⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-16 更新
Loudspeaker Beamforming to Enhance Speech Recognition Performance of Voice Driven Applications
Authors:Dimme de Groot, Baturalp Karslioglu, Odette Scharenborg, Jorge Martinez
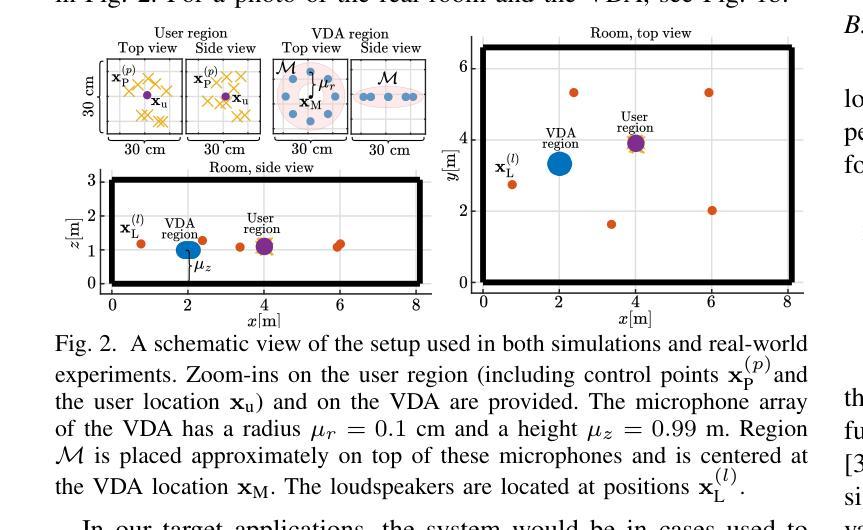
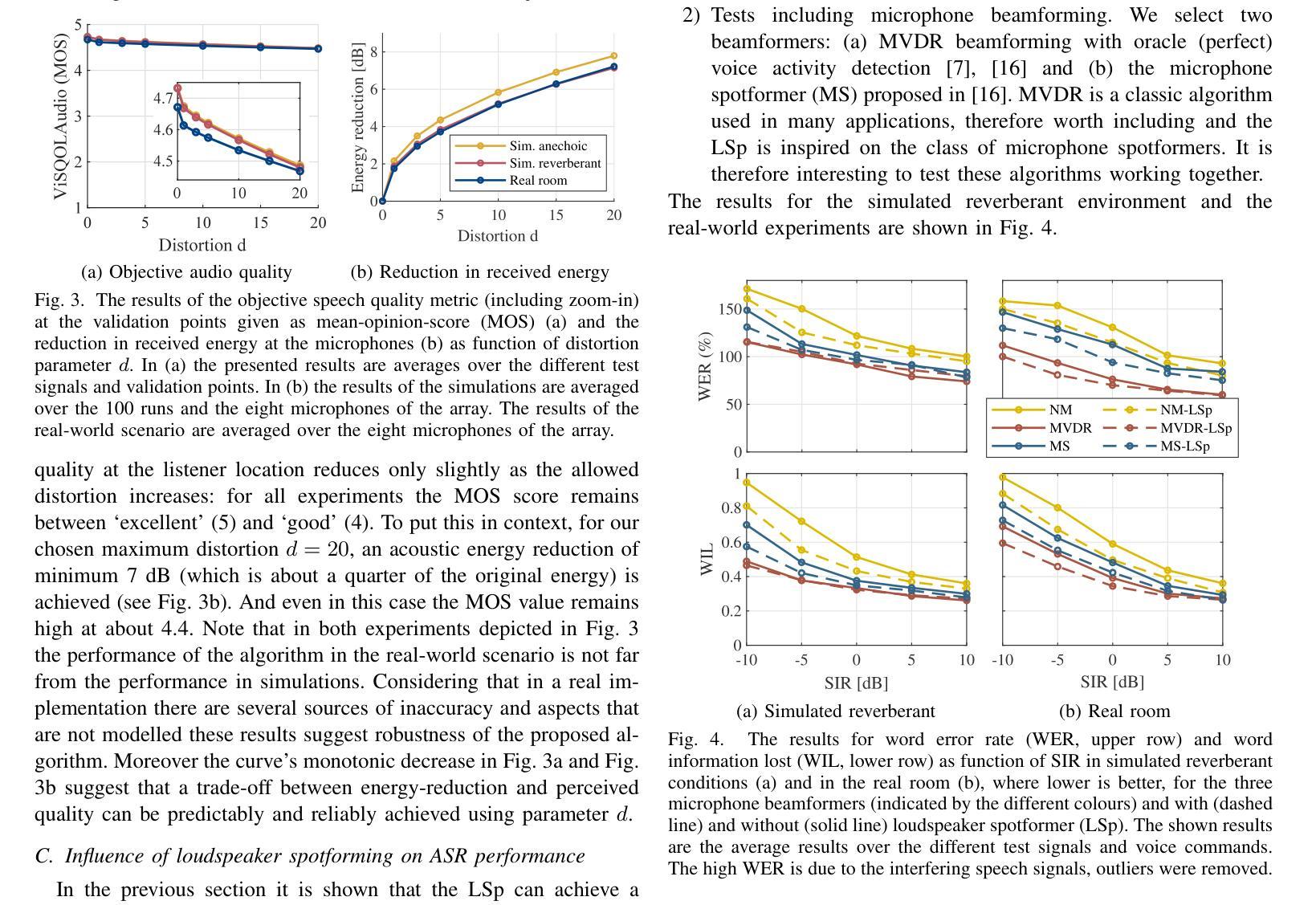
In this paper we propose a robust loudspeaker beamforming algorithm which is used to enhance the performance of voice driven applications in scenarios where the loudspeakers introduce the majority of the noise, e.g. when music is playing loudly. The loudspeaker beamformer modifies the loudspeaker playback signals to create a low-acoustic-energy region around the device that implements automatic speech recognition for a voice driven application (VDA). The algorithm utilises a distortion measure based on human auditory perception to limit the distortion perceived by human listeners. Simulations and real-world experiments show that the proposed loudspeaker beamformer improves the speech recognition performance in all tested scenarios. Moreover, the algorithm allows to further reduce the acoustic energy around the VDA device at the expense of reduced objective audio quality at the listener’s location.
在这篇论文中,我们提出了一种稳健的扬声器波束形成算法,用于提高在扬声器产生大部分噪音的场景中语音驱动应用的性能,例如在播放大声音乐时。扬声器波束形成器修改扬声器播放信号,以在设备周围创建一个低声学能量区域,从而实现语音驱动应用(VDA)的自动语音识别。该算法利用基于人类听觉感知的失真度量来限制人类听众感知到的失真。模拟和真实世界的实验表明,所提出的扬声器波束形成器在所有测试场景中提高了语音识别性能。此外,该算法允许在牺牲听众位置的客观音频质量的情况下,进一步减少VDA设备周围的声学能量。
论文及项目相关链接
PDF To appear at ICASSP 2025
Summary
本文提出了一种稳健的扬声器波束成形算法,用于提升在特定场景(如音乐播放等环境噪声主要来源于扬声器)下语音驱动应用的性能。该波束成形器通过修改扬声器播放信号,在设备周围创建一个低声能区域,用于自动语音识别。算法基于人类听觉感知的失真度量来限制人类听众感知到的失真。模拟和真实实验表明,所提出的扬声器波束成形器在所有测试场景中提高了语音识别性能。此外,该算法允许进一步降低VDA设备周围的声能,但可能会牺牲听众位置的客观音频质量。
Key Takeaways
- 论文提出了一种针对扬声器的波束成形算法,旨在提高语音驱动应用在有噪声场景中的性能。
- 该算法通过修改扬声器播放信号,在设备周围形成低声能区域,有助于自动语音识别。
- 算法考虑了人类听觉感知的失真度量,以限制听众感知到的失真。
- 模拟和真实实验表明,此算法提高了所有测试场景中的语音识别性能。
- 该算法允许进一步降低设备周围的声能,但可能影响听众位置的音频质量。
- 此算法特别适用于音乐播放等场景,其中扬声器是主要噪声来源。
点此查看论文截图



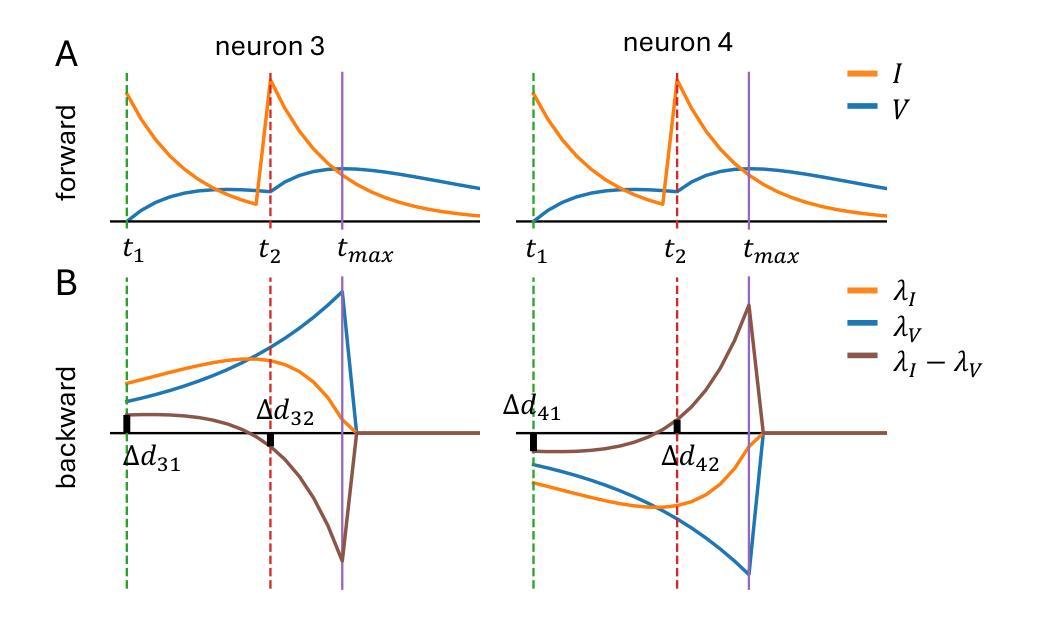
Efficient Event-based Delay Learning in Spiking Neural Networks
Authors:Balázs Mészáros, James C. Knight, Thomas Nowotny
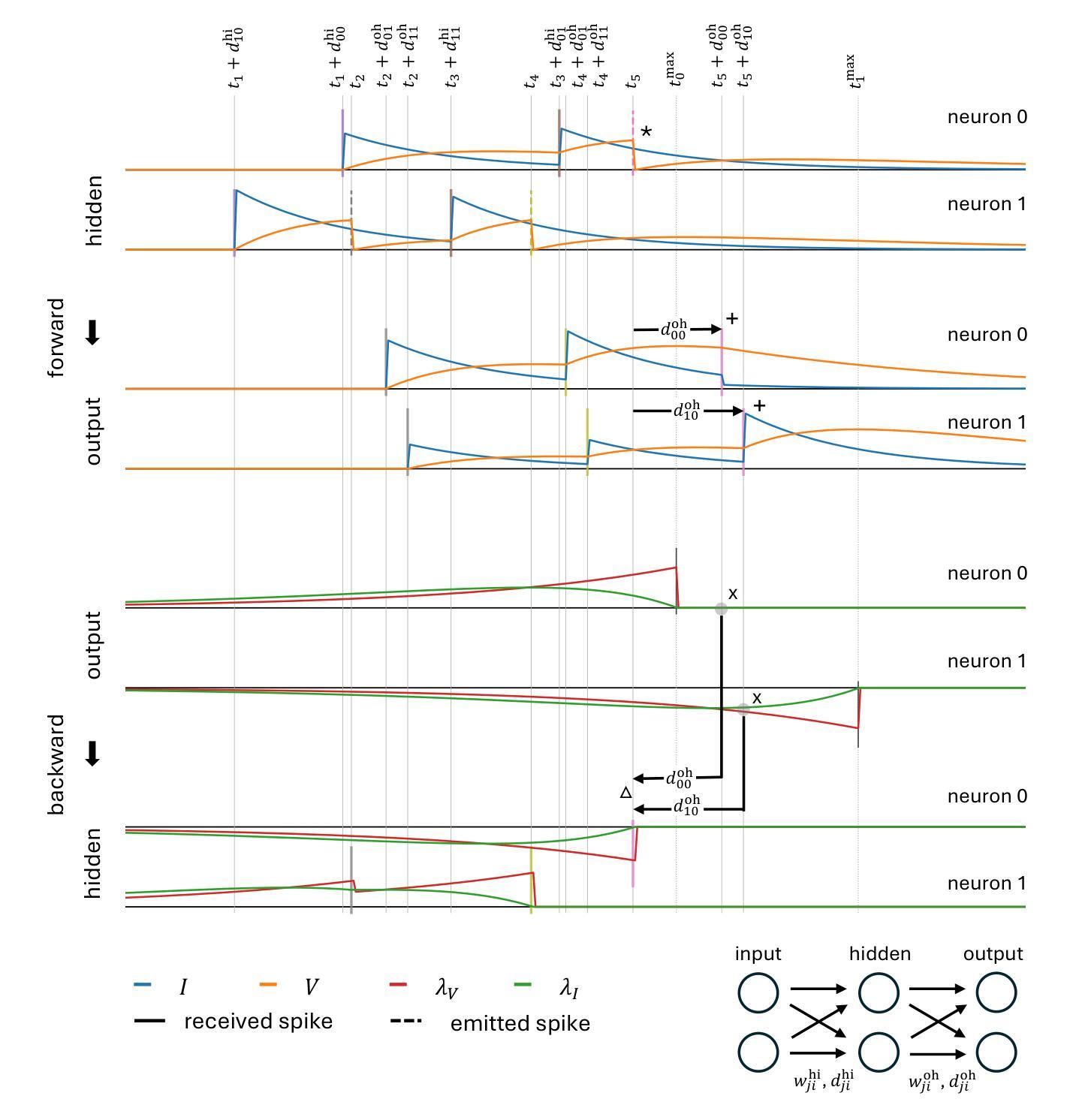
Spiking Neural Networks (SNNs) are attracting increased attention as a more energy-efficient alternative to traditional Artificial Neural Networks. Spiking neurons are stateful and intrinsically recurrent, making them well-suited for spatio-temporal tasks. However, this intrinsic memory is limited by synaptic and membrane time constants. A powerful additional mechanism are delays. In this paper, we propose a novel event-based training method for SNNs with delays, grounded in the EventProp formalism and enabling the calculation of exact gradients with respect to weights and delays. Our method supports multiple spikes per neuron and, to our best knowledge, is the first delay learning method applicable to recurrent connections. We evaluate our method on a simple sequence detection task, and the Yin-Yang, Spiking Heidelberg Digits and Spiking Speech Commands datasets, demonstrating that our algorithm can optimize delays from suboptimal initial conditions and enhance classification accuracy compared to architectures without delays. Finally, we show that our approach uses less than half the memory of the current state-of-the-art delay-learning method and is up to 26x faster.
脉冲神经网络(Spiking Neural Networks,简称SNNs)作为传统人工神经网络的一种能效更高的替代方案,正受到越来越多的关注。脉冲神经元具有状态和内在复现性,使其非常适合处理时空任务。然而,这种内在记忆受到突触和膜时间常数的限制。一种强大的附加机制是延迟。在本文中,我们提出了一种基于事件的新型脉冲神经网络延迟训练法,该方法以EventProp形式为基础,能够计算关于权重和延迟的确切梯度。我们的方法支持每个神经元的多次脉冲,据我们所知,这是首个适用于复现连接的延迟学习方法。我们在简单的序列检测任务以及阴阳、脉冲海德堡数字和脉冲语音命令数据集上评估了我们的方法,结果表明,我们的算法可以从次优初始条件优化延迟,并在分类准确性方面超过了没有延迟的架构。最后,我们还表明,我们的方法使用的内存不到当前最先进的延迟学习方法的一半,并且速度最快可达其26倍。
论文及项目相关链接
摘要
神经网络采用脉冲活动能节省能耗。脉冲神经元具备状态和时空递归属性,但其有限时间常数使得存储能力不足。对此不足的问题引入了延迟机制作为脉冲神经网络(SNNs)的一种强大补充。本文提出一种基于事件训练脉冲神经网络的新方法,以EventProp为理论基础,能够精确计算权重和延迟的梯度。该方法支持神经元多重脉冲,且是首个适用于递归连接的延迟学习方法。通过简单序列检测任务以及Yin-Yang、Spiking Heidelberg Digits和Spiking Speech Commands数据集进行验证,证明了该方法可以从不理想的初始条件优化延迟并提高分类精度,同时降低了当前最佳方法的内存消耗并提高了运行速度。
关键见解
- 脉冲神经网络(SNNs)作为传统人工神经网络节能的替代方案正受到广泛关注。
- 脉冲神经元具备状态和时空递归属性,但存在存储能力不足的问题。
- 为解决存储能力不足的问题引入了延迟机制作为补充。
- 提出一种基于事件训练脉冲神经网络的新方法,该方法能够精确计算权重和延迟的梯度并支持神经元多重脉冲。
- 此方法是首个适用于递归连接的延迟学习方法。
点此查看论文截图

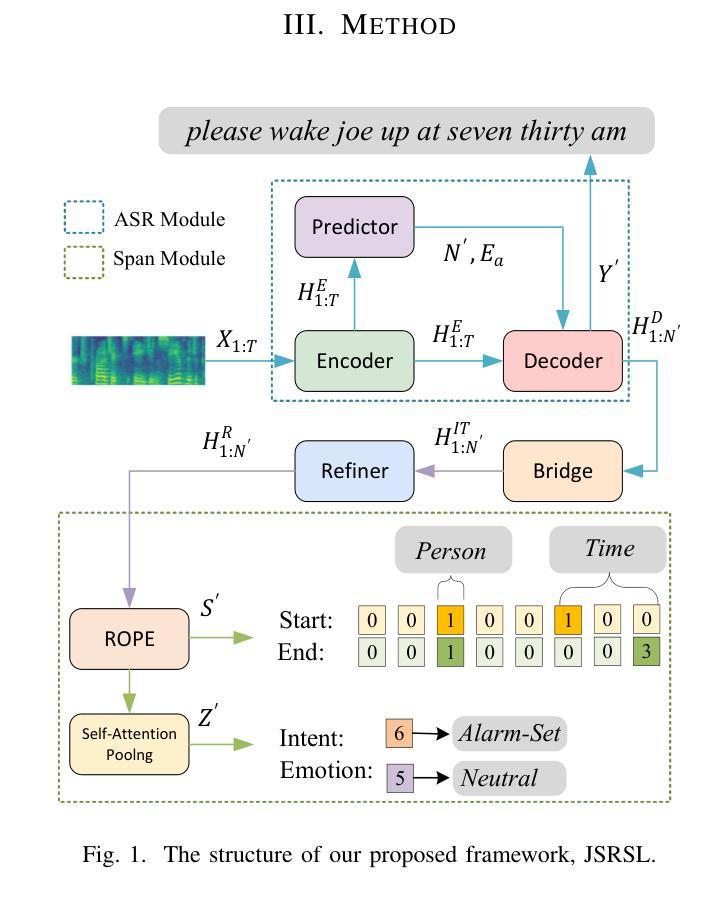
Joint Automatic Speech Recognition And Structure Learning For Better Speech Understanding
Authors:Jiliang Hu, Zuchao Li, Mengjia Shen, Haojun Ai, Sheng Li, Jun Zhang
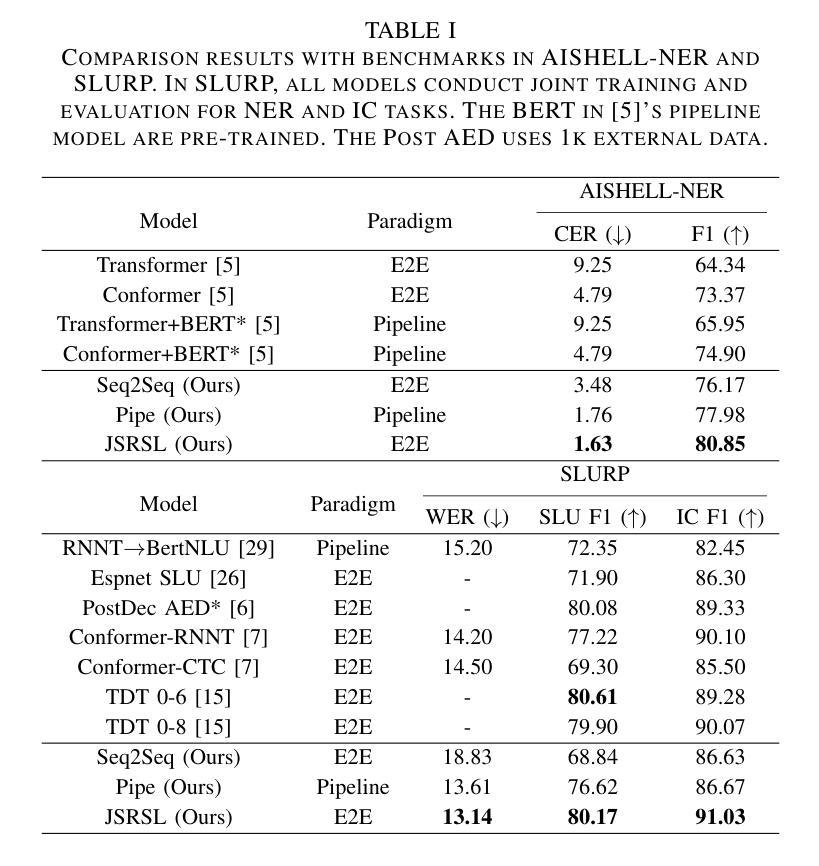
Spoken language understanding (SLU) is a structure prediction task in the field of speech. Recently, many works on SLU that treat it as a sequence-to-sequence task have achieved great success. However, This method is not suitable for simultaneous speech recognition and understanding. In this paper, we propose a joint speech recognition and structure learning framework (JSRSL), an end-to-end SLU model based on span, which can accurately transcribe speech and extract structured content simultaneously. We conduct experiments on name entity recognition and intent classification using the Chinese dataset AISHELL-NER and the English dataset SLURP. The results show that our proposed method not only outperforms the traditional sequence-to-sequence method in both transcription and extraction capabilities but also achieves state-of-the-art performance on the two datasets.
语音语言理解(SLU)是语音领域的一种结构预测任务。最近,将SLU视为序列到序列任务的许多工作都取得了巨大的成功。然而,这种方法不适用于同步语音识别和理解。在本文中,我们提出了一个联合语音识别和结构学习框架(JSRSL),这是一个基于范围的端到端SLU模型,可以同时准确转录语音并提取结构内容。我们使用AISHELL-NER中文数据集和SLURP英文数据集进行命名实体识别和意图分类实验。结果表明,我们提出的方法不仅在转录和提取能力上优于传统的序列到序列方法,而且在两个数据集上实现了最新性能。
论文及项目相关链接
PDF 5 pages, 2 figures, accepted by ICASSP 2025
Summary:
本文提出了一种联合语音识别与结构学习框架(JSRSL),该框架是一种基于跨度的端到端SLU模型,能同时准确转录语音并提取结构化内容。实验表明,与传统序列到序列方法相比,该方法在转录和提取能力方面表现更优秀,同时在中文数据集AISHELL-NER和英文数据集SLURP上取得了最新技术性能。
Key Takeaways:
- SLU被视为序列到序列任务并已有许多成功实践。
- 传统序列到序列方法不适用于同时语音识别的理解。
- 提出了一种联合语音识别与结构学习框架(JSRSL)。
- JSRSL是一个基于跨度的端到端SLU模型,可同时准确转录语音和提取结构化内容。
- 在中文数据集AISHELL-NER和英文数据集SLURP上进行了实验验证。
- JSRSL在转录和提取能力上超越了传统序列到序列方法。
- JSRSL取得了最新技术性能。
点此查看论文截图


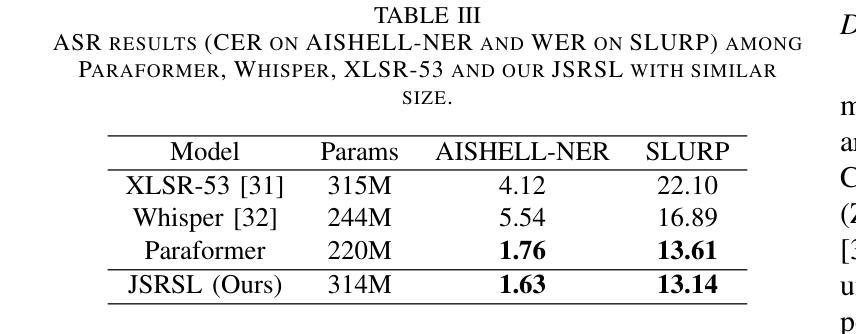
AdaCS: Adaptive Normalization for Enhanced Code-Switching ASR
Authors:The Chuong Chu, Vu Tuan Dat Pham, Kien Dao, Hoang Nguyen, Quoc Hung Truong
Intra-sentential code-switching (CS) refers to the alternation between languages that happens within a single utterance and is a significant challenge for Automatic Speech Recognition (ASR) systems. For example, when a Vietnamese speaker uses foreign proper names or specialized terms within their speech. ASR systems often struggle to accurately transcribe intra-sentential CS due to their training on monolingual data and the unpredictable nature of CS. This issue is even more pronounced for low-resource languages, where limited data availability hinders the development of robust models. In this study, we propose AdaCS, a normalization model integrates an adaptive bias attention module (BAM) into encoder-decoder network. This novel approach provides a robust solution to CS ASR in unseen domains, thereby significantly enhancing our contribution to the field. By utilizing BAM to both identify and normalize CS phrases, AdaCS enhances its adaptive capabilities with a biased list of words provided during inference. Our method demonstrates impressive performance and the ability to handle unseen CS phrases across various domains. Experiments show that AdaCS outperforms previous state-of-the-art method on Vietnamese CS ASR normalization by considerable WER reduction of 56.2% and 36.8% on the two proposed test sets.
句子内语言切换(CS)是指在单个发言中发生的两种语言之间的交替切换,对自动语音识别(ASR)系统来说是一个重大挑战。例如,当越南语说话者在他们的演讲中使用外语专有名词或专业术语时。由于ASR系统的训练是基于单语言数据以及CS的不可预测性,因此它们经常难以准确转录句子内的CS。对于资源贫乏的语言,这个问题更为突出,有限的可用数据阻碍了稳健模型的发展。在这项研究中,我们提出了AdaCS,这是一种结合自适应偏见注意力模块(BAM)的规范化模型,并将其集成到编码器-解码器网络中。这种新颖的方法为未知域的CS ASR提供了稳健的解决方案,从而极大地增强了我们对该领域的贡献。通过利用BAM来识别和规范化CS短语,AdaCS在推理过程中通过提供的单词列表增强了其自适应能力。我们的方法展示了令人印象深刻的表现,并具备处理各种领域中的未见CS短语的能力。实验表明,AdaCS在越南语CS ASR规范化方面优于以前的最先进方法,在两个建议的测试集上的WER分别降低了56.2%和36.8%。
论文及项目相关链接
PDF Accepted at ICASSP 2025
Summary
文中讨论了跨语料的语内混合转换(CS)问题对自动语音识别(ASR)系统的挑战,特别是在越南语使用者使用外语专有名词或专业术语的情况下。现有的ASR系统由于只训练在单语言数据上,无法准确转录这种不可预测的语内混合转换。对于资源匮乏的语言,这个问题更为突出。本文提出了一个集成自适应偏差注意模块(BAM)的标准化模型AdaCS来解决这一问题。通过利用BAM来识别和标准化CS短语,AdaCS在未见过的领域提供了稳健的解决方案,显著增强了处理不同领域未见CS短语的能力。实验表明,AdaCS在越南语CS ASR标准化方面优于以前的最先进方法,在提出的两个测试集上分别实现了可观的词错误率(WER)降低56.2%和36.8%。
Key Takeaways
- 语内代码转换(CS)指的是在同一句话内使用多种语言的情况,这对自动语音识别(ASR)系统是一个重大挑战。
- ASR系统在处理越南语中夹杂外语专有名词或专业术语时尤其难以准确转录。
- 现有的ASR系统主要基于单语言数据进行训练,无法有效处理这种不可预测的语内代码转换。
- 对于资源有限的语言(如越南语),开发稳健的ASR模型更加困难。
- AdaCS是一个新的标准化模型,它通过集成自适应偏差注意模块(BAM)来解决这个问题。
- BAM模块能够识别和标准化CS短语,使得AdaCS在未见过的领域表现出强大的稳健性。
点此查看论文截图



Improving Cross-Lingual Phonetic Representation of Low-Resource Languages Through Language Similarity Analysis
Authors:Minu Kim, Kangwook Jang, Hoirin Kim
This paper examines how linguistic similarity affects cross-lingual phonetic representation in speech processing for low-resource languages, emphasizing effective source language selection. Previous cross-lingual research has used various source languages to enhance performance for the target low-resource language without thorough consideration of selection. Our study stands out by providing an in-depth analysis of language selection, supported by a practical approach to assess phonetic proximity among multiple language families. We investigate how within-family similarity impacts performance in multilingual training, which aids in understanding language dynamics. We also evaluate the effect of using phonologically similar languages, regardless of family. For the phoneme recognition task, utilizing phonologically similar languages consistently achieves a relative improvement of 55.6% over monolingual training, even surpassing the performance of a large-scale self-supervised learning model. Multilingual training within the same language family demonstrates that higher phonological similarity enhances performance, while lower similarity results in degraded performance compared to monolingual training.
本文探讨了语言相似性如何影响低资源语言的跨语言语音表示中的语音识别处理。文章强调了有效的源语言选择。之前的跨语言研究使用了各种源语言来提高目标低资源语言的性能,但没有深入考虑语言的选择问题。我们的研究通过提供对语言选择的深入分析而脱颖而出,辅以评估多个语言家族之间语音相似度的实用方法。我们研究了家族内相似性对多语言训练性能的影响,这有助于理解语言动态。我们还评估了使用语音相似度较高的语言的影响,不论其属于哪个家族。对于音位识别任务,使用语音相似度高的语言进行训练,其性能相较于单语训练提高了55.6%,甚至超过了大规模自监督学习模型的性能。在同一语言家族中进行的多语言训练表明,更高的语音相似性可以提高性能,而较低的相似性则可能导致性能下降,相较于单语训练表现较差。
论文及项目相关链接
PDF 10 pages, 5 figures, accepted to ICASSP 2025
摘要
本文研究了语言相似性对低资源语言跨语言语音特征表示的影响,并着重于有效的源语言选择。以往的跨语言研究使用各种源语言来提高目标低资源语言的性能,但没有充分考虑语言选择问题。本研究通过深入分析语言选择,支持评估多种语言家族之间语音相似性的实用方法,突出了独特性。我们调查了家族内相似性对多语言训练性能的影响,这有助于理解语言动态。我们还评估了使用语音相似的语言(无论家族如何)的效果。在语音特征识别任务中,使用语音相似的语言相较于单语训练可以实现相对提高55.6%的性能,甚至超过大规模自监督学习模型的性能。在同一语言家族内进行的多语言训练表明,较高的语音相似性可以提高性能,而较低的相似性则可能导致性能下降,与单语训练相比。
关键见解
- 跨语言研究中,源语言的选择对于提高低资源语言的性能至关重要。
- 深入研究语言选择问题有其独特性,有助于理解不同语言间的动态关系。
- 在多语言训练中,同一语言家族内的语音相似性对性能有重要影响。
- 使用语音相似的语言进行训练可以显著提高语音特征识别的性能。
- 与单语训练相比,使用语音相似的语言可以提高性能高达55.6%。
- 在评估不同语言的语音相似性时,实用评估方法具有重要的研究价值。
点此查看论文截图

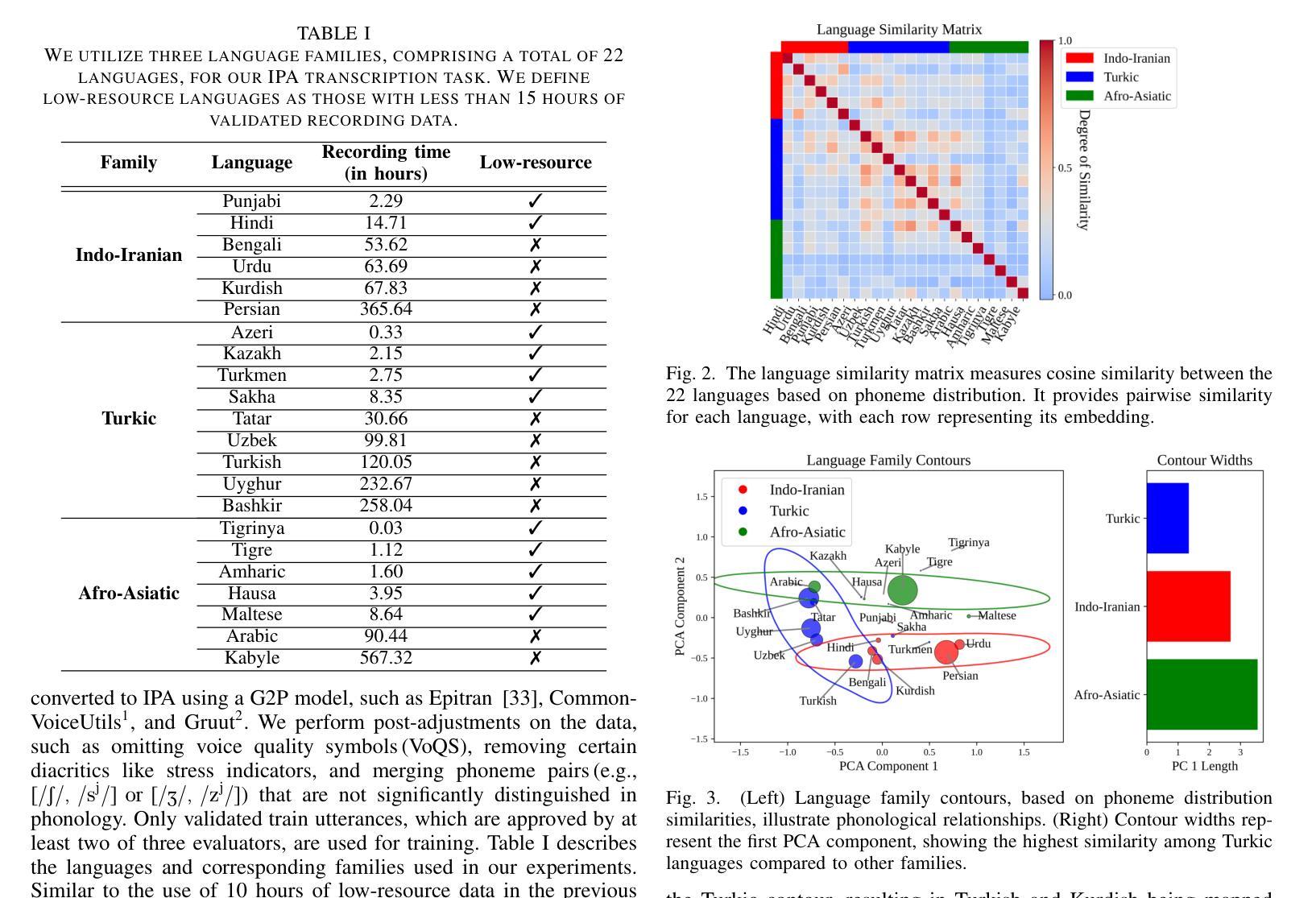
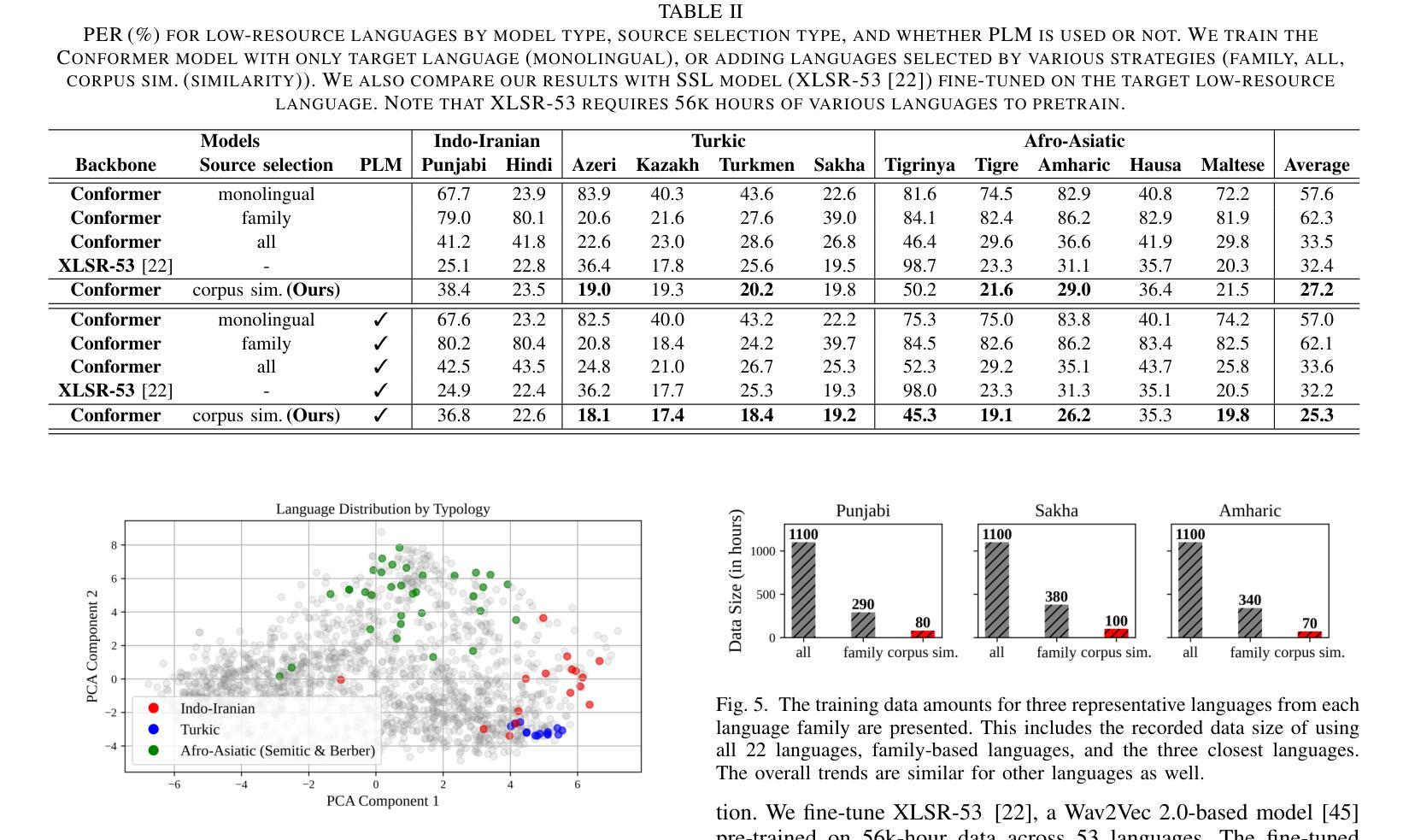
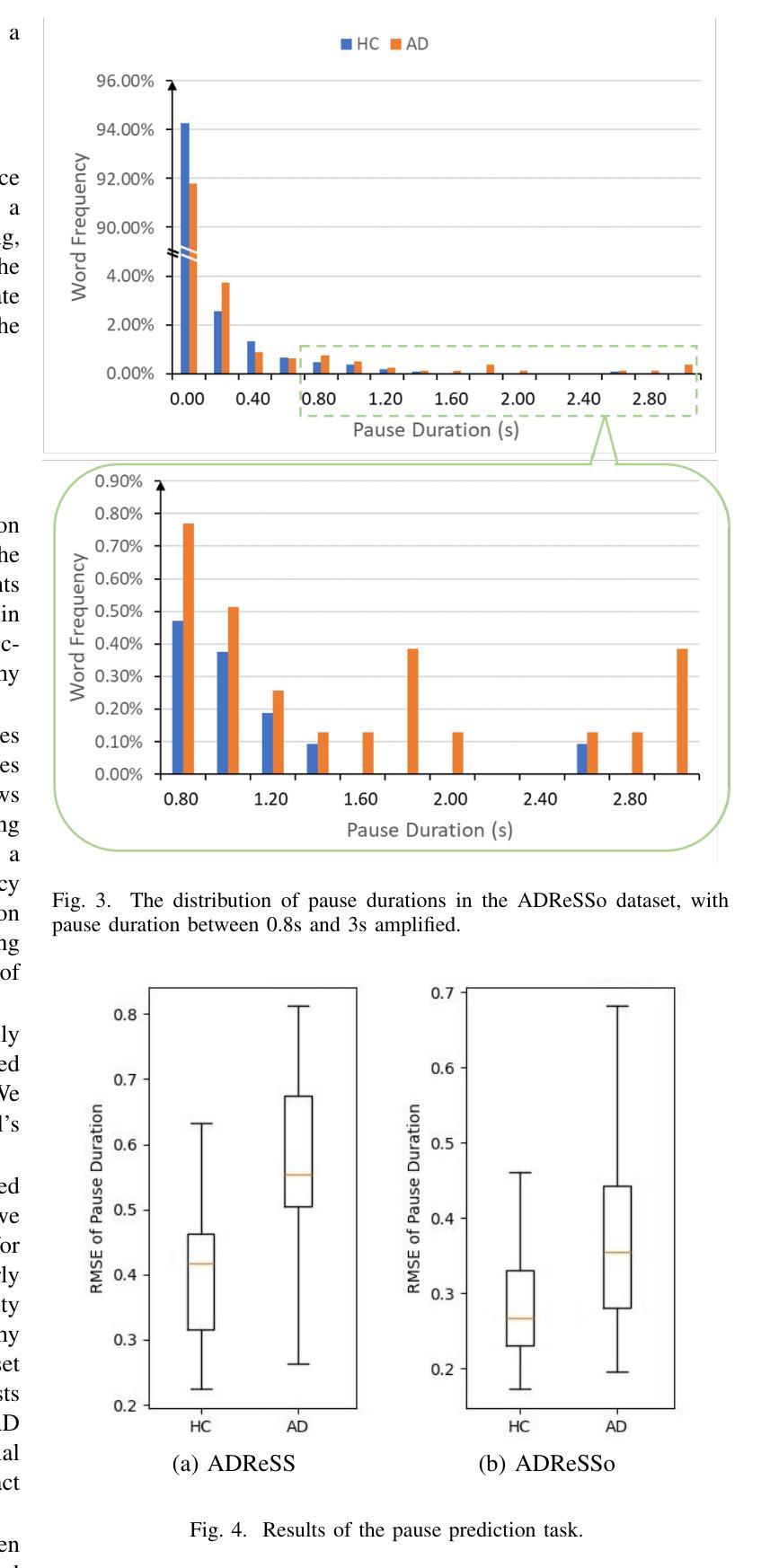
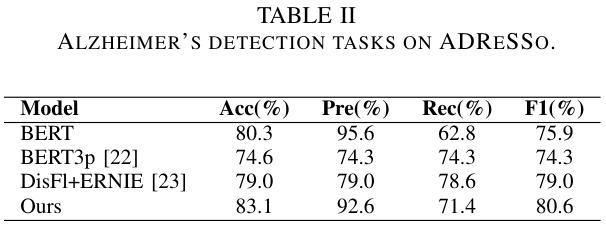
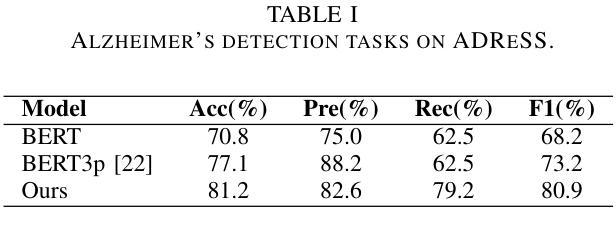
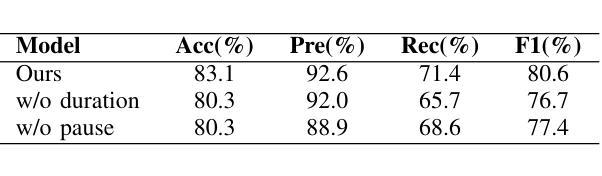
Integrating Pause Information with Word Embeddings in Language Models for Alzheimer’s Disease Detection from Spontaneous Speech
Authors:Yu Pu, Wei-Qiang Zhang
Alzheimer’s disease (AD) is a progressive neurodegenerative disorder characterized by cognitive decline and memory loss. Early detection of AD is crucial for effective intervention and treatment. In this paper, we propose a novel approach to AD detection from spontaneous speech, which incorporates pause information into language models. Our method involves encoding pause information into embeddings and integrating them into the typical transformer-based language model, enabling it to capture both semantic and temporal features of speech data. We conduct experiments on the Alzheimer’s Dementia Recognition through Spontaneous Speech (ADReSS) dataset and its extension, the ADReSSo dataset, comparing our method with existing approaches. Our method achieves an accuracy of 83.1% in the ADReSSo test set. The results demonstrate the effectiveness of our approach in discriminating between AD patients and healthy individuals, highlighting the potential of pauses as a valuable indicator for AD detection. By leveraging speech analysis as a non-invasive and cost-effective tool for AD detection, our research contributes to early diagnosis and improved management of this debilitating disease.
阿尔茨海默病(AD)是一种进行性神经退行性疾病,以认知衰退和记忆丧失为特征。早期发现AD对于有效干预和治疗至关重要。在本文中,我们提出了一种利用自发语言进行AD检测的新方法,该方法将停顿信息融入语言模型。我们的方法是将停顿信息编码为嵌入形式,并将其整合到典型的基于转换器的语言模型中,使其能够捕捉语音数据的语义和时间特征。我们在阿尔茨海默氏症痴呆症通过自发语言识别(ADReSS)数据集及其扩展数据集ADReSSo上进行了实验,将我们的方法与现有方法进行了比较。我们的方法在ADReSSo测试集上达到了83.1%的准确率。结果表明,我们的方法在区分AD患者和健康人群方面的有效性,强调停顿作为AD检测的重要指标的潜力。通过利用语音分析作为非侵入性和成本效益高的AD检测工具,我们的研究为这种疾病的早期诊断和治疗管理做出了贡献。
论文及项目相关链接
PDF accepted by ICASSP2025. Copyright 2025 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component
Summary
本文提出了一种结合停顿信息检测阿尔茨海默病(AD)的新方法。该方法将停顿信息编码为嵌入,并集成到基于变压器的语言模型中,使其能够捕捉语音数据的语义和时间特征。在阿尔茨海默症痴呆通过自发性言语识别(ADReSS)数据集及其扩展数据集ADReSSo上的实验表明,该方法在AD检测方面取得了83.1%的准确率。研究结果表明,停顿可能是检测AD的重要指标之一,而利用语音分析作为非侵入性和成本效益高的工具进行AD检测有助于早期诊断和治疗管理。
Key Takeaways
- 阿尔茨海默病(AD)是一种进行性神经退行性疾病,早期检测对有效干预和治疗至关重要。
- 本研究提出了一种结合停顿信息的AD检测方法,将其集成到基于变压器的语言模型中。
- 该方法能够捕捉语音数据的语义和时间特征。
- 在ADReSS和ADReSSo数据集上的实验结果表明,该方法在检测AD方面取得了显著成果,准确率为83.1%。
- 停顿信息作为检测AD的重要指标之一。
- 语音分析作为非侵入性和成本效益高的工具,有助于AD的早期诊断和治疗管理。
点此查看论文截图

Discrete Speech Unit Extraction via Independent Component Analysis
Authors:Tomohiko Nakamura, Kwanghee Choi, Keigo Hojo, Yoshiaki Bando, Satoru Fukayama, Shinji Watanabe
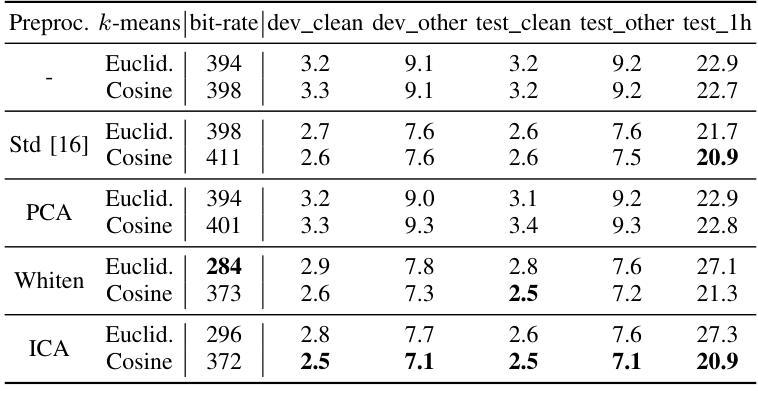
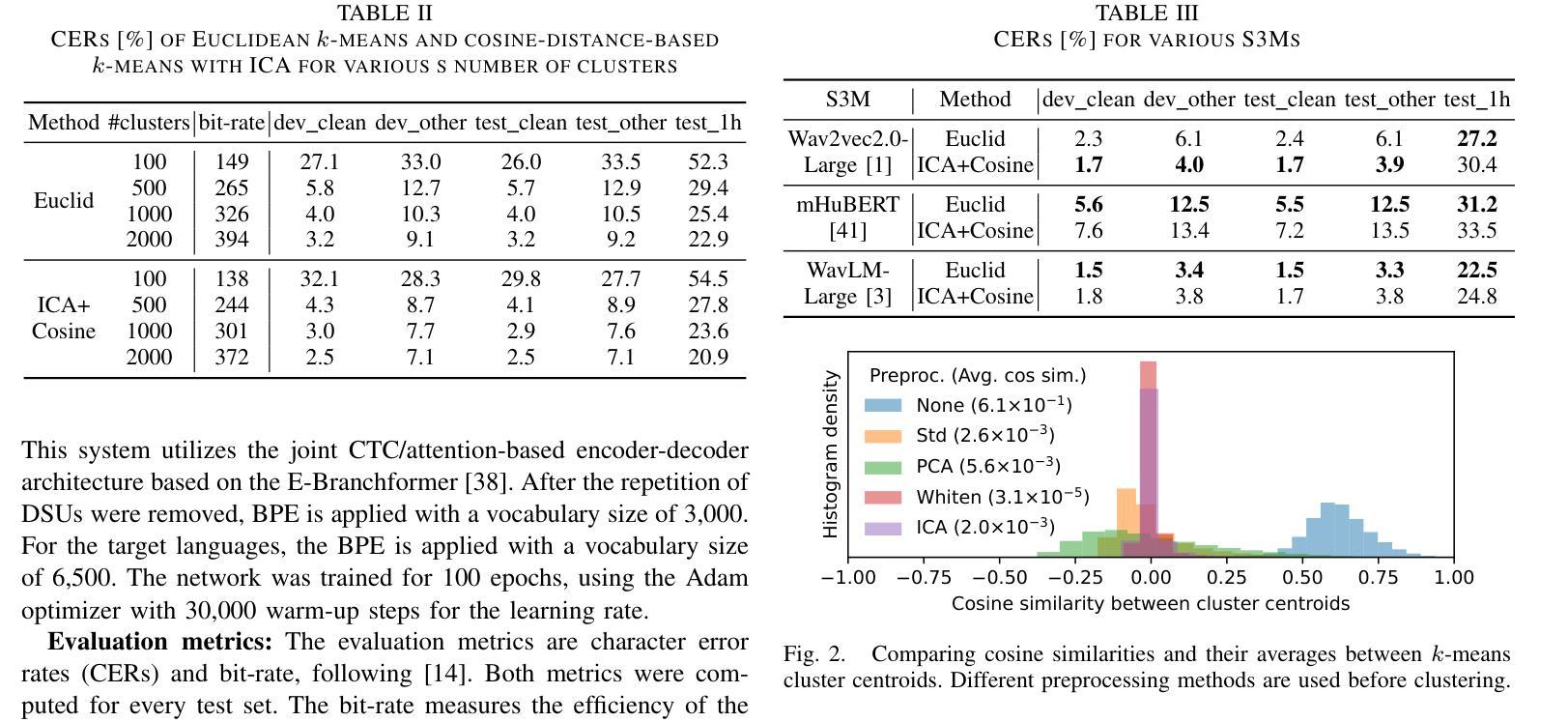
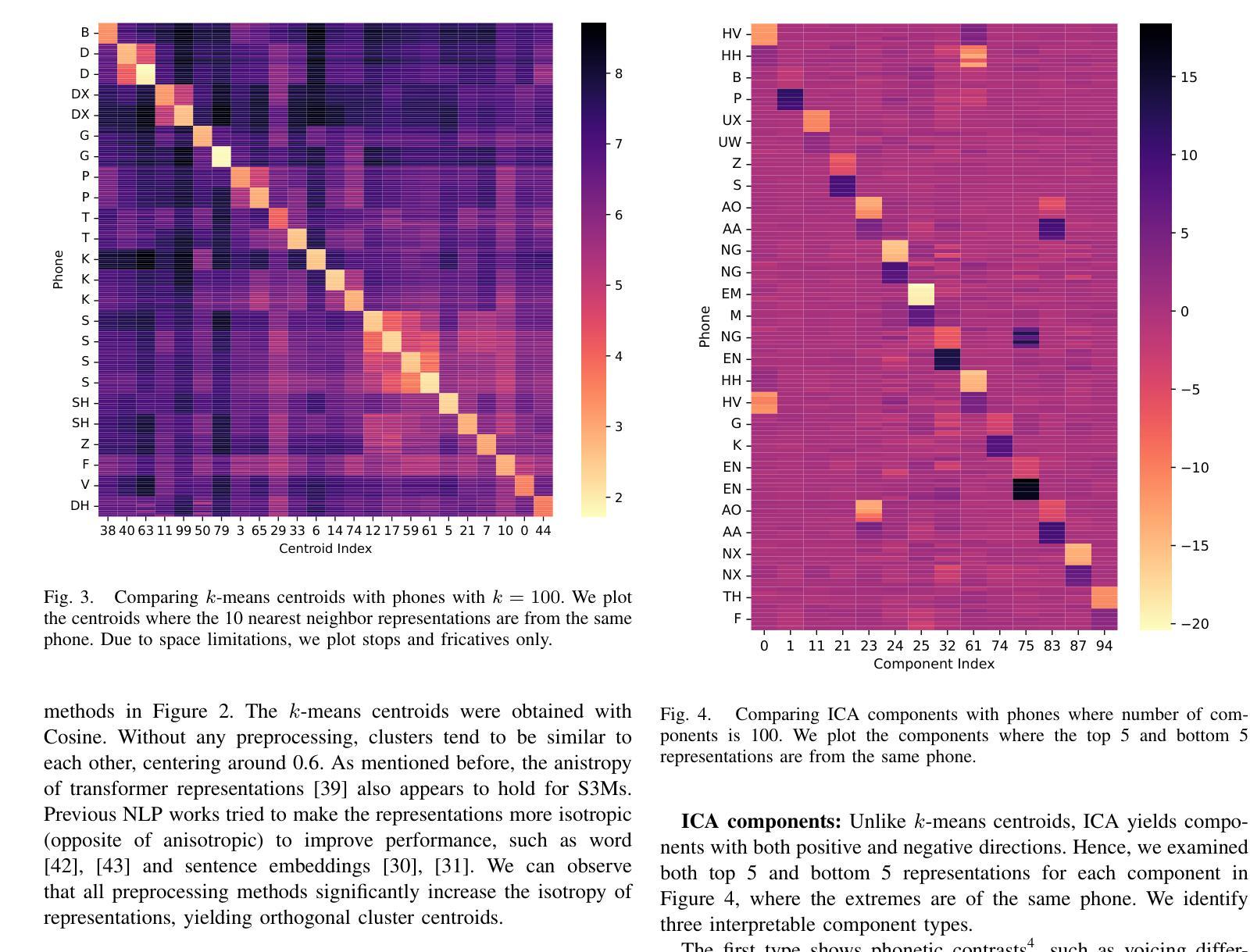
Self-supervised speech models (S3Ms) have become a common tool for the speech processing community, leveraging representations for downstream tasks. Clustering S3M representations yields discrete speech units (DSUs), which serve as compact representations for speech signals. DSUs are typically obtained by k-means clustering. Using DSUs often leads to strong performance in various tasks, including automatic speech recognition (ASR). However, even with the high dimensionality and redundancy of S3M representations, preprocessing S3M representations for better clustering remains unexplored, even though it can affect the quality of DSUs. In this paper, we investigate the potential of linear preprocessing methods for extracting DSUs. We evaluate standardization, principal component analysis, whitening, and independent component analysis (ICA) on DSU-based ASR benchmarks and demonstrate their effectiveness as preprocessing for k-means. We also conduct extensive analyses of their behavior, such as orthogonality or interpretability of individual components of ICA.
自监督语音模型(S3M)已成为语音处理领域的常用工具,用于为下游任务提供表征。通过对S3M表征进行聚类可以得到离散语音单元(DSU),它们可以作为语音信号的紧凑表征。DSU通常是通过K-means聚类获得的。使用DSU往往可以在各种任务中取得出色的性能,包括自动语音识别(ASR)。然而,尽管S3M表征具有高度的维度和冗余性,但对其进行预处理以更好地聚类仍尚未得到探索,而这可能会影响DSU的质量。在本文中,我们研究了线性预处理提取DSU的潜力。我们对标准化、主成分分析、白化以及独立成分分析(ICA)在基于DSU的ASR基准测试上进行了评估,证明了它们作为K-means预处理的有效性。我们还对其行为进行了广泛的分析,例如ICA各个组件的正交性或可解释性。
论文及项目相关链接
PDF Accepted to ICASSP 2025 SALMA Workshop. Code available at https://github.com/TomohikoNakamura/ica_dsu_espnet
Summary
本文探讨了自我监督语音模型(S3M)表示中的离散语音单元(DSU)的生成过程。通过对S3M表示进行聚类得到DSU,其在语音识别等任务中有良好表现。但当前对S3M表示进行预处理以改进聚类质量的研究仍然不足。本文尝试使用线性预处理方法来提取DSU,并对标准化、主成分分析、白化以及独立成分分析等方法进行了评估,证明了它们在k-means预处理中的有效性。同时,本文还对这些方法的行为进行了深入的分析。
Key Takeaways
- 自我监督语音模型(S3M)已成为语音处理社区中常见的工具,用于为下游任务提供表示。
- 通过聚类S3M表示得到离散语音单元(DSU),作为语音信号的紧凑表示。
- DSU在各种任务中表现出强大的性能,包括语音识别(ASR)。
- 尽管S3M表示具有高维度和冗余性,但对其进行预处理以改进聚类的研究尚未得到探索。
- 本文研究了线性预处理方法的潜力,用于提取DSU,包括标准化、主成分分析、白化和独立成分分析(ICA)。
- 评估这些方法在DSU基础上的ASR基准测试上表现出预处理的有效性。
点此查看论文截图

Multi-modal Speech Enhancement with Limited Electromyography Channels
Authors:Fuyuan Feng, Longting Xu, Rohan Kumar Das
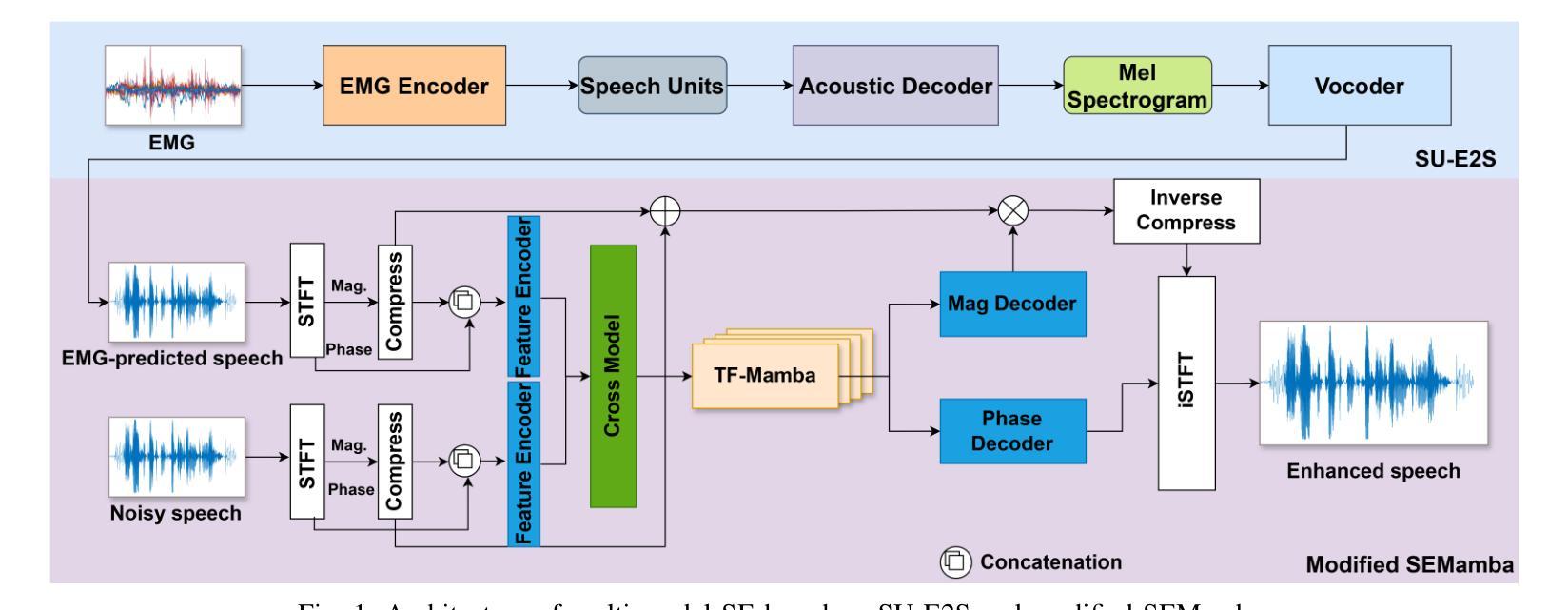
Speech enhancement (SE) aims to improve the clarity, intelligibility, and quality of speech signals for various speech enabled applications. However, air-conducted (AC) speech is highly susceptible to ambient noise, particularly in low signal-to-noise ratio (SNR) and non-stationary noise environments. Incorporating multi-modal information has shown promise in enhancing speech in such challenging scenarios. Electromyography (EMG) signals, which capture muscle activity during speech production, offer noise-resistant properties beneficial for SE in adverse conditions. Most previous EMG-based SE methods required 35 EMG channels, limiting their practicality. To address this, we propose a novel method that considers only 8-channel EMG signals with acoustic signals using a modified SEMamba network with added cross-modality modules. Our experiments demonstrate substantial improvements in speech quality and intelligibility over traditional approaches, especially in extremely low SNR settings. Notably, compared to the SE (AC) approach, our method achieves a significant PESQ gain of 0.235 under matched low SNR conditions and 0.527 under mismatched conditions, highlighting its robustness.
语音增强(SE)旨在提高各种语音应用程序的语音信号的清晰度、可懂度和质量。然而,气导语音非常容易受到环境噪声的影响,特别是在低信噪比(SNR)和非平稳噪声环境中。在这种情况下,采用多模态信息增强语音表现出了良好的前景。肌电图(EMG)信号能够捕捉到语音产生过程中的肌肉活动,对于恶劣条件下的语音增强具有抗噪声特性。以前的大多数基于EMG的SE方法需要35个EMG通道,这限制了其实用性。针对这一问题,我们提出了一种仅考虑使用经过修改的SEMamba网络并利用声学信号的8通道EMG信号的新型方法,该方法增加了跨模态模块。我们的实验表明,与传统的语音增强方法相比,我们的方法在语音质量和可懂度方面取得了显著的提升,特别是在极低SNR条件下。值得注意的是,与传统的SE(AC)方法相比,我们的方法在匹配的低SNR条件下实现了显著的PESQ增益为0.235,在失配条件下为0.527,凸显了其稳健性。
论文及项目相关链接
PDF Accepted by ICASSP 2025
Summary
该文探讨语音增强技术在低信噪比和非稳态噪声环境下的挑战,提出一种仅使用8通道肌电图信号和声音信号的改进SEMamba网络方法,显著提高了语音质量和清晰度。相较于传统方法,特别是在极低信噪比环境下,该方法表现更优,显示出其在复杂环境下的稳健性。
Key Takeaways
- 语音增强旨在提高语音信号的清晰度、可懂度和质量。
- 空气传导语音在恶劣环境下容易受到背景噪声干扰。
- 多模态信息融合在挑战场景下增强语音表现良好。
- 肌电图信号捕捉说话时肌肉活动,有助于增强恶劣条件下的语音质量。
- 大多数先前的基于肌电图的语音增强方法需要35个肌电图通道,限制了实用性。
- 提出一种新方法仅使用8通道肌电图信号和声音信号,通过改进SEMamba网络并结合跨模态模块实现语音增强。
点此查看论文截图

Speech Recognition for Automatically Assessing Afrikaans and isiXhosa Preschool Oral Narratives
Authors:Christiaan Jacobs, Annelien Smith, Daleen Klop, Ondřej Klejch, Febe de Wet, Herman Kamper
We develop automatic speech recognition (ASR) systems for stories told by Afrikaans and isiXhosa preschool children. Oral narratives provide a way to assess children’s language development before they learn to read. We consider a range of prior child-speech ASR strategies to determine which is best suited to this unique setting. Using Whisper and only 5 minutes of transcribed in-domain child speech, we find that additional in-domain adult data (adult speech matching the story domain) provides the biggest improvement, especially when coupled with voice conversion. Semi-supervised learning also helps for both languages, while parameter-efficient fine-tuning helps on Afrikaans but not on isiXhosa (which is under-represented in the Whisper model). Few child-speech studies look at non-English data, and even fewer at the preschool ages of 4 and 5. Our work therefore represents a unique validation of a wide range of previous child-speech ASR strategies in an under-explored setting.
我们为讲南非语和科萨语的学龄前儿童的故事开发自动语音识别(ASR)系统。口头叙事为评估儿童的语言发展提供了一种方式,在他们学会阅读之前。我们考虑了一系列先前的儿童语音ASR策略,以确定哪种策略最适合这种独特的场景。使用Whisper语音技术仅转录五分钟特定领域的儿童语音,我们发现额外的特定领域成人数据(与故事领域匹配的成人语音)提供了最大的改进,特别是与语音转换相结合时。半监督学习也有助于这两种语言,而参数高效的微调在南非语上有所帮助,但在科萨语上没有帮助(科萨语在Whisper模型中代表性不足)。很少有儿童语音研究关注非英语数据,甚至在学龄前年龄关注得更少(分别为四到五岁)。因此,我们的工作代表了在一个未被充分研究的场景中,对各种先前儿童语音ASR策略的广泛验证的独特性。
论文及项目相关链接
PDF Accepted to ICASSP 2025
Summary
本文研究了针对南非语和科萨语学龄前儿童讲述故事的自动语音识别(ASR)系统。文章探讨了儿童口语叙事在评估儿童语言发展中的作用,并在此特殊环境下评估了多种儿童语音ASR策略。研究发现,使用Whisper技术并结合仅五分钟领域内的儿童语音转录数据,引入匹配故事领域的成人语音数据能够提供最大改善,尤其在结合语音转换技术时更是如此。半监督学习对两种语言都有帮助,而参数高效的微调在南非语上有所帮助,但在科萨语上没有明显效果(科萨语在Whisper模型中表现不足)。本研究涉及非英语数据和4-5岁学龄前儿童的研究较少,因此,我们的工作代表了在此未充分探索的环境中,对各种先前儿童语音ASR策略的独特验证。
Key Takeaways
- 研究针对南非语和科萨语学龄前儿童讲述故事的自动语音识别(ASR)系统。
- 儿童口语叙事是评估儿童语言发展的重要方式。
- 使用Whisper技术并结合领域内的儿童语音数据,发现引入匹配故事领域的成人语音数据能够显著提高ASR系统的性能。
- 语音转换技术与成人语音数据结合能带来更好的效果。
- 半监督学习对两种语言都有帮助。
- 参数高效的微调在南非语上有效,但在科萨语上效果不明显。
点此查看论文截图




On Creating A Brain-To-Text Decoder
Authors:Zenon Lamprou, Yashar Moshfeghi
Brain decoding has emerged as a rapidly advancing and extensively utilized technique within neuroscience. This paper centers on the application of raw electroencephalogram (EEG) signals for decoding human brain activity, offering a more expedited and efficient methodology for enhancing our understanding of the human brain. The investigation specifically scrutinizes the efficacy of brain-computer interfaces (BCI) in deciphering neural signals associated with speech production, with particular emphasis on the impact of vocabulary size, electrode density, and training data on the framework’s performance. The study reveals the competitive word error rates (WERs) achievable on the Librispeech benchmark through pre-training on unlabelled data for speech processing. Furthermore, the study evaluates the efficacy of voice recognition under configurations with limited labeled data, surpassing previous state-of-the-art techniques while utilizing significantly fewer labels. Additionally, the research provides a comprehensive analysis of error patterns in voice recognition and the influence of model size and unlabelled training data. It underscores the significance of factors such as vocabulary size and electrode density in enhancing BCI performance, advocating for an increase in microelectrodes and refinement of language models.
脑解码已经作为神经科学中一个快速进步和广泛应用的神经解码技术。本文主要研究原始脑电图(EEG)信号在解码人脑活动中的应用,为我们更快速地理解和提升人脑功能提供了更有效的方法。本研究的调查重点在于针对与语言生成相关的神经信号,特别着重研究脑机接口(BCI)的效用,以及词汇大小、电极密度和训练数据对框架性能的影响。该研究通过在未标记数据上进行预训练揭示了达到Librispeech基准竞争的单词错误率(WERs),这对语音处理而言具有实现意义。此外,该研究还评估了在有限标记数据配置下语音识别的有效性,在利用显著更少的标签的同时超越了以前的最先进技术。此外,该研究还对语音识别中的错误模式以及模型大小和未标记训练数据的影响进行了全面的分析。它强调了扩大词汇量以及改进电极密度在提高BCI性能方面的重要性,主张增加微电极的数量以及对语言模型进行精炼优化。
论文及项目相关链接
Summary
大脑解码技术已逐渐成为神经科学领域快速发展的技术之一。本文聚焦于利用原始脑电图信号解码人类大脑活动,提供一种更快速、更有效的方法来提高我们对人类大脑的理解。研究重点探讨了脑机接口在解析与言语产生相关的神经信号方面的有效性,并特别关注词汇量、电极密度和训练数据对系统性能的影响。此外,研究还对利用非标记数据对Librispeech基准测试进行语音处理的竞争词错误率进行了评估。研究还探讨了模型大小和无标签训练数据对语音识别的错误模式的影响,并强调增加微电极数量和改进语言模型的重要性。
Key Takeaways
以下是关键观点的概要:
- 研究的重点在于应用脑电图信号解码人类大脑活动,促进人类对大脑理解的提高。
- 研究分析了脑机接口在解析与言语产生相关的神经信号方面的有效性。
- 探讨了词汇量、电极密度和训练数据对脑机接口性能的影响。词汇量丰富和电极密度增加能提高脑机接口性能。
- 研究评估了在Librispeech基准测试下,利用未标记数据进行预训练对语音处理的性能影响,其表现超过了先前的技术水平。
- 研究发现显著减少标签数量也能达到超越先前技术的效果。
- 研究对语音识别中的错误模式进行了全面的分析,探讨了模型大小和无标签训练数据对性能的影响。
点此查看论文截图


TTS-Transducer: End-to-End Speech Synthesis with Neural Transducer
Authors:Vladimir Bataev, Subhankar Ghosh, Vitaly Lavrukhin, Jason Li
This work introduces TTS-Transducer - a novel architecture for text-to-speech, leveraging the strengths of audio codec models and neural transducers. Transducers, renowned for their superior quality and robustness in speech recognition, are employed to learn monotonic alignments and allow for avoiding using explicit duration predictors. Neural audio codecs efficiently compress audio into discrete codes, revealing the possibility of applying text modeling approaches to speech generation. However, the complexity of predicting multiple tokens per frame from several codebooks, as necessitated by audio codec models with residual quantizers, poses a significant challenge. The proposed system first uses a transducer architecture to learn monotonic alignments between tokenized text and speech codec tokens for the first codebook. Next, a non-autoregressive Transformer predicts the remaining codes using the alignment extracted from transducer loss. The proposed system is trained end-to-end. We show that TTS-Transducer is a competitive and robust alternative to contemporary TTS systems.
这篇文章介绍了TTS-Transducer——一种新型文本到语音转换架构,它结合了音频编解码模型和神经转换器的优势。转换器以其出色的语音识别质量和稳健性而闻名,用于学习单调对齐,并避免使用明确的持续时间预测器。神经音频编解码器有效地将音频压缩成离散代码,揭示了将文本建模方法应用于语音生成的可能性。然而,由于音频编解码模型需要带有残差量化器的代码本,预测每帧多个令牌(tokens)的复杂性构成了重大挑战。所提议的系统首先使用转换器架构来学习令牌化文本和语音编解码令牌之间的单调对齐(针对第一个代码本)。接下来,非自回归Transformer使用从转换器损失中提取的对齐来预测剩余的代码。所提议的系统是端到端进行训练的。我们证明了TTS-Transducer是当代文本到语音转换系统的一个有竞争力和稳健的替代方案。
论文及项目相关链接
PDF Accepted by ICASSP 2025
摘要
本文主要介绍了TTS-Transducer,这是一种利用音频编解码器模型和神经转换器优势的新型文本转语音架构。转换器以其出色的质量和稳健性在语音识别领域备受赞誉,被用来学习单调对齐,并避免使用明确的持续时间预测器。神经音频编解码器能够有效地将音频压缩成离散代码,揭示了将文本建模方法应用于语音生成的可能性。然而,由于音频编解码器模型需要预测每帧的多个令牌并使用残留量化器来处理来自多个代码库的多个令牌的问题带来很大的挑战。所提出的方法首次使用转换器架构来学习标记化文本和语音编解码器令牌之间的单调对齐关系,用于第一个代码库。然后,非自回归Transformer使用从转换器损失中提取的对齐来预测剩余的编码。所提出的方法可以进行端到端的训练。我们证明了TTS-Transducer是当代TTS系统的一个有竞争力的稳健替代方案。
要点掌握
- TTS-Transducer是一种新型的文本转语音架构,结合了音频编解码器模型和神经转换器的优点。
- 转换器被用于学习单调对齐,避免了使用明确的持续时间预测器。这种对齐使得系统可以更好地匹配文本和语音之间的对应关系。
- 神经音频编解码器的使用有效地将音频压缩成离散代码,为语音生成提供了新思路。然而,从多个代码库中预测多个令牌带来了挑战。
- 所提出的方法使用转换器架构来学习文本和语音编解码器之间的单调对齐关系,并训练模型以预测剩余的编码。
- 该系统采用非自回归Transformer进行预测,这种结构使得系统的训练和预测效率更高。
- TTS-Transducer具有竞争力且稳健,可以作为当代TTS系统的替代方案。它可能会在未来成为文本转语音领域的一种重要技术趋势。
点此查看论文截图



MinMo: A Multimodal Large Language Model for Seamless Voice Interaction
Authors:Qian Chen, Yafeng Chen, Yanni Chen, Mengzhe Chen, Yingda Chen, Chong Deng, Zhihao Du, Ruize Gao, Changfeng Gao, Zhifu Gao, Yabin Li, Xiang Lv, Jiaqing Liu, Haoneng Luo, Bin Ma, Chongjia Ni, Xian Shi, Jialong Tang, Hui Wang, Hao Wang, Wen Wang, Yuxuan Wang, Yunlan Xu, Fan Yu, Zhijie Yan, Yexin Yang, Baosong Yang, Xian Yang, Guanrou Yang, Tianyu Zhao, Qinglin Zhang, Shiliang Zhang, Nan Zhao, Pei Zhang, Chong Zhang, Jinren Zhou
Recent advancements in large language models (LLMs) and multimodal speech-text models have laid the groundwork for seamless voice interactions, enabling real-time, natural, and human-like conversations. Previous models for voice interactions are categorized as native and aligned. Native models integrate speech and text processing in one framework but struggle with issues like differing sequence lengths and insufficient pre-training. Aligned models maintain text LLM capabilities but are often limited by small datasets and a narrow focus on speech tasks. In this work, we introduce MinMo, a Multimodal Large Language Model with approximately 8B parameters for seamless voice interaction. We address the main limitations of prior aligned multimodal models. We train MinMo through multiple stages of speech-to-text alignment, text-to-speech alignment, speech-to-speech alignment, and duplex interaction alignment, on 1.4 million hours of diverse speech data and a broad range of speech tasks. After the multi-stage training, MinMo achieves state-of-the-art performance across various benchmarks for voice comprehension and generation while maintaining the capabilities of text LLMs, and also facilitates full-duplex conversation, that is, simultaneous two-way communication between the user and the system. Moreover, we propose a novel and simple voice decoder that outperforms prior models in voice generation. The enhanced instruction-following capabilities of MinMo supports controlling speech generation based on user instructions, with various nuances including emotions, dialects, and speaking rates, and mimicking specific voices. For MinMo, the speech-to-text latency is approximately 100ms, full-duplex latency is approximately 600ms in theory and 800ms in practice. The MinMo project web page is https://funaudiollm.github.io/minmo, and the code and models will be released soon.
近期,大型语言模型(LLMs)和多模态语音文本模型的进步为无缝语音交互奠定了基础,实现了实时、自然、人性化的对话。之前的语音交互模型可分为原生和对齐两类。原生模型将语音和文本处理集成在一个框架中,但面临着序列长度不同和预训练不足等问题。对齐模型保留了文本LLM的功能,但往往受限于小数据集和狭窄的语音任务关注范围。在这项工作中,我们介绍了MinMo,一个用于无缝语音交互的多模态大型语言模型,拥有大约8亿参数。我们解决了先前对齐的多模态模型的主要局限性。我们通过多个阶段的语音到文本的对齐、文本到语音的对齐、语音到语音的对齐以及双向交互对齐,在140万小时的多样语音数据和广泛的语音任务上训练MinMo。经过多阶段训练后,MinMo在语音理解和生成的各种基准测试中达到了最先进的性能,同时保留了文本LLM的功能,还支持全双工对话,即用户与系统之间的同时双向通信。此外,我们提出了一种新颖而简单的语音解码器,在语音生成方面优于以前的模型。MinMo增强的指令遵循能力支持根据用户指令控制语音生成,包括各种细微差别,如情绪、方言和语速,以及模仿特定声音。对于MinMo来说,语音到文本的延迟大约为100毫秒,全双工延迟理论上约为600毫秒,实际上约为800毫秒。MinMo项目网页是https://funaudiollm.github.io/minmo,代码和模型将很快发布。
论文及项目相关链接
PDF Work in progress. Authors are listed in alphabetical order by family name
Summary
本文介绍了最新的大型语言模型(LLMs)和多模态语音文本模型进展,为无缝语音交互奠定了基础,实现了实时、自然和人性化的对话。研究团队提出了名为MinMo的多模态大型语言模型,通过多阶段训练,解决了先前对齐多模态模型的主要局限性。MinMo在语音理解和生成方面达到了最先进的技术性能,并保持了文本LLM的能力,还支持全双工对话。此外,研究团队还提出了一种新的简单语音解码器,在语音生成方面优于先前的模型。MinMo增强了指令跟随能力,支持根据用户指令控制语音生成,包括情感、方言和语速等细微差别,并可模仿特定声音。
Key Takeaways
- 大型语言模型和多模态语音文本模型的最新进展为无缝语音交互奠定了基础。
- MinMo是一个多模态大型语言模型,解决了先前模型的局限性,实现了无缝语音交互。
- MinMo通过多阶段训练,在语音理解和生成方面达到最先进的技术性能。
- MinMo保持了文本LLM的能力,支持全双工对话。
- MinMo采用了一种新的简单语音解码器,在语音生成方面优于先前的模型。
- MinMo增强了指令跟随能力,可根据用户指令控制语音生成的各种细微差别。
点此查看论文截图




Effective and Efficient Mixed Precision Quantization of Speech Foundation Models
Authors:Haoning Xu, Zhaoqing Li, Zengrui Jin, Huimeng Wang, Youjun Chen, Guinan Li, Mengzhe Geng, Shujie Hu, Jiajun Deng, Xunying Liu
This paper presents a novel mixed-precision quantization approach for speech foundation models that tightly integrates mixed-precision learning and quantized model parameter estimation into one single model compression stage. Experiments conducted on LibriSpeech dataset with fine-tuned wav2vec2.0-base and HuBERT-large models suggest the resulting mixed-precision quantized models increased the lossless compression ratio by factors up to 1.7x and 1.9x over the respective uniform-precision and two-stage mixed-precision quantized baselines that perform precision learning and model parameters quantization in separate and disjointed stages, while incurring no statistically word error rate (WER) increase over the 32-bit full-precision models. The system compression time of wav2vec2.0-base and HuBERT-large models is reduced by up to 1.9 and 1.5 times over the two-stage mixed-precision baselines, while both produce lower WERs. The best-performing 3.5-bit mixed-precision quantized HuBERT-large model produces a lossless compression ratio of 8.6x over the 32-bit full-precision system.
本文提出了一种针对语音基础模型的新型混合精度量化方法,该方法将混合精度学习和量化模型参数估计紧密集成到一个单一的模型压缩阶段中。在LibriSpeech数据集上对fine-tuned的wav2vec2.0-base和HuBERT-large模型进行的实验表明,所得的混合精度量化模型相对于各自的统一精度和两阶段混合精度量化基线,无损压缩比提高了高达1.7倍和1.9倍。这些基线在不同的、互不相关的阶段分别进行精度学习和模型参数量化。同时,相对于32位全精度模型,该模型在统计上没有增加词错误率(WER)。相较于两阶段混合精度基线,wav2vec2.0-base和HuBERT-large模型的压缩时间减少了最多1.9倍和1.5倍,同时两者都产生了更低的WER。表现最佳的3.5位混合精度量化HuBERT-large模型相对于32位全精度系统实现了8.6倍的无损压缩比。
论文及项目相关链接
PDF To appear at IEEE ICASSP 2025
Summary
本文介绍了一种新颖的混合精度量化方法,用于语音基础模型。该方法将混合精度学习和量化模型参数估计紧密集成到一个单一的模型压缩阶段。实验表明,该方法的压缩比例最高可达原有系统的两倍,同时不会增加词错误率(WER)。此外,该方法还显著减少了模型压缩时间。
Key Takeaways
- 介绍了一种新的混合精度量化方法用于语音基础模型。
- 集成混合精度学习与量化模型参数估计到一个单一压缩阶段。
- 实验结果表明混合精度量化模型的压缩率比基准高出约两倍,没有增加词错误率(WER)。
- 系统压缩时间减少了最高达到一半的基线值。同时实验结果展现出较好的性能。
- 混合精度量化的最佳表现是在使用 HuBERT-large 模型上,相较于原有的 32 位全精度系统实现了高达 8.6 倍的无损压缩率。
点此查看论文截图



Advancing Singlish Understanding: Bridging the Gap with Datasets and Multimodal Models
Authors:Bin Wang, Xunlong Zou, Shuo Sun, Wenyu Zhang, Yingxu He, Zhuohan Liu, Chengwei Wei, Nancy F. Chen, AiTi Aw
Singlish, a Creole language rooted in English, is a key focus in linguistic research within multilingual and multicultural contexts. However, its spoken form remains underexplored, limiting insights into its linguistic structure and applications. To address this gap, we standardize and annotate the largest spoken Singlish corpus, introducing the Multitask National Speech Corpus (MNSC). These datasets support diverse tasks, including Automatic Speech Recognition (ASR), Spoken Question Answering (SQA), Spoken Dialogue Summarization (SDS), and Paralinguistic Question Answering (PQA). We release standardized splits and a human-verified test set to facilitate further research. Additionally, we propose SingAudioLLM, a multi-task multimodal model leveraging multimodal large language models to handle these tasks concurrently. Experiments reveal our models adaptability to Singlish context, achieving state-of-the-art performance and outperforming prior models by 10-30% in comparison with other AudioLLMs and cascaded solutions.
新加坡式英语是一种根植于英语的克里奥尔语言,在多语言和多元文化背景下,它成为了语言学研究的关键焦点。然而,它的口语形式仍然被探索得不够充分,对于其语言结构和应用方面的见解有所局限。为了弥补这一空白,我们对最大的新加坡式英语口语语料库进行了标准化和注释,并引入了多任务国家语音语料库(MNSC)。这些数据集支持多种任务,包括自动语音识别(ASR)、口语问题回答(SQA)、口语对话摘要(SDS)和副语言问题回答(PQA)。我们发布了标准化的分割数据集和经过人工验证的测试集,以促进进一步的研究。此外,我们还推出了SingAudioLLM,这是一个多任务多模式模型,利用多模式大型语言模型同时处理这些任务。实验表明,我们的模型能够适应新加坡式英语的语境,取得了最先进的性能表现,与其他音频LLM和级联解决方案相比,性能提高了10-30%。
论文及项目相关链接
PDF Open-Source: https://github.com/AudioLLMs/Singlish
Summary
本文主要介绍了Singlish这一源自英语的有特色的克里奥尔语言在多语种、多元文化背景下的语言研究重要性。针对其口语形式探索不足的问题,提出了建立最大的口语Singlish语料库Multitask National Speech Corpus(MNSC),并标注数据集以支持自动语音识别(ASR)、口语问答(SQA)、口语对话摘要(SDS)和副语言问答(PQA)等多样化任务。同时,文章还介绍了针对这些任务的多模态大型语言模型SingAudioLLM的应用,实验证明该模型适应Singlish语境,性能优于其他AudioLLMs和级联解决方案。
Key Takeaways
- Singlish是一种重要的克里奥尔语言,具有独特的研究价值。
- 现有的关于Singlish的研究主要集中在其书面形式上,对其口语形式的研究仍然不足。
- Multitask National Speech Corpus(MNSC)是首个大规模的口语Singlish语料库,支持多种任务,如ASR、SQA等。
- SingAudioLLM是一个多模态大型语言模型,能够处理多种任务,包括ASR、SQA等。
- SingAudioLLM通过充分利用多模态数据来改进模型的性能。与传统的AudioLLMs和级联解决方案相比,SingAudioLLM性能更好,尤其是适应了Singlish语境的特殊性。
- 实验结果证明,对于涉及Singlish的语言任务,SingAudioLLM显著提升了表现效果。
点此查看论文截图




Attacking Voice Anonymization Systems with Augmented Feature and Speaker Identity Difference
Authors:Yanzhe Zhang, Zhonghao Bi, Feiyang Xiao, Xuefeng Yang, Qiaoxi Zhu, Jian Guan
This study focuses on the First VoicePrivacy Attacker Challenge within the ICASSP 2025 Signal Processing Grand Challenge, which aims to develop speaker verification systems capable of determining whether two anonymized speech signals are from the same speaker. However, differences between feature distributions of original and anonymized speech complicate this task. To address this challenge, we propose an attacker system that combines Data Augmentation enhanced feature representation and Speaker Identity Difference enhanced classifier to improve verification performance, termed DA-SID. Specifically, data augmentation strategies (i.e., data fusion and SpecAugment) are utilized to mitigate feature distribution gaps, while probabilistic linear discriminant analysis (PLDA) is employed to further enhance speaker identity difference. Our system significantly outperforms the baseline, demonstrating exceptional effectiveness and robustness against various voice anonymization systems, ultimately securing a top-5 ranking in the challenge.
本研究聚焦于ICASSP 2025信号处理挑战赛中的“第一语音隐私攻击者挑战”,旨在开发能够判断两个匿名语音信号是否来自同一说话人的说话人验证系统。然而,原始语音和匿名语音特征分布之间的差异使这一任务复杂化。为了应对这一挑战,我们提出了一种攻击者系统,该系统结合了数据增强增强特征表示和说话人身份差异增强分类器来提高验证性能,被称为DA-SID。具体来说,数据增强策略(如数据融合和SpecAugment)被用来缩小特征分布差距,概率线性判别分析(PLDA)被用来进一步增强说话人身份差异。我们的系统显著优于基线系统,表现出对各种语音匿名系统的出色效果和稳健性,最终在挑战中获得了前五名的排名。
论文及项目相关链接
PDF 2 pages, submitted to ICASSP 2025 GC-7: The First VoicePrivacy Attacker Challenge (by invitation), fixed a numerical typo: In Table II, the EER% for DA-SID w/o DA under T8-5 is corrected to 26.96
Summary
本文研究了ICASSP 2025信号处理挑战赛中的First VoicePrivacy Attacker Challenge。该挑战旨在开发能够确定两个匿名语音信号是否来自同一发言人的说话人验证系统。为解决原始语音与匿名化语音特征分布之间的差异带来的挑战,本文提出了一种结合数据增强特征表示和说话人身份差异分类器的攻击者系统,称为DA-SID。该系统采用数据融合和SpecAugment等数据增强策略来缩小特征分布差距,并使用概率线性判别分析(PLDA)进一步增强说话人身份差异识别。该系统显著优于基线方法,对各种语音匿名化系统表现出极强的有效性和鲁棒性,最终在挑战中跻身前五名。
Key Takeaways
- 第一项挑战是开发能够确定两个匿名语音信号是否来自同一发言人的说话人验证系统。
- 原始语音与匿名化语音的特征分布存在差异,使得这一任务更具挑战性。
- 提出了一种名为DA-SID的系统,结合数据增强特征表示和说话人身份差异分类器来改善验证性能。
- 数据融合和SpecAugment等数据增强策略用于缩小特征分布差距。
- 概率线性判别分析(PLDA)用于增强说话人身份差异的识别。
- 该系统显著优于基线方法,对各种语音匿名化系统具有很强的有效性和鲁棒性。
点此查看论文截图


Blind Estimation of Sub-band Acoustic Parameters from Ambisonics Recordings using Spectro-Spatial Covariance Features
Authors:Hanyu Meng, Jeroen Breebaart, Jeremy Stoddard, Vidhyasaharan Sethu, Eliathamby Ambikairajah
Estimating frequency-varying acoustic parameters is essential for enhancing immersive perception in realistic spatial audio creation. In this paper, we propose a unified framework that blindly estimates reverberation time (T60), direct-to-reverberant ratio (DRR), and clarity (C50) across 10 frequency bands using first-order Ambisonics (FOA) speech recordings as inputs. The proposed framework utilizes a novel feature named Spectro-Spatial Covariance Vector (SSCV), efficiently representing temporal, spectral as well as spatial information of the FOA signal. Our models significantly outperform existing single-channel methods with only spectral information, reducing estimation errors by more than half for all three acoustic parameters. Additionally, we introduce FOA-Conv3D, a novel back-end network for effectively utilising the SSCV feature with a 3D convolutional encoder. FOA-Conv3D outperforms the convolutional neural network (CNN) and recurrent convolutional neural network (CRNN) backends, achieving lower estimation errors and accounting for a higher proportion of variance (PoV) for all 3 acoustic parameters.
估计频率变化的声学参数对于提高真实空间音频创建的沉浸式感知至关重要。在本文中,我们提出了一个统一的框架,该框架可以盲估计混响时间(T60)、直达声与混响声之比(DRR)和清晰度(C50)在10个频率范围内,以采用一阶环绕声(FOA)录音作为输入。所提出的框架利用了一种名为谱时空协方差向量(SSCV)的新特性,有效地表示了FOA信号的时空以及频谱信息。我们的模型仅使用频谱信息,显著优于现有的单通道方法,将三种声学参数的估计误差减少了一半以上。此外,我们还引入了FOA-Conv3D,这是一种有效使用SSCV特性的新型后端网络,采用3D卷积编码器。FOA-Conv3D的表现优于卷积神经网络(CNN)和循环卷积神经网络(CRNN)的后端,实现了更低的估计误差,并且三种声学参数的方差占比(PoV)更高。
论文及项目相关链接
PDF Accepted by ICASSP2025
Summary
本文提出了一种统一框架,用于基于第一阶Ambisonics(FOA)录音输入,盲目估计十个频率带的混响时间(T60)、直达与混响比(DRR)和清晰度(C50)。该框架利用名为Spectro-Spatial协方差向量(SSCV)的新特性,有效地表示FOA信号的时空谱和空间信息。与仅使用谱信息的单通道方法相比,该模型在估计这三个声学参数时误差降低了超过一半。此外,还引入了FOA-Conv3D这一新型后端网络,利用SSCV特性与三维卷积编码器进行有效处理。相较于卷积神经网络(CNN)和循环卷积神经网络(CRNN)后端,FOA-Conv3D在估计误差和解释方差(PoV)方面表现更佳。
Key Takeaways
- 文章提出了一种统一框架用于估计频率变化的声学参数,包括混响时间、直达与混响比和清晰度。
- 该框架基于第一阶Ambisonics录音作为输入,能盲目估计十个频率带的声学参数。
- 提出了Spectro-Spatial协方差向量这一新特性,有效表示FOA信号的时空谱和空间信息。
- 与单通道方法相比,该模型在估计声学参数方面的性能有显著提高。
- 引入了FOA-Conv3D这一新型后端网络,更有效地处理FOA信号特征。
- FOA-Conv3D在估计误差和解释方差方面优于卷积神经网络和循环卷积神经网络后端。
点此查看论文截图




Biodenoising: Animal Vocalization Denoising without Access to Clean Data
Authors:Marius Miron, Sara Keen, Jen-Yu Liu, Benjamin Hoffman, Masato Hagiwara, Olivier Pietquin, Felix Effenberger, Maddie Cusimano
Animal vocalization denoising is a task similar to human speech enhancement, which is relatively well-studied. In contrast to the latter, it comprises a higher diversity of sound production mechanisms and recording environments, and this higher diversity is a challenge for existing models. Adding to the challenge and in contrast to speech, we lack large and diverse datasets comprising clean vocalizations. As a solution we use as training data pseudo-clean targets, i.e. pre-denoised vocalizations, and segments of background noise without a vocalization. We propose a train set derived from bioacoustics datasets and repositories representing diverse species, acoustic environments, geographic regions. Additionally, we introduce a non-overlapping benchmark set comprising clean vocalizations from different taxa and noise samples. We show that that denoising models (demucs, CleanUNet) trained on pseudo-clean targets obtained with speech enhancement models achieve competitive results on the benchmarking set. We publish data, code, libraries, and demos at https://mariusmiron.com/research/biodenoising.
动物发声去噪与人类语音增强任务类似,后者研究相对成熟。然而,相较于语音增强,动物发声去噪涵盖了更多种类的声音产生机制和录音环境,这种多样性对现有模型构成挑战。此外,与语音不同,我们缺乏包含清晰发声的大型多样化数据集。为解决这一问题,我们使用伪清洁目标作为训练数据,即预去噪发声和无发声的背景噪声片段。我们提出一个基于生物声学数据集和存储库的训练集,涵盖多种物种、声学环境和地理区域。此外,我们还引入了一个非重叠的基准测试集,包含来自不同分类群的干净发声和噪声样本。我们证明,使用语音增强模型获得的伪清洁目标进行训练的去噪模型(如demucs和CleanUNet)在基准测试集上取得了具有竞争力的结果。我们在https://mariusmiron.com/research/biodenoising上公开了数据、代码、库和演示。
论文及项目相关链接
PDF 5 pages, 2 tables
Summary
动物发声去噪与人类语音增强任务类似,但涉及更广泛的声源和录音环境,增加了处理难度。由于缺乏包含清晰发声的大型多元数据集,我们采用伪清洁目标作为训练数据,即预去噪发声和无发声的背景噪声片段。我们提出一个基于生物声学数据集和代表各种物种、声学环境及地理区域的资料库的训练集。此外,我们还引入了一个不包含重叠发声的基准测试集,包含来自不同分类群和噪声样本的清洁发声。研究显示,利用语音增强模型获得的伪清洁目标训练的降噪模型(如demucs和CleanUNet)在基准测试集上取得了具有竞争力的结果。相关数据、代码、库和演示内容已发布在https://mariusmiron.com/research/biodenoising。
Key Takeaways
- 动物发声去噪任务类似于人类语音增强,但面临更高的声音多样性和录音环境挑战。
- 缺乏大型多元数据集,因此使用伪清洁目标作为训练数据。
- 引入基于生物声学数据集和广泛资料库的训练集。
- 提出不包含重叠发声的基准测试集。
- 降噪模型(如demucs和CleanUNet)在基准测试集上取得竞争力结果。
- 伪清洁目标是通过语音增强模型获得的。
点此查看论文截图



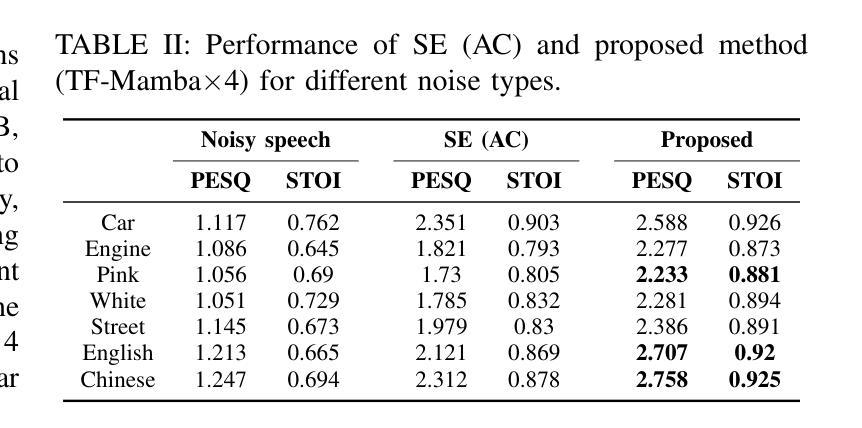
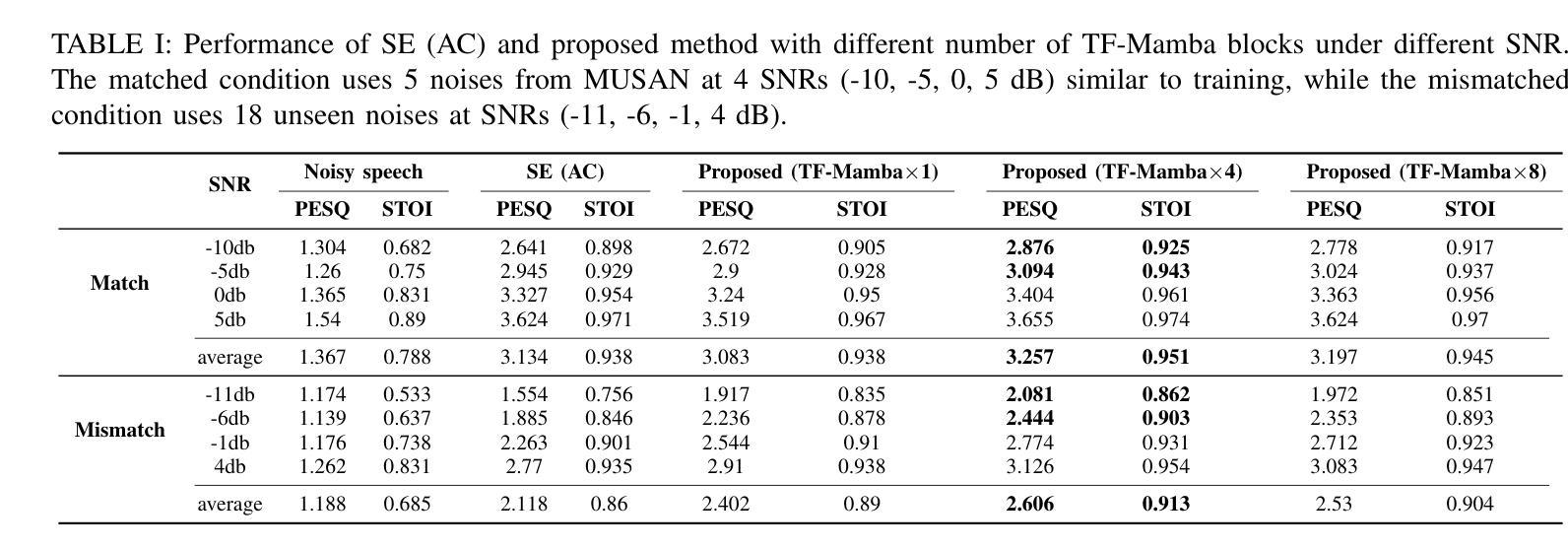
Leveraging Joint Spectral and Spatial Learning with MAMBA for Multichannel Speech Enhancement
Authors:Wenze Ren, Haibin Wu, Yi-Cheng Lin, Xuanjun Chen, Rong Chao, Kuo-Hsuan Hung, You-Jin Li, Wen-Yuan Ting, Hsin-Min Wang, Yu Tsao
In multichannel speech enhancement, effectively capturing spatial and spectral information across different microphones is crucial for noise reduction. Traditional methods, such as CNN or LSTM, attempt to model the temporal dynamics of full-band and sub-band spectral and spatial features. However, these approaches face limitations in fully modeling complex temporal dependencies, especially in dynamic acoustic environments. To overcome these challenges, we modify the current advanced model McNet by introducing an improved version of Mamba, a state-space model, and further propose MCMamba. MCMamba has been completely reengineered to integrate full-band and narrow-band spatial information with sub-band and full-band spectral features, providing a more comprehensive approach to modeling spatial and spectral information. Our experimental results demonstrate that MCMamba significantly improves the modeling of spatial and spectral features in multichannel speech enhancement, outperforming McNet and achieving state-of-the-art performance on the CHiME-3 dataset. Additionally, we find that Mamba performs exceptionally well in modeling spectral information.
在多通道语音增强中,有效捕捉不同麦克风间的空间和时间谱信息对于降噪至关重要。传统方法,如卷积神经网络(CNN)或长短期记忆(LSTM),试图对全频带和子频带的时间动态进行建模。然而,这些方法在完全建模复杂的时间依赖性方面面临局限,特别是在动态声学环境中。为了克服这些挑战,我们引入了改进的Mamba状态空间模型来修改当前先进的McNet模型,并进一步提出了MCMamba。MCMamba进行了全面改造,融合了全频带和窄频带空间信息与子频带和全频带频谱特征,为建模空间和频谱信息提供了更全面的方法。我们的实验结果表明,MCMamba在多通道语音增强的空间和频谱特征建模上有了显著改进,其性能超过了McNet,并在CHiME-3数据集上达到了最新水平。此外,我们发现Mamba在建模频谱信息方面的表现尤为出色。
论文及项目相关链接
PDF Accepted by ICASSP 2025
Summary
本文介绍了多通道语音增强中空间与光谱信息捕捉的重要性。针对传统方法如CNN和LSTM在复杂动态环境下的局限性,改进了现有先进模型McNet,引入了Mamba的状态空间模型的改进版,提出MCMamba模型。MCMamba模型重新整合了全频带和窄频带空间信息与子频带和全频带光谱特征,为空间与光谱信息的建模提供了更全面的方法。实验结果表明,MCMamba在多通道语音增强中显著提高了空间与光谱特征的建模效果,在CHiME-3数据集上表现优异。此外,Mamba在光谱信息建模中表现突出。
Key Takeaways
- 在多通道语音增强中,捕捉空间与光谱信息是关键,特别是在复杂动态环境下。
- 传统方法如CNN和LSTM在建模复杂的时间依赖性方面存在局限性。
- 改进了现有先进模型McNet,引入Mamba的状态空间模型的改进版,形成MCMamba模型。
- MCMamba模型整合了全频带和窄频带空间信息以及子频带和全频带光谱特征。
- 实验结果显示MCMamba在多通道语音增强中表现优异,特别是在CHiME-3数据集上。
- MCMamba显著提高了空间与光谱特征的建模效果,对比McNet有显著提升。
点此查看论文截图




Effective Integration of KAN for Keyword Spotting
Authors:Anfeng Xu, Biqiao Zhang, Shuyu Kong, Yiteng Huang, Zhaojun Yang, Sangeeta Srivastava, Ming Sun
Keyword spotting (KWS) is an important speech processing component for smart devices with voice assistance capability. In this paper, we investigate if Kolmogorov-Arnold Networks (KAN) can be used to enhance the performance of KWS. We explore various approaches to integrate KAN for a model architecture based on 1D Convolutional Neural Networks (CNN). We find that KAN is effective at modeling high-level features in lower-dimensional spaces, resulting in improved KWS performance when integrated appropriately. The findings shed light on understanding KAN for speech processing tasks and on other modalities for future researchers.
关键词识别(KWS)是智能语音助手设备的重要语音处理组件。本文旨在研究Kolmogorov-Arnold网络(KAN)是否可以提高KWS的性能。我们探索了各种方法,以将KAN集成到基于一维卷积神经网络(CNN)的模型架构中。我们发现,在低维空间中建模高级特征时,KAN具有很强的效果,并且在适当集成后,可以改善KWS的性能。这些发现有助于未来研究人员了解KAN在语音处理任务中的应用,并为其他模式提供启示。
论文及项目相关链接
PDF Accepted to ICASSP 2025
摘要
论文研究了Kolmogorov-Arnold Networks(KAN)在关键词识别(KWS)中的作用。该研究发现,通过合理整合,KAN能提升CNN模型在KWS上的性能,并能有效地在较低维度的空间中模拟高级特征。该研究的成果对于理解KAN在语音处理任务中的应用以及对未来研究者的其他模态研究都有重要意义。
关键见解
- 研究探讨了Kolmogorov-Arnold Networks(KAN)在语音处理领域的潜在应用,特别是与关键词识别(KWS)结合时的重要性。
- 该研究利用了具有语音助手功能的智能设备的语音处理组件。
- 研究表明,适当整合后,KAN能有效提高基于一维卷积神经网络(CNN)的模型架构在关键词识别方面的性能。
- KAN能够在较低维度的空间中模拟高级特征,这对于语音处理任务至关重要。
- 研究结果对于理解KAN在语音处理任务中的应用具有指导意义。
- 该研究为未来的研究者提供了对其他模态研究的启示和可能的方向。
点此查看论文截图








Improving Zero-Shot Chinese-English Code-Switching ASR with kNN-CTC and Gated Monolingual Datastores
Authors:Jiaming Zhou, Shiwan Zhao, Hui Wang, Tian-Hao Zhang, Haoqin Sun, Xuechen Wang, Yong Qin
The kNN-CTC model has proven to be effective for monolingual automatic speech recognition (ASR). However, its direct application to multilingual scenarios like code-switching, presents challenges. Although there is potential for performance improvement, a kNN-CTC model utilizing a single bilingual datastore can inadvertently introduce undesirable noise from the alternative language. To address this, we propose a novel kNN-CTC-based code-switching ASR (CS-ASR) framework that employs dual monolingual datastores and a gated datastore selection mechanism to reduce noise interference. Our method selects the appropriate datastore for decoding each frame, ensuring the injection of language-specific information into the ASR process. We apply this framework to cutting-edge CTC-based models, developing an advanced CS-ASR system. Extensive experiments demonstrate the remarkable effectiveness of our gated datastore mechanism in enhancing the performance of zero-shot Chinese-English CS-ASR.
kNN-CTC模型在单语言自动语音识别(ASR)中已被证明是有效的。然而,将其直接应用于多语言场景,如代码切换,仍然存在挑战。尽管有提高性能的潜力,但使用单一双语数据存储的kNN-CTC模型可能会无意中引入来自另一种语言的不希望有的噪声。为了解决这一问题,我们提出了一种基于kNN-CTC的新型代码切换ASR(CS-ASR)框架,该框架采用双单语数据存储和受控数据存储选择机制来减少噪声干扰。我们的方法选择适当的存储库来解码每一帧,确保语言特定信息的注入到ASR过程中。我们将此框架应用于最新的CTC模型,开发了一个先进的CS-ASR系统。大量实验证明,我们的受控数据存储机制在零中文-英文切换的CS-ASR性能提升中效果显著。
论文及项目相关链接
PDF Accepted by ICASSP 2025
总结
KNN-CTC模型在单语种自动语音识别(ASR)中表现优异,但在多语种场景如代码切换中直接应用时面临挑战。为解决从单一双语数据库中可能引入的干扰噪声问题,提出了基于KNN-CTC的代码切换ASR(CS-ASR)框架。该框架采用双单语数据库和门控数据库选择机制,减少噪声干扰,确保为每一帧解码注入特定语言信息。实验证明,门控数据库机制对提升零样本中文-英文CS-ASR的性能有显著效果。
关键见解
- KNN-CTC模型在单语种ASR中的有效性。
- 模型在多语种场景(如代码切换)中面临的挑战。
- 单一双语数据库可能引入干扰噪声的问题。
- 提出的CS-ASR框架采用双单语数据库和门控选择机制。
- 该机制能减少噪声干扰,确保为每一帧解码注入特定语言信息。
- 实验证明门控数据库机制对提升性能有显著效果。
点此查看论文截图