⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-16 更新
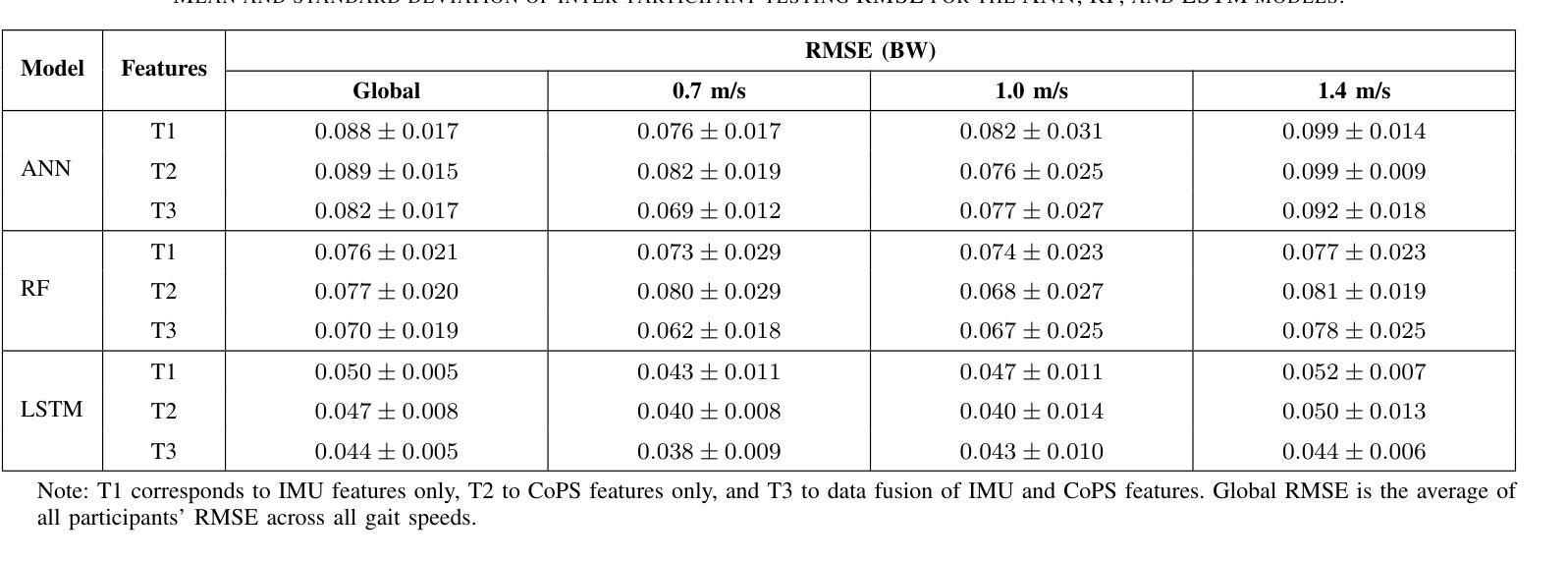
Reliable Vertical Ground Reaction Force Estimation with Smart Insole During Walking
Authors:Femi Olugbon, Nozhan Ghoreishi, Ming-Chun Huang, Wenyao Xu, Diliang Chen
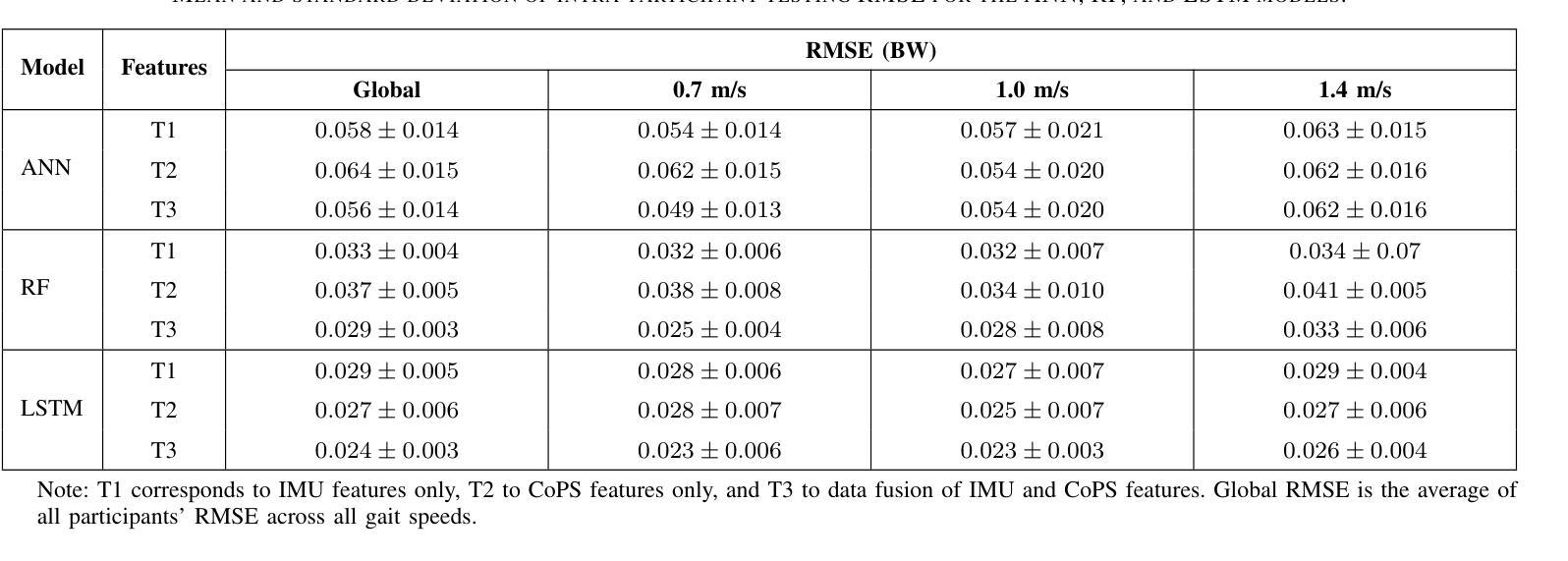
The vertical ground reaction force (vGRF) and its characteristic weight acceptance and push-off peaks measured during walking are important for gait and biomechanical analysis. Current wearable vGRF estimation methods suffer from drifting errors or low generalization performances, limiting their practical application. This paper proposes a novel method for reliably estimating vGRF and its characteristic peaks using data collected from the smart insole, including inertial measurement unit data and the newly introduced center of the pressed sensor data. These data were fused with machine learning algorithms including artificial neural networks, random forest regression, and bi-directional long-short-term memory. The proposed method outperformed the state-of-the-art methods with the root mean squared error, normalized root mean squared error, and correlation coefficient of 0.024 body weight (BW), 1.79% BW, and 0.997 in intra-participant testing, and 0.044 BW, 3.22% BW, and 0.991 in inter-participant testing, respectively. The difference between the reference and estimated weight acceptance and push-off peak values are 0.022 BW and 0.017 BW with a delay of 1.4% and 1.8% of the gait cycle for the intra-participant testing and 0.044 BW and 0.025 BW with a delay of 1.5% and 2.3% of the gait cycle for the inter-participant testing. The results indicate that the proposed vGRF estimation method has the potential to achieve accurate vGRF measurement during walking in free living environments.
垂直地面反作用力(vGRF)及其在行走过程中测量的特征性重量接受和推离峰值对于步态和生物力学分析具有重要意义。当前的可穿戴vGRF估计方法存在漂移误差或泛化性能低的问题,限制了其实际应用。本文提出了一种可靠估计vGRF及其特征峰值的新方法,使用从智能鞋垫收集的数据,包括惯性测量单元数据和最新引入的按压传感器中心数据。这些数据与机器学习算法融合,包括人工神经网络、随机森林回归和双向长短期记忆。所提出的方法优于当前最先进的方法,在受试者内部测试中的均方根误差、归一化均方根误差和相关性系数分别为0.024体重(BW)、1.79%BW和0.997,在受试者之间测试中的相应值分别为0.044BW、3.22%BW和0.991。在受试者内部测试中,参考与估计的重量接受和推离峰值之间的差异为0.022BW和0.017BW,延迟了步态周期的1.4%和1.8%;在受试者之间测试中,差异为0.044BW和0.025BW,延迟了步态周期的1.5%和2.3%。结果表明,所提出的vGRF估计方法具有在实现自由生活环境中行走时的准确vGRF测量的潜力。
论文及项目相关链接
Summary
该文提出一种利用智能鞋垫所采集的数据可靠估计垂直地面反作用力(vGRF)及其特征峰值的新方法。该方法融合了惯性测量单元数据和新增的中心压力传感器数据,并采用机器学习算法,包括人工神经网络、随机森林回归和双向长短时记忆模型。相较于现有方法,该方法在受试者内部和外部测试中都表现出更高的性能,测量误差小,并显示出在实际环境中准确测量vGRF的潜力。
Key Takeaways
- vGRF在行走过程中的步态和生物力学分析中具有重要意义。
- 当前可穿戴vGRF估计方法存在漂移误差或泛化性能低的问题,限制了实际应用。
- 本文提出一种基于智能鞋垫数据的新型vGRF估计方法,融合了IMU数据和中心压力传感器数据。
- 使用机器学习算法,包括ANN、RF和Bi-LSTM模型,进行数据处理。
- 该方法在受试者内部和外部测试中均表现出优异性能,测量误差小。
- vGRF估计方法与实际值之间的差异很小,且具有轻微的延迟。
点此查看论文截图


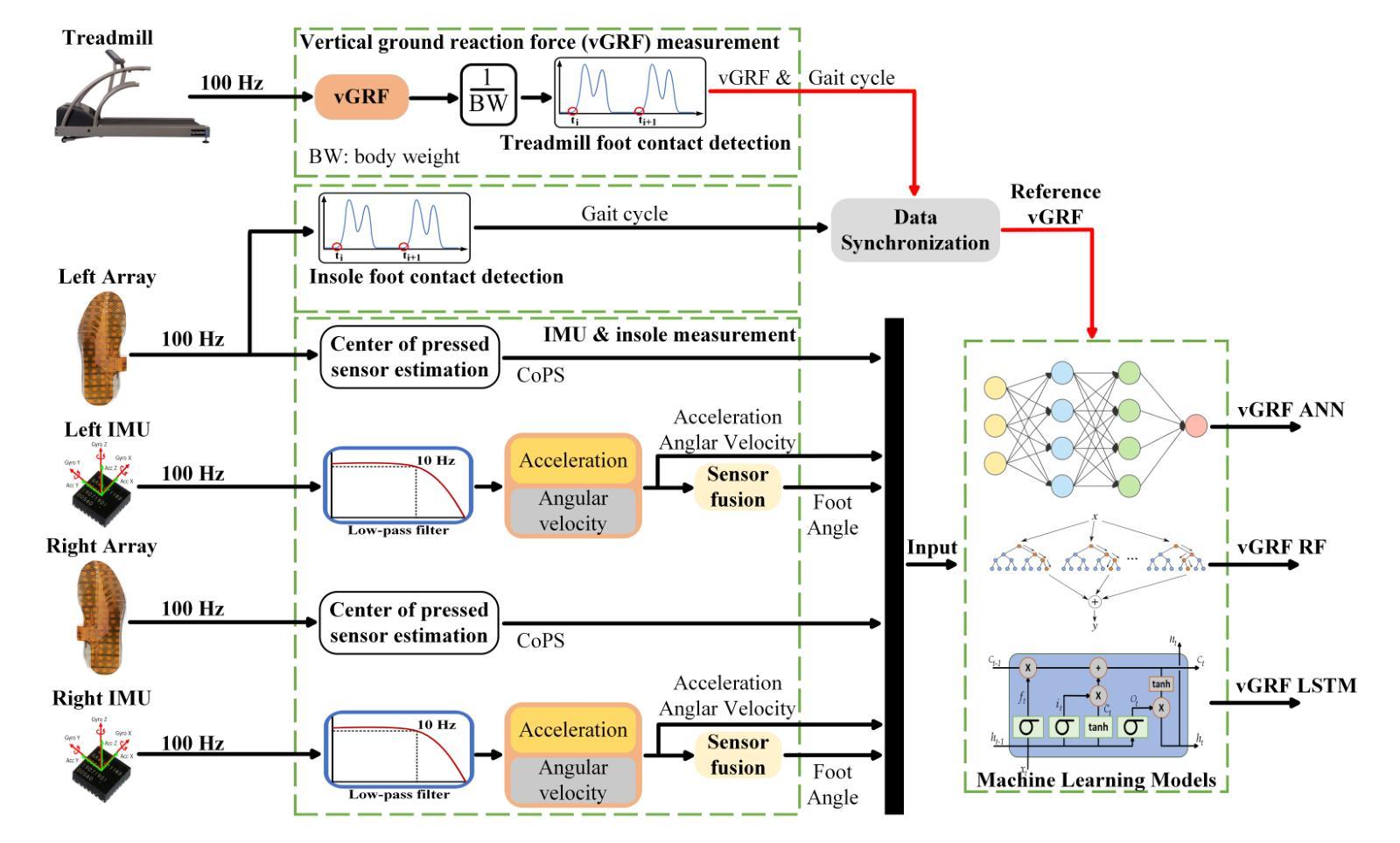

Retrieval-Augmented Dialogue Knowledge Aggregation for Expressive Conversational Speech Synthesis
Authors:Rui Liu, Zhenqi Jia, Feilong Bao, Haizhou Li
Conversational speech synthesis (CSS) aims to take the current dialogue (CD) history as a reference to synthesize expressive speech that aligns with the conversational style. Unlike CD, stored dialogue (SD) contains preserved dialogue fragments from earlier stages of user-agent interaction, which include style expression knowledge relevant to scenarios similar to those in CD. Note that this knowledge plays a significant role in enabling the agent to synthesize expressive conversational speech that generates empathetic feedback. However, prior research has overlooked this aspect. To address this issue, we propose a novel Retrieval-Augmented Dialogue Knowledge Aggregation scheme for expressive CSS, termed RADKA-CSS, which includes three main components: 1) To effectively retrieve dialogues from SD that are similar to CD in terms of both semantic and style. First, we build a stored dialogue semantic-style database (SDSSD) which includes the text and audio samples. Then, we design a multi-attribute retrieval scheme to match the dialogue semantic and style vectors of the CD with the stored dialogue semantic and style vectors in the SDSSD, retrieving the most similar dialogues. 2) To effectively utilize the style knowledge from CD and SD, we propose adopting the multi-granularity graph structure to encode the dialogue and introducing a multi-source style knowledge aggregation mechanism. 3) Finally, the aggregated style knowledge are fed into the speech synthesizer to help the agent synthesize expressive speech that aligns with the conversational style. We conducted a comprehensive and in-depth experiment based on the DailyTalk dataset, which is a benchmarking dataset for the CSS task. Both objective and subjective evaluations demonstrate that RADKA-CSS outperforms baseline models in expressiveness rendering. Code and audio samples can be found at: https://github.com/Coder-jzq/RADKA-CSS.
对话式语音合成(CSS)旨在以当前对话(CD)历史为参考,合成符合对话风格的表达性语音。不同于CD,存储的对话(SD)包含了早期用户代理互动阶段的保存对话片段,这些片段包含与CD中类似场景相关的风格表达知识。请注意,这些知识对于使代理能够合成能够产生共情反馈的表达性对话语音至关重要。然而,之前的研究忽略了这一方面。为了解决这一问题,我们提出了一种用于表达性CSS的检索增强对话知识聚合方案,称为RADKA-CSS,主要包括三个组件:1)为了有效地从SD中检索与CD在语义和风格上都相似的对话,我们首先建立一个包含文本和音频样本的存储对话语义风格数据库(SDSSD)。然后,我们设计了一种多属性检索方案,以匹配CD的对话语义和风格向量与SDSSD中的存储对话语义和风格向量,检索最相似的对话。2)为了有效地利用CD和SD中的风格知识,我们提出采用多粒度图结构对对话进行编码,并引入多源风格知识聚合机制。3)最后,将聚合的风格知识输入语音合成器,以帮助代理合成符合对话风格的表达性语音。我们基于DailyTalk数据集进行了全面深入的实验,该数据集是CSS任务的基准数据集。客观和主观评估表明,RADKA-CSS在表达性呈现方面优于基准模型。代码和音频样本可在:https://github.com/Coder-jzq/RADKA-CSS找到。
论文及项目相关链接
PDF Accepted by Information Fusion 2025
Summary
本文提出一种名为RADKA-CSS的检索增强对话知识聚合方案,用于表达性对话语音合成。该方案建立存储对话语义风格数据库,通过多属性检索方案匹配对话语义和风格向量,有效运用对话中的风格知识,并采用多粒度图结构编码对话,引入多源风格知识聚合机制。实验表明,RADKA-CSS在表达性渲染方面优于基准模型。
Key Takeaways
- 对话语音合成(CSS)旨在根据对话历史合成表达性语音,以匹配对话风格。
- 存储的对话(SD)包含与用户代理早期交互阶段的对话片段,包含与对话场景相关的风格表达知识。
- 提出的RADKA-CSS方案包括从SD中有效检索与当前对话(CD)在语义和风格上相似的对话。
- 建立存储对话语义风格数据库(SDSSD),采用多属性检索方案进行匹配。
- 采用多粒度图结构编码对话,并引入多源风格知识聚合机制来利用对话中的风格知识。
- 实验表明,RADKA-CSS在表达性渲染方面优于基准模型。
点此查看论文截图