⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-17 更新
SCOT: Self-Supervised Contrastive Pretraining For Zero-Shot Compositional Retrieval
Authors:Bhavin Jawade, Joao V. B. Soares, Kapil Thadani, Deen Dayal Mohan, Amir Erfan Eshratifar, Benjamin Culpepper, Paloma de Juan, Srirangaraj Setlur, Venu Govindaraju
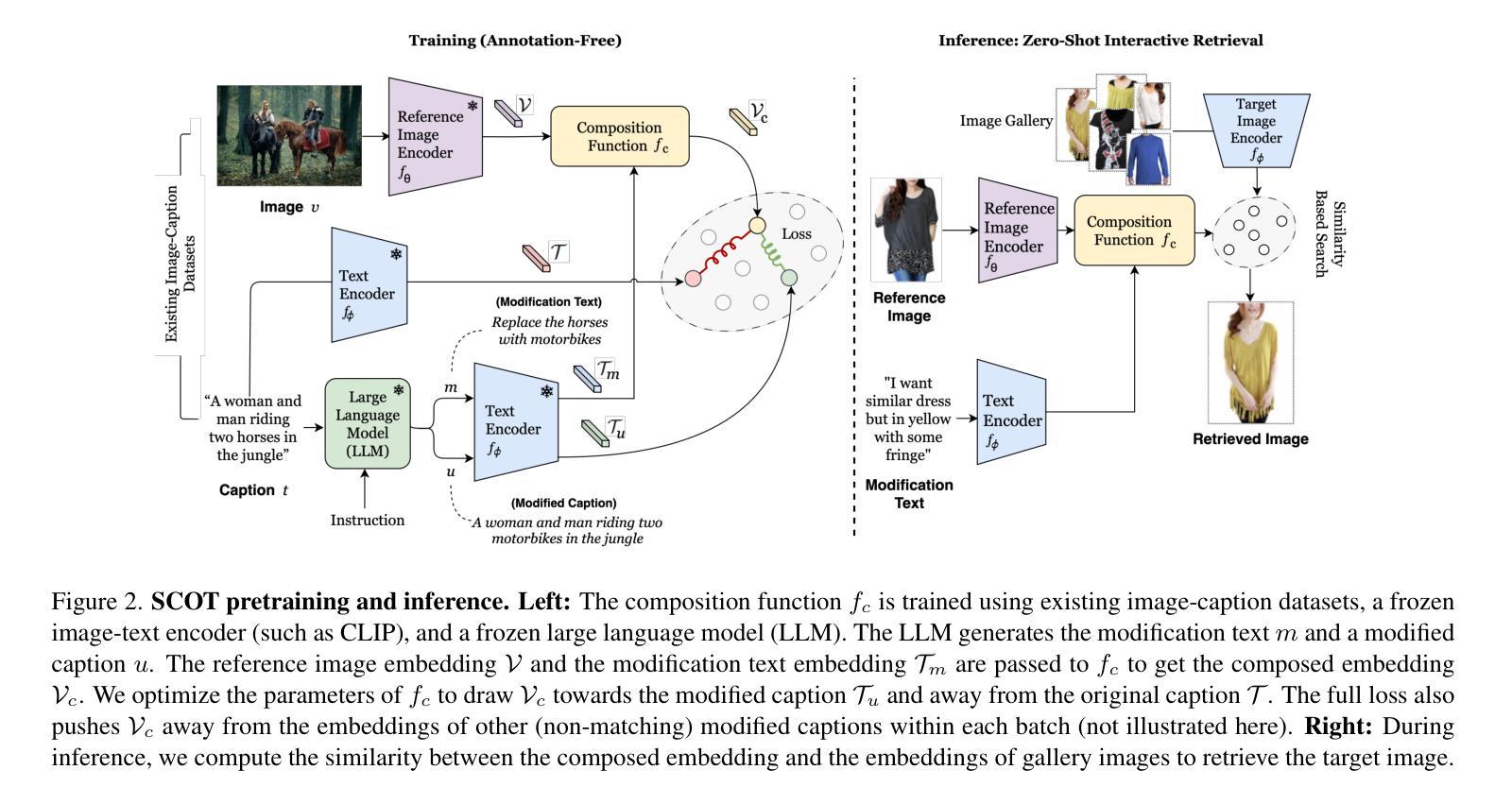
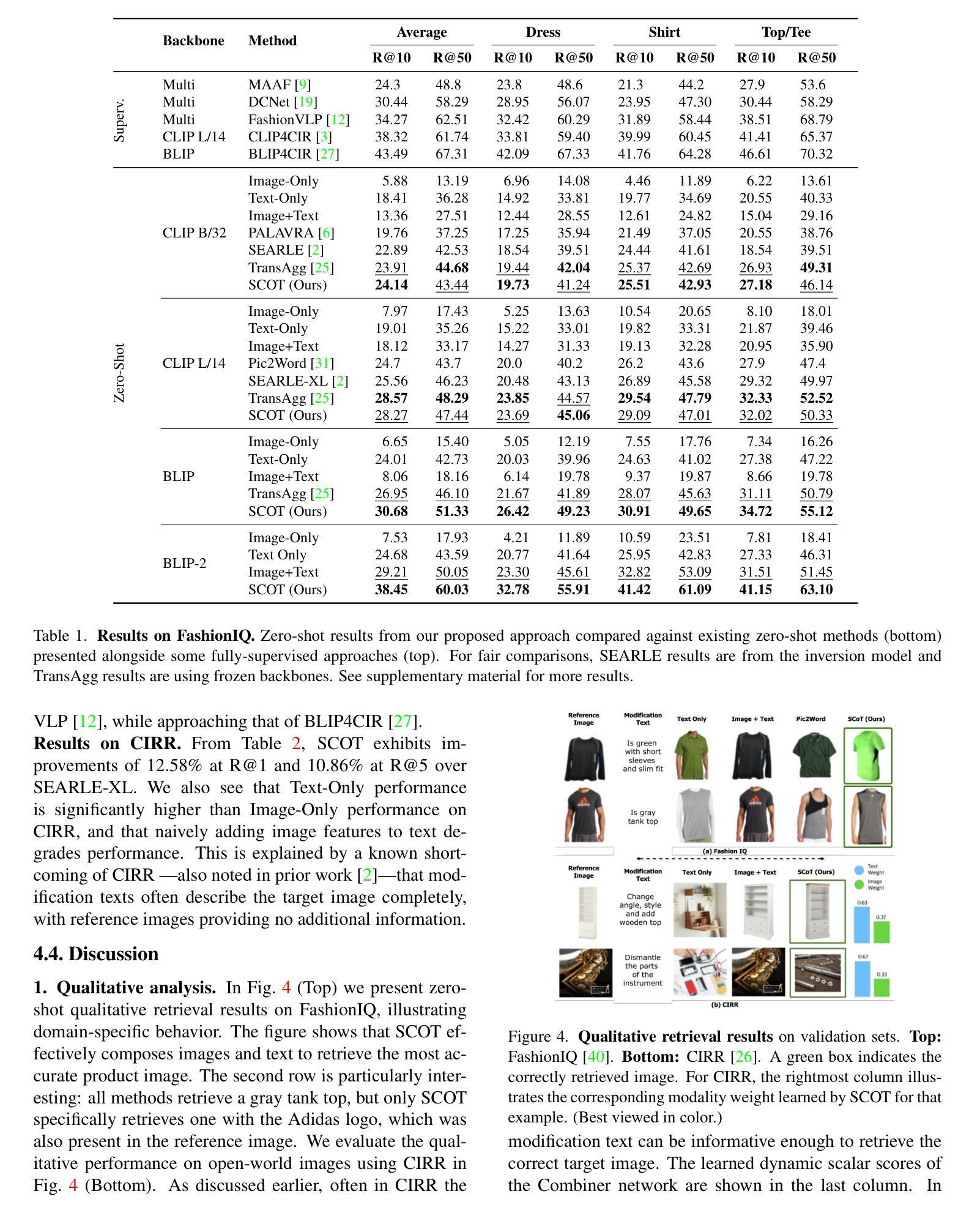
Compositional image retrieval (CIR) is a multimodal learning task where a model combines a query image with a user-provided text modification to retrieve a target image. CIR finds applications in a variety of domains including product retrieval (e-commerce) and web search. Existing methods primarily focus on fully-supervised learning, wherein models are trained on datasets of labeled triplets such as FashionIQ and CIRR. This poses two significant challenges: (i) curating such triplet datasets is labor intensive; and (ii) models lack generalization to unseen objects and domains. In this work, we propose SCOT (Self-supervised COmpositional Training), a novel zero-shot compositional pretraining strategy that combines existing large image-text pair datasets with the generative capabilities of large language models to contrastively train an embedding composition network. Specifically, we show that the text embedding from a large-scale contrastively-pretrained vision-language model can be utilized as proxy target supervision during compositional pretraining, replacing the target image embedding. In zero-shot settings, this strategy surpasses SOTA zero-shot compositional retrieval methods as well as many fully-supervised methods on standard benchmarks such as FashionIQ and CIRR.
组合式图像检索(CIR)是一种多模态学习任务,该任务中的模型会将用户提供的查询图像和文本修改相结合,以检索目标图像。CIR在各种领域中都找到了应用,包括产品检索(电子商务)和网页搜索。现有方法主要集中在全监督学习上,模型会在如FashionIQ和CIRR之类的带标签三元组数据集上进行训练。这带来了两个重大挑战:(i) 此类三元组数据集的整理工作劳动强度大;(ii) 模型缺乏对未见对象和领域的泛化能力。在本研究中,我们提出了SCOT(自监督组合训练),这是一种新型零样本组合预训练策略,它将现有的大型图像-文本对数据集与大型语言模型的生成能力相结合,以对比方式训练嵌入组合网络。具体来说,我们展示了来自大规模对比预训练视觉语言模型的文本嵌入,可以在组合预训练过程中作为代理目标监督来使用,以替代目标图像嵌入。在零样本设置下,该策略超越了最新零样本组合检索方法以及在FashionIQ和CIRR等标准基准测试上的许多全监督方法。
论文及项目相关链接
PDF Paper accepted at WACV 2025 in round 1
Summary
本文介绍了组合图像检索(CIR)任务,它结合了查询图像和用户提供的文本修改,以检索目标图像。现有方法主要关注全监督学习,需要大量标签数据集进行训练,但这种方法面临两个挑战:一是数据集制作成本高;二是模型缺乏对未见对象和领域的泛化能力。本研究提出了SCOT(自监督组合训练)策略,这是一种零样本组合预训练策略,结合了现有的大型图像文本对数据集和大型语言模型的生成能力,对比训练嵌入组合网络。研究结果表明,利用大规模对比预训练的视觉语言模型的文本嵌入作为组合预训练期间的代理目标监督,可替代目标图像嵌入。在零样本设置下,该策略超越了最先进的零样本组合检索方法以及许多全监督方法在标准基准测试上的表现。
Key Takeaways
- CIR是结合查询图像和用户提供的文本修改来检索目标图像的多模态学习任务,广泛应用于产品检索(电子商务)和网页搜索等领域。
- 现有方法主要依赖全监督学习,需要大量标签数据集进行训练,制作成本高且缺乏泛化能力。
- SCOT策略是一种零样本组合预训练策略,结合了图像文本对的大型数据集和大型语言模型的生成能力。
- SCOT策略通过利用对比训练的视觉语言模型的文本嵌入作为组合预训练期间的代理目标监督,实现了对目标图像嵌入的替代。
- 在零样本设置下,SCOT策略超越了众多先进方法在标准基准测试上的表现。
- SCOT策略有助于提高模型的泛化能力和数据效率。
点此查看论文截图