⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-13 更新
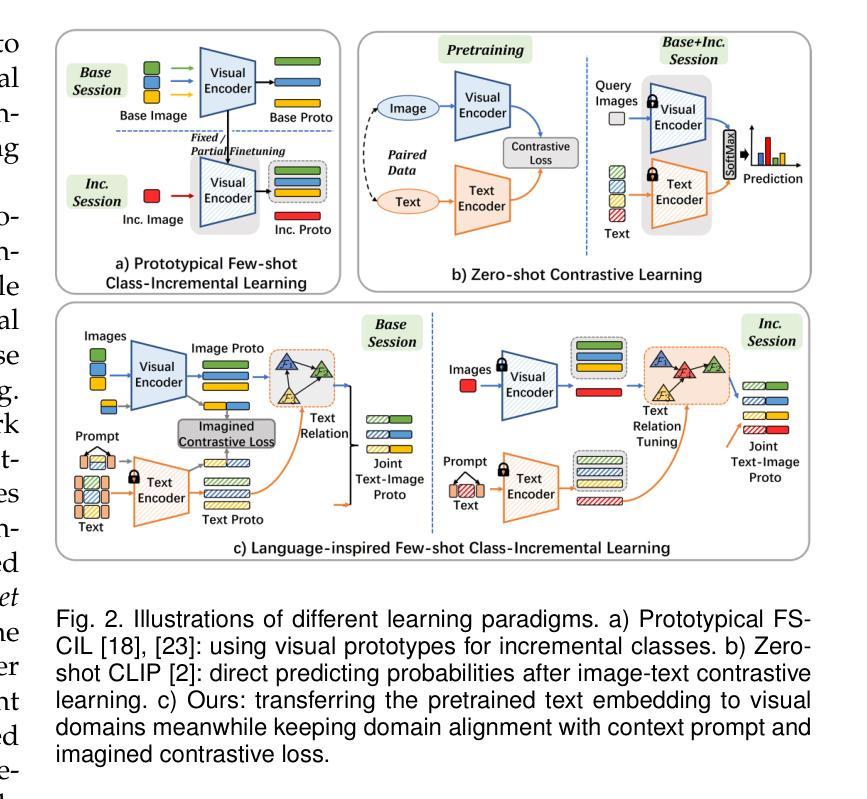
Language-Inspired Relation Transfer for Few-shot Class-Incremental Learning
Authors:Yifan Zhao, Jia Li, Zeyin Song, Yonghong Tian
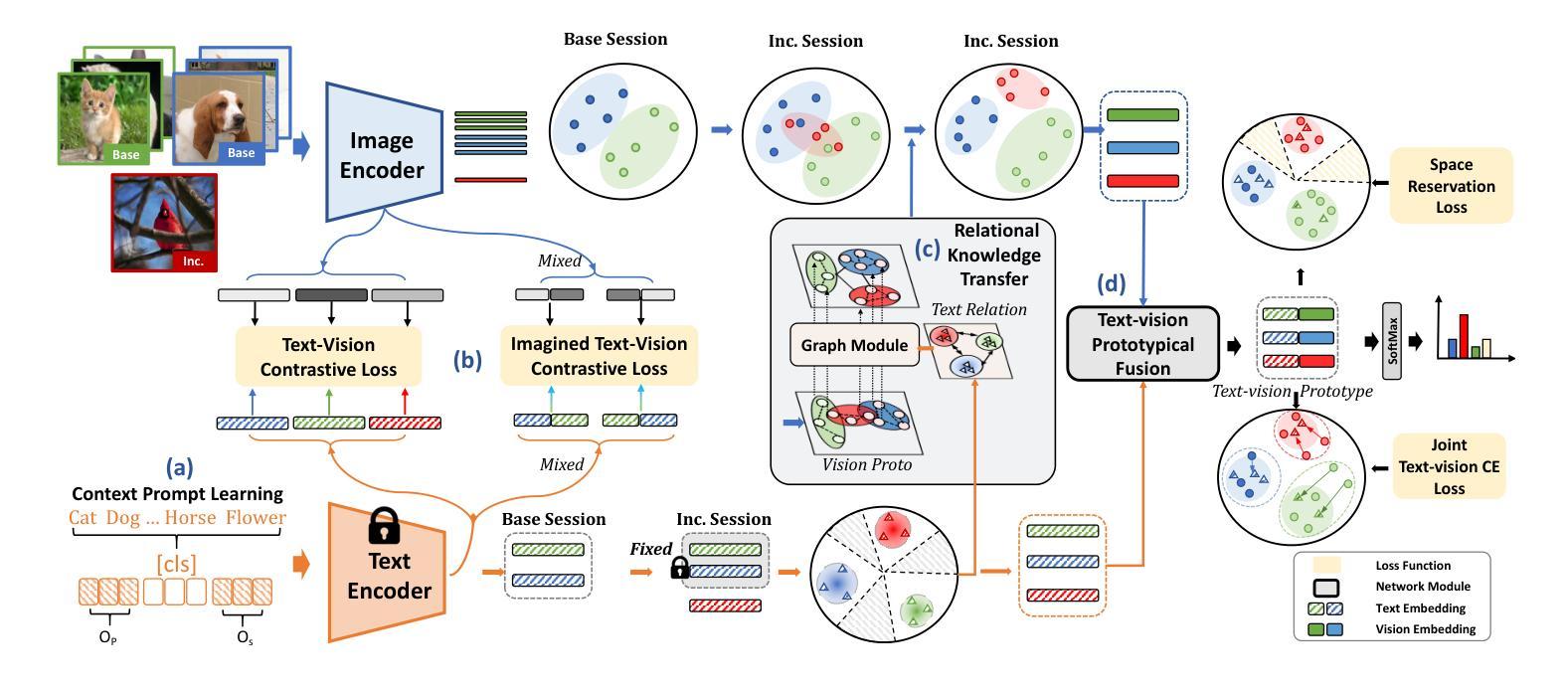
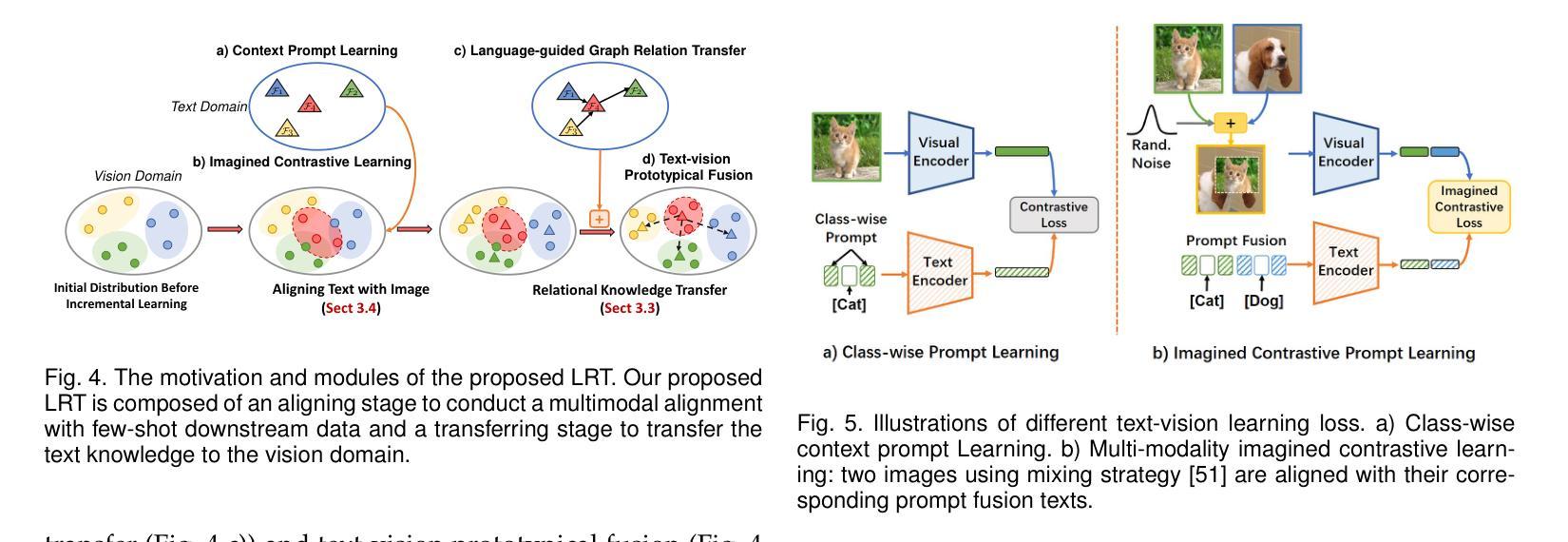
Depicting novel classes with language descriptions by observing few-shot samples is inherent in human-learning systems. This lifelong learning capability helps to distinguish new knowledge from old ones through the increase of open-world learning, namely Few-Shot Class-Incremental Learning (FSCIL). Existing works to solve this problem mainly rely on the careful tuning of visual encoders, which shows an evident trade-off between the base knowledge and incremental ones. Motivated by human learning systems, we propose a new Language-inspired Relation Transfer (LRT) paradigm to understand objects by joint visual clues and text depictions, composed of two major steps. We first transfer the pretrained text knowledge to the visual domains by proposing a graph relation transformation module and then fuse the visual and language embedding by a text-vision prototypical fusion module. Second, to mitigate the domain gap caused by visual finetuning, we propose context prompt learning for fast domain alignment and imagined contrastive learning to alleviate the insufficient text data during alignment. With collaborative learning of domain alignments and text-image transfer, our proposed LRT outperforms the state-of-the-art models by over $13%$ and $7%$ on the final session of mini-ImageNet and CIFAR-100 FSCIL benchmarks.
通过观察少数样本并用语言描述来描绘新型类别是人类学习系统的固有能力。这种终身学习能力有助于通过开放世界学习的增加来区分新旧知识,即所谓的少数类增量学习(FSCIL)。解决这个问题的现有工作主要依赖于视觉编码器的精细调整,这显示出基础知识和增量知识之间的明显权衡。受人类学习系统的启发,我们提出了一种新的语言启发关系转移(LRT)范式,通过联合视觉线索和文本描述来理解对象,包括两个主要步骤。首先,我们通过提出图关系转换模块将预训练的文本知识转移到视觉领域,然后通过文本视觉原型融合模块融合视觉和语言嵌入。其次,为了缓解因视觉微调而产生的领域差距,我们提出了上下文提示学习来进行快速领域对齐和想象中的对比学习,以缓解对齐过程中的文本数据不足。通过领域对齐和文本图像转移的协作学习,我们提出的LRT在mini-ImageNet和CIFAR-100 FSCIL基准测试的最后一期分别优于最新模型超过13%和7%。
论文及项目相关链接
PDF Accepted by IEEE TPAMI
Summary
本文介绍了人类学习系统中的一种能力:通过观察少量样本进行语言描述来描绘新类别。这种终身学习能力有助于通过开放世界学习的增加来区分新旧知识,即小样本类别增量学习(FSCIL)。为解决这一问题,现有工作主要依赖于视觉编码器的精细调整,这显示出基础知识和增量知识之间的权衡。受人类学习系统的启发,我们提出了一种新的语言启发关系转移(LRT)范式,通过联合视觉线索和文本描述来理解对象,包括两个主要步骤:首先将预训练的文本知识转移到视觉领域,然后融合视觉和语言嵌入。为缓解视觉微调带来的领域差距,我们提出了上下文提示学习和想象对比学习,以减轻对齐过程中的文本数据不足问题。通过领域对齐和文本图像转移的协作学习,我们提出的LRT在mini-ImageNet和CIFAR-100 FSCIL基准测试的最终阶段超越了最先进的模型,分别提高了13%和7%。
Key Takeaways
- 人类学习系统能够通过观察少量样本并用语言进行描述来描绘新类别,这被称为小样类别增量学习(FSCIL)。
- 现有方法主要通过精细调整视觉编码器来解决这一问题,但存在基础知识和增量知识之间的权衡。
- 引入语言启发关系转移(LRT)范式,结合视觉线索和文本描述来理解对象。
- LRT包括两个主要步骤:将文本知识转移到视觉领域,然后融合视觉和语言嵌入。
- 为解决视觉微调带来的领域差距问题,提出了上下文提示学习和想象对比学习。
- LRT在FSCIL基准测试上表现优异,提高了识别准确率。
点此查看论文截图

Zero-shot Shark Tracking and Biometrics from Aerial Imagery
Authors:Chinmay K Lalgudi, Mark E Leone, Jaden V Clark, Sergio Madrigal-Mora, Mario Espinoza
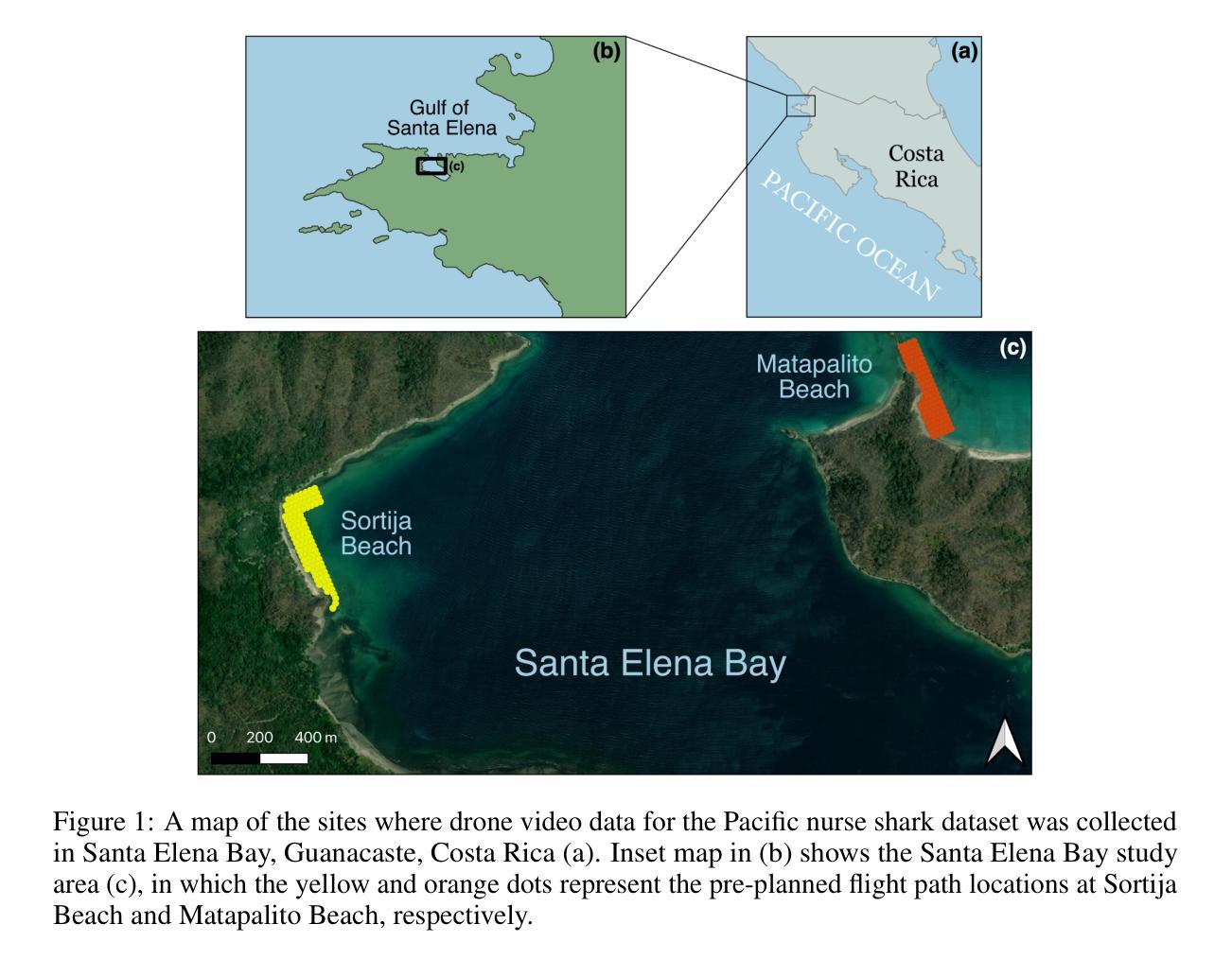
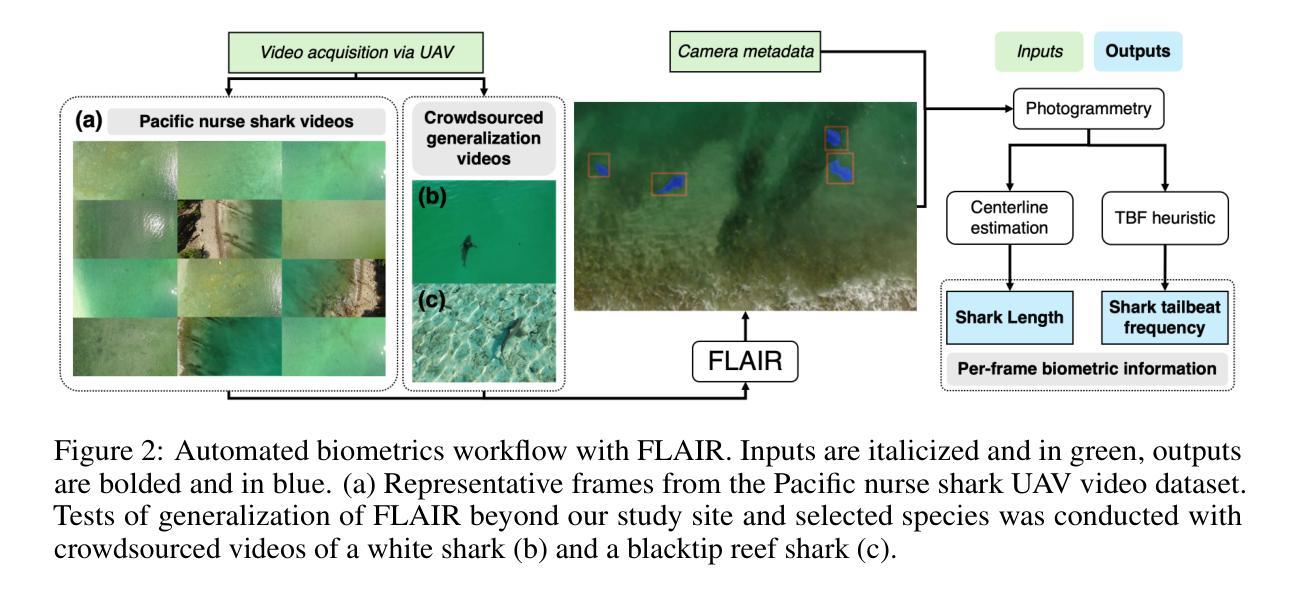
The recent widespread adoption of drones for studying marine animals provides opportunities for deriving biological information from aerial imagery. The large scale of imagery data acquired from drones is well suited for machine learning (ML) analysis. Development of ML models for analyzing marine animal aerial imagery has followed the classical paradigm of training, testing, and deploying a new model for each dataset, requiring significant time, human effort, and ML expertise. We introduce Frame Level ALIgment and tRacking (FLAIR), which leverages the video understanding of Segment Anything Model 2 (SAM2) and the vision-language capabilities of Contrastive Language-Image Pre-training (CLIP). FLAIR takes a drone video as input and outputs segmentation masks of the species of interest across the video. Notably, FLAIR leverages a zero-shot approach, eliminating the need for labeled data, training a new model, or fine-tuning an existing model to generalize to other species. With a dataset of 18,000 drone images of Pacific nurse sharks, we trained state-of-the-art object detection models to compare against FLAIR. We show that FLAIR massively outperforms these object detectors and performs competitively against two human-in-the-loop methods for prompting SAM2, achieving a Dice score of 0.81. FLAIR readily generalizes to other shark species without additional human effort and can be combined with novel heuristics to automatically extract relevant information including length and tailbeat frequency. FLAIR has significant potential to accelerate aerial imagery analysis workflows, requiring markedly less human effort and expertise than traditional machine learning workflows, while achieving superior accuracy. By reducing the effort required for aerial imagery analysis, FLAIR allows scientists to spend more time interpreting results and deriving insights about marine ecosystems.
无人机广泛用于研究海洋生物,这为从空中图像中提取生物信息提供了机会。从无人机获取的图像数据规模庞大,非常适合进行机器学习(ML)分析。针对海洋生物空中图像的机器学习模型开发遵循了为每个数据集训练、测试和部署新模型的经典范式,这需要大量时间、人力和机器学习专业知识。我们引入了Frame Level ALIgment和tRacking(FLAIR),它利用Segment Anything Model 2(SAM2)的视频理解能力和Contrastive Language-Image Pre-training(CLIP)的视听语言能力。FLAIR以无人机视频为输入,输出视频中感兴趣物种的分割掩膜。值得一提的是,FLAIR采用零样本方法,无需标记数据,无需训练新模型或微调现有模型即可推广到其他物种。我们使用包含太平洋护士鲨的无人机图像数据集训练了最先进的对象检测模型,以与FLAIR进行比较。我们证明FLAIR大大优于这些对象检测器,并且与两种人类循环提示SAM2的方法相比具有竞争力,实现了0.81的Dice得分。FLAIR很容易推广到其他鲨鱼物种,无需额外的人力投入,并且可以结合新颖启发式算法自动提取相关信息,包括长度和尾拍频率。FLAIR在加速空中图像分析工作流程方面具有巨大潜力,相比传统机器学习工作流程,它大大减少了人力和专业知识需求,同时实现了更高的准确性。通过减少空中图像分析所需的工作量,FLAIR让科学家能够花更多时间解释结果并得出关于海洋生态系统的见解。
论文及项目相关链接
摘要
无人机广泛用于海洋动物研究,提供从高空影像获取生物信息的机遇。大规模影像数据适合使用机器学习(ML)进行分析。本研究介绍了一种新方法FLAIR,它利用SAM2的视频理解能力和CLIP的视语言预训练能力,接受无人机视频输入并输出物种分割掩膜。FLAIR采用零样本方法,无需标注数据、训练新模型或微调现有模型即可推广到其他物种。在太平洋护士鲨的1.8万张无人机图像数据集上,我们训练了最先进的物体检测模型与FLAIR进行比较。结果显示,FLAIR大举超越了这些物体检测器,并与两种人类循环提示SAM2的方法竞争,实现了Dice评分0.81。FLAIR易于推广到其他鲨鱼物种,无需额外的人力投入,并能与新颖算法结合自动提取相关信息,如长度和尾波频率。FLAIR具有加速高空影像分析工作流程的巨大潜力,相比传统机器学习工作流程大大减少人力和专家需求,同时实现更高的精度。通过降低高空影像分析所需的努力,FLAIR使科学家有更多时间解读结果并挖掘海洋生态系统的见解。
关键见解
- 无人机广泛应用于海洋动物研究,为从高空影像获取生物信息提供机遇。
- 大规模影像数据适合使用机器学习进行分析。
- FLAIR方法利用SAM2的视频理解能力和CLIP的视语言预训练能力,接受无人机视频输入并输出物种分割掩膜。
- FLAIR采用零样本方法,无需标注数据、训练新模型或微调现有模型即可推广到其他物种。
- 在太平洋护士鲨的无人机图像数据集上,FLAIR显著优于物体检测器。
- FLAIR易于推广到其他鲨鱼物种,并能结合新颖算法自动提取相关信息。
- FLAIR具有加速高空影像分析工作流程的潜力,减少人力和专家需求,同时提高分析精度。
点此查看论文截图

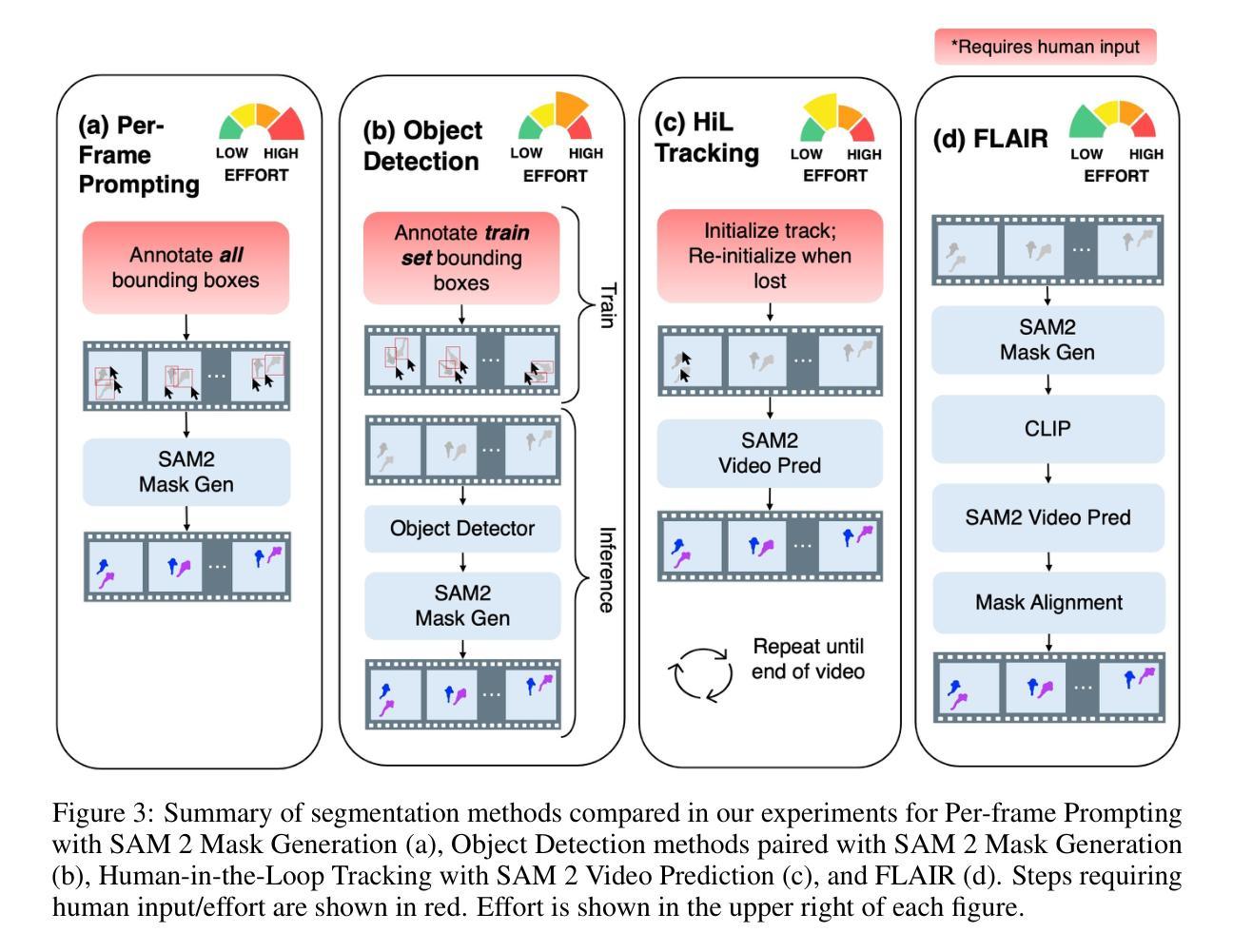
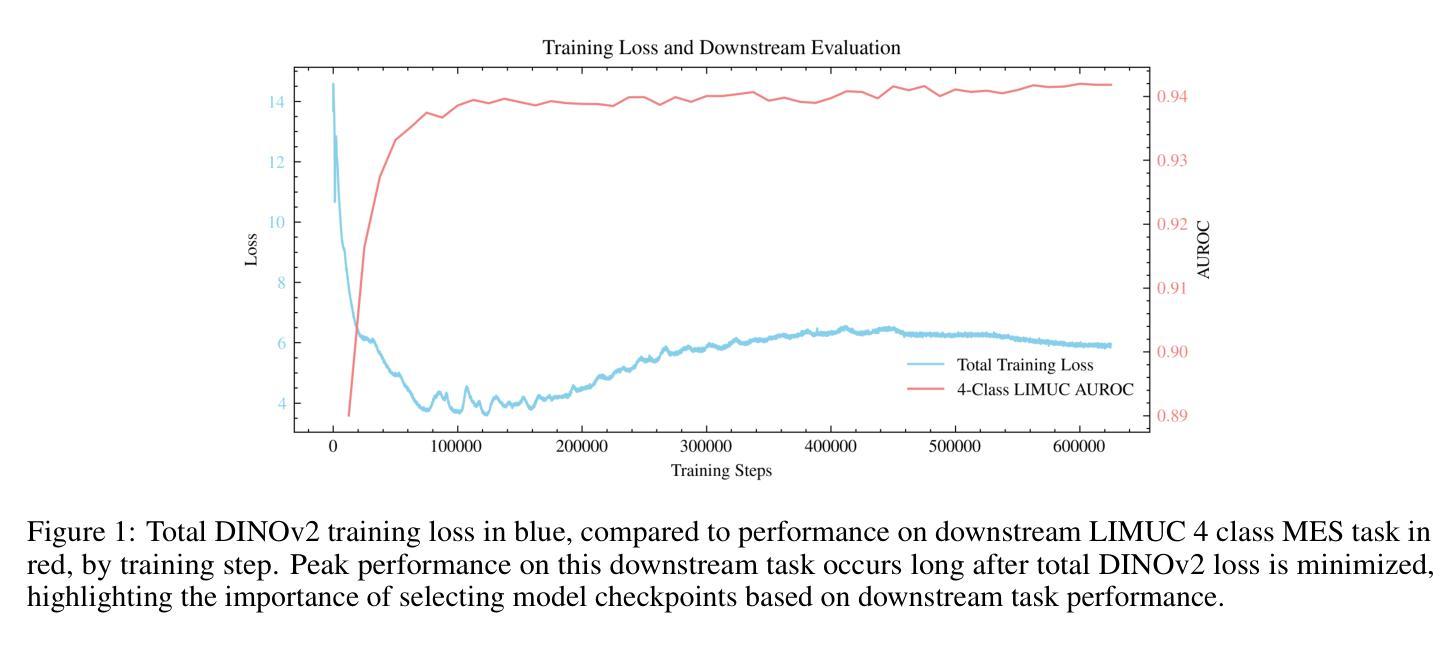
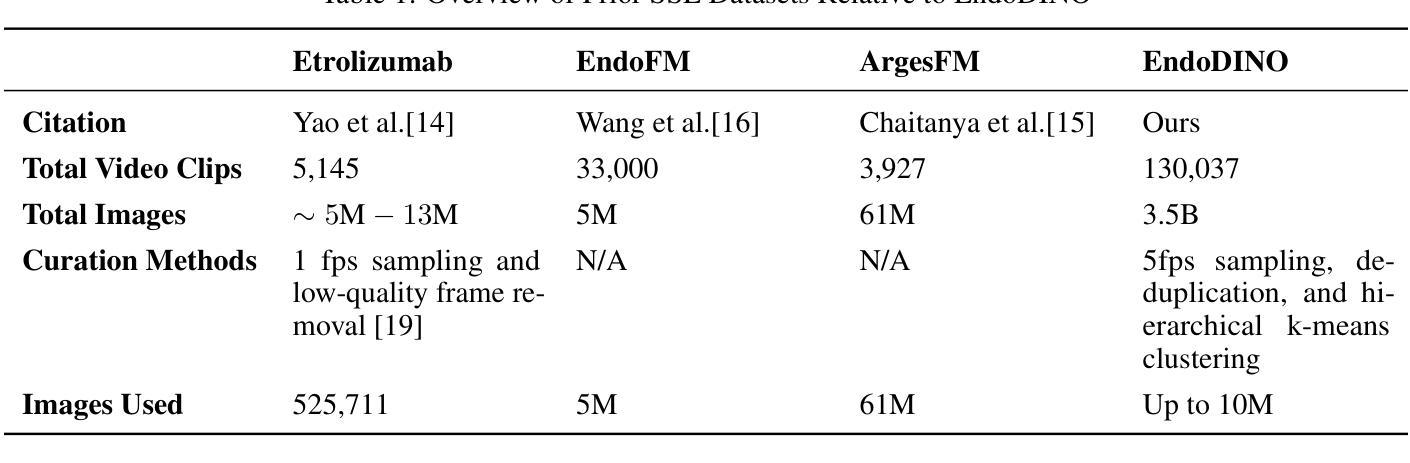
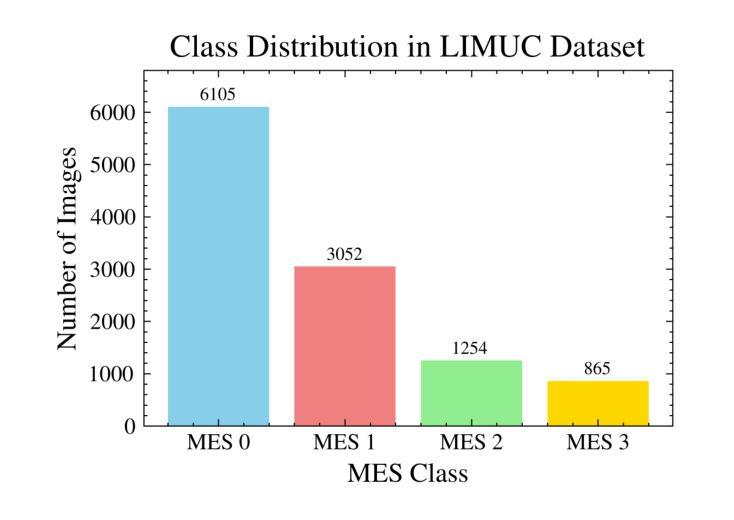
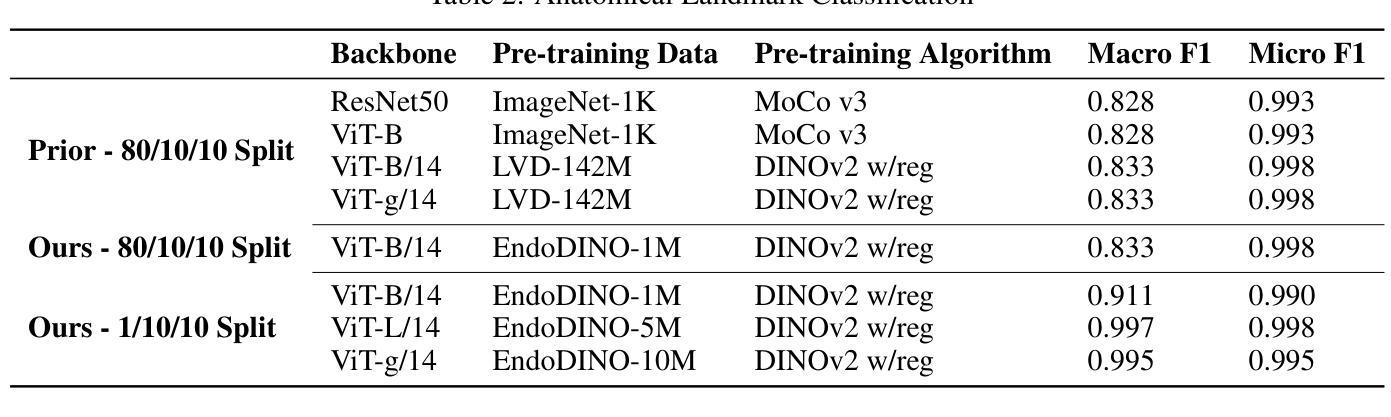
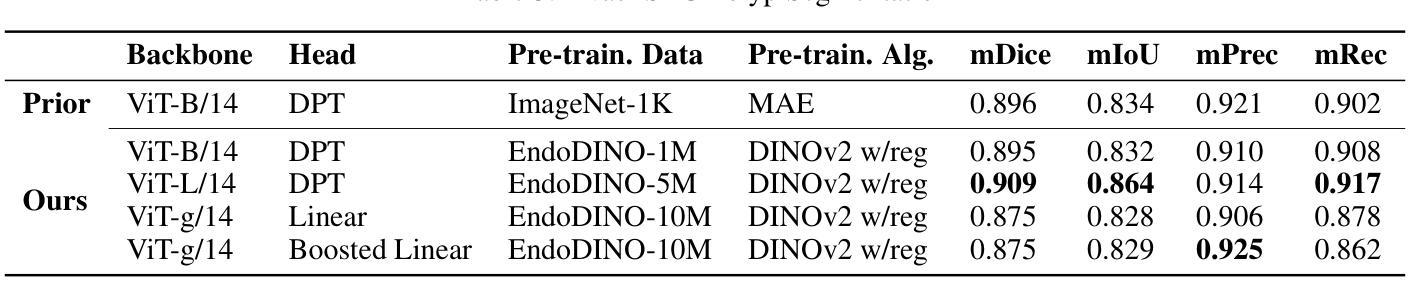
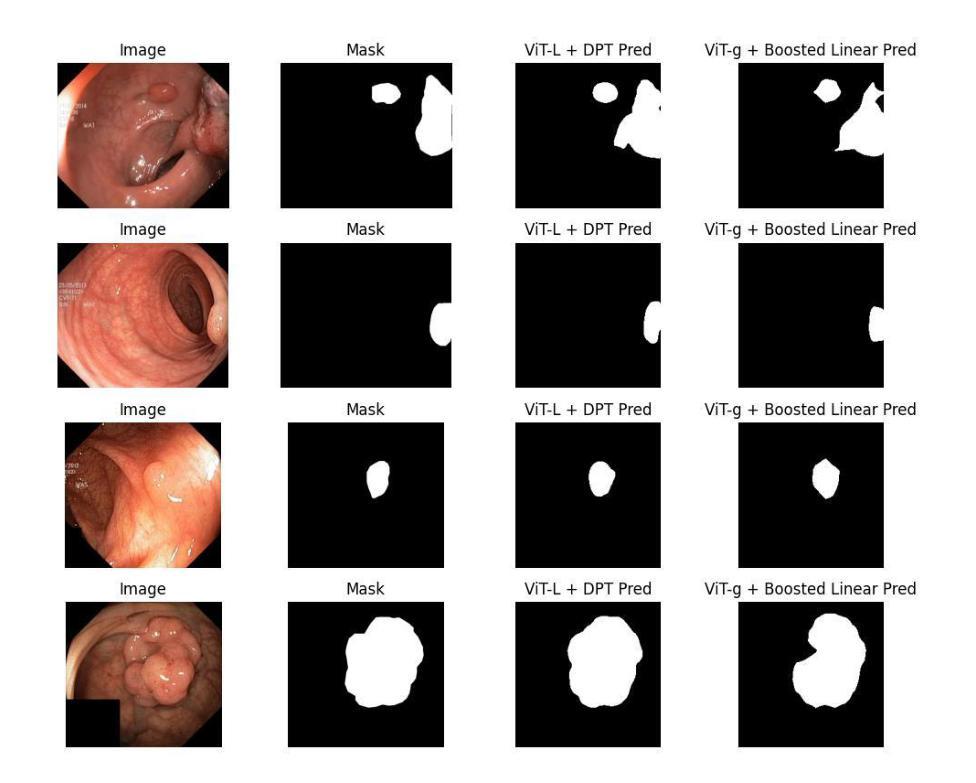
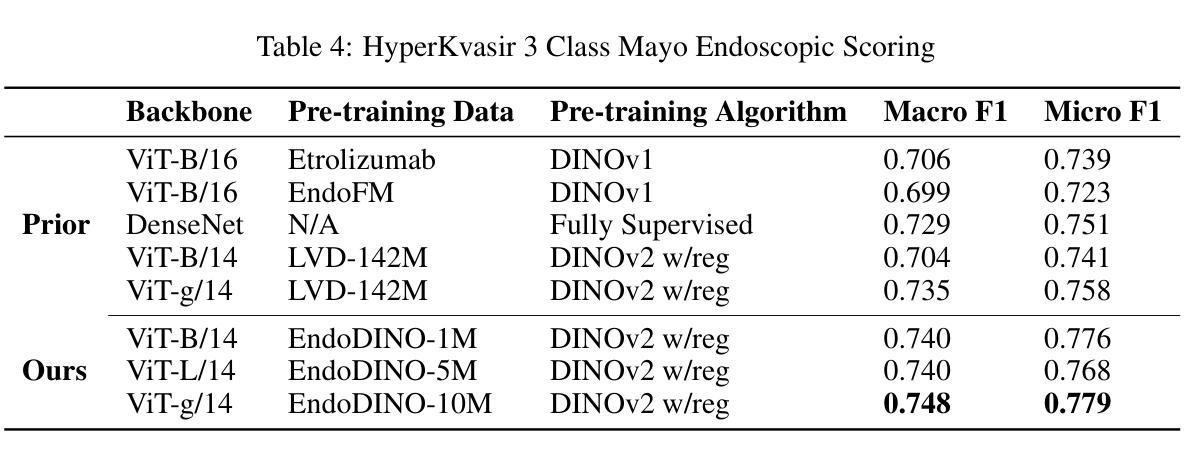
EndoDINO: A Foundation Model for GI Endoscopy
Authors:Patrick Dermyer, Angad Kalra, Matt Schwartz
In this work, we present EndoDINO, a foundation model for GI endoscopy tasks that achieves strong generalizability by pre-training on a well-curated image dataset sampled from the largest known GI endoscopy video dataset in the literature. Specifically, we pre-trained ViT models with 1B, 307M, and 86M parameters using datasets ranging from 100K to 10M curated images. Using EndoDINO as a frozen feature encoder, we achieved state-of-the-art performance in anatomical landmark classification, polyp segmentation, and Mayo endoscopic scoring (MES) for ulcerative colitis with only simple decoder heads.
在这项工作中,我们提出了EndoDINO,这是一个针对胃肠道内窥镜任务的基础模型。它通过预训练在文献中已知最大的胃肠道内窥镜视频数据集中精心挑选的图像数据集,实现了强大的泛化能力。具体来说,我们使用包含从10万到1亿张精选图像的多个数据集,对拥有1亿、3亿和8亿参数的ViT模型进行了预训练。以EndoDINO作为冻结的特征编码器,我们仅在简单的解码器头上实现了溃疡性结肠炎解剖学地标分类、息肉分割和梅奥内窥镜评分(MES)的最先进性能。
论文及项目相关链接
Summary:
本文介绍了EndoDINO,一种用于胃肠道内镜任务的通用模型。该模型通过在一个大型的胃肠道内镜视频数据集上预训练得到,具有出色的泛化能力。研究人员使用不同参数的ViT模型进行预训练,并使用简单的解码器实现了在解剖地标分类、息肉分割和溃疡性结肠炎的Mayo内镜评分上的最佳性能。
Key Takeaways:
- EndoDINO是一个用于胃肠道内镜任务的通用模型,通过预训练在大型数据集上实现强泛化能力。
- 该模型使用了ViT模型进行预训练,参数规模从千万级到百万级不等。
- EndoDINO通过预训练在大量精选图像数据集上进行训练。
- 使用EndoDINO作为特征编码器,实现了在解剖地标分类、息肉分割和溃疡性结肠炎评分上的最佳性能。
- 该模型采用简单的解码器头进行任务特定解码,展示了强大的性能。
- 该研究展示了使用大规模预训练模型的潜力,为未来相关任务提供了借鉴和参考。
点此查看论文截图

Leveraging Registers in Vision Transformers for Robust Adaptation
Authors:Srikar Yellapragada, Kowshik Thopalli, Vivek Narayanaswamy, Wesam Sakla, Yang Liu, Yamen Mubarka, Dimitris Samaras, Jayaraman J. Thiagarajan
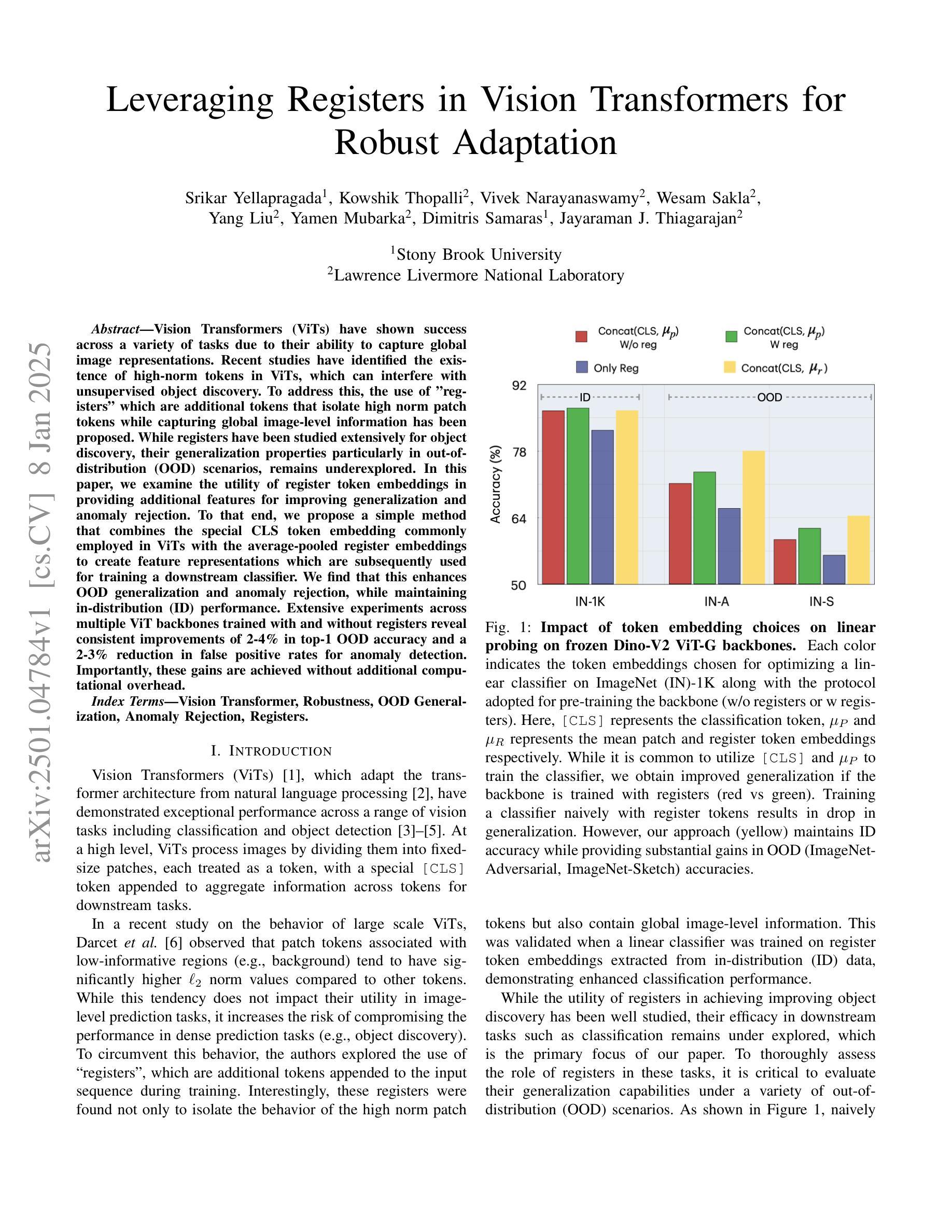
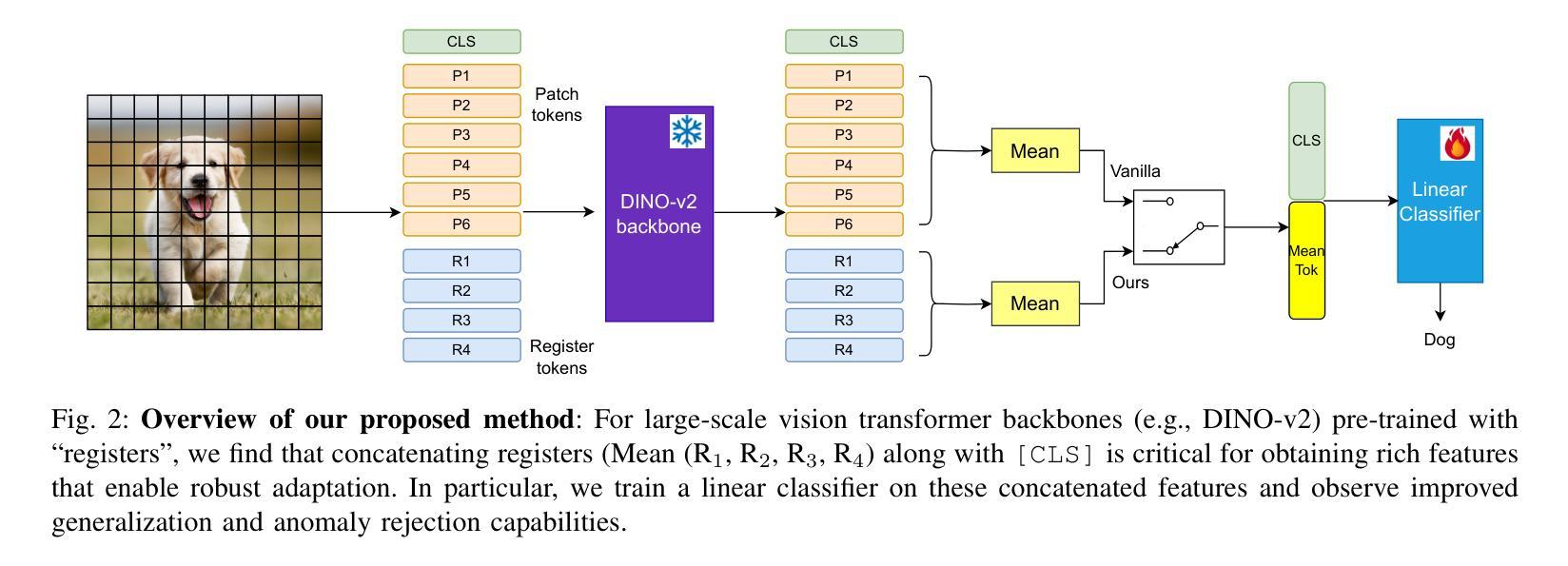
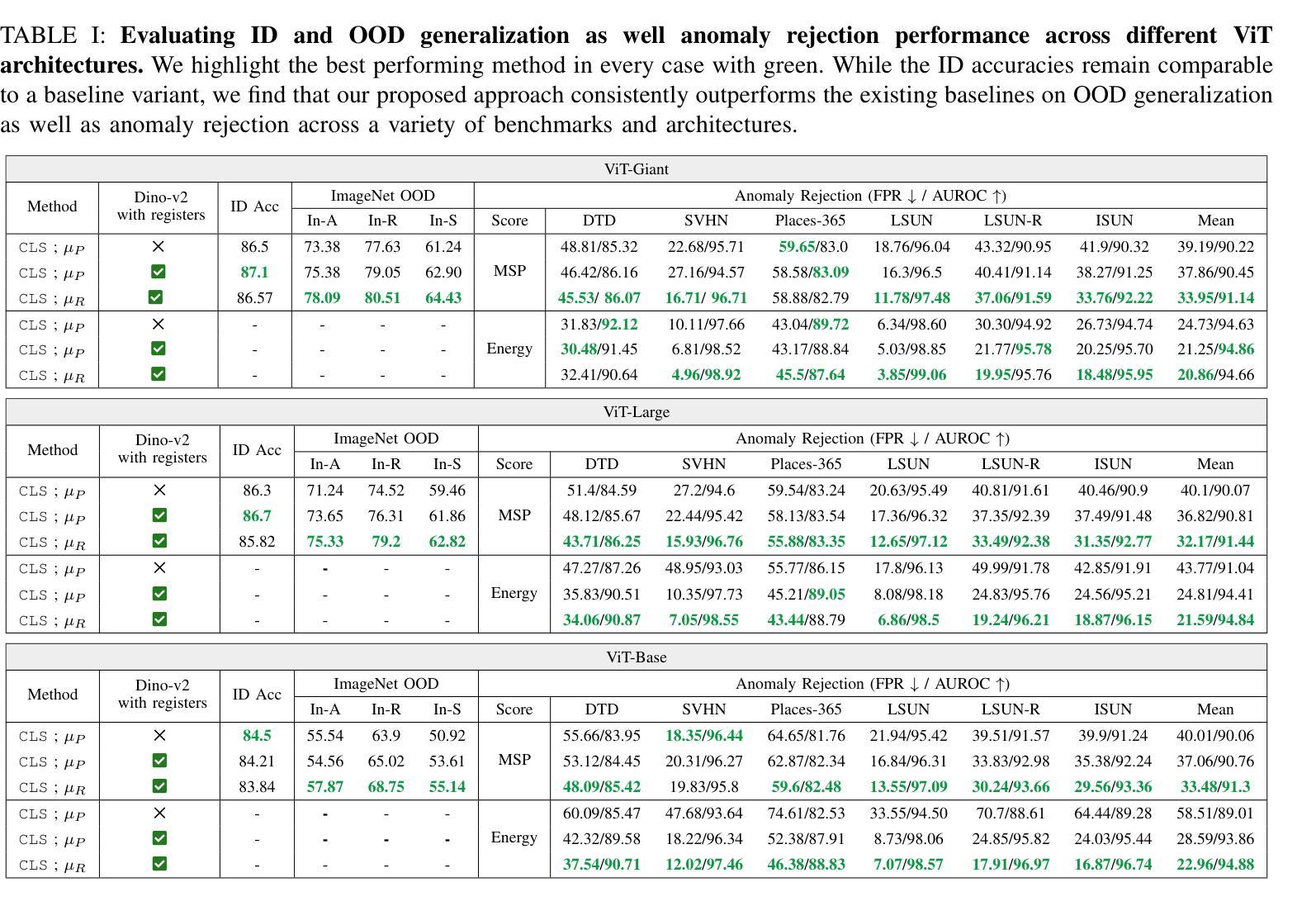
Vision Transformers (ViTs) have shown success across a variety of tasks due to their ability to capture global image representations. Recent studies have identified the existence of high-norm tokens in ViTs, which can interfere with unsupervised object discovery. To address this, the use of “registers” which are additional tokens that isolate high norm patch tokens while capturing global image-level information has been proposed. While registers have been studied extensively for object discovery, their generalization properties particularly in out-of-distribution (OOD) scenarios, remains underexplored. In this paper, we examine the utility of register token embeddings in providing additional features for improving generalization and anomaly rejection. To that end, we propose a simple method that combines the special CLS token embedding commonly employed in ViTs with the average-pooled register embeddings to create feature representations which are subsequently used for training a downstream classifier. We find that this enhances OOD generalization and anomaly rejection, while maintaining in-distribution (ID) performance. Extensive experiments across multiple ViT backbones trained with and without registers reveal consistent improvements of 2-4% in top-1 OOD accuracy and a 2-3% reduction in false positive rates for anomaly detection. Importantly, these gains are achieved without additional computational overhead.
视觉Transformer(ViTs)由于其捕捉全局图像表征的能力,在各种任务中取得了成功。最近的研究发现ViTs中存在高范数令牌,这可能会干扰无监督对象发现。为解决这一问题,提出了使用“寄存器”的方法,这些寄存器是额外的令牌,可以隔离高范数补丁令牌同时捕获全局图像级信息。虽然寄存器在对象发现方面得到了广泛的研究,但在超出分配范围的情境下(OOD)其通用属性仍未得到充分探索。在本文中,我们研究了寄存器令牌嵌入在提高通用性和异常拒绝方面的作用。为此,我们提出了一种简单的方法,该方法结合了视觉Transformer中常用的特殊CLS令牌嵌入和平均池化的寄存器嵌入,以创建特征表示,随后用于训练下游分类器。我们发现这增强了OOD的通用性和异常拒绝能力,同时保持了内部分布(ID)性能。使用和不使用寄存器的多个ViT主干的大量实验表明,在顶级OOD准确率上持续提高了2-4%,异常检测的误报率降低了2-3%。重要的是,这些收益的实现没有额外的计算开销。
论文及项目相关链接
PDF Accepted at ICASSP 2025
Summary
ViTs中的高范数令牌会干扰无监督对象发现。为解决这个问题,研究提出了使用“寄存器”来捕获全局图像级信息并隔离高范数斑块令牌。本文探讨了寄存器令牌嵌入在提高通用性和异常拒绝方面的作用。我们提出了一种简单的方法,将ViTs中常用的特殊CLS令牌嵌入与平均池化的寄存器嵌入相结合,创建用于训练下游分类器的特征表示。实验表明,这提高了OOD的通用性和异常拒绝能力,同时保持了ID性能。
Key Takeaways
- Vision Transformers (ViTs) 中的高范数令牌会干扰无监督对象发现。
- “寄存器”是一种额外的令牌,旨在隔离高范数斑块令牌,同时捕获全局图像级信息。
- 寄存器在对象发现方面的应用已经得到了广泛研究,但在OOD场景中的通用属性仍然未被充分探索。
- 结合CLS令牌嵌入和平均池化的寄存器嵌入创建的特征表示有助于改善通用性和异常拒绝。
- 这种方法在OOD场景下提高了顶级准确率2-4%,在异常检测中降低了误报率2-3%。
- 这些改进是在不增加计算开销的情况下实现的。
点此查看论文截图
Towards a Multimodal Large Language Model with Pixel-Level Insight for Biomedicine
Authors:Xiaoshuang Huang, Lingdong Shen, Jia Liu, Fangxin Shang, Hongxiang Li, Haifeng Huang, Yehui Yang
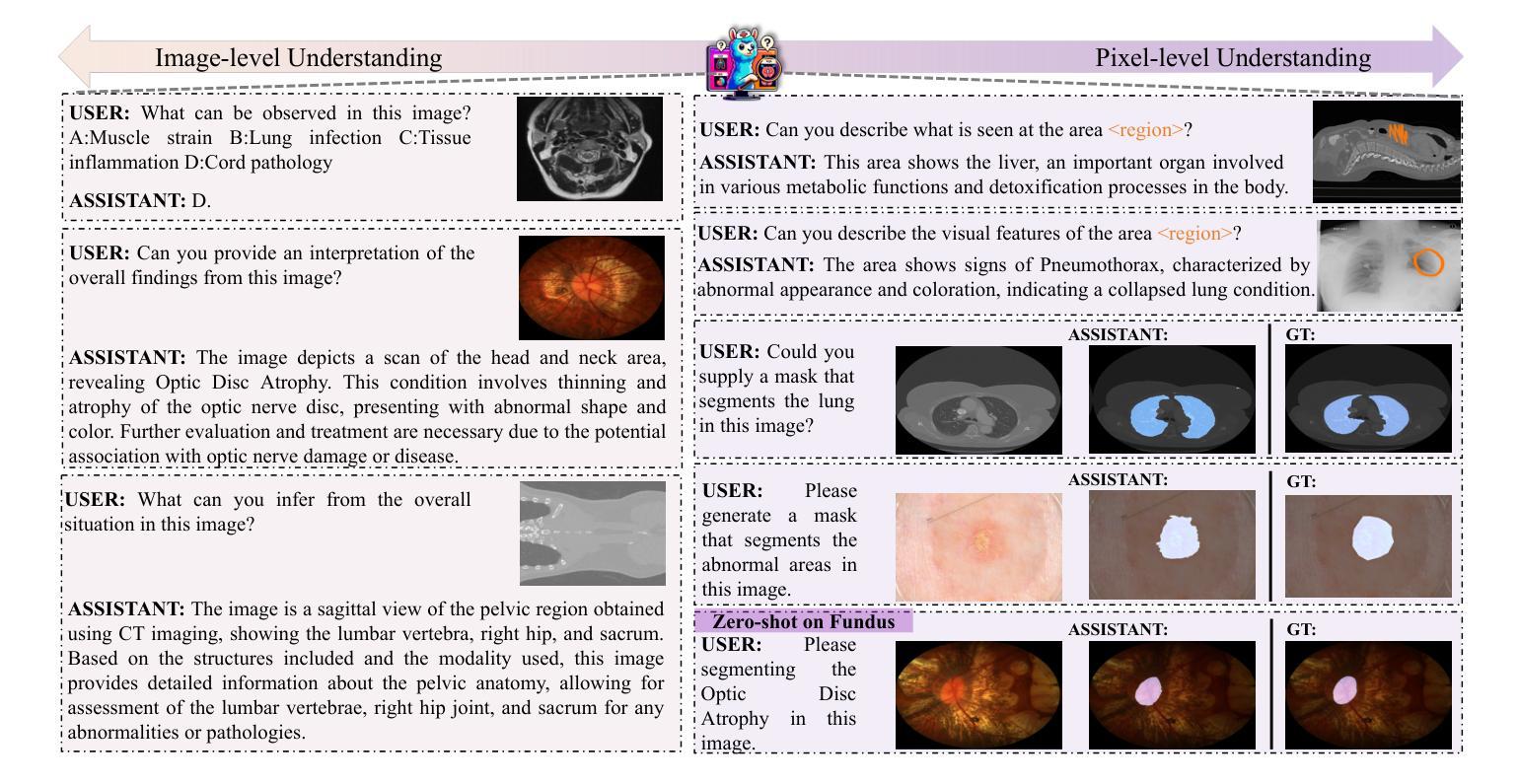
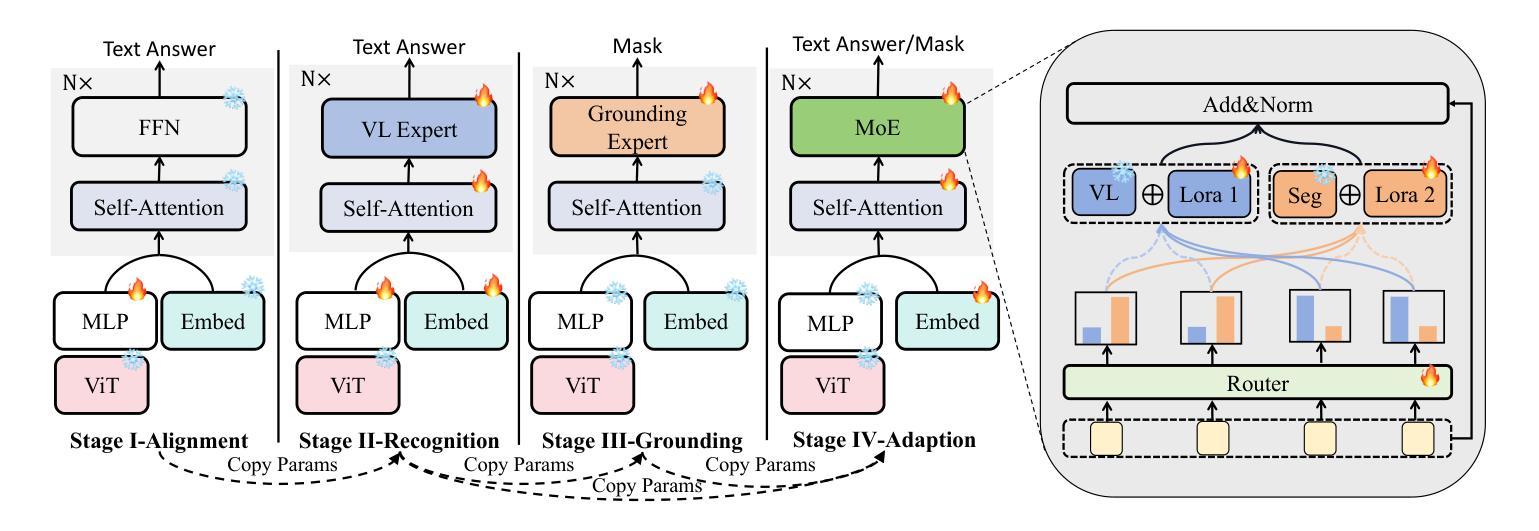
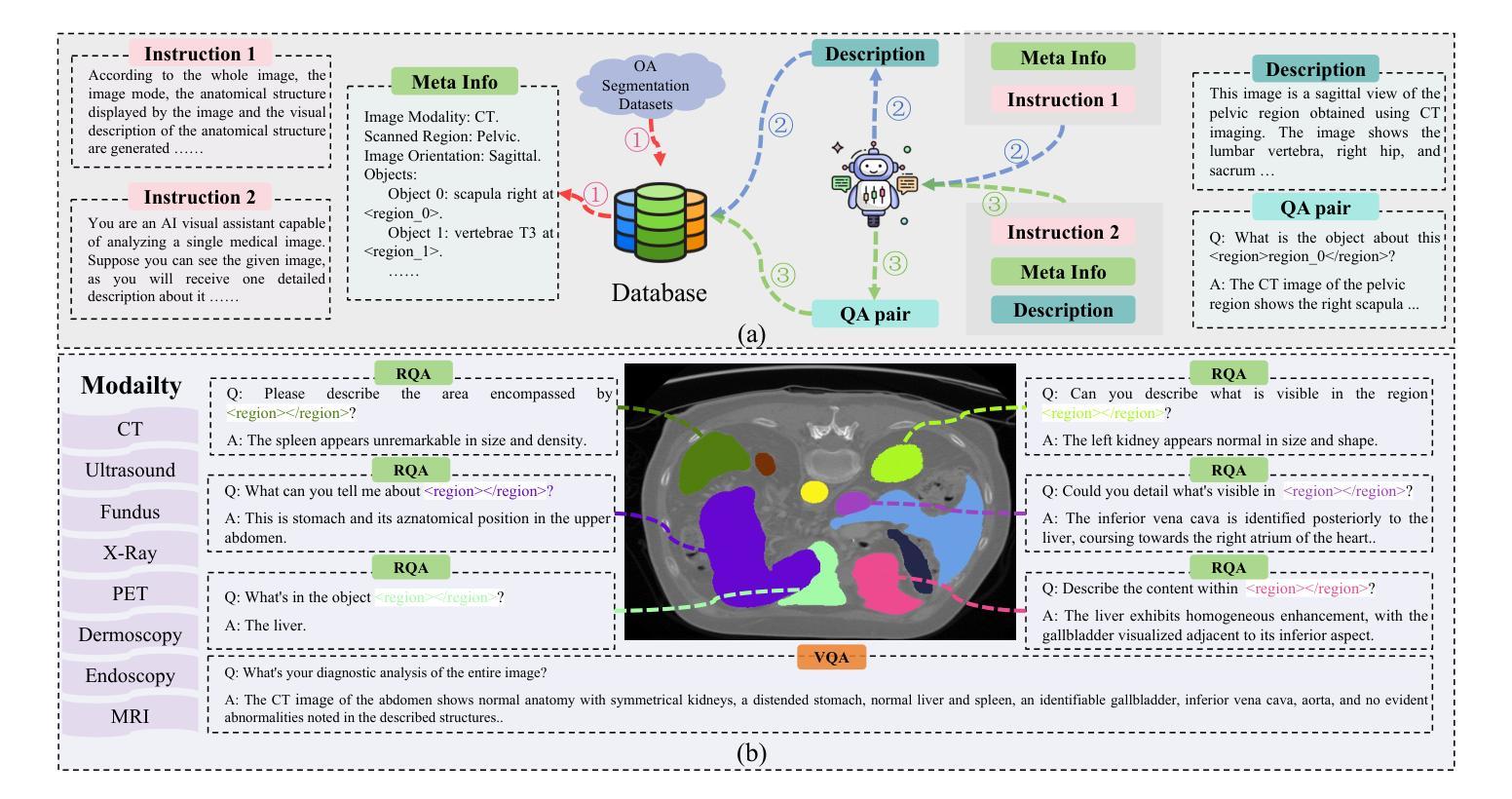
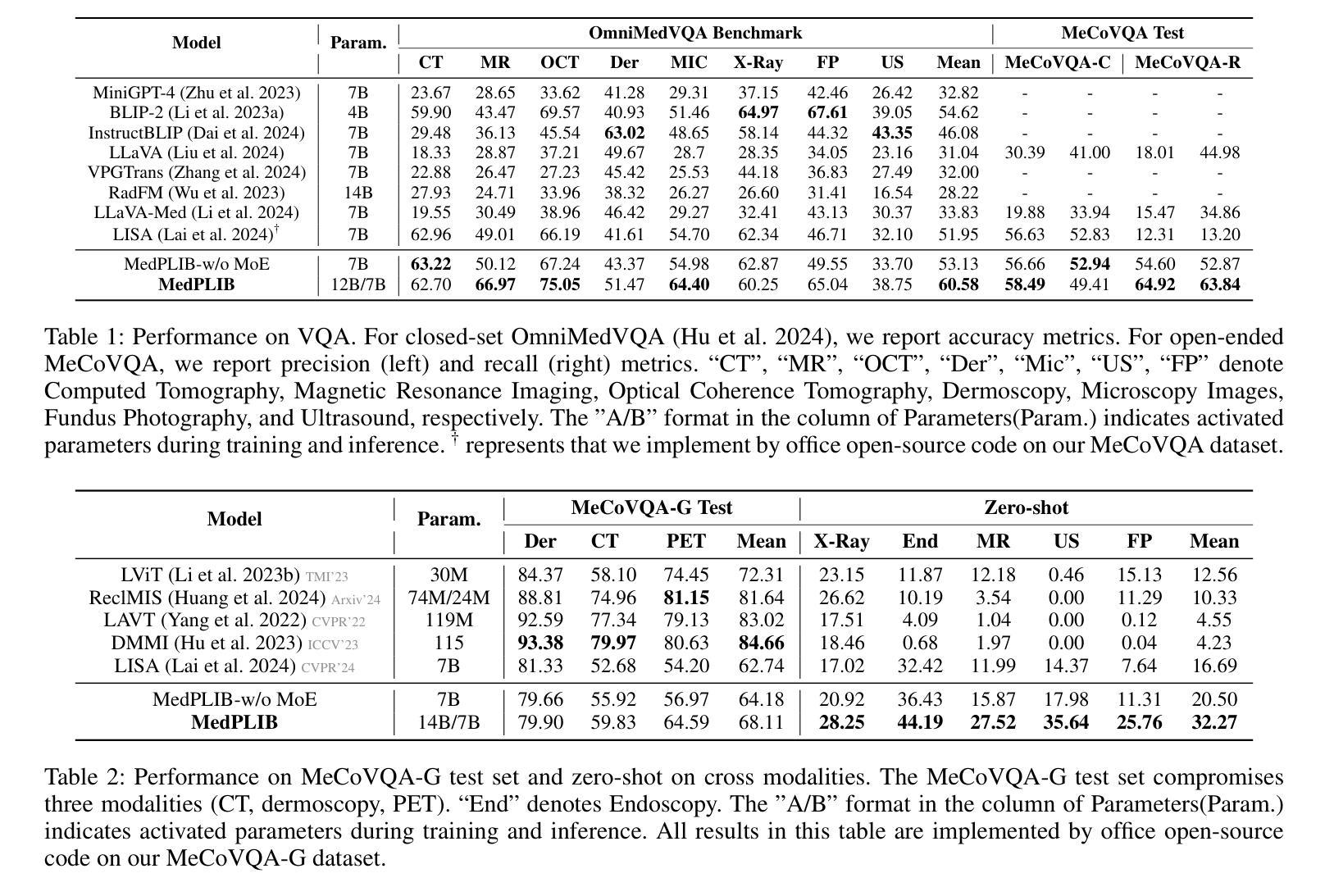
In recent years, Multimodal Large Language Models (MLLM) have achieved notable advancements, demonstrating the feasibility of developing an intelligent biomedical assistant. However, current biomedical MLLMs predominantly focus on image-level understanding and restrict interactions to textual commands, thus limiting their capability boundaries and the flexibility of usage. In this paper, we introduce a novel end-to-end multimodal large language model for the biomedical domain, named MedPLIB, which possesses pixel-level understanding. Excitingly, it supports visual question answering (VQA), arbitrary pixel-level prompts (points, bounding boxes, and free-form shapes), and pixel-level grounding. We propose a novel Mixture-of-Experts (MoE) multi-stage training strategy, which divides MoE into separate training phases for a visual-language expert model and a pixel-grounding expert model, followed by fine-tuning using MoE. This strategy effectively coordinates multitask learning while maintaining the computational cost at inference equivalent to that of a single expert model. To advance the research of biomedical MLLMs, we introduce the Medical Complex Vision Question Answering Dataset (MeCoVQA), which comprises an array of 8 modalities for complex medical imaging question answering and image region understanding. Experimental results indicate that MedPLIB has achieved state-of-the-art outcomes across multiple medical visual language tasks. More importantly, in zero-shot evaluations for the pixel grounding task, MedPLIB leads the best small and large models by margins of 19.7 and 15.6 respectively on the mDice metric. The codes, data, and model checkpoints will be made publicly available at https://github.com/ShawnHuang497/MedPLIB.
近年来,多模态大型语言模型(MLLM)取得了显著的进步,证明了开发智能生物医学助理的可行性。然而,当前生物医学领域的MLLM主要侧重于图像级别的理解,并将互动限制在文本命令上,从而限制了其能力边界和使用灵活性。在本文中,我们介绍了一种用于生物医学领域的新型端到端多模态大型语言模型,名为MedPLIB,它拥有像素级的理解。令人兴奋的是,它支持视觉问答(VQA)、任意像素级提示(点、边界框和自由形式形状)和像素级定位。我们提出了一种新颖的专家混合(MoE)多阶段训练策略,该策略将MoE分为视觉语言专家模型和像素定位专家模型的单独训练阶段,然后使用MoE进行微调。这种策略有效地协调了多任务学习,同时保持推理的计算成本相当于单个专家模型的成本。为了推动生物医学MLLM的研究进展,我们引入了医疗复杂视觉问答数据集(MeCoVQA),该数据集包含用于复杂医学图像问答和图像区域理解的8种模态。实验结果表明,MedPLIB在多个医学视觉语言任务上达到了最新水平。更重要的是,在像素定位任务的零样本评估中,MedPLIB在mDice指标上领先最佳小型和大型模型的差距分别为19.7和15.6。代码、数据和模型检查点将在https://github.com/ShawnHuang497/MedPLIB上公开提供。
论文及项目相关链接
PDF Accepted by AAAI2025
Summary
本文介绍了一种针对生物医学领域的新型端到端多模态大型语言模型——MedPLIB,它具备像素级理解能力,支持视觉问答、任意像素级提示和像素级定位。通过采用混合专家(MoE)的多阶段训练策略,实现了多任务学习的有效协调,同时保持了推理阶段的计算成本与单一专家模型相当。此外,文章还引入了医疗复杂视觉问答数据集MeCoVQA,用于复杂医疗影像问答和图像区域理解研究。实验结果表明,MedPLIB在多个医疗视觉语言任务上取得了最新成果,特别是在像素定位任务的零样本评估中,领先其他最佳小型和大型模型的mDice指标分别提高了19.7和15.6。
Key Takeaways
- MedPLIB是一个具备像素级理解能力的生物医学多模态大型语言模型。
- MedPLIB支持视觉问答、任意像素级提示和像素级定位。
- 采用混合专家(MoE)的多阶段训练策略,实现多任务学习的有效协调。
- 引入了医疗复杂视觉问答数据集MeCoVQA,用于医疗影像理解和问答。
- MedPLIB在多个医疗视觉语言任务上取得最新成果。
- 在像素定位任务的零样本评估中,MedPLIB表现优异,领先其他模型。
- MedPLIB的代码、数据和模型检查点将公开提供。
点此查看论文截图


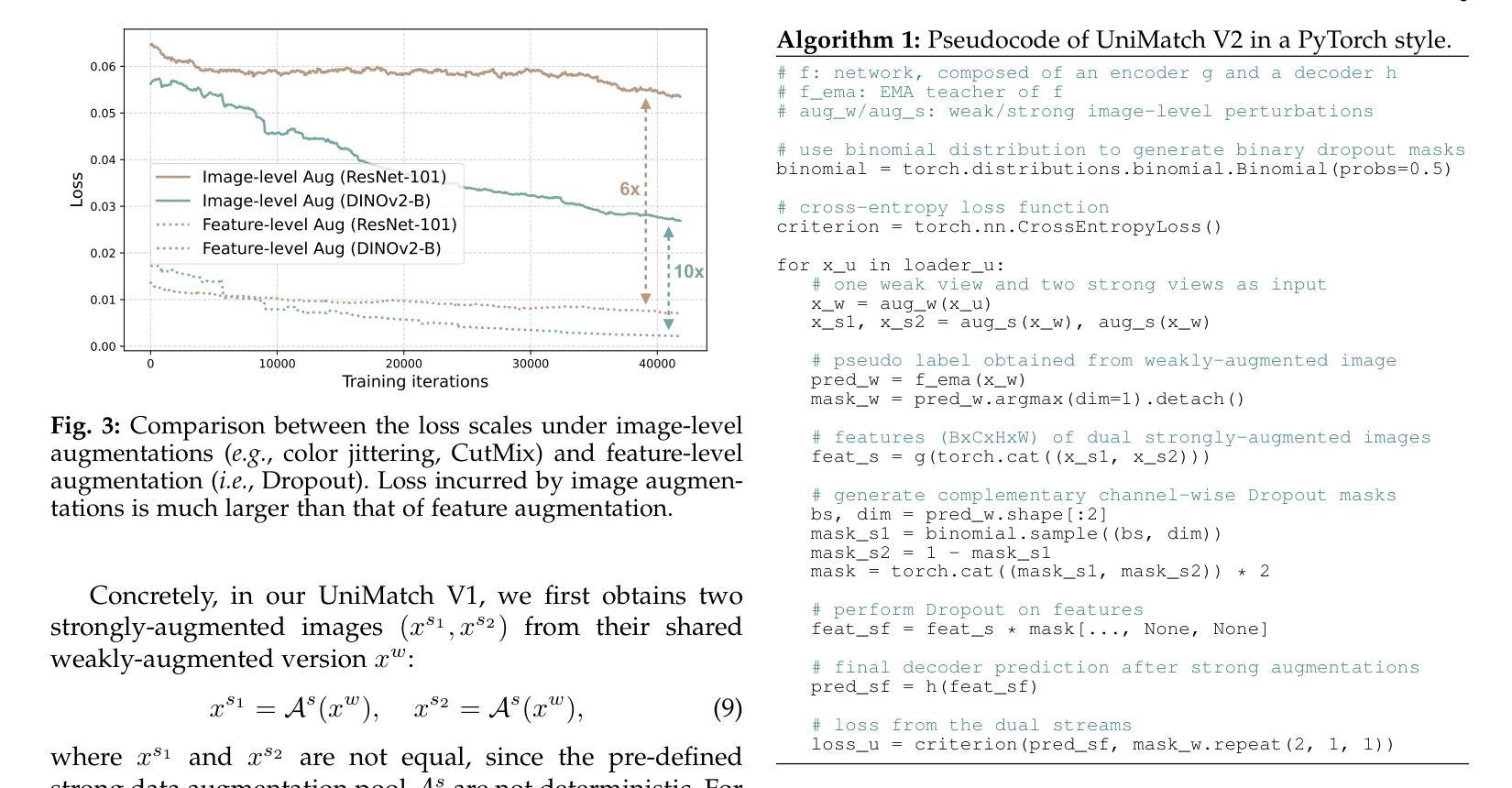
UniMatch V2: Pushing the Limit of Semi-Supervised Semantic Segmentation
Authors:Lihe Yang, Zhen Zhao, Hengshuang Zhao
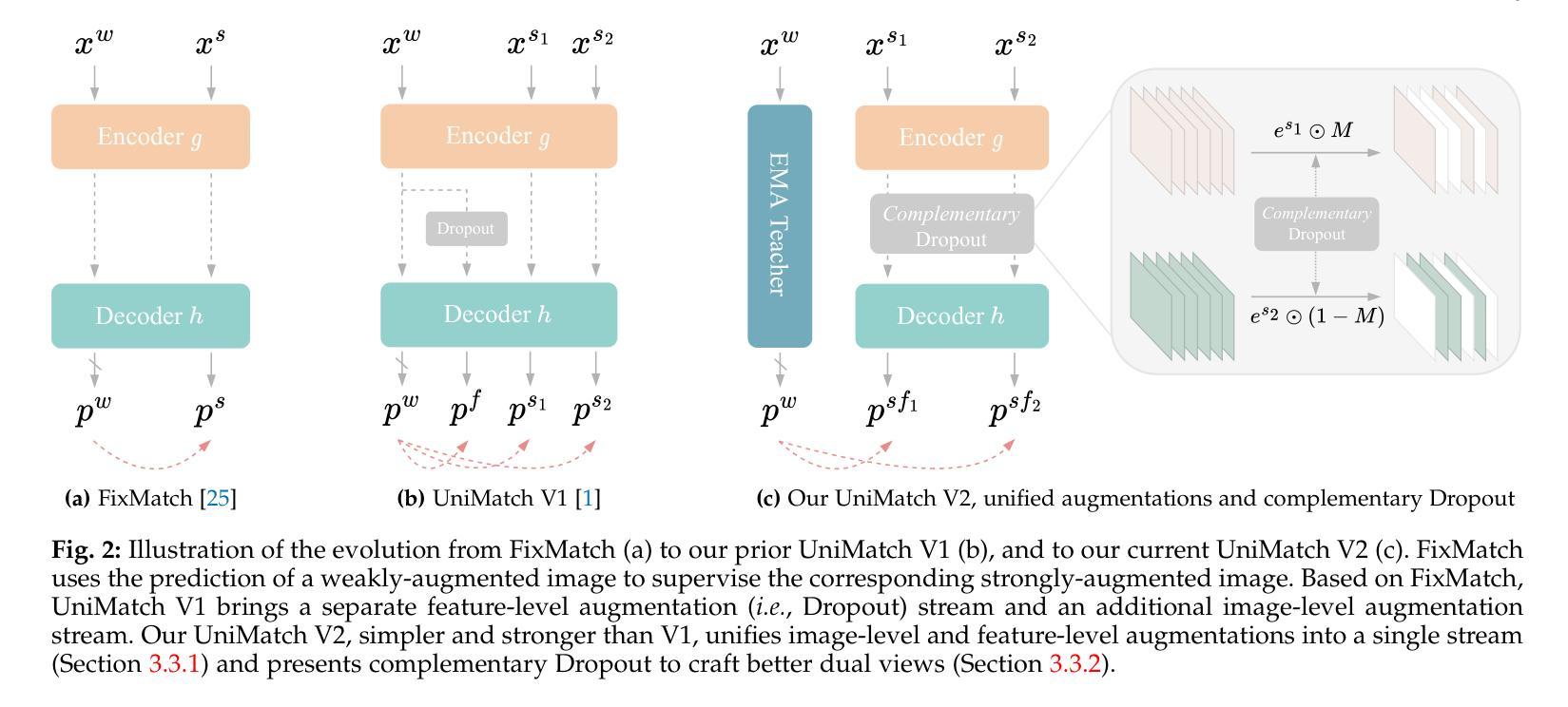
Semi-supervised semantic segmentation (SSS) aims at learning rich visual knowledge from cheap unlabeled images to enhance semantic segmentation capability. Among recent works, UniMatch improves its precedents tremendously by amplifying the practice of weak-to-strong consistency regularization. Subsequent works typically follow similar pipelines and propose various delicate designs. Despite the achieved progress, strangely, even in this flourishing era of numerous powerful vision models, almost all SSS works are still sticking to 1) using outdated ResNet encoders with small-scale ImageNet-1K pre-training, and 2) evaluation on simple Pascal and Cityscapes datasets. In this work, we argue that, it is necessary to switch the baseline of SSS from ResNet-based encoders to more capable ViT-based encoders (e.g., DINOv2) that are pre-trained on massive data. A simple update on the encoder (even using 2x fewer parameters) can bring more significant improvement than careful method designs. Built on this competitive baseline, we present our upgraded and simplified UniMatch V2, inheriting the core spirit of weak-to-strong consistency from V1, but requiring less training cost and providing consistently better results. Additionally, witnessing the gradually saturated performance on Pascal and Cityscapes, we appeal that we should focus on more challenging benchmarks with complex taxonomy, such as ADE20K and COCO datasets. Code, models, and logs of all reported values, are available at https://github.com/LiheYoung/UniMatch-V2.
半监督语义分割(SSS)旨在从廉价的未标记图像中学习丰富的视觉知识,以提高语义分割能力。在近期的工作中,UniMatch通过加强弱到强的一致性正则化,极大地改进了前人的研究。后续工作通常遵循类似的流程,并提出了各种精致的设计。尽管已经取得了进展,但奇怪的是,即使在众多强大的视觉模型的繁荣时代,几乎所有的SSS工作仍然坚持使用1)过时的ResNet编码器进行小规模ImageNet-1K预训练,以及2)在简单的Pascal和Cityscapes数据集上进行评估。
论文及项目相关链接
PDF Accepted by TPAMI
Summary
本文介绍了半监督语义分割(SSS)领域的研究现状。尽管已有许多优秀的模型和方法,但大多数SSS工作仍使用过时的ResNet编码器和小规模ImageNet-1K预训练,并在简单的Pascal和Cityscapes数据集上进行评估。本文主张将SSS的基线从基于ResNet的编码器切换到能力更强的基于ViT的编码器(例如,预训练在大量数据上的DINOv2)。简单的编码器更新(即使使用更少的参数)可以带来比精心设计的方法更大的改进。同时,本文提出了升级和简化的UniMatch V2,继承了V1的弱到强的一致性核心精神,但减少了训练成本,并提供了更一致的结果。此外,本文呼吁关注具有复杂分类的更具挑战性的基准测试,如ADE20K和COCO数据集。
Key Takeaways
- 半监督语义分割(SSS)旨在从大量的无标签图像中学习丰富的视觉知识,以提高语义分割的能力。
- UniMatch通过加强弱到强的一致性正则化来提高先前的模型性能。
- 当前SSS工作仍普遍采用过时的ResNet编码器和小规模ImageNet-1K预训练,并在简单的数据集上评估。
- 切换到能力更强的ViT编码器(如预训练在大量数据上的DINOv2)是必要的。
- 简单的编码器更新可以带来显著的改进,甚至超过复杂方法的设计。
- UniMatch V2是升级和简化的版本,继承了V1的核心精神,但减少了训练成本,并提供了更好的结果。
点此查看论文截图

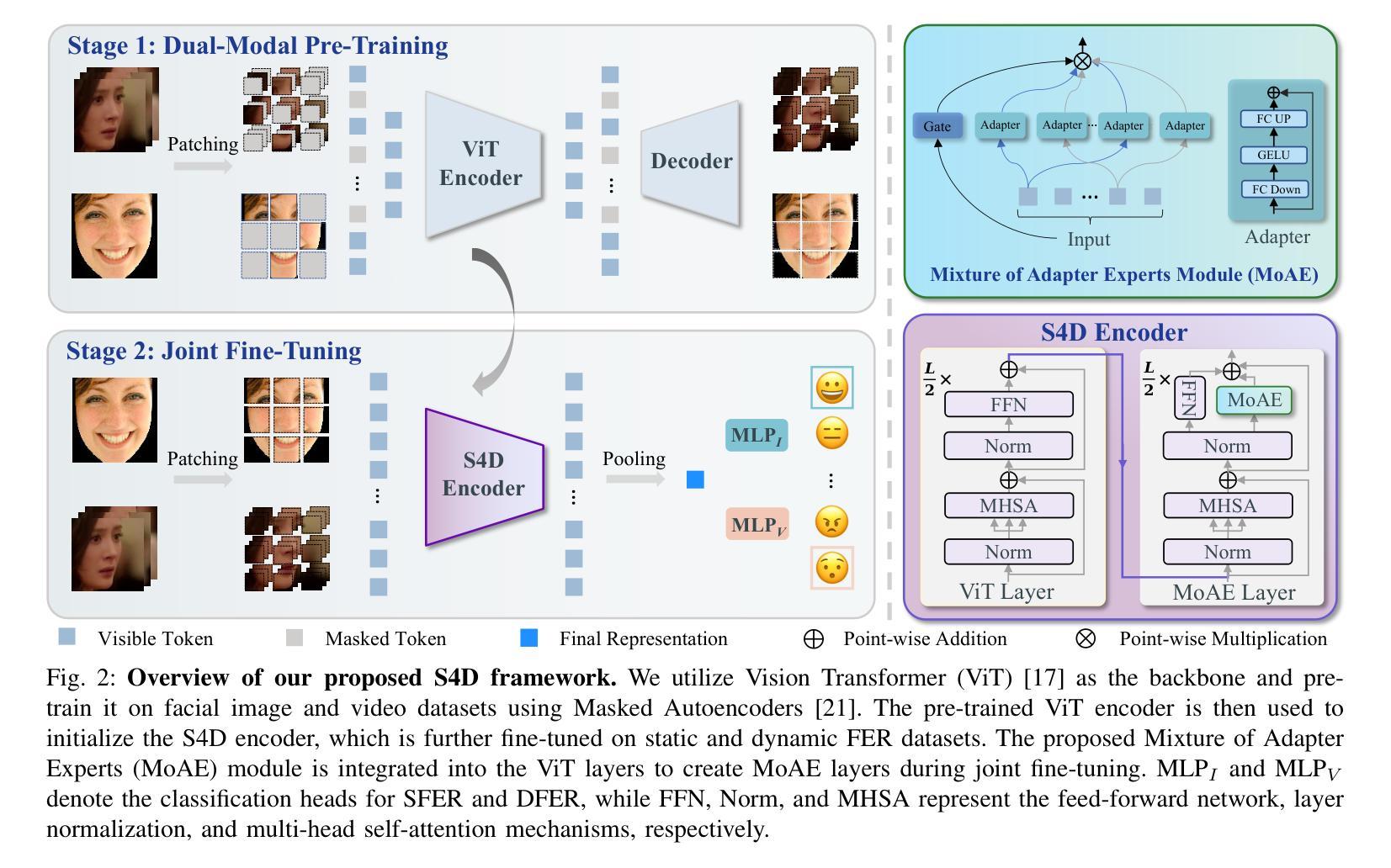
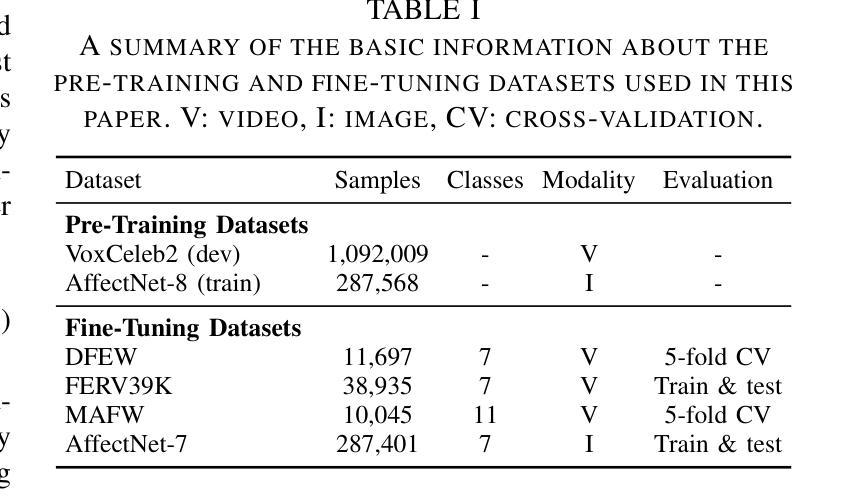
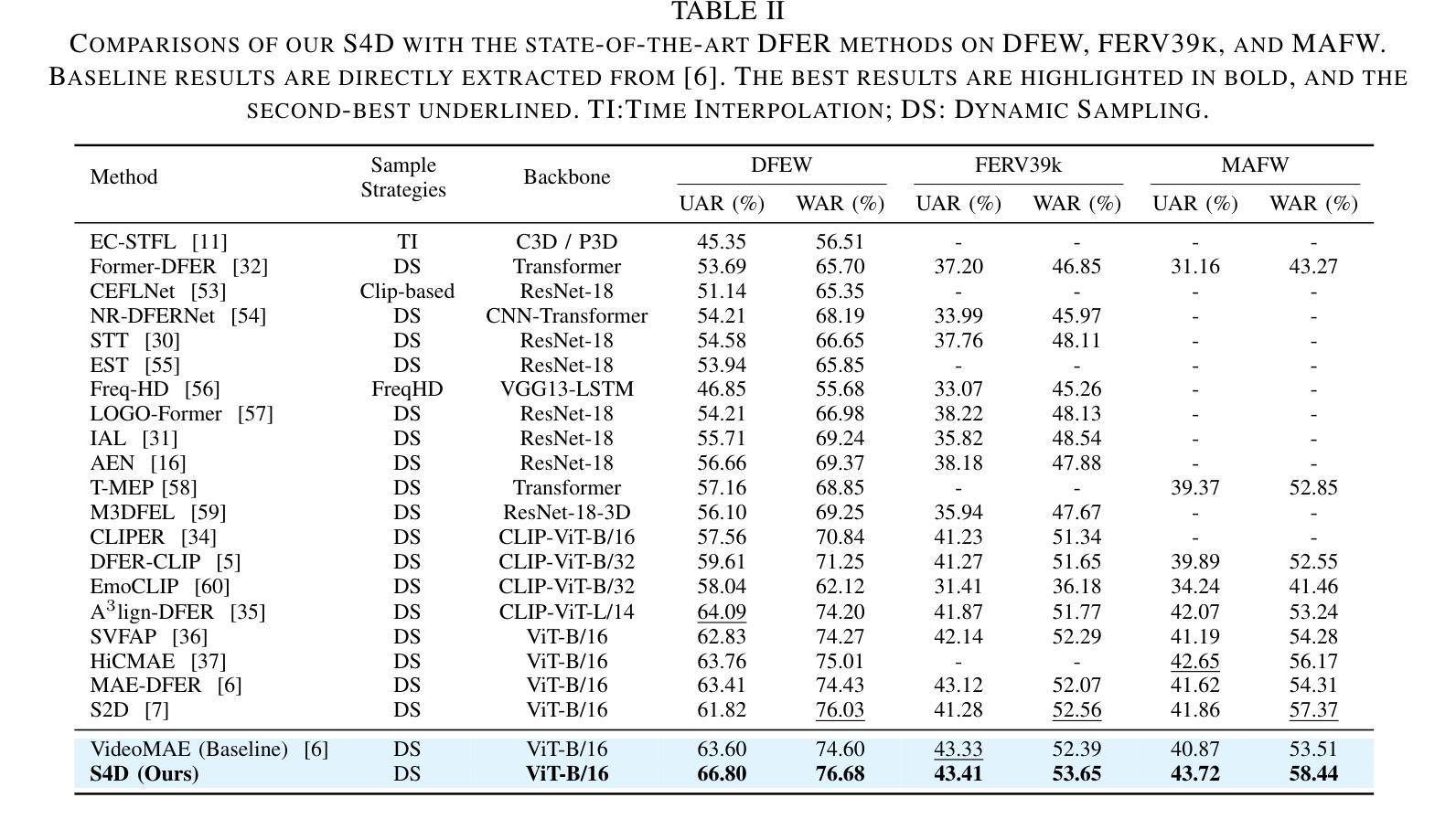
Static for Dynamic: Towards a Deeper Understanding of Dynamic Facial Expressions Using Static Expression Data
Authors:Yin Chen, Jia Li, Yu Zhang, Zhenzhen Hu, Shiguang Shan, Meng Wang, Richang Hong
Dynamic facial expression recognition (DFER) infers emotions from the temporal evolution of expressions, unlike static facial expression recognition (SFER), which relies solely on a single snapshot. This temporal analysis provides richer information and promises greater recognition capability. However, current DFER methods often exhibit unsatisfied performance largely due to fewer training samples compared to SFER. Given the inherent correlation between static and dynamic expressions, we hypothesize that leveraging the abundant SFER data can enhance DFER. To this end, we propose Static-for-Dynamic (S4D), a unified dual-modal learning framework that integrates SFER data as a complementary resource for DFER. Specifically, S4D employs dual-modal self-supervised pre-training on facial images and videos using a shared Vision Transformer (ViT) encoder-decoder architecture, yielding improved spatiotemporal representations. The pre-trained encoder is then fine-tuned on static and dynamic expression datasets in a multi-task learning setup to facilitate emotional information interaction. Unfortunately, vanilla multi-task learning in our study results in negative transfer. To address this, we propose an innovative Mixture of Adapter Experts (MoAE) module that facilitates task-specific knowledge acquisition while effectively extracting shared knowledge from both static and dynamic expression data. Extensive experiments demonstrate that S4D achieves a deeper understanding of DFER, setting new state-of-the-art performance on FERV39K, MAFW, and DFEW benchmarks, with weighted average recall (WAR) of 53.65%, 58.44%, and 76.68%, respectively. Additionally, a systematic correlation analysis between SFER and DFER tasks is presented, which further elucidates the potential benefits of leveraging SFER.
动态面部表情识别(DFER)是从表情的时空演变中推断情感,与仅依赖于单一静态图像的静态面部表情识别(SFER)不同。这种时间分析提供了更丰富的信息,并承诺具有更高的识别能力。然而,由于与SFER相比训练样本较少,当前的DFER方法往往表现出不尽如人意的性能。考虑到静态和动态表情之间的内在相关性,我们假设利用丰富的SFER数据可以增强DFER。为此,我们提出了Static-for-Dynamic(S4D),这是一个统一的双模态学习框架,它将SFER数据作为DFER的补充资源。具体来说,S4D采用面部图像和视频的双重模态自监督预训练,使用共享的Vision Transformer(ViT)编码器-解码器架构,产生改进的时空表示。然后,在多任务学习设置中,对静态和动态表情数据集进行微调预训练编码器,以促进情感信息交互。然而,我们研究中的普通多任务学习导致了负迁移。为了解决这一问题,我们提出了创新的Mixture of Adapter Experts(MoAE)模块,它有助于获取特定任务的知识,同时有效地从静态和动态表情数据中提取共享知识。大量实验表明,S4D对DFER有了更深入的理解,在FERV39K、MAFW和DFEW基准测试上创造了新的最佳性能,加权平均召回率分别为53.65%、58.44%和76.68%。此外,还进行了SFER和DFER任务之间的系统相关性分析,进一步阐明了利用SFER的潜在优势。
论文及项目相关链接
PDF The code and model are publicly available here https://github.com/MSA-LMC/S4D
Summary
动态面部表情识别(DFER)通过表情的时间演变来推断情绪,与仅依赖于单一静态图像的静态面部表情识别(SFER)不同。为提升DFER的性能,我们提出Static-for-Dynamic(S4D)框架,该框架利用丰富的SFER数据作为DFER的补充资源。S4D采用双模态自监督预训练,使用共享的Vision Transformer(ViT)编码器-解码器架构,在面部图像和视频上生成改进的时空表示。然后,对预训练的编码器进行微调,以在多任务学习设置中适应静态和动态表情数据集,促进情感信息交互。我们提出Mixture of Adapter Experts(MoAE)模块来解决多任务学习中的负迁移问题。实验表明,S4D在FERV39K、MAFW和DFEW基准测试上取得了突破性性能,加权平均召回率分别为53.65%、58.44%和76.68%。同时,我们进行了SFER和DFER任务之间的系统相关性分析。
Key Takeaways
- 动态面部表情识别(DFER)通过表情的时间演变推断情绪,较静态面部表情识别(SFER)具有更好的识别能力。
- 当前的DFER方法由于训练样本较少,性能常不满足要求。
- 提出Static-for-Dynamic(S4D)框架,利用丰富的SFER数据增强DFER性能。
- S4D采用双模态自监督预训练,使用共享的Vision Transformer架构,生成改进的时空表示。
- 使用多任务学习微调模型,促进情感信息交互。
- 提出Mixture of Adapter Experts(MoAE)模块解决多任务学习中的负迁移问题。
点此查看论文截图

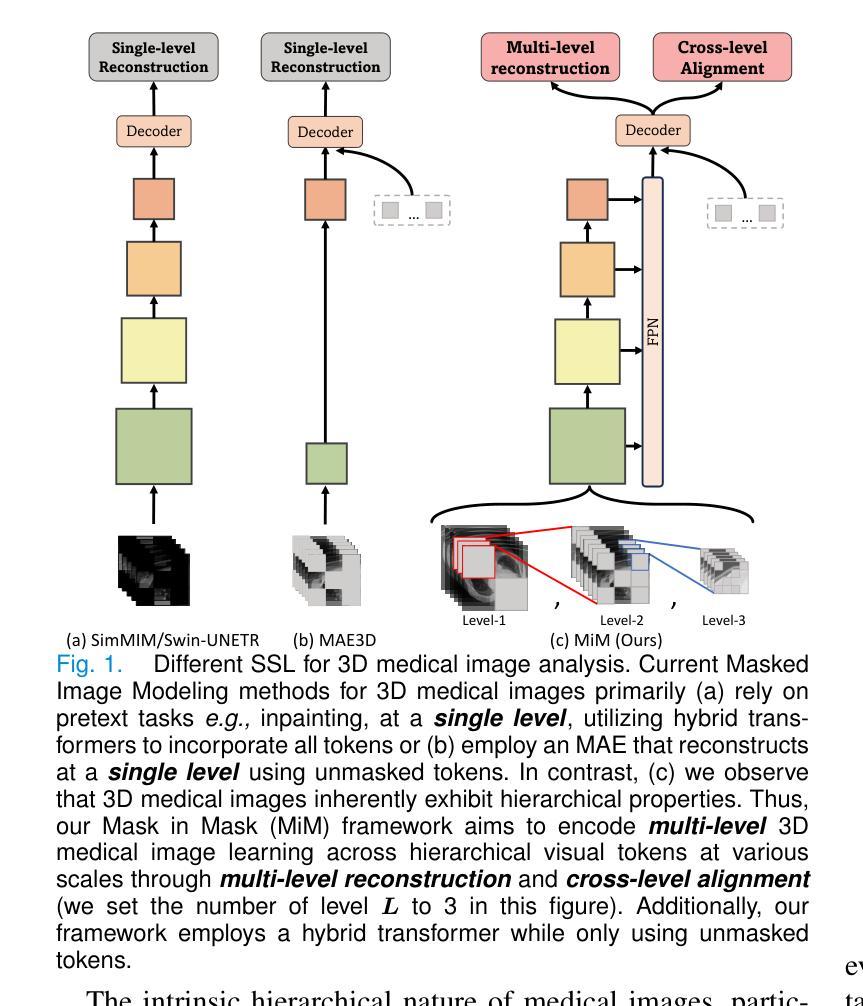
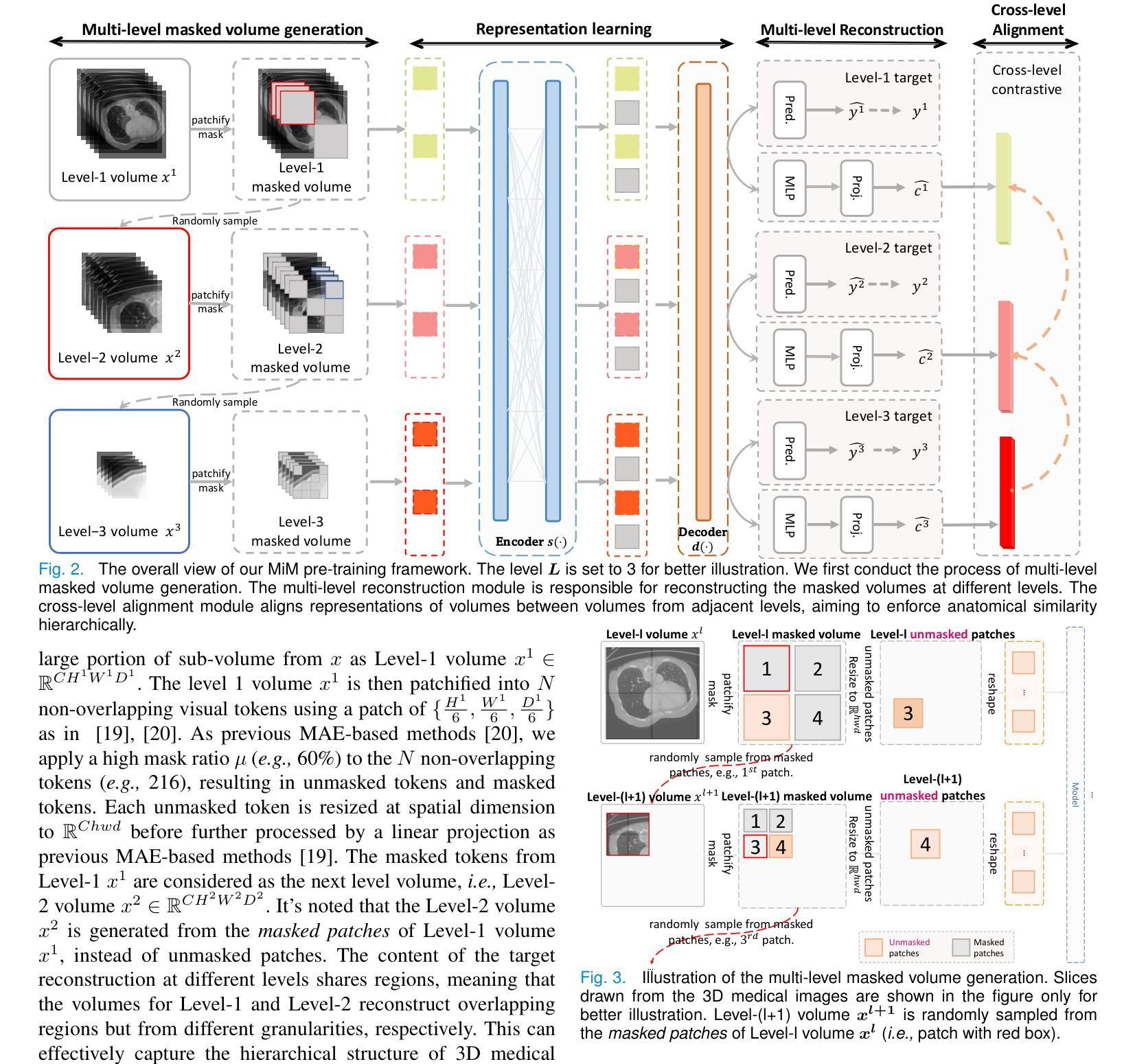
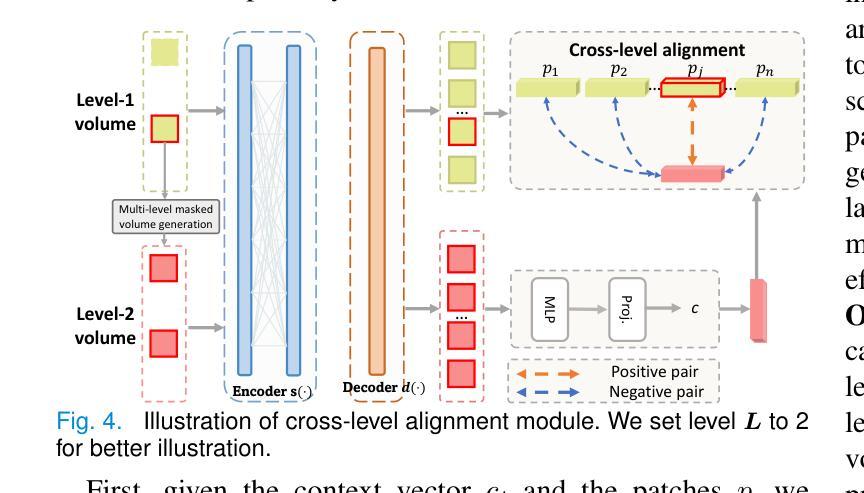
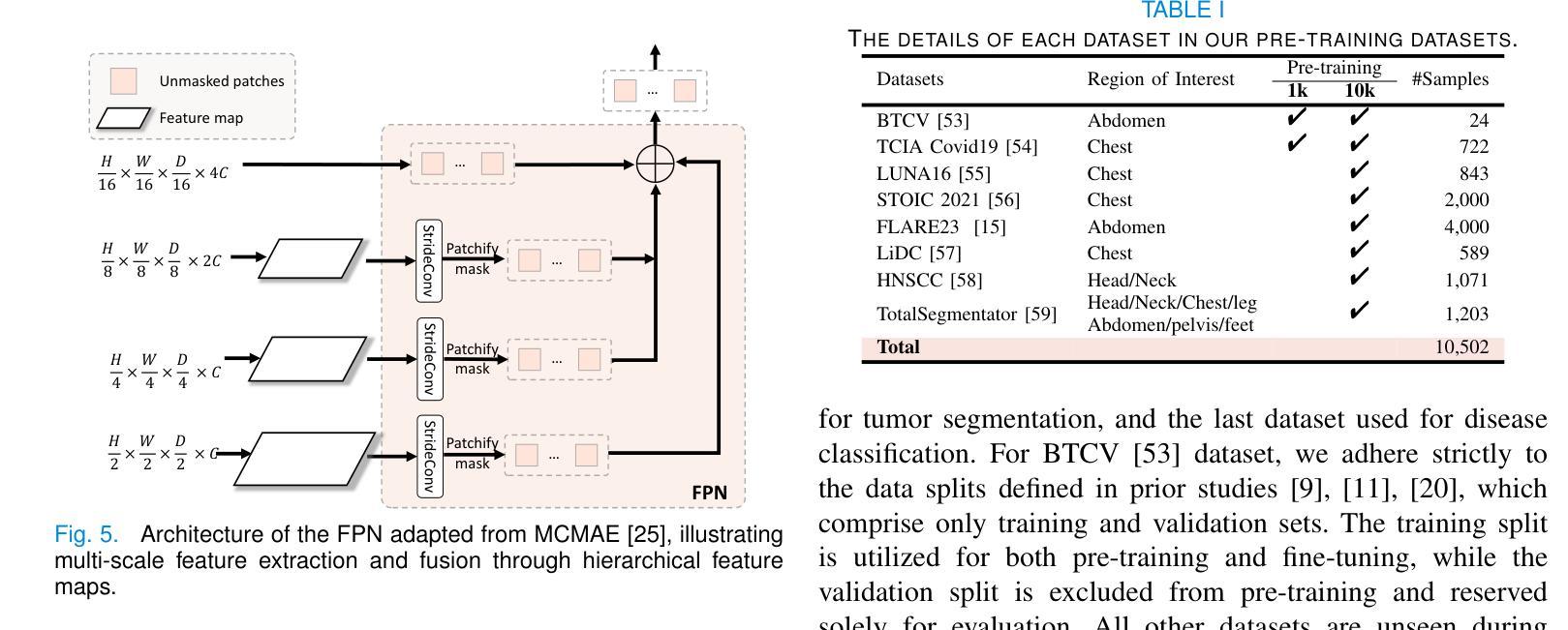
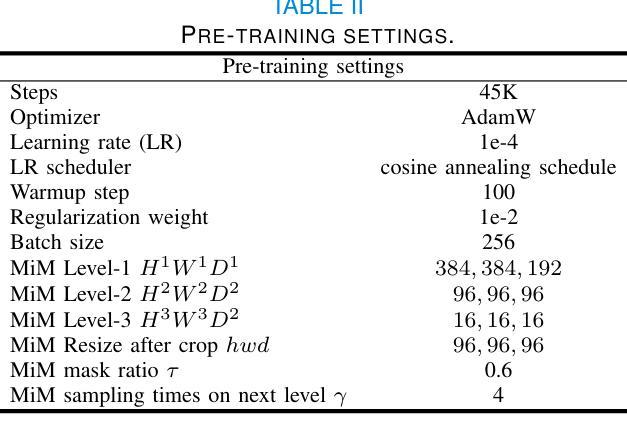
MiM: Mask in Mask Self-Supervised Pre-Training for 3D Medical Image Analysis
Authors:Jiaxin Zhuang, Linshan Wu, Qiong Wang, Peng Fei, Varut Vardhanabhuti, Lin Luo, Hao Chen
The Vision Transformer (ViT) has demonstrated remarkable performance in Self-Supervised Learning (SSL) for 3D medical image analysis. Masked AutoEncoder (MAE) for feature pre-training can further unleash the potential of ViT on various medical vision tasks. However, due to large spatial sizes with much higher dimensions of 3D medical images, the lack of hierarchical design for MAE may hinder the performance of downstream tasks. In this paper, we propose a novel \textit{Mask in Mask (MiM)} pre-training framework for 3D medical images, which aims to advance MAE by learning discriminative representation from hierarchical visual tokens across varying scales. We introduce multiple levels of granularity for masked inputs from the volume, which are then reconstructed simultaneously ranging at both fine and coarse levels. Additionally, a cross-level alignment mechanism is applied to adjacent level volumes to enforce anatomical similarity hierarchically. Furthermore, we adopt a hybrid backbone to enhance the hierarchical representation learning efficiently during the pre-training. MiM was pre-trained on a large scale of available 3D volumetric images, \textit{i.e.,} Computed Tomography (CT) images containing various body parts. Extensive experiments on thirteen public datasets demonstrate the superiority of MiM over other SSL methods in organ/lesion/tumor segmentation and disease classification. We further scale up the MiM to large pre-training datasets with more than 10k volumes, showing that large-scale pre-training can further enhance the performance of downstream tasks. The improvement also concluded that the research community should pay more attention to the scale of the pre-training dataset towards the healthcare foundation model for 3D medical images.
Vision Transformer(ViT)在用于3D医学图像分析的Self-Supervised Learning(SSL)中表现出了卓越的性能。使用Masked AutoEncoder(MAE)进行特征预训练可以进一步释放ViT在各种医学视觉任务上的潜力。然而,由于3D医学图像具有较大的空间尺寸和更高的维度,MAE缺乏层次设计可能会阻碍下游任务的性能。在本文中,我们提出了一种用于3D医学图像的全新预训练框架,称为“Mask in Mask(MiM)”,旨在通过从不同尺度的层次视觉标记中学习辨别性表示来改进MAE。我们从体积中引入了多个粒度的遮挡输入,然后在精细和粗略级别上同时进行重建。此外,还对相邻级别体积应用了跨级别对齐机制,以按层次强制执行解剖相似性。此外,我们采用混合骨干网以增强预训练过程中的层次表示学习。MiM在大量可用的3D体积图像上进行预训练,即包含各种身体部位的计算机断层扫描(CT)图像。在13个公共数据集上的大量实验表明,MiM在器官/病灶/肿瘤分割和疾病分类方面的表现优于其他SSL方法。我们进一步将MiM扩展到具有超过10k体积的大规模预训练数据集上,结果表明大规模预训练可以进一步提高下游任务的性能。改进的结果还表明,研究界应更加关注面向3D医学图像医疗保健基础模型的预训练数据集规模。
论文及项目相关链接
PDF submitted to a journal, updated v2
摘要
Vision Transformer(ViT)在3D医学图像分析的自我监督学习(SSL)中表现出卓越的性能。Masked AutoEncoder(MAE)的特征预训练可以进一步释放ViT在各种医学视觉任务上的潜力。然而,由于3D医学图像的空间尺寸大、维度高,MAE缺乏层次设计可能会阻碍下游任务的性能。本文提出一种新型的针对3D医学图像的“Mask in Mask(MiM)”预训练框架,旨在通过从各种尺度的层次视觉标记中学习辨别性表示来改进MAE。我们引入了多粒度的掩膜输入,这些输入在精细和粗糙级别上同时进行重建。此外,还应用了跨级别对齐机制,以强制相邻级别体积在解剖结构上的相似性。我们还采用混合骨干网,以在预训练期间更有效地进行层次表示学习。MiM在大量可用的3D体积图像上进行预训练,例如包含各种身体部位的计算机断层扫描(CT)图像。在13个公共数据集上的大量实验表明,MiM在器官/病变/肿瘤分割和疾病分类方面优于其他SSL方法。我们将MiM扩展到大规模预训练数据集,包含超过10k个体积的数据,显示大规模预训练可以进一步提高下游任务的性能。改进的结论还表明,研究界应更加关注面向3D医学图像的健康护理基础模型的预训练数据集规模。
关键见解
- Vision Transformer(ViT)在自我监督学习(SSL)的3D医学图像分析中具有卓越性能。
- Masked AutoEncoder(MAE)可用于特征预训练,释放ViT在医学视觉任务上的潜力。
- 由于3D医学图像的空间尺寸大、维度高,MAE的缺乏层次设计可能影响下游任务性能。
- 提出的Mask in Mask(MiM)预训练框架旨在通过层次视觉标记学习改进MAE。
- MiM引入多粒度掩膜输入,并在不同级别上进行重建。
- MiM采用跨级别对齐机制,确保相邻体积的解剖结构相似性。
点此查看论文截图