⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-16 更新
Threshold Attention Network for Semantic Segmentation of Remote Sensing Images
Authors:Wei Long, Yongjun Zhang, Zhongwei Cui, Yujie Xu, Xuexue Zhang
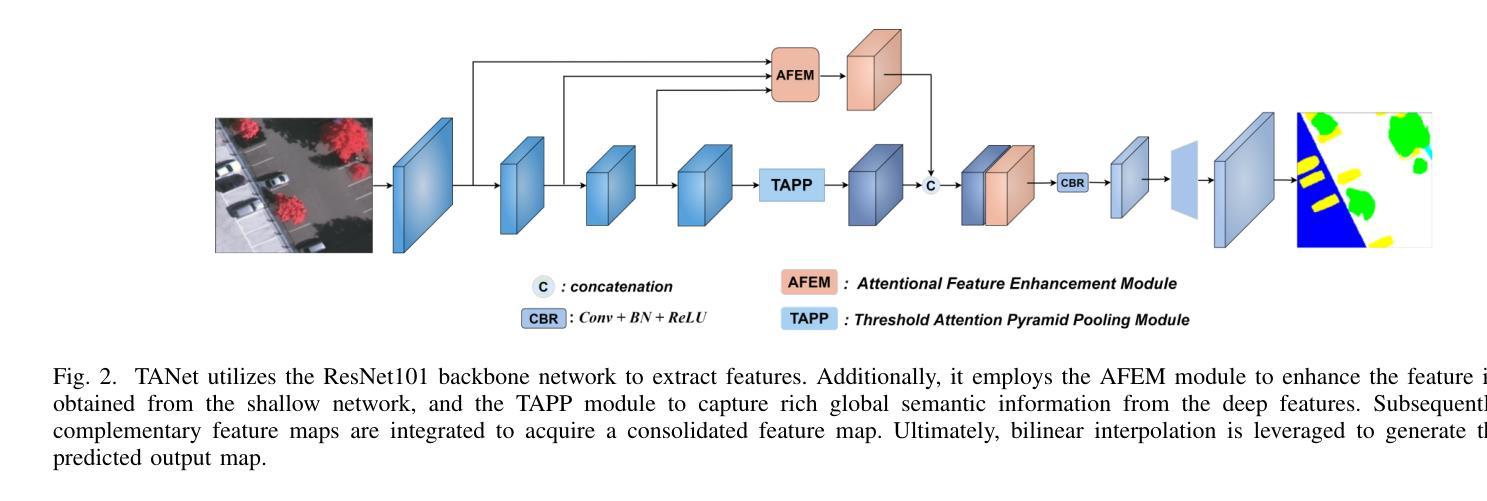
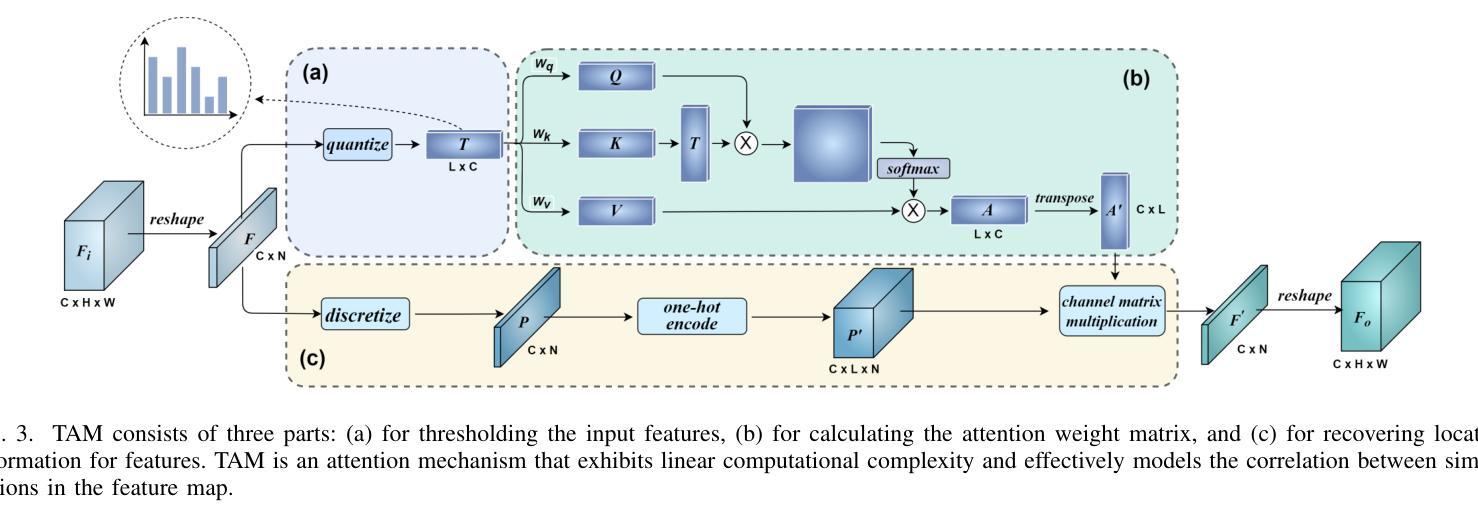
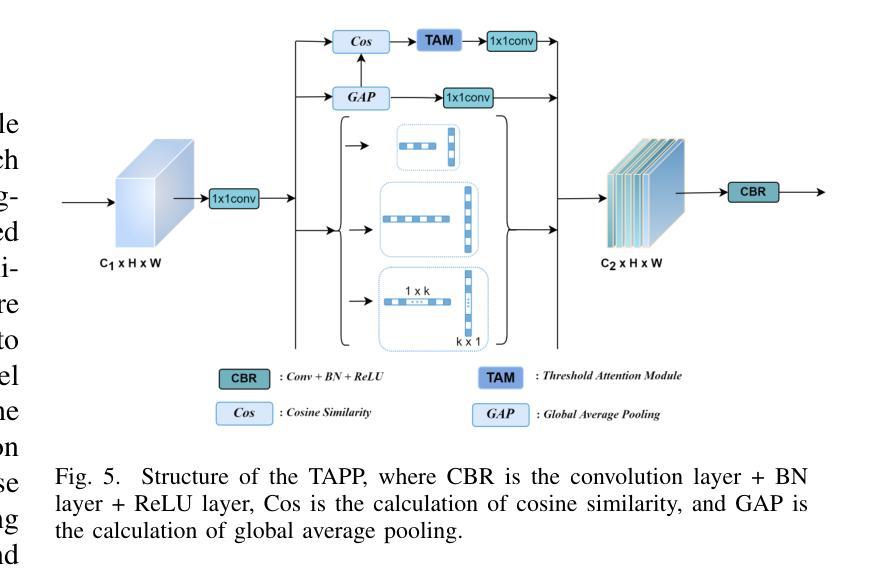
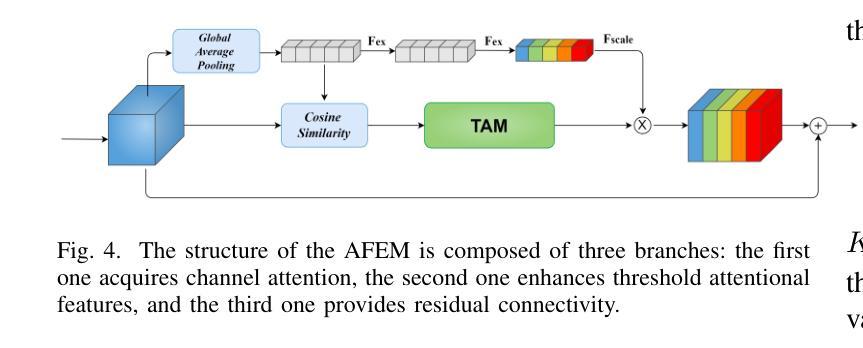
Semantic segmentation of remote sensing images is essential for various applications, including vegetation monitoring, disaster management, and urban planning. Previous studies have demonstrated that the self-attention mechanism (SA) is an effective approach for designing segmentation networks that can capture long-range pixel dependencies. SA enables the network to model the global dependencies between the input features, resulting in improved segmentation outcomes. However, the high density of attentional feature maps used in this mechanism causes exponential increases in computational complexity. Additionally, it introduces redundant information that negatively impacts the feature representation. Inspired by traditional threshold segmentation algorithms, we propose a novel threshold attention mechanism (TAM). This mechanism significantly reduces computational effort while also better modeling the correlation between different regions of the feature map. Based on TAM, we present a threshold attention network (TANet) for semantic segmentation. TANet consists of an attentional feature enhancement module (AFEM) for global feature enhancement of shallow features and a threshold attention pyramid pooling module (TAPP) for acquiring feature information at different scales for deep features. We have conducted extensive experiments on the ISPRS Vaihingen and Potsdam datasets. The results demonstrate the validity and superiority of our proposed TANet compared to the most state-of-the-art models.
遥感图像的语义分割对于各种应用至关重要,包括植被监测、灾害管理和城市规划。先前的研究表明,自注意力机制(SA)是设计分割网络的有效方法,能够捕获远程像素之间的依赖关系。自注意力机制使网络能够对输入特征之间的全局依赖关系进行建模,从而提高分割效果。然而,该机制中使用的注意力特征图的高密度导致计算复杂度呈指数增长。此外,它还引入了冗余信息,对特征表示产生负面影响。受传统阈值分割算法的启发,我们提出了一种新型阈值注意力机制(TAM)。该机制在降低计算成本的同时,更好地对特征图中不同区域的关联性进行建模。基于TAM,我们提出了用于语义分割的阈值注意力网络(TANet)。TANet包括一个注意力特征增强模块(AFEM),用于增强浅层特征的全局特征,以及一个阈值注意力金字塔池模块(TAPP),用于获取不同尺度的特征信息以供深度特征使用。我们在ISPRS Vaihingen和Potsdam数据集上进行了大量实验。结果表明,与我们提出的最新模型相比,我们所提出的TANet是有效和优越的。
论文及项目相关链接
Summary
这篇文本介绍了遥感图像语义分割的重要性及其在各种应用中的应用,包括植被监测、灾害管理和城市规划。文章指出,自注意力机制(SA)在设计分割网络时能有效捕捉长距离像素依赖关系,提高分割效果。然而,SA的高密度注意力特征映射导致了计算复杂性的指数增长,并引入了影响特征表示的冗余信息。为此,本文提出了一种新型阈值注意力机制(TAM),显著降低了计算成本,更好地建模了特征映射不同区域之间的相关性。基于TAM,本文提出了用于语义分割的阈值注意力网络(TANet)。TANet包括注意力特征增强模块(AFEM)用于增强浅层特征的全局特征,以及阈值注意力金字塔池模块(TAPP)用于获取不同尺度的深层特征信息。在ISPRS Vaihingen和Potsdam数据集上的实验结果表明,本文提出的TANet模型与最先进的模型相比具有有效性和优越性。
Key Takeaways
- 遥感图像语义分割在植被监测、灾害管理和城市规划等多个领域有广泛应用。
- 自注意力机制(SA)能捕捉长距离像素依赖关系,提高分割效果,但计算复杂度高,存在冗余信息。
- 提出的新型阈值注意力机制(TAM)能显著降低计算成本,更有效地建模特征映射不同区域间的相关性。
- 基于TAM的阈值注意力网络(TANet)由注意力特征增强模块(AFEM)和阈值注意力金字塔池模块(TAPP)组成。
- AFEM用于增强浅层特征的全局特征。
- TAPP用于获取不同尺度的深层特征信息。
点此查看论文截图


LarvSeg: Exploring Image Classification Data For Large Vocabulary Semantic Segmentation via Category-wise Attentive Classifier
Authors:Haojun Yu, Di Dai, Ziwei Zhao, Di He, Han Hu, Liwei Wang
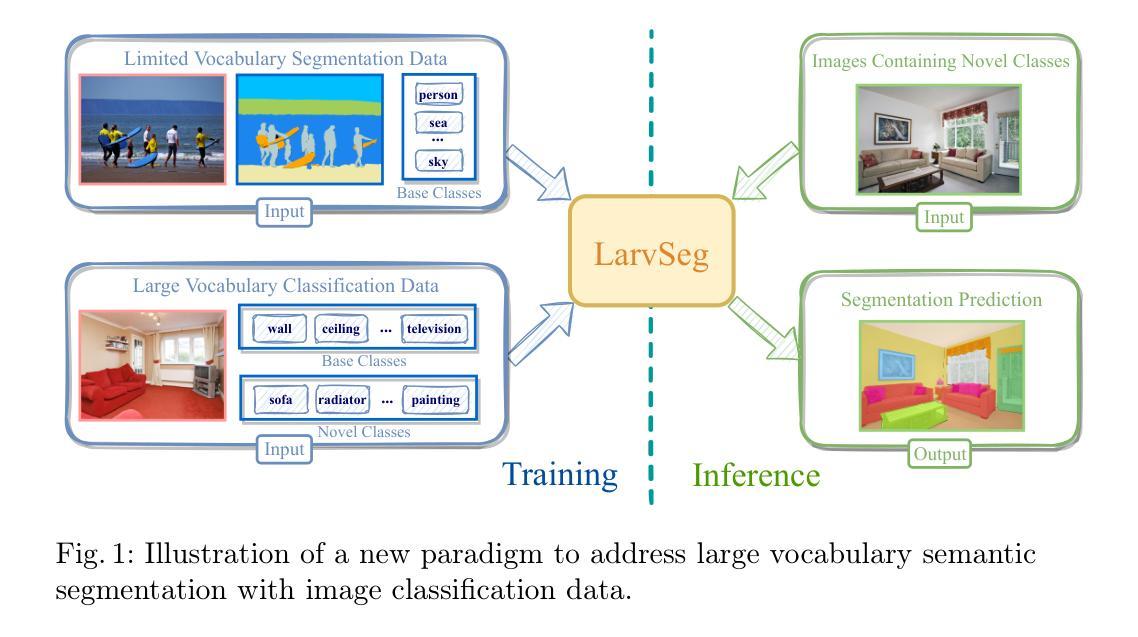
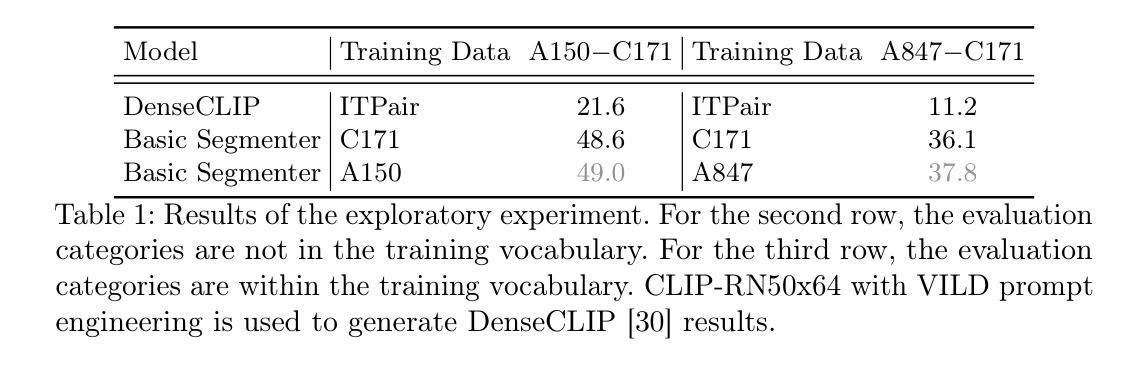
Scaling up the vocabulary of semantic segmentation models is extremely challenging because annotating large-scale mask labels is labour-intensive and time-consuming. Recently, language-guided segmentation models have been proposed to address this challenge. However, their performance drops significantly when applied to out-of-distribution categories. In this paper, we propose a new large vocabulary semantic segmentation framework, called LarvSeg. Different from previous works, LarvSeg leverages image classification data to scale the vocabulary of semantic segmentation models as large-vocabulary classification datasets usually contain balanced categories and are much easier to obtain. However, for classification tasks, the category is image-level, while for segmentation we need to predict the label at pixel level. To address this issue, we first propose a general baseline framework to incorporate image-level supervision into the training process of a pixel-level segmentation model, making the trained network perform semantic segmentation on newly introduced categories in the classification data. We then observe that a model trained on segmentation data can group pixel features of categories beyond the training vocabulary. Inspired by this finding, we design a category-wise attentive classifier to apply supervision to the precise regions of corresponding categories to improve the model performance. Extensive experiments demonstrate that LarvSeg significantly improves the large vocabulary semantic segmentation performance, especially in the categories without mask labels. For the first time, we provide a 21K-category semantic segmentation model with the help of ImageNet21K. The code is available at https://github.com/HaojunYu1998/large_voc_seg.
扩充语义分割模型的词汇量极具挑战性,因为大规模掩膜标签的标注工作繁重且耗时。最近,语言引导分割模型被提出来应对这一挑战。然而,当应用到分布外的类别时,它们的性能会显著下降。在本文中,我们提出了一种新的大词汇量语义分割框架,称为LarvSeg。不同于以前的工作,LarvSeg利用图像分类数据来扩展语义分割模型的词汇量,因为大词汇量分类数据集通常包含平衡类别且更容易获取。然而,对于分类任务,类别是图像级别的,而对于分割,我们需要在像素级别预测标签。为了解决这一问题,我们首先提出一个通用的基线框架,将图像级别的监督纳入像素级别的分割模型的训练过程中,使训练好的网络在新引入的类别上进行语义分割。然后我们发现一个训练在分割数据上的模型可以汇集超出训练词汇量的类别像素特征。受此启发,我们设计了一个类别特定的注意力分类器,对相应类别的精确区域施加监督,以提高模型性能。大量实验表明,LarvSeg显著提高了大词汇量语义分割的性能,特别是在没有掩膜标签的类别中。我们首次借助ImageNet21K提供了一个包含21K类别的语义分割模型。代码可在https://github.com/HaojunYu1998/large_voc_seg 获取。
论文及项目相关链接
PDF PRCV 2024
Summary
本文提出了一种新的大规模词汇语义分割框架——LarvSeg。它通过结合图像分类数据来扩展语义分割模型的词汇量,解决了标注大规模掩膜标签的劳动密集和时间消耗问题。该框架通过使用图像级别的监督信息训练像素级别的分割模型,使得模型能够在分类数据中对新引入的类别进行语义分割。此外,还设计了一个类别感知的分类器,以提高模型性能。实验表明,LarvSeg在大量词汇的语义分割任务上显著提高性能,特别是在没有掩膜标签的类别上。该模型首次提供了使用ImageNet21K数据的21K类别语义分割模型。
Key Takeaways
- LarvSeg利用图像分类数据来扩展语义分割模型的词汇量,解决大规模掩膜标签标注的挑战。
- 提出了一种结合图像级别监督信息训练像素级别分割模型的通用基线框架。
- 通过实验发现,在分割数据上训练的模型能够分组超出训练词汇量的类别像素特征。
- 受到了这一发现的启发,设计了一个类别感知的分类器,对相应类别的精确区域进行监管,以提高模型性能。
- LarvSeg在大量词汇的语义分割任务上表现优异,特别是在没有掩膜标签的类别上。
点此查看论文截图



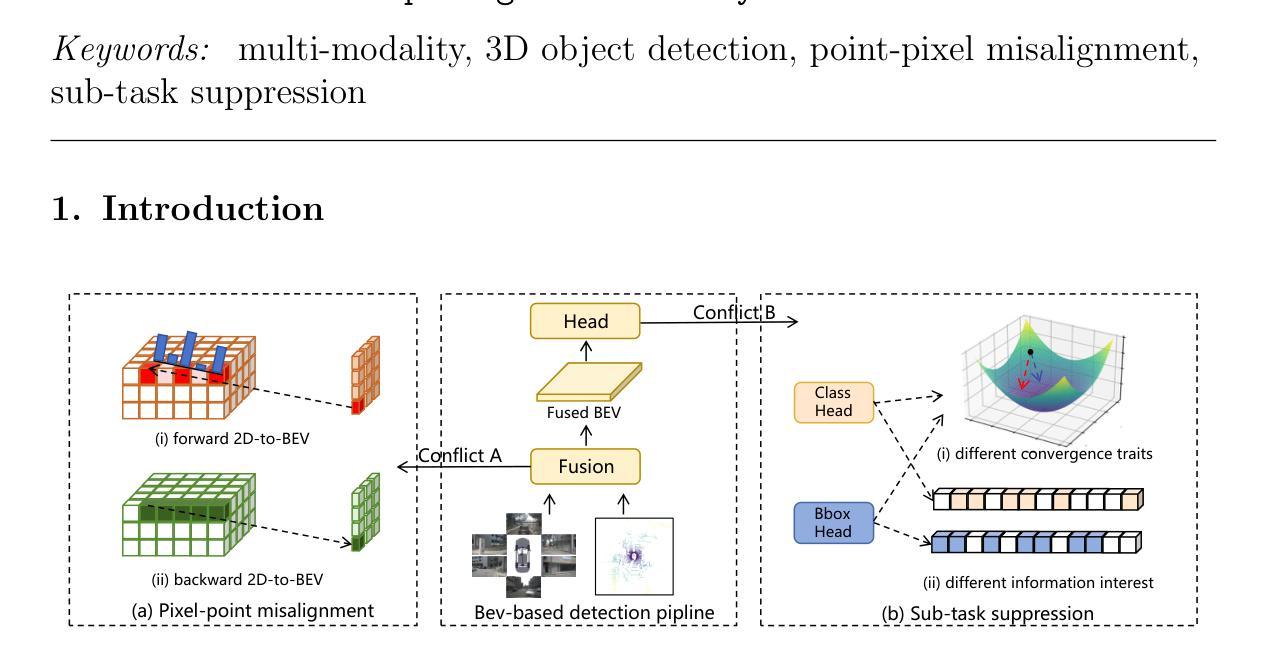
CoreNet: Conflict Resolution Network for Point-Pixel Misalignment and Sub-Task Suppression of 3D LiDAR-Camera Object Detection
Authors:Yiheng Li, Yang Yang, Zhen Lei
Fusing multi-modality inputs from different sensors is an effective way to improve the performance of 3D object detection. However, current methods overlook two important conflicts: point-pixel misalignment and sub-task suppression. The former means a pixel feature from the opaque object is projected to multiple point features of the same ray in the world space, and the latter means the classification prediction and bounding box regression may cause mutual suppression. In this paper, we propose a novel method named Conflict Resolution Network (CoreNet) to address the aforementioned issues. Specifically, we first propose a dual-stream transformation module to tackle point-pixel misalignment. It consists of ray-based and point-based 2D-to-BEV transformations. Both of them achieve approximately unique mapping from the image space to the world space. Moreover, we introduce a task-specific predictor to tackle sub-task suppression. It uses the dual-branch structure which adopts class-specific query and Bbox-specific query to corresponding sub-tasks. Each task-specific query is constructed of task-specific feature and general feature, which allows the heads to adaptively select information of interest based on different sub-tasks. Experiments on the large-scale nuScenes dataset demonstrate the superiority of our proposed CoreNet, by achieving 75.6% NDS and 73.3% mAP on the nuScenes test set without test-time augmentation and model ensemble techniques. The ample ablation study also demonstrates the effectiveness of each component. The code is released on https://github.com/liyih/CoreNet.
融合不同传感器的多模态输入是提高3D目标检测性能的有效途径。然而,当前的方法忽略了两个重要的冲突:点像素不对齐和子任务抑制。前者意味着来自不透明对象的像素特征被投射到世界空间中的同一射线的多个点特征上,后者则意味着分类预测和边界框回归可能会相互抑制。在本文中,我们提出了一种名为Conflict Resolution Network(CoreNet)的新方法来解决上述问题。具体来说,我们首先提出了一个双流转换模块来解决点像素不对齐问题。它包括基于射线和基于点的2D-to-BEV转换。它们都实现了从图像空间到世界空间的近似唯一映射。此外,我们引入了一个针对子任务抑制的特定任务预测器。它采用双分支结构,采用类特定查询和Bbox特定查询来对应子任务。每个特定任务查询由特定任务特征和一般特征构成,这使得头部能够根据不同的子任务自适应地选择感兴趣的信息。在大型nuScenes数据集上的实验表明,我们提出的CoreNet具有优越性,在nuScenes测试集上实现了75.6%的NDS和73.3%的mAP,无需测试时间增强和模型集成技术。丰富的消融研究也证明了每个组件的有效性。代码已发布在https://github.com/liyih/CoreNet。
论文及项目相关链接
PDF Accepted by Information Fusion 2025
Summary
本文提出了一种名为Conflict Resolution Network (CoreNet)的新方法,解决了多模态输入融合在3D目标检测中的两大冲突问题:点像素错位和子任务抑制。通过引入双流转换模块和针对任务的预测器,实现了对这两个问题的有效处理,提高了3D目标检测的性能。在nuScenes数据集上的实验证明了CoreNet的优越性。
Key Takeaways
- 多模态输入融合是提高3D目标检测性能的有效方式。
- 当前方法忽略了点像素错位和子任务抑制两大冲突。
- CoreNet通过引入双流转换模块解决点像素错位问题。
- CoreNet采用任务特定预测器解决子任务抑制问题。
- 双流转换模块包括基于射线和点基的2D-to-BEV转换,实现了从图像空间到世界空间的近似唯一映射。
- CoreNet在nuScenes数据集上的实验表现出优越性,达到了75.6%的NDS和73.3%的mAP。
点此查看论文截图

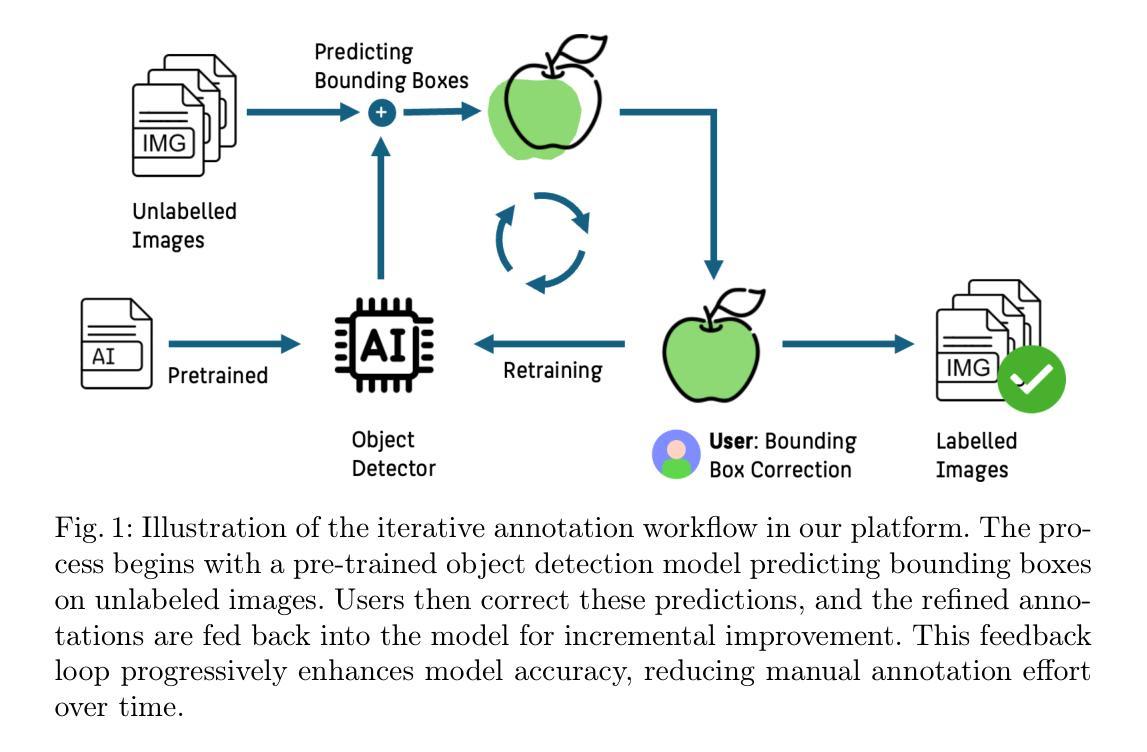
Feedback-driven object detection and iterative model improvement
Authors:Sönke Tenckhoff, Mario Koddenbrock, Erik Rodner
Automated object detection has become increasingly valuable across diverse applications, yet efficient, high-quality annotation remains a persistent challenge. In this paper, we present the development and evaluation of a platform designed to interactively improve object detection models. The platform allows uploading and annotating images as well as fine-tuning object detection models. Users can then manually review and refine annotations, further creating improved snapshots that are used for automatic object detection on subsequent image uploads - a process we refer to as semi-automatic annotation resulting in a significant gain in annotation efficiency. Whereas iterative refinement of model results to speed up annotation has become common practice, we are the first to quantitatively evaluate its benefits with respect to time, effort, and interaction savings. Our experimental results show clear evidence for a significant time reduction of up to 53% for semi-automatic compared to manual annotation. Importantly, these efficiency gains did not compromise annotation quality, while matching or occasionally even exceeding the accuracy of manual annotations. These findings demonstrate the potential of our lightweight annotation platform for creating high-quality object detection datasets and provide best practices to guide future development of annotation platforms. The platform is open-source, with the frontend and backend repositories available on GitHub (https://github.com/ml-lab-htw/iterative-annotate). To support the understanding of our labeling process, we have created an explanatory video demonstrating the methodology using microscopy images of E. coli bacteria as an example. The video is available on YouTube (https://www.youtube.com/watch?v=CM9uhE8NN5E).
自动目标检测在不同应用中的价值日益凸显,然而高效、高质量的标注仍然是一个持续的挑战。在本文中,我们介绍了一个交互式改进目标检测模型的平台的开发评估。该平台允许上传和标注图像,以及微调目标检测模型。用户随后可以手动审查和修改标注,进一步创建改进的快照,用于后续图像上传的自动目标检测——我们称之为半自动标注,这大大提高了标注效率。虽然通过迭代优化模型结果来加速标注已成为一种常见做法,但我们是首次就时间、精力和交互节省等方面定量评估其效益。我们的实验结果表明,与手动标注相比,半自动标注的时间减少了高达53%。重要的是,这些效率的提升并没有损害标注质量,甚至在某些情况下还超过了手动标注的准确度。这些发现证明了我们轻量级标注平台的潜力,可用于创建高质量的目标检测数据集,并为未来标注平台的发展提供了最佳实践指导。平台是开源的,前端和后端仓库可在GitHub上找到(https://github.com/ml-lab-htw/iterative-annotate)。为了支持对标注过程的理解,我们制作了一个解释性视频,使用大肠杆菌显微镜图像作为示例来展示方法。视频可在YouTube上观看(https://www.youtube.com/watch?v=CM9uhE8NN5E)。
论文及项目相关链接
PDF AI4EA24
Summary:本研究开发并评估了一个交互式平台,用于提高物体检测模型的性能。该平台支持图像上传、标注和模型微调。用户可手动审查和修正标注,创建改进后的快照用于后续自动物体检测。通过半自动标注,显著提高了标注效率,减少了时间和交互成本,同时保证了标注质量。平台开源,并提供相关视频教程支持理解标注过程。
Key Takeaways:
- 该平台旨在提高物体检测模型的性能,支持图像上传、标注和模型微调。
- 用户可以手动审查和修正标注,进一步改进自动物体检测效果。
- 平台通过半自动标注显著提高了标注效率,减少了时间和交互成本。
- 实验结果表明,半自动标注与传统手动标注相比,时间可减少高达53%。
- 平台在保证标注质量的同时实现了效率的提升,甚至在某些情况下超过了手动标注的准确度。
- 平台开源,并提供GitHub和YouTube上的相关资源以供学习和使用。
点此查看论文截图


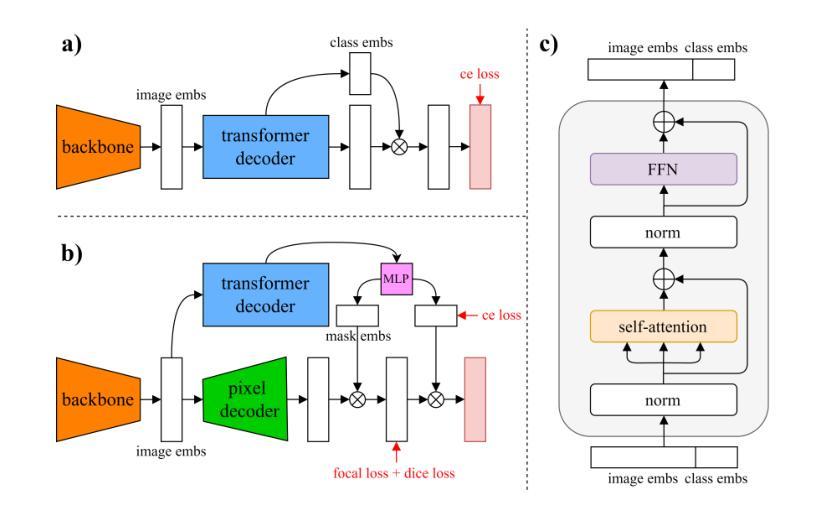
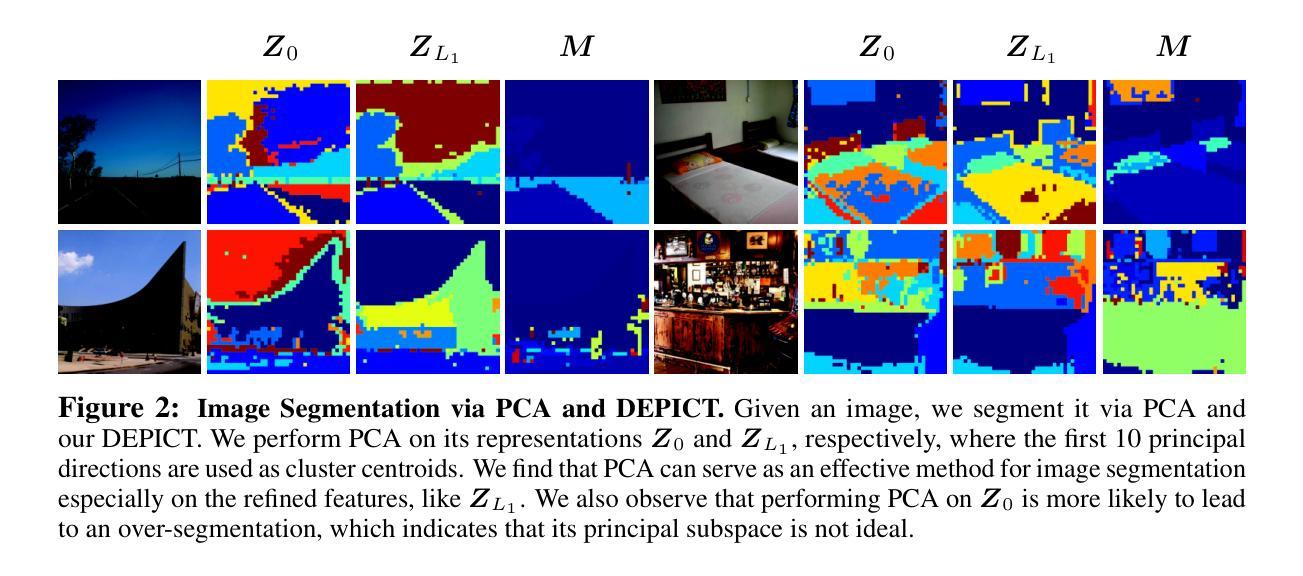
Rethinking Decoders for Transformer-based Semantic Segmentation: A Compression Perspective
Authors:Qishuai Wen, Chun-Guang Li
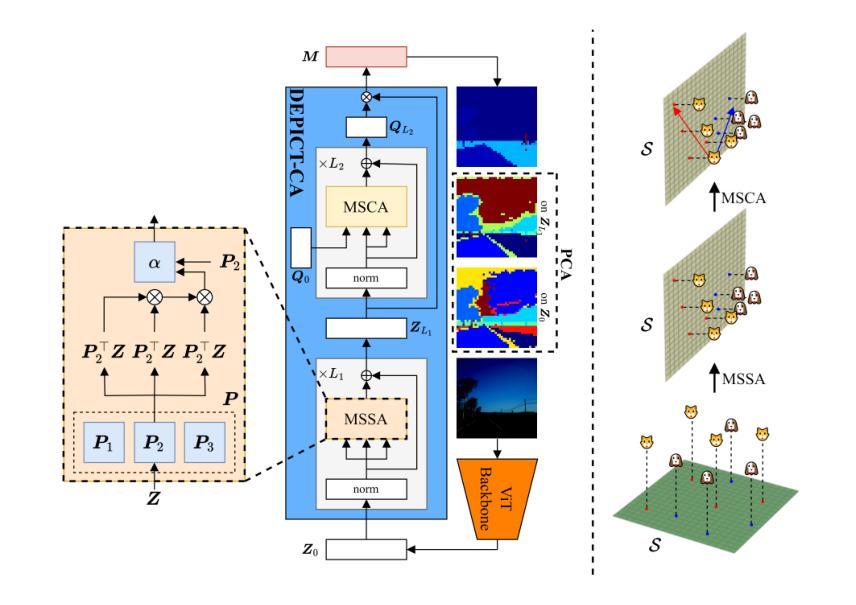
State-of-the-art methods for Transformer-based semantic segmentation typically adopt Transformer decoders that are used to extract additional embeddings from image embeddings via cross-attention, refine either or both types of embeddings via self-attention, and project image embeddings onto the additional embeddings via dot-product. Despite their remarkable success, these empirical designs still lack theoretical justifications or interpretations, thus hindering potentially principled improvements. In this paper, we argue that there are fundamental connections between semantic segmentation and compression, especially between the Transformer decoders and Principal Component Analysis (PCA). From such a perspective, we derive a white-box, fully attentional DEcoder for PrIncipled semantiC segemenTation (DEPICT), with the interpretations as follows: 1) the self-attention operator refines image embeddings to construct an ideal principal subspace that aligns with the supervision and retains most information; 2) the cross-attention operator seeks to find a low-rank approximation of the refined image embeddings, which is expected to be a set of orthonormal bases of the principal subspace and corresponds to the predefined classes; 3) the dot-product operation yields compact representation for image embeddings as segmentation masks. Experiments conducted on dataset ADE20K find that DEPICT consistently outperforms its black-box counterpart, Segmenter, and it is light weight and more robust.
基于Transformer的语义分割的先进方法通常采用Transformer解码器,通过交叉注意力从图像嵌入中提取额外的嵌入,通过自注意力对任一或两种嵌入进行精炼,并通过点积将图像嵌入投影到额外的嵌入上。尽管这些方法取得了显著的成功,但这些经验设计仍然缺乏理论证明或解释,从而阻碍了可能的原则性改进。在本文中,我们认为语义分割与压缩之间存在根本联系,特别是Transformer解码器与主成分分析(PCA)之间的联系。从这一角度出发,我们推导出了一个白盒、全注意力的解码器DEPICT(用于原则性语义分割),其解释如下:1)自注意力运算符通过完善图像嵌入来构建一个理想的主子空间,该空间与监督对齐并保留最多信息;2)交叉注意力运算符试图找到精炼图像嵌入的低阶逼近,这期望是一组正交基的子集,并与预定义的类别相对应;3)点积操作为图像嵌入生成紧凑的表示形式作为分割掩膜。在ADE20K数据集上进行的实验发现,DEPICT持续优于其黑盒竞品Segmenter,并且它更加轻便和稳健。
论文及项目相关链接
PDF NeurIPS2024. Code:https://github.com/QishuaiWen/DEPICT/
Summary:本文提出了一种基于主成分分析(PCA)的语义分割模型的全新理论框架DEPICT,它通过解释性的角度解析了Transformer解码器的内部机制。DEPICT通过自我关注操作精炼图像嵌入,构建一个理想的主成分子空间,并通过交叉关注操作寻找精炼图像嵌入的低秩近似,最后通过点积操作得到图像嵌入的紧凑表示作为分割掩码。实验证明,DEPICT在ADE20K数据集上表现优异,相较于非解释性的模型Segmenter具有更高的性能、更轻量级和更强的鲁棒性。
Key Takeaways:
- 该论文提出了一种基于主成分分析(PCA)和注意力机制的语义分割模型DEPICT,通过解释Transformer解码器的内部机制来构建模型。
- DEPICT通过自我关注操作精炼图像嵌入,构建一个理想的主分子空间以对齐监督信息并保留大部分信息。
- DEPICT利用交叉关注操作寻找精炼图像嵌入的低秩近似,该低秩近似对应于预定义类别的一组正交基。
- 点积操作用于产生图像嵌入的紧凑表示形式作为分割掩码。
- 实验结果表明,DEPICT在ADE20K数据集上的表现优于现有的黑箱模型Segmenter。
- DEPICT模型具有轻量级和高度鲁棒性的特点。
点此查看论文截图

Semantic Prompt Learning for Weakly-Supervised Semantic Segmentation
Authors:Ci-Siang Lin, Chien-Yi Wang, Yu-Chiang Frank Wang, Min-Hung Chen
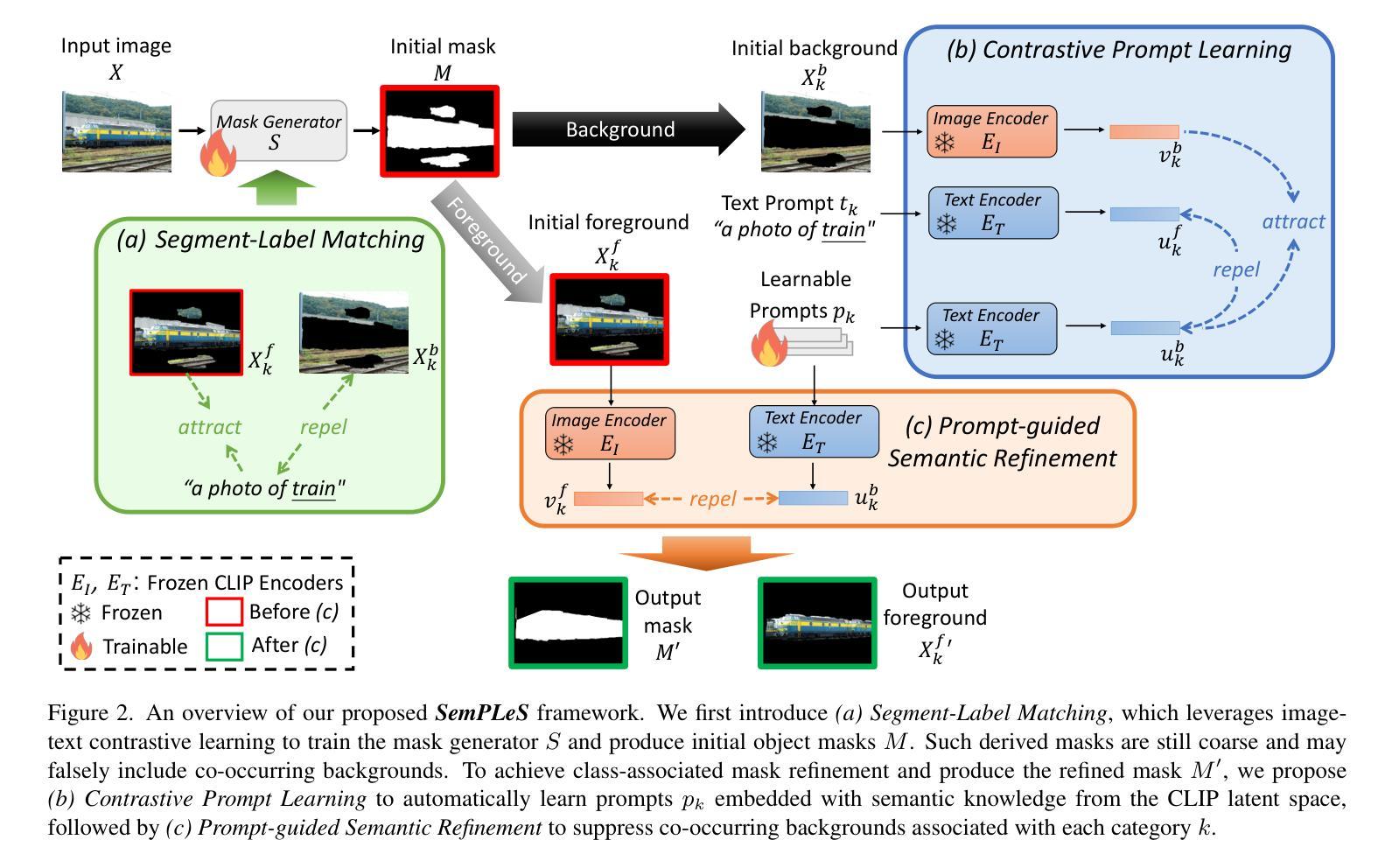
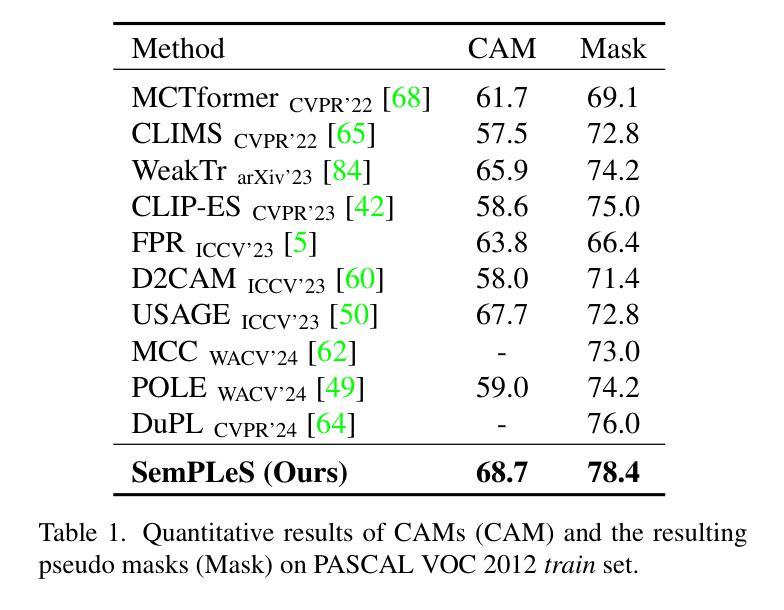
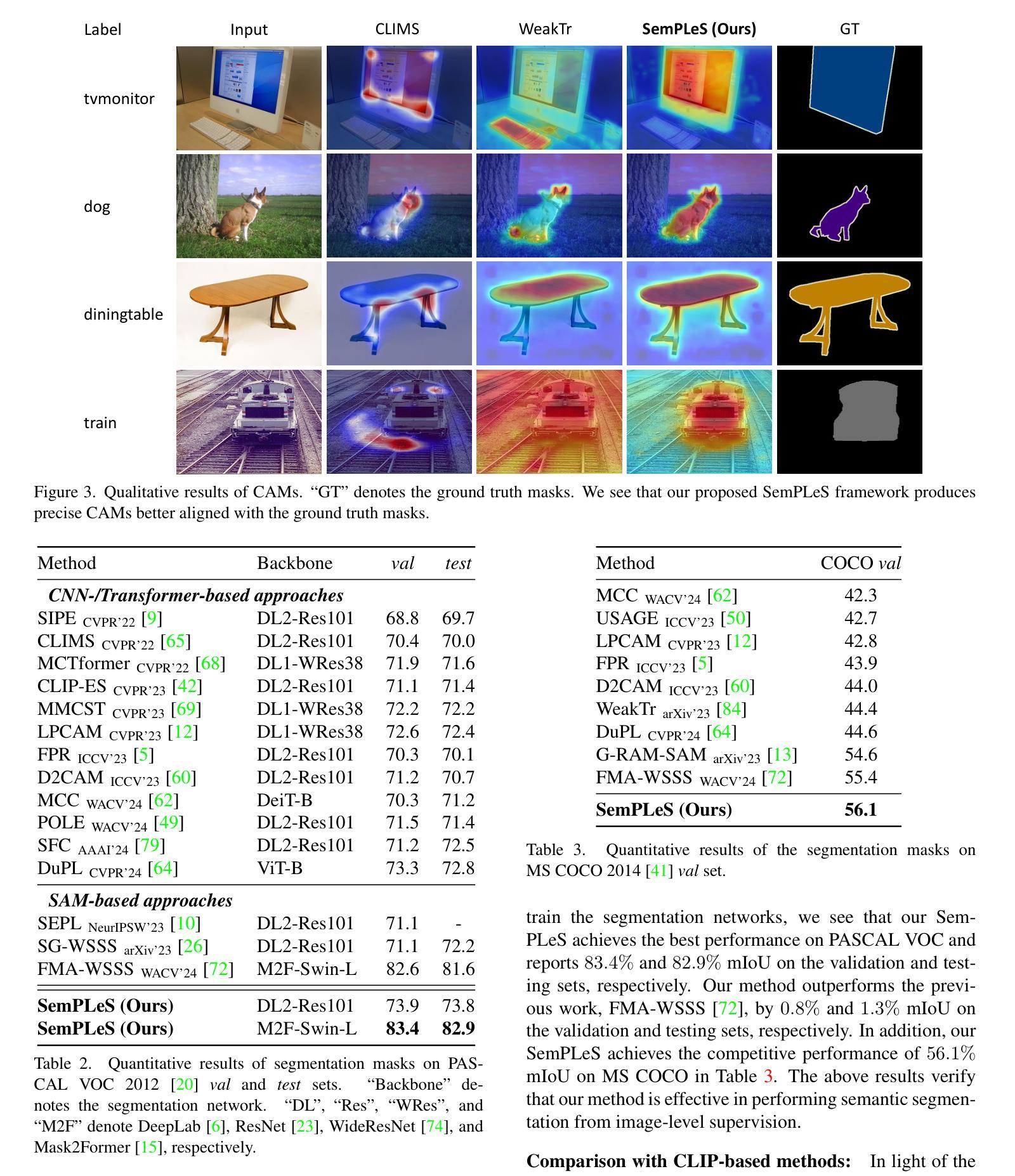
Weakly-Supervised Semantic Segmentation (WSSS) aims to train segmentation models using image data with only image-level supervision. Since precise pixel-level annotations are not accessible, existing methods typically focus on producing pseudo masks for training segmentation models by refining CAM-like heatmaps. However, the produced heatmaps may capture only the discriminative image regions of object categories or the associated co-occurring backgrounds. To address the issues, we propose a Semantic Prompt Learning for WSSS (SemPLeS) framework, which learns to effectively prompt the CLIP latent space to enhance the semantic alignment between the segmented regions and the target object categories. More specifically, we propose Contrastive Prompt Learning and Prompt-guided Semantic Refinement to learn the prompts that adequately describe and suppress the co-occurring backgrounds associated with each object category. In this way, SemPLeS can perform better semantic alignment between object regions and class labels, resulting in desired pseudo masks for training segmentation models. The proposed SemPLeS framework achieves competitive performance on standard WSSS benchmarks, PASCAL VOC 2012 and MS COCO 2014, and shows compatibility with other WSSS methods. Code: https://github.com/NVlabs/SemPLeS.
弱监督语义分割(WSSS)旨在使用仅带有图像级监督的图像数据来训练分割模型。由于无法获得精确的像素级注释,现有方法通常通过优化CAM(类激活映射)类热图来生成用于训练分割模型的伪掩码。然而,生成的热图可能只捕获对象类别的辨别性图像区域或相关的共发生背景。为了解决这些问题,我们提出了弱监督语义分割的语义提示学习(SemPLeS)框架,该框架学习有效地提示CLIP潜在空间,以增强分割区域与目标对象类别之间的语义对齐。更具体地说,我们提出了对比提示学习和提示引导语义细化,以学习足够描述并抑制与每个对象类别相关的共发生背景的提示。通过这种方式,SemPLeS可以在对象区域和类别标签之间实现更好的语义对齐,从而生成用于训练分割模型的理想伪掩码。所提出的SemPLeS框架在标准WSSS基准测试(PASCAL VOC 2012和MS COCO 2014)上取得了具有竞争力的性能,并显示出与其他WSSS方法的兼容性。代码地址:https://github.com/NVlabs/SemPLeS。
论文及项目相关链接
PDF WACV 2025. Code: https://github.com/NVlabs/SemPLeS. Project page: https://projectdisr.github.io/semples/
Summary
本文介绍了弱监督语义分割(WSSS)的挑战,并提出了一个新的框架SemPLeS来解决这个问题。SemPLeS利用CLIP潜在空间中的提示来学习有效地描述目标对象的语义信息,并抑制与之相关的背景。通过对比提示学习和提示引导语义细化,SemPLeS能够生成更准确的伪掩码来训练分割模型。该框架在PASCAL VOC 2012和MS COCO 2014等标准WSSS基准测试中取得了有竞争力的性能。
Key Takeaways
- 弱监督语义分割(WSSS)的目标是使用仅带有图像级别监督的图像数据来训练分割模型。
- 由于缺乏精确的像素级别注释,现有方法通常通过优化CAM热图来生成伪掩码进行训练。
- 提出的SemPLeS框架旨在解决现有方法可能只捕获对象类别的鉴别性图像区域或相关共发生背景的问题。
- SemPLeS利用CLIP潜在空间中的提示来学习有效地描述目标对象的语义信息,并抑制背景。
- 通过对比提示学习和提示引导语义细化,SemPLeS能更准确地描述和抑制与每个对象类别相关的共发生背景。
- SemPLeS框架在标准WSSS基准测试中表现出竞争力。
点此查看论文截图

On the Robustness of Object Detection Models on Aerial Images
Authors:Haodong He, Jian Ding, Bowen Xu, Gui-Song Xia
The robustness of object detection models is a major concern when applied to real-world scenarios. The performance of most models tends to degrade when confronted with images affected by corruptions, since they are usually trained and evaluated on clean datasets. While numerous studies have explored the robustness of object detection models on natural images, there is a paucity of research focused on models applied to aerial images, which feature complex backgrounds, substantial variations in scales, and orientations of objects. This paper addresses the challenge of assessing the robustness of object detection models on aerial images, with a specific emphasis on scenarios where images are affected by clouds. In this study, we introduce two novel benchmarks based on DOTA-v1.0. The first benchmark encompasses 19 prevalent corruptions, while the second focuses on the cloud-corrupted condition-a phenomenon uncommon in natural images yet frequent in aerial photography. We systematically evaluate the robustness of mainstream object detection models and perform necessary ablation experiments. Through our investigations, we find that rotation-invariant modeling and enhanced backbone architectures can improve the robustness of models. Furthermore, increasing the capacity of Transformer-based backbones can strengthen their robustness. The benchmarks we propose and our comprehensive experimental analyses can facilitate research on robust object detection on aerial images. The codes and datasets are available at: https://github.com/hehaodong530/DOTA-C.
对象检测模型在现实世界场景中的应用的鲁棒性是一个重要的关注点。当面对受污染影响的图像时,大多数模型的性能往往会下降,因为它们通常是在干净的数据集上进行训练和评估的。虽然许多研究已经探索了对象检测模型在自然图像上的鲁棒性,但关于应用于具有复杂背景、尺度变化大以及物体方向变化显著的高空图像模型的深入研究很少。本文解决了评估对象检测模型在高空图像上鲁棒性的挑战,特别是在图像受云层影响的情况下的场景。在这项研究中,我们基于DOTA-v1.0引入了两个新的基准测试。第一个基准测试包括19种常见的腐败形式,而第二个则专注于云层腐蚀的条件——这是一种在自然图像中很少见,但在航空摄影中经常发生的现象。我们系统地评估了主流对象检测模型的鲁棒性,并进行了必要的消融实验。通过我们的调查,我们发现旋转不变建模和增强的主干架构可以提高模型的鲁棒性。此外,增加基于Transformer的主干的容量可以加强其鲁棒性。我们提出的基准测试和全面的实验分析可以推动高空图像上鲁棒对象检测的研究。相关代码和数据集可在以下网址找到:[https://github.com/hehaodong530/DOTA-C]。
论文及项目相关链接
PDF accepted by IEEE TGRS
Summary:针对现实场景中的对象检测模型鲁棒性问题,该文对航拍图像的对象检测模型鲁棒性进行了评估。针对航拍图像复杂背景、尺度及方向变化等特点,引入两个基于DOTA-v1.0的新基准测试集,一个包含19种常见腐蚀情况,另一个专注于云腐蚀情况。通过系统评估主流对象检测模型的鲁棒性和进行必要的消融实验,发现旋转不变建模和增强主干架构能提高模型鲁棒性,增加基于Transformer的主干容量也能增强鲁棒性。提出的基准测试和实验分析有助于研究航拍图像上的稳健对象检测。
Key Takeaways:
- 对象检测模型在现实世界场景中的鲁棒性是一个重要问题,特别是在面对受腐蚀影响的图像时。
- 目前对航拍图像中的对象检测模型鲁棒性的研究较少,这些图像具有复杂背景、尺度及方向变化等特点。
- 引入两个新的基准测试集,一个包含多种常见腐蚀情况,另一个专注于云腐蚀情况。
- 系统评估主流对象检测模型的鲁棒性,发现旋转不变建模和增强主干架构能提高模型性能。
- 增加基于Transformer的主干容量也能增强模型的鲁棒性。
- 提出的基准测试和实验分析有助于推进航拍图像上的稳健对象检测研究。
点此查看论文截图