⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-16 更新
Omni-RGPT: Unifying Image and Video Region-level Understanding via Token Marks
Authors:Miran Heo, Min-Hung Chen, De-An Huang, Sifei Liu, Subhashree Radhakrishnan, Seon Joo Kim, Yu-Chiang Frank Wang, Ryo Hachiuma
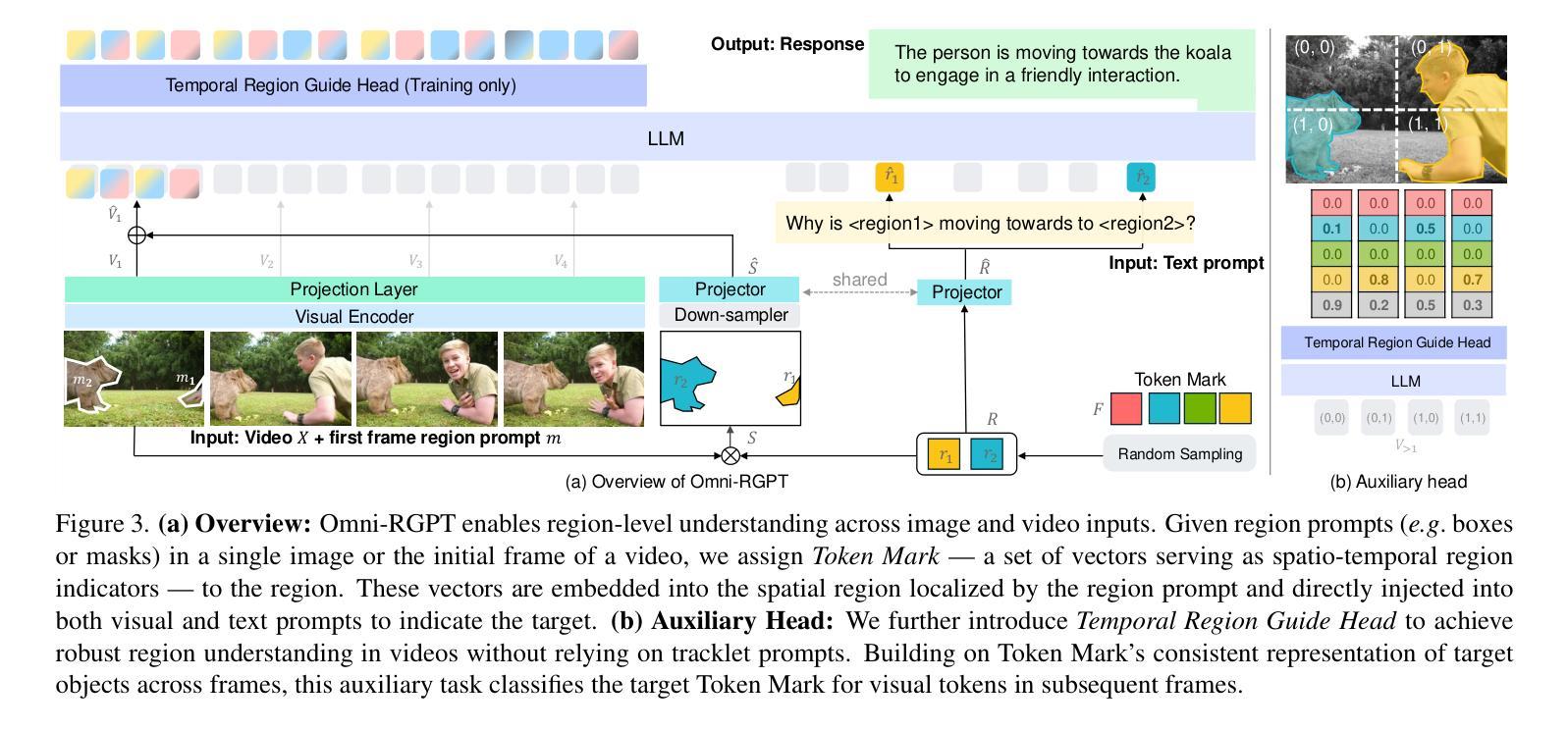
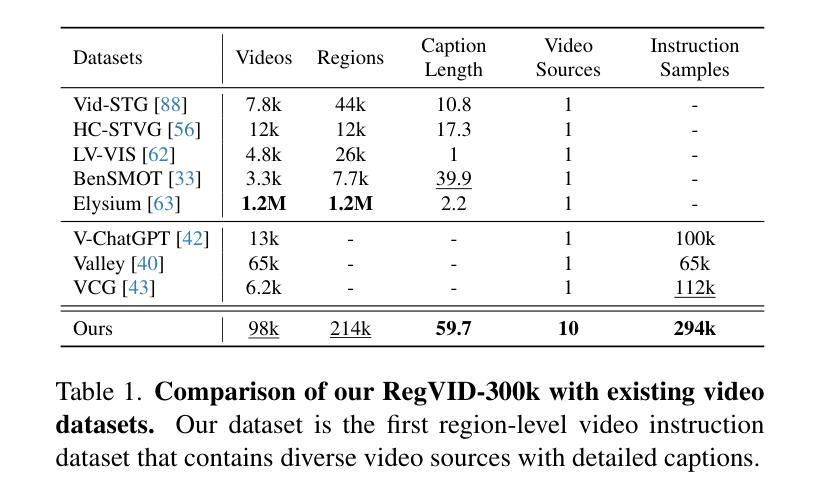
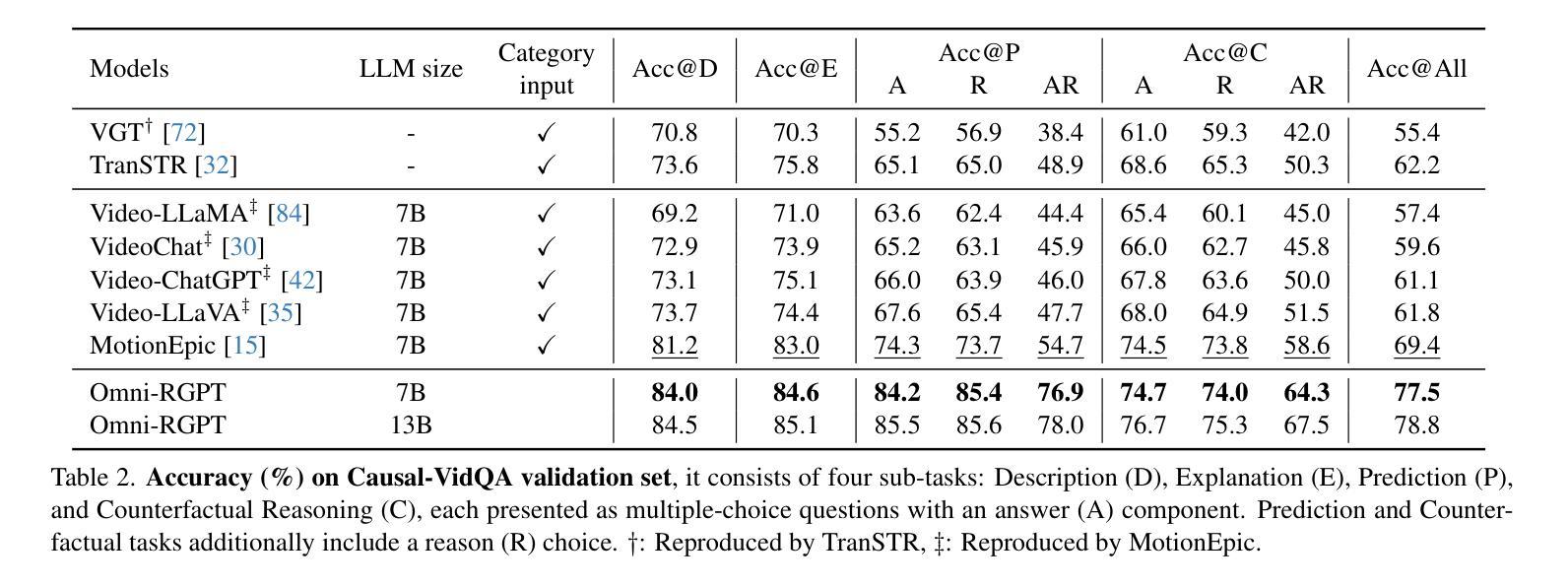
We present Omni-RGPT, a multimodal large language model designed to facilitate region-level comprehension for both images and videos. To achieve consistent region representation across spatio-temporal dimensions, we introduce Token Mark, a set of tokens highlighting the target regions within the visual feature space. These tokens are directly embedded into spatial regions using region prompts (e.g., boxes or masks) and simultaneously incorporated into the text prompt to specify the target, establishing a direct connection between visual and text tokens. To further support robust video understanding without requiring tracklets, we introduce an auxiliary task that guides Token Mark by leveraging the consistency of the tokens, enabling stable region interpretation across the video. Additionally, we introduce a large-scale region-level video instruction dataset (RegVID-300k). Omni-RGPT achieves state-of-the-art results on image and video-based commonsense reasoning benchmarks while showing strong performance in captioning and referring expression comprehension tasks.
我们提出了Omni-RGPT,这是一种多模态大型语言模型,旨在促进图像和视频的区域级理解。为了实现时空维度上的一致区域表示,我们引入了Token Mark,这是一组突出显示目标区域的令牌,直接嵌入到空间区域中,通过区域提示(例如,盒子或蒙版)建立与文本提示的直接联系,以指定目标。为了在不使用轨迹的情况下进一步支持稳健的视频理解,我们引入了一个辅助任务,通过利用令牌的连贯性来指导Token Mark,实现在视频中的稳定区域解释。此外,我们还引入了一个大规模的区域级视频指令数据集(RegVID-300k)。Omni-RGPT在图像和基于视频的共同理解基准测试上达到了最新水平,同时在描述和指代表达理解任务中表现出强大的性能。
论文及项目相关链接
PDF Project page: https://miranheo.github.io/omni-rgpt/
Summary:
我们提出了Omni-RGPT,这是一种多模态大型语言模型,旨在促进图像和视频的区域级理解。为实现时空维度上的一致区域表示,我们引入了Token Mark,这是一组在视觉特征空间中突出目标区域的令牌。这些令牌通过区域提示(如框或掩码)直接嵌入到空间区域中,并同时融入文本提示来指定目标,从而在视觉和文本令牌之间建立直接联系。为支持不需要轨迹的稳健视频理解,我们引入了一个辅助任务,通过利用令牌的一致性来指导Token Mark,实现在视频中的稳定区域解释。此外,我们还引入了一个大规模的区域级视频指令数据集(RegVID-300k)。Omni-RGPT在图像和视频常识推理基准测试上取得了最先进的成果,同时在描述和指代表达理解任务中表现出强大的性能。
Key Takeaways:
- Omni-RGPT是一种多模态大型语言模型,旨在促进图像和视频的区域级理解。
- Token Mark令牌用于在视觉特征空间中突出目标区域,并融入文本提示。
- 引入辅助任务,实现稳定区域解释,无需轨迹支持。
- 提出了大规模区域级视频指令数据集RegVID-300k。
- Omni-RGPT在图像和视频常识推理方面取得最先进成果。
- 该模型在描述和指代表达理解任务中表现出强大的性能。
点此查看论文截图


Tarsier2: Advancing Large Vision-Language Models from Detailed Video Description to Comprehensive Video Understanding
Authors:Liping Yuan, Jiawei Wang, Haomiao Sun, Yuchen Zhang, Yuan Lin
We introduce Tarsier2, a state-of-the-art large vision-language model (LVLM) designed for generating detailed and accurate video descriptions, while also exhibiting superior general video understanding capabilities. Tarsier2 achieves significant advancements through three key upgrades: (1) Scaling pre-training data from 11M to 40M video-text pairs, enriching both volume and diversity; (2) Performing fine-grained temporal alignment during supervised fine-tuning; (3) Using model-based sampling to automatically construct preference data and applying DPO training for optimization. Extensive experiments show that Tarsier2-7B consistently outperforms leading proprietary models, including GPT-4o and Gemini 1.5 Pro, in detailed video description tasks. On the DREAM-1K benchmark, Tarsier2-7B improves F1 by 2.8% over GPT-4o and 5.8% over Gemini-1.5-Pro. In human side-by-side evaluations, Tarsier2-7B shows a +8.6% performance advantage over GPT-4o and +24.9% over Gemini-1.5-Pro. Tarsier2-7B also sets new state-of-the-art results across 15 public benchmarks, spanning tasks such as video question-answering, video grounding, hallucination test, and embodied question-answering, demonstrating its versatility as a robust generalist vision-language model.
我们介绍了Tarsier2,这是一个最先进的大型视觉语言模型(LVLM),旨在生成详细和准确的视频描述,同时展现出卓越的一般视频理解能力。Tarsier2通过三个关键升级实现了重大进展:(1)将预训练数据从1100万扩展到4000万视频-文本对,丰富了数量和多样性;(2)在监督微调过程中进行精细的时间对齐;(3)使用基于模型的采样自动构建偏好数据,并应用DPO训练进行优化。大量实验表明,Tarsier2-7B在详细视频描述任务方面始终优于领先的专有模型,包括GPT-4o和Gemini 1.5 Pro。在DREAM-1K基准测试中,Tarsier2-7B的F1得分比GPT-4o高出2.8%,比Gemini-1.5-Pro高出5.8%。在人类并排评估中,Tarsier2-7B相对于GPT-4o性能优势为+8.6%,相对于Gemini-1.5-Pro性能优势为+24.9%。此外,Tarsier2-7B还在15个公共基准测试上创下了最新记录,涵盖视频问答、视频定位、幻觉测试和实体问答等多项任务,证明了其作为一个稳健的通用视觉语言模型的通用性。
论文及项目相关链接
Summary:
本文介绍了Tarsier2,这是一款先进的大型视觉语言模型(LVLM),用于生成详细准确的视频描述,并展现出卓越的视频理解能力。Tarsier2通过三个关键升级实现了显著进展:1)将预训练数据从1.1亿增加到4亿视频文本对,丰富数量和多样性;2)在监督微调过程中进行精细的时间对齐;3)使用模型采样自动构建偏好数据,并应用DPO训练进行优化。实验表明,Tarsier2-7B在详细视频描述任务上持续领先其他主流模型,包括GPT-4o和Gemini 1.5 Pro。在DREAM-1K基准测试中,Tarsier2-7B的F1分数较GPT-4o提高2.8%,较Gemini-1.5-Pro提高5.8%。此外,Tarsier2-7B还在15个公共基准测试上创下最新纪录,涵盖视频问答、视频定位、幻觉测试和嵌入式问答等多项任务,展现出其作为稳健通用视觉语言模型的多元性。
Key Takeaways:
- Tarsier2是一个用于生成详细准确视频描述的大型视觉语言模型(LVLM)。
- Tarsier2通过增加预训练数据、精细时间对齐和DPO训练优化实现了显著进展。
- Tarsier2-7B在详细视频描述任务上表现优越,领先GPT-4o和Gemini 1.5 Pro等模型。
- 在DREAM-1K基准测试中,Tarsier2-7B的F1分数较GPT-4o和Gemini-1.5-Pro有显著提高。
- Tarsier2-7B在多个公共基准测试上创下最新纪录,包括视频问答、视频定位、幻觉测试和嵌入式问答等任务。
- Tarsier2展现出其作为稳健通用视觉语言模型的多元性。
点此查看论文截图


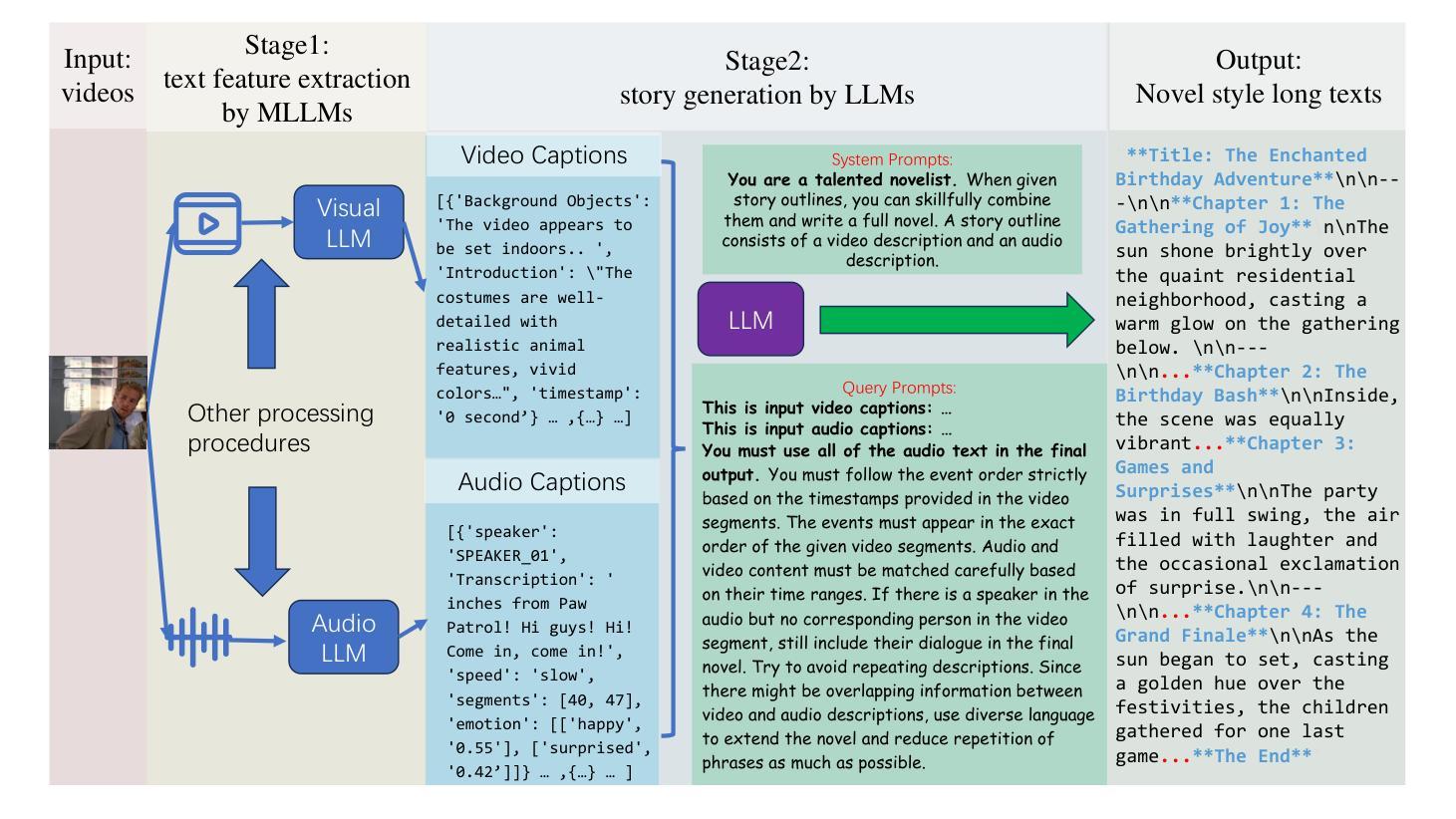
Movie2Story: A framework for understanding videos and telling stories in the form of novel text
Authors:Kangning Li, Zheyang Jia, Anyu Ying
In recent years, large-scale models have achieved significant advancements, accompanied by the emergence of numerous high-quality benchmarks for evaluating various aspects of their comprehension abilities. However, most existing benchmarks primarily focus on spatial understanding in static image tasks. While some benchmarks extend evaluations to temporal tasks, they fall short in assessing text generation under complex contexts involving long videos and rich auxiliary information. To address this limitation, we propose a novel benchmark: the Multi-modal Story Generation Benchmark (MSBench), designed to evaluate text generation capabilities in scenarios enriched with auxiliary information. Our work introduces an innovative automatic dataset generation method to ensure the availability of accurate auxiliary information. On one hand, we leverage existing datasets and apply automated processes to generate new evaluation datasets, significantly reducing manual efforts. On the other hand, we refine auxiliary data through systematic filtering and utilize state-of-the-art models to ensure the fairness and accuracy of the ground-truth datasets. Our experiments reveal that current Multi-modal Large Language Models (MLLMs) perform suboptimally under the proposed evaluation metrics, highlighting significant gaps in their capabilities. To address these challenges, we propose a novel model architecture and methodology to better handle the overall process, demonstrating improvements on our benchmark.
近年来,大规模模型取得了显著进展,同时出现了许多高质量的评价基准,用于评估其理解能力的各个方面。然而,大多数现有基准主要关注静态图像任务中的空间理解。尽管有些基准将评估扩展到时序任务,但它们在评估涉及长视频和丰富辅助信息的复杂上下文中的文本生成时仍显得不足。为了解决这一局限性,我们提出了一种新的基准:多模态故事生成基准(MSBench),旨在评估在丰富辅助信息场景下的文本生成能力。我们的工作引入了一种创新性的自动数据集生成方法,以确保准确辅助信息的可用性。一方面,我们利用现有数据集,应用自动化流程生成新的评估数据集,大大降低了手动操作的难度。另一方面,我们通过系统过滤来优化辅助数据,并利用最先进的模型来保证基准数据集公平公正和准确性。我们的实验表明,当前的多模态大型语言模型(MLLMs)在提出的评估指标下表现不佳,凸显了其在能力上的巨大差距。为了应对这些挑战,我们提出了一种新型模型架构和方法,以更好地处理整个过程,并在我们的基准测试上展示了改进。
论文及项目相关链接
Summary
近期大规模模型取得显著进展,伴随出现众多高质量评估基准,但多数主要关注静态图像的时空理解。尽管有些基准扩展到了时序任务,但在复杂语境下的文本生成评估,尤其是涉及长视频和丰富辅助信息的评估上仍有不足。为此,我们提出多模态故事生成基准(MSBench),旨在评估丰富情境下的文本生成能力。我们引入自动数据集生成方法,通过现有数据集生成新的评估数据集,减少手动操作。同时,我们系统化筛选精炼辅助数据,并利用先进模型确保基准数据集的公平性和准确性。实验显示,当前多模态大型语言模型(MLLMs)在提议的评估指标下表现欠佳,揭示其能力上的显著差距。为应对这些挑战,我们提出新型模型架构和方法,以更好地处理整体流程,并在我们的基准上实现改进。
Key Takeaways
- 现有评估基准主要关注静态图像的时空理解,缺乏复杂语境下的文本生成评估,尤其是涉及长视频和丰富辅助信息的评估。
- 提出多模态故事生成基准(MSBench),旨在评估丰富情境下的文本生成能力。
- 引入自动数据集生成方法,减少手动操作,确保准确辅助信息的可用性。
- 通过系统化筛选精炼辅助数据,确保基准数据集的公平性。
- 现有多模态大型语言模型(MLLMs)在提议的评估指标下表现不佳。
- 实验揭示了当前模型在文本生成能力上的显著差距。
点此查看论文截图