⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-16 更新
DM-Mamba: Dual-domain Multi-scale Mamba for MRI reconstruction
Authors:Yucong Meng, Zhiwei Yang, Zhijian Song, Yonghong Shi
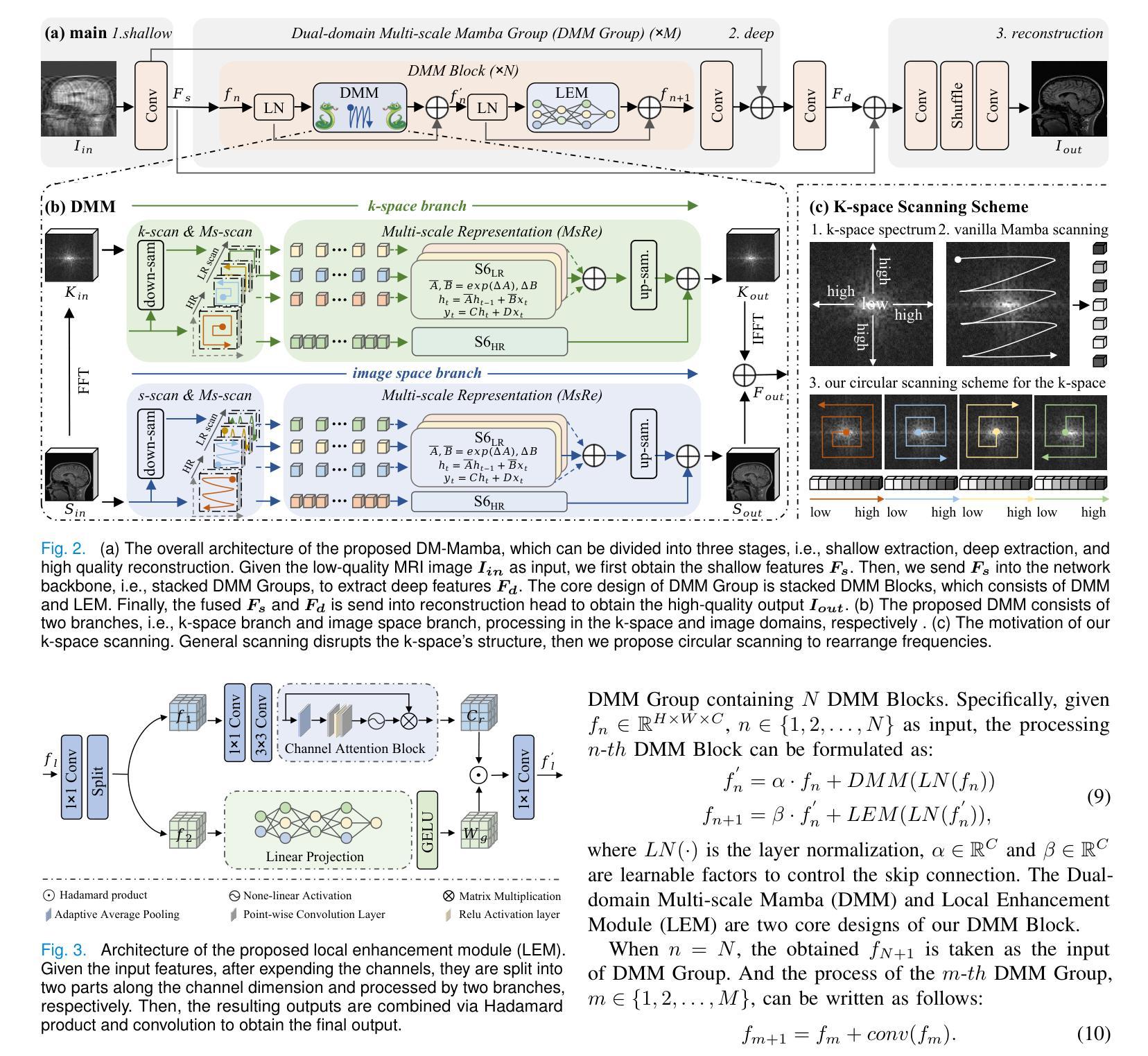
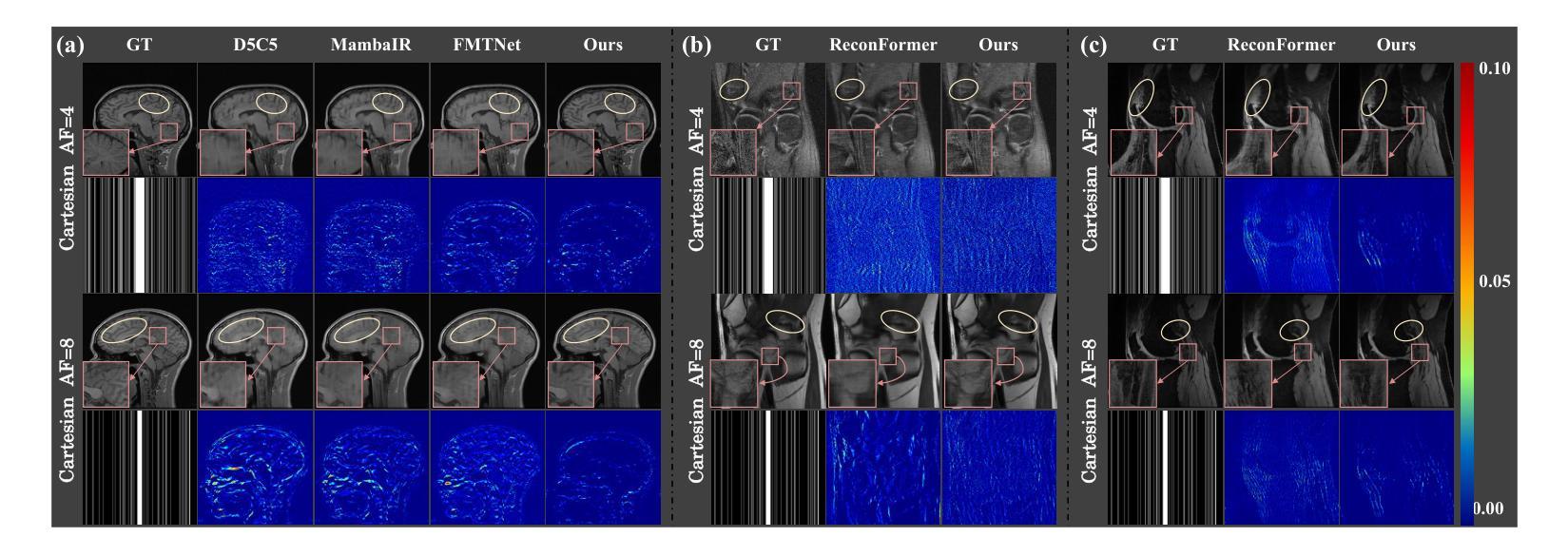
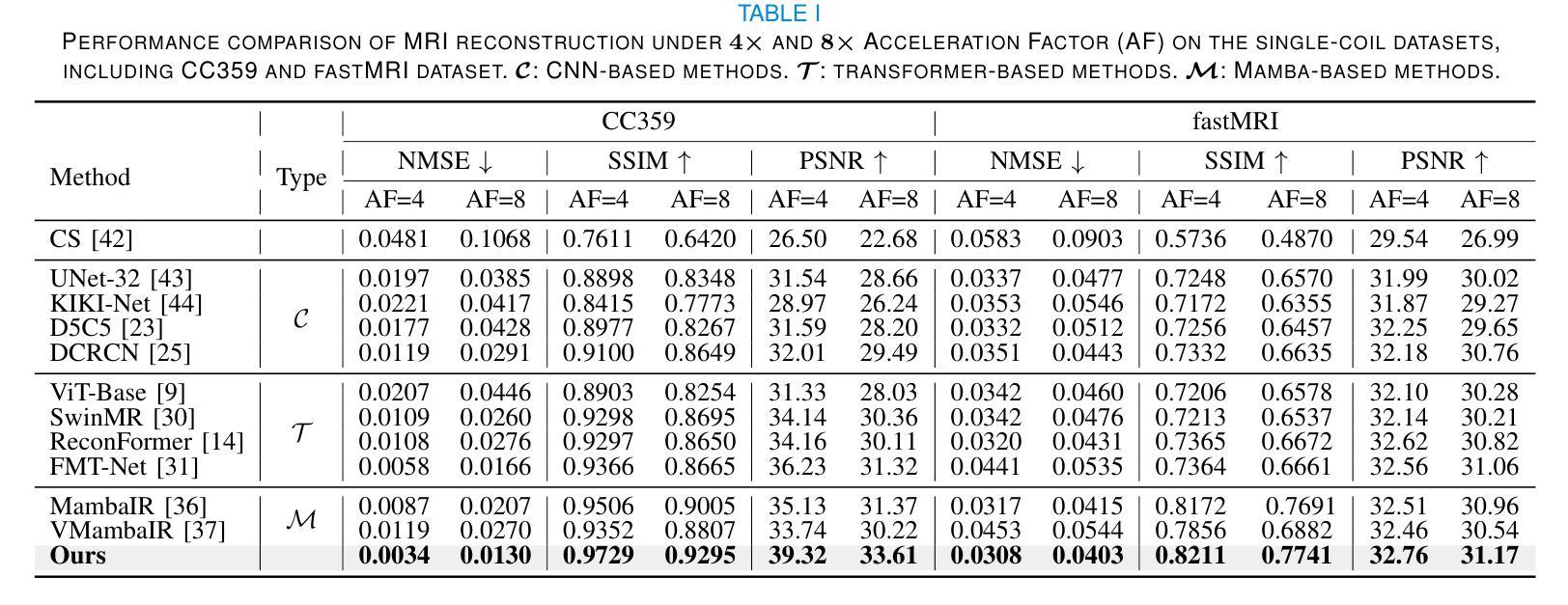
The accelerated MRI reconstruction poses a challenging ill-posed inverse problem due to the significant undersampling in k-space. Deep neural networks, such as CNNs and ViT, have shown substantial performance improvements for this task while encountering the dilemma between global receptive fields and efficient computation. To this end, this paper pioneers exploring Mamba, a new paradigm for long-range dependency modeling with linear complexity, for efficient and effective MRI reconstruction. However, directly applying Mamba to MRI reconstruction faces three significant issues: (1) Mamba’s row-wise and column-wise scanning disrupts k-space’s unique spectrum, leaving its potential in k-space learning unexplored. (2) Existing Mamba methods unfold feature maps with multiple lengthy scanning paths, leading to long-range forgetting and high computational burden. (3) Mamba struggles with spatially-varying contents, resulting in limited diversity of local representations. To address these, we propose a dual-domain multi-scale Mamba for MRI reconstruction from the following perspectives: (1) We pioneer vision Mamba in k-space learning. A circular scanning is customized for spectrum unfolding, benefiting the global modeling of k-space. (2) We propose a multi-scale Mamba with an efficient scanning strategy in both image and k-space domains. It mitigates long-range forgetting and achieves a better trade-off between efficiency and performance. (3) We develop a local diversity enhancement module to improve the spatially-varying representation of Mamba. Extensive experiments are conducted on three public datasets for MRI reconstruction under various undersampling patterns. Comprehensive results demonstrate that our method significantly outperforms state-of-the-art methods with lower computational cost. Implementation code will be available at https://github.com/XiaoMengLiLiLi/DM-Mamba.
加速MRI重建是一个具有挑战性的不适定反问题,这主要是由于k空间中的显著欠采样造成的。深度神经网络,如卷积神经网络和Vision Transformer,虽然在此任务中显示出显著的性能改进,但在全局感受野和高效计算之间遇到了困境。为此,本文率先探索Mamba,这是一种具有线性复杂度进行长距离依赖建模的新范式,用于高效且有效的MRI重建。然而,直接将Mamba应用于MRI重建面临三个主要问题:(1)Mamba的行级和列级扫描破坏了k空间的独特频谱,使得其在k空间学习方面的潜力尚未得到探索。(2)现有的Mamba方法展开特征映射具有多条冗长的扫描路径,导致长距离遗忘和较高的计算负担。(3)Mamba在处理空间变化内容时遇到困难,导致局部表示缺乏多样性。为解决这些问题,我们从以下角度提出用于MRI重建的双域多尺度Mamba:(1)我们率先在k空间学习中探索视觉Mamba。针对频谱展开定制循环扫描,有利于k空间的全局建模。(2)我们提出了一种多尺度Mamba,在图像和k空间域都采用了高效的扫描策略。它减轻了长距离遗忘问题,并在效率和性能之间实现了更好的权衡。(3)我们开发了一个局部多样性增强模块,以提高Mamba的空间变化表示能力。在三个公共数据集上进行了大量MRI重建实验,实验结果表明,在各种欠采样模式下,我们的方法显著优于最先进的方法,且计算成本更低。相关实现代码将发布在https://github.com/XiaoMengLiLiLi/DM-Mamba。
论文及项目相关链接
Summary
本文提出一种新型的MRI重建方法——双域多尺度Mamba技术。针对直接应用Mamba技术所面临的挑战,该方法结合卷积神经网络中的跨空间和谱领域提出创新性策略,旨在实现更高效且有效的MRI重建。该方法包括将Mamba引入k空间学习,提出多尺度Mamba以减轻计算负担和长范围遗忘问题,并增强局部多样性以增强空间变化的表示。实验结果证明了其在多种采样模式下的MRI重建任务上的优越性。
Key Takeaways
- Mamba技术被引入MRI重建领域,旨在解决计算效率和全局建模问题。
- 直接应用Mamba于MRI重建面临独特频谱的破坏、长范围遗忘和高计算负担等问题。
- 提出双域多尺度Mamba技术,结合图像和k空间域的多尺度分析,实现效率和性能的平衡。
- 引入局部多样性增强模块,提高空间变化内容的表示能力。
点此查看论文截图

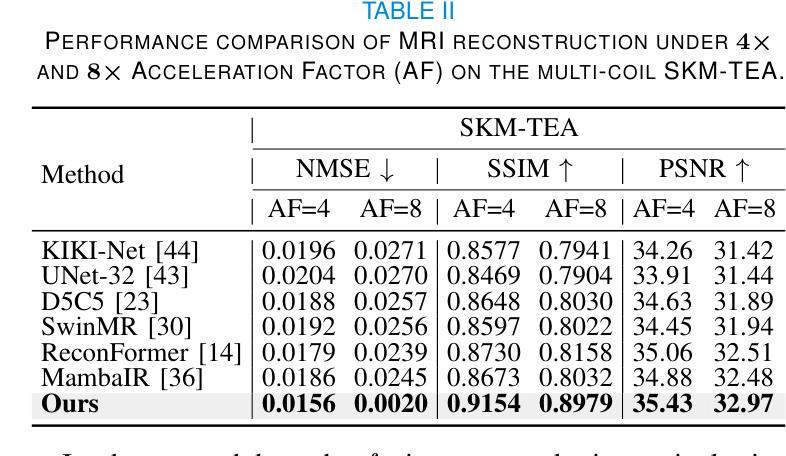
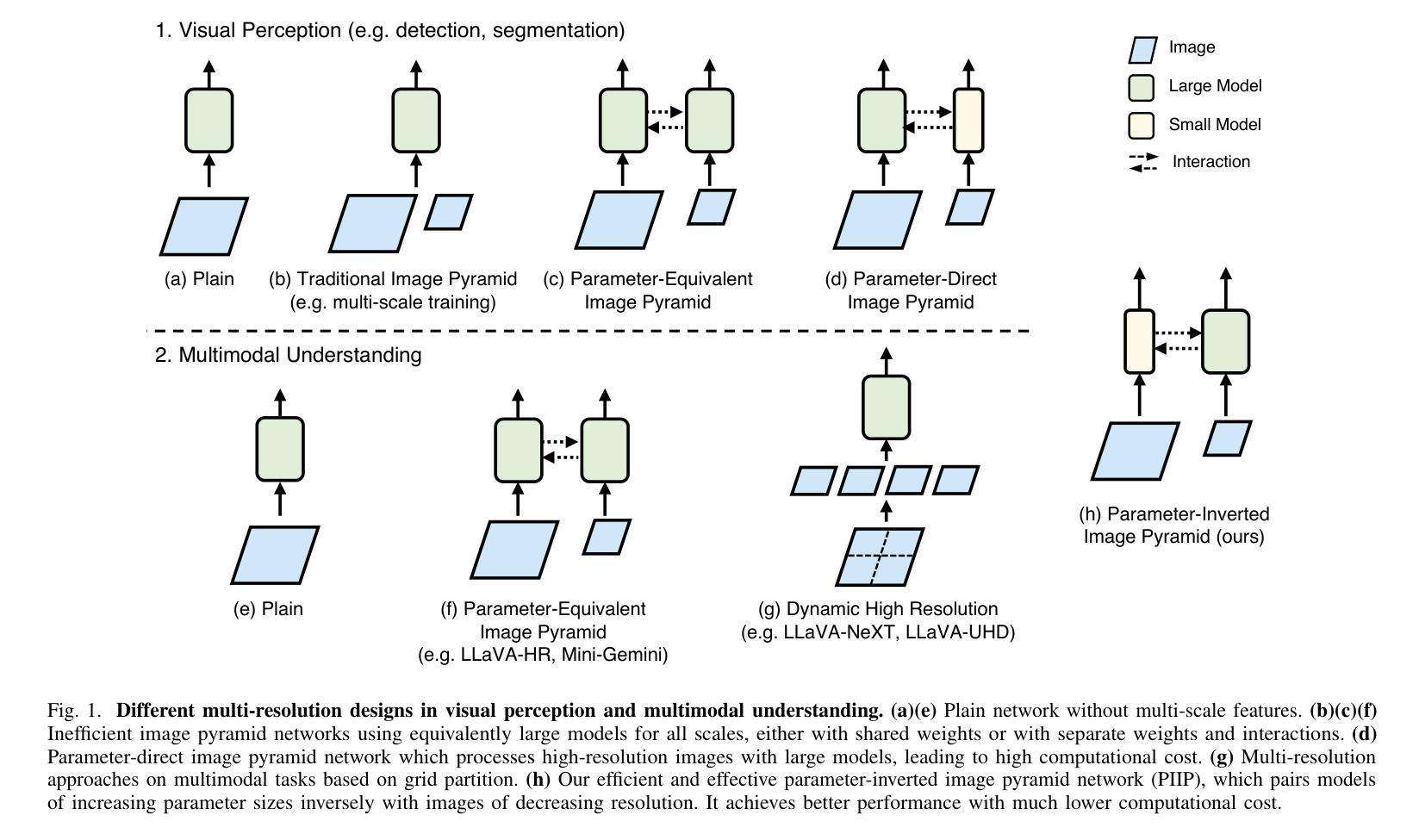
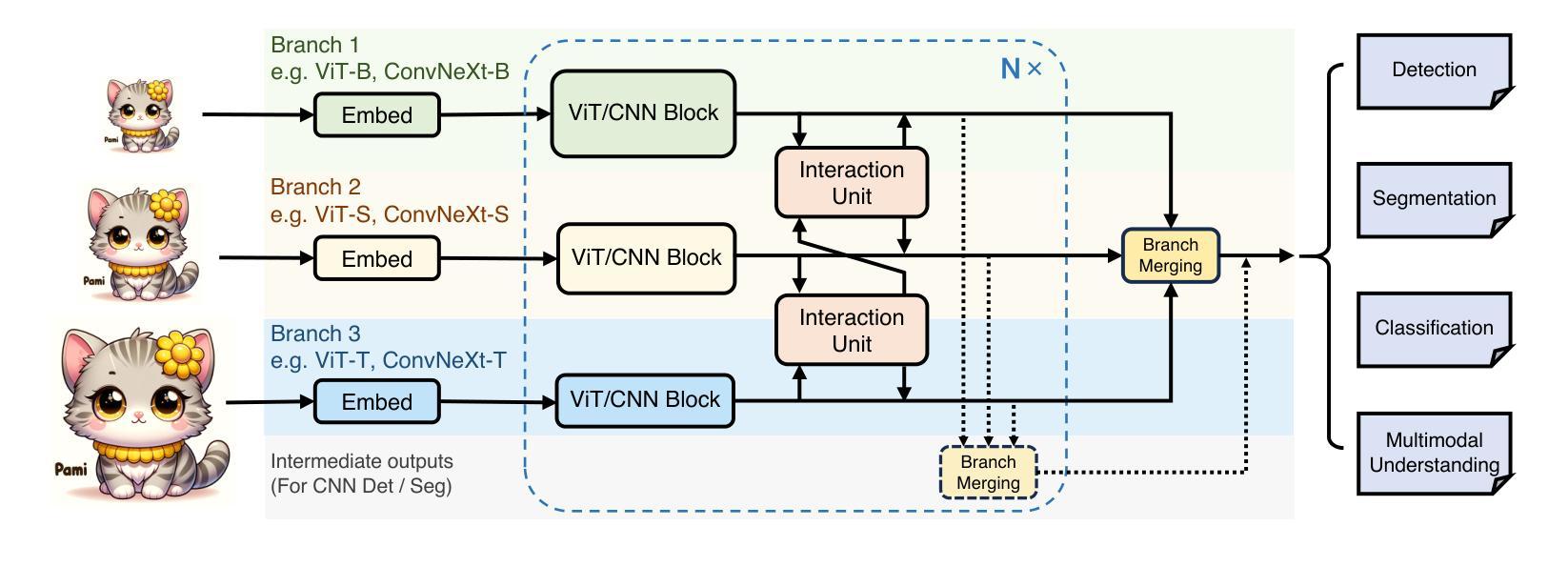
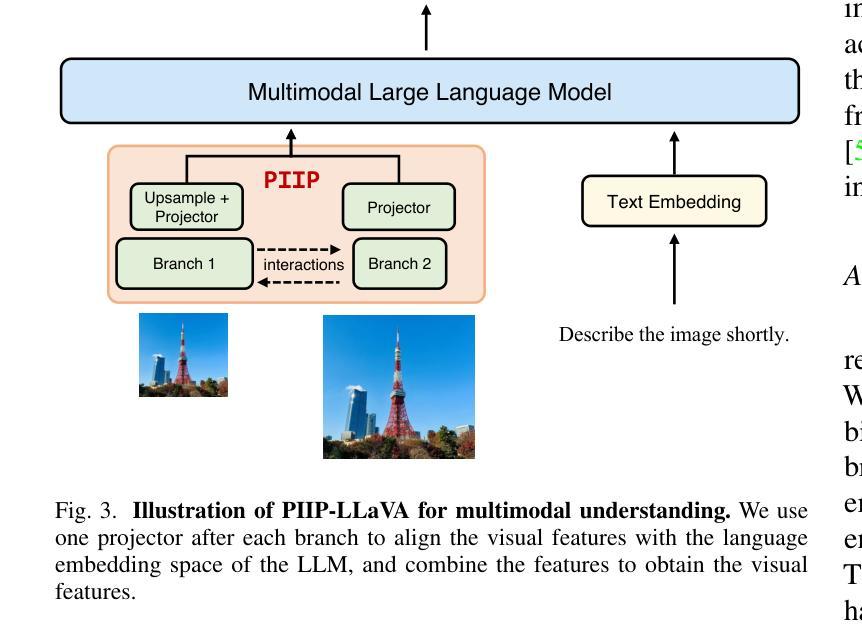
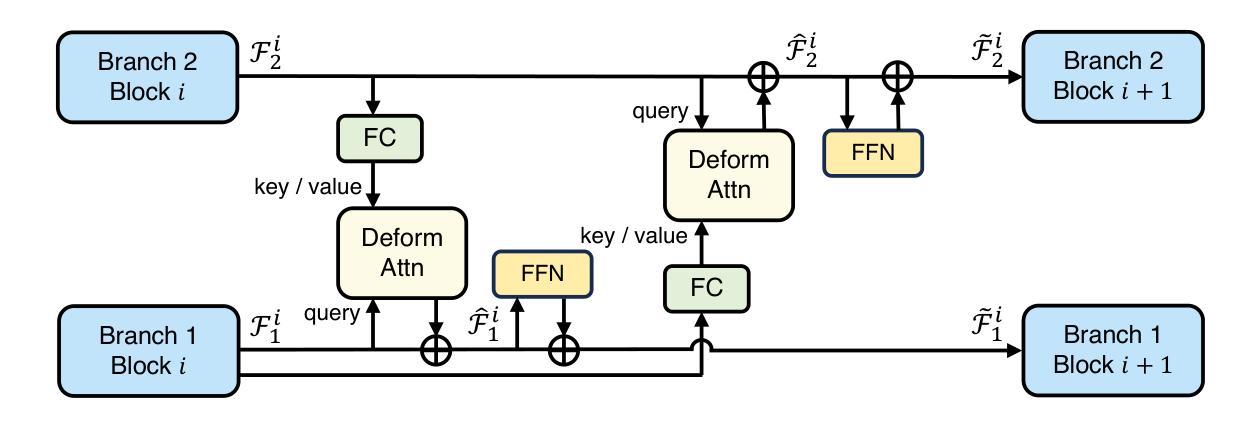
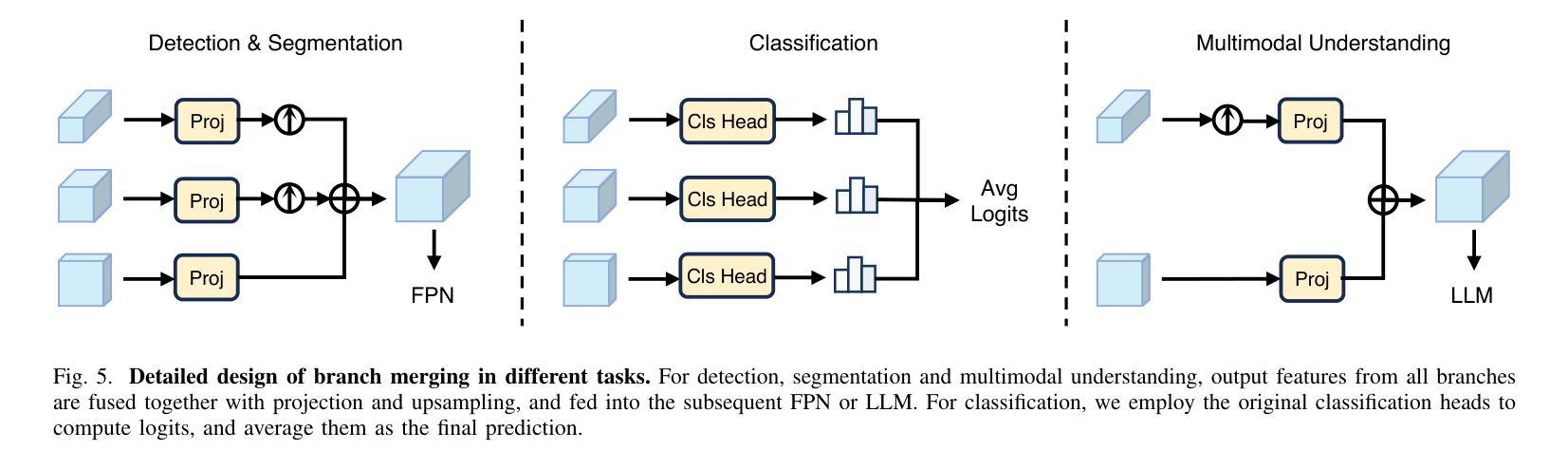
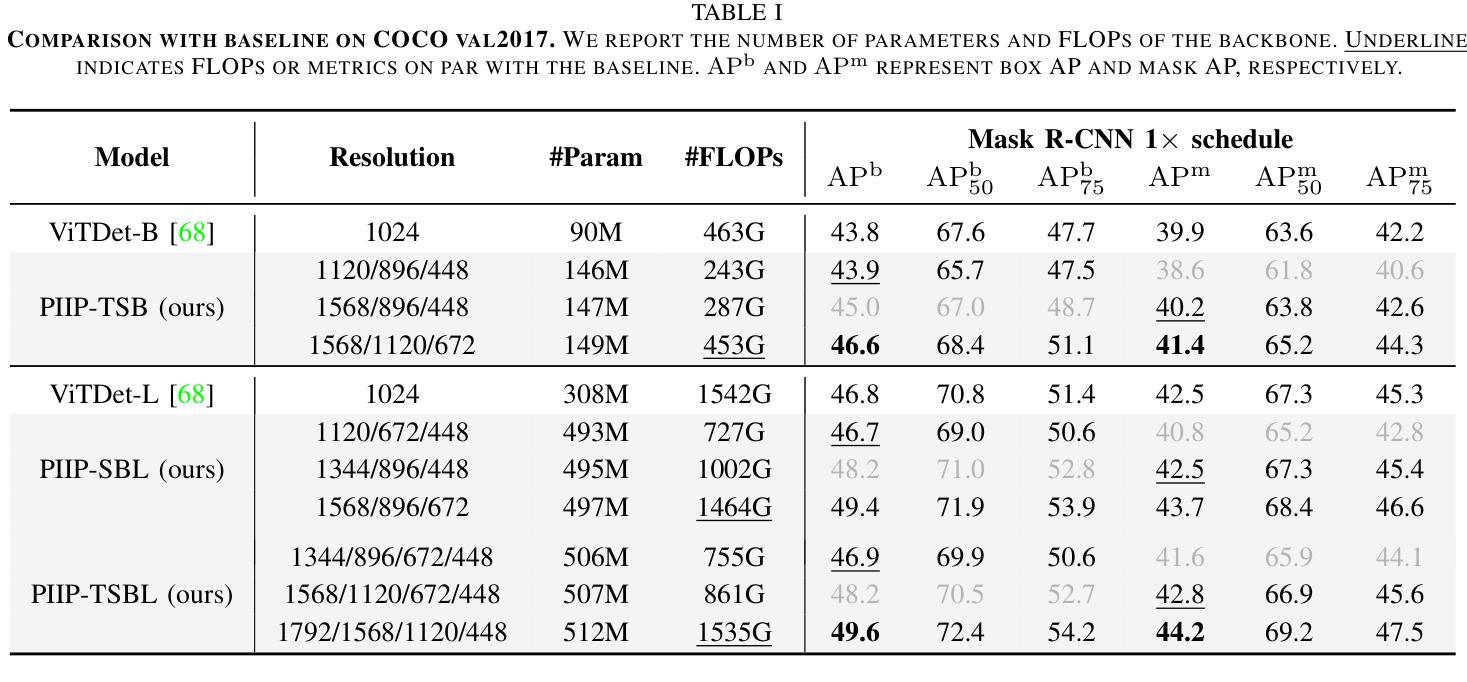
Parameter-Inverted Image Pyramid Networks for Visual Perception and Multimodal Understanding
Authors:Zhaokai Wang, Xizhou Zhu, Xue Yang, Gen Luo, Hao Li, Changyao Tian, Wenhan Dou, Junqi Ge, Lewei Lu, Yu Qiao, Jifeng Dai
Image pyramids are widely adopted in top-performing methods to obtain multi-scale features for precise visual perception and understanding. However, current image pyramids use the same large-scale model to process multiple resolutions of images, leading to significant computational cost. To address this challenge, we propose a novel network architecture, called Parameter-Inverted Image Pyramid Networks (PIIP). Specifically, PIIP uses pretrained models (ViTs or CNNs) as branches to process multi-scale images, where images of higher resolutions are processed by smaller network branches to balance computational cost and performance. To integrate information from different spatial scales, we further propose a novel cross-branch feature interaction mechanism. To validate PIIP, we apply it to various perception models and a representative multimodal large language model called LLaVA, and conduct extensive experiments on various tasks such as object detection, segmentation, image classification and multimodal understanding. PIIP achieves superior performance compared to single-branch and existing multi-resolution approaches with lower computational cost. When applied to InternViT-6B, a large-scale vision foundation model, PIIP can improve its performance by 1%-2% on detection and segmentation with only 40%-60% of the original computation, finally achieving 60.0 box AP on MS COCO and 59.7 mIoU on ADE20K. For multimodal understanding, our PIIP-LLaVA achieves 73.0% accuracy on TextVQA and 74.5% on MMBench with only 2.8M training data. Our code is released at https://github.com/OpenGVLab/PIIP.
图像金字塔已在高性能方法中广泛采用,以获得用于精确视觉感知和理解的多尺度特征。然而,当前图像金字塔使用相同的大规模模型来处理不同分辨率的图像,导致计算成本显著。为了解决这一挑战,我们提出了一种新型网络架构,称为参数倒置图像金字塔网络(PIIP)。具体而言,PIIP使用预训练模型(ViTs或CNN)作为分支来处理多尺度图像,其中高分辨率图像由较小的网络分支进行处理,以平衡计算成本和性能。为了整合不同空间尺度的信息,我们进一步提出了一种新型跨分支特征交互机制。为了验证PIIP的有效性,我们将其应用于各种感知模型和名为LLaVA的代表性多模态大型语言模型,并在各种任务(如目标检测、分割、图像分类和多模态理解)上进行了大量实验。PIIP相较于单分支和现有多分辨率方法取得了更优越的性能,且计算成本更低。当应用于大型视觉基础模型InternViT-6B时,PIIP在检测与分割方面的性能提高了1%-2%,仅使用原始计算的40%-60%,最终在MS COCO上实现了60.0的box AP,在ADE20K上实现了59.7的mIoU。对于多模态理解,我们的PIIP-LLaVA在TextVQA上达到了73.0%的准确率,在MMBench上达到了74.5%的准确率,且仅使用了2.8M的训练数据。我们的代码已发布在https://github.com/OpenGVLab/PIIP。
论文及项目相关链接
Summary
针对图像金字塔在处理多尺度图像时计算成本较高的问题,提出了参数倒置图像金字塔网络(PIIP)。PIIP利用预训练模型(如ViTs或CNNs)作为分支处理多尺度图像,通过不同分辨率的图像处理分支来平衡计算成本与性能。通过跨分支特征交互机制整合不同空间尺度的信息,并在各种感知模型和名为LLaVA的多模态大型语言模型上进行了验证。PIIP相较于单分支和现有多分辨率方法,在降低计算成本的同时实现了卓越的性能。应用于大型视觉基础模型InternViT-6B时,PIIP在检测和分割方面的性能提升1%-2%,在MS COCO上实现60.0 box AP,在ADE20K上实现59.7 mIoU。对于多模态理解,PIIP-LLaVA在TextVQA上达到73.0%的准确率,在MMBench上达到74.5%的准确率,仅使用2.8M训练数据。
Key Takeaways
- 当前图像金字塔使用同一大规模模型处理多分辨率图像存在计算成本较高的问题。
- PIIP网络利用预训练模型作为分支处理多尺度图像,以平衡计算成本和性能。
- PIIP通过跨分支特征交互机制整合不同空间尺度的信息。
- PIIP在多种视觉任务(如目标检测、分割、图像分类)上实现了优于单分支和现有多分辨率方法的性能。
- PIIP在大型视觉基础模型InternViT-6B上的性能提升显著,在MS COCO和ADE20K上的结果表现优异。
- 对于多模态理解,PIIP-LLaVA在TextVQA和MMBench任务上取得了良好成绩,且仅使用有限的训练数据。
- PIIP的代码已公开发布,便于其他研究者使用和进一步探索。
点此查看论文截图

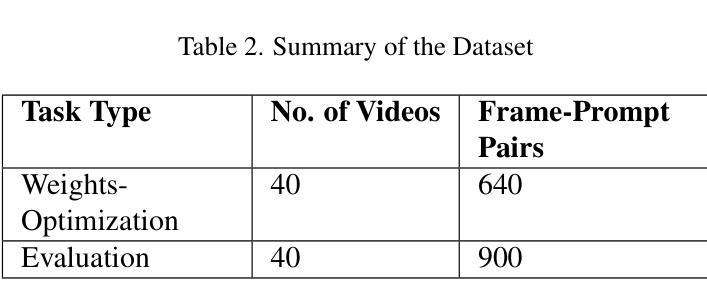
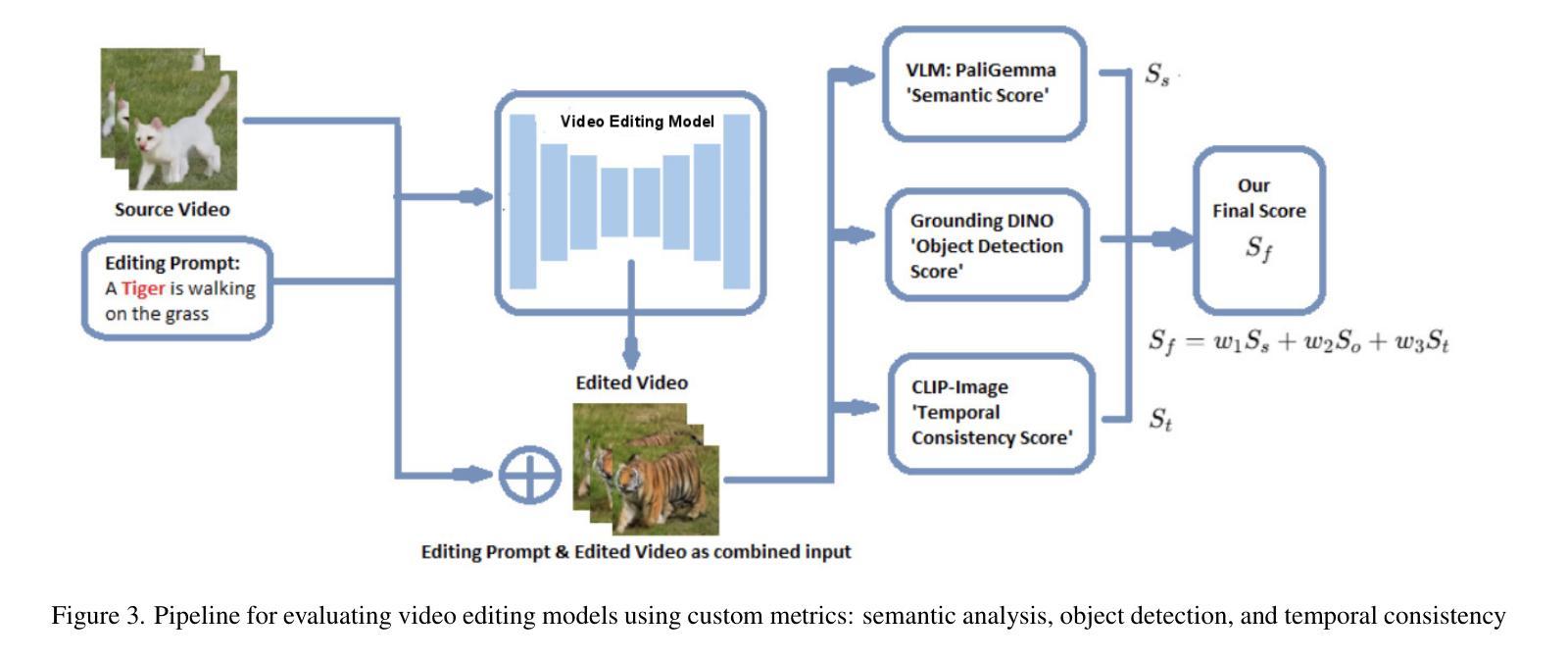
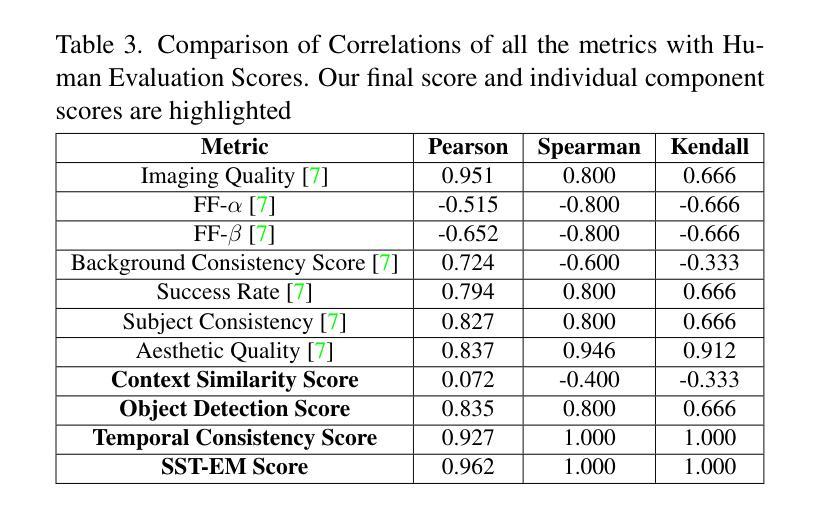
SST-EM: Advanced Metrics for Evaluating Semantic, Spatial and Temporal Aspects in Video Editing
Authors:Varun Biyyala, Bharat Chanderprakash Kathuria, Jialu Li, Youshan Zhang
Video editing models have advanced significantly, but evaluating their performance remains challenging. Traditional metrics, such as CLIP text and image scores, often fall short: text scores are limited by inadequate training data and hierarchical dependencies, while image scores fail to assess temporal consistency. We present SST-EM (Semantic, Spatial, and Temporal Evaluation Metric), a novel evaluation framework that leverages modern Vision-Language Models (VLMs), Object Detection, and Temporal Consistency checks. SST-EM comprises four components: (1) semantic extraction from frames using a VLM, (2) primary object tracking with Object Detection, (3) focused object refinement via an LLM agent, and (4) temporal consistency assessment using a Vision Transformer (ViT). These components are integrated into a unified metric with weights derived from human evaluations and regression analysis. The name SST-EM reflects its focus on Semantic, Spatial, and Temporal aspects of video evaluation. SST-EM provides a comprehensive evaluation of semantic fidelity and temporal smoothness in video editing. The source code is available in the \textbf{\href{https://github.com/custommetrics-sst/SST_CustomEvaluationMetrics.git}{GitHub Repository}}.
视频编辑模型已经取得了显著的进步,但是评估它们的性能仍然具有挑战性。传统的评估指标,如CLIP的文本和图像分数,通常存在不足:文本分数受限于不足的训练数据和层次依赖性,而图像分数则无法评估时间一致性。我们提出了SST-EM(语义、空间和时间评估指标),这是一个新的评估框架,它利用现代的视觉语言模型(VLMs)、目标检测和一致性检查。SST-EM包含四个组成部分:(1)使用VLM从帧中提取语义,(2)使用目标检测进行主要对象跟踪,(3)通过LLM代理进行对象精炼,(4)使用视觉转换器(ViT)进行时间一致性评估。这些组件被集成到一个统一的评价指标中,权重来源于人类评估和回归分析。SST-EM的名字反映了其在视频评估的语义、空间和时间方面的重点。SST-EM为视频编辑的语义保真度和时间平滑性提供了全面的评估。源代码可在\href{https://github.com/custommetrics-sst/SST_CustomEvaluationMetrics.git}{GitHub Repository}中找到。
论文及项目相关链接
PDF WACV workshop
Summary
本文介绍了视频编辑模型性能评估的挑战,提出一种新型评估框架SST-EM。该框架利用现代视觉语言模型、目标检测和时空一致性检查技术,包括语义提取、主要对象跟踪、特定对象优化和时空一致性评估四个组件。SST-EM为视频编辑的语义保真度和时间平滑度提供了全面的评估。
Key Takeaways
- 视频编辑模型性能评估存在挑战,传统评估指标如CLIP文本和图像分数常常不足。
- SST-EM是一个新型评估框架,包含四个组件:语义提取、主要对象跟踪、特定对象优化和时空一致性评估。
- SST-EM利用现代视觉语言模型、目标检测技术和时空一致性检查技术。
- SST-EM重视视频的语义、空间和时间的评价方面。
- SST-EM提供了对视频编辑的语义保真度和时间平滑度的全面评估。
- SST-EM的组件通过人类评估和回归分析来确定权重,集成到一个统一的度量标准中。
点此查看论文截图



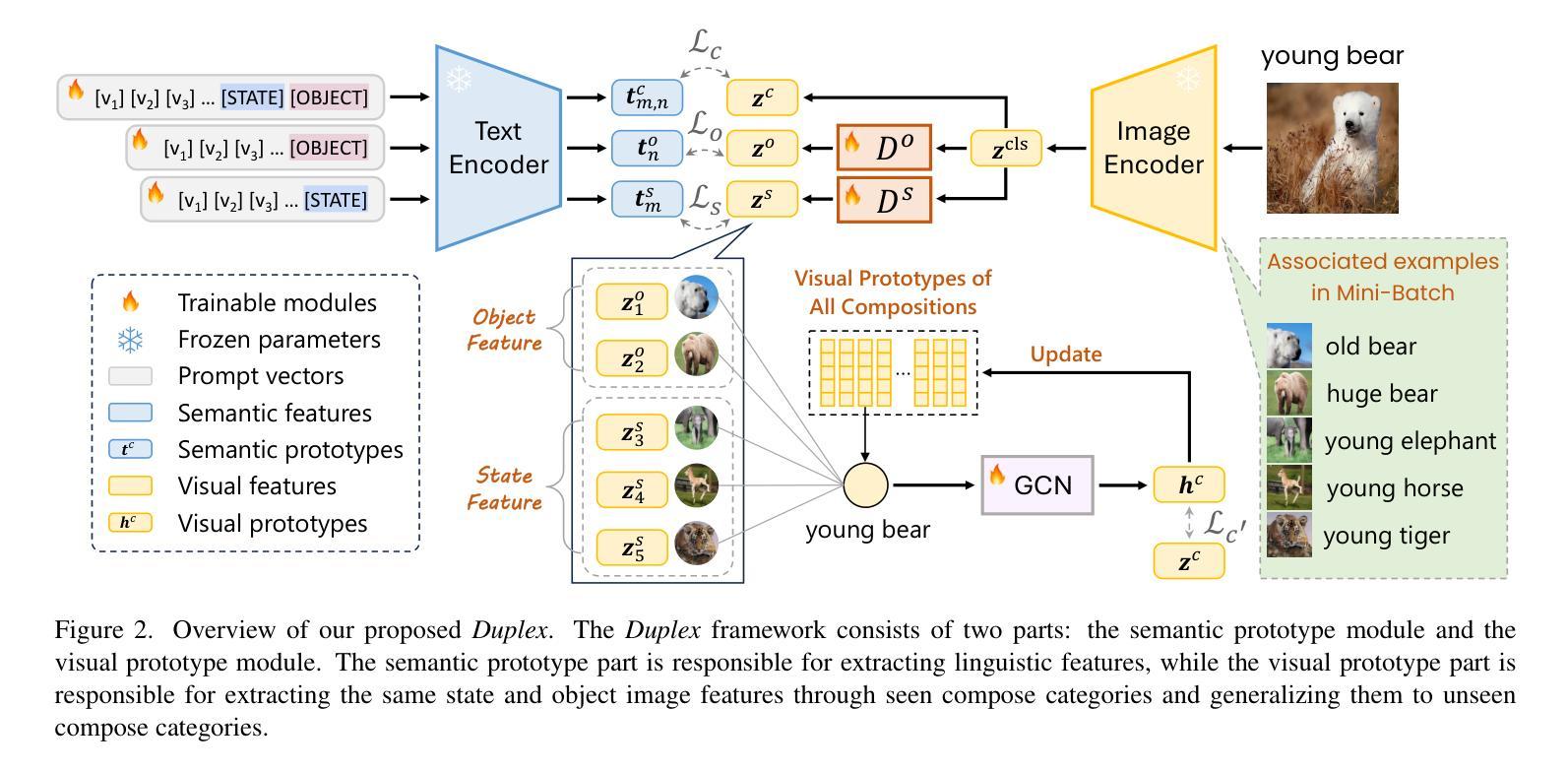
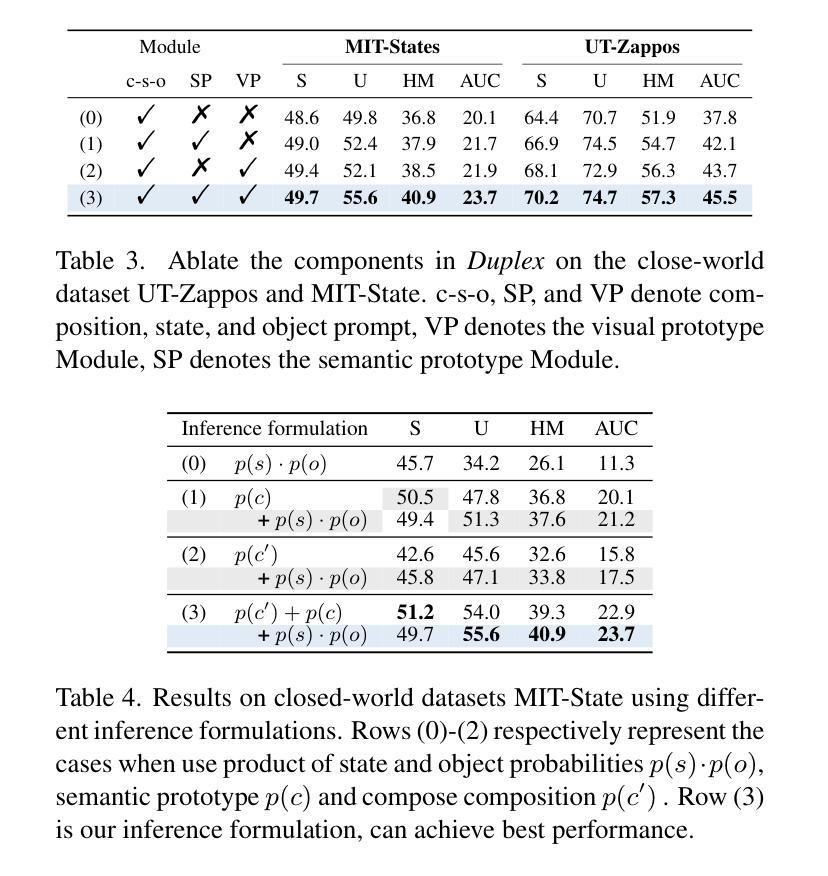
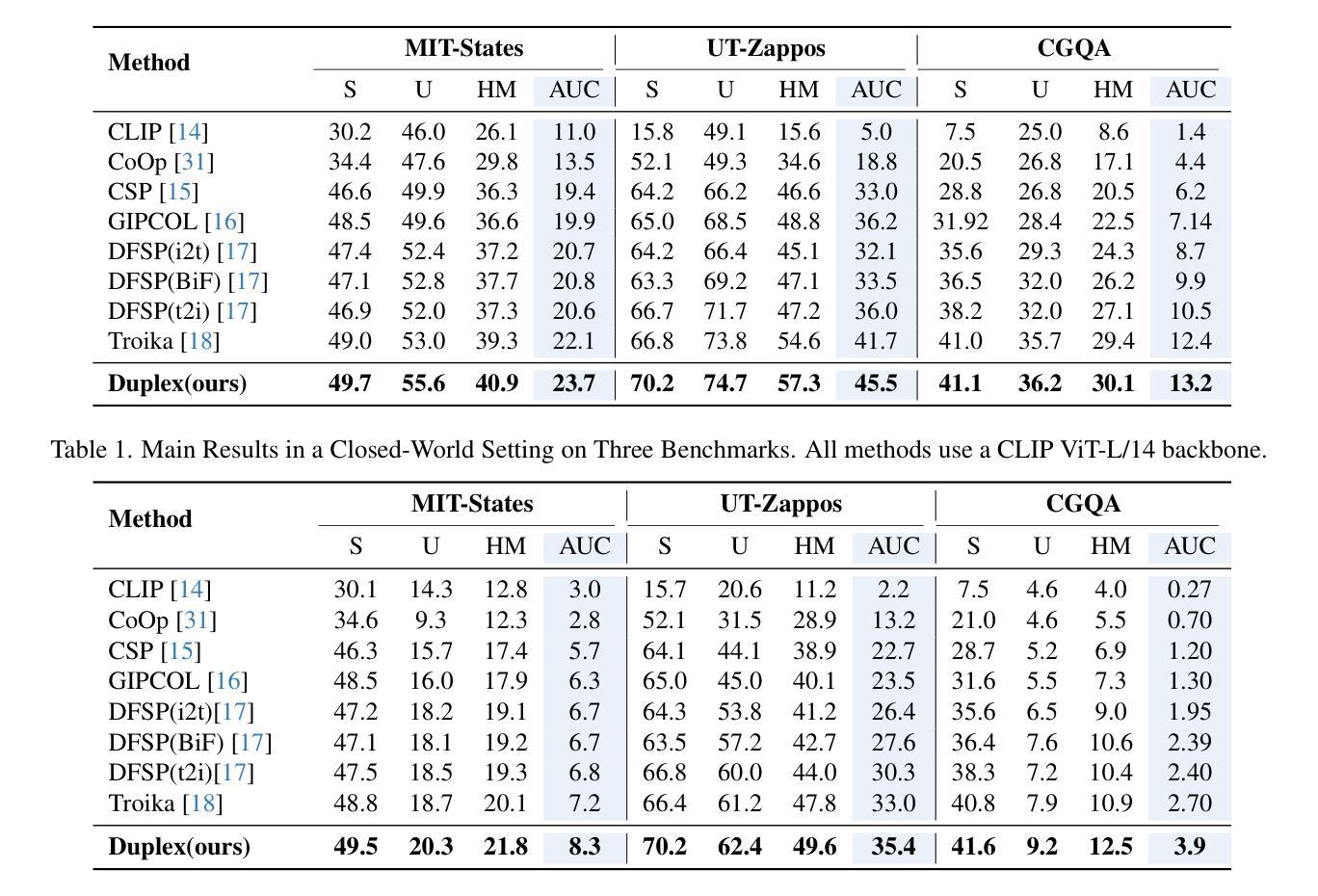
Duplex: Dual Prototype Learning for Compositional Zero-Shot Learning
Authors:Zhong Peng, Yishi Xu, Gerong Wang, Wenchao Chen, Bo Chen, Jing Zhang
Compositional Zero-Shot Learning (CZSL) aims to enable models to recognize novel compositions of visual states and objects that were absent during training. Existing methods predominantly focus on learning semantic representations of seen compositions but often fail to disentangle the independent features of states and objects in images, thereby limiting their ability to generalize to unseen compositions. To address this challenge, we propose Duplex, a novel dual-prototype learning method that integrates semantic and visual prototypes through a carefully designed dual-branch architecture, enabling effective representation learning for compositional tasks. Duplex utilizes a Graph Neural Network (GNN) to adaptively update visual prototypes, capturing complex interactions between states and objects. Additionally, it leverages the strong visual-semantic alignment of pre-trained Vision-Language Models (VLMs) and employs a multi-path architecture combined with prompt engineering to align image and text representations, ensuring robust generalization. Extensive experiments on three benchmark datasets demonstrate that Duplex outperforms state-of-the-art methods in both closed-world and open-world settings.
组合零射学习(CZSL)旨在使模型能够识别训练期间未出现的视觉状态和对象的新组合。现有方法主要集中在学习已见组合的语义表示上,但往往无法解开图像中状态和对象的独立特征,从而限制了它们对未见组合的推广能力。为了解决这一挑战,我们提出了Duplex,这是一种新型的双原型学习方法,它通过精心设计的双分支架构融合了语义和视觉原型,为组合任务实现了有效的表示学习。Duplex利用图神经网络(GNN)自适应地更新视觉原型,捕捉状态和对象之间的复杂交互。此外,它利用了预训练的视觉语言模型的强大视觉语义对齐功能,并采用多路径架构与提示工程相结合,对齐图像和文本表示,确保稳健的泛化能力。在三个基准数据集上的大量实验表明,Duplex在封闭世界和开放世界设置中均优于最新方法。
论文及项目相关链接
Summary
文本提出了一种解决方案Duplex来解决现有模型在处理组合零样本学习(CZSL)时面临的挑战。Duplex通过整合语义和视觉原型,通过精心设计双分支架构进行有效表征学习,实现图像中状态和对象的独立特征分离,从而应对未见组合的新识别任务。该解决方案采用图神经网络(GNN)自适应更新视觉原型,捕捉状态和对象间的复杂交互,并结合预训练视觉语言模型(VLMs)的强大视觉语义对齐能力,通过多路径架构和提示工程确保图像和文本表示的稳健泛化。在三个基准数据集上的实验表明,Duplex在封闭世界和开放世界设置中均优于现有方法。
Key Takeaways
- Compositional Zero-Shot Learning (CZSL)旨在使模型能够识别训练期间未出现的视觉状态和对象的新组合。
- 当前方法主要关注已见组合语义表示的学习,但往往无法分离图像中状态和对象的独立特征,限制了其泛化到未见组合的能力。
- Duplex是一种新型双原型学习方法,通过整合语义和视觉原型,应对未见组合的新识别任务。
- Duplex采用图神经网络(GNN)自适应更新视觉原型,以捕捉状态和对象间的复杂交互。
- 该解决方案利用预训练视觉语言模型(VLMs)的视觉语义对齐能力,确保图像和文本表示的稳健泛化。
- 通过多路径架构和提示工程,Duplex能够强化图像和文本之间的关联。
点此查看论文截图


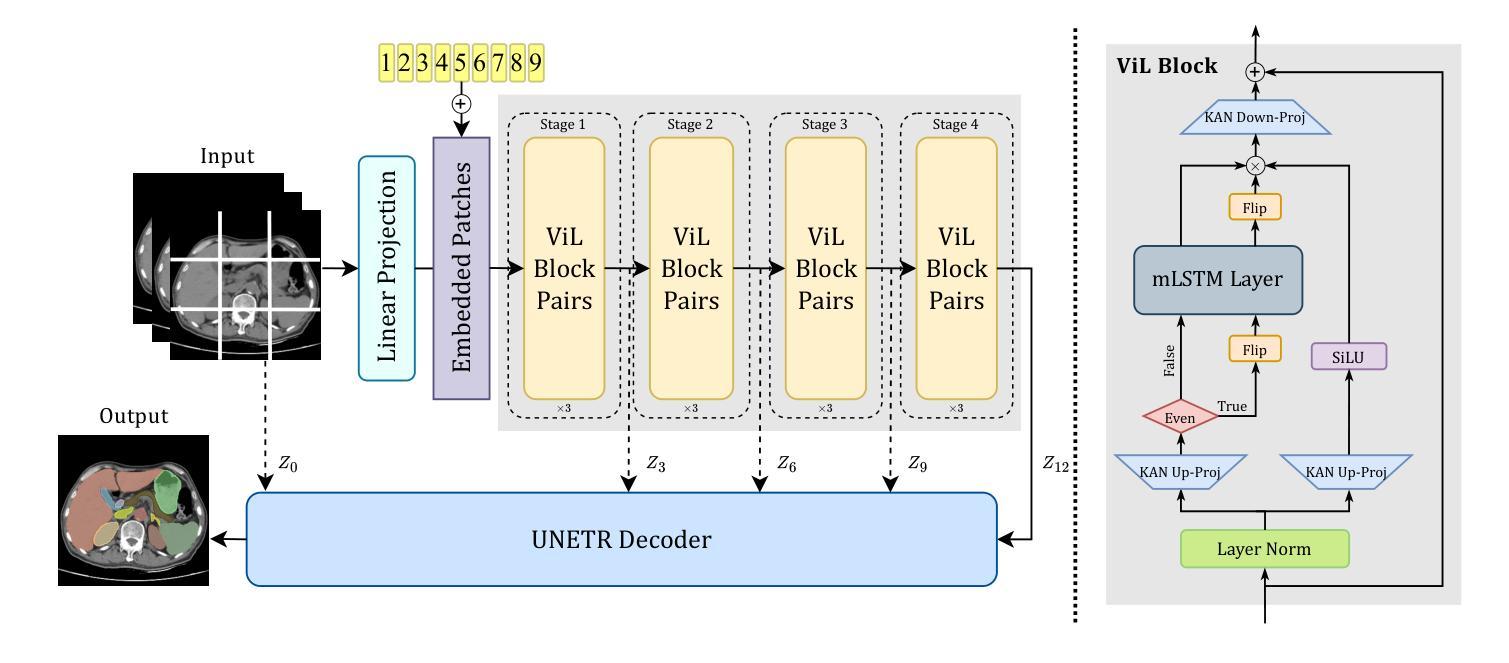
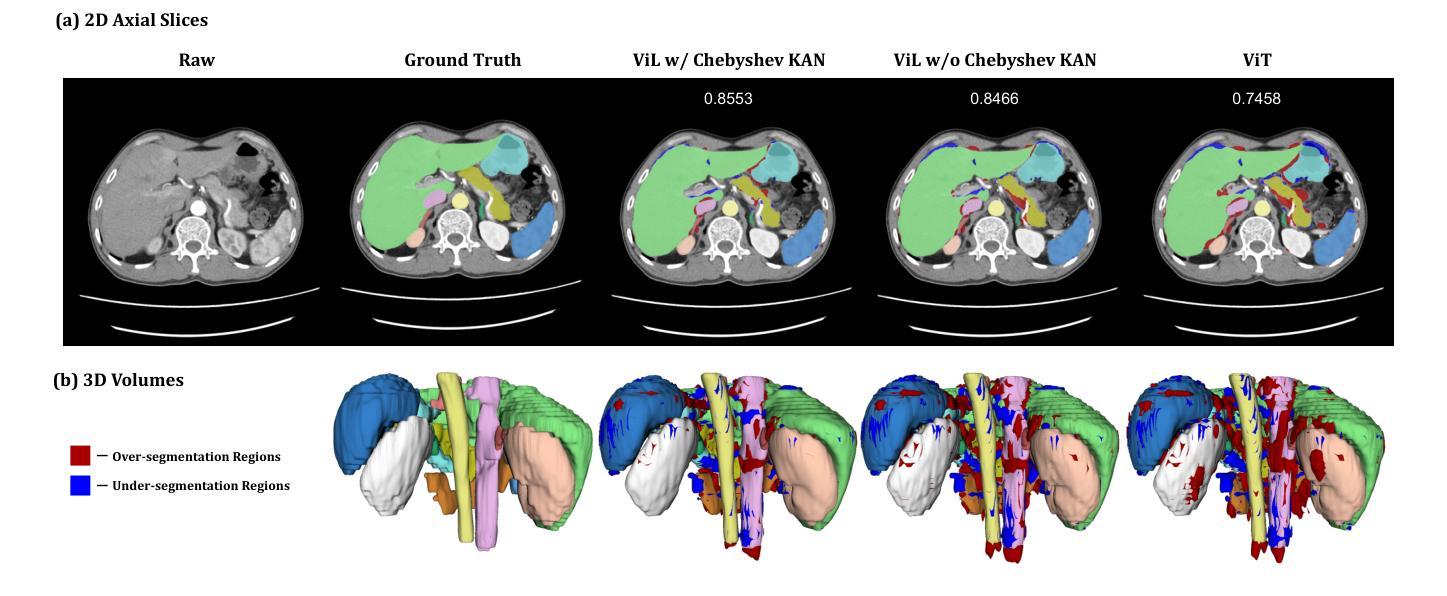
UNetVL: Enhancing 3D Medical Image Segmentation with Chebyshev KAN Powered Vision-LSTM
Authors:Xuhui Guo, Tanmoy Dam, Rohan Dhamdhere, Gourav Modanwal, Anant Madabhushi
3D medical image segmentation has progressed considerably due to Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs), yet these methods struggle to balance long-range dependency acquisition with computational efficiency. To address this challenge, we propose UNETVL (U-Net Vision-LSTM), a novel architecture that leverages recent advancements in temporal information processing. UNETVL incorporates Vision-LSTM (ViL) for improved scalability and memory functions, alongside an efficient Chebyshev Kolmogorov-Arnold Networks (KAN) to handle complex and long-range dependency patterns more effectively. We validated our method on the ACDC and AMOS2022 (post challenge Task 2) benchmark datasets, showing a significant improvement in mean Dice score compared to recent state-of-the-art approaches, especially over its predecessor, UNETR, with increases of 7.3% on ACDC and 15.6% on AMOS, respectively. Extensive ablation studies were conducted to demonstrate the impact of each component in UNETVL, providing a comprehensive understanding of its architecture. Our code is available at https://github.com/tgrex6/UNETVL, facilitating further research and applications in this domain.
3D医学图像分割由于卷积神经网络(CNN)和视觉转换器(ViT)的进展而取得了相当大的进展,但这些方法在平衡长程依赖获取与计算效率方面遇到了困难。为了解决这一挑战,我们提出了UNETVL(U-Net Vision-LSTM)这一新型架构,它利用了对时序信息处理方面的最新进展。UNETVL结合了Vision-LSTM(ViL)以提高其可扩展性和内存功能,并采用了高效的契比雪夫Kolmogorov-Arnold网络(KAN)来更有效地处理复杂和长程依赖模式。我们在ACDC和AMOS2022(挑战赛后的任务2)基准数据集上验证了我们的方法,相较于最新的先进方法,特别是在其前身UNETR上,显示出平均Dice分数的显著提高,ACDC上提高了7.3%,AMOS上提高了15.6%。进行了广泛的消融研究,以展示UNETVL中每个组件的影响,提供了对其架构的全面理解。我们的代码位于https://github.com/tgrex6/UNETVL,为这一领域的进一步研究和应用提供了便利。
论文及项目相关链接
Summary
UNETVL是一种结合卷积神经网络(CNN)和视觉Transformer(ViT)优点的新型架构,旨在解决医学图像分割中长距离依赖获取与计算效率之间的平衡问题。它通过引入视觉LSTM(ViL)提高可扩展性和记忆功能,并采用高效的Chebyshev Kolmogorov-Arnold网络(KAN)更有效地处理复杂和长距离依赖模式。在ACDC和AMOS2022基准数据集上的验证显示,与最新先进方法相比,尤其是在其前身UNETR上,平均Dice得分显著提高。该架构的综合研究证明了其每个组件的影响力。代码已公开供进一步研究应用。
Key Takeaways
- UNETVL是一种结合了CNN和ViT的新型架构,旨在解决医学图像分割中的长距离依赖问题。
- UNETVL引入视觉LSTM(ViL)以提高可扩展性和记忆功能。
- UNETVL采用高效的Chebyshev Kolmogorov-Arnold网络(KAN)处理复杂和长距离依赖模式。
- 在ACDC和AMOS2022基准数据集上的验证显示,UNETVL相对于其他最新方法有显著改善,特别是与其前身UNETR相比,其Dice得分有所提高。
- UNETVL的架构包括全面的研究分析,展示了每个组件的影响力。
- UNETVL的代码已公开,便于进一步研究和应用。
点此查看论文截图


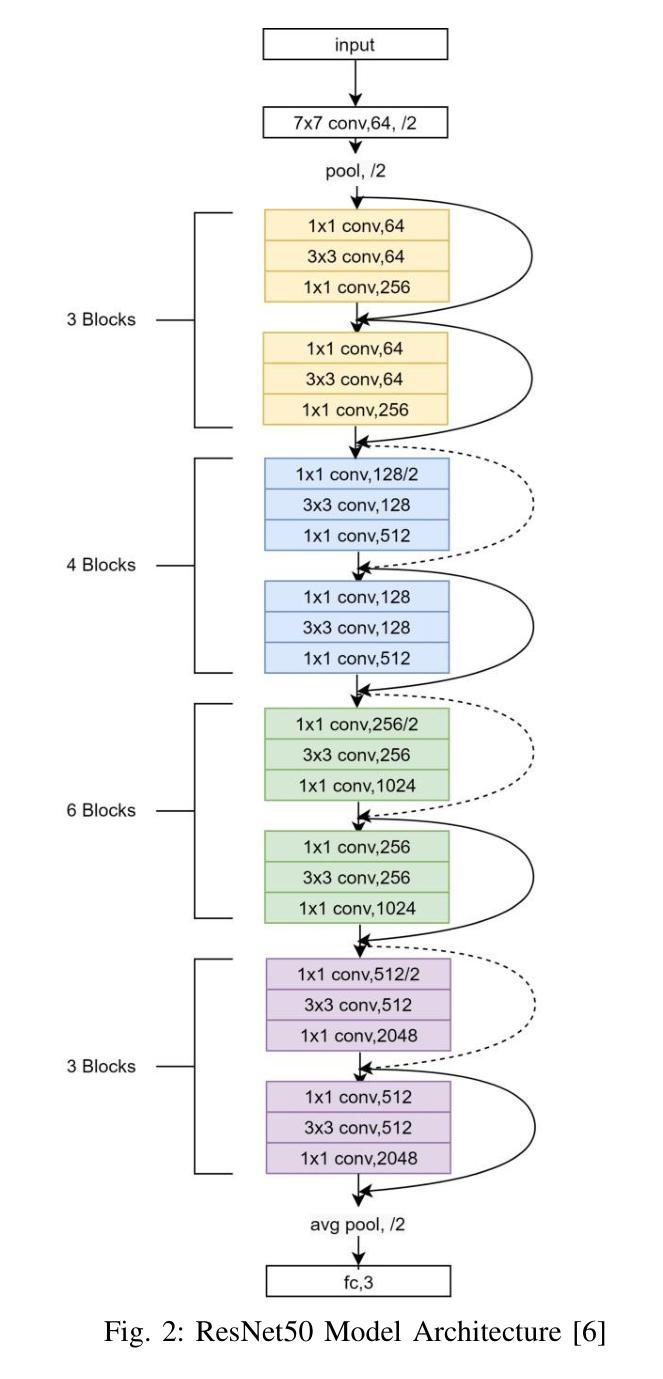
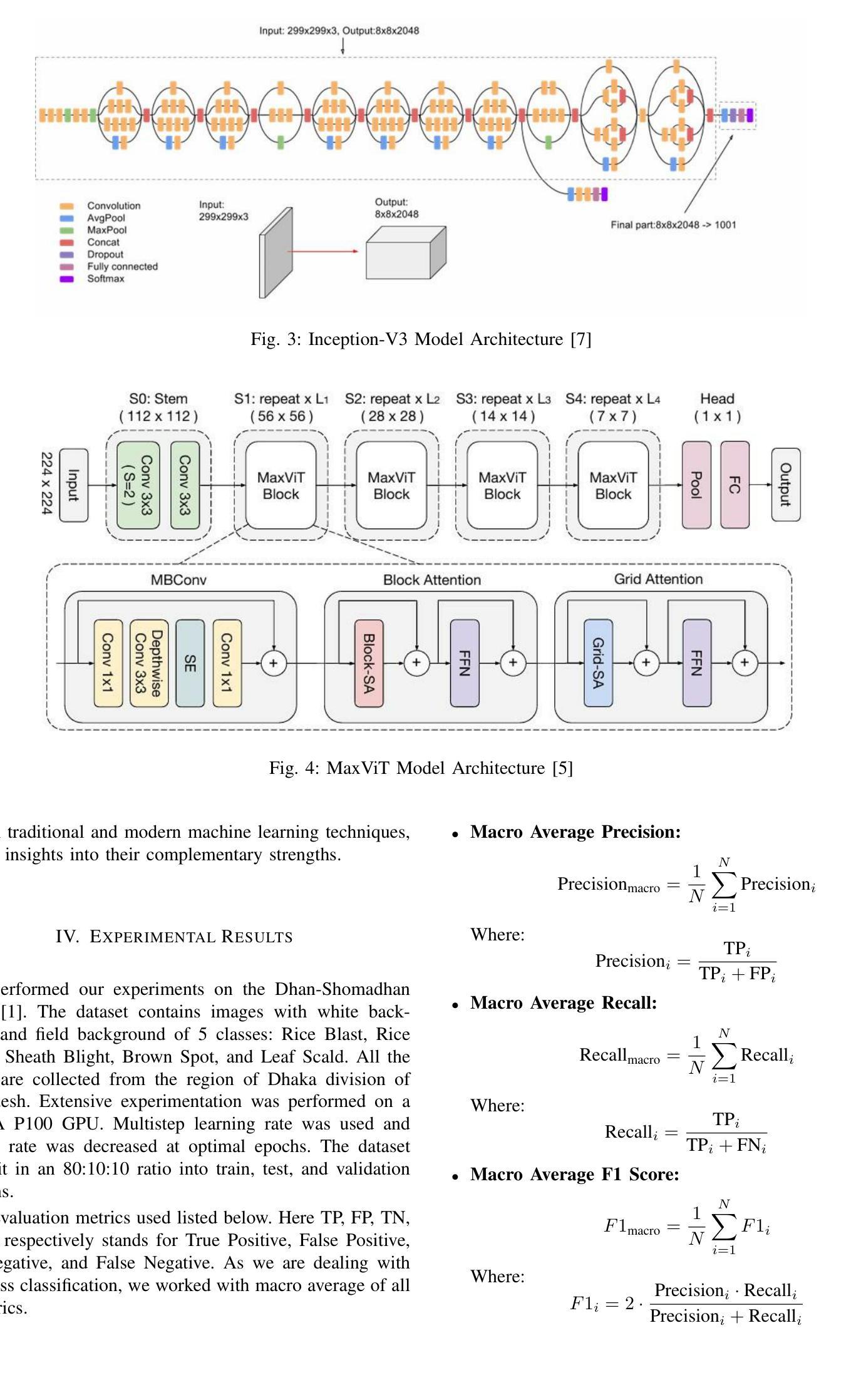
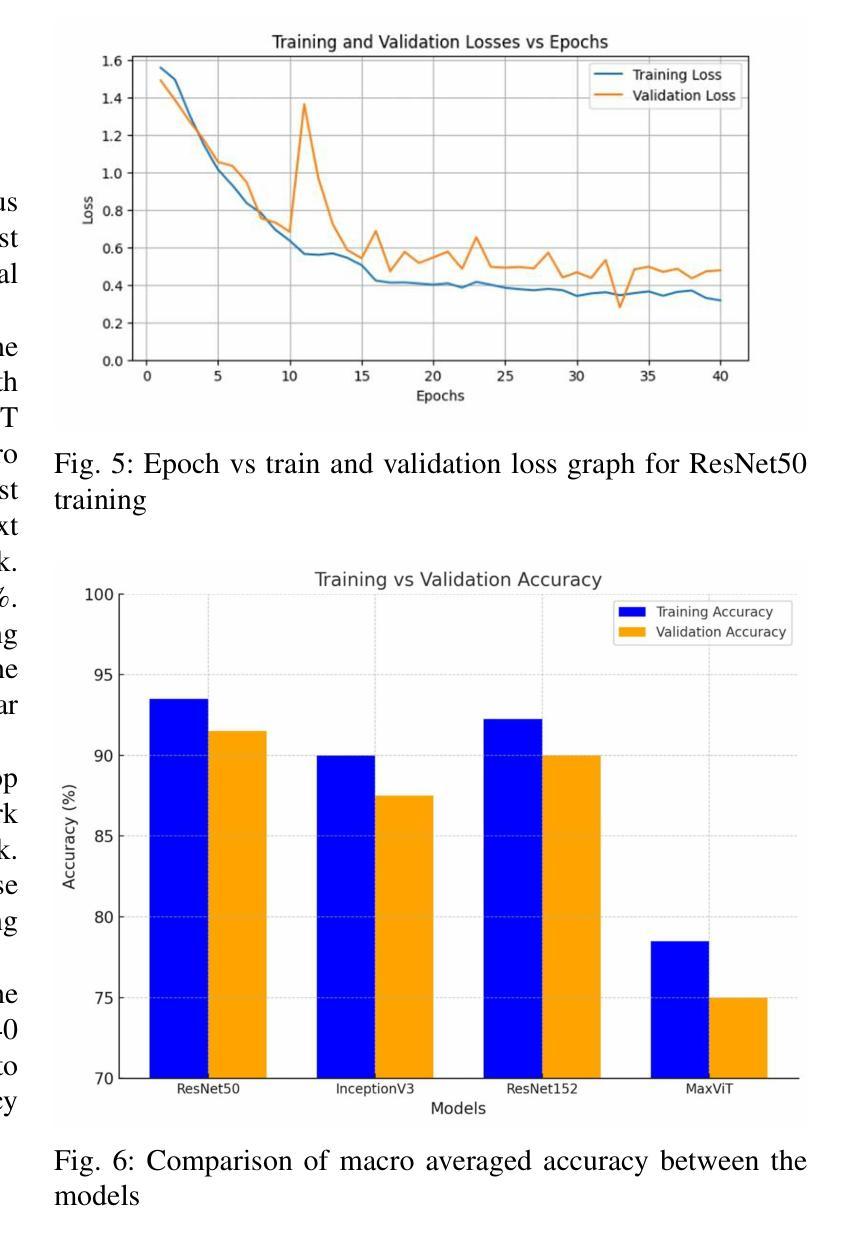
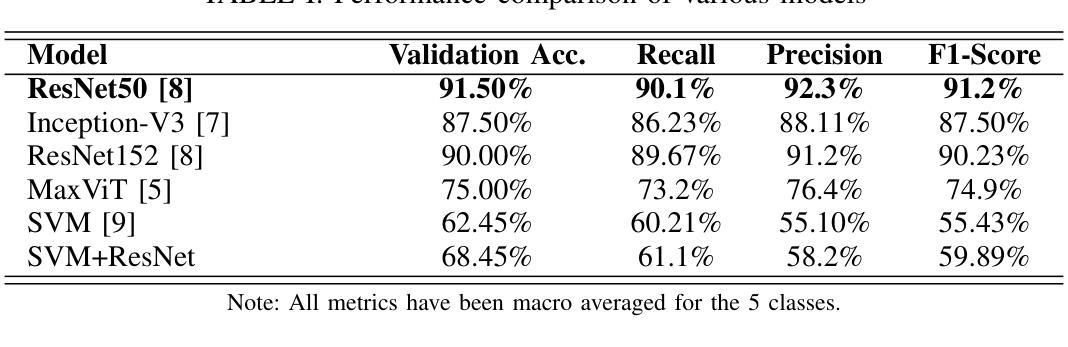
Rice Leaf Disease Detection: A Comparative Study Between CNN, Transformer and Non-neural Network Architectures
Authors:Samia Mehnaz, Md. Touhidul Islam
In nations such as Bangladesh, agriculture plays a vital role in providing livelihoods for a significant portion of the population. Identifying and classifying plant diseases early is critical to prevent their spread and minimize their impact on crop yield and quality. Various computer vision techniques can be used for such detection and classification. While CNNs have been dominant on such image classification tasks, vision transformers has become equally good in recent time also. In this paper we study the various computer vision techniques for Bangladeshi rice leaf disease detection. We use the Dhan-Shomadhan – a Bangladeshi rice leaf disease dataset, to experiment with various CNN and ViT models. We also compared the performance of such deep neural network architecture with traditional machine learning architecture like Support Vector Machine(SVM). We leveraged transfer learning for better generalization with lower amount of training data. Among the models tested, ResNet50 exhibited the best performance over other CNN and transformer-based models making it the optimal choice for this task.
在孟加拉国等国家,农业在为数众多的人口提供生计方面发挥着至关重要的作用。早期识别和分类植物病害对防止其扩散和尽量减少其对作物产量和质量的影响至关重要。可以使用各种计算机视觉技术进行此类检测和分类。虽然卷积神经网络(CNN)在此类图像分类任务中占据主导地位,但视觉转换器(vision transformers)在最近的时间中也同样表现出色。在本文中,我们研究了用于孟加拉国水稻叶片病害检测的各种计算机视觉技术。我们使用孟加拉国水稻叶片数据集Dhan-Shomadhan,对各种CNN和ViT模型进行实验。我们还比较了这种深度神经网络架构与诸如支持向量机(SVM)等传统机器学习架构的性能。我们利用迁移学习,以在较少训练数据的情况下实现更好的泛化。在测试的模型中,ResNet50在其他CNN和基于transformer的模型中表现出最佳性能,成为此任务的最佳选择。
论文及项目相关链接
PDF 6 pages, 6 figures
Summary
本文研究了计算机视觉技术在孟加拉国水稻叶片病害检测中的应用。通过使用Dhan-Shomadhan数据集,实验了CNN和ViT模型,并与传统的机器学习架构SVM进行了性能比较。利用迁移学习提高模型的泛化能力,并在少量训练数据下取得良好效果。在测试的模型中,ResNet50相较于其他CNN和基于transformer的模型表现出最佳性能,成为该任务的最优选择。
Key Takeaways
- 农业在孟加拉国具有重要地位,早期识别和分类植物病害对防止病害扩散和减少作物产量及品质的影响至关重要。
- 计算机视觉技术可用于植物病害的检测和分类。
- CNN和ViT模型在孟加拉国水稻叶片病害检测方面表现出良好性能。
- 与传统的机器学习架构相比,深度神经网络架构如CNN和ViT模型表现出更高的性能。
- 迁移学习可用于提高模型的泛化能力,并在有限训练数据下取得良好效果。
- 在实验中,ResNet50模型在病害检测任务上表现最佳,成为该任务的最优选择。
点此查看论文截图


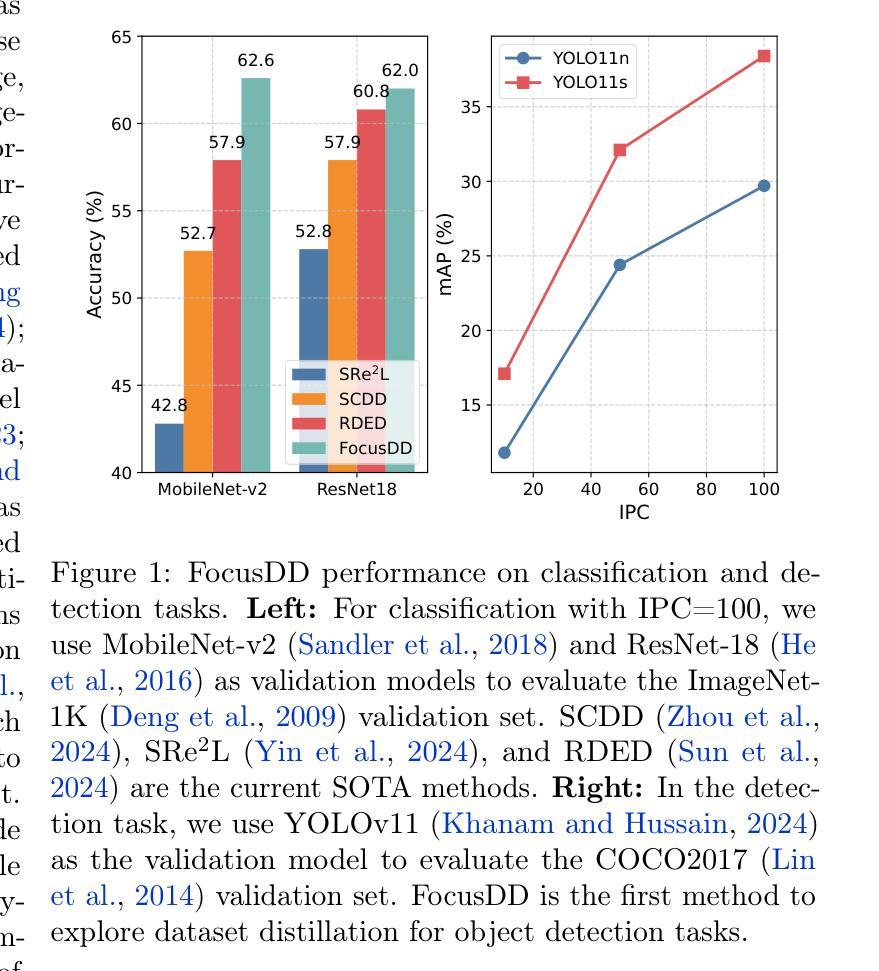
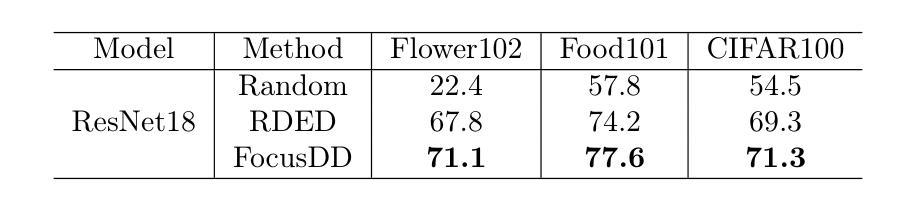
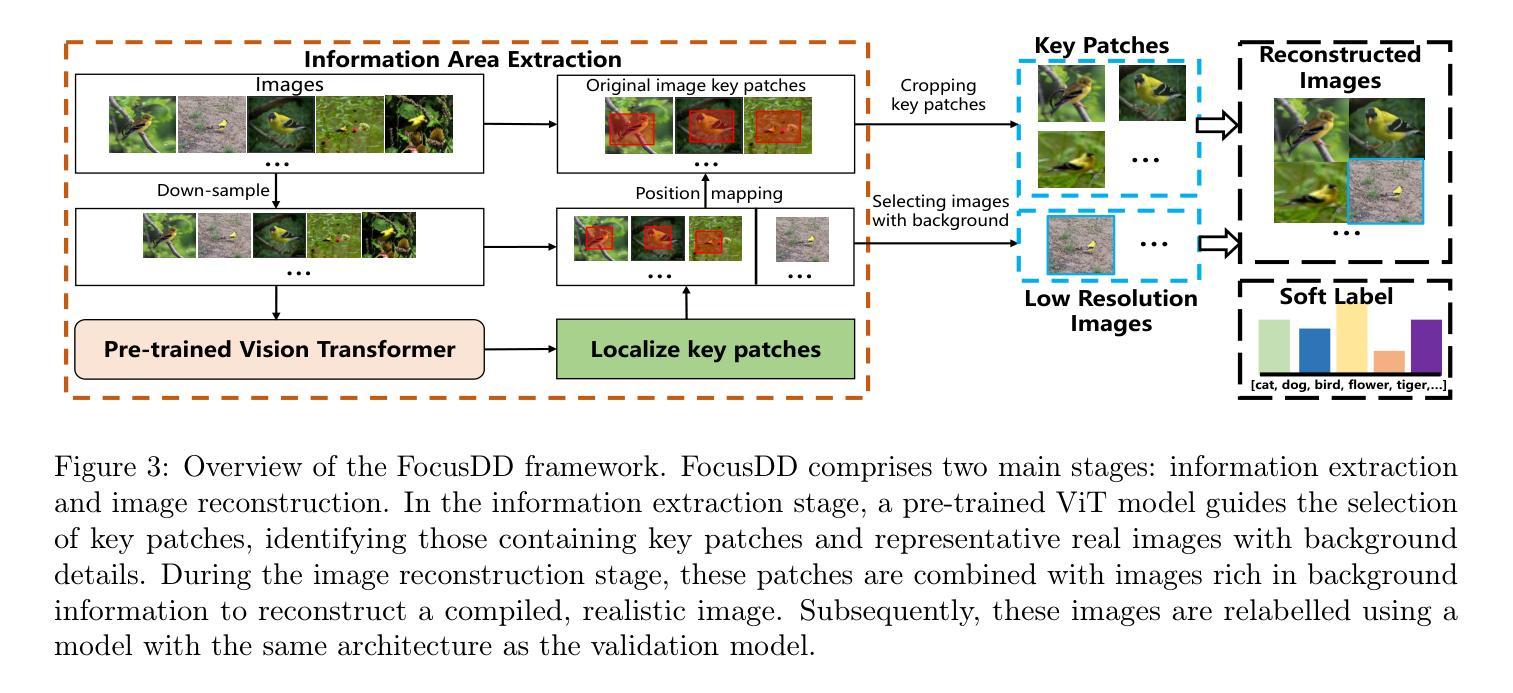
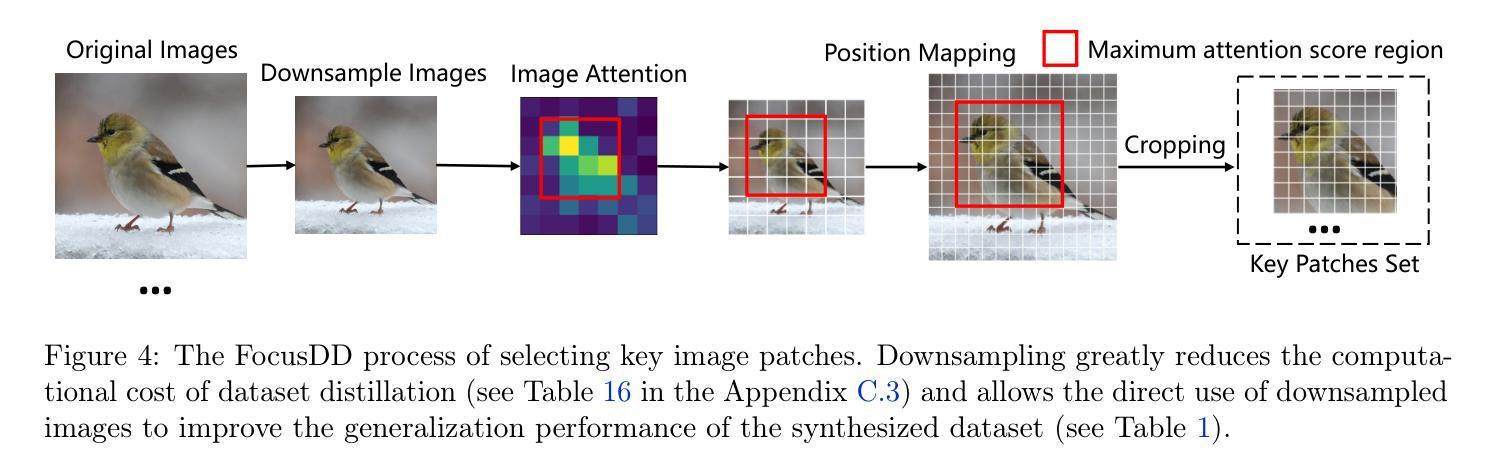
FocusDD: Real-World Scene Infusion for Robust Dataset Distillation
Authors:Youbing Hu, Yun Cheng, Olga Saukh, Firat Ozdemir, Anqi Lu, Zhiqiang Cao, Zhijun Li
Dataset distillation has emerged as a strategy to compress real-world datasets for efficient training. However, it struggles with large-scale and high-resolution datasets, limiting its practicality. This paper introduces a novel resolution-independent dataset distillation method Focus ed Dataset Distillation (FocusDD), which achieves diversity and realism in distilled data by identifying key information patches, thereby ensuring the generalization capability of the distilled dataset across different network architectures. Specifically, FocusDD leverages a pre-trained Vision Transformer (ViT) to extract key image patches, which are then synthesized into a single distilled image. These distilled images, which capture multiple targets, are suitable not only for classification tasks but also for dense tasks such as object detection. To further improve the generalization of the distilled dataset, each synthesized image is augmented with a downsampled view of the original image. Experimental results on the ImageNet-1K dataset demonstrate that, with 100 images per class (IPC), ResNet50 and MobileNet-v2 achieve validation accuracies of 71.0% and 62.6%, respectively, outperforming state-of-the-art methods by 2.8% and 4.7%. Notably, FocusDD is the first method to use distilled datasets for object detection tasks. On the COCO2017 dataset, with an IPC of 50, YOLOv11n and YOLOv11s achieve 24.4% and 32.1% mAP, respectively, further validating the effectiveness of our approach.
数据集蒸馏作为一种压缩现实世界数据集以进行高效训练的策略已经崭露头角。然而,它在处理大规模和高分辨率数据集时遇到了困难,从而限制了其实用性。本文介绍了一种新型的分辨率独立数据集蒸馏方法——Focus ed Dataset Distillation(FocusDD)。该方法通过识别关键信息斑块,实现在蒸馏数据中的多样性和现实性,从而确保蒸馏数据集在不同网络架构中的泛化能力。具体来说,FocusDD利用预先训练的视觉转换器(ViT)提取关键图像斑块,然后将其合成为单个蒸馏图像。这些捕获了多个目标的蒸馏图像不仅适用于分类任务,而且适用于对象检测等密集任务。为了进一步提高蒸馏数据集的泛化能力,对合成的每个图像都增加了原始图像的下采样视图。在ImageNet-1K数据集上的实验结果表明,以每类100张图像(IPC)计算,ResNet50和MobileNet-v2的验证准确率分别达到71.0%和62.6%,比最先进的方法分别高出2.8%和4.7%。值得注意的是,FocusDD是第一个使用蒸馏数据集进行对象检测任务的方法。在COCO2017数据集上,以每类50张图像(IPC)计算,YOLOv11n和YOLOv11s的mAP分别达到24.4%和32.1%,这进一步验证了我们的方法的有效性。
论文及项目相关链接
Summary
本文提出一种新型分辨率无关的数据集蒸馏方法——FocusDD。该方法利用预训练的Vision Transformer识别关键信息块,从大规模高分辨数据集中提取关键图像块并合成蒸馏数据图像,进而实现数据集的压缩和高效训练。FocusDD能应用于分类任务和密集任务如目标检测,并通过将合成图像与原始低分辨率图像结合,提高蒸馏数据集的泛化能力。在ImageNet-1K数据集上的实验表明,使用FocusDD的ResNet50和MobileNet-v2模型在100 IPC下达到71.0%和62.6%的验证精度,优于其他最新方法。此外,FocusDD是首个用于目标检测任务的数据集蒸馏方法,在COCO2017数据集上的实验验证了其有效性。
Key Takeaways
- FocusDD是一种分辨率无关的数据集蒸馏方法,适用于大规模高分辨数据集。
- 利用预训练的Vision Transformer提取关键图像块,合成蒸馏数据图像。
- FocusDD同时支持分类任务和目标检测任务。
- 通过结合合成图像和原始低分辨率图像,提高蒸馏数据集的泛化能力。
- 在ImageNet-1K数据集上的实验显示,FocusDD提高了模型的验证精度,优于其他最新方法。
- 实验结果表明,使用FocusDD的模型在资源有限的情况下表现良好,具有实际应用价值。
- FocusDD为数据集蒸馏在目标检测任务中的应用提供了有效方法。
点此查看论文截图


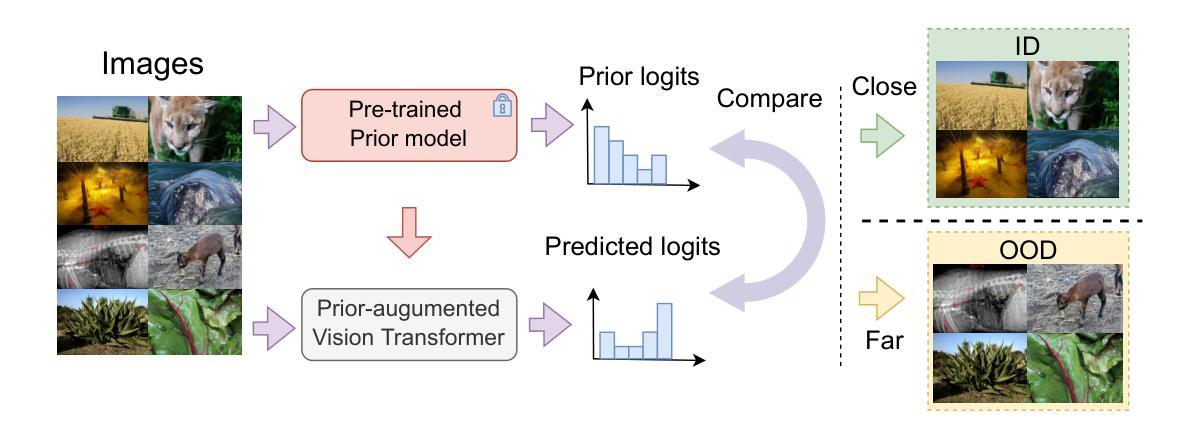
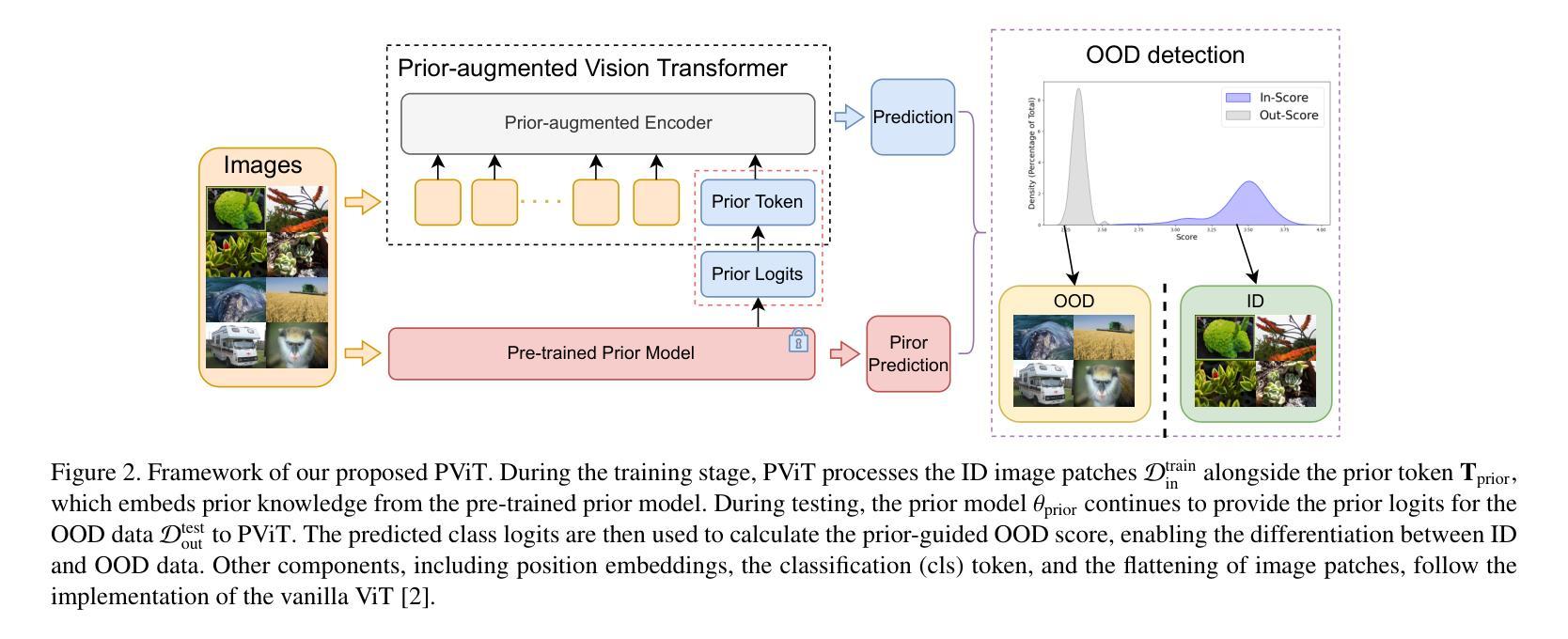
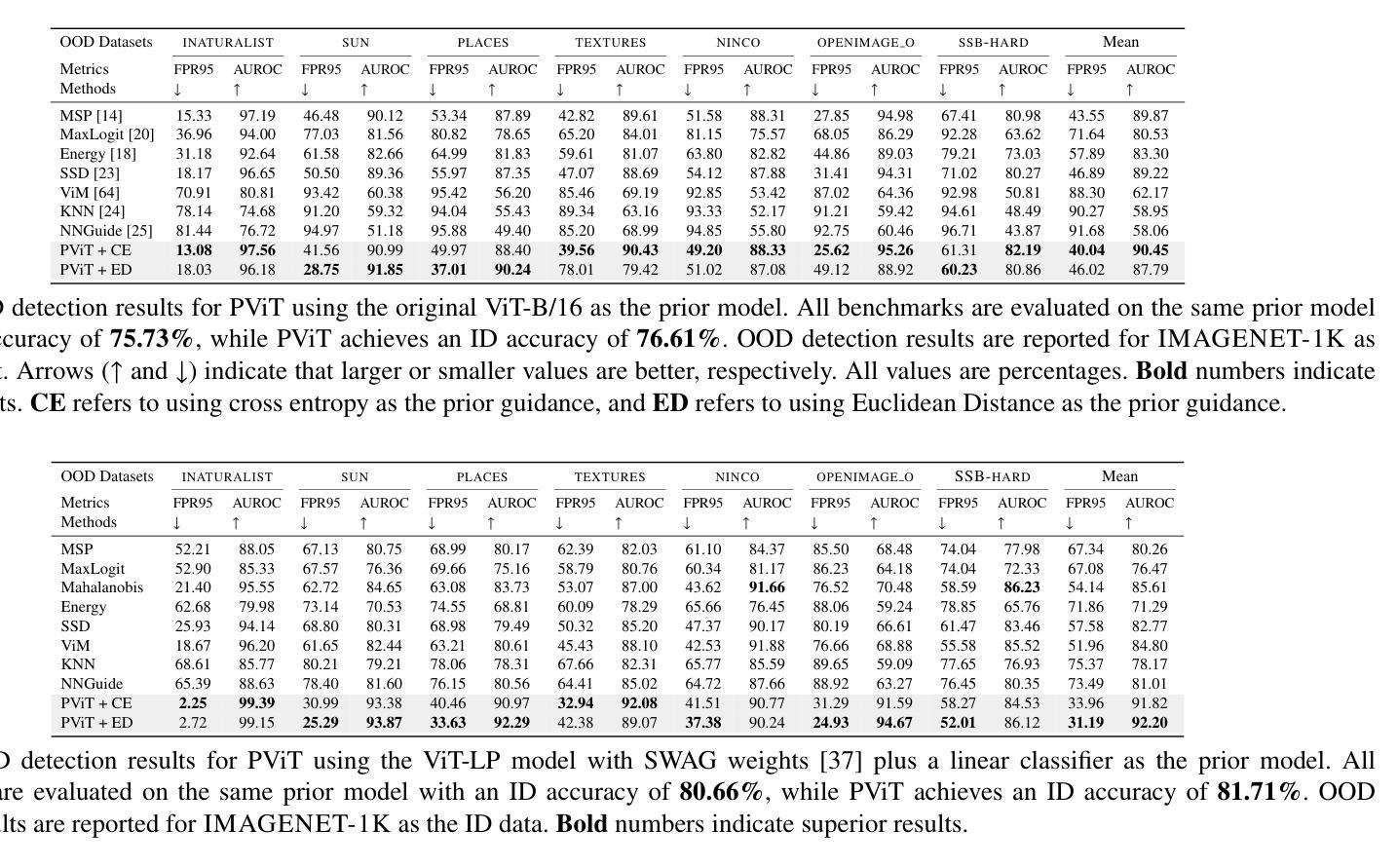
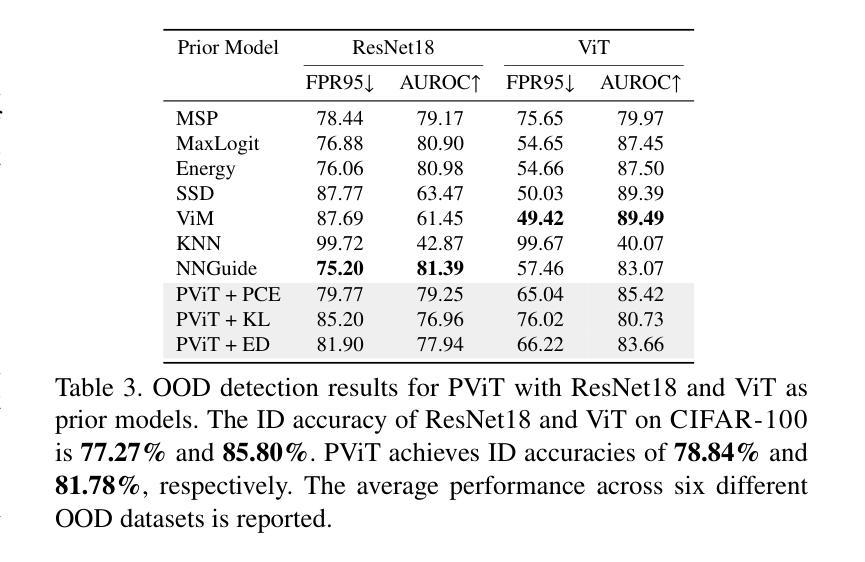
PViT: Prior-augmented Vision Transformer for Out-of-distribution Detection
Authors:Tianhao Zhang, Zhixiang Chen, Lyudmila S. Mihaylova
Vision Transformers (ViTs) have achieved remarkable success over various vision tasks, yet their robustness against data distribution shifts and inherent inductive biases remain underexplored. To enhance the robustness of ViT models for image Out-of-Distribution (OOD) detection, we introduce a novel and generic framework named Prior-augmented Vision Transformer (PViT). Taking as input the prior class logits from a pretrained model, we train PViT to predict the class logits. During inference, PViT identifies OOD samples by quantifying the divergence between the predicted class logits and the prior logits obtained from pre-trained models. Unlike existing state-of-the-art(SOTA) OOD detection methods, PViT shapes the decision boundary between ID and OOD by utilizing the proposed prior guided confidence, without requiring additional data modeling, generation methods, or structural modifications. Extensive experiments on the large-scale ImageNet benchmark, evaluated against over seven OOD datasets, demonstrate that PViT significantly outperforms existing SOTA OOD detection methods in terms of FPR95 and AUROC. The codebase is publicly available at https://github.com/RanchoGoose/PViT.
视觉Transformer(ViT)在各种视觉任务上取得了显著的成功,然而它们对数据分布变化和固有归纳偏好的鲁棒性仍然没有得到充分探索。为了增强ViT模型对图像分布外(OOD)检测的鲁棒性,我们引入了一种名为先验增强视觉Transformer(PViT)的新型通用框架。我们以预训练模型的先验类别逻辑值作为输入,训练PViT来预测类别逻辑值。在推理过程中,PViT通过量化预测类别逻辑值与从预训练模型获得的先验逻辑值之间的差异来识别OOD样本。与现有的最先进的OOD检测方法不同,PViT通过利用所提出的先验引导置信度来塑造ID和OOD之间的决策边界,无需额外的数据建模、生成方法或结构修改。在大型ImageNet基准测试上的实验,与七个OOD数据集进行评估,证明PViT在FPR95和AUROC方面显著优于现有的最先进的OOD检测方法。该代码库可在https://github.com/RanchoGoose/PViT公开访问。
论文及项目相关链接
Summary
基于预训练模型的先验类别logits,引入了一种名为Prior-augmented Vision Transformer(PViT)的新型通用框架,用于增强图像Out-of-Distribution(OOD)检测的鲁棒性。PViT通过衡量预测类别logits与先验logits之间的偏差来识别OOD样本。在大型ImageNet基准测试上,与七个OOD数据集进行对比实验,PViT在FPR95和AUROC方面显著优于现有最先进的OOD检测方法。
Key Takeaways
- PViT框架被引入以增强Vision Transformer(ViT)模型对图像Out-of-Distribution(OOD)检测的鲁棒性。
- 通过衡量预测类别logits与来自预训练模型的先验logits之间的偏差,PViT能够识别OOD样本。
- PViT通过利用提出的先验引导置信度来塑造ID与OOD之间的决策边界。
- PViT不需要额外的数据建模、生成方法或结构修改。
- 在大型ImageNet基准测试上进行了广泛实验,验证了PViT的有效性。
- 与七个OOD数据集对比实验表明,PViT在FPR95和AUROC方面显著优于现有最先进的OOD检测方法。
点此查看论文截图


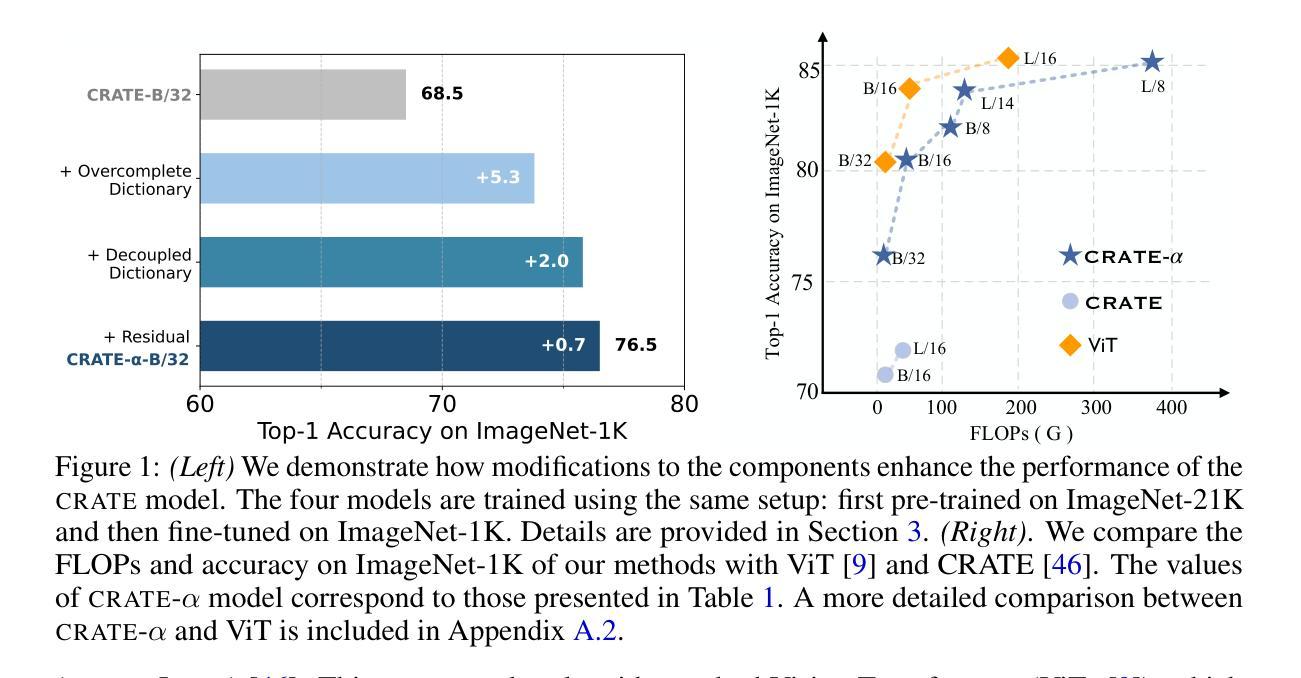
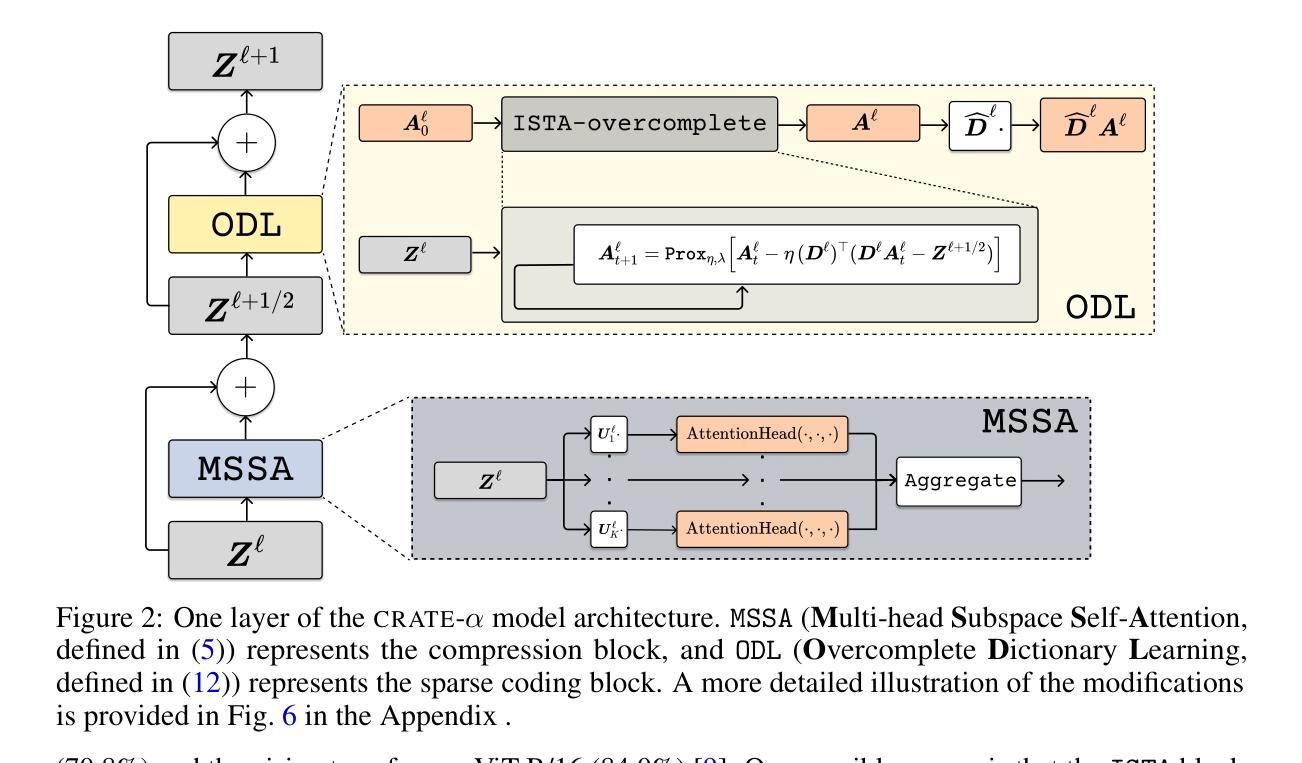
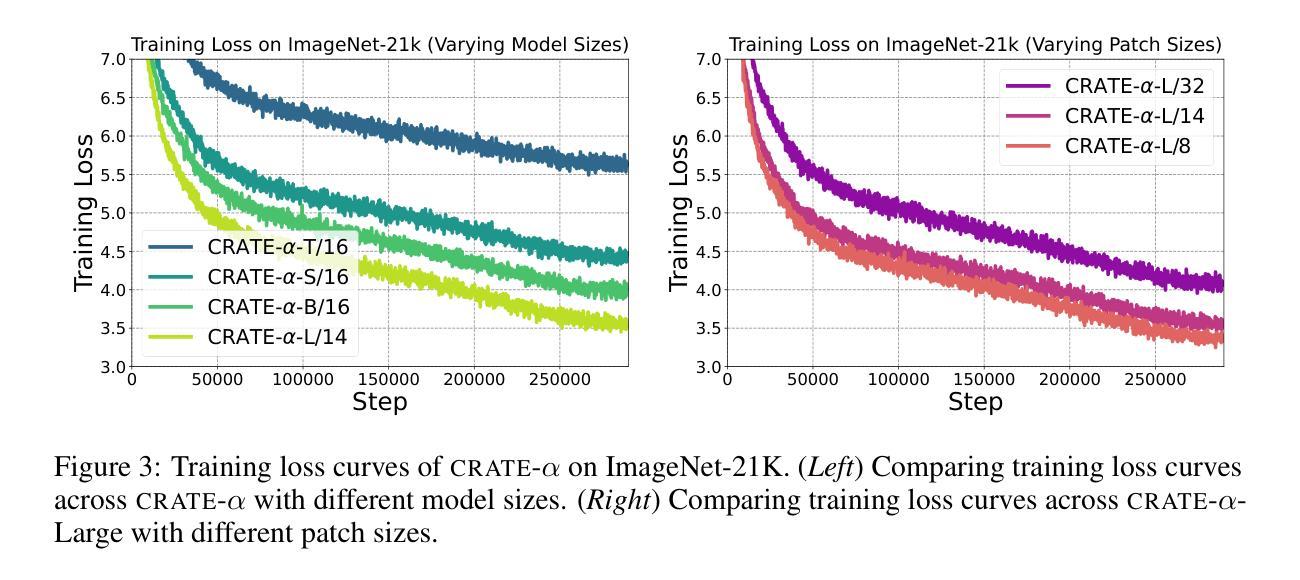
Scaling White-Box Transformers for Vision
Authors:Jinrui Yang, Xianhang Li, Druv Pai, Yuyin Zhou, Yi Ma, Yaodong Yu, Cihang Xie
CRATE, a white-box transformer architecture designed to learn compressed and sparse representations, offers an intriguing alternative to standard vision transformers (ViTs) due to its inherent mathematical interpretability. Despite extensive investigations into the scaling behaviors of language and vision transformers, the scalability of CRATE remains an open question which this paper aims to address. Specifically, we propose CRATE-$\alpha$, featuring strategic yet minimal modifications to the sparse coding block in the CRATE architecture design, and a light training recipe designed to improve the scalability of CRATE. Through extensive experiments, we demonstrate that CRATE-$\alpha$ can effectively scale with larger model sizes and datasets. For example, our CRATE-$\alpha$-B substantially outperforms the prior best CRATE-B model accuracy on ImageNet classification by 3.7%, achieving an accuracy of 83.2%. Meanwhile, when scaling further, our CRATE-$\alpha$-L obtains an ImageNet classification accuracy of 85.1%. More notably, these model performance improvements are achieved while preserving, and potentially even enhancing the interpretability of learned CRATE models, as we demonstrate through showing that the learned token representations of increasingly larger trained CRATE-$\alpha$ models yield increasingly higher-quality unsupervised object segmentation of images. The project page is https://rayjryang.github.io/CRATE-alpha/.
CRATE是一种白盒变压器架构,旨在学习压缩和稀疏表示,由于其固有的数学可解释性,它为标准视觉变压器(ViTs)提供了有趣的替代方案。尽管对语言和视觉变压器的规模行为进行了广泛的研究,但CRATE的可扩展性仍然是一个悬而未决的问题,本文旨在解决这个问题。具体来说,我们提出了CRATE-$\alpha$,它对CRATE架构设计中的稀疏编码块进行了战略性的最小修改,并设计了一种轻量级的训练配方,旨在提高CRATE的可扩展性。通过大量实验,我们证明了CRATE-$\alpha$可以有效地扩展到更大的模型和更大的数据集。例如,我们的CRATE-$\alpha$-B在ImageNet分类任务上的准确率超过了之前最佳的CRATE-B模型准确率3.7%,达到了83.2%。同时,当我们进一步扩大规模时,我们的CRATE-$\alpha$-L在ImageNet分类任务上的准确率达到了85.1%。值得注意的是,这些模型性能的提升是在保留甚至提高学到的CRATE模型的解释性的前提下实现的,我们通过对训练后的越来越大CRATE-$\alpha$模型的标记表示进行展示,证明了其进行图像的无监督对象分割的质量越来越高。项目页面是https://rayjryang.github.io/CRATE-alpha/。
论文及项目相关链接
PDF project page: https://rayjryang.github.io/CRATE-alpha/
摘要
CRATE是一种旨在学习压缩和稀疏表示的白盒变压器架构,为标准的视觉变压器(ViTs)提供了有趣的替代方案,由于其固有的数学可解释性。尽管已经对语言和视觉变压器的规模行为进行了广泛的研究,但CRATE的可扩展性仍然是一个悬而未决的问题,本文旨在解决这一问题。具体来说,我们提出了CRATE-$\alpha$,对CRATE架构设计中的稀疏编码块进行了战略性的最小修改,并设计了一种轻量级的训练配方,以提高CRATE的可扩展性。通过广泛的实验,我们证明了CRATE-$\alpha$可以有效地扩展更大的模型规模和数据集。例如,我们的CRATE-$\alpha$-B在ImageNet分类任务上的准确率比之前的最佳CRATE-B模型高出3.7%,达到83.2%。同时,当我们进一步扩展时,我们的CRATE-$\alpha$-L在ImageNet分类任务上的准确率达到了85.1%。更值得注意的是,这些模型性能的提升是在保持和可能提高CRATE模型的解释性下实现的,我们通过展示越来越大、经过训练的CRATE-$\alpha$模型的标记表示,可以获得越来越高质量的无监督图像对象分割来证实这一点。项目页面为https://rayjryang.github.io/CRATE-alpha/。
关键见解
- CRATE作为一种白盒变压器架构,具有学习压缩和稀疏表示的能力,为视觉变压器提供了可解释的替代方案。
- 论文旨在解决CRATE可扩展性的问题,提出CRATE-$\alpha$模型,通过战略性的最小修改和轻量级训练配方提高其可扩展性。
- CRATE-$\alpha$在ImageNet分类任务上表现出卓越的性能,较大模型CRATE-$\alpha$-B的准确率为83.2%,进一步扩展的CRATE-$\alpha$-L的准确率达到了85.1%。
- CRATE-$\alpha$在保持甚至提高模型的解释性的同时,实现了模型性能的提升。
- 越大、经过训练的CRATE-$\alpha$模型的标记表示,可以获得越来越优质的无监督图像对象分割,这证实了其在实际应用中的有效性。
- 项目页面提供了关于CRATE-$\alpha$的更多详细信息,包括模型的具体实现和实验结果等。
点此查看论文截图