⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-16 更新
SAR Strikes Back: A New Hope for RSVQA
Authors:Lucrezia Tosato, Flora Weissgerber, Laurent Wendling, Sylvain Lobry
Remote sensing visual question answering (RSVQA) is a task that automatically extracts information from satellite images and processes a question to predict the answer from the images in textual form, helping with the interpretation of the image. While different methods have been proposed to extract information from optical images with different spectral bands and resolutions, no method has been proposed to answer questions from Synthetic Aperture Radar (SAR) images. SAR images capture electromagnetic information from the scene, and are less affected by atmospheric conditions, such as clouds. In this work, our objective is to introduce SAR in the RSVQA task, finding the best way to use this modality. In our research, we carry out a study on different pipelines for the task of RSVQA taking into account information from both SAR and optical data. To this purpose, we also present a dataset that allows for the introduction of SAR images in the RSVQA framework. We propose two different models to include the SAR modality. The first one is an end-to-end method in which we add an additional encoder for the SAR modality. In the second approach, we build on a two-stage framework. First, relevant information is extracted from SAR and, optionally, optical data. This information is then translated into natural language to be used in the second step which only relies on a language model to provide the answer. We find that the second pipeline allows us to obtain good results with SAR images alone. We then try various types of fusion methods to use SAR and optical images together, finding that a fusion at the decision level achieves the best results on the proposed dataset. We show that SAR data offers additional information when fused with the optical modality, particularly for questions related to specific land cover classes, such as water areas.
遥感视觉问答(RSVQA)是一项任务,它会自动从卫星图像中提取信息,并处理问题以预测图像的文本形式的答案,有助于解释图像。虽然已经提出了不同的方法从具有不同光谱波段和分辨率的光学图像中提取信息,但还没有提出从合成孔径雷达(SAR)图像中回答问题的方法。SAR图像捕捉场景的电磁信息,并且受云层等大气条件的影响较小。在这项工作中,我们的目标是在RSVQA任务中引入SAR,寻找使用这种模态的最佳方式。在我们的研究中,我们研究了不同的RSVQA任务管道,考虑了SAR和光学数据的双重信息。为此,我们还提供了一个允许在RSVQA框架中引入SAR图像的数据集。我们提出了两种包含SAR模态的模型。第一种是端到端的方法,我们为SAR模态添加了一个额外的编码器。在第二种方法中,我们基于两阶段框架构建。首先,从SAR和(可选)光学数据中提取相关信息。然后将此信息转换为自然语言,用于第二步,该步骤仅依靠语言模型来提供答案。我们发现第二个管道允许我们仅使用SAR图像就获得良好的结果。然后,我们尝试了各种融合方法来同时使用SAR和光学图像,发现决策层融合在提出的数据集上取得了最佳效果。我们表明,SAR数据在与光学模态融合时提供了额外的信息,特别是对于与特定土地覆盖类相关的问题,例如水域。
论文及项目相关链接
PDF 26 pages, 6 figures
Summary
遥感视觉问答(RSVQA)能够从卫星图像中自动提取信息,并将问题转化为文本形式来预测答案,有助于图像解读。目前尚未有方法能够利用合成孔径雷达(SAR)图像回答问题。SAR图像捕捉场景电磁信息,较少受云层等大气条件影响。本研究旨在将SAR引入RSVQA任务,探索最佳使用方式。为此,研究提出两种包含SAR模态的模型。第一种是端到端方法,增加SAR模态的额外编码器。第二种是基于两阶段框架,首先提取SAR和(可选)光学数据的相关信息,然后将其翻译成自然语言,在仅依赖语言模型的情况下提供答案。研究发现,第二管道在使用仅SAR图像时即可获得良好结果。尝试将SAR和光学图像结合使用,发现决策级融合效果最佳。SAR数据在与光学模态融合时能提供额外信息,特别是在涉及特定土地覆盖类别的问题中表现突出,如水域。
Key Takeaways
- 遥感视觉问答(RSVQA)能够从卫星图像中提取信息并转化为文本形式的答案。
- 目前没有方法能够利用合成孔径雷达(SAR)图像回答问题。
- SAR图像捕捉场景的电磁信息,较少受大气条件影响。
- 研究提出两种包含SAR模态的模型:端到端方法和基于两阶段框架的方法。
- 第二管道在使用仅SAR图像时即可获得良好结果。
- 决策级融合在结合SAR和光学图像时效果最佳。
点此查看论文截图

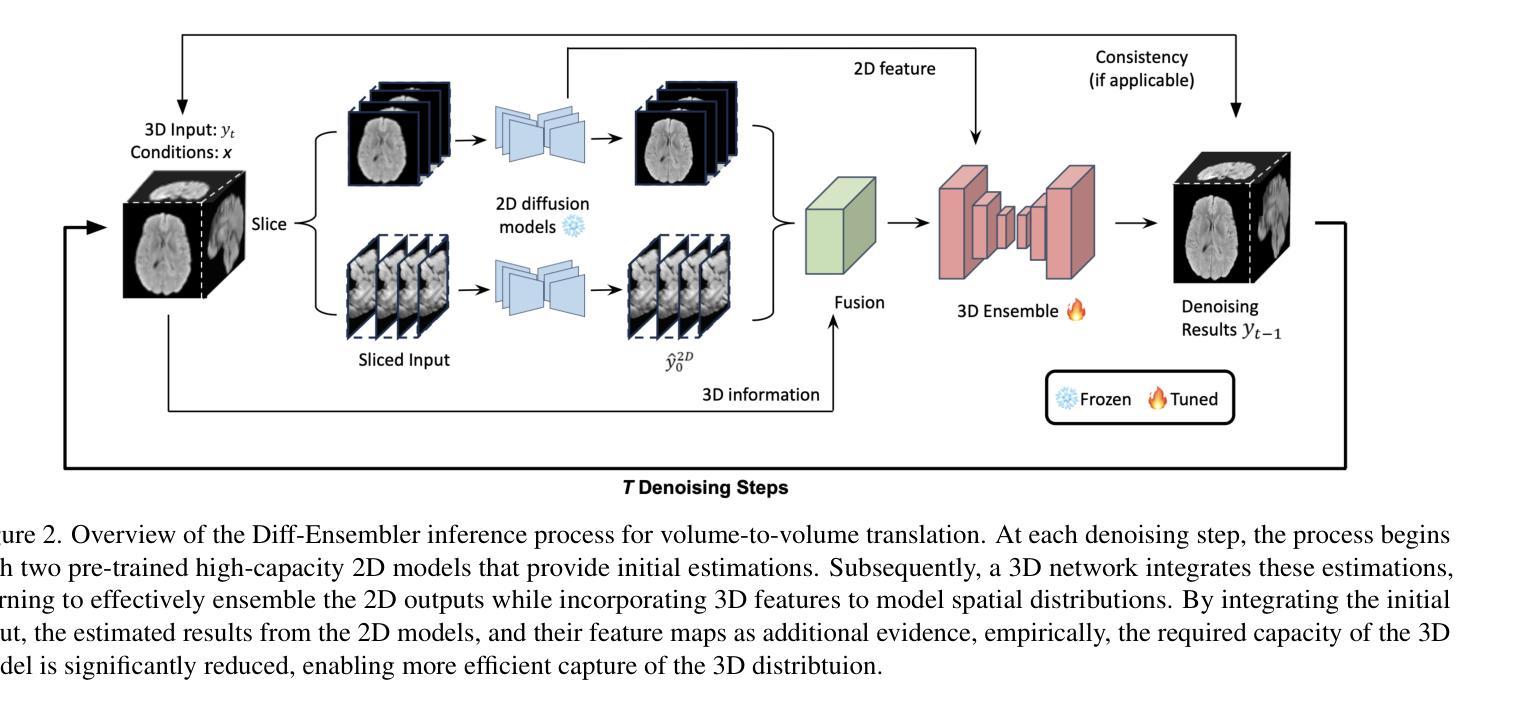
Diff-Ensembler: Learning to Ensemble 2D Diffusion Models for Volume-to-Volume Medical Image Translation
Authors:Xiyue Zhu, Dou Hoon Kwark, Ruike Zhu, Kaiwen Hong, Yiqi Tao, Shirui Luo, Yudu Li, Zhi-Pei Liang, Volodymyr Kindratenko
Despite success in volume-to-volume translations in medical images, most existing models struggle to effectively capture the inherent volumetric distribution using 3D representations. The current state-of-the-art approach combines multiple 2D-based networks through weighted averaging, thereby neglecting the 3D spatial structures. Directly training 3D models in medical imaging presents significant challenges due to high computational demands and the need for large-scale datasets. To address these challenges, we introduce Diff-Ensembler, a novel hybrid 2D-3D model for efficient and effective volumetric translations by ensembling perpendicularly trained 2D diffusion models with a 3D network in each diffusion step. Moreover, our model can naturally be used to ensemble diffusion models conditioned on different modalities, allowing flexible and accurate fusion of input conditions. Extensive experiments demonstrate that Diff-Ensembler attains superior accuracy and volumetric realism in 3D medical image super-resolution and modality translation. We further demonstrate the strength of our model’s volumetric realism using tumor segmentation as a downstream task.
尽管在医学图像体积到体积的翻译方面取得了一定的成功,但大多数现有模型在利用三维表示捕捉固有体积分布方面仍然存在困难。目前最先进的方法是通过加权平均组合多个基于二维的网络,从而忽略了三维空间结构。直接在医学影像中训练三维模型面临着计算需求高和需要大规模数据集等显著挑战。为了解决这些挑战,我们引入了Diff-Ensembler,这是一种新型混合的二维-三维模型,通过在每个扩散步骤中将垂直训练的二维扩散模型与三维网络组合,实现高效且有效的体积翻译。此外,我们的模型自然地可用于结合不同模态的扩散模型,实现输入条件的灵活和准确融合。大量实验表明,Diff-Ensembler在三维医学图像超分辨率和模态翻译方面达到了更高的准确性和体积真实性。我们进一步使用肿瘤分割作为下游任务来展示我们的模型在体积真实性方面的优势。
论文及项目相关链接
Summary
该文探讨了在医学图像体积转换领域中的挑战和解决方案。现有模型难以有效捕捉医学图像的内在体积分布,而直接训练三维模型面临计算需求高和需要大量数据集的问题。为此,提出了一种新型混合的二维-三维模型Diff-Ensembler,它通过集成垂直训练的二维扩散模型与每个扩散步骤中的三维网络,实现了高效且准确的体积转换。该模型还可以根据不同模态进行条件扩散模型的集成,从而实现输入条件的灵活和精确融合。实验证明,Diff-Ensembler在三维医学图像超分辨率和模态转换中达到了较高的准确性和体积逼真度,并在肿瘤分割等下游任务中表现出强大的体积逼真度。
Key Takeaways
- 现有模型在医学图像体积转换中面临挑战,难以捕捉内在体积分布。
- 直接训练三维模型在医学成像中面临高计算需求和大规模数据集的问题。
- Diff-Ensembler是一种新型混合二维-三维模型,通过集成垂直训练的二维扩散模型和三维网络,实现高效且准确的体积转换。
- Diff-Ensembler模型可以在不同模态下进行条件扩散模型的集成。
- Diff-Ensembler在三维医学图像超分辨率和模态转换中具有高准确性和体积逼真度。
- 该模型在肿瘤分割等下游任务中表现出强大的体积逼真度。
点此查看论文截图


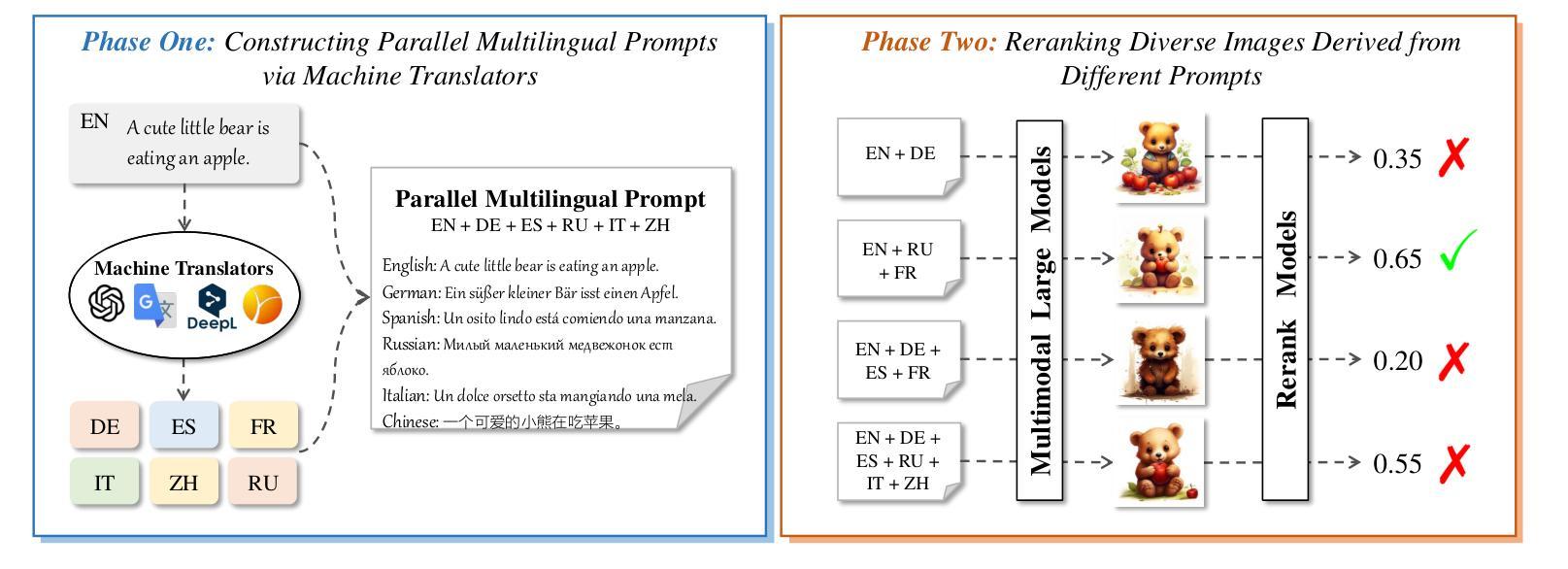
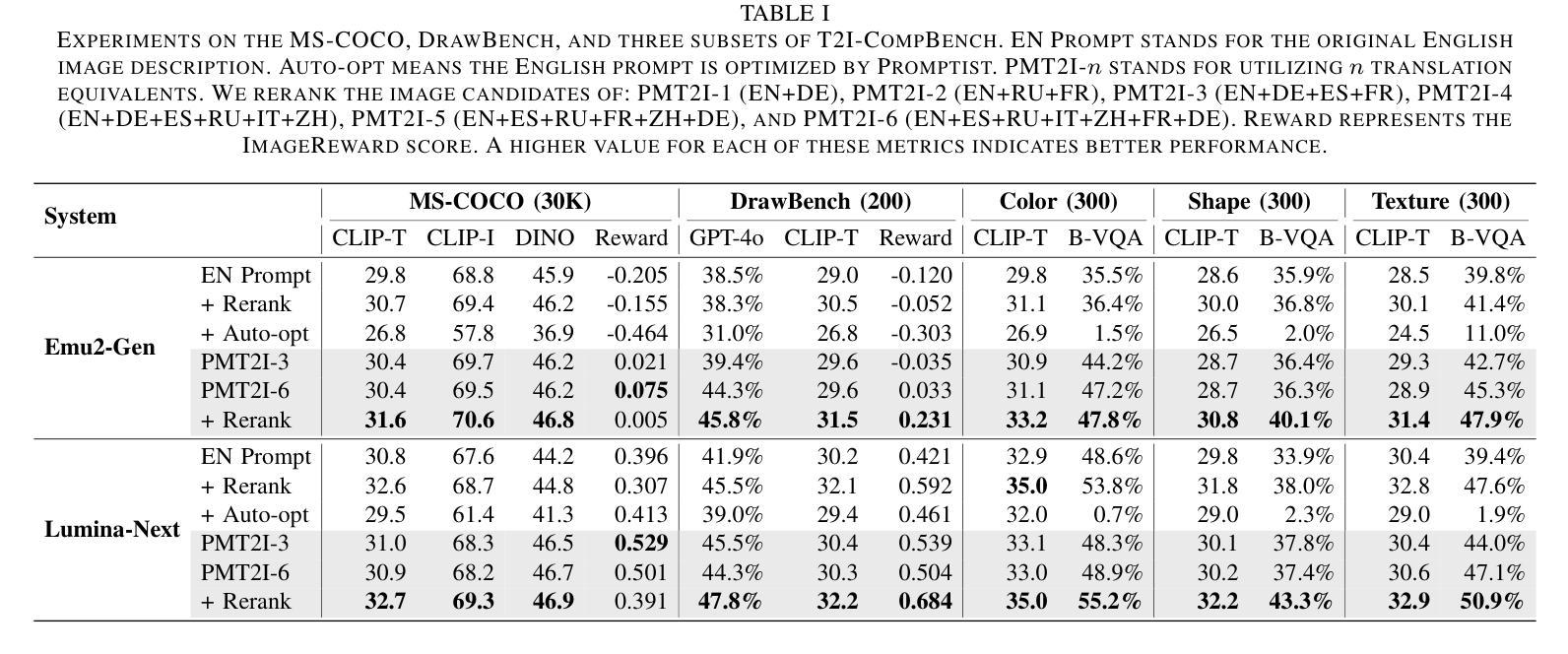
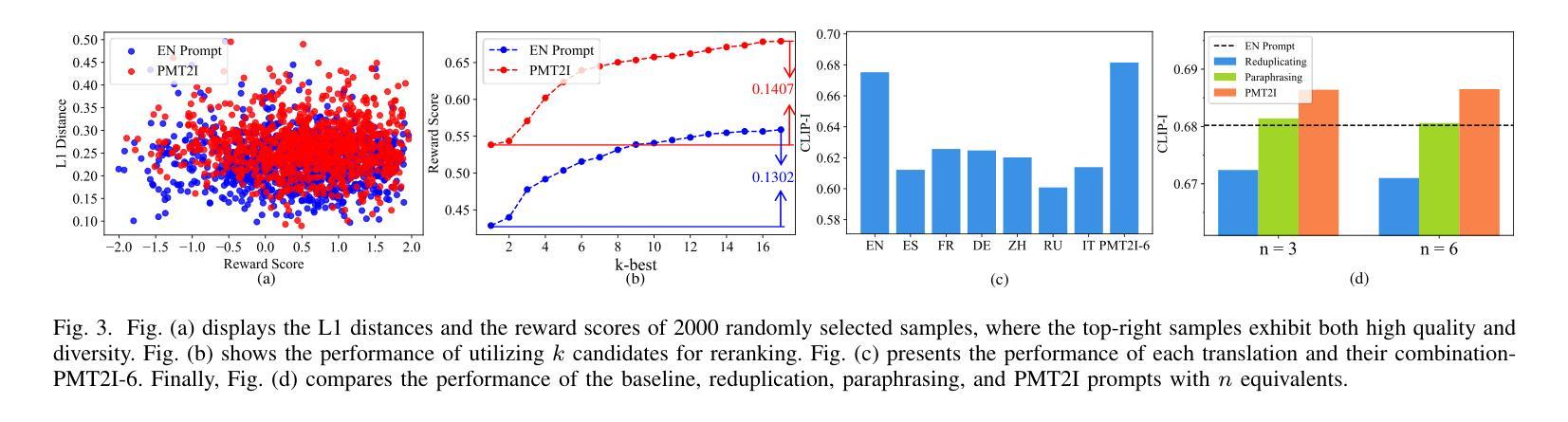
Boosting Text-To-Image Generation via Multilingual Prompting in Large Multimodal Models
Authors:Yongyu Mu, Hengyu Li, Junxin Wang, Xiaoxuan Zhou, Chenglong Wang, Yingfeng Luo, Qiaozhi He, Tong Xiao, Guocheng Chen, Jingbo Zhu
Previous work on augmenting large multimodal models (LMMs) for text-to-image (T2I) generation has focused on enriching the input space of in-context learning (ICL). This includes providing a few demonstrations and optimizing image descriptions to be more detailed and logical. However, as demand for more complex and flexible image descriptions grows, enhancing comprehension of input text within the ICL paradigm remains a critical yet underexplored area. In this work, we extend this line of research by constructing parallel multilingual prompts aimed at harnessing the multilingual capabilities of LMMs. More specifically, we translate the input text into several languages and provide the models with both the original text and the translations. Experiments on two LMMs across 3 benchmarks show that our method, PMT2I, achieves superior performance in general, compositional, and fine-grained assessments, especially in human preference alignment. Additionally, with its advantage of generating more diverse images, PMT2I significantly outperforms baseline prompts when incorporated with reranking methods. Our code and parallel multilingual data can be found at https://github.com/takagi97/PMT2I.
之前关于增强大型多模态模型(LMMs)以进行文本到图像(T2I)生成的工作主要集中在丰富上下文学习(ICL)的输入空间。这包括提供几个演示并优化图像描述以使其更详细和逻辑性强。然而,随着对更复杂和更灵活的图像描述的需求不断增长,增强在ICL范式内对输入文本的理解仍然是一个关键但尚未被充分研究的领域。在这项工作中,我们通过构建并行多语言提示来扩展这一研究领域,旨在利用大型多模态模型的多语言能力。更具体地说,我们将输入文本翻译成多种语言,并为模型提供原始文本和翻译文本。在三个基准测试上对两个大型多模态模型的实验表明,我们的方法PMT2I在总体、组合和精细评估中均取得了卓越的性能,特别是在与人类偏好对齐方面。此外,由于其生成更多样化图像的优势,当与重新排序方法相结合时,PMT2I明显超越了基线提示。我们的代码和多语言并行数据可以在 https://github.com/takagi97/PMT2I 找到。
论文及项目相关链接
PDF Accepted to ICASSP 2025
Summary
该论文针对文本转图像生成任务,探索了增强大型多模态模型(LMMs)输入文本理解的方法。通过构建平行多语言提示,利用模型的多语言能力,将输入文本翻译成多种语言并提供给模型。实验表明,该方法在通用、组合和精细评估中都取得了优越的性能,特别是在与人类偏好对齐方面。此外,该方法还能生成更多样化的图像,当与重排序方法结合时,显著优于基准提示。
Key Takeaways
- 该论文专注于增强大型多模态模型在文本转图像生成任务中对输入文本的理解。
- 通过构建平行多语言提示,利用模型的多语言能力。
- 将输入文本翻译成多种语言,并同时提供给模型原始文本和翻译文本。
- 实验表明,该方法在多种评估中都取得了优越性能。
- 该方法在人类偏好对齐方面表现特别出色。
- 与基准提示相比,该方法能生成更多样化的图像。
点此查看论文截图


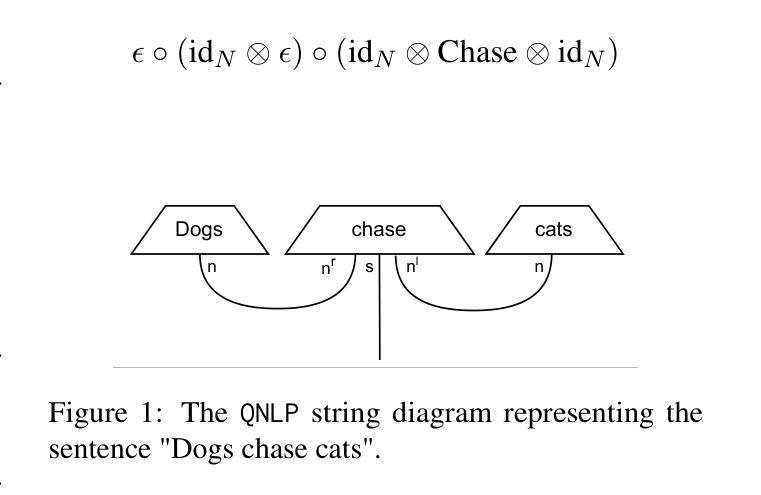
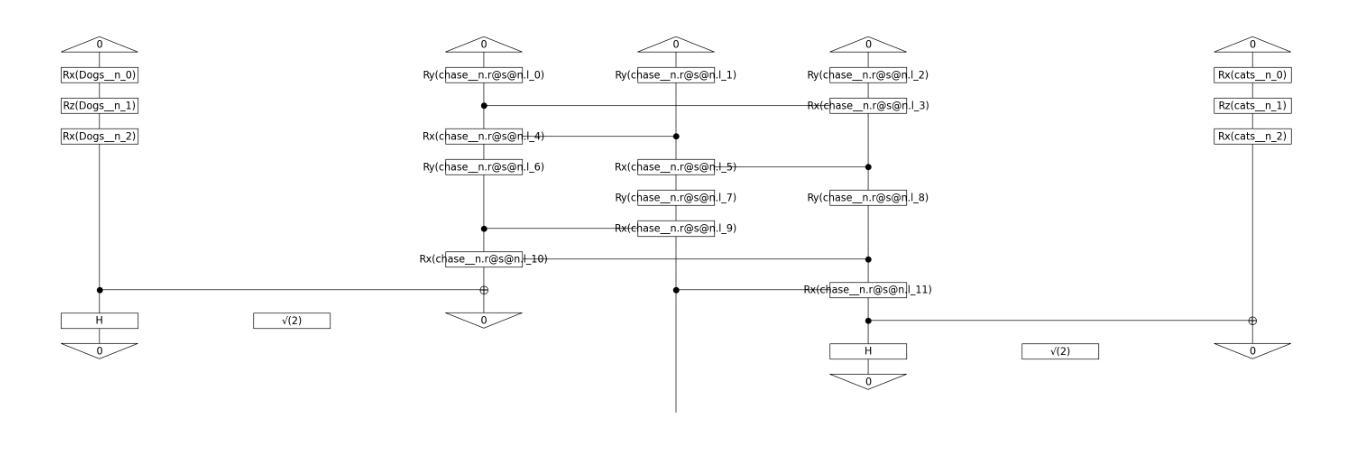
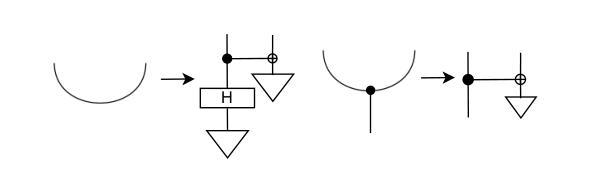
Multimodal Structure-Aware Quantum Data Processing
Authors:Hala Hawashin, Mehrnoosh Sadrzadeh
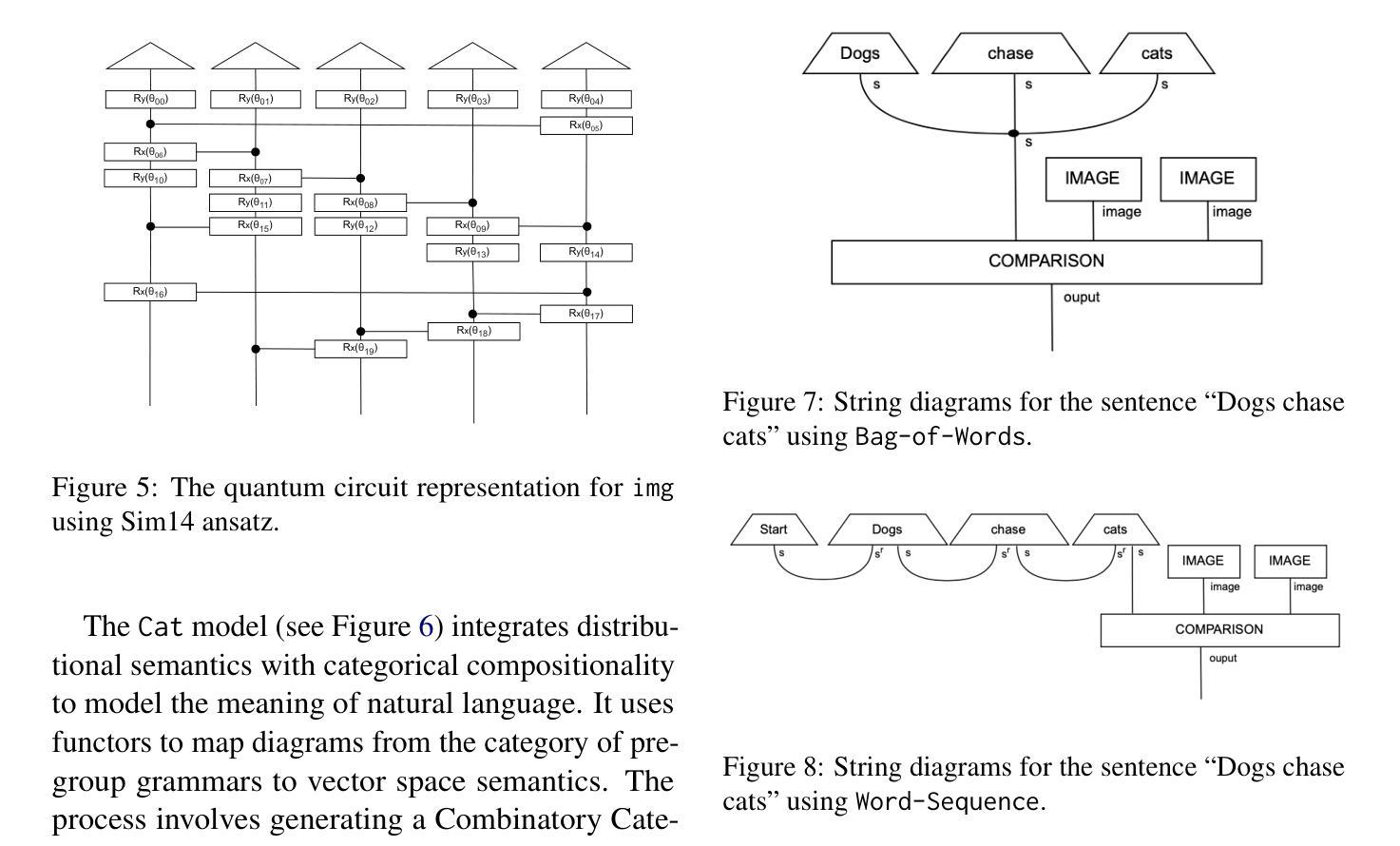
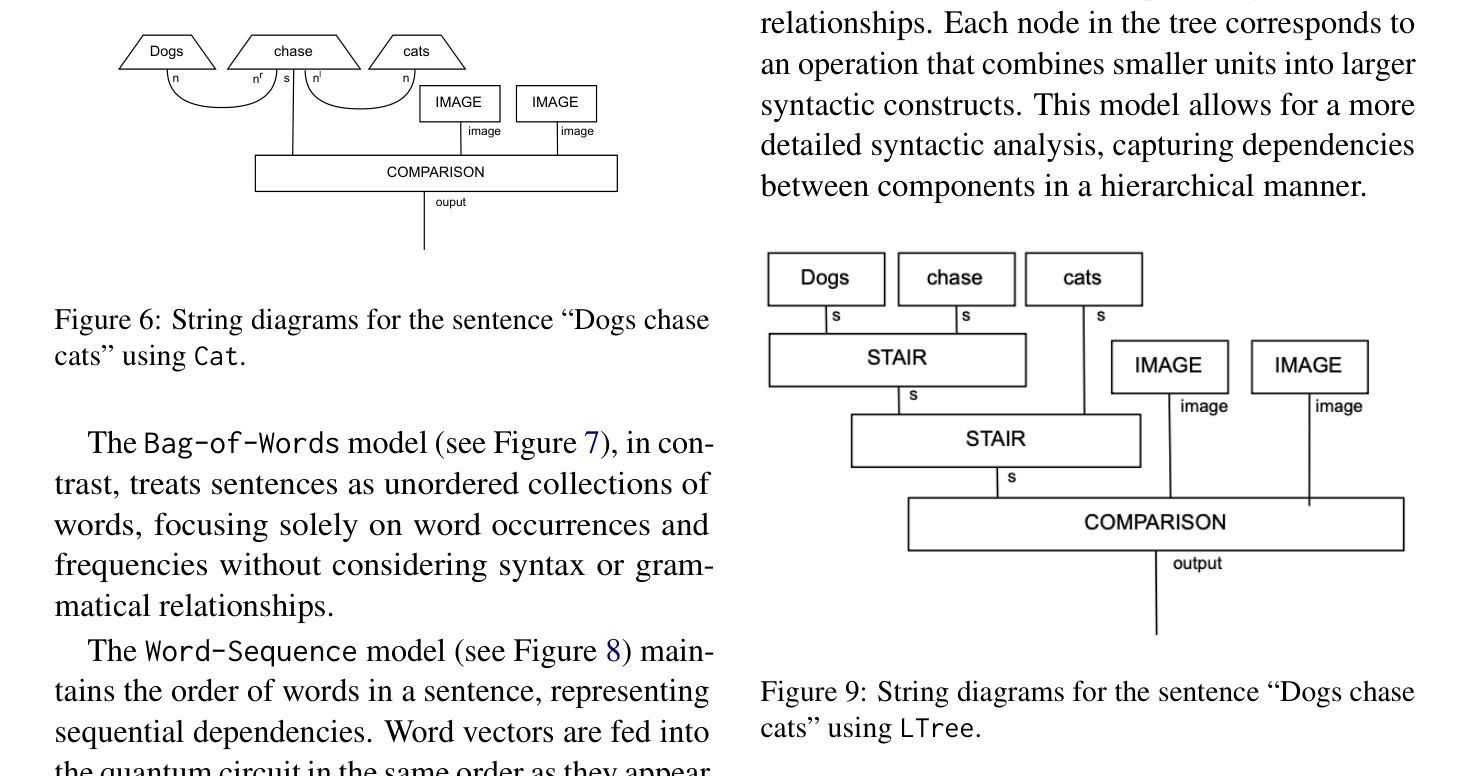
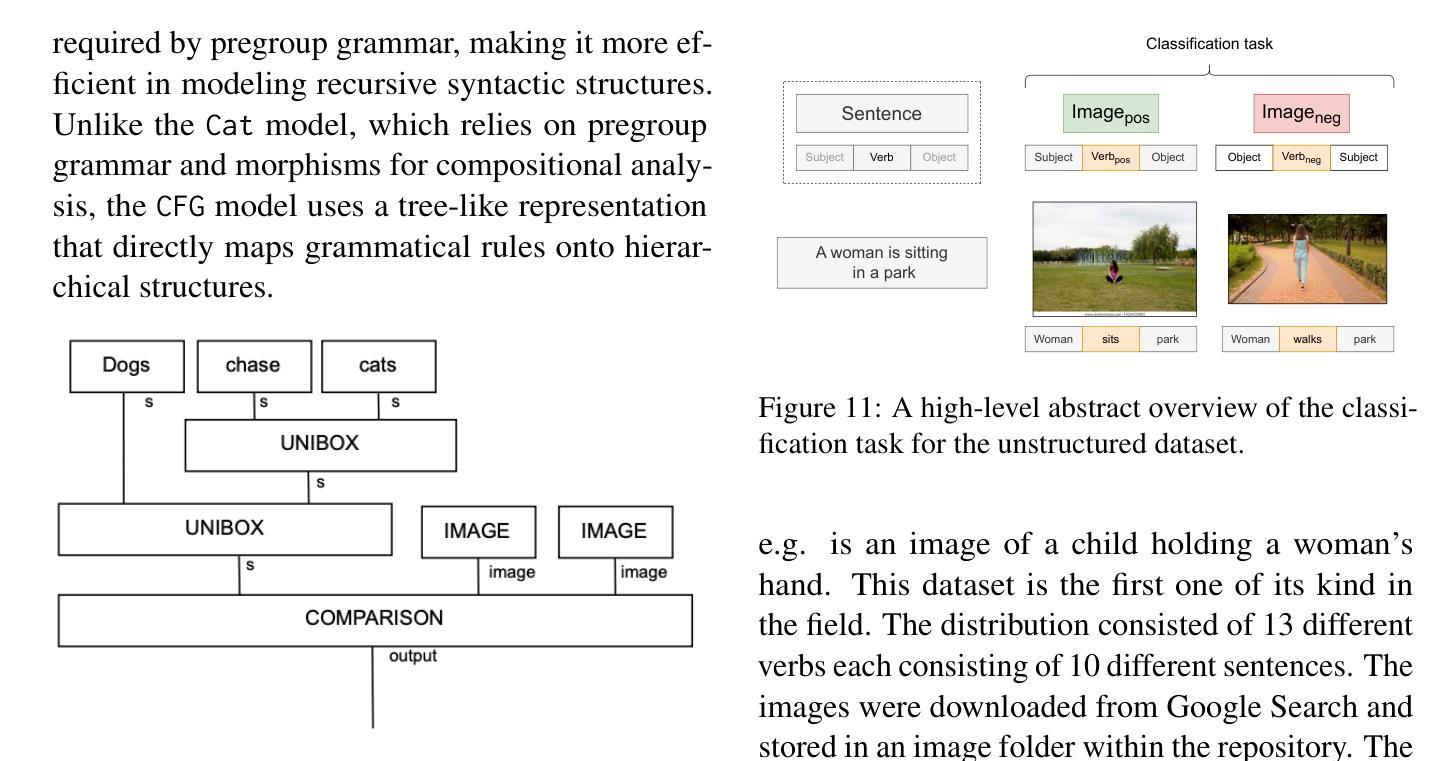
While large language models (LLMs) have advanced the field of natural language processing (NLP), their “black box” nature obscures their decision-making processes. To address this, researchers developed structured approaches using higher order tensors. These are able to model linguistic relations, but stall when training on classical computers due to their excessive size. Tensors are natural inhabitants of quantum systems and training on quantum computers provides a solution by translating text to variational quantum circuits. In this paper, we develop MultiQ-NLP: a framework for structure-aware data processing with multimodal text+image data. Here, “structure” refers to syntactic and grammatical relationships in language, as well as the hierarchical organization of visual elements in images. We enrich the translation with new types and type homomorphisms and develop novel architectures to represent structure. When tested on a main stream image classification task (SVO Probes), our best model showed a par performance with the state of the art classical models; moreover the best model was fully structured.
虽然大型语言模型(LLM)在自然语言处理(NLP)领域取得了进展,但它们的“黑箱”性质掩盖了它们的决策过程。为了解决这一问题,研究人员采用了使用高阶张量的结构化方法。这些方法能够模拟语言关系,但在经典计算机上进行训练时,由于体积过大而陷入困境。张量是量子系统的天然组成部分,在量子计算机上进行训练通过将文本转换为变分量子电路来解决这一问题。在本文中,我们开发了MultiQ-NLP:一个用于结构感知数据处理的多模态文本+图像数据框架。在这里,“结构”是指语言中的句法、语法关系以及图像中视觉元素分层组织。我们通过新型张量以及类型同构丰富了翻译内容,并开发了新型架构来表示结构。在主流图像分类任务(SVO Probes)测试中,我们最佳模型的性能与最新经典模型相当,而且该模型是完全结构化的。
论文及项目相关链接
PDF 10 Pages, 16 Figures
Summary
大型语言模型在自然语言处理领域取得了进展,但其“黑箱”性质掩盖了决策过程。为解决这个问题,研究者采用高阶张量构建结构化方法,虽然能建模语言关系,但在经典计算机上训练时因体积过大而受阻。张量是量子系统的自然元素,量子计算机训练通过将文本转换为变分量子电路提供解决方案。本文开发MultiQ-NLP框架,实现结构感知数据处理和多媒体文本+图像数据。这里,“结构”指语言中的语法和句法关系,以及图像中视觉元素分层组织。我们丰富翻译内容,发展新型架构来代表结构,并在主流图像分类任务(SVO Probes)上进行测试,最佳模型表现与最先进经典模型相当,且具备完全结构化特点。
Key Takeaways
- 大型语言模型(LLMs)在自然语言处理中取得进展,但存在“黑箱”问题,决策过程不透明。
- 高阶张量用于构建结构化方法,能够建模语言关系,但在经典计算机上训练受限。
- 张量是量子系统的自然元素,量子计算机训练通过变分量子电路解决大型语言模型的训练问题。
- 开发出MultiQ-NLP框架,实现结构感知数据处理和多媒体文本+图像数据处理。
- “结构”包括语言中的语法和句法关系,以及图像中视觉元素的分层组织。
- 通过丰富翻译内容和发展新型架构来代表结构,提高模型性能。
点此查看论文截图



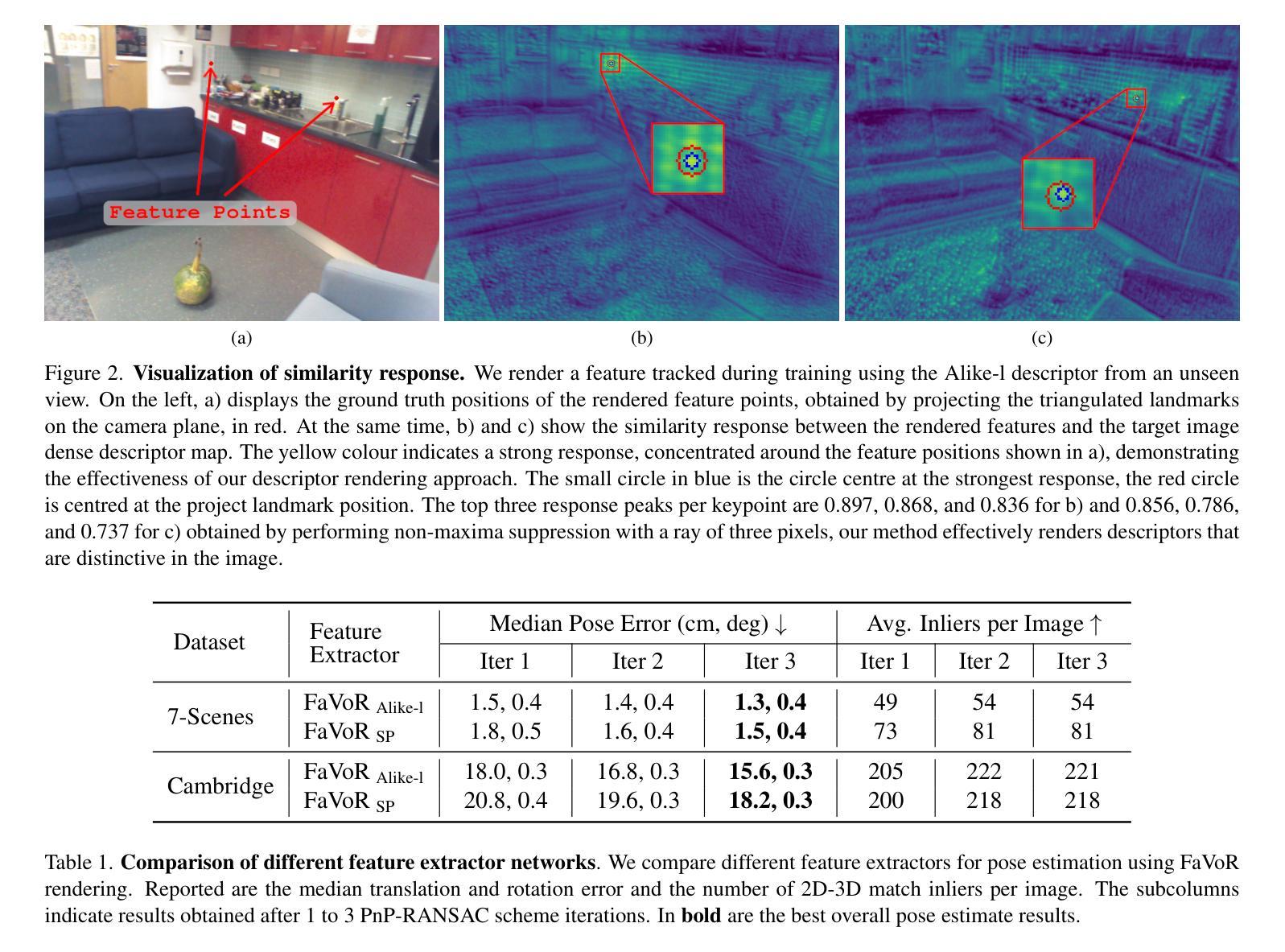
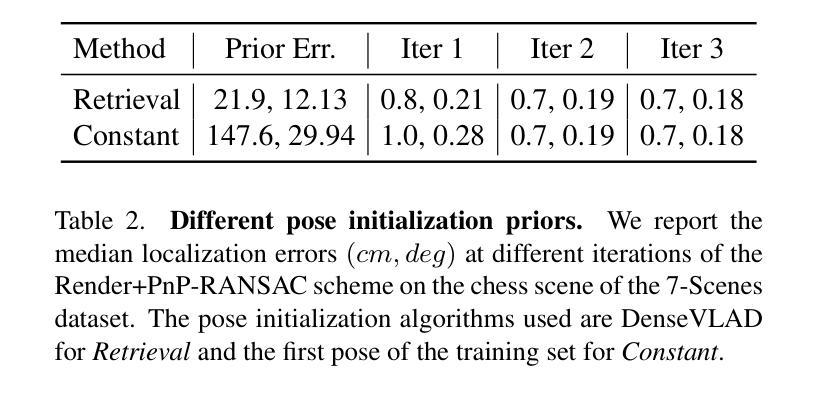
FaVoR: Features via Voxel Rendering for Camera Relocalization
Authors:Vincenzo Polizzi, Marco Cannici, Davide Scaramuzza, Jonathan Kelly
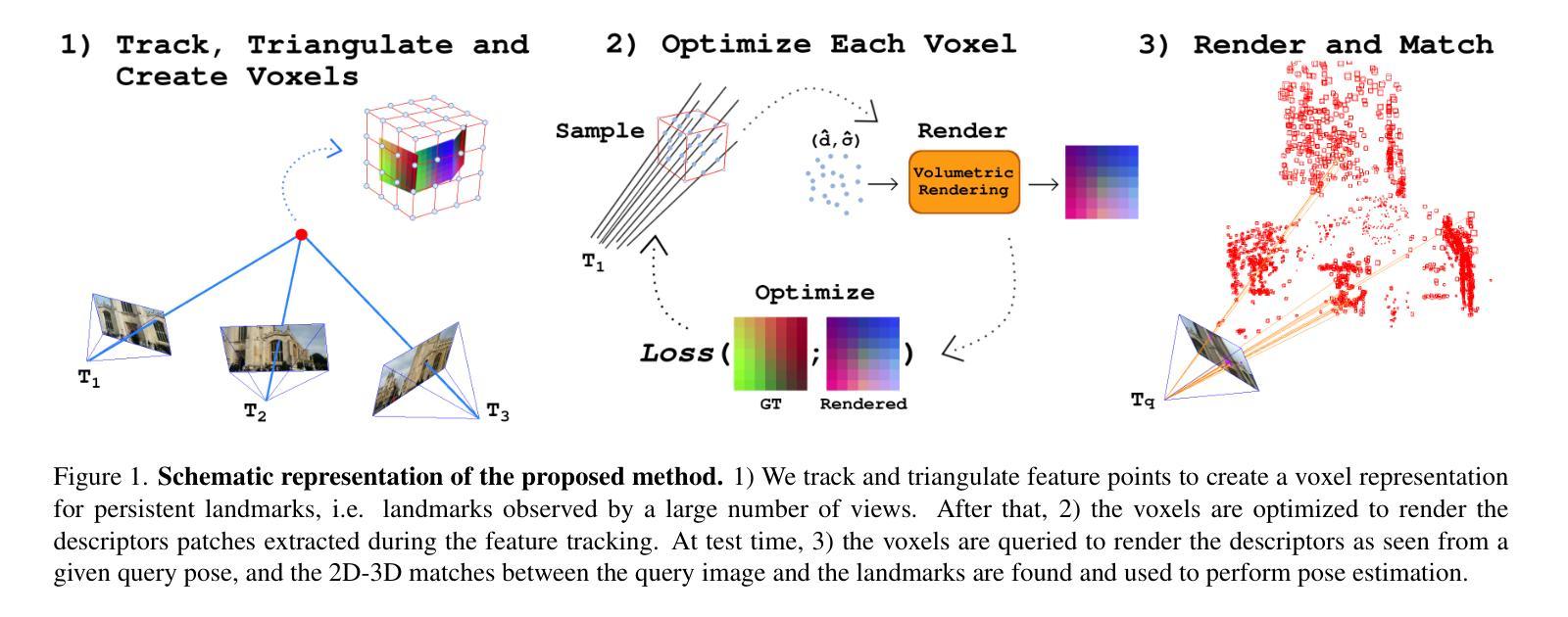
Camera relocalization methods range from dense image alignment to direct camera pose regression from a query image. Among these, sparse feature matching stands out as an efficient, versatile, and generally lightweight approach with numerous applications. However, feature-based methods often struggle with significant viewpoint and appearance changes, leading to matching failures and inaccurate pose estimates. To overcome this limitation, we propose a novel approach that leverages a globally sparse yet locally dense 3D representation of 2D features. By tracking and triangulating landmarks over a sequence of frames, we construct a sparse voxel map optimized to render image patch descriptors observed during tracking. Given an initial pose estimate, we first synthesize descriptors from the voxels using volumetric rendering and then perform feature matching to estimate the camera pose. This methodology enables the generation of descriptors for unseen views, enhancing robustness to view changes. We extensively evaluate our method on the 7-Scenes and Cambridge Landmarks datasets. Our results show that our method significantly outperforms existing state-of-the-art feature representation techniques in indoor environments, achieving up to a 39% improvement in median translation error. Additionally, our approach yields comparable results to other methods for outdoor scenarios while maintaining lower memory and computational costs.
相机重定位方法包括从密集图像对齐到直接从查询图像进行相机姿态回归。其中,稀疏特征匹配作为一种高效、通用且通常轻便的方法,具有众多应用。然而,基于特征的方法在视角和外观变化较大时往往会遇到困难,导致匹配失败和姿态估计不准确。为了克服这一局限性,我们提出了一种新的方法,该方法利用二维特征的全球稀疏但局部密集的3D表示。通过跟踪一系列帧中的地标并进行三角测量,我们构建了一个优化的稀疏体素地图,以呈现跟踪过程中观察到的图像补丁描述符。给定初始姿态估计,我们首先使用体积渲染技术从体素合成描述符,然后进行特征匹配以估计相机姿态。这种方法能够生成未见视图的描述符,增强了应对视角变化的稳健性。我们在7场景和剑桥地标数据集上对我们的方法进行了广泛评估。结果表明,我们的方法在室内环境下显著优于现有的最先进的特征表示技术,在中位平移误差上最多提高了39%。此外,我们的方法在室外场景的结果与其他方法相当,同时降低了内存和计算成本。
论文及项目相关链接
PDF Accepted to the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Tucson, Arizona, US, Feb 28-Mar 4, 2025
Summary
本文提出一种基于稀疏特征匹配的相机定位方法,通过全局稀疏、局部密集的三维特征表示来解决现有方法在面对视角和外观变化时的匹配失败和姿态估计不准确问题。该方法通过追踪和三角测量地标序列帧构建稀疏体素地图,优化渲染图像补丁描述符。给定初始姿态估计,通过体积渲染合成体素描述符,然后进行特征匹配估计相机姿态。此方法能生成未见视图的描述符,增强对视角变化的稳健性。在7场景和剑桥地标数据集上的评估显示,该方法在室内环境下显著优于现有特征表示技术,中位数平移误差最多提高39%。同时,对于室外场景,该方法在保持较低内存和计算成本的情况下,结果与其他方法相当。
Key Takeaways
- 相机定位方法包括从密集图像对齐到直接相机姿态回归查询图像等多种方法,其中稀疏特征匹配是一种高效、通用且轻量级的方法。
- 稀疏特征匹配在面临显著视角和外观变化时会出现匹配失败和姿态估计不准确的问题。
- 本文提出一种基于全局稀疏、局部密集的三维特征表示的新方法来解决上述问题。
- 方法通过追踪和三角测量地标序列帧构建稀疏体素地图,并优化渲染图像补丁描述符。
- 通过体积渲染合成体素描述符,进行特征匹配估计相机姿态。
- 该方法能生成未见视图的描述符,增强稳健性,特别是在室内环境下显著优于其他方法。
点此查看论文截图

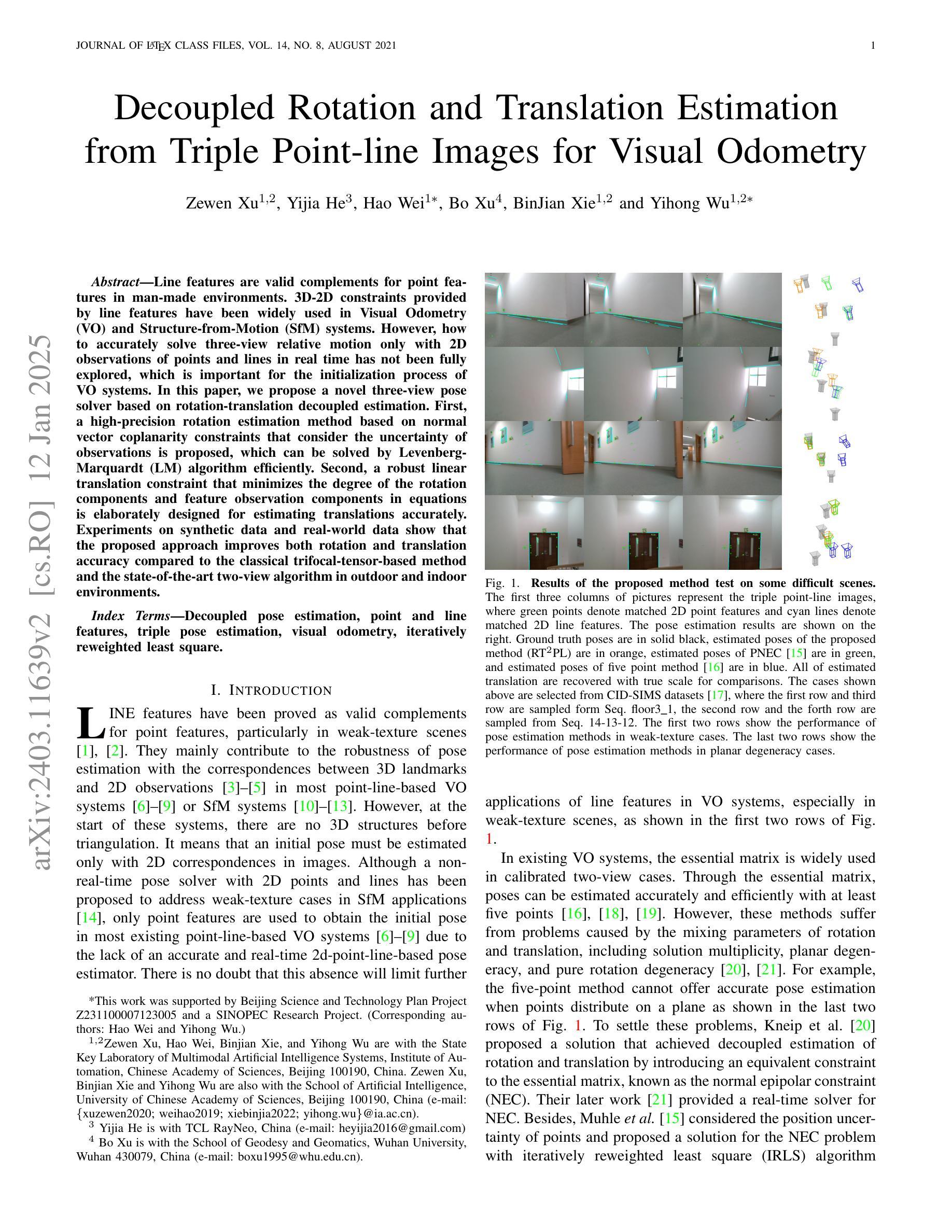
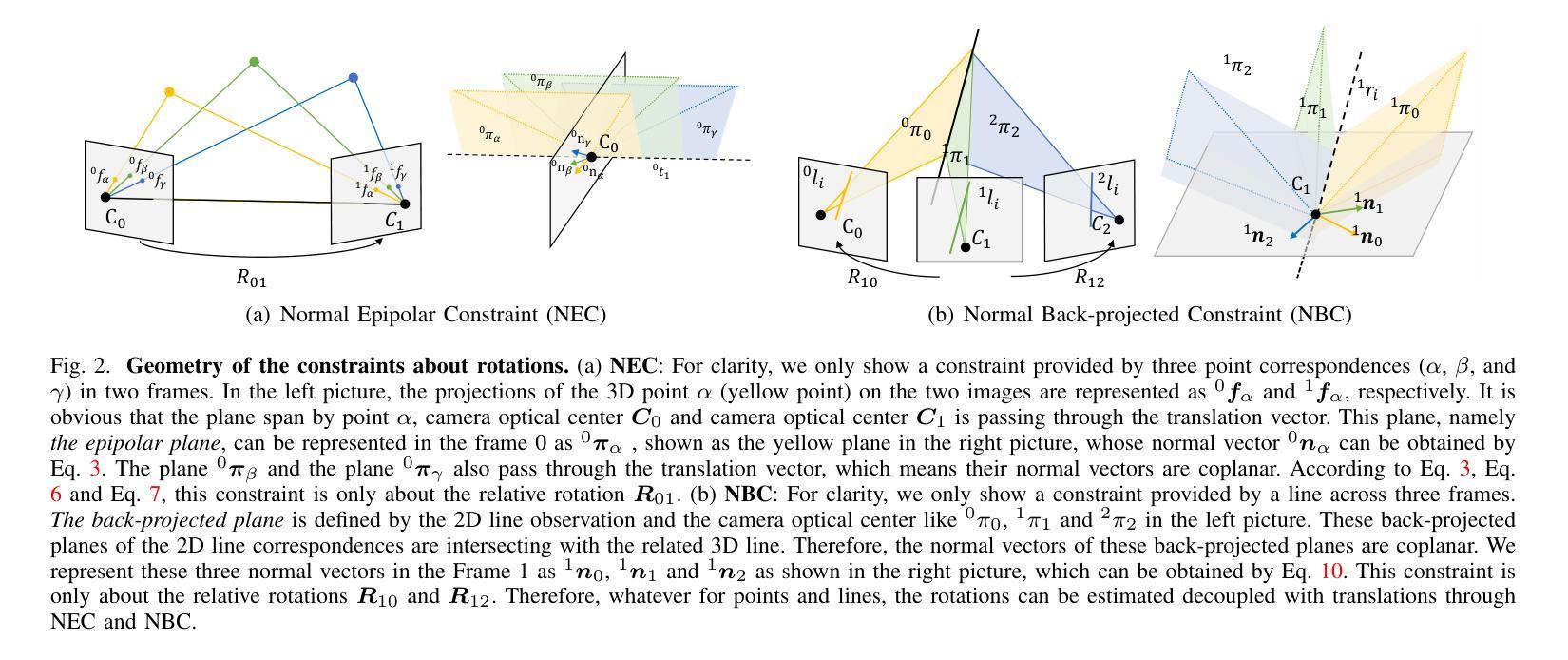
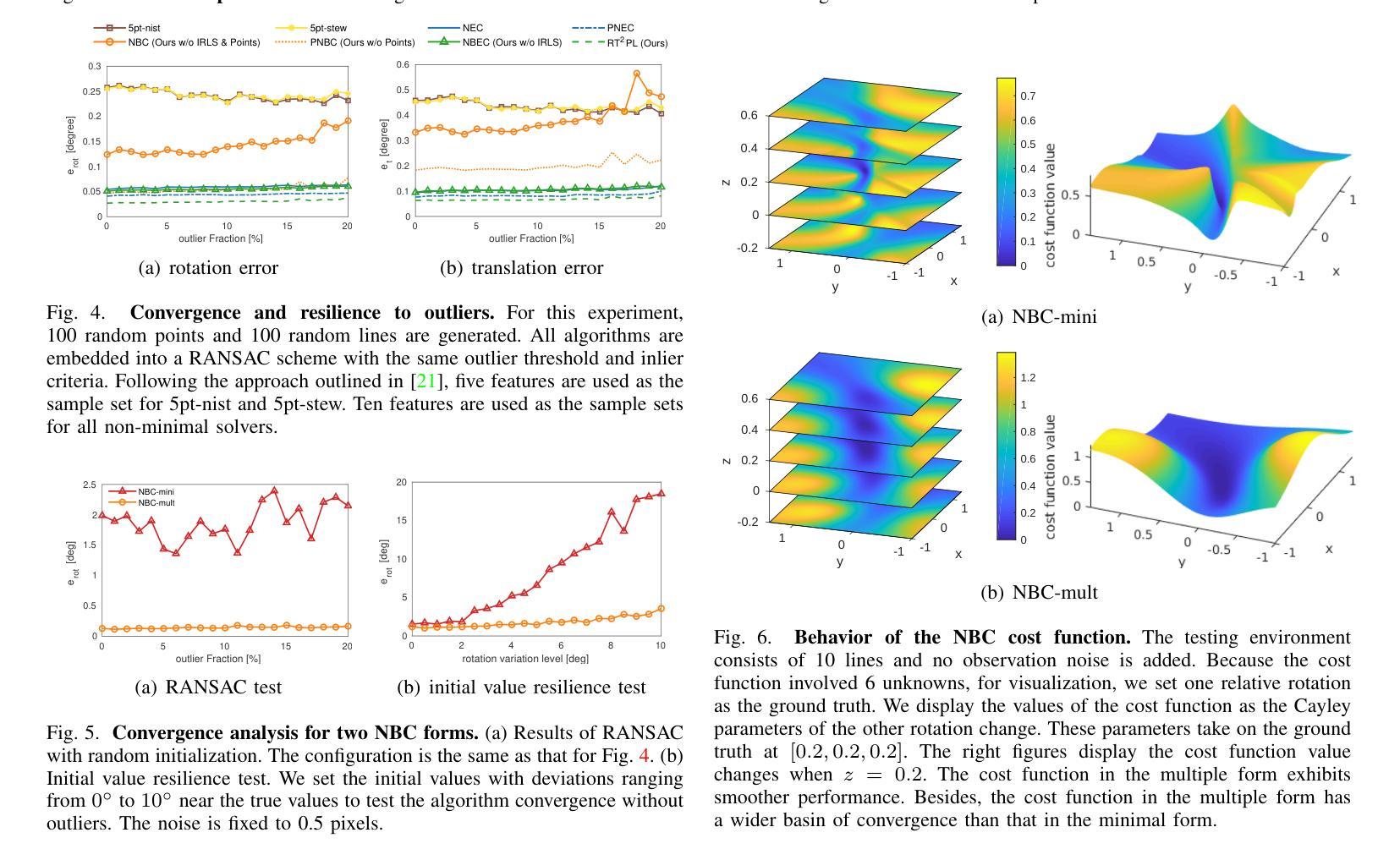
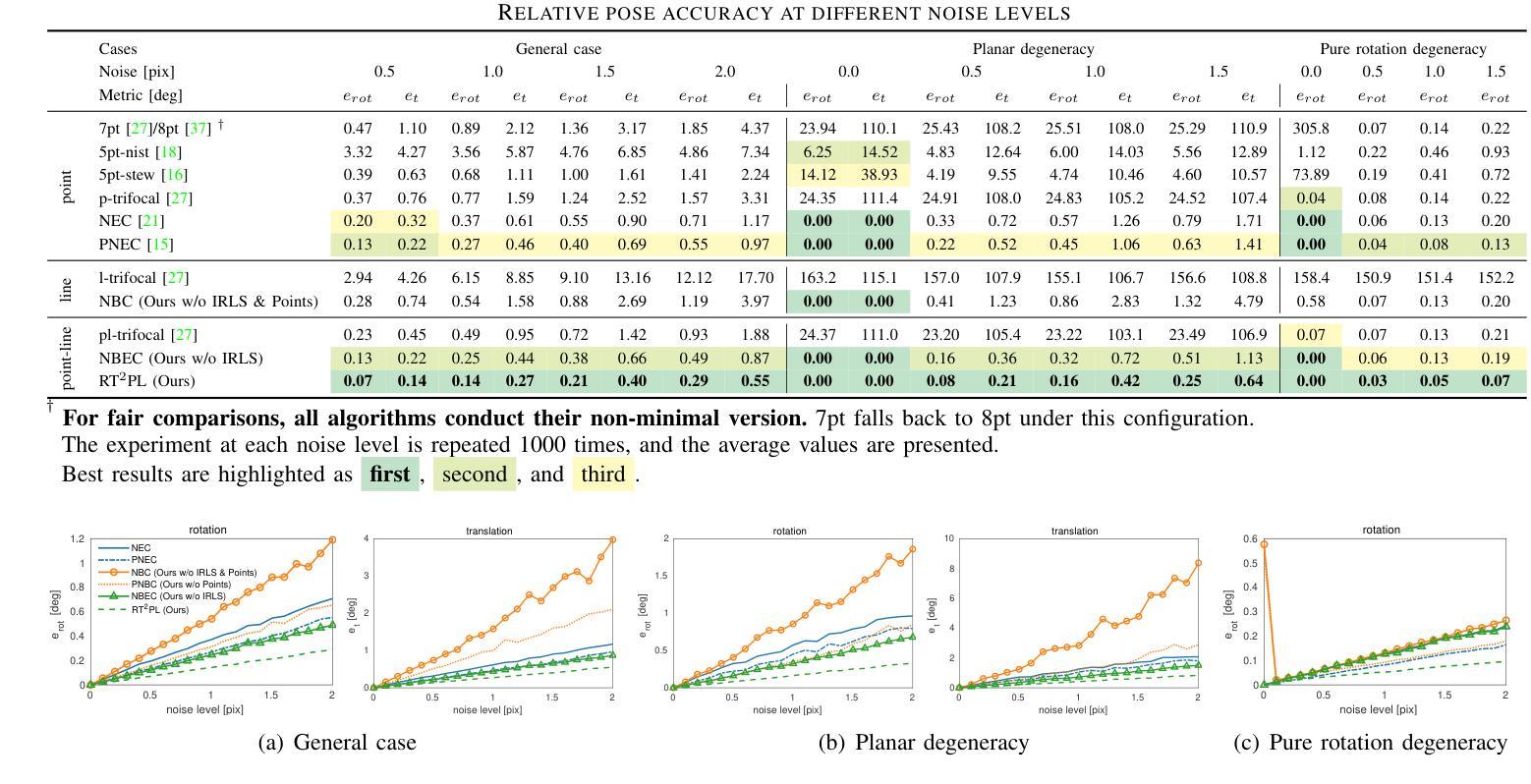
An Accurate and Real-time Relative Pose Estimation from Triple Point-line Images by Decoupling Rotation and Translation
Authors:Zewen Xu, Yijia He, Hao Wei, Bo Xu, BinJian Xie, Yihong Wu
Line features are valid complements for point features in man-made environments. 3D-2D constraints provided by line features have been widely used in Visual Odometry (VO) and Structure-from-Motion (SfM) systems. However, how to accurately solve three-view relative motion only with 2D observations of points and lines in real time has not been fully explored. In this paper, we propose a novel three-view pose solver based on rotation-translation decoupled estimation. First, a high-precision rotation estimation method based on normal vector coplanarity constraints that consider the uncertainty of observations is proposed, which can be solved by Levenberg-Marquardt (LM) algorithm efficiently. Second, a robust linear translation constraint that minimizes the degree of the rotation components and feature observation components in equations is elaborately designed for estimating translations accurately. Experiments on synthetic data and real-world data show that the proposed approach improves both rotation and translation accuracy compared to the classical trifocal-tensor-based method and the state-of-the-art two-view algorithm in outdoor and indoor environments.
线条特征是人造环境中点特征的有效补充。由线条特征提供的3D-2D约束已广泛应用于视觉里程计(VO)和从运动恢复结构(SfM)系统中。然而,如何仅利用实时的二维点对和线条观察来准确解决三视相对运动尚未得到充分探索。在本文中,我们提出了一种基于旋转平移解耦估计的新型三视姿态求解器。首先,提出了一种基于法线向量共面约束的高精度旋转估计方法,该方法考虑了观测的不确定性,可通过列文贝格-马夸尔特(LM)算法有效地解决。其次,为了准确估计平移,精心设计了一种稳健的线性平移约束,该约束最小化了方程中的旋转分量和特征观测分量的程度。在合成数据和真实世界数据上的实验表明,与基于三焦点张量的经典方法和室外和室内环境中的最新两视算法相比,所提出的方法提高了旋转和平移的准确性。
论文及项目相关链接
Summary:
本文提出一种基于旋转平移解耦估计的三视图姿态求解器。利用基于法向量共面约束的高精度旋转估计方法和精心设计的线性平移约束,实现了仅通过二维点线观测实时解决三视图相对运动的问题。实验表明,该方法相较于传统三焦点张量方法和当前主流的两视图算法,在室内外环境中提高了旋转和平移精度。
Key Takeaways:
- 线特征在人造环境中是点特征的有效补充,3D-2D约束在视觉里程计和从运动恢复结构系统中得到广泛应用。
- 本文提出了一种新的三视图姿态求解器,基于旋转平移解耦估计。
- 提出了一种考虑观测不确定性的基于法向量共面约束的高精度旋转估计方法,可通过Levenberg-Marquardt算法高效求解。
- 精心设计了一个线性平移约束,以最小化方程中的旋转分量和特征观测分量,从而更准确地估计平移。
- 实验表明,该方法在旋转和平移精度上优于传统的三焦点张量方法和当前主流的两视图算法。
- 该方法适用于室内外环境。
点此查看论文截图