⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-16 更新
MathReader : Text-to-Speech for Mathematical Documents
Authors:Sieun Hyeon, Kyudan Jung, Nam-Joon Kim, Hyun Gon Ryu, Jaeyoung Do
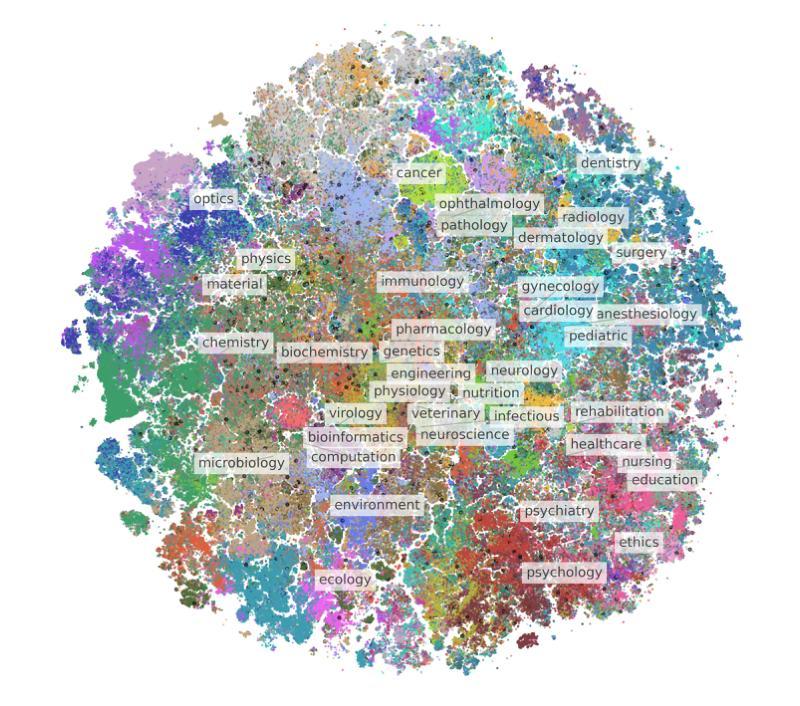
TTS (Text-to-Speech) document reader from Microsoft, Adobe, Apple, and OpenAI have been serviced worldwide. They provide relatively good TTS results for general plain text, but sometimes skip contents or provide unsatisfactory results for mathematical expressions. This is because most modern academic papers are written in LaTeX, and when LaTeX formulas are compiled, they are rendered as distinctive text forms within the document. However, traditional TTS document readers output only the text as it is recognized, without considering the mathematical meaning of the formulas. To address this issue, we propose MathReader, which effectively integrates OCR, a fine-tuned T5 model, and TTS. MathReader demonstrated a lower Word Error Rate (WER) than existing TTS document readers, such as Microsoft Edge and Adobe Acrobat, when processing documents containing mathematical formulas. MathReader reduced the WER from 0.510 to 0.281 compared to Microsoft Edge, and from 0.617 to 0.281 compared to Adobe Acrobat. This will significantly contribute to alleviating the inconvenience faced by users who want to listen to documents, especially those who are visually impaired. The code is available at https://github.com/hyeonsieun/MathReader.
微软、Adobe、苹果和OpenAI的TTS(文本转语音)文档阅读器已在全球范围内提供服务。它们对于普通的纯文本提供相对良好的TTS结果,但有时对于数学表达式会跳过内容或提供不满意的结果。这是因为现代学术论文大多使用LaTeX编写,当LaTeX公式被编译时,它们在文档中以独特的文本形式呈现。然而,传统的TTS文档阅读器只输出所识别的文本,而没有考虑到公式的数学意义。为了解决这一问题,我们提出了MathReader,它有效地整合了OCR、精细调整的T5模型和TTS。MathReader在处理包含数学公式的文档时,与现有的TTS文档阅读器(如Microsoft Edge和Adobe Acrobat)相比,展示了较低的单词错误率(WER)。与Microsoft Edge相比,MathReader将WER从0.510降低到0.281;与Adobe Acrobat相比,从0.617降低到0.281。这将极大地缓解用户(尤其是视力受损者)在聆听文档时所面临的诸多不便。相关代码可访问 https://github.com/hyeonsieun/MathReader。
论文及项目相关链接
PDF Accepted at ICASSP 2025
Summary
微软、Adobe、苹果和OpenAI的TTS(文本转语音)文档阅读器对普通文本提供较好的转换结果,但在处理数学表达式时有时会跳过内容或结果不尽人意。为解决此问题,我们推出了MathReader,它有效结合了OCR、精细调整的T5模型和TTS技术,降低了处理含数学公式文档的Word Error Rate(WER)。相较于Microsoft Edge和Adobe Acrobat的TTS文档阅读器,MathReader表现出更低的WER,为用户带来了极大的便利,特别是视力受损的用户。相关代码可访问https://github.com/hyeonsieun/MathReader了解。
Key Takeaways
- 微软、Adobe、苹果和OpenAI的TTS文档阅读器对普通文本表现良好,但在处理数学表达式时存在不足。
- MathReader结合了OCR、精细调整的T5模型和TTS技术,以处理数学公式为主的文档。
- MathReader相较于其他TTS文档阅读器,如Microsoft Edge和Adobe Acrobat,具有更低的Word Error Rate(WER)。
- MathReader在识别数学公式方面的准确性显著提高。
- MathReader的推出将极大便利需要听取文档内容的用户,特别是视力受损的用户。
- MathReader的代码可在GitHub上获取。
点此查看论文截图



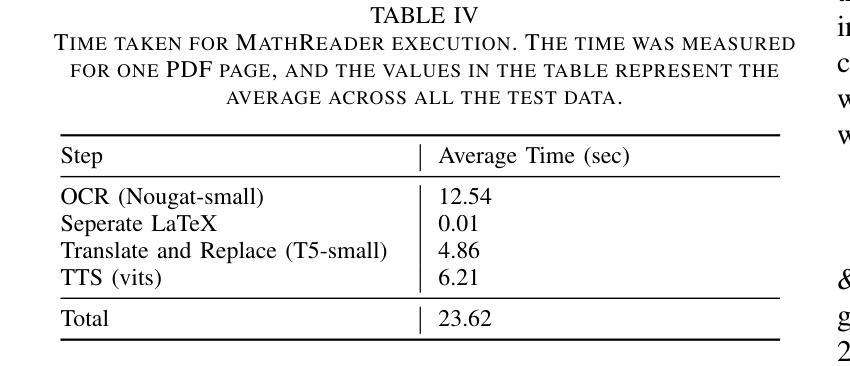
Retrieval-Augmented Dialogue Knowledge Aggregation for Expressive Conversational Speech Synthesis
Authors:Rui Liu, Zhenqi Jia, Feilong Bao, Haizhou Li
Conversational speech synthesis (CSS) aims to take the current dialogue (CD) history as a reference to synthesize expressive speech that aligns with the conversational style. Unlike CD, stored dialogue (SD) contains preserved dialogue fragments from earlier stages of user-agent interaction, which include style expression knowledge relevant to scenarios similar to those in CD. Note that this knowledge plays a significant role in enabling the agent to synthesize expressive conversational speech that generates empathetic feedback. However, prior research has overlooked this aspect. To address this issue, we propose a novel Retrieval-Augmented Dialogue Knowledge Aggregation scheme for expressive CSS, termed RADKA-CSS, which includes three main components: 1) To effectively retrieve dialogues from SD that are similar to CD in terms of both semantic and style. First, we build a stored dialogue semantic-style database (SDSSD) which includes the text and audio samples. Then, we design a multi-attribute retrieval scheme to match the dialogue semantic and style vectors of the CD with the stored dialogue semantic and style vectors in the SDSSD, retrieving the most similar dialogues. 2) To effectively utilize the style knowledge from CD and SD, we propose adopting the multi-granularity graph structure to encode the dialogue and introducing a multi-source style knowledge aggregation mechanism. 3) Finally, the aggregated style knowledge are fed into the speech synthesizer to help the agent synthesize expressive speech that aligns with the conversational style. We conducted a comprehensive and in-depth experiment based on the DailyTalk dataset, which is a benchmarking dataset for the CSS task. Both objective and subjective evaluations demonstrate that RADKA-CSS outperforms baseline models in expressiveness rendering. Code and audio samples can be found at: https://github.com/Coder-jzq/RADKA-CSS.
对话式语音合成(CSS)旨在以当前对话(CD)历史为参考,合成符合对话风格的表达性语音。不同于CD,存储的对话(SD)包含早期用户代理互动阶段的保存对话片段,这些片段包含与CD中类似场景相关的风格表达知识。请注意,这些知识对于使代理能够合成产生同理心反馈的表达性对话语音起着重要作用。然而,之前的研究忽略了这一方面。为了解决这一问题,我们提出了一种用于表达性CSS的检索增强对话知识聚合方案,称为RADKA-CSS,主要包括三个组件:1)有效地从SD中检索与CD在语义和风格上都相似的对话。首先,我们建立一个包含文本和音频样本的存储对话语义风格数据库(SDSSD)。然后,我们设计了一种多属性检索方案,以匹配CD的对话语义和风格向量与SDSSD中的存储对话语义和风格向量,检索最相似的对话。2)为了有效利用CD和SD中的风格知识,我们提出采用多粒度图结构对对话进行编码,并引入多源风格知识聚合机制。3)最后,将聚合的风格知识输入语音合成器,以帮助代理合成符合对话风格的表达性语音。我们基于DailyTalk数据集进行了全面深入的实验,该数据集是CSS任务的基准数据集。客观和主观评估结果表明,RADKA-CSS在表达性呈现方面优于基准模型。代码和音频样本可在:https://github.com/Coder-jzq/RADKA-CSS找到。
论文及项目相关链接
PDF Accepted by Information Fusion 2025
Summary
对话式语音合成(CSS)通过参考当前对话(CD)历史,合成符合对话风格的表达性语音。存储的对话(SD)包含用户与智能体交互的早期阶段的对话片段,包含与CD中相似的场景相关的风格表达知识。为解决这个问题,提出一种名为RADKA-CSS的检索增强对话知识聚合方案,包括三个主要部分:有效检索SD中与CD在语义和风格上相似的对话;利用CD和SD中的风格知识;将聚合的风格知识输入语音合成器,帮助智能体合成符合对话风格的表达性语音。实验证明RADKA-CSS在表达性渲染方面优于基准模型。
Key Takeaways
- 对话式语音合成(CSS)旨在参考当前对话历史来合成表达性语音,以符合对话风格。
- 存储的对话(SD)包含用户与智能体早期交互的对话片段,涉及与当前对话相似的场景的风格表达知识。
- RADKA-CSS是一种检索增强对话知识聚合方案,包括从SD中有效检索与CD相似的对话、利用对话中的风格知识、以及使用聚合的风格知识来合成表达性语音。
- 实验证明RADKA-CSS在表达性渲染方面优于基准模型。
- RADKA-CSS包括三个主要组件:多属性检索方案、基于多粒度图结构的对话编码和多源风格知识聚合机制。
- 使用的数据集是DailyTalk,一个用于CSS任务的基准数据集。
点此查看论文截图

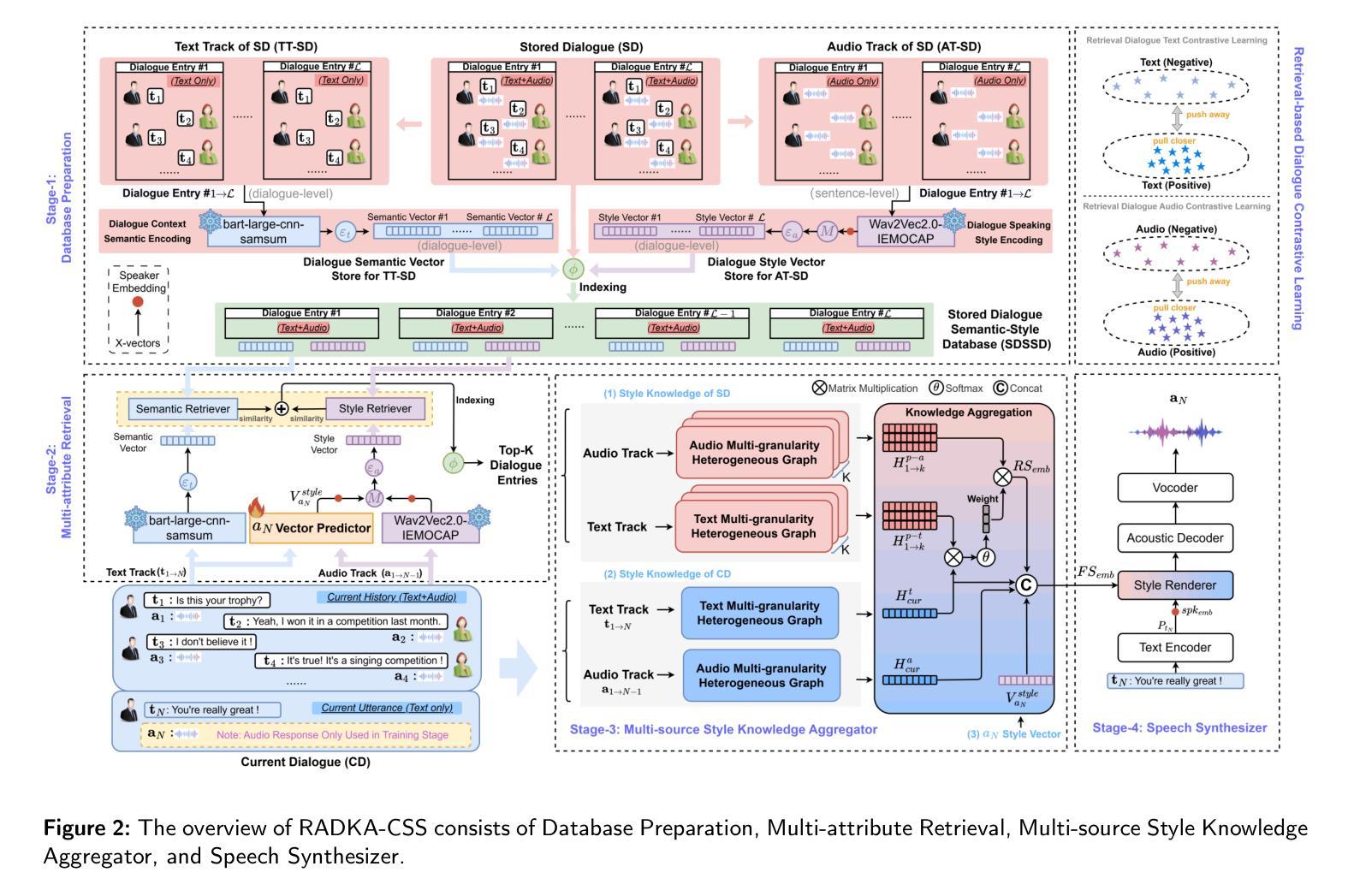

TTS-Transducer: End-to-End Speech Synthesis with Neural Transducer
Authors:Vladimir Bataev, Subhankar Ghosh, Vitaly Lavrukhin, Jason Li
This work introduces TTS-Transducer - a novel architecture for text-to-speech, leveraging the strengths of audio codec models and neural transducers. Transducers, renowned for their superior quality and robustness in speech recognition, are employed to learn monotonic alignments and allow for avoiding using explicit duration predictors. Neural audio codecs efficiently compress audio into discrete codes, revealing the possibility of applying text modeling approaches to speech generation. However, the complexity of predicting multiple tokens per frame from several codebooks, as necessitated by audio codec models with residual quantizers, poses a significant challenge. The proposed system first uses a transducer architecture to learn monotonic alignments between tokenized text and speech codec tokens for the first codebook. Next, a non-autoregressive Transformer predicts the remaining codes using the alignment extracted from transducer loss. The proposed system is trained end-to-end. We show that TTS-Transducer is a competitive and robust alternative to contemporary TTS systems.
本文介绍了TTS-Transducer,这是一种利用音频编解码模型和神经转换器优势的新型文本到语音转换架构。转换器以其出色的语音识别的质量和稳健性而闻名,用于学习单调对齐,并避免了使用明确的持续时间预测器。神经音频编解码器能够高效地将音频压缩成离散代码,显示出将文本建模方法应用于语音生成的可能性。然而,由于音频编解码模型需要使用残差量化器,每帧预测多个令牌(token)的代码会带来很大的挑战。所提议的系统首先使用转换器架构来学习令牌化文本和语音编解码令牌之间的单调对齐,用于第一个编解码器。接下来,非自回归的Transformer使用从转换器损失中提取的对齐来预测剩余的编码。所提议的系统是端到端进行训练的。我们证明了TTS-Transducer是当代TTS系统的一个有竞争力的稳健替代方案。
论文及项目相关链接
PDF Accepted by ICASSP 2025
Summary
文本介绍了基于音频编码模型和神经网络翻译器的新型文本到语音(TTS)架构——TTS-Transducer。Transducers以其出色的质量和稳健性在语音识别领域备受瞩目,被用于学习单调对齐并避免使用显式持续时间预测器。神经网络音频编码模型可以有效地将音频压缩成离散代码,展现了将文本建模方法应用于语音生成的可能性。然而,由于音频编码模型需要对多个帧进行预测,同时需要使用多个编码簿,这给预测带来了复杂性。本文提出的系统首先使用翻译器架构来学习文本编码与语音编码之间的单调对齐。接着,利用翻译器损失中提取的对齐信息,采用非自动回归转换器预测剩余的编码。系统可进行端到端的训练。研究证明,TTS-Transducer是一个有竞争力的当代TTS系统的稳健替代品。
Key Takeaways
- TTS-Transducer是一个新型文本到语音转换架构,结合了音频编码模型和神经翻译器的优点。
- Transducers在语音识别领域表现优异,被应用于TTS-Transducer中以学习单调对齐。
- 神经网络音频编码模型能有效压缩音频数据,为文本建模在语音生成中的应用提供了可能性。
- 预测多个帧的多个编码对系统带来了挑战,但通过翻译器架构和非自动回归转换器解决。
- TTS-Transducer系统通过端到端的训练方式优化。
- TTS-Transducer展示了相较于当代TTS系统的竞争力和稳健性。
点此查看论文截图

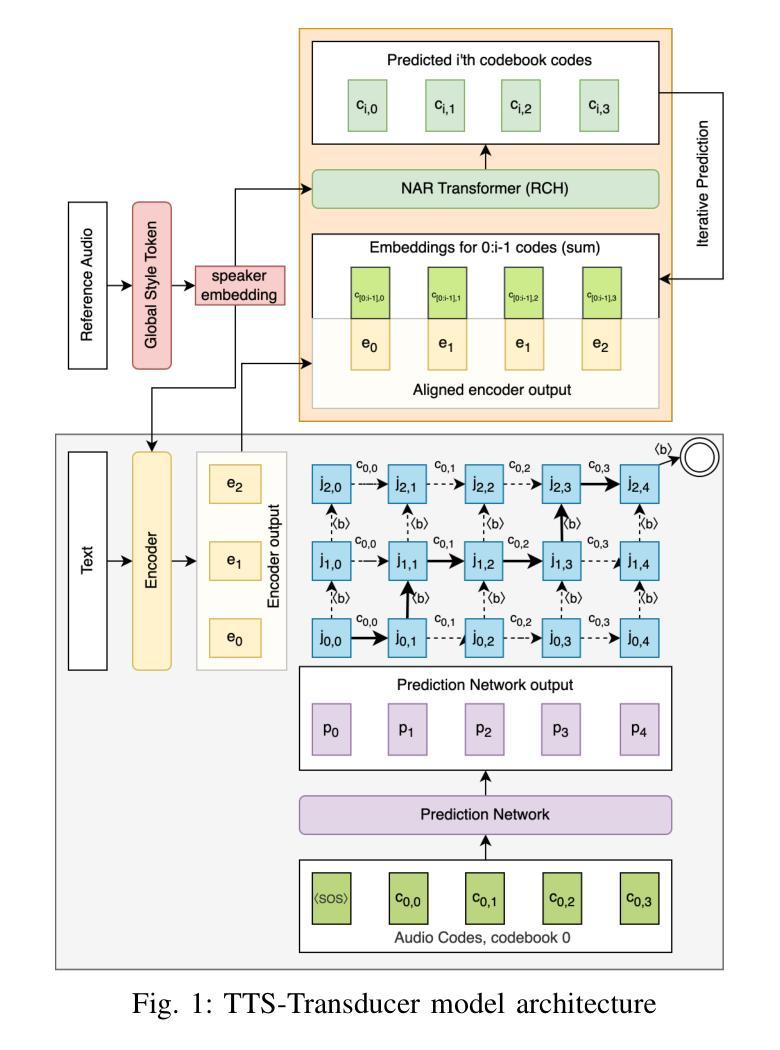
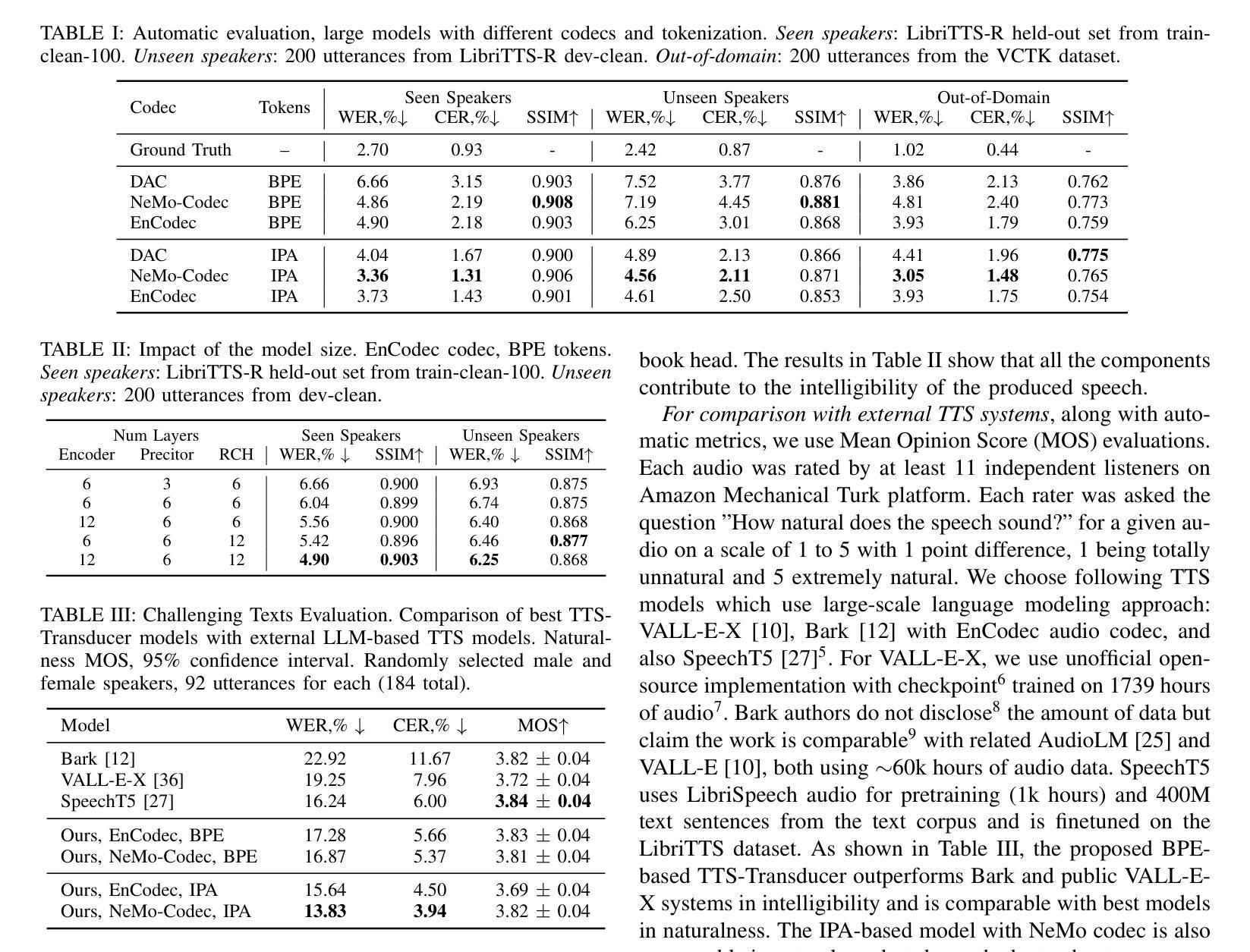
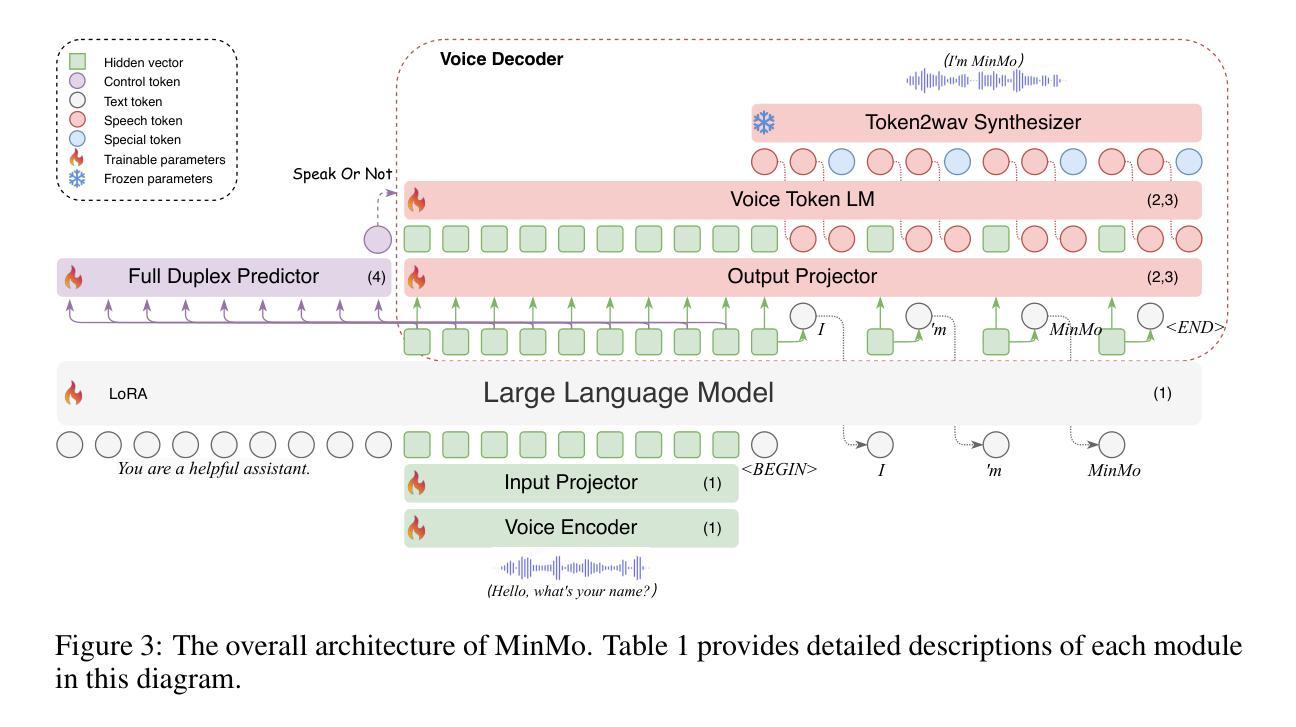
MinMo: A Multimodal Large Language Model for Seamless Voice Interaction
Authors:Qian Chen, Yafeng Chen, Yanni Chen, Mengzhe Chen, Yingda Chen, Chong Deng, Zhihao Du, Ruize Gao, Changfeng Gao, Zhifu Gao, Yabin Li, Xiang Lv, Jiaqing Liu, Haoneng Luo, Bin Ma, Chongjia Ni, Xian Shi, Jialong Tang, Hui Wang, Hao Wang, Wen Wang, Yuxuan Wang, Yunlan Xu, Fan Yu, Zhijie Yan, Yexin Yang, Baosong Yang, Xian Yang, Guanrou Yang, Tianyu Zhao, Qinglin Zhang, Shiliang Zhang, Nan Zhao, Pei Zhang, Chong Zhang, Jinren Zhou
Recent advancements in large language models (LLMs) and multimodal speech-text models have laid the groundwork for seamless voice interactions, enabling real-time, natural, and human-like conversations. Previous models for voice interactions are categorized as native and aligned. Native models integrate speech and text processing in one framework but struggle with issues like differing sequence lengths and insufficient pre-training. Aligned models maintain text LLM capabilities but are often limited by small datasets and a narrow focus on speech tasks. In this work, we introduce MinMo, a Multimodal Large Language Model with approximately 8B parameters for seamless voice interaction. We address the main limitations of prior aligned multimodal models. We train MinMo through multiple stages of speech-to-text alignment, text-to-speech alignment, speech-to-speech alignment, and duplex interaction alignment, on 1.4 million hours of diverse speech data and a broad range of speech tasks. After the multi-stage training, MinMo achieves state-of-the-art performance across various benchmarks for voice comprehension and generation while maintaining the capabilities of text LLMs, and also facilitates full-duplex conversation, that is, simultaneous two-way communication between the user and the system. Moreover, we propose a novel and simple voice decoder that outperforms prior models in voice generation. The enhanced instruction-following capabilities of MinMo supports controlling speech generation based on user instructions, with various nuances including emotions, dialects, and speaking rates, and mimicking specific voices. For MinMo, the speech-to-text latency is approximately 100ms, full-duplex latency is approximately 600ms in theory and 800ms in practice. The MinMo project web page is https://funaudiollm.github.io/minmo, and the code and models will be released soon.
近期的自然语言处理大型语言模型(LLM)和多模态语音文本模型的进展为无缝语音交互奠定了基础,实现了实时、自然、人性化的对话。以往的语音交互模型可分为原生和对齐两类。原生模型将语音和文本处理集成在一个框架中,但面临序列长度不一和预训练不足等问题。而对齐模型保留了文本LLM的功能,但往往受限于小数据集和狭窄的语音任务关注范围。在这项工作中,我们介绍了MinMo,这是一个用于无缝语音交互的多模态大型语言模型,拥有约8亿个参数。我们解决了以往对齐多模态模型的主要局限性。我们通过多个阶段的语音到文本对齐、文本到语音对齐、语音到语音对齐和双向交互对齐,在140万小时的各种语音数据上训练了MinMo模型,涵盖广泛的语音任务。经过多阶段训练后,MinMo在语音理解和生成方面达到了最先进的技术性能,同时保留了文本LLM的功能,并促进了全双工对话,即用户与系统之间的双向实时通信。此外,我们还提出了一种新颖而简洁的语音解码器,在语音生成方面优于以前的模型。MinMo的指令执行能力得到提升,可以支持用户根据指令控制语音生成,包括各种细微差别,如情感、方言和语速,以及模仿特定声音。MinMo的语音转文本延迟约为100毫秒,全双工理论延迟约为600毫秒,实际延迟约为800毫秒。MinMo项目网页是https://funaudiollm.github.io/minmo,代码和模型将很快发布。
论文及项目相关链接
PDF Work in progress. Authors are listed in alphabetical order by family name
Summary
最近的大型语言模型和多模态语音文本模型的进步为无缝语音交互奠定了基础,实现了实时、自然和人性化的对话。本研究介绍了MinMo,一种用于无缝语音交互的多模态大型语言模型,通过多阶段对齐训练,实现了先进的语音理解和生成性能,并保持了文本大型语言模型的能力。MinMo还支持全双工对话,并具有出色的语音生成控制器,可模仿特定的语音特征。
Key Takeaways
- 大型语言模型和多模态语音文本模型的进步促进了无缝语音交互的发展。
- MinMo模型通过多阶段训练,实现了先进的语音理解和生成性能。
- MinMo模型结合了文本大型语言模型的能力,并优化了语音交互。
- MinMo支持全双工对话,实现了用户与系统的实时双向交流。
- MinMo的语音生成控制器可模仿特定的语音特征,如情感、方言和语速。
- MinMo的语音到文本的延迟约为100毫秒,全双工延迟在理论上为600毫秒,实践中为800毫秒。
点此查看论文截图



Improving Robustness of Diffusion-Based Zero-Shot Speech Synthesis via Stable Formant Generation
Authors:Changjin Han, Seokgi Lee, Gyuhyeon Nam, Gyeongsu Chae
Diffusion models have achieved remarkable success in text-to-speech (TTS), even in zero-shot scenarios. Recent efforts aim to address the trade-off between inference speed and sound quality, often considered the primary drawback of diffusion models. However, we find a critical mispronunciation issue is being overlooked. Our preliminary study reveals the unstable pronunciation resulting from the diffusion process. Based on this observation, we introduce StableForm-TTS, a novel zero-shot speech synthesis framework designed to produce robust pronunciation while maintaining the advantages of diffusion modeling. By pioneering the adoption of source-filter theory in diffusion TTS, we propose an elaborate architecture for stable formant generation. Experimental results on unseen speakers show that our model outperforms the state-of-the-art method in terms of pronunciation accuracy and naturalness, with comparable speaker similarity. Moreover, our model demonstrates effective scalability as both data and model sizes increase. Audio samples are available online: https://deepbrainai-research.github.io/stableformtts/.
扩散模型在文本到语音(TTS)方面取得了显著的成功,甚至在零样本场景中也表现优异。近期的研究旨在解决推理速度与音质之间的权衡问题,这通常被认为是扩散模型的主要缺点。然而,我们发现一个重要的发音错误问题被忽视了。我们的初步研究表明,扩散过程导致的发音不稳定。基于此观察,我们引入了StableForm-TTS,这是一种新的零样本语音合成框架,旨在产生稳健的发音,同时保持扩散模型的优点。我们通过率先在扩散TTS中采用声源滤波器理论,提出了一个精细的结构来产生稳定的音轨。在未见过的说话人实验结果显示,我们的模型在发音准确性和自然度方面优于最新方法,并且在说话人相似性方面表现相当。此外,随着数据和模型规模的增加,我们的模型展示了有效的可扩展性。音频样本可在网上获取:https://deepbrainai-research.github.io/stableformtts/。
论文及项目相关链接
PDF Accepted to ICASSP 2025
Summary
文本主要介绍了Diffusion模型在文本到语音(TTS)领域的显著成功,特别是在零样本场景下的表现。文章针对Diffusion模型的主要缺点——推理速度与音质之间的权衡问题进行了改进,并指出被忽略的关键发音问题。基于此观察,文章提出了一种新的零样本语音合成框架StableForm-TTS,旨在产生稳健的发音同时保持Diffusion模型的优点。文章还引入了音源滤波理论来构建一个稳定的音域生成架构。实验结果表明,该模型在未见过的说话人上优于当前先进的方法,在发音准确性和自然性方面表现出优势,同时在说话人相似性方面表现相当。此外,该模型在数据和模型规模增加时显示出有效的可扩展性。
Key Takeaways
- Diffusion模型在文本到语音(TTS)领域取得了显著成功,特别是在零样本场景。
- 近期研究致力于解决Diffusion模型的推理速度与音质之间的权衡问题。
- 发现Diffusion模型中发音不稳定的问题被忽视。
- 引入StableForm-TTS框架,旨在产生稳健的发音同时保持Diffusion模型的优点。
- 首次将音源滤波理论应用于Diffusion TTS,提出稳定的音域生成架构。
- 实验证明StableForm-TTS在未见过的说话人上优于其他方法,表现出发音准确性和自然性优势。
点此查看论文截图