⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-17 更新
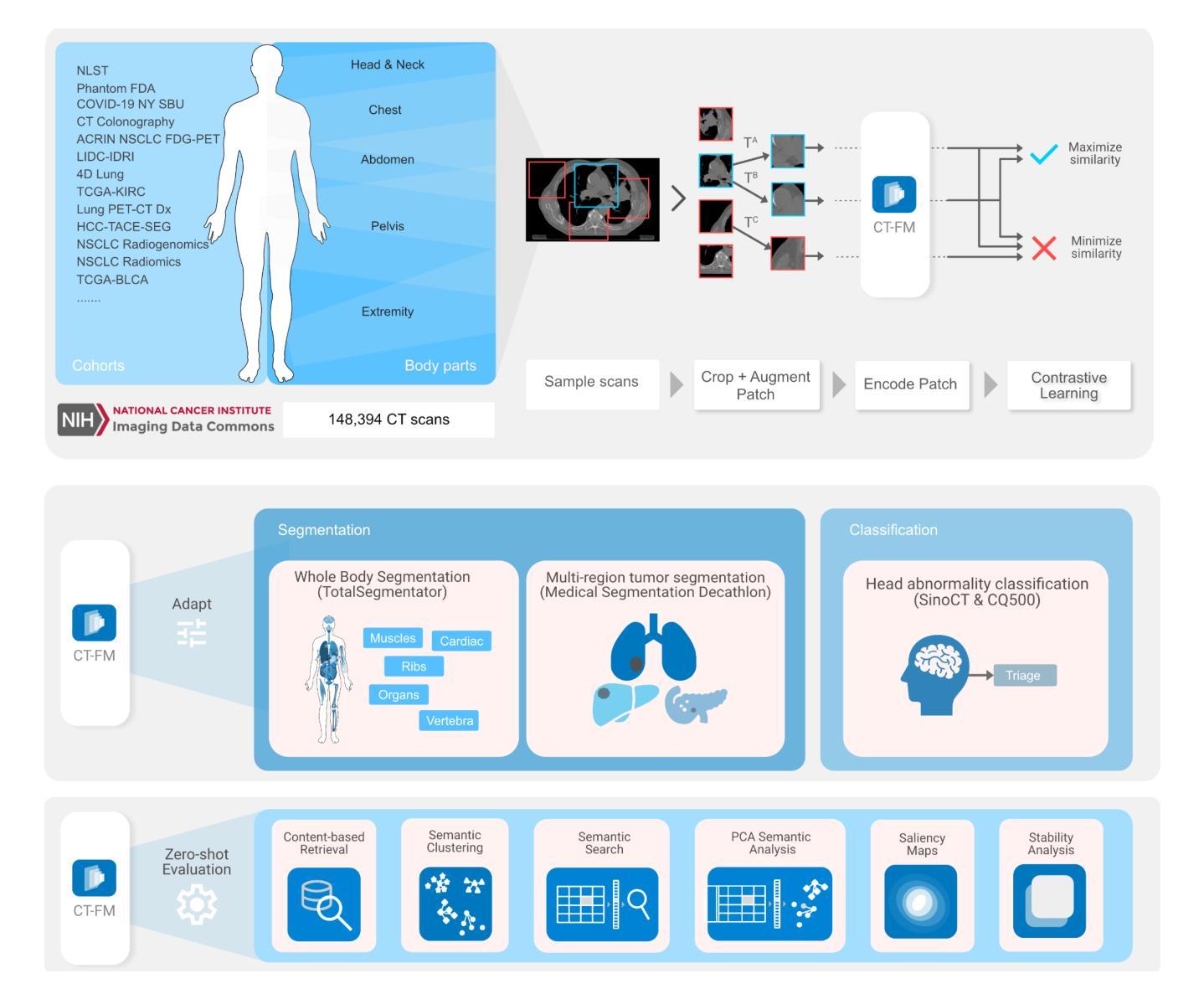
Vision Foundation Models for Computed Tomography
Authors:Suraj Pai, Ibrahim Hadzic, Dennis Bontempi, Keno Bressem, Benjamin H. Kann, Andriy Fedorov, Raymond H. Mak, Hugo J. W. L. Aerts
Foundation models (FMs) have shown transformative potential in radiology by performing diverse, complex tasks across imaging modalities. Here, we developed CT-FM, a large-scale 3D image-based pre-trained model designed explicitly for various radiological tasks. CT-FM was pre-trained using 148,000 computed tomography (CT) scans from the Imaging Data Commons through label-agnostic contrastive learning. We evaluated CT-FM across four categories of tasks, namely, whole-body and tumor segmentation, head CT triage, medical image retrieval, and semantic understanding, showing superior performance against state-of-the-art models. Beyond quantitative success, CT-FM demonstrated the ability to cluster regions anatomically and identify similar anatomical and structural concepts across scans. Furthermore, it remained robust across test-retest settings and indicated reasonable salient regions attached to its embeddings. This study demonstrates the value of large-scale medical imaging foundation models and by open-sourcing the model weights, code, and data, aims to support more adaptable, reliable, and interpretable AI solutions in radiology.
基础模型(FMs)在放射学中表现出了变革性的潜力,能够在不同的成像模式下执行多样且复杂的任务。在这里,我们开发了CT-FM,这是一个大规模基于3D图像的预训练模型,专为各种放射学任务而设计。CT-FM使用来自影像数据共享平台的14.8万份计算机断层扫描(CT)数据进行预训练,采用标签无关的对比学习。我们在四类任务中评估了CT-FM,即全身和肿瘤分割、头部CT筛查、医学图像检索和语义理解,其性能优于最新模型。除了定量成功之外,CT-FM还展示了在解剖区域进行聚类的能力,并能在扫描中识别相似的解剖和结构概念。此外,它在测试重测环境中表现稳健,其嵌入的显著区域也合理。本研究展示了大规模医学成像基础模型的价值,通过开源模型权重、代码和数据,旨在支持更具适应性、可靠性和可解释性的放射学人工智能解决方案。
论文及项目相关链接
PDF 6 figures, followed by 9 Extended Data Figures and a Supplementary Information document
Summary
大规模医学成像基础模型CT-FM在放射学中的潜力评估。该模型通过对比学习在来自成像数据共享中心的14.8万份计算机断层扫描(CT)扫描数据上进行预训练,展现出强大的跨模态表现能力。在全身和肿瘤分割、头部CT评估、医学图像检索和语义理解等任务中,CT-FM表现超越现有顶尖模型。此外,它还能进行解剖学区域聚类,识别不同扫描间的相似解剖结构和概念。模型的开源将促进放射学中适应性更强、更可靠和可解释的AI解决方案的发展。
Key Takeaways
- CT-FM是一个大规模基于3D图像的预训练模型,专为各种放射学任务设计。
- 该模型使用来自成像数据共享中心的14.8万份CT扫描数据进行预训练。
- 在全身和肿瘤分割、头部CT评估、医学图像检索和语义理解等任务中,CT-FM表现优越。
- CT-FM具备解剖学区域聚类能力,并能识别不同扫描间的相似解剖结构和概念。
- 模型在测试重测环境中表现稳健,并能合理识别关键区域。
- 通过开源模型权重、代码和数据,支持更适应、可靠和可解释的放射学AI解决方案的发展。
点此查看论文截图

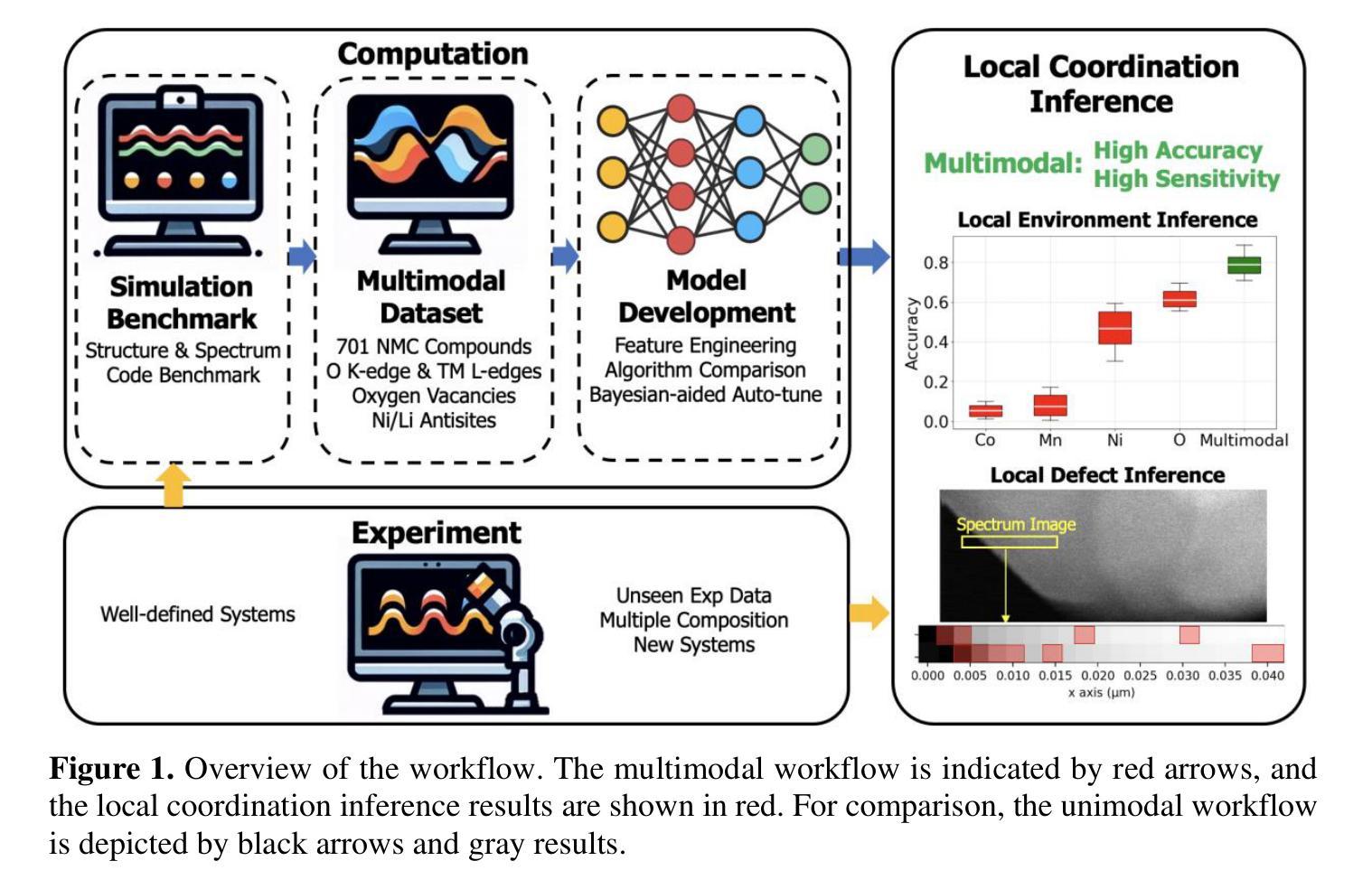
Revealing Local Structures through Machine-Learning- Fused Multimodal Spectroscopy
Authors:Haili Jia, Yiming Chen, Gi-Hyeok Lee, Jacob Smith, Miaofang Chi, Wanli Yang, Maria K. Y. Chan
Atomistic structures of materials offer valuable insights into their functionality. Determining these structures remains a fundamental challenge in materials science, especially for systems with defects. While both experimental and computational methods exist, each has limitations in resolving nanoscale structures. Core-level spectroscopies, such as x-ray absorption (XAS) or electron energy-loss spectroscopies (EELS), have been used to determine the local bonding environment and structure of materials. Recently, machine learning (ML) methods have been applied to extract structural and bonding information from XAS/EELS, but most of these frameworks rely on a single data stream, which is often insufficient. In this work, we address this challenge by integrating multimodal ab initio simulations, experimental data acquisition, and ML techniques for structure characterization. Our goal is to determine local structures and properties using EELS and XAS data from multiple elements and edges. To showcase our approach, we use various lithium nickel manganese cobalt (NMC) oxide compounds which are used for lithium ion batteries, including those with oxygen vacancies and antisite defects, as the sample material system. We successfully inferred local element content, ranging from lithium to transition metals, with quantitative agreement with experimental data. Beyond improving prediction accuracy, we find that ML model based on multimodal spectroscopic data is able to determine whether local defects such as oxygen vacancy and antisites are present, a task which is impossible for single mode spectra or other experimental techniques. Furthermore, our framework is able to provide physical interpretability, bridging spectroscopy with the local atomic and electronic structures.
材料原子结构为我们深入了解其功能提供了宝贵的见解。确定这些结构仍然是材料科学领域的一个基本挑战,特别是对于存在缺陷的系统。虽然存在实验和计算方法,但每种方法在解决纳米尺度结构方面都有其局限性。芯层光谱学,如X射线吸收(XAS)或电子能量损失光谱学(EELS),已被用于确定材料的局部键合环境和结构。最近,机器学习(ML)方法已被应用于从XAS/EELS中提取结构和键合信息,但大多数框架都依赖于单一数据流,这通常是不够的。在这项工作中,我们通过集成多模式从头模拟、实验数据获取和ML技术来解决这一挑战,以进行结构表征。我们的目标是利用来自多种元素和边缘的EELS和XAS数据来确定局部结构和属性。为了展示我们的方法,我们使用了各种用于锂离子电池的锂镍锰钴(NMC)氧化物化合物作为样本材料系统,包括具有氧空位和反位缺陷的化合物。我们成功地推断出了从锂到过渡金属等局部元素含量,并与实验数据定量吻合。除了提高预测精度外,我们发现基于多模式光谱数据的ML模型能够确定是否存在局部缺陷,如氧空位和反位,这是单一模式光谱或其他实验技术无法完成的任务。此外,我们的框架能够提供物理可解释性,将光谱与局部原子和电子结构相联系。
论文及项目相关链接
Summary
本文介绍了材料原子结构的重要性及其在研究中的挑战,特别是在存在缺陷的系统中。文章结合了多模态从头模拟、实验数据采集和机器学习技术,旨在利用电子能量损失谱(EELS)和X射线吸收谱(XAS)数据来确定局部结构和性质。文章以含有氧空位和反位缺陷的锂镍锰钴氧化物为例,展示了其成功推断出局部元素含量的能力,并与实验结果定量一致。此外,基于多模态光谱数据的机器学习模型还能够确定局部缺陷的存在,这是一项单一模式光谱或其他实验技术无法完成的任务。该框架还能够提供物理可解释性,将光谱与局部原子和电子结构相联系。
Key Takeaways
- 材料原子结构的研究对于理解其功能性至关重要,但在存在缺陷的系统中,确定这些结构仍是材料科学中的基本挑战。
- 核心层次光谱学,如XAS和EELS,已被用于确定材料的局部键合环境和结构。
- 机器学习(ML)方法已被应用于从XAS/EELS中提取结构和键合信息,但大多数框架依赖于单一数据流,这通常是不够的。
- 本文通过结合多模态从头模拟、实验数据采集和ML技术来解决这一挑战,旨在利用EELS和XAS数据确定局部结构和性质。
- 以含有氧空位和反位缺陷的锂镍锰钴氧化物为例子,展示了该方法在推断局部元素含量方面的成功,并与实验结果一致。
- 基于多模态光谱数据的ML模型能够确定局部缺陷的存在,这是单一模式光谱或其他实验技术无法做到的。
点此查看论文截图

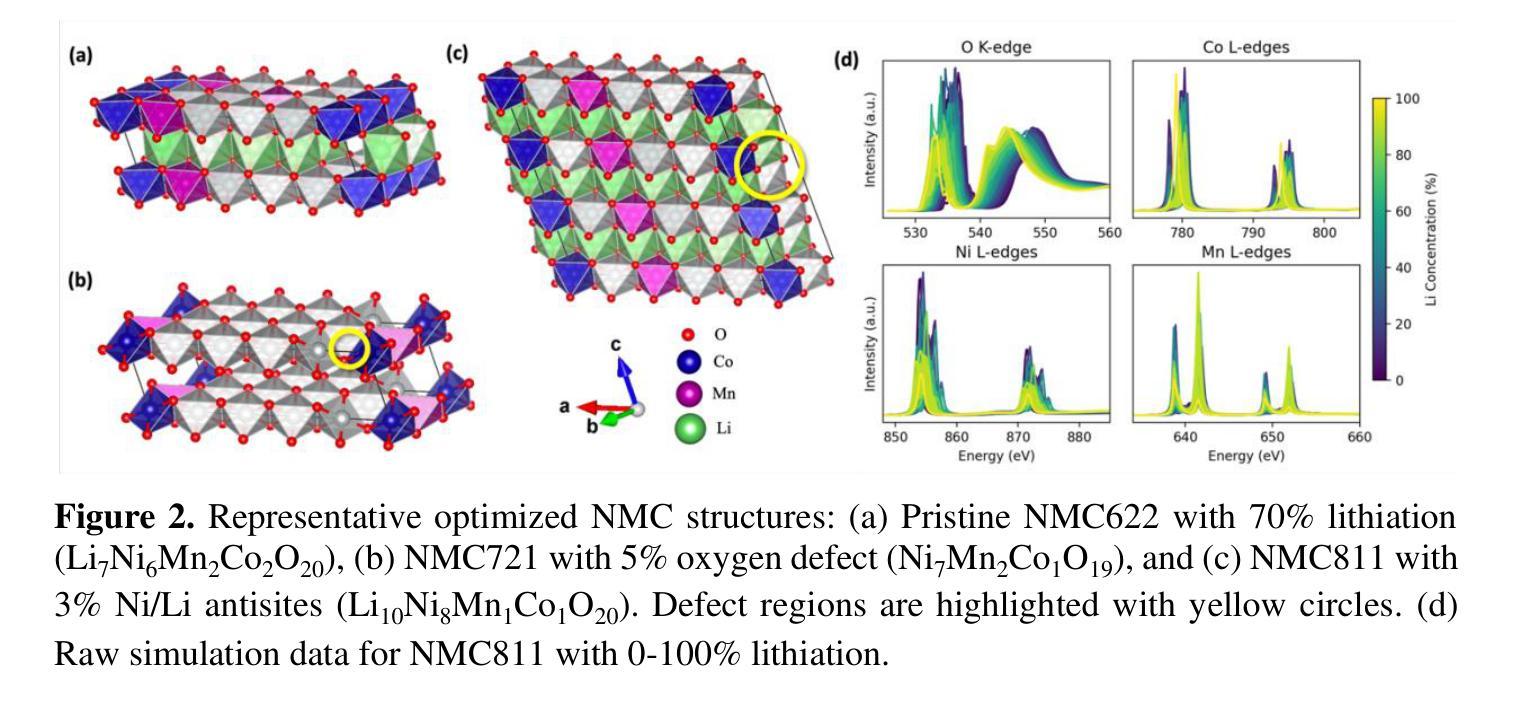
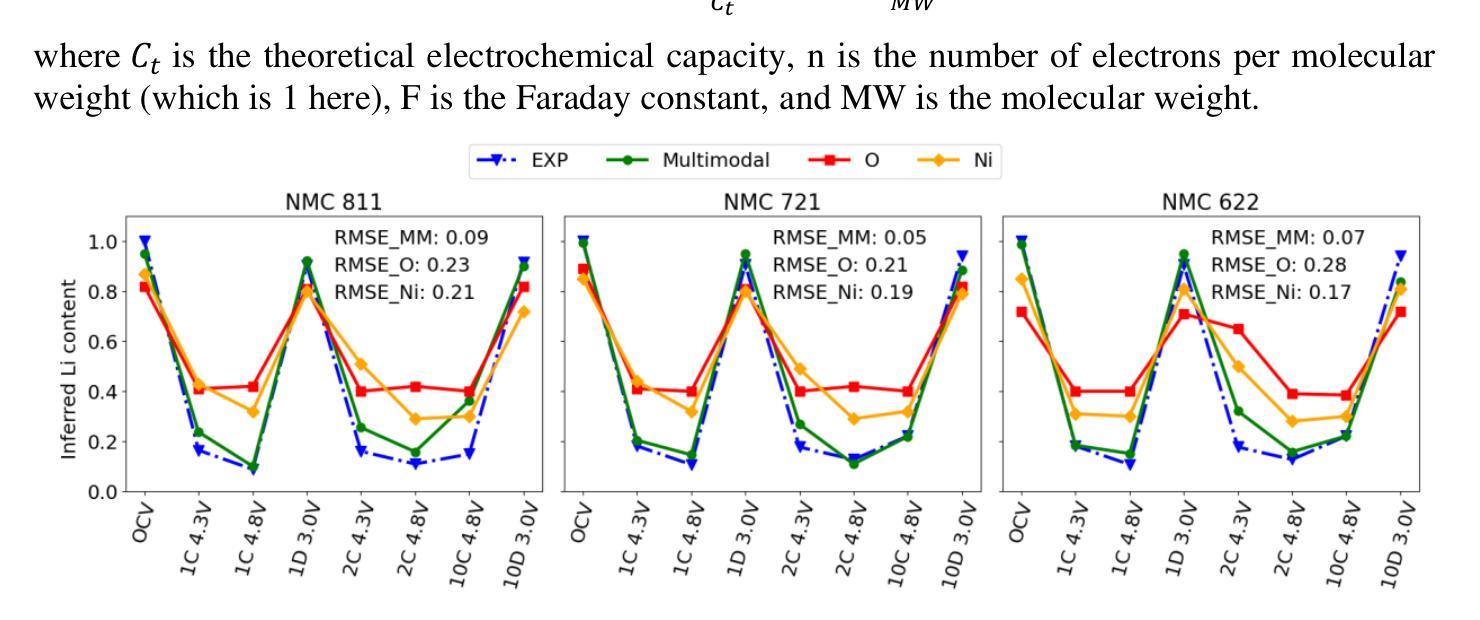
Multi-View Transformers for Airway-To-Lung Ratio Inference on Cardiac CT Scans: The C4R Study
Authors:Sneha N. Naik, Elsa D. Angelini, Eric A. Hoffman, Elizabeth C. Oelsner, R. Graham Barr, Benjamin M. Smith, Andrew F. Laine
The ratio of airway tree lumen to lung size (ALR), assessed at full inspiration on high resolution full-lung computed tomography (CT), is a major risk factor for chronic obstructive pulmonary disease (COPD). There is growing interest to infer ALR from cardiac CT images, which are widely available in epidemiological cohorts, to investigate the relationship of ALR to severe COVID-19 and post-acute sequelae of SARS-CoV-2 infection (PASC). Previously, cardiac scans included approximately 2/3 of the total lung volume with 5-6x greater slice thickness than high-resolution (HR) full-lung (FL) CT. In this study, we present a novel attention-based Multi-view Swin Transformer to infer FL ALR values from segmented cardiac CT scans. For the supervised training we exploit paired full-lung and cardiac CTs acquired in the Multi-Ethnic Study of Atherosclerosis (MESA). Our network significantly outperforms a proxy direct ALR inference on segmented cardiac CT scans and achieves accuracy and reproducibility comparable with a scan-rescan reproducibility of the FL ALR ground-truth.
在高分辨率全肺计算机断层扫描(CT)全肺吸气状态下,气道树腔与肺大小之比(ALR)是慢性阻塞性肺疾病(COPD)的主要风险因素。人们越来越有兴趣从心脏CT图像中推断ALR,这些图像在流行病学队列中广泛存在,以研究ALR与严重COVID-19和SARS-CoV-2感染后的急性后遗症(PASC)之间的关系。以前的心脏扫描包括了大约三分之二的肺体积,切片厚度是高分辨率(HR)全肺(FL)CT的5-6倍。在这项研究中,我们提出了一种新型基于注意力的多视角Swin Transformer,用于从分割的心脏CT扫描中推断全肺ALR值。我们利用在多元种族动脉粥样硬化研究(MESA)中获得的全肺和心脏CT配对图像进行有监督训练。我们的网络在分割的心脏CT扫描上的直接ALR推断表现显著优越,并且其准确性和可重复性可与全肺ALR真实值的扫描-重新扫描可重复性相当。
论文及项目相关链接
PDF Accepted to appear in Proceedings of International Symposium on Biomedical Imaging (ISBI), 2025
摘要
利用高分辨率全肺计算机断层扫描(CT)在完全吸气状态下评估的气道树腔与肺大小之比(ALR)是慢性阻塞性肺疾病(COPD)的主要风险因素。越来越多的研究兴趣在于,从在流行病学队列中广泛可用的心脏CT图像推断ALR,以研究ALR与严重COVID-19和SARS-CoV-2感染后的急性后遗症(PASC)之间的关系。先前的心脏扫描包括大约三分之二的肺总体积,切片厚度是高分辨率(HR)全肺(FL)CT的5-6倍。在这项研究中,我们提出了一种基于注意力的多视图Swin Transformer,可以从分段的心脏CT扫描推断FL ALR值。我们利用在多元种族动脉粥样硬化研究(MESA)中采集的配对全肺和心脏CT进行有监督训练。我们的网络在分段心脏CT扫描上的间接ALR推断表现显著优越,并且其准确性和再现性与FL ALR真实值的扫描-再扫描再现性相当。
要点
- 气道树腔与肺大小之比(ALR)是慢性阻塞性肺疾病(COPD)的重要风险因素。
- 心脏CT图像可用于推断ALR,这在流行病学研究中具有广泛应用。
- 先前的心脏CT扫描只包括大约三分之二的肺体积,且切片厚度较大。
- 提出一种基于注意力的多视图Swin Transformer,可从分段的心脏CT扫描推断全肺ALR值。
- 该方法利用配对全肺和心脏CT进行有监督训练。
- 该网络在间接ALR推断上表现优异,其性能和准确性可与全肺CT扫描的扫描-再扫描结果相比。
- 这种方法为通过心脏CT评估ALR提供了一种新的可能途径,有助于研究ALR与严重COVID-19和PASC之间的关系。
点此查看论文截图

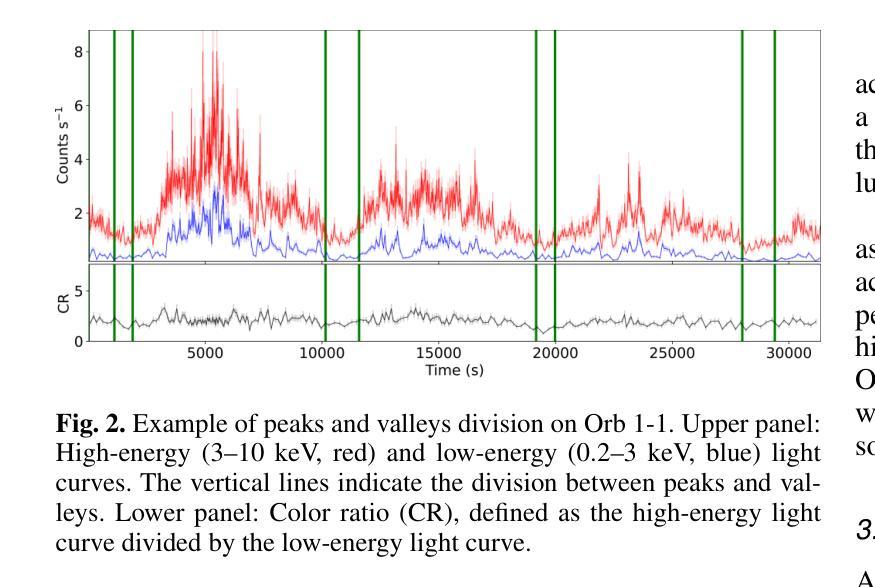
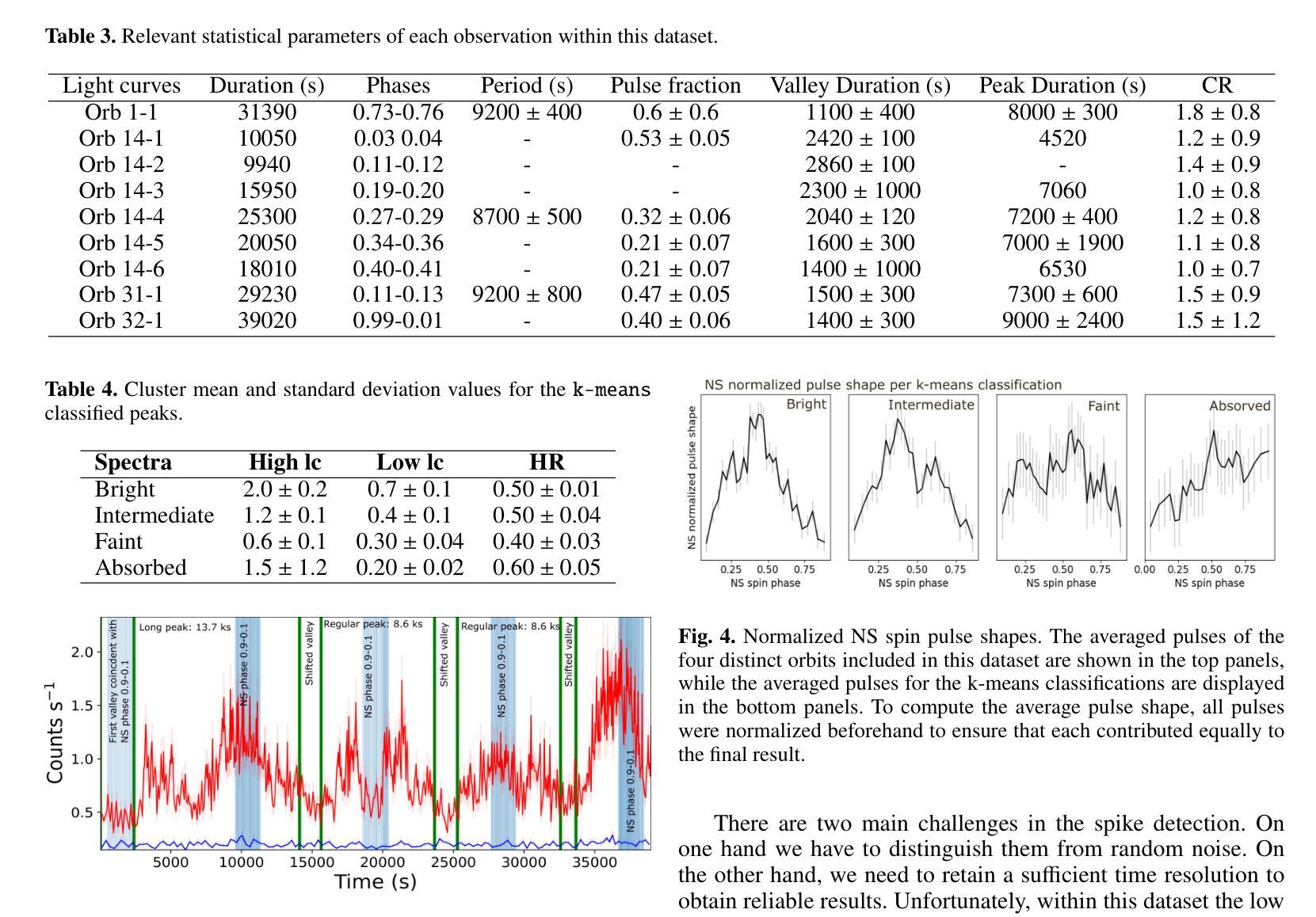
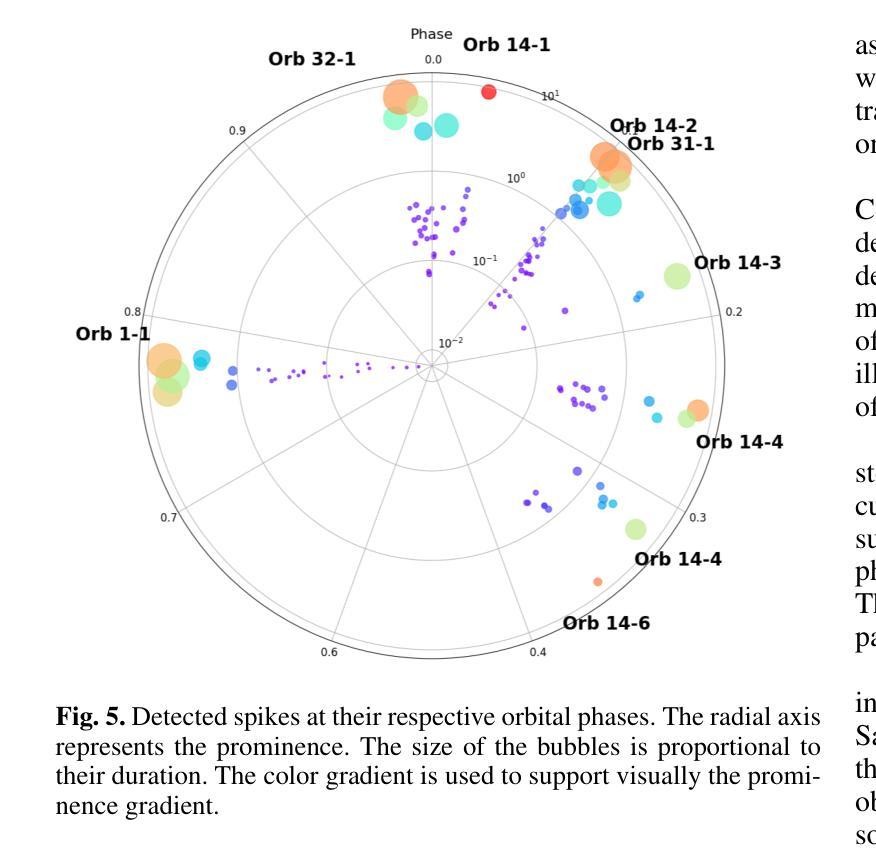
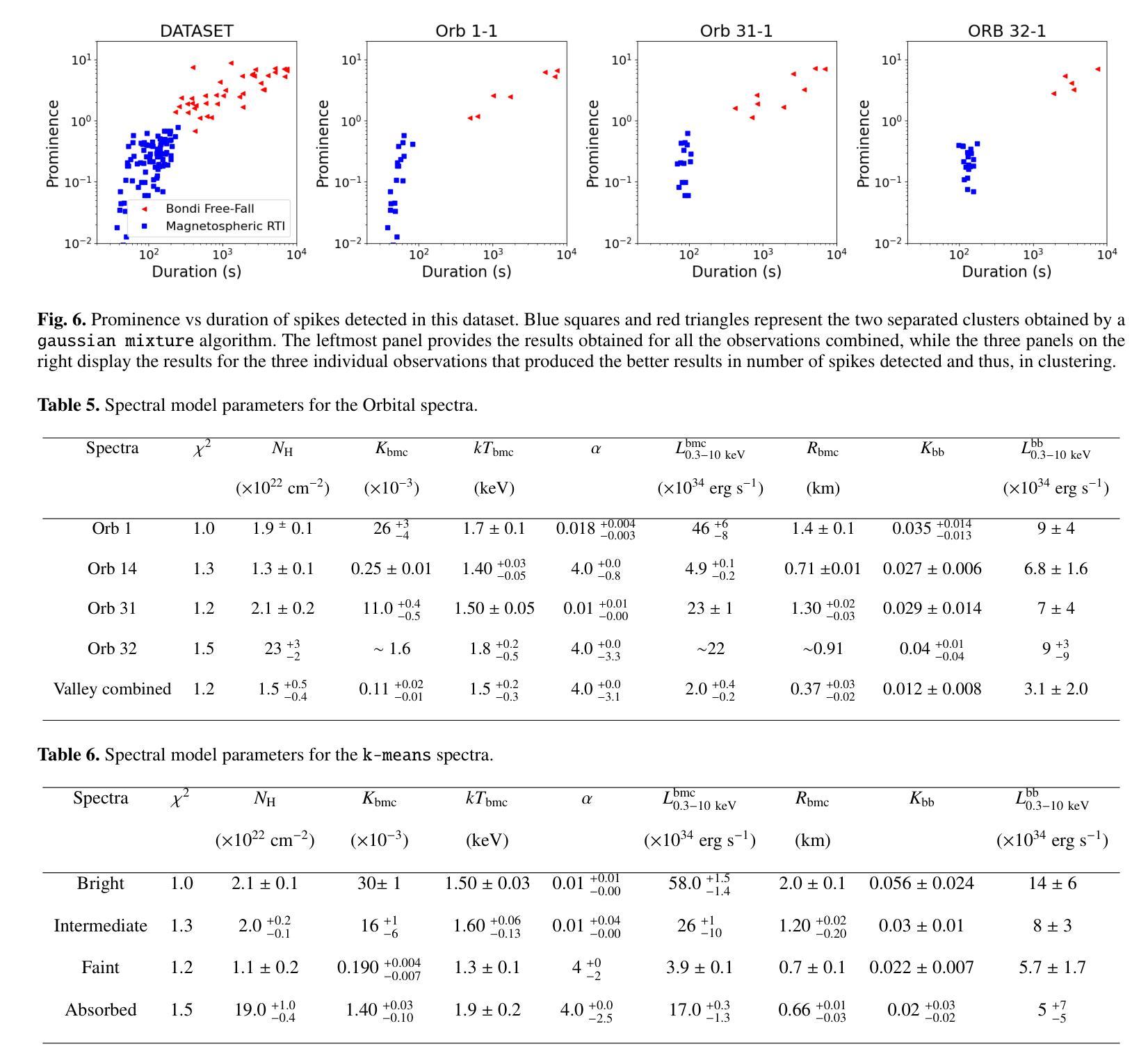
Cyclical accretion regime change in the slow X-ray pulsar 4U 0114+65 observed with Chandra
Authors:Graciela Sanjurjo-Ferrín, Jose Miguel Torrejón, Konstantin Postnov, Michael Nowak, Jose Joaquín Rodes-Roca, Lida Oskinova, Jessica Planelles-Villalva, Norber Schulz
4U 0114+65 is a high-mass X-ray binary system formed by the luminous supergiant B1Ia, known as V{*} V662 Cas, and one of the slowest rotating neutron stars (NS) with a spin period of about 2.6 hours. This fact provides a rare opportunity to study interesting details of the accretion within each individual pulse of the compact object. In this paper, we analyze 200 ks of Chandra grating data, divided into 9 uninterrupted observations around the orbit. The changes in the circumstellar absorption column through the orbit suggest an orbital inclination of $\sim$ $40^{\circ}$ with respect to the observer and a companion mass-loss rate of $\sim$ 8.6 10$^{-7}$ solar masses yr$^{-1}$. The peaks of the NS pulse show a large pulse-to-pulse variability. Three of them show an evolution from a brighter regime to a weaker one. We propose that the efficiency of Compton cooling in this source fluctuates throughout an accumulation cycle. After significant depletion of matter within the magnetosphere, since the settling velocity is $\sim \times$ 2 times lower than the free-fall velocity, the source gradually accumulates matter until the density exceeds a critical threshold. This increase in density triggers a transition to a more efficient Compton cooling regime, leading to a higher mass accretion rate and consequently to an increased brightness.
4U 0114+65是一个高质量X射线双星系统,由明亮的超巨星B1Ia(也称为V{*} V662 Cas)和自转周期约为2.6小时的中子星(NS)组成。这一事实提供了一个难得的机会,可以研究紧凑物体每个脉冲内的吸积过程的有趣细节。在本文中,我们分析了长达20万秒的Chandra光谱数据,这些数据被分为围绕轨道的9次不间断观测。恒星周围吸收柱在轨道上的变化表明轨道倾角约为$ 40^{\circ}$相对于观察者,并且伴随天体质量损失率约为每秒$ 8.6 \times 10^{-7}$个太阳质量。中子星脉冲峰值显示出巨大的脉冲间变异性。其中三个脉冲峰值表现出从较亮的状态向较弱的状态的转变。我们提出,此源的康普顿冷却效率在一个积累周期内存在波动。由于磁层内物质的大量消耗,由于沉降速度约为自由落体速度的$\frac{1}{2}$倍,物质逐渐在源处积累,直到密度超过临界阈值。密度的增加会引发向更有效的康普顿冷却状态的转变,从而导致更高的物质吸积率,进而导致亮度增加。
论文及项目相关链接
Summary
该文本描述了高质量X射线双星系统4U 0114+65的研究结果,该系统由超巨星B1Ia(称为V{*} V662 Cas)和最慢的中子星之一组成。通过对该系统的观测数据进行分析,发现其轨道倾角约为40°,并推测其伴星质量损失率约为每年损失太阳质量的8.6 x 10^-7倍。中子星脉冲峰值表现出显著的脉冲间变化,这些变化与源的康普顿冷却效率波动有关。在磁层物质大量耗尽后,由于沉降速度约为自由落体速度的两倍,物质逐渐积累直至密度超过临界阈值,触发向更有效的康普顿冷却机制的转变,导致更高的物质积累率和相应的亮度增加。
Key Takeaways
- 4U 0114+65是一个由超巨星B1Ia(V{*} V662 Cas)和最慢旋转的中子星之一组成的双星系统,为研究脉冲星体的细节提供了罕见的机会。
- 通过分析该系统长达近两年的连续观测数据,发现轨道倾角约为40°,推测伴星的质量损失率为每年损失太阳质量的特定值。这一发现对于理解双星系统的演化具有重要意义。
- 中子星脉冲峰值显示显著变化。这种变化被认为是由于该系统中康普顿冷却效率波动导致的,这可能进一步揭示了物质累积过程的复杂性。
- 在磁层物质大量耗尽后,系统的行为发生变化,表明物质的积累与密度阈值之间存在关联。当密度超过临界阈值时,系统会经历一种向更有效的冷却机制转变的过程。这一发现对于理解脉冲星的物理特性至关重要。
点此查看论文截图


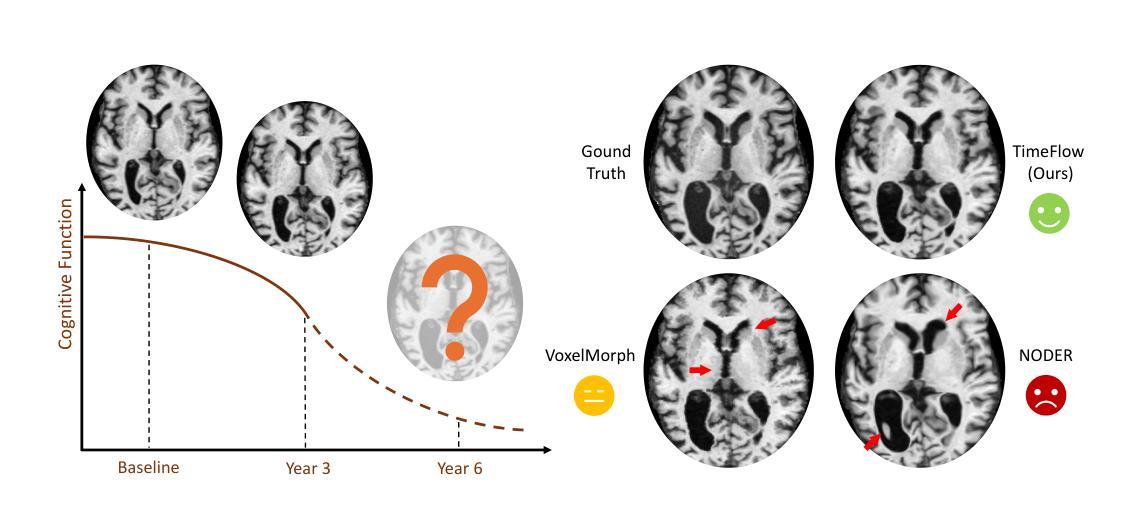
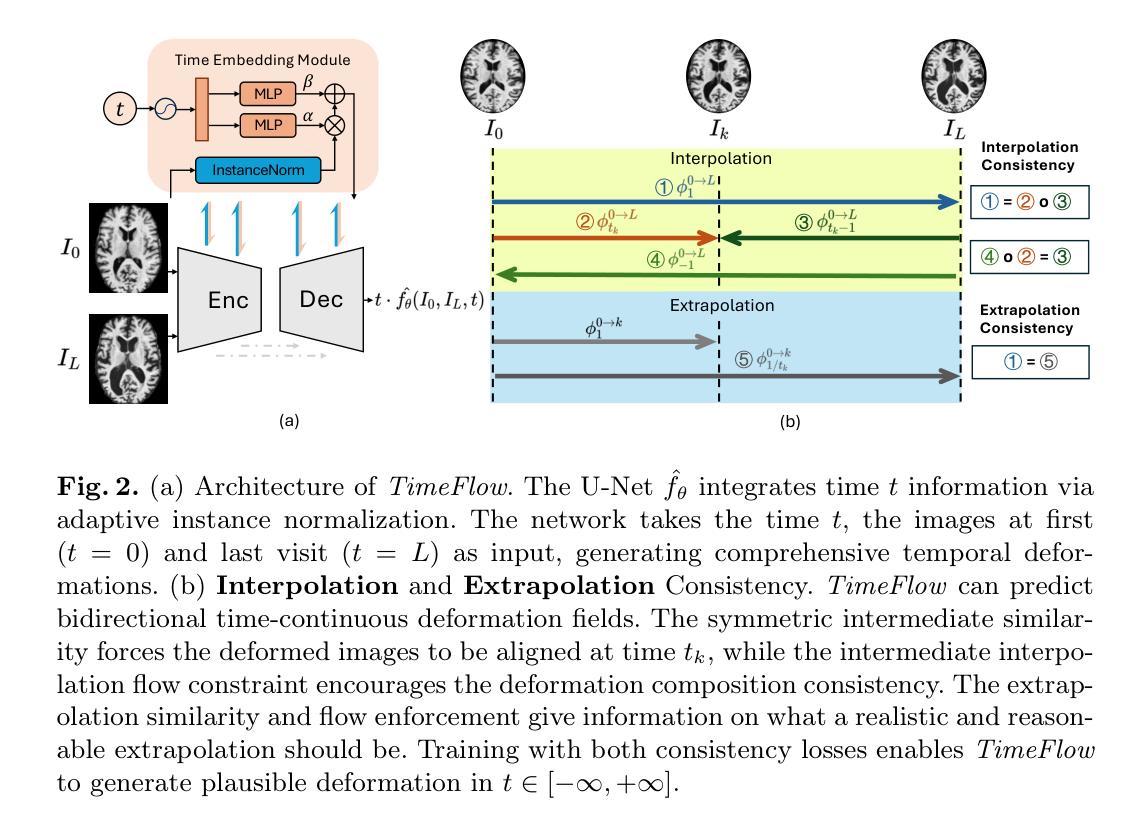
TimeFlow: Longitudinal Brain Image Registration and Aging Progression Analysis
Authors:Bailiang Jian, Jiazhen Pan, Yitong Li, Fabian Bongratz, Ruochen Li, Daniel Rueckert, Benedikt Wiestler, Christian Wachinger
Predicting future brain states is crucial for understanding healthy aging and neurodegenerative diseases. Longitudinal brain MRI registration, a cornerstone for such analyses, has long been limited by its inability to forecast future developments, reliance on extensive, dense longitudinal data, and the need to balance registration accuracy with temporal smoothness. In this work, we present \emph{TimeFlow}, a novel framework for longitudinal brain MRI registration that overcomes all these challenges. Leveraging a U-Net architecture with temporal conditioning inspired by diffusion models, TimeFlow enables accurate longitudinal registration and facilitates prospective analyses through future image prediction. Unlike traditional methods that depend on explicit smoothness regularizers and dense sequential data, TimeFlow achieves temporal consistency and continuity without these constraints. Experimental results highlight its superior performance in both future timepoint prediction and registration accuracy compared to state-of-the-art methods. Additionally, TimeFlow supports novel biological brain aging analyses, effectively differentiating neurodegenerative conditions from healthy aging. It eliminates the need for segmentation, thereby avoiding the challenges of non-trivial annotation and inconsistent segmentation errors. TimeFlow paves the way for accurate, data-efficient, and annotation-free prospective analyses of brain aging and chronic diseases.
预测未来的大脑状态对于理解健康老化和神经退行性疾病至关重要。纵向脑MRI注册是此类分析的核心,长期以来一直受限于其无法预测未来发展、依赖大量密集的纵向数据以及需要在注册精度与时间平滑之间取得平衡。在这项工作中,我们提出了\emph{TimeFlow}这一全新的纵向脑MRI注册框架,克服了上述所有挑战。TimeFlow利用受扩散模型启发的U-Net架构进行时间条件处理,能够实现准确的纵向注册,并通过未来图像预测进行前瞻性分析。与传统方法不同,TimeFlow无需依赖明确的平滑正则器和密集的序列数据即可实现时间的一致性和连续性。实验结果表明,与最先进的方法相比,TimeFlow在未来时间点预测和注册精度方面都表现出卓越的性能。此外,TimeFlow支持新型脑衰老生物学分析,可有效区分神经退行性疾病与健康衰老。它无需分割,从而避免了非平凡标注和不一致的分割错误所带来的挑战。TimeFlow为准确、高效且无标注的前瞻性分析脑衰老和慢性病铺平了道路。
论文及项目相关链接
Summary
本文介绍了一种名为TimeFlow的新型纵向脑MRI注册框架,它克服了现有方法的局限性,实现了准确的纵向注册和未来图像预测。TimeFlow采用U-Net架构,受扩散模型启发进行时间条件处理,可在无需明确平滑正则器和密集序列数据的情况下实现时间连贯性和连续性。实验结果表明,TimeFlow在未来时间点预测和注册准确性方面表现出卓越性能,并支持新型生物脑衰老分析,可区分神经退行性疾病和健康衰老。
Key Takeaways
- TimeFlow是一个新型的纵向脑MRI注册框架,能够预测未来的大脑状态。
- 它克服了现有方法的挑战,如无法预测未来发展、对密集纵向数据依赖以及需要在注册精度和时间平滑之间取得平衡。
- TimeFlow采用U-Net架构,结合扩散模型的时间条件,实现了准确且连贯的纵向注册。
- 该方法可在无需明确平滑正则器和密集序列数据的情况下实现时间连贯性和连续性。
- 实验结果表明,TimeFlow在未来时间点预测和注册准确性方面表现优异。
- TimeFlow支持新型生物脑衰老分析,并能区分神经退行性疾病和健康衰老。
点此查看论文截图

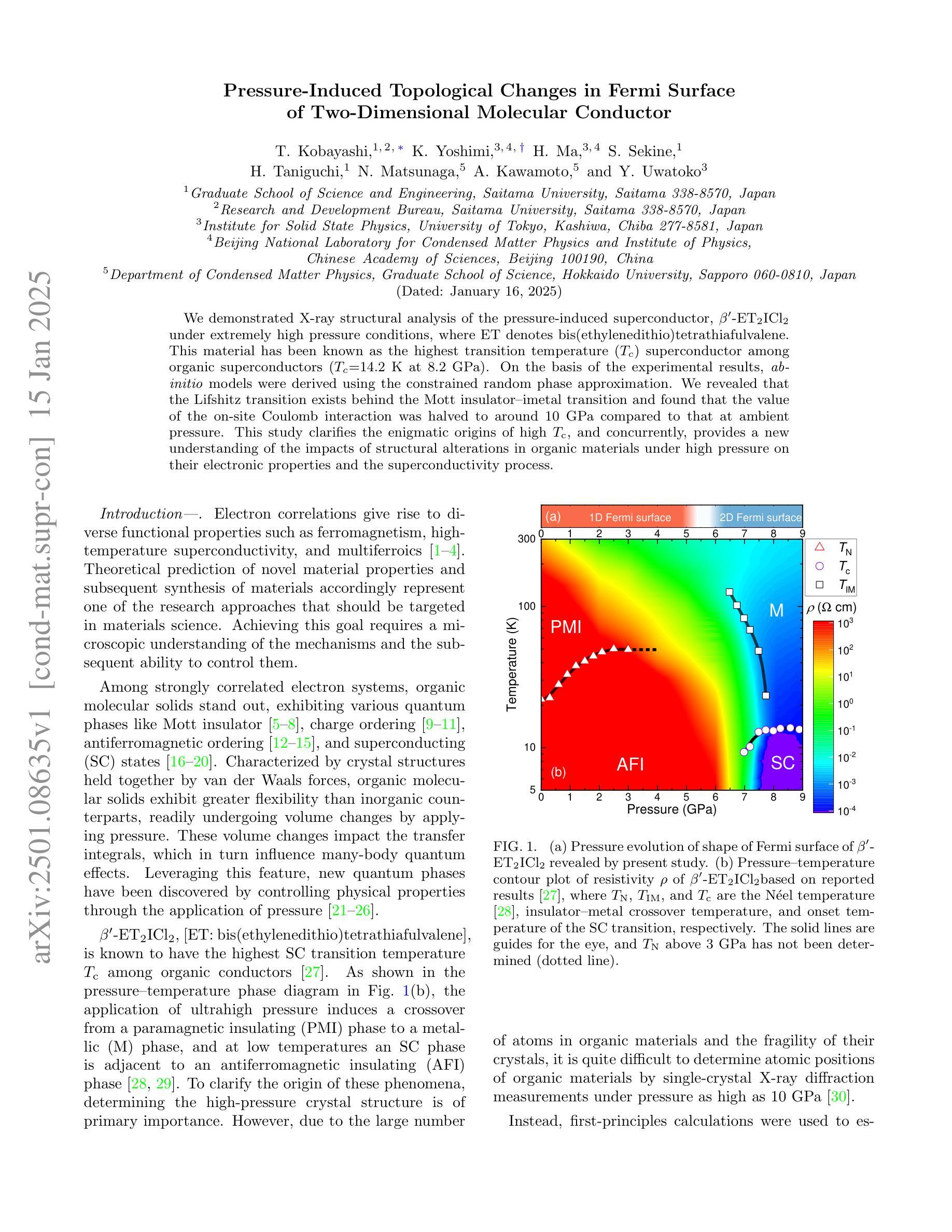
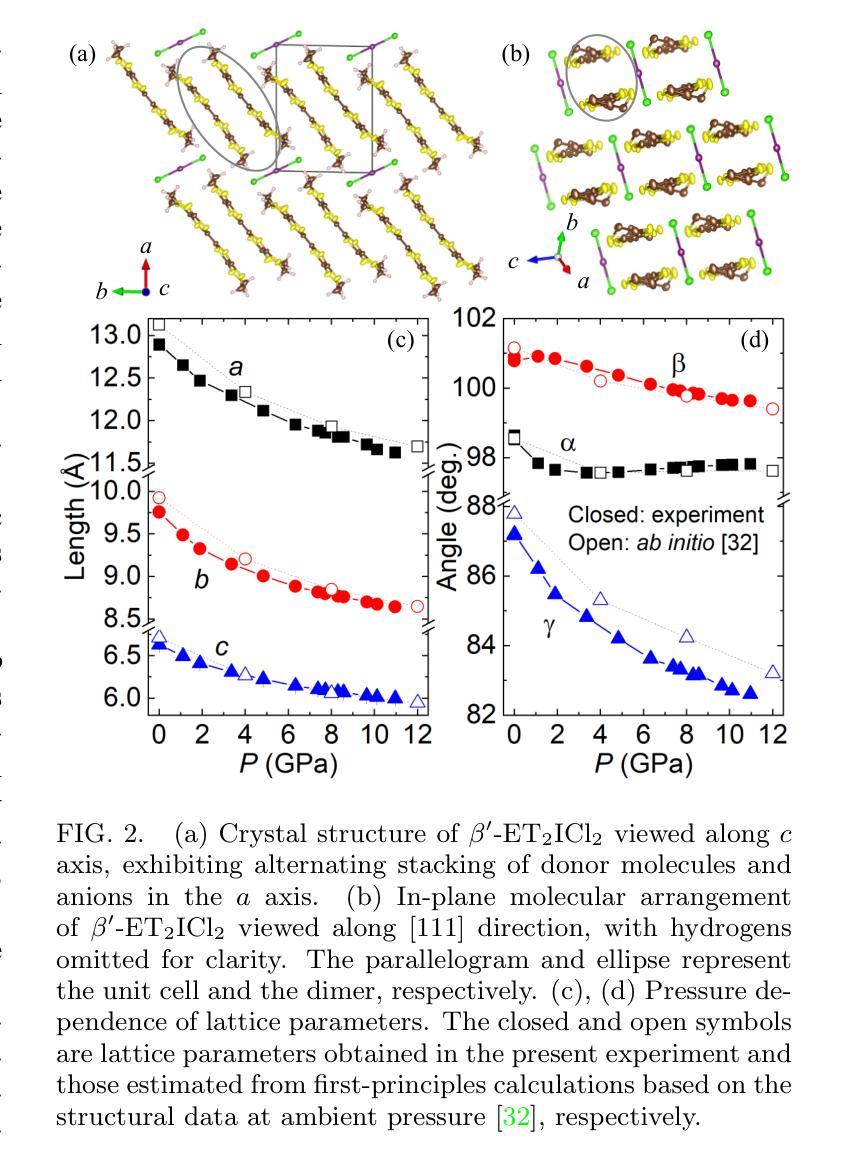
Pressure-induced topological changes in Fermi surface of two-dimensional molecular conductor
Authors:T. Kobayashi, K. Yoshimi, H. Ma, S. Sekine, H. Taniguchi, N. Matsunaga, A. Kawamoto, Y. Uwatoko
We demonstrated X-ray structural analysis of the pressure-induced superconductor, $\beta’$-ET$_2$ICl$2$ under extremely high-pressure conditions, where ET denotes bis(ethylenedithio)tetrathiafulvalene. This material has been known as the highest transition temperature ($T_c$) superconductor among organic superconductors ($T_c=14.2$ K at $8.2$ GPa). On the basis of the experimental results, ab-initio models were derived using the constrained random phase approximation. We revealed that the Lifshitz transition exists behind the Mott insulator-metal transition and found that the value of the on-site Coulomb interaction was halved to around $10$ GPa compared to that at ambient pressure. This study clarifies the enigmatic origins of high $T{\rm c}$, and concurrently, provides a new understanding of the impacts of structural alterations in organic materials under high pressure on their electronic properties and the superconductivity process.
我们对压力诱导的超导体β’-ET₂ICl₂进行了X射线结构分析,其中ET代表双(乙烯二硫代)四硫富瓦烯。这种材料在有机超导体中具有最高的转变温度(Tc),在8.2 GPa时的Tc为14.2 K。根据实验结果,我们使用约束随机相位逼近推导出了从头模型。我们揭示了Lifshitz转变存在于Mott绝缘体金属转变之后,并发现现场库仑相互作用值在约10 GPa时比环境压力下的值减少了一半。这项研究阐明了高Tc的神秘起源,同时提供了新的理解:在高压力下有机材料的结构变化对其电子特性和超导过程的影响。
论文及项目相关链接
PDF 8 pages, 4 figures; Supplemental Material: 9 pages, 6 figures, accepted for publication in Phys. Rev. Materials (Letter)
Summary
本研究对高压下压力诱导的超导体β’-ET₂ICl₂(其中ET代表双(乙二硫代)四硫富瓦烯)进行了X射线结构分析。该材料在有机超导体中具有最高的转变温度(Tc)。基于实验结果,采用约束随机相位近似法推导了从头算模型。研究揭示了Lifshitz转变存在于Mott绝缘体-金属转变之后,并发现与常压相比,在大约10 GPa时,在位库仑相互作用值减半。这项研究阐明了高Tc的奥秘,同时提供了新的理解:在高压下有机材料的结构变化对其电子属性和超导过程的影响。
Key Takeaways
- 研究进行了高压下超导体β’-ET₂ICl₂的X射线结构分析。
- 该材料在有机超导体中展现出最高的转变温度(Tc)。
- 通过约束随机相位近似法推导了实验结果的从头算模型。
- 研究揭示了Lifshitz转变与Mott绝缘体-金属转变之间的关系。
- 在约10 GPa的压力下,在位库仑相互作用值相比常压条件减半。
- 研究阐明了高压下有机材料结构变化对电子属性和超导过程的影响。
点此查看论文截图
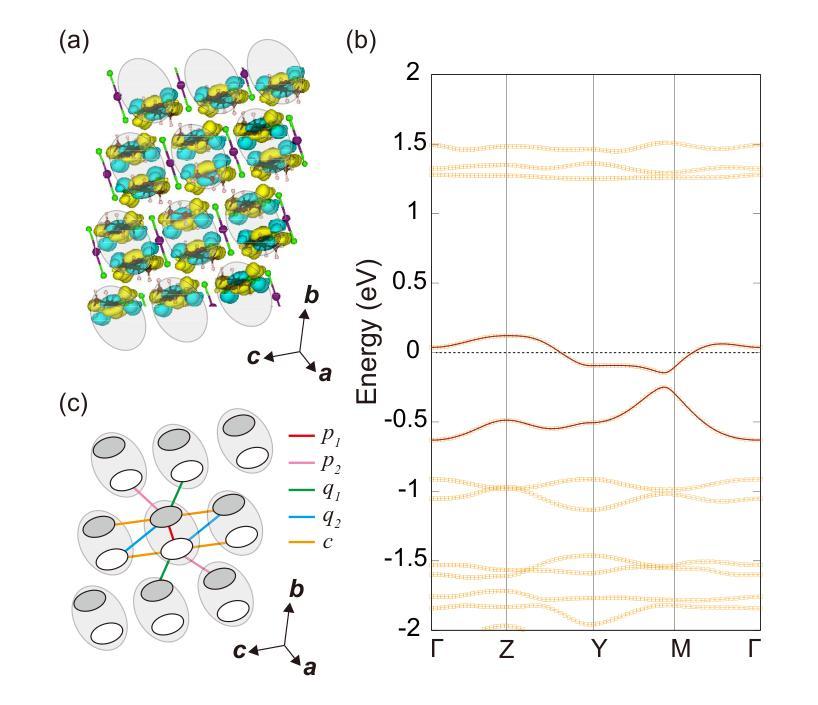
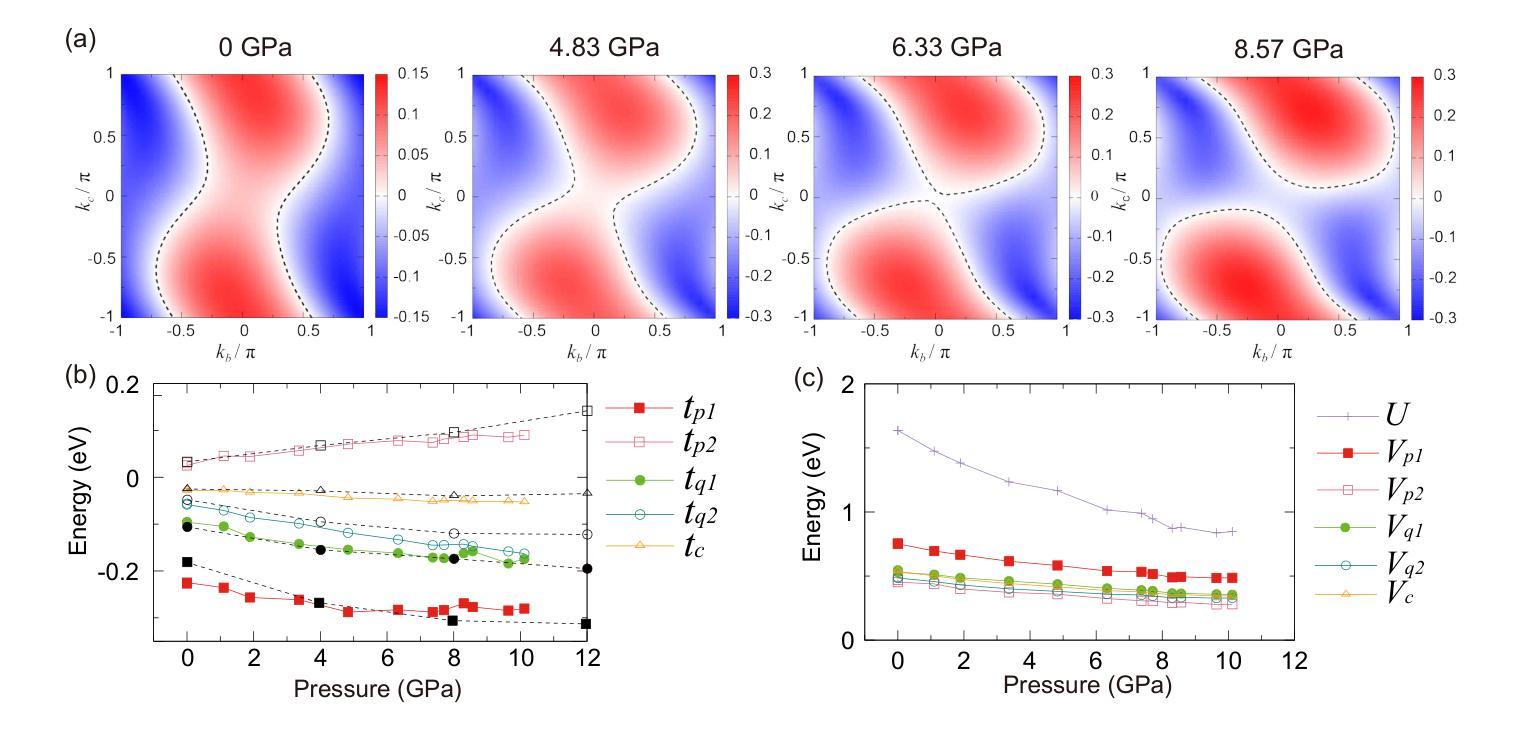
Densely Connected Parameter-Efficient Tuning for Referring Image Segmentation
Authors:Jiaqi Huang, Zunnan Xu, Ting Liu, Yong Liu, Haonan Han, Kehong Yuan, Xiu Li
In the domain of computer vision, Parameter-Efficient Tuning (PET) is increasingly replacing the traditional paradigm of pre-training followed by full fine-tuning. PET is particularly favored for its effectiveness in large foundation models, as it streamlines transfer learning costs and optimizes hardware utilization. However, the current PET methods are mainly designed for single-modal optimization. While some pioneering studies have undertaken preliminary explorations, they still remain at the level of aligned encoders (e.g., CLIP) and lack exploration of misaligned encoders. These methods show sub-optimal performance with misaligned encoders, as they fail to effectively align the multimodal features during fine-tuning. In this paper, we introduce DETRIS, a parameter-efficient tuning framework designed to enhance low-rank visual feature propagation by establishing dense interconnections between each layer and all preceding layers, which enables effective cross-modal feature interaction and adaptation to misaligned encoders. We also suggest using text adapters to improve textual features. Our simple yet efficient approach greatly surpasses state-of-the-art methods with 0.9% to 1.8% backbone parameter updates, evaluated on challenging benchmarks. Our project is available at \url{https://github.com/jiaqihuang01/DETRIS}.
在计算机视觉领域,参数高效调整(PET)正越来越多地取代传统的预训练后进行全面微调的模式。PET因其在大规模基础模型中的有效性而受到青睐,它能简化迁移学习成本并优化硬件利用率。然而,当前的PET方法主要是为单一模态优化设计的。虽然一些开创性的研究已经进行了初步的探索,但它们仍然停留在对齐编码器的层面(例如CLIP),并且缺乏对未对齐编码器的探索。这些方法在面临未对齐编码器时表现出性能不佳,因为它们无法在微调过程中有效地对齐多模态特征。在本文中,我们介绍了DETRIS,这是一个参数高效调整框架,旨在通过在各层和所有前层之间建立密集连接来增强低秩视觉特征传播,从而实现有效的跨模态特征交互和适应未对齐的编码器。我们还建议使用文本适配器来改善文本特征。我们简单而高效的方法在具有挑战性的基准测试中,以更新0.9%至1.8%的主干参数大大超越了最新方法。我们的项目可通过网址https://github.com/jiaqihuang01/DETRIS获取。
论文及项目相关链接
PDF Accepted by AAAI2025
Summary
参数高效调整(PET)方法正在改变计算机视觉领域中的预训练加全微调的传统模式。PET特别适用于大型基础模型,因为它能优化硬件使用并降低迁移学习成本。然而,当前PET方法主要针对单模态优化进行设计。尽管已有初步探索,但它们主要停留在对齐编码器(如CLIP)的层面,并未探索错配编码器。当使用错配编码器时,这些方法表现不佳,无法有效对齐多模态特征进行微调。本文介绍DETRIS,一种参数高效调整框架,旨在通过在各层与所有前置层之间建立密集互联,增强低秩视觉特征传播,实现跨模态特征的有效交互并适应错配编码器。本文还建议使用文本适配器来改善文本特征。通过简单的策略,我们的方法在具有挑战性的基准测试中大幅超越了现有技术,仅需更新0.9%至1.8%的主干参数。
Key Takeaways
- PET方法正在改变计算机视觉的传统训练模式,特别是在大型基础模型中。
- 当前PET方法主要面向单模态优化,对于错配编码器的性能表现不佳。
- DETRIS框架通过密集互联增强低秩视觉特征传播,有效实现跨模态特征交互。
- DETRIS能适应错配编码器,提高了方法的鲁棒性。
- 使用文本适配器来改善文本特征的方法被提出。
- DETRIS方法在具有挑战性的基准测试中显著超越了现有技术。
点此查看论文截图

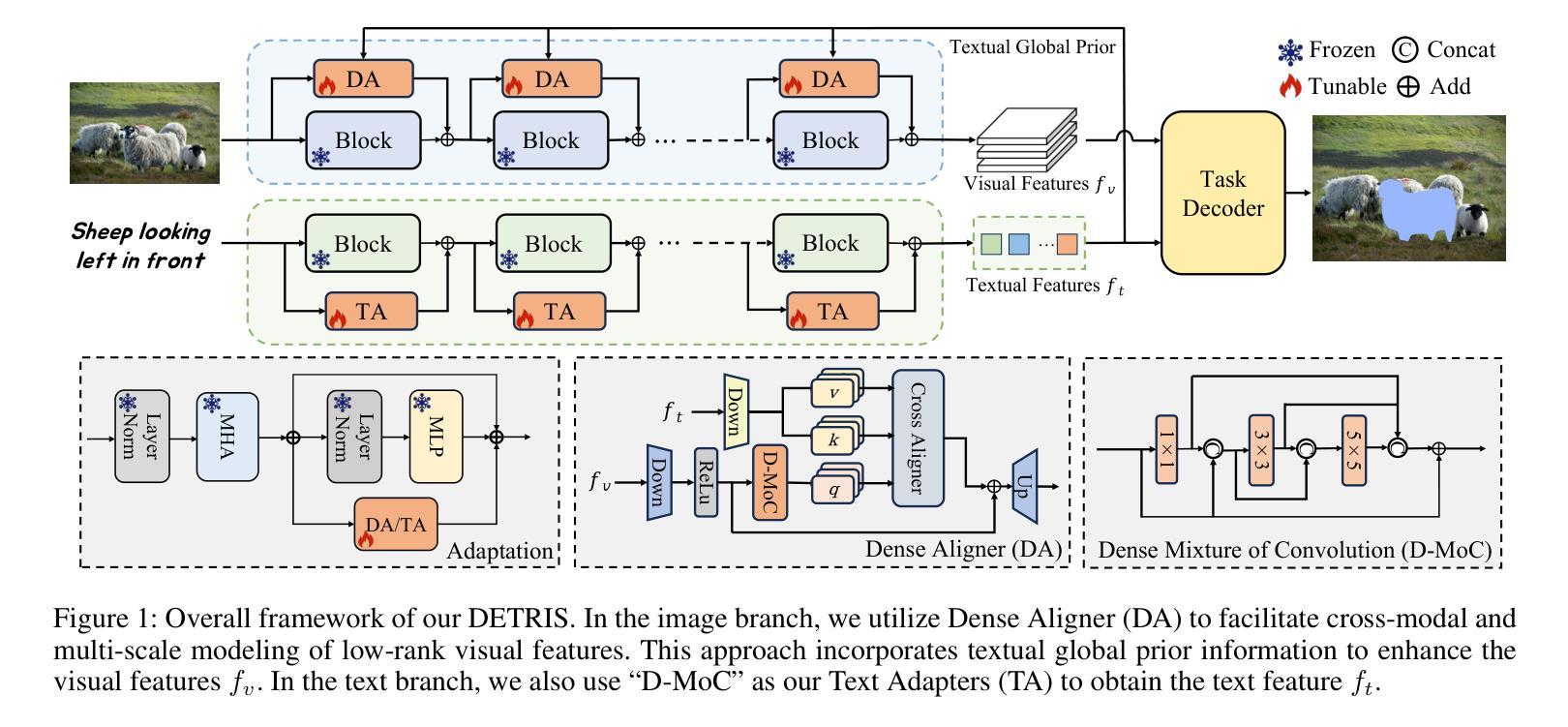

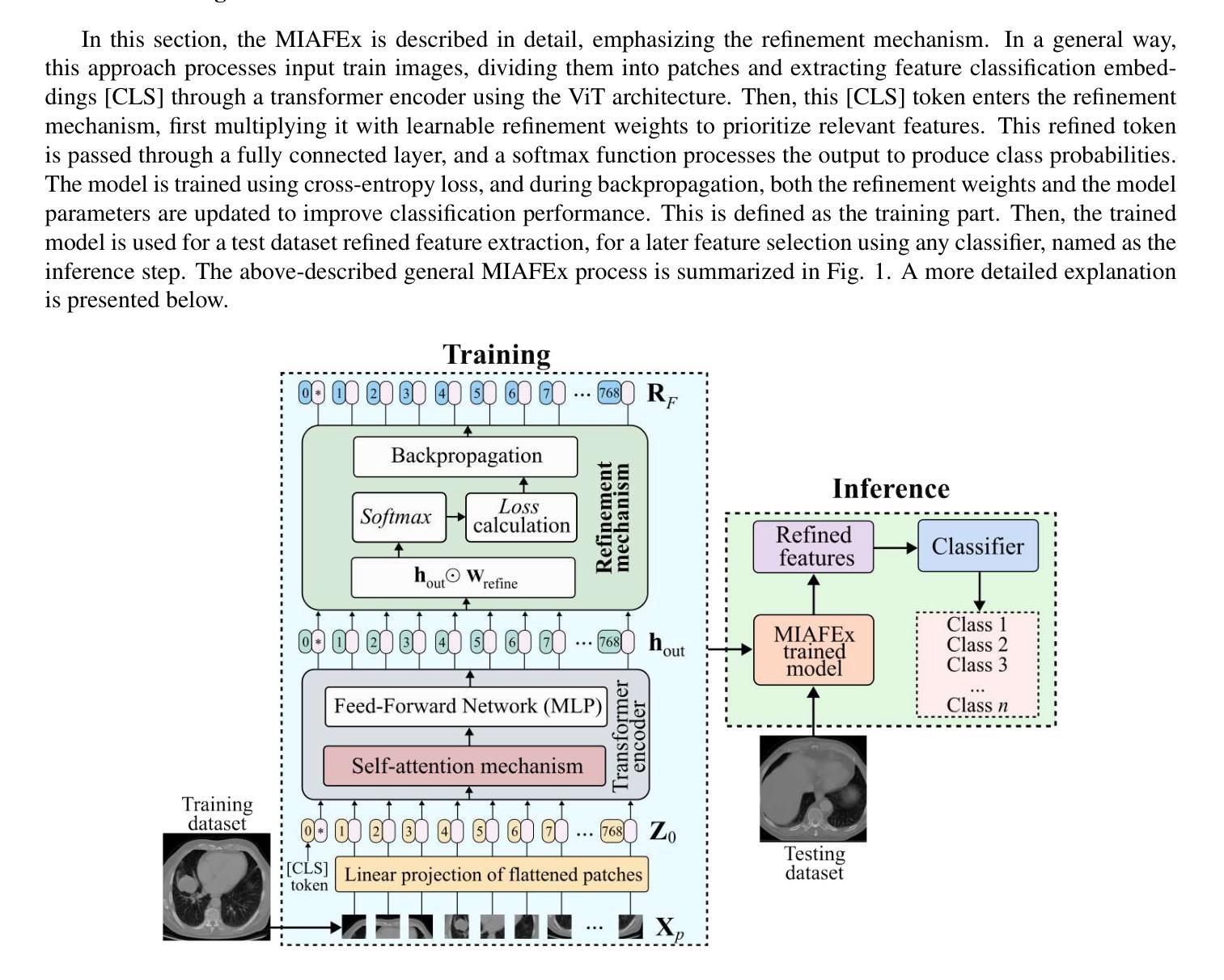
MIAFEx: An Attention-based Feature Extraction Method for Medical Image Classification
Authors:Oscar Ramos-Soto, Jorge Ramos-Frutos, Ezequiel Perez-Zarate, Diego Oliva, Sandra E. Balderas-Mata
Feature extraction techniques are crucial in medical image classification; however, classical feature extractors in addition to traditional machine learning classifiers often exhibit significant limitations in providing sufficient discriminative information for complex image sets. While Convolutional Neural Networks (CNNs) and Vision Transformer (ViT) have shown promise in feature extraction, they are prone to overfitting due to the inherent characteristics of medical imaging data, including small sample sizes or high intra-class variance. In this work, the Medical Image Attention-based Feature Extractor (MIAFEx) is proposed, a novel method that employs a learnable refinement mechanism to enhance the classification token within the Transformer encoder architecture. This mechanism adjusts the token based on learned weights, improving the extraction of salient features and enhancing the model’s adaptability to the challenges presented by medical imaging data. The MIAFEx output features quality is compared against classical feature extractors using traditional and hybrid classifiers. Also, the performance of these features is compared against modern CNN and ViT models in classification tasks, demonstrating its superiority in accuracy and robustness across multiple complex classification medical imaging datasets. This advantage is particularly pronounced in scenarios with limited training data, where traditional and modern models often struggle to generalize effectively. The source code of this proposal can be found at https://github.com/Oscar-RamosS/Medical-Image-Attention-based-Feature-Extractor-MIAFEx
特征提取技术在医学图像分类中至关重要。然而,除了传统的机器学习分类器外,经典的特征提取器在为复杂的图像集提供足够的鉴别信息时往往存在显著局限性。卷积神经网络(CNNs)和视觉转换器(ViT)在特征提取方面显示出潜力,但由于医学成像数据固有的特性,包括样本量小或类内方差高,它们容易过度拟合。在本文中,提出了一种医学图像注意力特征提取器(MIAFEx),这是一种采用可学习细化机制的新方法,旨在增强Transformer编码器架构中的分类令牌。这种机制根据学习到的权重调整令牌,提高了显著特征的提取能力,并增强了模型对医学成像数据挑战的适应性。MIAFEx输出特征质量与使用传统和混合分类器的经典特征提取器进行了比较。此外,这些特征在分类任务中的性能与现代的CNN和ViT模型相比也进行了比较,证明其在多个复杂的医学图像分类数据集上的准确性和稳健性方面具有优势。特别是在训练数据有限的情况下,传统和现代模型往往难以有效推广,MIAFEx的优势尤为突出。该提案的源代码可在https://github.com/Oscar-RamosS/Medical-Image-Attention-based-Feature-Extractor-MIAFEx找到。
论文及项目相关链接
PDF In preparation for Journal Submission
Summary
本文介绍了在医学图像分类中特征提取技术的重要性。传统特征提取器结合传统机器学习分类器在处理复杂图像集时提供足够的判别信息存在局限性。卷积神经网络(CNN)和视觉转换器(ViT)虽具有潜力,但由于医学成像数据的小样本量或高类内差异等固有特性,容易发生过拟合。为此,本文提出了医学图像注意力特征提取器(MIAFEx),这是一种采用可学习细化机制的新方法,用于增强Transformer编码器架构中的分类令牌。该机制基于学习到的权重调整令牌,提高了显著特征的提取,增强了模型对医学成像数据挑战的适应性。MIAFEx的特征质量与传统和混合分类器的经典特征提取器进行了比较,也与现代CNN和ViT模型在分类任务中的性能进行了比较,证明其在多个复杂医学图像分类数据集上的准确性和稳健性方面的优越性。在训练数据有限的情况下,这种优势尤为突出。
Key Takeaways
- 医学图像分类中,特征提取技术非常重要,但传统特征提取器和机器学习分类器在处理复杂图像集时存在局限性。
- CNN和ViT在医学图像特征提取中展现出潜力,但容易因数据特性(如小样本、高类内差异)而过度拟合。
- 新提出的MIAFEx采用可学习细化机制,增强Transformer编码器中的分类令牌,提高显著特征提取。
- MIAFEx的特征质量在与其他传统和现代模型比较中表现出优越性能,特别是在有限训练数据的场景下。
- MIAFEx模型在多个复杂的医学图像分类数据集上展示了高准确性和稳健性。
- 该研究的源代码可在指定链接找到。
- 注意力机制在医学图像特征提取中的应用为提高模型性能开辟了新的方向。
点此查看论文截图

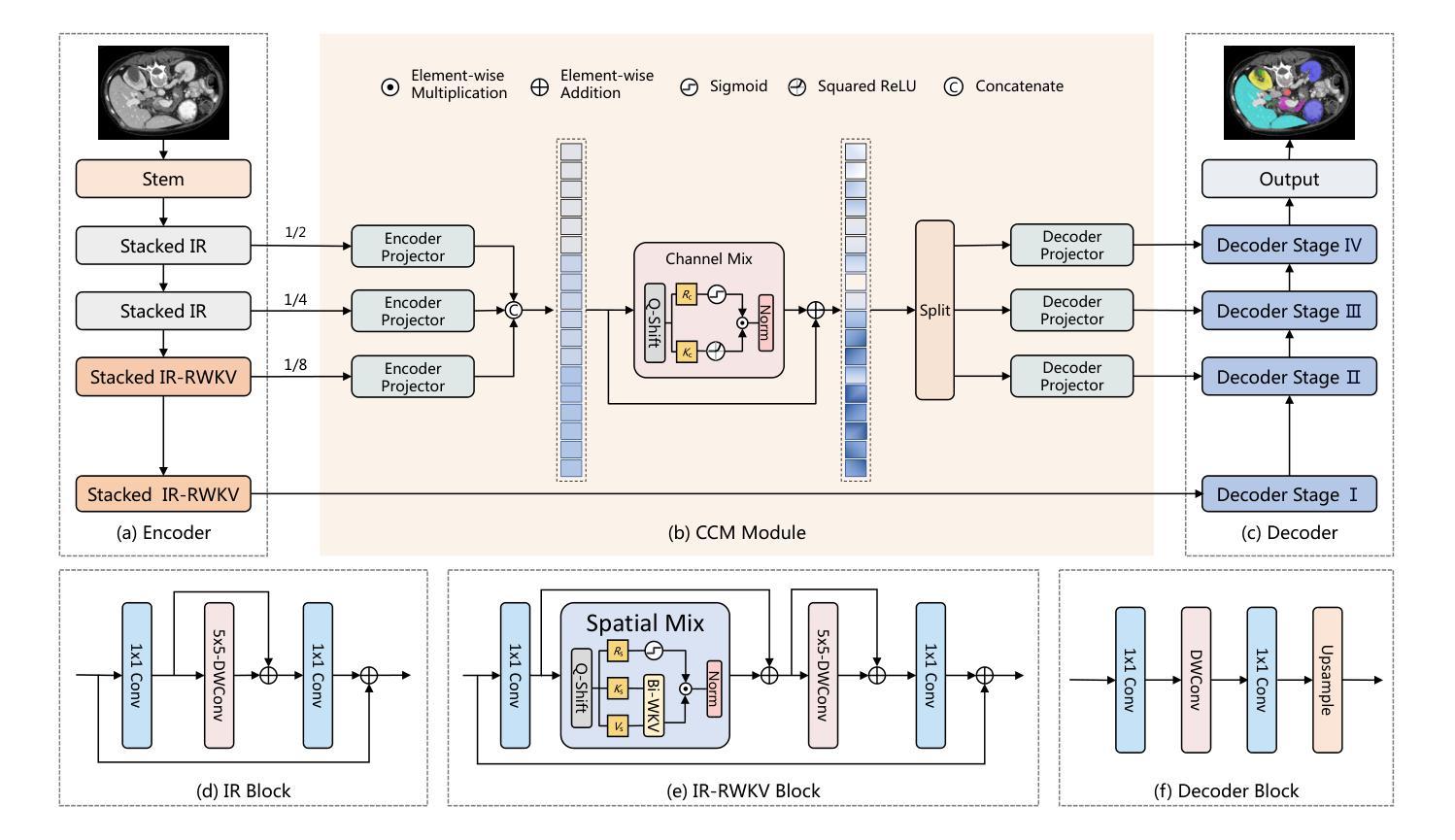
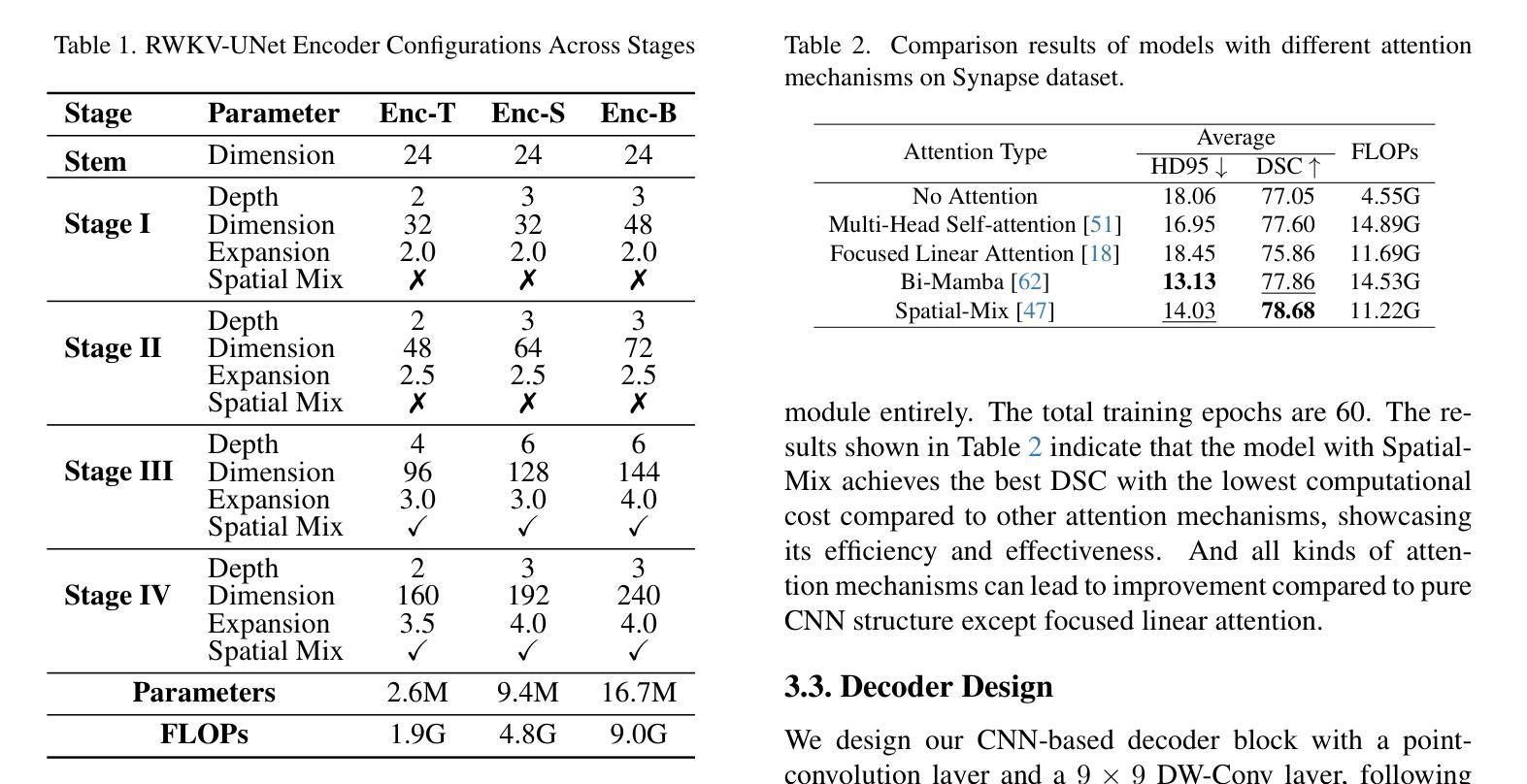
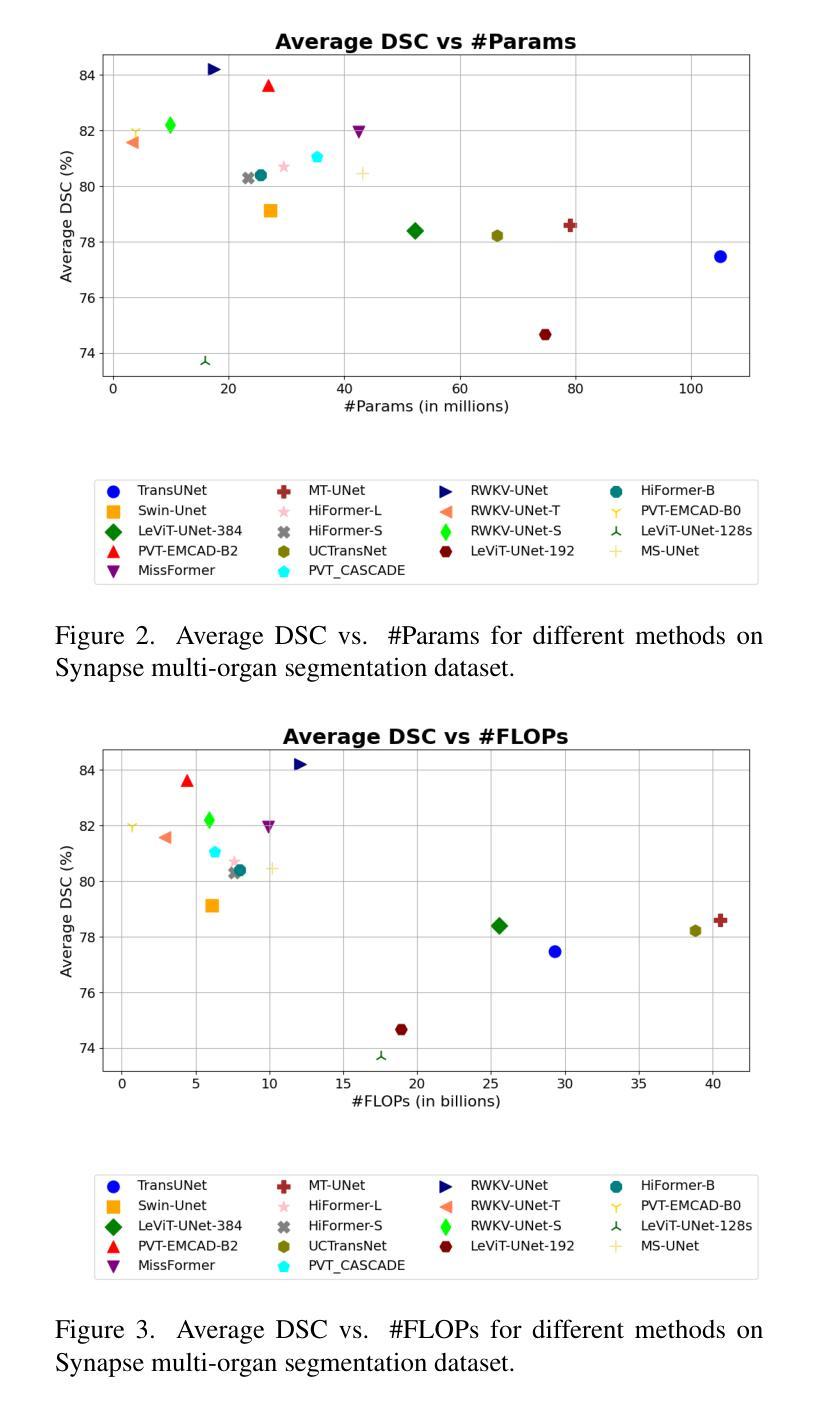
RWKV-UNet: Improving UNet with Long-Range Cooperation for Effective Medical Image Segmentation
Authors:Juntao Jiang, Jiangning Zhang, Weixuan Liu, Muxuan Gao, Xiaobin Hu, Xiaoxiao Yan, Feiyue Huang, Yong Liu
In recent years, there have been significant advancements in deep learning for medical image analysis, especially with convolutional neural networks (CNNs) and transformer models. However, CNNs face limitations in capturing long-range dependencies while transformers suffer high computational complexities. To address this, we propose RWKV-UNet, a novel model that integrates the RWKV (Receptance Weighted Key Value) structure into the U-Net architecture. This integration enhances the model’s ability to capture long-range dependencies and improve contextual understanding, which is crucial for accurate medical image segmentation. We build a strong encoder with developed inverted residual RWKV (IR-RWKV) blocks combining CNNs and RWKVs. We also propose a Cross-Channel Mix (CCM) module to improve skip connections with multi-scale feature fusion, achieving global channel information integration. Experiments on benchmark datasets, including Synapse, ACDC, BUSI, CVC-ClinicDB, CVC-ColonDB, Kvasir-SEG, ISIC 2017 and GLAS show that RWKV-UNet achieves state-of-the-art performance on various types of medical image segmentation. Additionally, smaller variants, RWKV-UNet-S and RWKV-UNet-T, balance accuracy and computational efficiency, making them suitable for broader clinical applications.
近年来,深度学习在医学图像分析方面取得了显著进展,尤其是卷积神经网络(CNN)和变压器模型的应用。然而,CNN在捕捉长距离依赖关系方面存在局限性,而变压器则面临计算复杂性高的问题。为了解决这一问题,我们提出了RWKV-UNet模型,这是一种将RWKV(Receptance Weighted Key Value)结构融入U-Net架构的新型模型。这种融合增强了模型捕捉长距离依赖关系并提高上下文理解的能力,这对于准确的医学图像分割至关重要。我们利用先进的倒残差RWKV(IR-RWKV)块构建了一个强大的编码器,结合了CNN和RWKV。我们还提出了跨通道混合(CCM)模块,通过多尺度特征融合改进跳过连接,实现全局通道信息集成。在Synapse、ACDC、BUSI、CVC-ClinicDB、CVC-ColonDB、Kvasir-SEG、ISIC 2017和GLAS等基准数据集上的实验表明,RWKV-UNet在各种类型的医学图像分割上达到了最先进的性能。此外,较小的变体RWKV-UNet-S和RWKV-UNet-T平衡了准确性和计算效率,使它们更适合更广泛的临床应用。
论文及项目相关链接
Summary
融合RWKV结构于U-Net架构中提出的RWKV-UNet模型,有效提升了捕捉长期依赖关系及理解上下文的能力,对于精准医学图像分割至关重要。通过引入IR-RWKV块和Cross-Channel Mix模块等技术手段,模型展现出卓越的医学图像分割性能,实现了在多个基准数据集上的最新技术水平。
Key Takeaways
- RWKV-UNet模型结合了RWKV结构和U-Net架构,增强了捕捉长期依赖关系和上下文理解能力。
- 通过引入IR-RWKV块,构建了强大的编码器。
- Cross-Channel Mix模块改善了跨尺度特征的融合,实现了全局通道信息集成。
- RWKV-UNet在多个基准数据集上实现了最先进的医学图像分割性能。
- 该模型提供了平衡准确性与计算效率的较小变体,即RWKV-UNet-S和RWKV-UNet-T。
- RWKV-UNet模型对于各种类型医学图像分割具有广泛应用潜力。
点此查看论文截图

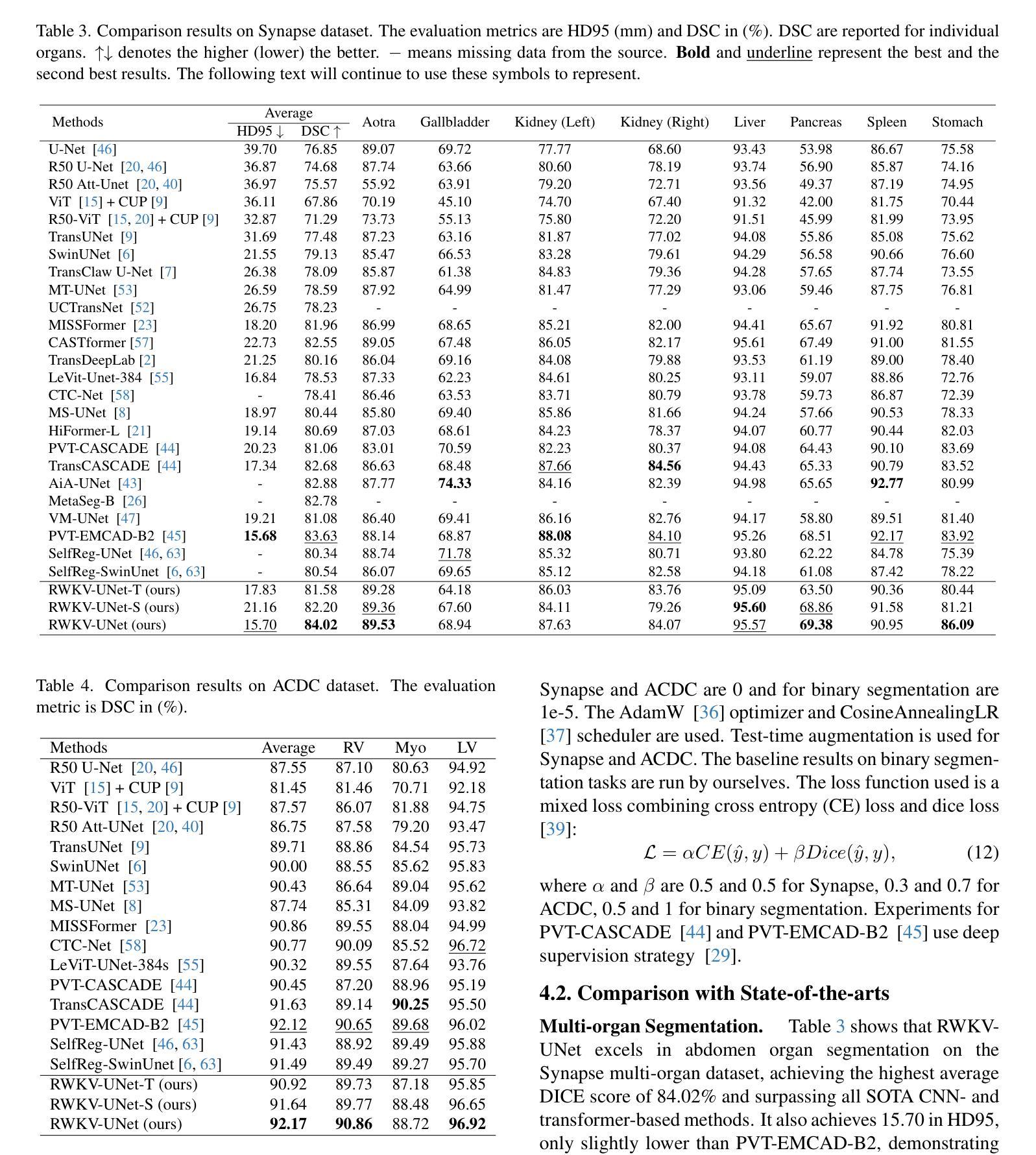
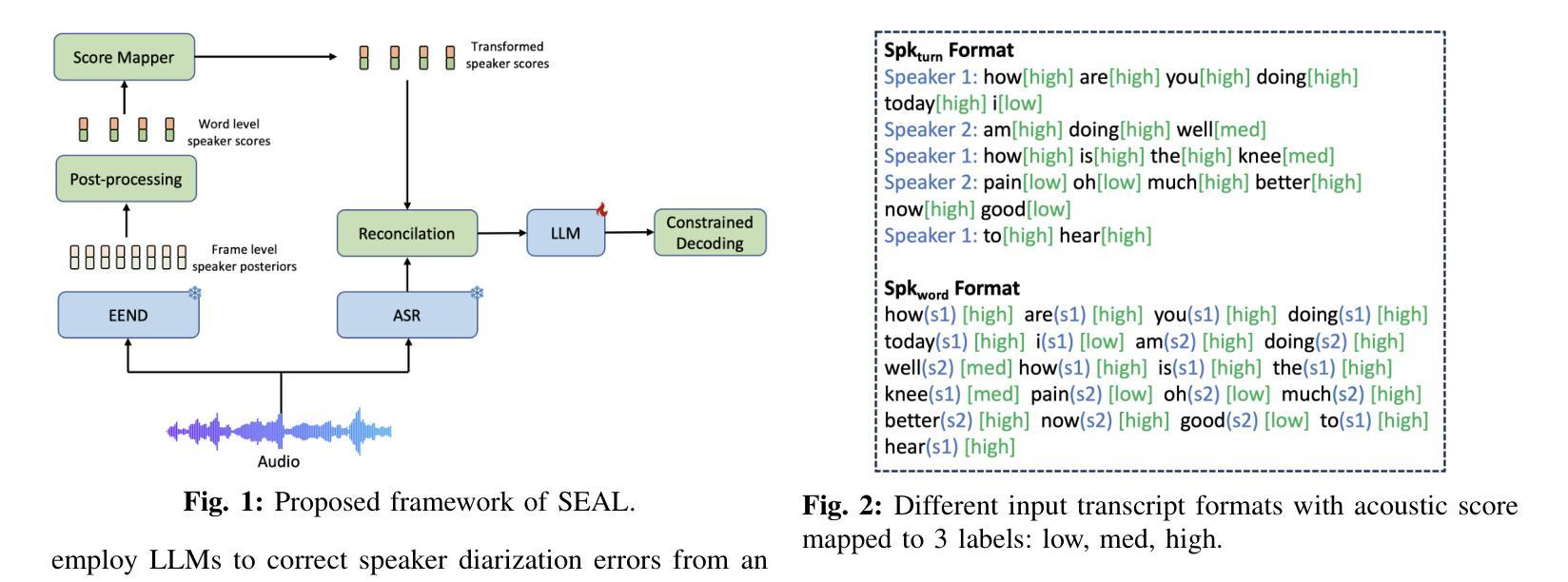
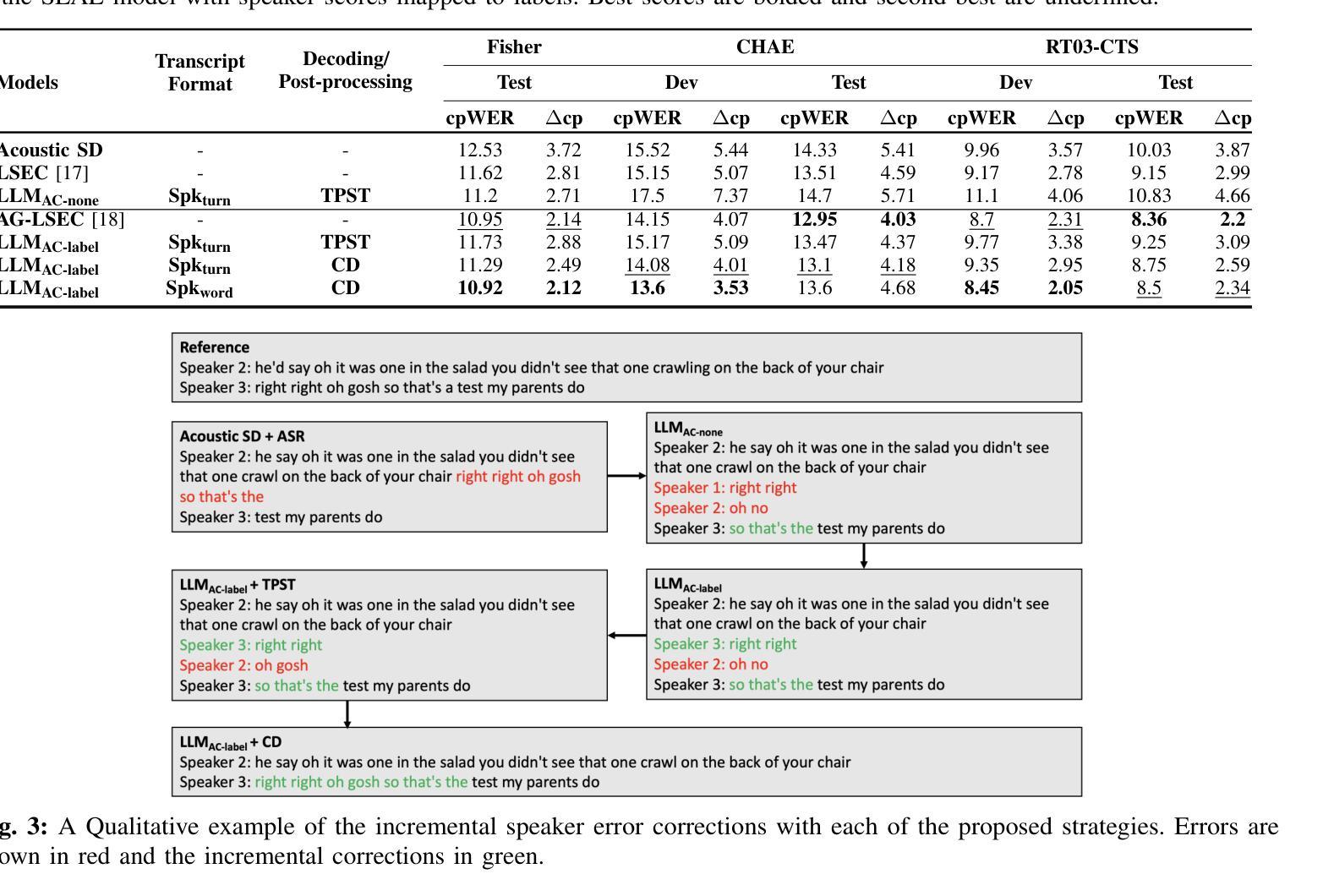
SEAL: Speaker Error Correction using Acoustic-conditioned Large Language Models
Authors:Anurag Kumar, Rohit Paturi, Amber Afshan, Sundararajan Srinivasan
Speaker Diarization (SD) is a crucial component of modern end-to-end ASR pipelines. Traditional SD systems, which are typically audio-based and operate independently of ASR, often introduce speaker errors, particularly during speaker transitions and overlapping speech. Recently, language models including fine-tuned large language models (LLMs) have shown to be effective as a second-pass speaker error corrector by leveraging lexical context in the transcribed output. In this work, we introduce a novel acoustic conditioning approach to provide more fine-grained information from the acoustic diarizer to the LLM. We also show that a simpler constrained decoding strategy reduces LLM hallucinations, while avoiding complicated post-processing. Our approach significantly reduces the speaker error rates by 24-43% across Fisher, Callhome, and RT03-CTS datasets, compared to the first-pass Acoustic SD.
说话人聚类(Speaker Diarization,SD)是现代端到端自动语音识别(ASR)系统的重要组成部分。传统的SD系统通常是基于音频的,独立于ASR运行,往往会在说话人转换和重叠语音的情况下引入说话人错误。最近,语言模型包括微调的大型语言模型(LLMs)通过利用转录输出中的词汇上下文,被证明是有效的第一次说话人错误校正器。在这项工作中,我们引入了一种新颖的声学条件方法,为LLM提供更多精细的来自声学聚类器的信息。我们还表明,更简单的约束解码策略减少了LLM的幻觉现象,同时避免了复杂的后处理过程。与第一次通过的声学SD相比,我们的方法在Fisher、Callhome和RT0subTitle> 数据集上将说话人错误率降低了高达百分之二十四至四十三。
论文及项目相关链接
PDF Accepted at ICASSP 2025
Summary
本文介绍了将新型声学条件化方法应用于语音识别领域中的说话人识别(Speaker Diarization, SD)。文章提出一种新的声学条件化策略来改进传统独立操作的传统音频为基础的传统说话人识别技术的问题,如说话人转换和重叠语音时的说话人错误。该研究通过引入大型语言模型(LLM)的第二遍纠错,将声学日记(acoustdic diarizer)提供的精细粒度信息注入其中。此外,研究表明更简单的约束解码策略可降低LLM幻想。实验结果在所有测试的数据集上减少了多达高达43%的说话人错误率。总体来说,这是一个将声学技术和语言模型紧密结合的解决方案,实现了高效准确的说话人识别。
Key Takeaways
- 传统说话人识别技术在处理音频时可能存在说话人转换和重叠语音时的错误问题。
- 大型语言模型(LLM)已被证明可以有效利用语境进行说话人错误纠正。
- 新提出的声学条件化策略旨在将声学日记中提供的精细粒度信息注入语言模型以提升说话人识别的准确性。
- 简单约束解码策略能减少语言模型产生的幻觉现象,同时避免复杂的后期处理步骤。
- 该方法显著降低了在Fisher、Callhome和RT03-CTS数据集上的说话人错误率,最高可达43%。
- 这是结合了声学技术和语言模型的优秀示例,充分展现了技术在提高语音识别效率方面的潜力。
点此查看论文截图



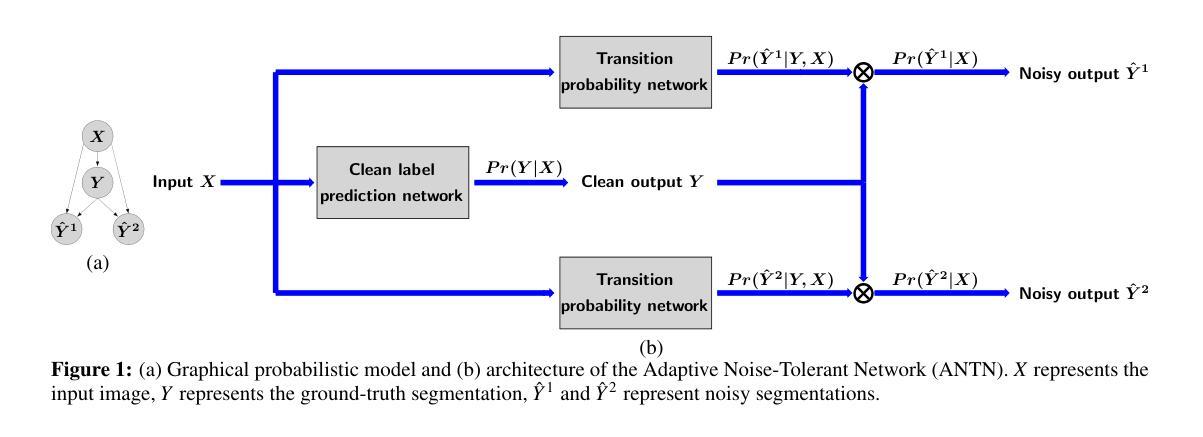
Adaptive Noise-Tolerant Network for Image Segmentation
Authors:Weizhi Li
Unlike image classification and annotation, for which deep network models have achieved dominating superior performances compared to traditional computer vision algorithms, deep learning for automatic image segmentation still faces critical challenges. One of such hurdles is to obtain ground-truth segmentations as the training labels for deep network training. Especially when we study biomedical images, such as histopathological images (histo-images), it is unrealistic to ask for manual segmentation labels as the ground truth for training due to the fine image resolution as well as the large image size and complexity. In this paper, instead of relying on clean segmentation labels, we study whether and how integrating imperfect or noisy segmentation results from off-the-shelf segmentation algorithms may help achieve better segmentation results through a new Adaptive Noise-Tolerant Network (ANTN) model. We extend the noisy label deep learning to image segmentation with two novel aspects: (1) multiple noisy labels can be integrated into one deep learning model; (2) noisy segmentation modeling, including probabilistic parameters, is adaptive, depending on the given testing image appearance. Implementation of the new ANTN model on both the synthetic data and real-world histo-images demonstrates its effectiveness and superiority over off-the-shelf and other existing deep-learning-based image segmentation algorithms.
与图像分类和标注不同,深度网络模型在传统计算机视觉算法中取得了卓越的性能优势,但深度学习在自动图像分割方面仍然面临重大挑战。其中一个障碍是获取真实分割作为深度网络训练的训练标签。尤其是当我们研究生物医学图像,如病理图像时,由于图像分辨率高、图像尺寸大且复杂,要求手动分割标签作为训练的真实标准是不现实的。在本文中,我们并不依赖干净的分割标签,而是研究将现成的分割算法产生的分割结果中可能存在的错误或噪声整合起来,通过一种新的自适应噪声容忍网络(ANTN)模型,探讨其是否能以及如何帮助我们获得更好的分割结果。我们将噪声标签深度学习扩展到图像分割领域,并引入两个新的观点:(1)多个噪声标签可以集成到一个深度学习模型中;(2)噪声分割建模包括概率参数是自适应的,这取决于给定的测试图像外观。在合成数据和真实世界病理图像上实现新的ANTN模型,证明了其在现成和其他现有基于深度学习的图像分割算法中的有效性和优越性。
论文及项目相关链接
Summary
医学图像分割领域仍面临挑战,尤其是获取高分辨率、大尺寸和复杂生物医学图像的手动分割标签作为训练依据不现实。本文研究如何通过自适应噪声容忍网络(ANTN)模型利用市场现成的分割算法产生的不完美或带噪声的分割结果来提升分割效果。该方法可将多个噪声标签集成到一个深度学习模型中,并且噪声分割建模具有适应性,取决于给定的测试图像外观。在合成数据和真实世界病理图像上的实验证明了ANTN模型的有效性和优越性。
Key Takeaways
- 医学图像分割面临挑战,主要由于获取手动分割标签作为训练依据不现实。
- 现有深度学习模型在图像分类和标注方面表现卓越,但在自动图像分割方面仍面临挑战。
- 本文引入自适应噪声容忍网络(ANTN)模型,能利用不完美或带噪声的分割结果。
- ANTN模型可将多个噪声标签集成到一个深度学习模型中。
- 噪声分割建模具有适应性,能根据测试图像外观调整。
- 在合成数据和真实世界病理图像上的实验证明了ANTN模型的有效性和优越性。
点此查看论文截图

A Pan-cancer Classification Model using Multi-view Feature Selection Method and Ensemble Classifier
Authors:Tareque Mohmud Chowdhury, Farzana Tabassum, Sabrina Islam, Abu Raihan Mostofa Kamal
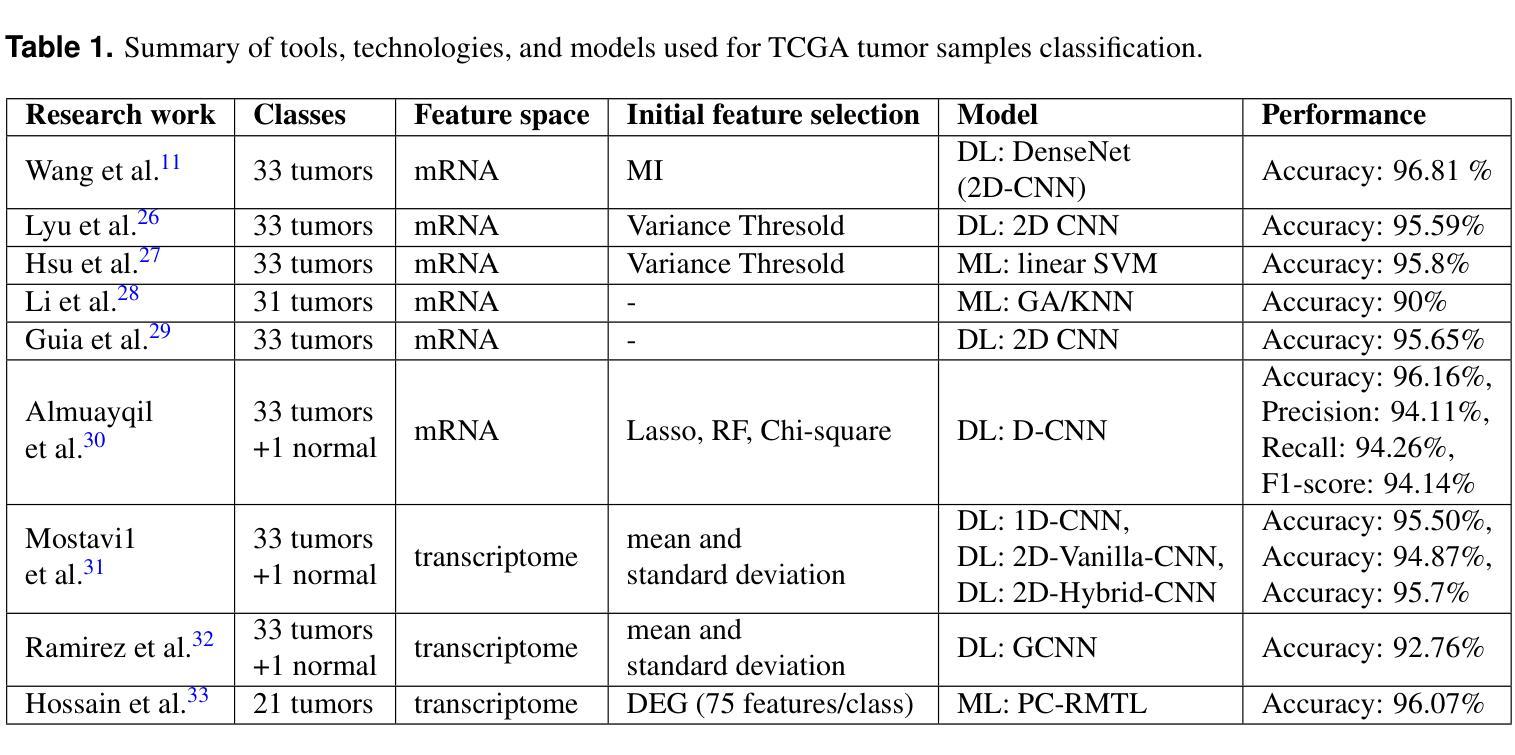
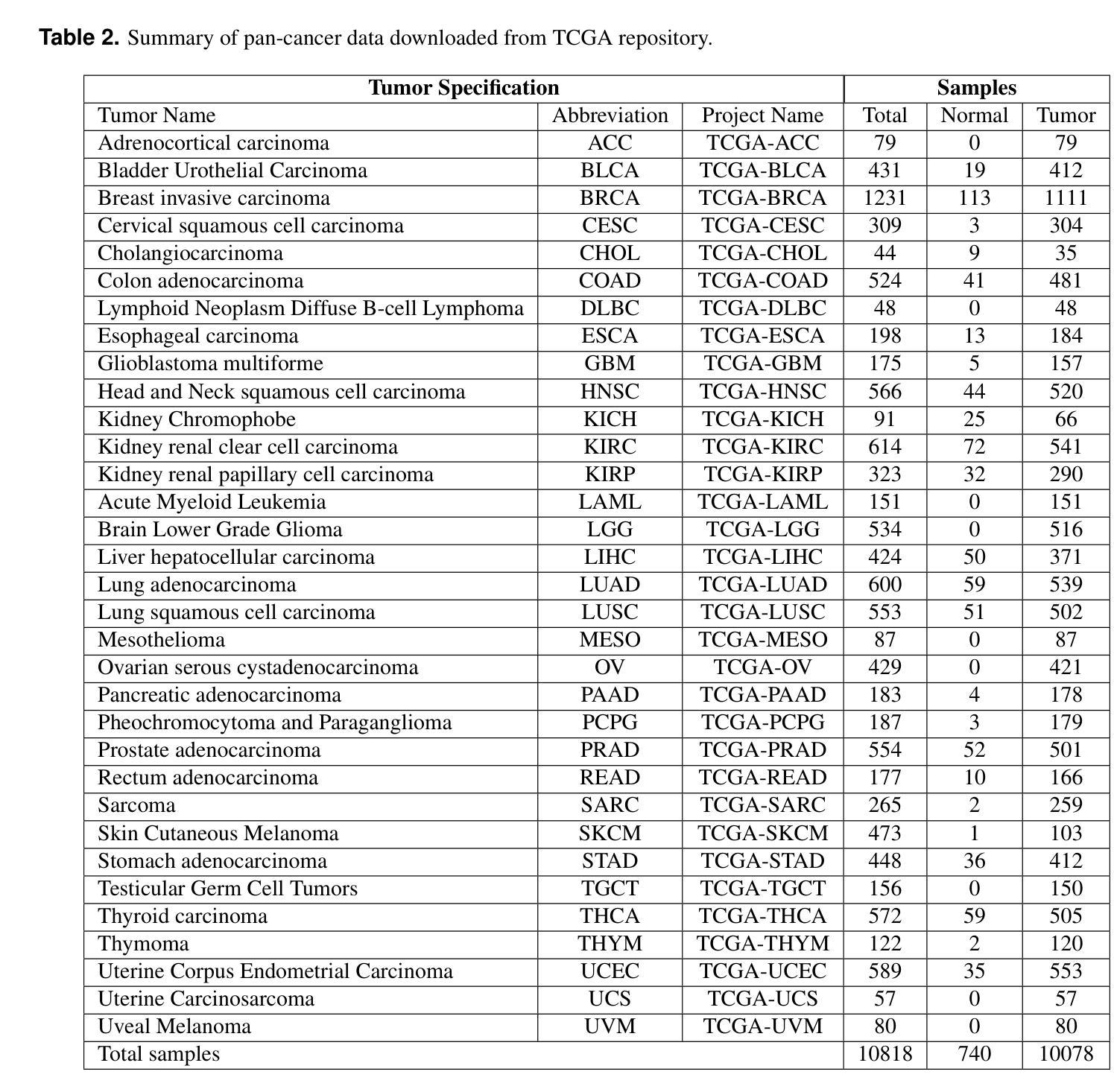
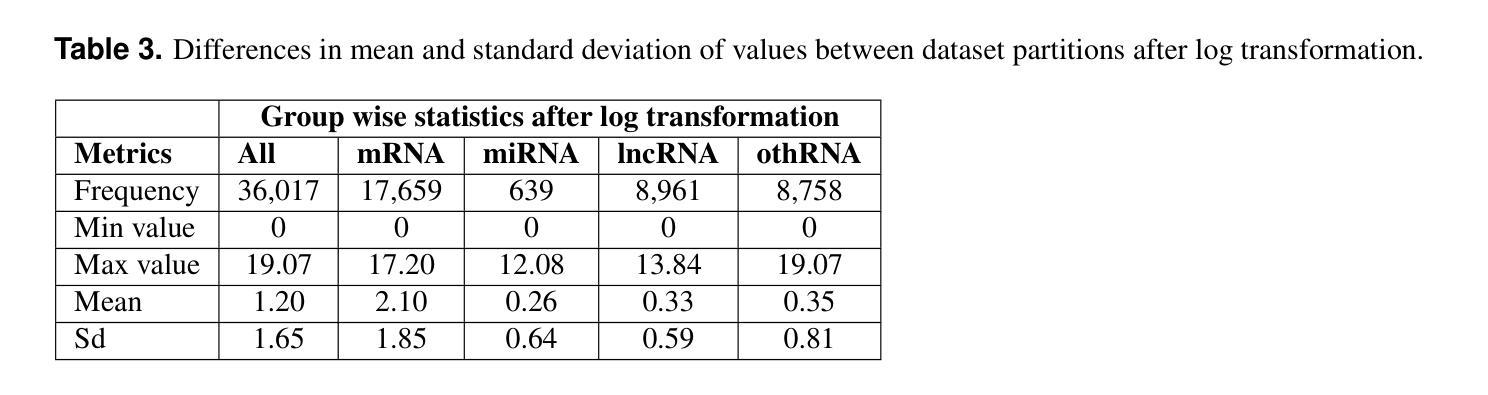
Accurately identifying cancer samples is crucial for precise diagnosis and effective patient treatment. Traditional methods falter with high-dimensional and high feature-to-sample count ratios, which are critical for classifying cancer samples. This study aims to develop a novel feature selection framework specifically for transcriptome data and propose two ensemble classifiers. For feature selection, we partition the transcriptome dataset vertically based on feature types. Then apply the Boruta feature selection process on each of the partitions, combine the results, and apply Boruta again on the combined result. We repeat the process with different parameters of Boruta and prepare the final feature set. Finally, we constructed two ensemble ML models based on LR, SVM and XGBoost classifiers with max voting and averaging probability approach. We used 10-fold cross-validation to ensure robust and reliable classification performance. With 97.11% accuracy and 0.9996 AUC value, our approach performs better compared to existing state-of-the-art methods to classify 33 types of cancers. A set of 12 types of cancer is traditionally challenging to differentiate between each other due to their similarity in tissue of origin. Our method accurately identifies over 90% of samples from these 12 types of cancers, which outperforms all known methods presented in existing literature. The gene set enrichment analysis reveals that our framework’s selected features have enriched the pathways highly related to cancers. This study develops a feature selection framework to select features highly related to cancer development and leads to identifying different types of cancer samples with higher accuracy.
准确地识别癌症样本对于精确诊断和治疗患者至关重要。传统方法在处理高维度和高特征样本计数比时会出现问题,这对于分类癌症样本至关重要。本研究旨在开发一种专门用于转录组数据的新型特征选择框架,并提出两种集成分类器。在特征选择方面,我们根据特征类型垂直划分转录组数据集。然后在每个分区上应用Boruta特征选择过程,组合结果,并在组合结果上再次应用Boruta。我们重复该过程并使用Boruta的不同参数来准备最终特征集。最后,我们构建了基于LR、SVM和XGBoost分类器的两个集成机器学习模型,采用最大投票和平均概率方法。我们使用10倍交叉验证来确保稳健可靠的分类性能。我们的方法以97.11%的准确率和0.9996的AUC值,相较于目前最先进的分类方法,对33种类型的癌症进行分类表现更佳。由于组织起源的相似性,传统上区分这其中的十二种癌症类型是一大挑战。我们的方法准确地识别了超过90%的这些十二种癌症类型的样本,这优于现有文献中提到的所有已知方法。基因集富集分析表明,我们的框架选择的特征与高度相关的癌症途径高度富集。本研究开发了一个特征选择框架来选择与癌症发展高度相关的特征,导致更准确地区分不同类型的癌症样本。
论文及项目相关链接
PDF 20 pages, 5 figures, 9 tables
Summary
本文研究旨在开发一种针对转录组数据的新型特征选择框架,并提出两种集成分类器,以提高癌症样本分类的准确性。该研究通过Boruta特征选择过程对转录组数据集进行分区并组合结果,构建了两个基于LR、SVM和XGBoost分类器的集成机器学习模型。在33种癌症分类中,该方法的准确率为97.11%,AUC值为0.9996,优于现有最先进的方法。特别是在12种传统上难以区分的癌症中,该方法能准确识别超过90%的样本,超越了现有文献中的所有已知方法。
Key Takeaways
- 研究旨在开发一种针对转录组数据的特征选择框架,以提高癌症样本分类的准确性。
- 通过分区和组合特征选择结果,使用Boruta特征选择过程。
- 构建了两个基于LR、SVM和XGBoost分类器的集成机器学习模型。
- 在33种癌症分类中,方法的准确率和AUC值均表现优异。
- 特别是在区分12种传统上难以区分的癌症时,该方法表现出高准确性。
- 基因集富集分析显示,所选特征与癌症相关途径高度相关。
点此查看论文截图

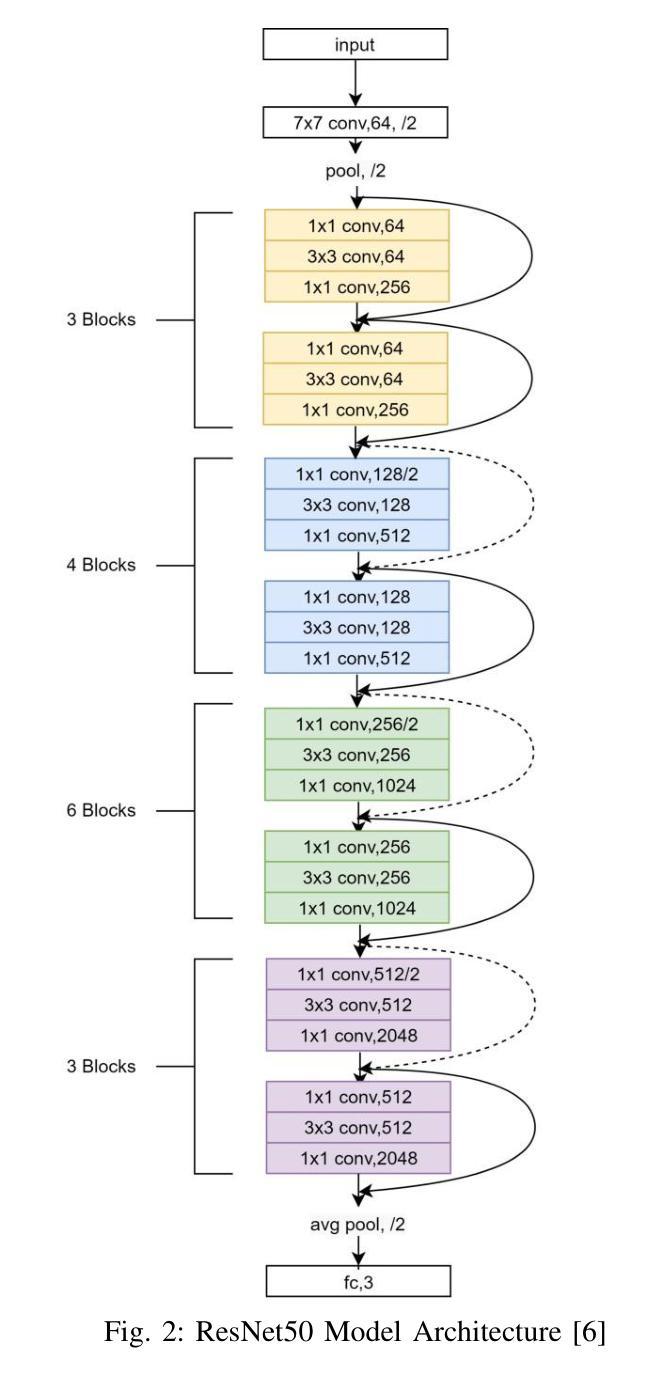
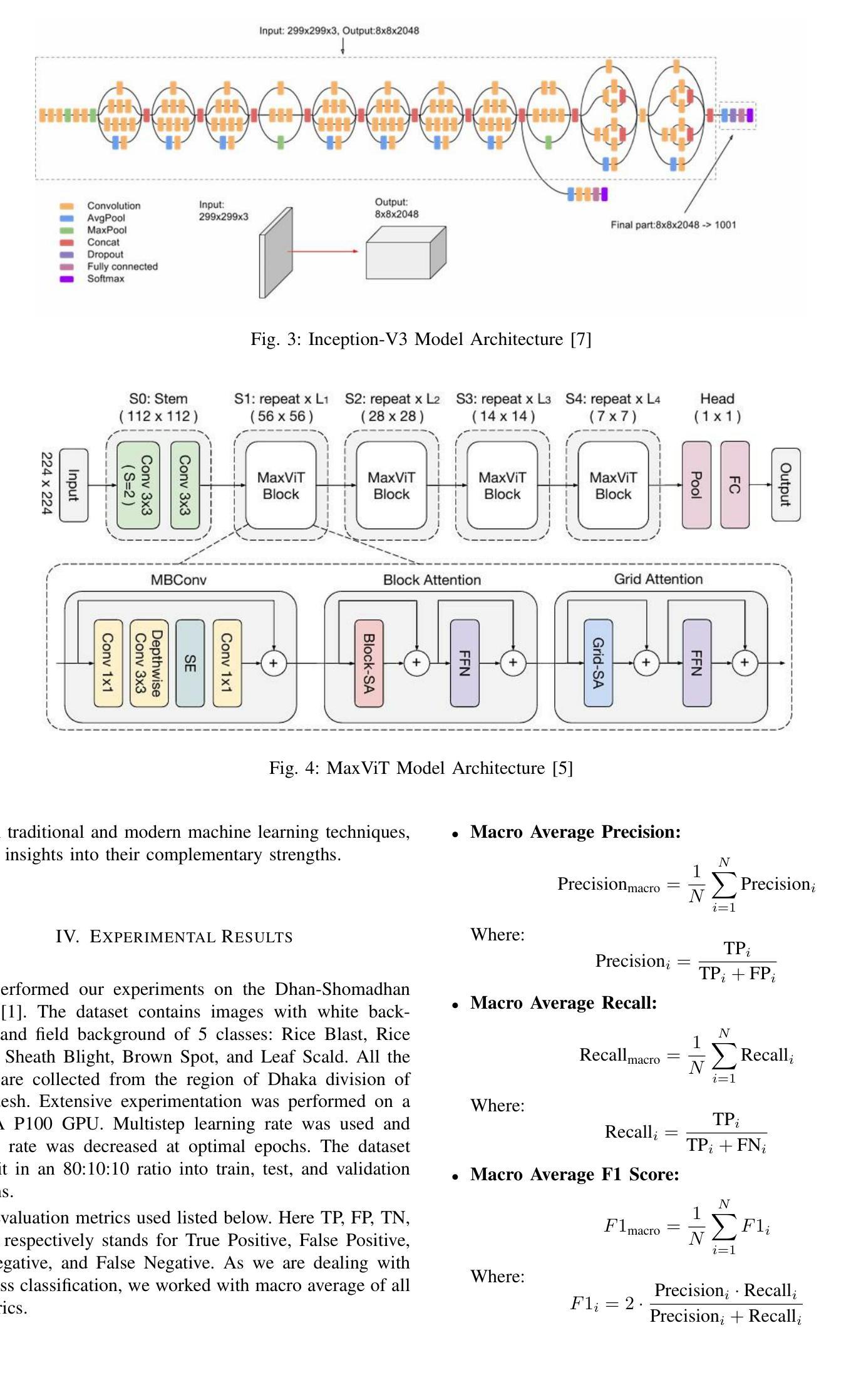
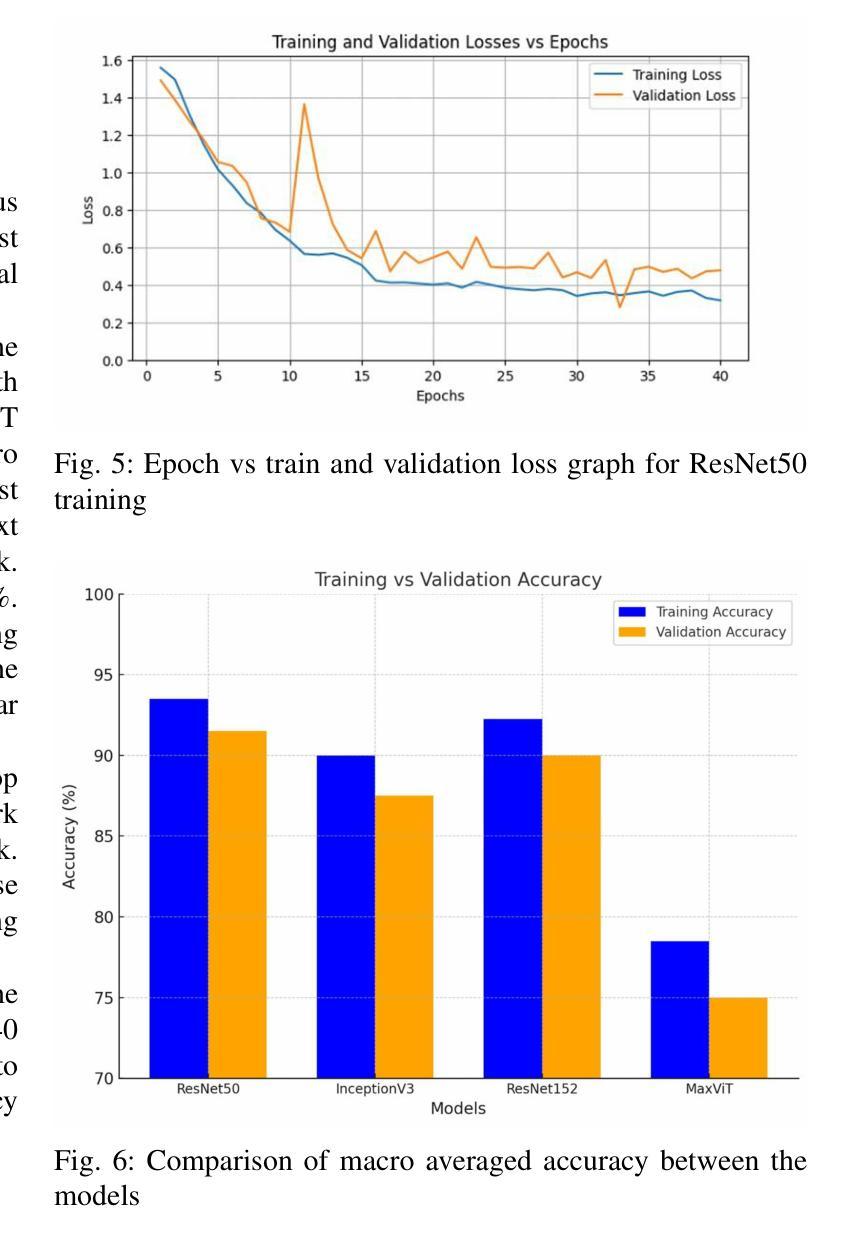
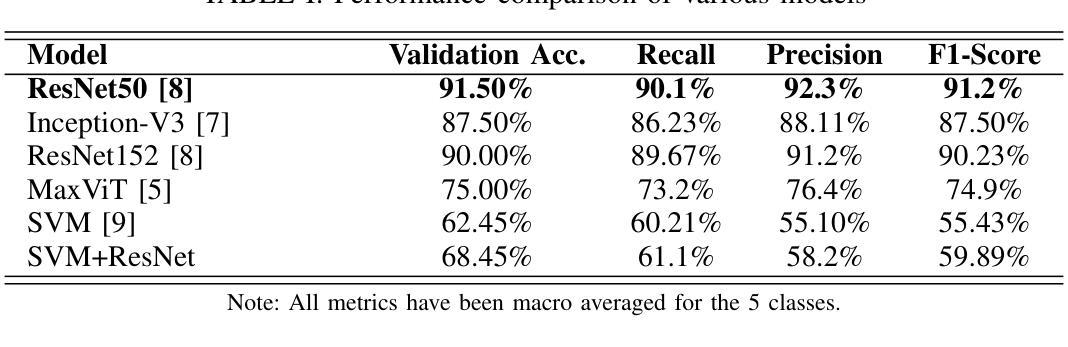
Rice Leaf Disease Detection: A Comparative Study Between CNN, Transformer and Non-neural Network Architectures
Authors:Samia Mehnaz, Md. Touhidul Islam
In nations such as Bangladesh, agriculture plays a vital role in providing livelihoods for a significant portion of the population. Identifying and classifying plant diseases early is critical to prevent their spread and minimize their impact on crop yield and quality. Various computer vision techniques can be used for such detection and classification. While CNNs have been dominant on such image classification tasks, vision transformers has become equally good in recent time also. In this paper we study the various computer vision techniques for Bangladeshi rice leaf disease detection. We use the Dhan-Shomadhan – a Bangladeshi rice leaf disease dataset, to experiment with various CNN and ViT models. We also compared the performance of such deep neural network architecture with traditional machine learning architecture like Support Vector Machine(SVM). We leveraged transfer learning for better generalization with lower amount of training data. Among the models tested, ResNet50 exhibited the best performance over other CNN and transformer-based models making it the optimal choice for this task.
在孟加拉国等国家,农业在为很大一部分人口提供生计方面发挥着至关重要的作用。早期识别和分类植物疾病对防止其传播以及尽量减少其对作物产量和质量的影响至关重要。可以使用各种计算机视觉技术进行此类检测和分类。虽然卷积神经网络(CNN)在此类图像分类任务中占据主导地位,但视觉变压器(ViT)在最近的时间中也同样表现出色。在本文中,我们研究了孟加拉国水稻叶病检测的各种计算机视觉技术。我们使用孟加拉国水稻叶病数据集Dhan-Shomadhan,对各种CNN和ViT模型进行实验。我们还比较了这种深度神经网络架构与诸如支持向量机(SVM)等传统机器学习架构的性能。我们利用迁移学习,以在少量训练数据的情况下实现更好的泛化。在测试的模型中,ResNet50在其他CNN和基于Transformer的模型中表现出最佳性能,成为此任务的最佳选择。
论文及项目相关链接
PDF 6 pages, 6 figures
Summary
本文研究了使用计算机视觉技术进行孟加拉国水稻叶片病害检测的方法。通过利用当地的Dhan-Shomadhan数据集进行实验,对比了CNN和ViT模型以及传统机器学习架构SVM的性能。借助迁移学习,模型在少量训练数据上表现出更好的泛化能力。结果表明,ResNet50相较于其他CNN和基于Transformer的模型表现最佳,成为此任务的最优选择。
Key Takeaways
- 孟加拉国农业中水稻叶片病害检测对防止病害扩散和保障作物产量与质量至关重要。
- 使用了多种计算机视觉技术,包括CNN和ViT模型进行病害检测与分类。
- 利用Dhan-Shomadhan数据集进行实验,涵盖多种水稻叶片病害。
- 迁移学习增强了模型在有限数据上的泛化能力。
- ResNet50模型在实验中表现最佳,相较于其他CNN和Transformer模型更具优势。
- CNN模型在此任务中的表现优于传统的机器学习架构如SVM。
点此查看论文截图


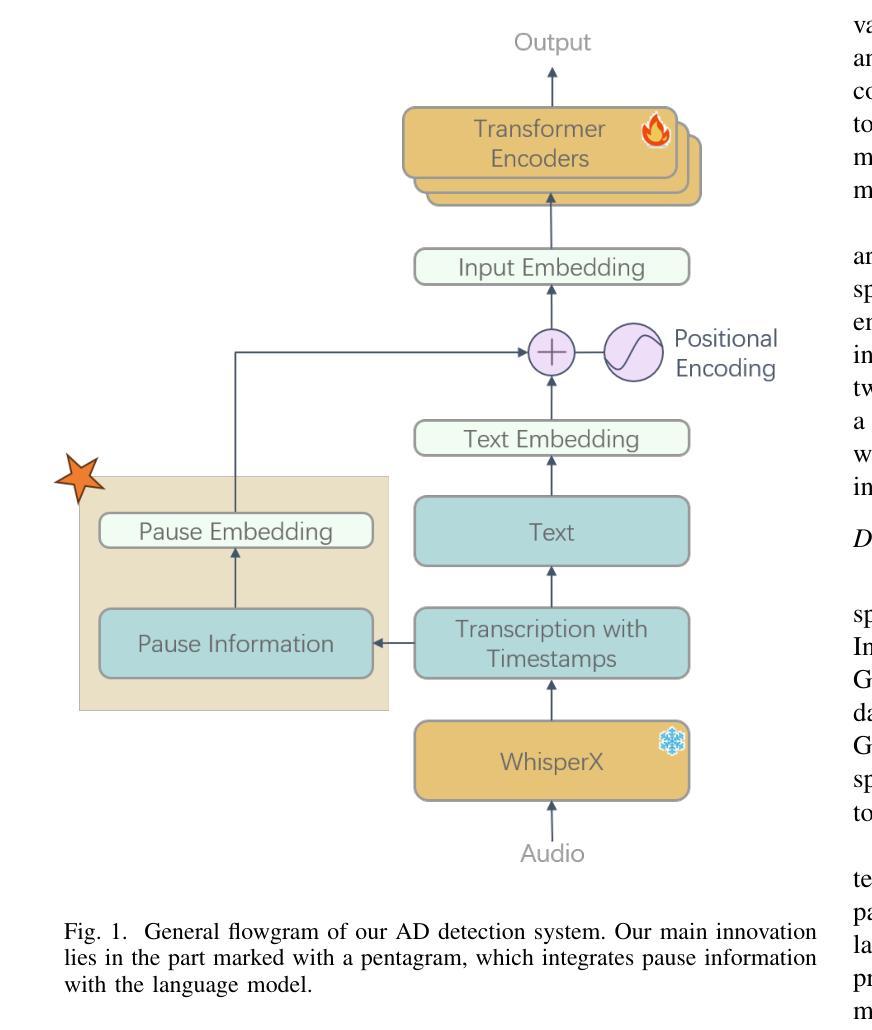
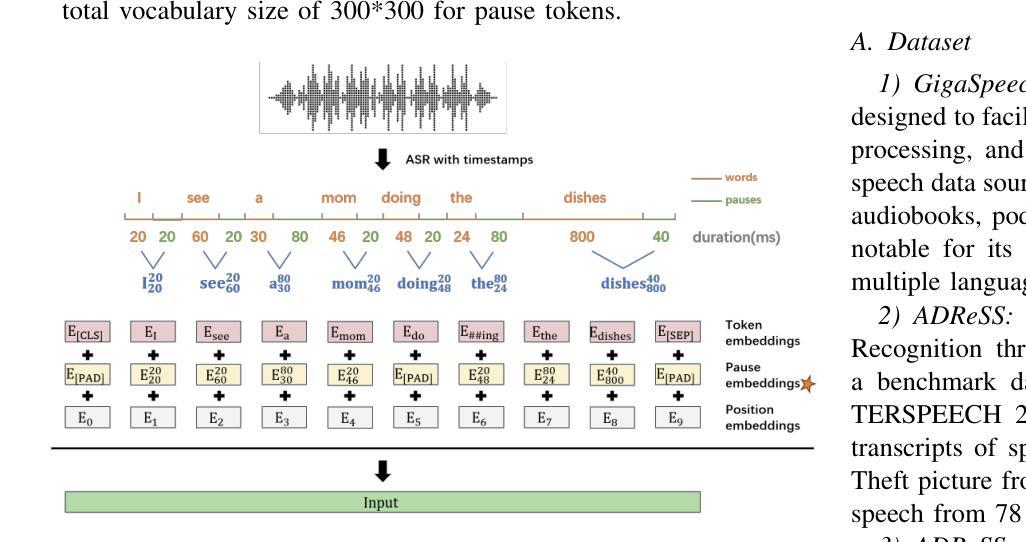
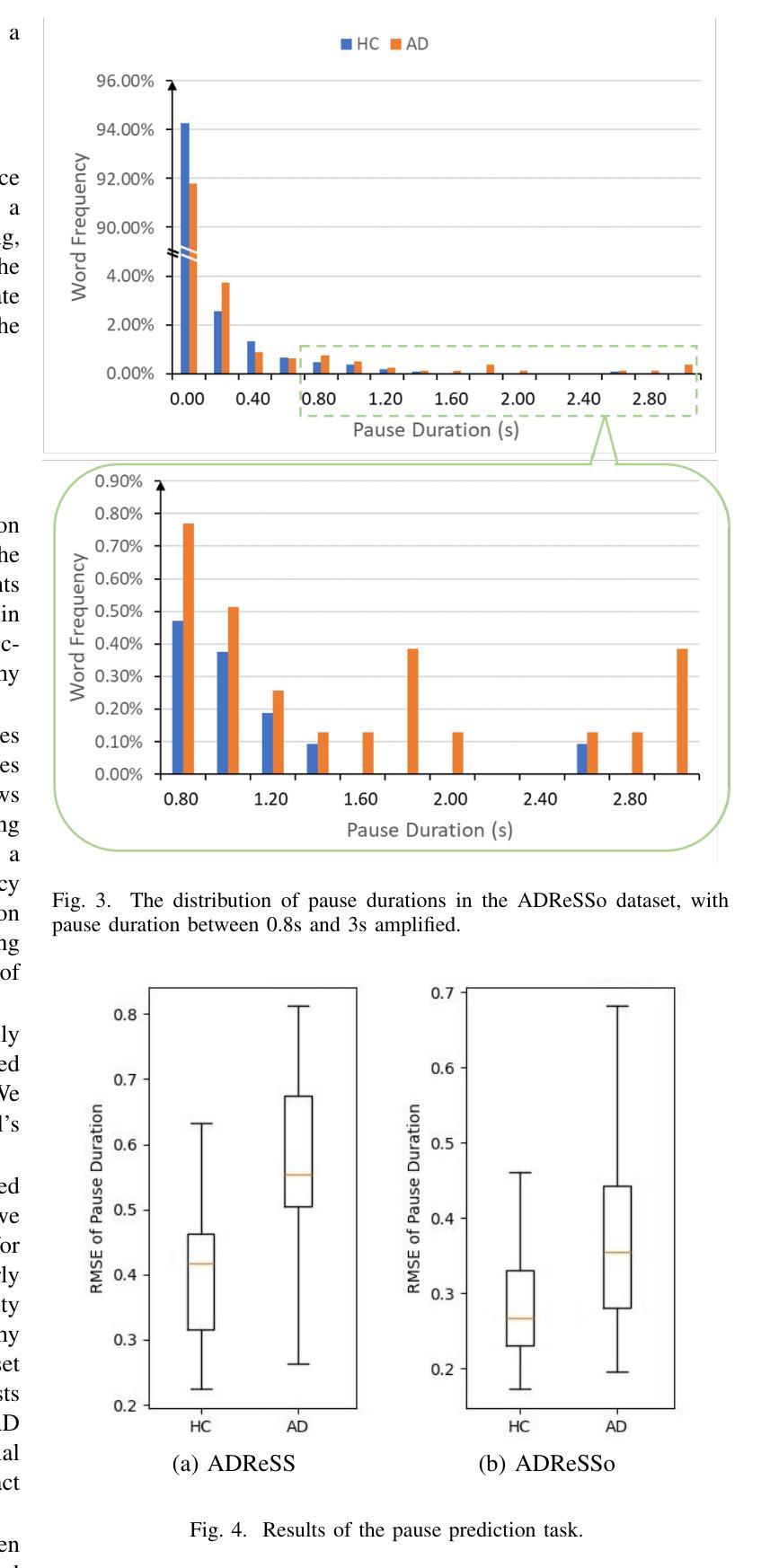
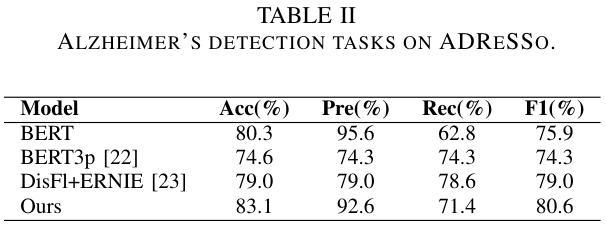
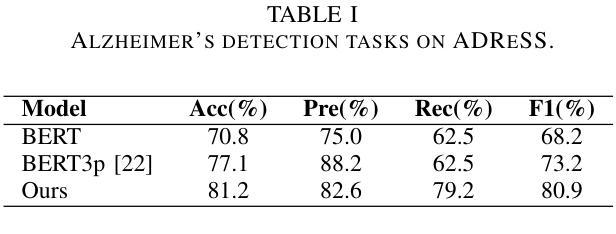
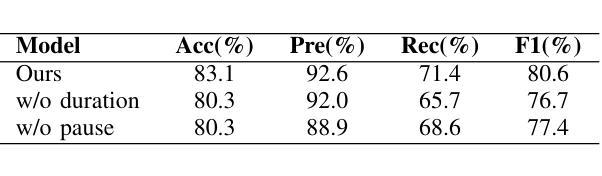
Integrating Pause Information with Word Embeddings in Language Models for Alzheimer’s Disease Detection from Spontaneous Speech
Authors:Yu Pu, Wei-Qiang Zhang
Alzheimer’s disease (AD) is a progressive neurodegenerative disorder characterized by cognitive decline and memory loss. Early detection of AD is crucial for effective intervention and treatment. In this paper, we propose a novel approach to AD detection from spontaneous speech, which incorporates pause information into language models. Our method involves encoding pause information into embeddings and integrating them into the typical transformer-based language model, enabling it to capture both semantic and temporal features of speech data. We conduct experiments on the Alzheimer’s Dementia Recognition through Spontaneous Speech (ADReSS) dataset and its extension, the ADReSSo dataset, comparing our method with existing approaches. Our method achieves an accuracy of 83.1% in the ADReSSo test set. The results demonstrate the effectiveness of our approach in discriminating between AD patients and healthy individuals, highlighting the potential of pauses as a valuable indicator for AD detection. By leveraging speech analysis as a non-invasive and cost-effective tool for AD detection, our research contributes to early diagnosis and improved management of this debilitating disease.
阿尔茨海默病(AD)是一种进行性神经退行性疾病,以认知衰退和记忆丧失为特征。阿尔茨海默病的早期发现对于有效的干预和治疗至关重要。在本文中,我们提出了一种结合停顿信息用于阿尔茨海默病检测的新方法。我们从自发语言中检测阿尔茨海默病,并将停顿信息编码成嵌入形式,并将其集成到典型的基于转换器的语言模型中,使其能够捕捉语音数据的语义和时间特征。我们在阿尔茨海默氏症通过自发语言进行痴呆识别(ADReSS)数据集及其扩展数据集ADReSSo上进行了实验,并将我们的方法与现有方法进行了比较。我们的方法在ADReSSo测试集上达到了83.1%的准确率。结果表明,我们的方法在区分阿尔茨海默病患者和健康个体方面非常有效,突显了停顿作为阿尔茨海默病检测的重要指标的潜力。通过利用语音分析作为非侵入性和成本效益高的工具进行阿尔茨海默病检测,我们的研究为这种疾病的早期诊断和治疗管理做出了贡献。
论文及项目相关链接
PDF accepted by ICASSP2025. Copyright 2025 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component
Summary
本文提出了一种结合停顿信息检测阿尔茨海默病的新方法。该方法将停顿信息编码为嵌入形式,并整合到基于转换器的语言模型中,从而捕捉语音数据的语义和时间特征。在阿尔茨海默症痴呆症通过自发语言识别(ADReSS)数据集及其扩展数据集ADReSSo上进行实验,该方法实现了83.1%的准确率,表明停顿可能是检测阿尔茨海默症的重要指标。
Key Takeaways
- 文章介绍了一种利用停顿信息检测阿尔茨海默病的新方法。
- 该方法整合了停顿信息到语言模型中,使其能够捕捉语音数据的语义和时间特征。
- 方法在ADReSS和ADReSSo数据集上进行了实验验证。
- 实验结果显示该方法准确率为83.1%,显示出停顿信息在AD检测中的重要性。
- 此方法为非侵入性和成本效益高的阿尔茨海默病检测工具提供了新的可能性。
- 研究结果有助于阿尔茨海默病的早期诊断和治疗管理。
点此查看论文截图

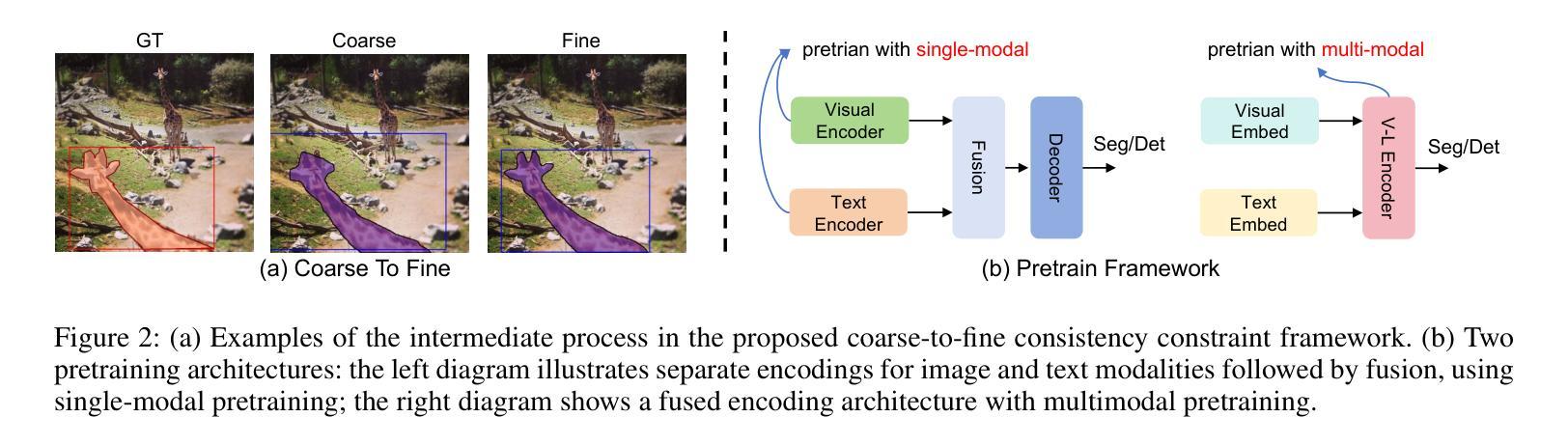
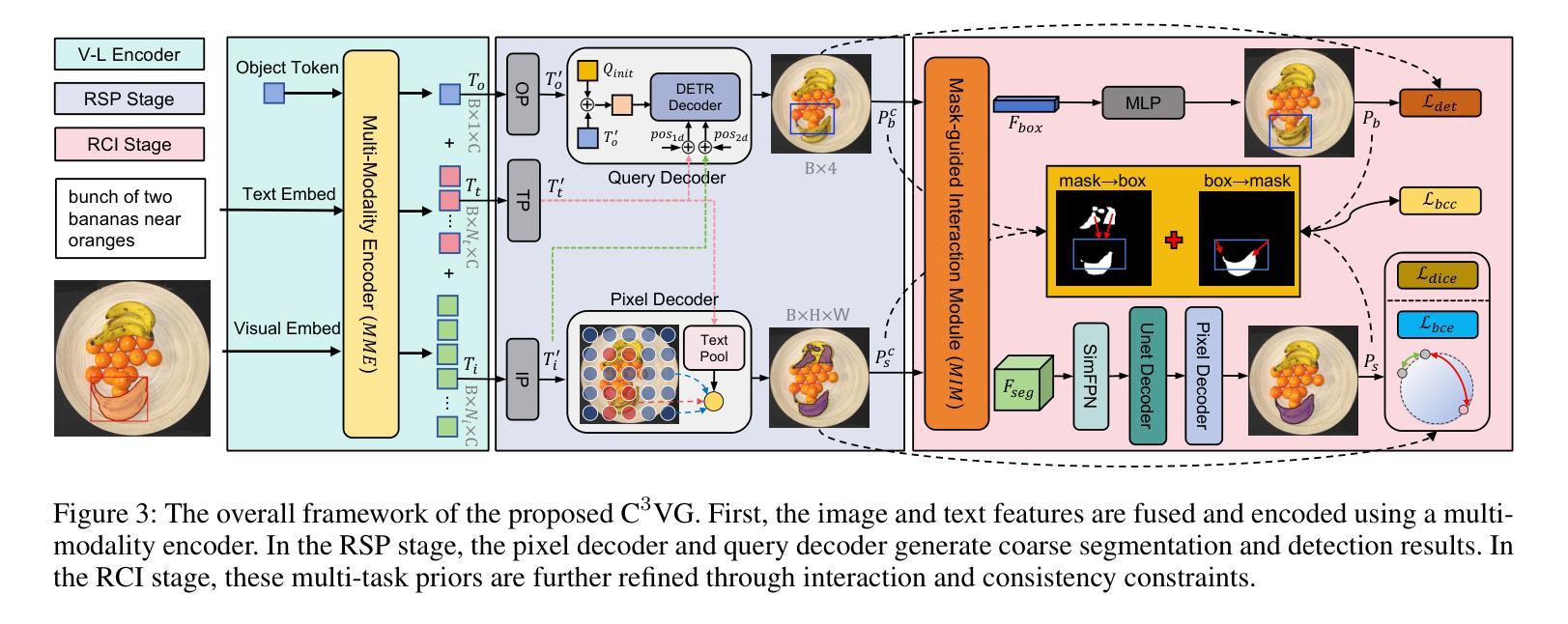
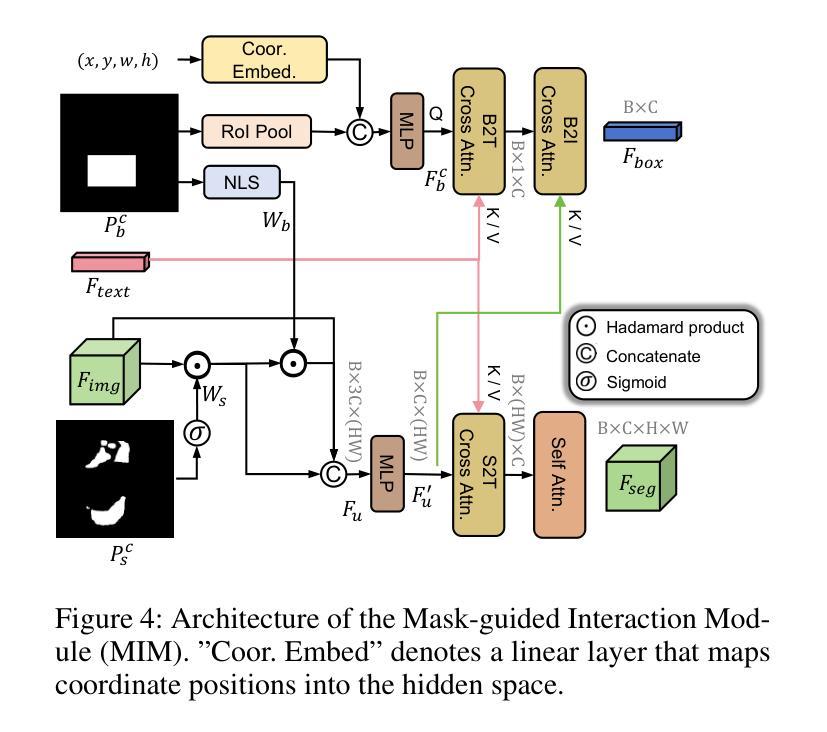
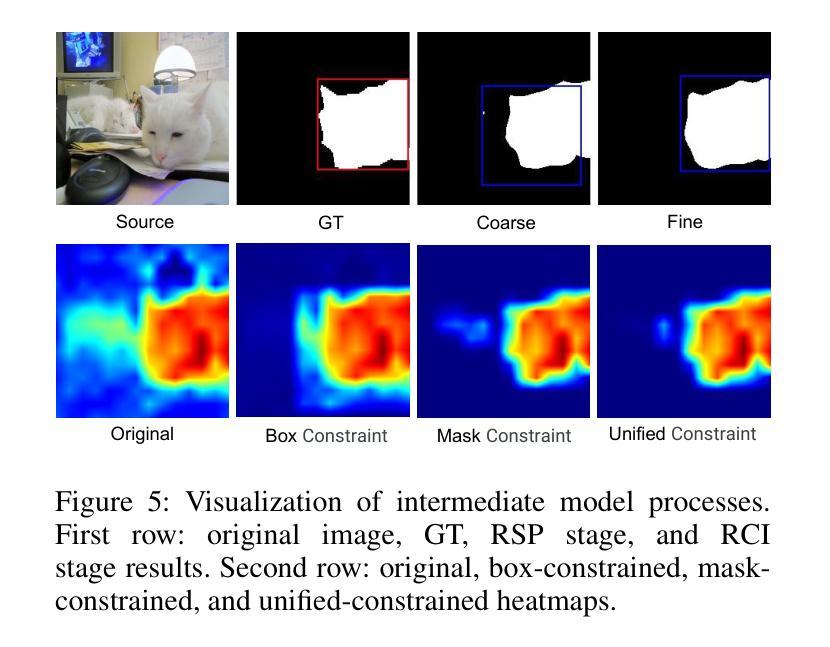
Multi-task Visual Grounding with Coarse-to-Fine Consistency Constraints
Authors:Ming Dai, Jian Li, Jiedong Zhuang, Xian Zhang, Wankou Yang
Multi-task visual grounding involves the simultaneous execution of localization and segmentation in images based on textual expressions. The majority of advanced methods predominantly focus on transformer-based multimodal fusion, aiming to extract robust multimodal representations. However, ambiguity between referring expression comprehension (REC) and referring image segmentation (RIS) is error-prone, leading to inconsistencies between multi-task predictions. Besides, insufficient multimodal understanding directly contributes to biased target perception. To overcome these challenges, we propose a Coarse-to-fine Consistency Constraints Visual Grounding architecture ($\text{C}^3\text{VG}$), which integrates implicit and explicit modeling approaches within a two-stage framework. Initially, query and pixel decoders are employed to generate preliminary detection and segmentation outputs, a process referred to as the Rough Semantic Perception (RSP) stage. These coarse predictions are subsequently refined through the proposed Mask-guided Interaction Module (MIM) and a novel explicit bidirectional consistency constraint loss to ensure consistent representations across tasks, which we term the Refined Consistency Interaction (RCI) stage. Furthermore, to address the challenge of insufficient multimodal understanding, we leverage pre-trained models based on visual-linguistic fusion representations. Empirical evaluations on the RefCOCO, RefCOCO+, and RefCOCOg datasets demonstrate the efficacy and soundness of $\text{C}^3\text{VG}$, which significantly outperforms state-of-the-art REC and RIS methods by a substantial margin. Code and model will be available at \url{https://github.com/Dmmm1997/C3VG}.
多任务视觉定位涉及基于文本表达的同时图像定位和分割。大多数先进的方法主要关注基于变压器的多模式融合,旨在提取鲁棒的多模式表示。然而,指代表达式理解(REC)和指代图像分割(RIS)之间的歧义容易出错,导致多任务预测之间的不一致。此外,对多模式的理解不足直接导致目标感知的偏见。为了克服这些挑战,我们提出了一种从粗到细的的一致性约束视觉定位架构(C^3VG),该架构在两阶段框架内集成了隐式和显式建模方法。首先,使用查询和像素解码器生成初步的检测和分割输出,这一过程被称为粗糙语义感知(RSP)阶段。这些粗略的预测随后通过提出的Mask引导交互模块(MIM)和一种新颖的显式双向一致性约束损失进行细化,以确保任务间的表示一致性,我们称之为精细化一致性交互(RCI)阶段。此外,为了解决对多模式理解不足的挑战,我们利用基于视觉语言融合表示的预训练模型。在RefCOCO、RefCOCO+和RefCOCOg数据集上的经验评估表明,C^3VG的有效性和稳健性,它显著优于最新的REC和RIS方法。代码和模型将在\url{https://github.com/Dmmm1997/C3VG}上提供。
论文及项目相关链接
PDF AAAI2025
Summary
本文提出一种名为$\text{C}^3\text{VG}$的视觉定位架构,该架构通过整合隐式和显式建模方法解决多任务视觉定位中的指代表达理解与指代图像分割之间的歧义问题。架构分为两个阶段:初步语义感知阶段和精细一致性交互阶段。初步阶段利用查询和像素解码器生成初步检测和分割输出;在第二阶段,通过掩膜引导交互模块和新型双向一致性约束损失函数对初步预测进行精细化,确保跨任务的表示一致性。同时,借助视觉-语言融合表示的预训练模型解决多媒体模态理解不足的问题。在RefCOCO、RefCOCO+和RefCOCOg数据集上的实证评估证明了$\text{C}^3\text{VG}$的有效性和优越性。
Key Takeaways
- 多任务视觉定位涉及同时执行图像的定位和分割任务,基于文本表达进行。
- 当前方法主要关注于基于转换器的多媒体融合,旨在提取稳健的多媒体表示。
- 指代表达理解与指代图像分割之间的歧义导致预测不一致。
- $\text{C}^3\text{VG}$架构分为两个阶段解决这些问题:初步语义感知和精细一致性交互。
- 架构利用掩膜引导交互模块和一致性约束损失函数确保跨任务的一致性表示。
- 利用预训练的视觉-语言融合模型解决多媒体模态理解不足的问题。
- 在多个数据集上的实证评估证明了$\text{C}^3\text{VG}$的有效性和优越性。
点此查看论文截图

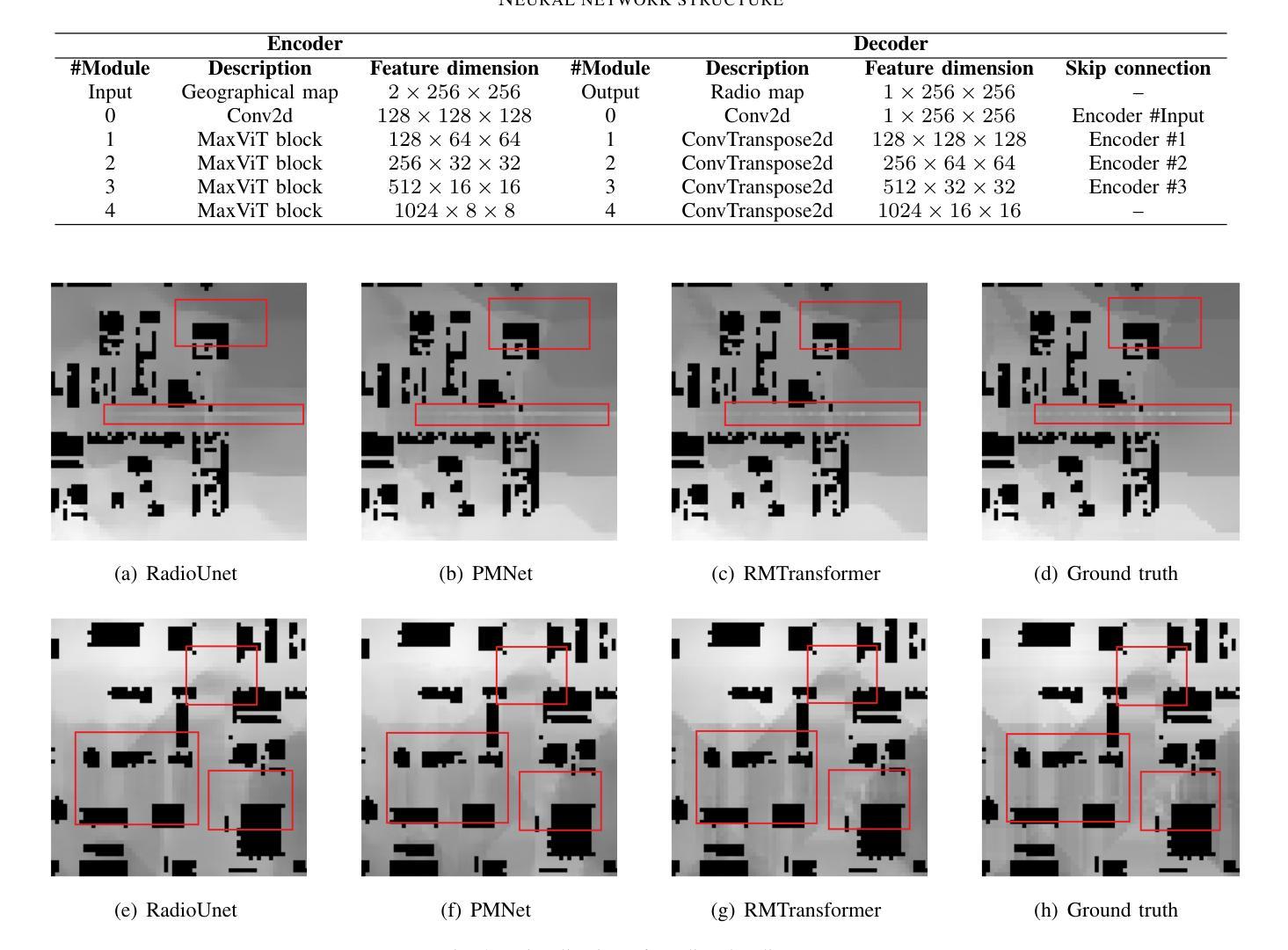
RMTransformer: Accurate Radio Map Construction and Coverage Prediction
Authors:Yuxuan Li, Cheng Zhang, Wen Wang, Yongming Huang
Radio map, or pathloss map prediction, is a crucial method for wireless network modeling and management. By leveraging deep learning to construct pathloss patterns from geographical maps, an accurate digital replica of the transmission environment could be established with less computational overhead and lower prediction error compared to traditional model-driven techniques. While existing state-of-the-art (SOTA) methods predominantly rely on convolutional architectures, this paper introduces a hybrid transformer-convolution model, termed RMTransformer, to enhance the accuracy of radio map prediction. The proposed model features a multi-scale transformer-based encoder for efficient feature extraction and a convolution-based decoder for precise pixel-level image reconstruction. Simulation results demonstrate that the proposed scheme significantly improves prediction accuracy, and over a 30% reduction in root mean square error (RMSE) is achieved compared to typical SOTA approaches.
无线电地图或路径损耗地图预测是无线网络建模和管理的重要方法。通过利用深度学习从地理地图构建路径损耗模式,可以建立传输环境的精确数字副本,与传统的模型驱动技术相比,计算开销更小,预测误差更低。虽然现有最先进的方法主要依赖于卷积架构,但本文引入了一种混合的transformer-卷积模型,称为RMTransformer,以提高无线电地图预测的准确性。所提出的模型采用基于多尺度transformer的编码器进行高效特征提取和基于卷积的解码器进行精确的像素级图像重建。仿真结果表明,该方案显著提高预测精度,与典型的最新方法相比,均方根误差(RMSE)降低了30%以上。
论文及项目相关链接
PDF Submitted to IEEE VTC 2025 Spring
Summary
本文介绍了利用深度学习构建地理地图的路径损耗模式以进行无线电地图预测的方法。文章提出一种混合transformer-卷积模型RMTransformer,采用基于多尺度transformer的编码器进行高效特征提取和基于卷积的解码器进行精确像素级图像重建,提高了无线电地图预测的精度。仿真结果表明,该方案实现了较高的预测精度,与现有先进技术相比,均方根误差降低了超过30%。
Key Takeaways
- 无线电地图预测在无线网络建模和管理中是关键方法。
- 深度学习被用于从地理地图构建路径损耗模式。
- 现有先进技术主要依赖卷积架构。
- 论文提出一种混合的transformer-卷积模型RMTransformer。
- RMTransformer包括一个多尺度基于transformer的编码器和基于卷积的解码器。
- 仿真结果显示RMTransformer显著提高预测精度。
点此查看论文截图

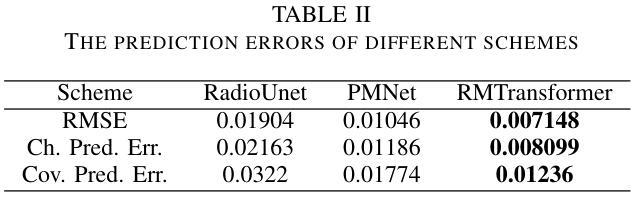
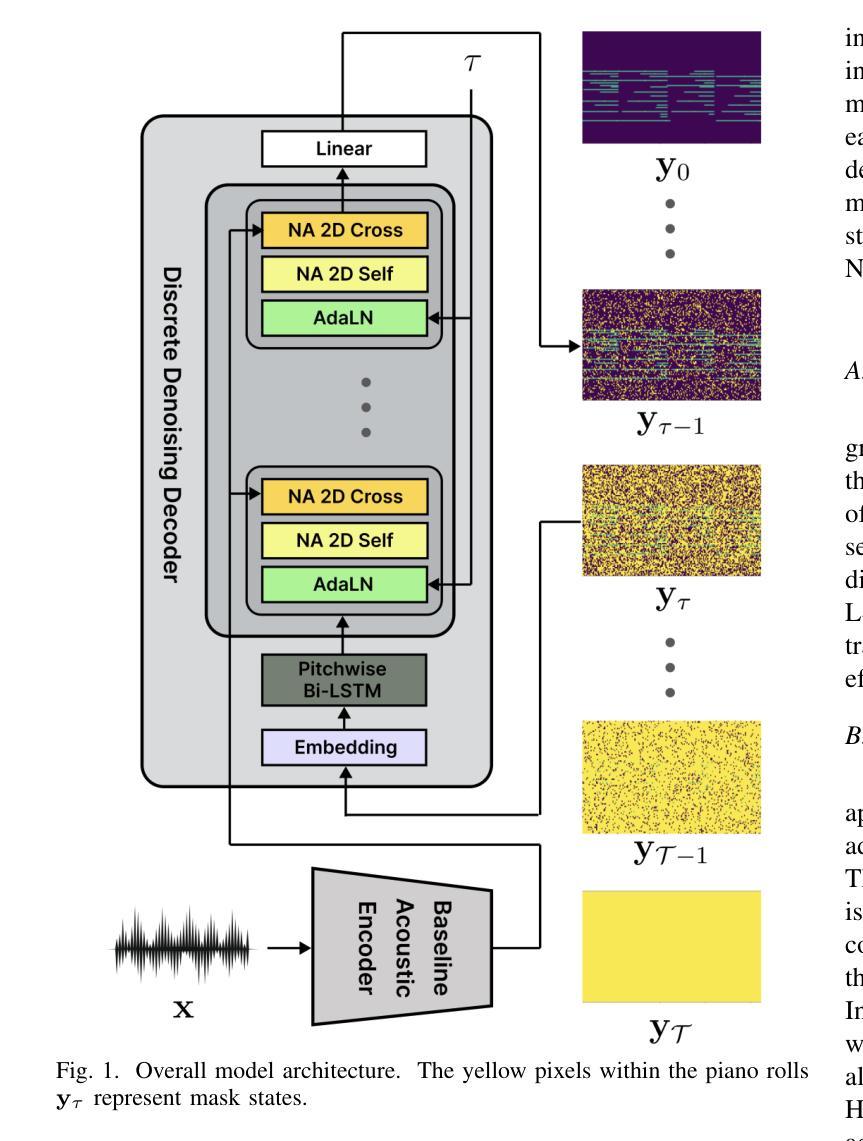
D3RM: A Discrete Denoising Diffusion Refinement Model for Piano Transcription
Authors:Hounsu Kim, Taegyun Kwon, Juhan Nam
Diffusion models have been widely used in the generative domain due to their convincing performance in modeling complex data distributions. Moreover, they have shown competitive results on discriminative tasks, such as image segmentation. While diffusion models have also been explored for automatic music transcription, their performance has yet to reach a competitive level. In this paper, we focus on discrete diffusion model’s refinement capabilities and present a novel architecture for piano transcription. Our model utilizes Neighborhood Attention layers as the denoising module, gradually predicting the target high-resolution piano roll, conditioned on the finetuned features of a pretrained acoustic model. To further enhance refinement, we devise a novel strategy which applies distinct transition states during training and inference stage of discrete diffusion models. Experiments on the MAESTRO dataset show that our approach outperforms previous diffusion-based piano transcription models and the baseline model in terms of F1 score. Our code is available in https://github.com/hanshounsu/d3rm.
扩散模型由于其在对复杂数据分布进行建模时的出色表现,在生成领域得到了广泛应用。此外,在判别任务(如图像分割)中,它们也展现出了具有竞争力的结果。尽管扩散模型在音乐自动转录方面也有所探索,但其性能尚未达到竞争水平。本文中,我们重点关注离散扩散模型的优化能力,并为钢琴转录提出了一种新型架构。我们的模型利用邻域注意力层作为去噪模块,根据预训练声学模型的微调特征,逐步预测目标高分辨率的钢琴乐谱。为了进一步提高优化效果,我们设计了一种新型策略,在离散扩散模型的训练和推理阶段应用不同的过渡状态。在MAESTRO数据集上的实验表明,我们的方法在F1分数方面优于之前的基于扩散的钢琴转录模型和基线模型。我们的代码可在https://github.com/hanshounsu/d3rm中找到。
论文及项目相关链接
PDF Accepted to ICASSP 2025
Summary
本文介绍了离散扩散模型在钢琴音乐转录方面的应用。该模型利用邻域注意力层作为去噪模块,逐渐预测目标高分辨率钢琴卷,同时基于预训练的声学模型的微调特征进行条件处理。为提高预测精度,本文还提出了一种在离散扩散模型的训练和推理阶段应用不同过渡状态的新策略。实验表明,该方法在MAESTRO数据集上的表现优于先前的扩散模型钢琴转录方法和基线模型。
Key Takeaways
- 离散扩散模型被用于钢琴音乐转录,展示其在音乐生成领域的潜力。
- 邻域注意力层作为去噪模块,提高了模型的预测能力。
- 模型利用预训练的声学模型的微调特征进行条件处理,以生成高分辨率的钢琴卷。
- 在训练和推理阶段采用不同的过渡状态,增强了模型的性能。
- 模型在MAESTRO数据集上的表现优于其他扩散模型钢琴转录方法和基线模型。
- 模型代码已公开发布在GitHub上供研究人员参考和使用。
点此查看论文截图


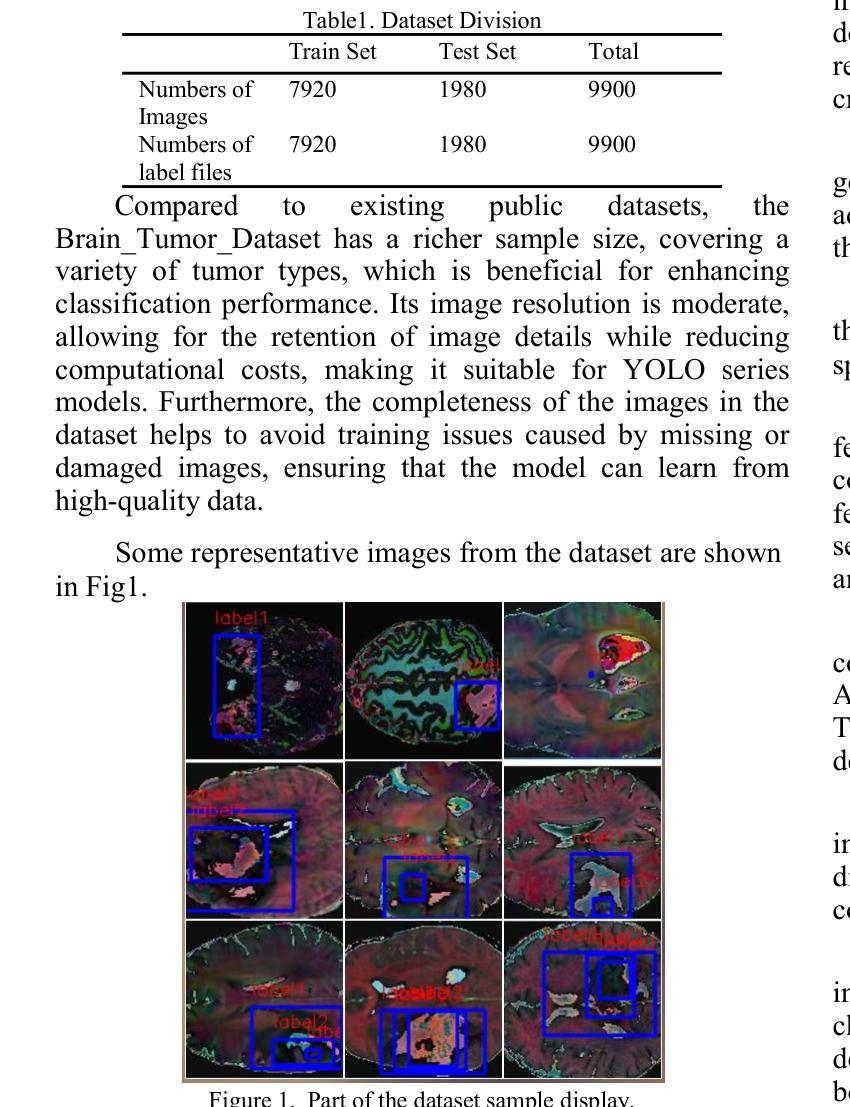
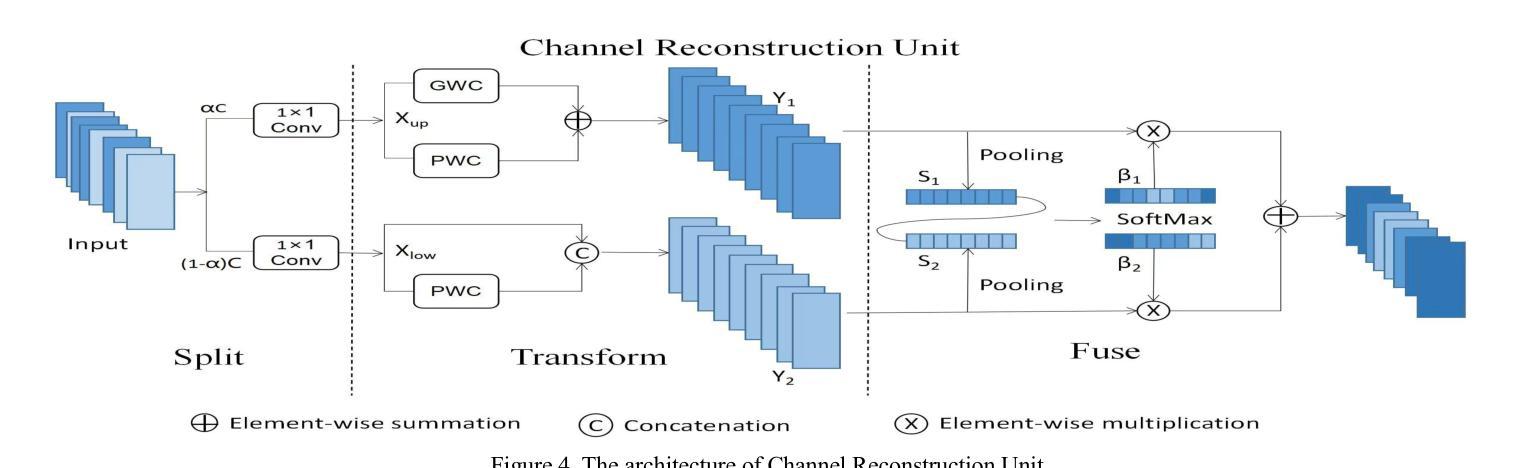
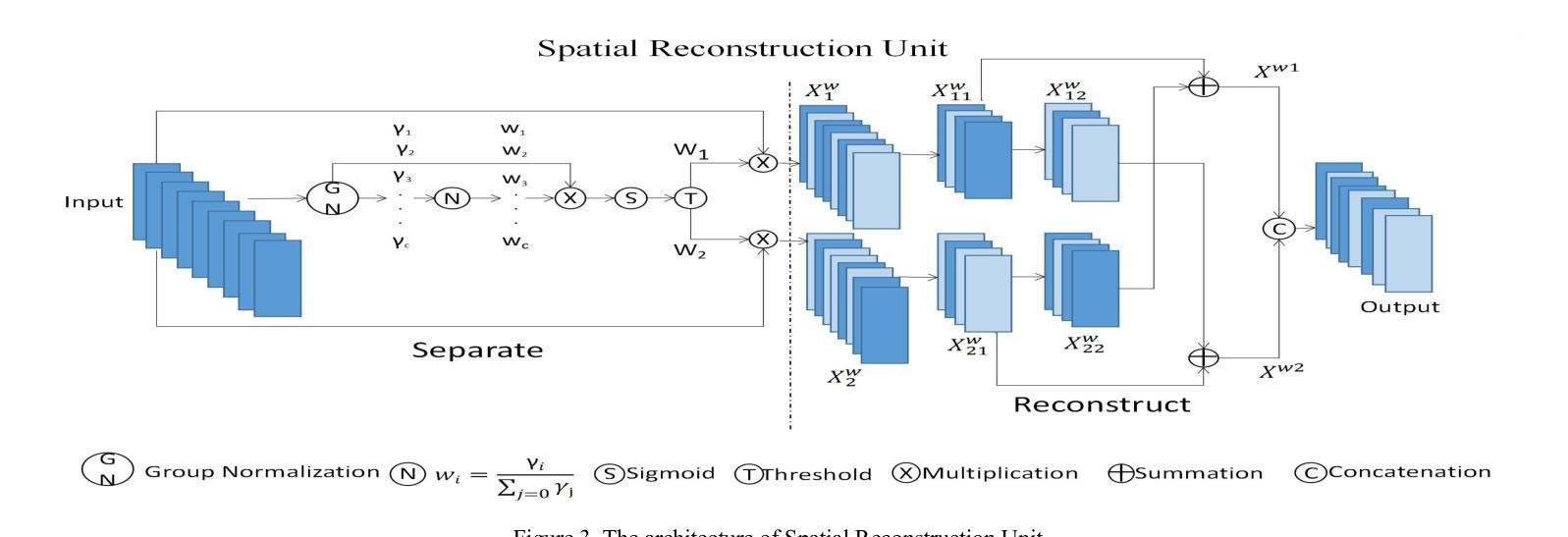
SCC-YOLO: An Improved Object Detector for Assisting in Brain Tumor Diagnosis
Authors:Runci Bai
Brain tumors can result in neurological dysfunction, alterations in cognitive and psychological states, increased intracranial pressure, and the occurrence of seizures, thereby presenting a substantial risk to human life and health. The You Only Look Once(YOLO) series models have demonstrated superior accuracy in object detection for medical imaging. In this paper, we develop a novel SCC-YOLO architecture by integrating the SCConv attention mechanism into YOLOv9. The SCConv module reconstructs an efficient convolutional module by reducing spatial and channel redundancy among features, thereby enhancing the learning of image features. We investigate the impact of intergrating different attention mechanisms with the YOLOv9 model on brain tumor image detection using both the Br35H dataset and our self-made dataset(Brain_Tumor_Dataset). Experimental results show that on the Br35H dataset, SCC-YOLO achieved a 0.3% improvement in mAp50 compared to YOLOv9, while on our self-made dataset, SCC-YOLO exhibited a 0.5% improvement over YOLOv9. SCC-YOLO has reached state-of-the-art performance in brain tumor detection. Source code is available at : https://jihulab.com/healthcare-information-studio/SCC-YOLO/-/tree/master
脑肿瘤可能导致神经功能障碍、认知和心理状态改变、颅内压升高以及癫痫发作,从而对人类生命和健康构成重大风险。You Only Look Once(YOLO)系列模型在医学图像目标检测中表现出了卓越的准确性。在本文中,我们通过将SCConv注意力机制融入YOLOv9,开发了一种新型的SCC-YOLO架构。SCConv模块通过减少特征之间的空间和通道冗余性,重建了一个高效的卷积模块,从而增强了图像特征的学习。我们使用Br35H数据集和我们自制的Brain_Tumor_Dataset数据集,研究了将不同注意力机制与YOLOv9模型集成对脑肿瘤图像检测的影响。实验结果表明,在Br35H数据集上,SCC-YOLO相较于YOLOv9在mAp50上提高了0.3%;而在我们自制的数据库上,SCC-YOLO相较于YOLOv9提高了0.5%。SCC-YOLO已经达到了脑肿瘤检测的最先进性能。源代码可访问:https://jihulab.com/healthcare-information-studio/SCC-YOLO/-/tree/master。
论文及项目相关链接
Summary
本论文开发了一种新型的SCC-YOLO架构,通过整合SCConv注意力机制到YOLOv9中,以提高对医学图像中的脑肿瘤检测精度。实验结果显示,在Br35H数据集上,SCC-YOLO相较于YOLOv9提高了0.3%的mAp50;在自定义数据集Brain_Tumor_Dataset上,其检测效果提升达到0.5%。当前模型已成为脑肿瘤检测领域的先进成果之一。
Key Takeaways
- 脑肿瘤对人类生命和健康存在重大风险,可能导致神经功能障碍、认知和心理状态改变、颅内压升高和癫痫发作。
- YOLO系列模型在医学图像目标检测中具有优越的准确性。
- 本研究开发了SCC-YOLO架构,通过整合SCConv注意力机制到YOLOv9中,旨在提高脑肿瘤检测的准确性。
- SCConv模块通过减少特征间的空间通道冗余来重构有效的卷积模块,从而增强图像特征的学习。
- 实验结果显示,在Br35H数据集和自定义Brain_Tumor_Dataset数据集上,SCC-YOLO相较于YOLOv9均有所提升。
- SCC-YOLO已达到脑肿瘤检测的领先水平,源代码已公开。
点此查看论文截图


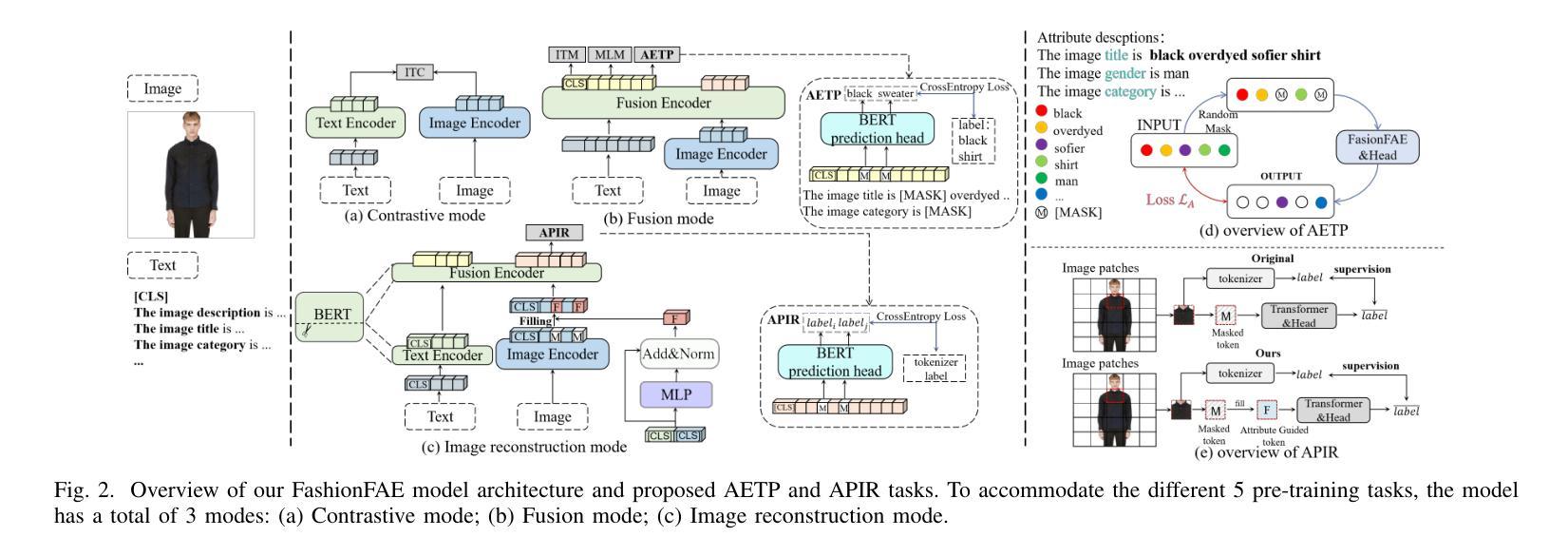
FashionFAE: Fine-grained Attributes Enhanced Fashion Vision-Language Pre-training
Authors:Jiale Huang, Dehong Gao, Jinxia Zhang, Zechao Zhan, Yang Hu, Xin Wang
Large-scale Vision-Language Pre-training (VLP) has demonstrated remarkable success in the general domain. However, in the fashion domain, items are distinguished by fine-grained attributes like texture and material, which are crucial for tasks such as retrieval. Existing models often fail to leverage these fine-grained attributes from both text and image modalities. To address the above issues, we propose a novel approach for the fashion domain, Fine-grained Attributes Enhanced VLP (FashionFAE), which focuses on the detailed characteristics of fashion data. An attribute-emphasized text prediction task is proposed to predict fine-grained attributes of the items. This forces the model to focus on the salient attributes from the text modality. Additionally, a novel attribute-promoted image reconstruction task is proposed, which further enhances the fine-grained ability of the model by leveraging the representative attributes from the image modality. Extensive experiments show that FashionFAE significantly outperforms State-Of-The-Art (SOTA) methods, achieving 2.9% and 5.2% improvements in retrieval on sub-test and full test sets, respectively, and a 1.6% average improvement in recognition tasks.
大规模视觉语言预训练(VLP)在通用领域已经取得了显著的成功。然而,在时尚领域,物品的区别在于细粒度属性,如质地和材质,这对于检索等任务至关重要。现有模型往往无法从文本和图像两种模态中利用这些细粒度属性。为了解决上述问题,我们针对时尚领域提出了一种新的方法,即细粒度属性增强VLP(FashionFAE),它专注于时尚数据的详细特征。提出了一种属性强调文本预测任务,用于预测物品的细粒度属性。这迫使模型关注文本模态的显著属性。此外,还提出了一种新的属性促进图像重建任务,通过利用图像模态的代表属性,进一步提高了模型的细粒度能力。大量实验表明,FashionFAE显著优于最新方法,在子测试集和全集测试集的检索任务上分别提高了2.9%和5.2%的准确率,在识别任务上平均提高了1.6%。
论文及项目相关链接
PDF 5 pages, Accepted by ICASSP2025, full paper
Summary
大规模视觉语言预训练(VLP)在通用领域取得了显著的成功,但在时尚领域,由于时尚产品之间主要通过精细属性(如纹理和材料)进行区分,现有模型往往无法充分利用这些精细属性。为解决这一问题,本文提出了一种针对时尚领域的新型方法——精细属性增强视觉语言预训练(FashionFAE),它侧重于捕捉时尚数据的详细特征。通过构建注重属性的文本预测任务和促进属性的图像重建任务,FashionFAE能够从文本和图像中提取和强化这些精细属性信息。实验表明,FashionFAE在检索任务上显著优于现有方法,在子测试集和全测试集上的检索性能分别提高了2.9%和5.2%,并在识别任务上平均提高了1.6%。
Key Takeaways
- 现有模型在时尚领域无法充分利用精细属性(如纹理和材料)。
- FashionFAE是一种针对时尚领域的新型预训练方法,旨在捕捉时尚数据的详细特征。
- FashionFAE通过构建注重属性的文本预测任务来提高模型对文本模态中显著属性的关注。
- FashionFAE引入了一种新的属性促进图像重建任务,通过利用图像模态中的代表性属性来增强模型的精细属性能力。
- 实验结果表明,FashionFAE在时尚检索任务上显著优于现有方法。
- 在子测试集和全测试集上,FashionFAE的检索性能分别提高了2.9%和5.2%。
点此查看论文截图

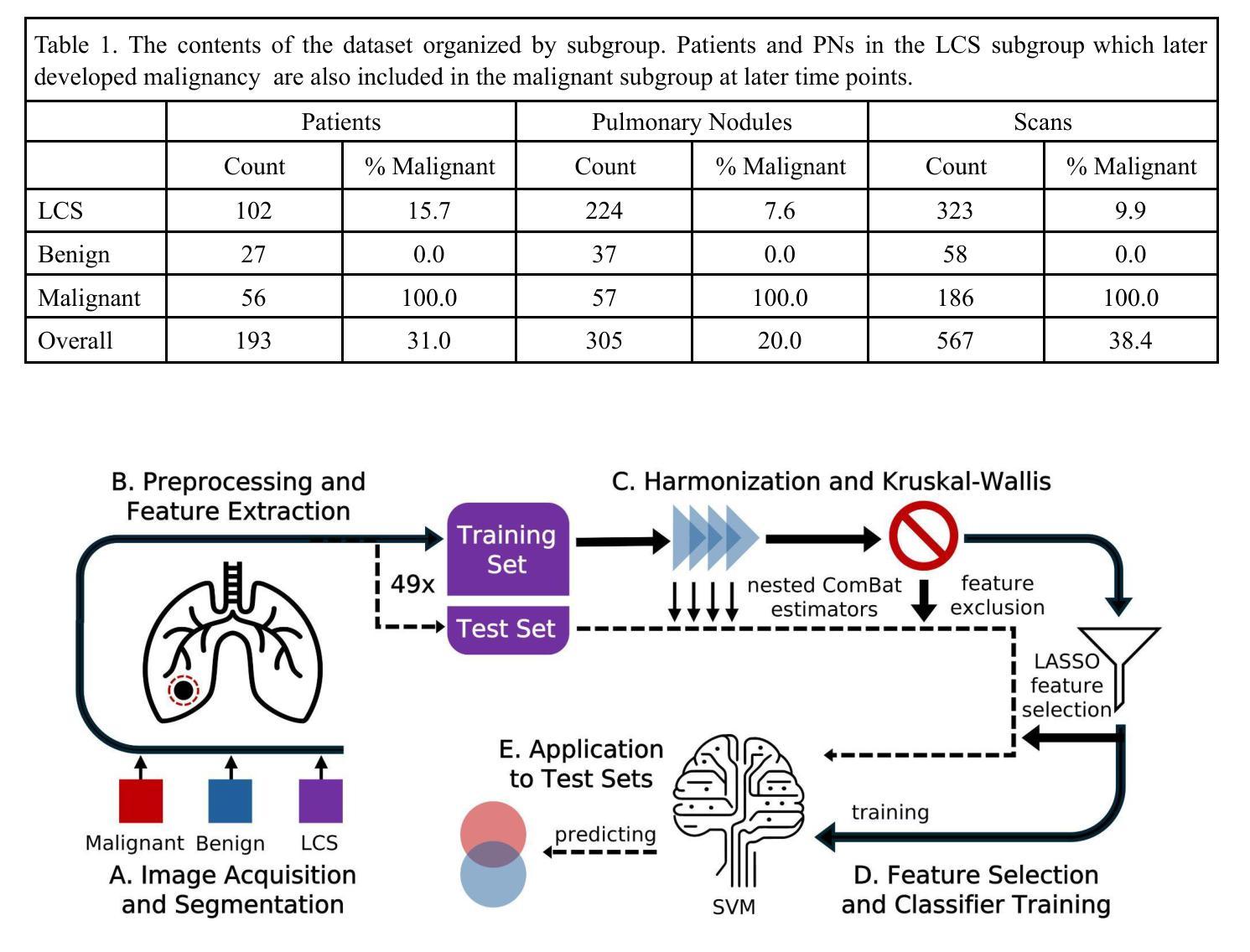
Evaluation of radiomic feature harmonization techniques for benign and malignant pulmonary nodules
Authors:Claire Huchthausen, Menglin Shi, Gabriel L. A. de Sousa, Jonathan Colen, Emery Shelley, James Larner, Einsley Janowski, Krishni Wijesooriya
BACKGROUND: Radiomics provides quantitative features of pulmonary nodules (PNs) which could aid lung cancer diagnosis, but medical image acquisition variability is an obstacle to clinical application. Acquisition effects may differ between radiomic features from benign vs. malignant PNs. PURPOSE: We evaluated how to account for differences between benign and malignant PNs when correcting radiomic features’ acquisition dependency. METHODS: We used 567 chest CT scans grouped as benign, malignant, or lung cancer screening (mixed benign, malignant). ComBat harmonization was applied to extracted features for variation in 4 acquisition parameters. We compared: harmonizing without distinction, harmonizing with a covariate to preserve distinctions between subgroups, and harmonizing subgroups separately. Significant ($p\le0.05$) Kruskal-Wallis tests showed whether harmonization removed acquisition dependency. A LASSO-SVM pipeline was trained on successfully harmonized features to predict malignancy. To evaluate predictive information in these features, the trained harmonization estimators and predictive model were applied to unseen test sets. Harmonization and predictive performance were assessed for 10 trials of 5-fold cross-validation. RESULTS: An average 2.1% of features (95% CI:1.9-2.4%) were acquisition-independent when harmonized without distinction, 27.3% (95% CI:25.7-28.9%) when harmonized with a covariate, and 90.9% (95% CI:90.4-91.5%) when harmonized separately. Data harmonized separately or with a covariate trained models with higher ROC-AUC for screening scans than data harmonized without distinction between benign and malignant PNs (Delong test, adjusted $p\le0.05$). CONCLUSIONS: Radiomic features of benign and malignant PNs need different corrective transformations to recover acquisition-independent distributions. This can be done by harmonizing separately or with a covariate.
背景:放射学提供有关肺结节的定量特征,有助于肺癌的诊断,但医学图像采集的差异性是临床应用中的障碍。良性肺结节与恶性肺结节之间的放射学特征可能因采集效果而有所不同。目的:我们评估了在纠正放射学特征的采集依赖性时,如何区分良性和恶性肺结节。方法:我们使用567张胸部CT扫描图像,按良性、恶性或肺癌筛查(混合良性、恶性)进行分组。应用ComBat方法对四个采集参数的差异进行协调处理。我们比较了三种协调方法:无区别的协调处理、用协变量协调处理以保留各亚组之间的差异以及分别协调处理亚组。通过显著性(p≤0.05)的Kruskal-Wallis检验来确定协调处理是否消除了采集依赖性。在成功协调的特征上应用了LASSO-SVM管道来预测恶性程度。为了评估这些特征中的预测信息,将训练好的协调估计器和预测模型应用于未见过的测试集上。对经过十次5倍交叉验证的协调处理和预测性能进行了评估。结果:当无区别地进行协调处理时,平均有2.1%(95%置信区间:1.9%-2.4%)的特征是独立于采集的;当用协变量进行协调处理时,有27.3%(95%置信区间:25.7%-28.9%)的特征独立于采集;当分别进行协调处理时,有90.9%(95%置信区间:90.4%-91.5%)的特征独立于采集。与无区别地协调处理良性和恶性肺结节的数据相比,分别或带有协变量协调处理的数据为筛查扫描提供了更高的ROC-AUC模型(经过调整的Delong检验,p≤0.05)。结论:良性和恶性肺结节的放射学特征需要不同的校正转换来恢复独立于采集的分布。这可以通过分别协调处理或使用协变量来实现。
论文及项目相关链接
PDF 15 pages, 3 figures, plus supplemental material; updated author list, corrected result in paragraph 3 of Discussion, updated Figure S1
Summary
本文研究了放射组学特征在肺结节诊断中的应用,并探讨了如何消除不同图像采集对放射组学特征的影响。通过对不同采集参数下的放射组学特征进行校正,研究发现在区分良恶性肺结节时,需要分别进行校正以获取独立的分布特征。通过应用特定的校正方法,可以提高对肺癌筛查扫描的预测模型的性能。
Key Takeaways
- 放射组学特征对于肺结节的良恶性诊断具有重要意义。
- 图像采集参数的差异会对放射组学特征产生影响,从而影响诊断的准确性。
- 通过对放射组学特征进行校正,可以消除图像采集参数的影响,提高诊断的准确性。
- 在区分良恶性肺结节时,需要分别进行校正以获得独立的分布特征。
- 应用特定的校正方法可以提高预测模型的性能。
- 校正方法包括无区别的校正、带有协变量的校正和分别校正等。
点此查看论文截图