⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-16 更新
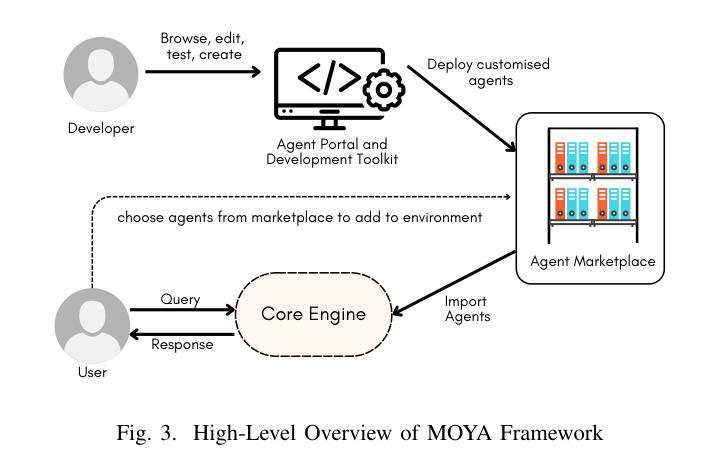
Engineering LLM Powered Multi-agent Framework for Autonomous CloudOps
Authors:Kannan Parthasarathy, Karthik Vaidhyanathan, Rudra Dhar, Venkat Krishnamachari, Basil Muhammed, Adyansh Kakran, Sreemaee Akshathala, Shrikara Arun, Sumant Dubey, Mohan Veerubhotla, Amey Karan
Cloud Operations (CloudOps) is a rapidly growing field focused on the automated management and optimization of cloud infrastructure which is essential for organizations navigating increasingly complex cloud environments. MontyCloud Inc. is one of the major companies in the CloudOps domain that leverages autonomous bots to manage cloud compliance, security, and continuous operations. To make the platform more accessible and effective to the customers, we leveraged the use of GenAI. Developing a GenAI-based solution for autonomous CloudOps for the existing MontyCloud system presented us with various challenges such as i) diverse data sources; ii) orchestration of multiple processes; and iii) handling complex workflows to automate routine tasks. To this end, we developed MOYA, a multi-agent framework that leverages GenAI and balances autonomy with the necessary human control. This framework integrates various internal and external systems and is optimized for factors like task orchestration, security, and error mitigation while producing accurate, reliable, and relevant insights by utilizing Retrieval Augmented Generation (RAG). Evaluations of our multi-agent system with the help of practitioners as well as using automated checks demonstrate enhanced accuracy, responsiveness, and effectiveness over non-agentic approaches across complex workflows.
云操作(CloudOps)是一个快速发展的领域,专注于云基础设施的自动化管理和优化,这对于在日益复杂的云环境中导航的组织来说至关重要。MontyCloud Inc.是云操作领域的主要公司之一,利用自主机器人管理云合规性、安全和持续运营。为了使平台对客户更加可用和有效,我们利用了GenAI。为现有的MontyCloud系统开发基于GenAI的自主云操作解决方案给我们带来了各种挑战,例如(i)多样化的数据源;(ii)多个流程的协同;(iii)处理复杂的工作流以自动化常规任务。为此,我们开发了MOYA,这是一个多代理框架,利用GenAI在自主性和必要的人工控制之间取得平衡。该框架整合了内部和外部系统,针对任务协同、安全和错误缓解等因素进行了优化,同时利用检索增强生成(RAG)提供准确、可靠和相关的见解。通过从业者帮助以及使用自动化检查对我们的多代理系统进行评估,表明在复杂的工作流中,与非代理方法相比,我们的系统在准确性、响应性和有效性方面都有所提高。
论文及项目相关链接
PDF The paper has been accepted as full paper to CAIN 2025 (https://conf.researchr.org/home/cain-2025), co-located with ICSE 2025 (https://conf.researchr.org/home/icse-2025). The paper was submitted to CAIN for review on 9 November 2024
Summary
云服务运营(CloudOps)领域正快速增长,专注于云基础设施的自动化管理和优化。MontyCloud公司利用自主机器人管理云合规性、安全和持续运营。为提升客户体验,公司采用GenAI技术构建解决方案,面临多样数据源、多流程编排和复杂工作流自动化等挑战。因此,公司开发了MOYA多智能体框架,融合GenAI技术并保持必要人工控制,优化任务编排、安全性和容错性,借助检索增强生成(RAG)提供精准、可靠和相关信息。评估显示,与无智能体方法相比,多智能体系统提高准确性、响应性和效率。
Key Takeaways
- Cloud Operations (CloudOps) 是一个迅速发展的领域,专注于云基础设施的自动化管理和优化。
- MontyCloud公司通过自主机器人管理云合规性、安全和持续运营。
- 为提升客户体验,MontyCloud采用GenAI技术构建解决方案,面临诸多挑战。
- 开发MOYA多智能体框架以应对挑战,融合GenAI并保持必要人工控制。
- MOYA框架优化任务编排、安全性和容错性。
- 利用检索增强生成(RAG)提供精准、可靠和相关信息。
点此查看论文截图


Cooperative Patrol Routing: Optimizing Urban Crime Surveillance through Multi-Agent Reinforcement Learning
Authors:Juan Palma-Borda, Eduardo Guzmán, María-Victoria Belmonte
The effective design of patrol strategies is a difficult and complex problem, especially in medium and large areas. The objective is to plan, in a coordinated manner, the optimal routes for a set of patrols in a given area, in order to achieve maximum coverage of the area, while also trying to minimize the number of patrols. In this paper, we propose a multi-agent reinforcement learning (MARL) model, based on a decentralized partially observable Markov decision process, to plan unpredictable patrol routes within an urban environment represented as an undirected graph. The model attempts to maximize a target function that characterizes the environment within a given time frame. Our model has been tested to optimize police patrol routes in three medium-sized districts of the city of Malaga. The aim was to maximize surveillance coverage of the most crime-prone areas, based on actual crime data in the city. To address this problem, several MARL algorithms have been studied, and among these the Value Decomposition Proximal Policy Optimization (VDPPO) algorithm exhibited the best performance. We also introduce a novel metric, the coverage index, for the evaluation of the coverage performance of the routes generated by our model. This metric is inspired by the predictive accuracy index (PAI), which is commonly used in criminology to detect hotspots. Using this metric, we have evaluated the model under various scenarios in which the number of agents (or patrols), their starting positions, and the level of information they can observe in the environment have been modified. Results show that the coordinated routes generated by our model achieve a coverage of more than $90%$ of the $3%$ of graph nodes with the highest crime incidence, and $65%$ for $20%$ of these nodes; $3%$ and $20%$ represent the coverage standards for police resource allocation.
巡逻策略的有效设计是一个困难且复杂的问题,特别是在中大型区域中。目标是以协调的方式,为给定区域内的巡逻队规划最佳路线,以实现区域的最大覆盖,同时尽量减少巡逻次数。在本文中,我们提出了一种基于去中心化部分可观察马尔可夫决策过程的多智能体强化学习(MARL)模型,用于规划城市环境中的不可预测巡逻路线,该环境被表示为一个无向图。该模型试图在给定时间范围内最大化一个刻画环境的目标函数。我们的模型经过测试,可优化马拉加市三个中型区域的警察巡逻路线。目的是根据该市的实时犯罪数据,最大化最易发生犯罪地区的监控覆盖率。为解决这一问题,我们研究了多种MARL算法,其中价值分解近端策略优化(VDPPO)算法表现最佳。我们还引入了一个新的指标——覆盖率指数,用于评估我们模型生成的路线覆盖性能。该指标受到犯罪学中长期用于检测热点区域的预测准确度指数(PAI)的启发。使用该指标,我们在各种场景中评估了模型,其中包括修改智能体(或巡逻队)的数量、他们的起始位置以及他们能在环境中观察到的信息量。结果表明,我们模型生成的协调路线能够覆盖超过百分之九十以上的具有最高犯罪发生率的三百分之一的图节点,以及百分之六十五的百分之二十的节点;百分之三和百分之二十代表了警察资源分配的覆盖范围标准。
论文及项目相关链接
Summary
巡逻策略的有效设计是一个复杂且困难的问题,特别是在中等和大型区域。本文提出一种基于分散式部分可观察马尔可夫决策过程的多智能体强化学习模型,用于规划城市环境中的不可预测巡逻路线。该模型旨在最大化在给定时间框架内刻画环境的目标函数。该模型在马拉加市三个中等规模区域进行了测试,目的是最大化最易犯罪地区的监视覆盖率,基于该市的实际犯罪数据。结果展示,该模型生成的协调路线能覆盖超过90%犯罪发生率最高的3%的节点和超过65%的犯罪发生率最高的20%的节点。这些百分比代表了警察资源分配的覆盖范围标准。
Key Takeaways
- 巡逻策略设计在中等和大型区域中尤为复杂和困难。
- 提出一种基于多智能体强化学习模型的巡逻策略规划方法,适用于城市环境。
- 模型旨在最大化在给定的时间框架内刻画环境的目标函数。
- 模型在基于实际犯罪数据的城市环境中进行了测试,旨在最大化最易犯罪区域的监视覆盖率。
- 采用了一种新型评价指标——覆盖率指数,用于评估模型生成的巡逻路线的覆盖性能。
- 测试结果表明,该模型生成的协调路线能覆盖高犯罪率区域的较高比例。
点此查看论文截图

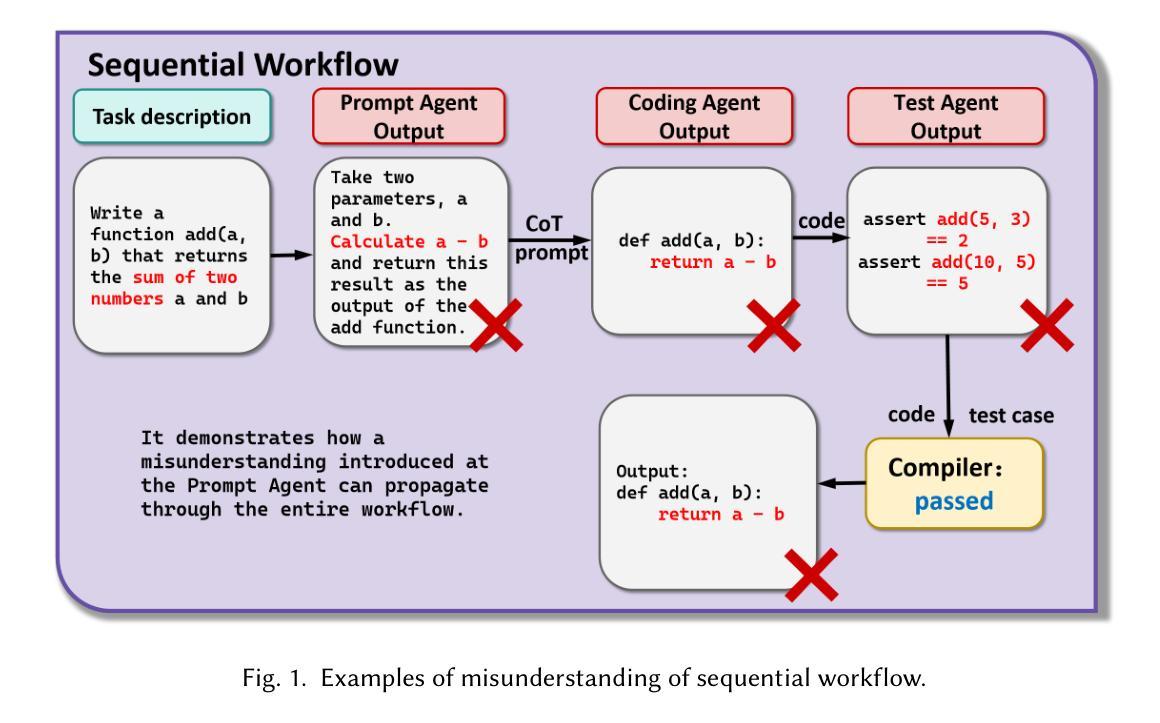
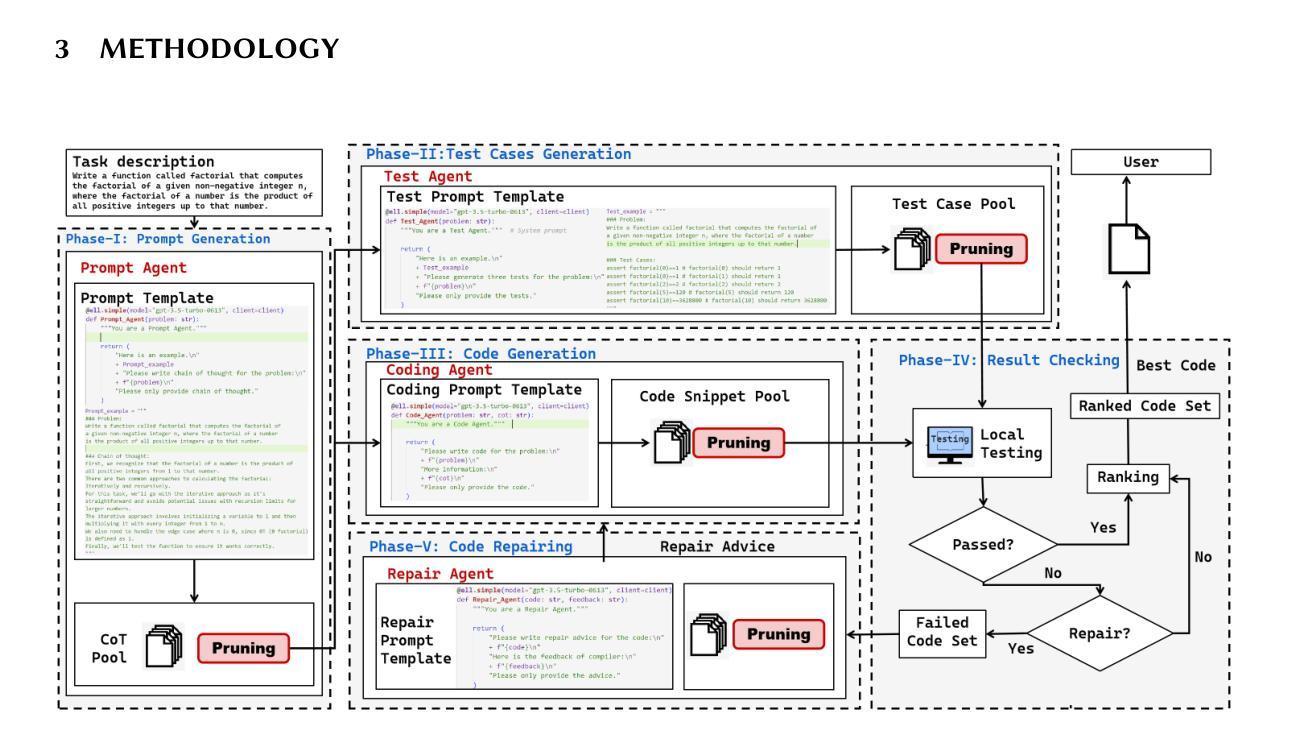
CodeCoR: An LLM-Based Self-Reflective Multi-Agent Framework for Code Generation
Authors:Ruwei Pan, Hongyu Zhang, Chao Liu
Code generation aims to produce code that fulfills requirements written in natural languages automatically. Large language Models (LLMs) like ChatGPT have demonstrated promising effectiveness in this area. Nonetheless, these LLMs often fail to ensure the syntactic and semantic correctness of the generated code. Recently, researchers proposed multi-agent frameworks that guide LLMs with different prompts to analyze programming tasks, generate code, perform testing in a sequential workflow. However, the performance of the workflow is not robust as the code generation depends on the performance of each agent. To address this challenge, we propose CodeCoR, a self-reflective multi-agent framework that evaluates the effectiveness of each agent and their collaborations. Specifically, for a given task description, four agents in CodeCoR generate prompts, code, test cases, and repair advice, respectively. Each agent generates more than one output and prunes away the low-quality ones. The generated code is tested in the local environment: the code that fails to pass the generated test cases is sent to the repair agent and the coding agent re-generates the code based on repair advice. Finally, the code that passes the most number of generated test cases is returned to users. Our experiments on four widely used datasets, HumanEval, HumanEval-ET, MBPP, and MBPP-ET, demonstrate that CodeCoR significantly outperforms existing baselines (e.g., CodeCoT and MapCoder), achieving an average Pass@1 score of 77.8%.
代码生成旨在自动生成满足自然语言编写要求的代码。大型语言模型(LLM)如ChatGPT在这方面表现出了有前景的效果。然而,这些LLM通常无法保证生成代码的语法和语义正确性。最近,研究者提出了多智能体框架,通过不同的提示来引导LLM分析编程任务、生成代码、执行测试,形成顺序工作流程。然而,工作流程的性能并不稳健,因为代码生成依赖于每个智能体的性能。为了解决这一挑战,我们提出了CodeCoR,一个自我反思的多智能体框架,用于评估每个智能体及其协作的有效性。具体来说,对于给定的任务描述,CodeCoR中的四个智能体分别生成提示、代码、测试用例和修复建议。每个智能体生成多个输出,并剔除低质量的输出。生成的代码会在本地环境中进行测试:未能通过生成的测试用例的代码将发送给修复智能体,编码智能体会基于修复建议重新生成代码。最后,返回通过最多生成测试用例的代码给用户。我们在四个广泛使用的数据集HumanEval、HumanEval-ET、MBPP和MBPP-ET上的实验表明,CodeCoR显著优于现有基线(如CodeCoT和MapCoder),平均Pass@1率达到77.8%。
论文及项目相关链接
Summary
基于自然语言要求自动生成代码的目标,大型语言模型(LLMs)如ChatGPT已展现出应用前景。然而,它们常无法确保生成代码的语法和语义正确性。近期,研究者提出多代理框架来指导LLMs分析编程任务、生成代码、进行测试。针对代码生成依赖于各代理表现的问题,我们提出CodeCoR,一种自我反思的多代理框架,评估各代理及其协作的有效性。CodeCoR包含四个代理,分别负责生成提示、代码、测试用例和修复建议。实验证明,CodeCoR在四个常用数据集上的表现显著优于现有基线方法,平均Pass@1得分率达77.8%。
Key Takeaways
- 大型语言模型(LLMs)如ChatGPT在代码自动生成方面具潜力,但存在语法和语义正确性问题。
- 多代理框架被提出用于指导LLMs进行编程任务分析、代码生成和测试。
- CodeCoR是一种自我反思的多代理框架,旨在评估各代理及其协作的有效性。
- CodeCoR包含四个代理,分别负责生成提示、代码、测试用例和修复建议。
- CodeCoR通过本地环境测试生成的代码,并根据测试结果进行修复和重新生成。
- CodeCoR在四个常用数据集上的表现优于现有方法,平均Pass@1得分率达77.8%。
- 该研究为解决LLM在代码生成中的挑战提供了有效方案。
点此查看论文截图


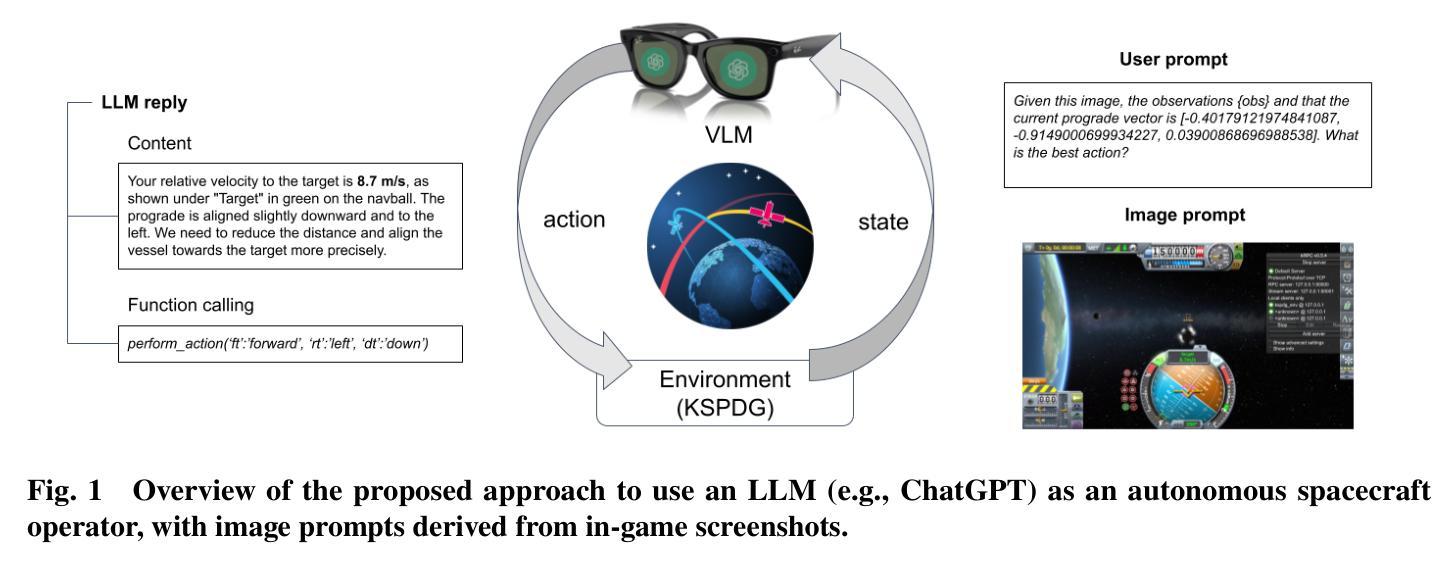
Visual Language Models as Operator Agents in the Space Domain
Authors:Alejandro Carrasco, Marco Nedungadi, Enrico M. Zucchelli, Amit Jain, Victor Rodriguez-Fernandez, Richard Linares
This paper explores the application of Vision-Language Models (VLMs) as operator agents in the space domain, focusing on both software and hardware operational paradigms. Building on advances in Large Language Models (LLMs) and their multimodal extensions, we investigate how VLMs can enhance autonomous control and decision-making in space missions. In the software context, we employ VLMs within the Kerbal Space Program Differential Games (KSPDG) simulation environment, enabling the agent to interpret visual screenshots of the graphical user interface to perform complex orbital maneuvers. In the hardware context, we integrate VLMs with robotic systems equipped with cameras to inspect and diagnose physical space objects, such as satellites. Our results demonstrate that VLMs can effectively process visual and textual data to generate contextually appropriate actions, competing with traditional methods and non-multimodal LLMs in simulation tasks, and showing promise in real-world applications.
本文探讨了视觉语言模型(VLMs)作为空间域操作代理的应用,重点关注软件和硬件操作范式。基于大型语言模型(LLMs)及其多模态扩展的进展,我们调查了VLMs如何增强空间任务中的自主控制和决策制定。在软件环境中,我们在Kerbal Space Program Differential Games(KSPDG)仿真环境中使用VLMs,使代理能够通过图形用户界面的视觉截图执行复杂的轨道机动。在硬件环境中,我们将VLMs与配备摄像头的机器人系统集成,以检查并诊断物理空间物体(如卫星)。我们的结果表明,VLMs可以有效地处理视觉和文本数据,以生成与上下文相关的操作,在仿真任务中与传统方法和非多模态LLMs竞争,并在实际世界应用中显示出巨大的潜力。
论文及项目相关链接
PDF Updated version of the paper presented in 2025 AIAA SciTech. https://arc.aiaa.org/doi/10.2514/6.2025-1543
Summary
本文探讨了视觉语言模型(VLMs)作为空间领域的操作代理人的应用,重点研究了软件和硬件操作范式。基于大型语言模型(LLMs)及其多模态扩展的进展,本文调查了VLMs如何增强空间任务中的自主控制和决策制定。在软件环境下,本文在Kerbal Space Program Differential Games(KSPDG)仿真环境中应用VLMs,使代理人能够通过图形用户界面的视觉截图执行复杂的轨道机动。在硬件环境下,本文将VLMs与配备摄像头的机器人系统集成,用于检查和诊断物理空间物体(如卫星)。结果表明,VLMs能够有效地处理视觉和文本数据,生成上下文相关的动作,在仿真任务中与传统方法和非多模态LLMs相竞争,并在实际应用中显示出潜力。
Key Takeaways
- VLMs被应用于空间领域的操作,涵盖了软件和硬件两个方面的操作范式。
- LLMs及其多模态扩展在VLMs的应用中起到了基础作用。
- VLMs能够在空间任务中增强自主控制和决策制定。
- 在软件环境下,VLMs在KSPDG仿真环境中能够解读GUI的视觉截图并执行复杂轨道机动。
- 在硬件环境下,VLMs与机器人系统集成,可用于检查和诊断物理空间物体。
- VLMs处理视觉和文本数据生成上下文相关动作的能力得到了验证。
点此查看论文截图

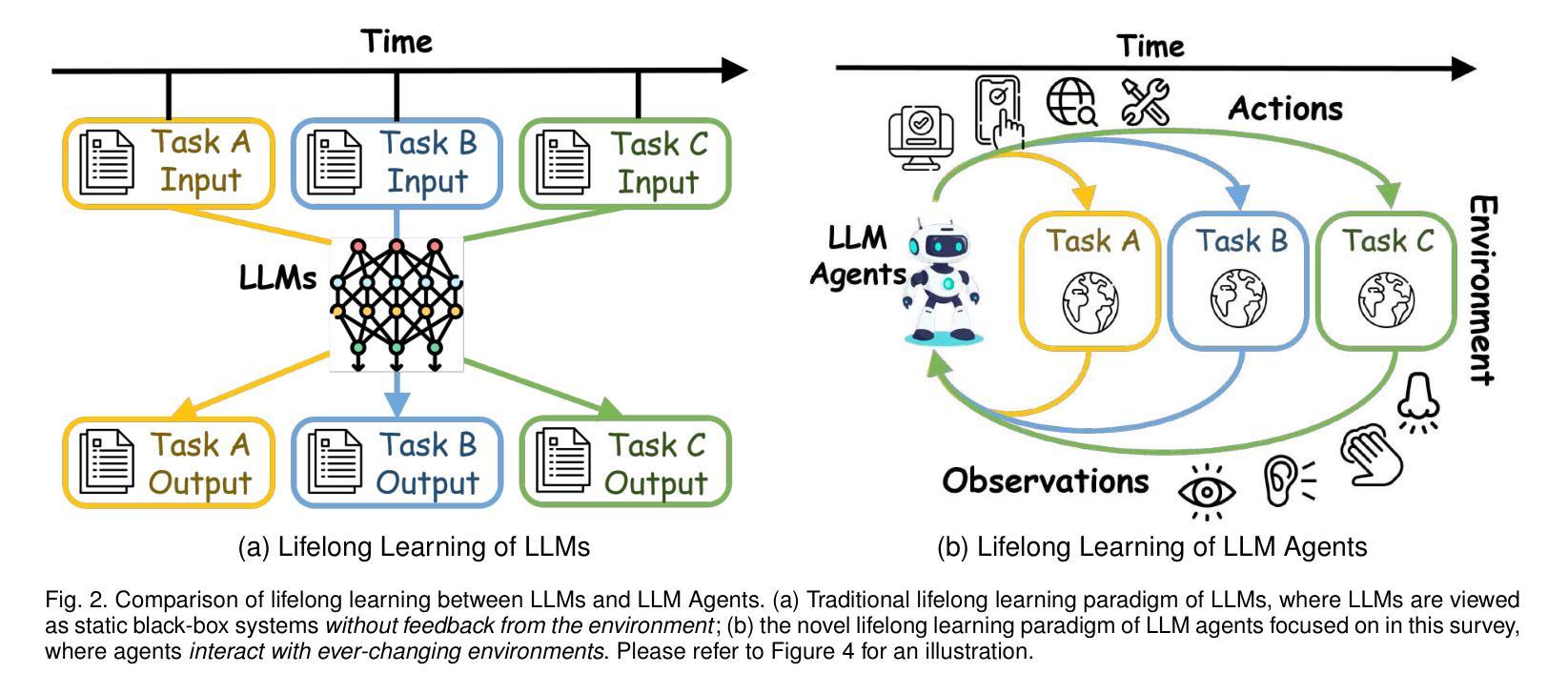
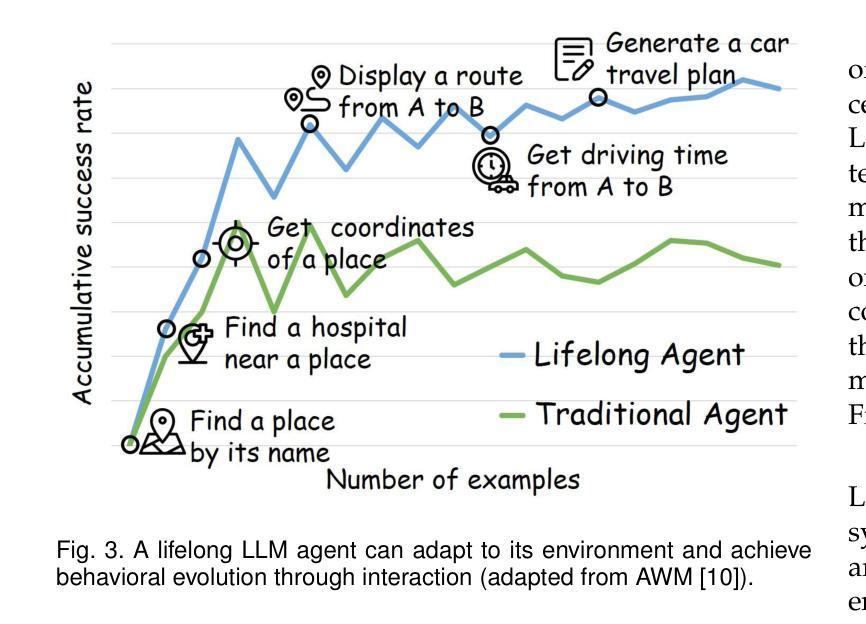
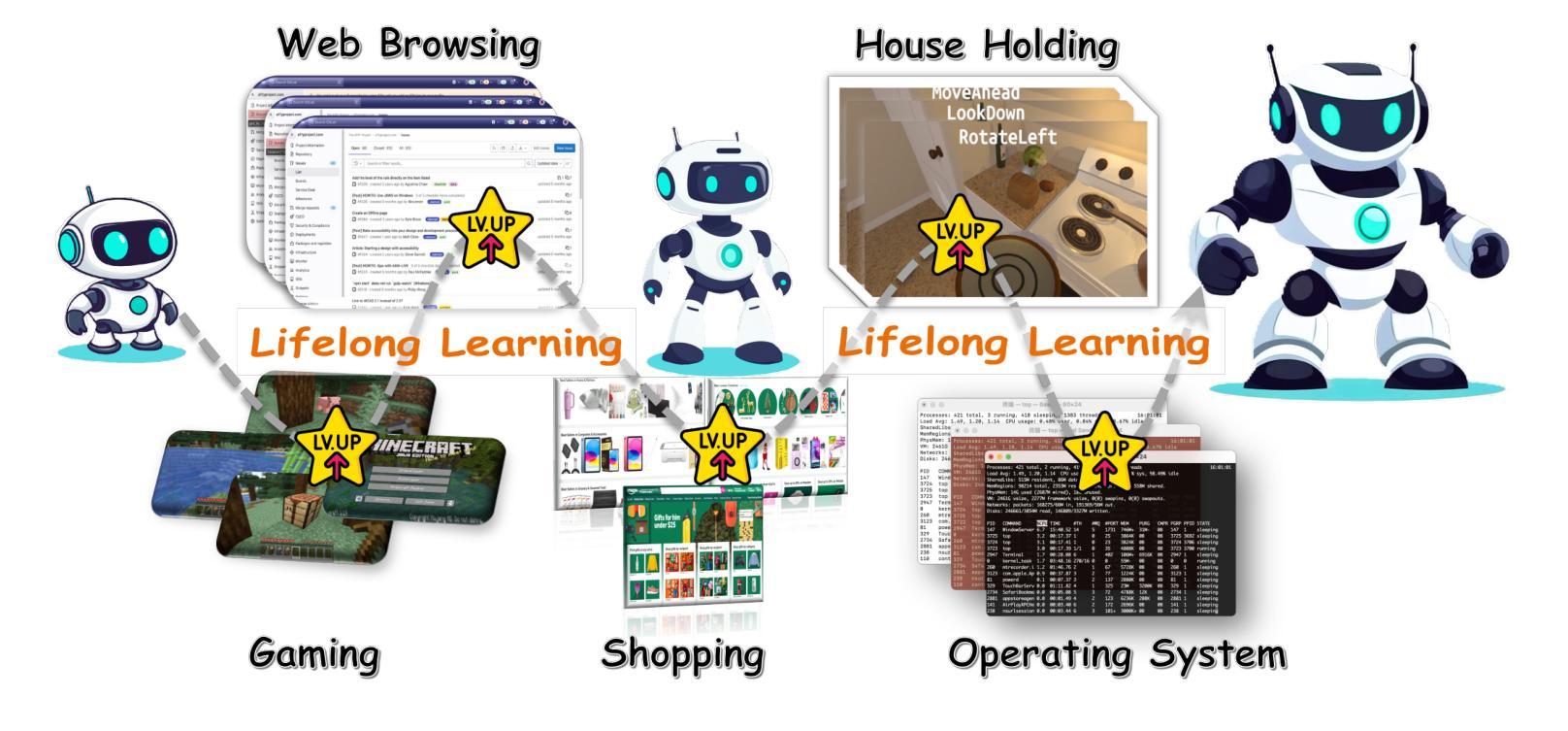
Lifelong Learning of Large Language Model based Agents: A Roadmap
Authors:Junhao Zheng, Chengming Shi, Xidi Cai, Qiuke Li, Duzhen Zhang, Chenxing Li, Dong Yu, Qianli Ma
Lifelong learning, also known as continual or incremental learning, is a crucial component for advancing Artificial General Intelligence (AGI) by enabling systems to continuously adapt in dynamic environments. While large language models (LLMs) have demonstrated impressive capabilities in natural language processing, existing LLM agents are typically designed for static systems and lack the ability to adapt over time in response to new challenges. This survey is the first to systematically summarize the potential techniques for incorporating lifelong learning into LLM-based agents. We categorize the core components of these agents into three modules: the perception module for multimodal input integration, the memory module for storing and retrieving evolving knowledge, and the action module for grounded interactions with the dynamic environment. We highlight how these pillars collectively enable continuous adaptation, mitigate catastrophic forgetting, and improve long-term performance. This survey provides a roadmap for researchers and practitioners working to develop lifelong learning capabilities in LLM agents, offering insights into emerging trends, evaluation metrics, and application scenarios. Relevant literature and resources are available at \href{this url}{https://github.com/qianlima-lab/awesome-lifelong-llm-agent}.
终身学习,也称为持续学习或增量学习,是推动人工智能通用智能(AGI)发展的关键因素,它使系统能够在动态环境中持续适应。虽然大型语言模型(LLM)在自然语言处理中展示了令人印象深刻的能力,但现有的LLM代理通常是为静态系统设计的,缺乏随时间适应新挑战的能力。这篇综述是首个系统地总结将终身学习融入LLM代理的潜在技术。我们将这些代理的核心组件分类为三个模块:用于多模态输入整合的感知模块、用于存储和检索不断更新的知识的记忆模块、以及用于与动态环境进行交互的行动模块。我们强调了这些支柱如何共同实现持续适应、减轻灾难性遗忘并提高长期性能。这篇综述为致力于开发LLM代理终身学习功能的研究人员和实践者提供了路线图,深入洞察新兴趋势、评估指标和应用场景。相关文献和资源可通过这个链接获取。
论文及项目相关链接
PDF 46 pages
Summary
终身学习(又称持续学习或增量学习)对于推动人工智能通用智能(AGI)的发展至关重要,它使系统能够在动态环境中持续适应。大型语言模型(LLM)在自然语言处理方面表现出令人印象深刻的能力,但现有的LLM代理通常是为静态系统设计的,缺乏随时间适应新挑战的能力。本文首次系统概述了将终身学习纳入LLM代理的潜在技术。我们将核心组件分类为三个模块:感知模块用于多模式输入集成,记忆模块用于存储和检索不断发展的知识,行动模块用于与动态环境进行交互。本文强调了这些支柱如何共同实现持续适应、减轻灾难性遗忘并提高长期性能。本文为研究人员和实践者提供了开发LLM代理中的终身学习能力的路线图,并深入探讨了新兴趋势、评估指标和应用场景。
Key Takeaways
- 终身学习对于推动人工智能通用智能(AGI)发展至关重要,它使系统能在动态环境中持续适应。
- 大型语言模型(LLM)在自然语言处理方面具有显著能力,但缺乏在新环境下随时间适应的能力。
- 融入终身学习的LLM代理具备三大核心模块:感知模块、记忆模块和行动模块。
- 感知模块负责多模式输入集成,记忆模块存储和检索知识,行动模块与动态环境交互。
- 这些模块共同实现持续适应、减轻灾难性遗忘及提高长期性能。
- 本文提供了开发LLM代理终身学习能力的路线图,涵盖新兴趋势、评估指标和应用场景。
- 可在this url获取相关文献和资源。
点此查看论文截图

Eliza: A Web3 friendly AI Agent Operating System
Authors:Shaw Walters, Sam Gao, Shakker Nerd, Feng Da, Warren Williams, Ting-Chien Meng, Hunter Han, Frank He, Allen Zhang, Ming Wu, Timothy Shen, Maxwell Hu, Jerry Yan
AI Agent, powered by large language models (LLMs) as its cognitive core, is an intelligent agentic system capable of autonomously controlling and determining the execution paths under user’s instructions. With the burst of capabilities of LLMs and various plugins, such as RAG, text-to-image/video/3D, etc., the potential of AI Agents has been vastly expanded, with their capabilities growing stronger by the day. However, at the intersection between AI and web3, there is currently no ideal agentic framework that can seamlessly integrate web3 applications into AI agent functionalities. In this paper, we propose Eliza, the first open-source web3-friendly Agentic framework that makes the deployment of web3 applications effortless. We emphasize that every aspect of Eliza is a regular Typescript program under the full control of its user, and it seamlessly integrates with web3 (i.e., reading and writing blockchain data, interacting with smart contracts, etc.). Furthermore, we show how stable performance is achieved through the pragmatic implementation of the key components of Eliza’s runtime. Our code is publicly available at https://github.com/ai16z/eliza.
基于大型语言模型(LLM)作为认知核心的AI Agent是一种智能代理系统,能够自主控制并确定在用户指令下的执行路径。随着LLM和各种插件(如RAG、文本到图像/视频/3D等)的能力爆发,AI Agent的潜力得到了极大的拓展,其能力日益增强。然而,在AI和web3的交汇点,目前还没有理想的代理框架能够无缝地将web3应用程序集成到AI代理功能中。在本文中,我们提出了Eliza,这是第一个开源的web3友好型代理框架,使web3应用程序的部署变得轻而易举。我们强调,Eliza的各个方面都是用户完全控制的常规Typescript程序,它能无缝地集成到webresive与区块链智能合约进行交互等)。此外,我们还展示了如何通过Eliza运行时关键组件的实际应用来实现稳定的性能。我们的代码公开在https://github.com/ai16z/eliza。
论文及项目相关链接
PDF 20 pages, 5 figures
Summary
基于大型语言模型(LLM)的认知核心的AI Agent智能体系,能自主控制和确定用户指令下的执行路径。随着LLM能力及各类插件如RAG、文本转图像/视频/3D等的爆发,AI Agent的潜力得到了极大的拓展。然而,在AI和Web3的交汇点,目前尚无理想的agentic框架能无缝集成Web3应用到AI Agent功能中。本文提出Eliza,首个开源的Web3友好型agentic框架,让Web3应用的部署变得轻松。Eliza的每个方面都是用户可控制的常规Typescript程序,并能无缝集成Web3(如读写区块链数据、与智能合约交互等)。
Key Takeaways
- AI Agent基于大型语言模型(LLM),能自主控制和确定执行路径。
- LLM及其插件的快速发展极大地拓展了AI Agent的潜力。
- 目前缺乏理想的框架来无缝集成Web3应用到AI Agent中。
- Eliza是首个开源的Web3友好型agentic框架,简化Web3应用的部署。
- Eliza的每个部分都是用户可控制的常规Typescript程序。
- Eliza能无缝集成Web3,包括读写区块链数据、与智能合约交互等。
点此查看论文截图

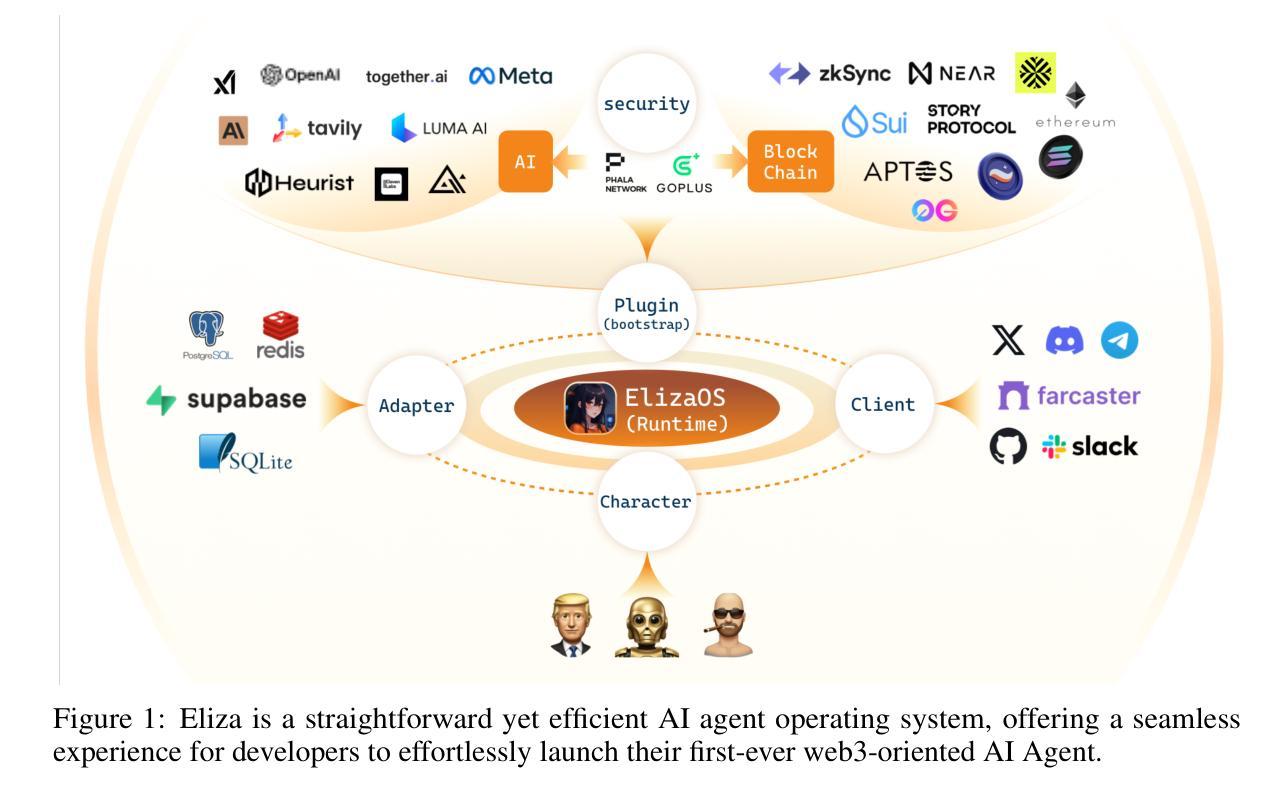

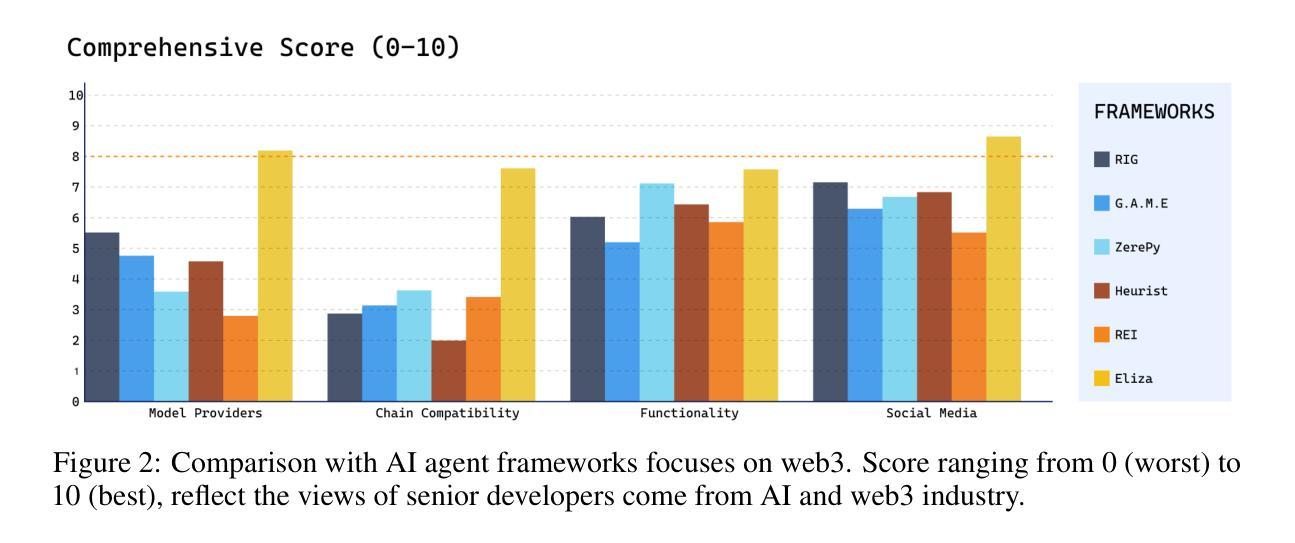
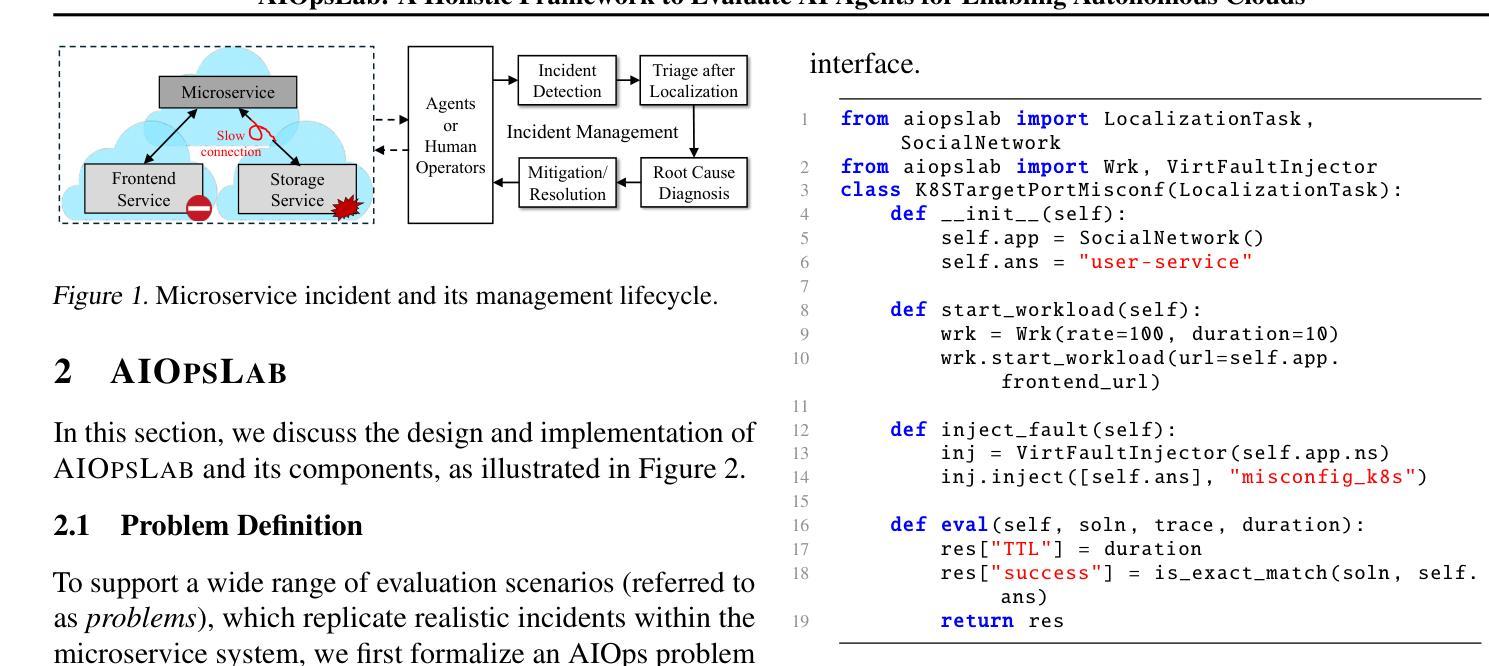
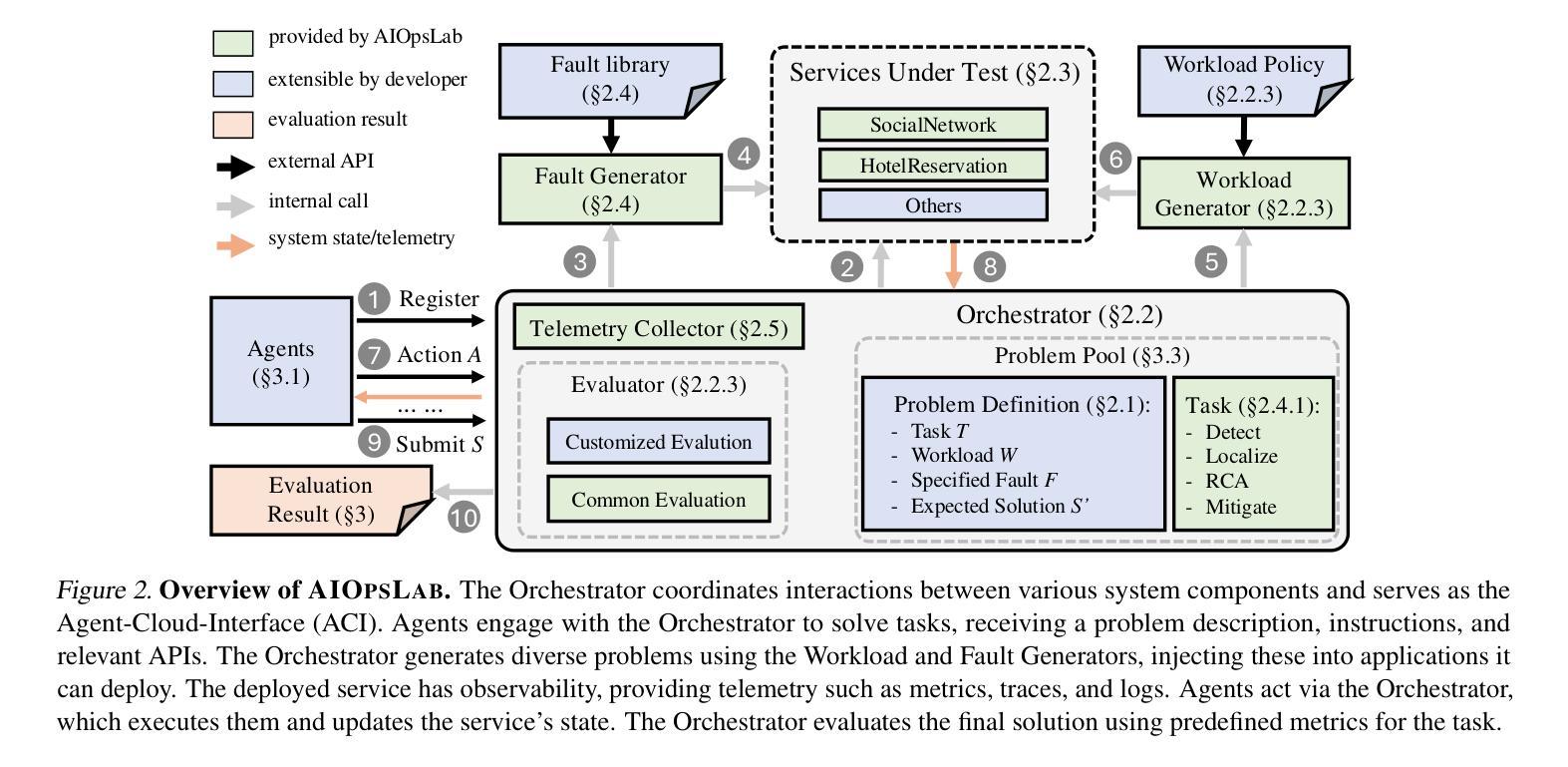
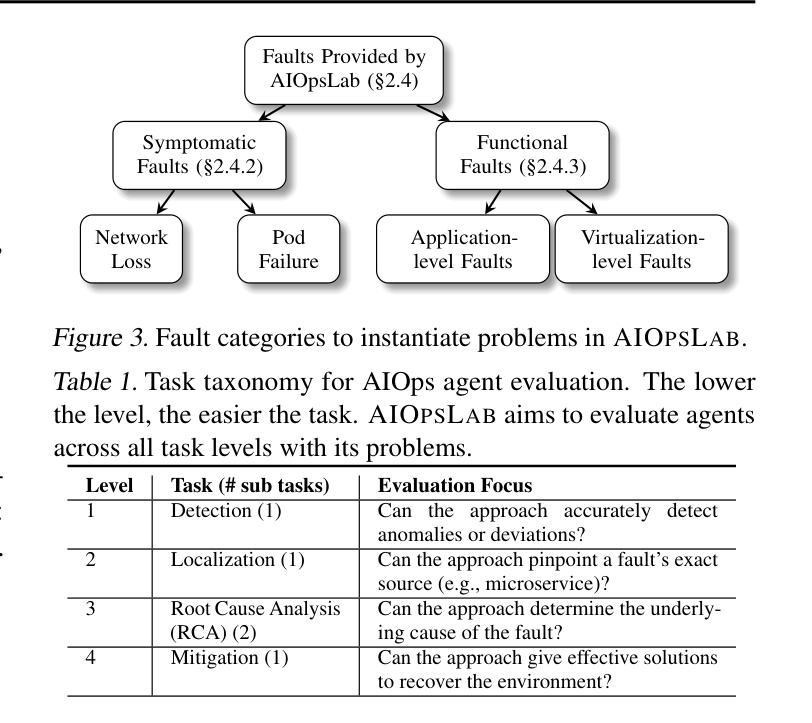
AIOpsLab: A Holistic Framework to Evaluate AI Agents for Enabling Autonomous Clouds
Authors:Yinfang Chen, Manish Shetty, Gagan Somashekar, Minghua Ma, Yogesh Simmhan, Jonathan Mace, Chetan Bansal, Rujia Wang, Saravan Rajmohan
AI for IT Operations (AIOps) aims to automate complex operational tasks, such as fault localization and root cause analysis, to reduce human workload and minimize customer impact. While traditional DevOps tools and AIOps algorithms often focus on addressing isolated operational tasks, recent advances in Large Language Models (LLMs) and AI agents are revolutionizing AIOps by enabling end-to-end and multitask automation. This paper envisions a future where AI agents autonomously manage operational tasks throughout the entire incident lifecycle, leading to self-healing cloud systems, a paradigm we term AgentOps. Realizing this vision requires a comprehensive framework to guide the design, development, and evaluation of these agents. To this end, we present AIOPSLAB, a framework that not only deploys microservice cloud environments, injects faults, generates workloads, and exports telemetry data but also orchestrates these components and provides interfaces for interacting with and evaluating agents. We discuss the key requirements for such a holistic framework and demonstrate how AIOPSLAB can facilitate the evaluation of next-generation AIOps agents. Through evaluations of state-of-the-art LLM agents within the benchmark created by AIOPSLAB, we provide insights into their capabilities and limitations in handling complex operational tasks in cloud environments.
AIOps的目标是自动化复杂的操作任务,如故障定位和根本原因分析等,以减轻人员工作量并最大限度地减少对客户的影响。虽然传统的DevOps工具和AIOps算法通常侧重于解决孤立的操作任务,但大型语言模型(LLM)和AI代理的最新进展正在通过实现端到端和多任务自动化来彻底改变AIOps。本文设想了一个未来,AI代理将能够自主管理整个事件生命周期中的操作任务,从而实现我们所谓的AgentOps自我修复云系统。实现这一愿景需要一个全面的框架来指导这些代理的设计、开发和评估。为此,我们推出了AIOPSLAB框架,它不仅部署微服务云环境、注入故障、生成工作量并导出遥测数据,还能协调这些组件并提供与代理交互和评估的接口。我们讨论了此类全面框架的关键要求,并展示了AIOPSLAB如何促进新一代AIOps代理的评估。通过AIOPSLAB创建的基准测试对最新LLM代理进行评估,我们深入了解它们在处理云环境中的复杂操作任务时的能力和局限性。
论文及项目相关链接
Summary
随着人工智能技术的不断进步,AI for IT Operations (AIOps)在自动化处理复杂的操作任务上表现出越来越强的潜力,旨在降低人力资源负担并最大限度地减少对客户的影响。传统的DevOps工具和AIOps算法主要关注解决孤立的操作任务,然而大型语言模型(LLMs)和AI代理的最新进展正在通过实现端到端多任务自动化来颠覆这一局面。未来的发展方向将是AI代理能够自主管理整个事件生命周期的操作任务,从而推动云系统的自我修复能力。为了实现这一愿景,需要一个全面的框架来指导这些代理的设计、开发和评估。本文介绍了AIOPSLAB框架,它不仅部署微服务云环境、注入故障、生成工作负载和导出遥测数据,而且协调这些组件并提供与代理交互和评估的接口。此外,本文还对这类全面框架的关键需求进行了讨论,并展示了AIOPSLAB如何能促进下一代AIOps代理的评估。通过对AIOPSLAB基准测试中先进的大型语言模型代理的评估,本文深入探讨了它们在处理云环境中的复杂操作任务方面的优势和局限性。
Key Takeaways
- AIOps旨在通过自动化复杂的操作任务来减轻人力资源负担并减少客户影响。
- 传统DevOps工具和AIOps算法主要关注孤立任务的自动化,而大型语言模型和AI代理的最新进展正在改变这一趋势。
- AI代理在未来将能够自主管理整个事件生命周期的操作任务,推动云系统的自我修复能力,实现AgentOps愿景。
- 需要一个全面的框架,如AIOPSLAB,来指导AI代理的设计、开发和评估。
- AIOPSLAB框架不仅部署微服务云环境,还能进行故障注入、工作负载生成、遥测数据导出,并提供与代理交互和评估的接口。
- 先进的大型语言模型代理在处理云环境中的复杂操作任务方面表现出一定的优势和局限性。
点此查看论文截图



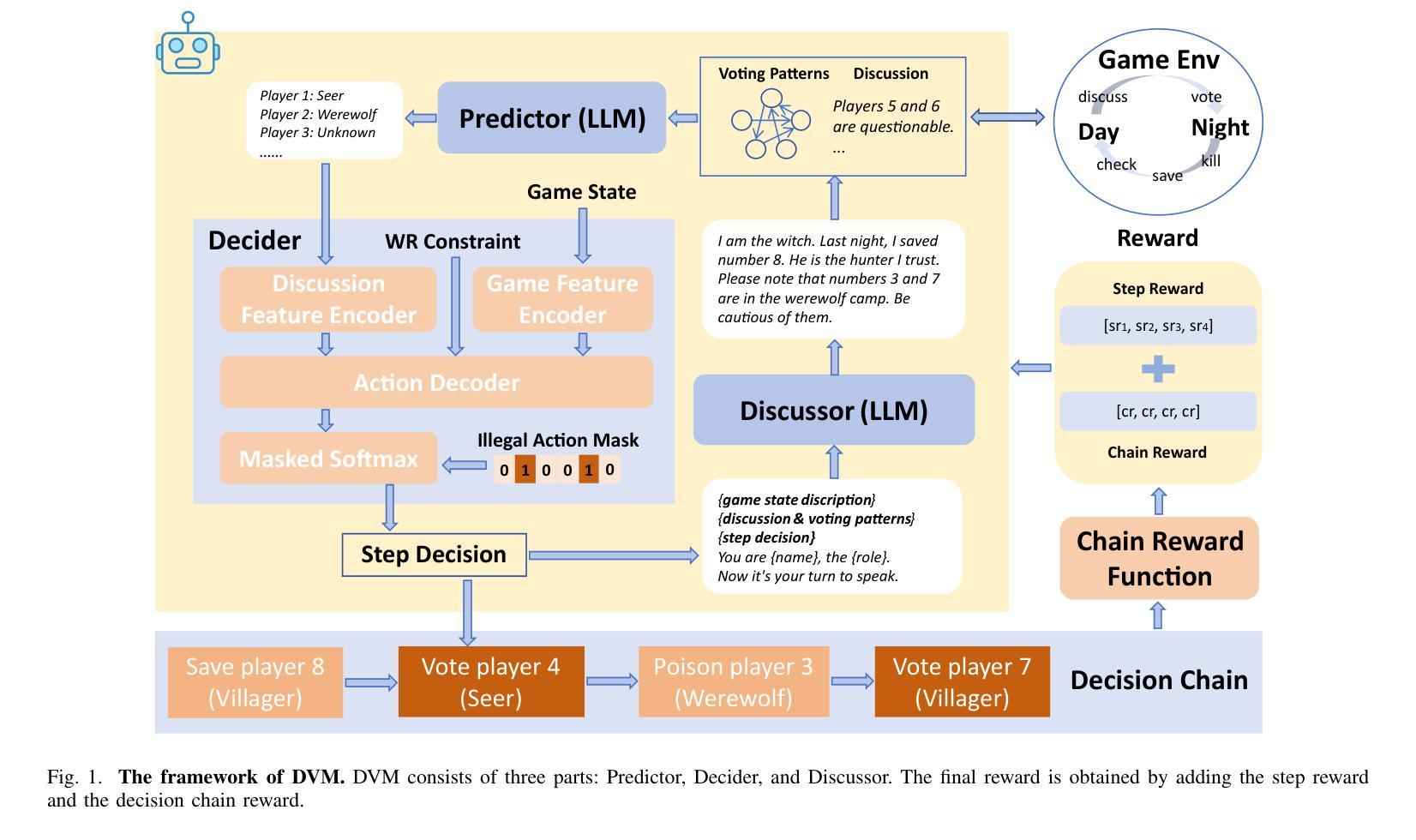
DVM: Towards Controllable LLM Agents in Social Deduction Games
Authors:Zheng Zhang, Yihuai Lan, Yangsen Chen, Lei Wang, Xiang Wang, Hao Wang
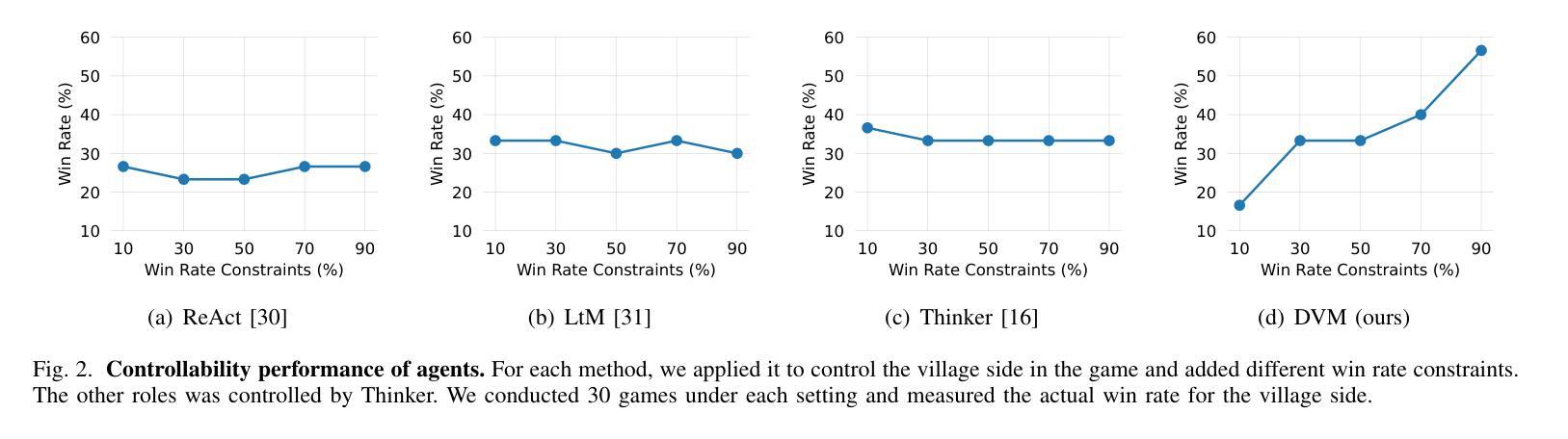
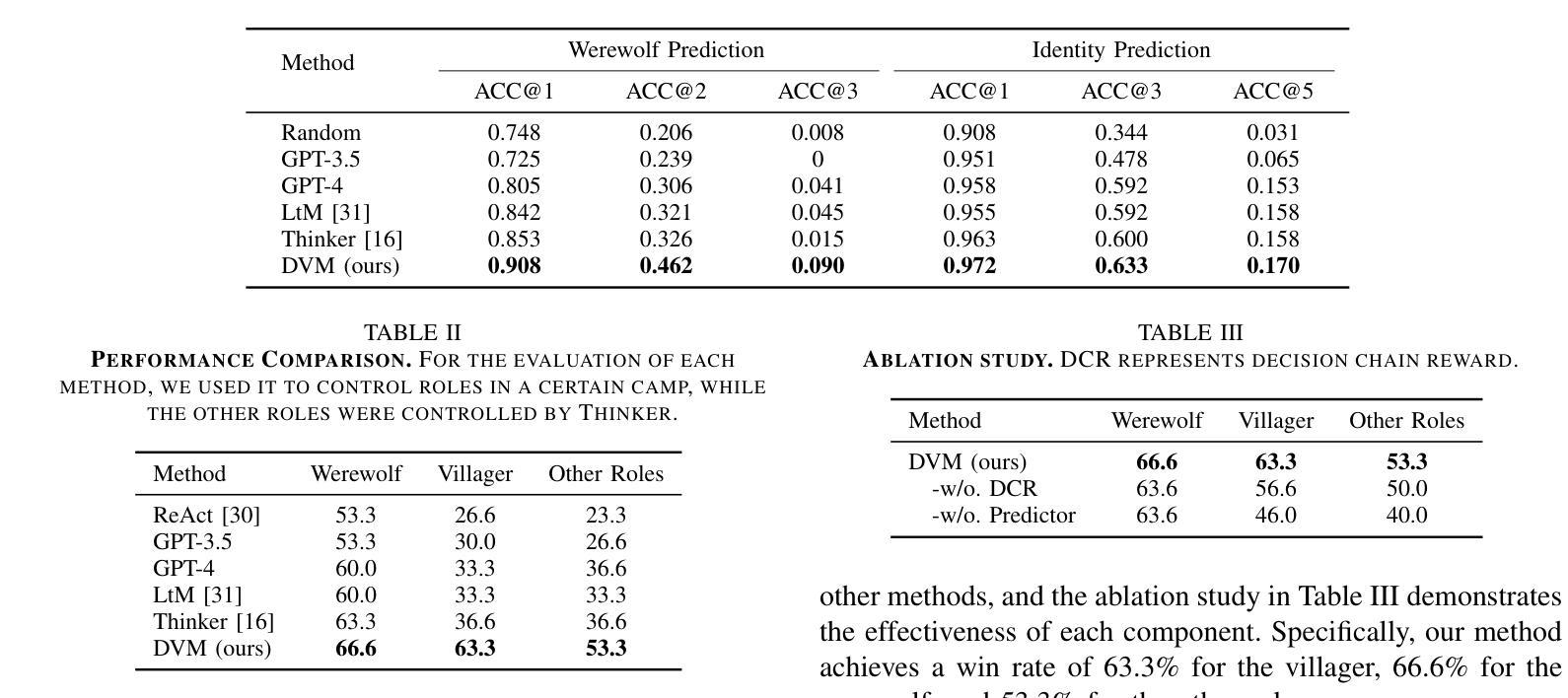
Large Language Models (LLMs) have advanced the capability of game agents in social deduction games (SDGs). These games rely heavily on conversation-driven interactions and require agents to infer, make decisions, and express based on such information. While this progress leads to more sophisticated and strategic non-player characters (NPCs) in SDGs, there exists a need to control the proficiency of these agents. This control not only ensures that NPCs can adapt to varying difficulty levels during gameplay, but also provides insights into the safety and fairness of LLM agents. In this paper, we present DVM, a novel framework for developing controllable LLM agents for SDGs, and demonstrate its implementation on one of the most popular SDGs, Werewolf. DVM comprises three main components: Predictor, Decider, and Discussor. By integrating reinforcement learning with a win rate-constrained decision chain reward mechanism, we enable agents to dynamically adjust their gameplay proficiency to achieve specified win rates. Experiments show that DVM not only outperforms existing methods in the Werewolf game, but also successfully modulates its performance levels to meet predefined win rate targets. These results pave the way for LLM agents’ adaptive and balanced gameplay in SDGs, opening new avenues for research in controllable game agents.
大型语言模型(LLM)已经提升了社交推理游戏(SDG)中的游戏代理的能力。这些游戏主要依赖于对话驱动的交互,并要求代理根据这些信息进行推断、决策和表达。虽然这一进展使得社交推理游戏中的非玩家角色(NPC)更加复杂和策略化,但需要对这些代理的熟练程度进行控制。这种控制不仅确保了NPC在游戏过程中能够适应不同的难度级别,而且还提供了关于LLM代理的安全性和公平性的见解。在本文中,我们提出了DVM,一个用于开发可控LLM代理的新型框架,并演示了其在最受欢迎的SDG之一“狼人杀”中的实现。DVM由三个主要组件组成:预测器、决策者和讨论者。通过结合强化学习与胜率约束的决策链奖励机制,我们能够使代理动态调整其游戏熟练程度以达到指定的胜率。实验表明,DVM不仅在“狼人杀”游戏中优于现有方法,而且能够成功调节其性能水平以达到预定的胜率目标。这些结果奠定了LLM代理在SDG中自适应和平衡游戏的基础,为可控游戏代理的研究开辟了新途径。
论文及项目相关链接
PDF Accepted by ICASSP 2025
Summary
大型语言模型(LLM)在游戏代理社交推理游戏(SDG)中的应用取得了进展。本文提出了DVM框架,用于开发可控的LLM游戏代理,并在最受欢迎的SDG之一“狼人杀”中进行了演示。DVM包括三个主要组件:预测器、决策者和讨论者。通过强化学习与胜率约束决策链奖励机制的集成,代理可以动态调整游戏技能以达到指定的胜率。实验表明,DVM不仅在游戏性能上优于现有方法,而且能够成功实现预定的胜率目标,为SDG中的LLM代理适应性平衡游戏铺平了道路。
Key Takeaways
- 大型语言模型(LLM)提升了游戏代理在社交推理游戏(SDG)中的能力。
- LLM在游戏中的控制是必要的,以确保非玩家角色(NPC)能够适应不同的难度级别,同时提供关于安全性和公平性的见解。
- DVM框架被提出来开发可控的LLM游戏代理,适用于社交推理游戏。
- DVM框架包括预测器、决策者和讨论者三个主要组件。
- 通过强化学习和胜率约束决策链奖励机制,DVM实现了代理的动态游戏技能调整。
- 实验表明,DVM在游戏性能上优于现有方法,并能成功实现预定的胜率目标。
点此查看论文截图

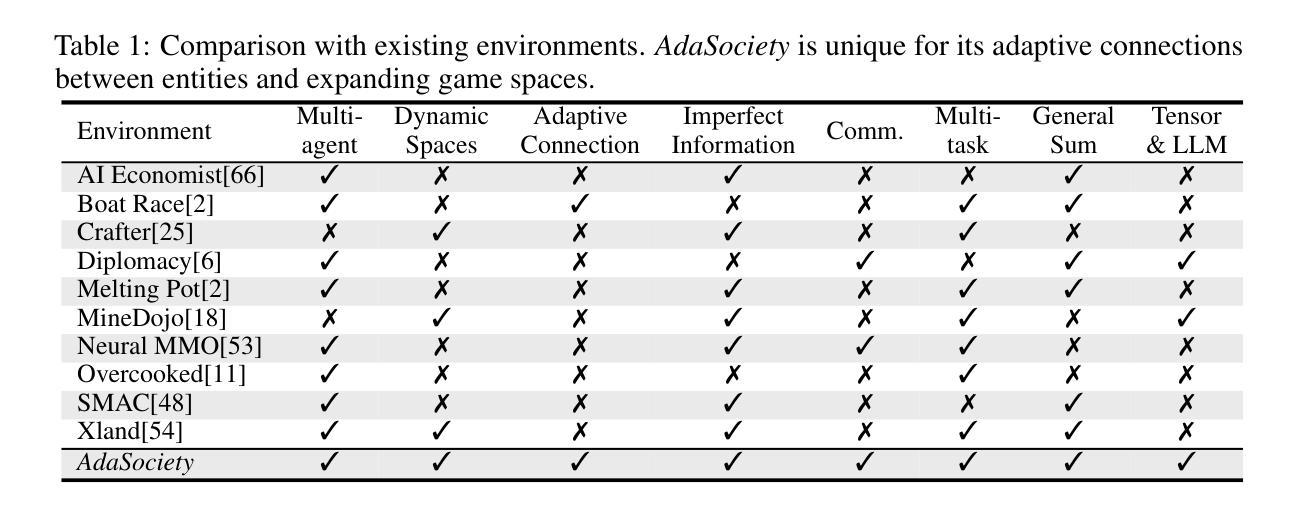
AdaSociety: An Adaptive Environment with Social Structures for Multi-Agent Decision-Making
Authors:Yizhe Huang, Xingbo Wang, Hao Liu, Fanqi Kong, Aoyang Qin, Min Tang, Song-Chun Zhu, Mingjie Bi, Siyuan Qi, Xue Feng
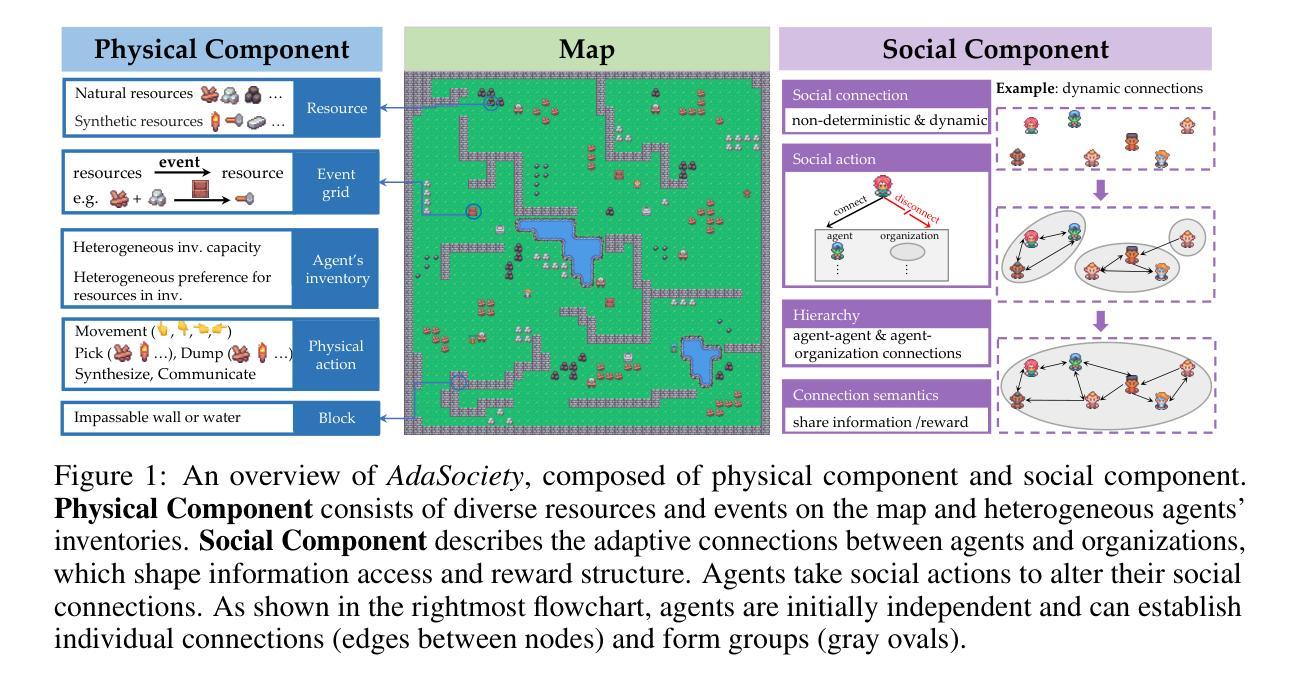
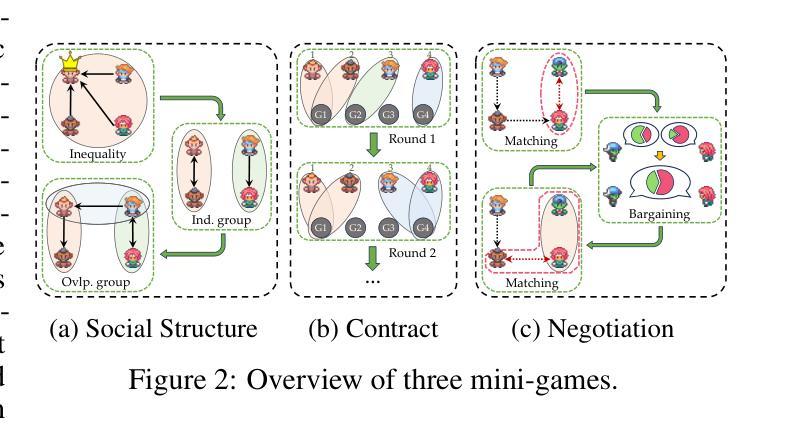
Traditional interactive environments limit agents’ intelligence growth with fixed tasks. Recently, single-agent environments address this by generating new tasks based on agent actions, enhancing task diversity. We consider the decision-making problem in multi-agent settings, where tasks are further influenced by social connections, affecting rewards and information access. However, existing multi-agent environments lack a combination of adaptive physical surroundings and social connections, hindering the learning of intelligent behaviors. To address this, we introduce AdaSociety, a customizable multi-agent environment featuring expanding state and action spaces, alongside explicit and alterable social structures. As agents progress, the environment adaptively generates new tasks with social structures for agents to undertake. In AdaSociety, we develop three mini-games showcasing distinct social structures and tasks. Initial results demonstrate that specific social structures can promote both individual and collective benefits, though current reinforcement learning and LLM-based algorithms show limited effectiveness in leveraging social structures to enhance performance. Overall, AdaSociety serves as a valuable research platform for exploring intelligence in diverse physical and social settings. The code is available at https://github.com/bigai-ai/AdaSociety.
传统的交互环境通过固定任务限制了代理的智能增长。最近,单代理环境通过基于代理行动生成新任务来解决这一问题,提高了任务的多样性。我们考虑多代理环境中的决策问题,其中的任务会受到社会连接的进一步影响,从而影响奖励和信息访问。然而,现有的多代理环境缺乏自适应的物理环境和社会连接的结合,阻碍了智能行为的学习。为了解决这一问题,我们推出了AdaSociety,这是一个可定制的多代理环境,具有扩展的状态和行动空间,以及明确且可改变的社会结构。随着代理的进步,环境会自适应地生成具有社会结构的新任务供代理执行。在AdaSociety中,我们开发了三个小型游戏,展示了不同的社会结构和任务。初步结果表明,特定的社会结构可以促进个人和集体的利益,然而目前的强化学习和基于大型语言模型的算法在利用社会结构提高性能方面显示出有限的有效性。总的来说,AdaSociety是一个有价值的研究平台,用于探索在不同物理和社会环境中的智能。代码可在https://github.com/bigai-ai/AdaSociety找到。
论文及项目相关链接
PDF Accepted at NeurIPS D&B 2024
Summary
本文介绍了传统交互环境在固定任务中限制智能代理的发展。近期,单代理环境通过生成基于代理行为的新任务,提高了任务多样性。文章探讨了多代理环境中的决策问题,其中任务受到社交连接的影响,社交连接会影响奖励和资讯获取。然而,现有的多代理环境缺乏自适应的物理环境和社交连接,阻碍了智能行为的学习。为解决这一问题,文章提出了AdaSociety,这是一个可定制的多代理环境,具有扩展的状态和行动空间,以及明确且可改变的社交结构。随着代理的进步,环境会自适应生成具有社交结构的新任务供代理执行。AdaSociety开发了三个小游戏,展示了不同的社交结构和任务。初步结果表明,特定的社交结构可以促进个人和集体的利益,但当前的强化学习和大型语言模型算法在利用社交结构提高性能方面效果有限。总体而言,AdaSociety是一个有价值的研究平台,可用于探索不同物理和社会环境下的智能问题。
Key Takeaways
- 传统交互环境在固定任务中限制智能代理的发展。
- 单代理环境通过生成基于代理行为的新任务来提高任务多样性。
- 多代理环境中的决策问题受到社交连接的影响。
- 现有多代理环境缺乏自适应的物理环境和社交连接。
- AdaSociety是一个可定制的多代理环境,具有扩展的状态和行动空间,以及明确的社交结构。
- AdaSociety环境中的社交结构会影响代理的任务和奖励。
点此查看论文截图

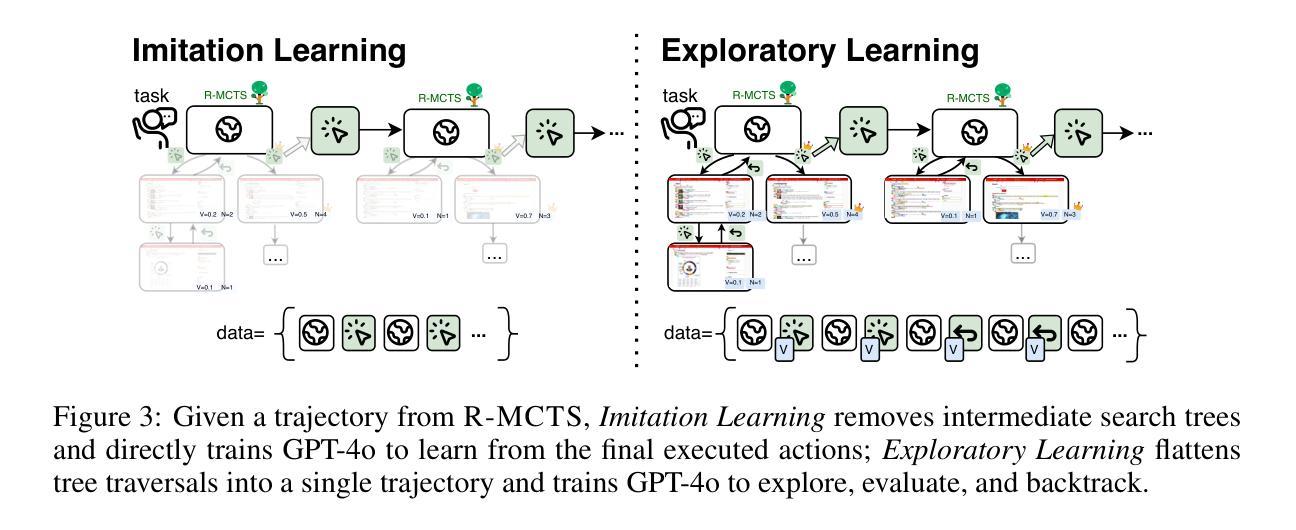
ExACT: Teaching AI Agents to Explore with Reflective-MCTS and Exploratory Learning
Authors:Xiao Yu, Baolin Peng, Vineeth Vajipey, Hao Cheng, Michel Galley, Jianfeng Gao, Zhou Yu
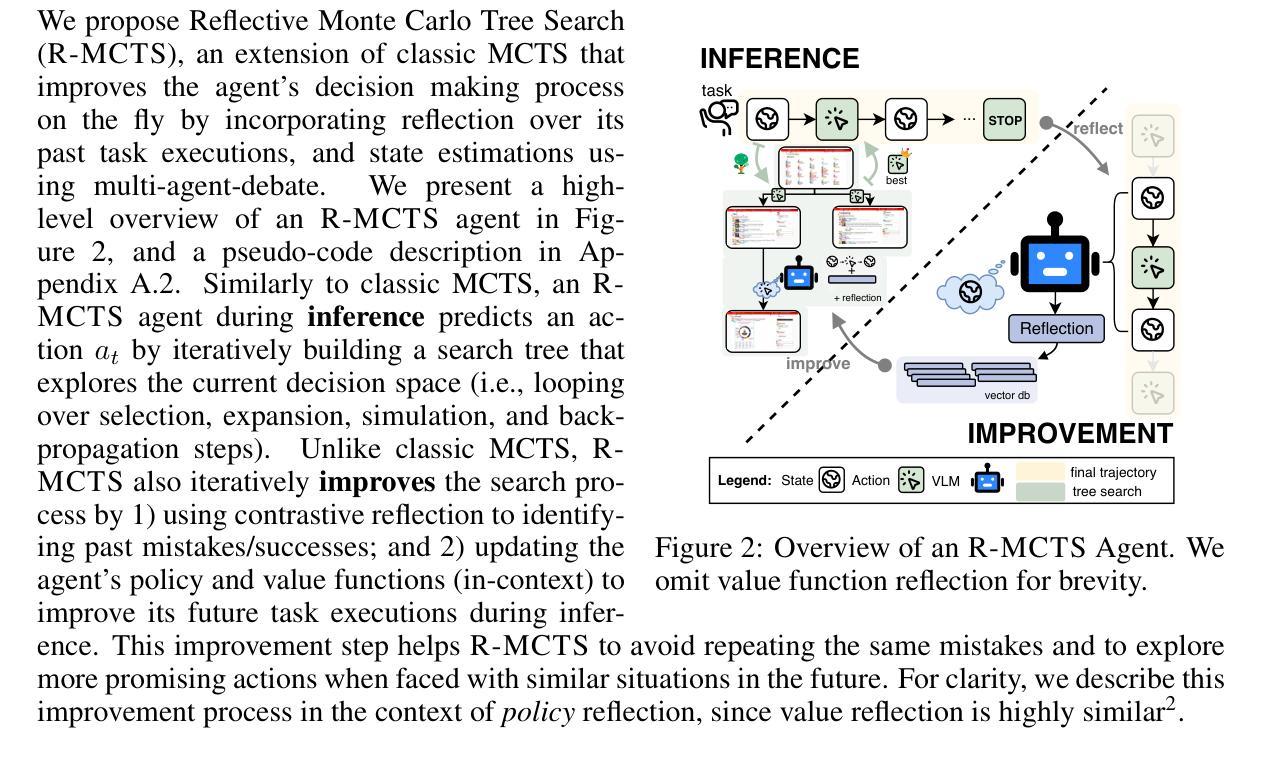
Autonomous agents have demonstrated significant potential in automating complex multistep decision-making tasks. However, even state-of-the-art vision-language models (VLMs), such as GPT-4o, still fall short of human-level performance, particularly in intricate web environments and long-horizon tasks. To address these limitations, we present ExACT, an approach to combine test-time search and self-learning to build o1-like models for agentic applications. We first introduce Reflective Monte Carlo Tree Search (R-MCTS), a novel test time algorithm designed to enhance AI agents’ ability to explore decision space on the fly. R-MCTS extends traditional MCTS by 1) incorporating contrastive reflection, allowing agents to learn from past interactions and dynamically improve their search efficiency; and 2) using multi-agent debate for reliable state evaluation. Next, we introduce Exploratory Learning, a novel learning strategy to teach agents to search at inference time without relying on any external search algorithms. On the challenging VisualWebArena benchmark, our GPT-4o based R-MCTS agent achieves a 6% to 30% relative improvement across various tasks compared to the previous state-of-the-art. Additionally, we show that the knowledge and experience gained from test-time search can be effectively transferred back to GPT-4o via fine-tuning. After Exploratory Learning, GPT-4o 1) demonstrates the ability to explore the environment, evaluate a state, and backtrack to viable ones when it detects that the current state cannot lead to success, and 2) matches 87% of R-MCTS’s performance while using significantly less compute. Notably, our work demonstrates the compute scaling properties in both training - data collection with R-MCTS - and testing time. These results suggest a promising research direction to enhance VLMs’ capabilities for agentic applications via test-time search and self-learning.
自主代理在自动化复杂的多步骤决策任务中表现出了巨大的潜力。然而,即使是最先进的视觉语言模型(VLMs),如GPT-4o,也达不到人类水平的性能,特别是在复杂的网络环境和长期任务中。为了解决这些限制,我们提出了ExACT方法,它将测试时间搜索和自学习相结合,用于构建适用于代理应用程序的o1类模型。我们首先介绍了反射蒙特卡洛树搜索(R-MCTS),这是一种新型的测试时间算法,旨在提高AI代理在飞行中探索决策空间的能力。R-MCTS通过以下两个方面扩展了传统的MCTS:1)融入对比反思,使代理能够从过去的交互中学习并动态提高搜索效率;2)使用多代理辩论进行可靠的状态评估。接下来,我们介绍了探索性学习,这是一种新的学习策略,旨在教会代理在推理时间进行搜索,而无需依赖任何外部搜索算法。在具有挑战性的VisualWebArena基准测试中,我们的基于GPT-4o的R-MCTS代理在各种任务上实现了相对于先前技术状态6%至30%的改进。此外,我们还表明,从测试时间搜索中获得的知识和经验可以有效地回馈到GPT-4o中进行微调。经过探索性学习后,GPT-4o 1)表现出探索环境、评估状态和回溯到可行状态的能力,当它检测到当前状态无法导致成功时;2)它的性能达到了R-MCTS的87%,同时使用的计算量大大减少。值得注意的是,我们的工作在训练和测试时间上都展示了计算扩展属性——通过R-MCTS进行数据采集。这些结果提示了一个有前景的研究方向,即通过测试时间搜索和自学习增强VLMs在代理应用程序中的能力。
论文及项目相关链接
Summary
自主代理在自动化复杂的多步骤决策任务中显示出巨大的潜力。然而,最先进的视觉语言模型(VLMs)如GPT-4o在精细的web环境和长期任务中仍无法达到人类水平的性能。为解决这些限制,我们提出了ExACT方法,结合测试时的搜索和自学习来构建适用于代理应用的o1级模型。我们介绍了Reflective Monte Carlo Tree Search(R-MCTS)这一新型测试时间算法,旨在提高AI代理在决策空间中的探索能力。R-MCTS通过融入对比反思和多代理辩论,提高了搜索效率。接着,我们引入了探索性学习这一新型学习策略,教授代理在推理时间进行搜索而无需依赖任何外部搜索算法。在具有挑战性的VisualWebArena基准测试中,我们的GPT-4o基础的R-MCTS代理在各项任务上实现了相对于之前最先进的6%~30%的相对改进。此外,我们展示了从测试时间搜索中获得的知识和经验可以有效地反馈给GPT-4o进行微调。经过探索性学习后,GPT-4o不仅能探索环境、评估状态,还能在检测到当前状态无法达成目标时回溯到可行的状态,并达到R-MCTS性能的87%,同时大幅减少计算量。我们的研究展示了在训练和测试时通过测试时间搜索和自学习提升VLMs在代理应用中的能力的潜力。
Key Takeaways
- 自主代理在自动化复杂决策任务中具有巨大潜力,但在精细web环境和长期任务中,现有模型如GPT-4o仍无法完全达到人类水平性能。
- ExACT方法结合了测试时的搜索和自学习,旨在提升VLMs在代理应用中的性能。
- 引入Reflective Monte Carlo Tree Search (R-MCTS)算法,通过对比反思和多代理辩论提高搜索效率。
- GPT-4o结合R-MCTS在VisualWebArena基准测试中实现了显著的性能提升。
- 测试时间获得的知识和经验可以通过微调反馈给模型,如GPT-4o在经过探索性学习后展现出高级别的环境探索、状态评估能力。
- 探索性学习使模型能够在检测到当前状态不可行时回溯到可行状态。
点此查看论文截图

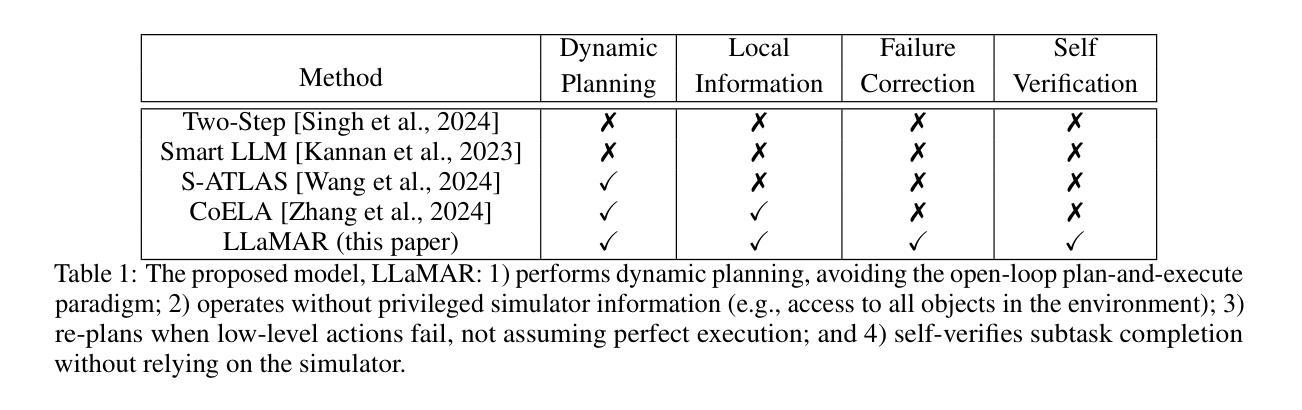
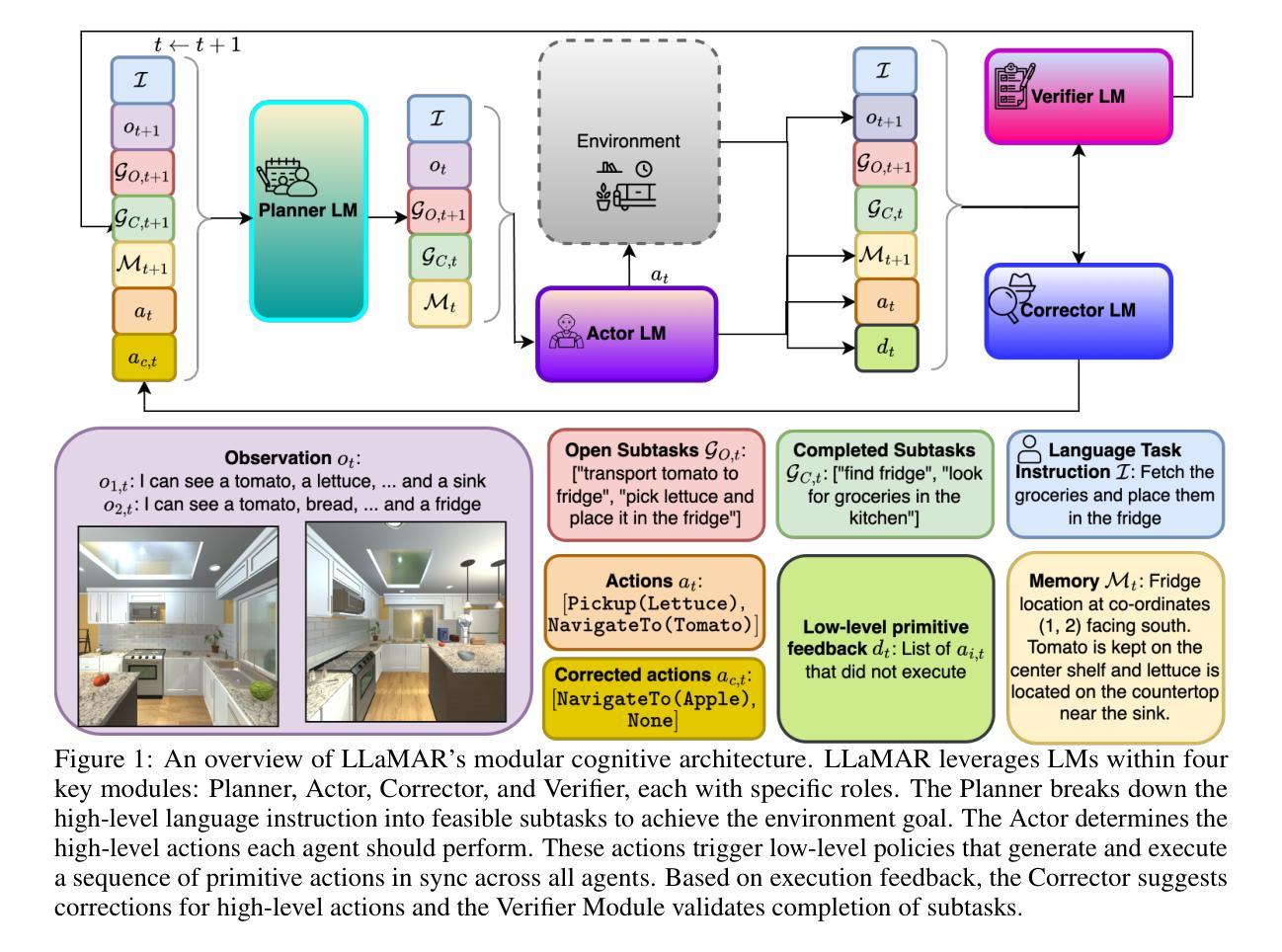
LLaMAR: Long-Horizon Planning for Multi-Agent Robots in Partially Observable Environments
Authors:Siddharth Nayak, Adelmo Morrison Orozco, Marina Ten Have, Vittal Thirumalai, Jackson Zhang, Darren Chen, Aditya Kapoor, Eric Robinson, Karthik Gopalakrishnan, James Harrison, Brian Ichter, Anuj Mahajan, Hamsa Balakrishnan
The ability of Language Models (LMs) to understand natural language makes them a powerful tool for parsing human instructions into task plans for autonomous robots. Unlike traditional planning methods that rely on domain-specific knowledge and handcrafted rules, LMs generalize from diverse data and adapt to various tasks with minimal tuning, acting as a compressed knowledge base. However, LMs in their standard form face challenges with long-horizon tasks, particularly in partially observable multi-agent settings. We propose an LM-based Long-Horizon Planner for Multi-Agent Robotics (LLaMAR), a cognitive architecture for planning that achieves state-of-the-art results in long-horizon tasks within partially observable environments. LLaMAR employs a plan-act-correct-verify framework, allowing self-correction from action execution feedback without relying on oracles or simulators. Additionally, we present MAP-THOR, a comprehensive test suite encompassing household tasks of varying complexity within the AI2-THOR environment. Experiments show that LLaMAR achieves a 30% higher success rate than other state-of-the-art LM-based multi-agent planners in MAP-THOR and Search & Rescue tasks. Code can be found at https://github.com/nsidn98/LLaMAR
自然语言模型(LMs)理解自然语言的能力使它们成为将人类指令解析为自主机器人任务计划的有力工具。与传统的依赖于特定领域知识和手工制定的规则的计划方法不同,语言模型能够从多样化的数据中概括知识,并适应各种任务,只需很少的调整,就像一个压缩的知识库。然而,标准形式的LM在处理长期任务时面临挑战,特别是在部分可观察的多智能体环境中。我们提出了一种基于LM的长期多智能体机器人规划器(LLaMAR),这是一种用于规划的认知架构,在部分可观察的环境中处理长期任务时达到了最先进的水平。LLaMAR采用计划-行动-修正-验证框架,允许从行动执行反馈中进行自我修正,无需依赖神谕或模拟器。此外,我们还推出了MAP-THOR测试套件,该测试套件涵盖了AI2-THOR环境中的各种复杂度的家庭任务。实验表明,在MAP-THOR和搜索与救援任务中,LLaMAR相较于其他先进的基于LM的多智能体规划器的成功率提高了30%。代码可在https://github.com/nsidn98/LLaMAR找到。
论文及项目相关链接
PDF 27 pages, 4 figures, 5 tables
Summary
语言模型(LMs)能够解析自然语言指令并转化为自主机器人的任务计划,显示出其在多智能体机器人领域的潜力。与传统的规划方法不同,语言模型可从多样化数据中推广并适应各种任务。针对长周期多智能体任务,特别是在部分可观察的环境中,我们提出了基于语言模型的长期规划器LLaMAR。它在AI2-THOR环境中的家务任务以及搜索和救援任务中实现了显著成效,成功率高出其他最新语言模型多智能体规划器30%。
Key Takeaways
- 语言模型(LMs)能够将自然语言指令转化为自主机器人的任务计划,具有强大的通用性。
- 相较于传统规划方法,语言模型能够从多样化数据中推广并适应各种任务。
- LLaMAR是一个针对多智能体机器人的长期规划器,特别适用于部分可观察的环境。
- LLaMAR采用计划-行动-纠正-验证框架,可从行动执行反馈中进行自我纠正。
- MAP-THOR是一个包含AI2-THOR环境中复杂家务任务的全面测试套件。
- 实验显示,LLaMAR在MAP-THOR和搜索与救援任务中的成功率高于其他最新语言模型多智能体规划器。
点此查看论文截图