⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-14 更新
Low-Resource Text-to-Speech Synthesis Using Noise-Augmented Training of ForwardTacotron
Authors:Kishor Kayyar Lakshminarayana, Frank Zalkow, Christian Dittmar, Nicola Pia, Emanuel A. P. Habets
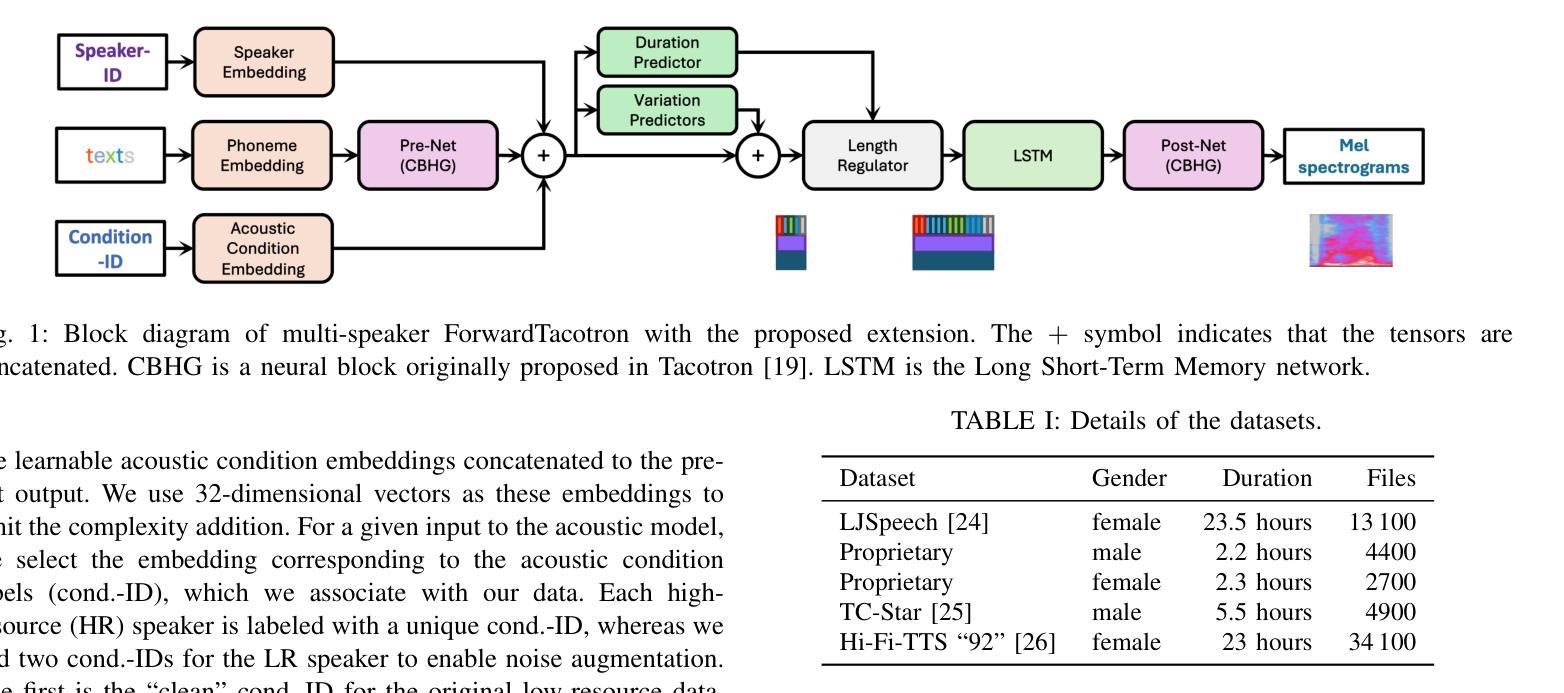
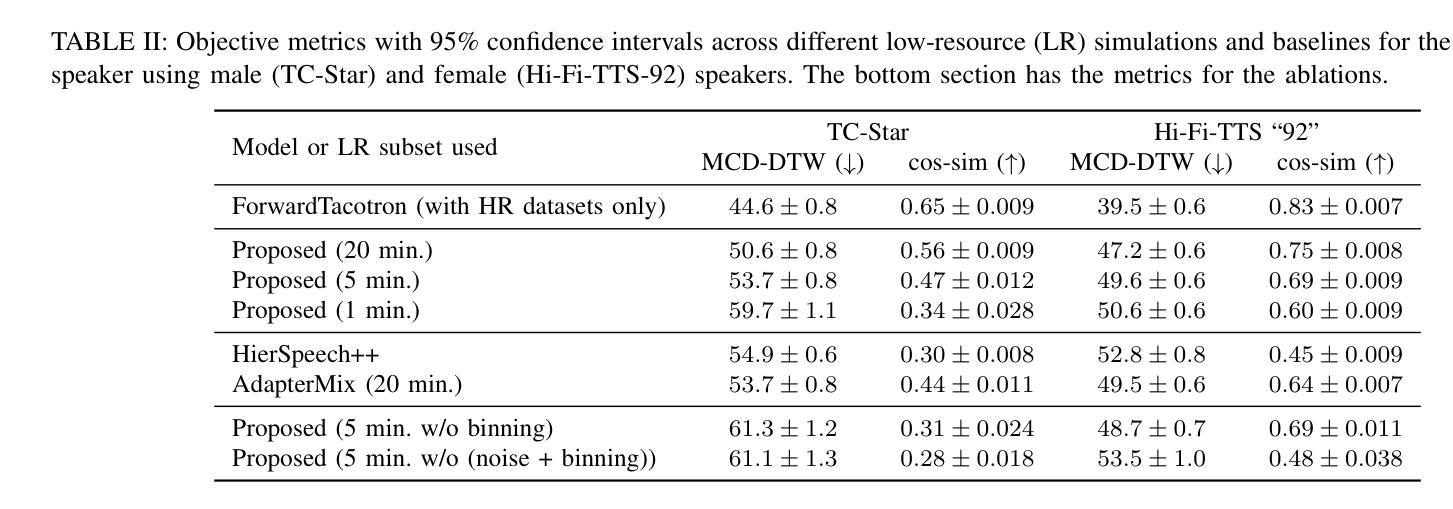
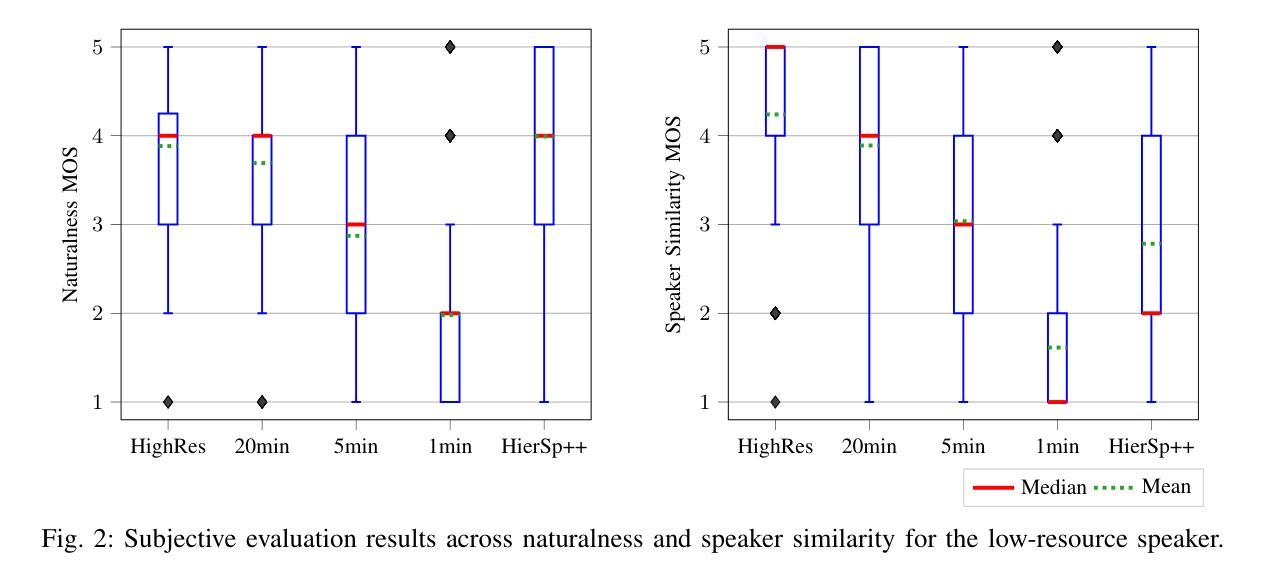
In recent years, several text-to-speech systems have been proposed to synthesize natural speech in zero-shot, few-shot, and low-resource scenarios. However, these methods typically require training with data from many different speakers. The speech quality across the speaker set typically is diverse and imposes an upper limit on the quality achievable for the low-resource speaker. In the current work, we achieve high-quality speech synthesis using as little as five minutes of speech from the desired speaker by augmenting the low-resource speaker data with noise and employing multiple sampling techniques during training. Our method requires only four high-quality, high-resource speakers, which are easy to obtain and use in practice. Our low-complexity method achieves improved speaker similarity compared to the state-of-the-art zero-shot method HierSpeech++ and the recent low-resource method AdapterMix while maintaining comparable naturalness. Our proposed approach can also reduce the data requirements for speech synthesis for new speakers and languages.
近年来,已经提出了多种文本到语音系统,用于在零样本、小样例和低资源场景中合成自然语音。然而,这些方法通常需要与许多不同说话人的数据进行训练。不同说话人的语音质量各不相同,并对低资源说话人可达到的质量设置了上限。在当前工作中,我们通过使用目标说话人的五分钟语音进行扩充和低资源说话人数据的噪声处理,以及采用多重采样技术进行训练,实现了高质量的语音合成。我们的方法只需要四个高质量、高资源的说话人,这在实践中很容易获得和使用。我们的低复杂度方法在提高说话人相似度方面优于最新的零样本方法HierSpeech++和最近的低资源方法AdapterMix,同时保持了相当的自然度。我们提出的方法还可以减少新说话人和新语言进行语音合成所需的数据要求。
论文及项目相关链接
PDF Accepted for publication at the 2025 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2025) to be held at Hyderabad, India
Summary
新一代文本转语音系统通过增强低资源说话者数据并引入多种采样技术,实现了高质量语音合成,仅需五分钟说话者语音数据即可实现高质量合成。此方法仅需四个高质量、高资源说话者,易于在实际中获得和使用。相较于当前最前沿的零样本方法(如 HierSpeech++)和低资源方法(如 AdapterMix),此方法在提高说话者相似性的同时保持了自然度。此外,该方法还降低了新说话者和新语言对语音合成所需的数据要求。
Key Takeaways
- 提出了一种新颖的文本转语音系统,用于在零样本、少样本和低资源场景下合成自然语音。
- 该方法通过使用少量的说话者语音数据(仅需五分钟)实现了高质量语音合成。
- 通过增强低资源说话者数据和引入多种采样技术,提高了语音合成的质量。
- 该方法仅需四个高质量、高资源的说话者,易于获取并应用于实际场景中。
- 与当前最前沿的零样本和低资源方法相比,该方法在维持自然度的同时,提高了说话者相似性。
- 该方法降低了新说话者和新语言对语音合成所需的数据要求。
点此查看论文截图

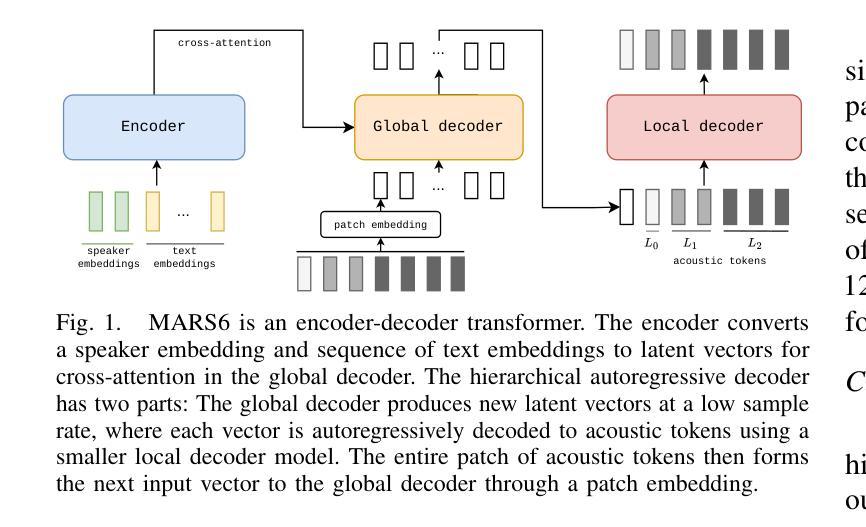
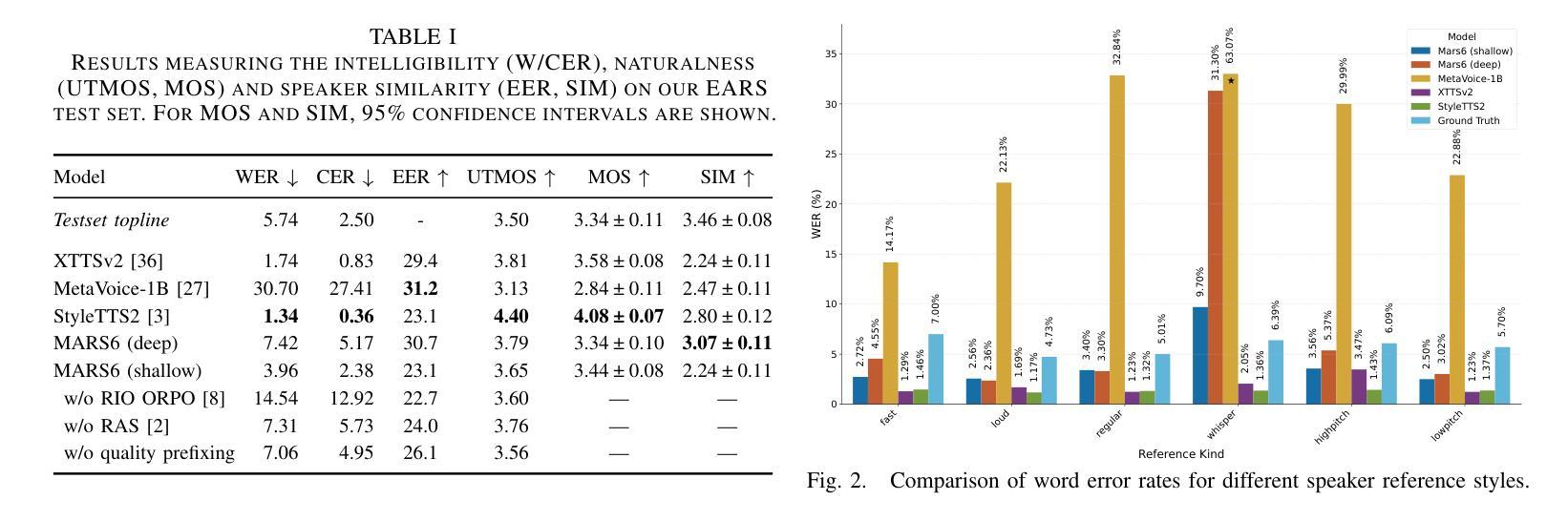
MARS6: A Small and Robust Hierarchical-Codec Text-to-Speech Model
Authors:Matthew Baas, Pieter Scholtz, Arnav Mehta, Elliott Dyson, Akshat Prakash, Herman Kamper
Codec-based text-to-speech (TTS) models have shown impressive quality with zero-shot voice cloning abilities. However, they often struggle with more expressive references or complex text inputs. We present MARS6, a robust encoder-decoder transformer for rapid, expressive TTS. MARS6 is built on recent improvements in spoken language modelling. Utilizing a hierarchical setup for its decoder, new speech tokens are processed at a rate of only 12 Hz, enabling efficient modelling of long-form text while retaining reconstruction quality. We combine several recent training and inference techniques to reduce repetitive generation and improve output stability and quality. This enables the 70M-parameter MARS6 to achieve similar performance to models many times larger. We show this in objective and subjective evaluations, comparing TTS output quality and reference speaker cloning ability. Project page: https://camb-ai.github.io/mars6-turbo/
基于编码器的文本到语音(TTS)模型已经表现出了令人印象深刻的零射击声克隆能力。然而,它们在处理更具表现力的参考或复杂的文本输入时经常遇到困难。我们推出了MARS6,这是一个强大的编码器-解码器转换器,用于快速、富有表现力的TTS。MARS6是建立在口语建模的最新改进基础上的。其解码器采用分层设置,新的语音标记符的处理速度仅为12Hz,能够在保留重建质量的同时,对长文本进行有效建模。我们结合了最近的训练和推理技术,以减少重复生成,提高输出稳定性和质量。这使得7000万的MARS6参数能够实现与许多更大模型的相似性能。我们在客观和主观评估中都展示了这一点,比较了TTS输出质量和参考说话人的克隆能力。项目页面:https://camb-ai.github.io/mars6-turbo/
论文及项目相关链接
PDF 5 pages, 2 figures, 1 table. Accepted at ICASSP 2025
摘要
基于编码器的文本到语音(TTS)模型具有令人印象深刻的零声母克隆能力,但对于更生动的参考或复杂的文本输入往往表现挣扎。我们推出MARS6,一个稳健的编码器-解码器转换器,用于快速、生动的TTS。MARS6建立在最新的口语建模改进之上。其解码器采用分层设置,新的语音令牌处理速率仅为12Hz,可在保留重建质量的同时,对长文本进行有效建模。我们结合了最新的训练和推理技术,以减少重复生成,提高输出稳定性和质量。这使得7000万参数的MARS6能够达到比许多更大模型的相似性能。我们在客观和主观评估中展示了这一点,比较了TTS输出质量和参考说话人的克隆能力。
要点
- MARS6是一个用于快速、生动TTS的稳健编码器-解码器转换器。
- MARS6建立在最新的口语建模改进之上,具有出色的文本到语音转换能力。
- 采用分层解码器设置,处理新语音令牌的速度快,仅为12Hz。
- MARS6可以有效地对长文本进行建模,同时保留重建质量。
- 通过结合最新的训练和推理技术,MARS6减少了重复生成,提高了输出稳定性和质量。
- MARS6的参数为70M,性能与许多更大的模型相当。
- 在客观和主观评估中,MARS6在TTS输出质量和参考说话人克隆能力方面表现出色。
点此查看论文截图

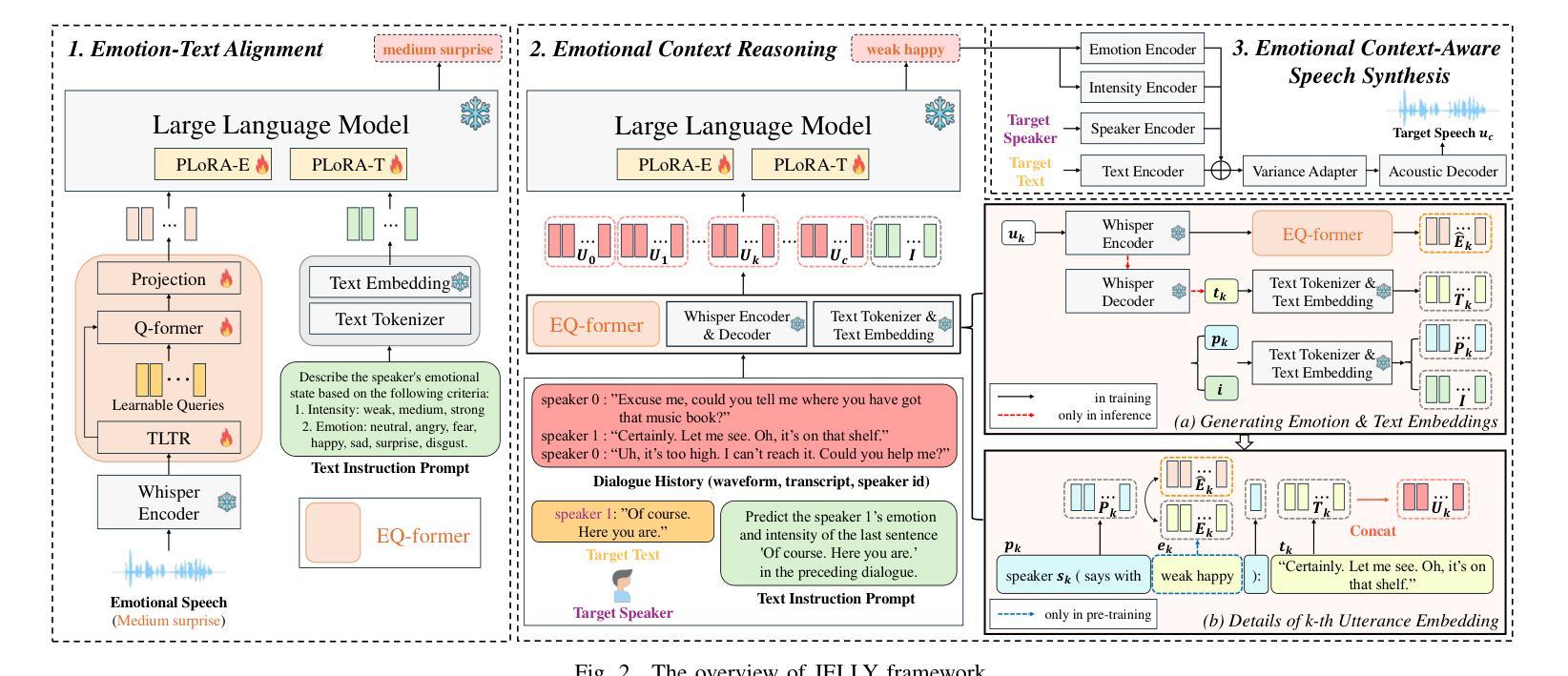
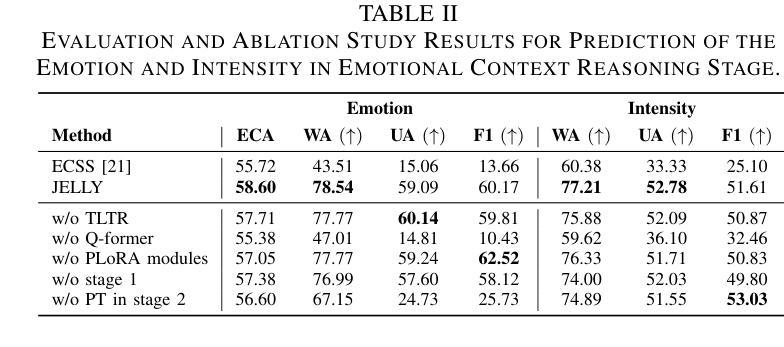
JELLY: Joint Emotion Recognition and Context Reasoning with LLMs for Conversational Speech Synthesis
Authors:Jun-Hyeok Cha, Seung-Bin Kim, Hyung-Seok Oh, Seong-Whan Lee
Recently, there has been a growing demand for conversational speech synthesis (CSS) that generates more natural speech by considering the conversational context. To address this, we introduce JELLY, a novel CSS framework that integrates emotion recognition and context reasoning for generating appropriate speech in conversation by fine-tuning a large language model (LLM) with multiple partial LoRA modules. We propose an Emotion-aware Q-former encoder, which enables the LLM to perceive emotions in speech. The encoder is trained to align speech emotions with text, utilizing datasets of emotional speech. The entire model is then fine-tuned with conversational speech data to infer emotional context for generating emotionally appropriate speech in conversation. Our experimental results demonstrate that JELLY excels in emotional context modeling, synthesizing speech that naturally aligns with conversation, while mitigating the scarcity of emotional conversational speech datasets.
最近,对话式语音合成(CSS)的需求不断增长,它能够通过考虑对话上下文来生成更自然的语音。为了解决这一问题,我们引入了JELLY,这是一个新型的CSS框架,通过微调大型语言模型(LLM)并集成多个局部LoRA模块,来生成对话中适当的语音。我们提出了一种情感感知的Q-former编码器,使LLM能够感知语音中的情感。该编码器经过训练,能够将语音情感与文本对齐,利用情感语音数据集。然后对整个模型进行对话语音数据的微调,以推断情感上下文,从而在对话中生成情感上适当的语音。我们的实验结果表明,JELLY在情感上下文建模方面表现出色,能够合成与对话自然对齐的语音,同时缓解了情感对话语音数据集稀缺的问题。
论文及项目相关链接
PDF Accepted by ICASSP 2025
Summary
近期对话式语音合成(CSS)需求增长,需生成更自然的语音并考虑对话上下文。为此,我们引入了JELLY这一新型CSS框架,它集成了情感识别和上下文推理,通过微调大型语言模型(LLM)和多个部分LoRA模块来生成适当的对话语音。我们提出了情感感知Q-former编码器,使LLM能够感知语音中的情感。编码器经过训练,能够将语音情感与文本对齐,利用情感语音数据集。整个模型进一步用对话语音数据进行微调,以推断情感上下文,生成与对话自然对齐的语音。
Key Takeaways
- JELLY是一个新型对话式语音合成(CSS)框架,旨在生成更自然的语音。
- 它通过集成情感识别和上下文推理来适应对话上下文。
- JELLY使用大型语言模型(LLM)并微调多个部分LoRA模块来实现这一目标。
- 提出了一种情感感知Q-former编码器,使LLM能够感知语音中的情感。
- 编码器利用情感语音数据集进行训练,实现语音情感与文本的对齐。
- 整个模型通过对话语音数据进一步微调,以推断情感上下文。
- 实验结果表明,JELLY在情感上下文建模方面表现出色,能够合成与对话自然对齐的语音,并缓解了情感对话语音数据集稀缺的问题。
点此查看论文截图


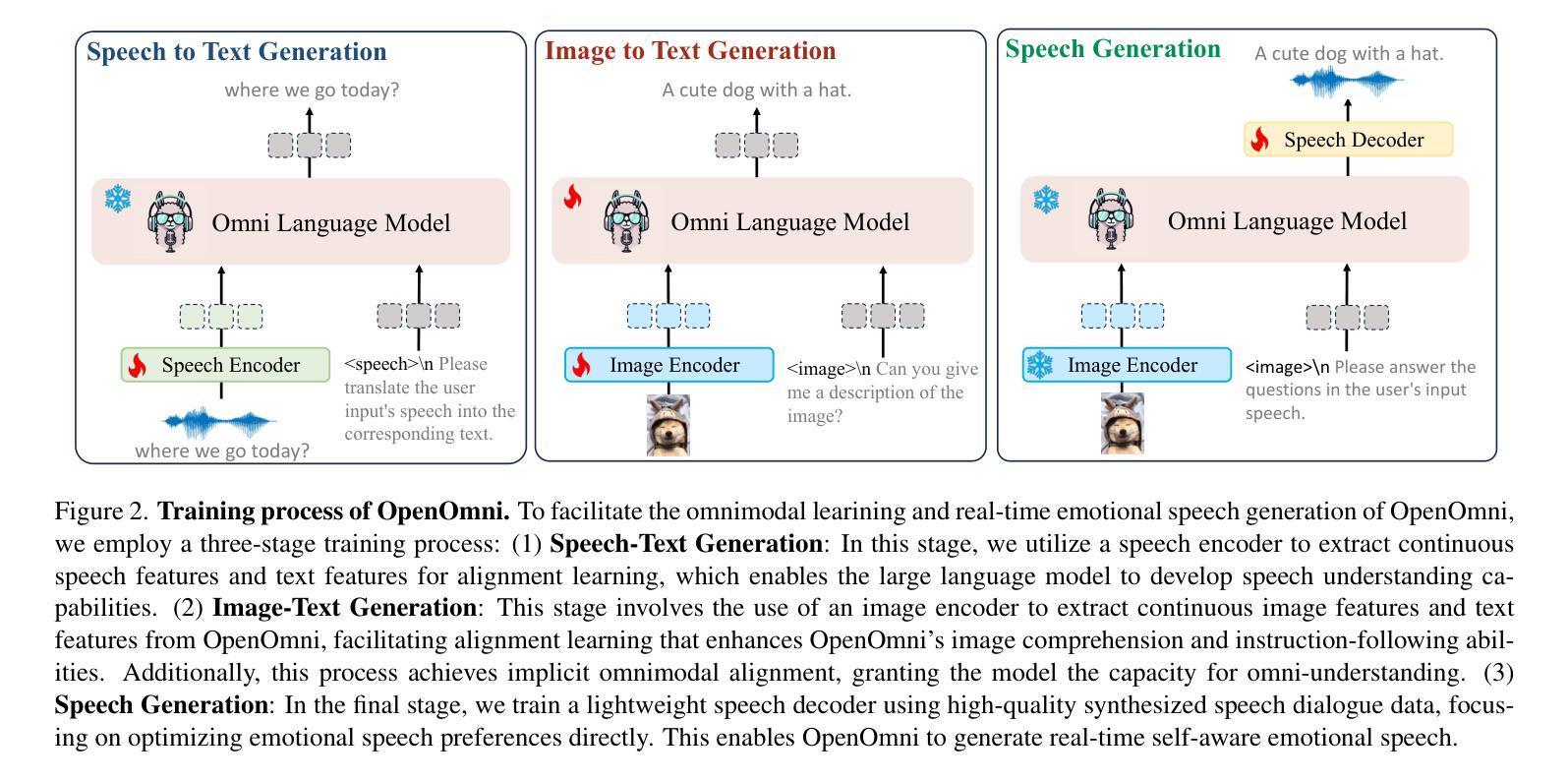
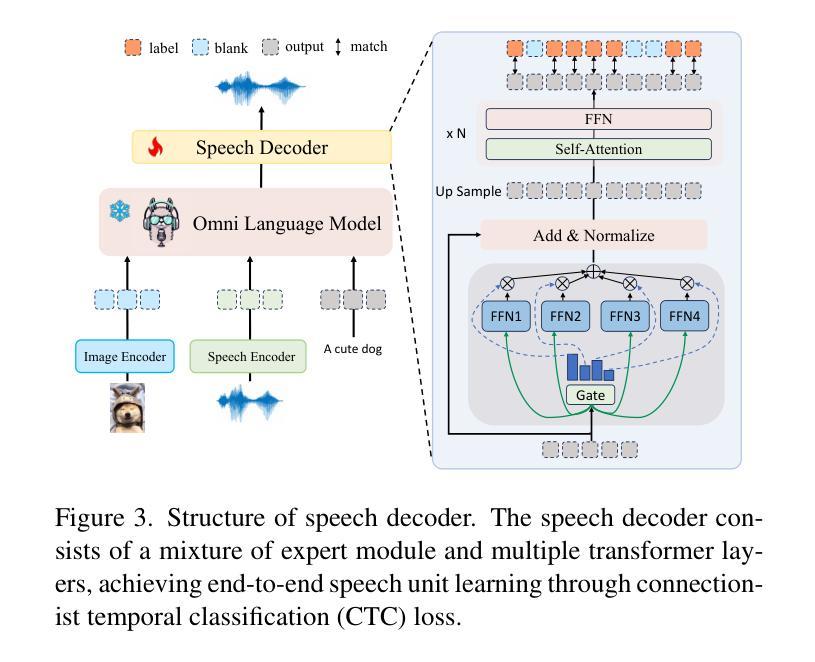
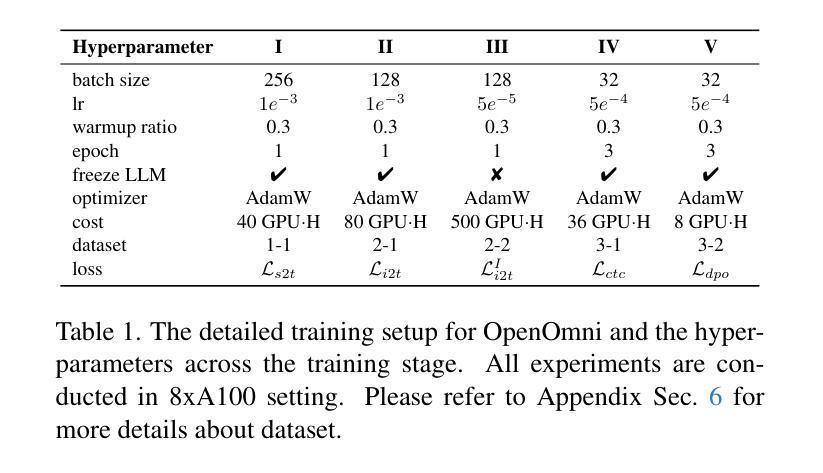
OpenOmni: Large Language Models Pivot Zero-shot Omnimodal Alignment across Language with Real-time Self-Aware Emotional Speech Synthesis
Authors:Run Luo, Ting-En Lin, Haonan Zhang, Yuchuan Wu, Xiong Liu, Min Yang, Yongbin Li, Longze Chen, Jiaming Li, Lei Zhang, Yangyi Chen, Hamid Alinejad-Rokny, Fei Huang
Recent advancements in omnimodal learning have been achieved in understanding and generation across images, text, and speech, though mainly within proprietary models. Limited omnimodal datasets and the inherent challenges associated with real-time emotional speech generation have hindered open-source progress. To address these issues, we propose openomni, a two-stage training method combining omnimodal alignment and speech generation to develop a state-of-the-art omnimodal large language model. In the alignment phase, a pre-trained speech model is further trained on text-image tasks to generalize from vision to speech in a (near) zero-shot manner, outperforming models trained on tri-modal datasets. In the speech generation phase, a lightweight decoder facilitates real-time emotional speech through training on speech tasks and preference learning. Experiments demonstrate that openomni consistently improves across omnimodal, vision-language, and speech-language evaluations, enabling natural, emotion-rich dialogues and real-time emotional speech generation.
近期多模态学习在图像、文本和语音的理解和生成方面取得了进展,但主要局限于专有模型内部。有限的多模态数据集和实时情感语音生成所固有的挑战阻碍了开源进度。为了解决这些问题,我们提出了openomni,这是一种结合多模态对齐和语音生成的两阶段训练方法,以开发先进的多模态大型语言模型。在对齐阶段,预训练的语音模型进一步在文本图像任务上进行训练,以(接近)零样本的方式从视觉到语音进行推广,超越了那些在三元模态数据集上训练的模型。在语音生成阶段,一个轻量级的解码器通过语音任务和偏好学习进行训练,促进实时情感语音的产生。实验表明,openomni在多模态、视觉语言和语音语言评估中持续改进,可实现自然、情感丰富的对话和实时情感语音生成。
论文及项目相关链接
Summary
开放omnimodal大型语言模型的研究取得进展,提出名为openomni的两阶段训练方法,通过omnimodal对齐和语音生成,实现跨图像、文本和语音的理解与生成。对齐阶段预训练语音模型在文本图像任务上进行进一步训练,以在零样本或接近零样本情况下从视觉到语音进行推广,表现出优于在三模态数据集上训练模型的效果。在语音生成阶段,使用轻量级解码器通过语音任务和偏好学习进行训练,实现实时情感语音生成。实验证明openomni在omnimodal、视觉语言和语音语言评估中表现优异,可实现自然、情感丰富的对话和实时情感语音生成。
Key Takeaways
- openomni是一种创新的双阶段训练方法,专注于Omnimodal大型语言模型的训练。
- 对齐阶段是预训练语音模型在文本图像任务上的进一步训练,实现视觉到语音的推广。
- openomni能够在零样本或接近零样本情况下表现优异,优于在三模态数据集上训练的模型。
- 语音生成阶段使用轻量级解码器进行实时情感语音生成。
- openomni支持实时情感语音生成和自然、情感丰富的对话。
- 实验证明openomni在多个评估中表现优异,包括omnimodal、视觉语言和语音语言评估。
点此查看论文截图

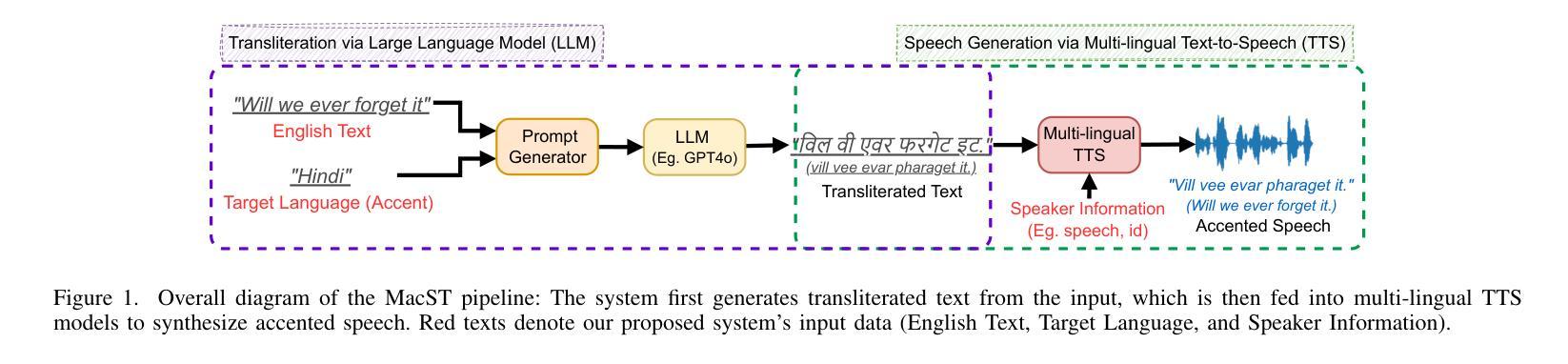
MacST: Multi-Accent Speech Synthesis via Text Transliteration for Accent Conversion
Authors:Sho Inoue, Shuai Wang, Wanxing Wang, Pengcheng Zhu, Mengxiao Bi, Haizhou Li
In accented voice conversion or accent conversion, we seek to convert the accent in speech from one another while preserving speaker identity and semantic content. In this study, we formulate a novel method for creating multi-accented speech samples, thus pairs of accented speech samples by the same speaker, through text transliteration for training accent conversion systems. We begin by generating transliterated text with Large Language Models (LLMs), which is then fed into multilingual TTS models to synthesize accented English speech. As a reference system, we built a sequence-to-sequence model on the synthetic parallel corpus for accent conversion. We validated the proposed method for both native and non-native English speakers. Subjective and objective evaluations further validate our dataset’s effectiveness in accent conversion studies.
在口音转换或口音转换中,我们旨在将语音中的口音进行转换,同时保留说话者的身份和语义内容。在这项研究中,我们提出了一种创建多口音语音样本的新方法,因此通过文本音译来训练口音转换系统,从而形成同一说话人的带口音语音样本对。我们首先使用大型语言模型(LLM)生成音译文本,然后将其输入多语种语音合成(TTS)模型以合成带口音的英语语音。作为参考系统,我们在合成平行语料库上建立了序列到序列的模型进行口音转换。我们对英语母语和非母语人士都验证了所提出的方法。主观和客观评估进一步验证了我们的数据集在口音转换研究中的有效性。
论文及项目相关链接
PDF This is accepted to IEEE ICASSP 2025; Project page with Speech Demo: https://github.com/shinshoji01/MacST-project-page
总结
在带有口音的语音转换或口音转换中,我们致力于将语音中的口音进行转换,同时保持说话人的身份和语义内容不变。本研究提出了一种新颖的方法,通过文本转译生成带有多种口音的语音样本对,用于训练口音转换系统。我们利用大型语言模型生成转译文本,然后将其输入多语种文本转语音模型,合成带有口音的英语语音。作为参考系统,我们在合成平行语料库上建立了序列到序列的模型进行口音转换。我们对英语母语和非母语人士都验证了所提出的方法。主观和客观评估进一步验证了我们的数据集在口音转换研究中的有效性。
关键见解
- 研究旨在实现口音转换,同时保持说话人的身份和语义内容不变。
- 提出了一种基于文本转译生成带有多种口音的语音样本对的新方法。
- 利用大型语言模型生成转译文本,并输入多语种文本转语音模型进行语音合成。
- 建立了序列到序列的模型作为参考系统,用于口音转换研究。
- 方法适用于英语母语和非母语人士。
- 主观和客观评估验证了数据集在口音转换研究中的有效性。
- 此方法为未来口音转换系统的训练和发展提供了新的思路和方向。
点此查看论文截图


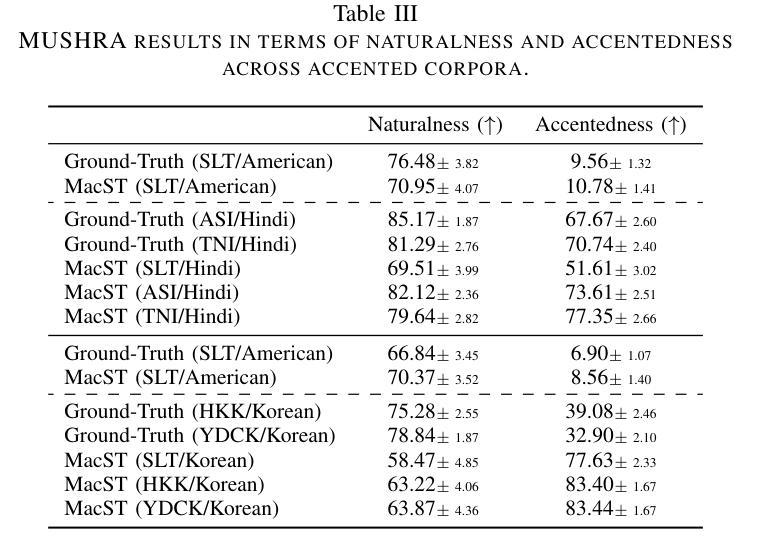
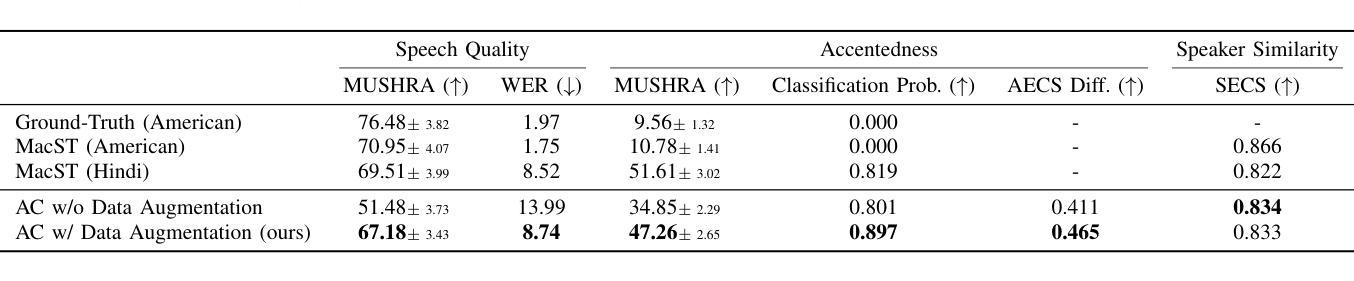
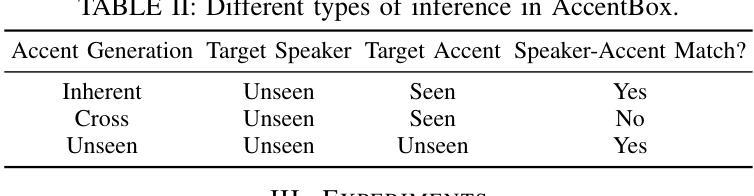
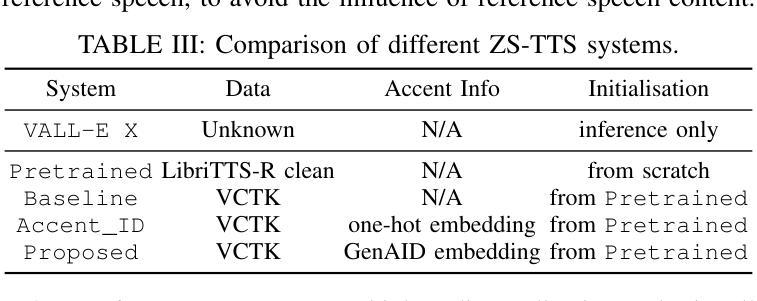
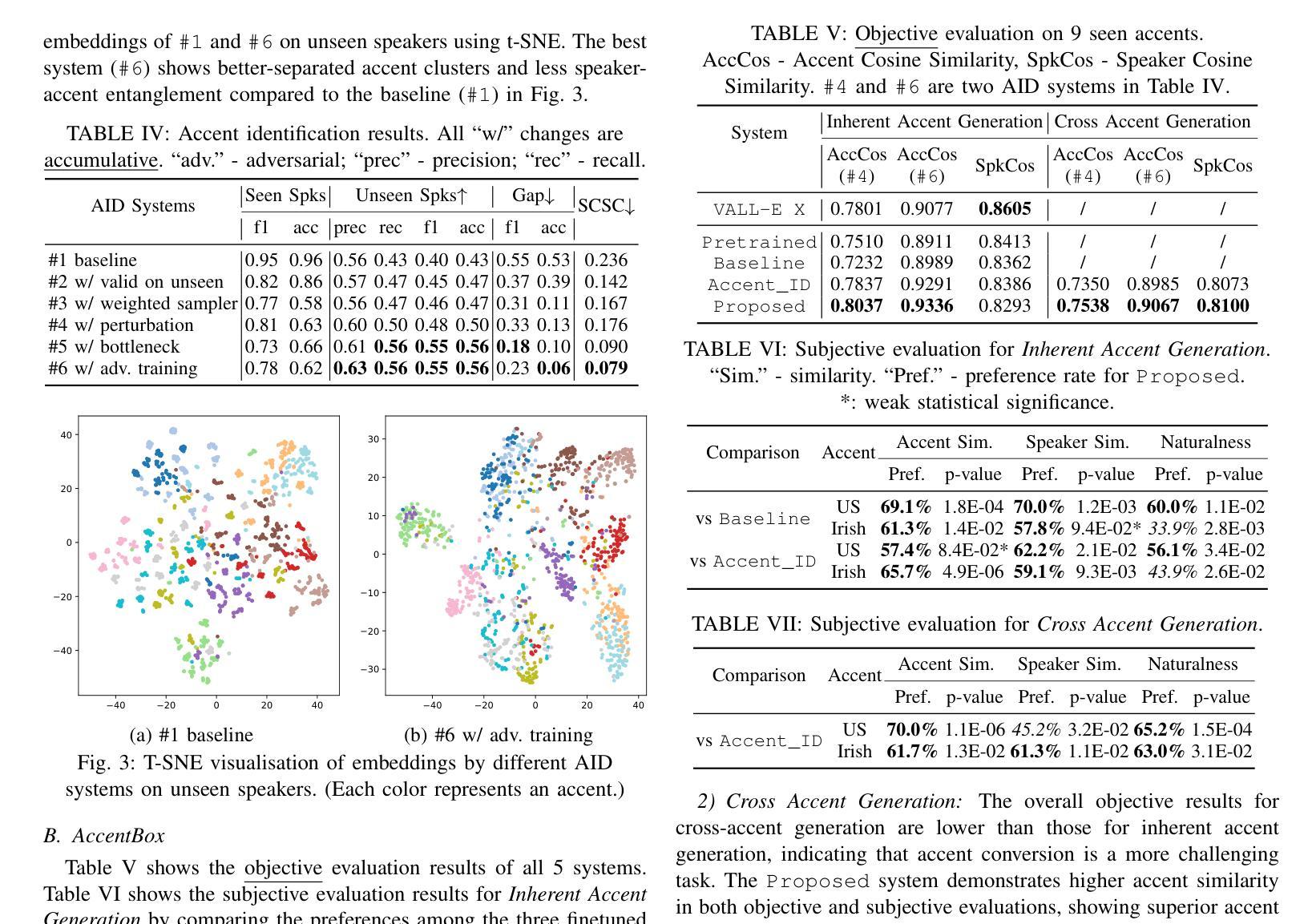
AccentBox: Towards High-Fidelity Zero-Shot Accent Generation
Authors:Jinzuomu Zhong, Korin Richmond, Zhiba Su, Siqi Sun
While recent Zero-Shot Text-to-Speech (ZS-TTS) models have achieved high naturalness and speaker similarity, they fall short in accent fidelity and control. To address this issue, we propose zero-shot accent generation that unifies Foreign Accent Conversion (FAC), accented TTS, and ZS-TTS, with a novel two-stage pipeline. In the first stage, we achieve state-of-the-art (SOTA) on Accent Identification (AID) with 0.56 f1 score on unseen speakers. In the second stage, we condition a ZS-TTS system on the pretrained speaker-agnostic accent embeddings extracted by the AID model. The proposed system achieves higher accent fidelity on inherent/cross accent generation, and enables unseen accent generation.
尽管最近的零样本文本到语音(ZS-TTS)模型在自然性和说话人相似性方面取得了很高的成就,但在口音的保真度和控制方面还存在不足。为了解决这一问题,我们提出了零样本口音生成,将外语口音转换(FAC)、带口音的TTS和ZS-TTS统一起来,采用新型的两阶段流程。在第一阶段,我们在未见过的说话人上实现了最先进的口音识别(AID),F1分数为0.56。在第二阶段,我们以由AID模型提取的预训练说话人无关口音嵌入为条件,对ZS-TTS系统进行调节。所提系统在固有/交叉口音生成方面实现了更高的口音保真度,并实现了未见口音的生成。
论文及项目相关链接
PDF Accepted by ICASSP 2025
Summary
近期虽然零样本文本转语音(ZS-TTS)模型在自然度和说话人相似性方面取得了很高的成就,但在口音的保真和控制方面仍存在不足。为解决这一问题,我们提出了零样本口音生成方法,统一了外籍口音转换(FAC)、带口音的TTS和ZS-TTS,采用新型两阶段流程。第一阶段,我们在未见过的说话人上实现了最先进的口音识别(AID)0.56 f1分数。第二阶段,我们以由AID模型提取的预训练说话人无关口音嵌入为条件,对ZS-TTS系统进行调节。所提出系统在生成内在/交叉口音方面实现了更高的口音保真度,并能生成未见过的口音。
Key Takeaways
- 零样本文本转语音(ZS-TTS)模型在口音的保真和控制方面存在挑战。
- 提出一种零样本口音生成方法,整合外籍口音转换(FAC)、带口音的TTS和ZS-TTS。
- 采用两阶段流程实现:第一阶段实现先进的口音识别(AID)。
- 第二阶段以由AID模型提取的预训练说话人无关口音嵌入为条件,调节ZS-TTS系统。
- 所提出系统在生成内在和交叉口音方面表现优异。
- 系统能够实现未见过的口音生成。
点此查看论文截图

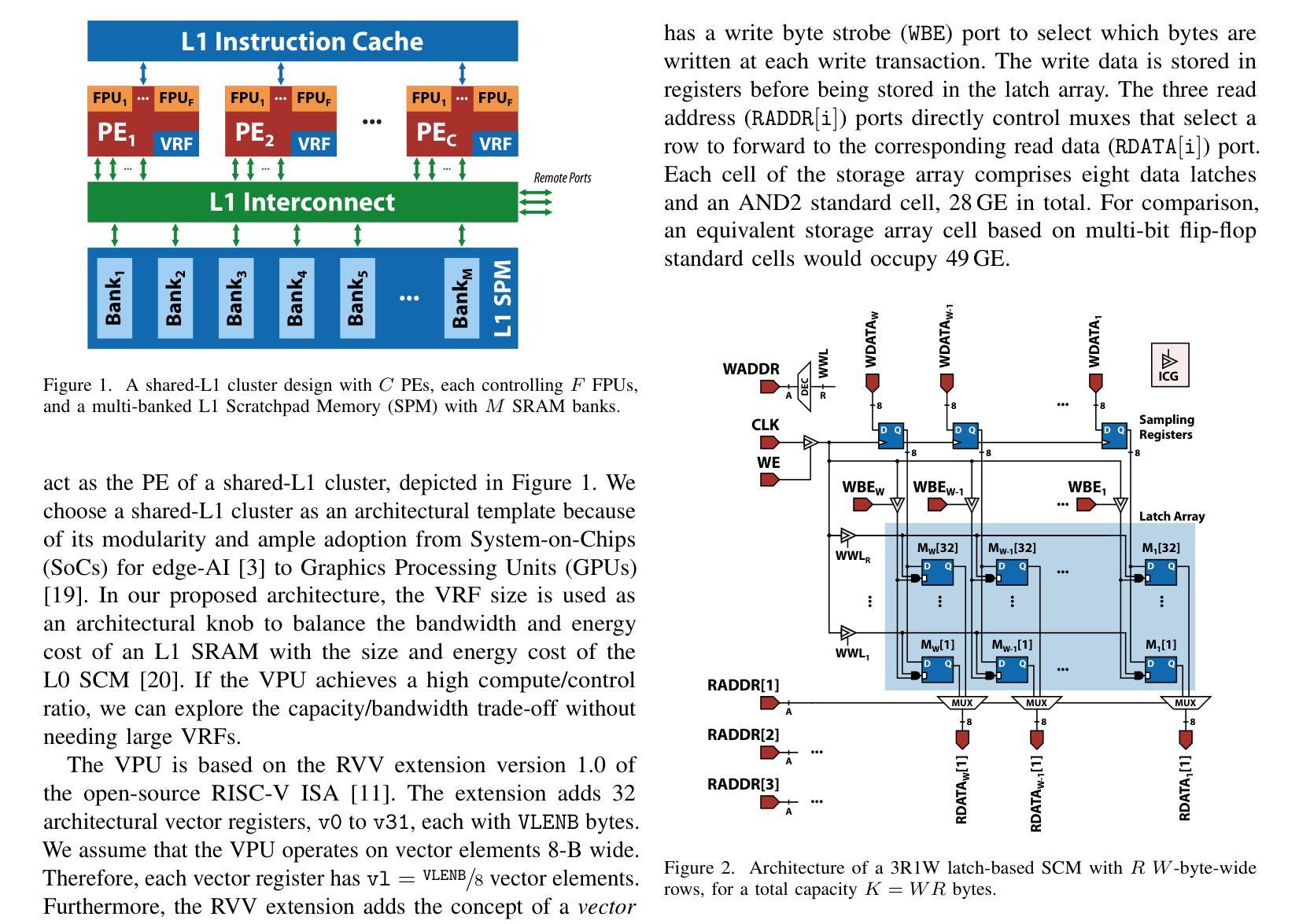
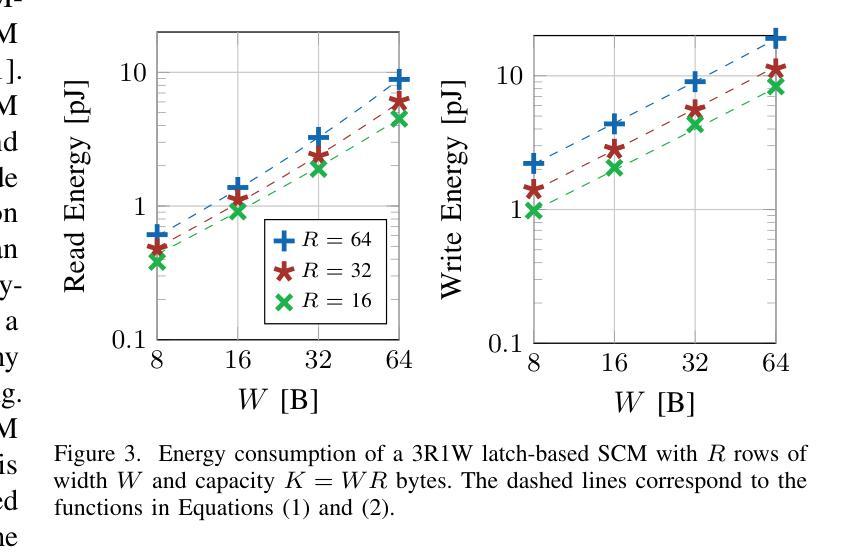
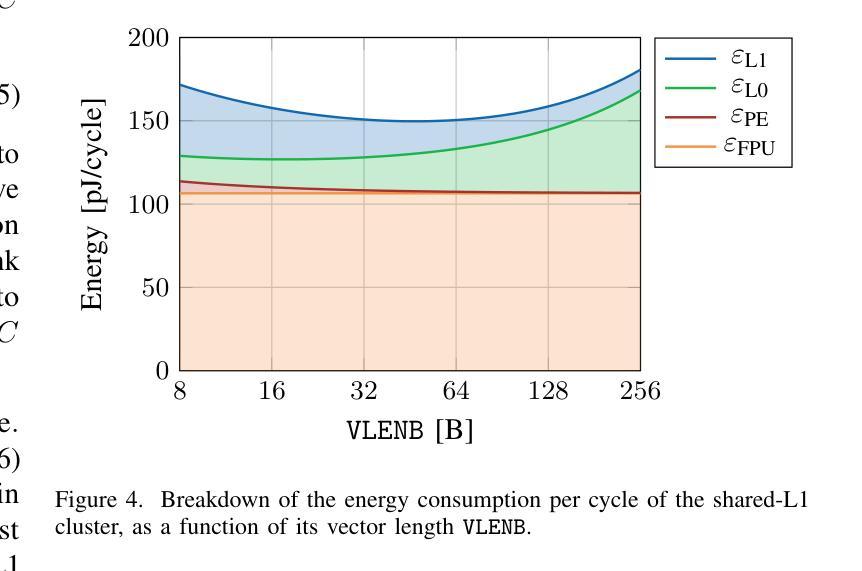
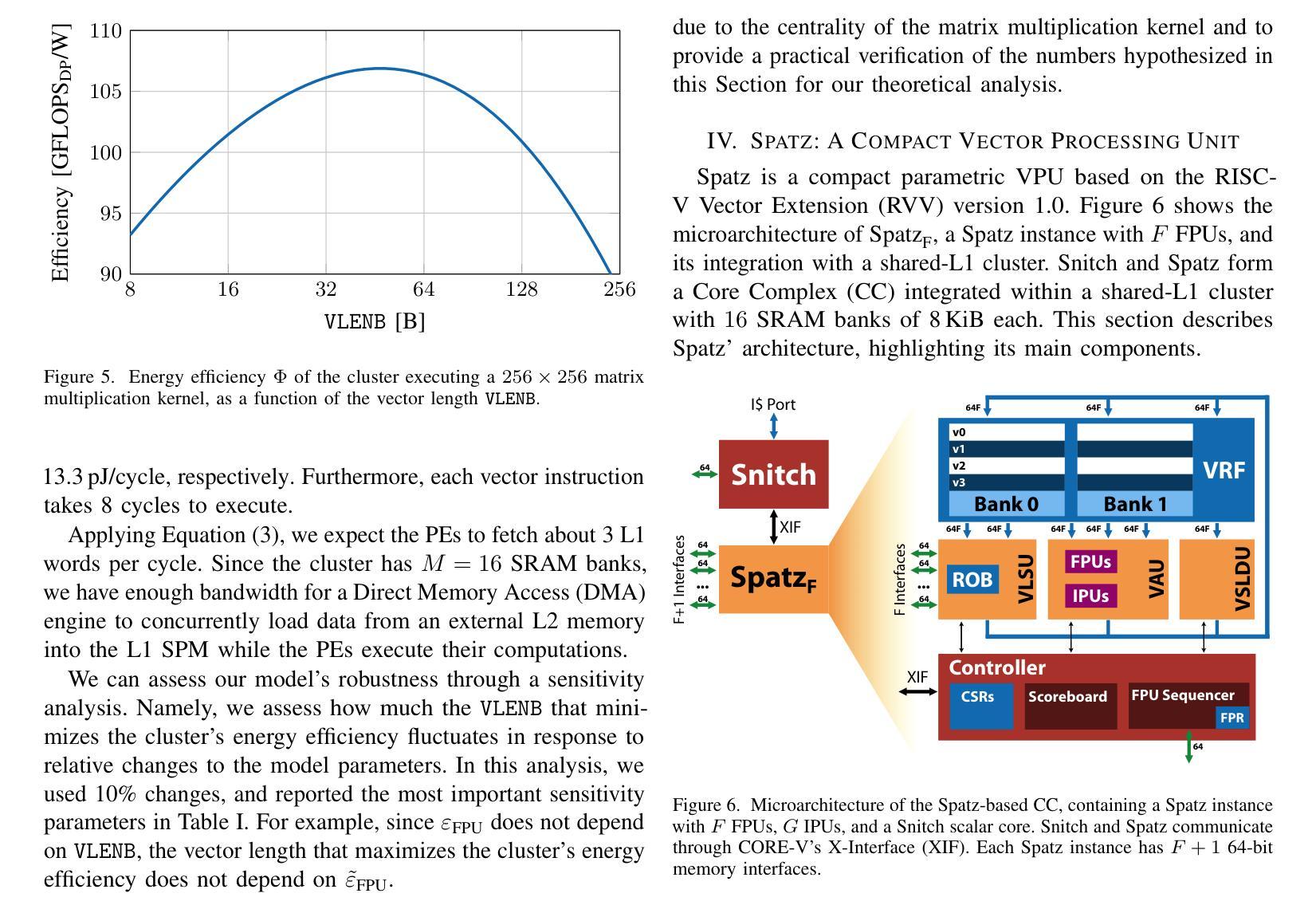
Spatz: Clustering Compact RISC-V-Based Vector Units to Maximize Computing Efficiency
Authors:Matteo Perotti, Samuel Riedel, Matheus Cavalcante, Luca Benini
The ever-increasing computational and storage requirements of modern applications and the slowdown of technology scaling pose major challenges to designing and implementing efficient computer architectures. To mitigate the bottlenecks of typical processor-based architectures on both the instruction and data sides of the memory, we present Spatz, a compact 64-bit floating-point-capable vector processor based on RISC-V’s Vector Extension Zve64d. Using Spatz as the main Processing Element (PE), we design an open-source dual-core vector processor architecture based on a modular and scalable cluster sharing a Scratchpad Memory (SCM). Unlike typical vector processors, whose Vector Register Files (VRFs) are hundreds of KiB large, we prove that Spatz can achieve peak energy efficiency with a latch-based VRF of only 2 KiB. An implementation of the Spatz-based cluster in GlobalFoundries’ 12LPP process with eight double-precision Floating Point Units (FPUs) achieves an FPU utilization just 3.4% lower than the ideal upper bound on a double-precision, floating-point matrix multiplication. The cluster reaches 7.7 FMA/cycle, corresponding to 15.7 DP-GFLOPS and 95.7 DP-GFLOPS/W at 1 GHz and nominal operating conditions (TT, 0.80V, 25C), with more than 55% of the power spent on the FPUs. Furthermore, the optimally-balanced Spatz-based cluster reaches a 95.0% FPU utilization (7.6 FMA/cycle), 15.2 DP-GFLOPS, and 99.3 DP-GFLOPS/W (61% of the power spent in the FPU) on a 2D workload with a 7x7 kernel, resulting in an outstanding area/energy efficiency of 171 DP-GFLOPS/W/mm2. At equi-area, the computing cluster built upon compact vector processors reaches a 30% higher energy efficiency than a cluster with the same FPU count built upon scalar cores specialized for stream-based floating-point computation.
随着现代应用程序计算与存储需求的日益增长以及技术规模缩减带来的放缓,设计并实现高效的计算机架构面临巨大挑战。为了缓解基于典型处理器的架构在内存指令和数据方面的瓶颈,我们推出了Spatz,这是一款基于RISC-V的向量扩展Zve64d的紧凑型64位浮点向量处理器。以Spatz为主要处理单元(PE),我们设计了一种基于模块化且可伸缩集群的开源双核向量处理器架构,该架构共享一个Scratchpad Memory(SCM)。不同于通常的向量处理器,其向量寄存器文件(VRF)通常有几百千字节大,我们证明Spatz仅使用基于锁定的VRF即可实现峰值能效,其大小仅为2KiB。使用GlobalFoundries的12LPP工艺实现的Spatz集群包含八个双精度浮点单元(FPU),其FPU利用率比双精度浮点矩阵乘法理想的上限仅低3.4%。该集群达到每秒执行浮点矩阵乘法运算7.7次(相当于在每秒条件下运行速度为每秒亿级双精度浮点数(GFLOPS)),消耗功率下可得到每瓦百万次双精度浮点数操作(DP-GFLOPS/W)为95.7的指标值,其中超过55%的功率消耗在FPU上。此外,最优平衡的Spatz集群在处理二维工作负载(具有7x7内核)时,其FPU利用率达到95%(每秒执行浮点矩阵乘法运算7.6次),具有出色的每瓦性能值高达每秒千万次双精度浮点操作数(DP-GFLOPS/W)以及极高的能效性能密度值高达每平方毫米每秒亿级双精度浮点数操作数(DP-GFLOPS/W/mm²)高达数百单位或接近更大的能力在相同面积下,基于紧凑向量处理器的计算集群比基于专门用于流式浮点计算的标量处理器的集群能效高出约百分之三十。这将为未来的计算机架构设计提供新的视角和解决方案。
论文及项目相关链接
PDF To be published in “IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems”
Summary
现代应用对计算和存储需求的不断增长以及技术缩微速度的放缓,给设计高效计算机架构带来了巨大的挑战。为此,研究团队提出了Spatz矢量处理器,它是基于RISC-V的Vector Extension Zve64d的64位浮点矢量处理器。Spatz作为主要的处理单元(PE),设计了一种基于模块化、可扩展集群的开源双核矢量处理器架构,通过共享一个Scratchpad内存(SCM)来突破指令和数据在内存方面的瓶颈。相较于传统的大型向量寄存器文件(VRF),Spatz以其仅2KiB的基于门控的VRF证明了其峰值能效的实现能力。在全球科技联盟成立流程中使用Spatz为基础集群的实施中实现了FPU应用的效率峰值利用率差距仅在理想上限值之下,提升了双精度浮点矩阵乘法的效能。其高效性能体现在多个方面,包括高运算速度、低功耗以及优秀的能效表现等。相较于传统的标量核心计算集群,Spatz所构建的矢量处理器集群在能效上更胜一筹。
Key Takeaways
- Spatz是基于RISC-V Vector Extension的新型矢量处理器,旨在应对现代应用对计算和存储的挑战。
- Spatz采用的双核架构以Scratchpad Memory为核心进行数据处理。它通过内存共享方式突破了处理器在执行指令和数据处理方面的瓶颈。相较于传统的大型向量处理器拥有较小体积的向量寄存器文件(VRF),能效性能却同样出色。
点此查看论文截图