⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-17 更新
Leveraging LLM Agents for Translating Network Configurations
Authors:Yunze Wei, Xiaohui Xie, Yiwei Zuo, Tianshuo Hu, Xinyi Chen, Kaiwen Chi, Yong Cui
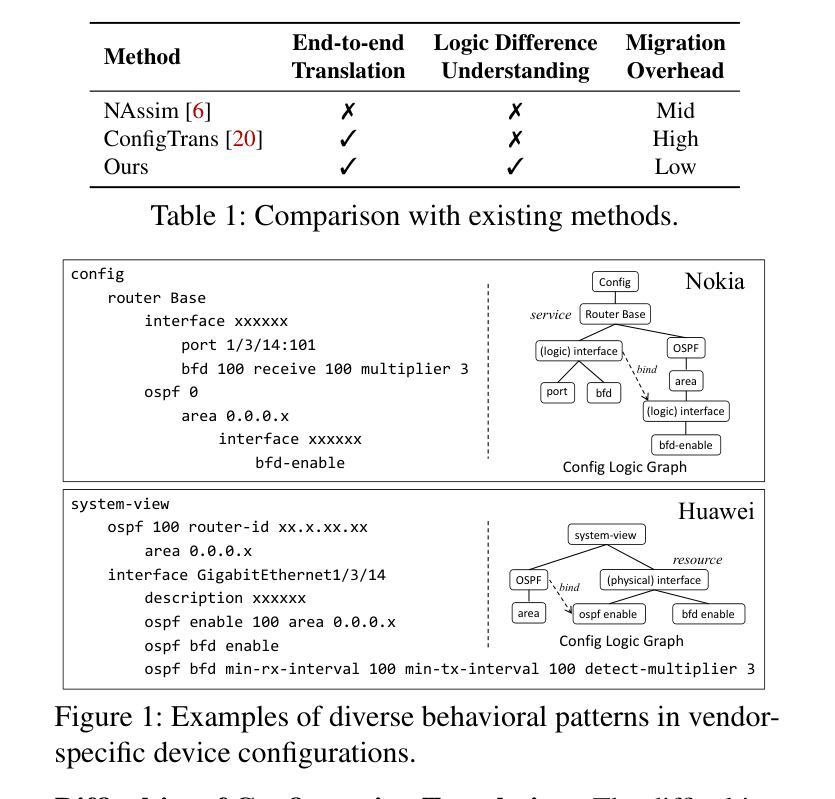
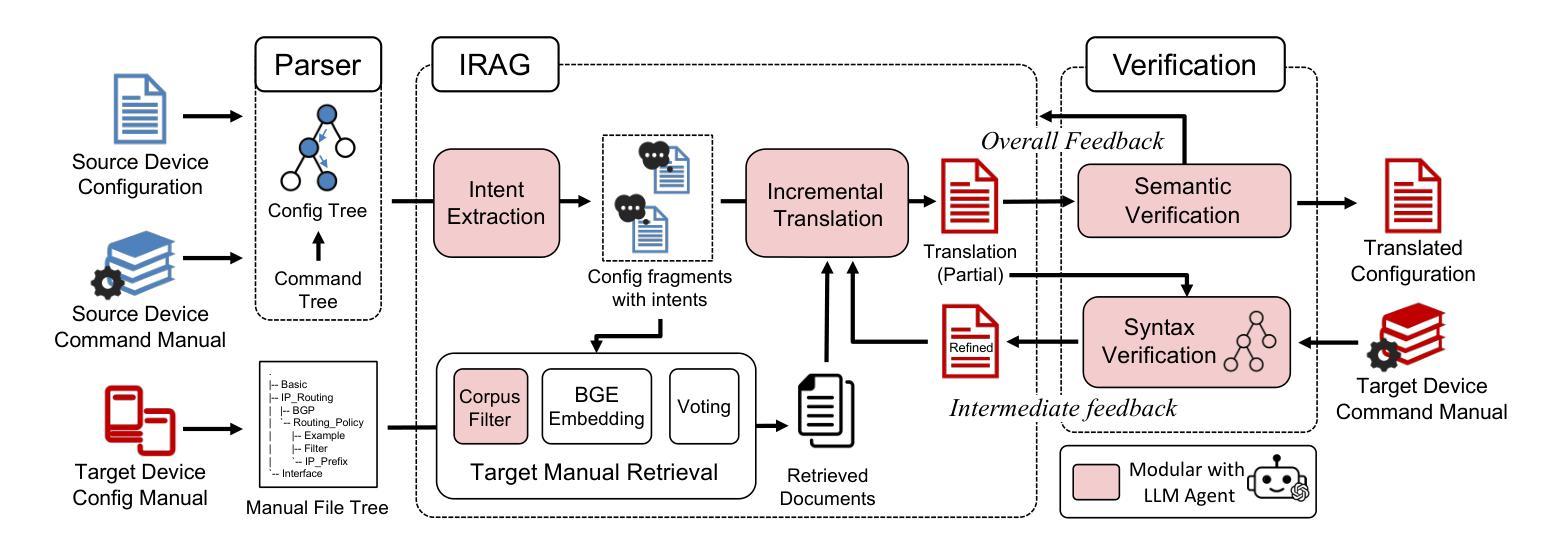
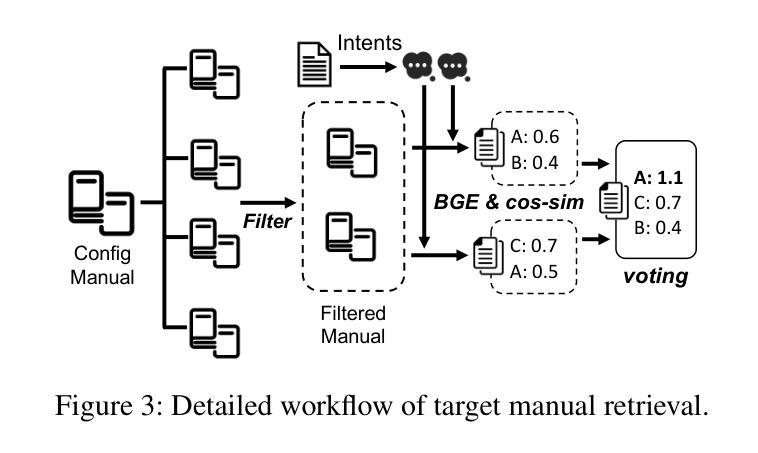
Configuration translation is a critical and frequent task in network operations. When a network device is damaged or outdated, administrators need to replace it to maintain service continuity. The replacement devices may originate from different vendors, necessitating configuration translation to ensure seamless network operation. However, translating configurations manually is a labor-intensive and error-prone process. In this paper, we propose an intent-based framework for translating network configuration with Large Language Model (LLM) Agents. The core of our approach is an Intent-based Retrieval Augmented Generation (IRAG) module that systematically splits a configuration file into fragments, extracts intents, and generates accurate translations. We also design a two-stage verification method to validate the syntax and semantics correctness of the translated configurations. We implement and evaluate the proposed method on real-world network configurations. Experimental results show that our method achieves 97.74% syntax correctness, outperforming state-of-the-art methods in translation accuracy.
配置翻译是网络运营中的一项重要且频繁的任务。当网络设备损坏或过时,管理员需要对其进行更换以维持服务的连续性。这些更换的设备可能来自不同的供应商,因此需要进行配置翻译以确保网络无缝运行。然而,手动进行配置翻译是一项劳动密集型且容易出错的过程。在本文中,我们提出了一种基于意图的利用大型语言模型(LLM)进行网络配置翻译的方法框架。我们的方法的核心是一个基于意图的检索增强生成(IRAG)模块,它能够将配置文件系统地分割成片段,提取意图,并生成准确的翻译。我们还设计了一个两阶段的验证方法来验证翻译配置的语法和语义的正确性。我们在真实世界的网络配置上实现了并评估了该方法。实验结果表明,我们的方法达到了97.74%的语法正确性,在翻译准确性方面优于现有技术。
论文及项目相关链接
摘要
网络配置翻译是网络操作中的一项重要且频繁的任务。当网络设备损坏或过时,管理员需要替换设备以维持服务连续性。由于替换设备可能来自不同的供应商,因此需要进行配置翻译以确保网络无缝运行。然而,手动进行配置翻译是一项劳动密集型且容易出错的工作。本文提出了一种基于意图的利用大型语言模型(LLM)进行网络配置翻译框架。该框架的核心是意图检索增强生成(IRAG)模块,它系统地分割配置文件片段、提取意图并生成准确翻译。此外,本文设计了一个两阶段验证方法来验证翻译配置语法和语义的正确性。我们在实际网络配置上实施并评估了该方法。实验结果表明,该方法达到了97.74%的语法正确性,在翻译准确度方面优于现有技术。
要点分析
- 配置翻译在网络操作中是关键且常见的任务,尤其在替换设备时。
- 不同供应商的设备需要配置翻译以确保无缝的网络运行。
- 手动配置翻译劳动强度大且易出错。
- 提出了一种基于意图的利用大型语言模型(LLM)进行网络配置翻译的框架。
- 框架核心为IRAG模块,可系统分割配置文件、提取意图并生成翻译。
- 设计了两阶段验证方法来确保翻译配置的语法和语义正确性。
点此查看论文截图

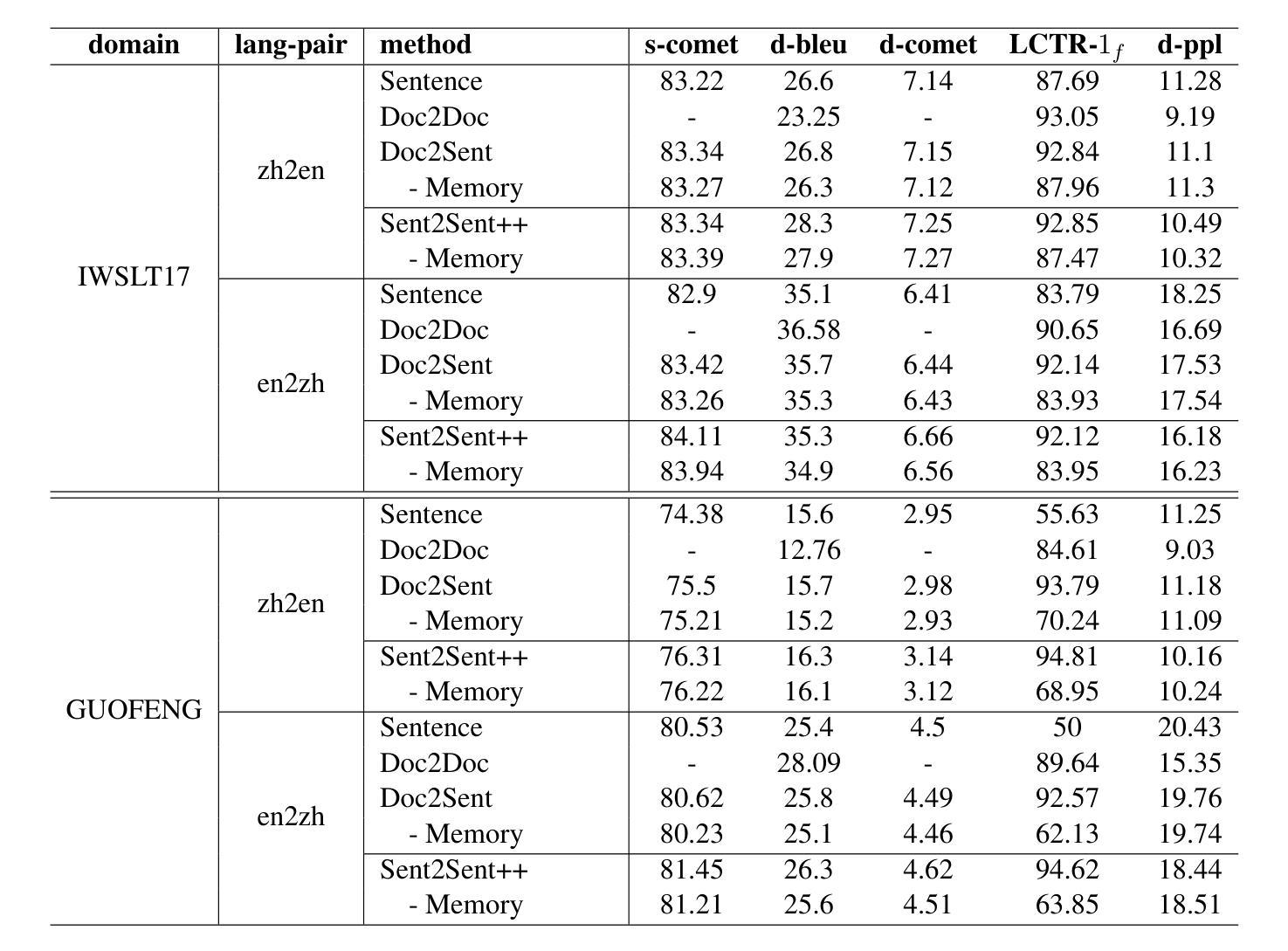
Doc-Guided Sent2Sent++: A Sent2Sent++ Agent with Doc-Guided memory for Document-level Machine Translation
Authors:Jiaxin Guo, Yuanchang Luo, Daimeng Wei, Ling Zhang, Zongyao Li, Hengchao Shang, Zhiqiang Rao, Shaojun Li, Jinlong Yang, Zhanglin Wu, Hao Yang
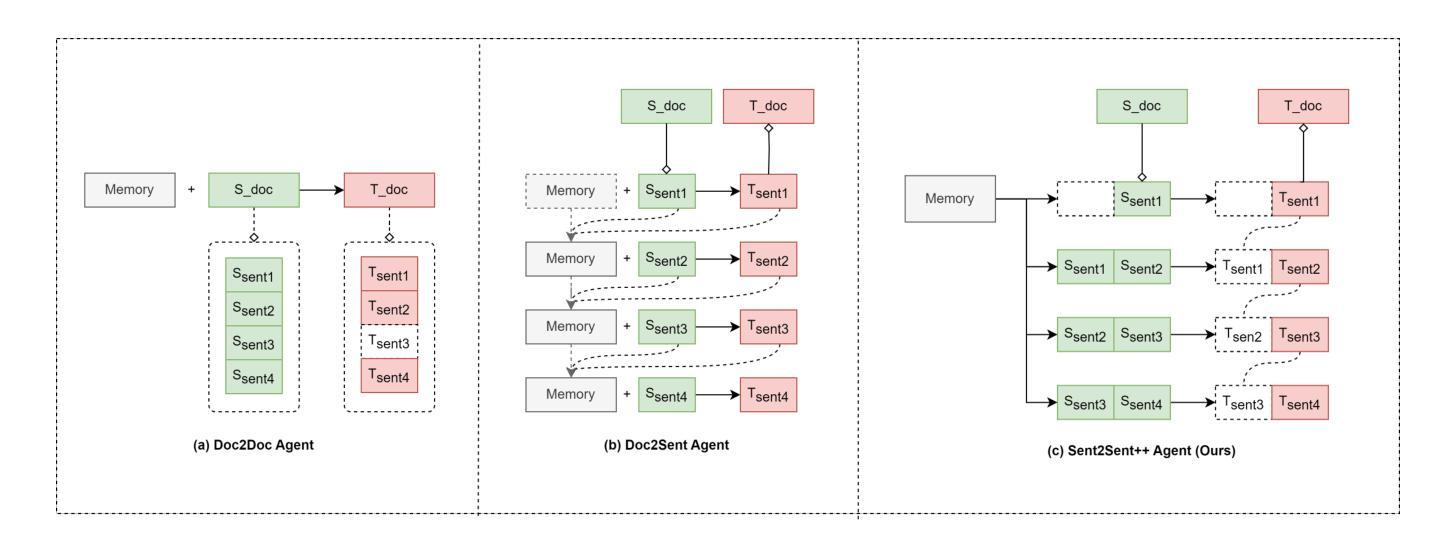
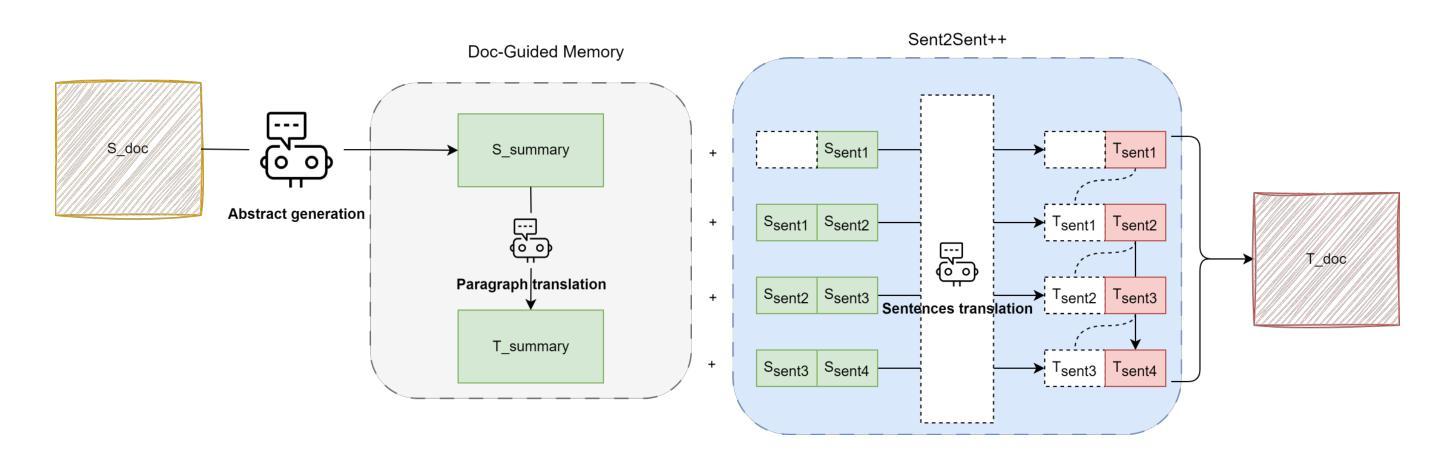
The field of artificial intelligence has witnessed significant advancements in natural language processing, largely attributed to the capabilities of Large Language Models (LLMs). These models form the backbone of Agents designed to address long-context dependencies, particularly in Document-level Machine Translation (DocMT). DocMT presents unique challenges, with quality, consistency, and fluency being the key metrics for evaluation. Existing approaches, such as Doc2Doc and Doc2Sent, either omit sentences or compromise fluency. This paper introduces Doc-Guided Sent2Sent++, an Agent that employs an incremental sentence-level forced decoding strategy \textbf{to ensure every sentence is translated while enhancing the fluency of adjacent sentences.} Our Agent leverages a Doc-Guided Memory, focusing solely on the summary and its translation, which we find to be an efficient approach to maintaining consistency. Through extensive testing across multiple languages and domains, we demonstrate that Sent2Sent++ outperforms other methods in terms of quality, consistency, and fluency. The results indicate that, our approach has achieved significant improvements in metrics such as s-COMET, d-COMET, LTCR-$1_f$, and document-level perplexity (d-ppl). The contributions of this paper include a detailed analysis of current DocMT research, the introduction of the Sent2Sent++ decoding method, the Doc-Guided Memory mechanism, and validation of its effectiveness across languages and domains.
人工智能领域在自然语言处理方面取得了重大进展,这主要归功于大型语言模型(LLM)的能力。这些模型构成了设计用于解决长上下文依赖的代理的后盾,特别是在文档级机器翻译(DocMT)中。DocMT具有独特的挑战,质量、一致性和流利性是评估的关键指标。现有的方法,如Doc2Doc和Doc2Sent,要么省略句子,要么牺牲流畅性。本文介绍了Doc-Guided Sent2Sent++代理,它采用增量句子级强制解码策略,确保每个句子都被翻译,同时提高相邻句子的流畅性。我们的代理利用Doc-Guided Memory,只关注摘要及其翻译,我们发现这是一种保持一致性的有效方法。通过跨多种语言和领域的广泛测试,我们证明了Sent2Sent++在质量、一致性和流畅性方面优于其他方法。结果表明,我们的方法在s-COMET、d-COMET、LTCR-$1_f$和文档级困惑度(d-ppl)等指标上取得了显著改进。本文的贡献包括对当前DocMT研究的详细分析、Sent2Sent++解码方法的引入、Doc-Guided Memory机制以及其在跨语言和领域中的有效性验证。
论文及项目相关链接
Summary
人工智能领域在自然语言处理方面取得显著进展,主要归功于大型语言模型(LLMs)的能力。本文介绍了一种新的文档级机器翻译(DocMT)代理——Doc-Guided Sent2Sent++,采用增量句子级强制解码策略,确保每句话的翻译并提升相邻句子的流畅度。通过测试,Sent2Sent++在质量、一致性和流畅性方面优于其他方法。
Key Takeaways
- 大型语言模型(LLMs)在人工智能的自然语言处理领域起到关键作用。
- 文档级机器翻译(DocMT)面临独特挑战,如质量、一致性和流畅性评价。
- 当前方法如Doc2Doc和Doc2Sent可能在句子遗漏或流畅性上有所欠缺。
- Sent2Sent++通过增量句子级强制解码策略提升句子的翻译质量和流畅性。
- Sent2Sent++采用Doc-Guided Memory机制,专注于摘要及其翻译,有效提高一致性。
- Sent2Sent++在多语言和跨领域测试中表现优越,尤其在s-COMET、d-COMET等指标上实现显著改进。
点此查看论文截图



Reciprocal Reward Influence Encourages Cooperation From Self-Interested Agents
Authors:John L. Zhou, Weizhe Hong, Jonathan C. Kao
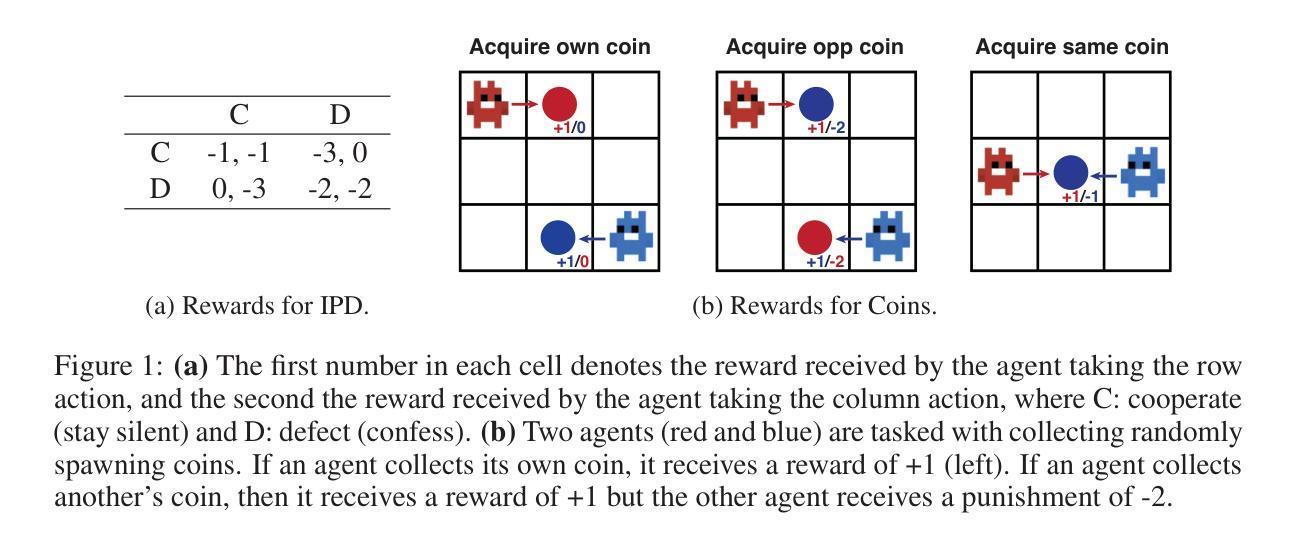
Cooperation between self-interested individuals is a widespread phenomenon in the natural world, but remains elusive in interactions between artificially intelligent agents. Instead, naive reinforcement learning algorithms typically converge to Pareto-dominated outcomes in even the simplest of social dilemmas. An emerging literature on opponent shaping has demonstrated the ability to reach prosocial outcomes by influencing the learning of other agents. However, such methods differentiate through the learning step of other agents or optimize for meta-game dynamics, which rely on privileged access to opponents’ learning algorithms or exponential sample complexity, respectively. To provide a learning rule-agnostic and sample-efficient alternative, we introduce Reciprocators, reinforcement learning agents which are intrinsically motivated to reciprocate the influence of opponents’ actions on their returns. This approach seeks to modify other agents’ $Q$-values by increasing their return following beneficial actions (with respect to the Reciprocator) and decreasing it after detrimental actions, guiding them towards mutually beneficial actions without directly differentiating through a model of their policy. We show that Reciprocators can be used to promote cooperation in temporally extended social dilemmas during simultaneous learning. Our code is available at https://github.com/johnlyzhou/reciprocator/.
自利个体间的合作是自然界中的普遍现象,但在人工智能主体间的交互中仍难以捉摸。相反,天真的强化学习算法通常在最简单的社会困境中收敛到帕累托占据主导地位的结局。关于对手塑造的新兴文献已经证明,通过影响其他主体的学习来达到亲社会结果的能力。然而,这些方法通过其他主体的学习过程进行差异化,或为元游戏动态进行优化,这分别依赖于对对手学习算法的特权访问或指数样本复杂性。为了提供一种独立于学习规则且样本效率高的替代方案,我们引入了互惠者,这是一种强化学习主体,其内在的动机是互惠对手行为对其回报的影响。这种方法试图通过增加有益行为后的回报(相对于互惠者)和减少有害行为后的回报来修改其他主体的Q值,从而在不直接区分其政策模型的情况下引导他们采取互利行动。我们证明了互惠者可以用于在同时学习中促进时间延长型社会困境中的合作。我们的代码可在https://github.com/johnlyzhou/reciprocator/获得。
论文及项目相关链接
PDF NeurIPS 2024
Summary
本文探讨了人工智能代理间合作现象的自然世界广泛存在与互动的问题。然而,单纯的强化学习算法在解决社会困境时通常会陷入帕累托最优解。对手塑造的新兴文献展示了通过影响其他代理学习达到利社会结果的能力。然而,当前方法通过对手学习算法的差异化学习步骤或通过元游戏动态进行优化,依赖特权访问对手学习算法或指数样本复杂性。为了提供一种独立于学习规则且样本效率高的替代方案,引入了互惠者,这是一种内在动机的强化学习代理,旨在互惠对手行为对其回报的影响。此方法通过增加有利于互惠者的行为后的回报和减少有害行为后的回报来修改其他代理的Q值,从而在不直接区分其政策模型的情况下引导其走向互利行为。结果显示,互惠者可用于在同时学习中促进长期社会困境中的合作。代码已公开发布于https://github.comcom/johnlyzhou/reciprocator/。
Key Takeaways
- 人工智能代理在解决社会困境时常常陷入帕累托最优解,缺乏自然世界中个体间的合作现象。
- 对手塑造方法能通过影响其他代理学习达到利社会结果。但当前方法面临特权访问对手学习算法或指数样本复杂性的问题。
- 引入了一种新的强化学习代理——互惠者(Reciprocators),其内在动机是互惠对手行为对回报的影响。
- 互惠者通过修改其他代理的Q值来引导其走向互利行为,而不直接区分其政策模型。
- 互惠者能在同时学习中促进长期社会困境中的合作。
- 该研究提供了一种独立于学习规则且样本效率高的方法来解决人工智能代理间的合作问题。
点此查看论文截图