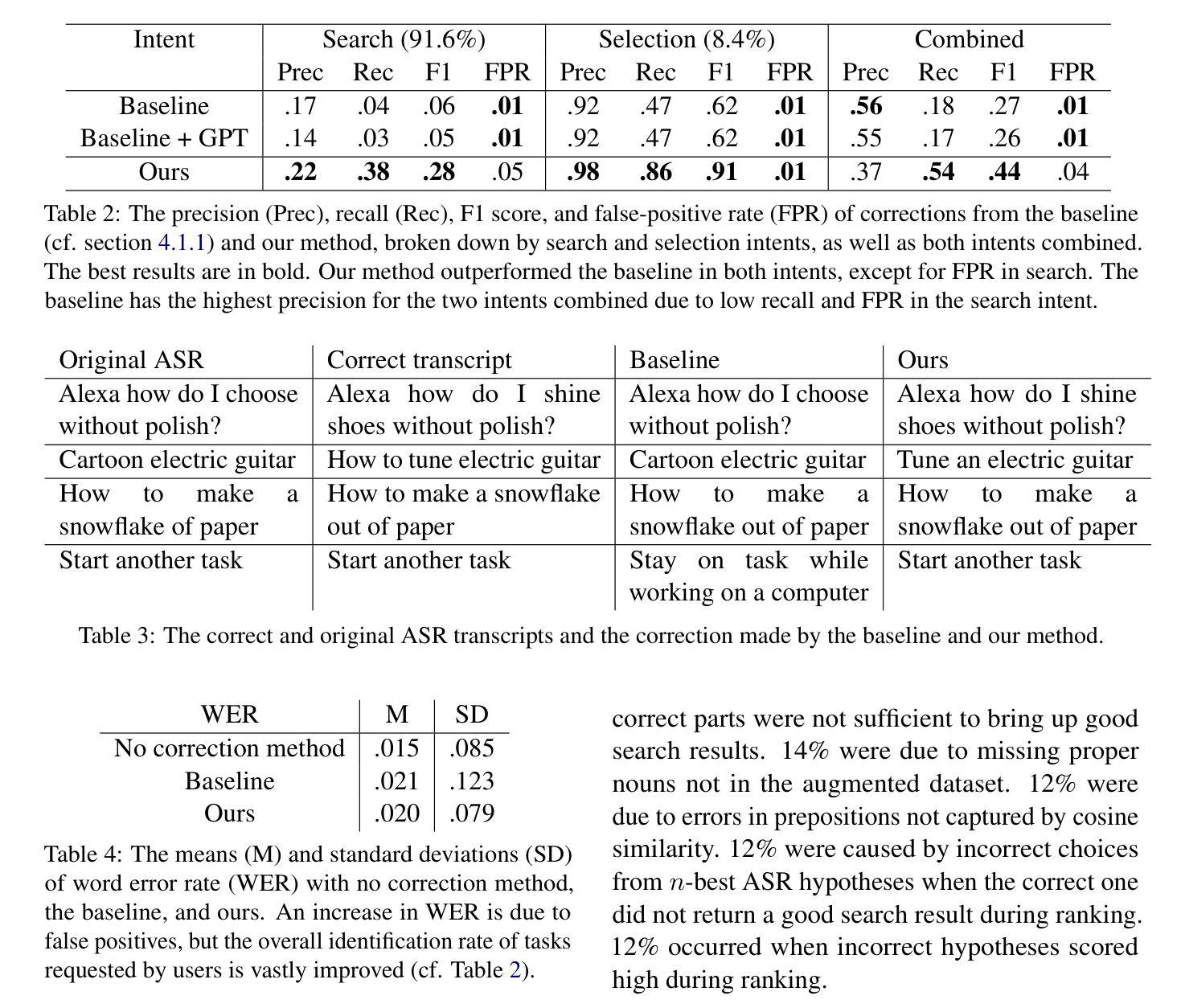
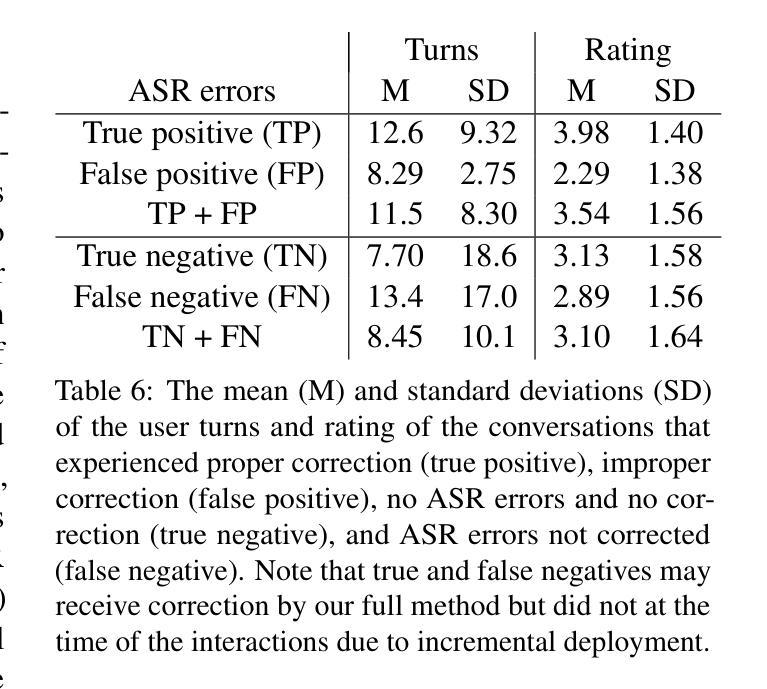
Contextual ASR Error Handling with LLMs Augmentation for Goal-Oriented Conversational AI
Authors:Yuya Asano, Sabit Hassan, Paras Sharma, Anthony Sicilia, Katherine Atwell, Diane Litman, Malihe Alikhani
General-purpose automatic speech recognition (ASR) systems do not always perform well in goal-oriented dialogue. Existing ASR correction methods rely on prior user data or named entities. We extend correction to tasks that have no prior user data and exhibit linguistic flexibility such as lexical and syntactic variations. We propose a novel context augmentation with a large language model and a ranking strategy that incorporates contextual information from the dialogue states of a goal-oriented conversational AI and its tasks. Our method ranks (1) n-best ASR hypotheses by their lexical and semantic similarity with context and (2) context by phonetic correspondence with ASR hypotheses. Evaluated in home improvement and cooking domains with real-world users, our method improves recall and F1 of correction by 34% and 16%, respectively, while maintaining precision and false positive rate. Users rated .8-1 point (out of 5) higher when our correction method worked properly, with no decrease due to false positives.
通用自动语音识别(ASR)系统在面向目标的对话中并不总是表现良好。现有的ASR校正方法依赖于用户先验数据或命名实体。我们将校正扩展到没有用户先验数据且表现出语言灵活性的任务,例如词汇和句法变化。我们提出了一种新的上下文增强方法,使用大型语言模型和排名策略,该策略结合了面向目标的对话式人工智能及其任务的对话状态中的上下文信息。我们的方法通过(1)词法和语义与上下文的相似度对最佳的ASR假设进行排名,(2)通过音素对应与ASR假设的上下文进行排名。在家庭改善和烹饪领域进行真实用户评估,我们的方法提高了修正的召回率和F1分数,分别为34%和16%,同时保持了精确度和误报率。用户在没有误报的情况下,我们的校正方法正常工作时的评分比原来高出0.8-1分(满分5分)。
论文及项目相关链接
PDF Accepted to COLING 2025 Industry Track
摘要
针对通用自动语音识别(ASR)系统在目标导向对话中的性能不佳问题,提出了一种结合大型语言模型和排名策略的新方法。该方法通过对话状态和任务的上下文信息,对ASR假设进行排名,并考虑词汇和语义相似性以及与语音假设的语音对应关系。在家居改善和烹饪领域进行真实用户评估表明,该方法提高了修正的召回率和F1分数,分别为34%和16%,同时保持精度和误报率。用户对我们的修正方法评价更高,且没有因误报而降低评价。
关键见解
- 通用自动语音识别(ASR)系统在目标导向对话中的性能有待提高。
- 现有ASR修正方法依赖用户先验数据或命名实体,而本文扩展了无先验用户数据的任务修正。
- 提出了一种新的结合大型语言模型和排名策略的方法,考虑词汇和语义相似性以及与ASR假设的语音对应关系。
- 方法通过对话状态和任务的上下文信息对ASR假设进行排名。
- 在家居改善和烹饪领域的真实用户评估中,该方法显著提高修正的召回率和F1分数。
- 用户对修正方法的评价更高,且在无误报情况下评价未降低。
- 该方法对于具有语言灵活性的任务,如词汇和句法变化,具有广泛的应用潜力。
点此查看论文截图



Comparing Self-Supervised Learning Models Pre-Trained on Human Speech and Animal Vocalizations for Bioacoustics Processing
Authors:Eklavya Sarkar, Mathew Magimai. -Doss
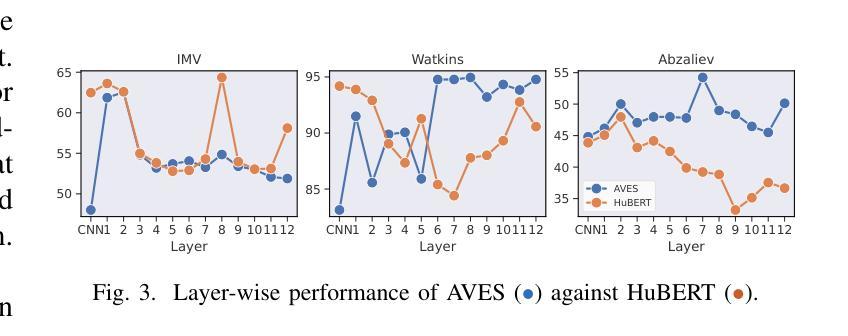
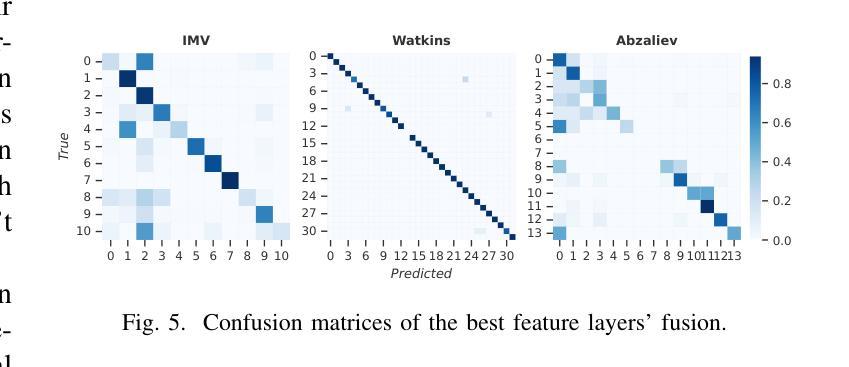
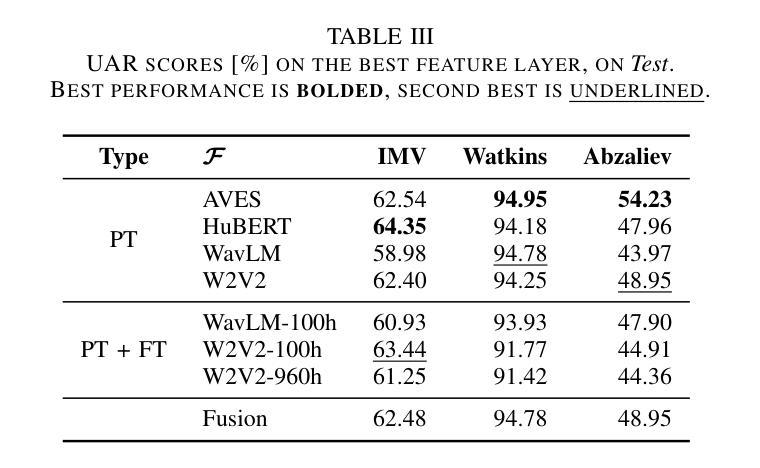
Self-supervised learning (SSL) foundation models have emerged as powerful, domain-agnostic, general-purpose feature extractors applicable to a wide range of tasks. Such models pre-trained on human speech have demonstrated high transferability for bioacoustic processing. This paper investigates (i) whether SSL models pre-trained directly on animal vocalizations offer a significant advantage over those pre-trained on speech, and (ii) whether fine-tuning speech-pretrained models on automatic speech recognition (ASR) tasks can enhance bioacoustic classification. We conduct a comparative analysis using three diverse bioacoustic datasets and two different bioacoustic tasks. Results indicate that pre-training on bioacoustic data provides only marginal improvements over speech-pretrained models, with comparable performance in most scenarios. Fine-tuning on ASR tasks yields mixed outcomes, suggesting that the general-purpose representations learned during SSL pre-training are already well-suited for bioacoustic tasks. These findings highlight the robustness of speech-pretrained SSL models for bioacoustics and imply that extensive fine-tuning may not be necessary for optimal performance.
自监督学习(SSL)基础模型已经作为强大、领域无关、通用的特征提取器出现,适用于多种任务。预训练在人类语音上的此类模型已显示出在高转移性生物声处理中的高可用性。本文调查了(i)直接预训练在动物鸣叫上的SSL模型是否比那些预训练在语音上的模型具有显著优势,以及(ii)是否在自动语音识别(ASR)任务上微调语音预训练模型可以增强生物声音分类。我们使用三个不同的生物声数据集和两个不同的生物声任务进行了比较分析。结果表明,在生物声音数据上进行预训练只略微改进了语音预训练模型,在大多数情况下性能相当。在ASR任务上进行微调会产生混合的结果,这表明在SSL预训练期间学习的通用表示已经非常适合生物声音任务。这些发现突出了语音预训练SSL模型在生物声学中的稳健性,并且暗示可能不需要大量微调就能达到最佳性能。
论文及项目相关链接
PDF Accepted at ICASSP 2025
Summary
本文探讨了自我监督学习(SSL)模型在动物声音处理方面的应用。研究发现,相较于在语音上预训练的模型,直接对动物鸣叫声进行预训练的SSL模型优势并不显著。此外,对语音预训练模型进行自动语音识别(ASR)任务的微调,对于生物声音分类的增强作用也表现不一。结果表明,在生物声音数据上进行预训练只带来了轻微的性能提升,并且在大多数场景中与语音预训练模型表现相当。这些发现突显了语音预训练的SSL模型在生物声音学中的稳健性,并暗示可能不需要大量微调即可获得最佳性能。
Key Takeaways
- SSL模型可以直接应用于动物声音处理,但相较于语音预训练模型,其优势并不显著。
- 在生物声音数据上进行预训练相较于语音预训练模型只带来了轻微的性能提升。
- 在大多数生物声音分类场景中,语音预训练模型的表现已经足够好。
- 对语音预训练模型进行ASR任务的微调对于生物声音分类的增强作用表现不一。
- 语音预训练的SSL模型在生物声音学中具有稳健性。
- 无需大量微调即可获得SSL模型的最佳性能。
点此查看论文截图

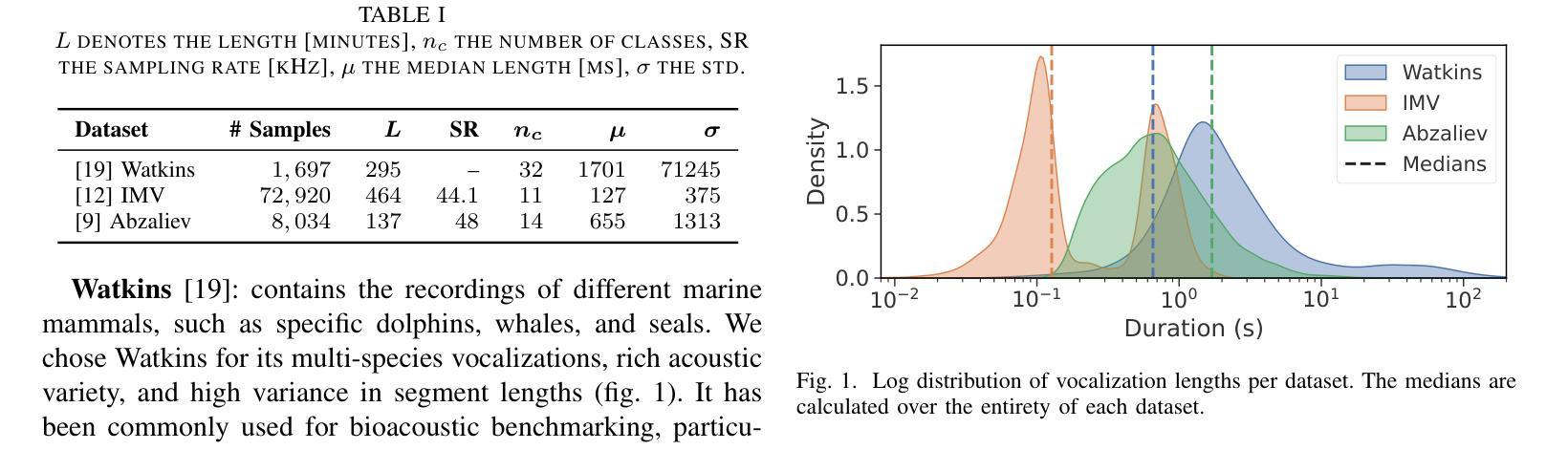
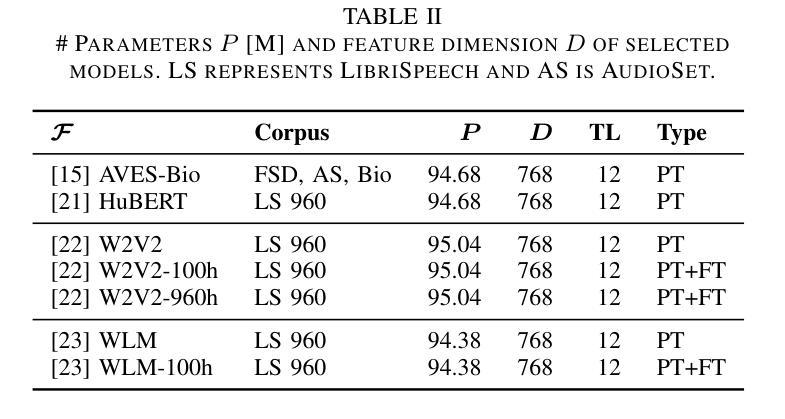
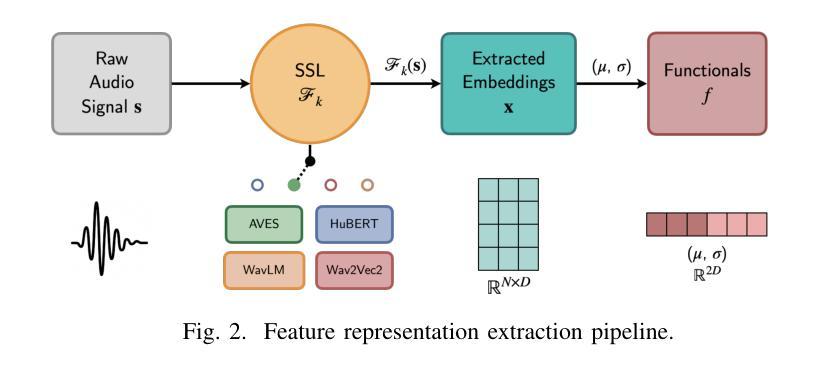
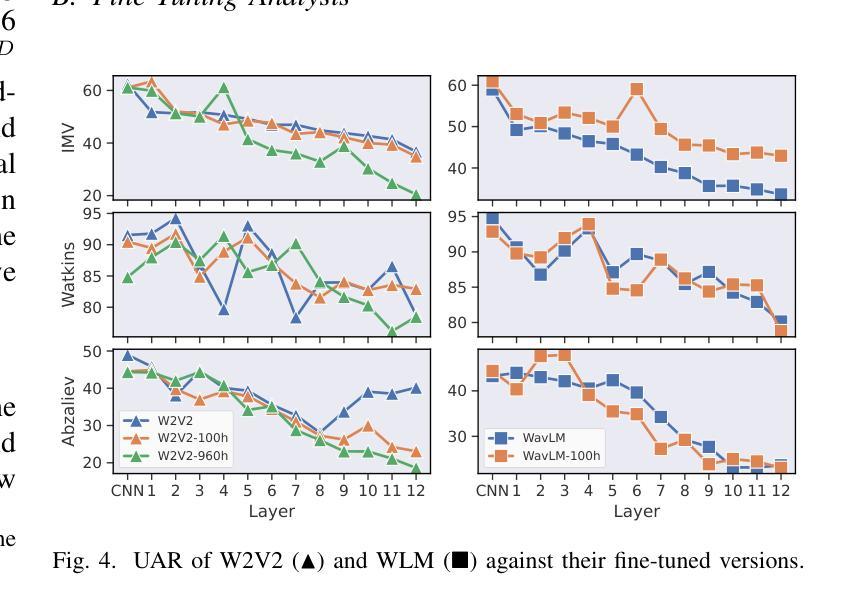
Estimation and Restoration of Unknown Nonlinear Distortion using Diffusion
Authors:Michal Švento, Eloi Moliner, Lauri Juvela, Alec Wright, Vesa Välimäki
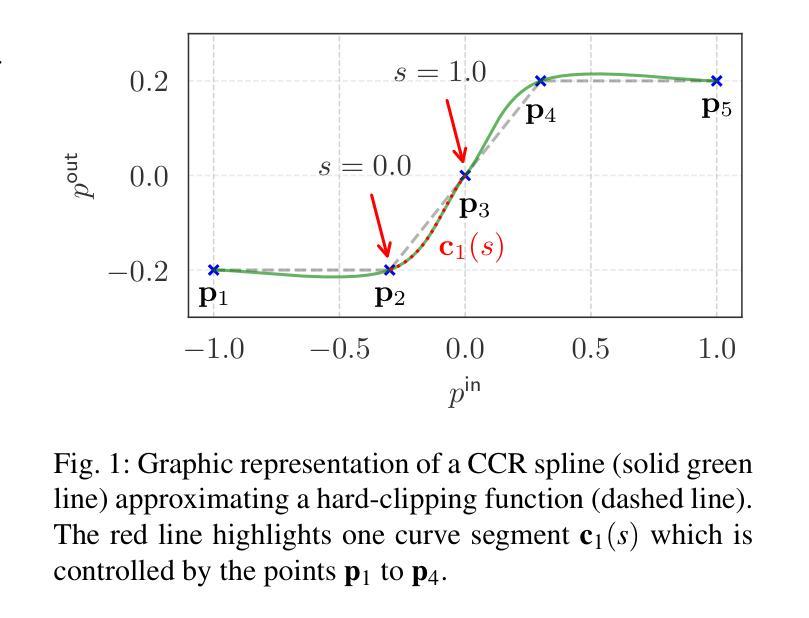
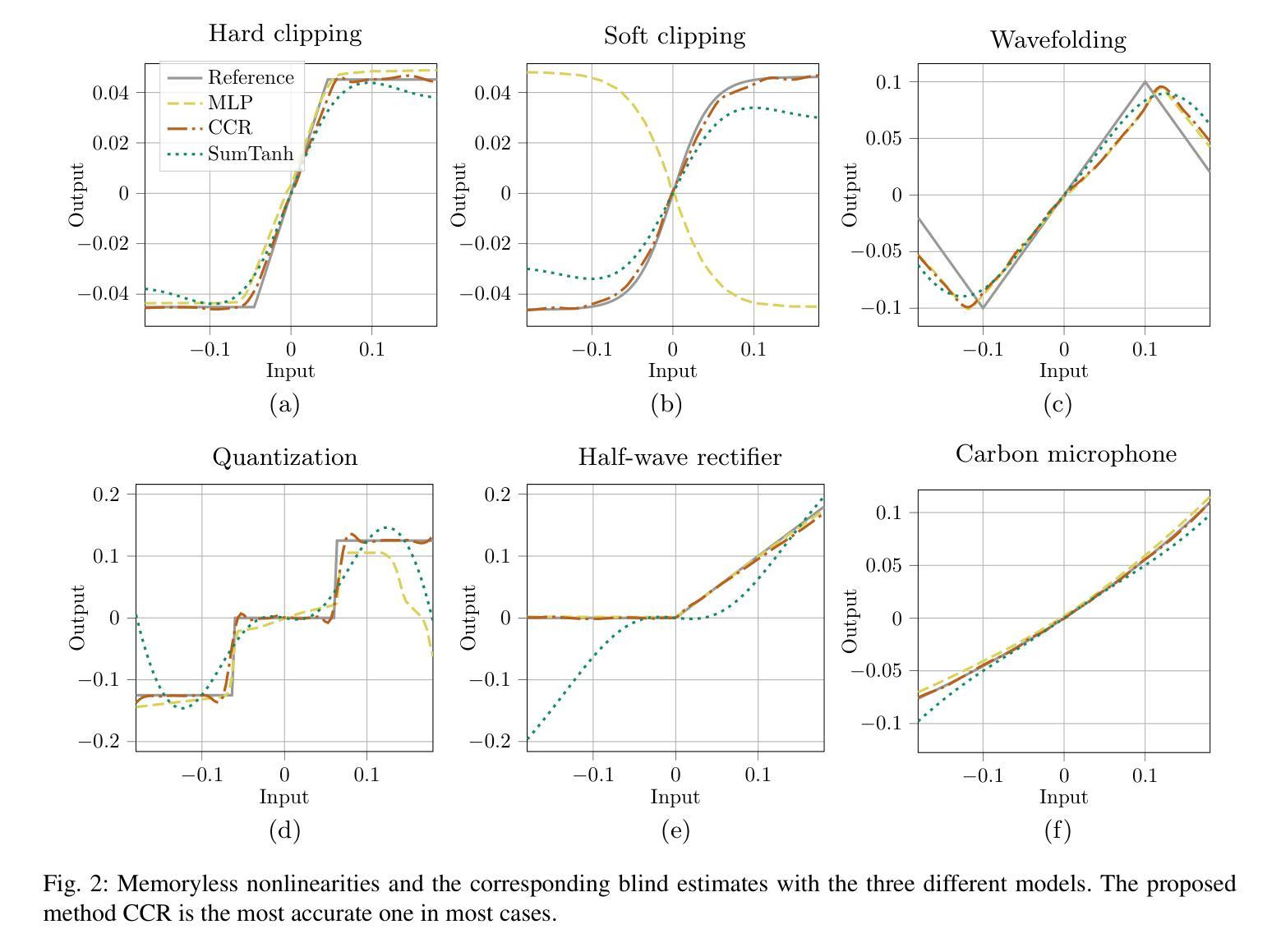
The restoration of nonlinearly distorted audio signals, alongside the identification of the applied memoryless nonlinear operation, is studied. The paper focuses on the difficult but practically important case in which both the nonlinearity and the original input signal are unknown. The proposed method uses a generative diffusion model trained unconditionally on guitar or speech signals to jointly model and invert the nonlinear system at inference time. Both the memoryless nonlinear function model and the restored audio signal are obtained as output. Successful example case studies are presented including inversion of hard and soft clipping, digital quantization, half-wave rectification, and wavefolding nonlinearities. Our results suggest that, out of the nonlinear functions tested here, the cubic Catmull-Rom spline is best suited to approximating these nonlinearities. In the case of guitar recordings, comparisons with informed and supervised methods show that the proposed blind method is at least as good as they are in terms of objective metrics. Experiments on distorted speech show that the proposed blind method outperforms general-purpose speech enhancement techniques and restores the original voice quality. The proposed method can be applied to audio effects modeling, restoration of music and speech recordings, and characterization of analog recording media.
本文研究了非线性失真音频信号的恢复以及所应用的无记忆非线性操作识别。文章重点关注在实际应用中非常重要但难度较大的情况,即非线性和原始输入信号均未知。提出的方法使用了一个在吉他或语音信号上无条件训练的生成扩散模型,在推理时间联合建模并反转非线性系统。输出中包含无记忆非线性函数模型和恢复的音频信号。成功的案例研究包括硬裁剪、软裁剪、数字量化、半波整流和波形折叠非线性的反转。我们的结果表明,在所测试的非线性函数中,立方Catmull-Rom样条最适合逼近这些非线性。在吉他录音的情况下,与有监督方法的比较表明,所提出的盲方法在客观指标方面至少与这些方法一样好。对失真语音的实验表明,提出的盲方法优于通用语音增强技术,并能恢复原始语音质量。该方法可应用于音频效果建模、音乐和语音记录的恢复以及模拟录音介质的表征。
论文及项目相关链接
PDF Submitted to the Journal of Audio Engineering Society, special issue “The Sound of Digital Audio Effects”
Summary
这篇论文研究的是非线性失真音频信号的恢复,以及记忆性非线性操作的应用识别。文章关注在未知非线性和原始输入信号的情况下,利用无条件训练在吉他或语音信号上的生成扩散模型,对非线性系统进行联合建模和反向运算。此方法可得到记忆性非线性函数模型和恢复的音频信号。成功应用案例包括硬裁剪、软裁剪、数字量化、半波整流和波折叠非线性的反向运算。实验表明,在所测试的非线性函数中,Catmull-Rom三次样条曲线最适合近似这些非线性。在吉他录音案例中,与有监督方法相比,此盲方法在客观指标上表现相当。在失真语音实验中,此盲方法优于通用语音增强技术,并能恢复原始语音质量。此方法可应用于音频效果建模、音乐和语音记录的恢复以及模拟录音媒体的特性。
Key Takeaways
- 论文研究了非线性失真音频信号的恢复和记忆性非线性操作的应用识别。
- 在未知非线性和原始输入信号的情况下,使用生成扩散模型进行建模和反向运算。
- 成功应用案例包括多种非线性操作的反向运算,如硬裁剪、软裁剪等。
- Catmull-Rom三次样条曲线最适合近似这些非线性。
- 在吉他录音案例中,盲方法与有监督方法表现相当。
- 在失真语音实验中,盲方法优于通用语音增强技术。
点此查看论文截图


Unmasking Deepfakes: Leveraging Augmentations and Features Variability for Deepfake Speech Detection
Authors:Inbal Rimon, Oren Gal, Haim Permuter
The detection of deepfake speech has become increasingly challenging with the rapid evolution of deepfake technologies. In this paper, we propose a hybrid architecture for deepfake speech detection, combining a self-supervised learning framework for feature extraction with a classifier head to form an end-to-end model. Our approach incorporates both audio-level and feature-level augmentation techniques. Specifically, we introduce and analyze various masking strategies for augmenting raw audio spectrograms and for enhancing feature representations during training. We incorporate compression augmentations during the pretraining phase of the feature extractor to address the limitations of small, single-language datasets. We evaluate the model on the ASVSpoof5 (ASVSpoof 2024) challenge, achieving state-of-the-art results in Track 1 under closed conditions with an Equal Error Rate of 4.37%. By employing different pretrained feature extractors, the model achieves an enhanced EER of 3.39%. Our model demonstrates robust performance against unseen deepfake attacks and exhibits strong generalization across different codecs.
随着深度伪造技术的快速发展,深度伪造语音的检测越来越具有挑战性。在本文中,我们提出了一种用于深度伪造语音检测的混合架构,该架构结合了自监督学习框架进行特征提取和分类器头以形成端到端模型。我们的方法结合了音频级别和特征级别的增强技术。具体来说,我们引入并分析了各种掩蔽策略,以增强原始音频频谱图并在训练期间优化特征表示。我们在特征提取器的预训练阶段引入了压缩增强技术,以解决小型单一语言数据集的限制。我们在ASVSpoof5(ASVSpoof 2024)挑战上评估了我们的模型,在封闭条件下的轨道1中取得了最先进的成果,等误率(Equal Error Rate)为4.37%。通过采用不同的预训练特征提取器,模型的EER提升至了3.39%。我们的模型对未见过的深度伪造攻击表现出稳健的性能,并且在不同的编解码器之间展现出强大的泛化能力。
论文及项目相关链接
Summary
随着深度伪造技术的快速发展,深度伪造语音的检测面临越来越大的挑战。本文提出了一种混合架构的深度伪造语音检测方案,该方案结合自监督学习框架进行特征提取和分类器头部以形成端到端模型。该方法结合了音频级别和特征级别的增强技术,引入并分析了各种掩码策略来增强原始音频频谱图,并在训练过程中改善特征表示。针对小语种单一数据集的限制,我们在特征提取器的预训练阶段引入了压缩增强技术。在ASVSpoof5(ASVSpoof 2024)挑战上评估该模型,在封闭条件下轨迹1中取得了最新技术成果,等误码率为4.37%。通过使用不同的预训练特征提取器,该模型的等误码率进一步提高至3.39%。该模型对未知的深度伪造攻击表现出稳健的性能,并在不同的编解码器之间展现出强大的泛化能力。
Key Takeaways
- 深度伪造语音检测面临挑战:随着深度伪造技术的快速发展,现有的语音检测方案已无法满足需求。
- 混合架构方案:结合自监督学习框架进行特征提取和分类器头部,形成端到端模型。
- 音频和特征级别增强:引入音频级别和特征级别的增强技术以提高模型性能。
- 掩码策略的应用:通过掩码策略增强原始音频频谱图,改善特征表示。
- 预训练阶段的压缩增强:针对小语种单一数据集的局限性,引入压缩增强技术。
- 模型在ASVSpoof5挑战上表现优异:在封闭条件下轨迹1的等误码率达到业界领先水平。
点此查看论文截图

ZipEnhancer: Dual-Path Down-Up Sampling-based Zipformer for Monaural Speech Enhancement
Authors:Haoxu Wang, Biao Tian
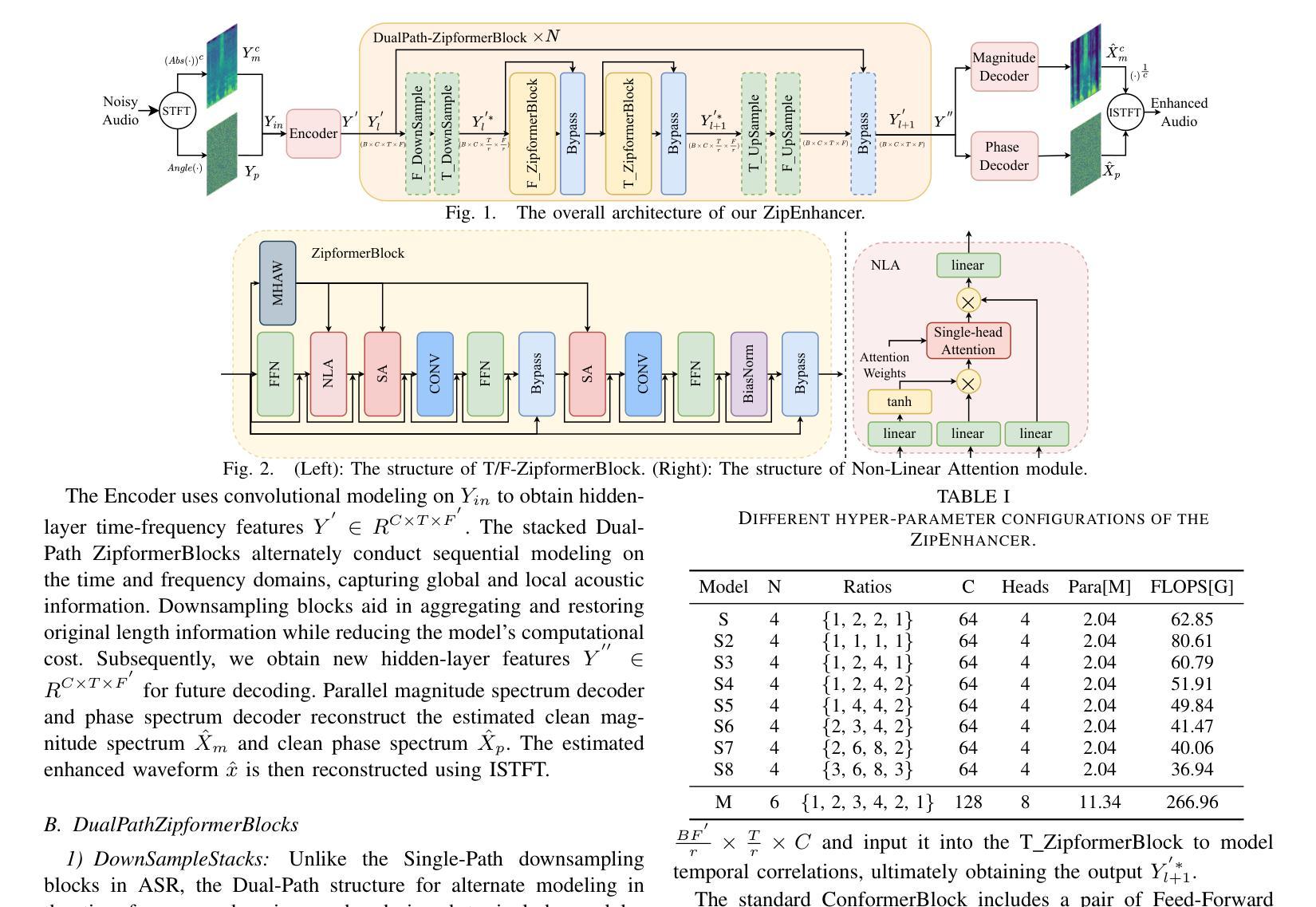
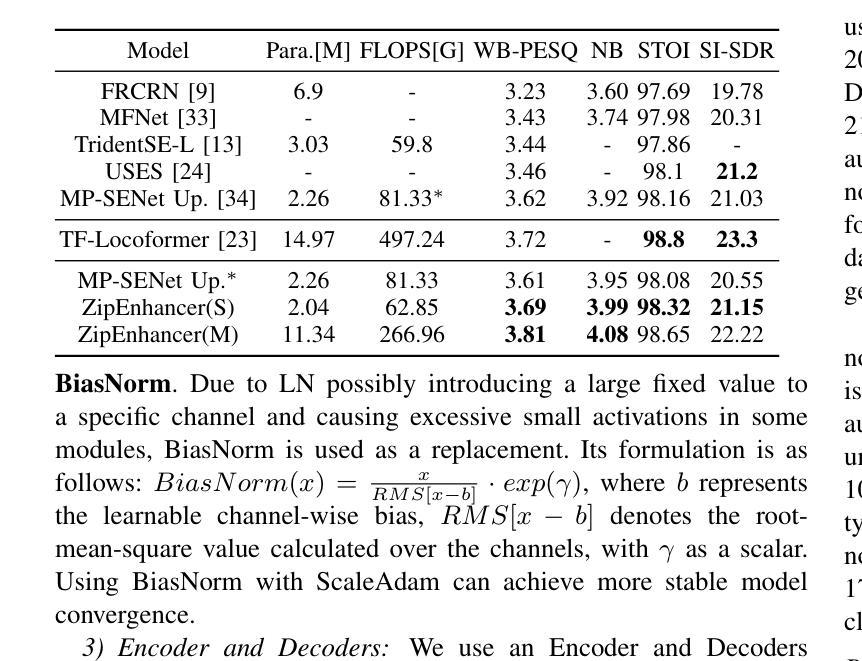
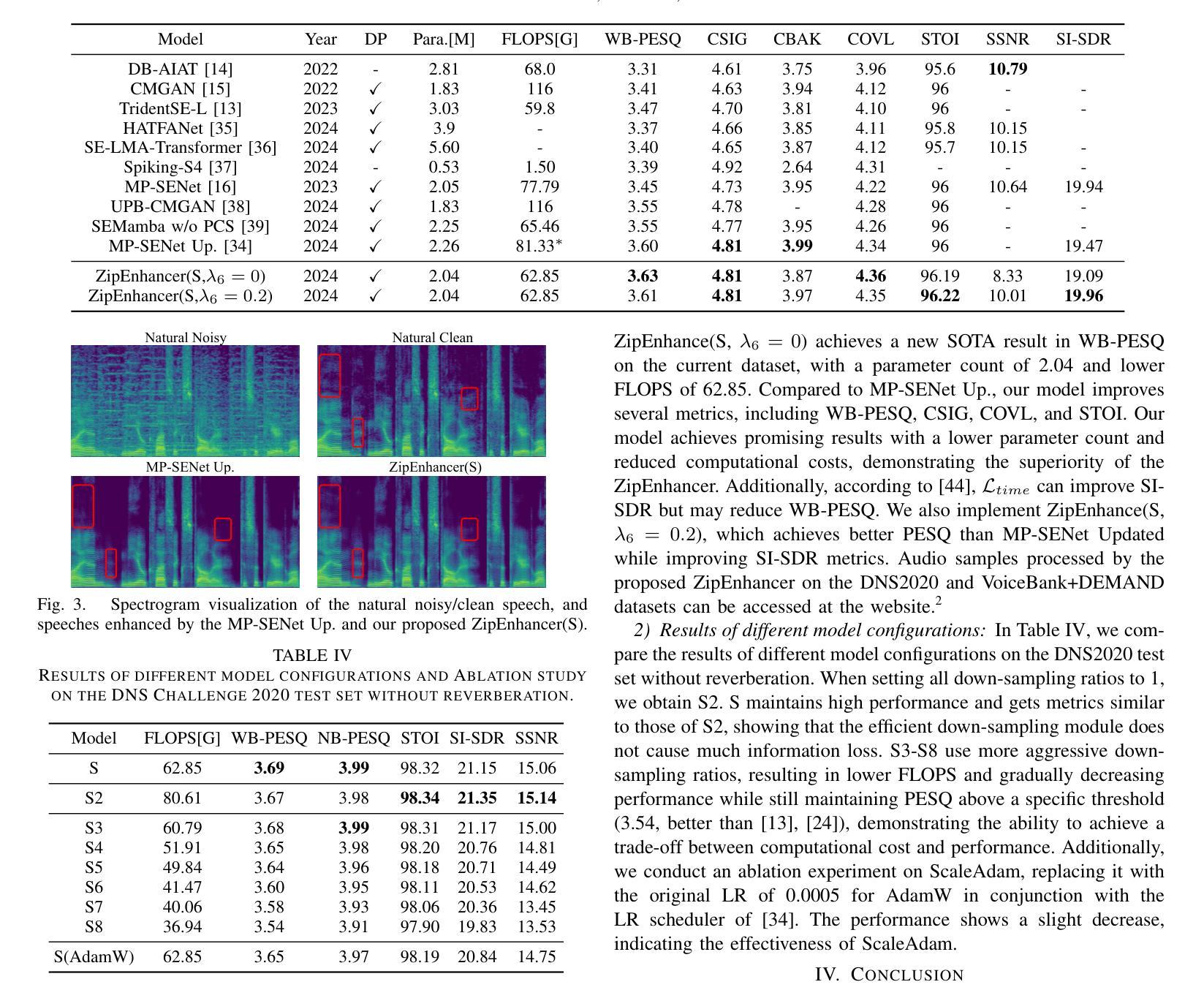
In contrast to other sequence tasks modeling hidden layer features with three axes, Dual-Path time and time-frequency domain speech enhancement models are effective and have low parameters but are computationally demanding due to their hidden layer features with four axes. We propose ZipEnhancer, which is Dual-Path Down-Up Sampling-based Zipformer for Monaural Speech Enhancement, incorporating time and frequency domain Down-Up sampling to reduce computational costs. We introduce the ZipformerBlock as the core block and propose the design of the Dual-Path DownSampleStacks that symmetrically scale down and scale up. Also, we introduce the ScaleAdam optimizer and Eden learning rate scheduler to improve the performance further. Our model achieves new state-of-the-art results on the DNS 2020 Challenge and Voicebank+DEMAND datasets, with a perceptual evaluation of speech quality (PESQ) of 3.69 and 3.63, using 2.04M parameters and 62.41G FLOPS, outperforming other methods with similar complexity levels.
相比之下,其他序列任务模型使用具有三个轴的特征进行隐藏层建模,而双路径时间和时频域语音增强模型虽然有效且参数较少,但由于其具有四个轴的隐藏层特征而计算量较大。我们提出了ZipEnhancer,这是一种基于双路径升降采样的Zipformer单声道语音增强方法,它结合了时间和频域的升降采样以降低计算成本。我们引入了ZipformerBlock作为核心模块,并提出了双路径DownSampleStacks的设计,实现了对称的缩小和放大。此外,我们还引入了ScaleAdam优化器和Eden学习率调度器以进一步提高性能。我们的模型在DNS 2020挑战赛和Voicebank+DEMAND数据集上取得了最新成果,使用204万参数和62.41G FLOPS的感知语音质量评估(PESQ)为3.69和3.63,优于其他具有相似复杂度的模型。
论文及项目相关链接
PDF Accepted by ICASSP 2025
Summary
本文介绍了Dual-Path时域和时频域语音增强模型的有效性,其隐藏层特征具有四轴,但参数较少且计算成本较高。为解决计算成本问题,本文提出了ZipEnhancer模型,该模型基于双路径上下采样技术的Zipformer设计,用于单声语音增强。此外,引入了ZipformerBlock作为核心组件和双路径下采样堆栈的对称扩展与缩小设计。通过引入ScaleAdam优化器和Eden学习率调度器进一步提高了性能。该模型在DNS 2020挑战和Voicebank+DEMAND数据集上取得了最新的最好结果,实现了良好的语音质量感知评价(PESQ)。
Key Takeaways
- Dual-Path时域和时频域语音增强模型具有四轴隐藏层特征,相较于其他序列任务建模方法更有效且参数更少。
- ZipEnhancer模型通过引入双路径上下采样技术的Zipformer设计,解决了计算成本较高的问题。
- ZipformerBlock被引入作为核心组件,双路径下采样堆栈设计实现了对称的缩小和扩展。
- ScaleAdam优化器和Eden学习率调度器的引入进一步提高了模型的性能。
- 该模型在DNS 2020挑战和Voicebank+DEMAND数据集上取得了最新的最好结果。
- 该模型的语音质量感知评价(PESQ)达到了较高的水平。
点此查看论文截图

JELLY: Joint Emotion Recognition and Context Reasoning with LLMs for Conversational Speech Synthesis
Authors:Jun-Hyeok Cha, Seung-Bin Kim, Hyung-Seok Oh, Seong-Whan Lee
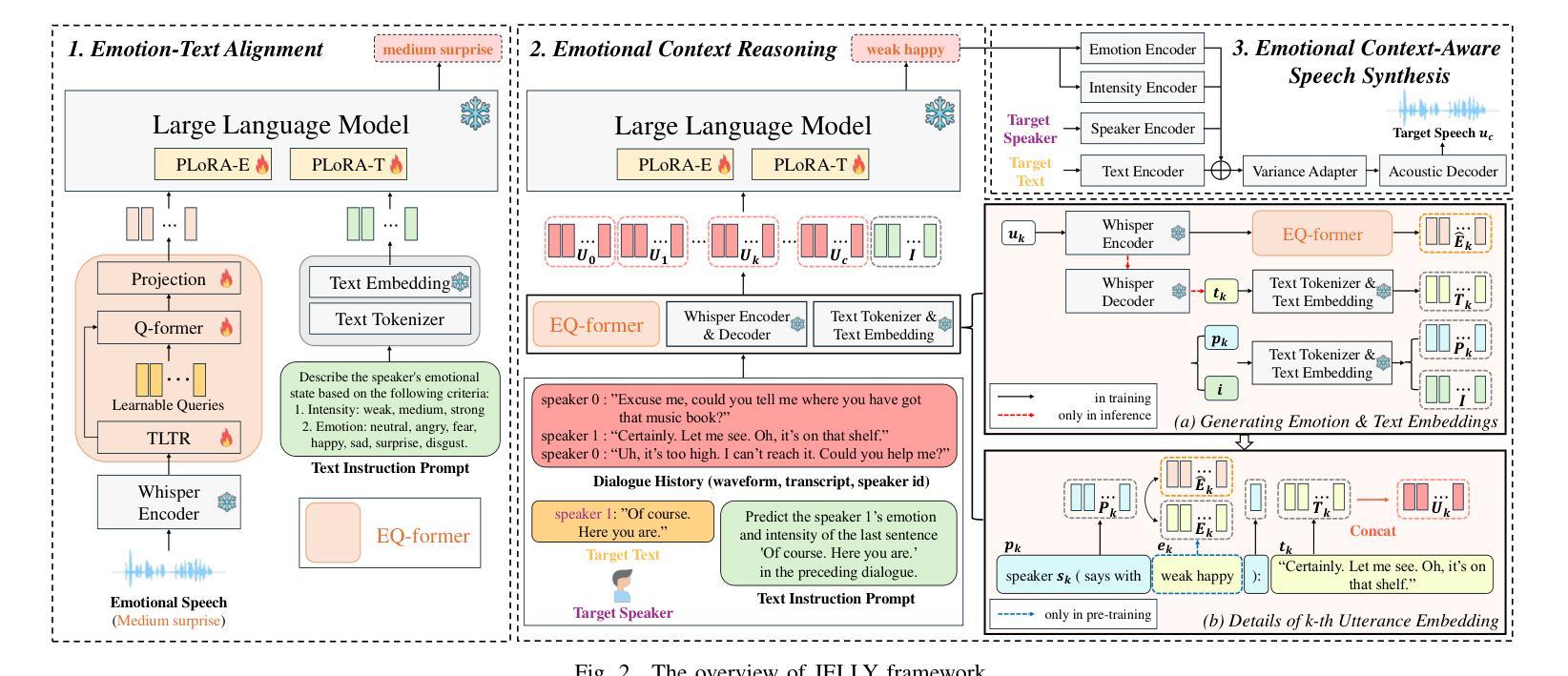
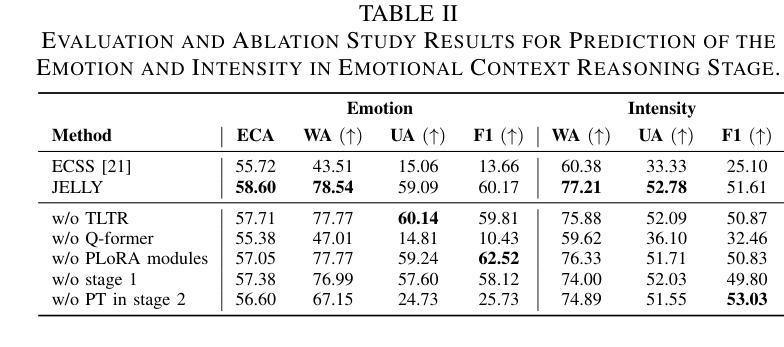
Recently, there has been a growing demand for conversational speech synthesis (CSS) that generates more natural speech by considering the conversational context. To address this, we introduce JELLY, a novel CSS framework that integrates emotion recognition and context reasoning for generating appropriate speech in conversation by fine-tuning a large language model (LLM) with multiple partial LoRA modules. We propose an Emotion-aware Q-former encoder, which enables the LLM to perceive emotions in speech. The encoder is trained to align speech emotions with text, utilizing datasets of emotional speech. The entire model is then fine-tuned with conversational speech data to infer emotional context for generating emotionally appropriate speech in conversation. Our experimental results demonstrate that JELLY excels in emotional context modeling, synthesizing speech that naturally aligns with conversation, while mitigating the scarcity of emotional conversational speech datasets.
最近,对话式语音合成(CSS)的需求不断增长,它可以通过考虑对话上下文来生成更自然的语音。为了解决这一问题,我们引入了JELLY,这是一个新型的CSS框架,通过微调大型语言模型(LLM)并集成多个局部LoRA模块,用于在对话中生成适当的语音。我们提出了一种情感感知Q-former编码器,使LLM能够感知语音中的情感。该编码器经过训练,能够将语音情感与文本对齐,利用情感语音数据集。然后对整个模型进行对话语音数据的微调,以推断情感上下文,从而在对话中生成情感上适当的语音。我们的实验结果表明,JELLY在情感上下文建模方面表现出色,能够合成与对话自然对齐的语音,同时缓解了情感对话语音数据集稀缺的问题。
论文及项目相关链接
PDF Accepted by ICASSP 2025
Summary
近期对话式语音合成(CSS)需求增长,考虑对话语境生成更自然的语音。为此,我们推出JELLY,一种新型CSS框架,通过微调大型语言模型(LLM)并结合多个局部可调整(LoRA)模块,生成对话中适当的语音。我们提出情感感知Q-former编码器,使LLM能够感知语音中的情感。编码器经过训练,使语音情感与文本对齐,并利用情感语音数据集。整个模型进一步用对话语音数据进行微调,以推断情感语境,生成对话中情感上适当的语音。实验结果表明,JELLY在情感语境建模上表现出色,能够合成与对话自然对齐的语音,同时缓解情感对话语音数据集缺乏的问题。
Key Takeaways
- JELLY是一个新型的对话式语音合成(CSS)框架,用于生成更自然的语音。
- 它通过整合情感识别和语境推理来适应对话语境。
- JELLY使用大型语言模型(LLM)并结合多个局部可调整(LoRA)模块来实现。
- 提出了情感感知Q-former编码器,使LLM能感知语音中的情感。
- 编码器经过训练,将语音情感与文本对齐,利用情感语音数据集。
- 整个模型用对话语音数据微调,以推断情感语境。
点此查看论文截图


Enhancing Listened Speech Decoding from EEG via Parallel Phoneme Sequence Prediction
Authors:Jihwan Lee, Tiantian Feng, Aditya Kommineni, Sudarsana Reddy Kadiri, Shrikanth Narayanan
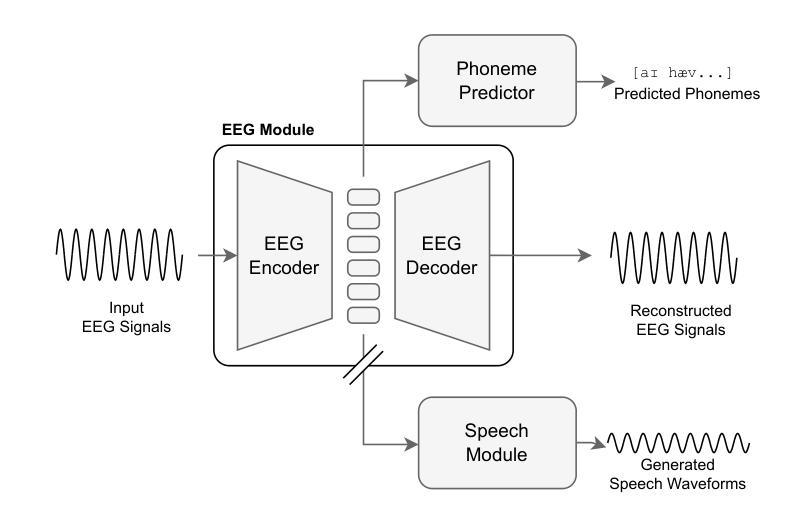
Brain-computer interfaces (BCI) offer numerous human-centered application possibilities, particularly affecting people with neurological disorders. Text or speech decoding from brain activities is a relevant domain that could augment the quality of life for people with impaired speech perception. We propose a novel approach to enhance listened speech decoding from electroencephalography (EEG) signals by utilizing an auxiliary phoneme predictor that simultaneously decodes textual phoneme sequences. The proposed model architecture consists of three main parts: EEG module, speech module, and phoneme predictor. The EEG module learns to properly represent EEG signals into EEG embeddings. The speech module generates speech waveforms from the EEG embeddings. The phoneme predictor outputs the decoded phoneme sequences in text modality. Our proposed approach allows users to obtain decoded listened speech from EEG signals in both modalities (speech waveforms and textual phoneme sequences) simultaneously, eliminating the need for a concatenated sequential pipeline for each modality. The proposed approach also outperforms previous methods in both modalities. The source code and speech samples are publicly available.
脑机接口(BCI)提供了许多以人类为中心的应用可能性,尤其对神经障碍患者产生了影响。从脑活动中解码文本或语音是一个相关域,这可能提高语音感知受损患者的生活质量。我们提出了一种利用辅助音素预测器同时解码文本音素序列的新方法,以增强从脑电图(EEG)信号中听取的语音解码效果。所提议的模型架构由三个主要部分组成:EEG模块、语音模块和音素预测器。EEG模块学习适当地表示EEG信号为EEG嵌入。语音模块从EEG嵌入生成语音波形。音素预测器输出解码的音素序列在文本模式下。我们提出的方法允许用户同时从EEG信号中获得两种模式的解码语音(语音波形和文本音素序列),而无需为每个模式使用串联的序贯管道。该方法在两个模态上的表现均优于以前的方法。源代码和语音样本可公开访问。
论文及项目相关链接
PDF ICASSP 2025
Summary
本文介绍了一种利用脑机接口(BCI)技术增强聆听语音解码的新方法。新方法利用脑电图(EEG)信号,通过辅助音素预测器同时解码文本音素序列,从而提高语音解码的准确性和质量。该方法包括EEG模块、语音模块和音素预测器三个部分,可同时输出语音波形和文本音素序列两种模态的解码语音。相较于之前的方法,该方法在两个模态上都表现出更高的性能。
Key Takeaways
- BCI技术在人类为中心的应用中具有广阔的前景,特别是在帮助具有神经障碍的人群方面。
- 提出了一种新方法,利用EEG信号和辅助音素预测器增强语音解码。
- 新方法包括EEG模块、语音模块和音素预测器三个主要部分。
- 该方法可以同时在两种模态(语音波形和文本音素序列)上输出解码语音。
- 与以前的方法相比,新方法在两种模态上都表现出卓越的性能。
- 该方法的源代码和语音样本已公开可用。
点此查看论文截图



Building Foundations for Natural Language Processing of Historical Turkish: Resources and Models
Authors:Şaziye Betül Özateş, Tarık Emre Tıraş, Ece Elif Adak, Berat Doğan, Fatih Burak Karagöz, Efe Eren Genç, Esma F. Bilgin Taşdemir
This paper introduces foundational resources and models for natural language processing (NLP) of historical Turkish, a domain that has remained underexplored in computational linguistics. We present the first named entity recognition (NER) dataset, HisTR and the first Universal Dependencies treebank, OTA-BOUN for a historical form of the Turkish language along with transformer-based models trained using these datasets for named entity recognition, dependency parsing, and part-of-speech tagging tasks. Additionally, we introduce Ottoman Text Corpus (OTC), a clean corpus of transliterated historical Turkish texts that spans a wide range of historical periods. Our experimental results show significant improvements in the computational analysis of historical Turkish, achieving promising results in tasks that require understanding of historical linguistic structures. They also highlight existing challenges, such as domain adaptation and language variations across time periods. All of the presented resources and models are made available at https://huggingface.co/bucolin to serve as a benchmark for future progress in historical Turkish NLP.
本文介绍了对计算语言学中尚未充分探索的领域——历史土耳其语的自然语言处理(NLP)的基础资源和模型。我们首次推出了历史土耳其语命名实体识别(NER)数据集HisTR和通用依存关系树库OTA-BOUN,以及使用这些数据集进行训练,用于命名实体识别、依存关系解析和词性标注任务的基于转换器的模型。此外,我们还介绍了奥斯曼文本语料库(OTC),这是一个跨越广泛历史时期的转写历史土耳其语文本的干净语料库。我们的实验结果表明,对历史土耳其语的计算分析有了显著的改进,在需要理解历史语言结构的任务中取得了令人鼓舞的结果。他们还强调了现有的挑战,如领域适应和时间跨度上的语言变化。所有提供的资源和模型都可在https://huggingface.co/bucolin找到,为历史土耳其语NLP的未来发展提供基准测试。
论文及项目相关链接
Summary
本文介绍了针对历史土耳其语的自然语言处理(NLP)的基础资源和模型。文章首次推出了HisTR命名实体识别(NER)数据集和OTA-BOUN历史土耳其语的通用依存关系树库,以及使用这些数据集训练的用于命名实体识别、依存关系解析和词性标注任务的基于转换器的模型。此外,还介绍了横跨广泛历史时期的清洁历史土耳其语文本语料库——奥斯曼文本语料库(OTC)。实验结果显著改善了历史土耳其语的计算分析,在需要理解历史语言结构的任务中取得了令人鼓舞的结果,同时也突显了领域适应性和时间跨度中的语言变化等现有挑战。所有资源和模型均可在https://huggingface.co/bucolin上找到,旨在为未来的历史土耳其语NLP进展提供基准测试。
Key Takeaways
- 文章介绍了针对历史土耳其语自然语言处理的基础资源和模型,填补了计算语言学领域对该语言的探索空白。
- 文章首次发布了HisTR命名实体识别数据集和OTA-BOUN历史土耳其语通用依存关系树库。
- 通过使用这些数据集训练的基于转换器的模型,在命名实体识别、依存关系解析和词性标注任务中取得了显著成果。
- 文章还介绍了奥斯曼文本语料库(OTC),这是一个清洁的历史土耳其语文本语料库,涵盖广泛的历史时期。
- 实验结果显著改善了历史土耳其语的计算分析,特别是在需要理解历史语言结构的任务中。
- 文章强调了领域适应性和时间跨度中的语言变化等现有挑战。
点此查看论文截图




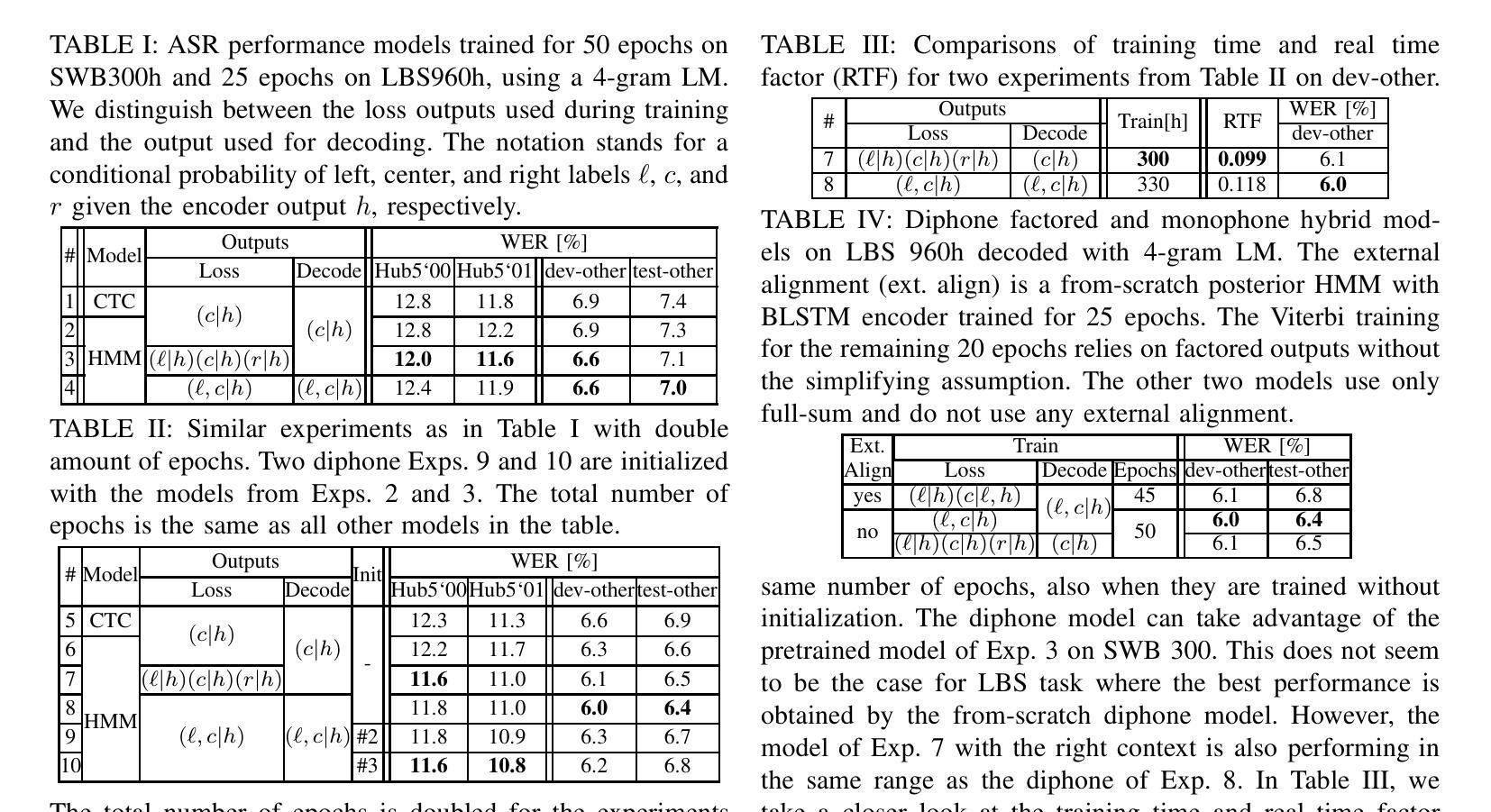
Right Label Context in End-to-End Training of Time-Synchronous ASR Models
Authors:Tina Raissi, Ralf Schlüter, Hermann Ney
Current time-synchronous sequence-to-sequence automatic speech recognition (ASR) models are trained by using sequence level cross-entropy that sums over all alignments. Due to the discriminative formulation, incorporating the right label context into the training criterion’s gradient causes normalization problems and is not mathematically well-defined. The classic hybrid neural network hidden Markov model (NN-HMM) with its inherent generative formulation enables conditioning on the right label context. However, due to the HMM state-tying the identity of the right label context is never modeled explicitly. In this work, we propose a factored loss with auxiliary left and right label contexts that sums over all alignments. We show that the inclusion of the right label context is particularly beneficial when training data resources are limited. Moreover, we also show that it is possible to build a factored hybrid HMM system by relying exclusively on the full-sum criterion. Experiments were conducted on Switchboard 300h and LibriSpeech 960h.
当前的时间同步序列到序列自动语音识别(ASR)模型是通过使用序列级别的交叉熵(对所有对齐进行求和)来训练的。由于采用了判别式公式,将正确的标签上下文纳入训练标准的梯度会导致归一化问题,并且从数学上定义不够明确。经典的混合神经网络隐马尔可夫模型(NN-HMM)凭借其内在的生成式公式,能够实现以正确的标签上下文进行条件设置。然而,由于隐马尔可夫模型的状态绑定,因此绝不会明确地建模正确的标签上下文的身份。在这项工作中,我们提出了一种具有辅助左和右标签上下文的分解损失,该损失对所有对齐进行了求和。我们表明,在训练数据资源有限的情况下,包含正确的标签上下文特别有益。此外,我们还表明,仅依靠全和准则来构建分解混合HMM系统是可能的。实验在Switchboard 300h和LibriSpeech 960h上进行。
论文及项目相关链接
PDF Accepted for presentation at ICASSP 2025
Summary:
当前时序同步的序列到序列语音识别模型采用序列级别的交叉熵进行训练,通过对齐求和实现。由于判别式公式的问题,将正确的标签上下文纳入训练标准的梯度会导致归一化问题并且数学上未明确定义。经典的混合神经网络隐马尔可夫模型(NN-HMM)具有其固有的生成式公式,可实现正确的标签上下文条件设置。然而,由于HMM的状态绑定,正确的标签上下文的身份从未被明确建模。在这项工作中,我们提出了一种带有辅助左右标签上下文的分解损失,通过对齐求和实现。我们表明,在训练数据资源有限的情况下,引入正确的标签上下文特别有益。此外,我们还展示了仅依靠全和准则建立分解混合HMM系统的可能性。实验在Switchboard 300h和LibriSpeech 960h上进行。
Key Takeaways:
- 当前ASR模型使用序列级别的交叉熵进行训练,通过对齐求和实现。
- 判别式公式在纳入正确的标签上下文时会导致训练问题。
- NN-HMM模型能够基于生成式公式实现正确的标签上下文条件设置。
- HMM的状态绑定导致正确的标签上下文未被明确建模。
- 提出的分解损失模型带有辅助的左右标签上下文,通过对齐求和实现。
- 在训练数据有限的情况下,引入正确的标签上下文特别有益。
- 仅靠全和准则建立分解混合HMM系统是可能的。
点此查看论文截图

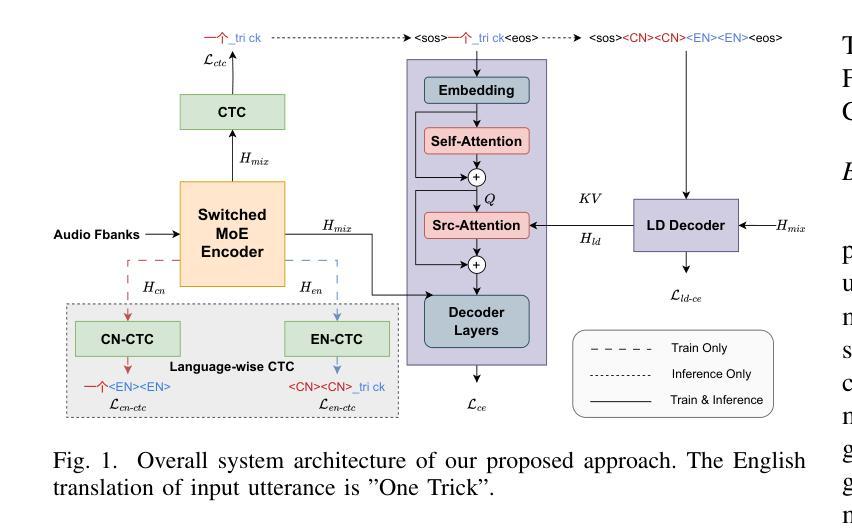
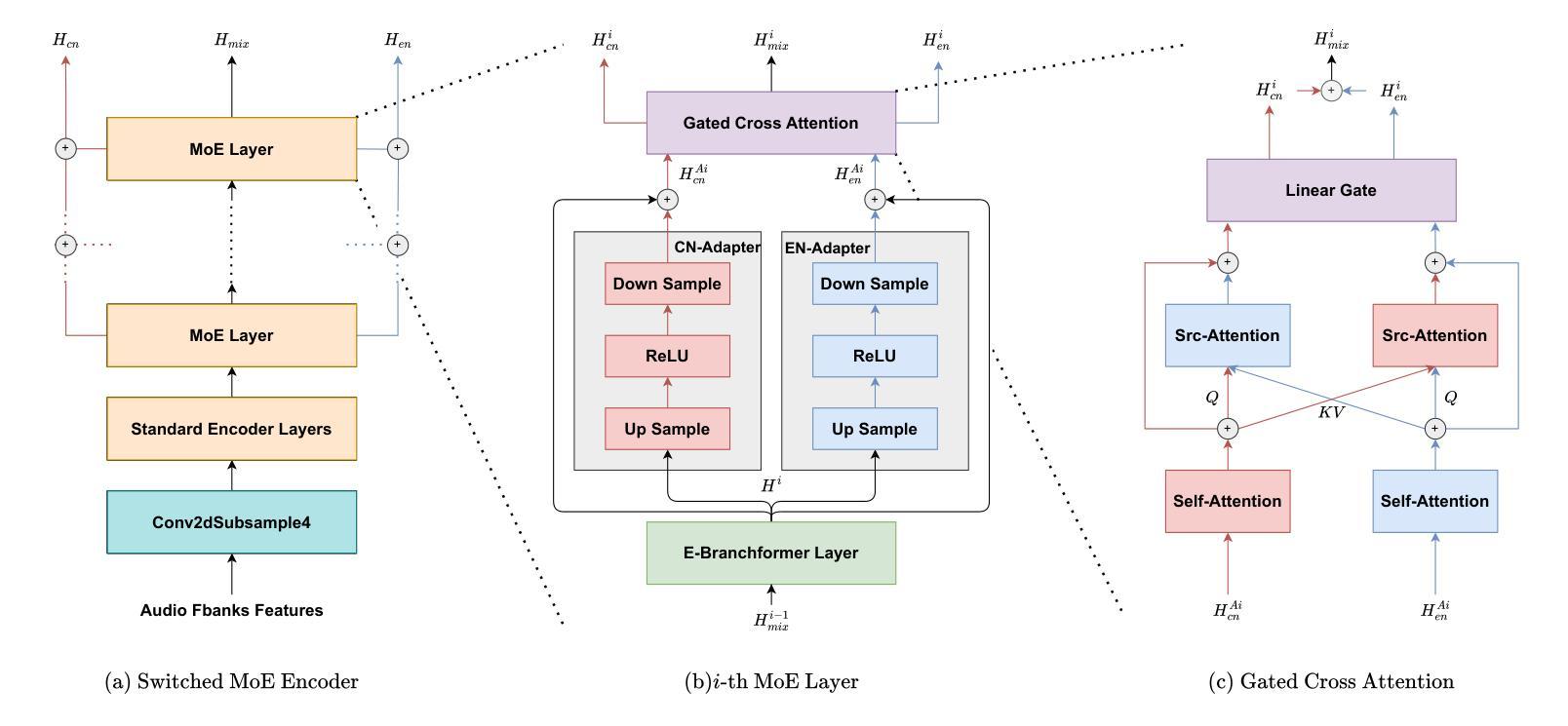
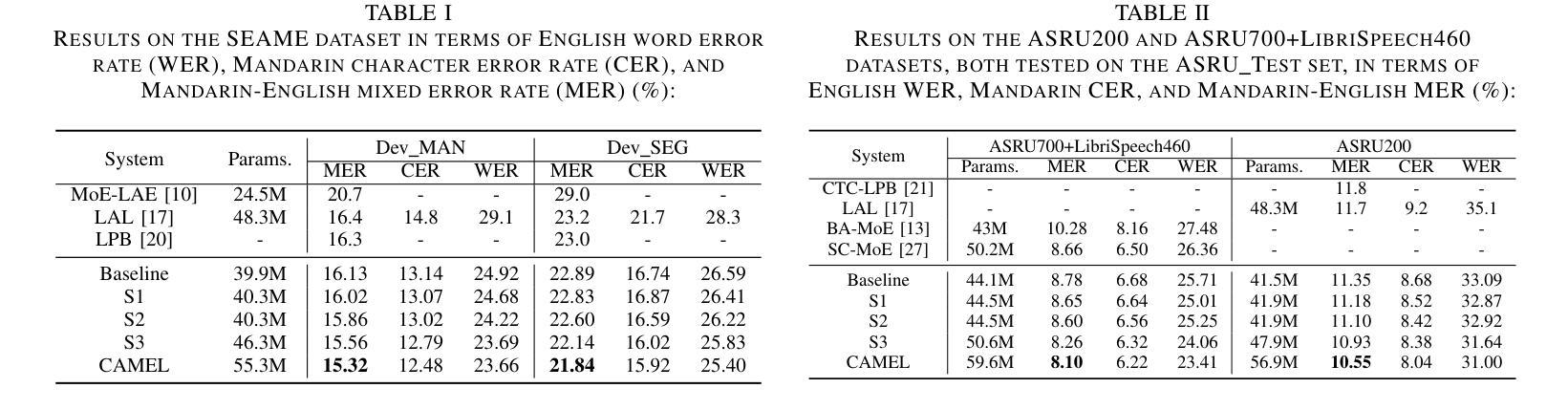
CAMEL: Cross-Attention Enhanced Mixture-of-Experts and Language Bias for Code-Switching Speech Recognition
Authors:He Wang, Xucheng Wan, Naijun Zheng, Kai Liu, Huan Zhou, Guojian Li, Lei Xie
Code-switching automatic speech recognition (ASR) aims to transcribe speech that contains two or more languages accurately. To better capture language-specific speech representations and address language confusion in code-switching ASR, the mixture-of-experts (MoE) architecture and an additional language diarization (LD) decoder are commonly employed. However, most researches remain stagnant in simple operations like weighted summation or concatenation to fuse languagespecific speech representations, leaving significant opportunities to explore the enhancement of integrating language bias information. In this paper, we introduce CAMEL, a cross-attention-based MoE and language bias approach for code-switching ASR. Specifically, after each MoE layer, we fuse language-specific speech representations with cross-attention, leveraging its strong contextual modeling abilities. Additionally, we design a source attention-based mechanism to incorporate the language information from the LD decoder output into text embeddings. Experimental results demonstrate that our approach achieves state-of-the-art performance on the SEAME, ASRU200, and ASRU700+LibriSpeech460 Mandarin-English code-switching ASR datasets.
代码切换自动语音识别(ASR)旨在准确转录包含两种或多种语言的语音。为了更好地捕获特定语言的语音表示并解决代码切换ASR中的语言混淆问题,通常采用基于专家的混合(MoE)架构和额外的语言分馏(LD)解码器。然而,大多数研究仍停留在加权求和或拼接等简单操作来融合特定语言的语音表示,留下了探索整合语言偏见信息增强的显著机会。在本文中,我们介绍了CAMEL,这是一种基于跨注意力的MoE和语言偏见方法的代码切换ASR。具体来说,在每个MoE层之后,我们利用强大的上下文建模能力,通过跨注意力融合特定语言的语音表示。此外,我们设计了一种基于源注意力的机制,将LD解码器的语言信息并入文本嵌入中。实验结果表明,我们的方法在SEAME、ASRU200、ASRU700和LibriSpeech460的普通话英语代码切换ASR数据集上达到了最新性能水平。
论文及项目相关链接
PDF Accepted by ICASSP 2025. 5 pages, 2 figures
Summary
本文介绍了针对双语或多语混合自动语音识别(ASR)技术的最新研究。研究提出了一种基于交叉注意力和语言偏好的混合专家(MoE)架构方法CAMEL,旨在更准确地转录包含两种或多种语言的语音。该方法通过融合语言特定语音表示和引入语言信息嵌入机制,提高了代码切换ASR的性能。实验结果表明,CAMEL在多个数据集上实现了先进的表现。
Key Takeaways
- 代码切换自动语音识别(ASR)的目标:准确转录包含两种或多种语言的语音。
- 现有方法存在的问题:多数研究仅通过简单操作(如加权求和或拼接)融合语言特定的语音表示,未能充分探索整合语言偏见信息的增强方式。
- CAMEL方法介绍:采用基于交叉注意力的混合专家(MoE)架构和语言偏见方法来解决这一问题。
- MoE架构中的创新点:在每个MoE层后,通过交叉注意力融合语言特定的语音表示,利用其强大的上下文建模能力。
- 语言信息嵌入机制:设计了一种基于源注意力的机制,将LD解码器的语言信息融入文本嵌入中。
- 实验结果:CAMEL在多个数据集上实现了先进的表现,包括SEAME、ASRU200、ASRU700和LibriSpeech的Mandarin-English代码切换ASR数据集。
点此查看论文截图


PFML: Self-Supervised Learning of Time-Series Data Without Representation Collapse
Authors:Einari Vaaras, Manu Airaksinen, Okko Räsänen
Self-supervised learning (SSL) is a data-driven learning approach that utilizes the innate structure of the data to guide the learning process. In contrast to supervised learning, which depends on external labels, SSL utilizes the inherent characteristics of the data to produce its own supervisory signal. However, one frequent issue with SSL methods is representation collapse, where the model outputs a constant input-invariant feature representation. This issue hinders the potential application of SSL methods to new data modalities, as trying to avoid representation collapse wastes researchers’ time and effort. This paper introduces a novel SSL algorithm for time-series data called Prediction of Functionals from Masked Latents (PFML). Instead of predicting masked input signals or their latent representations directly, PFML operates by predicting statistical functionals of the input signal corresponding to masked embeddings, given a sequence of unmasked embeddings. The algorithm is designed to avoid representation collapse, rendering it straightforwardly applicable to different time-series data domains, such as novel sensor modalities in clinical data. We demonstrate the effectiveness of PFML through complex, real-life classification tasks across three different data modalities: infant posture and movement classification from multi-sensor inertial measurement unit data, emotion recognition from speech data, and sleep stage classification from EEG data. The results show that PFML is superior to a conceptually similar SSL method and a contrastive learning-based SSL method. Additionally, PFML is on par with the current state-of-the-art SSL method, while also being conceptually simpler and without suffering from representation collapse.
自监督学习(SSL)是一种数据驱动的学习方法,它利用数据的固有结构来指导学习过程。与依赖于外部标签的监督学习相比,SSL利用数据的内在特性来产生自己的监督信号。然而,SSL方法的一个常见问题是表示崩溃,即模型输出一个恒定的输入不变的特征表示。这个问题阻碍了SSL方法在新数据模态的潜在应用,因为试图避免表示崩溃会浪费研究人员的时间和精力。本文介绍了一种用于时间序列数据的新型SSL算法,称为“从掩码潜在特征预测功能”(PFML)。PFML不是直接预测掩码输入信号或其潜在表示,而是给定一系列未掩码嵌入,通过预测与掩码嵌入相对应的输入信号统计功能来操作。该算法旨在避免表示崩溃,使其能够直接应用于不同的时间序列数据领域,如临床数据中的新型传感器模态。我们通过三个不同数据模态的复杂现实分类任务展示了PFML的有效性:从多传感器惯性测量单元数据进行婴儿姿势和运动分类,从语音数据进行情感识别,从脑电图数据进行睡眠阶段分类。结果表明,PFML优于一个概念相似的SSL方法和一个基于对比学习的SSL方法。此外,PFML与当前最先进的SSL方法不相上下,同时概念上更简单,并且没有遭受表示崩溃的问题。
论文及项目相关链接
Summary
本文介绍了一种针对时间序列数据的自我监督学习(SSL)新算法——基于掩码隐层的功能预测(PFML)。PFML通过预测对应掩码嵌入的统计功能,而不是直接预测掩码输入信号或其隐层表示,从而避免了表示崩溃问题。这使得PFML可直接应用于不同的时间序列数据领域,如临床数据中的新型传感器模态。通过跨三种不同数据模态的复杂现实分类任务验证,PFML在婴儿姿势和运动分类、情感识别以及睡眠阶段分类等应用中表现优异,优于一种概念相似的SSL方法和一种基于对比学习的SSL方法,并与当前最先进的SSL方法表现相当,同时概念更简单,且不存在表示崩溃问题。
Key Takeaways
- 自我监督学习(SSL)是一种利用数据内在结构来指导学习过程的数据驱动学习方法。
- SSL面临的一个常见问题是表示崩溃,即模型输出恒定的输入不变特征表示。
- PFML是一种针对时间序列数据的SSL新算法,通过预测掩码嵌入的统计功能来避免表示崩溃问题。
- PFML可直接应用于不同的时间序列数据领域,如新型传感器模态的临床数据。
- PFML在多种复杂现实分类任务中表现优异,包括婴儿姿势和运动分类、情感识别以及睡眠阶段分类。
- PFML优于其他SSL方法,且与当前最先进的SSL方法表现相当,同时概念更简单。
点此查看论文截图

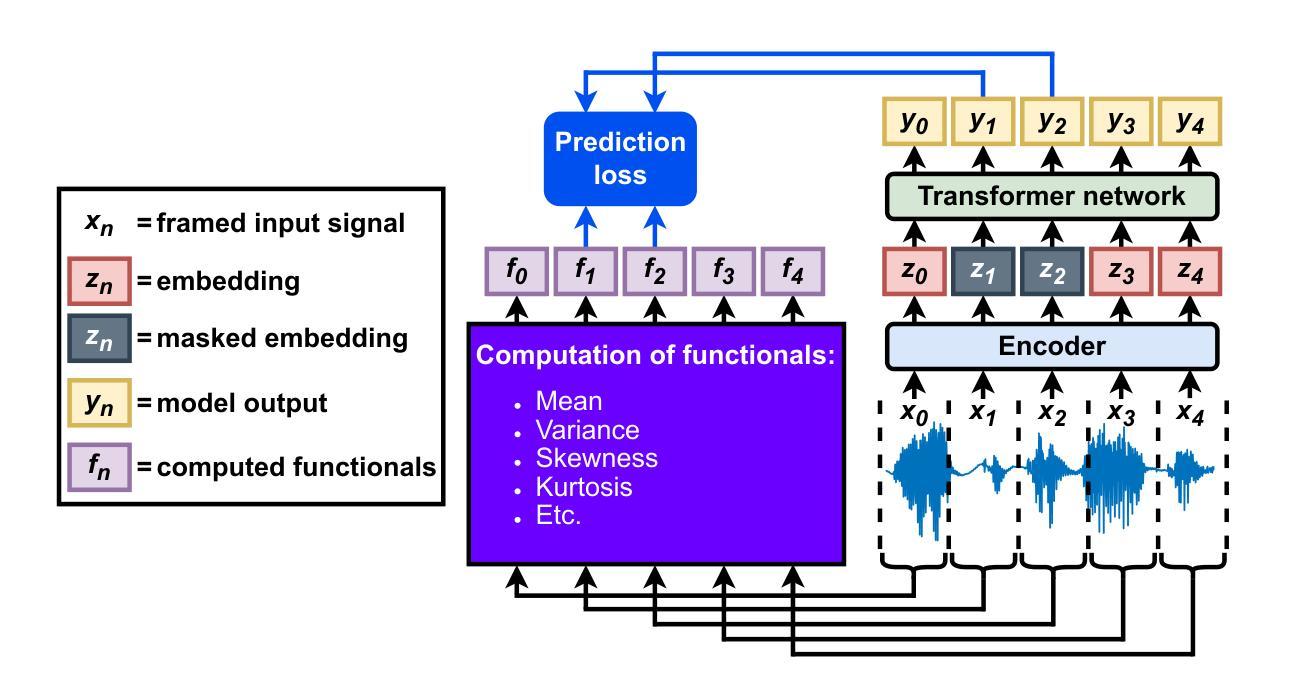
Mask-Weighted Spatial Likelihood Coding for Speaker-Independent Joint Localization and Mask Estimation
Authors:Jakob Kienegger, Alina Mannanova, Timo Gerkmann
Due to their robustness and flexibility, neural-driven beamformers are a popular choice for speech separation in challenging environments with a varying amount of simultaneous speakers alongside noise and reverberation. Time-frequency masks and relative directions of the speakers regarding a fixed spatial grid can be used to estimate the beamformer’s parameters. To some degree, speaker-independence is achieved by ensuring a greater amount of spatial partitions than speech sources. In this work, we analyze how to encode both mask and positioning into such a grid to enable joint estimation of both quantities. We propose mask-weighted spatial likelihood coding and show that it achieves considerable performance in both tasks compared to baseline encodings optimized for either localization or mask estimation. In the same setup, we demonstrate superiority for joint estimation of both quantities. Conclusively, we propose a universal approach which can replace an upstream sound source localization system solely by adapting the training framework, making it highly relevant in performance-critical scenarios.
由于神经驱动波束形成器的稳健性和灵活性,它成为在充满挑战的环境中实现语音分离的流行选择。在这种环境中,存在数量不一的同时说话人,以及噪声和回声。可以使用时间-频率掩模和相对于固定空间网格的说话人方向来估计波束形成器的参数。在某种程度上,通过确保空间分区数量多于语音源,可以实现说话人的独立性。在这项工作中,我们分析了如何将掩模和定位编码到这样的网格中,以实现两种数量的联合估计。我们提出了掩模加权空间可能性编码,并证明与针对定位或掩模估计优化的基线编码相比,该方法在两项任务中都取得了显著的性能。在同一设置中,我们证明了两种数量联合估计的优越性。总之,我们提出了一种通用方法,仅通过调整训练框架就可以替代上游声源定位系统,使其在性能至关重要的场景中具有重要意义。
论文及项目相关链接
PDF \copyright 2025 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
摘要
基于神经网络驱动的波束形成器因其稳健性和灵活性,在充满挑战的环境中,如存在多个同时发声的声源、噪声和回声等情况下,被广泛应用于语音分离。通过时间频率掩膜和相对于固定空间网格的声源方向,可以估算波束形成器的参数。通过增加空间分区数量以实现相对多的声源数量,从而实现某种程度的扬声器独立性。在这项研究中,我们分析了如何将掩膜和定位信息编码到网格中,以实现两种数量的联合估计。我们提出了掩膜加权空间可能性编码,并证明与针对定位或掩膜估计优化的基线编码相比,该方法在两项任务中都取得了显著的性能提升。在相同的设置下,我们证明了两种数量联合估计的优越性。总之,我们提出了一种通用方法,仅通过调整训练框架就能替代上游声源定位系统,使其在性能关键场景中具有重要意义。
关键见解
- 神经网络驱动的波束形成器在具有挑战性的环境中进行语音分离时表现出稳健性和灵活性。
- 时间频率掩膜和相对于固定空间网格的声源方向可用于估算波束形成器的参数。
- 通过确保更多的空间分区来实现相对多的声源数量,从而达到某种程度的扬声器独立性。
- 提出了掩膜加权空间可能性编码,实现掩膜和定位的联合估计。
- 与基线编码相比,该方法在定位和掩膜估计任务中都取得了显著的性能提升。
- 该方法通过调整训练框架可替代上游声源定位系统。
点此查看论文截图

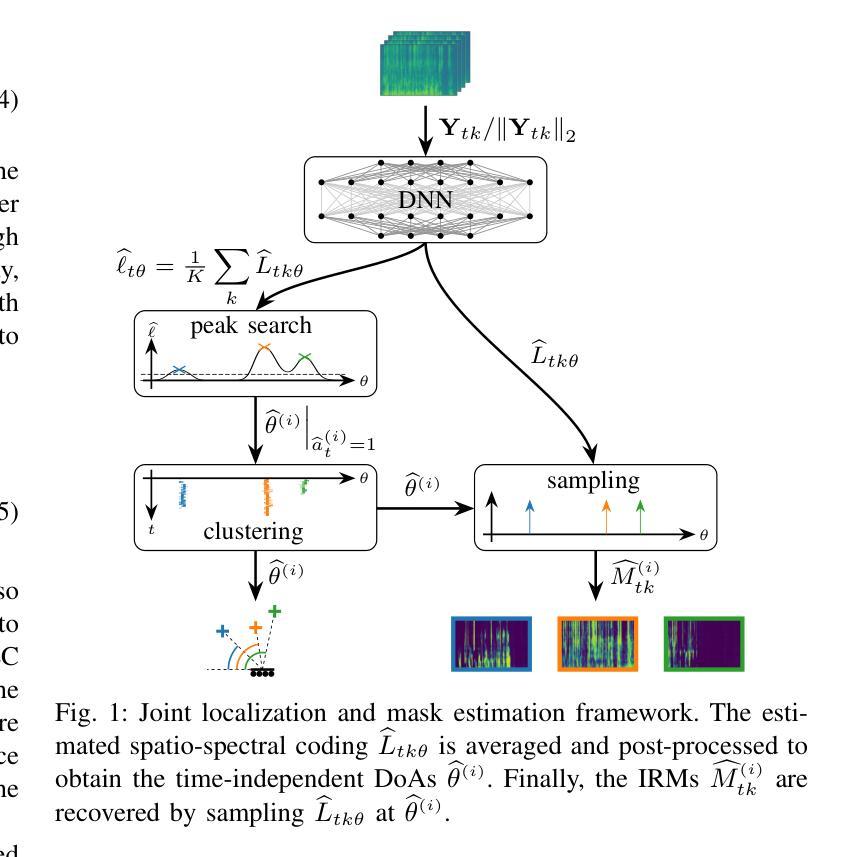
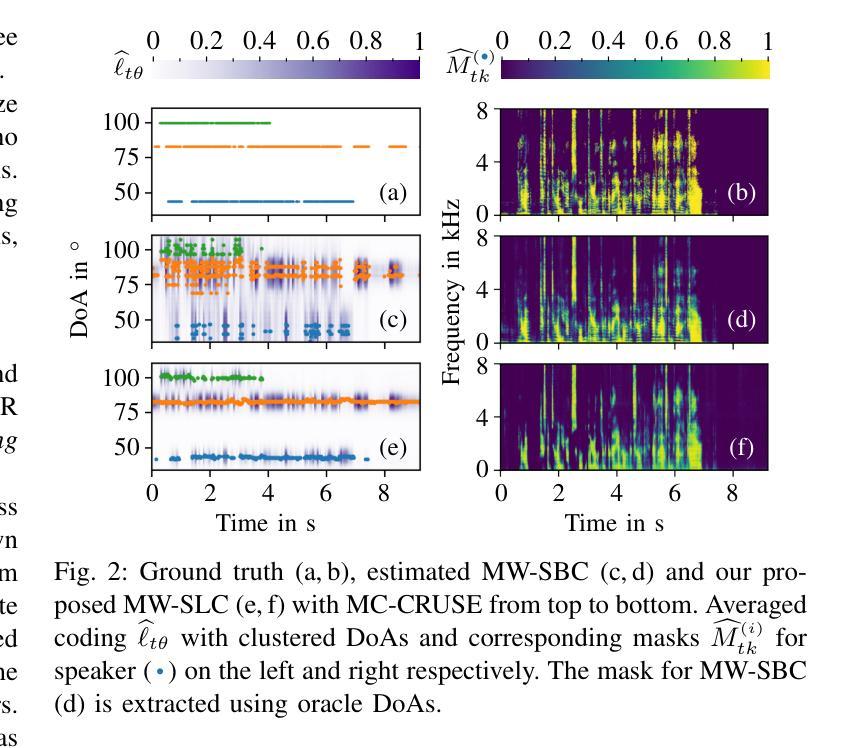
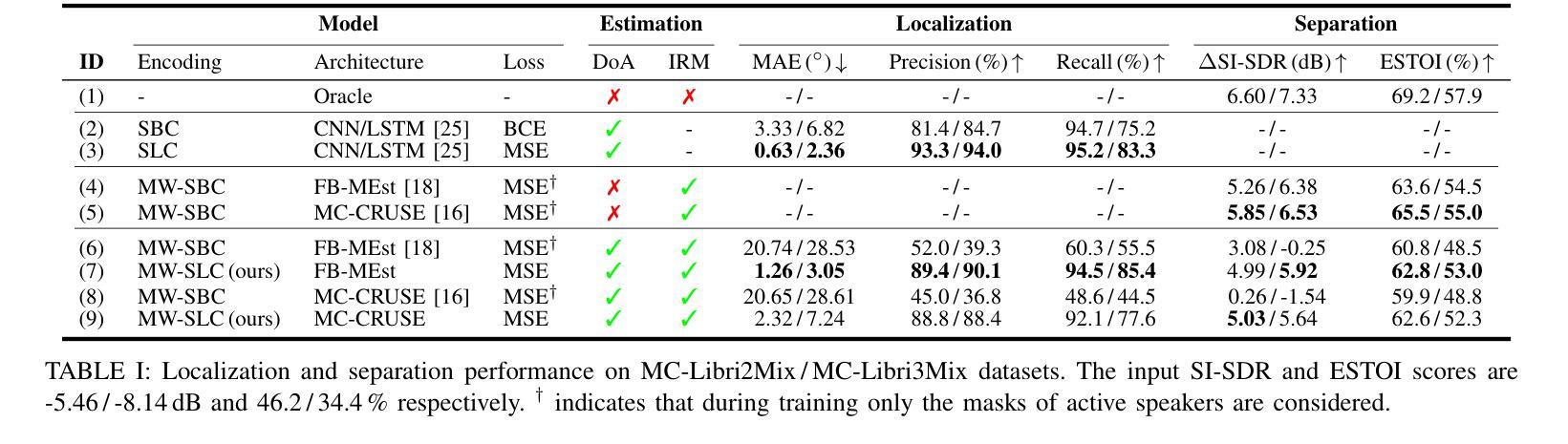
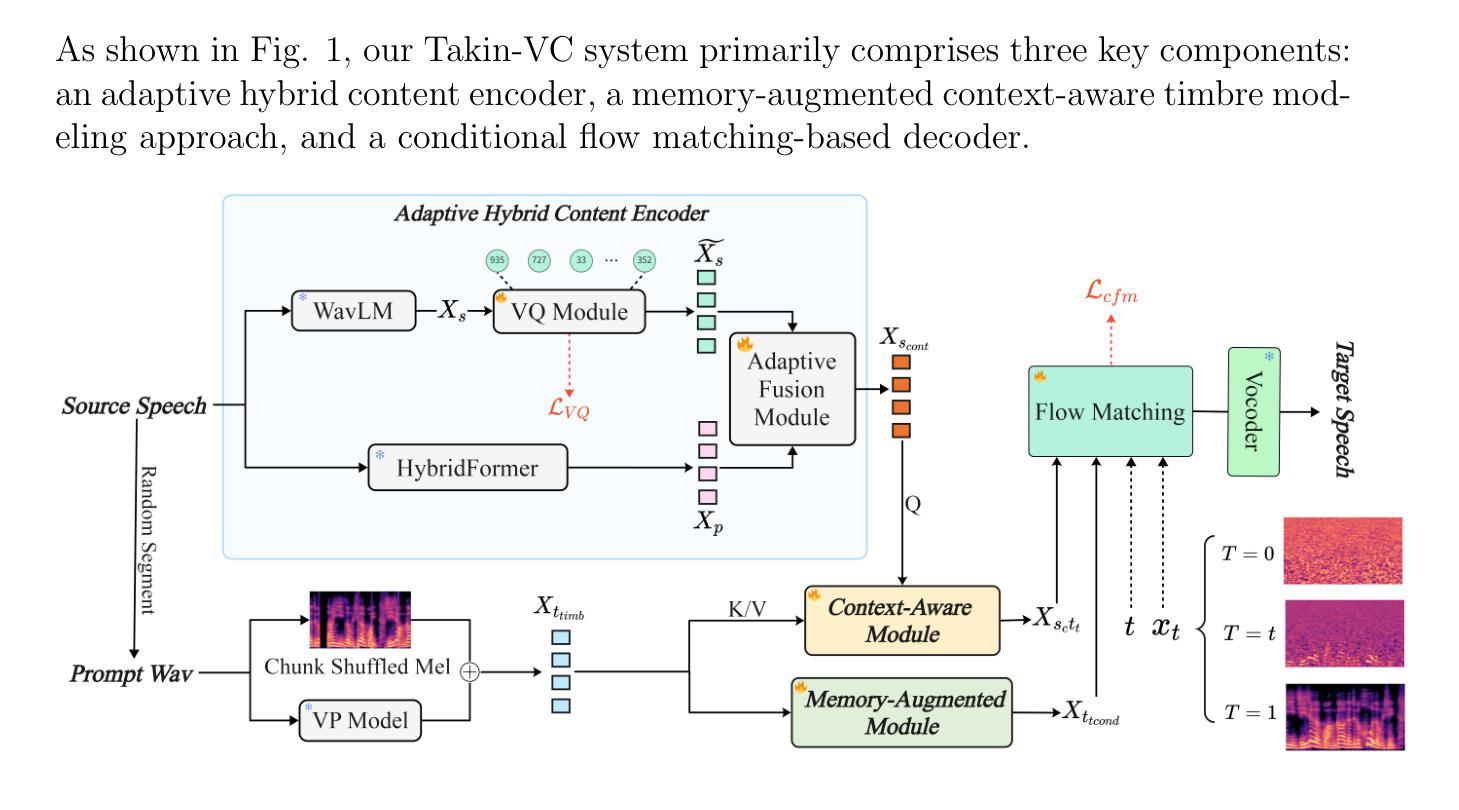
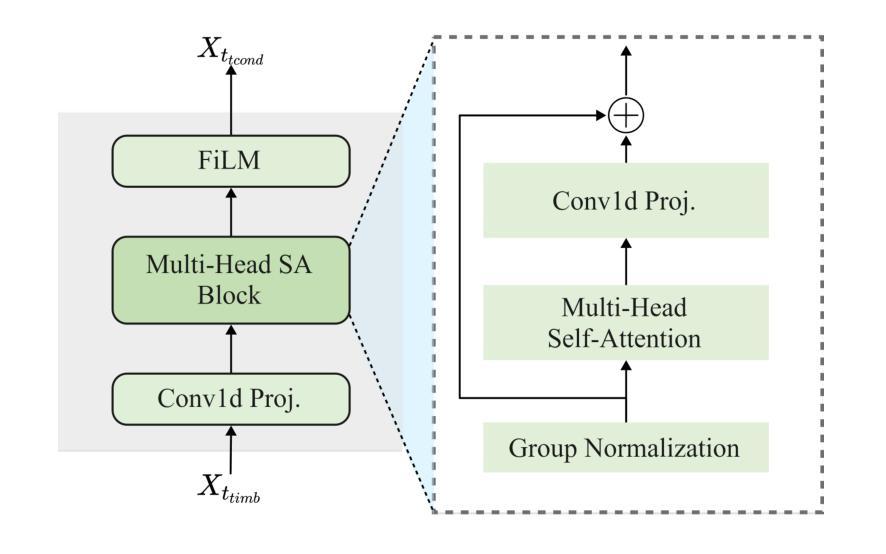
Takin-VC: Expressive Zero-Shot Voice Conversion via Adaptive Hybrid Content Encoding and Enhanced Timbre Modeling
Authors:Yuguang Yang, Yu Pan, Jixun Yao, Xiang Zhang, Jianhao Ye, Hongbin Zhou, Lei Xie, Lei Ma, Jianjun Zhao
Expressive zero-shot voice conversion (VC) is a critical and challenging task that aims to transform the source timbre into an arbitrary unseen speaker while preserving the original content and expressive qualities. Despite recent progress in zero-shot VC, there remains considerable potential for improvements in speaker similarity and speech naturalness. Moreover, existing zero-shot VC systems struggle to fully reproduce paralinguistic information in highly expressive speech, such as breathing, crying, and emotional nuances, limiting their practical applicability. To address these issues, we propose Takin-VC, a novel expressive zero-shot VC framework via adaptive hybrid content encoding and memory-augmented context-aware timbre modeling. Specifically, we introduce an innovative hybrid content encoder that incorporates an adaptive fusion module, capable of effectively integrating quantized features of the pre-trained WavLM and HybridFormer in an implicit manner, so as to extract precise linguistic features while enriching paralinguistic elements. For timbre modeling, we propose advanced memory-augmented and context-aware modules to generate high-quality target timbre features and fused representations that seamlessly align source content with target timbre. To enhance real-time performance, we advocate a conditional flow matching model to reconstruct the Mel-spectrogram of the source speech. Experimental results show that our Takin-VC consistently surpasses state-of-the-art VC systems, achieving notable improvements in terms of speech naturalness, speech expressiveness, and speaker similarity, while offering enhanced inference speed.
表达性零样本语音转换(VC)是一项关键且具有挑战性的任务,旨在将源音色转换为任意未见过的目标说话人,同时保留原始内容和表达品质。尽管近期在零样本VC方面取得了进展,但在说话人相似性和语音自然性方面仍有很大的改进潜力。此外,现有零样本VC系统难以完全再现高度表达性语音中的副语言信息,如呼吸、哭泣和情感细微差别,这限制了它们的实际应用。针对这些问题,我们提出了Takin-VC,一种通过自适应混合内容编码和增强记忆上下文感知音色建模的新型表达性零样本VC框架。具体来说,我们引入了一种创新的混合内容编码器,该编码器包含一个自适应融合模块,能够以隐式方式有效整合预训练WavLM和HybridFormer的量化特征,从而精确提取语言特征并丰富副语言元素。对于音色建模,我们提出了先进的增强记忆和上下文感知模块,以生成高质量的目标音色特征和融合表示,无缝对齐源内容与目标音色。为了提高实时性能,我们建议使用条件流匹配模型来重建源语音的梅尔频谱图。实验结果表明,我们的Takin-VC系统持续超越最先进的VC系统,在语音自然性、语音表达性和说话人相似性方面取得了显著改进,同时提高了推理速度。
论文及项目相关链接
PDF Work in Progress; Under Review
Summary
本文介绍了一种新型的表达式零样本语音转换框架Takin-VC,通过自适应混合内容编码和增强型记忆上下文感知音色建模,旨在解决零样本语音转换中的表达力、音色相似性、自然度以及实时性能的挑战。
Key Takeaways
- 表达零样本语音转换(VC)旨在将源音色转换为任意未见过的目标音色,同时保留原始内容和表达质量。
- 现有零样本VC系统在处理高度表达性的语音时,难以完全复制副语言信息(如呼吸、哭泣和情感细微差别),限制了其实用性。
- Takin-VC框架引入了一种创新性的混合内容编码器,通过自适应融合模块有效整合预训练WavLM和HybridFormer的量化特征,以提取精确的语言特征并丰富副语言元素。
- 针对音色建模,提出了先进的记忆增强和上下文感知模块,以生成高质量的目标音色特征和融合表示,无缝对齐源内容与目标音色。
- 为了提高实时性能,Takin-VC采用条件流匹配模型重建源语音的Mel光谱图。
- 实验结果表明,Takin-VC在语音自然度、表达力和音色相似性方面均超越现有VC系统,同时提高推理速度。
点此查看论文截图

MultiMed: Multilingual Medical Speech Recognition via Attention Encoder Decoder
Authors:Khai Le-Duc, Phuc Phan, Tan-Hanh Pham, Bach Phan Tat, Minh-Huong Ngo, Truong-Son Hy
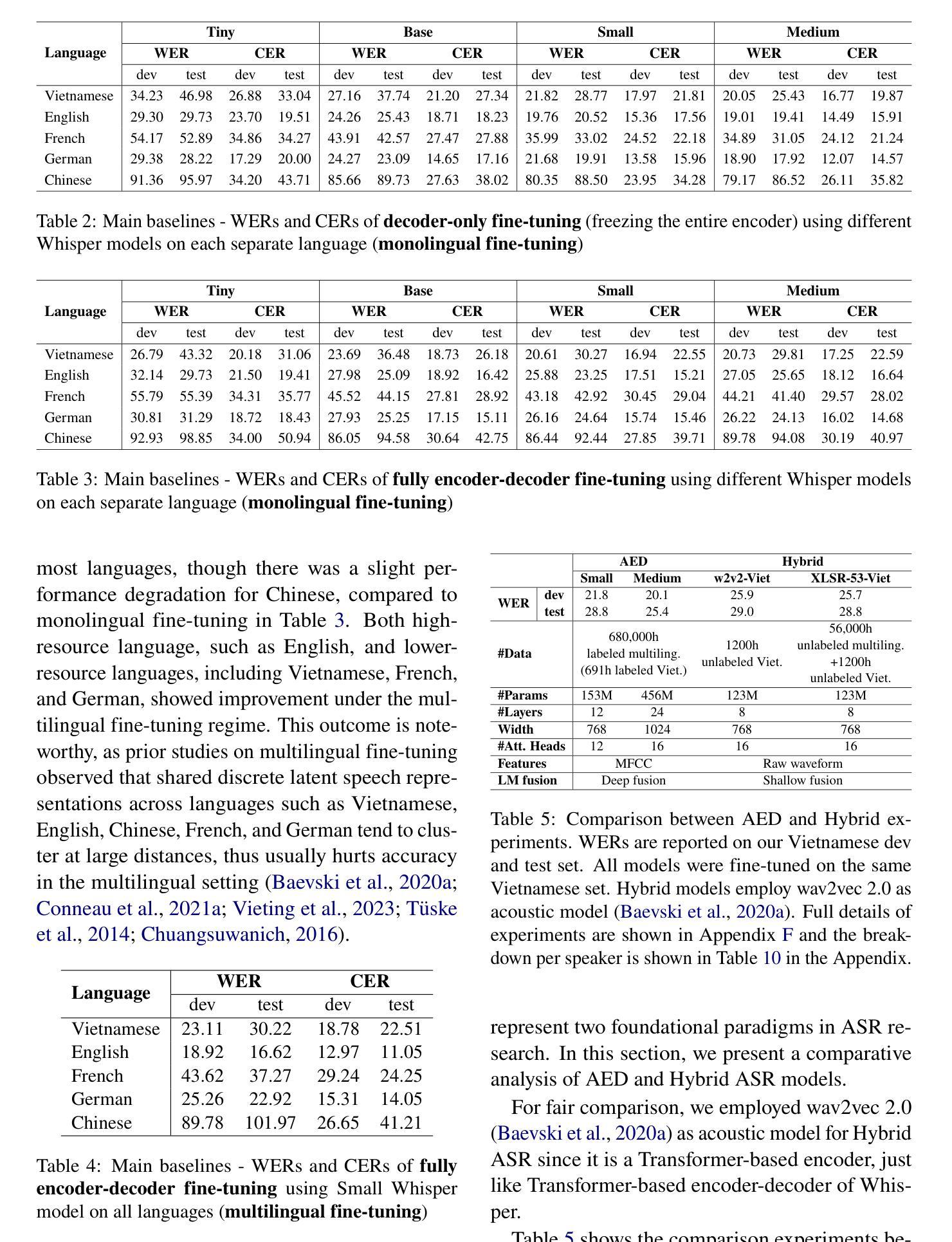
Multilingual automatic speech recognition (ASR) in the medical domain serves as a foundational task for various downstream applications such as speech translation, spoken language understanding, and voice-activated assistants. This technology enhances patient care by enabling efficient communication across language barriers, alleviating specialized workforce shortages, and facilitating improved diagnosis and treatment, particularly during pandemics. In this work, we introduce MultiMed, the first multilingual medical ASR dataset, along with the first collection of small-to-large end-to-end medical ASR models, spanning five languages: Vietnamese, English, German, French, and Mandarin Chinese. To our best knowledge, MultiMed stands as the world’s largest medical ASR dataset across all major benchmarks: total duration, number of recording conditions, number of accents, and number of speaking roles. Furthermore, we present the first multilinguality study for medical ASR, which includes reproducible empirical baselines, a monolinguality-multilinguality analysis, Attention Encoder Decoder (AED) vs Hybrid comparative study, a layer-wise ablation study for the AED, and a linguistic analysis for multilingual medical ASR. All code, data, and models are available online: https://github.com/leduckhai/MultiMed/tree/master/MultiMed
在医疗领域中,多语言自动语音识别(ASR)技术作为多种下游应用的基础任务,如语音翻译、口语理解和语音助手等。该技术通过克服语言障碍实现高效沟通、缓解专业劳动力短缺以及促进诊断和治疗的改进,特别是在疫情期间为患者护理带来提升。在这项工作中,我们介绍了MultiMed,它是首个多语言医疗ASR数据集,以及与覆盖五种语言(越南语、英语、德语、法语和普通话)的小到大的端到端医疗ASR模型集合。据我们所知,MultiMed在所有主要基准测试中均为世界上最大的医疗ASR数据集:总时长、录音条件数量、口音数量和说话角色数量。此外,我们首次进行了医疗ASR的多语言性研究,包括可复制的实证基准测试、单语言与多语言分析、注意力编码器解码器(AED)与混合技术的比较研究、AED的逐层消融研究以及多语言医疗ASR的语言分析。所有代码、数据和模型均可在网上找到:https://github.com/leduckhai/MultiMed/tree/master/MultiMed。
论文及项目相关链接
PDF Preprint, 38 pages
Summary
本文主要介绍了Multilingual自动语音识别(ASR)在医疗领域的重要性,并推出了MultiMed多语言医疗ASR数据集以及一系列涵盖五种语言的小到大的端到端医疗ASR模型。MultiMed是目前全球最大的医疗ASR数据集,包含可复现的实证基准测试、单语-多语分析、注意力编码器解码器(AED)与混合模型的比较,以及AED的逐层消融分析和多语言医疗ASR的语言学分析。所有代码、数据和模型均可在网上找到。
Key Takeaways
- Multilingual ASR在医疗领域有重要应用,如语言翻译、口语理解和语音助手等。
- MultiMed数据集是全球最大的医疗ASR数据集,包含多种语言和大量的录音、口音和说话人角色。
- 推出了涵盖五种语言的端到端医疗ASR模型。
- 提供了可复现的实证基准测试、单语-多语分析以及AED与Hybrid模型的比较。
- 进行了AED的逐层消融分析。
- 进行了多语言医疗ASR的语言学分析。
点此查看论文截图

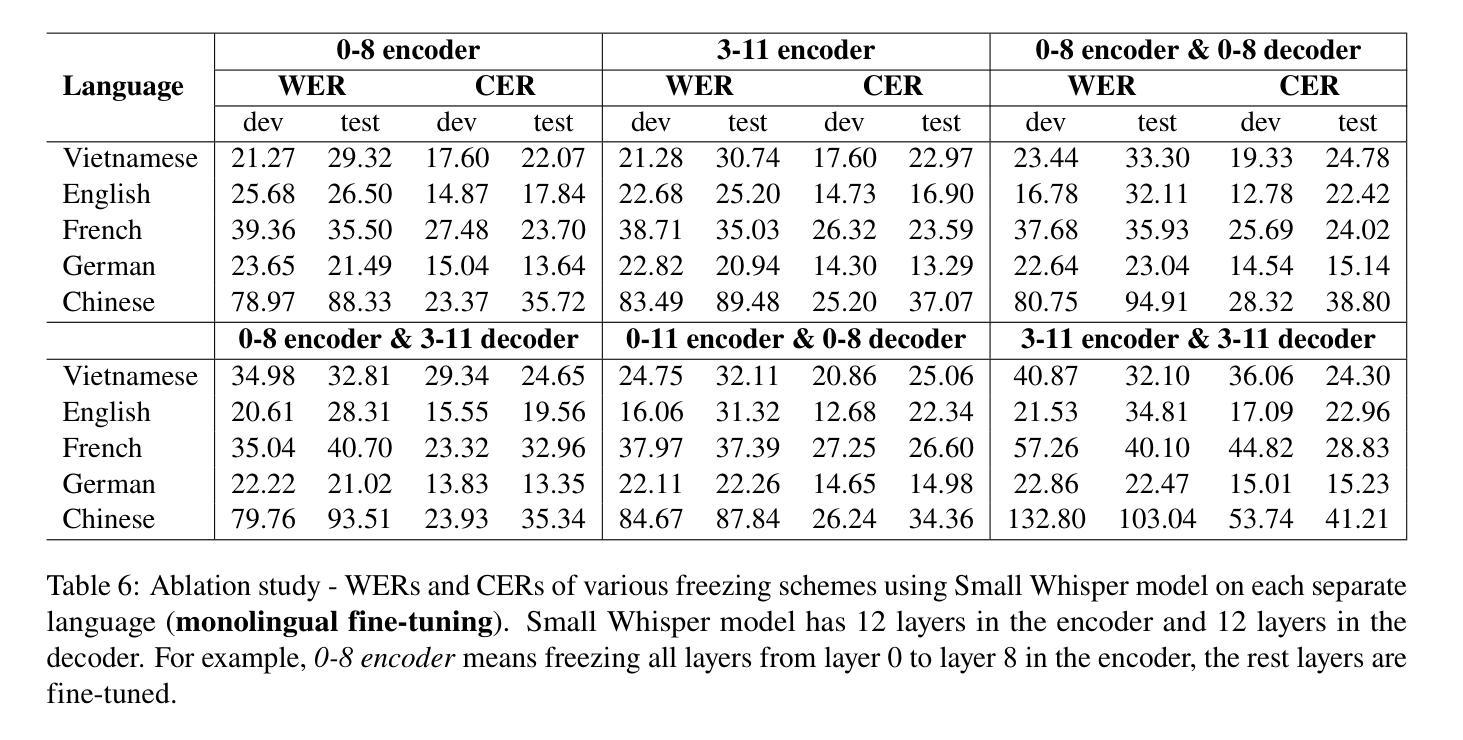
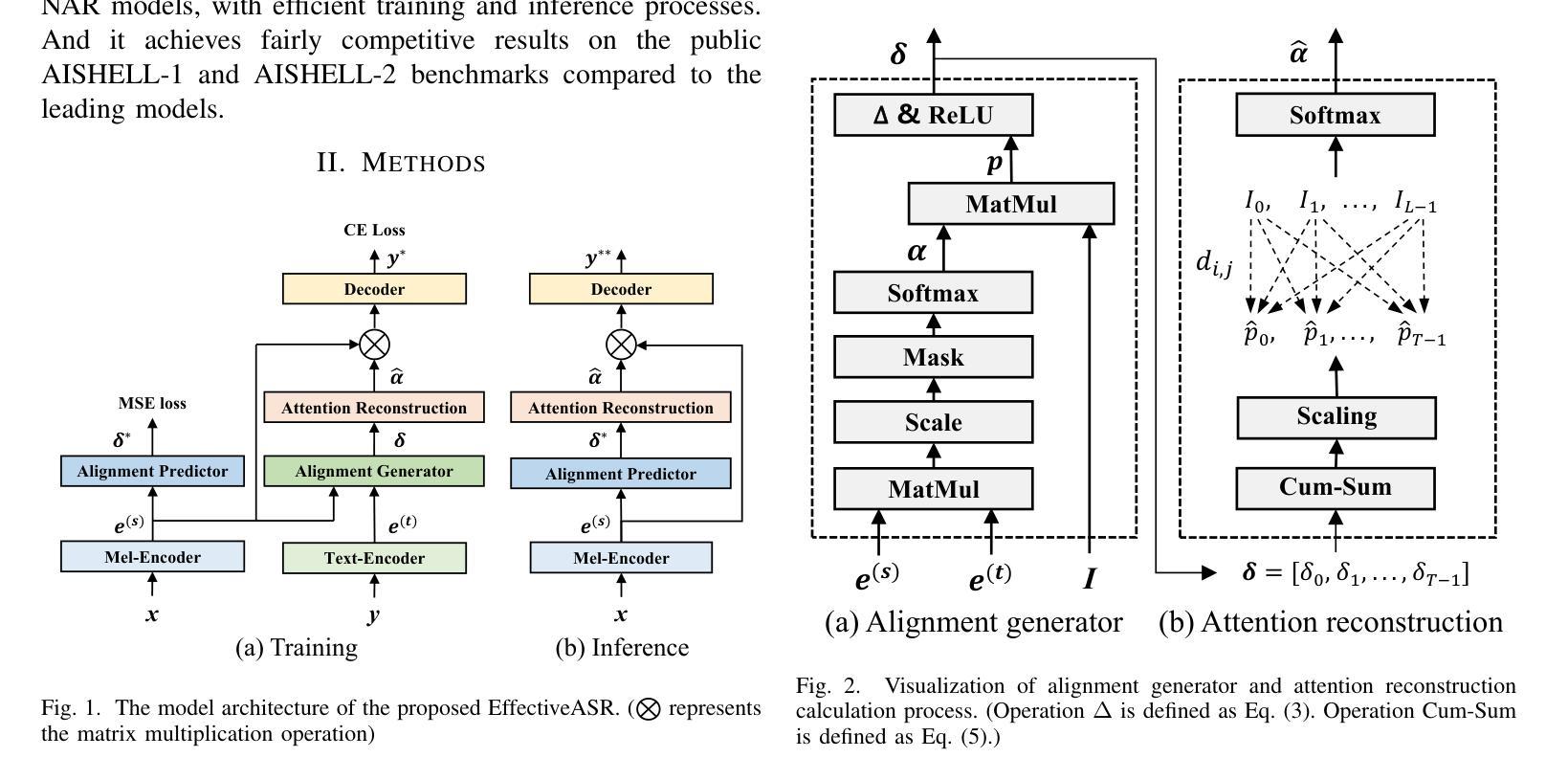
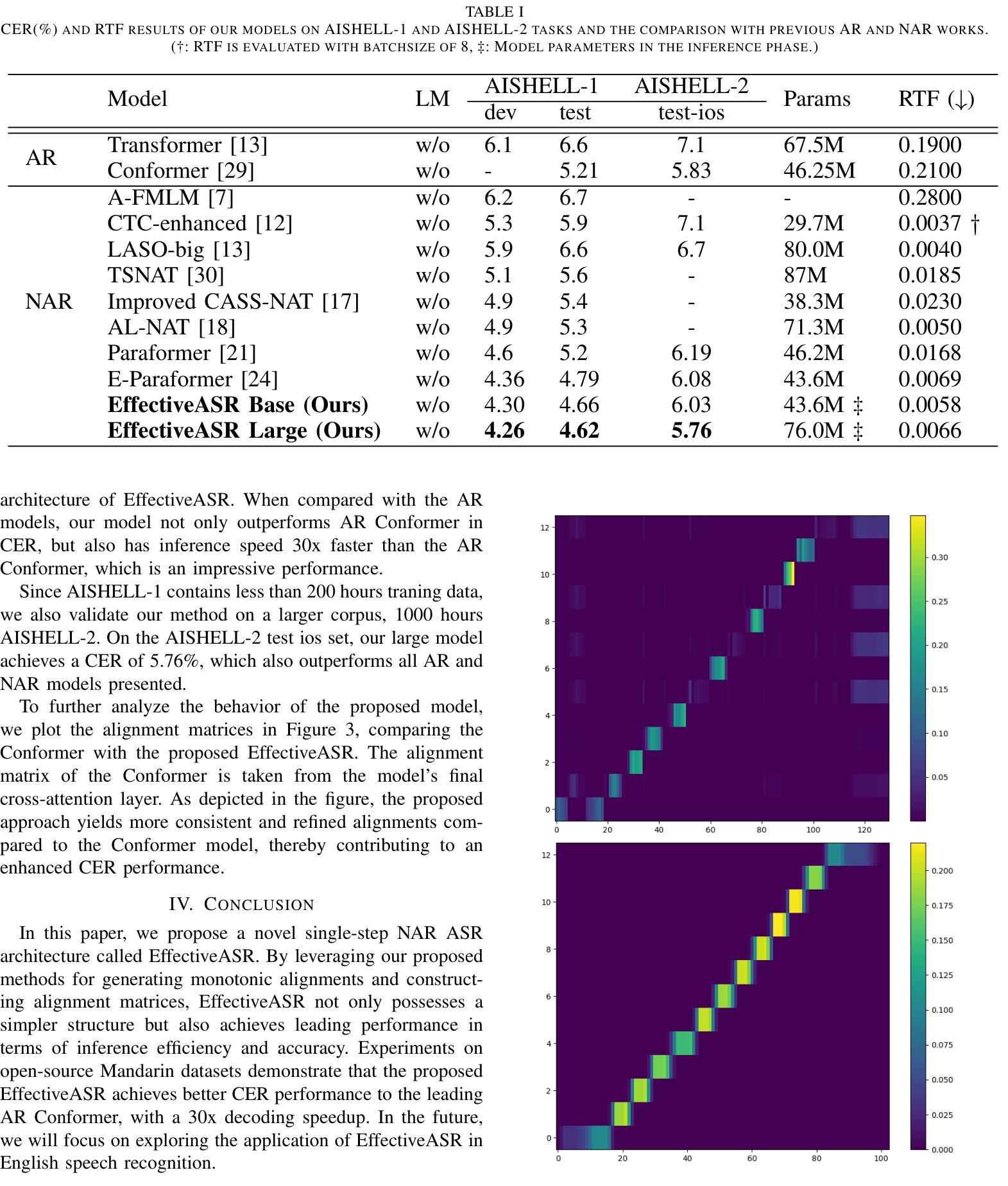
EffectiveASR: A Single-Step Non-Autoregressive Mandarin Speech Recognition Architecture with High Accuracy and Inference Speed
Authors:Ziyang Zhuang, Chenfeng Miao, Kun Zou, Ming Fang, Tao Wei, Zijian Li, Ning Cheng, Wei Hu, Shaojun Wang, Jing Xiao
Non-autoregressive (NAR) automatic speech recognition (ASR) models predict tokens independently and simultaneously, bringing high inference speed. However, there is still a gap in the accuracy of the NAR models compared to the autoregressive (AR) models. In this paper, we propose a single-step NAR ASR architecture with high accuracy and inference speed, called EffectiveASR. It uses an Index Mapping Vector (IMV) based alignment generator to generate alignments during training, and an alignment predictor to learn the alignments for inference. It can be trained end-to-end (E2E) with cross-entropy loss combined with alignment loss. The proposed EffectiveASR achieves competitive results on the AISHELL-1 and AISHELL-2 Mandarin benchmarks compared to the leading models. Specifically, it achieves character error rates (CER) of 4.26%/4.62% on the AISHELL-1 dev/test dataset, which outperforms the AR Conformer with about 30x inference speedup.
非自回归(NAR)自动语音识别(ASR)模型可以独立且同时进行令牌预测,从而实现高速推断。然而,与自回归(AR)模型相比,NAR模型的准确性仍存在差距。本文提出了一种具有高精度和推断速度的单步NAR ASR架构,称为EffectiveASR。它使用基于索引映射向量(IMV)的对齐生成器在训练过程中生成对齐,并对齐预测器来学习推断的对齐。它可以结合交叉熵损失和对齐损失进行端到端(E2E)训练。与领先模型相比,所提出的EffectiveASR在AISHELL-1和AISHELL-2普通话基准测试上取得了具有竞争力的结果。具体而言,它在AISHELL-1开发/测试数据集上实现了4.26%/4.62%的字符错误率(CER),这优于具有约30倍推断速度提升的AR Conformer模型。
论文及项目相关链接
PDF Accepted by IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP) 2025
Summary
非自回归(NAR)语音识别(ASR)模型通过独立且并行预测语音符号,实现了高速推断。本文提出了一种具有高精度和高速推断的单步NAR ASR架构,名为EffectiveASR。它使用基于索引映射向量(IMV)的对齐生成器在训练过程中生成对齐,并对齐预测器以学习推断时的对齐。它可以与交叉熵损失和对齐损失相结合进行端到端(E2E)训练。在AISHELL-1和AISHELL-2汉语基准测试中,EffectiveASR与领先模型相比取得了具有竞争力的结果。具体来说,它在AISHELL-1开发/测试数据集上实现了字符错误率(CER)为4.26%/4.62%,相较于自回归Conformer模型,在推断速度上加快了约30倍。
Key Takeaways
- NAR ASR模型通过独立预测语音符号实现高速推断。
- 本文介绍了一种名为EffectiveASR的单步NAR ASR架构,具有高精度和高速推断的特点。
- EffectiveASR使用IMV基于对齐生成器在训练过程中生成对齐。
- EffectiveASR可以通过结合交叉熵损失和对齐损失进行端到端(E2E)训练。
- EffectiveASR在AISHELL-1和AISHELL-2汉语基准测试中取得了具有竞争力的结果。
- EffectiveASR在AISHELL-1数据集上的字符错误率(CER)为4.26%和4.62%,性能优越。
点此查看论文截图

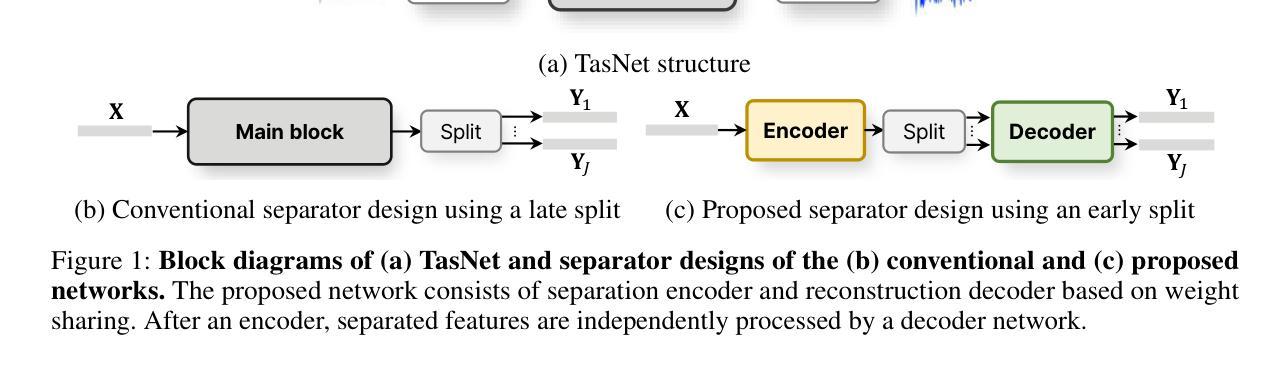
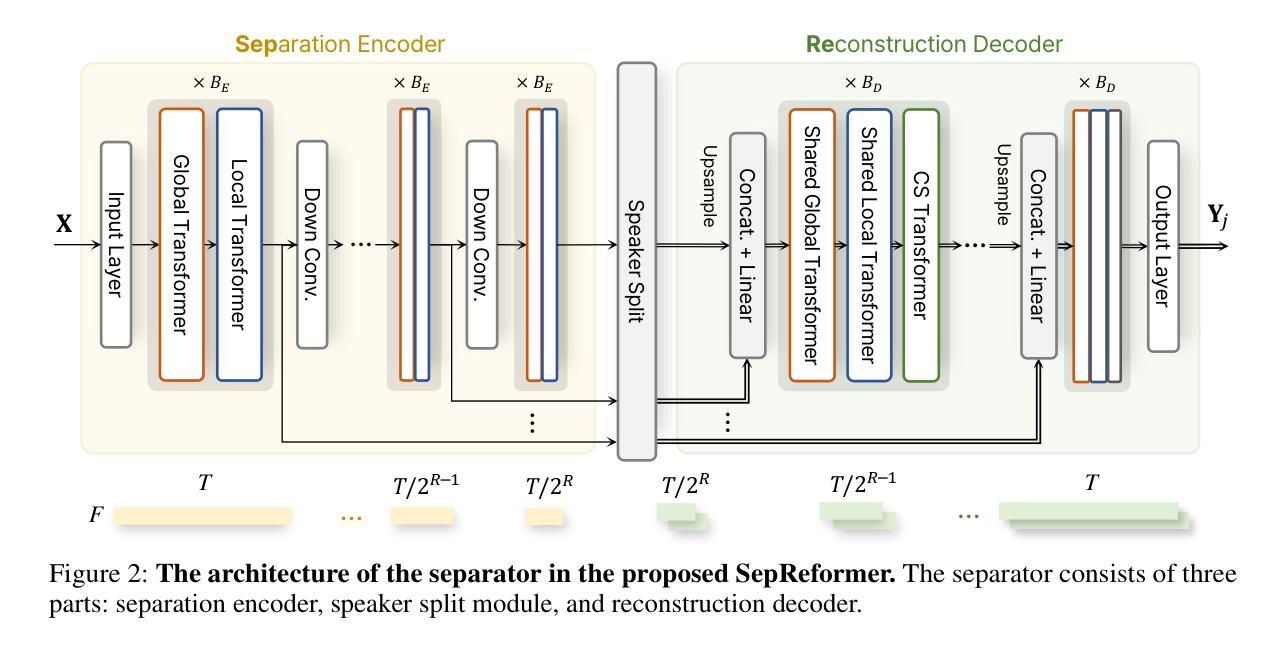
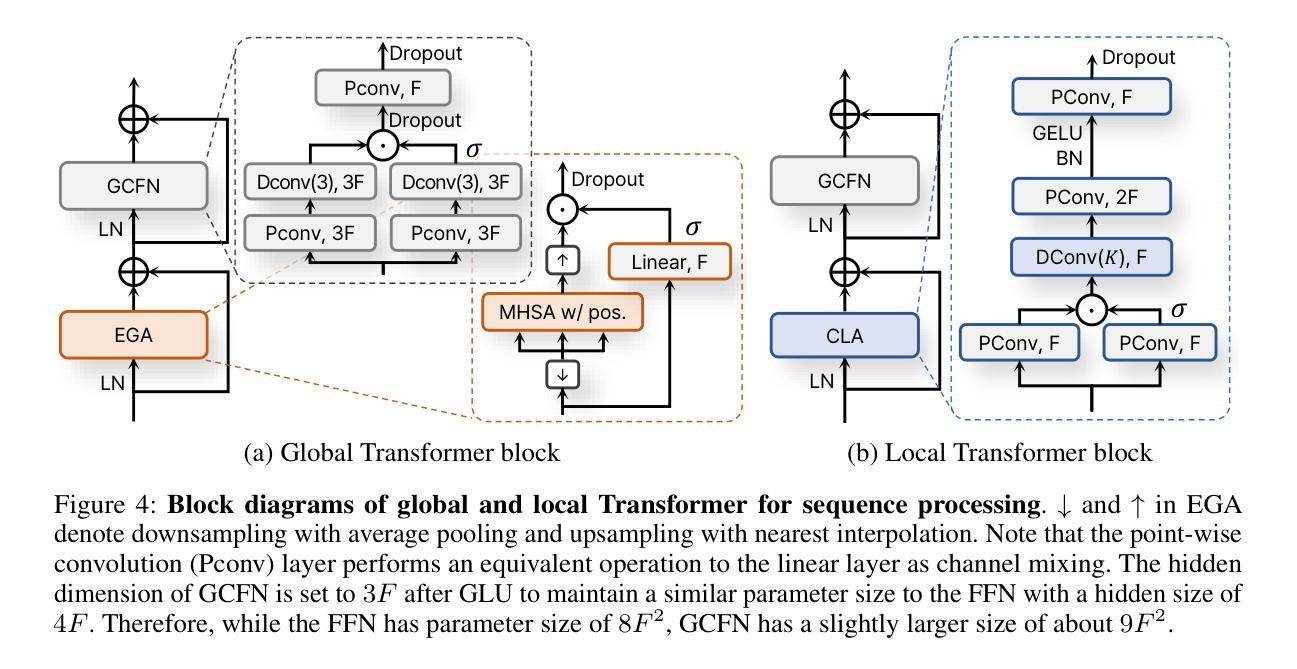
Separate and Reconstruct: Asymmetric Encoder-Decoder for Speech Separation
Authors:Ui-Hyeop Shin, Sangyoun Lee, Taehan Kim, Hyung-Min Park
In speech separation, time-domain approaches have successfully replaced the time-frequency domain with latent sequence feature from a learnable encoder. Conventionally, the feature is separated into speaker-specific ones at the final stage of the network. Instead, we propose a more intuitive strategy that separates features earlier by expanding the feature sequence to the number of speakers as an extra dimension. To achieve this, an asymmetric strategy is presented in which the encoder and decoder are partitioned to perform distinct processing in separation tasks. The encoder analyzes features, and the output of the encoder is split into the number of speakers to be separated. The separated sequences are then reconstructed by the weight-shared decoder, which also performs cross-speaker processing. Without relying on speaker information, the weight-shared network in the decoder directly learns to discriminate features using a separation objective. In addition, to improve performance, traditional methods have extended the sequence length, leading to the adoption of dual-path models, which handle the much longer sequence effectively by segmenting it into chunks. To address this, we introduce global and local Transformer blocks that can directly handle long sequences more efficiently without chunking and dual-path processing. The experimental results demonstrated that this asymmetric structure is effective and that the combination of proposed global and local Transformer can sufficiently replace the role of inter- and intra-chunk processing in dual-path structure. Finally, the presented model combining both of these achieved state-of-the-art performance with much less computation in various benchmark datasets.
在语音分离领域,时域方法已经成功地用可学习的编码器的潜在序列特征替换了时频域。传统上,特征在网络的最后阶段被分离成针对说话者的特征。然而,我们提出了一种更直观的策略,通过扩大特征序列到说话者的数量作为一个额外的维度来更早地分离特征。为了实现这一点,提出了一种不对称的策略,将编码器和解码器划分开来执行分离任务中的不同处理。编码器分析特征,编码器的输出被分割成要分离的说话者数量。然后,分离的序列被权重共享的解码器重建,该解码器也执行跨说话者的处理。不依赖说话者信息,解码器中的权重共享网络直接通过分离目标学习辨别特征。此外,为了提高性能,传统方法已经延长了序列长度,导致采用双路径模型,通过将其分割成块来有效处理更长的序列。为了解决这一问题,我们引入了全局和局部Transformer块,能够更高效地直接处理长序列,而无需分块和双路径处理。实验结果表明,这种不对称结构是有效的,所提出的全局和局部Transformer的组合可以充分替代双路径结构中块内和块间的处理角色。最后,结合这两种方法的模型在各种基准数据集上实现了最先进的性能,并大大减少了计算量。
论文及项目相关链接
PDF In NeurIPS 2024; Project Page: https://dmlguq456.github.io/SepReformer_Demo
Summary
本文介绍了语音分离领域的一种新方法,该方法采用可学习编码器的潜在序列特征替换时频域特征,并提前进行特征分离。通过扩展特征序列以匹配说话人数来实现此目的。文章提出了不对称策略,使编码器和解码器在分离任务中进行不同的处理。实验结果表明,该不对称结构结合全局和局部Transformer能够有效地实现语音分离,并达到了较高的性能水平。
Key Takeaways
- 使用可学习编码器的潜在序列特征替代传统的时间频域方法来进行语音分离。
- 提出一种提前特征分离的策略,通过扩展特征序列与说话人数匹配实现。
- 引入不对称策略,使编码器和解码器在语音分离任务中承担不同的角色。
- 解码器无需依赖说话者信息即可直接学习区分特征。
- 采用全局和局部Transformer以更有效地处理长序列,无需分段和双路径处理。
- 实验结果表明不对称结构的有效性,以及结合全局和局部Transformer在双路径结构中的优势。
点此查看论文截图