⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-16 更新
VINGS-Mono: Visual-Inertial Gaussian Splatting Monocular SLAM in Large Scenes
Authors:Ke Wu, Zicheng Zhang, Muer Tie, Ziqing Ai, Zhongxue Gan, Wenchao Ding
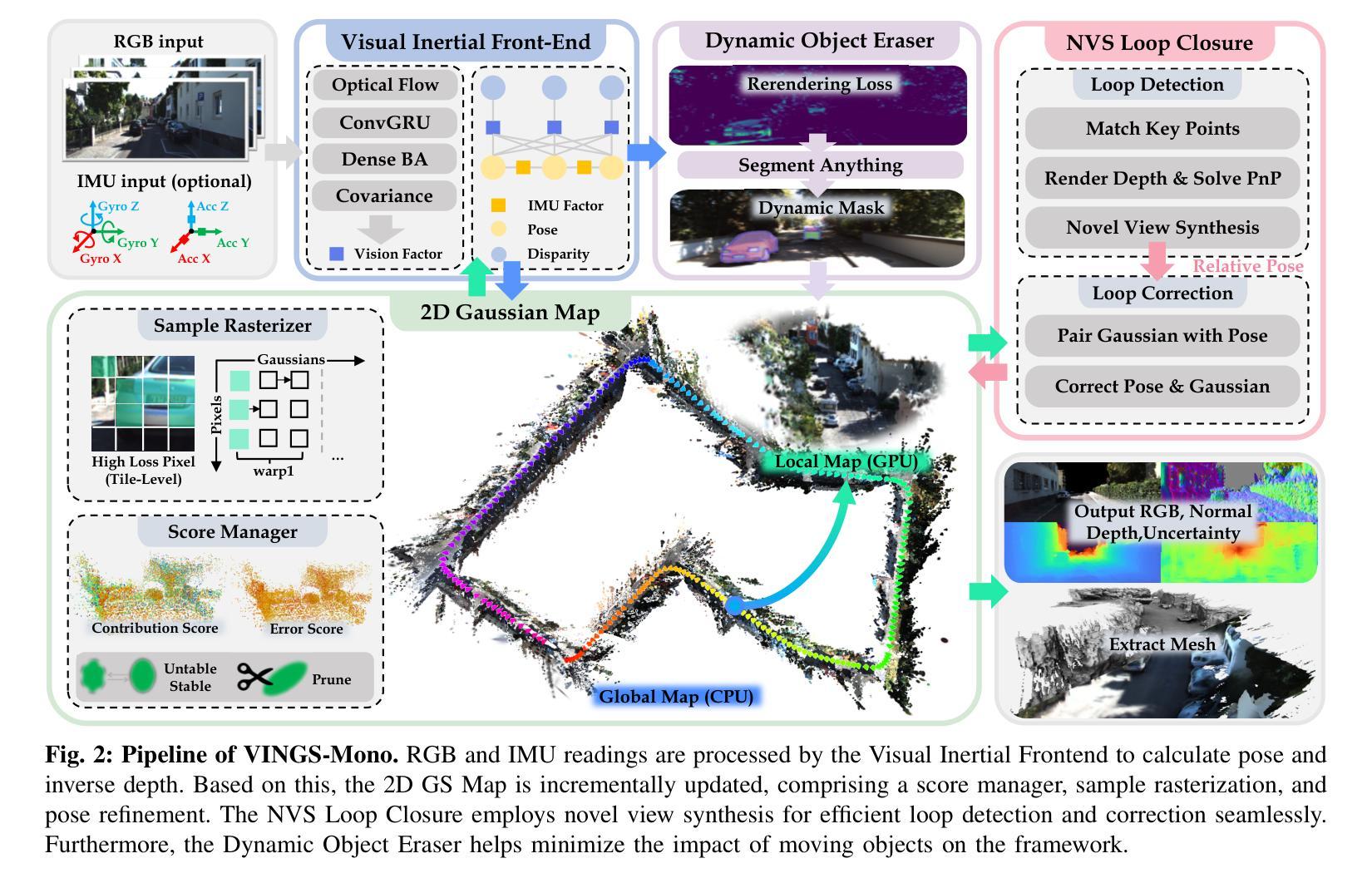
VINGS-Mono is a monocular (inertial) Gaussian Splatting (GS) SLAM framework designed for large scenes. The framework comprises four main components: VIO Front End, 2D Gaussian Map, NVS Loop Closure, and Dynamic Eraser. In the VIO Front End, RGB frames are processed through dense bundle adjustment and uncertainty estimation to extract scene geometry and poses. Based on this output, the mapping module incrementally constructs and maintains a 2D Gaussian map. Key components of the 2D Gaussian Map include a Sample-based Rasterizer, Score Manager, and Pose Refinement, which collectively improve mapping speed and localization accuracy. This enables the SLAM system to handle large-scale urban environments with up to 50 million Gaussian ellipsoids. To ensure global consistency in large-scale scenes, we design a Loop Closure module, which innovatively leverages the Novel View Synthesis (NVS) capabilities of Gaussian Splatting for loop closure detection and correction of the Gaussian map. Additionally, we propose a Dynamic Eraser to address the inevitable presence of dynamic objects in real-world outdoor scenes. Extensive evaluations in indoor and outdoor environments demonstrate that our approach achieves localization performance on par with Visual-Inertial Odometry while surpassing recent GS/NeRF SLAM methods. It also significantly outperforms all existing methods in terms of mapping and rendering quality. Furthermore, we developed a mobile app and verified that our framework can generate high-quality Gaussian maps in real time using only a smartphone camera and a low-frequency IMU sensor. To the best of our knowledge, VINGS-Mono is the first monocular Gaussian SLAM method capable of operating in outdoor environments and supporting kilometer-scale large scenes.
VINGS-Mono是一款针对大场景设计的单目(惯性)高斯混合(GS)SLAM框架。该框架包含四个主要组件:VIO前端、2D高斯地图、NVS环闭合和动态消除器。在VIO前端,RGB帧通过密集捆绑调整和不确定性估计来提取场景几何和姿态。基于这一输出,映射模块逐步构建并维护一个2D高斯地图。2D高斯地图的关键组件包括基于样本的渲染器、评分管理器和姿态优化器,它们共同提高了映射速度和定位精度。这使得SLAM系统能够处理大规模的城市环境,高达50万个高斯椭圆体。为了确保大规模场景中的全局一致性,我们设计了一个环闭合模块,该模块创新地利用高斯混合的Novel View Synthesis(NVS)功能进行环闭合检测和修正高斯地图。此外,我们提出了一个动态消除器来解决现实世界户外场景中动态物体不可避免的问题。在室内和室外环境的广泛评估表明,我们的方法实现了与视觉惯性测距相当的定位性能,同时超越了最新的GS/NeRF SLAM方法。在映射和渲染质量方面,它也大大优于所有现有方法。此外,我们开发了一个移动应用程序,并验证了我们框架能够仅使用智能手机摄像头和低频率IMU传感器在实时生成高质量高斯地图的能力。据我们所知,VINGS-Mono是第一款能够在户外环境中运行并支持公里级大场景的单目高斯SLAM方法。
论文及项目相关链接
摘要
VINGS-Mono是一款针对大场景设计的单目(惯性)高斯混合(GS)SLAM框架,包含VIO前端、2D高斯地图、NVS闭环和动态擦除器四个主要组件。框架中的RGB帧通过密集捆绑调整和不确定性估计来提取场景几何和姿态信息。在此基础上,构建并维护一个基于映射模块的二维高斯地图。NVS闭环利用高斯混合的Novel View Synthesis能力进行闭环检测和地图校正。此外,提出了动态擦除器来解决真实户外场景中不可避免的动态物体问题。评估表明,该方法在定位和渲染质量方面优于现有方法,可与视觉惯性里程计相提并论。我们还开发了一个移动应用,并验证了我们框架仅使用智能手机相机和低频率IMU传感器就能实时生成高质量的高斯地图。据我们所知,VINGS-Mono是第一个能够在户外环境中运行并支持公里级大场景的单目高斯SLAM方法。
关键见解
- VINGS-Mono是一款适用于大场景的SLAM框架,设计用于处理单目(惯性)数据。
- 它包含四个主要组件:VIO前端、二维高斯地图、NVS闭环和动态擦除器。
- VIO前端通过密集捆绑调整和不确定性估计处理RGB帧,以提取场景几何和姿态信息。
- 基于这些信息构建的二维高斯地图包括样本光栅化器、评分管理器和姿态优化器,以提高映射速度和定位精度。
- NVS闭环利用高斯混合的Novel View Synthesis能力进行闭环检测和地图校正,确保大规模场景中的全局一致性。
- 动态擦除器的引入解决了真实户外场景中动态物体的处理问题。
点此查看论文截图


Evaluating Human Perception of Novel View Synthesis: Subjective Quality Assessment of Gaussian Splatting and NeRF in Dynamic Scenes
Authors:Yuhang Zhang, Joshua Maraval, Zhengyu Zhang, Nicolas Ramin, Shishun Tian, Lu Zhang
Gaussian Splatting (GS) and Neural Radiance Fields (NeRF) are two groundbreaking technologies that have revolutionized the field of Novel View Synthesis (NVS), enabling immersive photorealistic rendering and user experiences by synthesizing multiple viewpoints from a set of images of sparse views. The potential applications of NVS, such as high-quality virtual and augmented reality, detailed 3D modeling, and realistic medical organ imaging, underscore the importance of quality assessment of NVS methods from the perspective of human perception. Although some previous studies have explored subjective quality assessments for NVS technology, they still face several challenges, especially in NVS methods selection, scenario coverage, and evaluation methodology. To address these challenges, we conducted two subjective experiments for the quality assessment of NVS technologies containing both GS-based and NeRF-based methods, focusing on dynamic and real-world scenes. This study covers 360{\deg}, front-facing, and single-viewpoint videos while providing a richer and greater number of real scenes. Meanwhile, it’s the first time to explore the impact of NVS methods in dynamic scenes with moving objects. The two types of subjective experiments help to fully comprehend the influences of different viewing paths from a human perception perspective and pave the way for future development of full-reference and no-reference quality metrics. In addition, we established a comprehensive benchmark of various state-of-the-art objective metrics on the proposed database, highlighting that existing methods still struggle to accurately capture subjective quality. The results give us some insights into the limitations of existing NVS methods and may promote the development of new NVS methods.
高斯贴图(GS)和神经辐射场(NeRF)是两项突破性的技术,它们彻底改变了新型视图合成(NVS)领域,通过从稀疏图像集合成多个视点,实现了沉浸式逼真的渲染和用户体验。NVS的潜在应用,如高质量虚拟和增强现实、详细的3D建模和逼真的医学器官成像,强调了从人类感知角度评估NVS方法质量的重要性。尽管之前的一些研究已经探索了NVS技术的主观质量评估,但它们仍然面临一些挑战,特别是在NVS方法选择、场景覆盖和评估方法方面。为了应对这些挑战,我们对包含基于GS和基于NeRF的方法的NVS技术进行了两项主观实验质量评估,侧重于动态和真实场景。该研究涵盖了360°、正面和单视点视频,同时提供了更丰富、数量更多的真实场景。与此同时,它是首次探索NVS方法在动态场景中对移动对象的影响。这两种类型的主观实验有助于从人类感知的角度充分理解不同观看路径的影响,为全参考和无参考质量指标的未来发展铺平道路。此外,我们在提出的数据库上建立了各种最新客观指标的综合基准测试,突出显示现有方法仍然难以准确捕捉主观质量。结果给我们提供了对现有NVS方法局限性的见解,并可能促进新型NVS方法的发展。
论文及项目相关链接
Summary
基于高斯融合(GS)和神经辐射场(NeRF)技术的视点合成(NVS)方法,在虚拟和增强现实、三维建模、医学成像等领域实现了沉浸式光栅渲染和用户体验。对于NVS技术的质量评估,尽管已有研究,但仍面临方法选择、场景覆盖和评价方法上的挑战。本研究通过两项主观实验对NVS技术质量进行评估,涉及动态和真实场景,探索了不同观看路径的影响,并为未来全参考和无参考质量指标的开发奠定了基础。同时,对现有先进客观指标的全面基准测试表明,现有方法仍难以准确捕捉主观质量,为NVS方法的发展提供了启示。
Key Takeaways
- Gaussian Splatting (GS) 和 Neural Radiance Fields (NeRF) 技术在视点合成(NVS)领域实现了重大突破,用于生成沉浸式光栅渲染。
- NVS技术在虚拟和增强现实、三维建模、医学成像等领域有广泛应用前景。
- NVS技术质量评估面临方法选择、场景覆盖和评价方法上的挑战。
- 通过两项主观实验对NVS技术质量进行评估,涵盖动态和真实场景,探索了不同观看路径的影响。
- 研究为全参考和无参考质量指标的开发奠定了基础。
- 建立了针对先进客观指标的全面基准测试,揭示了现有方法的局限性。
点此查看论文截图


SplatMAP: Online Dense Monocular SLAM with 3D Gaussian Splatting
Authors:Yue Hu, Rong Liu, Meida Chen, Andrew Feng, Peter Beerel
Achieving high-fidelity 3D reconstruction from monocular video remains challenging due to the inherent limitations of traditional methods like Structure-from-Motion (SfM) and monocular SLAM in accurately capturing scene details. While differentiable rendering techniques such as Neural Radiance Fields (NeRF) address some of these challenges, their high computational costs make them unsuitable for real-time applications. Additionally, existing 3D Gaussian Splatting (3DGS) methods often focus on photometric consistency, neglecting geometric accuracy and failing to exploit SLAM’s dynamic depth and pose updates for scene refinement. We propose a framework integrating dense SLAM with 3DGS for real-time, high-fidelity dense reconstruction. Our approach introduces SLAM-Informed Adaptive Densification, which dynamically updates and densifies the Gaussian model by leveraging dense point clouds from SLAM. Additionally, we incorporate Geometry-Guided Optimization, which combines edge-aware geometric constraints and photometric consistency to jointly optimize the appearance and geometry of the 3DGS scene representation, enabling detailed and accurate SLAM mapping reconstruction. Experiments on the Replica and TUM-RGBD datasets demonstrate the effectiveness of our approach, achieving state-of-the-art results among monocular systems. Specifically, our method achieves a PSNR of 36.864, SSIM of 0.985, and LPIPS of 0.040 on Replica, representing improvements of 10.7%, 6.4%, and 49.4%, respectively, over the previous SOTA. On TUM-RGBD, our method outperforms the closest baseline by 10.2%, 6.6%, and 34.7% in the same metrics. These results highlight the potential of our framework in bridging the gap between photometric and geometric dense 3D scene representations, paving the way for practical and efficient monocular dense reconstruction.
从单目视频中实现高保真3D重建仍然是一个挑战,这主要是由于传统方法(如结构从运动(SfM)和单目SLAM)在准确捕捉场景细节方面的固有局限性。虽然神经辐射场(NeRF)等可微分渲染技术解决了其中的一些挑战,但它们的高计算成本使它们不适合实时应用。此外,现有的3D高斯涂抹(3DGS)方法通常侧重于光度一致性,忽视了几何精度,并且未能利用SLAM的动态深度和姿态更新来进行场景细化。我们提出了一种结合密集SLAM和3DGS的框架,用于实时高保真密集重建。我们的方法引入了SLAM信息自适应细化,利用SLAM的密集点云来动态更新和细化高斯模型。此外,我们采用了几何引导优化,它结合了边缘感知几何约束和光度一致性,以联合优化3DGS场景表示的外观和几何结构,从而实现详细而准确的SLAM映射重建。在Replica和TUM-RGBD数据集上的实验证明了我们的方法的有效性,在单目系统中实现了最先进的成果。具体来说,我们的方法在Replica上实现了PSNR为36.864,SSIM为0.985,LPIPS为0.040的成绩,分别比之前的最佳成绩提高了10.7%、6.4%和49.4%。在TUM-RGBD上,我们的方法在相同的指标上比最接近的基线高出10.2%、6.6%和34.7%。这些结果突显了我们框架在桥接光度学和几何学密集3D场景表示方面的潜力,为实用和高效的单目密集重建铺平了道路。
论文及项目相关链接
摘要
针对从单目视频中实现高保真3D重建的问题,传统方法如SfM和单目SLAM在准确捕捉场景细节方面存在固有局限性。虽然NeRF等可微分渲染技术可以解决部分挑战,但其高计算成本使其不适合实时应用。本文提出一个结合密集SLAM与3DGS的框架,用于实时高保真密集重建。该方法引入SLAM信息自适应细化,利用SLAM的密集点云动态更新和细化高斯模型。同时结合几何引导优化,通过边缘感知几何约束和光度一致性联合优化3DGS场景表示的外观和几何,实现详细准确的SLAM映射重建。在Replica和TUM-RGBD数据集上的实验表明,该方法在单目系统中实现一流效果,其中在Replica上获得PSNR 36.864、SSIM 0.985和LPIPS 0.040的指标,相较于之前的最优方法分别提升了10.7%、6.4%和49.4%。在TUM-RGBD数据集上,该方法在相同指标上比最接近的基线高出10.2%、6.6%和34.7%。这证明了该框架在桥接光度与几何密集3D场景表示方面的潜力,为实用且高效的单目密集重建铺平了道路。
Key Takeaways
- 传统方法如SfM和单目SLAM在3D重建中面临准确捕捉场景细节的挑战。
- NeRF等可微分渲染技术虽能解决部分挑战,但计算成本高,不适合实时应用。
- 提出的框架结合密集SLAM与3DGS实现实时高保真密集重建。
- 引入SLAM信息自适应细化,利用SLAM的密集点云优化高斯模型。
- 结合几何引导优化,通过联合优化实现详细准确的SLAM映射重建。
- 在Replica和TUM-RGBD数据集上实现一流效果,较之前方法有明显提升。
点此查看论文截图


ActiveGAMER: Active GAussian Mapping through Efficient Rendering
Authors:Liyan Chen, Huangying Zhan, Kevin Chen, Xiangyu Xu, Qingan Yan, Changjiang Cai, Yi Xu
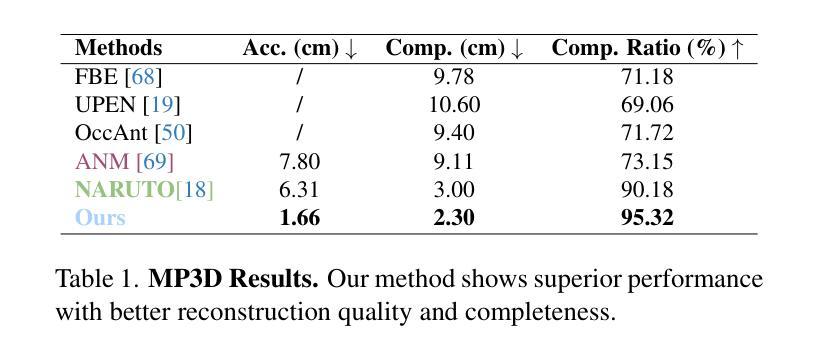
We introduce ActiveGAMER, an active mapping system that utilizes 3D Gaussian Splatting (3DGS) to achieve high-quality, real-time scene mapping and exploration. Unlike traditional NeRF-based methods, which are computationally demanding and restrict active mapping performance, our approach leverages the efficient rendering capabilities of 3DGS, allowing effective and efficient exploration in complex environments. The core of our system is a rendering-based information gain module that dynamically identifies the most informative viewpoints for next-best-view planning, enhancing both geometric and photometric reconstruction accuracy. ActiveGAMER also integrates a carefully balanced framework, combining coarse-to-fine exploration, post-refinement, and a global-local keyframe selection strategy to maximize reconstruction completeness and fidelity. Our system autonomously explores and reconstructs environments with state-of-the-art geometric and photometric accuracy and completeness, significantly surpassing existing approaches in both aspects. Extensive evaluations on benchmark datasets such as Replica and MP3D highlight ActiveGAMER’s effectiveness in active mapping tasks.
我们介绍了ActiveGAMER,这是一个利用3D高斯喷涂技术(3DGS)实现的主动映射系统,可以实现高质量、实时的场景映射和探索。与传统的基于NeRF的方法不同,这些方法计算量大,限制了主动映射的性能,我们的方法利用3DGS的高效渲染能力,能够在复杂环境中实现有效且高效的探索。我们的系统的核心是基于渲染的信息增益模块,该模块能够动态地识别最具信息量的观点,用于进行下一次最佳视角规划,提高几何和光度重建的精度。ActiveGAMER还整合了一个精心平衡的方案,结合了由粗到细的探究、后期优化和全局-局部关键帧选择策略,以最大限度地提高重建的完整性和逼真度。我们的系统以最先进的几何和光度准确性和完整性自主探索和重建环境,在两个方面都大大超越了现有方法。在诸如Replica和MP3D等基准数据集上的广泛评估凸显了ActiveGAMER在主动映射任务中的有效性。
论文及项目相关链接
Summary
新一代主动映射系统ActiveGAMER,利用3D高斯喷涂技术实现高质量、实时的场景映射和探索。与传统的NeRF方法相比,它采用高效渲染技术,提升复杂环境下的探索效率。其核心是信息增益模块,可动态识别最具信息量的视角进行最佳后续视图规划,提高几何和光度重建的准确性。ActiveGAMER结合粗到细探索、后期优化和全局局部关键帧选择策略,最大化重建的完整性和保真度。它在环境和数据集上的表现均超越现有方法。
Key Takeaways
- ActiveGAMER是一种高效的主动映射系统,采用3D高斯喷涂技术。
- 它通过高效渲染提升复杂环境下的探索效率。
- 核心的信息增益模块可动态识别最具信息量的视角。
- 该系统结合多种策略,包括粗到细探索、后期优化和关键帧选择。
- ActiveGAMER在几何和光度重建方面表现出色。
- 它在多个数据集上的表现均超越现有方法。
点此查看论文截图


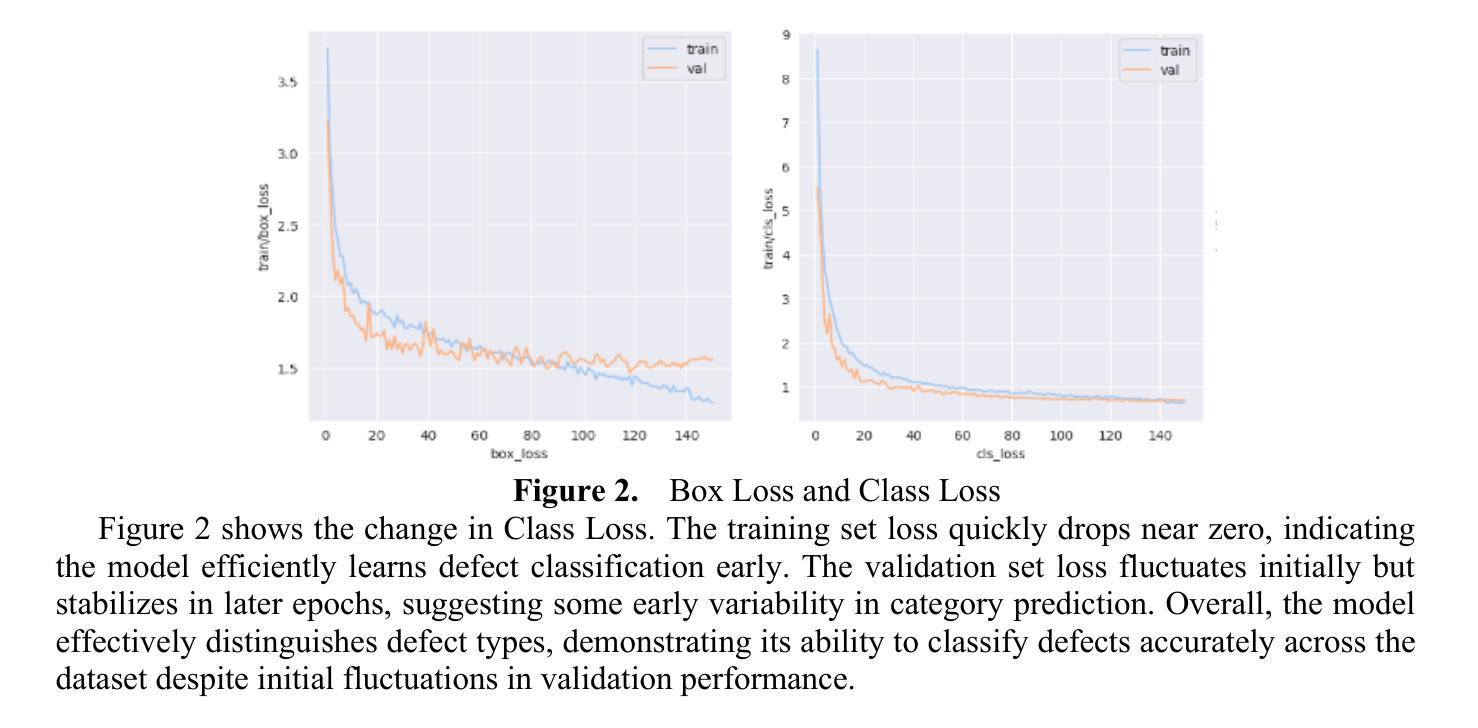
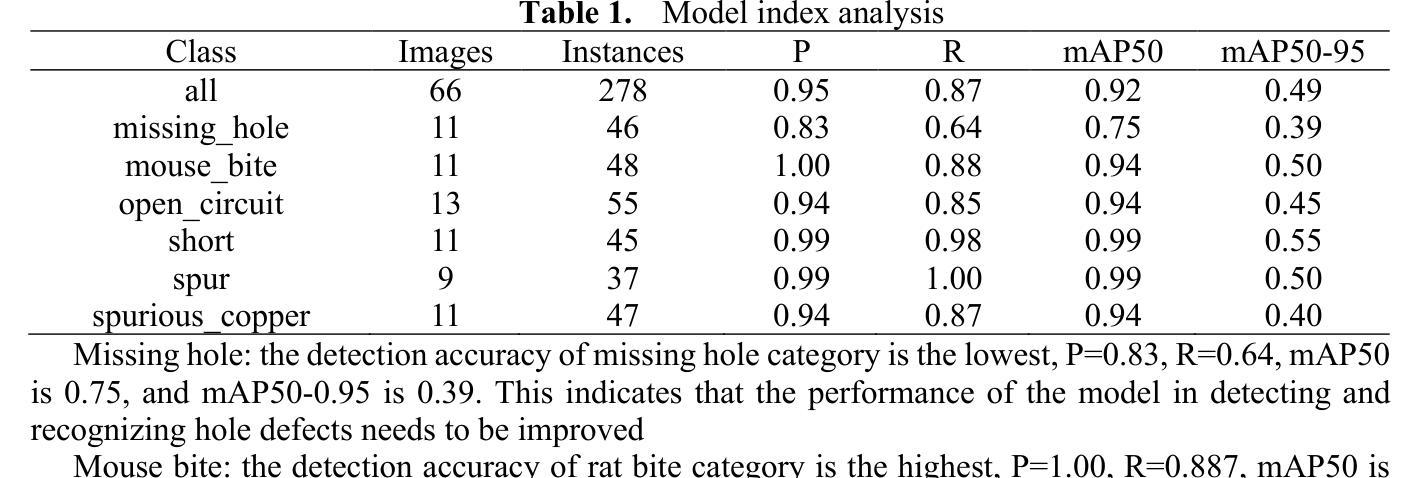
Defect Detection Network In PCB Circuit Devices Based on GAN Enhanced YOLOv11
Authors:Jiayi Huang, Feiyun Zhao, Lieyang Chen
This study proposes an advanced method for surface defect detection in printed circuit boards (PCBs) using an improved YOLOv11 model enhanced with a generative adversarial network (GAN). The approach focuses on identifying six common defect types: missing hole, rat bite, open circuit, short circuit, burr, and virtual welding. By employing GAN to generate synthetic defect images, the dataset is augmented with diverse and realistic patterns, improving the model’s ability to generalize, particularly for complex and infrequent defects like burrs. The enhanced YOLOv11 model is evaluated on a PCB defect dataset, demonstrating significant improvements in accuracy, recall, and robustness, especially when dealing with defects in complex environments or small targets. This research contributes to the broader field of electronic design automation (EDA), where efficient defect detection is a crucial step in ensuring high-quality PCB manufacturing. By integrating advanced deep learning techniques, this approach enhances the automation and precision of defect detection, reducing reliance on manual inspection and accelerating design-to-production workflows. The findings underscore the importance of incorporating GAN-based data augmentation and optimized detection architectures in EDA processes, providing valuable insights for improving reliability and efficiency in PCB defect detection within industrial applications.
本研究提出了一种利用改进型YOLOv11模型结合生成对抗网络(GAN)对印刷电路板(PCB)表面缺陷进行检测的先进方法。该方法专注于识别六种常见缺陷类型:缺孔、齿咬、开路、短路、毛刺和虚焊。通过采用GAN生成合成缺陷图像,数据集被丰富为多样且逼真的模式,提高了模型对毛刺等复杂和不常见缺陷的泛化能力。改进的YOLOv11模型在PCB缺陷数据集上进行了评估,在准确性、召回率和稳健性方面表现出显著的提升,特别是在处理复杂环境或小目标缺陷时。该研究对电子设计自动化(EDA)这一更广泛的领域有所贡献,其中高效的缺陷检测是确保高质量PCB制造的关键步骤。通过集成先进的深度学习技术,此方法提高了缺陷检测的自动化和精度,减少了对手动检查的依赖,并加速了设计到生产的流程。研究结果强调了在工业应用中,在EDA过程中融入基于GAN的数据增强和优化检测架构的重要性,为改善PCB缺陷检测的可靠性和效率提供了宝贵的见解。
论文及项目相关链接
Summary
该研究提出了一种基于改进YOLOv11模型和生成对抗网络(GAN)的表面缺陷检测新方法,主要应用于印刷电路板(PCBs)的缺陷检测。该方法可识别六种常见缺陷类型,包括缺孔、咬边、开路、短路、毛刺和虚拟焊接等。通过使用GAN生成合成缺陷图像,数据集得到了多样化和逼真的模式增强,提高了模型对复杂和罕见的缺陷如毛刺的通用化能力。在PCB缺陷数据集上评估的增强型YOLOv11模型,在准确性、召回率和稳健性方面表现出显著改进,特别是在处理复杂环境或小目标缺陷时。该研究为电子设计自动化(EDA)领域做出了贡献,其中高效的缺陷检测是保证高质量PCB制造的关键步骤。通过集成先进的深度学习技术,此方法提高了缺陷检测的自动化和精度,减少了对手动检查的依赖,并加速了从设计到生产的工作流程。研究结果强调了在工业应用中,在EDA过程中融入基于GAN的数据增强和优化检测架构的重要性,为改善PCB缺陷检测的可靠性和效率提供了宝贵见解。
Key Takeaways
- 研究提出了基于改进YOLOv11模型和GAN的表面缺陷检测新方法,可识别六种常见PCB缺陷类型。
- GAN用于生成合成缺陷图像,增强了数据集的多样性和现实性。
- 增强模型在PCB缺陷数据集上的性能显著,提高了准确性、召回率和稳健性。
- 方法适用于复杂环境或小目标缺陷的检测。
- 研究对电子设计自动化(EDA)领域有贡献,提高了缺陷检测的自动化和精度。
- 集成深度学习技术减少了对手动检查的依赖,加速了设计到生产的过程。
点此查看论文截图


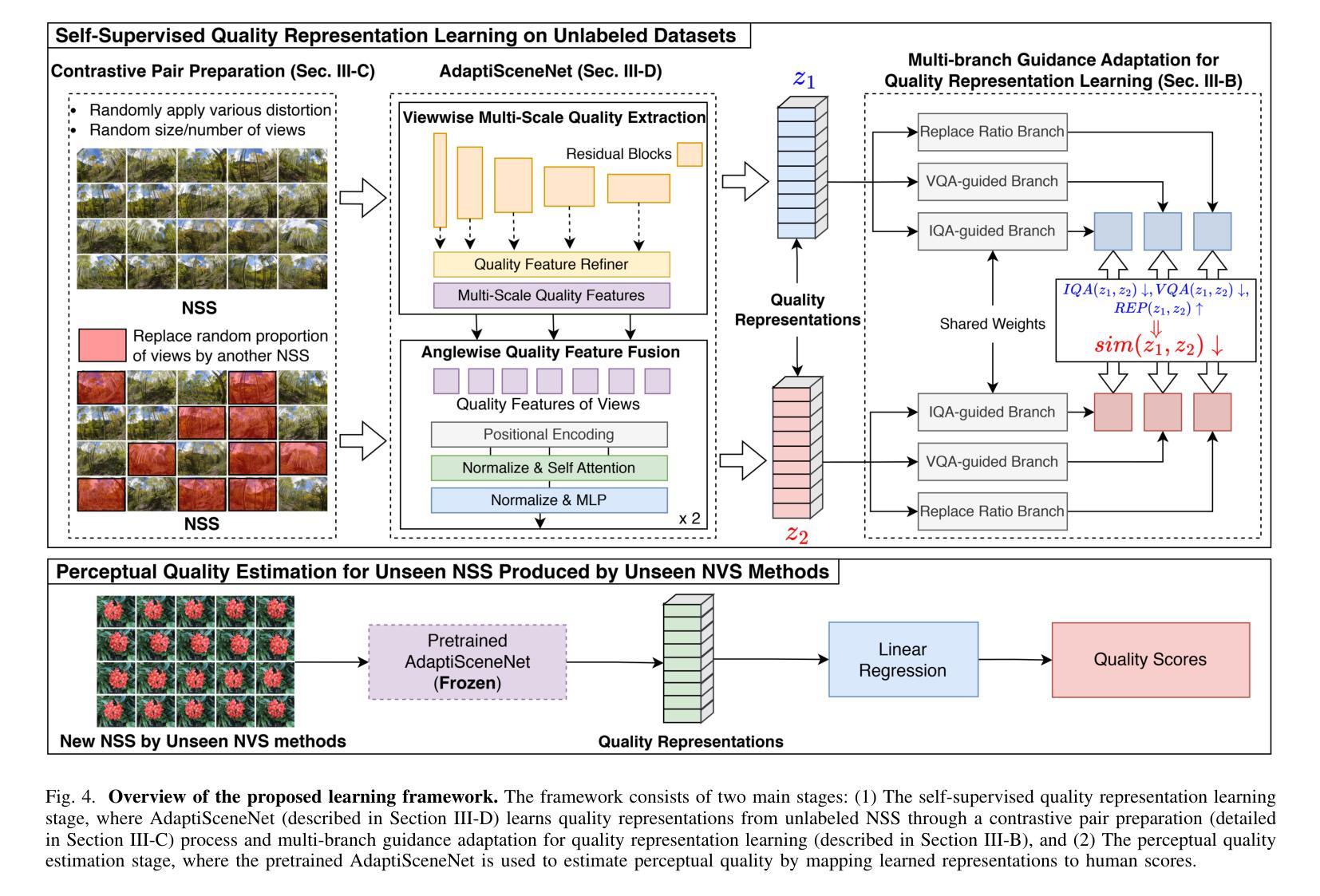
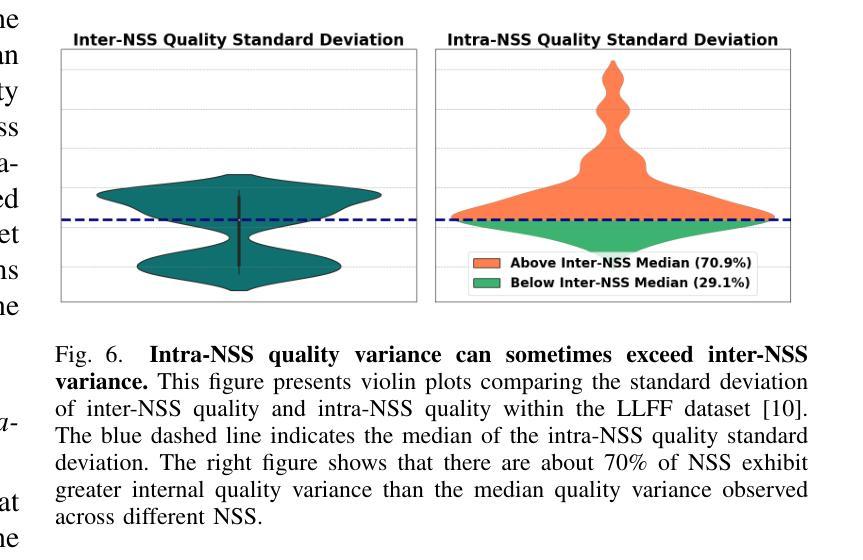
NVS-SQA: Exploring Self-Supervised Quality Representation Learning for Neurally Synthesized Scenes without References
Authors:Qiang Qu, Yiran Shen, Xiaoming Chen, Yuk Ying Chung, Weidong Cai, Tongliang Liu
Neural View Synthesis (NVS), such as NeRF and 3D Gaussian Splatting, effectively creates photorealistic scenes from sparse viewpoints, typically evaluated by quality assessment methods like PSNR, SSIM, and LPIPS. However, these full-reference methods, which compare synthesized views to reference views, may not fully capture the perceptual quality of neurally synthesized scenes (NSS), particularly due to the limited availability of dense reference views. Furthermore, the challenges in acquiring human perceptual labels hinder the creation of extensive labeled datasets, risking model overfitting and reduced generalizability. To address these issues, we propose NVS-SQA, a NSS quality assessment method to learn no-reference quality representations through self-supervision without reliance on human labels. Traditional self-supervised learning predominantly relies on the “same instance, similar representation” assumption and extensive datasets. However, given that these conditions do not apply in NSS quality assessment, we employ heuristic cues and quality scores as learning objectives, along with a specialized contrastive pair preparation process to improve the effectiveness and efficiency of learning. The results show that NVS-SQA outperforms 17 no-reference methods by a large margin (i.e., on average 109.5% in SRCC, 98.6% in PLCC, and 91.5% in KRCC over the second best) and even exceeds 16 full-reference methods across all evaluation metrics (i.e., 22.9% in SRCC, 19.1% in PLCC, and 18.6% in KRCC over the second best).
神经视图合成(NVS),如NeRF和3D高斯填充,能够有效地从稀疏的视点生成逼真的场景,通常通过PSNR、SSIM和LPIPS等质量评估方法进行评估。然而,这些全参考方法将合成视图与参考视图进行比较,可能无法完全捕捉神经合成场景(NSS)的感知质量,尤其是因为密集的参考视图有限。此外,获取人类感知标签的挑战阻碍了大规模标注数据集的产生,存在模型过拟合和泛化性降低的风险。为了解决这些问题,我们提出了NVS-SQA,这是一种NSS质量评估方法,通过自监督学习无参考质量表示,无需依赖人工标签。传统的自监督学习主要依赖于“同一实例,相似表示”的假设和大量数据集。然而,鉴于这些条件不适用于NSS质量评估,我们采用启发式线索和质量分数作为学习目标,同时配合专门的对比对准备过程,以提高学习的有效性和效率。结果表明,NVS-SQA在17种无参考方法中有很大优势(例如,SRCC平均提高109.5%,PLCC提高98.6%,KRCC提高91.5%);并且在所有评估指标上甚至超过了16种全参考方法(例如,SRCC提高22.9%,PLCC提高19.1%,KRCC提高18.6%)。
论文及项目相关链接
摘要
NeRF等相关技术能有效创建逼真的场景,但现有质量评估方法可能无法完全捕捉神经合成场景的感知质量。为此,提出一种无参考神经合成场景质量评估方法NVS-SQA,通过自监督学习无参考质量表示,无需依赖人工标签。NVS-SQA采用启发式线索和质量分数作为学习目标,并设计对比配对准备过程提高学习效率和效果。结果显示NVS-SQA在无参考方法中表现优异,并在所有评估指标上超越多数全参考方法。
关键见解
- 现有质量评估方法如PSNR、SSIM和LPIPS可能无法全面评估神经合成场景的感知质量,特别是在缺乏密集参考视图的情况下。
- 提出一种名为NVS-SQA的无参考质量评估方法,通过自监督学习捕捉神经合成场景的质量,无需依赖人工标签。
- NVS-SQA采用启发式线索和质量分数作为学习目标,适应于神经合成场景质量评估的特殊性。
- 对比配对准备过程有效提高NVS-SQA的学习效果和效率。
- NVS-SQA在多种评估指标上显著优于其他无参考和全参考方法。
- NVS-SQA的优异表现为神经渲染技术的质量评估提供了新的方向。
点此查看论文截图



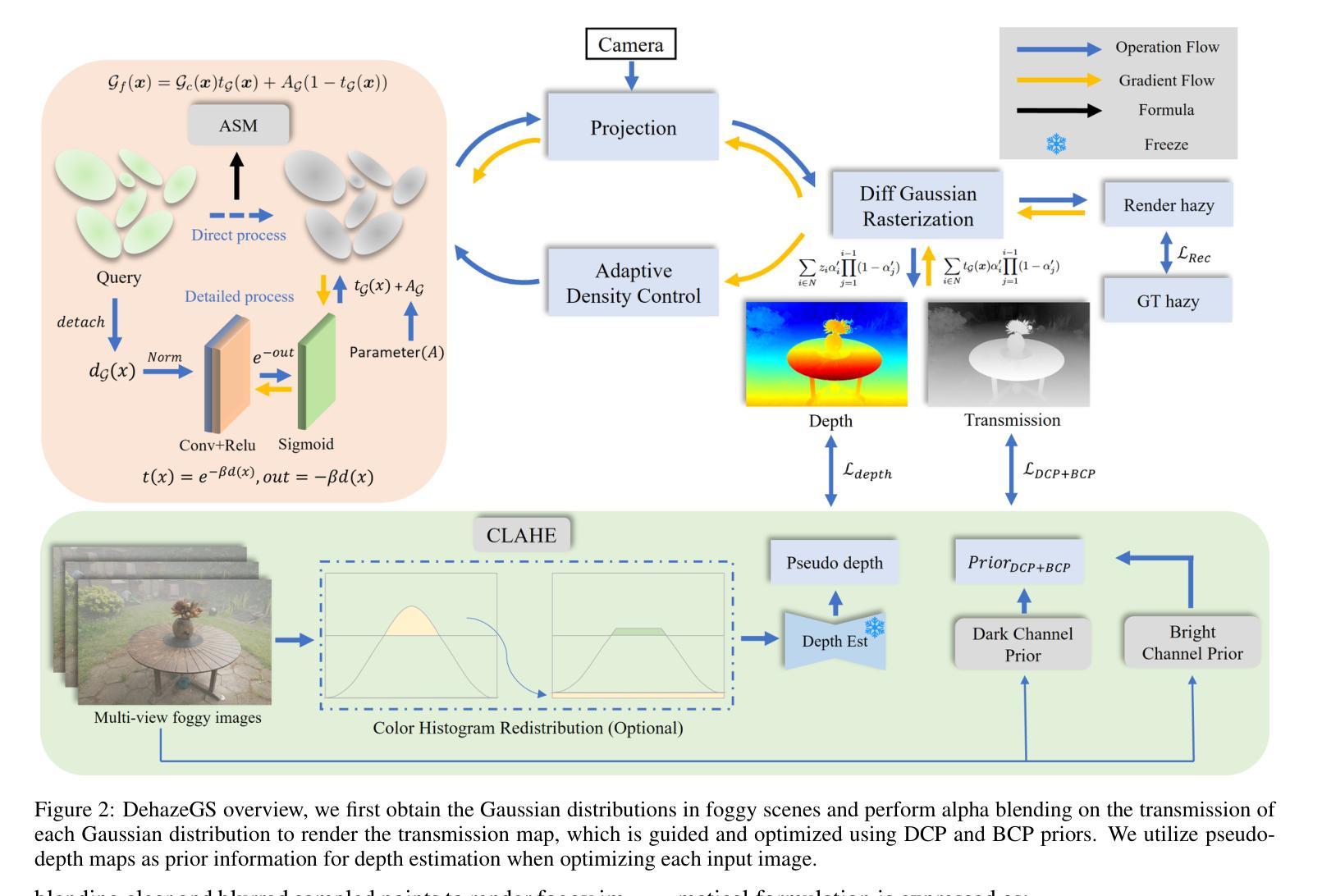
DehazeGS: Seeing Through Fog with 3D Gaussian Splatting
Authors:Jinze Yu, Yiqun Wang, Zhengda Lu, Jianwei Guo, Yong Li, Hongxing Qin, Xiaopeng Zhang
Current novel view synthesis tasks primarily rely on high-quality and clear images. However, in foggy scenes, scattering and attenuation can significantly degrade the reconstruction and rendering quality. Although NeRF-based dehazing reconstruction algorithms have been developed, their use of deep fully connected neural networks and per-ray sampling strategies leads to high computational costs. Moreover, NeRF’s implicit representation struggles to recover fine details from hazy scenes. In contrast, recent advancements in 3D Gaussian Splatting achieve high-quality 3D scene reconstruction by explicitly modeling point clouds into 3D Gaussians. In this paper, we propose leveraging the explicit Gaussian representation to explain the foggy image formation process through a physically accurate forward rendering process. We introduce DehazeGS, a method capable of decomposing and rendering a fog-free background from participating media using only muti-view foggy images as input. We model the transmission within each Gaussian distribution to simulate the formation of fog. During this process, we jointly learn the atmospheric light and scattering coefficient while optimizing the Gaussian representation of the hazy scene. In the inference stage, we eliminate the effects of scattering and attenuation on the Gaussians and directly project them onto a 2D plane to obtain a clear view. Experiments on both synthetic and real-world foggy datasets demonstrate that DehazeGS achieves state-of-the-art performance in terms of both rendering quality and computational efficiency.
当前的新型视图合成任务主要依赖于高质量、清晰的图像。然而,在雾天场景中,散射和衰减会显著降重建和渲染质量。尽管已经开发了基于NeRF的去雾重建算法,但它们使用深度全连接神经网络和按射线采样策略,导致计算成本高昂。此外,NeRF的隐式表示很难从雾蒙蒙的场景中恢复细节。相比之下,最近的3D高斯泼溅技术(Gaussian Splatting)在3D场景重建方面实现了高质量表现,它通过显式建模点云为3D高斯。在本文中,我们提出利用显式高斯表示,通过一个物理准确的正向渲染过程来解释雾蒙蒙图像的形成过程。我们引入了DehazeGS方法,该方法能够从参与介质中分解并渲染无雾背景,仅使用多视角雾蒙蒙图像作为输入。我们模拟了高斯分布内的传输来模拟雾的形成。在此过程中,我们联合学习大气光和散射系数,同时优化雾蒙蒙场景的高斯表示。在推理阶段,我们消除了散射和衰减对高斯的影响,并将其直接投影到二维平面上以获得清晰视图。在合成和真实世界的雾天数据集上的实验表明,DehazeGS在渲染质量和计算效率方面都达到了最先进的性能。
论文及项目相关链接
PDF 9 pages,4 figures
摘要
本文提出了一种利用显式高斯表示方法处理雾天图像的新算法DehazeGS。通过模拟雾的形成过程,从参与介质中提取并渲染出清晰的背景。该方法能同时学习大气光和散射系数,优化雾天场景的高斯表示,并在推理阶段消除散射和衰减对高斯的影响,将图像直接投影到二维平面上获得清晰视图。实验表明,DehazeGS在合成和真实雾天数据集上均达到了优异的表现。
要点解析
- 当前视图合成任务主要依赖于高质量清晰图像,但在雾天场景中,散射和衰减会严重影响重建和渲染质量。
- 虽然基于NeRF的去雾重建算法已经开发出来,但它们使用的深度全连接神经网络和按射线采样策略导致计算成本高。
- NeRF的隐式表示很难从雾天场景中恢复细节。
- 最近的3D高斯喷涂技术通过显式建模点云到3D高斯实现了高质量3D场景重建。
- 本文提出利用显式高斯表示法,通过物理准确的正向渲染过程解释雾天图像的形成过程。
- 提出的DehazeGS方法能够从参与介质中提取并渲染出清晰的背景,使用多视角雾天图像作为输入。
点此查看论文截图


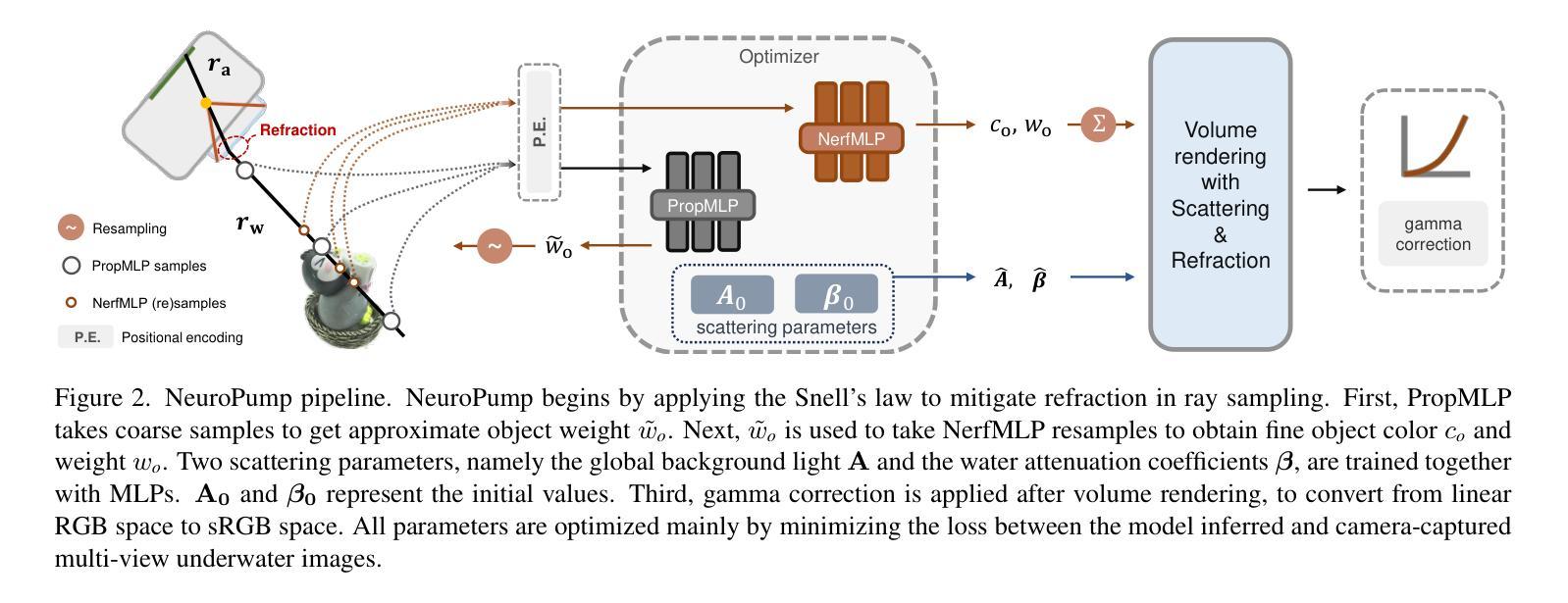
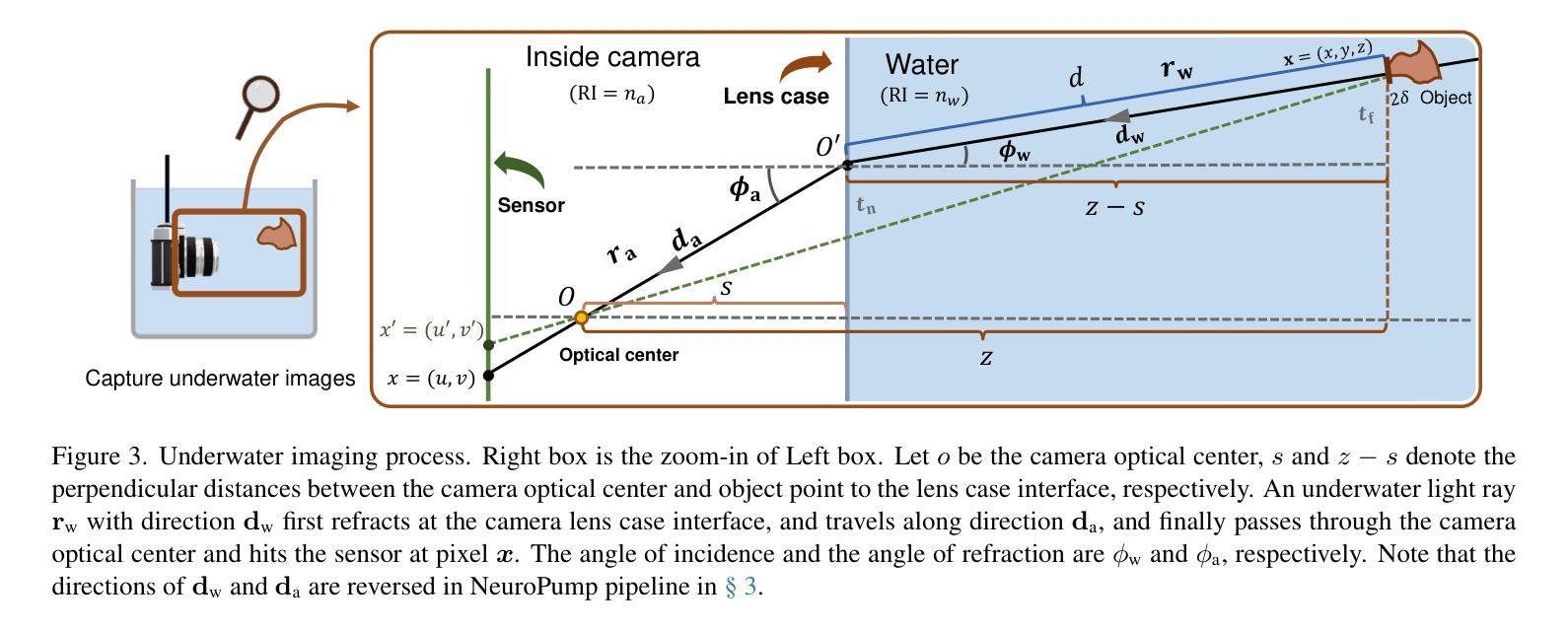
NeuroPump: Simultaneous Geometric and Color Rectification for Underwater Images
Authors:Yue Guo, Haoxiang Liao, Haibin Ling, Bingyao Huang
Underwater image restoration aims to remove geometric and color distortions due to water refraction, absorption and scattering. Previous studies focus on restoring either color or the geometry, but to our best knowledge, not both. However, in practice it may be cumbersome to address the two rectifications one-by-one. In this paper, we propose NeuroPump, a self-supervised method to simultaneously optimize and rectify underwater geometry and color as if water were pumped out. The key idea is to explicitly model refraction, absorption and scattering in Neural Radiance Field (NeRF) pipeline, such that it not only performs simultaneous geometric and color rectification, but also enables to synthesize novel views and optical effects by controlling the decoupled parameters. In addition, to address issue of lack of real paired ground truth images, we propose an underwater 360 benchmark dataset that has real paired (i.e., with and without water) images. Our method clearly outperforms other baselines both quantitatively and qualitatively. Our project page is available at: https://ygswu.github.io/NeuroPump.github.io/.
水下图像修复的目标是消除因水折射、吸收和散射造成的几何和色彩失真。先前的研究主要集中于修复色彩或几何形态,但据我们所知,并非两者兼修。然而,在实践中,逐一解决这两种校正可能很麻烦。在本文中,我们提出了NeuroPump,这是一种自监督方法,可同时优化和修复水下几何和色彩,就像将水排出一样。关键思想是在神经辐射场(NeRF)管道中显式建模折射、吸收和散射,使其不仅能同时进行几何和颜色校正,而且通过控制解耦参数,还能合成新视角和光学效果。此外,为了解决缺乏真实配对基准图像的问题,我们提出了一个水下360基准数据集,其中包含真实配对(即有水和无水的)图像。我们的方法在定量和定性方面均明显优于其他基线。我们的项目页面位于:https://ygswu.github.io/NeuroPump.github.io/。
论文及项目相关链接
摘要
本文提出一种名为NeuroPump的自监督方法,旨在同时优化和纠正水下图像的几何和颜色失真,就像将水排出一样。该方法的核心思想是在神经辐射场(NeRF)管道中显式建模折射、吸收和散射,实现几何和颜色的同时校正,并可通过控制解耦参数合成新视角和光学效应。为解决缺乏真实配对基准图像的问题,我们还提出了一个水下360度基准数据集,其中包含真实配对(即带水和不带水的)图像。我们的方法在定量和定性方面均明显超越其他基线。
要点
- 水下图像恢复旨在消除因水折射、吸收和散射引起的几何和颜色失真。
- 现有研究主要关注恢复颜色或几何,但本文方法可同时优化两者。
- 提出NeuroPump自监督方法,模拟“将水排出”的效果。
- 在NeRF管道中显式建模折射、吸收和散射。
- 通过控制解耦参数,可合成新视角和光学效应。
- 引入水下360度基准数据集,包含真实配对图像。
- NeuroPump在性能上超越其他方法。
点此查看论文截图

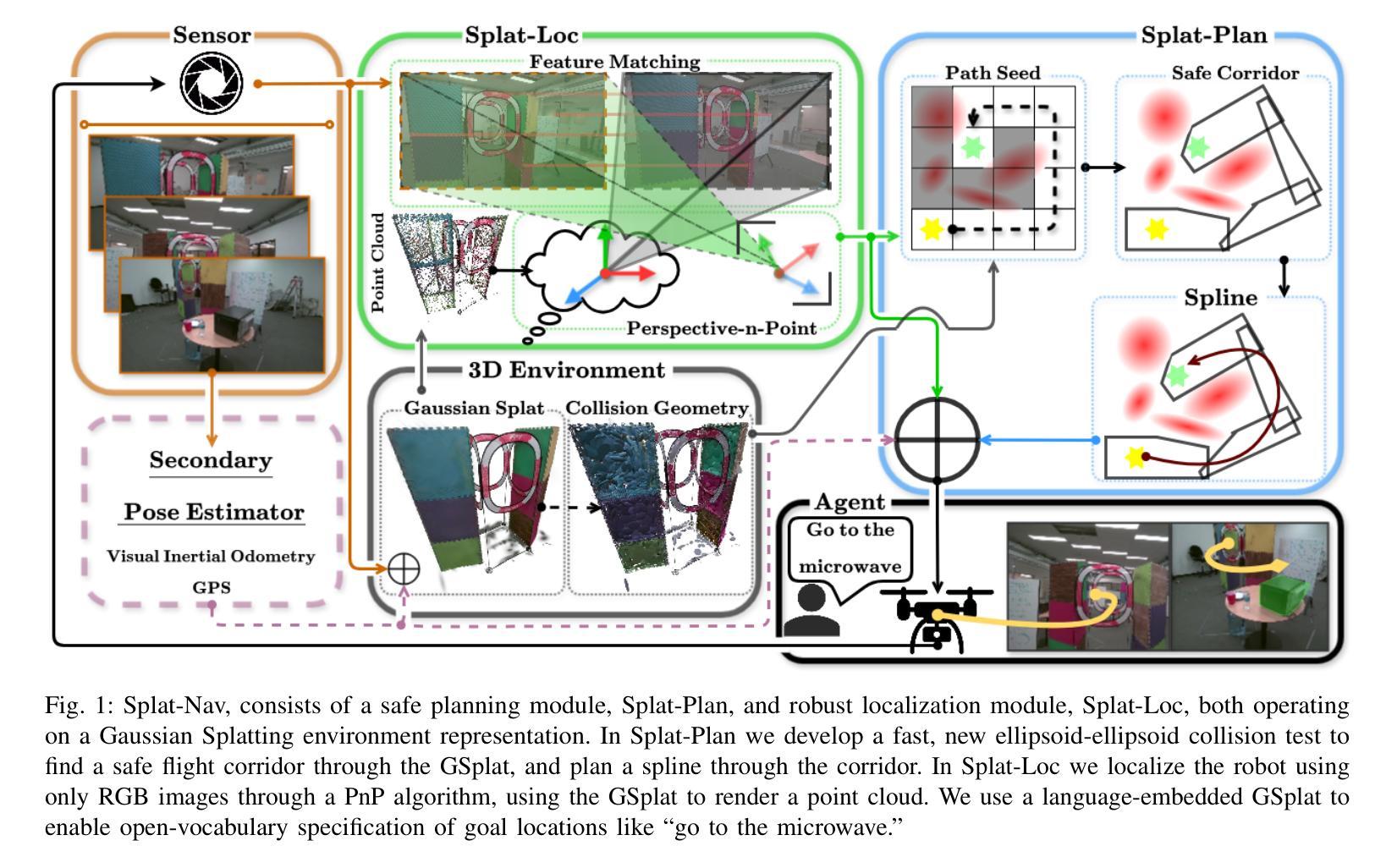
Splat-Nav: Safe Real-Time Robot Navigation in Gaussian Splatting Maps
Authors:Timothy Chen, Ola Shorinwa, Joseph Bruno, Aiden Swann, Javier Yu, Weijia Zeng, Keiko Nagami, Philip Dames, Mac Schwager
We present Splat-Nav, a real-time robot navigation pipeline for Gaussian Splatting (GSplat) scenes, a powerful new 3D scene representation. Splat-Nav consists of two components: 1) Splat-Plan, a safe planning module, and 2) Splat-Loc, a robust vision-based pose estimation module. Splat-Plan builds a safe-by-construction polytope corridor through the map based on mathematically rigorous collision constraints and then constructs a B'ezier curve trajectory through this corridor. Splat-Loc provides real-time recursive state estimates given only an RGB feed from an on-board camera, leveraging the point-cloud representation inherent in GSplat scenes. Working together, these modules give robots the ability to recursively re-plan smooth and safe trajectories to goal locations. Goals can be specified with position coordinates, or with language commands by using a semantic GSplat. We demonstrate improved safety compared to point cloud-based methods in extensive simulation experiments. In a total of 126 hardware flights, we demonstrate equivalent safety and speed compared to motion capture and visual odometry, but without a manual frame alignment required by those methods. We show online re-planning at more than 2 Hz and pose estimation at about 25 Hz, an order of magnitude faster than Neural Radiance Field (NeRF)-based navigation methods, thereby enabling real-time navigation. We provide experiment videos on our project page at https://chengine.github.io/splatnav/. Our codebase and ROS nodes can be found at https://github.com/chengine/splatnav.
我们提出了Splat-Nav,这是一个针对高斯Splatting(GSplat)场景的实时机器人导航流程。GSplat是一种强大的新型三维场景表示方法。Splat-Nav包含两个组件:1)Splat-Plan,一个安全规划模块;以及2)Splat-Loc,一个稳健的基于视觉的姿态估计模块。Splat-Plan通过构建安全的地图走廊来实现轨迹规划,并利用严格的数学碰撞约束来确定路径,然后通过此走廊构建贝塞尔曲线轨迹。Splat-Loc通过板载摄像头的RGB图像提供实时递归状态估计,并利用GSplat场景中的点云表示法来实现功能。这两个模块协同工作,使机器人能够重新规划平滑且安全的轨迹到达目标位置。目标可以通过位置坐标来指定,也可以通过使用语义GSplat语言命令来指定。我们在广泛的模拟实验中证明了与基于点云的方法相比的改进安全性。在总共的126次硬件飞行中,我们证明了与动作捕捉和视觉里程计相当的安全性和速度,但无需这些方法所需的手动帧对齐。我们展示了超过每秒两帧的在线重新规划速度和大约每秒25帧的姿态估计速度,比基于神经辐射场(NeRF)的导航方法快一个数量级,从而实现实时导航功能。关于我们的实验视频项目,请访问https://chengine.github.io/splatnav/。我们的代码库和ROS节点可以在https://github.com/chengine/splatnav找到。
论文及项目相关链接
Summary
高斯Splatting(GSplat)场景下的实时机器人导航流水线Splat-Nav包含两个组件:安全规划模块Splat-Plan和基于视觉的姿态估计模块Splat-Loc。Splat-Nav在地图中构建了一个基于数学严谨碰撞约束的多边形走廊,并在此基础上规划了一条贝塞尔曲线轨迹。Splat-Loc利用仅来自车载摄像头的RGB馈送信息,提供了实时递归状态估计。两个模块共同赋予机器人递归规划平滑安全轨迹的能力,以实现向目标位置的导航。在模拟实验中展示了与点云方法相比的安全性能提升,在硬件飞行测试中证明了等效的安全性和速度。在线规划速度超过每秒两帧,姿态估计速度约每秒二十五帧,比基于NeRF的导航方法快一个数量级,从而实现实时导航。相关实验视频和项目页面可在相应链接找到。
Key Takeaways
- Splat-Nav是专为高斯Splatting(GSplat)场景设计的实时机器人导航流水线。
- 包含两个核心组件:安全规划模块Splat-Plan和基于视觉的姿态估计模块Splat-Loc。
- Splat-Plan通过构建多边形走廊和贝塞尔曲线轨迹,实现安全导航。
- Splat-Loc利用RGB摄像头数据进行实时递归状态估计。
- 在模拟和硬件测试中,展示了相较于其他方法的提升,包括安全性和速度。
- 在线规划速度和姿态估计速度远超NeRF导航方法,实现实时导航。
点此查看论文截图