⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-14 更新
Beyond Flat Text: Dual Self-inherited Guidance for Visual Text Generation
Authors:Minxing Luo, Zixun Xia, Liaojun Chen, Zhenhang Li, Weichao Zeng, Jianye Wang, Wentao Cheng, Yaxing Wang, Yu Zhou, Jian Yang
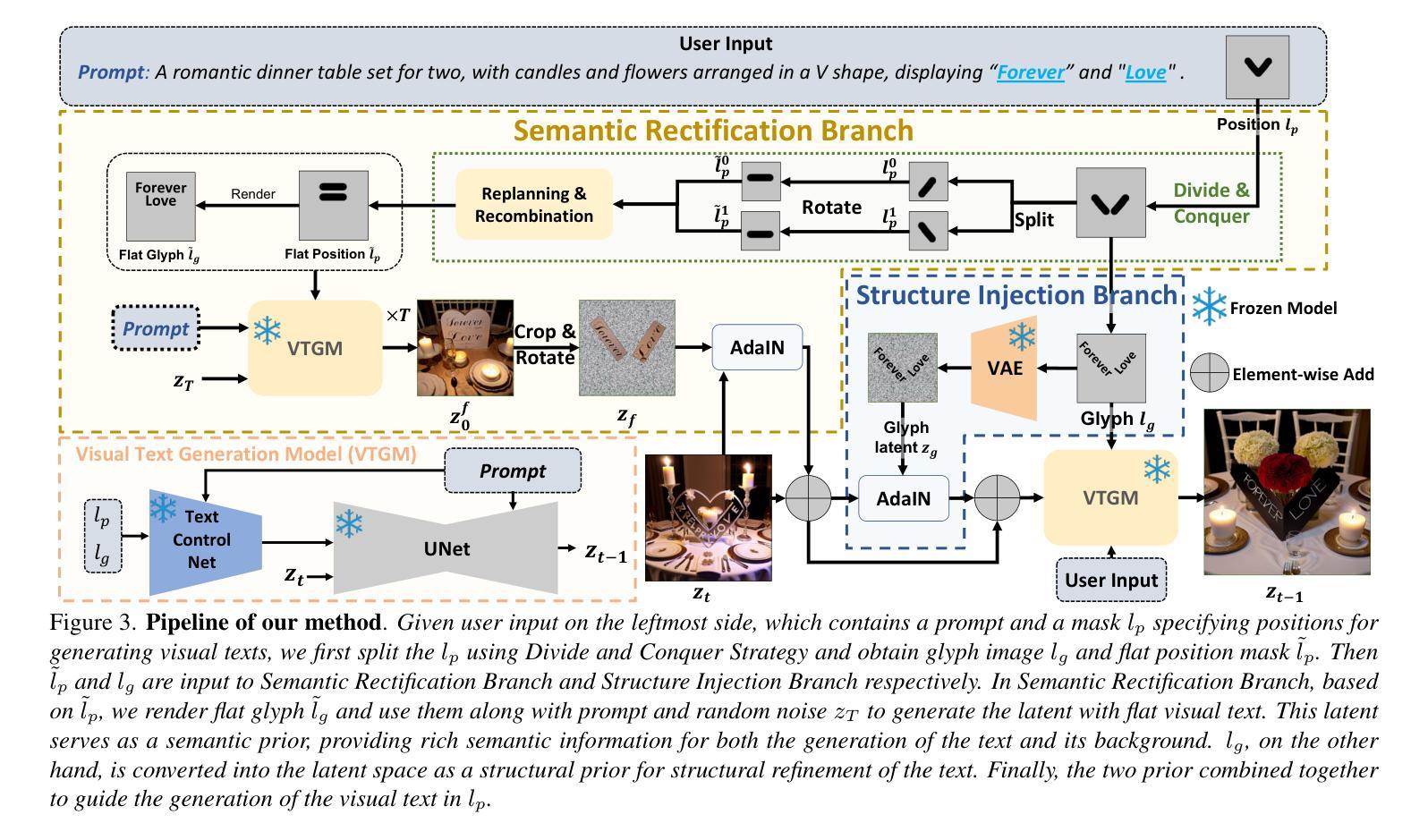
In real-world images, slanted or curved texts, especially those on cans, banners, or badges, appear as frequently, if not more so, than flat texts due to artistic design or layout constraints. While high-quality visual text generation has become available with the advanced generative capabilities of diffusion models, these models often produce distorted text and inharmonious text background when given slanted or curved text layouts due to training data limitation. In this paper, we introduce a new training-free framework, STGen, which accurately generates visual texts in challenging scenarios (\eg, slanted or curved text layouts) while harmonizing them with the text background. Our framework decomposes the visual text generation process into two branches: (i) \textbf{Semantic Rectification Branch}, which leverages the ability in generating flat but accurate visual texts of the model to guide the generation of challenging scenarios. The generated latent of flat text is abundant in accurate semantic information related both to the text itself and its background. By incorporating this, we rectify the semantic information of the texts and harmonize the integration of the text with its background in complex layouts. (ii) \textbf{Structure Injection Branch}, which reinforces the visual text structure during inference. We incorporate the latent information of the glyph image, rich in glyph structure, as a new condition to further strengthen the text structure. To enhance image harmony, we also apply an effective combination method to merge the priors, providing a solid foundation for generation. Extensive experiments across a variety of visual text layouts demonstrate that our framework achieves superior accuracy and outstanding quality.
在现实世界的图像中,倾斜或弯曲的文本,特别是在罐头、横幅或徽章上的文本,由于艺术设计或布局限制,其出现的频率几乎与平面文本一样多,甚至可能更多。虽然扩散模型的高级生成能力已经实现了高质量视觉文本生成,但由于训练数据限制,这些模型在给定的倾斜或弯曲的文本布局时,往往会产生失真的文本和不协调的文本背景。在本文中,我们介绍了一种新的无需训练框架STGen,它可以在具有挑战性的场景(例如倾斜或弯曲的文本布局)中准确生成视觉文本,同时协调其与文本背景的融合。我们的框架将视觉文本生成过程分解为两个分支:(i)语义校正分支,它利用模型生成平面但准确的视觉文本的能力来指导生成具有挑战性的场景。平面文本生成的潜在特征包含与文本本身及其背景相关的丰富语义信息。通过融入这些特征,我们可以纠正文本的语义信息并协调文本与其在复杂布局中的背景融合。(ii)结构注入分支,在推理过程中强化视觉文本结构。我们融入字形图像的潜在信息(富含字形结构),作为一种新的条件来加强文本结构。为了提高图像和谐度,我们还应用了一种有效的组合方法来合并先验信息,为生成提供了坚实的基础。跨越多种视觉文本布局的大量实验表明,我们的框架达到了更高的准确性和卓越的质量。
论文及项目相关链接
Summary
本文介绍了一种无需训练的新框架STGen,能准确生成具有挑战性的场景中的视觉文本(如斜体或曲文本布局),并和谐地融入文本背景。该框架通过语义校正分支和结构注入分支来实现,前者利用模型生成平面文本的语义信息来指导复杂布局中的文本生成,后者在推理过程中强化文本结构,并通过结合字形图像的潜在信息来增强文本结构。实验证明,该框架在多种视觉文本布局上实现了较高的准确性和优质的质量。
Key Takeaways
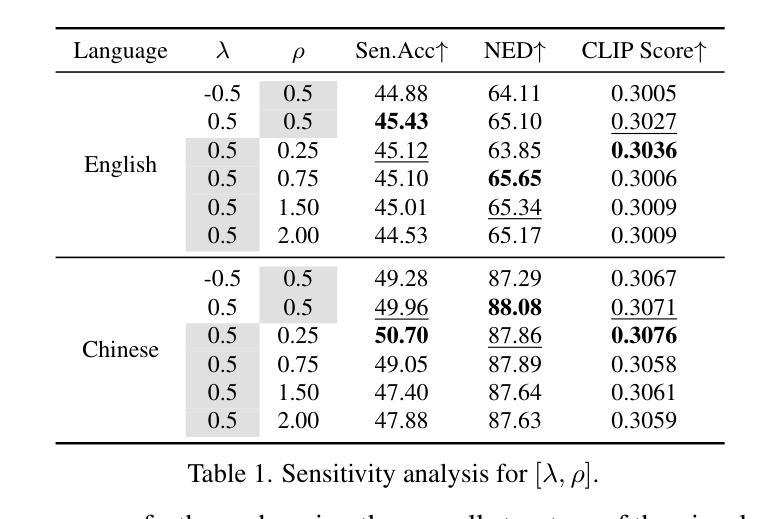
- 斜体或曲文本在真实世界图像中频繁出现,但现有扩散模型在生成此类文本时存在局限。
- 新框架STGen可准确生成斜体或曲文本,并和谐融入文本背景。
- STGen通过语义校正分支利用平面文本的语义信息,用于指导复杂布局中的文本生成。
- 结构注入分支在推理过程中强化文本结构,并结合字形图像的潜在信息。
- STGen使用有效的组合方法来合并先验信息,为生成提供坚实基础。
- 跨多种视觉文本布局的实验证明STGen具有较高的准确性和优质质量。
点此查看论文截图



StarGen: A Spatiotemporal Autoregression Framework with Video Diffusion Model for Scalable and Controllable Scene Generation
Authors:Shangjin Zhai, Zhichao Ye, Jialin Liu, Weijian Xie, Jiaqi Hu, Zhen Peng, Hua Xue, Danpeng Chen, Xiaomeng Wang, Lei Yang, Nan Wang, Haomin Liu, Guofeng Zhang
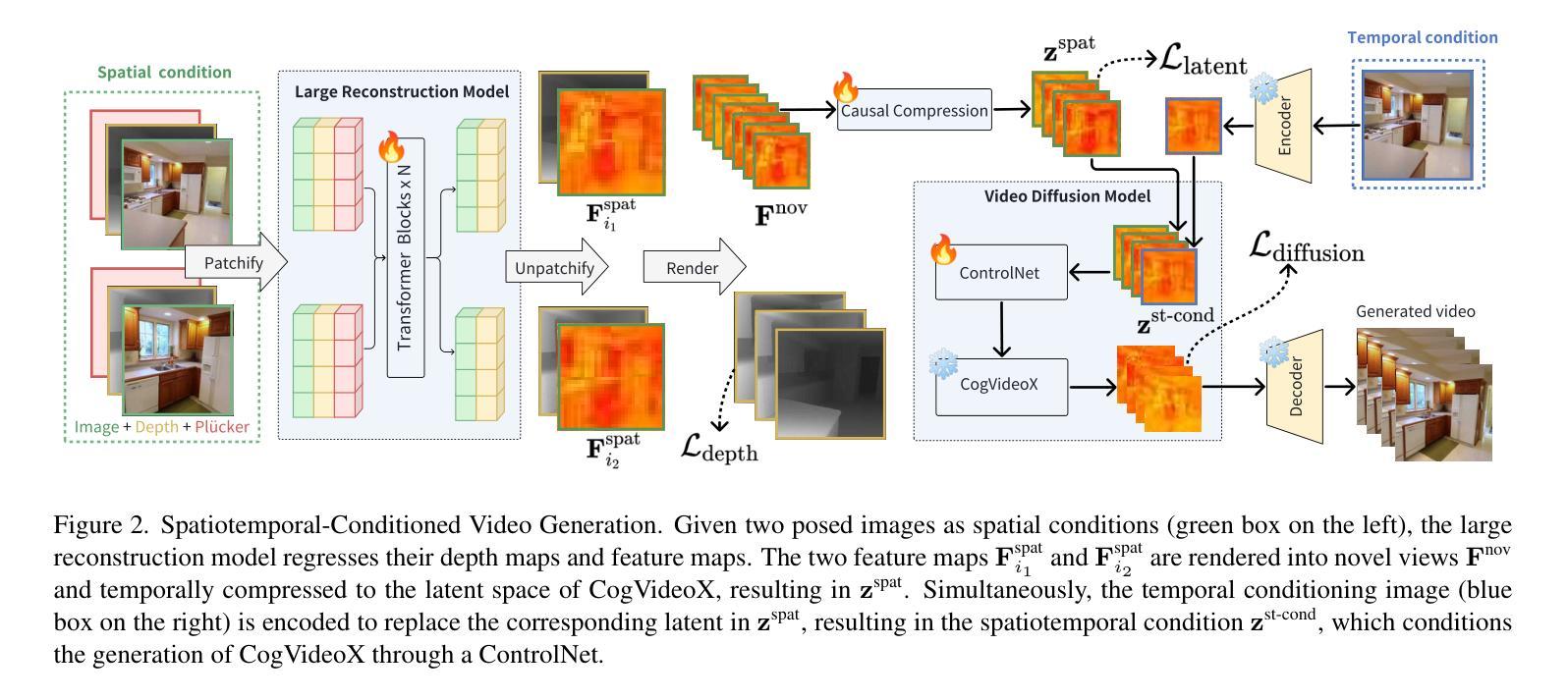
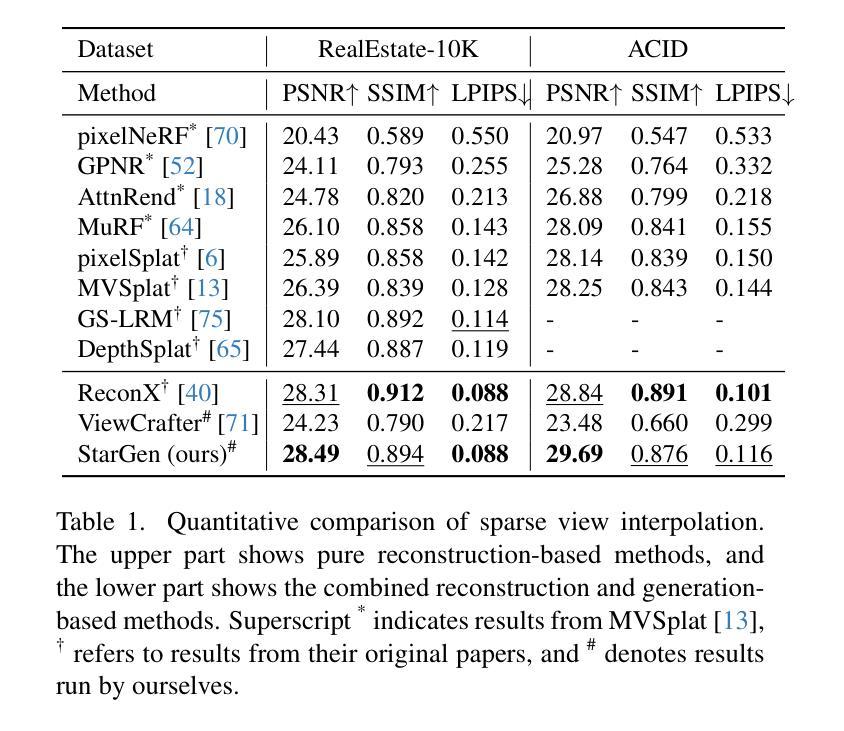
Recent advances in large reconstruction and generative models have significantly improved scene reconstruction and novel view generation. However, due to compute limitations, each inference with these large models is confined to a small area, making long-range consistent scene generation challenging. To address this, we propose StarGen, a novel framework that employs a pre-trained video diffusion model in an autoregressive manner for long-range scene generation. The generation of each video clip is conditioned on the 3D warping of spatially adjacent images and the temporally overlapping image from previously generated clips, improving spatiotemporal consistency in long-range scene generation with precise pose control. The spatiotemporal condition is compatible with various input conditions, facilitating diverse tasks, including sparse view interpolation, perpetual view generation, and layout-conditioned city generation. Quantitative and qualitative evaluations demonstrate StarGen’s superior scalability, fidelity, and pose accuracy compared to state-of-the-art methods.
最近重建和生成模型方面的进展大大提高了场景重建和新颖视角生成的能力。然而,由于计算限制,这些大型模型的每次推理都局限于一个小区域,使得大范围一致的场景生成具有挑战性。为了解决这一问题,我们提出了StarGen,这是一个采用预训练视频扩散模型的新型框架,以自回归的方式进行大范围场景生成。每个视频剪辑的生成都基于空间相邻图像的3D扭曲和先前生成的剪辑中时间上重叠的图像,提高了大范围场景生成中的时空一致性,并实现了精确的姿态控制。这种时空条件与各种输入条件兼容,能够促进包括稀疏视图插值、永久视图生成和布局控制城市生成在内的各种任务。定量和定性评估表明,StarGen在可扩展性、保真度和姿态准确性方面优于最先进的方法。
论文及项目相关链接
Summary
大型重建和生成模型的最新进展极大地促进了场景重建和新颖视角生成的能力。然而,由于计算限制,这些大型模型的每次推理都局限于小范围,使得长程一致场景生成面临挑战。为解决这一问题,我们提出StarGen框架,采用预训练视频扩散模型进行长程场景生成。每个视频剪辑的生成都基于空间相邻图像的3D变换和先前生成的剪辑中时间上重叠的图像,提高了长程场景生成的时空一致性并精确控制姿态。该时空条件与各种输入条件兼容,促进多种任务,包括稀疏视图插值、永久视图生成和布局控制城市生成。评估和测试表明,StarGen在可扩展性、保真度和姿态准确性方面优于最新方法。
Key Takeaways
- 大型重建和生成模型的最新进展促进了场景重建和新颖视角生成。
- 由于计算限制,现有模型在长程一致场景生成方面面临挑战。
- StarGen框架采用预训练视频扩散模型进行长程场景生成。
- StarGen利用3D变换和时空条件提高长程场景生成的时空一致性。
- StarGen支持多种任务,包括稀疏视图插值、永久视图生成和布局控制城市生成。
- StarGen在可扩展性、保真度和姿态准确性方面优于现有方法。
点此查看论文截图



Network Diffuser for Placing-Scheduling Service Function Chains with Inverse Demonstration
Authors:Zuyuan Zhang, Vaneet Aggarwal, Tian Lan
Network services are increasingly managed by considering chained-up virtual network functions and relevant traffic flows, known as the Service Function Chains (SFCs). To deal with sequential arrivals of SFCs in an online fashion, we must consider two closely-coupled problems - an SFC placement problem that maps SFCs to servers/links in the network and an SFC scheduling problem that determines when each SFC is executed. Solving the whole SFC problem targeting these two optimizations jointly is extremely challenging. In this paper, we propose a novel network diffuser using conditional generative modeling for this SFC placing-scheduling optimization. Recent advances in generative AI and diffusion models have made it possible to generate high-quality images/videos and decision trajectories from language description. We formulate the SFC optimization as a problem of generating a state sequence for planning and perform graph diffusion on the state trajectories to enable extraction of SFC decisions, with SFC optimization constraints and objectives as conditions. To address the lack of demonstration data due to NP-hardness and exponential problem space of the SFC optimization, we also propose a novel and somewhat maverick approach – Rather than solving instances of this difficult optimization, we start with randomly-generated solutions as input, and then determine appropriate SFC optimization problems that render these solutions feasible. This inverse demonstration enables us to obtain sufficient expert demonstrations, i.e., problem-solution pairs, through further optimization. In our numerical evaluations, the proposed network diffuser outperforms learning and heuristic baselines, by $\sim$20% improvement in SFC reward and $\sim$50% reduction in SFC waiting time and blocking rate.
网络服务越来越多地通过考虑串联的虚拟网络功能和相关流量流(称为服务功能链(SFC))来进行管理。为了在线处理SFC的连续到达,我们必须考虑两个紧密耦合的问题——SFC放置问题,将SFC映射到网络中的服务器/链接,以及SFC调度问题,确定每个SFC的执行时间。针对这两个优化的SFC整体问题解决起来极为具有挑战性。在本文中,我们提出了一种使用条件生成模型的新型网络扩散器来解决SFC放置调度优化问题。最近生成人工智能和扩散模型的进步使得可以从语言描述生成高质量图像/视频和决策轨迹成为可能。我们将SFC优化公式化为生成状态序列的规划问题,并在状态轨迹上执行图扩散以启用SFC决策提取,将SFC优化约束和目标作为条件。为了解决由于NP难度和SFC优化的指数问题空间而导致的演示数据缺乏的问题,我们还提出了一种新颖且有些独特的方法——我们不是解决这个困难优化的实例,而是首先从随机生成的解决方案开始作为输入,然后确定使这些解决方案可行的适当SFC优化问题。这种逆向演示使我们能够通过进一步的优化获得充足的专业演示,即问题解决方案对。在我们的数值评估中,所提出的网络扩散器在SFC奖励方面提高了约20%,在SFC等待时间和阻塞率方面减少了约50%,超过了学习和启发式基线。
论文及项目相关链接
PDF Accepted to IEEE INFOCOM 2025
摘要
随着网络服务越来越多地通过考虑链式虚拟网络功能和相关的流量流(称为服务功能链SFCs)进行管理,如何在线处理SFCs的连续到达成为一个重要问题。这涉及到两个紧密耦合的问题:SFC放置问题和SFC调度问题。本文将SFC优化问题表述为生成状态序列的规划问题,并利用扩散模型进行状态轨迹的图形扩散,以提取SFC决策。为了弥补因NP难度和指数级问题空间而缺乏演示数据的问题,本文采用逆向演示的方法,从随机生成的解决方案出发,确定可行的SFC优化问题。数值评估表明,所提出的网络扩散器在SFC奖励方面提高了约20%,在SFC等待时间和阻塞率方面减少了约50%,优于学习和启发式基线方法。
关键见解
- 服务功能链(SFCs)是管理服务的一种新方法,涉及将网络功能链接成链条来处理流量。
- SFC面临两个核心问题:SFC放置和SFC调度,这两个问题需要联合优化。
- 提出了一种基于条件生成建模的网络扩散器来解决SFC优化问题。
- 利用扩散模型在状态轨迹上进行图形扩散,以生成SFC决策。
- 为了解决因NP难度和指数级问题空间而缺乏演示数据的问题,采用逆向演示方法。
- 数值评估显示,网络扩散器在SFC奖励、等待时间和阻塞率方面表现优越。
- 这种方法的优点在于,即使面对复杂的网络环境和大量的SFC请求,也能有效地进行实时优化和响应。
点此查看论文截图

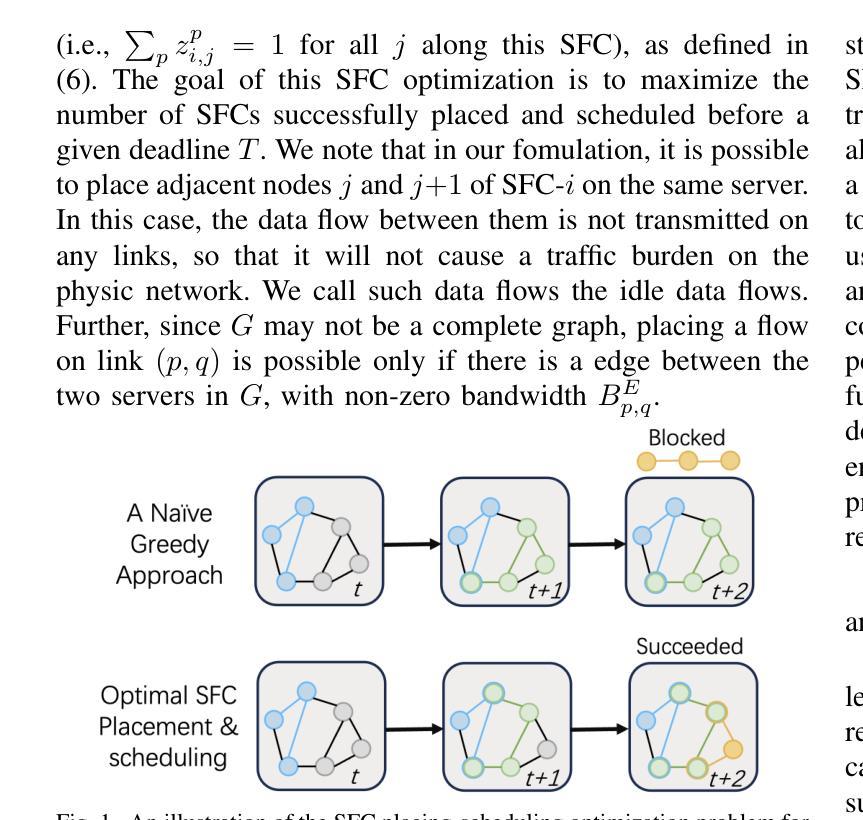
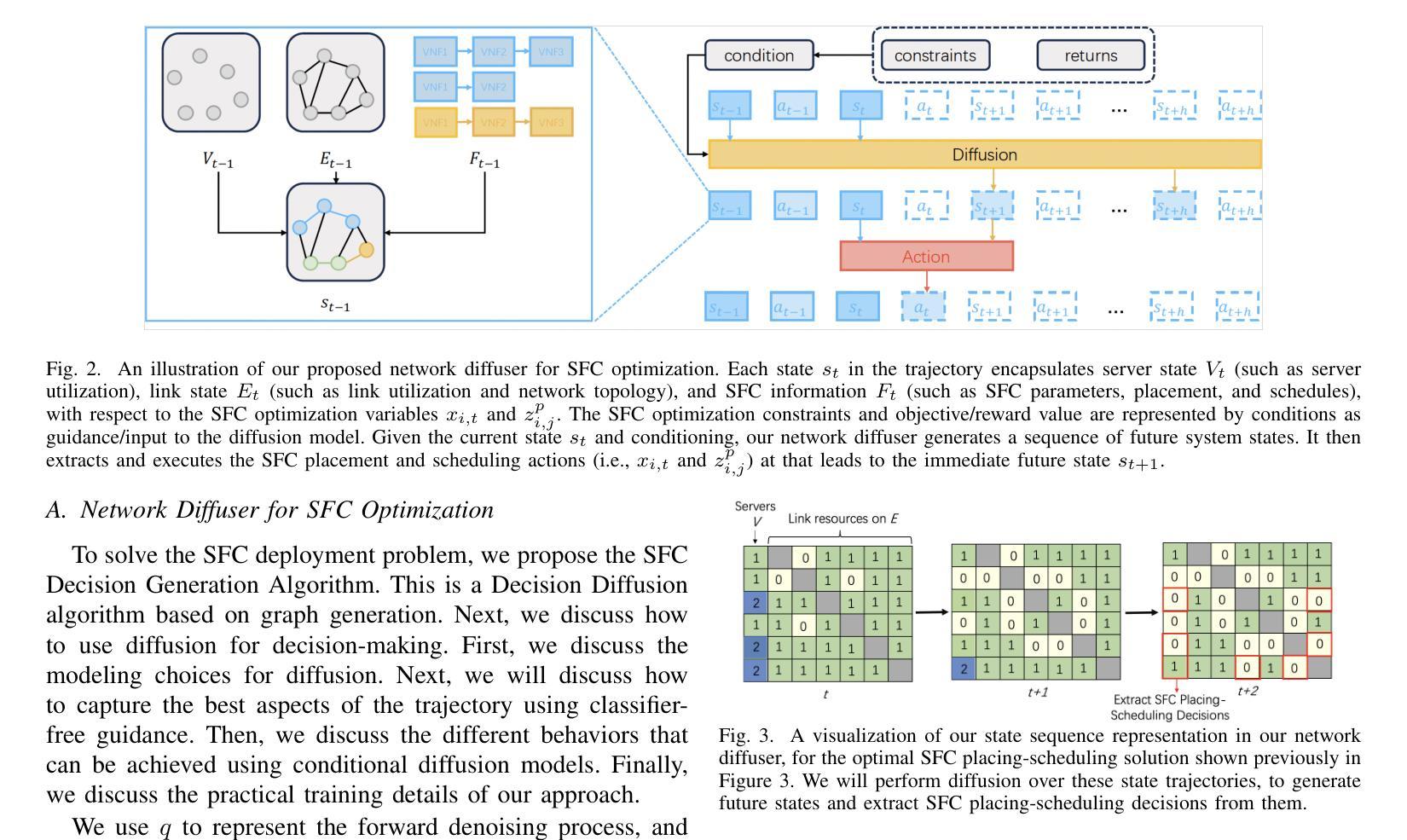

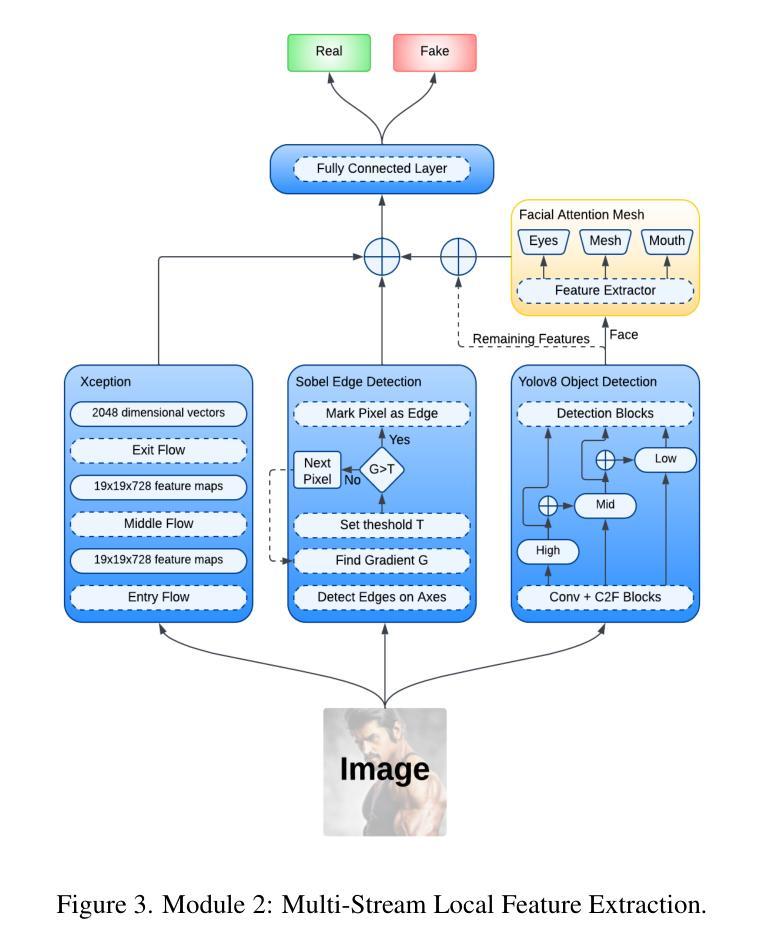
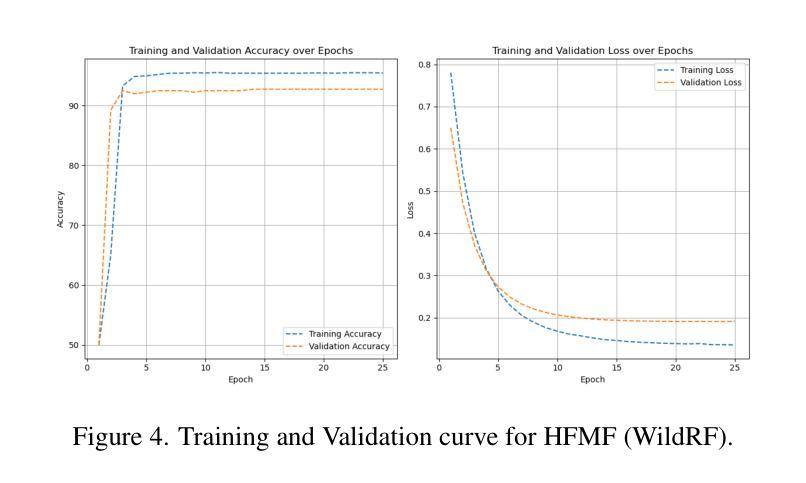
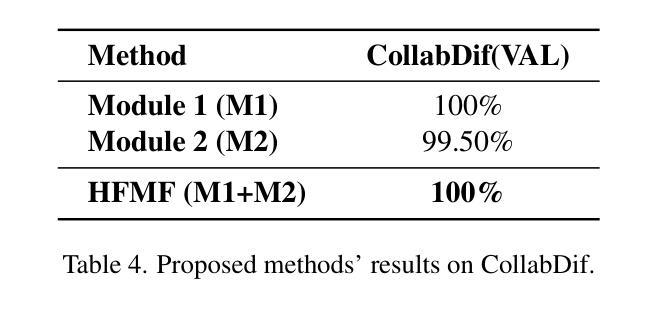
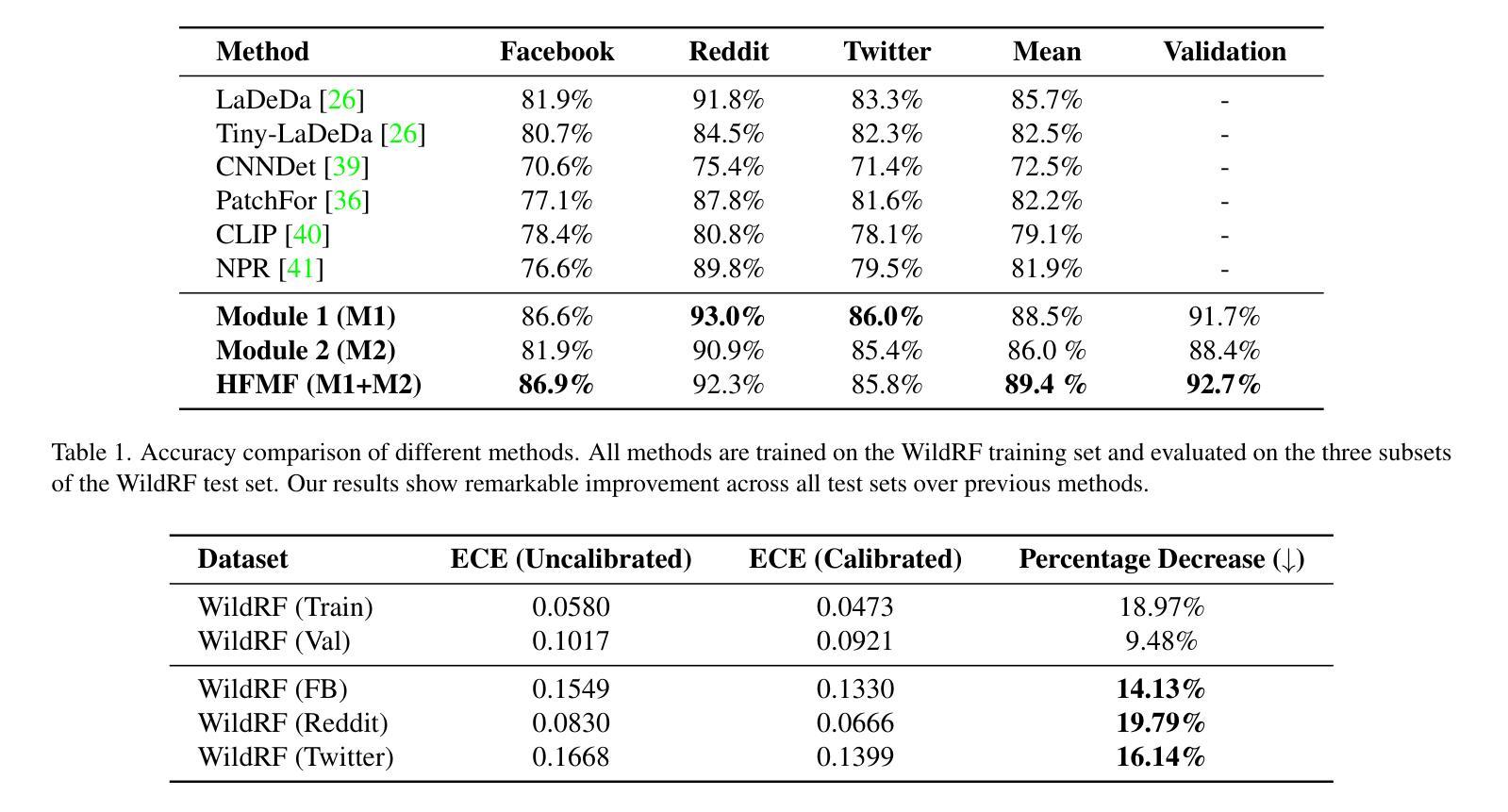
HFMF: Hierarchical Fusion Meets Multi-Stream Models for Deepfake Detection
Authors:Anant Mehta, Bryant McArthur, Nagarjuna Kolloju, Zhengzhong Tu
The rapid progress in deep generative models has led to the creation of incredibly realistic synthetic images that are becoming increasingly difficult to distinguish from real-world data. The widespread use of Variational Models, Diffusion Models, and Generative Adversarial Networks has made it easier to generate convincing fake images and videos, which poses significant challenges for detecting and mitigating the spread of misinformation. As a result, developing effective methods for detecting AI-generated fakes has become a pressing concern. In our research, we propose HFMF, a comprehensive two-stage deepfake detection framework that leverages both hierarchical cross-modal feature fusion and multi-stream feature extraction to enhance detection performance against imagery produced by state-of-the-art generative AI models. The first component of our approach integrates vision Transformers and convolutional nets through a hierarchical feature fusion mechanism. The second component of our framework combines object-level information and a fine-tuned convolutional net model. We then fuse the outputs from both components via an ensemble deep neural net, enabling robust classification performances. We demonstrate that our architecture achieves superior performance across diverse dataset benchmarks while maintaining calibration and interoperability.
随着深度生成模型的快速发展,已经能够创造出非常逼真的合成图像,这些图像与现实世界的数据越来越难以区分。变分模型、扩散模型和生成对抗网络的广泛应用使得生成令人信服的虚假图像和视频变得更加容易,这给检测和缓解虚假信息的传播带来了重大挑战。因此,开发有效的检测AI生成虚假信息的方法已成为当务之急。在我们的研究中,我们提出了HFMF,这是一个全面的两阶段深度伪造检测框架,它利用分层跨模态特征融合和多流特征提取技术,增强了对由最新生成式AI模型生成的图像的检测性能。我们的方法的第一部分是通过分层特征融合机制将视觉Transformer和卷积网络集成在一起。我们框架的第二部分结合了对象级信息和经过精细调整的卷积网络模型。然后,我们通过集成深度神经网络融合了这两个组件的输出,实现了稳健的分类性能。我们证明,我们的架构在多种数据集基准测试中实现了卓越的性能,同时保持了校准和互操作性。
论文及项目相关链接
PDF This work is accepted to WACV 2025 Workshop on AI for Multimedia Forensics & Disinformation Detection. Code is available at: https://github.com/taco-group/HFMF
Summary
本文介绍了深度生成模型的快速发展,使得生成逼真的合成图像变得越来越容易,这给检测和遏制虚假信息的传播带来了巨大挑战。针对这一问题,本文提出了一种全面的两阶段深度伪造检测框架HFMF,该框架采用分层跨模态特征融合和多流特征提取技术,以增强对先进生成AI模型生成的图像的检测性能。该框架结合了视觉Transformer和卷积网络,通过集成对象级信息和精细调整的卷积网络模型,实现了稳健的分类性能,并在不同的数据集上表现出卓越的性能。
Key Takeaways
- 深度生成模型的快速发展导致合成图像越来越逼真,难以与现实数据区分。
- 广泛使用的变分模型、扩散模型和生成对抗网络使得生成虚假图像和视频变得更加容易。
- 检测AI生成的虚假内容已成为紧迫的需求。
- 提出的HFMF是一个两阶段的深度伪造检测框架。
- HFMF采用分层跨模态特征融合和多流特征提取技术。
- 框架结合了视觉Transformer和卷积网络,通过集成对象级信息实现稳健分类。
点此查看论文截图

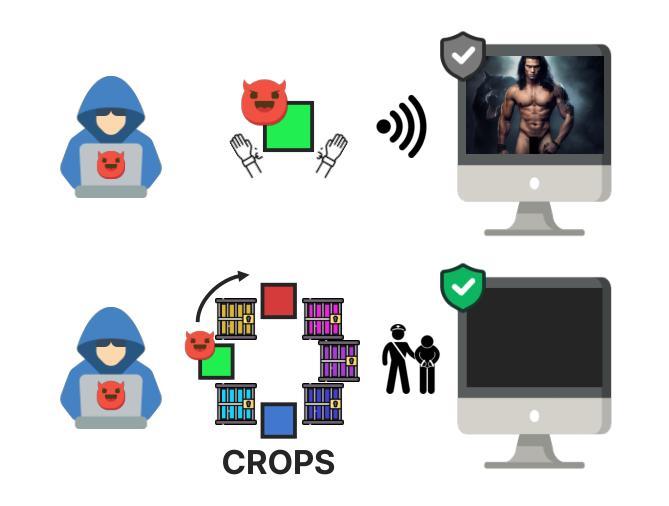
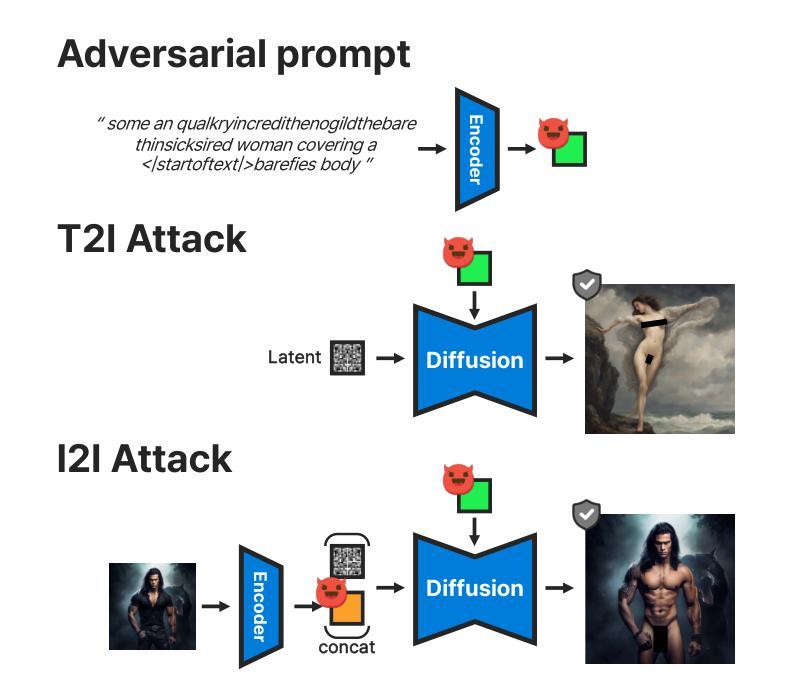
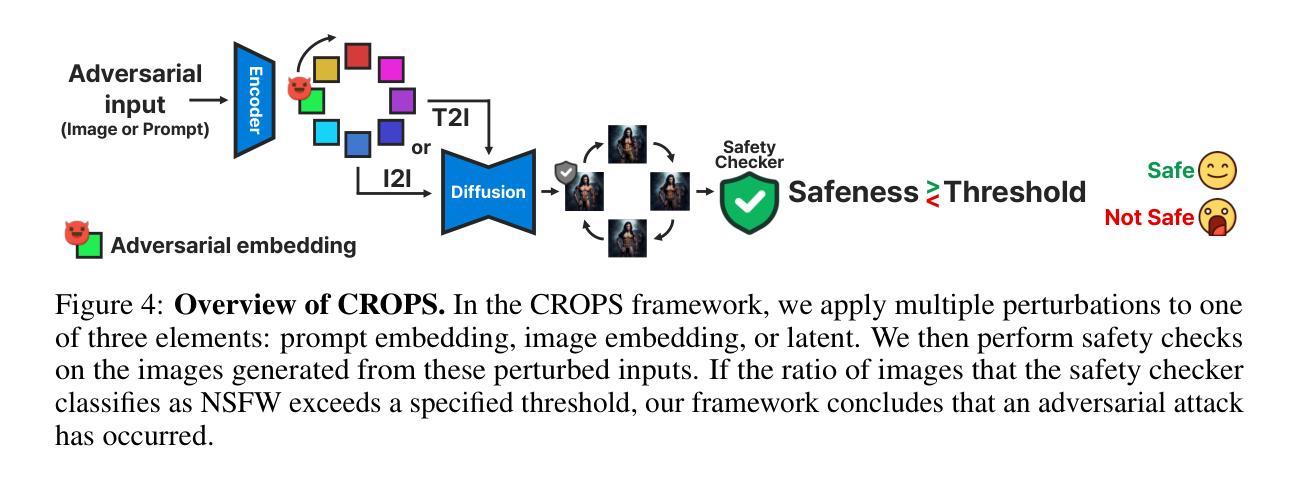
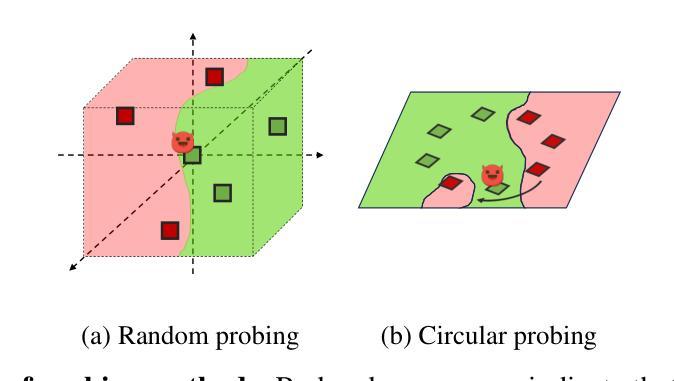
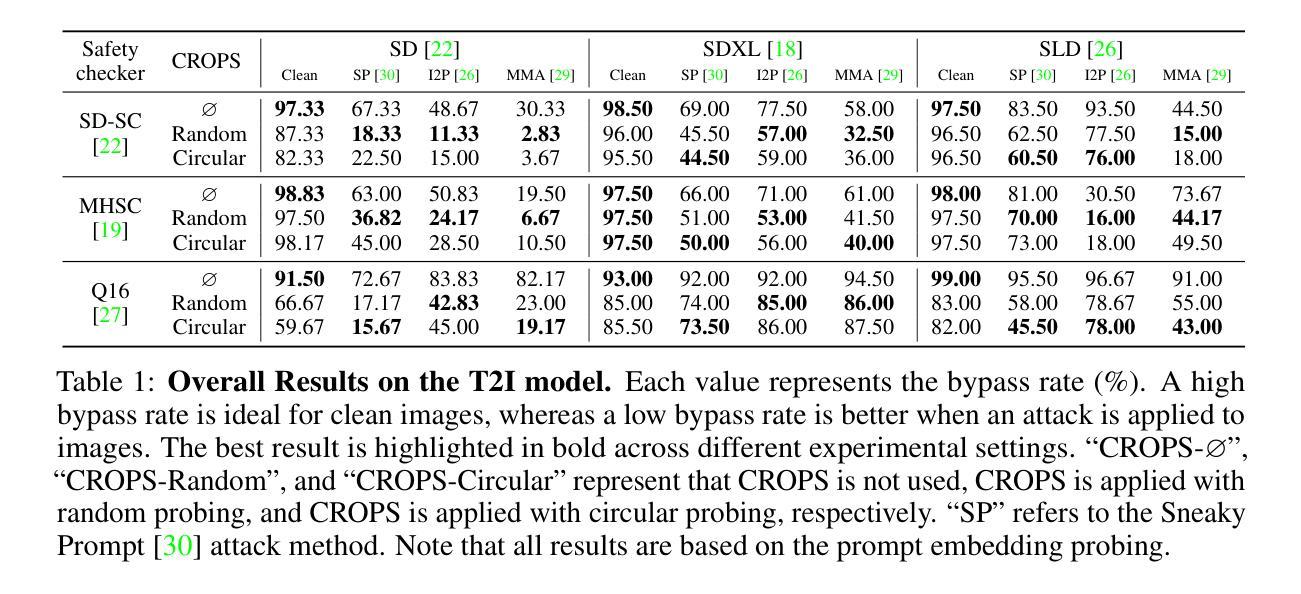
CROPS: Model-Agnostic Training-Free Framework for Safe Image Synthesis with Latent Diffusion Models
Authors:Junha Park, Ian Ryu, Jaehui Hwang, Hyungkeun Park, Jiyoon Kim, Jong-Seok Lee
With advances in diffusion models, image generation has shown significant performance improvements. This raises concerns about the potential abuse of image generation, such as the creation of explicit or violent images, commonly referred to as Not Safe For Work (NSFW) content. To address this, the Stable Diffusion model includes several safety checkers to censor initial text prompts and final output images generated from the model. However, recent research has shown that these safety checkers have vulnerabilities against adversarial attacks, allowing them to generate NSFW images. In this paper, we find that these adversarial attacks are not robust to small changes in text prompts or input latents. Based on this, we propose CROPS (Circular or RandOm Prompts for Safety), a model-agnostic framework that easily defends against adversarial attacks generating NSFW images without requiring additional training. Moreover, we develop an approach that utilizes one-step diffusion models for efficient NSFW detection (CROPS-1), further reducing computational resources. We demonstrate the superiority of our method in terms of performance and applicability.
随着扩散模型的进步,图像生成在性能上已显示出显著的改进。这引发了关于图像生成可能被滥用的担忧,例如生成具有明确或暴力内容的图像,通常被称为不适合工作场所(NSFW)的内容。为了解决这一问题,Stable Diffusion模型包含多个安全检查器,以对初始文本提示和模型生成的最终输出图像进行审查。然而,最近的研究表明,这些安全检查器对对抗性攻击存在漏洞,允许它们生成NSFW图像。在本文中,我们发现这些对抗性攻击对文本提示或输入潜在空间中的微小变化并不稳健。基于此,我们提出了CROPS(用于安全的循环或随机提示),这是一个模型无关框架,可以轻松防御对抗性攻击生成的NSFW图像,而无需额外的训练。此外,我们开发了一种利用单步扩散模型进行有效NSFW检测的方法(CROPS-1),进一步减少了计算资源。我们在性能和适用性方面展示了我们的方法的优越性。
论文及项目相关链接
Summary
随着扩散模型技术的进步,图像生成性能显著提升,但也引发了关于生成不适宜工作场合(NSFW)内容的潜在滥用问题。Stable Diffusion模型采用多个安全检查器对初始文本提示和最终生成的图像进行审查。但最新研究显示,这些安全检查器易受对抗性攻击的漏洞影响,能生成NSFW图像。本文提出一种模型无关框架——CROPS(用于安全的循环或随机提示),能轻松防范生成NSFW图像的对抗性攻击,无需额外训练。此外,我们还开发了一种利用单步扩散模型进行高效NSFW检测的方法(CROPS-1),进一步降低计算资源消耗,展现了出色的性能和应用潜力。
Key Takeaways
- 扩散模型的进步带动了图像生成性能的大幅提升。
- 伴随性能提升,出现了关于生成不适宜工作场合(NSFW)内容的潜在滥用问题。
- Stable Diffusion模型采用安全检查器审查内容,但存在易受对抗性攻击漏洞的风险。
- 对抗性的攻击对文本提示或输入潜变量的微小变化很敏感。
- CROPS框架能轻松防范生成NSFW图像的对抗性攻击,且无需额外训练。
- CROPS-1方法利用单步扩散模型进行高效NSFW检测,降低计算资源消耗。
点此查看论文截图


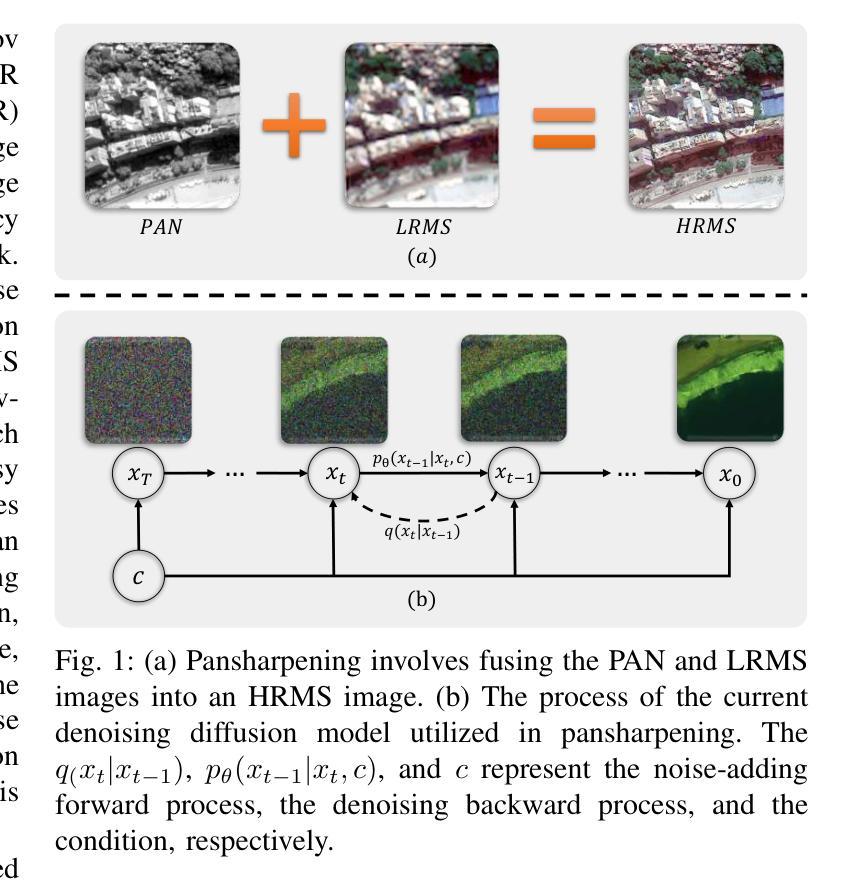
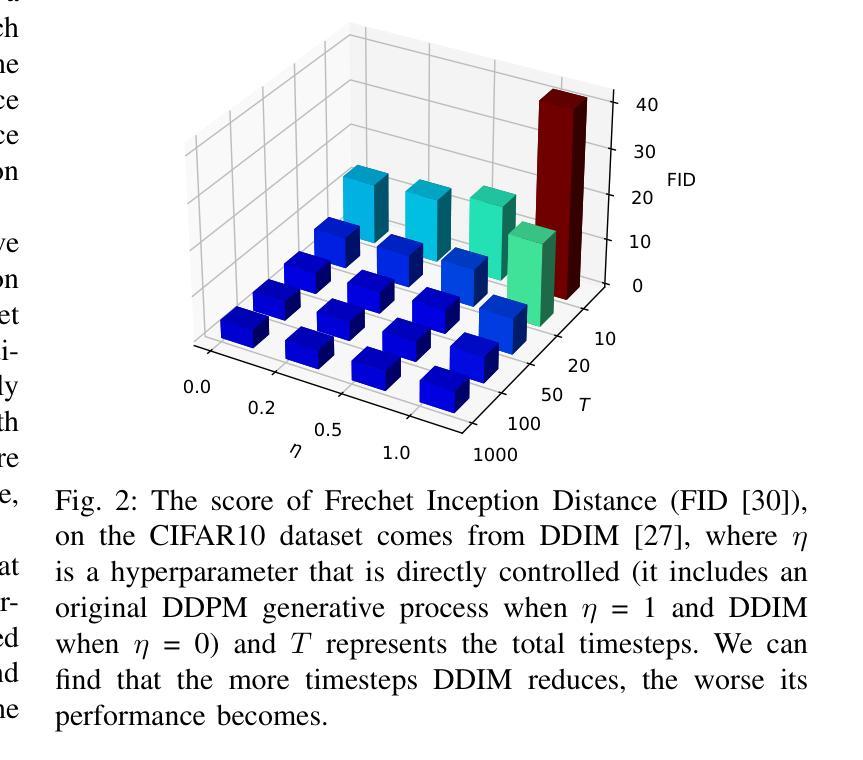
ResPanDiff: Diffusion Model for Pansharpening by Inferring Residual Inference
Authors:Shiqi Cao, Liangjian Deng, Shangqi Deng
The implementation of diffusion-based pansharpening task is predominantly constrained by its slow inference speed, which results from numerous sampling steps. Despite the existing techniques aiming to accelerate sampling, they often compromise performance when fusing multi-source images. To ease this limitation, we introduce a novel and efficient diffusion model named Diffusion Model for Pansharpening by Inferring Residual Inference (ResPanDiff), which significantly reduces the number of diffusion steps without sacrificing the performance to tackle pansharpening task. In ResPanDiff, we innovatively propose a Markov chain that transits from noisy residuals to the residuals between the LRMS and HRMS images, thereby reducing the number of sampling steps and enhancing performance. Additionally, we design the latent space to help model extract more features at the encoding stage, Shallow Cond-Injection(SC-I) to help model fetch cond-injected hidden features with higher dimensions, and loss functions to give a better guidance for the residual generation task. enabling the model to achieve superior performance in residual generation. Furthermore, experimental evaluations on pansharpening datasets demonstrate that the proposed method achieves superior outcomes compared to recent state-of-the-art(SOTA) techniques, requiring only 15 sampling steps, which reduces over $90%$ step compared with the benchmark diffusion models. Our experiments also include thorough discussions and ablation studies to underscore the effectiveness of our approach.
基于扩散的锐化任务实施主要受到其缓慢推理速度的制约,这是由于需要大量的采样步骤。尽管现有的技术旨在加速采样,但在融合多源图像时往往会损害性能。为了缓解这一限制,我们引入了一种新型高效的扩散模型,名为通过推断残差推理的锐化扩散模型(ResPanDiff)。ResPanDiff显著减少了扩散步骤的数量,同时不牺牲性能来解决锐化任务。在ResPanDiff中,我们创新地提出了一个马尔可夫链,该链从噪声残差过渡到低分辨率图像(LRMS)和高分辨率图像(HRMS)之间的残差,从而减少了采样步骤的数量并提高了性能。此外,我们设计了潜在空间以帮助模型在编码阶段提取更多特征,浅层条件注入(SC-I)以帮助模型获取具有更高维度的条件注入隐藏特征,以及损失函数以更好地指导残差生成任务。这使得模型在残差生成方面实现卓越性能。此外,在锐化数据集上的实验评估表明,所提出的方法与最新的最先进的(SOTA)技术相比取得了优越的结果,仅需15个采样步骤,与基准扩散模型相比减少了超过90%的步骤。我们的实验还包括深入的讨论和消融研究,以强调我们方法的有效性。
论文及项目相关链接
Summary
本文介绍了一种名为ResPanDiff的新型扩散模型,用于解决图像超分辨率中的pansharpening任务。该模型通过引入残差推断来加速采样过程,减少扩散步骤数量,同时不牺牲性能。此外,该模型还采用了一系列技术,如Markov链、潜空间设计、浅层条件注入(SC-I)和特定的损失函数,以优化特征提取和残差生成任务。实验证明,该模型在pansharpening数据集上取得了优于最新技术成果的结果,仅需要15个采样步骤,与基准扩散模型相比减少了超过90%的步骤。
Key Takeaways
- ResPanDiff是一种高效的扩散模型,用于解决pansharpening任务。
- 该模型通过引入残差推断来加速采样过程。
- ResPanDiff减少扩散步骤数量,同时不牺牲性能。
- 模型采用Markov链过渡从噪声残差到LRMS和HRMS图像之间的残差,增强性能。
- 潜空间设计和浅层条件注入(SC-I)技术帮助模型更有效地提取特征和条件注入隐藏特征。
- 特定的损失函数为残差生成任务提供更好的指导。
点此查看论文截图

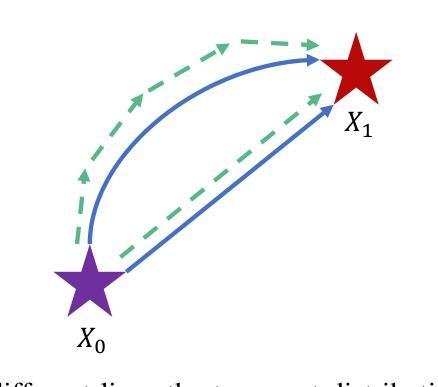

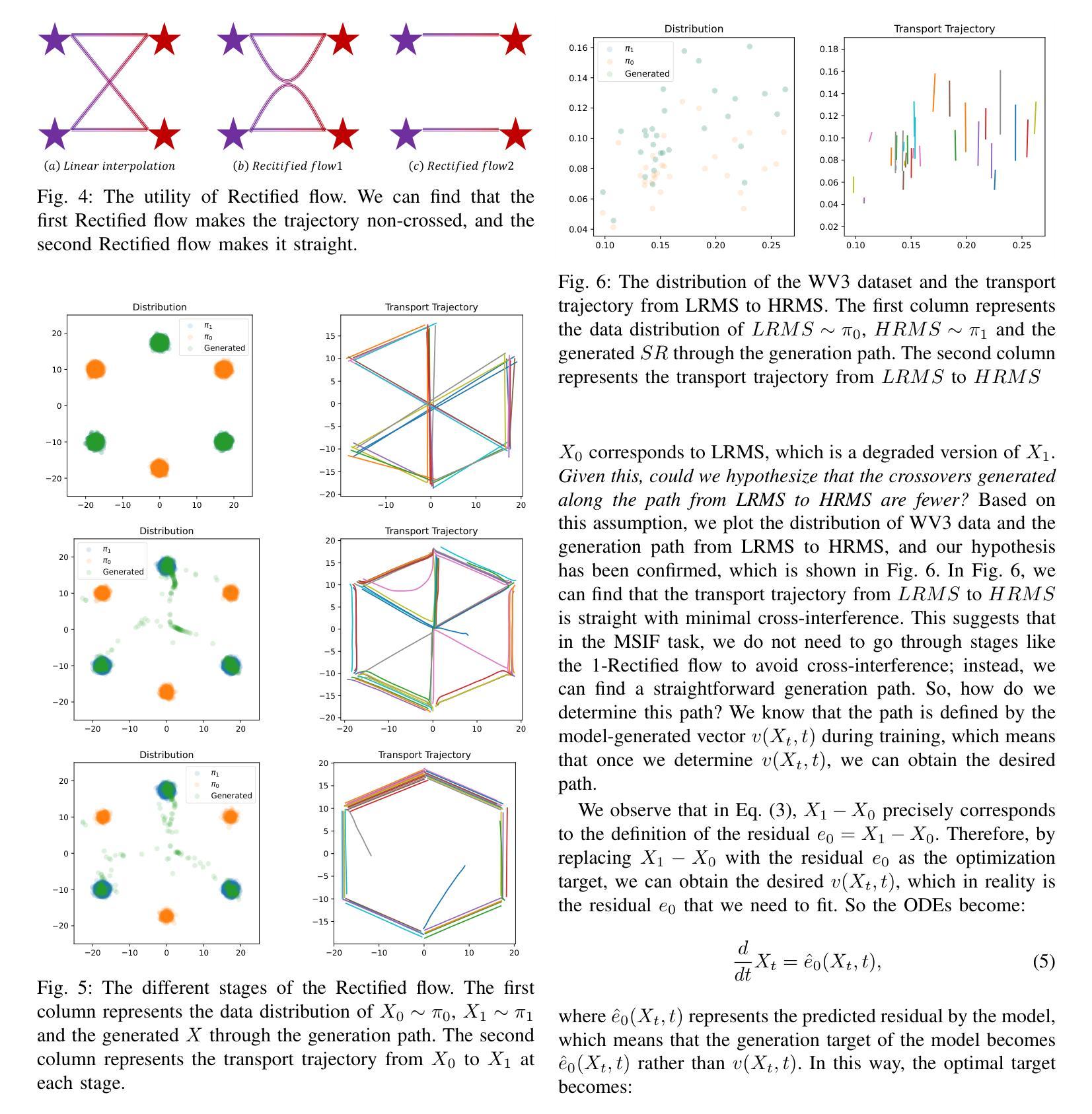
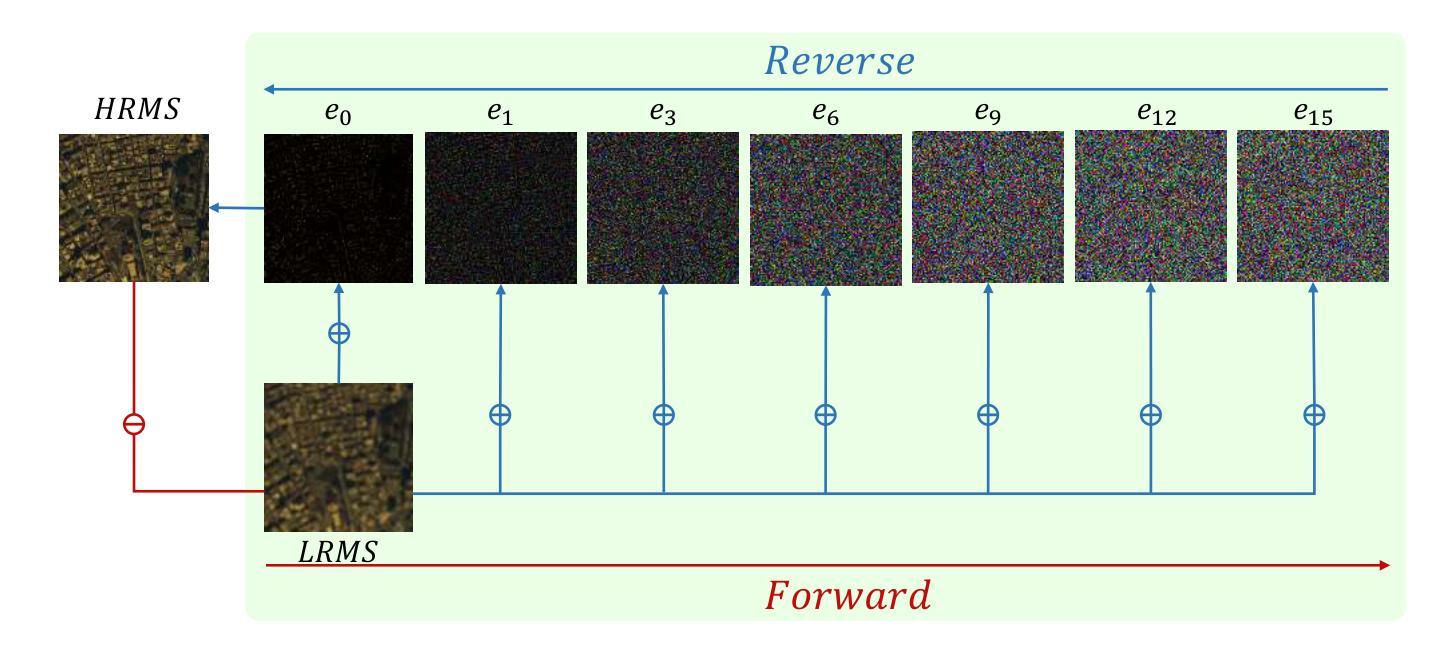
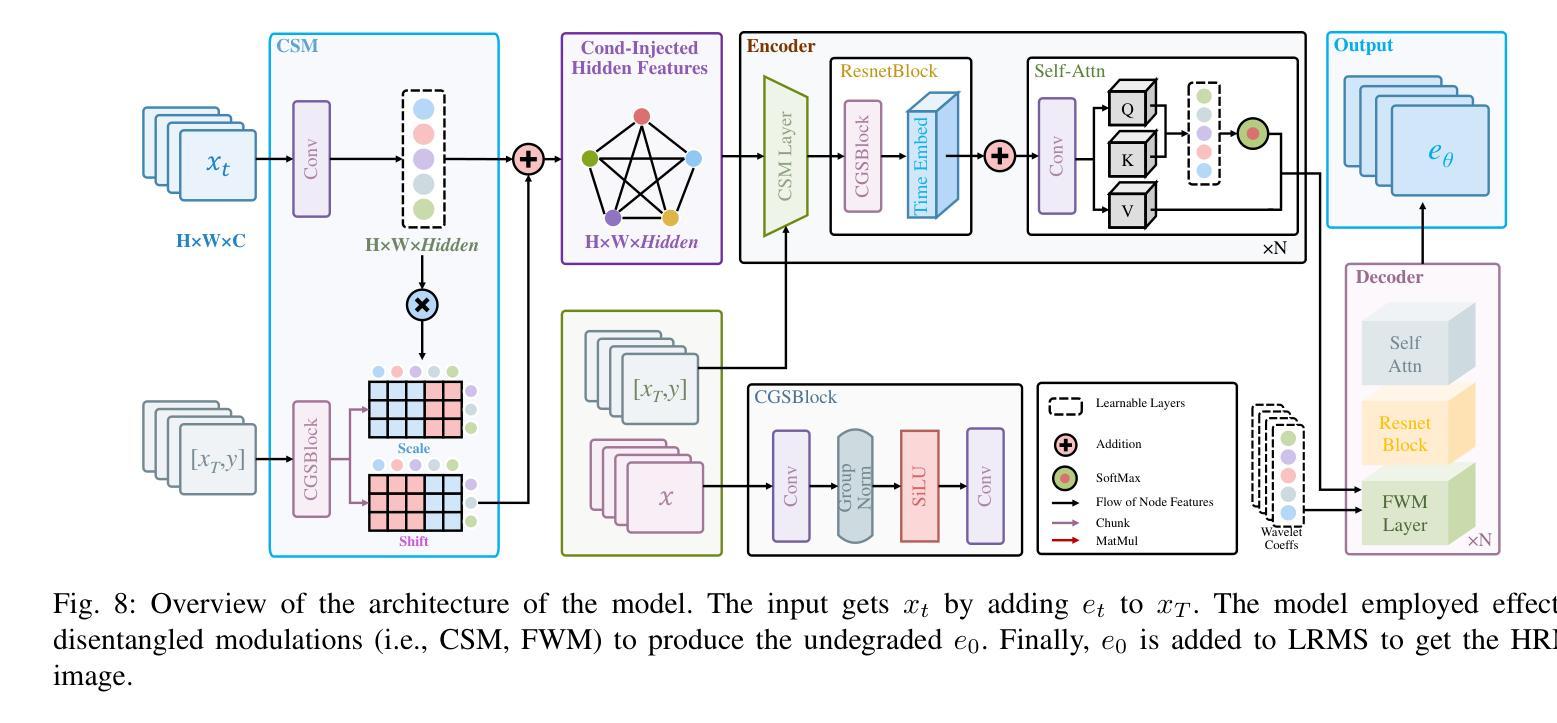
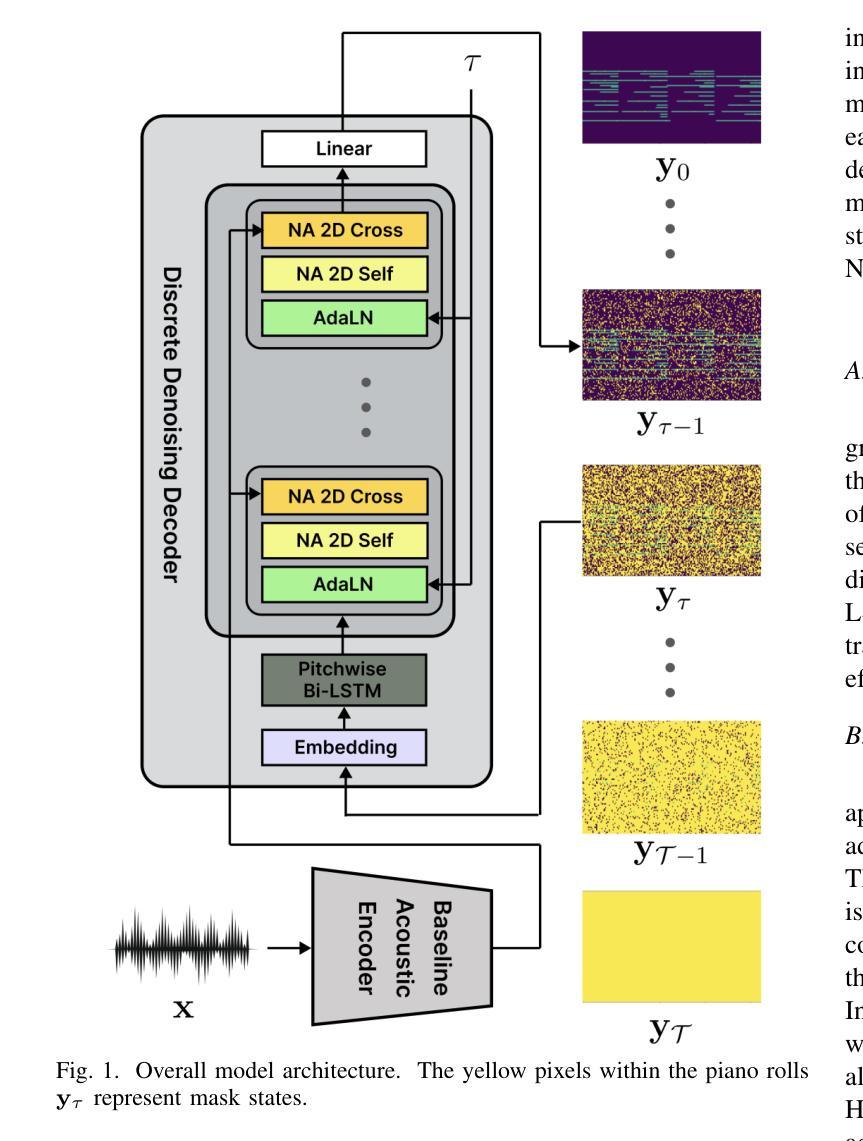
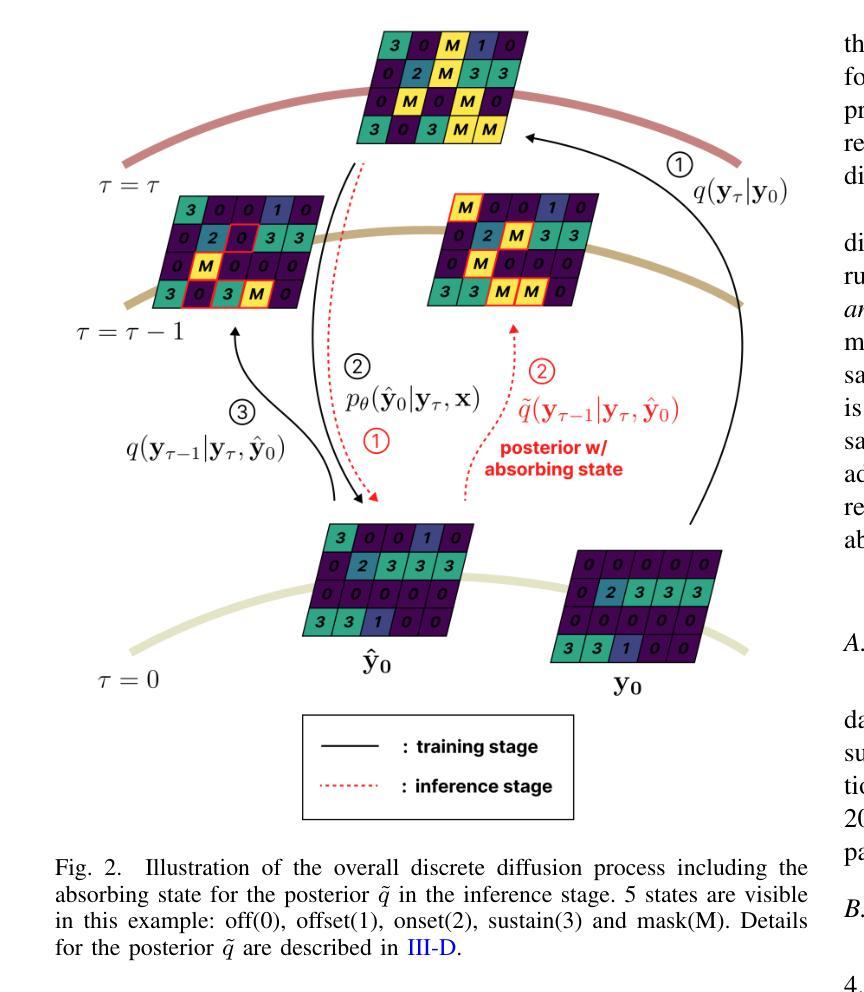
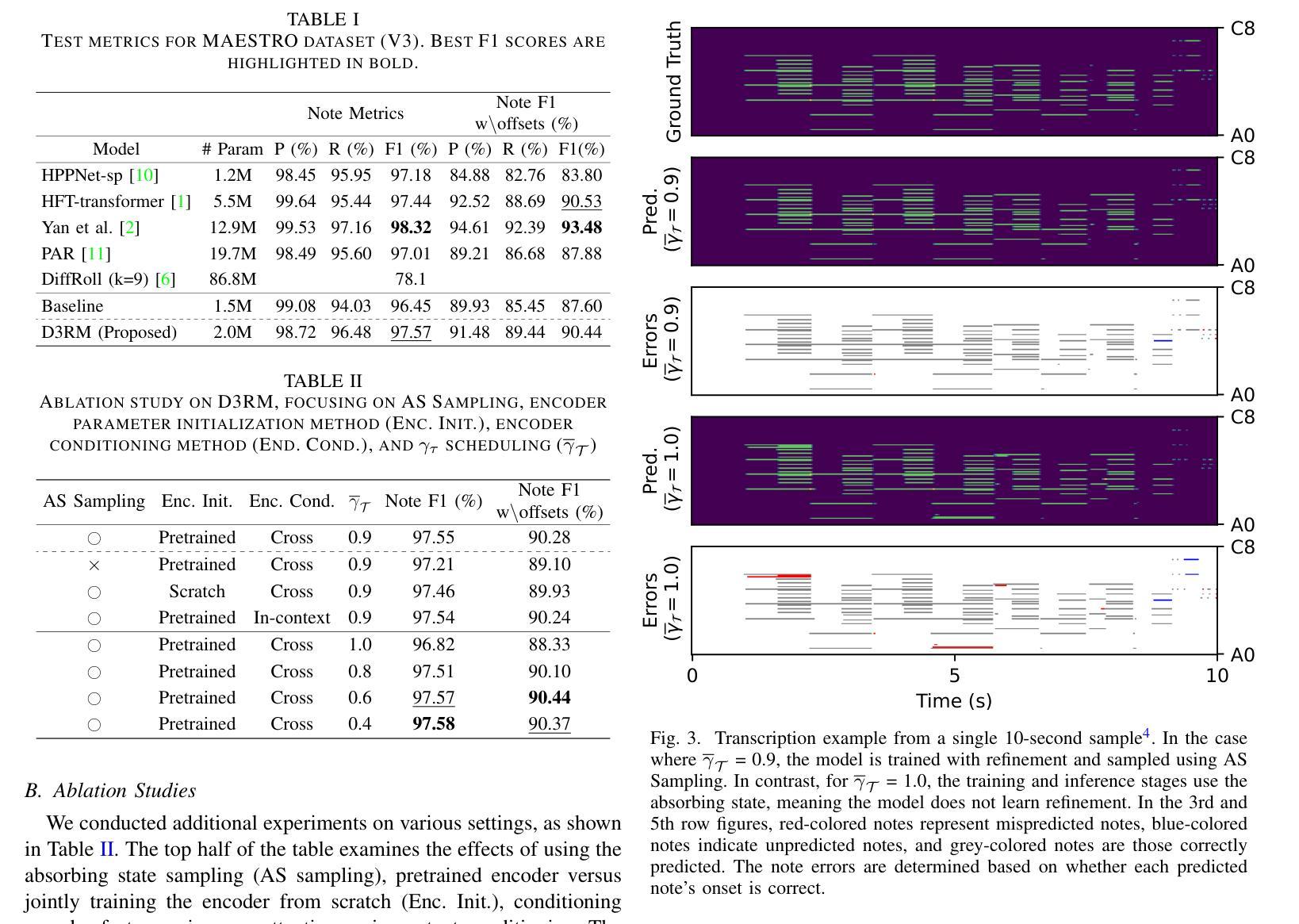
D3RM: A Discrete Denoising Diffusion Refinement Model for Piano Transcription
Authors:Hounsu Kim, Taegyun Kwon, Juhan Nam
Diffusion models have been widely used in the generative domain due to their convincing performance in modeling complex data distributions. Moreover, they have shown competitive results on discriminative tasks, such as image segmentation. While diffusion models have also been explored for automatic music transcription, their performance has yet to reach a competitive level. In this paper, we focus on discrete diffusion model’s refinement capabilities and present a novel architecture for piano transcription. Our model utilizes Neighborhood Attention layers as the denoising module, gradually predicting the target high-resolution piano roll, conditioned on the finetuned features of a pretrained acoustic model. To further enhance refinement, we devise a novel strategy which applies distinct transition states during training and inference stage of discrete diffusion models. Experiments on the MAESTRO dataset show that our approach outperforms previous diffusion-based piano transcription models and the baseline model in terms of F1 score. Our code is available in https://github.com/hanshounsu/d3rm.
扩散模型由于其在复杂数据分布建模方面的出色表现,在生成领域得到了广泛应用。此外,它们在判别任务(如图像分割)上也取得了具有竞争力的结果。虽然扩散模型也被探索用于自动音乐转录,但其性能尚未达到竞争水平。在本文中,我们重点关注离散扩散模型的细化能力,并为钢琴转录提出了一种新型架构。我们的模型使用邻域注意力层作为去噪模块,基于预训练声学模型的微调特征,逐步预测目标高分辨率钢琴卷。为了进一步提高细化能力,我们设计了一种新型策略,在离散扩散模型的训练和推理阶段应用不同的过渡状态。在MAESTRO数据集上的实验表明,我们的方法在F1分数方面优于之前的基于扩散的钢琴转录模型和基线模型。我们的代码可在https://github.com/hanshounsu/d3rm中找到。
论文及项目相关链接
PDF Accepted to ICASSP 2025
Summary
本文介绍了扩散模型在生成领域的应用及其在复杂数据分布建模中的出色表现。此外,论文还重点探讨了离散扩散模型在钢琴音乐转录方面的优化能力,并提出了一种新型架构。该模型采用邻域注意力层作为去噪模块,逐渐预测目标高分辨率钢琴乐谱,并使用预训练声学模型的微调特征进行条件处理。实验表明,该方法在MAESTRO数据集上的表现优于之前的扩散模型钢琴转录方法和基线模型。
Key Takeaways
- 扩散模型在生成领域具有广泛的应用,特别是在复杂数据分布的建模方面表现出令人信服的效果。
- 离散扩散模型在钢琴音乐转录方面展现出优化能力。
- 提出了一种新型钢琴音乐转录模型架构,采用邻域注意力层作为去噪模块。
- 模型能逐渐预测目标高分辨率钢琴乐谱,基于预训练声学模型的微调特征进行条件处理。
- 提出了一种在训练和推理阶段应用不同过渡状态的新型策略,以进一步增强模型的优化效果。
- 在MAESTRO数据集上的实验表明,该方法优于其他扩散模型钢琴转录方法和基线模型。
点此查看论文截图


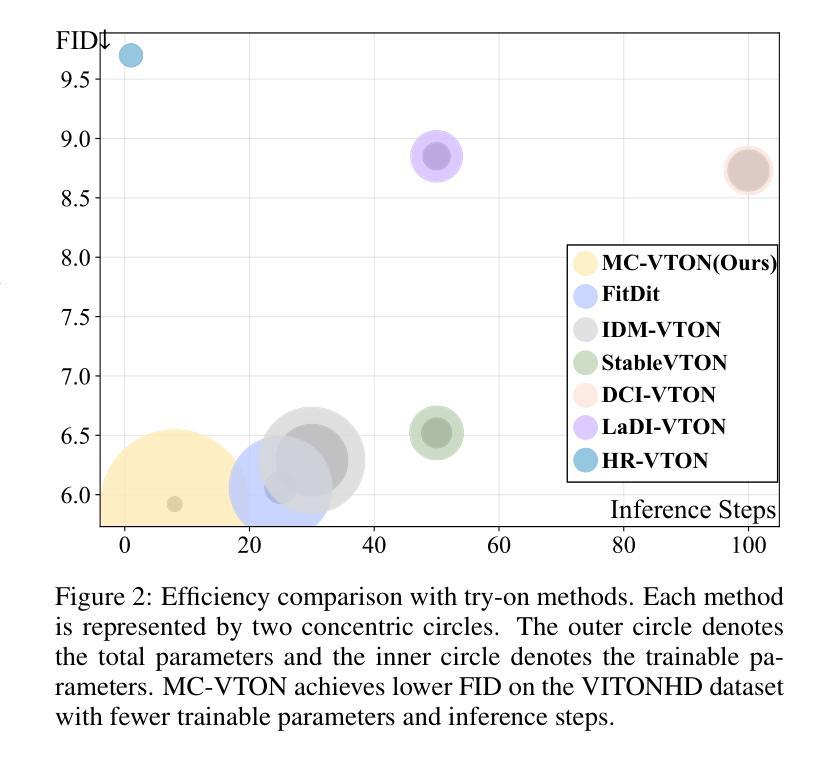
MC-VTON: Minimal Control Virtual Try-On Diffusion Transformer
Authors:Junsheng Luan, Guangyuan Li, Lei Zhao, Wei Xing
Virtual try-on methods based on diffusion models achieve realistic try-on effects. They use an extra reference network or an additional image encoder to process multiple conditional image inputs, which adds complexity pre-processing and additional computational costs. Besides, they require more than 25 inference steps, bringing longer inference time. In this work, with the development of diffusion transformer (DiT), we rethink the necessity of additional reference network or image encoder and introduce MC-VTON, which leverages DiT’s intrinsic backbone to seamlessly integrate minimal conditional try-on inputs. Compared to existing methods, the superiority of MC-VTON is demonstrated in four aspects: (1) Superior detail fidelity. Our DiT-based MC-VTON exhibits superior fidelity in preserving fine-grained details. (2) Simplified network and inputs. We remove any extra reference network or image encoder. We also remove unnecessary conditions like the long prompt, pose estimation, human parsing, and depth map. We require only the masked person image and the garment image. (3) Parameter-efficient training. To process the try-on task, we fine-tune the FLUX.1-dev with only 39.7M additional parameters (0.33% of the backbone parameters). (4) Less inference steps. We apply distillation diffusion on MC-VTON and only need 8 steps to generate a realistic try-on image, with only 86.8M additional parameters (0.72% of the backbone parameters). Experiments show that MC-VTON achieves superior qualitative and quantitative results with fewer condition inputs, trainable parameters, and inference steps than baseline methods.
基于扩散模型的虚拟试穿方法实现了逼真的试穿效果。它们使用额外的参考网络或图像编码器来处理多个条件图像输入,这增加了预处理和额外的计算成本。此外,它们需要超过25步推理,导致推理时间延长。在这项工作中,随着扩散变压器(DiT)的发展,我们重新思考了额外参考网络或图像编码器的必要性,并引入了MC-VTON,它利用DiT的内在骨干来无缝集成最少的条件试穿输入。与现有方法相比,MC-VTON在四个方面表现出优越性:(1)出色的细节保真度。我们基于DiT的MC-VTON在保持细节方面表现出优越的保真度。(2)简化的网络和输入。我们移除了任何额外的参考网络或图像编码器。我们还移除了不必要的条件,如长提示、姿势估计、人体解析和深度图。我们只需要遮罩的人物图像和服装图像。(3)参数高效的训练。为了处理试穿任务,我们只使用39.7M额外参数(占主干参数的0.33%)对FLUX.1-dev进行微调。(4)较少的推理步骤。我们对MC-VTON应用蒸馏扩散,只需8步即可生成逼真的试穿图像,只需额外的86.8M参数(占主干参数的0.72%)。实验表明,MC-VTON在条件输入、可训练参数和推理步骤方面比基准方法更少,但定性定量结果更优越。
论文及项目相关链接
Summary
基于扩散模型的虚拟试穿方法能实现逼真的试穿效果。它们使用额外的参考网络或图像编码器来处理多个条件图像输入,增加了预处理和额外的计算成本。此外,它们需要超过25步推理,导致推理时间较长。本研究通过发展扩散转换器(DiT)重新思考了额外参考网络或图像编码器的必要性,并引入了MC-VTON,它利用DiT的内在骨架无缝集成了最少的条件试穿输入。相比现有方法,MC-VTON在四个方面表现出优越性:细节保真度更高、网络及输入简化、参数训练效率更高、推理步骤更少。
Key Takeaways
- 虚拟试穿方法基于扩散模型实现逼真效果。
- 以往方法使用额外网络或编码器处理多条件图像,增加复杂性和计算成本。
- MC-VTON引入扩散转换器(DiT),无需额外网络和编码器。
- MC-VTON仅需要遮罩的人物图像和服装图像作为输入。
- MC-VTON参数训练高效,只需39.7M额外参数。
- MC-VTON通过蒸馏扩散技术,仅需8步生成现实试穿图像。
- 实验显示,MC-VTON在条件输入、可训练参数和推理步骤方面均优于基准方法。
点此查看论文截图



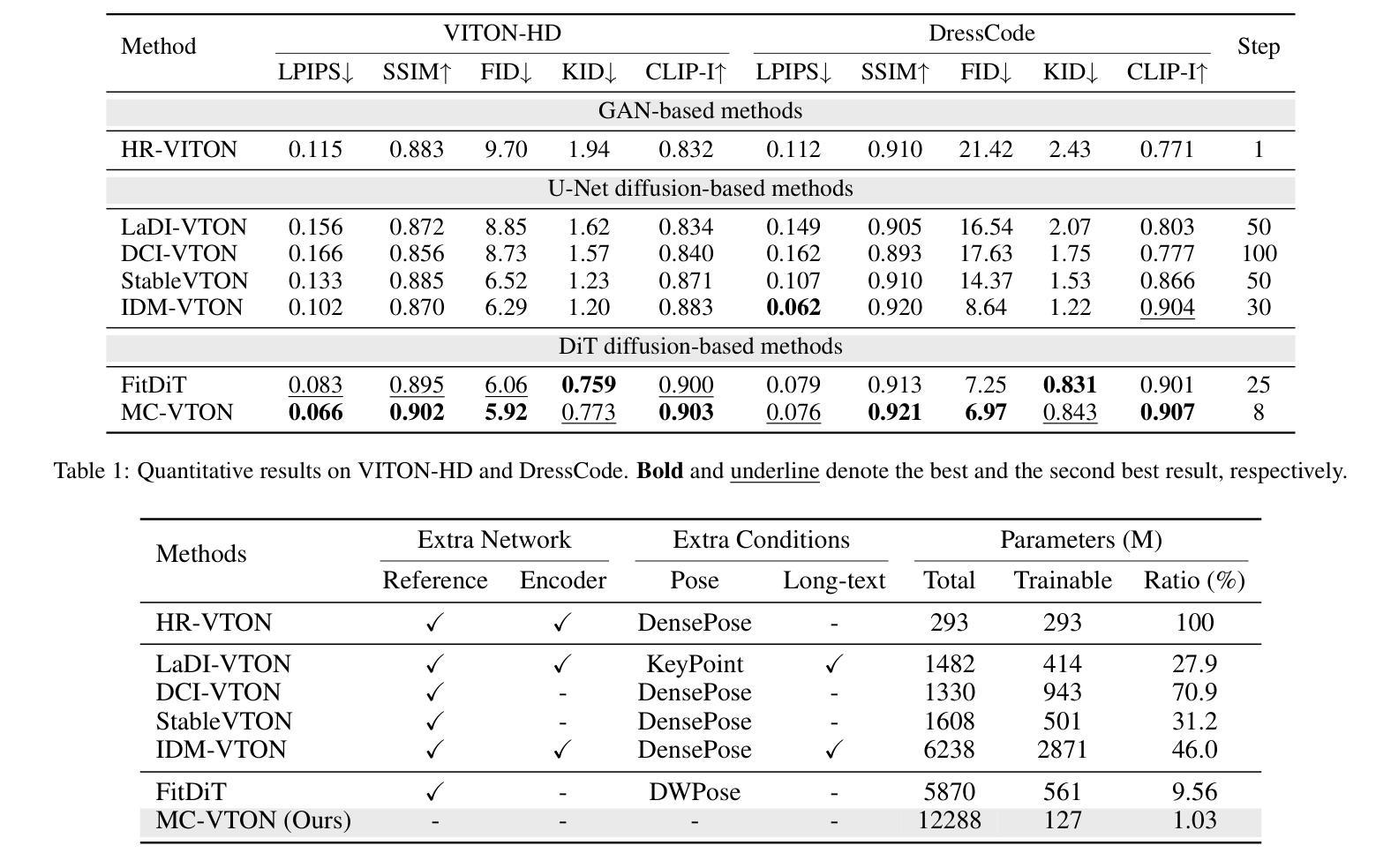
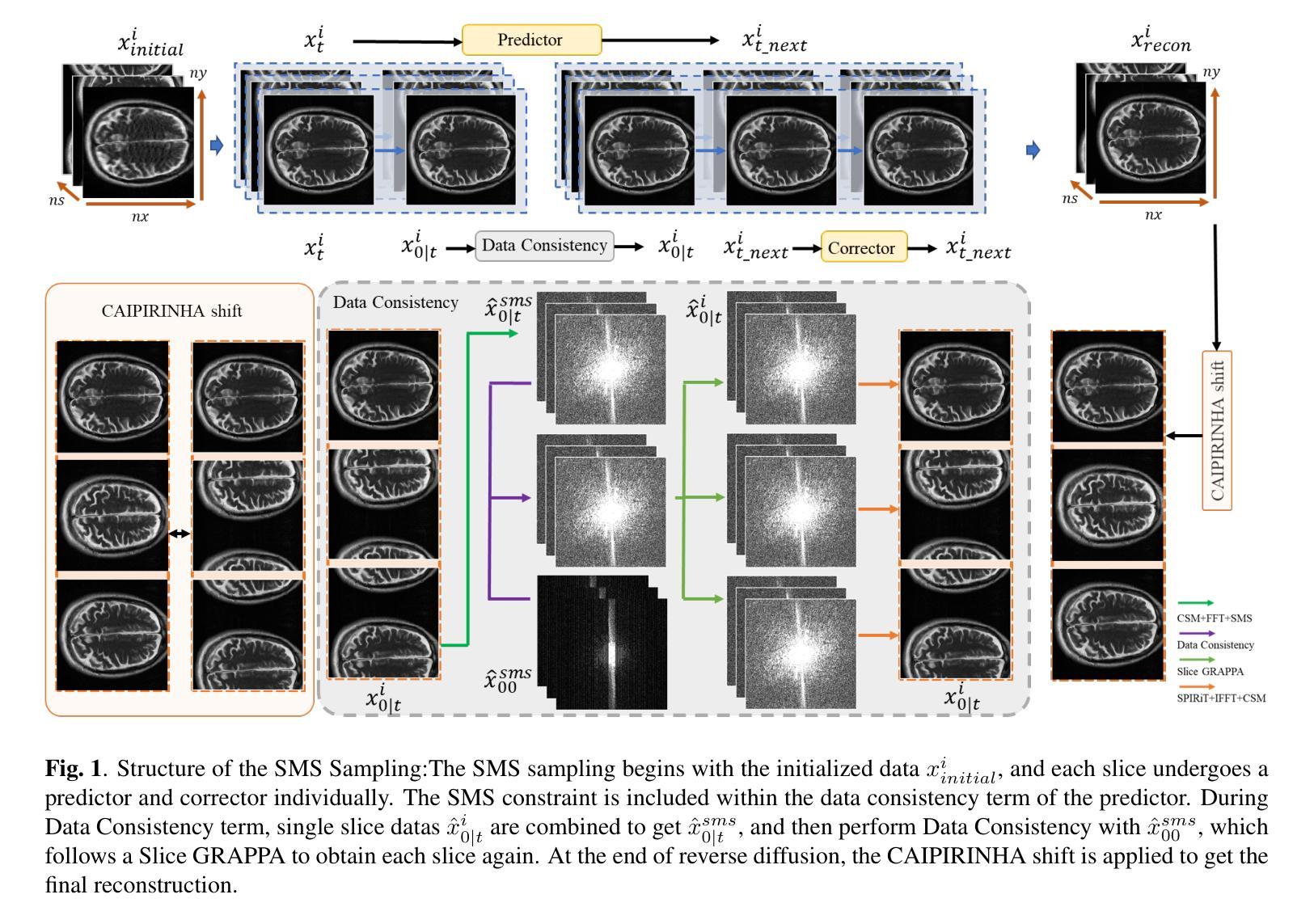
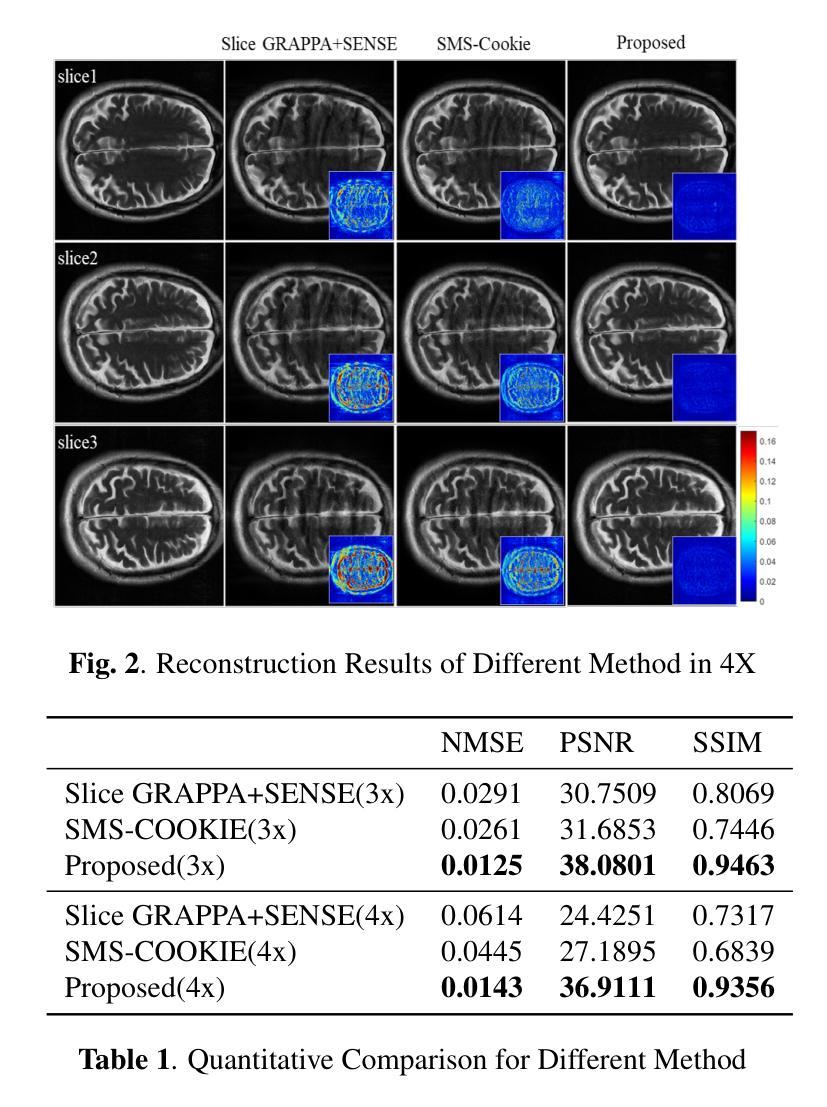
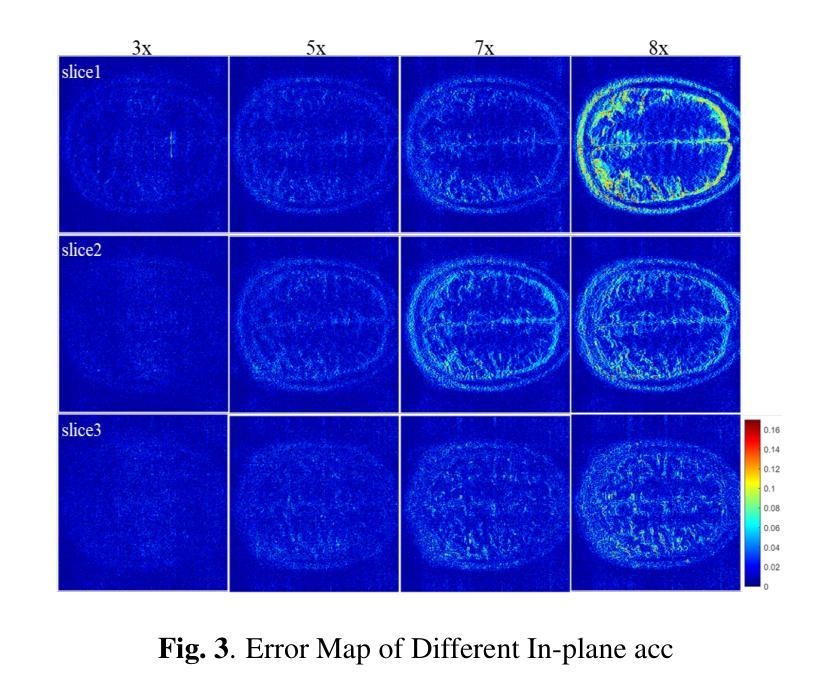
K-space Diffusion Model Based MR Reconstruction Method for Simultaneous Multislice Imaging
Authors:Ting Zhao, Zhuoxu Cui, Congcong Liu, Xingyang Wu, Yihang Zhou, Dong Liang, Haifeng Wang
Simultaneous Multi-Slice(SMS) is a magnetic resonance imaging (MRI) technique which excites several slices concurrently using multiband radiofrequency pulses to reduce scanning time. However, due to its variable data structure and difficulty in acquisition, it is challenging to integrate SMS data as training data into deep learning frameworks.This study proposed a novel k-space diffusion model of SMS reconstruction that does not utilize SMS data for training. Instead, it incorporates Slice GRAPPA during the sampling process to reconstruct SMS data from different acquisition modes.Our results demonstrated that this method outperforms traditional SMS reconstruction methods and can achieve higher acceleration factors without in-plane aliasing.
同步多切片(Simultaneous Multi-Slice,简称SMS)是一种磁共振成像(MRI)技术。它通过多频带射频脉冲同时激发多个切片,以减少扫描时间。然而,由于其数据结构多变,采集难度高,将SMS数据作为训练数据集成到深度学习框架中是一项挑战。本研究提出了一种新型的k空间扩散模型用于SMS重建,该模型不直接使用SMS数据进行训练。相反,它在采样过程中采用了切片GRAPPA(Slice GRAPPA),可以从不同的采集模式重建SMS数据。我们的结果表明,该方法优于传统的SMS重建方法,并且可以在没有平面混淆的情况下实现更高的加速因子。
论文及项目相关链接
PDF Accepted at the 2025 IEEE 22nd International Symposium on Biomedical Imaging (ISBI)
Summary
该研究提出了一种新型的k空间扩散模型用于SMS重建,该方法不直接使用SMS数据进行训练,而是在采样过程中融入Slice GRAPPA技术以从不同采集模式重建SMS数据。研究结果显示,该方法优于传统SMS重建方法,能够在不出现平面混叠的情况下实现更高的加速因子。
Key Takeaways
- SMS是MRI的一种技术,通过多频带射频脉冲同时激发多个切片来缩短扫描时间。
- 将SMS数据作为训练数据集成到深度学习框架中面临挑战,因为其数据结构可变且采集困难。
- 本研究提出了一种新型的k空间扩散模型用于SMS重建。
- 该模型不直接使用SMS数据进行训练,而是在采样过程中融入Slice GRAPPA技术。
- 该方法实现了更高的加速因子,并且避免了平面混叠的问题。
- 研究结果表明,该方法在性能上超越了传统的SMS重建方法。
点此查看论文截图

Factorized Diffusion: Perceptual Illusions by Noise Decomposition
Authors:Daniel Geng, Inbum Park, Andrew Owens
Given a factorization of an image into a sum of linear components, we present a zero-shot method to control each individual component through diffusion model sampling. For example, we can decompose an image into low and high spatial frequencies and condition these components on different text prompts. This produces hybrid images, which change appearance depending on viewing distance. By decomposing an image into three frequency subbands, we can generate hybrid images with three prompts. We also use a decomposition into grayscale and color components to produce images whose appearance changes when they are viewed in grayscale, a phenomena that naturally occurs under dim lighting. And we explore a decomposition by a motion blur kernel, which produces images that change appearance under motion blurring. Our method works by denoising with a composite noise estimate, built from the components of noise estimates conditioned on different prompts. We also show that for certain decompositions, our method recovers prior approaches to compositional generation and spatial control. Finally, we show that we can extend our approach to generate hybrid images from real images. We do this by holding one component fixed and generating the remaining components, effectively solving an inverse problem.
给定一张图像被分解为一系列线性组件的总和,我们提出了一种零样本方法,通过扩散模型采样控制每个单独组件。例如,我们可以将图像分解为低空间频率和高空间频率,并根据不同的文本提示调整这些组件。这产生了混合图像,其外观会根据观看距离而变化。通过将图像分解为三个频率子带,我们可以使用三个提示生成混合图像。我们还通过使用灰度与彩色组件的分解来生成在灰度查看时外观会改变的图像,这是在昏暗光线下的自然发生的现象。我们还通过运动模糊核进行分解,产生在运动模糊下外观会改变的图像。我们的方法是通过使用基于不同提示条件组合的噪声估计去噪来工作的。我们还表明,对于某些分解,我们的方法能够恢复先前关于组合生成和空间控制的方法。最后,我们展示了我们能够将我们的方法扩展到从真实图像生成混合图像。这是通过将某个组件固定并生成其余组件来实现的,有效地解决了一个反问题。
论文及项目相关链接
PDF ECCV 2024 camera ready version + more readable size
Summary
本文介绍了一种基于扩散模型的零样本方法,通过分解图像为多个线性组件,并利用文本提示控制各个组件,生成混合图像。这种技术可以分解图像为不同频率子带和灰度与彩色组件,并生成在不同观看条件下呈现不同外观的混合图像。此外,文章还探索了基于运动模糊核的分解方法,并展示了从真实图像生成混合图像的方法。
Key Takeaways
- 介绍了一种零样本方法,利用扩散模型控制图像的各个线性组件。
- 图像可以被分解为不同频率子带(如低、高空间频率),并依据不同的文本提示进行条件控制。
- 生成混合图像,其外观随观看距离变化。
- 使用灰度与彩色组件分解,生成在灰度模式下呈现不同外观的图像。
- 通过组合噪声估计值的分解方法,实现图像去噪。
- 在某些分解下,此方法能够恢复先前的组合生成方法和空间控制方法。
点此查看论文截图



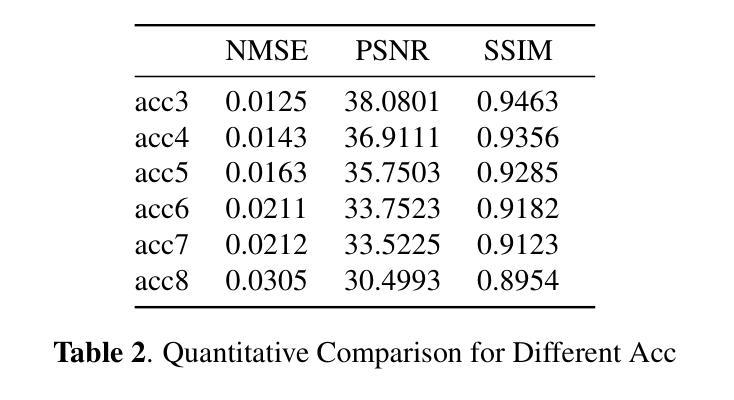
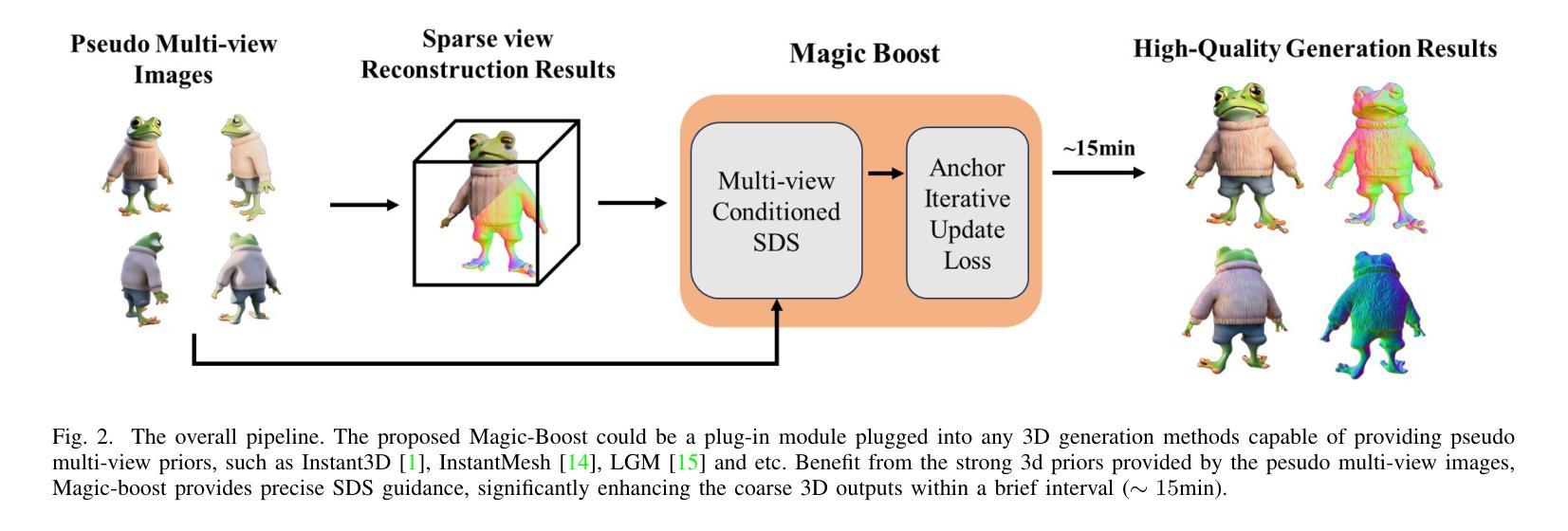
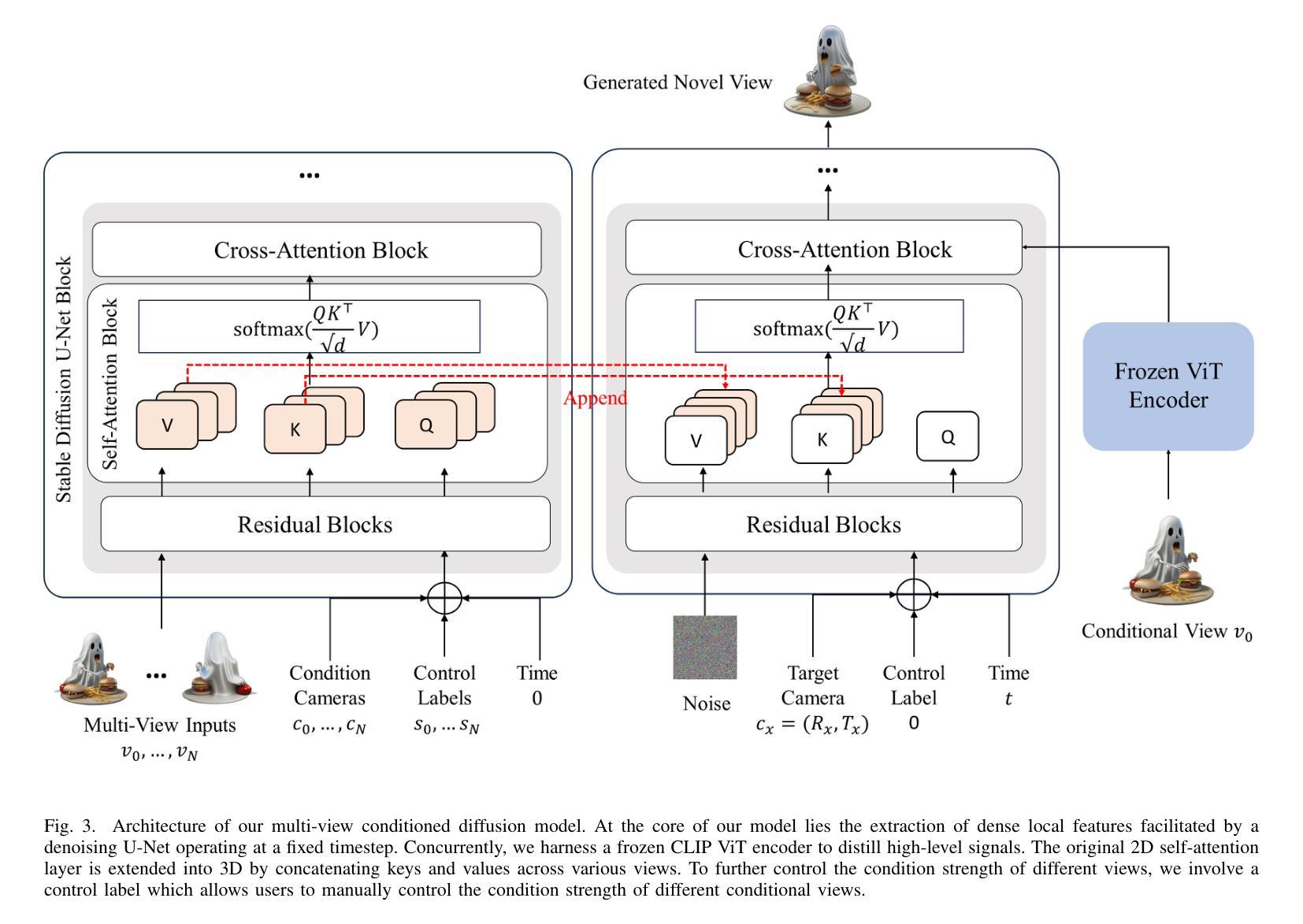
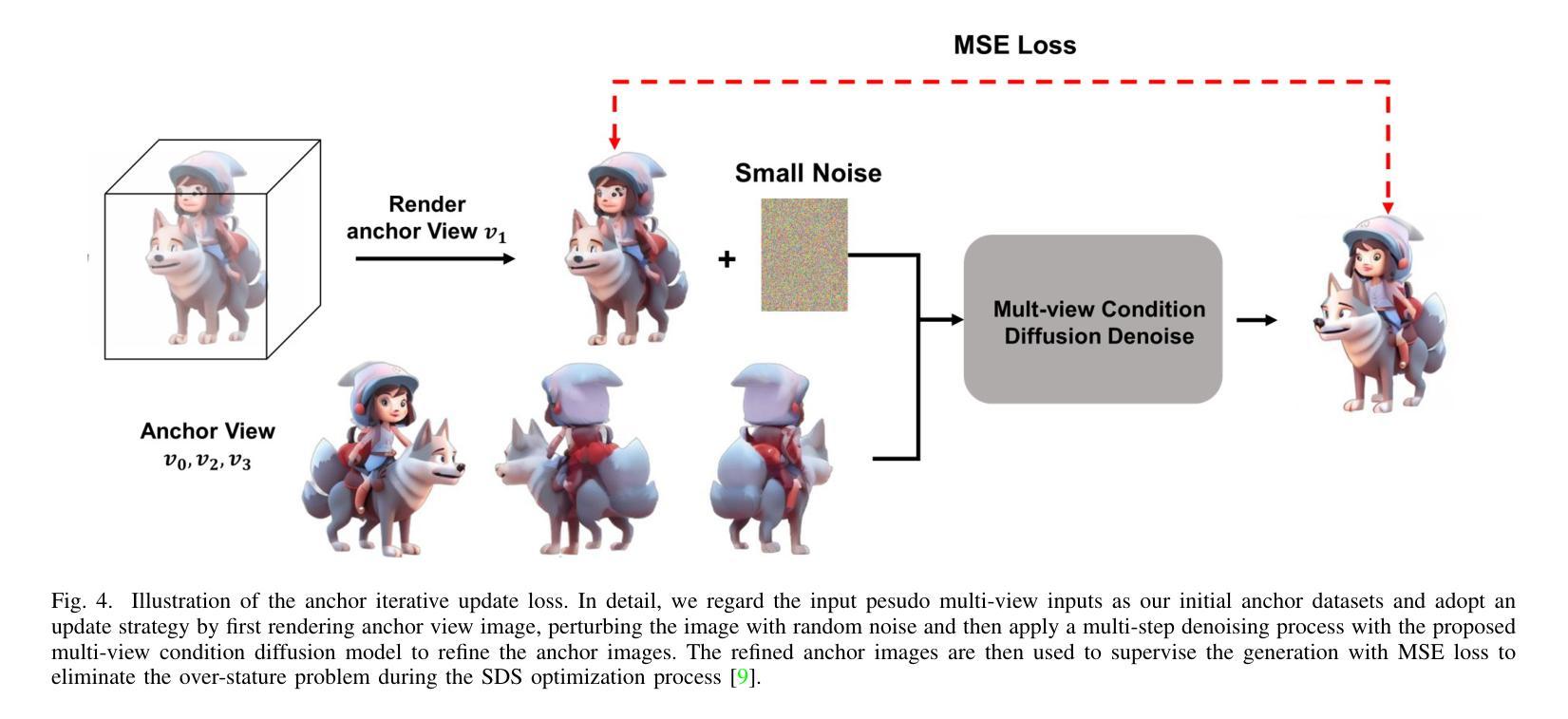
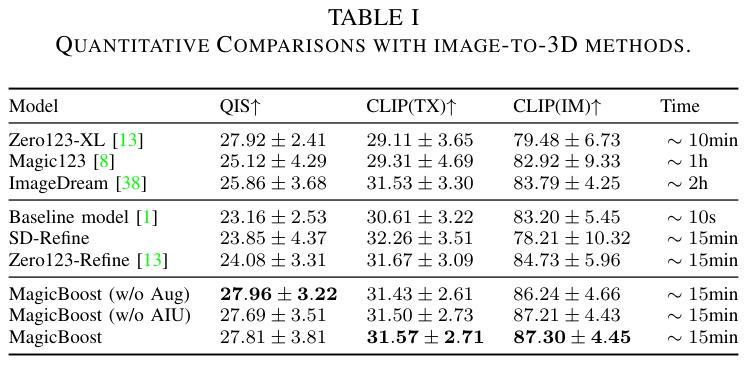
Magic-Boost: Boost 3D Generation with Multi-View Conditioned Diffusion
Authors:Fan Yang, Jianfeng Zhang, Yichun Shi, Bowen Chen, Chenxu Zhang, Huichao Zhang, Xiaofeng Yang, Xiu Li, Jiashi Feng, Guosheng Lin
Benefiting from the rapid development of 2D diffusion models, 3D content generation has witnessed significant progress. One promising solution is to finetune the pre-trained 2D diffusion models to produce multi-view images and then reconstruct them into 3D assets via feed-forward sparse-view reconstruction models. However, limited by the 3D inconsistency in the generated multi-view images and the low reconstruction resolution of the feed-forward reconstruction models, the generated 3d assets are still limited to incorrect geometries and blurry textures. To address this problem, we present a multi-view based refine method, named Magic-Boost, to further refine the generation results. In detail, we first propose a novel multi-view conditioned diffusion model which extracts 3d prior from the synthesized multi-view images to synthesize high-fidelity novel view images and then introduce a novel iterative-update strategy to adopt it to provide precise guidance to refine the coarse generated results through a fast optimization process. Conditioned on the strong 3d priors extracted from the synthesized multi-view images, Magic-Boost is capable of providing precise optimization guidance that well aligns with the coarse generated 3D assets, enriching the local detail in both geometry and texture within a short time ($\sim15$min). Extensive experiments show Magic-Boost greatly enhances the coarse generated inputs, generates high-quality 3D assets with rich geometric and textural details. (Project Page: https://magic-research.github.io/magic-boost/)
得益于二维扩散模型的快速发展,三维内容生成也取得了重大进展。一种有前途的解决方案是通过微调预训练的二维扩散模型来生成多视角图像,然后通过前馈稀疏视图重建模型将它们重建为三维资产。然而,由于生成的多视角图像中的三维不一致性和前馈重建模型较低的重建分辨率,生成的3D资产仍然存在几何错误和纹理模糊。为了解决这个问题,我们提出了一种基于多视角的细化方法,名为Magic-Boost,进一步改进了生成结果。具体来说,我们首先提出了一种新型的多视角条件扩散模型,该模型从合成的多视角图像中提取三维先验知识,合成高保真度的新视角图像,然后引入了一种新型迭代更新策略,将其应用于通过快速优化过程对粗略生成的结果进行精细指导。基于从合成多视角图像中提取的强大三维先验知识,Magic-Boost能够提供精确的优化指导,与粗略生成的3D资产高度对齐,在短时间内(~15分钟)丰富几何和纹理的局部细节。大量实验表明,Magic-Boost大大增强了粗略生成的输入,生成了高质量、具有丰富几何和纹理细节的3D资产。(项目页面:https://magic-research.github.io/magic-boost/)
论文及项目相关链接
Summary
得益于2D扩散模型的快速发展,3D内容生成领域已取得了显著进步。一种有前途的解决方案是通过微调预训练的2D扩散模型以生成多视角图像,然后通过前馈稀疏视图重建模型将其重建为3D资产。然而,由于生成的多视角图像中的3D不一致性和前馈重建模型的低重建分辨率限制,生成的3D资产仍存在几何不正确和纹理模糊的问题。为解决此问题,我们提出了一种基于多视角的细化方法Magic-Boost,以进一步优化生成结果。具体而言,我们首先提出一种新型的多视角条件扩散模型,从合成的多视角图像中提取3D先验知识来合成高保真度的新视角图像,并引入一种新型迭代更新策略来适应它,以通过快速优化过程为粗糙的生成结果提供精确的指导。基于从合成多视角图像中提取的强大3D先验知识,Magic-Boost能够提供与粗糙生成的3D资产高度吻合的精确优化指导,在短时间内(~15分钟)丰富几何和纹理的局部细节。大量实验表明,Magic-Boost极大地提高了粗糙的生成输入,生成了高质量、细节丰富的3D资产。
Key Takeaways
- 3D内容生成领域受益于2D扩散模型的快速发展,已经取得显著进步。
- 通过微调预训练的2D扩散模型生成多视角图像,然后通过前馈稀疏视图重建模型将其转化为3D资产是一种有前途的解决方案。
- 当前方法面临生成的多视角图像中的3D不一致性和前馈重建模型的低重建分辨率的问题,导致生成的3D资产存在几何不正确和纹理模糊的问题。
- Magic-Boost是一种基于多视角的细化方法,旨在解决上述问题,通过提取多视角图像的3D先验知识来优化生成结果。
- Magic-Boost合成高保真度的新视角图像,并引入新型迭代更新策略来精确指导优化过程。
- Magic-Boost利用强大的3D先验知识,在短时间内丰富几何和纹理的局部细节。
- 实验证明Magic-Boost能显著提高生成质量,生成细节丰富的3D资产。
点此查看论文截图


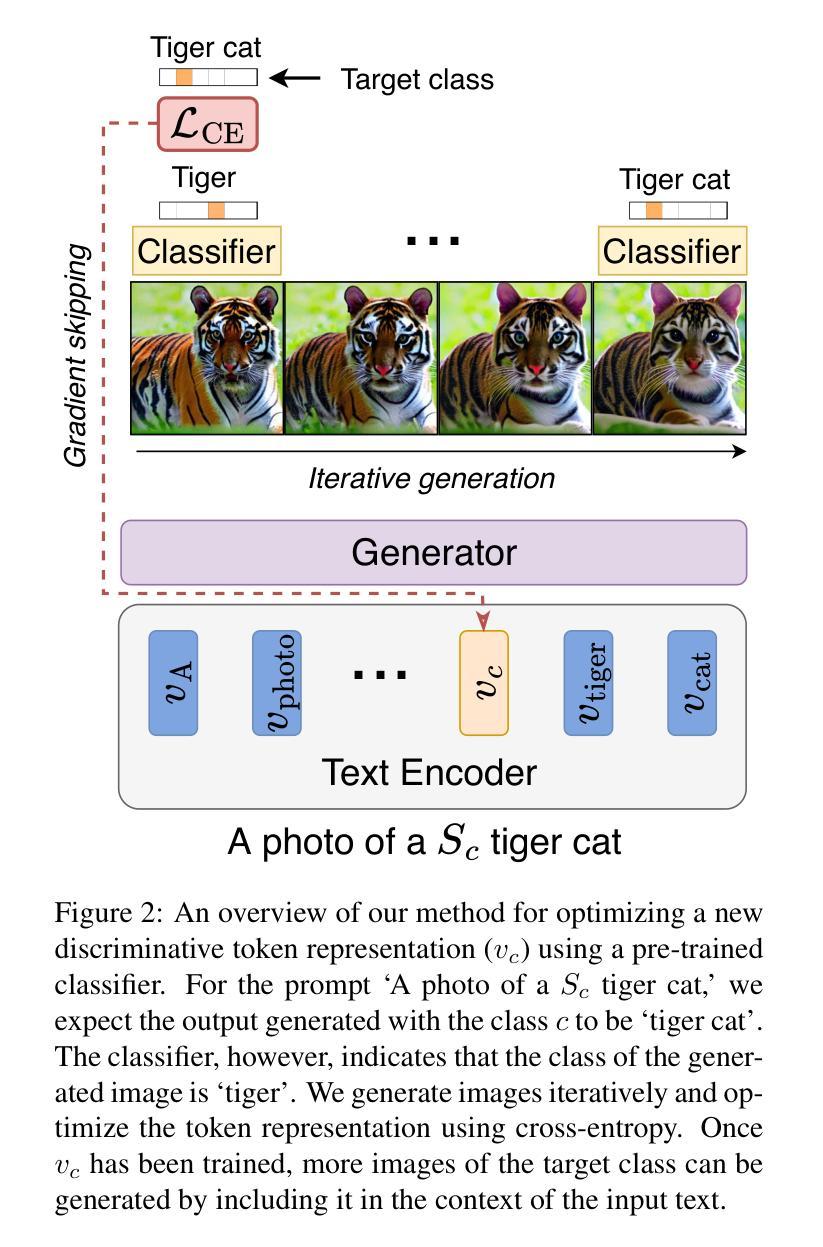
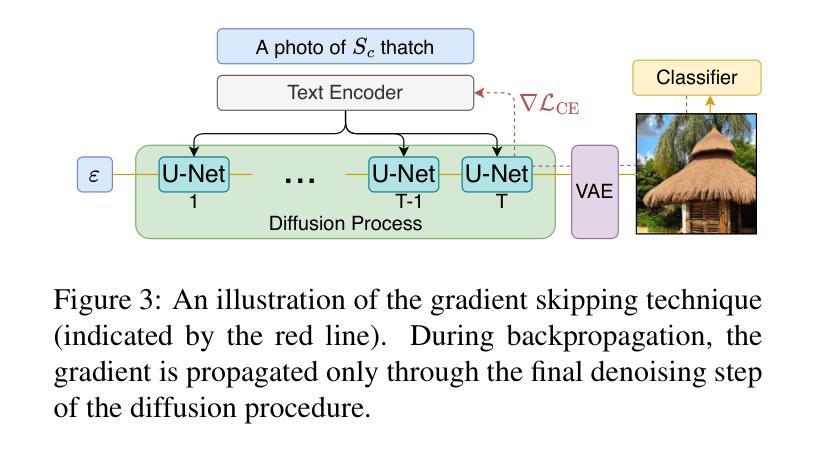
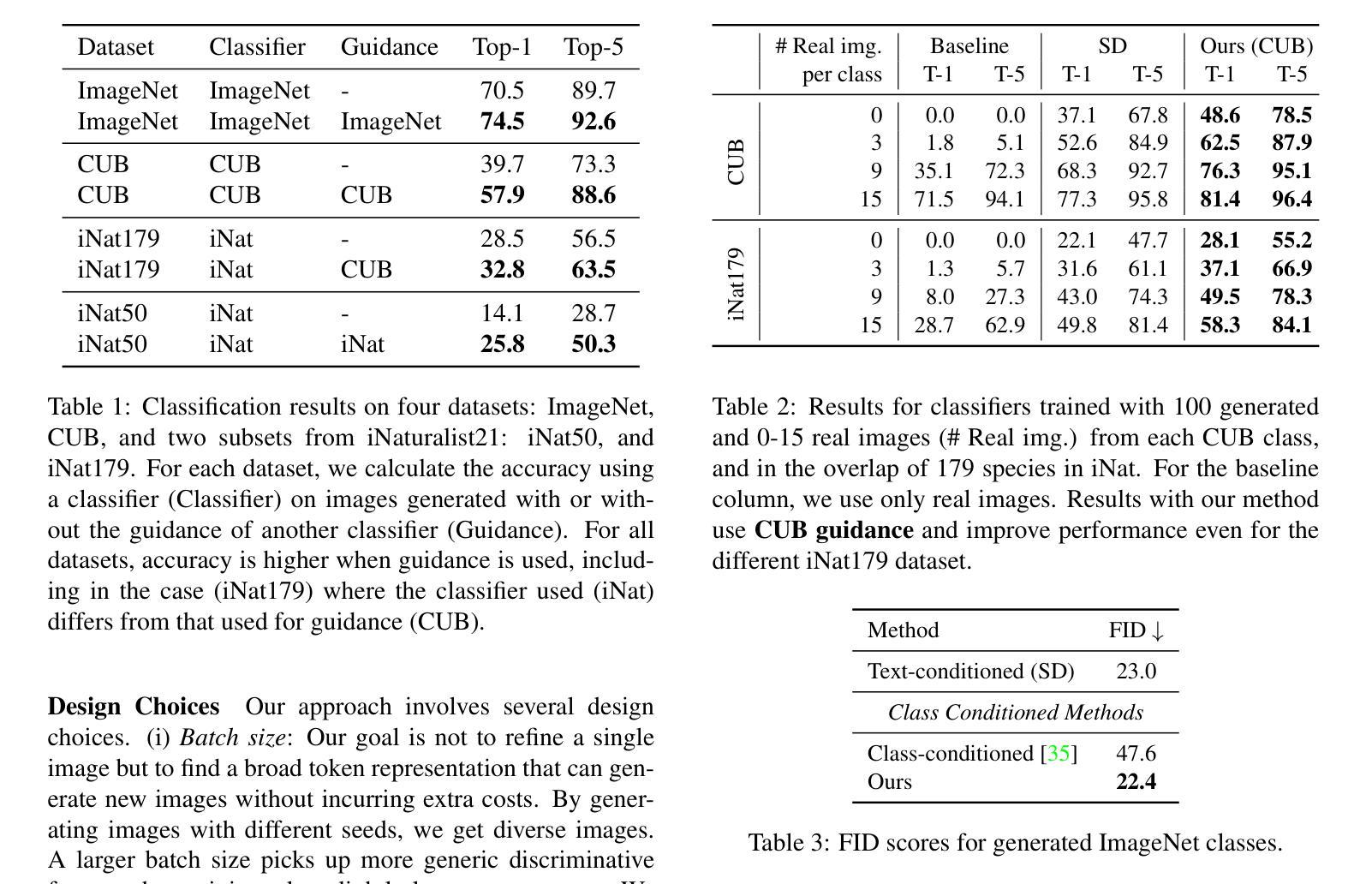
Discriminative Class Tokens for Text-to-Image Diffusion Models
Authors:Idan Schwartz, Vésteinn Snæbjarnarson, Hila Chefer, Ryan Cotterell, Serge Belongie, Lior Wolf, Sagie Benaim
Recent advances in text-to-image diffusion models have enabled the generation of diverse and high-quality images. While impressive, the images often fall short of depicting subtle details and are susceptible to errors due to ambiguity in the input text. One way of alleviating these issues is to train diffusion models on class-labeled datasets. This approach has two disadvantages: (i) supervised datasets are generally small compared to large-scale scraped text-image datasets on which text-to-image models are trained, affecting the quality and diversity of the generated images, or (ii) the input is a hard-coded label, as opposed to free-form text, limiting the control over the generated images. In this work, we propose a non-invasive fine-tuning technique that capitalizes on the expressive potential of free-form text while achieving high accuracy through discriminative signals from a pretrained classifier. This is done by iteratively modifying the embedding of an added input token of a text-to-image diffusion model, by steering generated images toward a given target class according to a classifier. Our method is fast compared to prior fine-tuning methods and does not require a collection of in-class images or retraining of a noise-tolerant classifier. We evaluate our method extensively, showing that the generated images are: (i) more accurate and of higher quality than standard diffusion models, (ii) can be used to augment training data in a low-resource setting, and (iii) reveal information about the data used to train the guiding classifier. The code is available at \url{https://github.com/idansc/discriminative_class_tokens}.
最近文本到图像扩散模型的进步使得能够生成多样且高质量的图像。虽然令人印象深刻,但这些图像往往无法描绘出细微的细节,并且由于输入文本的模糊性,容易出现错误。缓解这些问题的一种方法是使用类别标签数据集训练扩散模型。这种方法有两个缺点:一是与用于训练文本到图像模型的大规模爬取的文本图像数据集相比,监督数据集通常规模较小,影响生成图像的质量和多样性;二是输入是硬编码的标签,而不是自由形式的文本,限制了生成图像的控制性。
论文及项目相关链接
PDF ICCV 2023
摘要
近期文本到图像扩散模型的进展使得生成多样且高质量的图像成为可能。然而,生成的图像往往缺乏细微的细节描绘,并且由于输入文本的歧义而容易出现错误。为缓解这些问题,一种方法是使用分类标签数据集训练扩散模型。但这种方法存在两个缺点:一是监督数据集通常比用于训练文本到图像模型的大规模抓取文本图像数据集要小,影响生成图像的质量和多样性;二是输入是硬编码标签,而非自由形式的文本,限制了生成图像的控制能力。在此工作中,我们提出了一种非侵入式微调技术,该技术利用自由形式文本的表达能力,并通过预训练分类器的判别信号实现高精度。这是通过迭代修改文本到图像扩散模型中添加输入标记的嵌入来实现的,将生成的图像导向给定的目标类别,并根据分类器进行调整。我们的方法与先前的微调方法相比速度更快,并且不需要收集同类图像或重新训练噪声容忍分类器。我们进行了广泛的方法评估,证明生成的图像比标准扩散模型更准确、质量更高,可用于增强低资源设置中的训练数据,并揭示用于训练指导分类器的数据的信息。
关键见解
- 文本到图像扩散模型的最新进展能够生成多样且高质量的图像,但在描绘细微细节方面存在不足,且易受输入文本歧义的影响。
- 使用分类标签数据集训练扩散模型的方法存在两个主要缺点:数据集大小有限,以及输入形式限制(硬编码标签而非自由形式文本),这限制了生成图像的控制能力。
- 提出了一种非侵入式微调技术,结合自由形式文本的表达能力与预训练分类器的判别信号,以提高生成图像的质量和准确性。
- 该方法通过迭代修改文本到图像扩散模型中增加输入标记的嵌入来实现,使生成的图像能够导向特定类别,并根据分类器进行调整。
- 与其他微调方法相比,该方法具有更快的速度,且不需要收集同类图像或重新训练噪声容忍分类器。
- 评估表明,该方法生成的图像具有更高的准确性和质量,可用于增强低资源环境中的训练数据。
点此查看论文截图