⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-17 更新
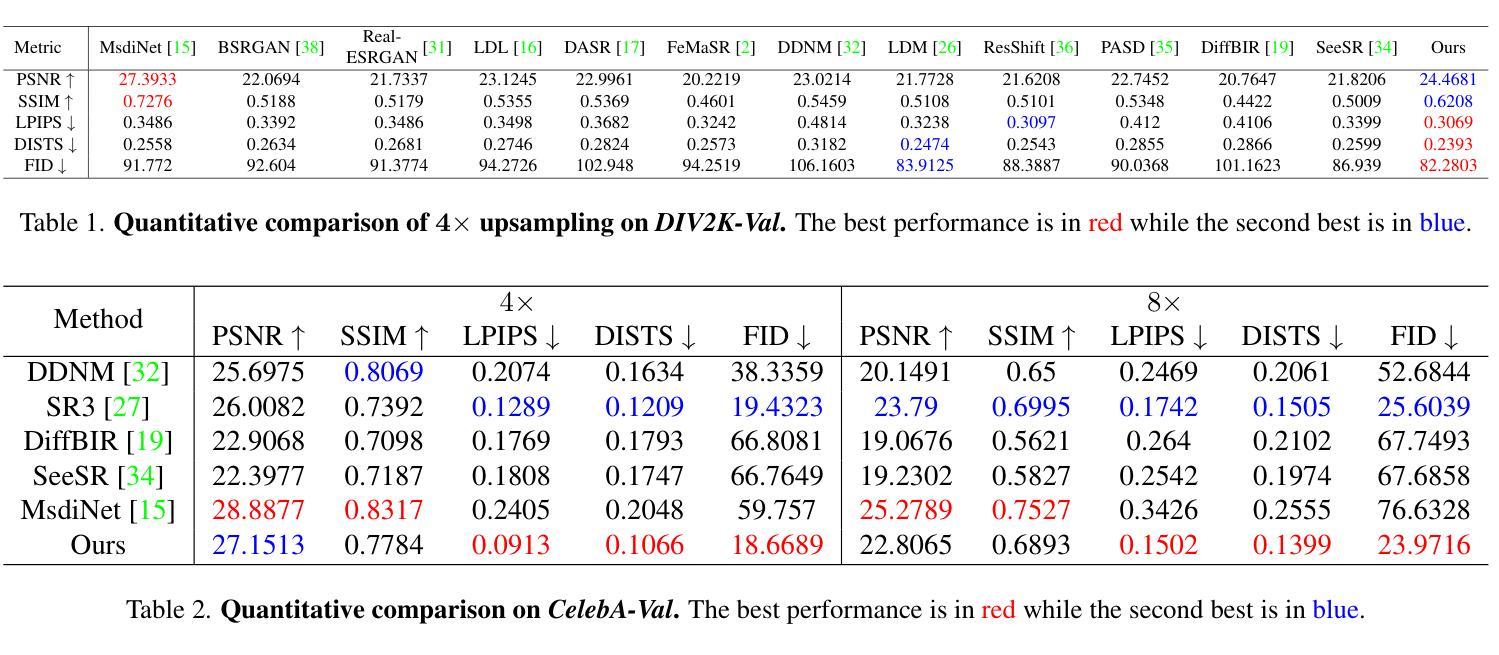
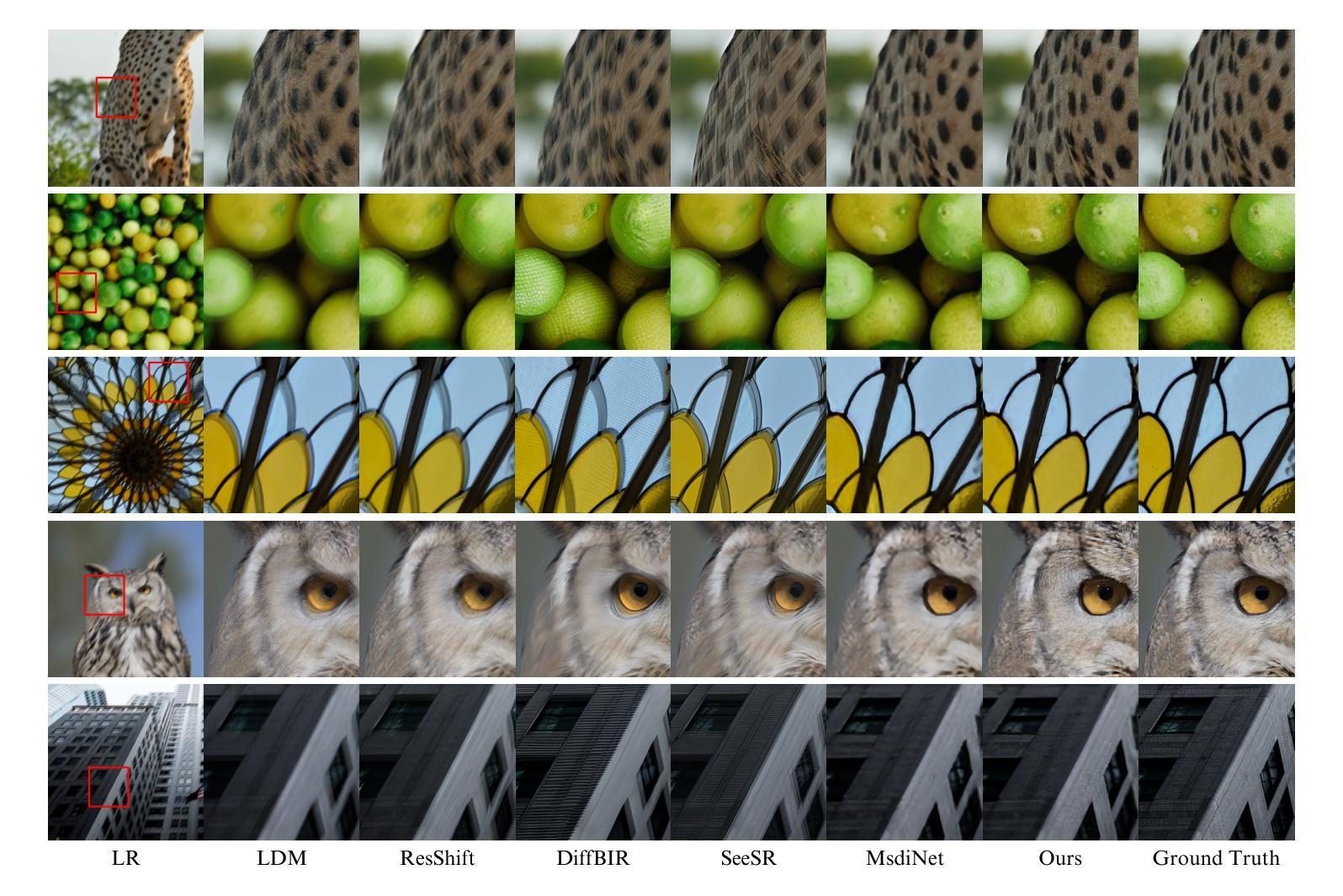
Boosting Diffusion Guidance via Learning Degradation-Aware Models for Blind Super Resolution
Authors:Shao-Hao Lu, Ren Wang, Ching-Chun Huang, Wei-Chen Chiu
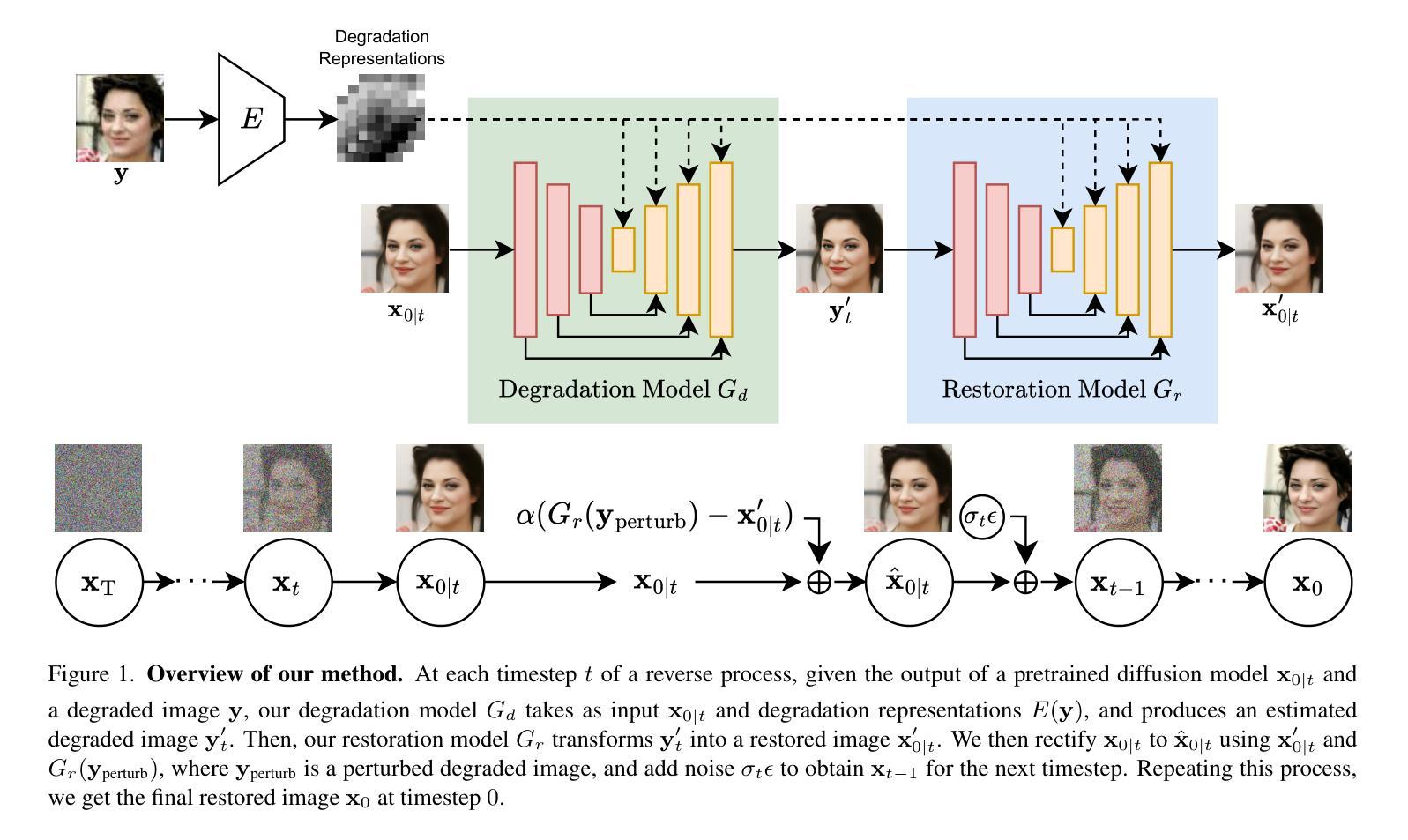
Recently, diffusion-based blind super-resolution (SR) methods have shown great ability to generate high-resolution images with abundant high-frequency detail, but the detail is often achieved at the expense of fidelity. Meanwhile, another line of research focusing on rectifying the reverse process of diffusion models (i.e., diffusion guidance), has demonstrated the power to generate high-fidelity results for non-blind SR. However, these methods rely on known degradation kernels, making them difficult to apply to blind SR. To address these issues, we introduce degradation-aware models that can be integrated into the diffusion guidance framework, eliminating the need to know degradation kernels. Additionally, we propose two novel techniques input perturbation and guidance scalar to further improve our performance. Extensive experimental results show that our proposed method has superior performance over state-of-the-art methods on blind SR benchmarks
最近,基于扩散的盲超分辨率(SR)方法已显示出生成具有丰富高频细节的高分辨率图像的强大能力,但详细的实现往往以保真度的损失为代价。与此同时,另一条研究线索集中在纠正扩散模型的反向过程(即扩散引导),并已证明其生成非盲SR高保真结果的能力。然而,这些方法依赖于已知的退化核,难以应用于盲SR。为了解决这些问题,我们引入了感知退化的模型,可以将其集成到扩散引导框架中,无需知道退化核。此外,我们提出了两种新技术:输入扰动和引导标量,以进一步提高性能。广泛的实验结果表明,我们的方法在盲SR基准测试上的性能优于最新技术。
论文及项目相关链接
PDF To appear in WACV 2025. Code is available at: https://github.com/ryanlu2240/Boosting-Diffusion-Guidance-via-Learning-Degradation-Aware-Models-for-Blind-Super-Resolution
Summary:
最近,基于扩散的盲超分辨率(SR)方法在生成具有丰富高频细节的高分辨率图像方面表现出强大的能力,但往往以保真度的损失为代价。同时,另一条研究线路聚焦于扩散模型的逆向过程修正(即扩散引导),已经证明可以生成非盲SR的高保真结果。然而,这些方法依赖于已知的退化核,难以应用于盲SR。为解决这些问题,我们引入了感知退化模型,可融入扩散引导框架,无需知道退化核。此外,我们提出两种新技术——输入扰动和引导标量,以进一步提高性能。广泛实验结果表明,我们的方法在盲SR基准测试上的表现优于现有先进技术。
Key Takeaways:
- 扩散模型在盲超分辨率(SR)领域展现强大的能力,但可能影响图像的保真度。
- 研究者提出了通过修正扩散模型的逆向过程来增强图像质量的方法。
- 当前方法依赖于已知的退化核,限制了它们在盲SR中的应用。
- 引入感知退化模型以解决上述问题,并与扩散引导框架结合。
- 提出两种新技术:输入扰动和引导标量,以进一步提高性能。
- 广泛实验证实,新方法在盲SR基准测试上表现优越。
点此查看论文截图


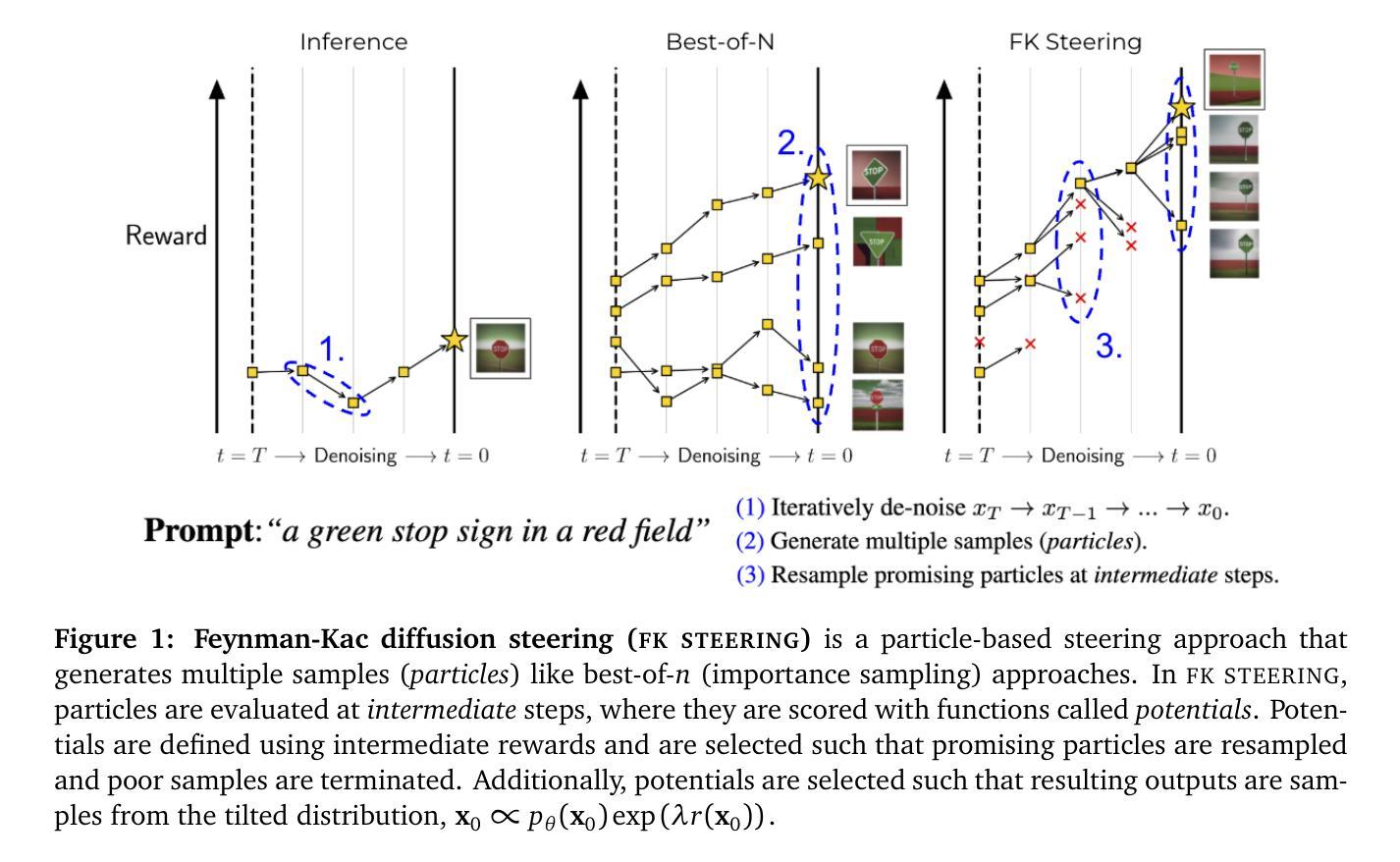
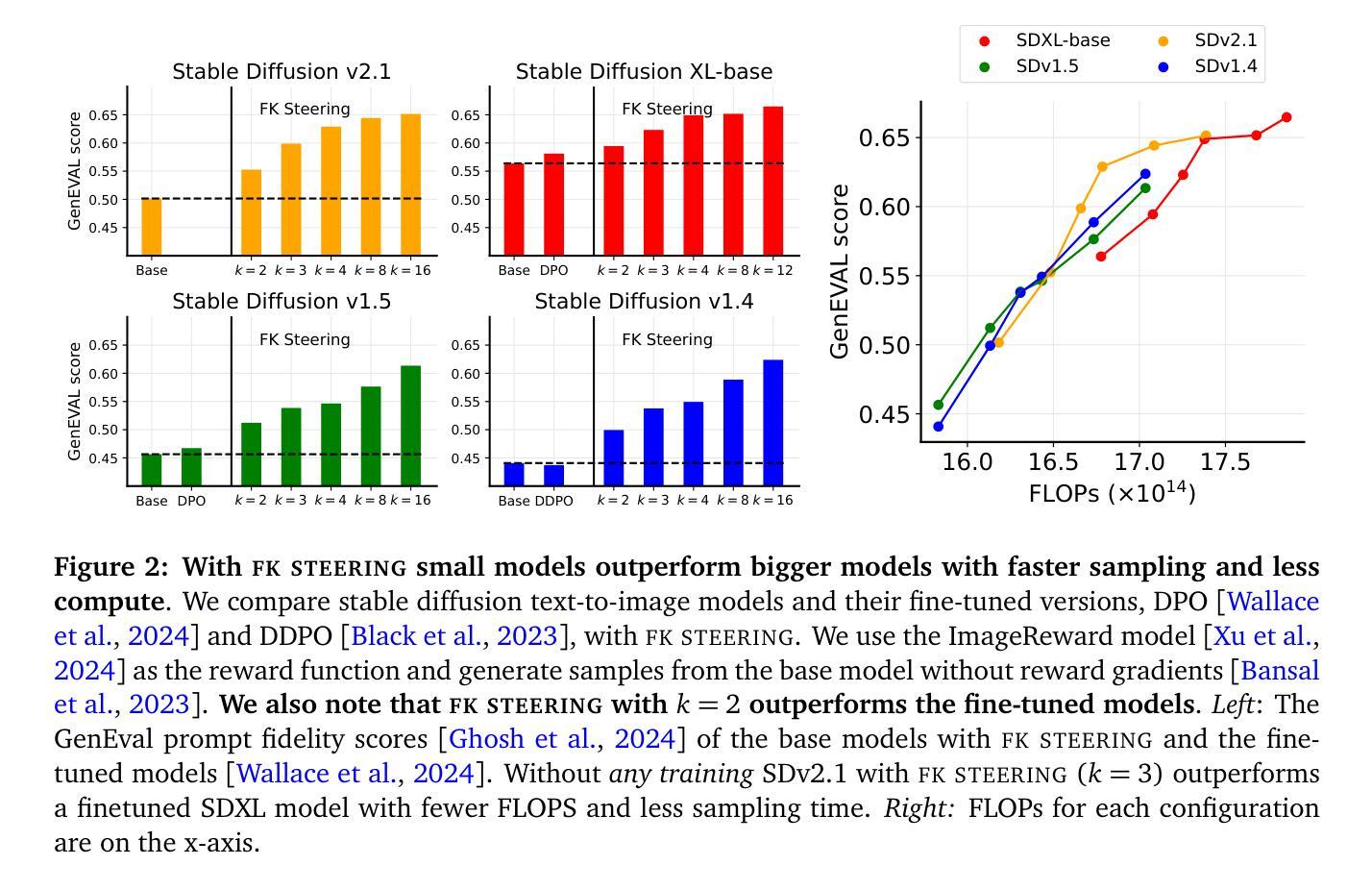
A General Framework for Inference-time Scaling and Steering of Diffusion Models
Authors:Raghav Singhal, Zachary Horvitz, Ryan Teehan, Mengye Ren, Zhou Yu, Kathleen McKeown, Rajesh Ranganath
Diffusion models produce impressive results in modalities ranging from images and video to protein design and text. However, generating samples with user-specified properties remains a challenge. Recent research proposes fine-tuning models to maximize rewards that capture desired properties, but these methods require expensive training and are prone to mode collapse. In this work, we propose Feynman Kac (FK) steering, an inference-time framework for steering diffusion models with reward functions. FK steering works by sampling a system of multiple interacting diffusion processes, called particles, and resampling particles at intermediate steps based on scores computed using functions called potentials. Potentials are defined using rewards for intermediate states and are selected such that a high value indicates that the particle will yield a high-reward sample. We explore various choices of potentials, intermediate rewards, and samplers. We evaluate FK steering on text-to-image and text diffusion models. For steering text-to-image models with a human preference reward, we find that FK steering a 0.8B parameter model outperforms a 2.6B parameter fine-tuned model on prompt fidelity, with faster sampling and no training. For steering text diffusion models with rewards for text quality and specific text attributes, we find that FK steering generates lower perplexity, more linguistically acceptable outputs and enables gradient-free control of attributes like toxicity. Our results demonstrate that inference-time scaling and steering of diffusion models, even with off-the-shelf rewards, can provide significant sample quality gains and controllability benefits. Code is available at https://github.com/zacharyhorvitz/Fk-Diffusion-Steering .
扩散模型在图像、视频、蛋白质设计和文本等多种模态中都取得了令人印象深刻的效果。然而,生成具有用户指定属性的样本仍然是一个挑战。最近的研究提出对模型进行微调,以最大化捕捉所需属性的奖励,但这些方法需要昂贵的训练,并且容易出现模式崩溃。在这项工作中,我们提出了费曼-卡克(FK)转向,这是一种使用奖励函数控制扩散模型的推理时间框架。FK转向通过采样多个相互作用的扩散过程系统(称为粒子)进行工作,并在中间步骤基于使用称为潜力的函数计算得分进行粒子重采样。潜力是通过中间状态的奖励定义的,并选择使得高价值表示粒子将产生高奖励样本。我们探索了不同的潜力、中间奖励和采样器选择。我们对文本到图像和文本扩散模型评估了FK转向。对于使用人类偏好奖励控制文本到图像模型,我们发现FK转向一个0.8B参数模型在提示忠实度上优于2.6B参数微调模型,具有更快的采样速度和无需训练。对于使用文本质量和特定文本属性的奖励控制文本扩散模型,我们发现FK转向产生了更低的困惑度、更在语言上可接受的输出,并实现了无毒性的梯度控制属性。我们的结果证明,即使在推理时间规模和扩散模型的转向,即使使用现成的奖励,也可以显著提高样本质量和可控性。相关代码可在https://github.com/zacharyhorvitz/Fk-Diffusion-Steering找到。
论文及项目相关链接
Summary
本文提出一种名为Feynman Kac(FK)steering的新方法,用于在推理时间控制扩散模型的奖励函数。该方法通过采样多个相互作用的扩散过程(称为粒子),在中间步骤基于计算得到的势能进行粒子重采样。奖励函数用于定义中间状态的势能,高势能值表示粒子将产生高奖励样本。实验结果显示,该方法在文本到图像和文本扩散模型的控制方面表现出色,能够提高样本质量和可控性。
Key Takeaways
- 扩散模型在多领域表现优异,但生成具有用户指定属性的样本仍是挑战。
- 现有方法需要昂贵的训练且易陷入模式崩溃。
- 引入Feynman Kac(FK)steering方法,通过推理时间的框架在扩散模型中控制奖励函数。
- FK steering通过采样多个相互作用的扩散过程(粒子),并在中间步骤基于势能重采样粒子。
- 势能是使用中间状态的奖励函数定义的,高势能值表示产生的样本具有更高的奖励。
- 实验结果显示,FK steering在文本到图像和文本扩散模型的控制方面效果显著,提高样本质量和可控性。
点此查看论文截图


ACE++: Instruction-Based Image Creation and Editing via Context-Aware Content Filling
Authors:Chaojie Mao, Jingfeng Zhang, Yulin Pan, Zeyinzi Jiang, Zhen Han, Yu Liu, Jingren Zhou
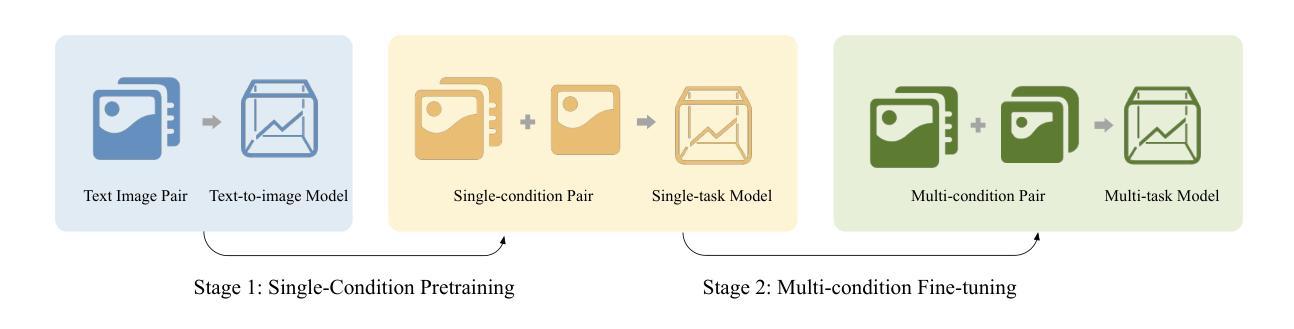
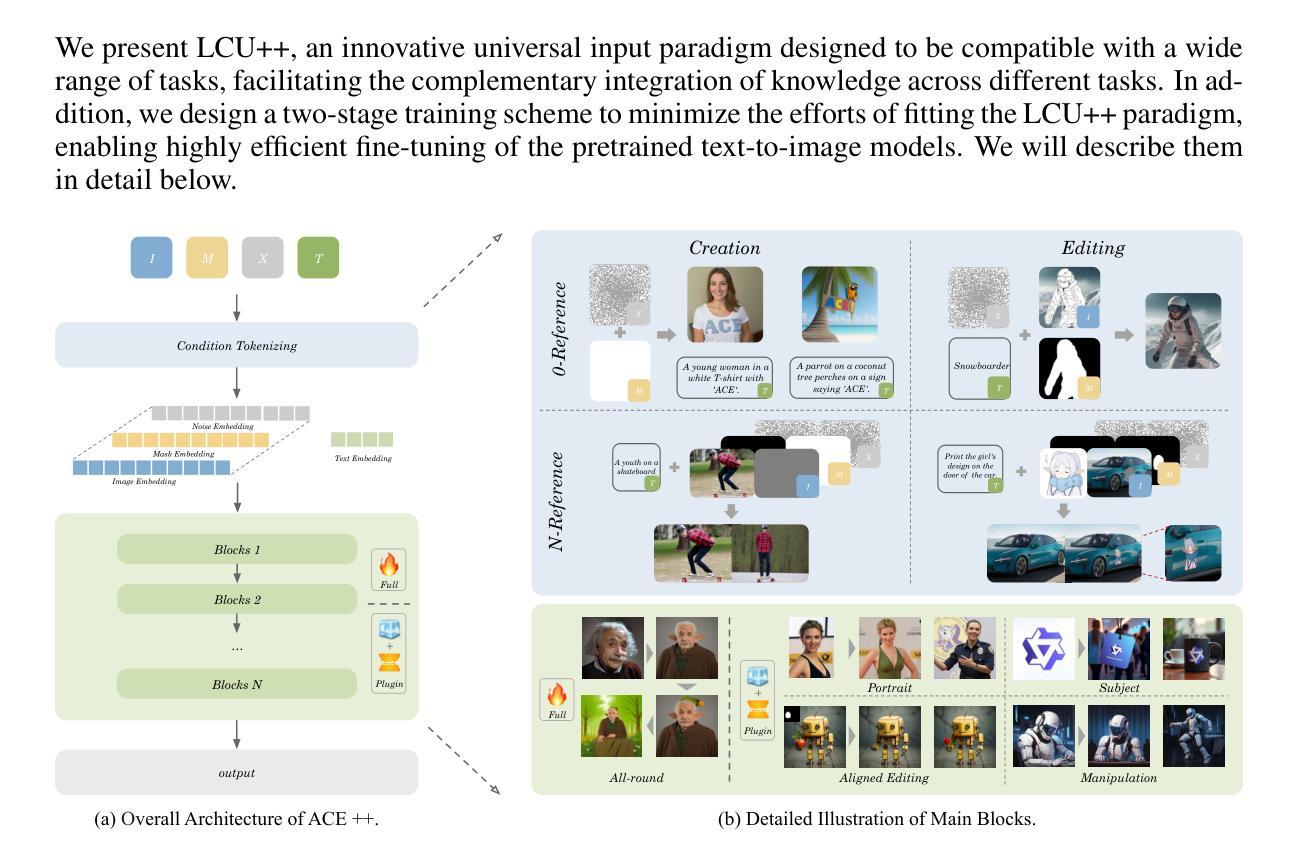
We report ACE++, an instruction-based diffusion framework that tackles various image generation and editing tasks. Inspired by the input format for the inpainting task proposed by FLUX.1-Fill-dev, we improve the Long-context Condition Unit (LCU) introduced in ACE and extend this input paradigm to any editing and generation tasks. To take full advantage of image generative priors, we develop a two-stage training scheme to minimize the efforts of finetuning powerful text-to-image diffusion models like FLUX.1-dev. In the first stage, we pre-train the model using task data with the 0-ref tasks from the text-to-image model. There are many models in the community based on the post-training of text-to-image foundational models that meet this training paradigm of the first stage. For example, FLUX.1-Fill-dev deals primarily with painting tasks and can be used as an initialization to accelerate the training process. In the second stage, we finetune the above model to support the general instructions using all tasks defined in ACE. To promote the widespread application of ACE++ in different scenarios, we provide a comprehensive set of models that cover both full finetuning and lightweight finetuning, while considering general applicability and applicability in vertical scenarios. The qualitative analysis showcases the superiority of ACE++ in terms of generating image quality and prompt following ability. Code and models will be available on the project page: https://ali-vilab. github.io/ACE_plus_page/.
我们报告了ACE++,这是一个基于指令的扩散框架,用于处理各种图像生成和编辑任务。我们受到FLUX.1-Fill-dev提出的填充任务输入格式的启发,改进了ACE中的长上下文条件单元(LCU),并将这一输入范式扩展到任何编辑和生成任务。为了充分利用图像生成的先验知识,我们开发了两阶段训练方案,以最小化调整强大文本到图像扩散模型(如FLUX.1-dev)的努力。在第一阶段,我们使用文本到图像模型的0-ref任务对模型进行预训练。社区中有许多基于文本到图像基础模型的后期训练模型,符合第一阶段的这种训练范式。例如,FLUX.1-Fill-dev主要处理绘画任务,并可作为初始化来加速训练过程。在第二阶段,我们对上述模型进行微调,以使用ACE中定义的所有任务来支持一般指令。为了促进ACE++在不同场景中的广泛应用,我们提供了一套全面的模型,涵盖全量微调和轻量级微调,同时考虑通用性和垂直场景的应用。定性分析展示了ACE++在生成图像质量和遵循提示方面的优越性。代码和模型将在项目页面上发表:https://ali-vilab.github.io/ACE_plus_page/。
论文及项目相关链接
Summary
ACE++是一个基于指令的扩散框架,用于处理各种图像生成和编辑任务。它改进了ACE中的长上下文条件单元(LCU),并扩展到任何编辑和生成任务。该框架采用两阶段训练方案,充分利用图像生成先验知识,最小化对强大文本到图像扩散模型(如FLUX.1-dev)进行微调的努力。通过预训练和微调过程,ACE++在图像生成质量和遵循指令方面表现出卓越性能。相关代码和模型可在项目页面获取。
Key Takeaways
- ACE++是一个基于指令的扩散框架,能够处理图像生成和编辑任务。
- 改进了ACE中的长上下文条件单元(LCU),并扩展该输入范式至所有编辑和生成任务。
- 采用两阶段训练方案,充分利用图像生成先验知识,减少微调强大文本到图像扩散模型的努力。
- 预训练阶段使用文本到图像模型的0-ref任务数据。
- ACE++提供全面的模型覆盖,包括完全微调和轻量级微调,考虑通用和垂直场景的应用。
- ACE++在图像生成质量和遵循指令方面表现出卓越性能。
- 相关代码和模型可在项目页面获取。
点此查看论文截图

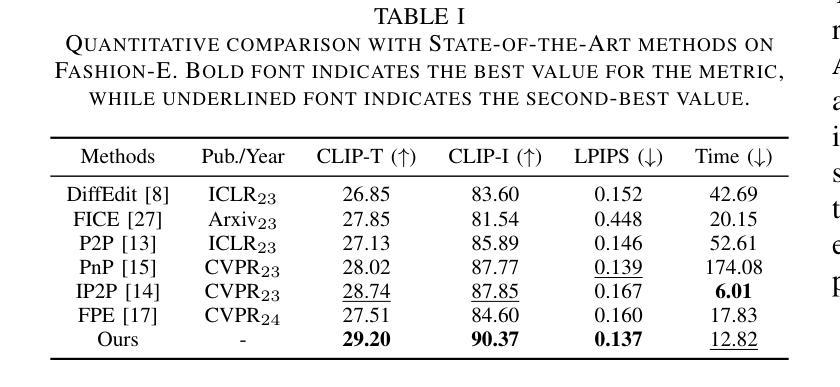
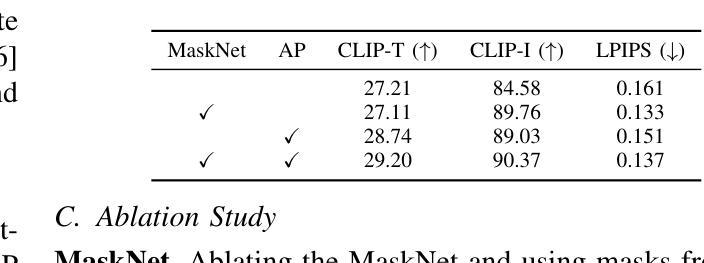
MADiff: Text-Guided Fashion Image Editing with Mask Prediction and Attention-Enhanced Diffusion
Authors:Zechao Zhan, Dehong Gao, Jinxia Zhang, Jiale Huang, Yang Hu, Xin Wang
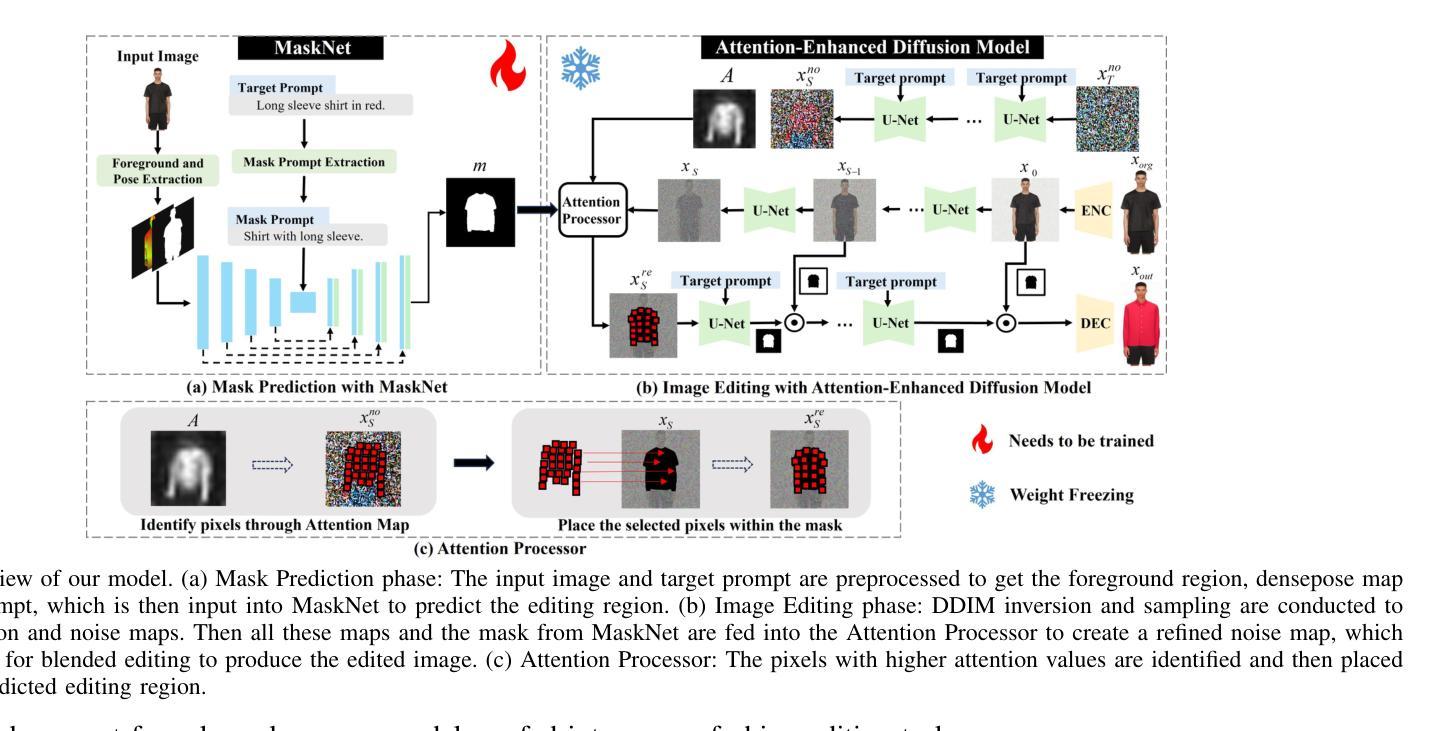
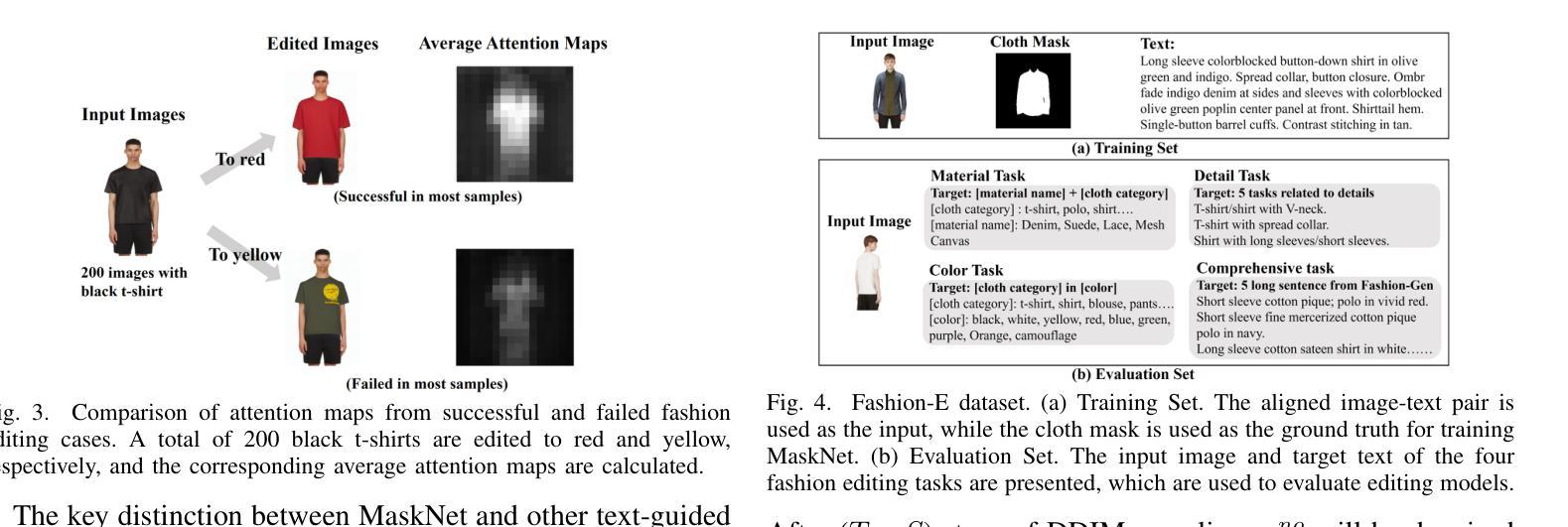
Text-guided image editing model has achieved great success in general domain. However, directly applying these models to the fashion domain may encounter two issues: (1) Inaccurate localization of editing region; (2) Weak editing magnitude. To address these issues, the MADiff model is proposed. Specifically, to more accurately identify editing region, the MaskNet is proposed, in which the foreground region, densepose and mask prompts from large language model are fed into a lightweight UNet to predict the mask for editing region. To strengthen the editing magnitude, the Attention-Enhanced Diffusion Model is proposed, where the noise map, attention map, and the mask from MaskNet are fed into the proposed Attention Processor to produce a refined noise map. By integrating the refined noise map into the diffusion model, the edited image can better align with the target prompt. Given the absence of benchmarks in fashion image editing, we constructed a dataset named Fashion-E, comprising 28390 image-text pairs in the training set, and 2639 image-text pairs for four types of fashion tasks in the evaluation set. Extensive experiments on Fashion-E demonstrate that our proposed method can accurately predict the mask of editing region and significantly enhance editing magnitude in fashion image editing compared to the state-of-the-art methods.
文本引导的图像编辑模型在通用领域已经取得了巨大的成功。然而,直接将这些模型应用于时尚领域可能会遇到两个问题:(1)编辑区域定位不准确;(2)编辑幅度较弱。为了解决这些问题,提出了MADiff模型。具体来说,为了更准确地识别编辑区域,提出了MaskNet,其中将前景区域、densepose和大语言模型的掩码提示输入到轻量级的UNet中,以预测编辑区域的掩码。为了增强编辑幅度,提出了注意力增强扩散模型,其中将噪声图、注意力图和MaskNet的掩码输入到提出的注意力处理器中,以产生精细的噪声图。通过将精细的噪声图集成到扩散模型中,编辑后的图像可以更好地与目标提示对齐。鉴于时尚图像编辑缺乏基准测试集,我们构建了一个名为Fashion-E的数据集,其中包括训练集中的28390个图像-文本对,以及评估集中的2639个图像-文本对,用于四种时尚任务。在Fashion-E上的大量实验表明,我们提出的方法能够准确预测编辑区域的掩码,并在时尚图像编辑中显著增强编辑幅度,与最先进的方法相比具有优势。
论文及项目相关链接
Summary
文本引导的图像编辑模型在通用领域取得了巨大成功,但在时尚领域应用时面临区域定位不准确和编辑强度弱的问题。为此,提出了MADiff模型,通过MaskNet更准确地识别编辑区域,并通过Attention-Enhanced Diffusion Model增强编辑强度。为缺乏时尚图像编辑的基准测试集,构建了Fashion-E数据集。实验证明,该方法能准确预测编辑区域掩膜,显著提高时尚图像编辑的编辑强度。
Key Takeaways
- 文本引导的图像编辑模型在时尚领域面临挑战,主要包括区域定位不准确和编辑强度弱。
- MADiff模型通过MaskNet和Attention-Enhanced Diffusion Model解决这些问题。
- MaskNet利用前景区域、densepose和大型语言模型的掩码提示来预测编辑区域的掩膜。
- Attention-Enhanced Diffusion Model通过结合噪声图、注意力图和MaskNet的掩码来生成更精细的噪声图,从而提高编辑强度。
- 整合精细噪声图到扩散模型中,使编辑后的图像更好地符合目标提示。
- 缺乏时尚图像编辑的基准测试集,因此构建了Fashion-E数据集来进行评估和实验。
点此查看论文截图


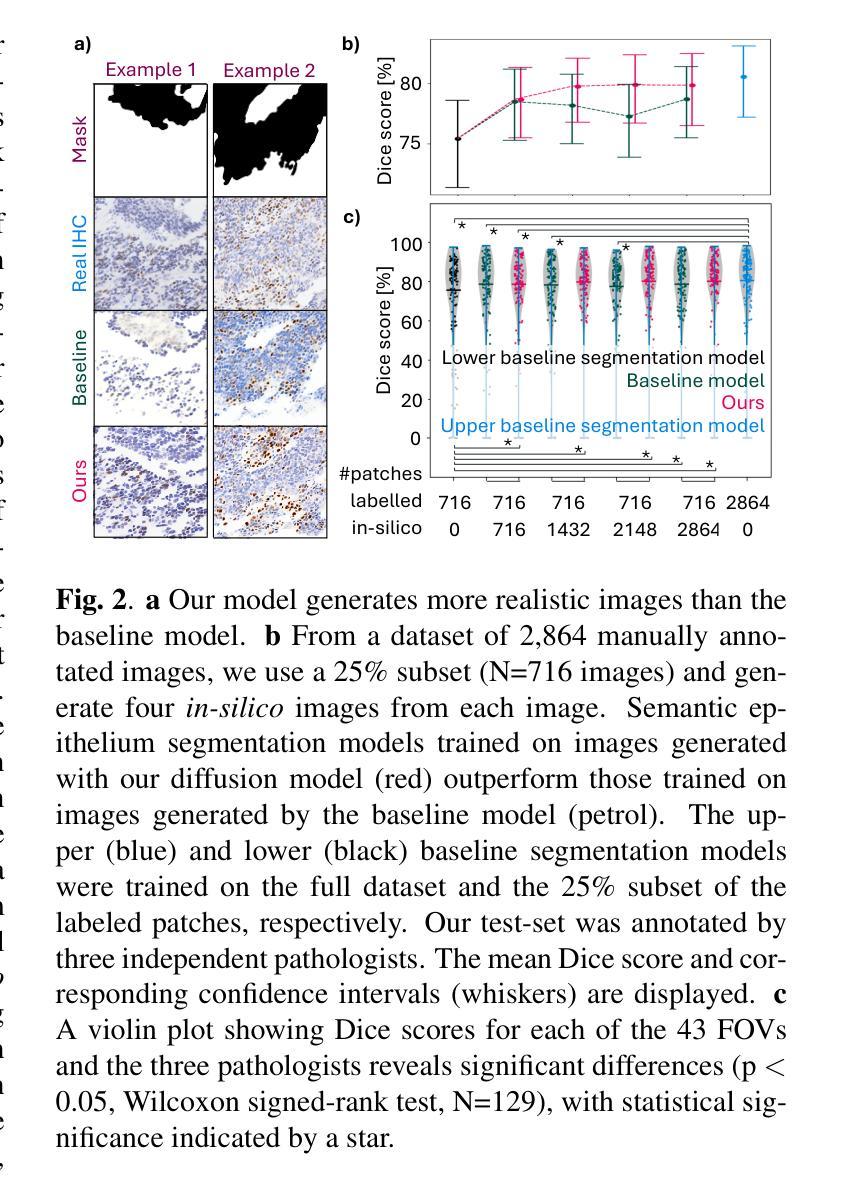
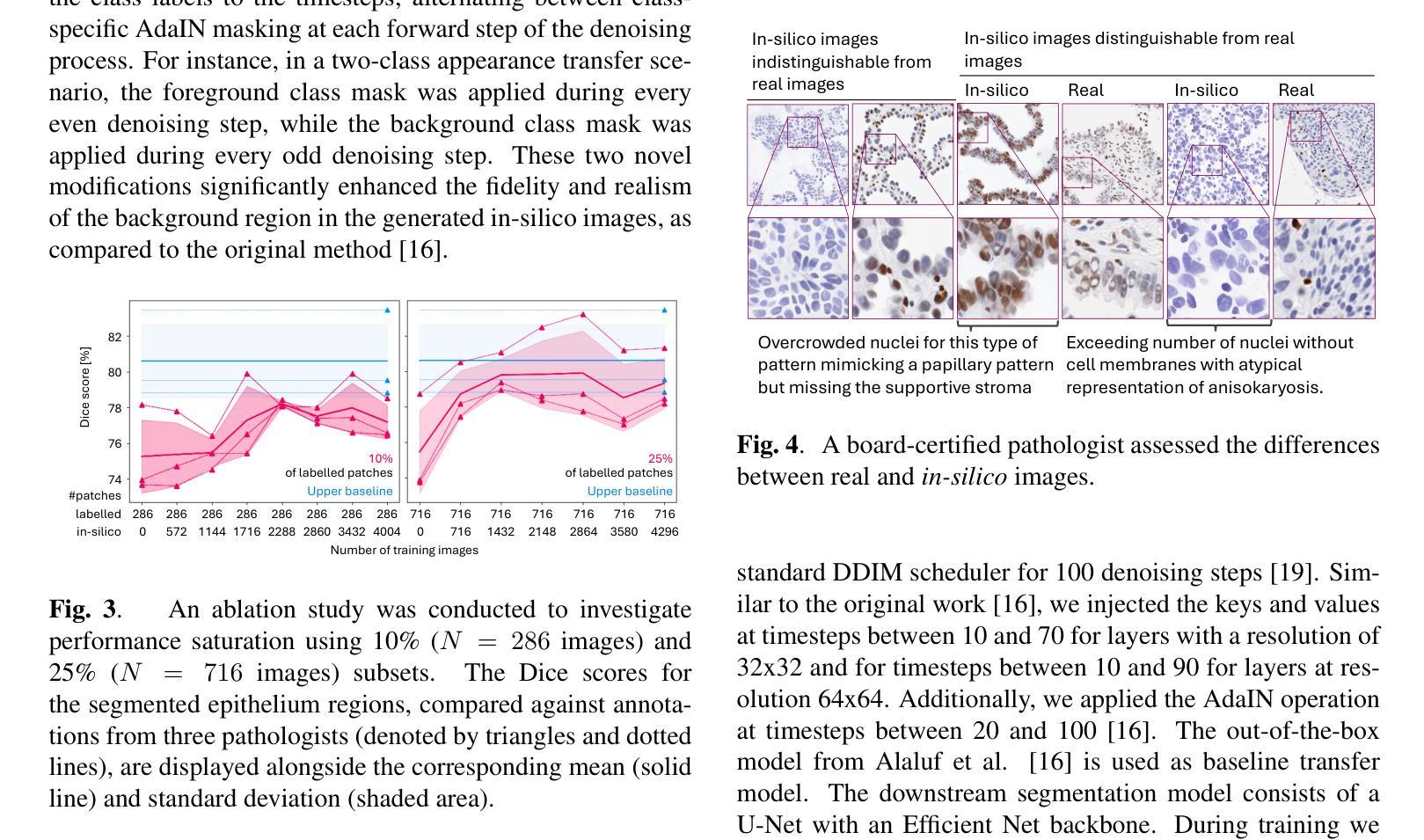
Mask-guided cross-image attention for zero-shot in-silico histopathologic image generation with a diffusion model
Authors:Dominik Winter, Nicolas Triltsch, Marco Rosati, Anatoliy Shumilov, Ziya Kokaragac, Yuri Popov, Thomas Padel, Laura Sebastian Monasor, Ross Hill, Markus Schick, Nicolas Brieu
Creating in-silico data with generative AI promises a cost-effective alternative to staining, imaging, and annotating whole slide images in computational pathology. Diffusion models are the state-of-the-art solution for generating in-silico images, offering unparalleled fidelity and realism. Using appearance transfer diffusion models allows for zero-shot image generation, facilitating fast application and making model training unnecessary. However current appearance transfer diffusion models are designed for natural images, where the main task is to transfer the foreground object from an origin to a target domain, while the background is of insignificant importance. In computational pathology, specifically in oncology, it is however not straightforward to define which objects in an image should be classified as foreground and background, as all objects in an image may be of critical importance for the detailed understanding the tumor micro-environment. We contribute to the applicability of appearance transfer diffusion models to immunohistochemistry-stained images by modifying the appearance transfer guidance to alternate between class-specific AdaIN feature statistics matchings using existing segmentation masks. The performance of the proposed method is demonstrated on the downstream task of supervised epithelium segmentation, showing that the number of manual annotations required for model training can be reduced by 75%, outperforming the baseline approach. Additionally, we consulted with a certified pathologist to investigate future improvements. We anticipate this work to inspire the application of zero-shot diffusion models in computational pathology, providing an efficient method to generate in-silico images with unmatched fidelity and realism, which prove meaningful for downstream tasks, such as training existing deep learning models or finetuning foundation models.
利用生成式人工智能创建计算机模拟数据,有望为计算病理学中的染色、成像和标注全切片图像提供成本效益更高的替代方案。扩散模型是生成计算机模拟图像的最先进解决方案,提供无与伦比的保真度和逼真度。使用外观转移扩散模型可以实现零样本图像生成,便于快速应用,且无需模型训练。然而,目前的外观转移扩散模型是为自然图像设计的,其主要任务是将前景对象从源域转移到目标域,而背景并不重要。但在计算病理学,特别是在肿瘤学中,定义图像中的哪些对象应归类为前景和背景并不简单,因为图像中的所有对象都可能对理解肿瘤微环境至关重要。我们通过修改外观转移指导,使类特定的AdaIN特征统计匹配在现有的分割掩膜之间交替,为免疫组织化学染色图像适用外观转移扩散模型做出贡献。所提出的方法在监督上皮分割的下游任务上的表现表明,模型训练所需的手动注释量可以减少75%,超过基线方法。此外,我们还与认证病理学家咨询,探讨未来的改进方向。我们预计这项工作将激发零样本扩散模型在计算病理学中的应用,提供一种高效的生成计算机模拟图像方法,具有无与伦比的保真度和逼真度,对于下游任务(如训练现有的深度学习模型或微调基础模型)具有实际意义。
论文及项目相关链接
PDF 5 pages
摘要
基于生成人工智能的体内数据创建成为计算病理学中对全切片图像进行染色、成像和注释的具有成本效益的替代方案。扩散模型是生成体内图像的最先进解决方案,具有无与伦比的保真度和逼真度。使用外观转移扩散模型可以实现零样本图像生成,促进快速应用并使模型训练变得不必要。然而,当前的外观转移扩散模型是为自然图像设计的,其主要任务是将前景对象从源域转移到目标域,而背景并不重要。在计算病理学(特别是在肿瘤学中),将图像中的哪些对象分类为前景和背景并不简单,因为了解肿瘤微环境需要对图像中的所有对象进行深入研究。我们通过对外观转移指导进行修改,将类特定的AdaIN特征统计匹配与现有分割掩模交替进行,以促进扩散模型在免疫组织化学染色图像中的应用。在下游的上皮细胞分割任务上展示了所提方法的性能,结果表明,通过所提方法可以减少模型训练所需的手动注释数量的75%,优于基线方法。此外,我们还与认证病理学家咨询了未来改进的方法。我们预计这项工作将激发零样本扩散模型在计算病理学中的应用,提供一种高效的方法生成具有无与伦比的保真度和逼真度的体内图像,这对下游任务(如训练现有深度学习模型或微调基础模型)具有实际意义。
关键见解
- 扩散模型成为生成计算病理学体内图像的最先进解决方案,具有高保真度和逼真度。
- 当前的外观转移扩散模型在设计上侧重于自然图像的前景对象转移,而计算病理学中的图像理解需要更全面的分析。
- 在免疫组织化学染色图像中应用扩散模型时,我们改进了外观转移指导,结合类特定的AdaIN特征统计匹配和现有分割掩模。
- 所提出的方法在下游的上皮细胞分割任务上表现出卓越性能,显著减少了模型训练所需的手动注释数量。
- 与认证病理学家的咨询为未来改进提供了方向。
- 零样本扩散模型的应用在计算病理学中具有巨大潜力,能够高效生成具有高保真度和逼真度的体内图像。
点此查看论文截图