⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-16 更新
MangaNinja: Line Art Colorization with Precise Reference Following
Authors:Zhiheng Liu, Ka Leong Cheng, Xi Chen, Jie Xiao, Hao Ouyang, Kai Zhu, Yu Liu, Yujun Shen, Qifeng Chen, Ping Luo
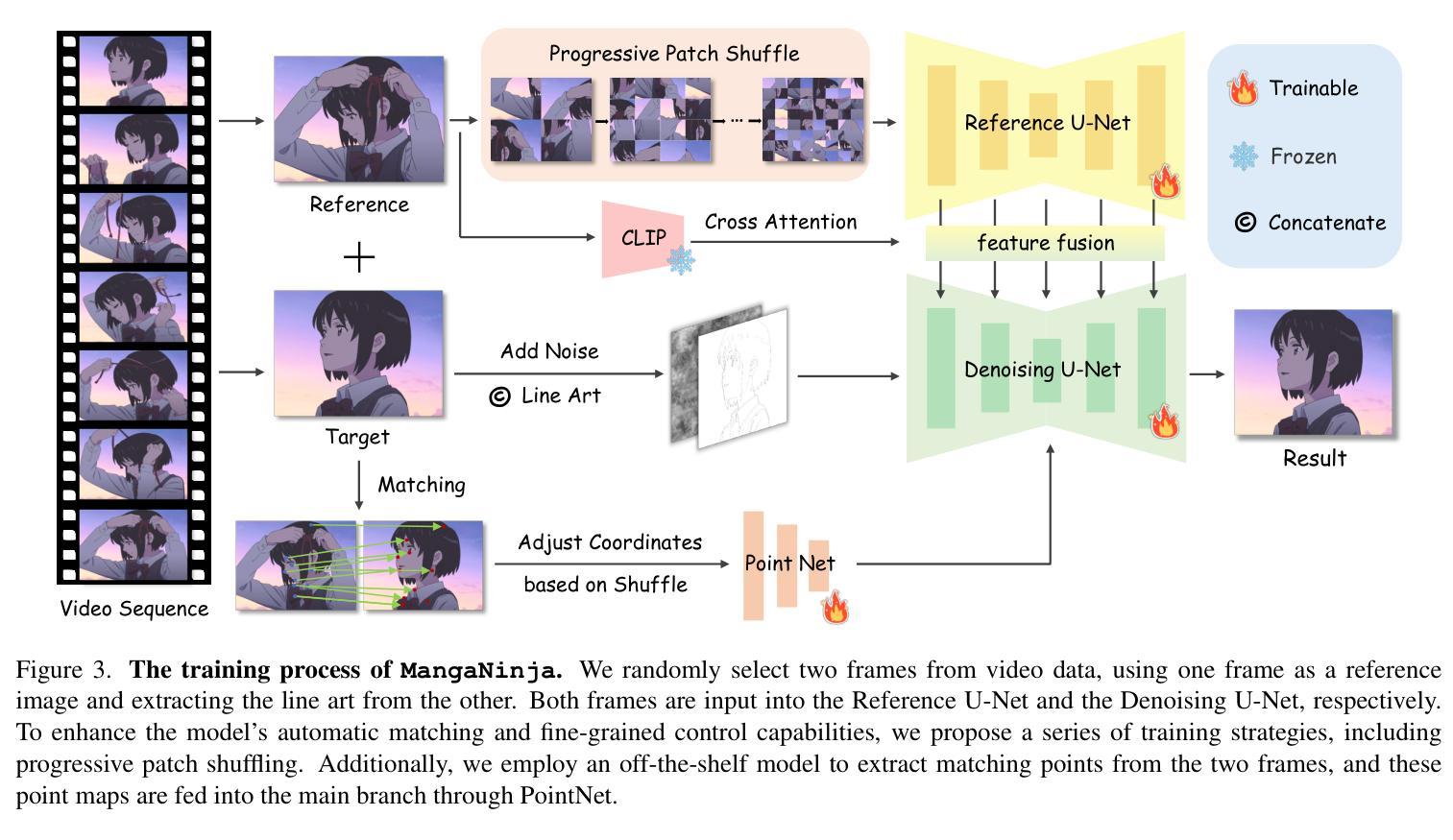
Derived from diffusion models, MangaNinjia specializes in the task of reference-guided line art colorization. We incorporate two thoughtful designs to ensure precise character detail transcription, including a patch shuffling module to facilitate correspondence learning between the reference color image and the target line art, and a point-driven control scheme to enable fine-grained color matching. Experiments on a self-collected benchmark demonstrate the superiority of our model over current solutions in terms of precise colorization. We further showcase the potential of the proposed interactive point control in handling challenging cases, cross-character colorization, multi-reference harmonization, beyond the reach of existing algorithms.
MangaNinjia源于扩散模型,专门用于参考引导的线艺术彩色化任务。我们采用了两种精心设计的方法,确保角色细节的精确转录,包括一个补丁洗牌模块,以促进参考彩色图像和目标线艺术之间的对应学习,以及一个点驱动的控制方案,以实现精细的颜色匹配。在自我收集的基准测试集上的实验表明,我们的模型在精确彩色化方面优于当前解决方案。我们还展示了所提出交互式点控制在处理跨角色彩色化、多参考融合等现有算法难以解决的情况时的潜力。
论文及项目相关链接
PDF Project page and code: https://johanan528.github.io/MangaNinjia/
Summary
基于扩散模型,MangaNinjia致力于实现参考引导的线艺术色彩化任务。通过融入两大精心设计,确保了角色细节的精准转录:一是贴片打乱模块,有助于参考色彩图像与目标线艺术之间的对应关系学习;二是点驱动控制方案,可实现精细色彩匹配。在自家收集的标准测试集上的实验证明,本模型在精确色彩化方面超越现有解决方案。此外,所提交互式点控制在处理跨角色色彩化、多参考调和等现有算法难以触及的挑战性问题时展现出巨大潜力。
Key Takeaways
- MangaNinjia基于扩散模型进行线艺术色彩化任务。
- 融入贴片打乱模块以促进参考色彩图像与目标线艺术间的对应关系学习。
- 采用点驱动控制方案以实现精细色彩匹配。
- 在自家收集的标准测试集上的实验显示,模型在精确色彩化方面表现优异。
- 交互式点控制在处理跨角色色彩化时具有巨大潜力。
- 多参考调和能力超越了现有算法的处理范围。
点此查看论文截图



Diffusion Adversarial Post-Training for One-Step Video Generation
Authors:Shanchuan Lin, Xin Xia, Yuxi Ren, Ceyuan Yang, Xuefeng Xiao, Lu Jiang
The diffusion models are widely used for image and video generation, but their iterative generation process is slow and expansive. While existing distillation approaches have demonstrated the potential for one-step generation in the image domain, they still suffer from significant quality degradation. In this work, we propose Adversarial Post-Training (APT) against real data following diffusion pre-training for one-step video generation. To improve the training stability and quality, we introduce several improvements to the model architecture and training procedures, along with an approximated R1 regularization objective. Empirically, our experiments show that our adversarial post-trained model, Seaweed-APT, can generate 2-second, 1280x720, 24fps videos in real time using a single forward evaluation step. Additionally, our model is capable of generating 1024px images in a single step, achieving quality comparable to state-of-the-art methods.
扩散模型广泛用于图像和视频生成,但其迭代生成过程缓慢且消耗资源。尽管现有的蒸馏方法已经显示出在图像领域进行一步生成的潜力,但它们仍然面临严重的质量下降问题。在这项工作中,我们提出了在扩散预训练之后使用对抗后训练(APT)进行一步视频生成的方法。为了改善训练稳定性和质量,我们对模型结构和训练程序进行了几项改进,并引入了一个近似R1正则化目标。实验证明,我们的对抗后训练模型Seaweed-APT可以实时生成2秒、1280x720、24帧的视频,只需进行一次前向评估步骤。此外,我们的模型能够一步生成1024px的图像,达到与最新技术相当的质量。
论文及项目相关链接
Summary
本文探讨了扩散模型在图像和视频生成中的广泛应用,但其迭代生成过程速度慢且消耗资源大。现有蒸馏方法虽可实现图像领域的一步生成,但质量仍有显著下降。本研究提出一种基于真实数据的对抗后训练(APT)方法,用于一步视频生成,并在扩散预训练后进行。为提高训练稳定性和质量,对模型架构和训练流程进行了改进,并引入了近似R1正则化目标。实验表明,对抗训练后的Seaweed-APT模型可实时生成2秒、1280x720、24帧的视频,仅需单次前向评估步骤。此外,该模型还能在单步生成1024像素图像,质量达到业界领先水平。
Key Takeaways
- 扩散模型广泛应用于图像和视频生成,但迭代生成过程存在速度慢和资源消耗大的问题。
- 现有蒸馏方法在图像一步生成方面存在质量下降的问题。
- 提出了基于真实数据的对抗后训练(APT)方法,用于一步视频生成。
- 引入模型架构和训练流程的改进,以及近似R1正则化目标,以提高训练稳定性和质量。
- 对抗训练后的Seaweed-APT模型可实时生成高质量的视频和图像。
- Seaweed-APT模型能生成2秒、1280x720、24帧的视频,且只需单次前向评估步骤。
- 该模型还能在单步生成1024像素图像,质量达到业界先进水平。
点此查看论文截图



FramePainter: Endowing Interactive Image Editing with Video Diffusion Priors
Authors:Yabo Zhang, Xinpeng Zhou, Yihan Zeng, Hang Xu, Hui Li, Wangmeng Zuo
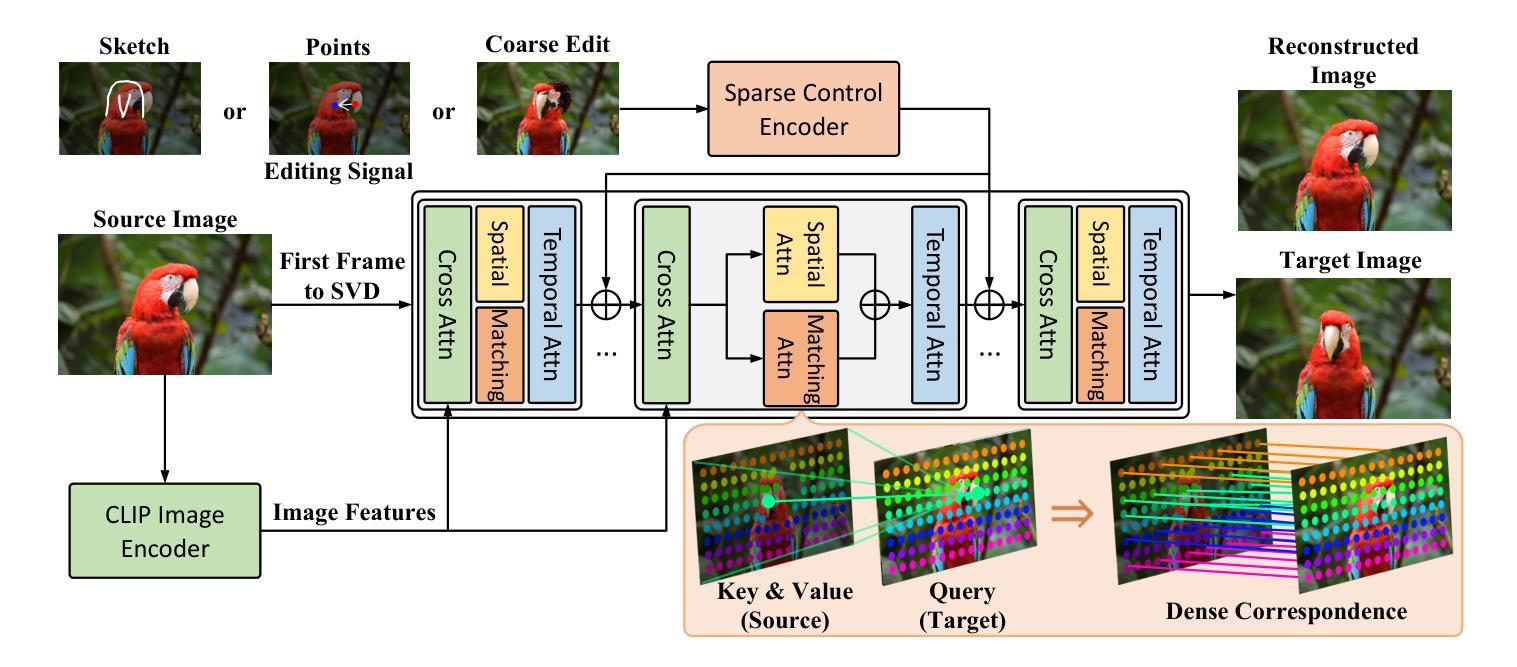
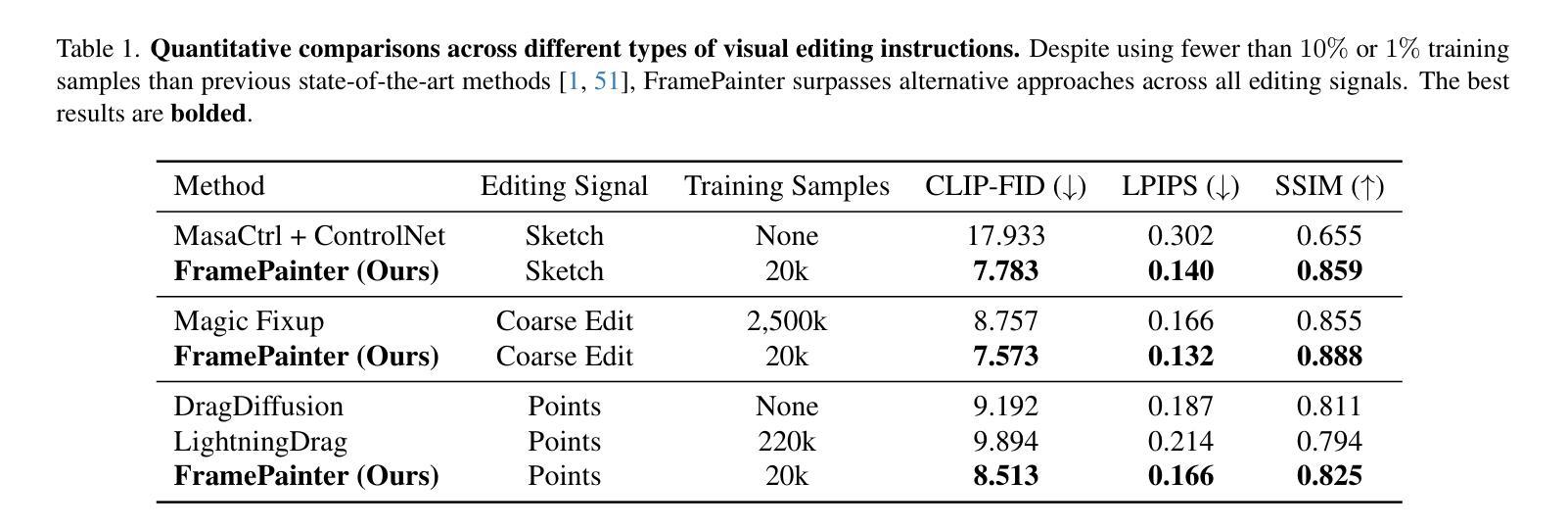
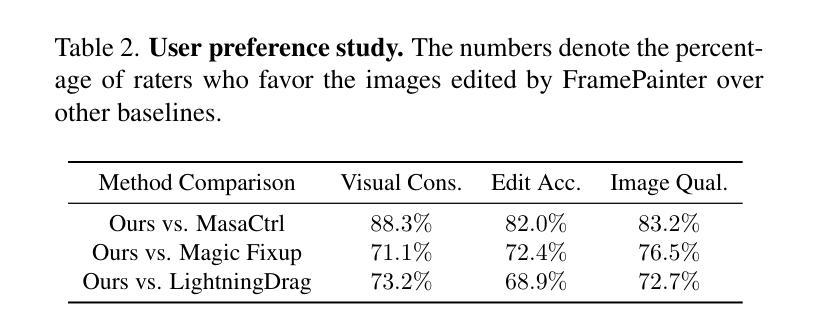
Interactive image editing allows users to modify images through visual interaction operations such as drawing, clicking, and dragging. Existing methods construct such supervision signals from videos, as they capture how objects change with various physical interactions. However, these models are usually built upon text-to-image diffusion models, so necessitate (i) massive training samples and (ii) an additional reference encoder to learn real-world dynamics and visual consistency. In this paper, we reformulate this task as an image-to-video generation problem, so that inherit powerful video diffusion priors to reduce training costs and ensure temporal consistency. Specifically, we introduce FramePainter as an efficient instantiation of this formulation. Initialized with Stable Video Diffusion, it only uses a lightweight sparse control encoder to inject editing signals. Considering the limitations of temporal attention in handling large motion between two frames, we further propose matching attention to enlarge the receptive field while encouraging dense correspondence between edited and source image tokens. We highlight the effectiveness and efficiency of FramePainter across various of editing signals: it domainantly outperforms previous state-of-the-art methods with far less training data, achieving highly seamless and coherent editing of images, \eg, automatically adjust the reflection of the cup. Moreover, FramePainter also exhibits exceptional generalization in scenarios not present in real-world videos, \eg, transform the clownfish into shark-like shape. Our code will be available at https://github.com/YBYBZhang/FramePainter.
交互式图像编辑允许用户通过绘图、点击和拖动等视觉交互操作来修改图像。现有方法通过视频构建这种监督信号,因为它们可以捕捉各种物理交互下物体的变化。然而,这些模型通常建立在文本到图像的扩散模型之上,因此需要(i)大量的训练样本和(ii)额外的参考编码器来学习现实世界的动力学和视觉一致性。在本文中,我们将此任务重新表述为图像到视频生成问题,以便利用强大的视频扩散先验来降低训练成本并确保时间一致性。具体来说,我们引入了FramePainter作为这种表述的有效实例化。它以稳定的视频扩散进行初始化,仅使用轻量级的稀疏控制编码器来注入编辑信号。考虑到时间注意在处理两帧之间的大动作时的局限性,我们进一步提出匹配注意力来扩大感受野,同时鼓励编辑图像标记和源图像标记之间建立密集对应关系。我们强调了FramePainter在各种编辑信号中的有效性和效率:它在使用的训练数据远少于以前的最先进方法的情况下主导了性能,实现了高度无缝和连贯的图像编辑,例如自动调整杯子的反射。此外,FramePainter在现实视频中没有出现的场景中也有出色的泛化能力,例如将小丑鱼变形为类似鲨鱼的外形。我们的代码将在https://github.com/YBYBZhang/FramePainter上提供。
论文及项目相关链接
PDF Code: https://github.com/YBYBZhang/FramePainter
Summary
本文提出将交互式图像编辑任务重新构建为图像到视频生成问题,通过利用视频扩散先验知识,减少训练成本并确保时间一致性。文章介绍了一种高效的方法FramePainter,它仅使用轻量级的稀疏控制编码器来注入编辑信号。针对大运动帧间处理中临时注意力机制的局限性,文章进一步提出了匹配注意力来扩大感受野并鼓励编辑和源图像标记之间的密集对应关系。FramePainter在各种编辑信号上的表现有效且高效,它显著优于使用较少训练数据的前瞻方法,可实现无缝且连贯的图像编辑。
Key Takeaways
- 交互式图像编辑允许用户通过绘制、点击和拖动等视觉交互操作来修改图像。
- 现有方法通过视频构建监督信号,以捕捉各种物理交互中物体的变化。
- 本文将任务重新构建为图像到视频生成问题,利用视频扩散先验知识,降低训练成本并确保时间一致性。
- 引入FramePainter方法,仅使用轻量级的稀疏控制编码器来注入编辑信号,实现高效图像编辑。
- 针对大运动帧间处理的局限性,提出了匹配注意力机制来扩大感受野并加强编辑和源图像之间的对应关系。
- FramePainter在多种编辑信号上表现优异,使用较少的训练数据即可实现无缝且连贯的图像编辑,如自动调整杯子的反射等。
点此查看论文截图



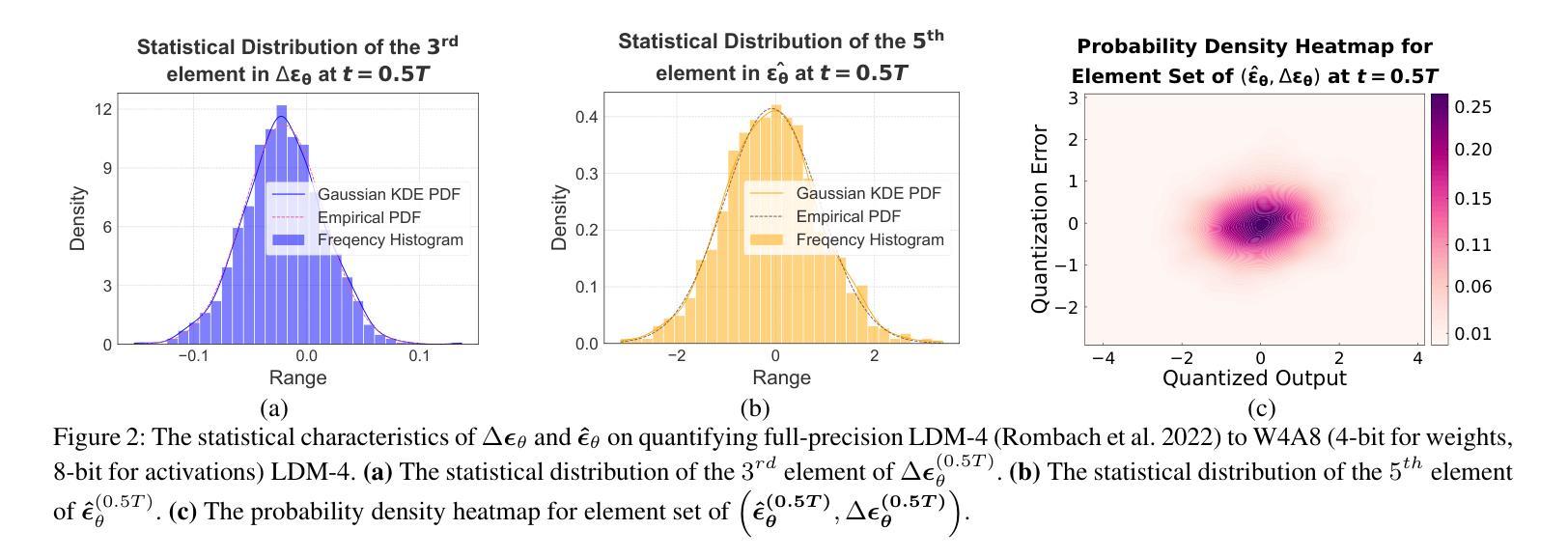
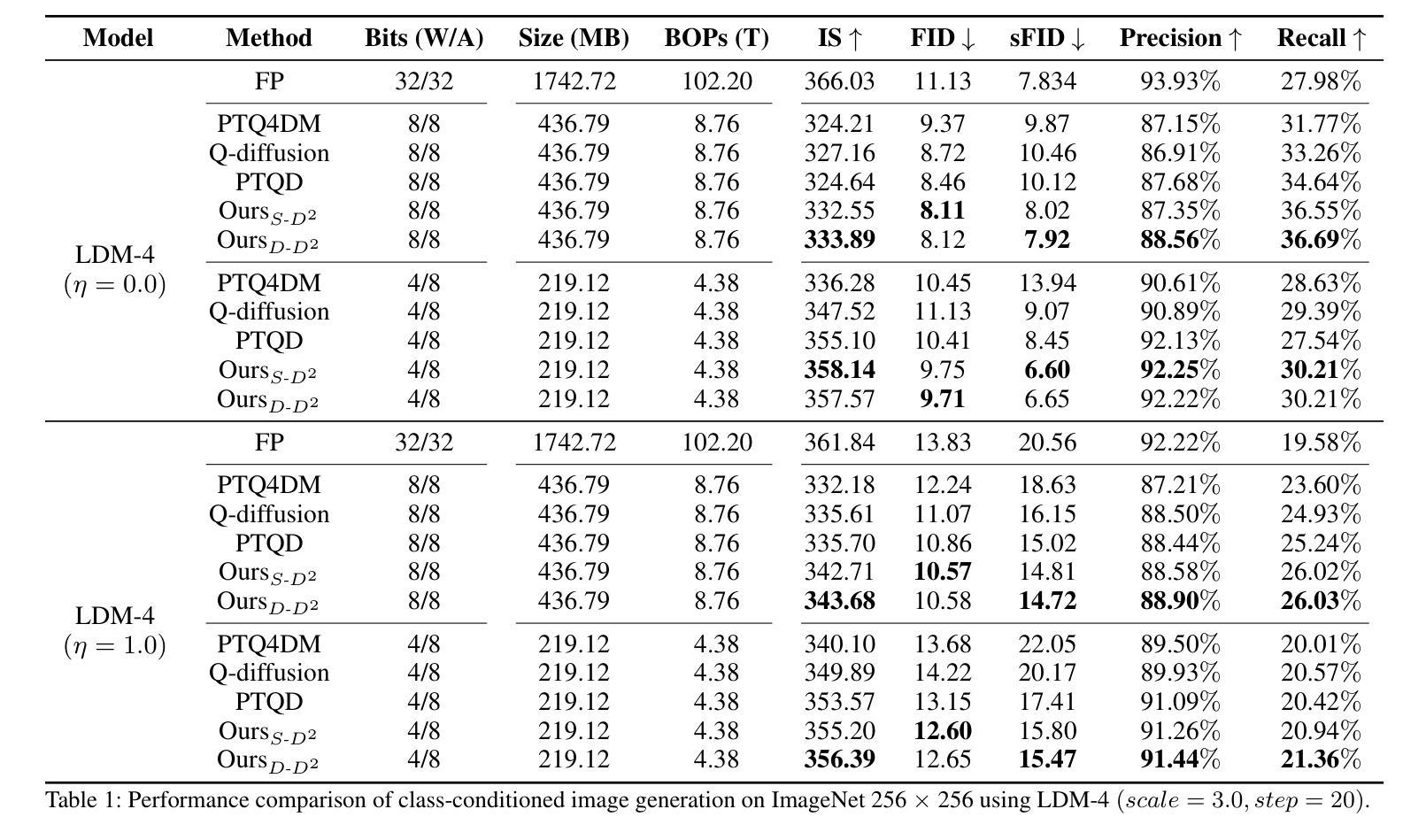
D$^2$-DPM: Dual Denoising for Quantized Diffusion Probabilistic Models
Authors:Qian Zeng, Jie Song, Han Zheng, Hao Jiang, Mingli Song
Diffusion models have achieved cutting-edge performance in image generation. However, their lengthy denoising process and computationally intensive score estimation network impede their scalability in low-latency and resource-constrained scenarios. Post-training quantization (PTQ) compresses and accelerates diffusion models without retraining, but it inevitably introduces additional quantization noise, resulting in mean and variance deviations. In this work, we propose D2-DPM, a dual denoising mechanism aimed at precisely mitigating the adverse effects of quantization noise on the noise estimation network. Specifically, we first unravel the impact of quantization noise on the sampling equation into two components: the mean deviation and the variance deviation. The mean deviation alters the drift coefficient of the sampling equation, influencing the trajectory trend, while the variance deviation magnifies the diffusion coefficient, impacting the convergence of the sampling trajectory. The proposed D2-DPM is thus devised to denoise the quantization noise at each time step, and then denoise the noisy sample through the inverse diffusion iterations. Experimental results demonstrate that D2-DPM achieves superior generation quality, yielding a 1.42 lower FID than the full-precision model while achieving 3.99x compression and 11.67x bit-operation acceleration.
扩散模型在图像生成方面已经达到了前沿水平。然而,其漫长的去噪过程和计算密集型的评分估计网络阻碍了其在低延迟和资源受限场景中的可扩展性。后训练量化(PTQ)能够在不进行二次训练的情况下压缩和加速扩散模型,但它不可避免地引入了额外的量化噪声,导致均值和方差偏差。在本研究中,我们提出了D2-DPM,这是一种双重去噪机制,旨在精确缓解量化噪声对噪声估计网络的不利影响。具体来说,我们首先把量化噪声对采样方程的影响分解为两个组成部分:均值偏差和方差偏差。均值偏差会改变采样方程的漂移系数,影响轨迹趋势,而方差偏差会放大扩散系数,影响采样轨迹的收敛性。因此,提出的D 是在每个时间点对量化噪声进行去噪后。实验结果表明,D2-DPM达到了出色的生成质量,与全精度模型相比,FID降低了提高了1.4倍性能提升以及减少了训练所需的代码库压缩到原有尺寸的千分之三之一以及显著降低了执行推理的计算速度仅到原来性能的千分之一之六十七。具体而言相较于全精度模型(FID值较高),其取得了更低的FID值同时压缩比达到约百分之一并且加速计算了接近十一倍半的推理速度。
论文及项目相关链接
PDF 9 pages, 4 figures, acceptted by AAAI2025
Summary
扩散模型在图像生成领域表现卓越,但其漫长的去噪过程和计算密集型的评分估计网络限制了其在低延迟和资源受限场景的应用。本文提出一种双去噪机制D2-DPM,旨在精确缓解量化噪声对噪声估计网络的不利影响。通过实验验证,D2-DPM在生成质量上达到优于全精度模型的效果,降低了1.42的FID得分,同时实现了3.99倍的压缩和11.67倍的位操作加速。
Key Takeaways
- 扩散模型在图像生成上表现优秀,但存在去噪过程漫长和计算资源密集的问题。
- 量化噪声对扩散模型的性能产生负面影响。
- 提出的D2-DPM双去噪机制能够精确缓解量化噪声的不利影响。
- D2-DPM将量化噪声的影响分解为两个组成部分:均值偏差和方差偏差。
- D2-DPM在每个时间步进行去噪操作,然后通过逆向扩散迭代进一步去噪。
- 实验结果表明,D2-DPM在生成质量上优于全精度模型,降低了FID得分。
点此查看论文截图